Collaborative Multi-Agent Multi-Armed Bandit Learning for Small-Cell Caching
Abstract
This paper investigates learning-based caching in small-cell networks (SCNs) when user preference is unknown. The goal is to optimize the cache placement in each small base station (SBS) for minimizing the system long-term transmission delay. We model this sequential multi-agent decision making problem in a multi-agent multi-armed bandit (MAMAB) perspective. Rather than estimating user preference first and then optimizing the cache strategy, we propose several MAMAB-based algorithms to directly learn the cache strategy online in both stationary and non-stationary environment. In the stationary environment, we first propose two high-complexity agent-based collaborative MAMAB algorithms with performance guarantee. Then we propose a low-complexity distributed MAMAB which ignores the SBS coordination. To achieve a better balance between SBS coordination gain and computational complexity, we develop an edge-based collaborative MAMAB with the coordination graph edge-based reward assignment method. In the non-stationary environment, we modify the MAMAB-based algorithms proposed in the stationary environment by proposing a practical initialization method and designing new perturbed terms to adapt to the dynamic environment. Simulation results are provided to validate the effectiveness of our proposed algorithms. The effects of different parameters on caching performance are also discussed.
Index Terms:
Wireless caching, multi-armed bandit, multi-agent, coordination graph, small-cell networks, reinforcement learning.I Introduction
In recent decades, the proliferation of mobile devices results in a steep growth of mobile data traffic, which imposes heavy pressure on backhaul links with limited capacity in cellular networks. Due to the fact that only a small number of files accounts for the majority of the data traffic, caching popular files at small base stations (SBSs) has been widely adopted to reduce the traffic congestion and alleviate the backhaul pressure [2, 3]. Many previous works have studied the cache placement problem with various cache strategies and performance metrics. In [4, 5, 6], the authors focus on the deterministic caching that SBSs cache files entirely without partitioning. The works [7, 8, 9] consider the probabilistic caching that SBSs cache files according to certain well-designed probabilities. The authors in [10, 11, 12] consider the coded caching that files are partitioned into multiple segments, and these segments after coding are cached at SBSs. However, these works on wireless caching rely on a strong assumption that file popularity or user preference is perfectly known in advance, which is somehow unrealistic in general. Therefore, caching design without the knowledge of file popularity or user preference is a necessary but challenging issue. The aim of this work is to address the above issue by investigating the caching design when user preference is unknown.
Several works have studied the wireless caching problem without the knowledge of file popularity or user preference. Some of them tackle this problem by first estimating file popularity (or the number of requests) and then optimizing the cache strategy based on the estimated file popularity (or estimated number of requests) [13, 14, 15, 16, 17, 18, 19, 20]. The authors in [15, 16] estimate the file popularity by using multi-armed bandit (MAB) and then the SBS caches the most popular files in the single SBS scenario. In [17], the authors utilize MAB to estimate the local popularity and then optimize the coded caching in the multiple SBSs scenario. The work [18] also utilizes MAB to estimate local popularity of each SBS and then optimize the cache strategies to minimize the total cost of multiple SBSs with centralized and distributed algorithms. In [20], the authors estimate the local popularity and global popularity first, and then utilize Q-learning to choose cache actions with local popularity, global popularity and cache strategy as state.
Note that all these works [15, 16, 17, 13, 18, 14, 19, 20] only focus on the file popularity (local or global) or the requests collected from multiple users in a cell since they either assume that different users have the same preference or adopt cache hit as the performance metric. However, different users may have different preferences in practice. Moreover, adjacent SBSs need to design their cache strategies collaboratively as they can communicate with a common set of users. If we consider file popularity from a set of users rather than user preference, SBSs cannot know whether these requests are from the users that are only covered by one SBS or the users that are covered by multiple SBSs. Therefore, SBSs cannot design the cache strategy collaboratively. Thus, some recent works[21, 22, 23, 24] focus on the caching strategy design based on user preference rather than file popularity when user preference is unknown. Recently, the work [21] utilizes contextual MAB to learn the context-specific content popularity online and takes the dependence of user preference on their context into account. With the estimated context-specific content popularity, SBSs cache files to maximize the accumulated cache hits. In [22], the authors propose an online content popularity prediction algorithm by leveraging the content features and user preference. Then they propose two learning-based edge caching architectures to design the caching policy. Though the authors in [21, 22] consider the multiple SBSs scenario, the correlations among SBSs are not considered. In [23], the authors propose a new Bayesian learning method to predict personal preference and estimate the individual content request probability. Based on the estimated individual content request probability, a reinforcement learning algorithm is proposed to optimize the deterministic caching by maximizing the system throughput. The work [24] first utilizes the expectation maximization method to estimate the user preference and activity level based on the probabilistic latent semantic analysis model. A low-complexity algorithm is then developed to optimize the D2D cache strategies by maximizing the offloading probability based on the estimated user preference and activity level. However, a training phase is required in [23, 24], which cannot well adapt to the time-varying environment, comparing to online methods. Due to the fact that context information of users is private and the historical request number of a single user is often very limited, online estimation of user preference is very difficult in practice. Therefore, some works try to make caching decisions directly, rather than estimating user preference first and then optimizing cache, to minimize the long-term cost or maximize the long-term reward by using reinforcement learning [25, 26] and deep reinforcement leaning [27]. However, these works [25, 26, 27] only focus on the single-cell performance and no coordination among multiple SBSs exists. To our best knowledge, an online collaborative caching problem without the prior knowledge of user preference at the user level has not been well studied in the literature.
In this paper, we aim to optimize the collaborative caching among multiple SBSs by minimizing the accumulated transmission delay over a finite time horizon in cache-enabled wireless networks when user preference is unknown. The cache strategies need to be optimized collaboratively since each user can be covered by multiple SBSs and experiences different delays when it is served by different SBSs. Thus, SBSs need to learn and decide the cache strategies collaboratively at each time slot over a finite time horizon. Since earlier decision of caching would shape our knowledge of caching rewards that our future action depends upon, this problem is fundamentally a sequential multi-agent decision making problem. Rather than estimating user preference first and then optimizing the cache strategy, we learn the cache strategies directly at SBSs online by utilizing multi-agent MAB (MAMAB). This is because estimating the preference of each individual user is difficult due to the limited number of requests from a single user. Besides, contextual information of users, such as age and gender may not be utilized to estimate user preference due to privacy concerns. On the other hand, the caching reward in the MAMAB framework considered in our work is defined as the transmission delay reduction compared to the case without caching. It represents the aggregate effect of all user requests and hence can be learned more accurately and with faster speed. Our prior conference paper [1] considered the distributed and edge-based collaborative MAMAB algorithms only in the stationary environment, without the theoretical proof of performance guarantee. The main contributions and results of this journal version are summarized as follows.
