CNNs with Multi-Level Attention for Domain Generalization
Abstract.
In the past decade, deep convolutional neural networks have achieved significant success in image classification and ranking and have therefore found numerous applications in multimedia content retrieval. Still, these models suffer from performance degradation when neural networks are tested on out-of-distribution scenarios or on data originating from previously unseen data Domains. In the present work, we focus on this problem of Domain Generalization and propose an alternative neural network architecture for robust, out-of-distribution image classification. We attempt to produce a model that focuses on the causal features of the depicted class for robust image classification in the Domain Generalization setting. To achieve this, we propose attending to multiple-levels of information throughout a Convolutional Neural Network and leveraging the most important attributes of an image by employing trainable attention mechanisms. To validate our method, we evaluate our model on four widely accepted Domain Generalization benchmarks, on which our model is able to surpass previously reported baselines in three out of four datasets and achieve the second best score in the fourth one.
1. Introduction
One of the most fundamental prerequisites for training robust and generalizable machine learning (ML) models, is the ability to learn representations which adequately encapsulate the underlying generating processes of a data distribution (Bengio et al., 2013; Schölkopf, 2022; Schölkopf et al., 2021). One way of approaching the above problem, is to guide a model to learn disentangled representations from the training data and uncover the ones which remain invariant (Arjovsky et al., 2020) under distribution shift. For example, a photograph of a dog shares similar traits with an image of a cartoon dog, or even a sketch of a dog. A generalizable model should be able to recognize the same class despite it being found in separate Domains.

Our proposed framework.
ML models are trained under the assumption that the training and test data distributions are independent and identically distributed. In practice however, Deep Learning (DL) models are expected to mitigate, or not be affected by, the distribution shift between their training data and data they have not been presented with before. This is often not the case, as DL models often learn representations which entangle class-discriminative attributes with correlated, though irrelevant, features of images. They therefore fail to produce informative features and to generalize to unseen data domains (Recht et al., 2019). To this end, Domain Generalization (DG) (Zhou et al., 2022; Wang et al., 2022) methods aim at developing robust models which can generalize to unseen test data domains. Such methods attempt to address this problem by leveraging multiple domains in the training set, simulating biases found in real-world settings, synthesizing samples through augmentation and learning invariant representations through self-supervision (see Section 2).
In 2017, Transformer networks (Vaswani et al., 2017) were proposed as a model for Natural Language Processing (NLP). Transformers introduced a self-attention mechanism for providing additional contextual information to each word in an embedded sentence. Since their outstanding success in several NLP tasks, Transformers and self-attention mechanisms have slowly but steadily gained ground in the Computer Vision community (Guo et al., 2022), achieving significant advances in the field (Hu et al., 2018; Woo et al., 2018; Yang et al., 2020). In this work, we argue that by attending to features extracted from multiple layers of a convolutional neural network via multi-head self-attention mechanisms, a model can be trained to learn representations which reflect class-specific, domain-invariant attributes of an image. As a result, the trained model will be less affected by out-of-distribution data samples as it will base its predictions on the causal characteristics of the depicted class. Our contributions can be summarized in the following points:
-
•
We introduce a novel neural network architecture that utilizes self-attention (Vaswani et al., 2017) to attend to representations extracted throughout a Convolutional Neural Network (CNN), for robust out-of-distribution image classification in the DG setting
- •
-
•
We provide qualitative visual results of our model’s inference process and its ability to focus on the invariant and causal features of a class via saliency maps
In the next section we briefly present the most important contributions in DG, along with relative previous work in visual attention, from which we drew inspiration for our proposed algorithm.
2. Related Work
2.1. Domain Generalization
There have been numerous efforts to address challenges related to domain shift in the past ((Diou et al., 2010), (Wang and Deng, 2018), (Weiss et al., 2016)), however DG methods are different in that the model does not have any samples from the target domain(s) during training.
