Clustered Embedding Learning for Recommender Systems
Abstract.
In recent years, recommender systems have advanced rapidly, where embedding learning for users and items plays a critical role. A standard method learns a unique embedding vector for each user and item. However, such a method has two important limitations in real-world applications: 1) it is hard to learn embeddings that generalize well for users and items with rare interactions; and 2) it may incur unbearably high memory costs when the number of users and items scales up. Existing approaches either can only address one of the limitations or have flawed overall performances. In this paper, we propose Clustered Embedding Learning (CEL) as an integrated solution to these two problems. CEL is a plug-and-play embedding learning framework that can be combined with any differentiable feature interaction model. It is capable of achieving improved performance, especially for cold users and items, with reduced memory cost. CEL enables automatic and dynamic clustering of users and items in a top-down fashion, where clustered entities jointly learn a shared embedding. The accelerated version of CEL has an optimal time complexity, which supports efficient online updates. Theoretically, we prove the identifiability and the existence of a unique optimal number of clusters for CEL in the context of nonnegative matrix factorization. Empirically, we validate the effectiveness of CEL on three public datasets and one business dataset, showing its consistently superior performance against current state-of-the-art methods. In particular, when incorporating CEL into the business model, it brings an improvement of in AUC, which translates into a significant revenue gain; meanwhile, the size of the embedding table gets times smaller.111The code is avaliable at: https://doi.org/10.5281/zenodo.7620448.
1. Introduction
Recommender systems, which support many real-world applications, have become increasingly accurate in recent years. Important improvements are brought about by the use of deep learning (Cheng et al., 2016; Guo et al., 2017) and the leverage of user historical data (Zhou et al., 2018, 2019). In these systems, embedding learning (i.e., learning vector representations) for users and items plays a critical role.
The standard method, full embedding, learns a unique vector representation for each user and item. However, this approach faces important limitations in practice. Firstly, for cold users and items that have insufficient historical interactions (which commonly exist in practice), it is hard for them to learn an embedding that generalizes well on their own. Secondly, web-scale recommender systems usually involve an enormous number of users and items; the memory cost incurred by full embedding can be prohibitively high: 1 billion users, each assigned a dimensional embedding in -bit floating point, require GB of memory.
To mitigate the problem of cold users and items, a common idea is to impose regularization, e.g., forcing all embeddings to follow a given clustering structure (Almutairi et al., 2021; Yang et al., 2016). However, using a fixed predefined clustering structure lacks flexibility; the given clustering structure can hardly be optimal. Besides, existing methods (Almutairi et al., 2021; Yang et al., 2016) require training in full embedding, still suffering from high memory costs.
To mitigate the problem of high memory cost, hashing (Weinberger et al., 2009; Yan et al., 2021a; Tan et al., 2020; Shi et al., 2020) is typically adopted to map entities to a fixed-size embedding table. This can directly tackle the problem of memory cost. However, forcing a hashing that is essentially random (Weinberger et al., 2009; Yan et al., 2021a) leads to unsatisfactory performance; the performances of current learning-to-hash methods (Tan et al., 2020; Shi et al., 2020) also have a large space for improvements. Besides, pretraining a hash function (Tan et al., 2020) or binding each hash bucket with a warm user (Shi et al., 2020) also makes these methods lack flexibility.
In chasing a more flexible and integrated solution to these two problems, while at the same time improving the performance, we propose in this paper Clustered Embedding Learning (CEL). CEL achieves dynamic and automatic clustering of users and items, which gives it the potential to have superior performance. In CEL, entities within the same cluster may use and jointly learn a shared embedding; thus it can significantly reduce the memory cost.
CEL performs clustering in a top-down (i.e., divisive) fashion, starting with a single cluster that includes all users (or items) and recursively splitting a cluster into two. Given that we want to share information among similar entities, such divisive clustering is a natural choice: sharing information of all entities at the beginning, then seeking to refine the clustering when possible.
Though being a natural thought, implementing divisive clustering for embedding learning is challenging. In the circumstance of shared embedding, it appears to have no standard to differentiate entities within the same cluster. To tackle this problem, we propose to refer to their gradients with respect to the shared embedding, since the differences in the gradients indicate their different desired optimization directions of the embedding. Then naturally, we propose to split the cluster along the first principal component of the gradients.
After cluster split and associated embedding optimizations, the current cluster assignment might have room for improvement, e.g., the embedding of some other cluster might better fit the interactions of an entity. Thus, fine-grained automatic cluster optimization also requires enabling cluster reassignment. Given that the training loss appears to be the only referable metric, we propose to conduct cluster reassignment based on direct loss minimization.
With such a cluster split and reassignment paradigm, CEL is ideally a sustainable framework that can not only support starting with zero data, but also can automatically increase the number of clusters, as well as automatically optimize the cluster reassignments, as the interaction data increases and the number of users/items increases.

We validate the proposed CEL both theoretically and empirically. Firstly, we prove the identifiability and the existence of a unique optimal number of clusters for CEL in the context of nonnegative matrix factorization. Then, we show that the accelerated version of CEL (CEL-Lite) has an optimal time complexity, which allows efficient online updates. Finally, we conduct extensive experiments on public real-world datasets as well as a private business dataset, integrated with various feature interaction models (including NMF, DIN, and DeepFM); the results show that CEL consistently outperforms current state-of-the-art methods. In particular, when incorporating CEL into the business model, it brings an improvement of in AUC, which translates into a significant revenue gain; meanwhile, the size of the embedding table gets 2650 times smaller.
2. Related Works
One line of research regularizes the embeddings to follow a given clustering structure to improve their qualities. For example, Joint NMF and K-Means (JNKM) (Yang et al., 2016) forces the embeddings to follow a K-clustering structure; eTree (Almutairi et al., 2021) learns the embeddings under an implicit tree (i.e., hierarchical clustering). Prior works in this line also include HSR (Wang et al., 2018), HieVH (Sun et al., 2017), etc. The major distinction of our work is that CEL does not predefine the clustering structure. Instead, it automatically optimizes the number of clusters and the cluster assignment. Besides, these methods require training in full embedding size, while CEL is trained with reduced embedding size.
Another line of work uses the hash to share and jointly learn the embeddings. The plain version applies the modulo operation (Weinberger et al., 2009) on the hash ID of each entity to obtain its hash code (i.e., the embedding index). Sharing embedding within each hash bucket, the embedding size can be reduced by the magnitude of the modulo divisor. Binary Hash (BH) (Yan et al., 2021a; Zhang et al., 2016) adopts a code block strategy on binarized hash IDs to reduce direct collisions. Adaptive Embedding (AE) (DeepRec, 2021) explicitly avoids collisions for warm users who have sufficient historical data. However, the hash assignments in these methods are essentially random and will not adapt/learn during learning. There are also several works that tried to learn a hash function. For example, HashGNN (Tan et al., 2020) learns a binary code hash function with graph neural networks. However, it requires pretraining a hash function. Preference Hash (PreHash) (Shi et al., 2020) learns to hash users with similar preferences to the same bucket. PreHash binds a warm user to each bucket, while the embedding of other users is a weighted sum of the embeddings of their top- related buckets. By contrast, CEL does not force bindings between users and clusters.
Some other works seek to reduce memory cost by reducing the embedding dimension or the number of bits for each dimension (i.e., quantization) (Ginart et al., 2021; Liu et al., 2020; Yan et al., 2021b; Zhang et al., 2016; Yang et al., 2019), which are orthogonal to our work in the perspective of reducing the memory cost. The type of clustering algorithms most relevant to CEL is Divisive Hierarchical Clustering (DHC) (Roux, 2015). Particularly, Principal Direction Divisive Partitioning (PDDP) (Boley, 1998) splits clusters via principal coordinate analysis (Gower, 2014), which is remotely related to our proposed GPCA (Section 3.2.2).

