Co-occurrence order-preserving pattern mining
Abstract.
Recently, order-preserving pattern (OPP) mining has been proposed to discover some patterns, which can be seen as trend changes in time series. Although existing OPP mining algorithms have achieved satisfactory performance, they discover all frequent patterns. However, in some cases, users focus on a particular trend and its associated trends. To efficiently discover trend information related to a specific prefix pattern, this paper addresses the issue of co-occurrence OPP mining (COP) and proposes an algorithm named COP-Miner to discover COPs from historical time series. COP-Miner consists of three parts: extracting keypoints, preparation stage, and iteratively calculating supports and mining frequent COPs. Extracting keypoints is used to obtain local extreme points of patterns and time series. The preparation stage is designed to prepare for the first round of mining, which contains four steps: obtaining the suffix OPP of the keypoint sub-time series, calculating the occurrences of the suffix OPP, verifying the occurrences of the keypoint sub-time series, and calculating the occurrences of all fusion patterns of the keypoint sub-time series. To further improve the efficiency of support calculation, we propose a support calculation method with an ending strategy that uses the occurrences of prefix and suffix patterns to calculate the occurrences of superpatterns. Experimental results indicate that COP-Miner outperforms the other competing algorithms in running time and scalability. Moreover, COPs with keypoint alignment yield better prediction performance.
1. Introduction
A time series is a set of numerical values derived from consecutive records over a fixed time interval. Time series exist in many fields, such as market prediction (marketprediction, ), taxi demand prediction (taxiprediction, ), stock price prediction (stockpriceprediction, ; temperatureprediction, ), and brain EEG analysis (braineeg, ). Mining hidden information in time series can be used for big data analysis techniques (wutmis2022, ), such as clustering (Hanclustering2022, ), classification (deepforest, ), pattern recognition (Lirecognition2011, ; Yanrecognition2020, ) and predication (Leeprediction2022, ). Therefore, time series mining methods are significant and various algorithms have been proposed (Gharghabi1timeseries2020, ; Gharghabi2timeseries2018, ). For example, inspired by the three-way decisions theory (Zhan2threeway2022, ; seqthreeway, ), the NTP-Miner algorithm converts time series to characters and divides the alphabet into three regions: strong, medium, and weak, which can be applied to cluster analysis (WuNTP-Miner2022, ). The TBOPE classification algorithm builds an ensemble classifier that can improve classification performance (Baiclassification2021, ). The OWSP-Miner algorithm can recognize self-adaptive one-off weak-gap strong patterns, which are more valuable in real life (WuOWSP-Miner2022, ). Most time series mining must use representation methods to convert time series into discretized characters (pyramidpattern, ). Commonly used methods are piecewise linear approximation (PLA) (StoracePiecewise2004, ), piecewise aggregate approximation (PAA) (ChakrabartiLocally2002, ), and symbolic aggregate approximation (SAX) (LinExperiencing2007, ). However, the above-mentioned symbolization methods easily lead to the loss of trend information inside the original time series.
Recently, a method without symbolization named order-preserving pattern (OPP) matching has been proposed which can find all occurrences of a given OPP on numeric strings (Kimmatching2014, ). An OPP can represent a trend, which is a relative order that can effectively reflect fluctuations without discretizing the values into symbols (copp, ). Inspired by OPP matching, a new sequential pattern mining method, named OPP mining was proposed (WuOPP-Miner2022, ), which can discover frequent OPPs in time series. To improve the mining performance and discover all strong rules, order-preserving rule mining was explored (WuOPR-Miner2022, ). However, there are two main issues in the current research.
(1) The existing algorithms cannot cope with distortion and mine redundant patterns, since these algorithms mine directly on the original time series. For example, an OPP is (1,2,3,4,5), which represents an uptrend and can be replaced by the already discovered pattern (1,2), since (1,2) also represents an uptrend. Therefore, it is necessary to discover fewer and more targeted patterns that are more meaningful and unaffected by distortion.
(2) More importantly, the existing algorithms, such as OPP-Miner (WuOPP-Miner2022, ) and OPR-Miner (WuOPR-Miner2022, ), mine all of the patterns and use them for time series clustering and classification. But, in some cases, researchers want to discover patterns related to a specific pattern in historical data, and then utilize a summary of past trends to predict future changes. In this case, mining all the patterns would yield numerous meaningless results.
To tackle the above two issues, two methods need to be employed, respectively. For distortion, the keypoint alignment method (Lahrechekeypoints2021, ) can be used. Thus, to reduce distortion interference in time series, we do not mine on the original time series, but rather on the time series after extracting keypoints. Moreover, to avoid mining redundant patterns, co-occurrence pattern mining can be selected (danguoco, ; mcor, ). The reason is as follows. Although top-k pattern mining (Dong2Top-k2019, ; Gao3Top-k2016, ), closed pattern mining (Wu1closed2020, ; Truong2closed2019, ), and maximal pattern mining (Li1maximal2022, ; Vo2maximal2017, ) can reduce the number of patterns, users may be interested in a part of patterns, rather than all patterns, since all patterns are not sufficiently targeted. For example, when users know a specific prefix pattern in advance to make predictions, they only want to discover patterns with the same specific prefix pattern, and this mining method is called co-occurrence pattern mining (danguoco, ; mcor, ). This problem still exists in time series. For example, in time series prediction, users hope to use historical data to predict future values. Therefore, users know the latest values that can be further extracted as a prefix pattern. Based on the prefix pattern, users can predict future values. Thus, co-occurrence pattern mining is more targeted. An illustrative example is as follows.
Example 0.
Suppose we have a time series t = (16,8,11,10,12,16,17,13,20,18,21,22,18,14,21,24,23,27,25) shown in Fig. 1 and a predefined support threshold minsup=3. According to OPP-Miner, there are seven frequent OPPs: (1,2), (2,1), (1,2,3), (1,3,2), (2,1,3), (1,3,2,4), (2,1,3,4). Obviously, it is difficult for users to apply these trends information directly. We know that the latest three values of t are () = (23,27,25) whose relative order is (1,3,2), since =23 is the smallest value, =27 is the third smallest value, and =25 is the second smallest value. Moreover, it is easy to know OPP (1,3,2) occurs four times in t: (), (), (), and (). Thus, (1,3,2) is a frequent OPP. Hence, when we make a prediction, actually, we know the specific prefix pattern.

Now, we use the specific prefix pattern (1,3,2) to predict the further trend. Therefore, we only need to discover the patterns whose prefix pattern is (1,3,2). These discovered patterns are called co-occurrence order-preserving patterns (COPs). According to historical information, we know that (1,3,2,4) is also a frequent OPP and its prefix pattern is (1,3,2). Hence, (1,3,2,4) is a COP. Thus, compared with seven frequent OPPs, COP (1,3,2,4) is more targeted in predicting future trends. For example, is 28, which is greater than . Thus, the relative order of (, ) is (1,3,2,4), which means that the prediction is correct. If is less than , then the prediction is not correct.
From the above description, mining COPs with keypoint alignment for time series prediction is meaningful. The main contributions are as follows.
-
•
To avoid mining irrelevant trends and to obtain better prediction performance for time series, we explore COP mining, which can mine all COPs with the same prefix pattern, and we propose the COP-Miner algorithm.
-
•
COP-Miner is composed of three parts: extracting keypoints to reduce distortion interference and avoid mining redundant patterns, preparation stage to prepare for the first round of mining, and iteratively calculating supports of superpatterns and mining frequent COPs.
-
•
We propose the concept of fusion pattern which can effectively reduce the number of candidate patterns.
-
•
To further improve the efficiency of support calculation, we propose a support calculation method with an ending strategy which uses the occurrences of prefix and suffix patterns to calculate the occurrences of superpatterns.
-
•
To validate the performance of COP-Miner, we select ten competing algorithms and nine real time series datasets. Our experimental results verify that COP-Miner outperforms other competing algorithms and COPs with keypoint alignment yield better prediction performance.
2. Related work
Sequential pattern mining (SPM) is an important research direction in big data analysis (patternmining, ; wangapin, ; wu2014apin, ; Mavroudopoulos2022, ), which is widely used in bioinformatics (Zhangbioinformatics2021, ), keyword extraction (keywu2017, ; oneoffguo, ), feature selection (Wu1Top-k2021, ; gan2022, ; featureselection, ), and sequence classification (zengyouhe, ; li2012tkdd, ; philippe, ). To meet different needs in real life, various pattern mining methods have been proposed (gantkdd, ), such as episode pattern mining (Aoepisode2019, ), negative SPM (wunegativetkdd, ), three-way SPM (Min1threeway2020, ; threeway, ), contrast SPM (copp, ; Licontrast2020, ), high-utility SPM (gengmengkbs, ; Nawtmis, ; ganutil, ), spatial co-location pattern mining (Wang1colocation2022, ; Wang2colocation2018, ), and gap constraints SPM (nosep, ). However, most of these schemes aim to discover all patterns, which leads to numerous information that is not of interest to users. To reduce the number of mined patterns, top-k SPM (Dong2Top-k2019, ; Gao3Top-k2016, ), closed SPM (Wu1closed2020, ; Truong2closed2019, ), and maximal SPM (Li1maximal2022, ; Vo2maximal2017, ) have been proposed. However, in some cases, users have certain prior knowledge and want to obtain patterns with a specific prefix pattern. To solve this problem, some co-occurrence SPM methods were proposed, such as maximal co-occurrence SPM(mcor, ) and top-k co-occurrence patterns mining (Amagata1co-occurrence2019, ).