DG problems can be broadly categorized into two main settings, namely multi-source and single-source DG (Zhou et al., 2022). In multi-source DG, all algorithms assume that their training data originate from (where ) distinct but known data domains. These algorithms take advantage of domain labels in order to discover invariant representations among the separate marginal distributions. Most previously proposed methods fall under this category. The authors of (Sun and Saenko, 2016) propose deep CORAL, a method which aligns the second-order statistics between source and target domains in order to minimize the domain shift among their distributions. In (Nam et al., 2021), Style-Agnostic networks, or SagNets, use an adversarial learning paradigm to disentangle the style encodings of each domain and reduce style-biased predictions. With a different approach, the authors of (Zhou et al., 2021) investigate the usage of data augmentation and style-mixing techniques for producing robust models. Another popular approach in multi-source DG is Meta-learning, which focuses on learning the optimal parameters for a source model from previous experiment metadata. (Li et al., 2018b; Finn et al., 2017) and Adaptive Risk Minimization (ARM) (Zhang et al., 2021b), all propose meta-learning algorithms for adapting to unseen domains. Finally, (Du et al., 2020) uses episodic training in the meta-learning setting to extract invariant representations across source domains. On the other hand, single-source DG methods hold no information about the presence of separate domains in their training data, but assume that it originates from a single distribution. Therefore, all single-source DG algorithms, such as our own, operate in a domain-agnostic manner and do not take advantage of domain labels. In (Carlucci et al., 2019), the authors combine self-supervised learning with a jigsaw solving objective in order to reduce the model’s proneness to learning semantic features. Additionally, in (Zhang et al., 2021a) the authors attempt to remove feature dependencies in their model via sample weighting. Finally, RSC (Huang et al., 2020) is a self-challenging training heuristic to discard representations associated with very high gradients, which forces the network to activate features correlated with the class and not the domain.
2.2. Visual Attention
Attention mechanisms have long been introduced in CV (Itti and Koch, 2001), inspired by the human visual system’s ability to efficiently analyze complex scenes. More recently, attention mechanisms have been proposed for the interpretation of the output of Convolutional Neural Networks (CNNs), where they act as dynamic re-weighting processes which attend to the most important features of the input image. In (Zhou et al., 2016), the authors propose CAM, a post-hoc model interpretation algorithm for estimating attention maps in classification CNNs. Methods incorporating attention mechanisms into CNNs for image classification have also been proposed in the past (Wang et al., 2017; Chen et al., 2019; Ren et al., 2022; Yu et al., 2022). In (Jetley et al., 2018), the authors introduce an end-to-end trainable mechanism for CNNs, by computing compatibility scores between intermediate features of the network and a global feature map. In (Woo et al., 2018), the Convolutional Block Attention Module, or CBAM, leverages both spatial and channel attention modules for adaptive feature refinement. Recently, several methods have been proposed which replace CNNs with self-attention and multi-head attention mechanisms (Vaswani et al., 2017) applied directly on the image pixels (Carion et al., 2020; Dosovitskiy et al., 2021; Liu et al., 2021), leading to transformer-based methods for CV (Han et al., 2023).
3. Methodology
Information passed through popular Convolutional Neural Network architectures, such as ResNets (He et al., 2016), tends to get entangled with non-causal attributes of an image due to correlations in the data distribution (Recht et al., 2019). Our method is built around the hypothesis that this problem can be mitigated if we allow the network to select intermediate feature maps throughout a CNN for representation learning. We therefore extract feature maps at multiple network layers and pass them through a multi-head attention mechanism (Figure 2). In our implementation we consider self dot-product attention with 3 heads. Given an intermediate feature map , where b is the batch size, c is the number of channels and h and w are the height and width of the feature map, we aim to attend to each of the channels. As a first step, we flatten the feature maps M into a dimension of . We follow by linearly projecting the flattened feature maps into a dimension Tensor, where is the size of each channel’s embedded feature map. Each channel can be thought of as the token in the classic Transformer architecture. Given the embedded feature maps and trainable weight matrices ( the inner self-attention layer dimension), we create the query, key and value vectors: , which are fed to the multi-head attention block. The self-attention layer is defined as:
| (1) |
while the multi-head attention is:
| (2) |
where:
| (3) |
After the extracted feature maps have been attended to and re-weighted, we pass them through a Multi-Layer Perceptron (MLP) in order to allow our model to learn a mapping between the processed features. The MLP consists of two Linear layers, activated by the GELU function (Hendrycks and Gimpel, 2016). Finally, the projected features are flattened, concatenated and passed through a fully connected classification layer for the final decision. Our proposed framework is visualized in Figure 1.