(a) (b)
3. The Proposed Framework
In this section, we present Clustered Embedding Learning (CEL) as a plug-and-play embedding learning framework which can be integrated with any differentiable feature interaction model such as Nonnegative Matrix Factorization (NMF), NeuMF (He et al., 2017), Wide&Deep (Cheng et al., 2016), DeepFM (Guo et al., 2017), MMoE (Ma et al., 2018), DIN (Zhou et al., 2018) and DIEN (Zhou et al., 2019). We illustrate the role of embedding learning in the behavior prediction that is commonly used in recommender systems in Figure 1.
Assume we have a user-item interaction data matrix of users and items, where denotes the interaction (rating, click, etc.) of the user on the item. We aim to recover the data matrix with two low-rank matrices, i.e., , where and can be regarded as the user embedding matrix and the item embedding matrix, respectively. Each row of (or ) corresponds to the embedding of a user (or item). is the embedding dimension. The prediction is produced by a differentiable feature interaction model that takes the embedding of user and the embedding of item as inputs. Generally, embedding learning can be formulated as an optimization problem:
| (1) |
where contains 1s at the indices of observed entries in , and 0s otherwise. denotes the Frobenius norm and denotes element-wise multiplication.
CEL clustering can be similarly applied to users and items. For clarity, we will only discuss the clustering of items. To initiate the clustering of items, we decompose the item embedding matrix as a product following a clustering structure:
| (2) |
where and denote the cluster assignment matrix and the cluster embedding matrix of items, respectively. denotes the current number of clusters and denotes the current number of splits. We adopt hard cluster assignment: each row of has exactly one , while the other entries are zero.
CEL solves Eq. (1) by alternatively performing embedding optimization and cluster optimization (Figure 2).
3.1. Embedding Optimization
In embedding optimization, we optimize and subject to a fixed . The optimization of can be directly conducted with Eq. (1) and (2). Since hard cluster assignment is adopted, the embedding of each cluster can be optimized separately.
The loss of the cluster embedding of can be denoted as:
| (3) |
where colon stands for the slicing operator that takes all values of the respective field, and maps a vector into a diagonal matrix. It has .
3.2. Cluster Optimization
In this section, we introduce the two proposed cluster optimization operations: cluster reassignment and cluster split. We assume that the reassignment occurs every steps of embedding optimization, while the split occurs every steps of embedding optimization.
3.2.1. Cluster Reassignment
An item assigned to a sub-optimal cluster can result in performance loss. When the embeddings have been optimized, we may perform cluster reassignment so that an item can be assigned to a better cluster. Reassignment is an important step toward automatically grouping similar items.
One problem CEL faces is how to measure the distance between an item and a cluster, since their representations are in different domains: items have interaction data, while clusters have cluster embeddings. A natural metric seems to be the fitness of the cluster embedding to the item. Thus, we seek to directly minimize the loss of each item w.r.t. their cluster assignments:
| (4) |
With fixed embeddings, the reassignment of each item is independent, therefore Eq. (4) can also be equivalently formulated as a set of sub-problems, one for each item:
3.2.2. Cluster Split with GPCA
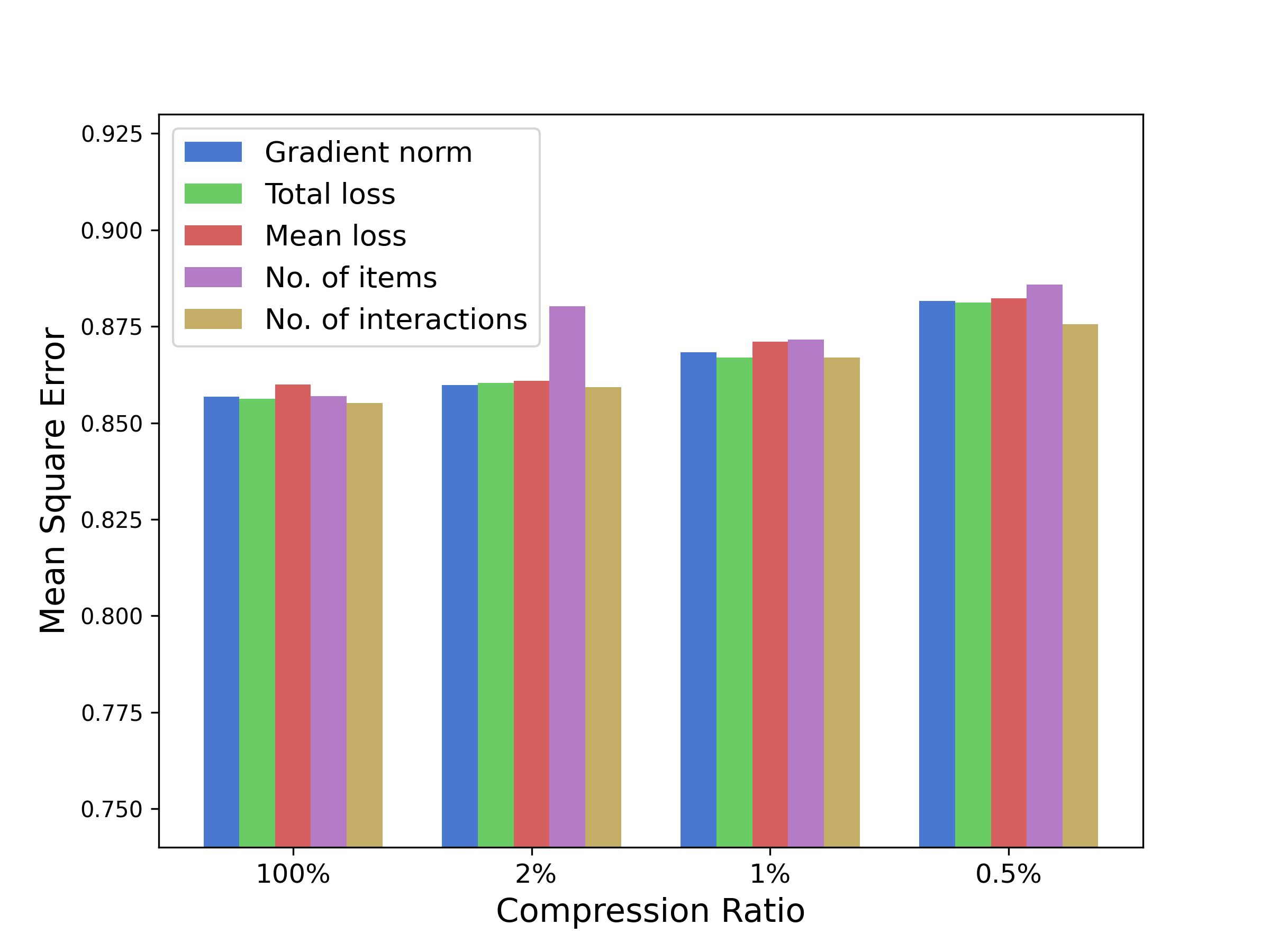
With embeddings optimized, we may consider cluster split to achieve a finer clustering. Each time we select one cluster and split it into two. There are many heuristic criteria for choosing the cluster. For example, we may choose the cluster that has the largest: total loss, mean loss, number of associated items, or number of associated interactions (). According to our experiments, they generally lead to similarly good results. This demonstrates the robustness of CEL upon cluster-choosing criteria. In this paper, we adopt the number of associated interactions as the default criterion.
