Collaborative Propagation on Multiple Instance Graphs
for 3D Instance Segmentation with Single-point Supervision
Abstract
Instance segmentation on 3D point clouds has been attracting increasing attention due to its wide applications, especially in scene understanding areas. However, most existing methods operate on fully annotated data while manually preparing ground-truth labels at point-level is very cumbersome and labor-intensive. To address this issue, we propose a novel weakly supervised method RWSeg that only requires labeling one object with one point. With these sparse weak labels, we introduce a unified framework with two branches to propagate semantic and instance information respectively to unknown regions using self-attention and a cross-graph random walk method. Specifically, we propose a Cross-graph Competing Random Walks (CRW) algorithm that encourages competition among different instance graphs to resolve ambiguities in closely placed objects, improving instance assignment accuracy. RWSeg generates high-quality instance-level pseudo labels. Experimental results on ScanNet-v2 and S3DIS datasets show that our approach achieves comparable performance with fully-supervised methods and outperforms previous weakly-supervised methods by a substantial margin.
1 Introduction
With the rapid development of 3D sensing technology, point cloud based scene understanding has become a popular research topic in recent years. Instance segmentation is one of the most fundamental tasks in this field and has many applications in robotics, autonomous driving, AR/VR, etc. Given a 3D point cloud depicting a scene, this task requires predicting not only a semantic category but also an instance id to differentiate objects at point level. Many deep learning methods have been developed for this task, showing promising results. However, most of these methods operate on point-wise fully annotated data to supervise the network training.

Manually creating data annotations at point level is very cumbersome and labor-intensive. Although some tools have been adopted to assist, the average time used to annotate one scene is about 22.3 minutes on ScanNet-v2 dataset [10]. To alleviate this issue, several types of weak annotations have been proposed, such as scene-level annotation, subcloud-level annotation [47], 2D image based annotation and 3D bounding box annotation [1, 8]. However, not all weak label types are easy to obtain in practice. In this work, we adopt the annotation method used in SegGroup [40] and “One Thing One Click” [33], which only requires annotating a single point for each object. As shown in Figure 2, this results in very sparse initial annotations, with less than 0.02% of total points requiring labeling. According to [40, 33], this annotation method takes less than two minutes per scene, significantly reducing the need for human effort.

Tao et al. [40] and Tang et al. [39] have investigated the ”One-thing-one-click” approach to address the challenge of weakly supervised 3D instance segmentation. These techniques construct graphs on top of the over-segmentation outcomes and apply Graph Convolution Network (GCN) or inter-superpoint affinity for label propagation. However, these approaches encounter some issues. SegGroup [40] relies solely on a cross-entropy loss for its semantic prediction with a greedy algorithm for clustering, hence lacking instance-related information. Besides, this method is only designed for the purpose of generating pseudo labels, and therefore requires to utilize these pseudo labels as ground-truth to train a separate network for prediction. 3D-WSIS [39] utilizes an offset loss and an affinity loss to produce better discriminative features, but their graph is based on the over-segmented point clouds, and the feature of each supervoxel is simply obtained through average pooling of point features and coordinates. The size of supervoxels can vary significantly in their setup, and the initial weak labels can be located at any part of objects, resulting in an unbalanced attraction to neighboring nodes. This may lead to difficulty in identifying precise boundaries, particularly when multiple instances are located close to each other.
In this paper, we propose a novel weakly supervised learning approach, named RWSeg, for 3D point cloud instance segmentation. With only one point annotation per instance, we focus on two key considerations: (1) effective feature propagation is critical for generating high-quality pseudo labels, and (2) leveraging the interactions among instance graphs can be beneficial in finding more accurate instance boundaries and improving the quality of clustering. To address the limitations of previous methods, we are motivated to develop a unified structure for both feature learning and feature propagation.
Convolutional Neural Network (CNN) can extract good local features. However, long-range dependencies can hardly be captured due to its relatively small receptive field. The limitations of CNNs in capturing long-range dependencies are exacerbated in weakly supervised learning scenarios, where only a limited number of certain labels are available to supervise the training process. To this end, we introduce a self-attention module after the 3D CNN backbone, which can effectively propagate long-range information to unknown regions.
For instance pseudo label generation, a customized random walk algorithm on point-level is developed for 3D weakly instance segmentation. The point clouds are first split by their categories, and for each category, multiple instance graphs are built and random walk propagation is performed on each of them. The total energy on each individual graph is identical, based on the assumption that same-class objects tend to have similar sizes. A competing mechanism is designed to perform collaborative propagation on multiple instance graphs. To sum up, the key contributions of our work are as follows:
-
•
We design a unified framework for weakly supervised 3D instance segmentation. To enhance the feature propagation, we introduce a self-attention module to capture long-range dependencies.