However, the above methods mainly focused on mining character sequences (such as biological and customer purchase behavior sequences), which are difficult to apply directly to time series (such as temperature changes and stock trading volumes). At present, the prevailing solution is to discretize the values into symbols by symbolic methods, such as PLA (StoracePiecewise2004, ), PAA (ChakrabartiLocally2002, ), and SAX (LinExperiencing2007, ), and then apply the above SPM algorithms to find frequent patterns in time series. But the drawbacks of symbolization cannot be ignored. First of all, the symbolization of time series may bring some noise. More importantly, it is difficult to discover the potential trends in time series, since the symbolization methods convert the real values into different symbols which means that these methods focus too much on specific values and ignore trends.
We have noticed a new approach in the field of pattern matching named OPP matching, which does not require symbolization of time series. For example, Kim et al. (Kimmatching2014, ) proposed an OPP matching solution and indicated trends based on the relative order of numerical values. Moreover, Kim et al. (oppmatchingscaling, ) studied an approximate order-preserving pattern matching problem with scaling. Inspired by OPP matching, our previous work proposed the OPP-Miner algorithm to discover all frequent OPPs (WuOPP-Miner2022, ) and further proposed the OPR-Miner algorithm to mine strong order-preserving rules from all frequent OPPs (WuOPR-Miner2022, ). The common characteristic of OPP-Miner and OPR-Miner is the discovery of all frequent patterns.
To mine patterns with user-specified prefix pattern, inspired by co-occurrence pattern mining (danguoco, ; mcor, ), we present a COP mining scheme for time series prediction. COP mining can discover fewer and more targeted patterns. Although we can employ OPP-Miner (WuOPP-Miner2022, ) or EFO-Miner (WuOPR-Miner2022, ) to discover all frequent OPPs at first, and then select the COPs, it is obviously inefficient and belongs to the brute-force approach, since this approach will discover many irrelevant patterns. Therefore, to discover COPs efficiently, we specially design an algorithm named COP-Miner.
3. Problem definition
This section presents the related concepts of COPs with specific prefix patterns for time series.
Definition 0.
(Original time series) An original time series is a finite sequence of numerical values derived from consecutive records over a fixed time interval, denoted by t = (), where 1 .
Considering that a time series can be disturbed easily by distortion, resulting in warping, scaling, and data perturbation, we extract the keypoints of a time series to eliminate distortion.
Definition 0.
(Keypoint time series) For a time series t, is a keypoint, iff it is the local minimum or local maximum and satisfies the following conditions (Lahrechekeypoints2021, ). The new time series k, called keypoint time series, is a time series composed of all keypoints in t.
-
(1)
If i=1 or i=N, then is the first or last point.
-
(2)
If and , or and , then is a local minimum point.
-
(3)
If and , or and , then is a local maximum point.
An illustrative example of time series and keypoint time series is shown as follows.
Example 0.
Suppose we have a time series t = (16,8,11,10,12,16,17,13,20,18,21,22,18,14,21,24,23,27, 25,28). =16 is a keypoint, since it is the first point. =8 is a keypoint, since =8 =16 and =8 =11. However, is not a keypoint, since =10 =12 =16. After extracting all keypoints, k = (16,8,11,10,17,13,20,18,22,14,24,23,27,25,28).
Definition 0.
(Sub-time series and keypoint sub-time series) Sub-time series p is also a group of numerical values () (1 ). After extracting keypoints, q = () (1 ) is a keypoint sub-time series of p.
Definition 0.
(OPP) The rank of an element in a sub-time series q is its rank order, denoted by . An order-preserving pattern (OPP) is represented by the relative order of q, described by o = R(q) = ().
Example 0.
Suppose we have a sub-time series p = (5,3,7,13,8). After extracting keypoints of p, the new keypoints sub-time series q is (5,3,13,8). Since 5 is the second smallest value in q, its rank order is two, i.e., (5)=2. Similarly, (3)=1, (13)=4, and (8)=3. The OPP of q is R(q) = (2,1,4,3).
Now, we give the definitions of occurrence, support, and frequent OPP.
Definition 0.
(Occurrence and support) For a keypoint time series k = () and an OPP o = (), is an occurrence of o in k, iff R(k’) = o, where k’ is a sub-time series (, , ) ( and ). The number of occurrences of o in k is called the support, denoted by sup(o, k).
Definition 0.
(Frequent OPP) If the support of OPP o in k is no less than the user-specified support threshold minsup (i.e., ), then o is a frequent OPP.
Example 0.
Suppose we have the same keypoint time series k as in Example 3 and keypoint sub-time series q = (5,3,13,8), and we set minsup=3. According to Definition 5, o = R(q) = (2,1,4,3). The relative order of sub-time series () = (11,10,17,13) are (2,1,4,3). Similarly, = = = (2,1,4,3). Therefore, , , , and are four occurrences of o in k. Thus, sup(o, k) = 4 is no less than minsup. Hence, o = (2,1,4,3) is a frequent OPP.
Based on the definition of frequent OPP, we present the definitions of prefix OPP, COP, and our problem.
Definition 0.
(Prefix OPP and suffix OPP, order-preserving subpattern and order-preserving superpattern) For an OPP x = (), pattern e = is the prefix OPP of x, denoted by e = prefixorder(x), and pattern s = is the suffix OPP of x, denoted by s = suffixorder(x). Moreover, e and s are the order-preserving subpatterns of x, and x is the order-preserving superpattern of e and s.
Definition 0.
(COP) Suppose we have a frequent OPP c = . If the relative order of () is o = , then pattern c is a COP of o.
Definition 0.
(Problem statement) Suppose we have a time series t, a user-specified minimum support threshold minsup, and a sub-time series p. After extracting keypoints, we obtain keypoint time series k and keypoint sub-time series q. Then, we get OPP o=R(q). Our goal is to discover all frequent COPs of pattern o in k.
Example 0.
We use the same keypoint time series k as in Example 3 and keypoint sub-time series q = (5,3,13,8), and we set minsup=3. According to Exampel 9, R(q) = (2,1,4,3). According to Definition 7, we know that , , , and are four occurrences of pattern c = (2,1,4,3,5). Thus, pattern c is a frequent COP of q, since its prefix OPP is (2,1,4,3) which is the same as R(q).
For clarification, the used symbols are listed in Table 1.
| Symbol | Description |
|---|---|
| t = | Original time series |
| k = | Keypoint time series |
| p = | User-specified sub-time series |
| q = | Keypoint sub-time series |
| o = | A frequent OPP, o = R(q) |
| = | Occurrences of OPP o |
| e = prefixorder(x) | Prefix OPP of x |
| s = suffixorder(x) | Suffix OPP of x |
| b = | Binary sequence after time series k conversion |
| d = | Binary sequence after pattern s conversion |
| u = | u = of, superpattern with length m+1 |
| v = | v = of, superpattern with length m+1 |
| c = | COP of pattern o |
4. Proposed algorithm
Although OPP-Miner (WuOPP-Miner2022, ) and EFO-Miner (WuOPR-Miner2022, ) can discover all frequent patterns, for COP mining, it is inefficient to obtain all frequent patterns and then to discover COPs. To tackle COP mining, we propose COP-Miner, which has three parts: a local extremum point (LEP) algorithm to extract keypoints shown in Section 4.1, a preparation stage to realize the first round of mining shown in Section 4.2, and iteratively calculating supports and mining frequent COPs shown in Section 4.3. Fig. 2 shows the framework of COP-Miner and the COP-Miner algorithm and its time and space complexities analysis are shown in Section 4.4.

4.1. Extracting keypoints
Traditional OPP mining operates directly on the original time series to find sub-time series with the same trend. But there are two issues that should be considered. On the one hand, there is a lot of redundant information in the mining results. For example, OPP (1,2) indicates an upward trend, and OPP (1,2,3) also indicates a continuous upward trend. On the other hand, point-by-point analysis of time series cannot cope with sequences in noisy environments like scaling, warping, and shifting. Therefore, the first key task in COP mining is to extract keypoints. Hence, we extract keypoints according to Definition 2, and the pseudo-code of the local extremum point (LEP) algorithm is shown in Algorithm 1.
Input: Time series t
Output: Keypoint time series k
4.2. Preparation stage
This section is designed to prepare for the first round of mining. The related definitions and examples are as follows.
Definition 0.
(Fusion pattern) For a keypoint sub-time series q and its corresponding OPP o = R(q), if suffixorder(o) = prefixorder(f), then f = () is called a fusion pattern of OPP o.
There are several methods to calculate the occurrences of the prefix OPP and suffix OPP.