The key challenge for CEL is how to split a cluster. With hard cluster reassignment and embedding sharing, embeddings within a cluster are the same. Thus we need a representation that can differentiate items in the same cluster. To tackle this problem, we propose Gradient Principal Component Analysis (GPCA) that splits clusters according to items’ gradients w.r.t. their shared embedding, which indicates their different desired optimization directions of the embedding. Such a split strategy can help achieve finer-grained clustering of similar items while further minimizing the loss.
Specifically, we assemble the gradients of items of a given cluster into a matrix , , where and denotes the cluster to be split. Then, we normalize (as a standard procedure before performing PCA, without changing its notation) and compute its first principal component:
| (5) |
After that, we split the cluster into two according to their first principal component scores :
| (6) |
One set of items is still assigned to cluster , while the other set is assigned to a new cluster . We may adjust the threshold to control/balance the number of items in each cluster.
We present the pseudocode of CEL in Algorithm 1.
3.3. Theoretical Analysis of CEL under NMF
CEL can be integrated with any differentiable feature interaction model, however, most of them (e.g., when involving other features or integrated with neural networks) are hard to analyze. Even so, we are able to study the theoretical properties of CEL when it is integrated with Nonnegative Matrix Factorization (NMF). These analyses can to some extent demonstrate the validity of CEL.
In NMF, and , which factorizes the data matrix into the product of two low-rank matrices. Despite that low-rank matrix factorization generally has no unique solution, nonnegativity helps establish the identifiability of NMF. NMF can thus produce essentially unique low-dimensional representations (Lee and Seung, 1999). The NMF of is regarded as essentially unique if the nonnegative matrix and are identifiable up to a permutation and scaling. We show that the solution of CEL is identifiable:
Theorem 1.
(Identifiability of CEL) Assume that the data matrix follows , where , , , , , has no repeated rows and, without loss of generality, . If is of full-column rank and rows of are sufficiently scattered, then , and are essentially unique.
The formal definitions (e.g., sufficiently scattered) (Almutairi et al., 2021; Yang et al., 2016; Fu et al., 2018) and detailed proofs are provided in Appendix B.
We assume to be of full-column rank, which means there is no empty cluster. Enforcing such a condition in our implementation has improved the model performance. The assumption of being sufficiently scattered is common and is likely to be satisfied as shown by (Almutairi et al., 2021). Based on Theorem 1, we can further deduce the existence of a unique optimal number of clusters:
Proposition 0.
(Optimal Number of Clusters of CEL) Under the assumptions of Theorem 1 and further assume that the data matrix can also be decomposed as , where , , , , , and . If is of full-column rank and the rows of are sufficiently scattered, then has only distinct rows, which can be obtained via permutation and scaling of the rows in .
The proof is built on the fact that the identifiability of CEL implies is a permutation and scaling of . The implication of Proposition 2 is twofold: 1) there exists a unique optimal number of clusters222A formal proof is provided in Appendix B.; 2) once the optimal number of clusters is reached, further split is unnecessary and will only introduce duplicated cluster embeddings.
Based on this observation and given that we do not have the exact formulation of the optimal number, we will keep splitting, while always initializing the embedding of the newly split cluster to be the same as the chosen cluster (this will retain the optimality of the previous solution). Besides, in online learning settings where we continually receive streaming data, the optimal number of clusters may keep increasing. In this sense, cluster split is well-motivated and makes CEL a sustainable learning framework.
3.4. CEL-Lite for Efficient Online Update
3.4.1. Online Learning.
Modern recommender systems generally deal with a massive amount of data. Such systems are thus usually updated in an online fashion: data arrive in sequence over time, and updates take place when the accumulated data reaches a predefined quantity. This framework closely follows the online learning paradigm and allows the model to rapidly adapt to the newest data.
We adapt CEL into CEL-Lite for the online learning setting by optimizing its efficiency in dealing with batch data. CEL-Lite has a theoretically optimal time complexity and inherits most of the advantages of CEL. CEL-Lite is also suitable when we have access to the full data but want to train the model in an online fashion.
3.4.2. Data and Embedding Optimization.
Under the online setting, each new batch consists of a set of user-item interactions . To enable the usage of interaction history as well as mitigate catastrophic forgetting (Kirkpatrick et al., 2017), we buffer from online batches a small number of the latest interactions () from each user and item for experience replay (Rolnick et al., 2019), which is commonly used in online systems. Since each interaction is represented by a triplet of user Id, item Id, rating, the storage cost incurred by buffering is acceptable. Moreover, the interactions can be stored in distributed file systems, unlike the embeddings or model parameters which must be stored in memory for efficient updates.
In CEL-Lite, one step of embedding optimization is performed for each batch via stochastic gradient descent with related buffered interactions. The overall time complexity of embedding optimization is then at most , where denotes the total number of interactions .
3.4.3. Efficient Cluster Reassignment.
To achieve fast cluster reassignment, we incorporate the following accelerations into CEL-Lite: 1) only considers additional randomly sampled clusters for each reassignment; 2) only items involved in the current batch are considered for reassignment.
With these two strategies, the cluster assignments are only improved locally. Nevertheless, with sufficient updates, it may be able to converge to the global optimal. Accordingly to our experiments, such accelerations significantly improve efficiency, while only incurring a small drop in performance. The time complexity of each reassignment is now only , where is the batch size. Given there are batches, there are at most cluster reassignments. Thus, the overall time complexity is .
3.4.4. Efficient Cluster Split.
To control the overall complexity of cluster split for CEL-Lite, we propose to constrain the number of associated interactions in each cluster and ensure clusters are approximately balanced. These two conditions limit the maximal number of split operations and the time complexity of each split. Concretely, we set up the following split strategies:
Strategy 1.
If an item has more than interactions, it will directly split and form a cluster by itself.
Strategy 2.
A cluster will split if and only if it has more than associated interactions (). The split should be balanced such that the difference between the number of associated interactions of resulting clusters is within .
Strategy 1 handles extremely warm items. After executing strategy 1, each clustered item has no more than interactions; strategy 2 then gets to easily balance the splits, which can be done by tuning333The tuning of can be done by Quickselect in . the threshold in Eq. (6).
With strategy 1 and 2, all clusters have at least interactions. Therefore, there are at most clusters and hence at most GPCA splits in total. Calculating the gradient of each item with only their buffered interactions, the time complexity of a single GPCA split is approximately , which is no more than . The overall time complexity of splits is thus .
Note that we use a constant in strategies 1 and 2 for simplicity and ease of use in practice. It can in fact generalize to any monotonically nondecreasing sublinear functions of without altering the overall time complexity. These strategies allow the maximum number of clusters to grow according to , which practices our theoretical results in Section 3.3.
3.4.5. The Optimal Time Complexity
Regarding as constants, each of the three optimizations of CEL-Lite is of a time complexity of . Thus, the overall complexity of CEL-Lite is also . Note that once we need to process all the data and each invokes an update of the embedding, the time complexity is already . That is, the time complexity of in a sense is the lower bound of embedding learning.
4. Experiments
| Dataset | Users | Items | No. interactions |
| MovieLens-1m | |||
| Video Games | |||
| Electronics | |||
| One-day Sales | m | m | m |
In this section, we empirically analyze CEL and compare it with related embedding learning baselines, including: Vanilla full embedding; eTree (Almutairi et al., 2021); JNKM (Yang et al., 2016); Modulo (Weinberger et al., 2009) (i.e., with plain hash); BH (Yan et al., 2021a); AE (DeepRec, 2021); HashGNN (Tan et al., 2020); and PreHash (Shi et al., 2020). They are tested with a variety of feature interaction models, including: NMF, DeepFM (Guo et al., 2017), DIN (Zhou et al., 2018), and a business model from an E-commerce platform.
