Clustering based Multiple Anchors HDMR \authorheadM. Xiong, L. Chen, J. Ming, X. Pan, & X. Yan \corrauthor[2]Ju Ming \corremail[email protected]
mm/dd/yyyy \dataFmm/dd/yyyy
Clustering based Multiple Anchors High-Dimensional Model Representation
Abstract
In this work, a cut high-dimensional model representation (cut-HDMR) expansion based on multiple anchors is constructed via the clustering method. Specifically, a set of random input realizations is drawn from the parameter space and grouped by the centroidal Voronoi tessellation (CVT) method. Then for each cluster, the centroid is set as the reference, thereby the corresponding zeroth-order term can be determined directly. While for non-zero order terms of each cut-HDMR, a set of discrete points is selected for each input component, and the Lagrange interpolation method is applied. For a new input, the cut-HDMR corresponding to the nearest centroid is used to compute its response. Numerical experiments with high-dimensional integral and elliptic stochastic partial differential equation as backgrounds show that the CVT based multiple anchors cut-HDMR can alleviate the negative impact of a single inappropriate anchor point, and has higher accuracy than the average of several expansions.
keywords:
high-dimensional model representation, clustering method, centroidal Voronoi tessellation, multiple anchors model, Lagrange interpolation method, nearest principle1 Introduction
High-dimensional model representation (HDMR) [1, 2, 3], also known as analysis of variance (ANOVA), describes the mapping relationship between high-dimensional input and model output through a multivariate function with hierarchical structure. This hierarchical expansion is composed of a constant function, several univariate functions, bivariate functions, etc., which respectively represent the impact of the corresponding input variables on the output. In spite of the finite expansion, HDMR in many cases would provide an accurate expression for the target system, and this expansion is usually truncated into a lower-order representation with given accuracy in practical applications [4, 5, 6, 7, 8]. In addition to establishing low-cost surrogate models for high-dimensional complex systems, HDMR expansion can also be used as a quantitative model assessment tool for sensitivity analysis and reliability analysis [9, 10, 11, 12, 13, 14, 15].
There are two main types of HDMR: ANOVA-HDMR and cut-HDMR [4, 16, 1, 17]. The statistical significance of the former makes it very important in the field of sensitivity analysis. Unfortunately, each expansion term involves the multiple-dimension integration over the input subspace, which resulted in the limited use of ANOVA-HDMR for high-dimensional problem, this dilemma can be avoided by using random sampling HDMR (RS-HDMR) techniques [18, 19, 20], i.e. by employing the Monte Carlo (MC) simulation to approximate these integrations. However, the required sample size increases exponentially with the order of truncated expression and the dimension of input space, and computing a large number of samples from complex system is also a nearly burden. To overcome such challenges, cut-HDMR, also referred to as anchored-ANOVA expansion, uses Dirac measure to given a cheap and readily available rough estimate of the involved high-dimensional integration, and thus the corresponding approximation error mainly depends on the choice of the reference points, i.e., anchors. Due to the fact that the cut-HDMR expansion represents the objective function precisely by a linear combination of component functions defined along cut lines, planes and hyperplanes passing through a reference point, cut-HDMR is more attractive in practical applications. The existing anchor selection strategies include drawn randomly from parameter space, the center of random input space, the input vector corresponding to the mean of response [7, 8], the centroid of sparse quadrature grids [16], and dimension weighting based on the quasi-MC method [21], etc. Except for the single anchor technique, the multiple anchors cut-HDMR has been developed and used to eliminate the unimportant terms in the expansion [22, 1].
Several novel forms have been derived from the traditional HDMR. For example, ANOVA-HDMR based on cut-HDMR expansion was proposed for global sensitivity analysis, which can not only alleviate the high computational cost of ANOVA-HDMR, but also handle the problem involving the statistics, e.g. expected value and variance, of objective function that is unable to generate by cut-HDMR [6]. In addition, classical metamodeling techniques are combined with HDMR and used in engineering design and optimization. Shan and Wang integrated radial basis function with HDMR, termed RBF-HDMR, for dealing with high dimensional, expensive, and black-box problems [23]. Then, Cai and Liu et al. used adaptive methods to improve the RBF-HDMR [24, 25]. Yue at al. used polynomial chaos expansion and HDMR to build an adaptive model to provide simple and explicit approximations for high-dimensional systems [17]. Anand et al. coupled proper orthogonal decomposition with HDMR to produce a novel, effecient and cheaper reconstruction strategy [26]. Tang et al. employed Kriging-based cut-HDMR technique to improve the performance of metamodel-assisted optimization [27], then this method was developed by Ji et al. and used for interval investigation of uncertainty problems [28]. Recently, this method has been enhanced and applied to various optimization problems [29, 30, 31]. More combinations of HDMR expansions and other methods, such as support vector regression, Gaussian process regression and principal component analysis, can be seen in [32, 33, 34, 35, 36]. Moreover, different HDMR expansions for high dimensional problems have been compared by Chen et al. [37, 38]. The accuracy of cut-HDMR is often improved by using multiple anchors. Li et al. proposed Multi-Cut-HDMR, which constructs several truncated expansions at different reference points and uses the distances to the anchors to define the weights [1]. Labovsky and Gunzburger directly make the weights equal [22]. More variants of multiple anchors model can be found in [39, 40].
