Class Knowledge Overlay to Visual Feature Learning for Zero-Shot Image Classification
Abstract
New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
keywords:
MSC:
41A05, 41A10, 65D05, 65D17 \KWDImage understanding , Zero-shot learning , Image classification , Knowledge representation , Generative adversarial network , Semi-supervised learningGraphical Abstract (Optional)
To create your abstract, please type over the instructions in the template box below. Fonts or abstract dimensions should not be changed or altered.
Class Knowledge Overlay to Visual Feature Learning for Zero-Shot Image Classification
Cheng Xie, Ting Zeng, Hongxin Xiang, Keqin Li, Yun Yang, Qing Liu
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7275d418-a0a4-4299-a3df-2f6d014b1640/modelFrame.jpeg) New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
Research Highlights (Required)
1.
We propose a novel ZSL model based on knowledge-to-visual learning that outperforms state-of-the-art models on several benchmarks.
2.
We propose class knowledge overlay (CKO) to obtain more knowledge from similar categories that effectively improves the effect of knowledge-to-visual learning.
3.
We re-train the ZSL model by applying synthetic examples on a semi-supervised learning (SSL) process. It significantly reinforces category training and predicting.
1 Introduction
Humans can distinguish at least 30,000 basic object categories and any more subordinate ones [5]. Humans can also create new categories dynamically from a few or even zero examples [13]. In contrast, most existing computer vision techniques require tens of hundreds of labeled examples to learn a recognition model. Besides, it is difficult to guarantee that the recognition model is fully trained for each category, especially since many new categories do not have samples. Inspired by the humans’ ability to recognize without seeing the samples, the research area of zero-shot learning (ZSL) has received increasing attention in recent years.
In ZSL, unseen categories without examples can be recognized by transferring knowledge obtained from the seen categories [30]. Specifically, ZSL is designed to find an intermediate knowledge representation (e.g., attributes or textual features) to transfer the knowledge learned from the seen categories to the unseen ones [45]. There are three paradigms for transferring knowledge:
(1) To use the semantic attributes to annotate images while new categories can be predicted by extracting and compositing semantic attributes from new examples [25]. However, the performance of these methods is rather primitive because the methods are proposed at the early stage of ZSL, which cannot find a proper way to integrate the attributes into the image.
(2) To use semantic embedding methods [2, 45, 22, 14, 7] to learn the mapping from visual space to the semantic space. Ref.[45] builds upon the recently introduced Graph Convolutional Network (GCN) [23] and proposes an approach that uses both semantic embeddings and the categorical relationships to predict the classifiers. Ref.[7] proposes a novel zero-shot learning model that forms a neighborhood-preserving structure in the semantic embedding space and utilizes it to predict for unseen classes. Ref.[14] proposes a novel manifold distance computed on a semantic class prototype graph, which takes into account the rich intrinsic semantic structure. Other semantic embedding algorithms have also been investigated such as semi-supervised max-margin learning frameworks [27, 28] or multi-task learning [19, 21, 20]. However, semantic embedding always suffers from the domain shift problem [12] since the learning process is over-fitted with embedded attributes.
(3) To use knowledge-to-visual mapping technology to embed the attributes or Wikipedia articles into an image, Ref.[24] reduces the domain shift and the overfitting problem, effectively. Most state-of-the-art ZSL models are based on knowledge-to-visual mapping [16, 42, 45, 53, 47, 18], which can be classified into GAN-based methods [53, 47, 18] and VAE-based methods [44, 43]. GAN-based methods use category semantics and Gaussian noise as inputs to the generator to generate visual features. The generator is trained to perform a minimum-maximum game with the discriminator. The VAE-based method associates the conditional generator network with an additional encoder that approximates the posterior distribution in order to infer the latent factors, and trains the two models by maximizing the lower limit of variation. However, to our best knowledge, the best result obtained from the state-of-the-art ZSL models has only 12.5% accuracy in the Caltech UCSD Birds-2011(CUB) dataset (a common dataset widely used for ZSL task) [22]. This value is slightly lower than that of the standard recognition tasks. Consequently, there are still many challenges to be overcome in ZSL models.
