Collective Behavior Clone with Visual Attention
via Neural Interaction Graph Prediction
Abstract
In this paper, we propose a framework, collective behavioral cloning (CBC), to learn the underlying interaction mechanism and control policy of a swarm system. Given the trajectory data of a swarm system, we propose a graph variational autoencoder (GVAE) to learn the local interaction graph. Based on the interaction graph and swarm trajectory, we use behavioral cloning to learn the control policy of the swarm system. To demonstrate the practicality of CBC, we deploy it on a real-world decentralized vision-based robot swarm system. A visual attention network is trained based on the learned interaction graph for online neighbor selection. Experimental results show that our method outperforms previous approaches in predicting both the interaction graph and swarm actions with higher accuracy. This work offers a promising approach for understanding interaction mechanisms and swarm dynamics in future swarm robotics research. Code and data are available6.
I Introduction
Behavioral cloning (BC) is a supervised learning approach that enables agents to replicate expert behaviors. In this paper, we extend BC to address the problem of collective behavioral cloning (CBC), which focuses on learning the control policy of a swarm system based on its observed trajectories. The goal of CBC is to identify and replicate the underlying mechanisms that govern the formation of collective behaviors in swarms. This approach has significant implications for understanding and predicting complex group dynamics, such as crowd movement in urban environments. Moreover, CBC provides valuable insights into natural swarm systems, including animal groups like bird flocks or fish schools, offering a novel perspective on the emergence of collective intelligence.
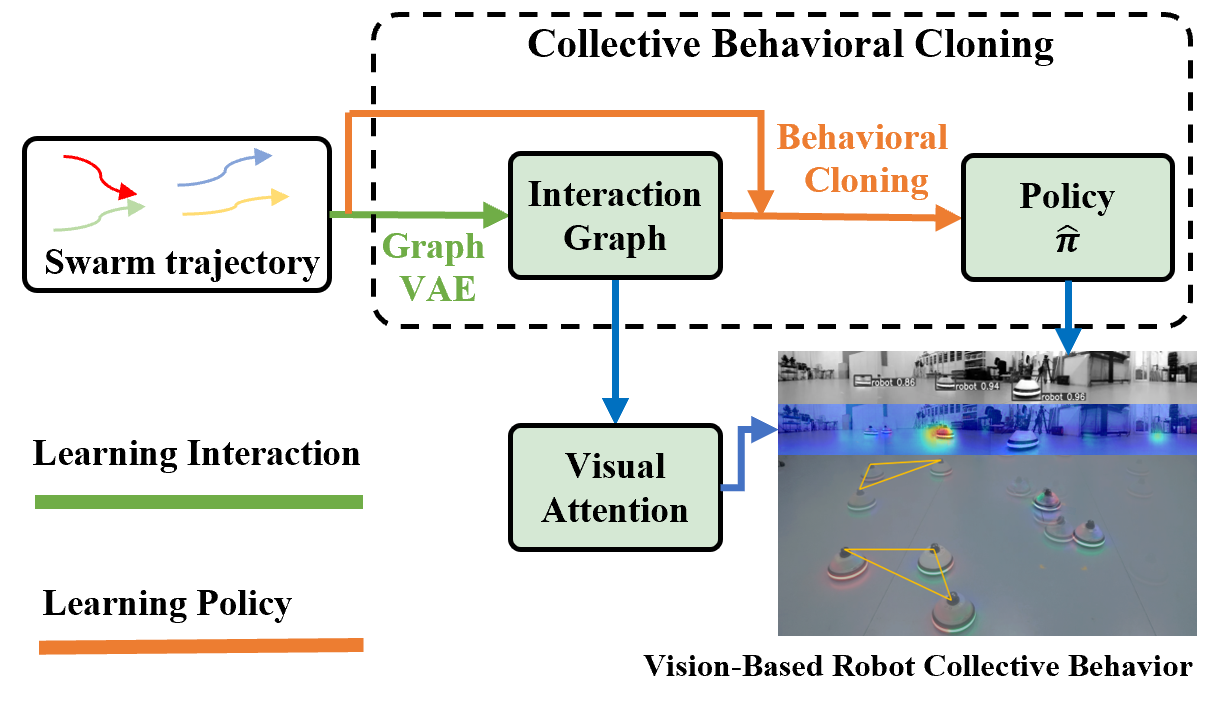
In contrast to BC, CBC presents greater learning challenges due to the unknown local interaction mechanisms in swarm systems. Knowing which neighboring agents are interacting with each other is crucial for the collective behavior policy. BC focuses solely on learning the expert’s policy, whereas CBC must learn both the expert’s policy and the local interaction mechanism at a given time. The key challenge of CBC lies in the fact that the local interaction mechanisms of a swarm system cannot be directly observed. Several local interaction mechanisms have been proposed in previous research, such as range-based models, topological models, and visual attention[1, 2, 3], which aim to achieve swarm behaviors. However, these models are typically human-designed and may not be consistent with the actual interaction mechanisms within a natural swarm.
To address the challenge of understanding local interaction mechanisms and learning the underlying policy behind the collective behavior, we propose the CBC framework in this paper. We propose a graph variational autoencoder (GVAE) model to learn the local interaction mechanism. Based on the learned interaction mechanism, we select interacting neighbors and learn the control policy that governs the swarm’s collective behavior. We also design a vision-based decentralized robot swarm system and demonstrate CBC in practice. In this system, the visual attention network is used for online selection of interacting robots, as vision is the only sensory modality available in our decentralized setup.
The three main contributions of this paper are as follows:
1) We propose a novel framework, collective behavioral cloning (CBC), to learn both the interaction mechanisms and control policy from swarm trajectory data. Our method shows higher accuracy in terms of action and trajectory error thanks to the learned interaction graph.
2) We enhance the GVAE model for improved interaction graph prediction. Our method outperforms state-of-the-art methods, demonstrating higher precision in predicting interaction graphs within swarm environments.
3) We deploy the proposed framework on a real-world vision-based robotic swarm system, effectively demonstrating its feasibility and practicality in challenging scenarios that involve wireless communication denial and full decentralization.