-
•
We propose a novel algorithm to perform collaborative propagation on multiple instance graphs to generate high-quality instance pseudo labels. The designed competing mechanism helps to resolve ambiguous cases in 3D instance segmentation task.
-
•
With significantly fewer annotations, our method bridges the gap between weakly supervised learning and fully supervised learning in 3D instance segmentation.
2 Related Work
Fully supervised 3D segmentation
To effectively process unstructured and unordered 3D data , current feature learning methods can be broadly categorized into two types: point-based methods [28, 37, 38, 41, 49, 53, 13, 18] and voxel-based methods [16, 17, 23, 27]. Voxel-based approaches involve transforming data into 3D volumetric grids, whereas point-based methods operate directly on the individual points. Instance segmentation on point clouds can be seen as a joint task of segmentation and localization. Proposal-based methods [45, 24, 51, 14] detect object boundaries explicitly and then perform binary mask segmentation as the final output. On the other hand, proposal-free methods [45, 32, 46, 35, 26, 25, 19, 6, 29, 12] directly regress instance centroids without performing the detection task. Jiang et al. [25] utilized a submanifold sparse convolution [17] based 3D U-net and proposed to use a breadth-first search clustering algorithm on dual coordinate sets.
Weakly supervised segmentation
Numerous weakly supervised methods have been proposed for image segmentation [3, 22, 36, 34, 2, 55, 5]. Wei et al. [48] proposed the first weakly supervised approach for point cloud semantic segmentation, utilizing Class Activation Map (CAM) to generate point-level pseudo labels with subcloud-level annotations. Several subsequent works [50, 44, 33, 11] also addressed weakly segmentation on point clouds with lesser supervision. There have been limited attempts to solve 3D weakly supervised instance segmentation. Hou et al. [21] designed a pre-training method to assist prediction, while Tao et al. [40] proposed Seggroup with graph convolution network (GCN) for instance label propagation. However, Seggroup lacks the ability to learn discriminative features for separating instances. Tang et al. [39] proposed to learn discriminative features and use inter-superpoint affinity for label propagation. However, their method did not fully utilize all the spatial information and may affect their performance on ambiguous cases. Liao et al. [1] and J. Chibane et al. [8] proposed using 3D bounding boxes as supervision. However, box annotation provides much richer information than clicking one point per instance, and most non-overlapped objects can already be defined by 3D bounding box. This may lessen the significance of their work.
3 Method
In this section, we first introduce our data annotation setting for point cloud instance segmentation in Section 3.1. Then, Section 3.2 describes our training strategy. Lastly, Section 3.3 and 3.4 present our approach in detail, including network architecture, semantic branch, instance branch and proposed pseudo label generation algorithm.
3.1 Weak Annotation
Following SegGroup [40], we adopt the annotation setting of one point per object, as shown in Figure 2. To create initial pseudo labels, we spread the labels from annotated points to nearby points within the same supervoxel segment. These segments are generated by unsupervised over-segmentation method [15] based on the surface normals of points. Points within the same segment have high internal consistency, which are used as the initial ground-truth to supervise the network training.

3.2 Learning Strategy
As shown in Figure 3, the network training of our method consists of two stages. The first stage is supervised by the initial weak labels. Afterward, predictions with high confidence from our pseudo label generation algorithm are further updated as new ground-truth labels for next stage training. With this learning strategy, the quality of learned features can be consistently improved
3.3 Network Architecture
Our network takes point cloud as input where is the number of points in . It uses a shared U-Net backbone and two separate branches for point-level semantic feature learning and instance centroid regression. In the semantic branch, a self-attention based module is used to further enhance semantic features, especially for those regions without supervision. Following that, our proposed Cross-Graph Competing Random Walks (CRW) algorithm leverages learned features and existing ground-truth weak labels to generate instance-level pseudo labels. With refined weak labels, the network can be further trained to produce better features. All proposed modules are within the unified framework, as shown in Figure 2.
Semantic segmentation branch
The submanifold sparse convolution [17] based backbone network can extract point-wise features with good local information capturing. However, to enhance the network’s ability to capture long-range feature dependencies and extend its receptive field, we propose incorporating a self-attention module to further refine the semantic features. In order to reduce the computational complexity of self-attention and ensure local geometric consistency, we utilize a supervoxel generation method [31]. Specifically, for each supervoxel set, we apply average pooling to both point coordinates and semantic features. Following [42, 54], we build a self-attention layer across all the supervoxels and then interpolate the output to the original size of the input point cloud. During training, we use a conventional cross-entropy loss with incomplete labels to supervise the process. The structure diagram and formulas of the self-attention module are provided in the supplementary.
