Client Contribution Normalization for Enhanced Federated Learning
Abstract
Mobile devices, including smartphones and laptops, generate decentralized and heterogeneous data, presenting significant challenges for traditional centralized machine learning models due to substantial communication costs and privacy risks. Federated Learning (FL) offers a promising alternative by enabling collaborative training of a global model across decentralized devices without data sharing. However, FL faces challenges due to statistical heterogeneity among clients, where non-independent and identically distributed (non-IID) data impedes model convergence and performance. This paper focuses on data-dependent heterogeneity in FL and proposes a novel approach leveraging mean latent representations extracted from locally trained models. The proposed method normalizes client contributions based on these representations, allowing the central server to estimate and adjust for heterogeneity during aggregation. This normalization enhances the global model’s generalization and mitigates the limitations of conventional federated averaging methods. The main contributions include introducing a normalization scheme using mean latent representations to handle statistical heterogeneity in FL, demonstrating the seamless integration with existing FL algorithms to improve performance in non-IID settings, and validating the approach through extensive experiments on diverse datasets. Results show significant improvements in model accuracy and consistency across skewed distributions. Our experiments with six FL schemes—FedAvg, FedProx, FedBABU, FedNova, SCAFFOLD, and SGDM highlight the robustness of our approach. This research advances FL by providing a practical and computationally efficient solution for statistical heterogeneity, contributing to the development of more reliable and generalized machine learning models.
Index Terms:
Federated learning, statistical heterogeneity, mean latent representations, normalizationI Introduction
Mobile devices have become ubiquitous sources of decentralized and heterogeneous data. These devices, owned and operated by individuals generate vast amounts of diverse data. Machine learning models predominantly rely on centralized training, where data from these devices is collected on a single central server. However, this approach entails transferring data to a centralized server, incurring substantial communication costs and posing risks to data privacy [23]. Moreover, it raises significant concerns regarding data privacy and security [8]. To address these challenges, the concept of isolated training at the user level has been proposed. While this approach preserves data privacy by keeping data on the user’s device, it encounters limitations related to the sufficiency of individual user data for training reliable machine learning models.
Federated Learning (FL) [12, 25, 19] emerges as a subset of collaborative learning specifically designed to address privacy concerns inherent in centralized learning. FL operates within a distributed machine learning framework, enabling models to be trained on local data without the necessity of sharing the data itself. Despite its potential, FL encounters its own array of challenges. One primary concern is statistical heterogeneity among clients. In real-world scenarios, data distributions across clients are often non-independent and identically distributed (non-IID), leading to challenges in model convergence and performance. Federated averaging (FedAvg), a widely used aggregation method in FL, faces significant drawbacks when dealing with non-IID data distributions. These drawbacks include a biased global model, slower convergence, poor generalization, and client drift.
This paper investigates challenges associated with data dependency in FL, focusing on addressing statistical heterogeneity. Our proposed approach utilizes mean latent representations extracted from locally trained models. The key strength of our method lies in normalizing client contribution values through their respective mean latent representations. The server evaluates distances among clients in the representation space, enabling the estimation of heterogeneity and subsequent adjustment of each client’s model contribution during the aggregation process. This normalization enhances the generalization of the global model. Unlike existing methods that primarily focus on adjusting local training processes or introducing regularization terms, our approach operates at the aggregation level. This allows for seamless integration with existing FL algorithms without requiring modifications to local training procedures or model architectures, making it a more versatile and practical solution for addressing non-IID data challenges in FL.
The main contributions of this work are as follows:
-
•
We propose a novel normalization scheme using mean latent representations to address statistical heterogeneity in FL.
-
•
We demonstrate the seamless integration of our method with existing FL algorithms, enhancing their performance in non-IID settings.
-
•
Through extensive experiments, we show significant improvements in model accuracy and consistency across diverse datasets and skewed distributions.
To evaluate the effectiveness of our proposed approach, we conduct a comprehensive series of experiments across various datasets with differing data distributions. We integrate our approach with six different FL schemes: FedAvg [2], FedProx [14], FedBABU [21], FedNova [28], SCAFFOLD [11], and SGDM [16]. We consistently observe enhancements in the performance of the global model, validating the efficacy of our approach.