-
•
We formulate the collaborative caching optimization problem to minimize the accumulated transmission delay over a finite time horizon in cache-enabled wireless networks without the knowledge of user preference. By defining the reward of caching, we first model this sequential decision making problem in a MAMAB perspective, which is a classical reinforcement learning framework. We then solve this MAMAB problem in both stationary and non-stationary environment.
-
•
In the stationary environment, we first propose two high-complexity agent-based collaborative MAMAB algorithms with the performance guarantee that the regret is bounded by , where is the total number of time slots. To reduce the computational complexity, we also propose a distributed MAMAB algorithm, which ignores the SBSs coordination. By taking both SBS coordination and computational complexity into account, we propose an edge-based collaborative MAMAB algorithm based on the coordination graph edge-based reward assignment method. We also modify the above MAMAB algorithms by designing new perturbed terms to achieve a better performance.
-
•
In the non-stationary environment, we modify the MAMAB algorithms proposed in the stationary environment by proposing a practical initialization method and designing new perturbed terms in order to adapt to the dynamic environment.
-
•
Simulation results are provided to demonstrate the effectiveness of our proposed algorithms in both stationary (synthesized data) and non-stationary environment (Movielens data set) by comparing with some benchmark algorithms. The effects of communication distance, cache size and user mobility on caching performance are also discussed.
The rest of the paper is organized as follows. The system model is introduced in Section II. Then we formulate the problem in Section III. In Section IV and Section V, we solve this problem in stationary and non-stationary environment, respectively. We then present the simulation results in Section VI. Finally, we conclude the paper in Section VII.
Notations: This paper uses bold-face lower-case for vectors and bold-face uppercase for matrices. denotes the zero vector. denotes the indicator operator that if the event is true and otherwise.
II System Model
II-A Network Model
We consider a SCN where cache-enabled SBSs and users are located in a finite region as illustrated in Fig. 1. The sets of users and SBSs are denoted as and , respectively. We assume that SBSs have a limited communication distance , which means that SBS can communicate with user if the distance between them does not exceed . Thus, we define the neighbor SBSs of user as the set of SBSs that can communicate with user , which is denoted as . We sort the distance for in an increasing order such that denotes the index of the -th nearest SBS to user . Similarly, the set of the neighbor users of SBS is denoted as .

II-B Cache Model
There is a file library with size and all files are assumed to be the same normalized size of 111For the unequal size case, we can divide each files into chunks of equal size, so the analysis and algorithms in this paper still can be applied.. Each SBS is equipped with a local cache with size . Define a cache matrix to denote the cache strategy of SBSs at time slot . The cache matrix should satisfy the cache size constraint for at each time slot.
II-C Service Model
We adopt the total transmission delay as the performance metric. When SBS serves its neighbor user by transmitting a file with unit size, the user will experience a transmission delay . We model the transmission delay in the noise-limited network and hence interference can be neglected. By considering the large-scale fading only, the signal-to-noise ratio (SNR) between user and SBS is given by , where is the transmission power of SBSs, is the path loss exponent and is the Gaussian white noise power. The transmission delay between user and its neighbor SBS by transmitting a file with unit size is , where is the bandwidth. Note that users will experience a larger transmission delay if they are served by farther SBSs. For the non-neighbor SBSs , the transmission delay since the communication link cannot be established between them.
Each user requests for files according to its own preference. The requests of user at time slot is denoted as a set with . This means that a user can request any number of files at a time slot since a time slot contains several hours or even one day in practice. Therefore, SBSs can satisfy multiple requests at a time slot. For a user requesting file at a given time instance, it will be served by the nearest neighbor SBS that caches file . If none of its neighbor SBSs caches file , the core network will satisfy this request, which induces a much larger transmission delay comparing to the delay when requests are served by SBSs locally, i.e., for . Note that when is large enough, all users can be connected to all SBSs in . This fully connected network is actually a special case of our problem. All parameters are summarized in Table I.
| Notation | Definition |
|---|---|
| SBSs set | |
| Users set | |
| Files set | |
| Neighbor SBSs set of user | |
| Neighbor users set of SBS | |
| Cache matrix | |
| Requests set of user | |
| Cache size | |
| Index of -th nearest SBS of user | |
| Communication distance | |
| Transmission delay between SBS and user | |
| Transmission delay of the core network |
III Problem Formulation
Our goal is to design cache strategies online to minimize the accumulated transmission delay over a time horizon when user preference is unknown. In this section, we model this cache optimization problem as a sequential multi-agent decision making problem and reformulate this problem in a MAMAB perspective.
For a user that requests file at time slot , it can be satisfied by either one neighbor SBS or the core network. If at least one neighbor SBS that caches the requested file of the user, the user will be served by the nearest SBS that caches the requested file. In this case, the transmission delay depends on the nearest neighbor SBS that caches the requested file, regardless of other farther SBSs. If none of the neighbor SBSs caches the requested file, i.e., for all , the user will be served by the core network and experience a much larger delay . Since we focus on the transmission delay from the user perspective, the total transmission delay of the network at time slot is the sum of all individual delays for all users, which is given by:
| (1) |
We aim to minimize the accumulated transmission delay of the network over the time horizon by learning and optimizing the cache strategy at each time slot when the requests of all users are not known in advance. The optimization problem is formulated as:
| (2a) | ||||
| s.t | (2b) | |||
| (2c) |
Note that the optimization problem P1 is a classical caching optimization problem and has been solved if user requests and transmission delays between SBSs and users are perfectly known in advance, which is very difficult in practice. Most traditional learning-based caching works estimate the file popularity first and then optimize the cache strategy since they adopt cache hit rate as the performance metric and assume that different users have the same preference. While for optimization problem P1, estimating requests of a single user online is much more difficult than estimating file popularity since the request number of a single user is much smaller than the request number from multiple users in a cell. Besides, users contextual information, such as age and gender, are private and we cannot utilize them to group users and learn preference from a group of users as work [21] does.222To our best knowledge, there is no work that estimates user preference online. References [23, 24] obtain the accurate values of estimated user preference in the training phase, which cannot adapt to time-varying environment well. Therefore, the conventional predict-then-optimize approach cannot be utilized in this problem. Besides, the optimization problem P1 is still NP-complete [5] even when the user requests and transmission delays between SBSs and users are perfectly known. Note that the proposed greedy algorithm in [5] to solve P1 has a high computational complexity since the greedy algorithm needs to exhaustively search all feasible file-SBS pairs and choose the best one at each step. This step is repeated until the caches of all SBSs are full. Therefore, instead of estimating the user requests first and then optimizing the cache strategy, we would like to learn the cache strategy directly with a low-complexity algorithm to make sequential caching decisions. Note that reinforcement learning is an effective tool to solve sequential decision making problems. Rather than applying other reinforcement learning algorithms, such as Q-learning, we model this multi-agent sequential decision making problem in a MAMAB perspective since MAB represents a simple class of online learning models with fewer assumptions of the environment. Furthermore, we shall show that the performance of the proposed MAMAB algorithms can be theoretically guaranteed later in Lemma 2.