Instance centroid offset branch
Parallel to the semantic branch, we apply a 2-layers MLP upon point features to predict point-wise centroid shift vector . The instance centroid is defined as the mean coordinates of all points with the same instance label. Following [25], We use an regression loss and a cosine similarity based direction loss to train the offset prediction. We only consider foreground points with weak labels or pseudo weak labels for supervision. With initial weak labels, real centroids of instances can hardly be inferred. However, we found it is still beneficial to apply offset loss, as it can help to slightly shift points towards inner part of objects.
The final joint loss function can be written as
| (1) |
3.4 Pseudo label Generation
After training with the initial weak labels, we now have a network that can make semantic prediction and offset prediction, which can be further utilized to generate pseudo instance labels. However, due to the limited supervision used during model training, the quality of the prediction may not be very accurate at the first iteration. To address this issue, we propose a random walk-based algorithm to generate reliable pseudo labels for unlabelled points.
In this section, we first describe how we construct an individual graph in Figure 4 and then present the details of cross-graph competing mechanism and the clustering algorithm in Figure 5. The core idea of our algorithm is to enable interactions among instance graphs and gradually updates seeding points until reaching a signal equilibrium state.

Building graph on the point cloud
According to the semantic predictions from the semantic branch on point clouds , we treat each foreground semantic category as a target group. For each group, we build fully connected and undirected instance graphs, with being the number of instances. As shown in Figure 4, the nodes of each graph are points from all instances. Each node in each graph is associated with an initial binary label (score), as detailed in the paragraph below. The instance graphs have the same nodes and edges, with the only difference being they have different initial graph node score vectors.
For the -th instance graph, its initial graph node score vector is defined by its binary instance label mask , with the -th element if the -th node (point) has an instance label of . The -th element of is:
| (2) |
where is the number of nodes in the graph. The process of normalizing seeding points’ initial scores involves dividing them by the total number of nodes corresponding to the same instance id. This normalization aims to achieve equitable allocation of the initial potential among instance graphs, thereby preventing any undue advantage for instances having a larger number of positive weak labels.

The random walk operation on each graph can be modeled with an transition matrix . denotes the transition probability between -th and -th nodes, with a higher value indicating a higher transition probability.
To build transition matrix , we first consider a pairwise kernel function to derive a symmetric affinity matrix , which helps to enhance local smoothness. For each edge connecting the -th and -th nodes, we define its weight as:
| (3) |
where is a hyperparameter, and are point coordinates. We use the predicted offset vector from the instance branch to shift points from their original coordinates toward their instance centers. Node pairs with small euclidean distances in the 3D space tend to have high similarities.
Next, we formulate the transition matrix by the following rules. Specifically, we assign a weight of zero to the edges connecting nodes belonging to different instance labels, in order to restrict the direct interaction between them.
| (4) |
where and are the instance labels of two nodes. Lastly, transition matrix needs to be normalized:
| (5) |
This transition matrix is shared among each group of instance graphs.
Random walk algorithm is performed by repeatedly adjusting node vector via the transition matrix . At -th iteration, the adjustment can be expressed as
| (6) |
where is a blending coefficient between propagated scores and the initial scores.
When repeatably applying unlimited random steps on a graph, it will reach equilibrium. The final steady-state of random walk algorithm can be written as
| (7) |
Input: coordinates ; number of instances per category ( is the total number of valid classes); hyperparameter ; max iteration number and ; instance weak labels ; semantic prediction ; offset prediction
Output:
Instance pseudo label prediction


Cross-graph Competing Random Walks (CRW)
On top of the random walk algorithm, we design a mechanism to encourage competitive interactions among instance graphs, in Figure 5. Intuitively, the idea is to suppress a point’s activation score in the current graph if its scores in other instance graphs are relatively high. However, the level of repulsive effect needs to be well controlled. Otherwise, too strong repulsive effects are likely to distort the results from the random walk.
Based on the random walk results, we apply a softmax function to every node score to adjust the probability distribution over the instance graphs. Elements in the score vector are re-scaled to the range of , and the score values of the same positioned nodes on instance graphs are summed to .
| (8) |
where denotes the score of the -th node on -th graph. In this simple manner, we bring repulsive interaction among instance graphs. A point that receives less competition from other instance graphs will be adjusted to a relatively higher score, and vice versa.