II Related Works
Modeling Swarm Behaviors. In swarm robotics, researchers have extensively explored collective behaviors from the perspectives of physics and biology to understand the mechanisms behind coordinated movement. This behavior typically unfolds in two stages: the neighbor selection stage and the motion decision stage [1, 2]. Numerous classical models have been proposed to explain motion decision-making. For instance, the model in [4] uses the average direction of neighbors to form a self-propelled system, while [5] introduces interaction rules based on separation, alignment, and cohesion (SAC) to model swarm dynamics. The neighbor selection stage involves choosing which agents to interact with. Various human-designed models have been proposed to model this process, such as range-based, K-nearest, and vision-based selection rules [1, 2, 3]. These interaction selection models and control policies have been applied in practical robot swarms [6, 7, 8, 9, 10]. In this paper, we differ from the traditional first-principle-based modeling by employing learning-based methods to discover the underlying interaction patterns and motion decision processes directly from trajectory data of swarm systems. This approach allows us to replicate and deepen our understanding of collective behaviors.
Neural Interaction Graph Prediction. Modeling the hidden interaction in multi-agent systems with graph representation learning has made tremendous progress in recent studies[11, 12, 13, 14, 15, 16, 17, 18]. Graph models can learn inter-agent relations from swarm trajectories. In this way, the underlying interaction pattern of the swarm system can be revealed. Neural interaction graph prediction can be mainly divided into two groups. One group[16, 17, 15, 18] combines graph neural network with the variational autoencoder (VAE) to infer the relations and predict trajectories in a multi-agent system. The other group[11, 12, 13, 14] uses transformer architecture and multi-head attention to predict agent trajectories while modeling interactions in multi-agent systems. In this work, we propose a model based on the graph VAE and achieve better accuracy for graph prediction in the swarm setting.
Visual-Attention for Robotics. Visual attention is a fundamental feature of visual sensing that actively filters out the task-relevant area within an image. Deep neural networks[19] have been proposed to imitate the visual attention mechanism. Visual attention has been applied to various robotic tasks as well. Some works use visual attention as an enhancement for trajectory planning [20], cooperative drone control[21], and autonomous driving[22]. Incorporating visual attention into decentralized vision-based swarms has not yet been fully explored in the literature. In this work, since the vision-based robot swarm system is decentralized and wireless communication is not available, we use the visual-attention network to select interaction targets during the online running.
III Problem Formulation
A multi-agent system can be viewed as a spatio-temporal graph , where each agent represents a node, and edges are formed between agents that interact with each other. In swarm robotics, the control policy that drives collective behavior is typically formulated as:
| (1) |
where is the states of the agents that belong to the interaction agents set of the th agent. Here, refers to the set of agents that are connected to the th agent in the graph . In the following part of this paper, we refer to as the interaction graph, which represents the local connectivity structure of the th agent within the spatio-temporal graph . In the context of swarm robotics[1, 2, 23], swarm control policy is also divided into two stages, namely the neighbor selection stage and the motion decision stage. The neighbor selection stage refers to obtaining with a certain neighbor selection rule. The motion decision stage refers to generating the action with based on . Here the states can be the relative position or velocity between the agents. The policy outputs an action that governs the collective behavior of the swarm, such as flocking, milling, or swarming. To summarize, the goal of CBC is to learn the policy and interacting graph from a given trajectory data of a swarm system.
IV Method
IV-A Overview
The CBC framework consists of two primary phases: 1) learning the local interaction graph and 2) learning the control policy.
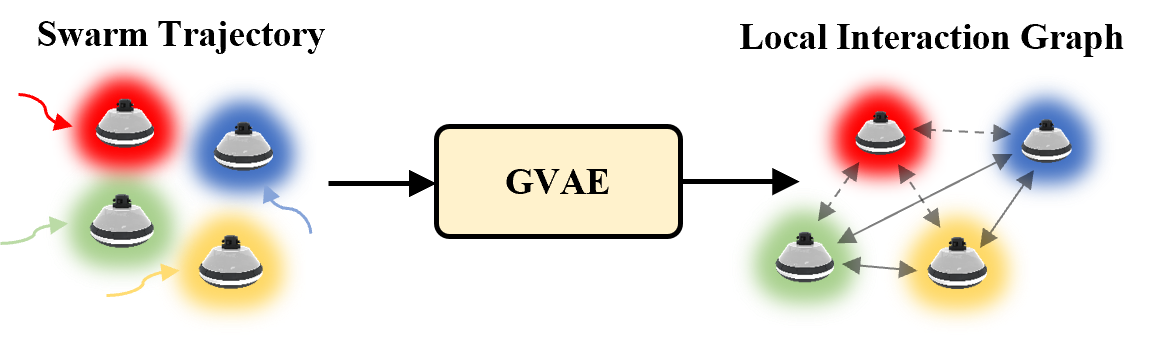
Learning the Interaction Graph. A multi-agent system can be interpreted as a dynamic graph in space and time, where each agent is represented as a node, and interactions between agents are represented by edges connecting them. Given the trajectories of the swarm system, our goal is to learn which agents are connected and interacting at any given time. We propose a Graph Variational Autoencoder (GVAE) model that utilizes a graph neural network to extract features from historical trajectories. The VAE then predicts the edges of the graph, representing the interactions between agents. This process also corresponds to the neighbor selection stage in swarm robotics[1, 23]. These predicted edges determine which neighboring agent’s states should be fed into the policy for decision-making. The detailed structure of the GVAE model is introduced in Section IV-B.
Learning the Control Policy. The control policy learning module follows the general behavioral cloning framework. Since a multilayer perceptron (MLP) can serve as a universal function approximator, we use an MLP as the action network for behavioral cloning:
| (2) |
where is the learned control policy, and represents the MLP parameters. takes the states of the selected neighbors in and outputs the action for the agent. The loss function for control policy learning is the mean squared error between the velocity action predicted by the MLP and the actual velocity action in the swarm trajectory data, governed by .
| (3) |
This process also corresponds to the motion decision stage in swarm robotics.