-
1)
A simple method is to enumerate all possible patterns and to use a pattern matching method to calculate the supports of these patterns. The principle of the enumeration method is as follows. We enumerate all fusion patterns. Suppose the length of suffixorder(o) is m-1. It is easy to know there are m fusion patterns. Thus, we need to calculate the occurrences of m+1 patterns using pattern matching method. Obviously, this is a brute-force method.
-
2)
An efficient method is to reduce the number of support calculations using the pattern matching method, since this is the most time-consuming step. To tackle this issue effectively, according to the principle of EFO-Miner (WuOPR-Miner2022, ), we need to calculate the occurrences of pattern suffixorder(o) and its fusion patterns.
In this paper, we adopt the second method. For example, suppose the user specified a sub-time series (5,3,7,13,8). After extracting keypoints, the corresponding keypoint sub-time series is (5,3,13,8). o = R(q) = (2,1,4,3), which indicates that o is the prefix pattern specified by user, and o is an OPP corresponding to keypoint sub-time series. Firstly, we need to obtain o’s suffix OPP (1,3,2), since this is the common part of prefix pattern and its fusion patterns. Secondly, we employ the pattern matching method to calculate the occurrences of pattern (1,3,2). Finally, according to the principle of EFO-Miner (WuOPR-Miner2022, ), to calculate the supports of candidate superpatterns, we calculate the occurrences of the prefix pattern, i.e., the occurrences of pattern (2,1,4,3) and the occurrences of the suffix patterns, i.e., the occurrences of all fusion patterns of pattern (2,1,4,3).
Therefore, in the preparation stage, we have four steps: obtaining s = suffixorder(o), calculating the occurrences of pattern s, verifying the occurrences of pattern o based on , and calculating the occurrences of all fusion patterns of pattern o.
Step 1. Obtain suffix OPP s of pattern o according to Definition 10.
Example 0.
Suppose we have a pattern o = (2,1,4,3). Thus, its suffix is (1,4,3), and the corresponding suffix OPP is s = (1,3,2).
Step 2. Use the filtration and verification (FAV) algorithm (WuOPP-Miner2022, ) to calculate the occurrences of pattern s. The FAV has three steps: filtration, SBNDM2 matching, and verification. The filtration strategy is adopted to convert the time series and pattern into a binary sequence and a binary pattern. SBNDM2 matching (DurianImproving2010, ) is used to find the possible occurrences of a binary pattern in a binary sequence. The verification strategy is employed to check whether the possible occurrences are occurrences. This step is called filtration and verification (FAV).
Example 3 illustrates the principle of FAV.
Example 0.
Suppose we have the same keypoint time series k as in Example 3 and s = (1,3,2). Table 2 shows the element index of k. According to the filtration strategy, keypoint time series k is transformed into a binary sequence b. If , then =1; otherwise, =0. For example, and are 16 and 8, respectively. Thus, , i.e., =0. Similarly, =1. Finally, b = (0,1,0,1,0,1,0,1,0,1,0,1,0,1). Moreover, , since and are 1 and 3, respectively. Thus, =1. Similarly, =0. Therefore, s is transformed into d = (1,0). Then, according to SBNDM2 matching, we know that is a possible occurrence of pattern d in sequence b. Similarly, , , , , and are also possible occurrences. Finally, according to the verification strategy, we verify whether is an occurrence. For pattern d = (1,0), in b means () whose corresponding sub-time series in k is (). is the occurrence of pattern s in k, since , which is consistent with . Similarly, , , , and are also occurrences of pattern s, while is not.
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k | 16 | 8 | 11 | 10 | 17 | 13 | 20 | 18 | 22 | 14 | 24 | 23 | 27 | 25 | 28 |
Step 3. Verify the occurrences of pattern o based on . We know that s = () is the suffix pattern of o = (). Suppose is an occurrence of s, which means that the OPP of sub-time series () is R(s). Now, we verify whether is also an occurrence of o, which means verifying whether the OPP of sub-time series ( ) is o based on R(s). To verify it easily, we propose the lower position and upper position at first.
Definition 0.
(Lower position and upper position) We compare the values in () and () correspondingly. If , then j+1 is an unchanged position; otherwise, j+1 is a changed position. Among the unchanged positions, if the value in is the maximum value, then is called the lower position. Among the changed positions, if the value in is the minimum value, then is called the upper position.
Example 0.
In Example 2, we know s = (1,3,2) and o = (2,1,4,3). Now, we compare the values in (1,3,2) and (1,4,3) correspondingly. Obviously, 2 is an unchanged position, since ==1. Moreover, 2 is the lower position, since 2 is the only unchanged position. Similarly, 3,4 are changed positions, since =3 =4 and =2 =3. Among the changed positions 3,4, the value in 4 is the minimum value, since =3 =4. Thus, 4 is the upper position.
Then, based on lower and upper positions, we verify whether and are true. If it is true, then is also an occurrence of o; otherwise, is not. It is worth noting that or can be null. If it is null, the corresponding comparison is pruned.
Example 0.
In Example 5, we know that 2 and 4 are the lower and upper positions, respectively. Moreover, the length of pattern s = (1,3,2) is 3. Thus, m=3+1=4. For occurrence in Example 3, c-m+1=1. Then, we verify whether and are true or not. is not an occurrence of pattern o in k, since . Similarly, for occurrence , we verify whether and . We know that is an occurrence, since =11, =10, and =13. Moreover, , , and are three occurrences of o in k. Now, we validate that or can be null. Suppose o = (4,1,3,2) and s = (1,3,2). Thus, 2,3,4 are unchanged positions, while the changed position is null. Therefore, 3 is the lower position and the upper position is null, which means that we only need to verify whether .
The pseudo-code of verification occurrences for pattern (VOP) o is shown in Algorithm 2.
Input: OPP o and its suffix pattern s, occurrences of s: , keypoint time series k
Output: Occurrences of o:
Step 4. Calculate the occurrences of all fusion patterns of pattern o. In this step, the main issue is that given pattern s, sub-time series () according to occurrence , and new value , we calculate the OPP of k’ = (), i.e., R(k’). An easy method is to adopt a linear search method by comparing with () to obtain f = () based on (). Obviously, this method is inefficient. An efficient method is to employ the binary search method to calculate the relative order of , i.e., v = , which means that is the v-th smallest in k’. Furthermore, each in is calculated according to the binary search method. All fusion patterns are stored into a set , and corresponding occurrences are stored into .
Example 0.
We use Table 2 and Example 3 to illustrate this example. We know that s = (1,3,2) and = 4,6,8,12,14. Taking as an example, we calculate the OPP of (8,11,10,17). We can employ the binary search method, since (1,3,2) is the relative order of (8,11,10). It is easy to know that the rank order of 17 in (8,11,10,17) is 4. Thus, as an occurrence of (1,3,2,4) is stored into . Similarly, we know that the rank orders of , , , and are 4. Hence, = 5,7,9,13,15, and is (1,3,2,4).
The pseudo-code of calculating fusion patterns (CFP) is shown in Algorithm 3.
Input: Suffix pattern s of o, occurrences of s: , keypoint time series k
Output: Fusion patterns , occurrences of :
4.3. Calculating supports of superpatterns
Now, we know the occurrences of prefix OPP and suffix OPP. To calculate the supports of superpatterns, we propose the algorithm CSS based on pattern fusion whose principle is shown as follows.
Suppose = and = are occurrences of OPPs o = () and f = (), respectively. There are two cases for pattern o fused with pattern f.
Case 1: If = , then two superpatterns with length m+1, u = () and v = () are generated by u, v = o f, where and . For , if , then ; otherwise, if , then . Furthermore, the occurrences of u and v are calculated as follows: may be an occurrence of u or v, iff =+1. Then, we need to determine the values of and , where begin= and end=.
(1) If , then is not an occurrence of any superpattern.
(2) If , then is an occurrence of u, i.e., is added into , and and are pruned from and , respectively.
(3) If , then is an occurrence of v, i.e., is added into , and and are pruned from and , respectively.
Case 2: If , then a superpattern with length m+1, u = () is generated by u = o f.
(1) If , then =. For , if , then +1=; otherwise, +1=+1.
(2) If , then =+1. For , if , then +1=; otherwise, +1=+1.
Moreover, the occurrences of pattern u are calculated as follows: is an occurrence of u, iff =+1, i.e., is added into , and and are pruned from and , respectively. =.
According to Cases 1 and 2, we know that if we find an occurrence of the superpattern, then an element will be pruned from . Therefore, the size of gradually decreases. To further improve efficiency, we propose an ending strategy.
Ending strategy. If , then CSS is terminated.
Example 8 illustrates the principle of CSS.
Example 0.
In this example, we use the results of Examples 6 and 7. We know that o = (2,1,4,3) and = 6,8,12,14, = (1,3,2,4) and = 5,7,9,13,15. Pattern o can be fused with each frequent fusion pattern in using CSS. If =3, then a pattern that does not meet the threshold can be pruned. Suppose f = = (1,3,2,4). Patterns o and f can be fused into one pattern, i.e., o f = u = (2,1,4,3,5), since , which belongs to Case 2. We know the first element of is 6, and 7 is in . Thus, is an occurrence of u, i.e., is added into , and and are pruned from and , respectively. Similarly, , , and are also three occurrences of u; , , and are added into , i.e., = 7,9,13,15 and =4; , , and are pruned from ; , , and are pruned from , i.e., = and = 5. Hence, u = (2,1,4,3,5) is a frequent COP with length 5, since =4. Now, CSS is terminated, since the size of is zero.