The subsequent sections of this paper are structured as follows. Section 2 reviews related literature, Section 3 discusses the problem setting and our approach, Section 4 presents experimental results. Finally, Section 6 presents the conclusion of our paper.
II Related Work
FL is a continuously evolving field in machine learning with several possibilities. It holds a crucial role in distributed machine learning, particularly when addressing data-dependent challenges. One of the central issues in FL is handling non-IID data, which presents a substantial challenge. Addressing this challenge is crucial for improving the robustness and generalization of FL models across diverse and heterogeneous data sources. This section provides a summary of the existing work in the field and clarifies the motivation behind our research.
Conventional FL methods rely on various techniques, such as Federated Stochastic Gradient Descent (FedSGD) and Federated Averaging (FedAvg), for global model aggregation. FedSGD involves the selection of multiple clients to compute gradients based on their local data, which are subsequently averaged to generate a global model update. FedAvg allows clients to perform multiple batch updates and share model weights with the centralized server, rather than gradients. In FedAvg, the centralized server aggregates the received model weights using a weighted average [2].
System heterogeneity is also a significant challenge in FL, as participating clients may have varying storage, communication, and computation capabilities. Furthermore, clients may drop out during training due to factors such as energy constraints and connectivity issues [1]. Communication cost poses yet another major challenge in FL, often serving as a bottleneck when model convergence requires numerous rounds, each involving the transfer of large model parameters. Some works address this by employing model compression techniques such as weight pruning and quantization, though these methods can result in performance loss due to the inherent lossy compression [9, 24]. Other techniques like variance reduction [15], dynamic regularizers, and the use of different client subsets for distinct communication rounds have been introduced to reduce communication costs and handle client heterogeneity. FedPCC represents an efficient methodology based on the parallelism of communication and computation among devices for FL in wireless networks [29].
II-A Statistical Heterogeneity in Federated Learning
There exists a vast amount of literature in deep learning to handle statistical heterogeneity using approaches like multitask learning and meta-learning. Recently, these methods of handling non-IID data have been incorporated in FL settings [18, 22, 4]. For instance, MOCHA allows personalization in FL by learning separate but related models at each participating device using multitask learning [26]. Despite these advances, the key challenge of statistical heterogeneity still remains open. Hsu et al. explore the performance of FL approaches on classification tasks and show that FedAvg starts performing poorly with increasing non-IIDness [10]. Other works focus on heterogeneity in computation cost in FL [27, 1]. Additionally, Luo et al. introduced the EdgeFed (Edge FL) approach, which employs an edge server to aggregate weight updates between the centralized server and the clients [17].
Although various methods have targeted data heterogeneity in FL, most of them introduce additional regularizers to handle the non-IID data at the client end. FedProx uses a dynamic regularizer to handle non-IID data at the client end [14]. SCAFFOLD highlights the drawbacks of FedAvg and proposes the use of control variate (variance reduction) to handle client drift in the presence of heterogeneous data, [11]. The recently introduced FedBABU algorithm uniquely updates the model’s body (extractor) during federated training, leaving the head unaltered and randomly initialized [21]. FedNova addresses heterogeneity by normalizing the number of local iterations at each client, assigning weights to clients during aggregation based on these normalized iterations [28]. In FL, Stochastic Gradient Descent with Momentum (SGDM) [30] is employed to optimize model parameters across distributed clients.
In FL, the contribution factor plays a pivotal role in the aggregation process, influencing how individual models contribute to the global model. FedAvg utilizes the number of samples from each local model as a key factor in determining its contribution value during the aggregation process [2]. Various similarity-based approaches have been proposed to tackle issues posed by non-IID data and malicious clients. The adaptive federated averaging method, proposed by Muñoz-González et al., calculates the cosine similarity between local model gradients and the weighted average of all local models in each round and aggregates the global model using contribution values [20]. Similarly, the FLTrust approach introduced by Cao et al. measures cosine similarity between a local model and the server model trained with a small root dataset [3].