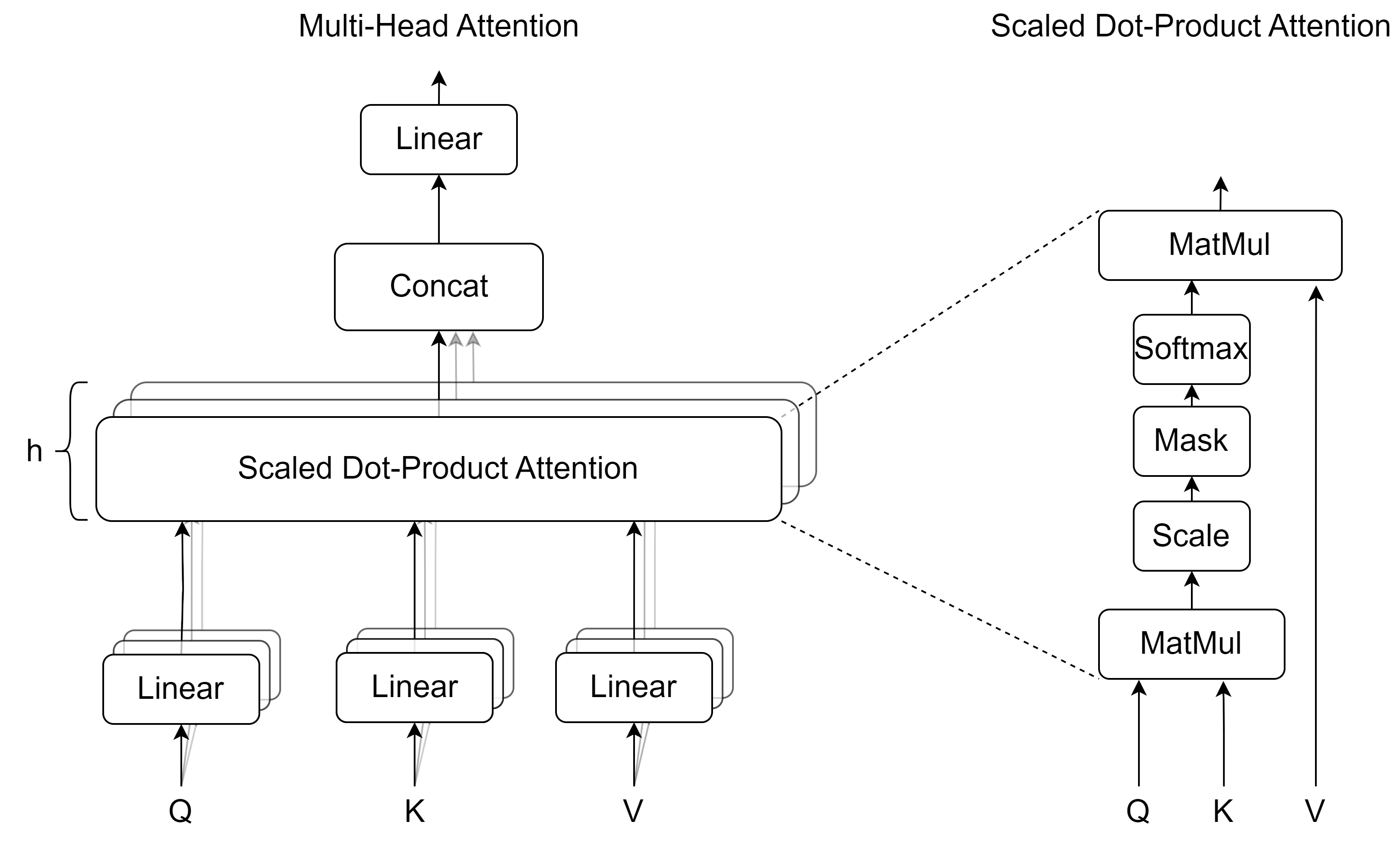
Visualization of the Multi-Head Attention
4. Experimental Setup
In our experiments, we build our method on a vanilla ResNet-50 (He et al., 2016) model, pre-trained on ImageNet. For our method, we choose to extract intermediate feature maps from the 3rd, 7th and 13th bottleneck blocks of the backbone ResNet-50 model, as shown in Fig 1. We train our model with the SGD optimizer for 30 epochs and a batch size of 32 images. The learning rate is set at 0.001 and decays with a rate 0.1 at epoch 24. The proposed framework was implemented with the PyTorch library (Paszke et al., 2019) and trained on a NVIDIA RTX A5000 GPU.
We evaluate our method against 8 previous state-of-the-art algorithms, which use a ResNet-50 as their base model. Specifically, the baseline models we select are: ERM(Vapnik, 1999), RSC (Huang et al., 2020), MIXUP (Yan et al., 2020), CORAL(Sun and Saenko, 2016), MMD (Li et al., 2018a), SagNet (Nam et al., 2021), SelfReg (Kim et al., 2021) and ARM (Zhang et al., 2021b). The above algorithms are a mix of both multi-source and single-source methods allowing us to demonstrate the effectiveness of our proposed method. The hyperparameters of each algorithm are set to reflect the ones in the original papers. All baselines are implemented and executed using the DomainBed (Gulrajani and Lopez-Paz, 2021) codebase for a fair comparison. The presented experimental results are averaged over 3 runs.