The datasets considered include: MovieLens, a review dataset with user ratings () on movies; Video Games and Electronics, review datasets with user ratings () of products from Amazon; and One-day Sales, sub-sampled real service interaction data within a day of the E-commerce platform Shopee. The key statistics of these datasets are given in Table 1.
The original eTree and JNKM do not share embedding within clusters. To make the comparison thorough, we adapt eTree such that in the test phase, leaf nodes (users/items) will share the embedding of their parent nodes. Similarly, we adapt JNKM such that clustered items share the embedding of their cluster in the test phase. PreHash has a hyperparameter that selects top- related clusters for each user or item. We report its results with different values of .
We reuse to also denote: the number of parent nodes in eTree; the number of clusters in JNKM; and the number of hash buckets in hash-based methods. We refer to as the compression ratio.
| Feature Interaction Model | NMF | DIN | |||||||||
| Compression Ratio | |||||||||||
| LTC | LMC | SIT | |||||||||
| Vanilla full embedding | ✓ | ✕ | ✓ | - | - | - | - | - | - | ||
| eTree | ✕ | ✕ | ✕ | ||||||||
| JNKM | ✕ | ✕ | ✕ | ||||||||
| Modulo | ✓ | ✓ | ✓ | - | - | ||||||
| BH | ✓ | ✓ | ✓ | - | - | ||||||
| AE | ✓ | ✓ | ✓ | - | - | ||||||
| HashGNN | ✕ | ✕ | ✕ | - | - | ||||||
| PreHash () | ✓ | ✓ | ✕ | - | - | ||||||
| PreHash () | ✕ | ✓ | ✕ | - | - | ||||||
| CEL (Ours) | ✕ | ✓ | ✓ | 0.7784 | 0.7858 | 0.7926 | 0.7718 | 0.7787 | 0.7868 | ||
| CEL-Lite (Ours) | ✓ | ✓ | ✓ | ||||||||
4.1. Performance Versus Baselines
4.1.1. Rating Prediction
In this experiment, we perform rating prediction on the MovieLens datasets. We adopt NMF as well as DIN (both with ) as our feature interaction models, respectively. We set and for CEL, while , , , for CEL-Lite. Since some baselines apply their methods only on items or users, to ensure a fair comparison, for this experiment we only compress (clustering, hashing, etc.) the item embeddings while keeping full user embeddings for all methods.
The results are shown in Table 2. It can be observed that CEL outperforms existing baselines under all settings. According to our results, training with predefine clustering structure, eTree and JNKM brings clear improvements over vanilla methods in the full embedding setting. However, they consistently underperform CEL, especially when using a compressed embedding table. For hash based methods, the improvements brought by BH and AE (over naive Modulo) are relatively limited, while HashGNN and PreHash achieve more clear performance gains. Among them, PreHash with achieves the best performance in the compressed settings. Nevertheless, CEL clearly outperforms PreHash. Meanwhile, the results of this experiment demonstrate that CEL-Lite, being much more computationally efficient than CEL, has a similar performance to CEL and still clearly outperforms other baselines. The degradation in performance might be attributed to its subsampling accelerations.
In addition, we check in Table 2 three important properties for each method: Low Time Consumption (LTC), which indicates whether it achieves a time complexity of for both training and test. In particular, algorithms whose time complexity scales linearly with is not regarded as being LTC. Thus, eTree, JNKM, PreHash (with ), and CEL is not regarded as LTC. Neither does HashGNN, as it requires running GNN aggregation of neighborhoods, which has a worst case time complexity exponential in ; Low Memory Consumption (LMC), which indicates whether the method can significantly reduce the memory cost for both training and testing compared with full embedding. JNKM, eTree, and HashGNN require a full embedding table during training, thus do not satisfy LMC; Support Incremental Training (SIT), which indicates whether the method supports incremental training, is crucial for practical systems. As the data increases, the predefined tree/clustering structure of eTree/JNKM can be sub-optimal, the pretrained hash function of HashGNN may become outdated, and the pre-specified pivot users in PreHash may become less representative. As a result, these methods may require periodical retraining.
| Dataset | Video Games | Electronics | ||||||||||||||
| Feature Interaction | DeepFM | DIN | DeepFM | DIN | ||||||||||||
| Compression Ratio | ||||||||||||||||
| Vanilla full embedding | - | - | - | - | - | - | - | - | - | - | - | - | ||||
| Modulo | - | - | - | - | ||||||||||||
| HashGNN | - | - | - | - | ||||||||||||
| PreHash () | - | - | - | - | ||||||||||||
| CEL-Lite | ||||||||||||||||
4.1.2. Online Conversion Prediction
To promote desirable behaviors from users, such as clicks and purchases, conversion rate prediction is an important learning task in online E-commerce systems. In this section, we test the models with the conversion prediction task, i.e., predicting whether a user will perform a desirable behavior on an item. We use the Video Games and Electronics datasets for this experiment, treating ratings not less than as positive feedback (i.e., conversions). For performance evaluation, we use the standard Area under the ROC Curve (AUC) on the test sets, which can be interpreted as the probability that a random positive example gets a score higher than a random negative example.
The experiment is conducted in an online fashion, such that the data is received incrementally over time. We adopt HashGNN and PreHash, the top-2 performing hash methods in the rating prediction experiment (as well as the naive Modulo) as our baselines, though they do not support incremental training. The hash function of HashGNN requires pretraining with full data before starting the actual embedding learning, thus we allow it to access the full data before the online training. PreHash requires binding the warmest users to its buckets, we thus allow it to go through all data to find the warmest users before the online training. It is worth noting that, unlike these two methods, CEL(-Lite) can naturally start embedding learning from scratch without any extra information.
In this experiment, we compress both the user embeddings and the item embeddings. To further demonstrate that our method works well with different feature interaction models, we adopt DeepFM in this experiment, while keeping using DIN. We set and . We set , , and for CEL-Lite.
The results are shown in Table 3. It can be observed that CEL-Lite still clearly outperforms the baselines.
| Dataset | One-day Sales | ||||
|
Full | 1m | 100k | 10k | |
| Business Model | |||||
| CEL-Lite | - | - | |||
4.1.3. Integrated with Business Model
To further validate the performance of CEL-Lite, we conduct experiments on dataset from the E-commerce platform Shopee, that needs to handle billions of requests per day. We use the model deployed in that platform as our baseline, which is a fine-tuned business model that has a sophisticated network structure and heavy feature engineering. It optionally uses full embedding, or uses Modulo to compress the size of embedding table. In this experiments, we integrate CEL-Lite into this business model, replacing its embedding learning module.
As shown in Table 4, CEL-Lite with a small number of clusters (with 10k or 100k embedding entities for users and items, respectively) outperforms the business model with full embedding, and more significantly, the business model with compression. Specifically, CEL-Lite achieves an improvement of in AUC with the embedding table size being 2650 times smaller. Note that a gain in absolute AUC is regarded as significant for the conversion rate tasks in practice (Cheng et al., 2016; Zhou et al., 2018).




(a) (b) (c)
4.2. Personalization and Cold-start Problems
4.2.1. Personalization.
When training with shared embeddings, we may choose to untie the cluster assignments at a specific point to learn a personalized embedding (with the shared embedding as initialization) for each user and item. After being untied, embeddings can be further optimized according to their own historical data. This makes sense if we want a full embedding, in case we have enough data and memory. We refer to this procedure as personalization, which is similar to the personalization in federated learning settings (Tan et al., 2022). There are various personalization techniques. We leave them for future investigations. Here, we simply add the following distance regularization to the original objective to guide the personalization:
We set in our experiment. Table 2&3 shows CEL with personalization achieves the best results. In particular, it has outperformed all other full embedding methods.