While these approaches have made significant progress, several limitations persist. Many methods rely on specific model architectures or introduce substantial computational overhead. Some require modifications to local training procedures or model structures, limiting their applicability. The trade-off between addressing heterogeneity and maintaining model generalization remains a challenge.
Our work addresses these gaps by proposing a flexible, computationally efficient plug-in solution that integrates seamlessly with existing FL algorithms. By utilizing mean latent representations, we offer a versatile approach to normalize client contributions without modifying local training procedures or model architectures. This not only enhances the performance of FL algorithms in non-IID settings but also provides a practical framework for real-world applications where data heterogeneity is prevalent. Through extensive experiments, we demonstrate significant improvements in model accuracy and consistency across diverse datasets and skewed distributions.


(a)
(b)
III Methodology
In FL, the central server aggregates the local models received from participating clients and broadcasts the aggregated model to all clients. In the conventional FL setting [2], the overall objective function is defined as the weighted sum of the local objectives :
| (1) |
Here, gives the aggregated loss after convergence, represents the optimal weights, is the total number of clients and is the weight associated with client , ensuring that . The local objective function is defined as:
| (2) |
The expected value is taken over all possible data points drawn from the dataset according to the distribution .
In FedAvg, the importance factor depends on the number of samples of that particular client. However, different data distributions at clients induce various data-dependent issues, and information about only the number of samples at each client is not enough to account for these issues [7].
III-A Mean Latent Representation
At each client, we utilize the activations derived from the final hidden layer of the local model as a representation of semantic features, capturing valuable information about the variation in data across different clients. Each client transmits both its model weights and mean latent representation to the centralized server. During aggregation, the server calculates similarity among the values of all participating clients using the Cosine similarity metric:
| (3) |
The similarity matrix is defined as follows:
| (4) |
The contribution factor for client is defined as:
| (5) |
III-B Integration with Existing FL Algorithms
The proposed approach handles variability in data distribution among participating clients using . It normalizes the contribution of individual clients during aggregation by integrating into the mainstream FL framework and modifying the global objective as follows:
| (6) |
where is the importance function defined by the mainstream FL framework, and is the dot product of the importance function vector () and the proposed .
This integration allows our approach to be easily incorporated into existing FL algorithms. For example, in FedAvg, we replace the standard aggregation step with our normalized version:
| (7) |
where is the global model at round , and is the local model of client at round .
Fig. 1 (a) illustrates the behavior of our proposed approach, controlled by the contribution factor, in a simulated data setting with three clients. Two clients have data from eight CINIC-10 classes, while the third has data from the remaining two. We compare FedAvg and Normalized FedAvg by plotting the similarity between the local and global weight matrices after each round, as shown in Fig. 1(b). The proposed normalization approach prioritizes client 3, bringing its model closer to the global model, unlike FedAvg, which treats all clients equally, resulting in client 3’s model being further from the global model. The inset highlights this effect, demonstrating the effectiveness of our approach in achieving a more balanced weight distribution among clients. Algorithm 1 outlines the methodology employed in the proposed approach.
III-C Computational Overhead
Our approach introduces three main computational steps: (1) mean latent representation computation, (2) inter-client similarity calculation, and (3) contribution factor derivation. These processes are efficiently integrated into the FL pipeline, occurring once per communication round without requiring significant additional data transfer.
III-D Normalization with Temperature Scaling
To reduce abrupt changes in contribution values across consecutive rounds, we use temperature scaling. We modify equation (5) as:
| (8) |
where is the normalized contribution factor for node with temperature scaling. A temperature value less than 1 results in refinement of the contribution value obtained using the mean latent representation. We perform all our experiments using this temperature scaling approach to ensure consistent and stable evaluation of client contributions.
IV Experimental Results
This section presents a rigorous analysis of our proposed approach’s performance across diverse data settings, comparing it with baseline methods. We employ three distinct datasets to comprehensively assess the robustness and efficacy of our method under varying degrees of data heterogeneity.