4.1. Datasets
To evaluate the robustness of our method we experiment on four well-known and publicly available DG benchmark datasets, namely PACS (Li et al., 2017), VLCS (Torralba and Efros, 2011), TerraIncognita (Beery et al., 2018) and Office-Home (Venkateswara et al., 2017). Specifically:
-
•
PACS contains images originating from the Photo, Art Painting, Cartoon and Sketch domains. It also contains a total of 9,991 images and 7 class labels.
-
•
VLCS incorporates 10,729 real-world images from the PASCAL VOC, LabelMe, Caltech 101 and SUN09 datasets (or domains) and depicts 5 classes in total.
-
•
Terra Incognita contains photographs of wild animals taken by trap cameras at 4 different locations (L100, L38, L43 and L46). This dataset contains 10 classes and 24,788 images in total.
-
•
Office-Home comprises four domains of Art, Clipart, Product and Real-World images. The dataset contains 15,588 examples and 65 classes in total.
For each respective dataset we follow the standard leave-one-domain-out cross-validation DG protocol, as described in (Li et al., 2017; Ghifary et al., 2015). In this setting, a target domain is selected and held out from the model’s training data split. The generalizability of the trained model is then measured by its accuracy on the unseen data originating from the target domain. For example, in the first experiment with the PACS dataset, the domains of Photo, Cartoon and Sketch are selected as Source domains while the Art Painting domain is held out as the Target. Therefore, the model is trained on data from the source domains and evaluated on previously unseen art images.
4.2. Results
The results of our experiments are presented in Table 1. The effectiveness of our method is demonstrated in the experimental outcome, as our model is able to surpass previously proposed state-of-the-art algorithms in the PACS, Terra Incognita and Office-Home datasets, while achieving the second best performance in VLCS. In PACS, our model surpasses the previous best model by 1.06%, while in TerraIncognita and Office-Home our implementation exceeds the baselines by 0.98% and 1.33% respectively. What’s more, even though our algorithm is not able to achieve the top score in VLCS, it remains highly competitive and ranks as second best among its predecessors.
| Method | PACS | VLCS | Terra | Office | Average |
|---|---|---|---|---|---|
| ERM | 83.32 | 76.82 | 62.27 | 46.25 | 68.42 |
| RSC | 83.62 | 75.96 | 66.09 | 46.60 | 68.07 |
| CORAL | 83.57 | 76.97 | 68.60 | 48.05 | 69.30 |
| MIXUP | 83.70 | 78.62 | 68.17 | 46.05 | 69.14 |
| MMD | 82.82 | 76.72 | 67.12 | 46.30 | 68.24 |
| SagNet | 84.46 | 76.29 | 66.42 | 48.60 | 68.94 |
| SelfReg | 84.16 | 75.46 | 65.73 | 47.00 | 68.09 |
| ARM | 83.78 | 76.38 | 63.49 | 45.50 | 67.29 |
| Ours | 85.52 | 78.05 | 69.58 | 49.93 | 70.77 |
To further support our claims, we also provide visual examples of our model’s inference process via saliency maps. Specifically, we select to implement the Image-Specific Class Saliency method as proposed in (Simonyan et al., 2014). In the above method, a visual map of the pixels contributing the most to the model’s prediction is produced by computing and visualizing the gradient of the loss function with respect to the input image. As depicted in Figure 3, the darker a pixel, the more significant it is to the model. We choose to visualize 4 images of the ”elephant class” from the four different domains in PACS. When compared to the baseline ERM model, our method seems to base its decisions on features of the depicted object (e.g. tusk of the elephant in the Art image) and pay less attention to irrelevant attributes, such as the noisy backgrounds (e.g. tree leaves in the Photo domain). This visual evidence proves promising towards researching alternative architectures containing both convolutional and attention layers for the DG setting.