IV-B Neural Interaction Graph Prediction
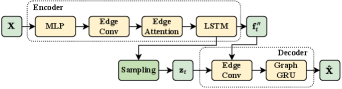
Overview. We use a GVAE model to learn the local interaction graph. Structure of the GVAE is shown in Fig. 3. The goal of GVAE is to learn the underlying interaction graph edges from the global trajectory of the swarm. The trajectory of the swarm is defined as , where denotes the sequence length, denotes the number of agents, and denotes the feature dimension. The trajectory feature of each agent contains its position and velocity in the global frame. The latent interaction graph is defined as , which is represented by a probability adjacent matrix at each timestamp. The key novel features of our model are as follows. First, we apply an attention mechanism across node-level embedding to model the relative importance. Additionally, we leverage the modern graph edge convolution operators for feature extraction in both the encoder and decoder to achieve better expressiveness.
Encoder. The GVAE employs an encoder-decoder structure. First, a multi-layer perceptron (MLP) extracts the node embedding from the raw swarm trajectory. This node embedding is then encoded using an edge convolution layer [24],
| (4) |
where denotes the th agent, is a MLP network, denotes the concatenation of the two embedding, and denotes the graph neighbors. We set the graph to be fully connected at this stage.
Since the interaction graph operates at the edge level, we convert the node-level embedding into an edge-level embedding and apply a dot-product attention mechanism to model potential interactions between the th and th agents,
| (5) |
To handle time-varying interaction graphs, the node-level embedding obtained from the graph network block is fed into a long short-term memory (LSTM) module to further extract time-specific features and latent graph logits ,
| (6) |
Sampling. The encoder outputs latent graph logits for potential interactions. To enable gradient-friendly categorical sampling, we follow the standard VAE approach and use Gumbel-Softmax [25] to obtain the sampled latent edge probabilities between the th and th agents,
| (7) |
where is a sample vector from Gumbel distribution[25] and temperature controls the smoothness.
Decoder. The decoder takes the sampled latent interaction graphs and the node embedding . These features are fed into a weighted edge convolution layer,
| (8) |
to extract the decoded node-level embedding, where we use the edge probabilities from the encoder as weights for aggregation. The node-level embedding is then fed into a graph gated recurrent unit (GRU) to recover the trajectories.
Loss Functions. The loss function follows the general form of VAE and consists of a reconstruction term and a prior term. The reconstruction term measures the difference between the reconstructed trajectory and the ground truth,
| (9) |
where is a hyperparameter that reflects the prior variance of agent trajectories. The prior term measured by KL-divergence regulates the distribution of the latent variables:
| (10) |
IV-C Vision-Based Robot Swarm System
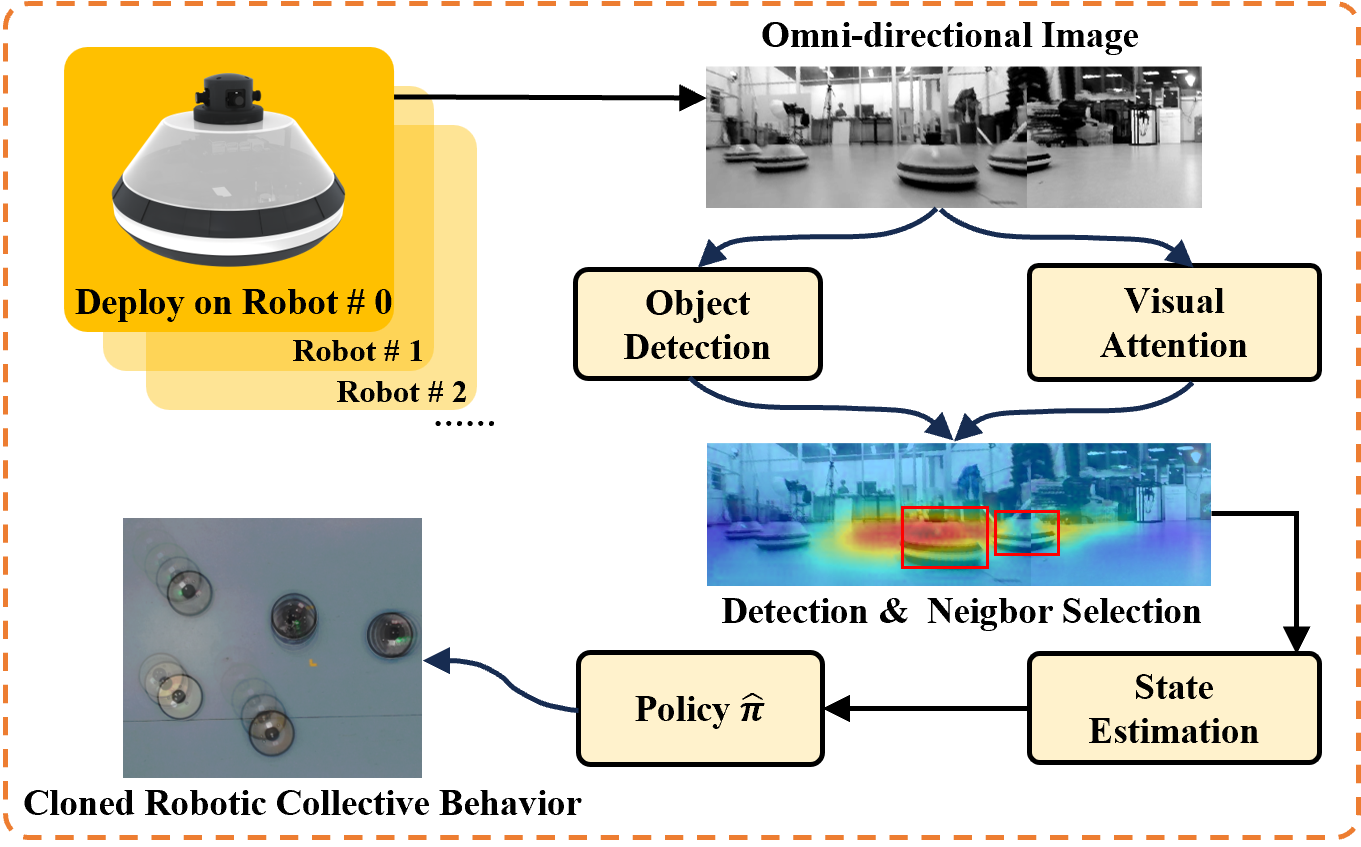
Overview To test the proposed CBC framework in practice, we design a vision-based robot swarm system. The system structure is shown in Fig 4. In practice, since the robot swarm operates in a decentralized manner with no inter-robot communication, the selection of interaction neighbors must be achieved through vision. Neighbor selection in the vision-based robot swarm is handled by a visual attention network and an object detection network. Specifically, we train a U-Net [26] as the visual attention network to predict regions of the image that receive the highest attention, and a YOLOv5 [27] network to detect other robots. The YOLOv5 model detects all robots within the image, while the visual attention network predicts areas of high interest. Robots detected within these high-attention areas are then selected as the target robots to engage with. In summary, the visual attention network acts as a proxy for the interaction graph learned by the GVAE during online operation, enabling neighbor selection without relying on communication.