Now, we prove that the ending strategy is correct. Before this, we first show that COP mining satisfies anti-monotonicity.
Theorem 9.
COP mining satisfies anti-monotonicity, that is, the support of a superpattern is not greater than that of its subpattern.
Proof.
Suppose is an occurrence of superpattern x = (). Then we can safely say that is an occurrence of subpattern () according to Cases 1 and 2. Therefore, the number of occurrences of a superpattern is not greater than that of its subpattern, i.e., the support of a superpattern is not greater than that of its subpattern. Hence, COP mining satisfies anti-monotonicity.
∎
Theorem 10.
The ending strategy is correct.
Proof.
When pattern o fuses with pattern f, if an occurrence of superpattern u or v is found, then the corresponding occurrence of is removed, which means that the size of gradually decreases. We know that COP mining satisfies anti-monotonicity. Therefore, when , if pattern o fuses with a new pattern w, then the support of superpattern is also less than minsup. Hence, CSS can be terminated, which means that we do not need to fuse pattern o with the other patterns in . ∎
The pseudo-code of CSS is shown in Algorithm 4.
Input: Keypoint time series k, OPP o of keypoint sub-time series q, occurrences of o: ,
fusion patterns , occurrences of : , and minsup
Output: Frequent COP set and their occurrences
4.4. COP-Miner
To mine all COPs of the given pattern o = R(q), we propose COP-Miner, whose main steps are as follows.
Step 1: Extract keypoints of time series t and sub-time series p using the LEP algorithm, and then obtain keypoint time series k and keypoint sub-time series q.
Step 2: Adopt the method of preparation stage to calculate the occurrences of pattern o and further generate all fusion patterns , thereby calculating the occurrences of all fusion patterns of pattern o.
Step 3: Use the CSS algorithm to calculate the supports of superpatterns, and then mine frequent COPs with length m+1.
Step 4: For each frequent pattern h in , adopt the CFP algorithm to calculate the occurrences of all fusion patterns of pattern h.
Step 5: Iterate Steps 3 and 4, until is empty.
Example 11 is used to illustrate the principle of COP-Miner.
Example 0.
Suppose we have the same time series t as in Example 3 and pattern p = (5,3,7,13,8), and we set minsup=3.
According to Step 1, we obtain keypoint time series k shown in Table 2 and keypoint sub-time series q = (5,3,13,8) using the LEP algorithm.
According to Step 2, the OPP of q is o = R(q) = (2,1,4,3), and we adopt the method of preparation stage to calculate the occurrences = 6,8,12,14. There is one fusion pattern = (1,3,2,4), whose occurrences is = 5,7,9,13,15.
According to Step 3, pattern o and fusion pattern can be fused into a superpattern u = (2,1,4,3,5) and = 7,9,13,15 using the CSS algorithm.
According to Step 4, u is the only frequent COP, and we store u into . Using the CFP algorithm, we discover two fusion patterns = (1,4,3,5,2) and = (1,3,2,5,4), whose occurrences are = 10 and = 8,14. is empty, since these two fusion patterns of pattern u are infrequent.
Therefore, all frequent COPs of pattern q are in C = (2,1,4,3,5).
The pseudo-code of COP-Miner is shown in Algorithm 5.
Input: Time series t, pattern p, minsup
Output: Frequent COPs C
Theorem 12.
The time complexity of COP-Miner is , where , , , , and are the lengths of the original time series t, the given prefix pattern p, the keypoint time series k, the keypoint pattern q, and the number of iterations of Line 8 in COP-Miner which means that the maximum length of the mined pattern is d+m, respectively.
Proof.
Line 1 of COP-Miner extracts the keypoints of the original time series and the given prefix pattern. The time complexity of Line 1 is . Line 2 calculates suffixorder(q) whose time complexity is . The time complexity of generating binary sequences in FAV is . The time complexity of SBNDM2 matching in FAV is . The time complexity of verification in FAV is . Thus, the time complexity of Line 3 is . The maximal length of Occs is less than . Thus, the time complexity of Line 4 (the VOP algorithm) is . Moreover, the time complexity of Line 2 in the CFP algorithm is . Therefore, the time complexity of Line 5 (the CFP algorithm) is . The CSS algorithm has two parts: generating superpatterns and calculating their occurrences. Thus, the time complexity of Line 6 (the CSS algorithm) is . The time complexity of Lines 8 to 15 is , since the number of iterations of Line 8 is . Hence, the time complexity of COP-Miner is .
∎
Theorem 13.
The space complexity of COP-Miner is .
Proof.
The space complexity of Line 1 of COP-Miner is , since LEP converts t and p into k and q, respectively. The space complexity of Line 2 is . The space complexity of Line 3 is . The space complexity of Line 4 (the VOP algorithm) is . The space complexity of Line 5 (the CFP algorithm) is . Moreover, the space complexity of Lines 8 to 15 is . Hence, the space complexity of COP-Miner is .
∎
5. Experimental results and analysis
In this section, we consider the performance of COP-Miner from multiple perspectives. Moreover, we answer the following five research questions (RQs) through experiments:
RQ1: Do we need to specially design an algorithm?
RQ2: What is the effect of each strategy in COP-Miner?
RQ3: Does COP-Miner have better scalability than other competing algorithms?
RQ4: How do different parameters affect the performance of COP-Miner?
RQ5: What is the impact of keypoint extraction on time series prediction?
To answer RQ1, we compared the efficiency of COP-Miner with OPP-Miner and EFO-Miner, which mine all OPPs and then filter COPs. To address RQ2, we proposed COP-kom, COP-noVOP, COP-noCFP, COP-efo, COP-enum, COP-noending, and FAV-sliding to verify the efficiency of COP-Miner (see Section 5.3). To answer RQ3, we conducted experiments on datasets of different lengths to report the performance of scalability (see Section 5.4). To address RQ4, we explored the effects of prefix patterns with different lengths and minimum support thresholds on the running time of the algorithm (see Section 5.5). To solve RQ5, we selected two models: autoregressive integrated moving average (ARIMA) (ARIMA, ; LiARIMA2022, ), dynamic time warping (DTW) (KeoghDTW2005, ), and proposed COP-noLEP to verify the prediction performance(see Section 5.6).
5.1. Datasets
We used nine real datasets for experimental evaluation. The electrocardiogram (ECG) datasets include KURIAS_HeartRate, KURIAS_PAxis, and KURIAS_PRInterval. They are part of a 12-lead ECG database with standardized diagnostic ontology, which can be downloaded at https://physionet.org /content/kurias-ecg/1.0/KURIAS-ECG. The stock datasets are the opening price of the S&P 500 and listed stocks on the New York Stock Exchange, which can be downloaded at https://www.yahoo.com/. To validate the performance of COP-Miner on large-scale dataset, we generated a synthetic real dataset named Big_NYSE by enlarging SDB8 440 times. The PM2.5 and temperature datasets are the records of Chengdu and Guangzhou, respectively, which can be downloaded at https://archive.ics.uci. edu/ml/datasets.php. The CSSE COVID-19 dataset is the information on the number of confirmed cases in Alabama, USA, which can be downloaded at https://datahub.io/core/covid-19. The specific description of each dataset is shown in Table 3.
| Dataset | Name | Type | Total length |
|---|---|---|---|
| SDB1 | KURIAS_HeartRate | ECG | 13,863 |
| SDB2 | KURIAS_PAxis | ECG | 13,863 |
| SDB3 | KURIAS_PRInterval | ECG | 13,863 |
| SDB4 | S&P 500 | Stock | 23,046 |
| SDB5 | ChengduPM2.5 | PM2.5 | 28,900 |
| SDB6 | GuangZhouTemp | Temperature | 52,582 |
| SDB7 | US_Alabama_Confirmed | CSSE COVID-19 | 56,304 |
| SDB8 | NYSE | Stock | 60,000 |
| SDB9 | Big_NYSE | Stock | 26,400,000 |
We ran the experiments presented in this paper on a computer with Intel(R) Core(TM) i5-5200U, 2.20GHZ CPU, 4.0GB RAM, and the Windows 10 64-bit operating system. The programming environment was IntelliJ IDEA 2019.2. All the algorithms and datasets can be downloaded from https://github.com/wuc567/Pattern-Mining/tree/master/COP-Miner.
5.2. Baseline methods
To evaluate the efficiency and prediction performance of the COP-Miner algorithm, we designed four experiments and selected ten competing algorithms for comparison.
1. OPP-Miner (WuOPP-Miner2022, ) and EFO-Miner (WuOPR-Miner2022, ): To validate that it is necessary to design a special algorithm, we applied OPP-Miner and EFO-Miner, which adopt a pattern matching strategy and subpattern’s matching results to calculate the support of superpattern, respectively. They both generate COPs based on find-all-frequent OPPs.