In this work, we no longer consider the traditional single anchor HDMR expansion, but the multiple anchors model with clustering technique. Centroidal Voronoi tessellation (CVT) clustering, also known as -means, can be used in data compression, quadrature, distribution of resources, model order reduction and other fields [41, 42, 43]. Karcılı and Tunga combined it with HDMR to provide an efficient image retrieval method [44]. But here, based on the relationship between cut-HDMR expansion and Taylor series, the CVT clustering method which minimizes the sum of variances within the classes is used to provide anchor points for cut-HDMR expansions. By selecting each centroid as the anchor, the corresponding cut-HDMR expansion can be established, where the non-zero order terms are approximated by the Lagrange interpolation method. Therefore, several independent expressions will be obtained. The response of a new input is not approximated by the average of multiple expressions as in [22], but is calculated from the cut-HDMR expansion associated with the nearest centroid. We denote the method of combining cut-HDMR and CVT clustering to construct multiple anchor points expansion as the CVT-HDMR. Numerical experiments show that our proposed method outperforms the average of several cut-HDMR expansions. In addition, the CVT-HDMR expansion is more accurate than the traditional single anchor cut-HDMR expansion based on the parameter space center and sparse grids center respectively.
The rest of this paper is organized as follows. In section 2, we introduce the traditional cut-HDMR expansion, its relationship with the Taylor series, and the Lagrange interpolation method for approximating the non-zero order terms of cut-HDMR expansion. In section 3, the CVT clustering method is described, then the details of CVT-HDMR is given in Algorithm 1. The effectiveness of our proposed method is verified in section 4. Finally, some conclusions are given in section 5.
2 Anchor based HDMR
Consider the following system
| (1) |
where is random input vector with given probability density function , is the output of system, and is a mapping from input to output. Suppose that the components of are independent and identically distributed (i.i.d.) with ranges and densities for , i.e.,
| (2) |
Here, independence ensure can be written as a product of marginal densities, and identical distribution is made only to simplify notation. Denote as a multi-index with cardinality , the subset of parameters is written as , parameter set satisfies and , subspaces and are defined as and respectively.
Next, the traditional cut-HDMR expansion, its relationship with the Taylor series, and the Lagrange interpolation method are described in detail.
2.1 HDMR and anchor method
Using HDMR, the response can be written as the following hierarchical structure
| (3) |
Different component functions and higher-order terms lead to different expression (3). In order to get a unique representation, additional structure is imposed as following minimization problem [2]
| (4) |
subject to
| (5) |
for any and . The constrain condition (5) makes the terms in (3) satisfy orthogonality
| (6) |
Then the terms in expansion (3) can be determined by
| (7) | |||
| (8) |
It can be noted from (7) and (8) that is the expectation of function , and involves the corresponding conditional expectation. Their statistical significance is crucial for global sensitivity analysis.
The integrals in formulas (7) and (8) are intractable for high-dimensional problems. To overcome this challenge, Dirac measure based cut-HDMR is applied in this work. For a given anchor (or reference) point , it is known from the independence hypothesis that the Lebesgue measure satisfies
| (9) |
Then the component functions can be represented as
| (10) | |||
| (11) |
where denotes that the components of are equal to anchor point except for those having indices belonging to , that is,
| (12) |
Therefore, the zeroth-, first-, and second-order terms take the forms
| (13) | |||
| (14) | |||
| (15) |
and higher-order terms are defined in analogous manner. Echoing formulas (5) and (6), the terms in the cut-HDMR expansion satisfy
| (16) |
and orthogonality
| (17) |
Clearly, the zeroth-order term in cut-HDMR is the system response at anchor point , the first- and second-order terms involve the lines and planes passing through the anchor, respectively. Similarly, higher-order terms are hyperplanes that pass through the given point. Although the component functions of cut-HDMR do not have the statistical interpretations as (7)-(8), the low computational cost makes it more practical and attractive in science and engineering.
Compared to formula (3), the lower order HDMR expansion can usually provide a good approximation for the objective function. The truncated HDMR with order has form
| (18) |
Interestingly, for a given function and reference point , in addition to using HDMR, function can also be expressed by the Taylor series when it is differentiable. The correspondence between the two representations is discussed below.