In this study, we identify two critical problems in the ZSL process that might affect its performance. The first problem is inadequate knowledge, which is caused by two aspects. On the one hand, the semantic features are not enough to describe the fine-grained visual features of a category; on the other hand, the semantic features and visual features are not fully expressed when embedded, especially in two very similar categories with no difference in embedding space. The second problem is inadequate examples. Because the seen classes may rarely (or almost never) intersect the unseen classes, it is difficult to achieve better performance only by relying on the seen class examples. Especially in the same attribute or text description, the visual appearance may be significantly different. For example, pigs and zebras have the same attribute ”tail” semantically, but they are completely different visually. In this study, to solve the first problem, we propose a class knowledge overlay calculation method to gather more knowledge from similar categories that help the model to learn more knowledge. To solve the second problem, we propose a semi-supervised process to generate synthetic examples to re-train the ZSL model that helps the model to predict unseen categories. The experimental results show that our approach outperforms the state-of-the-art methods in several benchmark datasets. Succinctly, we highlight the contributions of the work as following:
-
1.
We propose a novel ZSL model based on knowledge-to-visual learning that outperforms state-of-the-art models on several benchmarks.
-
2.
We propose class knowledge overlay (CKO) to obtain more knowledge from similar categories that effectively improves the effect of knowledge-to-visual learning.
-
3.
We re-train the ZSL model by applying synthetic examples on a semi-supervised learning (SSL) process. It significantly reinforces category training and predicting.
2 Related works
A key idea of zero-shot learning is to find a appropriate embedding space that seen and unseen classes can share. There are three types of embedding in zero-shot learning approaches, which are to (a) map from the visual feature space to the semantic space [11, 12, 32, 40, 52], (b) or conversely [4, 33, 48, 53], (c) or jointly map from both the visual and semantic space to common space [49, 26, 3], respectively.
2.1 Semantic Attributes
Semantic attributes refer to express a class or an instance using attributes. ZSL uses attributes as side information and consists of two steps: 1) to train the seen classes: gain knowledge about attributes; 2) to inference the unseen classes: classify some unseen objects via known knowledge. This is the first and most basic method of ZSL. In 2009, a pioneering study on ZSL, Ref. [25], proposed direct attribute prediction(DAP) and indirect attribute prediction(IAP). They are the main forms of attribute-based learning which learns the attribute classifier first and then seeks the most promising unseen class. Ref. [50] proposed an author-topic model to describe the attribute-specific distributions of image features. Ref. [41] has proposed a weighted version of DAP based on the observation probability of the attributes. However, attribute-based learning ignores the associations between different attributes, and it is more accurate in predicting attributes than classes. Furthermore, attributes need a large number of experts to label, which is inefficient. On the contrary, our approach does not depend on any prior attributes.
2.2 Semantic Embedding
Semantic embedding is a text-to-vector technique that can be used for mapping the visual feature to semantic space. The semantic embedding-based learning is one of the most widely used methods [11, 12, 32, 40, 52]. Attribute label embedding(ALE) [2], proposed a label embedding framework to solve the prediction of classes aiming at the attribute learning directly. It not only takes attribute as side information but also takes word vector and hierarchy label embedding(HLE) as side information. Besides, inspired by ALE, Ref. [3] proposed structured joint embedding(SJE), a structured joint framework and used various side information to replace the era of artificial annotation attributes in ZSL tasks. In 2016, LatEm [46], a nonlinear model of SJE, was proposed. It has a stronger expressive ability and can be adapted to different types of samples. The semantic similarity embedding (SSE) [52] not only maintains semantic consistency but also ensures the accuracy of classification. The above studies directly transfer the visual feature space to the semantic space, which leads to the problem of the large semantic gap problem. In 2017, Ref. [24] introduced semantic autoencoder(SAE), a bidirectional encoding and decoding method that significantly reduces the semantic gap. However, the experimental results of SAE are not optimistic because the feature space transferring technique cannot eliminate the semantic gap.