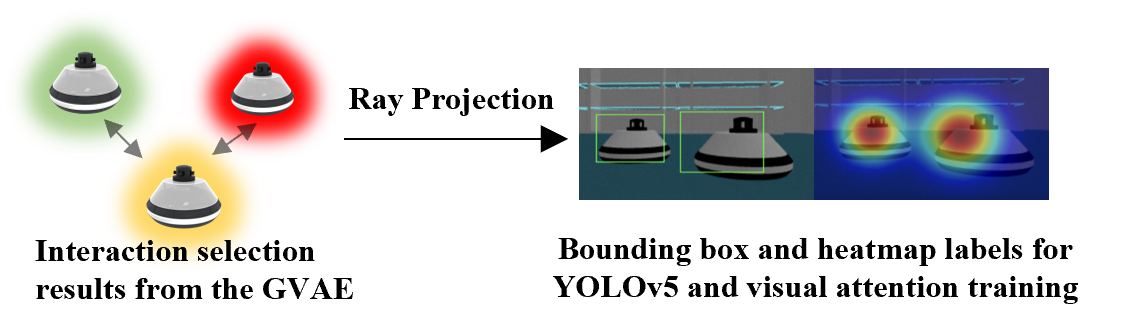
To ensure that the neighbor selection is consistent with the learned interaction graph from the GVAE, the training labels for the visual attention network are generated using both the interaction prediction results and the robot trajectory. Given some swarm trajectory data, which represents the collective behavior to be cloned, the following process is used for visual attention network training: 1) The swarm is run according to the trajectory, with image and trajectory data being recorded and synchronized. 2) The GVAE is applied to obtain the interaction graph and neighbor selection results at each timestamp. 3) For each pair of robots connected in the interaction graph, based on their relative poses and camera parameters, each robot is projected onto the other’s image space. 4) A Gaussian blur is then applied at the projection point to create a heatmap label. 5) These heatmap labels are used to train the visual attention network. Kullback–Leibler divergence between the heatmap labels and predicted attention map is used as the training loss. The kernel size of the Gaussian blur for heat map is , where is the relative distance and is a scaling factor. This indicates that the closer the interacting robot is, the larger the kernel size will be in the heatmap. Fig. 5 shows the projection process.
Since the swarm control policy relies on the states of interacting robots, i.e. the relative positions and velocities, a Kalman state estimator is used to estimate the states of high-attention interacting robots. Using the estimated motions, the learned policy outputs actions that generate the collective behavior to be cloned.
State Estimation. Since the swarm control policy relies on the states of interacting robots, we introduce how to estimate the robot states from image bounding box observations here. The state estimation follows the pseudo-linear Kalman filter (PLKF) based on visual bounding box observations[28]. The target state , where is the relative position and is the relative velocity. The state transition and process covariance are given by
| (11) | |||
| (12) |
where is the position variance, is the velocity variance. The observations, i.e. the bearing vector and target field angle with noise can be extracted from the bounding box and camera parameters:
| (13) |
where is the physical diameter of the target, and are noises in zero-mean Gaussian distribution with the covariance of and . We choose the target field angle to represent the relative size measurement because remains invariant to camera rotation[28]. The observation equation of PLKF is
| (14) |
where . The observation noise is computed by combining Eq. 13 and Eq. 14:
| (15) |
Since can be viewed as a linear combination of Gaussian noise and , the observation covariance is given by
| (16) |
V Experimental Evaluations
V-A Results of Neural Interaction Graph Prediction
In this part, we aim to evaluate the interaction graph prediction ability of the GVAE model.
Data. We simulate the trajectory of a robot swarm with pre-defined interaction graph and control policy to build a custom benchmark dataset. In the simulation, a leader moves in a pre-defined pattern such as a circular, a linear motion, or a U-turn, and other agents follow its movements to form flocking behavior. A potential-field-like policy is employed to create flocking behavior for followers,
| (17) |
where denotes the relative position between the th and th agent. is a scaling factor, and is the interacting graph. The interaction graph across agents is evenly generated with range-based[23, 6], K-nearest[23, 7, 6], and vision-only methods[9, 3]. In this way, we have the ground truth result of which agents are interacting with each other at a given time. By comparing the predicted interaction graph edge with the ground truth data, we can evaluate the performance of our model. The initial positions of all agents are randomly generated in a 6m6m area. The control policy drives each agent to its migration destination while avoiding collision, forming a flocking behavior. We set the maximum speed of each agent at 0.2 m/s. The number of agents ranges from 3 to 9. 50K of simulations are generated for each experiment. The training, validation, and testing data are with a ratio of 80/10/10.
Implementation Details. We train our GVAE model for 100 epochs on an RTX 4090 GPU, using the Adam optimizer with a learning rate of and a batch size of 64. Both the MLP and LSTM hidden dimensions are set to 256, and ELU activation is applied to all MLP layers. The temperature for the Gumbel-softmax sampler is fixed at 0.5. The prior variance of the trajectory .