Before reformulating P1 as a MAMAB problem, we define the reward of caching as the transmission delay reduction compared to the case without caching. Note that SBSs can observe the transmission delay if they serve their neighbor users with caching files. Besides, all SBSs know the transmission delay when users are served by the core network. Therefore, SBSs can observe the transmission delay and calculate the reward of caching files if they serve their neighbor users. The reward of SBS by caching file at time slot is given by:
| (3) |
By defining the reward, we can reformulate P1 without loss of optimality as:
| (4) | ||||
| s.t |
Optimization problem P2 is a MAMAB problem, where each SBS is seen as an agent and each file is seen as an arm. SBSs decide the cache strategy based on its cumulative knowledge to maximize the accumulated reward with unknown distributions of the reward for caching different files. We can solve the optimization problem P2 by estimating the reward and then designing cache strategy at each time slot. Actually, P2 can be divided into independent sub-optimization problems, one for each time slot, called the single-period optimization (SPO) problem. For each SPO problem, the cache strategy is optimized with the estimated reward based on the historical reward observations. The objective of P2 is to maximize the accumulated reward over a time horizon based on its cumulative knowledge. Therefore, there exists a tradeoff between exploration (i.e., caching all files a sufficient number of times to estimate the reward more accurately) and exploitation (i.e., caching files to maximize the estimated reward).
For this MAMAB problem, its main difficulty compared to the single agent MAB problem is that there exists collisions among different agents (SBSs), i.e., for a user requesting a file, only the nearest neighbor SBS that caches the requested file can serve the user and obtain the reward while farther neighbor SBSs obtain no reward even if they cache the requested file. Therefore, how to make the caching decisions coordinately is challenging. In this paper, we utilize a coordination graph [28, 29] to represent the dependencies among SBSs, as shown in Fig. 1. In the coordination graph, each SBS represents a vertex. An edge indicates that the corresponding SBS and cover the common users, i.e., , which means that the cache strategies of SBS and need to be designed coordinately. Specially, each SBS has a self edge . We define the neighbor of the vertex in the coordination graph as . As we can see in (3), the reward of SBS by caching file depends on the joint cache action of SBSs and , which is denoted as . Therefore, can be rewritten as . Due to the fact that the user requests are unknown before designing the cache strategy, we can not analyse the property of the reward to solve the optimization problem. In this case, we can utilize MAMAB to estimate the reward and then decide the cache strategy directly.
IV Cache Strategy in Stationary Environment
In this section, we aim to solve P2 in the stationary environment. We first introduce the stationary environment and give the specific form of P2. Then we solve this problem with MAMAB-based methods in both distributed and collaborative manners. Finally, we modify the MAMAB algorithms by designing new perturbed terms to achieve a better performance.
IV-A Stationary Environment
The stationary environment is described as follows. The file library is a static set with fixed size and user preference is time-invariant. Denote as the probability that user requests file , which satisfies and . Each user is assumed to request one file at each time slot independently according to its own user preference. Moreover, the locations of users are fixed. Thus, transmission delays are time-invariant and can be observed when SBSs serve users or computed if the communication distance is known.
In this stationary environment, the expected reward of SBS by caching file is given by:
| (5) |
Since user preference is time-invariant, the solutions of different SPO problems of P2 are identical. Hence, we only need to focus on one SPO problem, which is given by:
| (6a) | ||||
| s.t | (6b) | |||
| (6c) |
Then we aim to solve the SPO problem P3 by using MAMAB-based algorithms in both distributed and collaborative manners with different reward decomposition methods.
IV-B Agent-based Collaborative MAMAB
In the following, we propose two agent-based collaborative MAMAB algorithms with different reward decomposition methods from the SBS perspective and user perspective, respectively.
IV-B1 SBS perspective
From (6a), it is observed that the total reward function is decomposed into a linear combination of local agent-dependent reward functions . The reward that SBS can obtain depends on the joint . In the initial phase , SBSs cache files randomly to make each joint action appear at least once. Note that can contain multiple time slots actually. The number of times that appears until is denoted as . Besides, if appears at time slot , we update the average reward of SBS with joint action as:
| (7) |
where is the observed reward of SBS with joint action at time slot . Each SBS needs to share its cache strategy with its neighbor in the coordination graph in order to update and . Note that the average reward is inaccurate when is small and hence utilizing the the average reward to decide the cache strategy is not appropriate. Therefore, we define the estimated reward by adding a perturbed term to the average reward similar to [30], which can achieve a good tradeoff between exploration and exploitation. The estimated reward is updated as:
| (8) |
where is the upper bound on the reward of SBS with joint action as:
| (9) |
Note that this perturbed term corresponds to the upper confidence bound (UCB) in MAB, which is utilized in the combinatorial MAB problem [30] with a single SBS. This UCB term can also be utilized in this MAMAB problem since the reward of each SBS for a fixed joint action has a stationary distribution in the stationary environment and the theoretical proof is shown later in Lemma .
With the estimated reward, we can optimize the cache strategy by maximizing the total estimated reward at each time slot with the cache size constraint. Note that this problem is NP-complete and the commonly used greedy algorithm has a high computational complexity[5]. Therefore, we propose a low-complexity coordinate ascent algorithm [31] to obtain the solutions. Coordinate ascent algorithm is an anytime algorithm that is appropriate for real-time multi-agent systems where decision making must be done under time constraints. Given a random initial cache strategy, each SBS optimizes its own cache and share its optimized cache strategy with its neighbor SBSs in the coordination graph sequentially while the other SBSs stay the same. This step is repeated until no improvement can be made under the time constraints. The details of the coordinate ascent algorithm are given in Algorithm 1.
For the performance of Algorithm 1, we have the following lemma.
Lemma 1.
Proof.
See Appendix A. ∎
Note that SBS with joint action only can obtain the reward for file if , the number of effective action space is , which grows exponentially with . Therefore, this agent-based collaborative MAMAB in a SBS perspective has a high computational complexity and a slow learning speed.