2.3 Semantic-to-Visual Mapping
Different from semantic embedding, semantic-to-visual mapping is designed to learn the mappings from semantic space to visual space. Currently, most approaches follow the idea of semantic-to-visual mapping [4, 33, 48] and lead a new era of ZSL. The Ref. [53] combined the generative adversarial network (GAN) and ZSL to transform the ZSL problem into an ”imagination” problem. The method implements semantic-to-visual mapping using ”imagining” visual features from semantic features. Other studies [1, 3, 26, 36, 39, 49, 51, 53] show that these approaches yielded optimistic results. However, these approaches cannot ”imagine” the visual features of the unseen classes if the corresponding semantics have not appeared. In this study, we use both semantics from one class and the ”class knowledge overlay” to obtain more semantics from other similar classes. This approach significantly enriches the semantics for semantic-to-visual mapping.
3 Methodology
The core of our approach is the design of a semantic-to-visual learning model. The overall method is demonstrated in Fig.1. First, visual features are extracted by fast region-based convolutional network(fast-RCNN)(Section 3.2). Then, semantic features are extracted from Wikipedia articles by CKO and TF-IDF (Section 3.3). Next, a GAN model is trained with triplet loss to ”imagine” the synthetic visual features from semantic features (Section 3.4). Finally, a semi-supervised learning (SSL) algorithm is used to re-train the GAN model.
3.1 Notations
Suppose there is a series of data points from the original image dataset and label respectively. We use subscripts and to represent datasets of unseen and seen classes after splitting the dataset, respectively. The visual features can be extracted by using original images . The semantics of seen and unseen categories are represented as , which come from the semantic space . For the -th class, the representation of the class name is , where is the sets of all class names. The goal of ZSL is to predict based on and . Generator and discriminator are represented as where represents the mapping relationship of semantic features into visual features, and represents the corresponding class labels in visual features . We converted the parameters of and into and .
3.2 Visual Feature Extraction
The visual features are extracted by the visual feature extraction methods described below: the fast-RCNN framework and the VGG16 architecture are used as the backbones to detect seven parts of the birds. First, the features of the input images are extracted by VGG16. The proposed region of interest(ROI) pooling layer in [15] is input into an n-ways softmax layer and a boundary box regression. Then, it is regarded as a detected visual feature when the proposed area is larger than a confidence threshold; otherwise, it is regarded as a missing part. Finally, the detected region is input into the visual encoder subnet and eventually encoded into 512-dimensional feature vectors for each part. The visual features of these seven parts are concatenated together to form 3584-dimensional visual features .
3.3 Semantic Feature Extraction

Class Knowledge Overlay: The overall flow of the CKO algorithm is shown in the Algorithm 1. First, the word2vec is applied to transform each class to a vector. Second, a cosine similarity is used to calculate the similarity scores among the class vectors and the top-k similar classes of each class are ranked. Finally, the Wikipedia text of the category is represented by concatenating its own Wikipedia text and the Wikipedia text of the top-k similar classes. Fig.2 shows the similarity results of Logger-Head Shrike and other classes. Obviously, Logger-Head Shrike has a high similarity score to Great-Grey Shrike, which demonstrates that Great-Grey Shrike is likely to contain the knowledge of Logger-Head Shrike.
Semantic Embedding: The Wikipedia texts are tokenized into words, firstly. Then, some necessary preprocesses, such as removing stop words, porter stemmer, and tokenization [34], are applied to reduce inflected words to their word stem. Finally, the text encoder, TF-IDF, is used to extract and embed the semantic features.
3.4 Knowledge-to-Visual Learning
Visual Feature Generation: Text encoder is used to embed texts. The embedded texts are used as input to a generator ( for short), which is a multi-layer perceptron with random noise . Through this process, visual features can be generated by .