IV-A Implementation Details
We utilize a VGG-16 model architecture for all experiments. Each client executes two local epochs per communication round, with a total of 200 communication rounds. The Adam optimizer is employed with a batch size of 64. The mean latent representation is derived from the final hidden layer of VGG-16, projecting the output into a 128-dimensional vector. Our comparative analysis involves six baseline FL techniques: FedAvg [19], FedProx [14], FedBABU [21], SCAFFOLD [11], SGDM [30], and FedNova [28].
IV-B Datasets and Data Distribution
We conduct experiments on CIFAR-10 [13], FEMNIST [5], and CINIC-10 [6]. CIFAR-10 is used to evaluate performance under controlled non-IID settings with varying degrees of heterogeneity. FEMNIST is selected to assess the approach’s efficacy on naturally heterogeneous data with imbalanced class distributions. CINIC-10 is employed to test robustness against augmented and transformed data distributions. For CIFAR-10 and CINIC-10, we generate non-IID distributions using a Dirichlet distribution with concentration parameter . Lower values induce higher data heterogeneity, allowing us to systematically evaluate our method’s performance across a spectrum of non-IID scenarios.
IV-C Results and Analysis
IV-C1 CIFAR-10
Table I presents the results on CIFAR-10 with 50 clients and and . The proposed normalization approach consistently improves performance across all baseline methods, with gains of 3-5% in accuracy. SGDM with normalization achieves the highest accuracy (82.68% for ), indicating the synergistic effect of momentum and our contribution-based normalization. The performance gap between normalized and original methods is more pronounced for , suggesting our approach’s enhanced efficacy in highly heterogeneous settings. Notably, FedAvg shows the lowest performance among all methods, particularly in the highly non-IID scenario (), highlighting its limitations in handling heterogeneous data distributions.