Then, for each instance, we pick a fixed percentage (i.e. ) of newly predicted pseudo labels with high confidence to be updated as seeding points for the next iteration. The selection is based on the sorted node scores. Only unlabelled points can be considered as new seeding points. Our approach gradually groups relatively confident points into seeds and performs a random walk step at each iteration.
| Semantic mIoU | Label | wall floor cab bed chair sofa table door wind bkshf pic cntr desk curt fridg showr toil sink bath ofurn | avg |
| MPRM [48] | Scene | 47.3 41.1 10.4 43.2 25.2 43.1 21.9 9.8 12.3 45.0 9.0 13.9 21.1 40.9 1.8 29.4 14.3 9.2 39.9 10.0 | 24.4 |
| MPRM [48] | Subcloud | 58.0 57.3 33.2 71.8 50.4 69.8 47.9 42.1 44.9 73.8 28.0 21.5 49.5 72.0 38.8 44.1 42.4 20.0 48.7 34.4 | 47.4 |
| SegGroup [40] | 0.02% | 71.0 82.5 63.0 52.3 72.7 61.2 65.1 66.7 55.9 46.3 42.7 50.9 50.6 67.9 67.3 70.3 70.7 53.1 54.5 63.7 | 61.4 |
| RWSeg (Ours) | 0.02% | 88.8 94.4 80.2 82.4 85.9 91.2 76.5 76.6 78.2 87.5 66.3 64.1 67.7 85.6 86.9 88.9 92.4 71.5 91.7 75.3 | 81.6 |
| Instance AP | Metric | cab bed chair sofa table door wind bkshf pic cntr desk curt fridg showr toil sink bath ofurn | avg |
| RWSeg (Ours) | AP | 59.0 65.9 70.3 82.1 59.3 38.2 54.0 68.0 54.7 35.6 35.8 48.0 73.9 80.6 88.4 44.6 85.4 54.3 | 61.0 |
| AP50 | 85.7 94.2 93.8 90.3 87.1 60.8 77.1 84.5 81.6 79.9 74.1 69.7 92.1 92.4 97.8 82.3 97.4 77.6 | 84.4 | |
| AP25 | 96.4 99.0 98.3 95.7 95.2 87.0 91.6 91.5 92.8 96.3 93.9 87.5 99.2 97.4 99.3 95.8 100.0 92.8 | 95.0 |
4 Experiments
Datasets
In this section, we show our experimental results on two public datasets: ScanNet-v2 [10] and S3DIS [4] to show the effectiveness of our proposed method. ScanNet-v2 dataset [10] is a popular 3D indoor dataset containing 2.5 million RGB-D views in 1513 real-world scenes, covering 20 semantic categories. The evaluation metrics of 3D instance segmentation are mean average precisions at different overlap percentages, i.e., [email protected], [email protected] and mAP respectively. S3DIS dataset [4] has 272 scenes under six large-scale indoor areas. Unlike ScanNet [10], all 13 classes including background are annotated as instances and require prediction. We use the mean precision (mPre) and mean recall (mRec) with an IoU threshold of 0.5 as the evaluation metric.
Implementation details
We set the voxel size as for submanifold sparse convolution [17] based backbone, following [25]. Our network is trained on a single GPU card. For each stage of training, the backbone network and self-attention module are trained sequentially, with a batch size of 4 and 2 respectively. We set and in the self-attention module as two-layer MLPs with the hidden dimension of 64 and 32 respectively. For CRW algorithm, we set hyerparameters and as 50%. Due to GPU memory limit, we subsample the input point cloud to CRW if the point number is above 25k. Last output remains at original resolution. For network training, we use Adam solver for optimization with an initial learning rate of 0.001.
Pseudo label evaluation
As shown in Table 1 and Table 2, we present the quality of our generated pseudo labels based. Reported final pseudo labels are created after two stages of network training. Our network is trained only on the training set of ScanNet-v2 [10] with 1201 scenes, no extra data is needed. In Table 1, the semantic quality of our pseudo labels largely outperforms previous methods by at least . Besides, we also report the instance quality of pseudo labels in Table 2. However, no available data from other methods can be used for comparison at present. Our qualitative pseudo labels can be used by any fully supervised method to resolve their annotation cost issue.
Prediction evaluation
Different from weakly supervised methods like SegGroup [40] that require training another a new network for prediction, we can directly adopt other methods on the same network for prediction without retraining. Here we employ a Breadth-First Search (BFS) clustering algorithm from PointGroup [25] to our network. In Table 3, we compare the prediction results with fully supervised PointGroup [25] and other weakly supervised methods on ScanNet-v2 [10] validation set.
Our method significantly outperforms SegGroup [40] and 3D-WSIS [39] over all evaluation metrics, generally by an absolute margin of around 10 points. Remarkably, with only of annotated points, we achieve comparable results with fully supervised method [25]. We also report the instance segmentation results on ScanNet-v2 [10] test set in Table 4. Our method again performs significantly better than other weakly supervised methods which use the same amount of annotations. For S3DIS [4] dataset, we report Area 5 and 6-fold cross validation results in Table 5.