Because of the sparsity of training data (about 60 pictures per class of CUB datasets, and the distribution of visual features has about 3500 dimensions), it is difficult for the generator to achieve good results in transforming class knowledge into visual features. Ref.[53] reported that classes have the following characteristics in the visual space: the distance of intra-classes is short, the distance of inter-classes is long, and an overlap rarely occurs. Therefore, a new constraint can be added to the knowledge-to-visual features generation to make the synthetic visual features have the same visual distribution as the seen classes. The constraint is defined as follows:
| (1) | ||||
where is the number of seen classes, is the th visual feature of class , denotes the synthetic-visual features of category in the seen class, denotes a class that does not belong to class , represents the minimum distance between two different class clusters, and represents any measure. In this study, Euclidean distance is used as a measure. Finally, the loss of generator is defined as:
| (2) | ||||
where the first two terms approximate Wasserstein distance of the distribution of real features and fake features, the third and forth terms are classification losses of real and synthesized features. is a regularization coefficient.
Discriminator: The discriminator ( for short) accepts two inputs: fake visual features from or real visual features from images. Then it propagates them forward to a full connection layer with a ReLu activator. Next, two subnetworks are used to distinguish whether features are real or fake and classify the category label of these features. The loss function of is the same with the previous work[53].
3.5 Semi-supervised Learning
During each SSL iteration, a conventional classifier are trained by using examples from . In this paper, the conventional classifier is k-NearestNeighbor model. Then, the classifier predicts pseudo-labels, which have highest class probability in all classes, for each unseen class sample in . Those samples whose class probability is above a certain threshold are stored in a set of . In the next training, the training set is updated to . Because at the beginning of training, the model only trains the seen classes data. After the semi-supervised learning, the unseen classes with pseudo labels will be added to the training set. If the pseudo label is marked as unseen class, then a new class is introduced in the training set. So we need to dynamically add new neurons to the subnetwork in the discriminator, which are used to classify new classes, and include this new category when calculating the triplet loss. The detailed training process of GAN with SSL is shown in Algorithm 2.
3.6 Training and Testing
Training: Semantic features are extracted using the proposed class knowledge overlay(CKO), and visual features are extracted. through real images and generators. Then, ACGAN is trained with iterations, including the training generator’s ability to generate visual features using semantic features with tripletloss, and the the training discriminator to judge visual features as fake or real and predict the class labels. After the ACGAN training is completed, the generator uses the visual features generated by the semantic features of unseen classes and the corresponding semantic labels to train the traditional classifier(eg. Decision Tree, SVM,…). The trained classifier will give the label probability for visual features of the unseen class. For labels with a probability higher than a certain threshold, their visual features are added to the training set. Repeat the above process until the semi-supervised process is executed.
Testing: After training, we obtain the generation model , which can transform semantic features of classes into synthetic visual features. In the testing process, the model compares the real visual features (from the new coming image) with the synthetic visual features (from the text of class). Then, the model decides the class of the new coming image.
4 Experiments
4.1 Experimental Setup
4.1.1 Datasets
Our approach was compared with the state-of-the-art methods on two benchmarks: Caltech UCSD Birds-2011(CUB) and North America Birds(NAB). The CUB dataset contains 200 fine-grained classes of the birds with 11,788 images. The NAB dataset is a larger dataset of 48,562 images across 1011 bird classes. Besides, the raw textual sources from English Wikipedia-v01.02.2016 are adopted. Fig.3 shows the class knowledge overlay of CUB data set. The class knowledge is embedded into vectors by using word2vec. The overlay is calculated by using Euclidean distance. This obviously shows that CKO not only integrates the semantic features of the same parent category (such as black-footed albatross and laysan albatross, up to 88% similarity), but also integrates the semantic features of different parent categories with high similarity (laysan albatross and parakeet auklet, up to 74% similarity), and class overlay of category information of different superclass can add more semantic features.