2. COP-kom: To validate the efficiency of the FAV (WuOPP-Miner2022, ) algorithm, we proposed COP-kom, which applies the KMP-Order-Matcher (Kimmatching2014, ) algorithm to obtain the occurrences of suffixorder(q).
3. COP-noVOP: To validate the efficiency of the VOP algorithm, we developed COP-noVOP, which does not use the VOP algorithm, but rather applies a linear search to obtain the occurrences of pattern q.
4. COP-noCFP: To validate the efficiency of CFP algorithm, we developed COP-noCFP, which does not use a binary search, but rather applies a linear search to calculate the occurrences of all fusion patterns.
5. COP-efo: To evaluate the superiority of the method of the preparation stage, we proposed COP-efo, which employs EFO-Miner (WuOPR-Miner2022, ) to calculate the occurrences of prefix pattern q and its fusion patterns.
6. COP-enum: To analyze the performance of pattern fusion strategy in CSS, we proposed COP-enum algorithm, which generates candidate patterns using an enumeration method.
7. COP-noending: To verify the effectiveness of the ending strategy, we developed COP-noending, which adopts the CSS algorithm to calculate the support, but does not use the ending strategy.
8. FAV-sliding: To verify the efficiency of the CSS algorithm, we designed FAV-sliding, which employs FAV (WuOPP-Miner2022, ) to calculate the occurrences of pattern s, and then uses the sliding windows to calculate the occurrences of superpatterns.
9. COP-noLEP: To verify the influence of extracting keypoints on the prediction performance, we developed COP-noLEP to generate COPs, which does not use the LEP algorithm, but rather mines COPs directly from the original time series.
5.3. Performance of COP-Miner
To determine the necessity of specially designing COP-Miner, we selected OPP-Miner and EFO-Miner as the competing algorithms. To evaluate the performance of the FAV, VOP, and CFP algorithms, we employed COP-kom, COP-noVOP, and COP-noCFP as competing algorithms. To evaluate the performance of the method of the preparation stage, we designed COP-efo as a competing algorithm. To evaluate the performance of the pattern fusion strategy and ending strategy, we employed COP-enum and COP-noending as competing algorithms. Moreover, to examine the performance of the CSS algorithm, we designed FAV-sliding as a competing algorithm. We set minsup=10 on SDB1-SDB8 and set minsup=6000 on SDB9. Since all ten algorithms are complete, they mine the same number of frequent patterns. When the length of a given pattern is six, i.e., = = (1,5,2,6,3,4), = (1,5,3,4,2,6), = (1,4,3,6,5,2), = = = = (1,3,2,5,4,6), and = (3,6,4,5,1,2), there are 5, 5, 6, 24, 21, 2, 2, 82, and 52 frequent COPs mined from SDB1-SDB9, respectively. Figs. 3 and 4 show the comparisons of running time and memory usage, respectively. We also show the comparisons of the numbers of candidate patterns and the number of occurrences of superpatterns in Figs. 5 and 6, respectively. It is worth noting that the information regarding the OPP-Miner and FAV-sliding algorithms are not presented in Fig. 6, since they do not use the occurrences of subpatterns to calculate the support of superpattern.




The results give rise to the following observations.
1. COP-Miner runs faster and costs less memory than both OPP-Miner and EFO-Miner. For example, on SDB9, it can be seen from Fig. 3 that OPP-Miner and EFO-Miner require 11,179.622s and 1,053.261s of running time, respectively, while COP-Miner needs 280.130s. Thus, COP-Miner is about 40 times and 4 times faster than OPP-Miner and EFO-Miner, respectively. In Fig. 4, OPP-Miner and EFO-Miner occupy 8,191.4Mb and 6,509.3Mb of running memory, respectively, while COP-Miner occupies only 2,099.8Mb. The reason is as follows. Both OPP-Miner and EFO-Miner discover COPs based on finding all frequent OPPs, which is a brute-force method to discover COPs. Thus, the two algorithms have to check more candidate patterns and generate more occurrences of superpatterns. Figs. 5 and 6 also verify these claims. From Fig. 5, OPP-Miner and EFO-Miner generate 12,153 and 10,404 candidate patterns, respectively, while COP-Miner generates only 64. From Fig. 6, EFO-Miner makes 441,900,345 comparisons while COP-Miner makes only 1,553,928. We can find the same effect on other datasets. Therefore, COP-Miner outperforms OPP-Miner and EFO-Miner, and it is necessary to specially design an algorithm for COP mining.
2. COP-Miner runs faster and requires less memory than COP-kom, COP-noVOP, and COP-noCFP. For example, on SDB4, it can be seen from Fig. 3 that COP-kom, COP-noVOP, and COP-noCFP require 0.400s, 0.380s, and 0.392s, respectively, while COP-Miner only needs 0.360s. From Fig. 4, COP-kom, COP-noVOP, and COP-noCFP occupy 9.380Mb, 4.915Mb, and 7.874Mb, respectively, while COP-Miner occupies only 4.594Mb. The reasons are as follows. The four algorithms employ the same CSS algorithm to calculate the supports of superpatterns. Thus, from Figs. 5 and 6, we know that the four algorithms generate the same number of candidate patterns and occurrences of superpatterns. For example, on SDB4, the four algorithms generate 57 candidate patterns and make 3,860 comparisons. The difference between COP-kom and COP-Miner is that COP-kom uses the KMP-Order-Matcher (Kimmatching2014, ) algorithm to find the occurrences of suffixorder(q), while COP-Miner adopts the FAV algorithm. The results indicate that FAV is more effective than KMP-Order-Matcher. Similarly, the results validate that the designed VOP algorithm is more efficient than the linear search to obtain the occurrences of pattern q, and the binary search in CFP is more effective than the linear search to calculate the occurrences of fusion patterns. Therefore, COP-Miner outperforms COP-kom, COP-noVOP, and COP-noCFP.
3. COP-Miner runs faster and consumes less memory than COP-efo. For example, on SDB6, from Fig. 3, COP-efo requires 0.497s, while COP-Miner only needs 0.349s. In Fig. 4, COP-efo occupies 21.822Mb, while COP-Miner occupies only 8.665Mb. The reason is as follows. COP-efo employs EFO-Miner to calculate the occurrences of prefix pattern q and its fusion patterns, which requires pattern fusion and multiple support calculations. Thus, COP-efo has to generate more occurrences of superpatterns. Fig. 6 also validates this claim. On SDB6, COP-efo makes 101,420 comparisons, while COP-Miner makes only 609. Moreover, from Fig. 5, COP-Miner and COP-efo each generate 11 candidate patterns, since they all apply the CSS algorithm to calculate the supports of superpatterns. The same effect can be found on all other datasets. Hence, the method of preparation stage is more efficient than EFO-Miner in calculating the occurrences of pattern q and its fusion patterns, and COP-Miner outperforms COP-efo.
4. COP-Miner runs faster and requires less memory than both COP-enum and COP-noending. For example, on SDB8, from Fig. 3, COP-enum and COP-noending require 0.492s and 0.478s of running time, respectively, while COP-Miner needs 0.464s. In Fig. 4, COP-enum and COP-noending occupy 10.762MB and 9.865MB of running memory, respectively, while COP-Miner occupies only 9.461Mb. The reasons are as follows. The enumeration method generates more candidate patterns than the pattern fusion strategy. Fig. 5 also validates this claim. On SDB8, COP-enum checks 1,039 candidate patterns, while COP-Miner only checks 97. The ending strategy can further reduce the number of occurrences of superpatterns. Fig. 6 also validates this claim. On SDB8, COP-noending makes 3,345 comparisons, while COP-Miner makes 3,298. The same effect can be found on all other datasets. Therefore, COP-Miner outperforms COP-enum and COP-noending.
5. COP-Miner runs faster and consumes less memory than FAV-sliding. For example, on SDB2, it can be seen from Fig. 3 that FAV-sliding requires 0.297s, while COP-Miner needs 0.230s. In Fig. 4, FAV-sliding occupies 11.886Mb, while COP-Miner occupies 10.189Mb. The reason is as follows. We know that FAV-sliding adopts sliding windows to calculate the occurrences of all possible superpatterns. This method can be seen as a linear search to find the co-occurrence patterns. Thus, FAV-sliding has to check more candidate patterns. Fig. 5 also validates this claim. On SDB2, FAV-sliding checks 28 candidate patterns, while COP-Miner only checks 19. The same effect can be found on all other datasets. Hence, COP-Miner outperforms FAV-Sliding.
In summary, the experimental results verify that COP-Miner yields better performance than the other nine competing algorithms.
5.4. Scalability
To evaluate the scalability of COP-Miner, we selected SDB8 with length 60K as the experimental dataset. Moreover, we created 120K, 180K, 240K, 300K, 360K, 420K, and 480K, which were two, three, four, five, six, seven, and eight times the size of SDB8, respectively. We set minsup=30 and the prefix pattern was (1,3,2,5,4,6). Comparisons of running time and memory usage are shown in Figs. 7 and 8, respectively.