Results. We compare the interaction graph predictions of our GVAE with those from other open-source state-of-the-art (SOTA) relational inference methods on the aforementioned swarm data. The results are shown in Table I. While all the methods predict both the trajectories and interaction graph edges, our focus is on graph prediction. We present a comparison of graph edge prediction performance in terms of precision, recall, and F1 score.
We first compare our method to the linear correlation of the velocities between two agents (denoted as “VC” in Table I), which is a straightforward, non-learning approach for determining inter-agent relations. Then we compare our method with other SOTA methods that predict interaction graph edges. GST[11] is based on mulit-head attention mechanism and is used in human interaction prediction for robot navigation. dNRI[17], NRI[16] and IMMA[15] use a VAE to predict the agent trajectory and interaction graph edges. GAT[29] is a graph attention network and uses an attention mechanism to model the mutual relation.
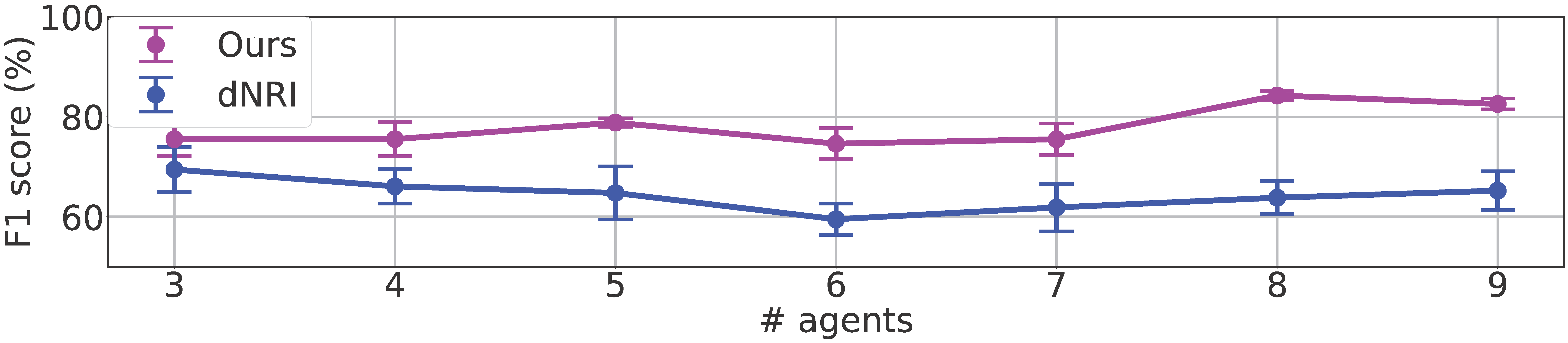
Results in Table I show that our model gives better performance compared with other methods. Since scalability is an important aspect of swarming, we also compare our model’s performance in terms of agent number. Fig. 6 shows the results. Our model consistently outperforms the strongest baseline (dNRI) across all agent numbers. The results demonstrate that our GVAE model shows improved accuracy for interaction graph edge prediction in the swarm setting, which lays the foundation for collective behavioral cloning in real-world swarm data.
| Methods | Model Type | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| VC | Non-learning | 67.89 ± 2.89 | 58.38 ± 2.21 | 62.72 ± 1.67 |
| GST[11] | Transformer | 58.85 ± 28.23 | 16.21 ± 6.33 | 25.18 ± 10.32 |
| dNRI[17] | VAE | 84.60 ± 2.96 | 53.46 ± 0.97 | 65.49 ± 1.12 |
| NRI[16] | VAE | 61.25 ± 2.90 | 38.96 ± 0.66 | 47.59 ± 0.88 |
| GAT[29] | Graph Net | 49.89 ± 4.12 | 62.23 ± 3.28 | 55.38 ± 2.81 |
| IMMA[15] | VAE | 26.19 ± 2.43 | 32.73 ± 2.72 | 29.09 ± 2.12 |
| Ours | VAE | 91.20 ± 2.48 | 73.84 ± 2.64 | 78.04 ± 2.80 |


V-B Results of Collective Behavioral Cloning
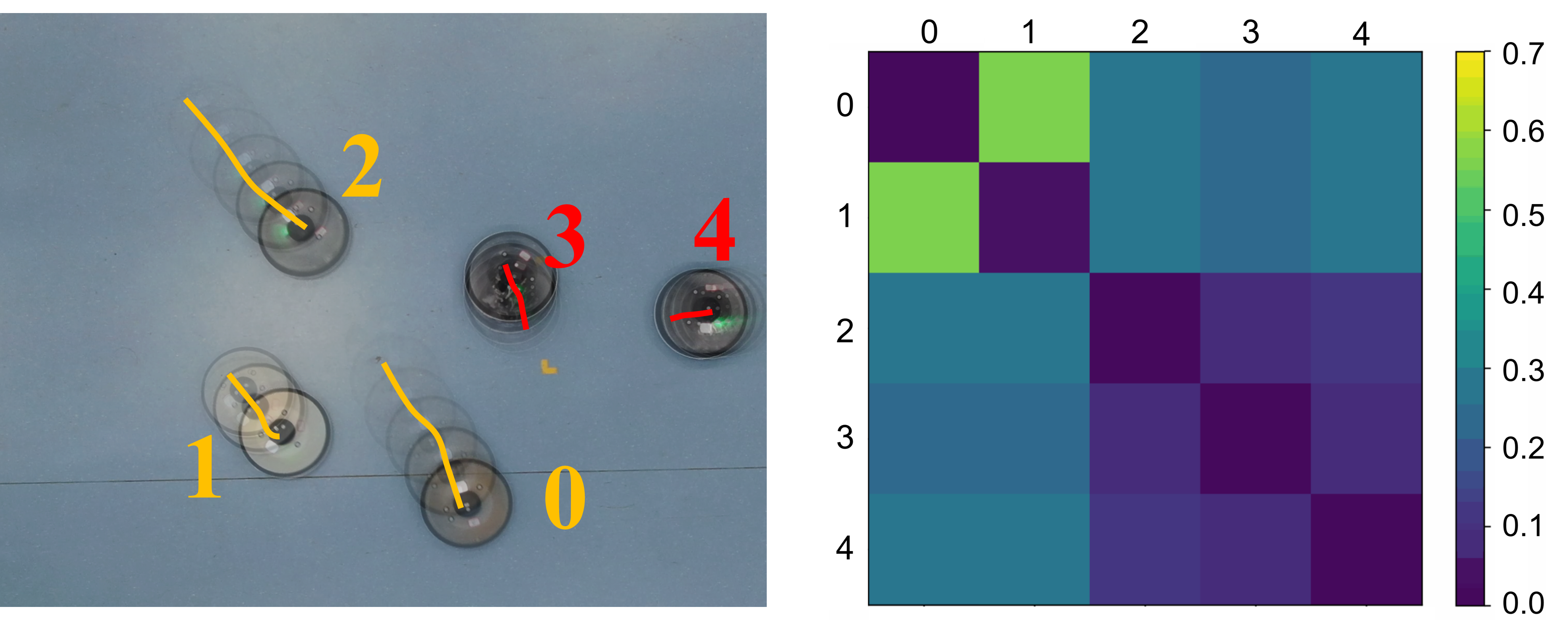
Overview. In this section, we deploy the algorithms on a real-world vision-based robot swarm to evaluate the performance of CBC. We use the control policy in Eq. 17 to generate swarm trajectory data. The action generated by is a 3-dimensional vector, representing the linear velocity and angular velocity . We use a total of 5 robots, divided into two groups. Group I consists of 3 robots, one robot moves in a predefined trajectory as the leader, and the other two robots are the followers. Group II consists of 2 robots performing a random walk. Robots within Group I are fully connected and continuously interact with each other, while there is no interaction between robots in Group I and Group II. We use a two-layer MLP with 512 hidden units as to clone the expert