4.1.2 Split Methods
In zero-shot learning, there are two commonly used training/testing set segmentation methods: Super-Category-Shared splitting (SCS) and Super-Category-Exclusive splitting (SCE), which are used in [10, 16, 22, 53]. In the case of SCS-split, there are more than one seen class belonging to the same super category for each unseen class. For example, the classes ”Tennessee Warbler” and ”Wilson Warbler” are in the training set and in the testing set, respectively, but the super category is ”Warbler” in CUB2011. Same as CUB2011, ”Cooper’s Hawk” in the training set and ”Harris’s Hawk” in the testing set have the same super category ”Hawk” in NABirds. Compared with SCS, in the case of SCE-split, the classes with the same super category either belong to the training set(seen) or to the testing set(unseen). For instance, if ”Caspian Tern” is selected as the training set, then all other terns are selected as the training set. Therefore, in SCE, the correlation between the seen and unseen classes is minimal. Consequently, the classification accuracy based SCE-split is lower than the SCS-split.
4.1.3 Evaluation Metric
4.1.4 Implementation Details
| CUB | NAB | |||
| parameters | SCS | SCE | SCS | SCE |
| margin | 0.1 | 0.1 | 0.2 | 0.1 |
| topK | 4 | 1 | 3 | 1 |
| confidence | 0.5 | 0.7 | 0.6 | 0.4 |
Semantic Features: In this study, the Wikipedia text was used as side information to match some visual features with the words in it. Although Wikipedia texts are more expressive and discriminating than attribute representations, they usually have more noise. In this case, the methods described in Section 3.3 were used to process the Wikipedia texts. Then, TF-IDF was used to extract the semantic features from the processed texts. The dimension of these features is 7551 and 13,217 in CUB2011 and NAB Wikipedia datasets, respectively.
Visual Features: There are seven parts of the input image, (1) head, (2) back, (3) belly, (4) breast, (5) leg, (6) wing, and (7) tail for capturing the different characteristics of birds. For each part of the bird, a 512-dimensional vector can be obtained after applying the Multi-Layer Perceptron(MLP) with two hidden layers(each with a size of 512). For the CUB2011 dataset, seven bird parts were used as visual features, whereas in the NAB dataset, the ”leg” part was deleted since there are no annotations for the ”leg” part in the NAB dataset. The remaining six parts were retained as visual features. Therefore, the feature dimensions extracted from CUB2011 and NAB datasets were 3584 and 3072, respectively.
Model Setting: The seen dataset is divided into training set and validation set according to the ratio of 9:1. The semantic features were input into a MLP in the semantic-to-visual generation method. Firstly, the MLP used a 1000-dimensional full connection layer to reduce the dimensions of the semantic features. Then random noise was added to the semantic features of dimension reduction. Finally, two full-connection layers with LeakyRelu and Tanh were used to generate visual features. Table 1 shows the hyperparameters of our method under different settings. For the study of hyperparameters see Section 4.5. Our model is trained with Adam, using the default parameters , and the learning rate . And and are set. The KNN model (K = 20) was trained to evaluate the seen class and the unseen class in every 40 iterations. The unseen class accuracy, which the highest generalized accuracy of the seen class in validation set corresponds to, was selected as the final result. The generalized accuracy is calculated as follows:
| (3) |
where, , the presents the update frequency of . denotes the sample numbers of a seen classes, denotes the number of all classes, denotes the seen classes number, denotes the prediction probability of the nth sample on the class, denotes the real class label of the nth sample. Argmax function indicates the predictive label of . In this study, we set and .
4.2 Performance Evaluation
4.2.1 Comparative Methods
Nine latest methods were used in the comparisons with our methods: ZSLNS [35], SynCfast [6], ZSLPP [10], GDAN [17], CIZSL [9], CANZSL [8], GAN-ZSL [53], CorrectionNet [16], S2GA-DET [22]. All the comparisons used the same splits. For the first three methods, we cite the results from [53]. The results of last five methods are cited in their respective papers, which report the maximum of the results. For GDAN, we reproduce report the best results by using source code it provide.