| Method | Supervision | AP | AP50 | AP25 |
| Full Supervision: | ||||
| PointGroup [25] | 100% | 34.8 | 56.9 | 71.3 |
| Init+Act. Point Supervision: | ||||
| CSC-20 (PointGroup) [21] | 20 pts/scene | - | 27.2 | - |
| CSC-50 (PointGroup) [21] | 50 pts/scene | - | 35.7 | - |
| SPIB [1] | 100% Box | - | 38.6 | 61.4 |
| Box2Mask [8] | 100% Box | - | 59.7 | 71.8 |
| TWIST [9] | 1% | 9.6 | 17.1 | 26.2 |
| TWIST [9] | 5% | 27.0 | 44.1 | 56.2 |
| TWIST [9] | 10% | 30.6 | 49.7 | 63.0 |
| TWIST [9] | 20% | 32.8 | 52.9 | 66.8 |
| One Obj One Pt Supervision: | ||||
| SegGroup (PointGroup) [40] | 0.02% | 23.4 | 43.4 | 62.9 |
| 3D-WSIS [39] | 0.02% | 28.1 | 47.2 | 67.5 |
| RWSeg (Ours) | 0.02% | 34.7 | 56.4 | 71.2 |
| Method | Supervision | AP | AP50 | AP25 |
| Full Supervision: | ||||
| SoftGroup [43] | 100% | 50.4 | 76.1 | 86.5 |
| HAIS [7] | 100% | 45.7 | 69.9 | 80.3 |
| SSTNet [30] | 100% | 50.6 | 69.8 | 78.9 |
| OccuSeg [19] | 100% | 48.6 | 67.2 | 78.8 |
| PointGroup [25] | 100% | 40.7 | 63.6 | 77.8 |
| 3D-MPA [14] | 100% | 35.5 | 61.1 | 73.7 |
| MTML [26] | 100% | 28.2 | 54.9 | 73.1 |
| 3D-BoNet [51] | 100% | 25.3 | 48.8 | 68.7 |
| 3D-SIS [24] | 100% | 16.1 | 38.2 | 55.8 |
| GSPN [52] | 100% | 15.8 | 30.6 | 54.4 |
| One Obj One Pt Supervision: | ||||
| SegGroup (PointGroup) [40] | 0.02% | 24.6 | 44.5 | 63.7 |
| 3D-WSIS [39] | 0.02% | 25.1 | 47.0 | 67.8 |
| RWSeg (Ours) | 0.02% | 34.8 | 56.7 | 73.9 |
| Area 5 | 6-fold | ||||
| Method | Supv. | mPre | mRec | mPre | mRec |
| Full Supervision: | |||||
| PointGroup [25] | 100% | 61.9 | 62.1 | 69.6 | 69.2 |
| One Obj One Pt Supervision: | |||||
| SegGroup (PointGroup) [40] | 0.02% | 47.2 | 34.9 | 56.7 | 43.3 |
| 3D-WSIS [39] | 0.02% | 50.8 | 38.9 | 59.3 | 46.7 |
| RWSeg (Ours) | 0.02% | 60.1 | 45.8 | 68.9 | 56 |
4.1 Ablation Study
In this section, we proceed to study the impacts of different components of our proposed method. Table 6 shows the network performance at different stages of training. We use “Self-Attn” to represent the self-attention module in our network. In the setting of “3D U-Net + Self-Attn”, we freeze the backbone network and only train self-attention module, which shows the effectiveness of this component. Stage 1 training is supervised by initial weak labels. And Stage 2 training is supervised by the generated pseudo labels from our algorithm at the end of Stage 1. With our training strategy, the quality of semantic features can be steadily improved.
| mIoU | Method | train set | val set |
| Stage 1 | 3D U-Net | 74.6 | 61.7 |
| Stage 1 | 3D U-Net + Self-Attn | 78.9 | 66 |
| Stage 2 | 3D U-Net | 80 | 68.4 |
| Stage 2 | 3D U-Net + Self-Attn | 81.6 | 70.3 |
Ablations on Cross-graph Competing Random Walks (CRW)
To make fair comparisons on clustering algorithms for pseudo label generation, we train a PointGroup [25] backbone network with initial weak labels. On top of the shared network, we evaluate the performance of our CRW and other baseline methods in Table 7. “PointGroup BFS” represents a popular Breadth-First Search algorithm used in fully supervised 3D instance segmentation. K-means [20] is a simple yet powerful unsupervised clustering algorithm to separate samples in groups of equal variance. Its character suits our task very well by nature. However, we found K-means is very sensitive to noise. The performance highly depends on the quality of semantic predictions and shift vectors. In contrast, our CRW is more robust and works well in different situations.