2.2 Cut-HDMR expansion and Taylor series
Here, we introduce the relationship between the Taylor series and the cut-HDMR expansion. The Taylor series of differentiable function at reference point is
| (19) |
Obviously, the constant term in the cut-HDMR expansion is consistent with that in the Taylor series, i.e. . For , substituting into (2.2) and subtracting from both sides can give
| (20) |
It can be seen from (2.2) that the first-order term of the cut-HDMR expansion is the sum of the Taylor series terms which only contain variable . Similarly, for , the component function is the sum of the Taylor series terms involving both only variables and , i.e.,
| (21) |
Therefore, the non-zero order terms in the cut-HDMR expansion have the following mathematical explanations
| (22) |
where , multi-index set satisfies , is positive integer set with order .
Lemma 2.1 ([45]).
There exist a constant and vector , such that the remainder of order Taylor series of differentiable function can be written as
| (23) |
If all -th order partial derivatives of function are bounded in magnitude by constant , i.e.,
| (24) |
holds, then tends to 0 when and
| (25) |
where
| (26) |
Lemma 2.1 states that the error of truncated Taylor series depends not only on the truncation number , but also on the smoothness of function and the distance from the reference point . The following Corollary 2.2 can be easily derived from formulas (3), (2.2) and (22).
Corollary 2.2.
For a differentiable function with support , given the reference point and the truncation number , , the truncated cut-HDMR expansion is more accurate than the truncated Taylor series.
Remark 2.3.
From the above discussion and remainder term (25), it can be found that the accuracy of truncated cut-HDMR depends on the distance to the reference point. In order to obtain high-precision cut-HDMR, a suitable strategy for selecting anchors is the clustering method, which can control the distance within the class.
2.3 Lagrange interpolation method for component functions
If the anchor point is selected, the zeroth-order term of cut-HDMR can be obtained directly by calculating the system with input . In order to get the th-order term , functions and need to be determined, where . It can be seen from (12) that is a function with respect to variables . To obtain its approximate expression, the Lagrange interpolation method is considered here.
For , given a set of discrete points with size . Then the function can be approximated by interpolation nodes spanned by discrete points in the directions as
| (27) |
where , , is one-dimensional Lagrange interpolation polynomial and takes the form
| (28) |
node denotes the components of are equal to discrete points when the indices belonging to , and the rest are consistent with the anchor , i.e.,
| (29) |
Substituting (27) into the recursive formula (11) can provide the explicit approximations for the cut-HDMR expression terms. For example, the first-order term can be approximated as
| (30) |
and the approximate second-order term can be written as
| (31) |
Similarly, the Lagrange interpolation expressions for higher-order terms can be given. Note that using the interpolation method to approximate all terms requires a total of models to be evaluated.
3 Select anchor points by clustering
The choice of anchor point is critical because it affects the accuracy of cut-HDMR expansion. Existing choices include drawn randomly from parameter space, the center of random input space, the input vector corresponding to the mean of response, etc. These are all single anchor methods. In order to possibly alleviate the negative impact of a single inappropriate anchor point on the model, the cut-HDMR based on multiple anchor points have been proposed. Labovsky and Gunzburger [22] used the average of several cut-HDMR expansions based on different anchor points to approximate system response, and then used the model to identify important parameters. Since the average value cannot exceed the best result of its components, the preference is to choose the most appropriate one to approximate the response of a given input.
According to Remark 2.3, the CVT clustering centroids of random input space are set as anchors to minimize the sum of distances between the random input samples and the nearest anchor point. The cut-HDMR expansion can be established for each centroid. The closer to the reference point, the higher the accuracy of truncated cut-HDMR approximation. Based on this idea, the nearest principle is used to assign an approximate representation to the new simulation. That is, the cut-HDMR expansion corresponding to the nearest centroid is applied to evaluate the system for a given input. Next, the CVT clustering method and the clustering based cut-HDMR are described in detail.
3.1 CVT clustering method
By Remark 2.3 and the nearest principle, multiple anchors are desired to be as dispersed as possible in the parameter space , so they are set as the centroids of the CVT clustering in this work. CVT clustering, also known as -means in statistics, uses distance as a metric to divide the given space or sample set into several clusters with equal variance, and each centroid is usually applied to characterize the corresponding cluster.
Given a positive integer , a set of generators , and a set of random input realizations with size , which drawn from space according to the probability density function . Then the Voronoi set corresponding to generator is defined by
| (32) |
where and represents Euclidean -norm. If the equal sign in (32) holds, the sample is assigned to or randomly so that the set satisfies for , and . Then is called a Voronoi diagram or Voronoi tessellation of data set , and the Voronoi tessellation energy of generator is defined as
| (33) |
Further, the total energy of set with generators is given by
| (34) |
Denote the cardinality of Voronoi set as for , then the cluster centroid can be defined as
| (35) |
where . If for , then is called a CVT of data set . Clearly, is proportional to the variance of set when , and the construction of CVT is a process of energy minimization.