The performance of our method (GAN-CST) was evaluated on two benchmark datasets by using two segmentation methods: SCE and SCS. As shown in Table 2, compared to the state-of-the-art methods, GAN-CST obtain the best result in SCS-split on CUB dataset and SCE-split on NAB dataset, which increases by 0.66% and 7.22%. Compared with the latest generative ZSL methods (CIZSL, CANZSL, GDAN), except for the slightly lower SCE-split of CUB dataset, 14.1% vs. 14.4%, our method exceeds these methods by up to 11.83%. Since there are some correlations between the training set and the test set in the SCS-split, it is difficult to detect more correlations by adding some test samples into the training dataset with semi-supervised learning. Therefore, the improvement of GAN-CST is not apparent on the SCS-split. However, some improvements were still achieved compared to the GAN-ZSL method in the SCS-split.
| CUB | NAB | |||
|---|---|---|---|---|
| Methods | SCS | SCE | SCS | SCE |
| ZSLNS [35] | 29.1 | 7.3 | 24.5 | 6.8 |
| SynCfast [6] | 28.0 | 8.6 | 18.4 | 3.8 |
| ZSLPP [10] | 37.2 | 9.7 | 30.3 | 8.1 |
| GAN-ZSL [53] | 43.7 | 10.3 | 35.6 | 8.6 |
| CorrectionNet [16] | 45.8 | 10.0 | 37.0 | 9.5 |
| S2GA-DET [22] | 42.9 | 10.9 | 39.4 | 9.7 |
| CIZSL [9] | 44.6 | 14.4 | 36.6 | 9.3 |
| CANZSL [8] | 45.8 | 14.3 | 38.1 | 8.9 |
| GDAN [17] | 44.2 | 13.7 | 38.3 | 8.7 |
| GAN-CST | 46.1 | 14.1 | 38.6 | 10.4 |
4.2.2 Ablation Study
| CUB | NAB | |||
| method | SCS | SCE | SCS | SCE |
| ACGAN | 43.7 | 10.3 | 35.6 | 8.6 |
| ACGAN (+TL) | 44.1 | 11.6 | 35.9 | 8.9 |
| ACGAN (+CKO) | 44.6 | 12.1 | 37.3 | 9.3 |
| ACGAN (+SSL) | 43.8 | 10.9 | 36.6 | 8.8 |
| ACGAN (+CKO+SSL) | 44.9 | 11.6 | 36.2 | 9.2 |
| ACGAN (+CKO+TL) | 44.3 | 13.1 | 38.1 | 8.1 |
| ACGAN (+SSL+TL) | 44.6 | 13.3 | 36.5 | 9.7 |
| GAN-CST | 46.1 | 14.1 | 38.6 | 10.4 |
Extensive ablation experiments were conducted to observe the effect of triplet loss(TL), class knowledge overlay(CKO), semi-supervised learning(SSL) and their combinations on the results. Table 3 illustrates the results of the ablation studies. Note that ACGAN is our basic structure. Obviously, our method after adding each component exceeds ACGAN, which shows the effectiveness of each of our components. In addition, the table also shows that the combination of multiple components can improve the performance of the model in most cases. Therefore, the superposition of the methods has a positive correlation with the final prediction accuracy.