4.2.2. Mitigating Cold-start Problems.
We investigate the test loss of items with respect to the number of associated interactions in the training set (on the MovieLens-1m dataset, with a compression ratio of ). As shown in Figure 3, CEL significantly outperforms PreHash on cold items. This could be because PreHash emphasizes the warm items, while the cold items are roughly represented as a weighted sum of the warm ones. This may also be why PreHash performs slightly better in the interval of . On the other hand, we can see that if we do personalization for CEL, the performance of cold items degenerates. This strongly evidences those cold items cannot be well optimized with only their own data, and CEL can help in this regard. Personalization brings benefits for the intervals of , hence can have a better overall performance. We further try only personalizing the warm items (), and find a improvement on test MSE.
4.2.3. Sparsity and Compression Ratio.
To investigate the impact of data sparsity and compression ratio on CEL, we create a dense MovieLens-1m dataset by filtering out the users and items with no more than interactions, and a sparse MovieLens-1m dataset by randomly dropping interactions (but still ensuring at least sample) for each user.
As shown in Figure 4, on the dense and original datasets, increasing the number of clusters consistently improves the overall performance of CEL; while on the sparse dataset, the optimal compression ratio occurs at : further splits will degenerate its performance.
We can also see that personalization at different compression ratios consistently brings improvement over CEL on the dense and original datasets, which is reasonable as warm items may have dominated the overall performance in these datasets. By contrast, on the sparse dataset, personalization consistently leads to degeneration of performance. More specifically, on the dense dataset, increasing the number of clusters consistently improves the performance of personalization, while on the original and sparse dataset, there is an optimal compression ratio of for personalization.
Overall, the number of clusters is not the more the better. Too many clusters on a sparse dataset or a dataset that has many cold items, may lead to performance degeneration: partially on cold items or even the overall performance.
4.3. Ablation Studies on Clustering
4.3.1. Interpretation of Clustering.
To see how and how well CEL clusters items, we visualize the learned clusters of CEL on MovieLens-1m at in Figure 5.
We find that at this stage, the clusters are mainly divided according to the ratings of items. The standard deviations of ratings within clusters are generally low. This result is reasonable because the task is to predict the ratings.
We can also see that movies within a cluster appear to have some inner correlation. For example, cluster mainly consists of action or science fiction action movies; cluster mainly consists of music or animation movies that are suitable for children; cluster mainly consists of crime movies that have gangster elements; and cluster contains movies directed by Stanley Kubrick. Note that such information is not fed to the model in any form, but learned by CEL automatically. A calculation of the averaged entropy of the distribution of genres in each cluster further evidences that CEL can better distinguish movies of different genres than others.
Interestingly, we find movies of the same type may form multiple clusters of different average ratings. For example, clusters and are both mostly action, but with a clear difference in their ratings.
| Number of clusters () | ||||
| Initialization | Continue Running | |||
| By Genre | - | - | - | |
| By Avr. Rating | - | |||
| By Genre | CEL | |||
| By Avr. Rating | CEL | |||
| None | CEL | |||
4.3.2. Rule-based Clusterings
CEL achieves automatic clustering of entities, but it is still not clear how it works against rule-based clusterings. Given that we find in the initial stage CEL mainly clusters items according to the genres and ratings of movies on the MovieLens dataset. In this section, we compare CEL with rule-based clustering based on genres (partitioning movies according to their genres in the meta data; there are 18 genres in total) and ratings (partitioning movies evenly according to their averaged rating).
As shown in Table 5, neither of these two rule-based clusterings works well. We further try using these two rule-based clusterings as initialization for CEL, to see whether it can help improve the performance. As we can see, such initialization brings either no or insignificant improvements.

4.3.3. Split Methods
| MovieLens | 100k | 1m |
| Random Split | ||
| User-Inspired Bisecting 2-Means | ||
| Gradient Bisecting 2-Means | ||
| Gradient Random Projection | ||
| GPCA |
We test several different split methods, including: Random Split, which randomly splits items into two sets; Bisecting 2-Means, an advanced split method from DHC (Steinbach et al., 2000), which bisects items into 2 clusters according to the distance between item representations; Random Projection, which is similar to GPCA but projects the gradients in a random direction instead of the first principal component; and GPCA. Bisecting 2-Means is performed either on the gradient matrix or on the user-inspired representations (i.e., representing an item by averaging the embeddings of its associated users). For all methods, we split till a compression ratio of .
The results are shown in Table 6. We can see that random split yields the worst result, which indicates the importance of split methods; Bisecting 2-Means works better on gradients than user-inspired representations, which suggests the gradients are more informative; Bisecting 2-Means and random project of gradient works less than GPCA, which suggests the rationality of split according to the first principal component.
5. Conclusions
In this paper, we proposed Clustered Embedding Learning (CEL), a novel embedding learning framework that can be plugged into any differentiable feature interaction model. It is capable of achieving improved performance with reduced memory costs. We have shown the theoretical identifiability of CEL and the optimal time complexity of CEL-Lite. Our extensive experiments suggested that CEL can be a powerful component for practical recommender systems.
We have mainly considered the embeddings of users and items in this paper. Nevertheless, CEL can be similarly applied to other ID features or categorical features, such as shop ID or seller ID in E-commerce, search words in search engines, object categories, and geographic locations. We leave these for future work.
Acknowledgments
This research is supported in part by the National Natural Science Foundation of China (U22B2020); the National Research Foundation Singapore and DSO National Laboratories under the AI Singapore Programme (AISG2-RP-2020-019); the RIE 2020 Advanced Manufacturing and Engineering Programmatic Fund (A20G8b0102), Singapore; the Nanyang Assistant Professorship; the Shanghai University of Finance and Economics Research Fund (2021110066).
References
- (1)
- Almutairi et al. (2021) Faisal M Almutairi, Yunlong Wang, Dong Wang, Emily Zhao, and Nicholas D Sidiropoulos. 2021. eTREE: Learning Tree-structured Embeddings. In Proc. AAAI, Vol. 35. 6609–6617.
- Boley (1998) Daniel Boley. 1998. Principal direction divisive partitioning. Data mining and knowledge discovery 2, 4 (1998), 325–344.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proc. DLRS. 7–10.
- DeepRec (2021) DeepRec. 2021. Adaptive Embedding. https://github.com/alibaba/DeepRec/blob/main/README.md.
- Fu et al. (2018) Xiao Fu, Kejun Huang, and Nicholas D Sidiropoulos. 2018. On identifiability of nonnegative matrix factorization. IEEE Signal Processing Letters 25, 3 (2018), 328–332.
- Ginart et al. (2021) Antonio A Ginart, Maxim Naumov, Dheevatsa Mudigere, Jiyan Yang, and James Zou. 2021. Mixed dimension embeddings with application to memory-efficient recommendation systems. In Proc. IEEE ISIT. IEEE, 2786–2791.
- Gower (2014) John C Gower. 2014. Principal coordinates analysis. Wiley StatsRef: Statistics Reference Online (2014), 1–7.
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
- He et al. (2017) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. In Proc. WWW. 173–182.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. PNAS 114, 13 (2017), 3521–3526.
- Lee and Seung (1999) Daniel D Lee and H Sebastian Seung. 1999. Learning the parts of objects by non-negative matrix factorization. Nature 401, 6755 (1999), 788–791.