Saliency map visualizations
5. Conclusions
In this paper, we introduced a novel approach for image classification in the Domain Generalization setting. The basic idea behind our implementation was to allow the model to select the most class-discriminative and domain-invariant representations via multi-head self-attention mechanisms which attend to intermediate feature maps extracted from multiple layers of a convolutional neural network. The generalization ability of our model is supported by extensive experimental results on four publicly available and well-known DG benchmarks, in which our model either surpasses previously proposed algorithms or remains highly competitive. In addition, we provide visual qualitative examples of our model’s inference process through saliency maps. The visual results demonstrate the fact that our model tends to disregard spurious correlations in its input images, such as background noise, and is able to base its predictions on class-specific attributes. However, our method still has room for improvement. The employment of multiple multi-head attention mechanisms and concatenation of embedded feature maps adds a significant computation and memory overhead, which is reflected by the relatively small image batch size in our experiments. For future work, we aim to further research the intersection between visual attention and fully convolutional networks in order to propose mechanisms which will be able to explicitly pay attention to the causal features of a class.
Acknowledgements.
The work leading to these results has received funding from the European Union’s Horizon 2020 research and innovation programme under Grant Agreement No. 965231, project REBECCA (REsearch on BrEast Cancer induced chronic conditions supported by Causal Analysis of multi-source data).References
- (1)
- Arjovsky et al. (2020) Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. 2020. Invariant Risk Minimization. arXiv:1907.02893 [cs, stat] (March 2020). arXiv: 1907.02893.
- Beery et al. (2018) Sara Beery, Grant Van Horn, and Pietro Perona. 2018. Recognition in terra incognita. In Proceedings of the European conference on computer vision (ECCV). 456–473.
- Bengio et al. (2013) Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 8 (Aug. 2013), 1798–1828. Conference Name: IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. Springer, 213–229.
- Carlucci et al. (2019) Fabio M. Carlucci, Antonio D’Innocente, Silvia Bucci, Barbara Caputo, and Tatiana Tommasi. 2019. Domain Generalization by Solving Jigsaw Puzzles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Chen et al. (2019) Weijie Chen, Di Xie, Yuan Zhang, and Shiliang Pu. 2019. All you need is a few shifts: Designing efficient convolutional neural networks for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7241–7250.
- Diou et al. (2010) Christos Diou, George Stephanopoulos, Panagiotis Panagiotopoulos, Christos Papachristou, Nikos Dimitriou, and Anastasios Delopoulos. 2010. Large-scale concept detection in multimedia data using small training sets and cross-domain concept fusion. IEEE transactions on circuits and systems for video technology 20, 12 (2010), 1808–1821.
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations.
- Du et al. (2020) Yingjun Du, Jun Xu, Huan Xiong, Qiang Qiu, Xiantong Zhen, Cees G. M. Snoek, and Ling Shao. 2020. Learning to Learn with Variational Information Bottleneck for Domain Generalization. In Computer Vision – ECCV 2020. Springer International Publishing, Cham.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research). PMLR.
- Ghifary et al. (2015) Muhammad Ghifary, W. Bastiaan Kleijn, Mengjie Zhang, and David Balduzzi. 2015. Domain Generalization for Object Recognition With Multi-Task Autoencoders. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
- Gulrajani and Lopez-Paz (2021) Ishaan Gulrajani and David Lopez-Paz. 2021. In Search of Lost Domain Generalization. In International Conference on Learning Representations.
- Guo et al. (2022) Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R Martin, Ming-Ming Cheng, and Shi-Min Hu. 2022. Attention mechanisms in computer vision: A survey. Computational Visual Media 8, 3 (2022), 331–368.
- Han et al. (2023) Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, Zhaohui Yang, Yiman Zhang, and Dacheng Tao. 2023. A Survey on Vision Transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 1 (Jan. 2023), 87–110. Conference Name: IEEE Transactions on Pattern Analysis and Machine Intelligence.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Hendrycks and Gimpel (2016) Dan Hendrycks and Kevin Gimpel. 2016. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016).
- Hu et al. (2018) Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7132–7141.
- Huang et al. (2020) Zeyi Huang, Haohan Wang, Eric P. Xing, and Dong Huang. 2020. Self-Challenging Improves Cross-Domain Generalization. In ECCV.
- Itti and Koch (2001) Laurent Itti and Christof Koch. 2001. Computational modelling of visual attention. Nature reviews neuroscience 2, 3 (2001), 194–203.
- Jetley et al. (2018) Saumya Jetley, Nicholas A. Lord, Namhoon Lee, and Philip Torr. 2018. Learn to Pay Attention. In International Conference on Learning Representations.