policy . The input to the MLP consists of the estimated relative 2D velocities and positions of the interacting robots from the PLKF. The input dimension is set to , where is the maximum number of robots in the experiments. When the number of interacting robots is less than , the remaining part of the input tensor is padded with the states of the last interacting robot. After generating the flocking trajectory data, we use GVAE to learn the interaction graph edge. With the learned local interaction graph edge, we use the projection approach introduced in Section III-C to generate heat map labels. Then with the heat map labels, the visual attention network is trained for interaction agent selection within the image.
System Implementation We test our framework on a real-world robotic swarm system. Each robot is equipped with a set of 4 cameras, oriented in different directions to provide an omnidirectional view. The onboard computer is an Nvidia Jetson Xavier NX (6 ARM cores, 8GB memory, and 21 TOPS of AI computing power). Ground truth trajectories of the robots are provided by a motion tracking system. To accelerate onboard inference and manage models efficiently, we utilize Nvidia TensorRT for inference acceleration and Triton for multi-model inference scheduling.
| Interaction Methods | AE | TE [m] | AMD [m] |
|---|---|---|---|
| Vision-Only | 0.092 ± 0.033 | 3.01 ± 0.89 | 1.65 ± 0.49 |
| Range-Based | 0.051 ± 0.020 | 1.88 ± 0.55 | 0.95 ± 0.40 |
| K-Nearest | 0.060 ± 0.021 | 1.79 ± 0.68 | 2.01 ± 0.30 |
| Ours (Learning-based) | 0.028 ± 0.016 | 0.95 ± 0.40 | 0.85 ± 0.31 |
Results of CBC. The goal of the CBC experiment is to train a policy to replicate the actions of . We evaluate the performance using three metrics: action error (AE), trajectory error (TE), and average mutual distance (AMD). AE measures the mean error between the expert policy and the cloned policy ; TE represents the accumulated trajectory error between the behavior generated by and ; and AMD calculates the average mutual distance among robots in the same group during the experiment. The results are shown in Table II, which demonstrates that our method exhibits the smallest action error, trajectory error, and average mutual distance. This is because our approach leverages the learned local interaction graph and a visual attention model to select interacting robots, whereas other methods rely on hand-crafted interaction rules, which are not consistent with the real interaction graph observed in the expert-generated swarm data.
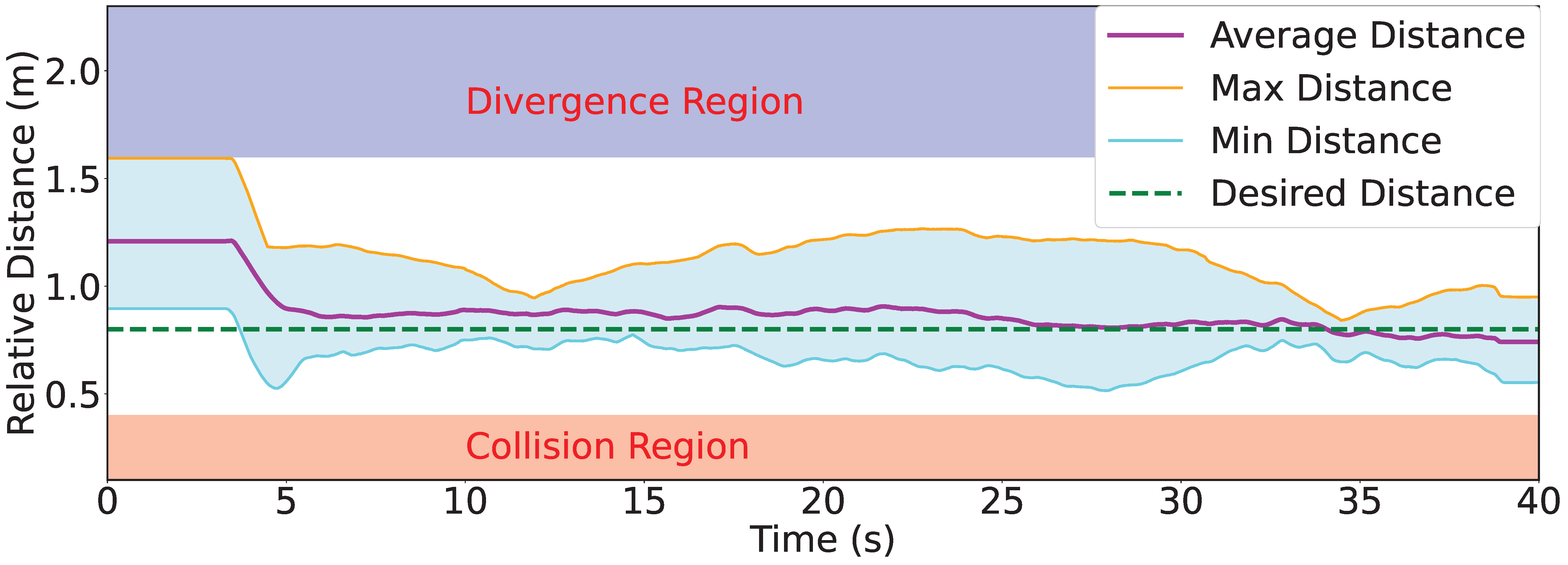
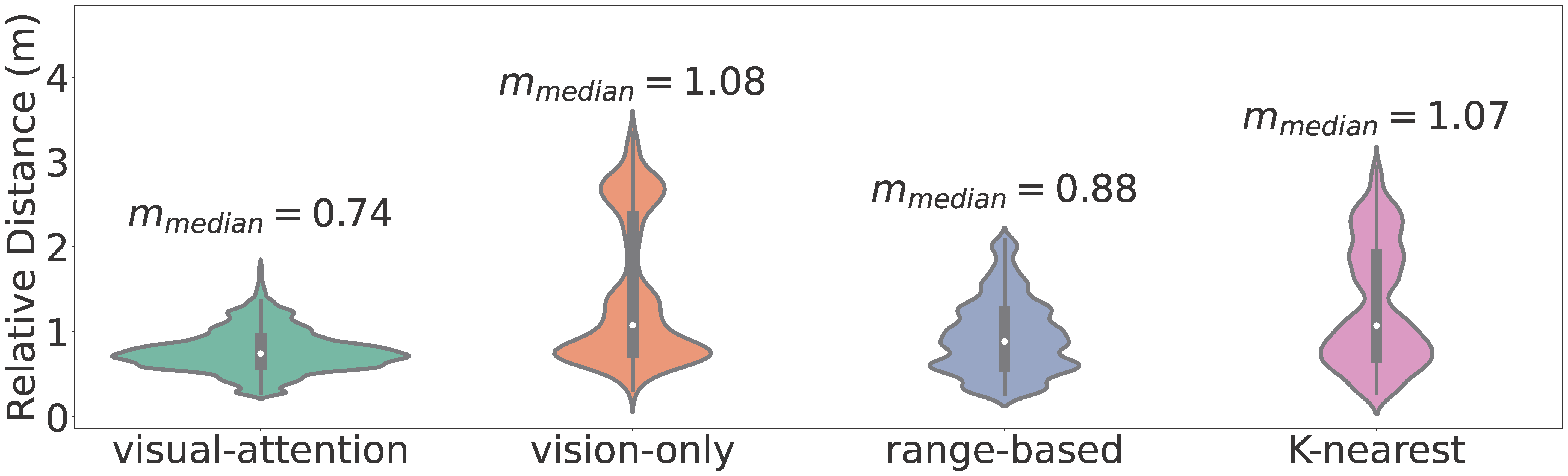