| Baseline Methods | AP | AP50 | AP25 |
| PointGroup BFS [25] | 15.8 | 32.4 | 58.9 |
| K-means† [20] | 14.5 | 28.5 | 66.9 |
| K-means‡ [20] | 23.5 | 44.1 | 72.5 |
| CRW† (Ours) | 53.2 | 80.6 | 95.2 |
| CRW‡ (Ours) | 55 | 82 | 95.9 |
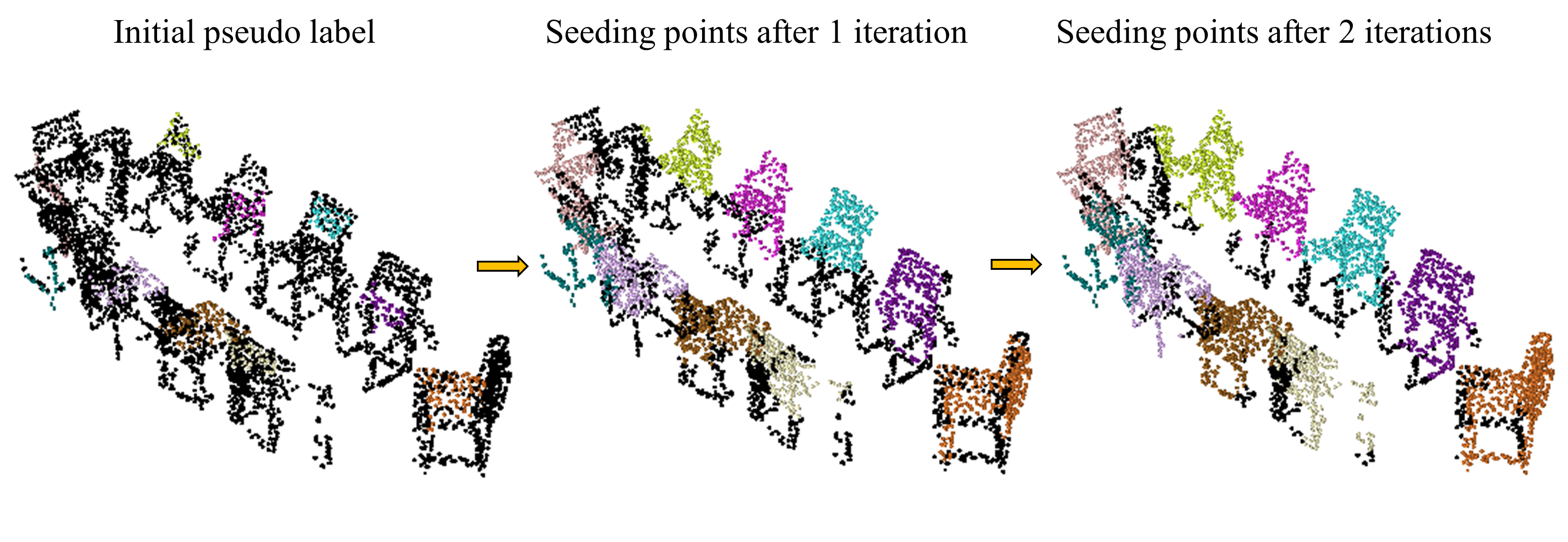
Figure 8 shows the change of seeding regions during the process of Cross-graph Competing Random Walks. At each step, the top of the new predictions on unlabelled points are added as seed. It can be seen that new seeding points tend to be distributed at those regions relatively far from other seeds, as a result of cross-graph competition.
| Iteration number () | 0 | 1 | 5 | 10 |
| chair AP | 64.2 | 66.3 | 67.4 | 67.4 |
| bookshelf AP | 48.1 | 51.0 | 52.3 | 52.3 |
The impact of using multiple random walk steps in Cross-graph Competing Random Walks (CRW) is shown in Table 8. As we expected, cross-graph competition is useful to resolve those ambiguous cases in instance segmentation, where objects from same category are compactly placed. Meanwhile, for those sparsely placed object categories, such as bathtub and door, their instance segments can already be well defined by proposed basic random walk algorithm. Competitions usually not exist for such cases.
5 Conclusion
In this paper, we propose a novel weakly supervised method for 3D instance segmentation on point clouds. With significantly fewer annotations, our network uses a self-attention module to propagate semantic features and a random walk based algorithm with cross-graph competition to generate high-quality pseudo labels. Comprehensive experiments show that our method achieves solid improvements on performance. The limitations of our method are discussed in the supplementary material.
Acknowledgement
This study is supported under the RIE2020 Industry Alignment Fund – Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s). This research work is also supported by the Agency for Science, Technology and Research (A*STAR) under its MTC Young Individual Research Grant (Grant No. M21K3c0130) and MTC Programmatic Funds (Grant No. M23L7b0021). This research is also partly supported by the MoE AcRF Tier 2 grant (MOE-T2EP20220-0007) and the MoE AcRF Tier 1 grant (RG14/22).
References
- [1] Point cloud instance segmentation with semi-supervised bounding-box mining. CoRR, abs/2111.15210, 2021.