- Kim et al. (2021) Daehee Kim, Youngjun Yoo, Seunghyun Park, Jinkyu Kim, and Jaekoo Lee. 2021. SelfReg: Self-supervised Contrastive Regularization for Domain Generalization. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Montreal, QC, Canada, 9599–9608.
- Li et al. (2017) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. 2017. Deeper, Broader and Artier Domain Generalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
- Li et al. (2018b) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. 2018b. Learning to generalize: Meta-learning for domain generalization. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Li et al. (2018a) Haoliang Li, Sinno Jialin Pan, Shiqi Wang, and Alex C Kot. 2018a. Domain generalization with adversarial feature learning. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5400–5409.
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision. 10012–10022.
- Nam et al. (2021) Hyeonseob Nam, HyunJae Lee, Jongchan Park, Wonjun Yoon, and Donggeun Yoo. 2021. Reducing domain gap by reducing style bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8690–8699.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. Curran Associates, Inc.
- Recht et al. (2019) Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. Do imagenet classifiers generalize to imagenet?. In International Conference on Machine Learning. PMLR, 5389–5400.
- Ren et al. (2022) Sucheng Ren, Daquan Zhou, Shengfeng He, Jiashi Feng, and Xinchao Wang. 2022. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10853–10862.
- Schölkopf (2022) Bernhard Schölkopf. 2022. Causality for machine learning. In Probabilistic and Causal Inference: The Works of Judea Pearl. 765–804.
- Schölkopf et al. (2021) Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. 2021. Toward Causal Representation Learning. Proc. IEEE (2021).
- Simonyan et al. (2014) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Visualising image classification models and saliency maps. Deep Inside Convolutional Networks (2014).
- Sun and Saenko (2016) Baochen Sun and Kate Saenko. 2016. Deep coral: Correlation alignment for deep domain adaptation. In European conference on computer vision. Springer, 443–450.
- Torralba and Efros (2011) Antonio Torralba and Alexei A. Efros. 2011. Unbiased look at dataset bias. In CVPR 2011.
- Vapnik (1999) Vladimir Vapnik. 1999. The nature of statistical learning theory. Springer science & business media.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc.
- Venkateswara et al. (2017) Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. 2017. Deep hashing network for unsupervised domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5018–5027.
- Wang et al. (2017) Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang. 2017. Residual attention network for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition. 3156–3164.
- Wang et al. (2022) Jindong Wang, Cuiling Lan, Chang Liu, Yidong Ouyang, Tao Qin, Wang Lu, Yiqiang Chen, Wenjun Zeng, and Philip Yu. 2022. Generalizing to unseen domains: A survey on domain generalization. IEEE Transactions on Knowledge and Data Engineering (2022).
- Wang and Deng (2018) Mei Wang and Weihong Deng. 2018. Deep visual domain adaptation: A survey. Neurocomputing 312 (2018), 135–153.
- Weiss et al. (2016) Karl Weiss, Taghi M Khoshgoftaar, and DingDing Wang. 2016. A survey of transfer learning. Journal of Big data 3, 1 (2016), 1–40.
- Woo et al. (2018) Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. 2018. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV). 3–19.
- Yan et al. (2020) Shen Yan, Huan Song, Nanxiang Li, Lincan Zou, and Liu Ren. 2020. Improve unsupervised domain adaptation with mixup training. arXiv preprint arXiv:2001.00677 (2020).
- Yang et al. (2020) Yiding Yang, Jiayan Qiu, Mingli Song, Dacheng Tao, and Xinchao Wang. 2020. Distilling knowledge from graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7074–7083.
- Yu et al. (2022) Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. 2022. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10819–10829.
- Zhang et al. (2021b) Marvin Zhang, Henrik Marklund, Nikita Dhawan, Abhishek Gupta, Sergey Levine, and Chelsea Finn. 2021b. Adaptive risk minimization: Learning to adapt to domain shift. Advances in Neural Information Processing Systems 34 (2021), 23664–23678.
- Zhang et al. (2021a) Xingxuan Zhang, Peng Cui, Renzhe Xu, Linjun Zhou, Yue He, and Zheyan Shen. 2021a. Deep Stable Learning for Out-of-Distribution Generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Zhou et al. (2016) Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2921–2929.
- Zhou et al. (2022) Kaiyang Zhou, Ziwei Liu, Yu Qiao, Tao Xiang, and Chen Change Loy. 2022. Domain generalization: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022).
- Zhou et al. (2021) Kaiyang Zhou, Yongxin Yang, Yu Qiao, and Tao Xiang. 2021. Domain Generalization with MixStyle. In International Conference on Learning Representations.