Fig. 9 depicts the average relative distance among agents of Group I during one experiment episode. The desired relative distance (0.8 m) is defined by the expert policy . The curve indicates that the policy learned by our CBC framework can keep the swarm coherent while avoiding collision. Fig. 10 shows the results of relative distance distribution during the experiment. While other methods often lead the swarm to diverge, our method with the learned interaction selection mechanism keeps the swarm coherent at the desired mutual distance. This is because the visual-attention model actively filters task-specific robots to interact with, whereas other methods may include irrelevant ones, as all robots appear identical. The robotic flocking experiment involving two groups demonstrates that our CBC framework achieves more robust and stable performance, owing to the learned interaction graph. Table III lists the onboard running statistics of primary operating modules. The statistics demonstrate that our visual-attention-based swarm framework can be effectively deployed on real-world robotic systems with limited computational resources.
Experiment Details. In the experiment, the YOLOv5 and U-Net are converted to TensorRT model with half-precision (FP16) mode. YOLOv5 is trained on 1,996 simulation images and 3,281 real-world images for 100 epochs, achieving a mAP50 of 92%. The visual attention model is a five-level U-Net[26] with (32,64,128,256,512) convolutional filters of kernel size (3,3,3,5,5). The scaling factor for heatmap generation is set to 20. The final control command operates at a frequency of 30 Hz. The maximum interaction range of the range-based method is 1.6 m for comparison. Since we divide the robots into 2 groups and the maximum number of robots in each group is 3, the number of selected targets of the K-nearest is set at 2. The GVAE achieves a F1 score of 78%. The PLKF achieves an estimation accuracy of 0.078 ± 0.035 m within a detection range of 3 m. The variance of bearing and angle observations in the PLKF is determined based on the ground truth of the bounding box. The process noise of the PLKF is set as follows: , . The visual measurement noise of the PLKF is set as follows: , .
| Modules | Input Shape | Running time (ms) | CPU (%) |
|---|---|---|---|
| Image Concatenation | 4.28 ± 0.27 | 15.0 | |
| Object Detection | 10.90 ± 5.30 | 24.0 | |
| Visual Attention | 14.42 ± 6.41 | 54.6 | |
| PLKF | N/A | 0.93 ± 0.11 | 8.9 |
| Robot Controller | N/A | 0.59 ± 0.09 | 3.9 |
| Triton Server | N/A | N/A | 25.5 |
VI Conclusions
In this paper, we introduce a collective behavioral cloning (CBC) framework to learn the interaction graph and control policies of a swarm system, given its trajectory data. To capture the underlying interaction graph, we propose a Graph Variational Autoencoder (GVAE) model. Compared to previous models, our GVAE shows improved accuracy in predicting the interaction graph edges. We employ imitation learning to learn the control policy. The CBC framework is then deployed in a real-world, vision-based robot swarm system, where a visual attention network is used as a proxy for interaction neighbor selection. Our experiments demonstrate that the CBC framework can effectively learn both the interaction graph and control policy, leading to smaller action and trajectory errors. Future work may involve using this framework to study complex behaviors in humans or natural swarms.