The results give rise to the following observations.
From Figs. 7 and 8, we know that both the running time and memory usage of COP-Miner show linear growth with the increase of the size of the dataset. For example, the size of 480K is eight times of SDB8. COP-Miner takes 0.422s on 60K, and 1.008s on 480K, giving 1.008/0.422=2.389. The memory usage of COP-Miner is 19.059MB on 60K, and 81.521MB on 480K, giving 81.521/19.059=4.277. Thus, the running time and memory usage grow significantly slower than the increase in the dataset size. These results indicate that the time and space complexities of COP-Miner are positively related to the dataset size. This phenomenon can be found on all other datasets. More importantly, we can see that COP-Miner is about two times faster than COP-efo, and the memory usage of COP-efo also exceeds COP-Miner. Therefore, we conclude that COP-Miner has strong scalability, since the mining performance does not degrade as the dataset size increases.
5.5. Influence of parameters
We evaluated the effects of prefix patterns with different lengths and minsup on running time. To examine the influence, we selected SDB8 as the experimental dataset, which is the largest dataset in Table 3, and selected COP-kom, COP-noVOP, COP-noCFP, COP-efo, COP-enum, and COP-noending as the competing algorithms.
1) Influence of prefix patterns with different lengths:
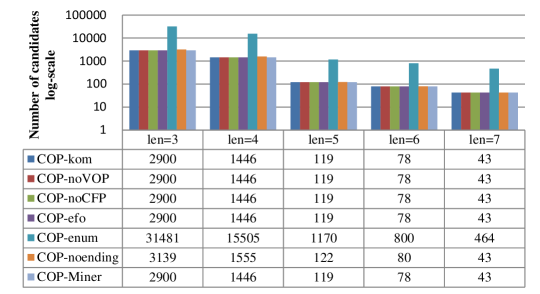
To report the influence of prefix patterns with different lengths on running time, we set minsup=12. The prefix patterns on SDB8 are (1,3,2), (1,3,2,4), (1,3,2,5,4), (1,3,2,5,4,6), and (1,4,2,6,5,7,3) with lengths 3, 4, 5, 6, and 7, respectively, and all the seven algorithms discover 2121, 1059, 94, 64, and 36 COPs for the five prefix patterns with different lengths, respectively. The comparisons of running time and numbers of candidate patterns on SDB8 are shown in Figs. 9 and 10, respectively.

The results give rise to the following observations.
As the length of the prefix pattern increases, the running time decreases, since the numbers of COPs and candidate patterns decrease. For example, from Figs. 9 and 10, when len=3, COP-Miner takes 2.075s, checks 2900 candidate patterns, and discovers 2121 COPs, whereas when len=7, COP-Miner takes 0.430s, checks 43 candidate patterns, and discovers 36 COPs. This phenomenon can be found on all other algorithms. The reason is as follows. As the length of the prefix pattern increases, fewer patterns can be found, thereby reducing the number of candidate patterns generated. We know that the fewer the candidate patterns, the shorter the running time. Thus, the running time also decreases. More importantly, COP-Miner outperforms other competing algorithms for any length prefix pattern, since it is the fastest algorithm, as explained in the analysis in Section 5.3.
2) Influence of different minsup:
To report the influence of different minsup on running time, we set minsup=8, 10, 12, 14, 16. The prefix pattern on SDB8 is (1,3,2,5,4,6). The seven algorithms discover 97, 82, 64, 48, and 39 COPs for five different minsup, respectively. The comparisons of running time and numbers of candidate patterns on SDB8 are shown in Figs. 11 and 12, respectively.


The results give rise to the following observations.
As the minsup increases, the running time decreases, since the numbers of candidate patterns and COPs decrease. For example, from Figs. 11 and 12, when minsup=8, COP-Miner takes 0.559s, checks 119 candidate patterns, and discovers 97 COPs, whereas when minsup=16, COP-Miner takes 0.440s, checks 51 candidate patterns, and discovers 39 COPs. This phenomenon can be found on all other algorithms. The reason for this is as follows. We know that for a certain prefix pattern, fewer patterns can be frequent patterns and candidate patterns as minsup increases. Hence, fewer COPs can be found and the running time also decreases. Moreover, COP-Miner outperforms other competing algorithms for any minsup, since it is the fastest algorithm, as explained in the analysis in Section 5.3.
5.6. Case study
In this section, we predict intervals of future values based on trend patterns found in historical time series by using COP mining. Fig. 13 gives the specific prediction by using COPs obtained on the training set of SDB6. The left side of the vertical line is the prefix pattern p = (1,3,2,4) obtained from the historical data. The right side of the vertical line is based on the mined COPs to predict the trend that may occur in the next stage. We selected the two patterns with the highest frequency and the second highest frequency on the training set to predict the possible intervals at the sixth time point. The two dotted lines represent the possible interval, and the results predicted that the sixth hour should be warmer than 29.3 degrees Celsius. The solid line represents the actual trend and the actual temperature at that time was 29.8.

To compare the prediction performance of COP-Miner, we selected two commonly used models: ARIMA (LiARIMA2022, ) and DTW (KeoghDTW2005, ) as comparison models, which predict the OPPs of subsequences similar to the prefix pattern on the original time series. Moreover, we also employed COP-noLEP as a competing algorithm to generate COPs, which does not use the LEP algorithm to eliminate the distortion of time series. We selected SDB1-SDB9 to evaluate the prediction performance and divided each dataset into a training set and a test set in a ratio of 8:2. The prefix patterns used for training are shown in Table 4.
| Dataset | Prefix pattern | Dataset | Prefix pattern | Dataset | Prefix pattern |
|---|---|---|---|---|---|
| SDB1 | (1,3,2,4) | SDB2 | (1,4,2,3) | SDB3 | (3,2,4,1) |
| SDB4 | (3,1,5,2,4) | SDB5 | (3,1,2,4,5) | SDB6 | (1,4,2,3) |
| SDB7 | (1,3,2) | SDB8 | (3,2,5,1,4) | SDB9 | (2,4,3,6,5,8,1,7) |
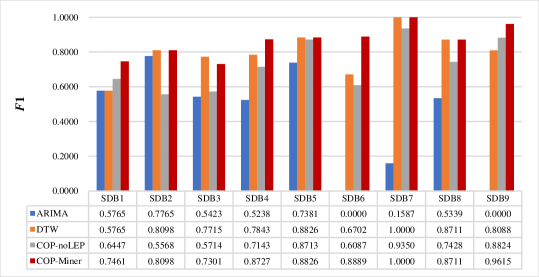
To evaluate the performance of prediction based on the co-occurrence patterns, there are three commonly used criteria: precision Pr = , recall Re = , and F1-score F1 = , where TP, FP, and FN are the numbers of the correctly predicted patterns, wrongly predicted patterns, and unpredicted patterns in the test set, respectively. There is no wrongly predicted pattern, i.e. FP=0, which means that the frequent co-occurrence patterns mined in the training set all appear in the test set of these nine datasets. Thus, Pr=1. Therefore, we did not choose precision as the criterion, but rather chose recall and F1-score. Recall can analyze the weight of the co-occurrence patterns mined through the training set in the test set. F1-score is a comprehensive consideration of precision and recall, which can more comprehensively evaluate the accuracy of the prediction results. Taking SDB8 as an example, we selected the top two COPs in the training set for COP-Miner: (4,3,6,1,5,2), (4,3,6,2,5,1). This result means that the value of the sixth point should be smaller than the corresponding true value of rank 3. In the test set, all length-6 patterns with the prefix pattern (3,2,5,1,4) are (3,2,6,1,5,4), (4,3,6,1,5,2), (4,2,6,1,5,3), and (4,3,6,2,5,1), and their supports are 20, 118, 54, and 132, respectively. The sum of supports of patterns (4,3,6,1,5,2), (4,3,6,2,5,1) and total supports are 118+132=250 and 324, respectively. Thus, recall and F1-score of COP-Miner on the test set are Re==0.7716 and F1==0.8711. Comparison of recall and F1-score results are shown in Figs. 14 and 15, respectively.

The results give rise to the following observations.
COP-Miner has higher accuracy than ARIMA and DTW prediction models. For example, on SDB1, the recall and F1-score of COP-Miner are 0.5950 and 0.7461, respectively, while those of ARIMA and DTW both are 0.4050 and 0.5765, respectively. This phenomenon can be found on most other datasets. The reason is as follows. The prediction results of ARIMA and DTW cannot accurately describe the trend characteristics, while COP-Miner is closer to the real data as a whole. Therefore, COP-Miner has better prediction accuracy than ARIMA and DTW.
COP-Miner has higher accuracy than COP-noLEP. For example, on SDB4, the recall and F1-score of COP-Miner are 0.7742 and 0.8727, respectively, while those of COP-noLEP are 0.5556 and 0.7143. This phenomenon can be found on all other datasets. The reason for this is as follows. The difference between COP-Miner and COP-noLEP is that COP-Miner uses the LEP algorithm to extract keypoints, while COP-noLEP does not. The results indicate that LEP can improve accuracy by removing unimportant trend information in time series. Therefore, COP-Miner yields better prediction accuracy than COP-noLEP.