| Approach | Original | Normalized | ||
|---|---|---|---|---|
| FedAvg | 69.68 | 74.36 | 74.44(4.76) | 79.29(4.93) |
| FedProx | 72.95 | 75.18 | 77.04(4.09) | 80.32(5.14) |
| SCAFFOLD | 71.96 | 75.26 | 77.98(6.02) | 81.38(6.12) |
| SGDM | 72.10 | 78.14 | 76.02(3.92) | 82.68(4.54) |
| FedNova | 71.02 | 76.26 | 76.88(5.86) | 81.58(5.32) |
| FedBABU | 72.92 | 75.32 | 79.30(6.38) | 81.37(6.05) |
IV-C2 FEMNIST
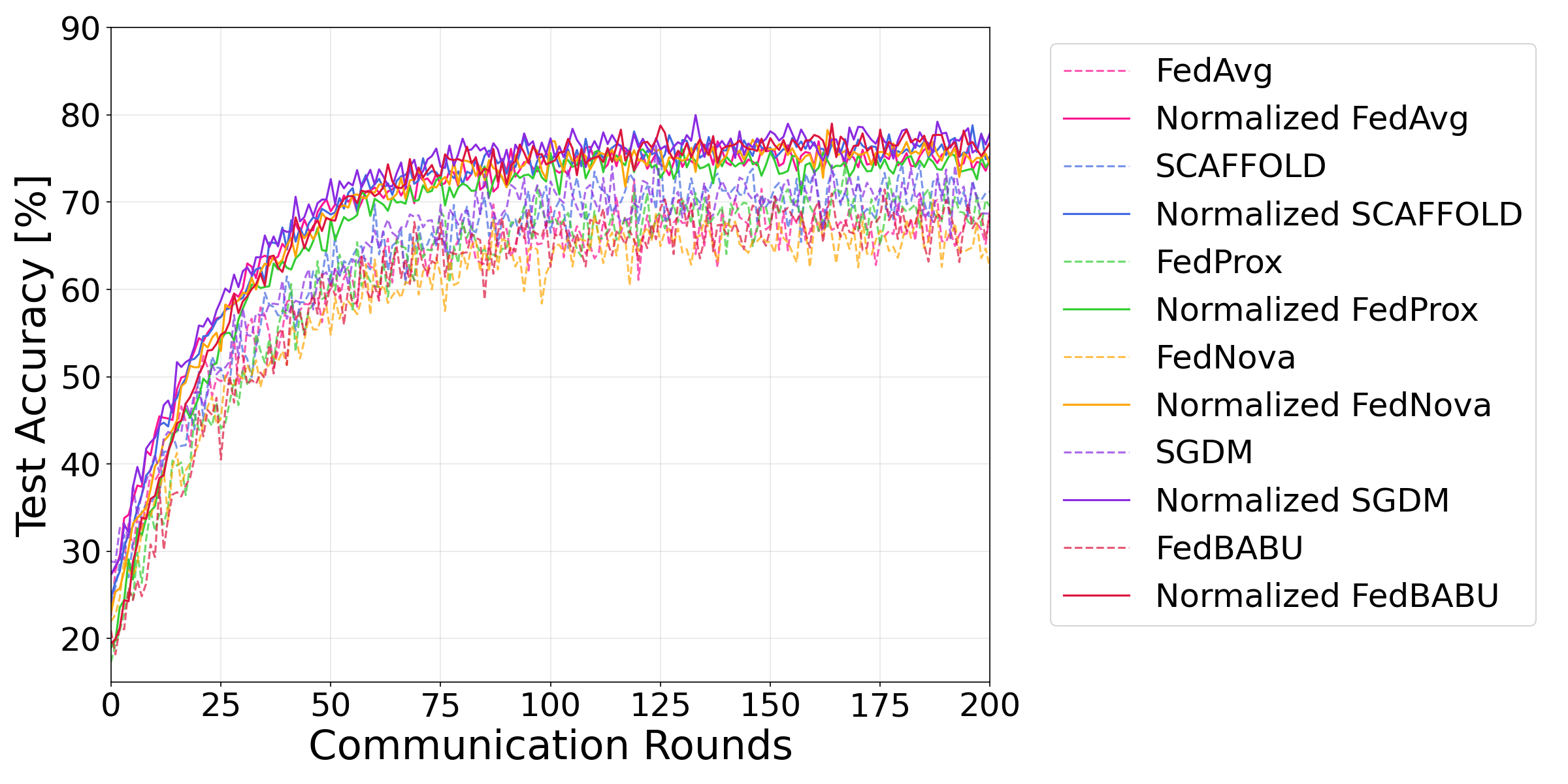
Table II shows results on FEMNIST with 10 and 20 clients. The normalization approach yields substantial improvements, with up to 9% accuracy gain for FedNova with 20 clients. SGDM consistently outperforms other methods, suggesting the momentum term’s effectiveness in handling the natural heterogeneity of handwritten characters. The performance improvement is more significant with 20 clients, indicating our method’s scalability to larger client pools. FedNova shows notable improvement when normalized, particularly in the 20-client scenario, demonstrating its effectiveness in managing varying local update frequencies across clients.
| Approach | Original | Normalized | ||
|---|---|---|---|---|
| 10 Clients | 20 Clients | 10 Clients | 20 Clients | |
| FedAvg | 61.06 | 67.89 | 67.28(6.22) | 75.18(7.29) |
| FedProx | 64.08 | 69.37 | 68.40(4.32) | 74.44(5.07) |
| SCAFFOLD | 65.08 | 71.17 | 70.08(5.00) | 76.20(5.03) |
| SGDM | 66.89 | 71.18 | 71.98(5.09) | 77.14(5.96) |
| FedNova | 62.26 | 66.01 | 71.12(6.86) | 75.64(9.63) |
| FedBABU | 65.50 | 67.86 | 72.32(6.82) | 76.64(8.78) |
Figure 2 illustrates the convergence behavior of different methods on FEMNIST. The normalized approaches consistently achieve higher accuracy and faster convergence, particularly in the early stages of training. This acceleration in convergence is crucial for reducing communication rounds in practical FL deployments, where network efficiency is a key concern.