References
- [1] Z. Zheng, Y. Zhou, Y. Xiang, X. Lei, and X. Peng, “Emergence of collective behaviors for the swarm robotic through visual attention-based selective interaction,” IEEE Robotics and Automation Letters, 2024.
- [2] K. Li, L. Li, R. Groß, and S. Zhao, “A collective perception model for neighbor selection in groups based on visual attention mechanisms,” New Journal of Physics, vol. 26, no. 1, p. 012001, 2024.
- [3] F. Schilling, E. Soria, and D. Floreano, “On the scalability of vision-based drone swarms in the presence of occlusions,” IEEE Access, vol. 10, pp. 28133–28146, 2022.
- [4] T. Vicsek, A. Czirók, E. Ben-Jacob, I. Cohen, and O. Shochet, “Novel type of phase transition in a system of self-driven particles,” Physical review letters, vol. 75, no. 6, p. 1226, 1995.
- [5] I. D. Couzin, J. Krause, R. James, G. D. Ruxton, and N. R. Franks, “Collective memory and spatial sorting in animal groups,” Journal of theoretical biology, vol. 218, no. 1, pp. 1–11, 2002.
- [6] Z. Huang, Z. Yang, R. Krupani, B. Şenbaşlar, S. Batra, and G. S. Sukhatme, “Collision avoidance and navigation for a quadrotor swarm using end-to-end deep reinforcement learning,” in IEEE International Conference on Robotics and Automation (ICRA), pp. 300–306, IEEE, 2024.
- [7] E. Soria, F. Schiano, and D. Floreano, “Distributed predictive drone swarms in cluttered environments,” IEEE Robotics and Automation Letters, vol. 7, no. 1, pp. 73–80, 2022.
- [8] S. Batra, Z. Huang, A. Petrenko, T. Kumar, A. Molchanov, and G. S. Sukhatme, “Decentralized control of quadrotor swarms with end-to-end deep reinforcement learning,” in Conference on Robot Learning (CoRL), pp. 576–586, PMLR, 2022.
- [9] F. Schilling, F. Schiano, and D. Floreano, “Vision-based drone flocking in outdoor environments,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2954–2961, 2021.
- [10] F. Schilling, J. Lecoeur, F. Schiano, and D. Floreano, “Learning vision-based flight in drone swarms by imitation,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4523–4530, 2019.
- [11] S. Liu, P. Chang, Z. Huang, N. Chakraborty, K. Hong, W. Liang, D. L. McPherson, J. Geng, and K. Driggs-Campbell, “Intention aware robot crowd navigation with attention-based interaction graph,” in IEEE International Conference on Robotics and Automation (ICRA), pp. 12015–12021, IEEE, 2023.
- [12] Z. Huang, R. Li, K. Shin, and K. Driggs-Campbell, “Learning sparse interaction graphs of partially detected pedestrians for trajectory prediction,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1198–1205, 2021.
- [13] A. Vemula, K. Muelling, and J. Oh, “Social attention: Modeling attention in human crowds,” in IEEE international Conference on Robotics and Automation (ICRA), pp. 4601–4607, IEEE, 2018.
- [14] C. Yu, X. Ma, J. Ren, H. Zhao, and S. Yi, “Spatio-temporal graph transformer networks for pedestrian trajectory prediction,” in European Conference on Computer Vision (ECCV), pp. 507–523, Springer, 2020.
- [15] F.-Y. Sun, I. Kauvar, R. Zhang, J. Li, M. J. Kochenderfer, J. Wu, and N. Haber, “Interaction modeling with multiplex attention,” in Advances in Neural Information Processing Systems (NIPS), vol. 35, pp. 20038–20050, 2022.
- [16] T. Kipf, E. Fetaya, K.-C. Wang, M. Welling, and R. Zemel, “Neural relational inference for interacting systems,” in International Conference on Machine Learning (ICML), pp. 2688–2697, PMLR, 2018.
- [17] C. Graber and A. G. Schwing, “Dynamic neural relational inference,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8513–8522, 2020.
- [18] V. M. Dax, J. Li, E. Sachdeva, N. Agarwal, and M. J. Kochenderfer, “Disentangled neural relational inference for interpretable motion prediction,” IEEE Robotics and Automation Letters, 2023.
- [19] M. J. Islam, R. Wang, and J. Sattar, “SVAM: saliency-guided visual attention modeling by autonomous underwater robots,” in Proceedings of Robotics: Science and Systems (RSS), 2022.
- [20] S. Wapnick, T. Manderson, D. Meger, and G. Dudek, “Trajectory-constrained deep latent visual attention for improved local planning in presence of heterogeneous terrain,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 460–467, IEEE, 2021.
- [21] L. Yin, M. Chahine, T.-H. Wang, T. Seyde, C. Liu, M. Lechner, R. Hasani, and D. Rus, “Towards cooperative flight control using visual-attention,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6334–6341, IEEE, 2023.
- [22] C. Liu, Y. Chen, M. Liu, and B. E. Shi, “Using eye gaze to enhance generalization of imitation networks to unseen environments,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 5, pp. 2066–2074, 2020.
- [23] B. T. Fine and D. A. Shell, “Unifying microscopic flocking motion models for virtual, robotic, and biological flock members,” Autonomous Robots, vol. 35, pp. 195–219, 2013.
- [24] Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic Graph CNN for Learning on Point Clouds,” ACM Transactions on Graphics, vol. 38, no. 5, pp. 1–12, 2019.
- [25] E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,” in International Conference on Learning Representations (ICLR), 2017.
- [26] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pp. 234–241, Springer, 2015.
- [27] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779–788, 2016.
- [28] Z. Ning, Y. Zhang, J. Li, Z. Chen, and S. Zhao, “A bearing-angle approach for unknown target motion analysis based on visual measurements,” The International Journal of Robotics Research, pp. 1–20, 2024.
- [29] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio, “Graph attention networks,” in International Conference on Learning Representations (ICLR), 2018.