- [2] Jiwoon Ahn, Sunghyun Cho, and Suha Kwak. Weakly supervised learning of instance segmentation with inter-pixel relations. In CVPR, pages 2209–2218, 2019.
- [3] Jiwoon Ahn and Suha Kwak. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In CVPR, pages 4981–4990, 2018.
- [4] Iro Armeni, Ozan Sener, Amir R. Zamir, Helen Jiang, Ioannis Brilakis, Martin Fischer, and Silvio Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2016.
- [5] Aditya Arun, CV Jawahar, and M Pawan Kumar. Weakly supervised instance segmentation by learning annotation consistent instances. In ECCV, pages 254–270, 2020.
- [6] Shaoyu Chen, Jiemin Fang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Hierarchical aggregation for 3d instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15467–15476, October 2021.
- [7] Shaoyu Chen, Jiemin Fang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Hierarchical aggregation for 3d instance segmentation. In ICCV, 2021.
- [8] Julian Chibane, Francis Engelmann, Tuan Anh Tran, and Gerard Pons-Moll. Box2mask: Weakly supervised 3d semantic instance segmentation using bounding boxes. In European Conference on Computer Vision (ECCV). Springer, October 2022.
- [9] Ruihang Chu, Xiaoqing Ye, Zhengzhe Liu, Xiao Tan, Xiaojuan Qi, Chi-Wing Fu, and Jiaya Jia. Twist: Two-way inter-label self-training for semi-supervised 3d instance segmentation. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1090–1099, 2022.
- [10] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017.
- [11] Shichao Dong and Guosheng Lin. Weakly supervised 3d instance segmentation without instance-level annotations, 2023.
- [12] Shichao Dong, Guosheng Lin, and Tzu-Yi Hung. Learning regional purity for instance segmentation on 3d point clouds. In European Conference on Computer Vision, pages 56–72. Springer, 2022.
- [13] Nico Engel, Vasileios Belagiannis, and Klaus Dietmayer. Point transformer. IEEE Access, 9:134826–134840, 2021.
- [14] Francis Engelmann, Martin Bokeloh, Alireza Fathi, Bastian Leibe, and Matthias Nießner. 3d-mpa: Multi proposal aggregation for 3d semantic instance segmentation, 2020.
- [15] Pedro F. Felzenszwalb and Daniel P. Huttenlocher. Efficient graph-based image segmentation. IJCV, 59(2):167–181, 2004.
- [16] Zan Gojcic, Caifa Zhou, Jan D. Wegner, Leonidas J. Guibas, and Tolga Birdal. Learning multiview 3d point cloud registration. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [17] Benjamin Graham and Laurens van der Maaten. Submanifold sparse convolutional networks. CoRR, abs/1706.01307, 2017.
- [18] Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin, and Shi-Min Hu. Pct: Point cloud transformer. Computational Visual Media, 7(2):187–199, Apr 2021.
- [19] Lei Han, Tian Zheng, Lan Xu, and Lu Fang. Occuseg: Occupancy-aware 3d instance segmentation, 2020.
- [20] J. A. Hartigan and M. A. Wong. A k-means clustering algorithm. JSTOR: Applied Statistics, 28(1):100–108, 1979.
- [21] Ji Hou, Benjamin Graham, Matthias Nießner, and Saining Xie. Exploring data-efficient 3d scene understanding with contrastive scene contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15587–15597, 2021.
- [22] Zilong Huang, Xinggang Wang, Jiasi Wang, Wenyu Liu, and Jingdong Wang. Weakly-supervised semantic segmentation network with deep seeded region growing. In CVPR, pages 7014–7023, 2018.
- [23] Maximilian Jaritz, Jia-Yuan Gu, and Hao Su. Multi-view pointnet for 3d scene understanding. ArXiv, abs/1909.13603, 2019.
- [24] Hou Ji, Angela Dai, and Matthias Nießner. 3d-sis: 3d semantic instance segmentation of rgb-d scans. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2019.
- [25] Li Jiang, Hengshuang Zhao, Shaoshuai Shi, Shu Liu, Chi-Wing Fu, and Jiaya Jia. Pointgroup: Dual-set point grouping for 3d instance segmentation, 2020.
- [26] Jean Lahoud, Bernard Ghanem, Marc Pollefeys, and Martin R. Oswald. 3d instance segmentation via multi-task metric learning, 2019.
- [27] Lei Li, Siyu Zhu, Hongbo Fu, Ping Tan, and Chiew-Lan Tai. End-to-end learning local multi-view descriptors for 3d point clouds. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [28] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points. In NeurIPS, pages 820–830. Curran Associates, Inc., 2018.
- [29] Zhihao Liang, Zhihao Li, Songcen Xu, Mingkui Tan, and Kui Jia. Instance segmentation in 3d scenes using semantic superpoint tree networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2783–2792, October 2021.