3.2 Clustering based cut-HDMR
In our work, the centroids of CVT clustering are used as the reference points of cut-HDMR expansions to establish a multiple anchors model. For , let
| (36) |
be the -th cut-HDMR expression generated with centroid , where , non-zero order terms are approximated by Lagrange interpolation method as introduced in section 2.3. To mitigate the effect of anchor location, Labovsky and Gunzburger in [22] proposed to approximate the response using the average of several cut-HDMR, i.e. . But here, for a new random input , the expansion corresponding to the closest centroid is chosen to calculate the response, i.e.,
| (37) |
For and , denote as the size of discrete point set in -th direction for constructing function . Therefore, in order to obtain expansions , and , the total number of models need to be evaluated is
| (38) |
For saving calculation cost, the coordinates of anchor points are also included in the corresponding discrete point set.
In practice, low-order HDMR expansions typically provide accurate approximations for a given function. Therefore, the following truncated form with order is considered in (37)
| (39) |
where positive integer . Then the computational cost of constructing truncated expansions using the Lagrange interpolation method is proportional to
| (40) |
which is much less than (38) when .
From formula (29), it can be observed that the nodes used in the Lagrange interpolation only take different values when the indices belonging to set , and the rest are consistent with the anchor . Therefore, it is not necessary to set the same discrete nodes for different anchor points, because the total number of models required to be evaluated does not decrease. That is, each anchor can have its own interpolation node set. For anchor , , the discrete points in the -th direction are selected as follows:
-
i)
denote the minimum and maximum values in the -th direction of set are and , respectively. Let ;
-
ii)
the midpoint of adjacent nodes with the largest interval in is also selected and incorporated into , then rearrange the set by value. Continue selecting the midpoint until the size of set is equal to .
Note that the nearest centroid principle is used to calculate the response of a new input here. Therefore, for each anchor , the corresponding interpolation node set does not necessarily cover the entire parameter space , and it can exist in the cluster as much as possible. When the size of node set is large enough that the interpolation error can be ignored, these two selection methods have little effect on the model accuracy.
The CVT based multiple anchor points cut-HDMR (CVT-HDMR) expansion is described in Algorithm 1, and the following theorem gives the approximate error of order truncated representation.
Theorem 3.1.
If and are large enough that the interpolation errors of non-zero order terms are negligible, and holds for a given function , then there are constants for such that the approximate error of order truncated CVT-HDMR with cluster number satisfies
| (41) |
where is the dimension of random input , is a CVT of input space , denotes the cardinality of set , represents the Voronoi tessellation energy corresponding to centroid , and indicator in is determined by nearest centroid.
Proof 3.2.
If the Lagrange interpolation errors of non-zero order terms are negligible, i.e. for , then similar to the remainder (2.1) of Taylor series, there exist a constant and vector such that the term with form (22) satisfies
If all th-order partial derivatives of function are bounded by constant , i.e.,
Then using the geometric mean less than the quadratic mean can obtain
Further, from the CVT of input space , and the relationship between arithmetic mean and quadratic mean can get
This proof is completed.
Theorem 3.1 states that the approximate expression has
| (42) |
Further, the distance between input and the corresponding anchor can be effectively controlled by using the CVT clustering centroids and the nearest principle. And the global error bound can be expressed by CVT clustering energy .
Remark 3.3.
There are three main reasons why we consider using the nearest principle for the CVT clustering centroids rather than the average of several expansions in the multiple anchors model: i) the average value will not be better than the best one in the components, unless all components are equal; ii) the accuracy of cut-HDMR expansion depends on the distance from the anchor point, which can be known from Theorem 3.1 or its relationship with the Taylor series; iii) CVT method takes distance as the clustering measure to minimize the sum of variances within the classes. That is to say, with the CVT centroids as the anchor points, the nearest principle will minimize the sum of distances from a given sample set to the corresponding anchor point, thus controlling the approximate error of the CVT-HDMR expansion.
4 Numerical experiments
In our experiments, a high-dimensional function integral and an elliptic stochastic partial differential equation (SPDE) are used as research backgrounds to illustrate the performance of CVT-HDMR expansion, and the proposed method is compared with the traditional single anchor cut-HDMR and multiple anchors model proposed in [22]. In the following experiments, random point indicates that the anchor is randomly drawn from the given parameter space , mean point denotes the anchor belongs to set and its response is closest to the mean of system output, CVT represents our CVT-HDMR expansion, and Ave-HDMR indicates the response is approximated by the average of multiple anchor points cut-HDMR, which is proposed by Labovsky and Gunzburger [22]. All computations were performed using MATLAB R2017a on a personal computer with 2.3 GHz CPU and 256 GB RAM.
4.1 Integration of high-dimensional function
Consider the quadrature test function [16]
| (43) |
with dimension . The input belongs to and satisfies the following uniform and standard beta distributions respectively, i.e.,
-
•
uniform: ;
-
•
standard beta: ;
where , and is the normalizing beta function. To measure the accuracy of the truncated CVT-HDMR expansion, define the relative error as
| (44) |
where is the th-order CVT-HDRM expansion with cluster number . Data set is composed of 20000 input samples.