IV-C3 CINIC-10
Table III presents results on CINIC-10 with 100 clients and and . The normalization approach consistently outperforms original methods across all values, with improvements ranging from 2% to 7%. The performance gap between normalized and original methods narrows as increases, indicating our method’s particular effectiveness in highly heterogeneous settings. SGDM with normalization achieves the highest accuracy (85.04% for ), suggesting a synergistic effect between momentum-based optimization and our contribution-based normalization. Interestingly, FedProx shows significant improvement when normalized, especially at higher values, indicating that the proximal term combined with our normalization approach effectively manages client drift in less heterogeneous scenarios.
| Approach | FedAvg | FedProx | SCAFFOLD | SGDM | FedNova | FedBABU | |
|---|---|---|---|---|---|---|---|
| Org | 71.16 | 72.54 | 71.38 | 71.68 | 70.44 | 71.96 | |
| Norm | 77.24 | 76.54 | 78.52 | 78.30 | 77.74 | 78.06 | |
| Org | 73.74 | 74.92 | 73.92 | 76.12 | 74.46 | 74.14 | |
| Norm | 78.08 | 79.46 | 77.68 | 82.48 | 79.12 | 79.86 | |
| Org | 76.00 | 77.46 | 76.62 | 78.36 | 77.14 | 77.78 | |
| Norm | 78.88 | 81.02 | 80.14 | 84.06 | 81.62 | 81.22 | |
| Org | 77.64 | 78.38 | 77.20 | 79.52 | 78.02 | 78.20 | |
| Norm | 79.54 | 81.96 | 80.10 | 85.04 | 82.22 | 82.10 |
IV-D Discussion
Our experimental results demonstrate the efficacy of the normalization approach across diverse data settings and baseline FL methods. The normalization approach enhances accuracy across all tested datasets, FL methods, and heterogeneity levels, showing particular effectiveness in highly heterogeneous settings (low values). This improvement is crucial for real-world FL applications where data distributions across clients are often highly skewed. The consistent superior performance of SGDM with normalization suggests a complementary relationship between momentum-based optimization and our contribution-based normalization, potentially opening avenues for further research into hybrid optimization strategies in FL.
The approach’s effectiveness scales well with increasing client numbers, as evidenced by the FEMNIST results, indicating its suitability for large-scale FL deployments. Normalized methods consistently achieve faster convergence, particularly in early training stages, potentially reducing communication rounds in practical FL deployments. This acceleration in convergence is especially valuable in bandwidth-constrained or high-latency network environments, where minimizing communication overhead is critical.
The performance improvements across different methods provide insights into the interaction between our approach and existing FL techniques. For instance, the significant improvement in FedNova’s performance when normalized suggests that our approach effectively complements methods designed to handle heterogeneity. Similarly, the enhanced performance of FedProx with normalization indicates that our method can work synergistically with proximal term regularization to manage client drift. These findings underscore the proposed approach’s potential in enhancing FL performance across diverse real-world scenarios characterized by data heterogeneity.
V Conclusion
This paper introduces a novel approach to address statistical heterogeneity in FL through mean latent representations from locally trained models. Our method normalizes client contributions during aggregation, effectively mitigating the challenges of non-IID data distributions across diverse clients. The proposed normalization technique shows significant advantages such as low computational overhead, broad applicability, and seamless integration with various FL frameworks. This research opens up several promising avenues for future work, including the extension of the contribution factor for optimized client selection and malicious client detection, exploration of adaptive normalization techniques and integration with privacy-preserving mechanisms. As FL continues to gain prominence in privacy-preserving distributed machine learning, our approach represents a significant advancement in addressing the challenges of statistical heterogeneity, paving the way for more robust and efficient FL systems across diverse real-world applications.
References
- [1] K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konečnỳ, S. Mazzocchi, B. McMahan et al., “Towards federated learning at scale: System design,” Proceedings of Machine Learning and Systems, vol. 1, pp. 374–388, 2019.
- [2] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191.
- [3] X. Cao, M. Fang, J. Liu, and N. Z. Gong, “Fltrust: Byzantine-robust federated learning via trust bootstrapping,” arXiv preprint arXiv:2012.13995, 2020.
- [4] Z. Chen, P. Tian, W. Liao, and W. Yu, “Zero knowledge clustering based adversarial mitigation in heterogeneous federated learning,” IEEE Transactions on Network Science and Engineering, vol. 8, no. 2, pp. 1070–1083, 2020.