IV-B2 User perspective
Note that from the SBS perspective, the action space of is fixed. However, the reward distributions of SBS for some different are independent and identical and can be combined to reduce the action space. For example, if there is only one user covered by two SBSs, the reward distributions of SBS with joint action and are identical since will always be served by SBS if . Therefore, we focus on the reward of SBSs from the user perspective by decomposing total reward function into a linear combination of local agent-dependent reward functions as:
| (10) |
where is the joint action that SBS caches file while SBSs in do not and , where is the set of SBSs that are closer to user than SBS . The reason for only considering joint action is that SBS can serve user if and only if it is the nearest SBS that caches the requested file of user . In the initial phase , SBSs cache files randomly to make each joint action appear at least once similar to the agent-based collaborative MAMAB from the SBS perspective. The number of times that appears until is denoted as . Besides, if joint action appears at time slot , we update the average reward as:
| (11) |
where is the reward of SBS obtained by serving user with file . Note that each SBS needs to share its cache strategy with its neighbor in the coordination graph in order to update and average reward . By adding a perturbed term similar to (8), the estimated reward with joint action at time slot t is given by:
| (12) |
where is the upper bound on the reward of SBS with as:
| (13) |
SBSs optimize the cache strategies to maximize the total estimated reward at each time slot by utilizing Algorithm 1. Note that the effective action space of depends on the number of users and is in the worst case. Therefore, we conclude that commonly used agent-based collaborative MAMAB from the SBS perspective can be seen as the worst case of this new agent-based collaborative MAMAB algorithm from the user perspective. By analyzing the property of the caching problem, our proposed algorithm from the user perspective decreases the action space greatly compared to that from the SBS perspective when the user number is small by combining some joint actions together. However, as the user number keeps growing, the action space can be still very large as it grows exponentially with , which causes a high computational complexity and a slower learning speed.
Lemma 2.
The -approximation regret of these two agent-based collaborative MAMAB algorithms using an -approximation is on the order of .
Proof.
See Appendix B. ∎
This regret bound guarantees that the algorithm has an asymptotically optimal performance since . Therefore, we conclude that these two agent-based collaborative MAMAB algorithms converge to the optimal offline cache strategy in the stationary environment.
IV-C Distributed MAMAB
To avoid the curse of dimensionality, we try to solve P3 in a distributed manner. In this case, each SBS is regarded as an independent learner and it learns its own cache strategy independently without information exchange with other SBSs. Therefore, the total reward function is decomposed into a linear combination of agent-independent reward functions as:
| (14) |
which means each SBS totally ignores the reward and action of other SBSs. Note that (14) is not equivalent to (6a). It is just a function decomposition method, which is called the independent learner approach [32, 29] and is commonly used in reinforcement learning. In independent learner approach, the agents ignore the actions and rewards of the other agents, and learn their strategies independently. In the initial phase , each SBS independently caches all files once. The number of times that appears until is denoted as . Besides, if appears at time slot , the average reward of SBS with caching action is updated as:
| (15) |
where is the observed reward of SBS with action at time slot . By adding a perturbed term similar to (8), the estimated reward with at time slot is given by:
| (16) |
where is the upper bound on the reward of SBS with action and is given by:
| (17) |
Each SBS optimizes its cache strategy by maximizing its own estimated reward at each time slot independently. In this case, the effective action space is and has a linear growth speed of the number of SBSs, which has a low computational complexity and a fast learning speed. However, the performance is poor since there is no coordination among SBSs.
IV-D Edge-based Collaborative MAMAB
Based on the analysis of the above three MAMAB approaches, it is clear that a good solution should consider both SBS coordination and computational complexity simultaneously. Therefore, we propose a coordination graph edge-based reward assignment method by assigning the reward of SBSs to the edges in the coordination graph . In this case, we decompose the total reward function into a linear combination of edge-independent reward functions as:
| (18) |
where is the reward of the edge with joint action . Note that (18) and (6a) are not equivalent. It is just a reward assignment method by dividing the reward of agents to the edges in the coordination graph, which is utilized in reinforcement learning to reduce the complexity [29]. The main difficulty is how to design the specific coordination graph edge-based reward assignment method based on the problem property.
The coordination graph edge-based reward assignment method runs as follows. For a user requesting file at time slot , we assume that it is served by its neighbor SBS and SBS can obtain a reward . Note that SBS knows the locations of other SBSs and its serving user . If SBS is the nearest SBS of , then the reward obtained by serving will be entirely assigned to its self edge . This is because will always be served by in this case, regardless of whether other SBSs cache file or not. When SBS is not the nearest SBS of , it serves if and only if the nearer neighbor SBSs of do not cache the requested file . In this case, the reward is divided equally among the edges between the serving SBS and all the nearer neighbor SBSs with joint action since the reward depends on cache actions of SBS and . These split rewards on edges are stored at the serving SBS since only SBS caches the requested file and obtains the reward while other nearer SBSs not.
SBSs cache files randomly to make each joint action for appear at least once in the initial phase .333Note that the initial phase in the edge-based collaborative MAMAB algorithm is much shorter than the agent-based ones due to its smaller action space. At each time slot , SBSs update the number of times that joint action appears until , which is denoted as . If appears at time slot , the average reward of the edge with action pair is updated as:
| (19) |
where is the reward assigned to the edge with at time slot . Note that each SBS needs to share its cache strategy with its neighbor in the coordination graph in order to update and average reward . Moreover, each SBS only needs to store the reward of edge with joint action for and its self edge with action due to the coordination graph edge-based reward assignment method. By adding a perturbed term similarly, the estimated reward of the edge with joint action at time slot is given by:
| (20) |
where is the upper bound of the reward on the edge with joint action and it is given by:
| (21) |
SBSs optimize the cache strategies to maximize the total estimated reward at each time slot by utilizing Algorithm 1. Specifically, we choose cache strategy obtained from the distributed MAMAB algorithm as the initial cache strategy in Algorithm 1 to have a better performance and a faster convergence speed. Note that the edge-based collaborative MAMAB algorithm not only considers the SBS coordination, but also reduces the computational complexity greatly with effective action space , which grows linearly with the number of edges. The details of this algorithm are given in Algorithm 2.
IV-E Tradeoff between Exploration and Exploitation
As we have discussed, we add a perturbed term to the average reward to achieve the tradeoff between exploration and exploitation. However, there also exists some simple methods that can achieve a good tradeoff in MAMAB problems. One such simple and widely used algorithm is the -greedy algorithm, which caches files to maximize the total average reward with probability and caches files randomly with probability . -greedy algorithm can also be divided into different manners similarly with different reward decomposition methods.
We also propose a new perturbed term to update the estimated reward by exploiting the particular structure of the problem similar to [15] and the new perturbed term is rather than if the reward upper bound . Otherwise, the perturbed term is . The MAMAB algorithms with new perturbed terms are called MAMAB-v2 algorithms.