It is easy to calculate the exact solution of integral is 1 when satisfies uniform distribution. For the standard beta distribution, the 6-dimensional 10-level sparse grid based on the 1-dimensional Gauss-Patterson quadrature rule [48, 49, 50] is used to compute the integral and as its exact solution. The integrals of cut-HDMR expansions based on different anchors are all calculated by 9-level sparse grids. Note that the test function is explicit, so no interpolation is involved.
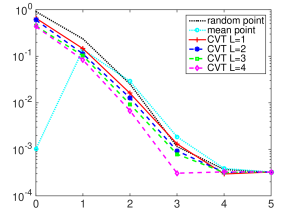
Table 1 gives the total CVT clustering energy of data set composed of 20000 samples. As the cluster number increases, the energy decreases gradually. The relative errors of quadrature test function approximated by the cut-HDMR expansions based on different anchors are listed in Table 2, and the results are visually shown in Figure 1. Although these approximation errors are almost equal when , they are different for lower order truncations. Obviously, it can not guarantee the accuracy of cut-HDMR expansion when the anchor is selected from parameter space randomly. Mean points with are well done for these two cases, because their zeroth-order terms are close to the expectations of function . Therefore, increasing the terms will lead to poor approximations until the expansions are sufficiently accurate. Note that the anchor point corresponding to in our model is close to the centroid of sparse grid proposed in [16], which is the center of input space under uniform distribution. Compared with the above classical single anchor cut-HDMR expansions, our multiple anchors CVT-HDMR model can provide higher accuracy, and gradually improve with the increase of . This is consistent with the theoretical results described in section 3.2. The distance between input and the anchor decreases with the increase of cluster number, resulting in smaller and smaller approximate errors.
| 1 | 2 | 3 | 4 | |
| 9.9845 | 8.7224 | 7.9745 | 7.3553 | |
| 9.9722 | 8.7307 | 7.9489 | 7.3634 |
| Uniform | Standard beta | ||||||||||
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | ||
| random point | 1.6773 | 0.1725 | 0.0048 | 0.0027 | 0.0026 | 2.3651 | 0.2526 | 0.0115 | 0.0037 | 0.0032 | |
| mean point | 0.2367 | 0.0174 | 0.0033 | 0.0026 | 0.0026 | 1.3908 | 0.2899 | 0.0186 | 0.0039 | 0.0032 | |
| CVT | 0.2542 | 0.0158 | 0.0022 | 0.0026 | 0.0026 | 1.4592 | 0.1606 | 0.0131 | 0.0030 | 0.0033 | |
| 0.1835 | 0.0143 | 0.0022 | 0.0026 | 0.0026 | 1.1248 | 0.1273 | 0.0093 | 0.0032 | 0.0032 | ||
| 0.2539 | 0.0108 | 0.0019 | 0.0026 | 0.0026 | 1.0249 | 0.0932 | 0.0079 | 0.0032 | 0.0032 | ||
| 0.1935 | 0.0079 | 0.0025 | 0.0026 | 0.0026 | 0.8343 | 0.0677 | 0.0031 | 0.0033 | 0.0032 | ||
(a) (b)

4.2 Elliptic SPDE with Gaussian distributed variables
Next, using an elliptic SPDE with Gaussian distributed random variables to verify the effectiveness of our method.
| (45) |
where , source term is given by
| (46) |
and diffusion function satisfies
| (47) |
Here, is eigenpair of covariance function
| (48) |
the dimension of random input is , and parameter for .
In our computation, the discrete solution is generated by the finite element method with mesh size , i.e. . The error measures are defined as
| (49) |
where and denote the expectation and variance, respectively. These error statistics are estimated by the Monte Carlo method with 5000 samples. Here, the size of data set is set to , the truncated order of HDMR expansion is , and the number of discrete points in each direction is equal to . Then simulations are needed for constructing a cut-HDMR, and the total evaluations for building the CVT-HDMR is . Therefore, there should not be too many anchors in our model for complex problems.