- [5] G. Cohen, S. Afshar, J. Tapson, and A. Van Schaik, “Emnist: Extending mnist to handwritten letters,” in 2017 International Joint Conference on Neural Networks (IJCNN). IEEE, 2017, pp. 2921–2926.
- [6] L. N. Darlow, E. J. Crowley, A. Antoniou, and A. J. Storkey, “Cinic-10 is not imagenet or cifar-10,” arXiv preprint arXiv:1810.03505, 2018.
- [7] M. Dhada, A. K. Jain, and A. K. Parlikad, “Empirical convergence analysis of federated averaging for failure prognosis,” IFAC-PapersOnLine, vol. 53, no. 3, pp. 360–365, 2020.
- [8] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He, “Accurate, large minibatch sgd: Training imagenet in 1 hour,” arXiv preprint arXiv:1706.02677, 2017.
- [9] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
- [10] T.-M. H. Hsu, H. Qi, and M. Brown, “Federated visual classification with real-world data distribution,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part X 16. Springer, 2020, pp. 76–92.
- [11] S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 5132–5143.
- [12] J. Konečnỳ, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” arXiv preprint arXiv:1610.05492, 2016.
- [13] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” ., 2009.
- [14] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” arXiv preprint arXiv:1812.06127, 2018.
- [15] X. Liang, S. Shen, J. Liu, Z. Pan, E. Chen, and Y. Cheng, “Variance reduced local sgd with lower communication complexity,” arXiv preprint arXiv:1912.12844, 2019.
- [16] W. Liu, L. Chen, Y. Chen, and W. Zhang, “Accelerating federated learning via momentum gradient descent,” IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 8, pp. 1754–1766, 2020.
- [17] B. Luo, X. Li, S. Wang, J. Huang, and L. Tassiulas, “Cost-effective federated learning design,” in IEEE INFOCOM 2021-IEEE Conference on Computer Communications. IEEE, 2021, pp. 1–10.
- [18] O. Marfoq, G. Neglia, A. Bellet, L. Kameni, and R. Vidal, “Federated multi-task learning under a mixture of distributions,” Advances in Neural Information Processing Systems, vol. 34, pp. 15 434–15 447, 2021.
- [19] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- [20] L. Muñoz-González, K. T. Co, and E. C. Lupu, “Byzantine-robust federated machine learning through adaptive model averaging,” arXiv preprint arXiv:1909.05125, 2019.
- [21] J. Oh, S. Kim, and S.-Y. Yun, “FedBABU: Toward enhanced representation for federated image classification,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=HuaYQfggn5u
- [22] J. Pang, Y. Huang, Z. Xie, Q. Han, and Z. Cai, “Realizing the heterogeneity: A self-organized federated learning framework for iot,” IEEE Internet of Things Journal, vol. 8, no. 5, pp. 3088–3098, 2020.
- [23] J. Poushter et al., “Smartphone ownership and internet usage continues to climb in emerging economies,” Pew research center, vol. 22, no. 1, pp. 1–44, 2016.
- [24] X. Qu, J. Wang, and J. Xiao, “Quantization and knowledge distillation for efficient federated learning on edge devices,” in 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), 2020, pp. 967–972.
- [25] R. Shokri and V. Shmatikov, “Privacy-preserving deep learning,” in Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1310–1321.
- [26] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” Advances in neural information processing systems, vol. 30, 2017.
- [27] N. H. Tran, W. Bao, A. Zomaya, M. N. Nguyen, and C. S. Hong, “Federated learning over wireless networks: Optimization model design and analysis,” in IEEE INFOCOM 2019-IEEE Conference on Computer Communications. IEEE, 2019, pp. 1387–1395.
- [28] J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” arXiv preprint arXiv:2007.07481, 2020.
- [29] H. Zhang, H. Tian, M. Dong, K. Ota, and J. Jia, “Fedpcc: Parallelism of communication and computation for federated learning in wireless networks,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 6, no. 6, pp. 1368–1377, 2022.
- [30] M. Zinkevich, M. Weimer, L. Li, and A. Smola, “Parallelized stochastic gradient descent,” Advances in neural information processing systems, vol. 23, 2010.