- Liu et al. (2020) Haochen Liu, Xiangyu Zhao, Chong Wang, Xiaobing Liu, and Jiliang Tang. 2020. Automated embedding size search in deep recommender systems. In Proc. SIGIR. 2307–2316.
- Ma et al. (2018) Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939.
- Rolnick et al. (2019) David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. 2019. Experience replay for continual learning. Advances in NeurIPS 32 (2019).
- Roux (2015) Maurice Roux. 2015. A comparative study of divisive hierarchical clustering algorithms. arXiv preprint arXiv:1506.08977 (2015).
- Shi et al. (2020) Shaoyun Shi, Weizhi Ma, Min Zhang, Yongfeng Zhang, Xinxing Yu, Houzhi Shan, Yiqun Liu, and Shaoping Ma. 2020. Beyond user embedding matrix: Learning to hash for modeling large-scale users in recommendation. In Proc. SIGIR. 319–328.
- Steinbach et al. (2000) Michael Steinbach, George Karypis, and Vipin Kumar. 2000. A comparison of document clustering techniques. (2000).
- Sun et al. (2017) Zhu Sun, Jie Yang, Jie Zhang, and Alessandro Bozzon. 2017. Exploiting both vertical and horizontal dimensions of feature hierarchy for effective recommendation. In Proc. AAAI, Vol. 31.
- Tan et al. (2022) Alysa Ziying Tan, Han Yu, Lizhen Cui, and Qiang Yang. 2022. Towards personalized federated learning. IEEE Transactions on Neural Networks and Learning Systems (2022).
- Tan et al. (2020) Qiaoyu Tan, Ninghao Liu, Xing Zhao, Hongxia Yang, Jingren Zhou, and Xia Hu. 2020. Learning to hash with graph neural networks for recommender systems. In Proc. TheWebConf 2020. 1988–1998.
- Wang et al. (2018) Suhang Wang, Jiliang Tang, Yilin Wang, and Huan Liu. 2018. Exploring hierarchical structures for recommender systems. IEEE Transactions on Knowledge and Data Engineering 30, 6 (2018), 1022–1035.
- Weinberger et al. (2009) Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg. 2009. Feature hashing for large scale multitask learning. In Proc. ICML. 1113–1120.
- Yan et al. (2021a) Bencheng Yan, Pengjie Wang, Jinquan Liu, Wei Lin, Kuang-Chih Lee, Jian Xu, and Bo Zheng. 2021a. Binary code based hash embedding for web-scale applications. In Proc. CIKM. 3563–3567.
- Yan et al. (2021b) Bencheng Yan, Pengjie Wang, Kai Zhang, Wei Lin, Kuang-Chih Lee, Jian Xu, and Bo Zheng. 2021b. Learning Effective and Efficient Embedding via an Adaptively-Masked Twins-based Layer. In Proc. CIKM. 3568–3572.
- Yang et al. (2016) Bo Yang, Xiao Fu, and Nicholas D Sidiropoulos. 2016. Learning from hidden traits: Joint factor analysis and latent clustering. IEEE Transactions on Signal Processing 65, 1 (2016), 256–269.
- Yang et al. (2019) Jiwei Yang, Xu Shen, Jun Xing, Xinmei Tian, Houqiang Li, Bing Deng, Jianqiang Huang, and Xian-sheng Hua. 2019. Quantization networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7308–7316.
- Zhang et al. (2016) Hanwang Zhang, Fumin Shen, Wei Liu, Xiangnan He, Huanbo Luan, and Tat-Seng Chua. 2016. Discrete collaborative filtering. In Proc. SIGIR. 325–334.
- Zhou et al. (2019) Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proc. AAAI, Vol. 33. 5941–5948.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proc. SIGKDD. 1059–1068.
| Datasets | MovieLens-100k | MovieLens-1m | MovieLens-10m | |||||||||
| Compression Ratio | ||||||||||||
| Vanilla full embedding | - | - | - | - | - | - | - | - | - | |||
| eTree | ||||||||||||
| JNKM | ||||||||||||
| Modulo | - | - | - | |||||||||
| BH | - | - | - | |||||||||
| AE | - | - | - | |||||||||
| PreHash () | - | - | - | |||||||||
| PreHash () | - | - | - | |||||||||
| CEL (Ours) | ||||||||||||
| CEL-Lite (Ours) | ||||||||||||
Appendix A Appendix
In this appendix, we provide some important implementation details and some additional ablation studies. Detailed proofs about identifiability (Appendix B), detailed time complexity analysis and proofs (Appendix C), and more implementation details and results (Appendix D), can be found in https://arxiv.org/abs/2302.01478.
A.1. More Details about Experiment Settings
We apply stochastic gradient descent with a learning rate and for CEL and CEL-Lite, respectively. We also adopt the gradient averaging technique (Appendix D.3). The total number of iterations and other hyperparameters on each dataset is tuned by validation.
By default, we set the initial number of clusters to be in all of our experiments. We have tuned (when , as initialization, the users/items are mapped randomly into clusters) and find a generally consistent performance when is relatively small ().
When splitting with GPCA, we use a priority queue to keep track of the clusters. We set the cluster splitting threshold , and the split is stopped when the total number of clusters reaches the given compression ratio.
We perform -fold cross validation for the rating prediction task, and train with random seeds for other tasks, reporting the average.
For the public datasets used in this paper, we use a split ratio of for dividing the train set and the test set. For Amazon datasets, we report the test performance of items/users which have interaction(s) on the training set.
In our implementation, DIN and DeepFM utilize the sparse features from the available meta data. Such sparse features allow feature crossing in DeepFM. Following the common heuristic (He et al., 2017), we use and neurons in the two hidden layers of DIN, respectively. We use the same network architecture for DeepFM. The business model has a sophisticated network structure and heavy feature engineering, which leads to more than m trainable non-embedding parameters.
On MovieLens datasets, the genre of each movie is provided in the metadata. We define the the genre distributions, i.e., a distribution for genre in clusters. We thus can calculate the averaged entropy (e.g., in Figure 5) of the genre distribution in the clusters, which can be expressed below
Lower entropy indicates a better distinction of genres.



(a) (b) (c) (d)
A.2. On Datasets of Different Scales
Besides MovieLens-1m, we also performed experiments on the dataset of MovieLens-100k, MovieLens-10m, and MovieLens-25m, which contains 100k, 10m, and 25m interactions respectively. As the results shown in Table 7 and 8, CEL consistently outperforms baselines. Other observations are also in line with our discussion in the main paper.
| Datasets | MovieLens-25m | |||
| Compression Ratio | ||||
| Vanilla full embedding | - | - | - | |
| Modulo | - | |||
|
PreHash (
|
- | |||
| CEL-Lite (Ours) |
p |
|||
A.3. Ablation Studies: Split
In this section, we perform a thorough study of the split in CEL.
A.3.1. Split vs. No Split
We first provide empirical evidence of the benefit of CEL split operation by ablations studies. For no split, we initialize the number of clusters to be exactly the maximum allowed number. The assignments are randomly initialized. Note that reassignments are still allowed. The results in Table 9 show that the split operation does bring benefits compared with no split. Another strong evidence supporting the superior performance of our GPCA split can be found in Table 6.
| MovieLens-1m | NMF | DIN | ||||
| Compression Ratio | ||||||
| CEL (no split) | 0.7582 | 0.7991 | 0.8025 | 0.7428 | 0.7824 | 0.8023 |
| CEL | 0.7474 | 0.7846 | 0.7926 | 0.7390 | 0.7787 | 0.7868 |
A.3.2. Criterion for Choosing the Split Cluster
We test cluster choosing criteria, results shown in Figure 6. We can see that they generally lead to similarly good performance. It demonstrates the robustness of CEL upon cluster choosing criteria. It is worth noting that the mean loss criterion performs worse than the others, probably because the cold items tend to have larger men loss than the warm items, as revealed by our experiment on Figure 3. Thus focusing on the mean may overly emphasize the cluster with cold items, and thus lead to undesired behavior. Thus in this sense, the total loss (or other criteria) may perform better than the mean.