4.2.1 Construction of CVT-HDMR expansion
Table 3 lists the CVT clustering energy of data set composed of 5000 samples, which decreases with the increase of cluster number . Figure LABEL:eg2_F_C0 displays the diffusion functions associated with all CVT clustering centroids for different , and they have obvious differences. Table 4 gives the total number of simulations used for constructing the CVT-HDMR expansion. As increases, the sample size required to construct our model increases linearly. In our computational, the data needed for the single anchor cut-HDMR based on random point and mean point are consistent with in CVT-HDMR, both of which are 391. Note that the random input satisfies Gaussian distribution, so the sparse grid centroid is equivalent to the center of parameter space , and can be approximated by the anchor point of CVT-HDMR at .
| 1 | 2 | 3 | 4 | |
| 2.4713 | 2.1361 | 1.9083 | 1.7370 |
| 1 | 2 | 3 | 4 | |
| 391 | 782 | 1173 | 1564 |
4.2.2 Effectiveness of CVT-HDMR
In our calculations, the discrete point set is chosen in the entire parameter space in order to compare with other models first. Table 5 lists the error estimate of traditional single anchor cut-HDMR based on each centroid , which is generated by CVT clustering method. The results show that the accuracy of cut-HDMR expansions obtained from different anchor points will vary greatly, which intuitively indicates the importance of anchor point location. In order to mitigate the negative effect of “poor” anchor, the multiple anchors model is proposed. Table 6 gives the error estimations of CVT-HDMR and Ave-HDMR under the same construction cost. Compared with the results in Table 5, the detrimental effects of improper anchors can be balanced by averaging several cut-HDMR expressions, but its accuracy does not exceed the best one among the selected anchors for a given . While our model have a significant improvement. The accuracy of CVT-HDMR increases with the increase of cluster number when . It can be seen from the variances that the stability is also guaranteed. Although the errors corresponding to is slightly larger than that of , the results are acceptable. The main reasons for this phenomenon are that the data set is limited, and the sample points on the interfaces will increase with the increase of . Here, the multiple anchors models are also compared with the single anchor expansion based on the mean point. Clearly, the mean point is not appropriate as the anchor in this experiment. A realization of elliptic SPDE and its approximation errors associated with different methods and different are shown in Figures 3 and 4, respectively.
| 1 | 2 | 3 | 4 | |||||||
| anchor | ||||||||||
| 0.4870 | 1.6299 | 0.3636 | 1.9776 | 0.3002 | 1.6136 | 1.9376 | 0.3129 | 0.6407 | 2.6331 | |
| 0.1000 | 0.9609 | 0.0645 | 1.5619 | 0.0198 | 1.2544 | 1.3267 | 0.0218 | 0.1750 | 3.0557 | |
| CVT-HDMR | Ave-HDMR | mean point | |||||
| 2 | 3 | 4 | 2 | 3 | 4 | - | |
| 0.3760 | 0.2212 | 0.2426 | 0.6631 | 0.6427 | 0.6041 | 0.9913 | |
| 0.0766 | 0.0197 | 0.0424 | 0.1715 | 0.1574 | 0.1374 | 0.3704 | |
(a) (b)








In order to compare with other methods in the above experiments, the discrete point set used to construct the expansion covers the whole parameter space for . But for our model, the points only need to cover the Voronoi set . Table 7 gives the error estimates of the CVT-HDMR expansion, where and in point set are the minimum and maximum values of the -th direction of set , respectively. Compared with Table 6, it can be observed that when the offline cost of model construction is equal, higher accuracy can be obtained by using the interpolation nodes covering the corresponding area since the interpolation error is reduced. This further verifies the proposed method is better than the Ave-HDMR expansion.
| 2 | 3 | 4 | |
| 0.2627 | 0.1747 | 0.2022 | |
| 0.0272 | 0.0095 | 0.0322 |
A single simulation of elliptic SPDE (45) using the finite element method with mesh size takes 0.6082 seconds, while our CVT-HDMR expansion takes only 0.1132 seconds to obtain an accurate approximation of the response. The construction of HDMR in the offline stage is expensive, but it can be balanced by the fast calculation in online stage. Therefore, this method can be used for problems that require a lot of repeated calculations.
5 Conclusions
Based on the CVT clustering method, we provide a construction strategy for the multiple anchors cut-HDMR expansion, which applies the centroids as the anchors to establish the corresponding expansions, and then uses the nearest principle to generate the approximate response of the given input. Numerical experiments show that the CVT-HDMR method is more accurate and stable than the single anchor model and the average of several cut-HDMR expansions. However, with the increase of the cluster number , the construction cost of the CVT-HDMR increases linearly, and the number of samples on the interface also increases, which affects the accuracy of the CVT-HDMR expansion. Therefore, it is necessary to study the appropriate cluster number for this multiple anchors model. In addition, the specific application of the CVT-HDMR expansion is also a subject worth studying in the future.
References
- [1] Li, G., Rosenthal, C., and Rabitz, H., High dimensional model representations, J. Phys. Chem. A, 105(33), 2001.
- [2] Rabitz, H. and Aliş, Ö.F., General foundations of high-dimensional model representations, J. Math. Chem., 25(2):197–233, 1999.
- [3] Sobol’, I.M., Sensitivity estimates for nonlinear mathematical models, Math. Modeling Comput. Experiment, 1(4):407–414 (1995), 1993.
- [4] Cao, Y., Chen, Z., and Gunzburger, M., ANOVA expansions and efficient sampling methods for parameter dependent nonlinear PDEs., Int. J. Numer. Anal. Model., 6(2):256–273, 2009.