V Cache Strategy in Non-Stationary Environment
In this section, we aim to solve P2 in the non-stationary environment. We first give a brief introduction of the non-stationary environment. Then we modify our proposed MAMAB algorithms to make them adapt to the non-stationary environment. Finally, we discuss the tradeoff between exploration and exploitation.
V-A Non-stationary Environment
The non-stationary environment is described as follows. The file library is a dynamic set with new files entering and old files leaving over time. Besides, user preference changes irregularly over time and the number of requests for each user at a time slot is random. Note that users can keep silent and request no file at some time slots, the set of active users that request files also changes over time. Moreover, we take user mobility into account that user locations can change at different time slots. Thus, transmission delay also varies over time and cannot be known in advance. This non-stationary environment is more realistic since the real world scenario is actually non-stationary. However, this non-stationary environment also brings some challenges since it is time-varying and more stochastic. Therefore, we need to modify the algorithms proposed in the stationary environment to adapt to this non-stationary environment.444Nota that we only modify the distributed and edge-based collaborative MAMAB in this work since the action space of the agent-based collaborative MAMAB is too large, which is almost impractical to be utilized in the non-stationary environment.
V-B Modified MAMAB
Note that the proposed MAMAB algorithms in stationary environment have some prior information of the environment, such as static file set. However, SBSs have no knowledge of these information in the non-stationary environment. Therefore, we need to define an active file set at each time slot due to the fact that the file library is dynamic over time. is the set of files that are requested from time slot to and needs to be updated at the end of each time slot based on the receiving requests. Besides, we assign a large enough initial value to all joint actions of new added files in , rather than caching files randomly, to make each new joint action appear at least once. This new initialization method can reduce the explorations in the initial phase greatly and improve the performance compared to the initial phase in the stationary environment. Moreover, we need to design new UCB terms accordingly since SBSs have no information of the reward upper bound .
V-B1 Modified Distributed MAMAB
From the distributed MAMAB algorithm in the stationary environment, it is observed that the average reward if . Therefore, each SBS only initializes the estimated reward when for all active files , where is a large enough number in order to make each active file can be cached at SBSs at least once. At each time slot , each SBS updates the estimated reward for all files that have been cached at least once as:
| (22) |
where . Comparing with the distributed MAMAB in the stationary environment, we utilize the maximal average reward to represent the upper bound of the reward due to the upper bound of the reward cannot be obtained and changes over time in the non-stationary environment. Then each SBS decides its cache strategy by maximizing its own estimated reward. After caching action has been done, each SBS updates the number of times that appears and the average reward according to (15) based on the observed reward similar to the distributed MAMAB in the stationary environment. Finally, SBSs update the active file set at the end of time slot based on their receiving requests and initialize the estimated reward when for new added files.
V-B2 Modified Edge-based Collaborative MAMAB
From Algorithm 2, it is observed that the average reward if action pair when or . Therefore, we only need to focus on the edge when only one of them caches the file and the other does not, i.e., , and , which are called effective joint actions. We initialize the estimated reward of all effective joint actions with a large enough number . At time slot , SBSs update the estimated reward of all effective joint actions that appear at least once as:
| (23) |
where is seen as the upper bound of the reward on the edge with joint action for all active files at time slot . Then SBSs decide their cache strategies collaboratively to maximize the total estimated reward according to Algorithm 1. SBSs update and average reward according to (19) if joint action appears based on the observed reward that follow the coordination graph edge-based reward assignment. Finally, SBSs update the active file set at the end of time slot based on their receiving requests and initialize the estimated reward for all effective joint actions of new added files.
V-C Tradeoff between Exploration and Exploitation
As we have discussed, by adding the perturbed term to the average reward as the estimated reward is a good way to achieve the tradeoff between exploration and exploitation in the stationary environment. However, our proposed perturbed terms do not have theoretical performance guarantee in the non-stationary environment. Therefor, we can also utilize the -greedy algorithm to achieve the tradeoff between exploration and exploitation, which is simple but effective in many scenarios. In the -greedy algorithm, SBSs cache files to maximize the total average reward with probability and caches files randomly with probability . Note that -greedy algorithm can also be divided into both distributed and collaborative manners similarly with different average reward update manners.
VI Simulation Results
In this section, we demonstrate the performance of our proposed algorithms in both stationary environment and non-stationary environment. Simulations are performed in a square area of . Both SBSs and users are uniformly distributed in this plane. Unless otherwise stated, the system parameters are set as follows: bandwidth , transmission power of SBSs W, Gaussian white noise power W, path loss exponent and the core network transmission delay .
VI-A Stationary Environment
In the stationary environment, we assume that users request for files according to independent Zipf distributions. Specifically, the probability of user requesting file is denoted as , where is the Zipf parameter of user and means that file is the -th most interested file of . Unless otherwise stated, the simulation parameters are set as follows: the number of files , cache size and time horizon . We utilize the average transmission delay as the performance metric, which is defined as the ratio of the total transmission delay to the the number of time slots.


To evaluate the performance of the algorithms proposed in this paper, we compare them with the following benchmark algorithms:
Oracle Coordinate Ascent Algorithm: Cache files according to Algorithm 1 with random initial strategy and choose the best one when user preference is known.
Oracle Greedy Algorithm [5]: SBSs Cache files greedily when user preference is known.
CUCB Algorithm [17]: Each SBS estimates its local file popularity by using CUCB algorithm and then the cache strategy is optimized with the estimated local popularity coordinately.
Least Frequently Used (LFU) Algorithm [33]: Replace the file with the minimum requested times in the cache of each SBS with the requested file that is not available.
Least Recently Used (LRU) Algorithm [33]: Replace the least recently used file in the cache of each SBS with the requested file that is not available.
In this subsection, we first show the regret of MAMAB and MAMAB-v2 algorithms in both distributed and collaborative manners. Then, we evaluate the performance of our proposed algorithms by comparing them with benchmark algorithms. Finally, we demonstrate the performances of our proposed algorithms with respect to different communication distance and cache size.
For presentation convenience, the agent-based collaborative MAMAB in SBS perspective and user perspective are denoted as “Agent-based-1 C-MAMAB” and “Agent-based-2 C-MAMAB”, respectively. The edge-based collaborative MAMAB is denoted as “Edge-based C-MAMAB”. All the plots are obtained after averaging over independent realizations.