A.3.3. Threshold for GPCA Split
We test different thresholds for split with GPCA. The results are shown in Table 10, where we split till a compression ratio of . As we can see, they generally lead to similarly good performance, indicating the robustness of GPCA split w.r.t the threshold . For the other results reported in this paper, we adopt a default value of . Noted that GPCA always finds a significant principal component: the eigenvalue decompositions in our experiments show that the largest eigenvalue is usually times larger than the second largest eigenvalue.
| MovieLens | 100k | 1m |
| 0.8684 | 0.7795 | |
| median of the principal component scores | 0.8691 | 0.7807 |
| chosen to balance the split of data (Section 3.4) | 0.8689 | 0.7808 |
A.4. Ablation Studies: Reassignment
A.4.1. Reassignment
We conduct an experiment to quantify the effect of reassignment. The results as in Table 11 show that under the two scenarios we tested, performing extensive steps of reassignments will lead to slight overfitting, while performing few steps of reassignment will lead to underfitting. Thus the total number of reassignments (as well as ) is a hyperparameter that can be tuned (e.g., by grid search). This reveals the rationale behind our strategy of a constant number of reassignments.
| MovieLens-1m | Compression Ratio | Compression Ratio | ||||
| Total no. of reassignments | ||||||
| CEL (training MSE) | 0.7307 | 0.7318 | 0.7329 | 0.7071 | 0.7179 | 0.7187 |
| CEL (test MSE) | 0.7931 | 0.7926 | 0.7939 | 0.7867 | 0.7858 | 0.7860 |
A.4.2. Retrain with the Learned Clustering
We further conduct experiments to retraining with the learned clustering structure. The settings of the retraining are identical to the training from which we obtained the clustering structure, so that only difference is that now the assignment is fixed (no cluster split nor cluster reassignment). The results are shown in Table 12. As can be seen, the test performance of retraining is nearly identical to that of training, indicating that our CEL algorithm has learned effective clustering structures that can generalize well with different initialization of embeddings. It also implies that CEL does not encounter obvious optimization difficulties during the training to obtain such a clustering structure.
| Datasets | MovieLens-100k | MovieLens-1m | ||||
| Compression Ratio | ||||||
| CEL | 0.8671 | 0.8707 | 0.8906 | 0.7507 | 0.7858 | 0.7926 |
| CEL (Retrain) | - | 0.8704 | 0.8905 | - | 0.7858 | 0.7927 |
Appendix B More about Identifiability of CEL
B.1. Definitions of Related Concepts
B.1.1. Essentially Uniqueness.
We say that the NMF of is essentially unique, if the nonnegative matrix and are identifiable up to a common permutation and scaling/counter-scaling, that is, implies and for a permutation matrix and a full-rank diagonal scaling matrix .
B.1.2. Sufficiently Scatteredness.
To investigate the identifiability, it is a common practice to assume the rows of are sufficiently scattered (Almutairi et al., 2021; Yang et al., 2016; Fu et al., 2018). Formally, it should have the following property.
Definition 0.
(Sufficiently Scattered) (Fu et al., 2018) The rows of a nonnegative matrix are said to be sufficiently scattered if: 1) ; and 2) . Here and are the conic hull of and its dual cone, respectively; , ; is the boundary of a set.
The sufficiently scattered condition essentially means that contains , a central region of the nonnegative orthant, as its subset.
B.2. Proof of Theorem 1
First we have the following lemma, which is taken from the previous work (Fu et al., 2018).
Lemma 0.
(NMF Identifiability) Suppose where and are two nonnegative matrices, and . If further assume that the rows of are sufficiently scattered. Then and are essentially unique.
Note that this lemma is a direct implication of Theorem 1 in (Fu et al., 2018).
Proof.
(Proof of Theorem 1) We assumed the rows of are sufficiently scattered. Since is a permutation with repetition of rows in , rows of are sufficiently scattered (because following from our assumption of being of full-column rank). Now, since is of full-column rank and rows of are sufficiently scattered, and in are essentially unique by Lemma 2.
Given that is of full-column rank, is a permutation with repetition of distinct rows in and every row in appears in . Regarding as the subject of decomposition, and can be uniquely determined up to a permutation. Note that there is no diagonal scaling ambiguity between and , since we have required to be a matrix of .
Overall, , and are essentially unique. ∎
B.3. Proof of Proposition 2
Proof.
Following the proof of Theorem 1, we can similarly deduce that and are essentially unique. Thus where is a full rank diagonal nonnegative matrix and is a permutation matrix. From the assumption we know that there are only distinct rows in , thus distinct rows in . From the assumption that being of full-column rank, we know that all rows of appears in , which implies only distinct rows in , and they corresponds to a permutation/scaling of the rows in . ∎
B.4. Uniqueness of the Optimal Cluster Number
Proposition 0.
(Irreducibility of the Optimal Cluster Number) Following from the assumptions of Theorem 1, there does not exist a decomposition of the data matrix such that , where , , , , , , and is of full-column rank.
Proof.
Suppose such matrix decomposition exists. Then by Proposition 2 we know that for the decomposition in Theorem 1, will have repeated rows. This will violate our assumption of having no repeated rows, which proves the above proposition by contradiction. The above proposition shows that no satisfies Theorem 1. ∎
Corollary 0.
(Uniqueness of the Optimal Cluster Number) Following from the assumptions of Theorem 1, there does not exist a decomposition of the data matrix such that , where , has no repeated rows, , , , , and is of full-column rank.
In summary, our Theorem 1 has identified a set of solutions of , and , such that the solutions do not contain repeated rows in (otherwise the solution can be further reduced to a simpler form). Such a set of irreducible solutions naturally leads to an optimal cluster number. Also, the (essentially) uniqueness of the solutions implies the uniqueness of the optimal cluster number.
Appendix C More on Complexity of CEL(-Lite)
C.1. Time and Space Complexities of GPCA
For CEL, time complexity of GPCA is , which is linear in and is the same as gradient calculation. PCA (including eigen decomposition) only involves an matrix. Its time complexity is , where is usually small. The space complexity is also low, which can be as low as in theory. Thus, split with GPCA is both time and space efficient. The time complexity can be further reduced via parallel computation.
Note that when we use a constant number of (less or equal to) buffer interactions for each item considered in the GPCA, the time complexity will reduce to .
C.2. Time Complexity of CEL-Lite Formally
Theorem 1.
The time complexity of CEL-Lite is .
Proof.
The total time complexity is the sum of time complexity of embedding optimization and cluster optimization. The cluster optimization consists of split and reassignments.
Firstly, all reassignments can be processed within time since it involves total batch; each batch incurs time from sub-problems with candidate clusters and a constant number of buffered history considered.