4.3 Generalized Zero-shot Learning
| CUB | NAB | |||
|---|---|---|---|---|
| Methods | SCS | SCE | SCS | SCE |
| ZSLNS [35] | 14.7 | 4.4 | 9.3 | 2.3 |
| SynCfast [6] | 13.1 | 4.0 | 2.7 | 3.5 |
| ZSLPP [10] | 30.4 | 6.1 | 12.6 | 3.5 |
| GAN-ZSL [53] | 35.4 | 8.7 | 20.4 | 5.8 |
| CorrectionNet [16] | 41.9 | 9.0 | 25.4 | 7.6 |
| CIZSL [9] | 39.2 | 11.9 | 24.5 | 6.4 |
| CANZSL [8] | 40.2 | 12.5 | 25.6 | 6.8 |
| GDAN [17] | 38.7 | 10.9 | 24.1 | 5.9 |
| GAN-CST | 40.5 | 12.7 | 24.9 | 7.9 |
In the ZSL domain, it is not sufficient to only consider the performance of the unseen classes. A more generalized evaluation criterion is needed. In [53], a generalized evaluation metric, which considers the accuracy of the seen and unseen classes, was proposed for ZSL. A balance parameter was used to draw the curves of the seen and unseen classes(SUC, the accuracy of the seen classes is the vertical axis and the accuracy of the unseen classes is the horizontal axis), and the area under SUC (AUSUC) was used to represent the generalization ability of the ZSL model. Table 4 shows the AUSUC scores between our method and the other methods. The AUSUC score of our method increased by 1.6% and 3.95%, respectively, on two benchmark datasets with SCE splitting compared to the other methods. In the SCS-split, our method is slightly lower than CorrectionNet and CANZSL, only 1.4% and 0.7%, but still surpasses a large number of the state-of-the-art methods.
We also evaluate the AUSUC scores of each component in our method. Fig.4 shows that the effect of triplet loss on the result performance is relatively stable, while the performance of CKO and SSL methods changes greatly. This is because the CKO and SSL sometimes introduce some noise that affects the training of the model. However, the generalization of each combination reached the state-of-the-art standard.




In addition, we use another GZSL setting that emerges recently to evaluate the proposed method on AwA1 and AwA2 datasets. These two datasets are based on attribute and respectively contain 30,475 and 37,322 images of 200 animals with 40 seen and 10 unseen classes with 85-dimensional attributes. In this setting, test set includes data samples from both the seen and unseen classes. We follow the same setting in [48], which adopt the average per-class top-1 accuracy S and U, as well as their harmonic mean to evaluate the performance of the model and combines the seen and unseen classes as the search space. The Table 5 shows that the proposed method compared with seven latest methods. The results show our GAN-CST exceeds a large number of the latest method. Especially in the S of AwA1 dataset and S and H of AwA2 dataset, the best performances are achieved, which are 97.2%, 94.0% and 85.6%, respectively. An obvious rule can be observed: our GAN-CST improves the U accuracy while ensuring a high S accuracy. Although AwA1 has achieved better performance on U and H compared to our method, the performance of our method on S far exceeds it, and the accuracy on S is almost 100%. This shows that our method can well retain the discriminative features of seen classes while improving the performance of unseen classes.
| AwA1 | AwA2 | |||||
|---|---|---|---|---|---|---|
| Methods | S | U | H | S | U | H |
| f-CLSWGAN [35] | 61.4 | 57.9 | 59.6 | 68.9 | 52.1 | 59.4 |
| CADA-VAE [6] | 72.8 | 57.3 | 64.1 | 75.0 | 55.8 | 63.9 |
| LisGAN [10] | 76.3 | 52.6 | 62.3 | - | - | - |
| GMN [53] | 79.2 | 70.8 | 74.8 | - | - | - |
| GXE [16] | 89.0 | 87.7 | 88.4 | 90.0 | 80.2 | 84.8 |
| CE [9] | 87.7 | 71.2 | 78.6 | 86.1 | 71.3 | 78.0 |
| Deep-CDM [8] | - | - | - | 82.5 | 77.6 | 80.0 |
| GAN-CST | 97.2 | 73.9 | 84.0 | 94.0 | 78.6 | 85.6 |
4.4 Zero-Shot Retrieval
The task of zero-shot retrieval means to retrieve the relevant images from unseen classes giving the semantic representation of the specified class in unseen class set. We use mean average precision (mAP) to evaluate the performance. For comparing with other methods fairly, we report the performance of different settings in Table 6: retrieving 25%, 50%, 100% of the number of images for each class from the whole dataset are ranked based on their final semantic similarity scores. The precision is defined as the ratio of the number of correct retrieved images to that of all retrieved images.