Time evolutions for the regret of MAMAB and MAMAB-v2 algorithms in different manners are plotted in Fig. 2(a) and Fig. 2(b), respectively. The regret is defined as the accumulated difference between the oracle coordinate ascent algorithm and the corresponding MAMAB algorithm. It is observed that Agent-based-1 C-MAMAB performs worst in Fig. 2(a) due to its large action space, which causes slow convergence speed. The Edge-based C-MAMAB outperforms three other MAMAB algorithms since it considers both SBS coordination and dimensions of action space, though it has no performance guarantee. In both MAMAB and MAMAB-v2 algorithms, Edge-based ones perform best and Agent-based-2 outperforms Agent-based-1, which means the large action space degrades the performance greatly. Comparing MAMAB and MAMAB-v2 algorithms, we find that MAMAB-v2 outperforms MAMAB notably by designing a new perturbed term, which means that they can achieve a better tradeoff between exploration and exploitation555MAMAB-v2 algorithms also outperform the -greedy and these results are not shown is this paper due to the page limit.. Therefore, we only focus on MAMAB-v2 algorithms in the following parts.
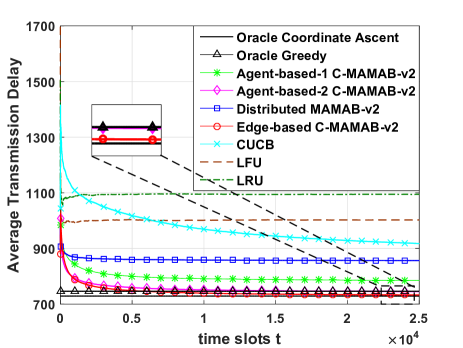

Fig. 3(a) and Fig. 3(b) compare the performance of MAMAB-v2 with some benchmark algorithms. It is shown that the low-complexity oracle coordinate ascent algorithm outperforms oracle greedy algorithm and they both can be seen as the performance upper bound since they know the full knowledge of user preference. Besides, MAMAB-v2 algorithms outperform LRU and LFU since they concentrate on the reward that SBSs can obtain rather than users requests. Moreover, MAMAB-v2 outperforms CUCB algorithm since it distinguishes user preference and file popularity. Besides, MAMAB-v2 also has a faster learning speed than predict-then-optimize CUCB method when users have the same preference. For different MAMAB-v2 algorithms, the Edge-based C-MAMAB-v2 performs best and almost can achieve the performance of the oracle algorithms. The Agent-based-1 C-MAMAB outperforms the distributed MAMAB when users have the same preference since it considers the SBS coordination. However, when users have different preference, Agent-based-1 C-MAMAB-v2 almost performs the same as the distributed one since the correlations among SBSs are weak.


Fig. 5 illustrates the average transmission delay of different MAMAB-v2 algorithms after time slots versus different communication distances . By increasing , the number of users that can be covered by multiple SBSs increases and the correlations among SBSs becomes stronger. Fig. 5 shows that both distributed and collaborative MAMAB-v2 algorithms almost can achieve the performance of the oracle greedy algorithm. This is because many users only have one neighbor SBS when is small and almost no correlations exist among SBSs. By increasing the communication distance , it is observed that the gap between oracle greedy algorithm and distributed MAMAB-v2 increases. This is because distributed MAMAB-v2 totally ignores the correlations among SBSs while the correlations among SBSs become larger when grows. The gap between oracle greedy and Agent-based-1 also increases when grows since the performance becomes poor when the action space is too large. While for the Agent-based-2 and Edge-based C-MAMAB-v2, they perform close to the oracle greedy for all since they take both SBS coordination and action space into account.
Fig. 5 depicts the average transmission delay of different algorithms after time slots versus different cache size . Note that the average transmission delay decreases as increases since more user requests can be satisfied by SBSs locally. However, the delay decreasing speed becomes smaller as the cache size increases, which is consistent with the Zipf distribution that a small number of popular files produce the majority of the data traffic. The Edge-based and Agent-based-2 C-MAMAB-v2 almost can achieve the performance of the oracle greedy. Comparing the performance of the Agent-based-1 C-MAMAB-v2 and distributed MAMAB-v2, it is observed that Agent-based-1 C-MAMAB-v2 performs better than distributed MAMAB-v2 when is large since it can make a better utilization of cache size by considering SBS coordination.
VI-B Non-stationary Environment




In this work, we model the non-stationary environment by using the data set from MovieLens [34]. This data set contains ratings of movies and these ratings were made by users from the year to . Due to the fact that a user only rating the movies after watching them, we assume that a rating of a user corresponds to a file request in this work. The time horizon is divided into time slots (days) and SBSs update the cache once everyday. Unless otherwise stated, Unless otherwise stated, we assume that locations of users are fixed at different time slots but the set of active users changes over time 666Note that users always request files at fixed locations in practice, such as at home or office. Therefore, we only consider the dynamic active users set and ignore the mobility of users., and the simulation parameters are set as follows: the number of SBSs and cache size . We utilize the average transmission delay as the performance metric, which is defined as the ratio of the total transmission delay to the the number of requests. To evaluate the performance of our proposed algorithms, we compare them with the following benchmark algorithms:
Oracle Coordinated Ascent Algorithm: Optimize the cache by utilizing the Algorithm 1 at each time slot when the user requests and transmission delays between SBSs and users are perfectly known in advance777The reason for choosing the coordinated ascent algorithm rather than the oracle greedy algorithm in the stationary environment is the high computation complexity of the greedy algorithm with large number of uses and files..
Distributed/Edge-based Collaborative -Greedy Algorithm (D/C--Greedy): SBSs cache files according to the -greedy algorithm based on the corresponding average reward rather than the estimated reward that contains the perturbed term.
Ridge Regression Algorithm: Each SBS estimates the number of requests for its neighbor users via ridge regression by utilizing all requests information, rather than only utilizing the information of caching files as [19], and then caches the most popular files at each time slot.
m-CACao[21]: SBSs cache files according to the context-aware proactive caching algorithm.
In this subsection, we first discuss the tradeoff between exploration and exploitation of modified MAMAB algorithms in the non-stationary environment. Then we validate the effectiveness of our proposed modified MAMAB algorithms. Finally, we discuss the effects of user mobility and communication distance of modified MAMAB algorithms. For presentation convenience, our proposed modified MAMAB algorithm in distributed and edge-based collaborative manners are denoted as “M-D-MAMAB” and “M-C-MAMAB”, respectively.
Fig. 7 illustrates the performance of our proposed modified MAMAB algorithms and -greedy algorithms with different values. It is observed that edge-based collaborative algorithms outperform the corresponding distributed algorithms. Comparing three distributed algorithms and three collaborative algorithms, we find that when the cache size is large (), our proposed modified MAMAB algorithms with perturbed terms can achieve a better tradeoff compared to -greedy algorithms. This is because large cache size can make SBSs play all actions sufficient times and hence our modified MAMAB algorithms have a fast learning speed to learn the reward of different actions accurately. However, when the cache size is small (), it is illustrated that -greedy algorithm with performs better than -greedy algorithm with and modified MAMAB algorithms in both distributed and edge-based collaborative manners. This means that when the cache size is small, doing more exploitations is better since SBSs have a lower speed to learn the reward accurately with such a small cache size.