- [30] Zhihao Liang, Zhihao Li, Songcen Xu, Mingkui Tan, and Kui Jia. Instance segmentation in 3d scenes using semantic superpoint tree networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2783–2792, 2021.
- [31] Yangbin Lin, Cheng Wang, Dawei Zhai, Wei Li, and Jonathan Li. Toward better boundary preserved supervoxel segmentation for 3d point clouds. ISPRS Journal of Photogrammetry and Remote Sensing, 143:39 – 47, 2018. ISPRS Journal of Photogrammetry and Remote Sensing Theme Issue “Point Cloud Processing”.
- [32] Chen Liu and Yasutaka Furukawa. MASC: multi-scale affinity with sparse convolution for 3d instance segmentation. CoRR, 2019.
- [33] Zhengzhe Liu, Xiaojuan Qi, and Chi-Wing Fu. One thing one click: A self-training approach for weakly supervised 3d semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1726–1736, June 2021.
- [34] George Papandreou, Liang-Chieh Chen, Kevin P. Murphy, and Alan L. Yuille. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In ICCV, pages 1742–1750, 2015.
- [35] Quang-Hieu Pham, Thanh Nguyen, Binh-Son Hua, Gemma Roig, and Sai-Kit Yeung. Jsis3d: Joint semantic-instance segmentation of 3d point clouds with multi-task pointwise networks and multi-value conditional random fields. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [36] Pedro O. Pinheiro and Ronan Collobert. From image-level to pixel-level labeling with convolutional networks. In CVPR, pages 1713–1721, 2015.
- [37] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 77–85, 2016.
- [38] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, 2017.
- [39] Linghua Tang, Le Hui, and Jin Xie. Learning inter-superpoint affinity for weakly supervised 3d instance segmentation. In ACCV, 2022.
- [40] An Tao, Yueqi Duan, Yi Wei, Jiwen Lu, and Jie Zhou. SegGroup: Seg-level supervision for 3D instance and semantic segmentation. arXiv preprint, 2020.
- [41] Hugues Thomas, Charles R. Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, François Goulette, and Leonidas J. Guibas. Kpconv: Flexible and deformable convolution for point clouds. ArXiv, abs/1904.08889, 2019.
- [42] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- [43] Thang Vu, Kookhoi Kim, Tung M. Luu, Xuan Thanh Nguyen, and Chang D. Yoo. Softgroup for 3d instance segmentation on 3d point clouds. In CVPR, 2022.
- [44] Haiyan Wang, Xuejian Rong, Liang Yang, Jinglun Feng, Jizhong Xiao, and Yingli Tian. Weakly supervised semantic segmentation in 3D graph-structured point clouds of wild scenes. arXiv preprint arXiv:2004.12498, 2020.
- [45] Weiyue Wang, Ronald Yu, Qiangui Huang, and Ulrich Neumann. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In CVPR, 2018.
- [46] Xinlong Wang, Shu Liu, Xiaoyong Shen, Chunhua Shen, and Jiaya Jia. Associatively segmenting instances and semantics in point clouds. In CVPR, 2019.
- [47] Jiacheng Wei, Guosheng Lin, Kim-Hui Yap, Tzu-Yi Hung, and Lihua Xie. Multi-path region mining for weakly supervised 3d semantic segmentation on point clouds. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [48] Jiacheng Wei, Guosheng Lin, Kim-Hui Yap, Tzu-Yi Hung, and Lihua Xie. Multi-path region mining for weakly supervised 3d semantic segmentation on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4384–4393, 2020.
- [49] Wenxuan Wu, Zhongang Qi, and Li Fuxin. Pointconv: Deep convolutional networks on 3d point clouds. arXiv preprint arXiv:1811.07246, 2018.
- [50] Xun Xu and Gim Hee Lee. Weakly supervised semantic point cloud segmentation: Towards 10x fewer labels. In CVPR, pages 13706–13715, 2020.
- [51] Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning object bounding boxes for 3d instance segmentation on point clouds, 2019.
- [52] Li Yi, Wang Zhao, He Wang, Minhyuk Sung, and Leonidas Guibas. Gspn: Generative shape proposal network for 3d instance segmentation in point cloud. arXiv preprint arXiv:1812.03320, 2018.
- [53] Hengshuang Zhao, Li Jiang, Chi-Wing Fu, and Jiaya Jia. PointWeb: Enhancing local neighborhood features for point cloud processing. In CVPR, 2019.
- [54] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, and Vladlen Koltun. Point transformer. In ICCV, 2021.
- [55] Yanzhao Zhou, Yi Zhu, Qixiang Ye, Qiang Qiu, and Jianbin Jiao. Weakly supervised instance segmentation using class peak response. In CVPR, pages 2209–2218, 2018.