6. Conclusion
To discover all COPs with the same prefix pattern efficiently, we propose the COP-Miner algorithm, which consists of three parts: 1) extracting keypoints, 2) preparation stage, and 3) iteratively calculating supports and mining frequent COPs. To reduce distortion interference in time series and avoid mining redundant patterns, we propose the LEP algorithm to extract local extreme points and to obtain keypoint sub-time series and keypoint time series, which can effectively improve the prediction performance compared to mining directly on the original time series. To prepare for the first round of mining, we propose the method of the preparation stage, which contains four steps: obtaining the suffix OPP of the keypoint sub-time series, calculating the occurrences of the suffix OPP, verifying the occurrences of the keypoint sub-time series, and calculating the occurrences of all fusion patterns of keypoint sub-time series. To calculate the support effectively, we propose the CSS algorithm, which adopts a pattern fusion method to generate candidate patterns and an ending strategy to further prune redundant patterns. Experimental results from nine real datasets verified that COP-Miner yields better running performance and scalability than other ten competing algorithms, especially on large-scale datasets, COP-Miner is about 40 times and 4 times faster than OPP-Miner and EFO-Miner, respectively. More importantly, COPs with keypoint alignment yield better prediction performance.
Acknowledgement
This work was supported by Hebei Social Science Foundation Project (No. HB19GL055).
References
- [1] Daichi Amagata and Takahiro Hara. Mining top-k co-occurrence patterns across multiple streams. IEEE Transactions on Knowledge and Data Engineering, 29(10):2249–2262, 2019.
- [2] Xiang Ao, Haoran Shi, Jin Wang, Luo Zuo, Hongwei Li, and Qing He. Large-scale frequent episode mining from complex event sequences with hierarchies. ACM Transactions on Intelligent Systems and Technology, 10(4):36, 2019.
- [3] Bing Bai, Guiling Li, Senzhang Wang, Zongda Wu, and Wenhe Yan. Time series classification based on multi-feature dictionary representation and ensemble learning. Expert Systems with Applications, 169:114162, 2021.
- [4] G. E. P. Box and David A. Pierce. Distribution of residual autocorrelations in autoregressive-integrated moving average time series models. Journal of the American Statistical Association, 65(332):1509–1526, 1970.
- [5] Kaushik Chakrabarti, Eamonn Keogh, Sharad Mehrotra, and Michael Pazzani. Locally adaptive dimensionality reduction for indexing large time series databases. ACM Transactions on Database Systems, 27(2):188–228, 2002.
- [6] Shuhui Cheng, Youxi Wu, Yan Li, Fang Yao, and Fan Min. TWD-SFNN: Three-way decisions with a single hidden layer feedforward neural network. Information Sciences, 579:15–32, 2021.
- [7] Chenglong Dai, Jia Wu, Dechang Pi, Stefanie I. Becker, Lin Cui, Qin Zhang, and Blake Johnson. Brain EEG time-series clustering using maximum-weight clique. IEEE Transactions on Cybernetics, 52(1):357–371, 2022.
- [8] Xiangjun Dong, Ping Qiu, Jinhu Lü, Longbing Cao, and Tiantian Xu. Mining top-k useful negative sequential patterns via learning. IEEE Transactions on Neural Networks and Learning Systems, 30(9):2764–2778, 2019.
- [9] Philippe Fournier-Viger, Wensheng Gan, Youxi Wu, Mourad Nouioua, Wei Song, Tin C. Truong, and Hai Van Duong. Pattern mining: Current challenges and opportunities. DASFAA 2022: Database Systems for Advanced Applications, pages 34–49, 2022.
- [10] Wensheng Gan, Jerry Chun-Wei Lin, Philippe Fournier-Viger, Han-Chieh Chao, and Philip S. Yu. A survey of parallel sequential pattern mining. ACM Transactions on Knowledge Discovery from Data, 13(3):25, 2019.
- [11] Chao Gao, Lei Duan, Guozhu Dong, Haiqing Zhang, Hao Yang, and Changjie Tang. Mining top-k distinguishing sequential patterns with flexible gap constraints. In International Conference on Web-Age Information Management, pages 82–94. Springer, 2016.
- [12] Shaghayegh Gharghabi, Shima Imani, Anthony Bagnall, Amirali Darvishzadeh, and Eamonn Keogh. Matrix profile XII: MPdist: A novel time series distance measure to allow data mining in more challenging scenarios. In IEEE International Conference on Data Mining, pages 965–970. IEEE, 2018.
- [13] Shaghayegh Gharghabi, Shima Imani, Anthony Bagnall, Amirali Darvishzadeh, and Eamonn Keogh. An ultra-fast time series distance measure to allow data mining in more complex real-world deployments. Data Mining and Knowledge Discovery, 34(4):1104–1135, 2020.
- [14] Dan Guo, Xuegang Hu, Fei Xie, and Xindong Wu. Pattern matching with wildcards and gap-length constraints based on a centrality-degree graph. Applied Intelligence, 39(1):57–74, 2013.
- [15] Dan Guo, Ermao Yuan, Xuegang Hu, and Xindong Wu. Co-occurrence pattern mining based on a biological approximation scoring matrix. Pattern Analysis and Applications, 21(4):977–996, 2018.
- [16] Nan Han, Shaojie Qiao, Kun Yue, Jianbin Huang, Tingting Tang Qiang He, Faliang Huang, Chunlin He, and Chang-An Yuan. Algorithms for trajectory points clustering in location-based social networks. ACM Transactions on Intelligent Systems and Technology, 13(3):43, 2022.
- [17] Zengyou He, Ziyao Wu, Guangyao Xu, Yan Liu, and Quan Zou. Decision tree for sequences. IEEE Transactions on Knowledge and Data Engineering, 35(1):251–263, 2023.
- [18] Gengsen Huang, Wensheng Gan, Jian Weng, and Philip S. Yu. US-rule: Discovering utility-driven sequential rules. ACM Transactions on Knowledge Discovery from Data, 17(1):10, 2023.
- [19] Eamonn Keogh and Chotirat Ann Ratanamahatana. Exact indexing of dynamic time warping. Knowledge and Information Systems, 7:358–386, 2005.
- [20] Jinil Kim, Peter Eades, Rudolf Fleischer, Seok-Hee Hong, Costas S. Iliopoulos, Kunsoo Park, Simon J. Puglisi, and Takeshi Tokuyama. Order-preserving matching. Theoretical Computer Science, 525:68–79, 2014.
- [21] Youngho Kim, Munseong Kang, Joong Chae Na, and Jeong Seop Sim. Order-preserving pattern matching with scaling. Information Processing Letters, 180:106333, 2023.
- [22] Abdelmadjid Lahreche and Bachir Boucheham. A fast and accurate similarity measure for long time series classification based on local extrema and dynamic time warping. Expert Systems with Applications, (168):114374, 2021.
- [23] Wu Lee, Yuliang Shi, Hongfeng Sun, Lin Cheng, Kun Zhang, Xinjun Wang, and Zhiyong Chen. MSIPA: Multi-scale interval pattern-aware network for ICU transfer prediction. ACM Transactions on Knowledge Discovery from Data, 16(1):1–17, 2022.
- [24] Chun Li, Qingyan Yang, Jianyong Wang, and Ming Li. Efficient mining of gap-constrained subsequences and its various applications. ACM Transactions on Knowledge Discovery from Data, 6(1):2, 2012.
- [25] Qing Li, Jinghua Tan, Jun Wang, and Hsinchun Chen. A multimodal event-driven LSTM model for stock prediction using online news. IEEE Transactions on Knowledge and Data Engineering, 33(10):3323–3337, 2021.
- [26] Qingzhe Li, Liang Zhao, Yi-Ching Lee, and Jessica Lin. Contrast pattern mining in paired multivariate time series of a controlled driving behavior experiment. ACM Transactions on Spatial Algorithms and Systems, 6(4):25, 2020.
- [27] Yan Li, Lei Yu, Jing Liu, Lei Guo, Youxi Wu, and Xindong Wu. NetDPO: (delta, gamma)-approximate pattern matching with gap constraints under one-off condition. Applied Intelligence, 52(11):12155–12174, 2022.
- [28] Yan Li, Chang Zhang, Jie Li, Wei Song, Zhenlian Qi, Youxi Wu, and Xindong Wu. MCoR-Miner: Maximal co-occurrence nonoverlapping sequential rule mining. IEEE Transactions on Knowledge and Data Engineering, 35(9):9531–9546, 2023.
- [29] Yan Li, Shuai Zhang, Lei Guo, Jing Liu, Youxi Wu, and Xindong Wu. NetNMSP: Nonoverlapping maximal sequential pattern mining. Applied Intelligence, 52(9):9861–9884, 2022.
- [30] Yangfan Li, Kenli Li, Cen Chen, Xu Zhou, Zeng Zeng, and Keqin Li. Modeling temporal patterns with dilated convolutions for time-series forecasting. ACM Transactions on Knowledge Discovery from Data, 16(1):1–22, 2022.