Fig. 7 illustrates the performance of our proposed modified MAMAB and some reference algorithms. It is observed that the oracle coordinate ascent performs best since it knows all information of user requests and transmission delays between users and SBSs in advance. M-C-MAMAB outperforms M-D-MAMAB since it considers the SBSs cooperation. Besides, our proposed modified MAMAB algorithms outperform the ridge regression and m-CACao since they focus on the reward rather than the request number from a set of users. Therefore, we can conclude that MAMAB is more appropriate to solve this sequential decision making problem than the ridge regression that first utilizes all requests information to predict local popularity and then caches the most popular files. Moreover, M-D-MAMAB can tackle the cooperative caching problem among SBSs better than existing algorithms.
In Fig. 9, the effects of user mobility on the caching performance of modified MAMAB algorithms are evaluated. It is observed that modified MAMAB algorithms have a good performance no matter users are static or mobile. However, the gap between M-D-MAMAB and M-C-MAMAB becomes smaller when we take user mobility into account. This is because that M-D-MAMAB ignores the coordination among SBSs and has a smaller action space, and hence it has a faster learning speed to learn the reward accurately. Therefore, we can conclude that M-D-MAMAB is more robust than M-C-MAMAB when users are moving over time.
In Fig. 9, the performance of modified MAMAB algorithms after days versus is evaluated. By increasing , the average transmission delay of modified MAMAB algorithms decreases since more users can be covered and served by SBSs locally as grows. Comparing the performance of the modified MAMAB in distributed and collaborative manners, they perform the same when is small ( m). When becomes larger ( m), it is observed that the M-D-MAMAB even outperforms the collaborative one. This is because some joint actions of M-C-MAMAB only can serve a small number of users and have a small reward, but they still need to have enough explorations. Thus, SBSs choose these joint actions with small reward many times and lose the chance for more exploitations. But as keeps growing ( m), the correlations among SBSs become stronger and the number of users that are covered by multiple SBSs becomes larger, M-C-MAMAB outperforms M-D-MAMAB since it considers the coordination among SBSs and achieves a good tradeoff between exploration and exploitation.
VII Conclusion
In this work, we investigated the collaborative caching optimization problem to minimize the accumulated transmission delay without the knowledge of user preference. We model this sequential multi-agent decision making problem in a MAMAB perspective and solve it by learning cache strategy directly online in both stationary and non-stationary environment. In the stationary environment, we proposed multiple efficient MAMAB algorithms in both distributed and collaborative manners to solve the problem. In the agent-based collaborative MAMAB, we provided a strong performance guarantee by proving that its regret is bounded by . However, the computational complexity is high. For the distributed MAMAB, it has a low computational complexity but the correlations among SBSs are ignored. To achieve a better balance between SBS coordination and computational complexity, we also proposed a coordination graph edge-based reward assignment method in the edge-based collaborative MAMAB. In the non-stationary environment, we modified the MAMAB-based algorithms proposed in the stationary environment by proposing a practical initialization method and designing new perturbed terms to adapt to the dynamic environment better. Simulation results demonstrated the effectiveness of our proposed algorithms. The effects of the communication distance and cache size were also discussed.
Appendix A Proof of Lemma 1
is the cache strategy that SBS caches nothing and the other SBSs cache according to . is the optimal cache strategy. We utilize to combine different cache strategies together, e.g., , which means that SBS caches files in both and while the other SBSs cache files according to , and , which means that each SBS cache files in both and . Then, we can obtain:
| (24) |
where step (a) follows from the fact that caching more files increases the reward. Step (b) is obtained from that for any strategies and and A, we have since SBS and may cover the common users. For step (c) and (e), they are obtained from . This is because the cache strategy and may cache the common files. Step (d) follows from that is the optimal cache strategy of SBS when other SBSs adopt according to obtained from Algorithm 1. Therefore, we have , and the proof is completed.
Appendix B Proof of Lemma 2
The proofs of two agent-based collaborative MAMAB are similar and we only focus on the agent-based collaborative MAMAB in a SBS perspective. The reward of SBS with joint action is a random variable with expectation . The optimal reward is denoted as respect to the the expectation vector . For variable , the mean value of it after this joint action appears times is . In the -th time slot, let be the event that the oracle fails to produce an -approximate answer with respect to the estimated reward . We have 888The coordinate ascent oracle is proven to be an approximation with and in Appendix A.. The bad cache actions is denoted as . Then we define and .
We maintain counter for each joint action and we have since each joint action appear once in the initial phase. At each time slot , if we choose a bad action , we increase one minimum counter by one at this bad time slot, i.e., . Therefore, we have .
Define , where is the bounded smoothness function[30]. For a bad time slot with action , we have
| (25) |
Note that we have
| (26) |
where the last inequality comes from the Chernoff-Hoeffding Inequality.
Define a random variable and event
. We have . From (8), we have . Thus, implies that . In other words, we have , where is the vector of for all .
Let and define . Then we have
| (27) | |||
| (28) |
Therefore, if holds at time slot , we have
| (29) |
Since we have , contradicts the definition of . Therefore, we have . Then we can conclude that . Then we have
| (30) |
Therefore, the regret is given by
| (31) |
Therefore, the proof is completed. For the agent-based collaborative MAMAB in a user perspective, the proof is similar and hence is omitted here.
References
- [1] X. Xu and M. Tao, “Collaborative multi-agent reinforcement learning of caching optimization in small-cell networks,” in IEEE Proc. Global Commun. Conf., Dec. 2018.
- [2] X. Wang, M. Chen, T. Taleb, A. Ksentini, and V. C. Leung, “Cache in the air: exploiting content caching and delivery techniques for 5g systems,” IEEE Commun. Mag., vol. 52, no. 2, pp. 131–139, Feb. 2014.
- [3] E. Bastug, M. Bennis, and M. Debbah, “Living on the edge: The role of proactive caching in 5g wireless networks,” IEEE Commun. Mag., vol. 52, no. 8, pp. 82–89, Aug. 2014.
- [4] X. Peng, J.-C. Shen, J. Zhang, and K. B. Letaief, “Backhaul-aware caching placement for wireless networks,” in IEEE Proc.Global Commun. Conf., Dec. 2015, pp. 1–6.
- [5] K. Shanmugam, N. Golrezaei, A. G. Dimakis, A. F. Molisch, and G. Caire, “Femtocaching: Wireless content delivery through distributed caching helpers,” IEEE Trans. Inf. Theory, vol. 59, no. 12, pp. 8402–8413, Dec. 2013.