Secondly, all the split operations can be processed within time complexity. Here, we change in strategies 1&2 to a monotonically non-decreasing sublinear function to make it more general, where denotes the number of interactions in the current training step , which is used to distinguish from , the total number of interactions collected during the entire online learning. Then, strategies 1&2 ensure each newly split cluster in the current training step will have interactions. This will remain true through the entire training, since the non-decreasing function ensures that such cluster will still have interactions even it splits in any future iteration . We now denote the number of newly split cluster in the current training step as and suppose the training lasts for a total of steps. Thus we can sum over them and obtain . Now, recall that the time complexity of each split operation is when only a constant number of history considered. The time complexity for all splits in step then requires time, where accounts for the new interactions from the reassignment or new batch data in step . As a result, we know that the overall time complexity for all splits are .444Note that strategy 1 incurs at most time complexity additionally.
Note that the embedding optimization also takes time. So, the overall time complexity of CEL-Lite is . ∎
C.3. Complexity Analysis for CEL
In contrast to CEL-Lite, CEL assumes the data matrix is known a priori to the embedding learning. For CEL, in each step of optimization we will need to process the entire data matrix. With our framework in Section 3, CEL splits once per steps of embedding optimizations, until we have reached a desired cluster number (corresponding to a desired compression ratio). We perform the reassignment once per steps of embedding optimizations. Suppose the training lasts for a total of steps (of embedding optimization). is a constant and maybe not negligible (or even very large) depending on the learning rate and the convergence speed.
Theorem 2.
CEL with the maximum cluster number being fixed to has a time complexity of .
Proof.
The embedding optimizations have a time complexity of for each step. So the total time complexity of steps of embedding optimization is .
For the split operations, we can imagine a binary tree starting from a single root node. The children represent two clusters from the split of their parent, and let the value of a node represents the interactions (number of interactions associated with it). The time complexity will sum up all the nodes in the tree (except leaf nodes). We can easily verify that processing all nodes in a particular level (depth) of the tree sums to time complexity if the level is completely filled (will be less if it is not completely filled), since the numbers of interactions associated to the nodes sums to . So now we will need to compute the depth of the tree. The tree is strictly a binary tree (but not necessarily full) with a maximum depth . Therefore, the splits have a time complexity of .
For the reassignment, the time complexity of each reassignment is . We have totally reassignments, so we have a total time complexity of for reassignment.
Thus, the overall time complexity is . ∎
C.4. Practical Time Complexities
Our theoretical analysis (Section 3.4 and above) has shown CEL(-Lite) to be an efficient framework. Empirically, for example, for MovieLens-1M with DIN at the compression ratio of (Table 2), CEL runs for 1592s, while PreHash () takes 7256s. On large-scale datasets, Electronics with DIN at the compression ratio of (Table 3) as the example, CEL-Lite converges within 9366s. In comparison, PreHash () takes 31087s and the fastest baseline Modulo takes 6305s.
Appendix D More Details and Results
D.1. Initialization
All the embeddings (vectors) are randomly initialized: We first initialize the full embedding. We sample a vector consisting of random Gaussian entries (), then divided by the maximum absolute value to map each entry to a range of . For NMF, we take the absolute value of each entry to ensure the nonnegativity. Note that after each embedding optimization, we also apply the absolute function. Secondly, we initialize the cluster assignment such that users/items are assigned to clusters randomly. Then the cluster embeddings are initialized as the center of its associated users/items.
D.2. Baseline Implementation Details
D.2.1. eTree and JNKM implementation details.
For eTree, we adopt a tree structure of depth . The first layer is a single root node, the second layer consists of nodes, while the leaf nodes on the last layer represent the items. For JNKM, there are a total of clusters. During test prediction, we only keep the embeddings of second layer nodes of eTree, or the cluster embeddings of JNKM.
D.2.2. BH and AE implementation details.
BH requires setting a hyperparameter (integer) that indicates the number of binary code blocks. Note that the total length of the binary coding should satisfy , while the total embedding size is should be close to . We always choose an appropriate so that its memory usage is just slightly larger than the embedding size required by the corresponding compression ratio in each experiment. The rest of the settings follow the original paper (Yan et al., 2021a). For AE, we allow the top warmest items to have their own embedding, and the rest of the items are assigned to share the other embeddings through the Modulo hash method.
D.2.3. PreHash implementation details.
PreHash requires setting a hyperparameter to select the top- bucket for each user/item. In our experiments, we set to range from to . The number of buckets is determined by the corresponding compression ratio in each experiment. For the rating prediction with NMF (Table 2), we do not use the historical interactions of users while hashing. Instead, we learn the hash assignment (weights associated with each bucket) during training. This is to ensure a fair comparison, since the historical interactions are also not used by the other baselines in the comparison. For the online conversion rate prediction (Table 3), we follow the original paper and use the user history to calculate the hash assignment. We collect and update the user history after receiving the streamed online data. The buckets are initialized randomly and then bind to the anchor users identified throughout online learning. The same operation is applied to items to reduce the item embedding size accordingly. The rest of the settings follow the original paper (Shi et al., 2020).


(a) (b)
D.3. Gradient Averaging and Optimizer
We optimize with respect to and via first order optimizers, e.g., (plain) gradient descent (GD) and Adam. Since the number of assigned items can be significantly different among clusters, there may exhibit significant differences in gradient scales. To synchronize gradient descent training among different clusters, we divide the loss of each cluster by the number of associated items to switch from the total loss to the averaged loss:
| (7) |
where is the learning rate, and the divisor is equal to the number of items assigned to the cluster. We refer to it as the gradient averaging. It ensures that embeddings of all clusters are updated at a similar pace, avoiding larger clusters to be updated much faster.
We performed ablation studies on the optimizer used for gradient descent and the effect of gradient averaging. We found gradient averaging significantly reduces overfitting and keeps training stable.
Table 13 and 14 present the results of CEL with NMF on the MovieLens-100k dataset.555The trend for other feature interaction models and on other datasets are similar. The results show that gradient averaging largely improves the training result of GD, while such improvement is less obvious for Adam. It could be because Adam, to some extent, has invariance towards the gradient scale. Among them, GD + gradient averaging achieves the best result overall.
Interestingly, without gradient averaging, we observe that the test MSE will start to go up after steps of embedding optimization, while training MSE will keep going down. It is possibly: Without gradient averaging, the embedding of clusters with limited assignments (and associated data) will be updated at the same speed as the big clusters. Such fast update of embeddings for small clusters may overfit it to its limited interactions.
| Compression Ratio | GD w. grad avr | GD wo. grad avr | Adam w. grad avr | Adam wo. grad avr |
| 0.9022 | 1.023 | 0.9139 | 0.9189 | |
| 0.9012 | 1.019 | 0.9150 | 0.9280 |
| GD | Adam | AdaGrad | RMSProp |
| 0.8654 | 0.8720 | 0.9160 | 0.8754 |
D.4. Norm Regularization
To handle the scaling arbitrary between and in NMF, we adopt a common solution by adding norm regularizations of and to the original objective function:
| (8) |
We set for our experiments.
D.5. The Sufficiently Scattered Condition
As introduced in Appendix B, the sufficiently scattered condition being satisfied essentially means that conic hull of rows of contains a central region of the nonnegative orthant as its subset, illustrated in Figure 7(a). Although it is hard to visualize or verify whether the sufficiently scattered condition is satisfied, we can easily check whether a cluster embedding (a row of ) lies outside the central region . We thus perform such studies in Figure 7(b). We can see that in all settings, eventually all cluster embeddings will lie outside the central region , implying that the embeddings (rows of ) tend to satisfy the sufficiently scattered condition. Moreover, a larger compression ratio (which leads to a finer clustering structure) is more likely to get the embeddings to lie outside . Although there is no explicit regularization that encourages the clusters to be scattered, the norm penalty we applied in equation (8) tends to push the embeddings to the boundary of the nonnegative orthant, which is a possible cause that we eventually learn a spread set of clusters.