- [5] Rabitz, H., Aliş, Ö.F., Shorter, J., and Shim, K., Efficient input-output model representations, Comput. Phys. Commun., 117(1-2):11–20, 1999.
- [6] Smith, R.C., Uncertainty Quantification: Theory, Implementation, and Applications, Vol. 12, SIAM, 2013.
- [7] Sobol’, I.M., Theorems and examples on high dimensional model representation, Reliab. Eng. Syst. Saf., 79(2):187–193, 2003.
- [8] Wang, X., On the approximation error in high dimensional model representation, In 2008 Winter Simulation Conference, pp. 453–462. IEEE, 2008.
- [9] Cheng, K., Lu, Z., Ling, C., and Zhou, S., Surrogate-assisted global sensitivity analysis: an overview, Struct. Multidiscip. Optim., 61(3):1187–1213, 2020.
- [10] Chowdhury, R., Rao, B., and Prasad, A.M., High-dimensional model representation for structural reliability analysis, Commun. Numer. Methods Eng., 25(4):301–337, 2009.
- [11] Chowdhury, R. and Rao, B., Hybrid high dimensional model representation for reliability analysis, Comput. Meth. Appl. Mech. Eng., 198(5-8):753–765, 2009.
- [12] Huang, H., Wang, H., Gu, J., and Wu, Y., High-dimensional model representation-based global sensitivity analysis and the design of a novel thermal management system for lithium-ion batteries, Energy Conv. Manag., 190:54–72, 2019.
- [13] Kubicek, M., Minisci, E., and Cisternino, M., High dimensional sensitivity analysis using surrogate modeling and high dimensional model representation, Int. J. Uncertain. Quantif., 5(5), 2015.
- [14] Li, D., Tang, H., Xue, S., and Guo, X., Reliability analysis of nonlinear dynamic system with epistemic uncertainties using hybrid Kriging-HDMR, Probab. Eng. Mech., 58:103001, 2019.
- [15] Wang, H., Chen, L., Ye, F., and Chen, L., Global sensitivity analysis for fiber reinforced composite fiber path based on D-MORPH-HDMR algorithm, Struct. Multidiscip. Optim., 56(3):697–712, 2017.
- [16] Gao, Z. and Hesthaven, J.S., On ANOVA expansions and strategies for choosing the anchor point, Appl. Math. Comput., 217(7):3274–3285, 2010.
- [17] Yue, X., Zhang, J., Gong, W., Luo, M., and Duan, L., An adaptive PCE-HDMR metamodeling approach for high-dimensional problems, Struct. Multidiscip. Optim., 64(1):141–162, 2021.
- [18] Li, G., Wang, S.W., and Rabitz, H., Practical approaches to construct RS-HDMR component functions, J. Phys. Chem. A, 106(37):8721–8733, 2002.
- [19] Li, G., Hu, J., Wang, S.W., Georgopoulos, P.G., Schoendorf, J., and Rabitz, H., Random sampling-high dimensional model representation (RS-HDMR) and orthogonality of its different order component functions, J. Phys. Chem. A, 110(7):2474–2485, 2006.
- [20] Mukhopadhyay, T., Dey, T., Chowdhury, R., Chakrabarti, A., and Adhikari, S., Optimum design of FRP bridge deck: an efficient RS-HDMR based approach, Struct. Multidiscip. Optim., 52(3):459–477, 2015.
- [21] Zhang, Z., Choi, M., and Karniadakis, G.E. Anchor points matter in ANOVA decomposition. In Spectral and High Order Methods for Partial Differential Equations, pp. 347–355. Springer, 2011.
- [22] Labovsky, A. and Gunzburger, M., An efficient and accurate method for the identification of the most influential random parameters appearing in the input data for PDEs, SIAM-ASA J. Uncertain. Quantif., 2(1):82–105, 2014.
- [23] Shan, S. and Wang, G.G., Metamodeling for high dimensional simulation-based design problems, J. Mech. Des., 132(5), 2010.
- [24] Cai, X., Qiu, H., Gao, L., Yang, P., and Shao, X., An enhanced RBF-HDMR integrated with an adaptive sampling method for approximating high dimensional problems in engineering design, Struct. Multidiscip. Optim., 53(6):1209–1229, 2016.
- [25] Liu, H., Hervas, J.R., Ong, Y.S., Cai, J., and Wang, Y., An adaptive RBF-HDMR modeling approach under limited computational budget, Struct. Multidiscip. Optim., 57(3):1233–1250, 2018.
- [26] Anand, V., Patnaik, B.S.V., and Rao, B.N., Efficient Extraction of Vortex Structures by Coupling Proper Orthogonal Decomposition (POD) and High–Dimensional Model Representation (HDMR) Techniques, Numer Heat Tranf. B-Fundam., 61(3):229–257, 2012.