- [31] Zhenhui Li, Jiawei Han, Ming Ji, Lu-An Tang, Yintao Yu, Bolin Ding, Jae-Gil Lee, and Roland Kays. MoveMine: Mining moving object data for discovery of animal movement patterns. ACM Transactions on Intelligent Systems and Technology, 2(4):37, 2011.
- [32] Jessica Lin, Eamonn Keogh, Li Wei, and Stefano Lonardi. Experiencing SAX: A novel symbolic representation of time series. Data Mining and Knowledge Discovery, 15:107–144, 2007.
- [33] Qi Lin, Wensheng Gan, Yongdong Wu, Jiahui Chen, and Chien-Ming Chen. Smart system: Joint utility and frequency for pattern classification. ACM Transactions on Management Information Systems, 13(4):43, 2022.
- [34] Kunpeng Liu, Yanjie Fu, Le Wu, Xiaolin Li, Charu Aggarwal, and Hui Xiong. Automated feature selection: A reinforcement learning perspective. IEEE Transactions on Knowledge and Data Engineering, 35(3):2272–2284, 2023.
- [35] Pengfei Ma, Youxi Wu, Yan Li, Lei Guo, He Jiang, Xingquan Zhu, and Xindong Wu. HW-Forest: Deep forest with hashing screening and window screening. ACM Transactions on Knowledge Discovery from Data, 16(6):123, 2022.
- [36] Ioannis Mavroudopoulos and Anastasios Gounaris. SIESTA: A scalable infrastructure of sequential pattern analysis. IEEE Transactions on Big Data, 9(3):975–990, 2023.
- [37] Fan Min, Zhi-Heng Zhang, Wen jie Zhai, and Rong-Ping Shen. Frequent pattern discovery with tri-partition alphabets. Information Sciences, 507:715–732, 2020.
- [38] Saqib Nawaz, Philippe Fournier-Viger, M. Zohaib Nawaz, Guoting Chen, and Youxi Wu. MalSPM: Metamorphic malware behavior analysis and classification using sequential pattern mining. Computers & Security, 118:102741, 2022.
- [39] Saqib Nawaz, Philippe Fournier-Viger, Unil Yun, Youxi Wu, and Wei Song. Mining high utility itemsets with hill climbing and simulated annealing. ACM Transactions on Management Information Systems, 13(1):4, 2022.
- [40] Filipe Rodrigues, Loulia Markou, and Francisco C. Pereira. Combining time-series and textual data for taxi demand prediction in event areas: A deep learning approach. Information Fusion, 49:120–129, 2019.
- [41] Marco Storace and Oscar De Feo. Piecewise-linear approximation of nonlinear dynamical systems. IEEE Transactions on Circuits and Systems I: Regular Papers, 51(4):830–842, 2004.
- [42] Tin Truong, Hai Duong, B Le, and Philippe Fournier-Viger. FMaxCloHUSM: An efficient algorithm for mining frequent closed and maximal high utility sequences. Engineering Applications of Artificial Intelligence, 85:1–20, 2019.
- [43] Bay Vo, Sang Pham, Tuong Le, and Zhi-Hong Deng. A novel approach for mining maximal frequent patterns. Expert Systems with Applications, 73:178–186, 2017.
- [44] Lizhen Wang, Xuguang Bao, and Lihua Zhou. Redundancy reduction for prevalent co-location patterns. IEEE Transactions on Knowledge and Data Engineering, 30(1):142–155, 2018.
- [45] Lizhen Wang, Yuan Fang, and Lihua Zhou. Preference-based spatial co-location pattern mining. Springer Singapore, 2022.
- [46] Wei Wang, Jing Tian, Fang Lv, Guodong Xin, Yingfan Ma, and Bailing Wang. Mining frequent pyramid patterns from time series transaction data with custom constraints. Computers & Security, 100:102088, 2021.
- [47] Yuehua Wang, Youxi Wu, Yan Li, Fang Yao, Philippe Fournier-Viger, and Xindong Wu. Self-adaptive nonoverlapping sequential pattern mining. Applied Intelligence, 52(6):6646–6661, 2022.
- [48] Xindong Wu, Xingquan Zhu, and Minghui Wu. The evolution of search: Three computing paradigms. ACM Transactions on Management Information Systems, 13(2):20, 2022.
- [49] Youxi Wu, Mingjie Chen, Yan Li, Jing Liu, Zhao Li, Jinyan Li, and Xindong Wu. ONP-Miner: One-off negative sequential pattern mining. ACM Transactions on Knowledge Discovery from Data, 17(3):37, 2023.
- [50] Youxi Wu, Shuhui Cheng, Yan Li, Rongjie Lv, and Fan Min. STWD-SFNN: Sequential three-way decisions with a single hidden layer feedforward neural network. Information Sciences, 632:299–323, 2023.
- [51] Youxi Wu, Meng Geng, Yan Li, Lei Guo, Zhao Li, Philippe Fournier-Viger, Xingquan Zhu, and Xindong Wu. HANP-Miner: High average utility nonoverlapping sequential pattern mining. Knowledge-Based Systems, 229:107361, 2021.
- [52] Youxi Wu, Qian Hu, Yan Li, Lei Guo, Xingquan Zhu, and Xindong Wu. OPP-Miner: Order-preserving sequential pattern mining for time series. IEEE Transactions on Cybernetics, 53(5):3288–3300, 2023.
- [53] Youxi Wu, Lanfang Luo, Yan Li, Lei Guo, Philippe Fournier-Viger, Xingquan Zhu, and Xindong Wu. NTP-Miner: Nonoverlapping three-way sequential pattern mining. ACM Transactions on Knowledge Discovery from Data, 16(3):51, 2022.
- [54] Youxi Wu, Yufei Meng, Yan Li, Lei Guo, Xingquan Zhu, Philippe Fournier-Viger, and Xindong Wu. COPP-Miner: Top-k contrast order-preserving pattern mining for time series classification. IEEE Transactions on Knowledge and Data Engineering, 2023.
- [55] Youxi Wu, Yao Tong, Xingquan Zhu, and Xindong Wu. NOSEP: Nonoverlapping sequence pattern mining with gap constraints. IEEE Transactions on Cybernetics, 48(10):2809–2822, 2018.
- [56] Youxi Wu, Lingling Wang, Jiadong Ren, Wei Ding, and Xindong Wu. Mining sequential patterns with periodic wildcard gaps. Applied Intelligence, 41(1):99–116, 2014.
- [57] Youxi Wu, Xiaohui Wang, Yan Li, Lei Guo, Zhao Li, Ji Zhang, and Xindong Wu. OWSP-Miner: Self-adaptive one-off weak-gap strong pattern mining. ACM Transactions on Management Information Systems, 13(3):25, 2022.
- [58] Youxi Wu, Yuehua Wang, Yan Li, Xingquan Zhu, and Xindong Wu. Top-k self-adaptive contrast sequential pattern mining. IEEE Transactions on Cybernetics, 52(11):11819–11833, 2022.
- [59] Youxi Wu, Xiaoqian Zhao, Yan Li, Lei Guo, Xingquan Zhu, Philippe Fournier-Viger, and Xindong Wu. OPR-Miner: Order-preserving rule mining for time series. IEEE Transactions on Knowledge and Data Engineering, 35(11):11722–11735, 2023.
- [60] Youxi Wu, Changrui Zhu, Yan Li, Lei Guo, and Xindong Wu. NetNCSP: Nonoverlapping closed sequential pattern mining. Knowledge-Based Systems, 196:105812, 2020.
- [61] Fei Xie, Xindong Wu, and Xingquan Zhu. Efficient sequential pattern mining with wildcards for keyphrase extraction. Knowledge-Based Systems, 115:27–39, 2017.
- [62] Surong Yan, Kwei-Jay Lin, Xiaolin Zheng, and Wenyu Zhang. Using latent knowledge to improve real-time activity recognition for smart IoT. IEEE Transactions on Knowledge and Data Engineering, 32(3):574–587, 2020.
- [63] Jinyoung Yeo, Seungwon Hwang, Sungchul Kim, Eunyee Koh, and Nedim Lipka. Conversion prediction from clickstream: Modeling market prediction and customer predictability. IEEE Transactions on Knowledge and Data Engineering, 32(2):246–259, 2020.
- [64] Jianming Zhan, Jin Ye, Weiping Ding, and Peide Liu. A novel three-way decision model based on utility theory in incomplete fuzzy decision systems. IEEE Transactions on Fuzzy Systems, 30(7):2210–2226, 2022.
- [65] Shuainan Zhang, Yafeng He, Xuzhao Li, Wude Yang, and Ying Zhou. Biolabel-led research pattern positions the effects and mechanisms of Sophorae Tonkinensis radix et rhizome on lung diseases: A novel strategy for computer-aided herbal medicine research based on omics and bioinformatics. Computers in Biology and Medicine, 136:104769, 2021.
- [66] Branislav Đurian, Jan Holub, Hannu Peltola, and Jorma Tarhio. Improving practical exact string matching. Information Processing Letters, 110(4):148–152, 2010.