- [6] E. Bastug, M. Bennis, M. Kountouris, and M. Debbah, “Cache-enabled small cell networks: Modeling and tradeoffs,” EURASIP J. on Wireless Commun. and Netw., vol. 2015, no. 1, pp. 1–11, Feb. 2015.
- [7] B. Blaszczyszyn and A. Giovanidis, “Optimal geographic caching in cellular networks,” in IEEE Proc. Int. Conf. Commun., Jun. 2015, pp. 3358–3363.
- [8] S. H. Chae and W. Choi, “Caching placement in stochastic wireless caching helper networks: Channel selection diversity via caching,” IEEE Trans. Wireless Commun., vol. 15, no. 10, pp. 6626–6637, Oct. 2016.
- [9] Y. Chen, M. Ding, J. Li, Z. Lin, G. Mao, and L. Hanzo, “Probabilistic small-cell caching: Performance analysis and optimization,” IEEE Trans. Veh. Technol., vol. 66, no. 5, pp. 4341–4354, May. 2017.
- [10] M. A. Maddah-Ali and U. Niesen, “Fundamental limits of caching,” IEEE Trans. Inf. Theory, vol. 60, no. 5, pp. 2856–2867, May. 2014.
- [11] X. Xu and M. Tao, “Modeling, analysis, and optimization of coded caching in small-cell networks,” IEEE Trans. Commun., vol. 65, no. 8, pp. 3415–3428, Aug. 2017.
- [12] A. Tang, S. Roy, and X. Wang, “Coded caching for wireless backhaul networks with unequal link rates,” IEEE Trans. Commun., vol. 66, no. 1, pp. 1–13, Jan. 2018.
- [13] M. Leconte, G. Paschos, L. Gkatzikis, M. Draief, S. Vassilaras, and S. Chouvardas, “Placing dynamic content in caches with small population,” in IEEE Proc. Int. Conf. Comput. Commun., Apr. 2016, pp. 1–9.
- [14] S. Li, J. Xu, M. van der Schaar, and W. Li, “Trend-aware video caching through online learning,” IEEE Trans. Multimedia, vol. 18, no. 12, pp. 2503–2516, Dec. 2016.
- [15] P. Blasco and D. Gündüz, “Learning-based optimization of cache content in a small cell base station,” in IEEE Proc. Int. Conf. Commun., Jun. 2014, pp. 1897–1903.
- [16] P. Blasco and D. Gunduz, “Multi-armed bandit optimization of cache content in wireless infostation networks,” in IEEE Proc. Int. Symp. Inf. Theory, Jun. 2014, pp. 51–55.
- [17] A. Sengupta, S. Amuru, R. Tandon, R. M. Buehrer, and T. C. Clancy, “Learning distributed caching strategies in small cell networks,” in IEEE Proc. Int. Symp. Wireless Commun. Syst., Aug. 2014, pp. 917–921.
- [18] J. Song, M. Sheng, T. Q. Quek, C. Xu, and X. Wang, “Learning-based content caching and sharing for wireless networks,” IEEE Trans. Commun., vol. 65, no. 10, pp. 4309–4324, Oct. 2017.
- [19] P. Yang, N. Zhang, S. Zhang, L. Yu, J. Zhang, and X. S. Shen, “Content popularity prediction towards location-aware mobile edge caching,” IEEE Trans. Multimedia, pp. 1–1, Sep. 2018.
- [20] A. Sadeghi, F. Sheikholeslami, and G. B. Giannakis, “Optimal and scalable caching for 5g using reinforcement learning of space-time popularities,” IEEE J. Sel. Topics Signal Process., vol. 12, no. 1, pp. 180–190, Feb. 2018.
- [21] S. Müller, O. Atan, M. van der Schaar, and A. Klein, “Context-aware proactive content caching with service differentiation in wireless networks,” IEEE Tran. Wireless Commun., vol. 16, no. 2, pp. 1024–1036, Feb. 2017.
- [22] Y. Jiang, M. Ma, M. Bennis, F. Zheng, and X. You, “User preference learning based edge caching for fog-ran,” arXiv preprint arXiv:1801.06449, 2018.
- [23] P. Cheng, C. Ma, M. Ding, Y. Hu, Z. Lin, Y. Li, and B. Vucetic, “Localized small cell caching: A machine learning approach based on rating data,” IEEE Trans. Commun., pp. 1–1, 2018.
- [24] B. Chen and C. Yang, “Caching policy for cache-enabled D2D communications by learning user preference,” IEEE Trans. Commun., pp. 1–1, 2018.
- [25] S. O. Somuyiwa, D. G nd z, and A. Gyorgy, “Reinforcement learning for proactive caching of contents with different demand probabilities,” in Proc. Int. Symp. Wireless Commun. Syst, Aug 2018, pp. 1–6.
- [26] K. Guo, C. Yang, and T. Liu, “Caching in base station with recommendation via Q-learning,” in IEEE Proc. Wireless Commun. Netw. Conf., Mar. 2017, pp. 1–6.
- [27] C. Zhong, M. C. Gursoy, and S. Velipasalar, “A deep reinforcement learning-based framework for content caching,” in Proc. Annual Conf. Inf. Sci. Syst. (CISS), Mar. 2018, pp. 1–6.
- [28] C. Guestrin, D. Koller, and R. Parr, “Multiagent planning with factored MDPs,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2002, pp. 1523–1530.
- [29] J. R. Kok and N. Vlassis, “Collaborative multiagent reinforcement learning by payoff propagation,” J. Mach. Learn. Res., vol. 7, pp. 1789–1828, Sep. 2006.
- [30] W. Chen, Y. Wang, and Y. Yuan, “Combinatorial multi-armed bandit: General framework and applications,” in International Conference on Machine Learning, 2013, pp. 151–159.
- [31] N. Vlassis, R. Elhorst, and J. R. Kok, “Anytime algorithms for multiagent decision making using coordination graphs,” in Proc. Int. Conf. Syst., Man Cybern. (ICSMC), vol. 1, Oct. 2004, pp. 953–957.
- [32] C. Claus and C. Boutilier, “The dynamics of reinforcement learning in cooperative multiagent systems,” AAAI/IAAI, vol. 1998, no. 746-752, p. 2, 1998.
- [33] D. Lee, J. Choi, J.-H. Kim, S. H. Noh, S. L. Min, Y. Cho, and C. S. Kim, “LRFU: a spectrum of policies that subsumes the least recently used and least frequently used policies,” IEEE Trans. Comput., vol. 50, no. 12, pp. 1352–1361, Dec 2001.
- [34] F. M. Harper and J. A. Konstan, “The movielens datasets: History and context,” ACM Trans. Interact. Intell. Syst., vol. 5, no. 4, pp. 1–19, Dec. 2015.