- [27] Tang, L., Wang, H., and Li, G., Advanced high strength steel springback optimization by projection-based heuristic global search algorithm, Mater. Des., 43:426–437, 2013.
- [28] Ji, L., Chen, G., Qian, L., Ma, J., and Tang, J., An iterative interval analysis method based on Kriging-HDMR for uncertainty problems, Acta Mech. Sin., 38(7):1–13, 2022.
- [29] Chen, L., Li, E., and Wang, H., Time-based reflow soldering optimization by using adaptive Kriging-HDMR method, Solder. Surf. Mt. Technol., 28(2):101–113, 2016.
- [30] Li, E. and Wang, H., An alternative adaptive differential evolutionary algorithm assisted by expected improvement criterion and cut-HDMR expansion and its application in time-based sheet forming design, Adv. Eng. Softw., 97:96–107, 2016.
- [31] Li, E., Ye, F., and Wang, H., Alternative Kriging-HDMR optimization method with expected improvement sampling strategy, Eng. Comput., 2017.
- [32] Hajikolaei, K.H. and Gary Wang, G., High dimensional model representation with principal component analysis, J. Mech. Des., 136(1):011003, 2014.
- [33] Haji Hajikolaei, K., Cheng, G.H., and Wang, G.G., Optimization on metamodeling-supported iterative decomposition, J. Mech. Des., 138(2):021401, 2016.
- [34] Huang, Z., Qiu, H., Zhao, M., Cai, X., and Gao, L., An adaptive SVR-HDMR model for approximating high dimensional problems, Eng. Comput., 32(3):643–667, 2015.
- [35] Li, G., Xing, X., Welsh, W., and Rabitz, H., High dimensional model representation constructed by support vector regression. I. Independent variables with known probability distributions, J. Math. Chem, 55(1):278–303, 2017.
- [36] Ren, O., Boussaidi, M.A., Voytsekhovsky, D., Ihara, M., and Manzhos, S., Random sampling high dimensional model representation gaussian process regression (RS-HDMR-GPR) for representing multidimensional functions with machine-learned lower-dimensional terms allowing insight with a general method, Comput. Phys. Commun., 271:108220, 2022.
- [37] Chen, L., Wang, H., Ye, F., and Hu, W., Comparative study of HDMRs and other popular metamodeling techniques for high dimensional problems, Struct. Multidiscip. Optim., 59(1):21–42, 2019.
- [38] Chen, L., Wang, H., Fan, Y., and Hu, W., Correction to: Comparative study of HDMRs and other popular metamodeling techniques for high dimensional problems, Struct. Multidiscip. Optim., 61(1):433–435, 2020.
- [39] Baran, M. and Bieniasz, L.K., Experiments with an adaptive multicut-HDMR map generation for slowly varying continuous multivariate functions, Appl. Math. Comput., 258:206–219, 2015.
- [40] Li, G., Schoendorf, J., Ho, T.S., and Rabitz, H., Multicut-hdmr with an application to an ionospheric model, J. Comput. Chem., 25(9):1149–1156, 2004.
- [41] Du, Q., Faber, V., and Gunzburger, M., Centroidal Voronoi tessellations: Applications and algorithms, SIAM Rev., 41(4):637–676, 1999.
- [42] Du, Q., Emelianenko, M., and Ju, L., Convergence of the Lloyd algorithm for computing centroidal Voronoi tessellations, SIAM J. Numer. Anal., 44(1):102–119, 2006.
- [43] Burkardt, J., Gunzburger, M., and Lee, H.C., Centroidal Voronoi tessellation-based reduced-order modeling of complex systems, SIAM J. Sci. Comput., 28(2):459–484, 2006.
- [44] Karcılı, A. and Tunga, B., Content based image retrieval using HDMR constant term based clustering, In International Conference on Mathematics and its Applications in Science and Engineering, pp. 35–45. Springer, 2022.
- [45] Davis, P.J., Interpolation and approximation, Courier Corporation, 1975.
- [46] Lloyd, S., Least squares quantization in PCM, IEEE Trans. Inf. Theory, 28(2):129–137, 1982.
- [47] MacQueen, J., Some methods for classification and analysis of multivariate observations, In Proc. Fifth Berkeley Sympos. Math. Statist. and Probability (Berkeley, Calif., 1965/66), Vol. I: Statistics, pp. 281–297. Univ. California Press, Berkeley, Calif., 1967.
- [48] Heiss, F. and Winschel, V., Likelihood approximation by numerical integration on sparse grids, J. Econom., 144(1):62–80, 2008.
- [49] Patterson, T.N., The optimum addition of points to quadrature formulae, Math. Comput., 22(104):847–856, 1968.
- [50] Petras, K., Smolyak cubature of given polynomial degree with few nodes for increasing dimension, Numer. Math., 93(4):729–753, 2003.