Table 6 presents the comparison results of different approaches for mean accuracy precision (mAP) on CUB and NABird datasets. We note that the proposed approach has achieved consistent improvement compared with GAN-ZSL and beats all the competitors.
| CUB | NAB | |||||
|---|---|---|---|---|---|---|
| Methods | 25 | 50 | 100 | 25 | 50 | 100 |
| ESZSL[37] | 27.9 | 27.3 | 22.7 | 28.9 | 27.8 | 20.9 |
| ZSLNS[35] | 29.2 | 29.5 | 23.9 | 28.8 | 27.3 | 22.1 |
| ZSLPP[10] | 42.3 | 42.0 | 36.6 | 36.9 | 35.7 | 31.3 |
| GAN-Only[53] | 18.0 | 17.5 | 15.2 | 21.7 | 20.3 | 16.6 |
| GAN-ZSL[53] | 49.7 | 48.3 | 40.3 | 41.6 | 37.8 | 31.0 |
| GAN-CST | 51.6 | 50.4 | 43.6 | 44.9 | 41.3 | 35.0 |

We also visualize some qualitative results of our approach on two datasets, shown in Fig. 5. Each row is a class, and the class name and precision are shown on the left. The first column is the benchmark. The following five columns are Top-5 without considering the instances in the first column. Some instances are hard to distinguish even for humans, but the model can recognize. For example, the top-5 retrieval images of class ”Northern Waterthrush” are all from their ground truth class since their visual features are similar. However, the query ”Mountain Bluebird” retrieves some instances from its affinal class ”Florida Scrub Jay” since their visual features are too similar to distinguish.
4.5 Hyperparameter Study











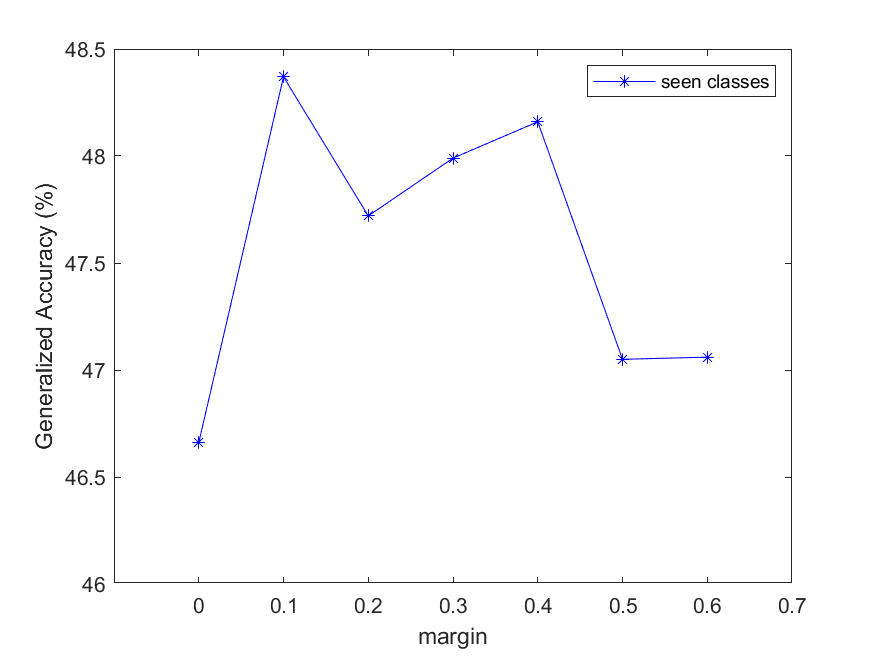
In this section, different hyperparameters were set to observe their impact on the performance of our model. Three groups of experiments were conducted. The hyperparameter settings are shown in Table 7. Fig.6 and 7 show the generalized accuracy curves with different splitting methods and different hyperparameters in two benchmark datasets. The horizontal axis represents the values of the hyperparameters, while the vertical axis represents the generalization accuracy of the seen classes (calculated by formula 3). The values of the hyperparameters corresponding to the highest generalization accuracy are set as the parameters of the model. Table 1 summarizes the values of the hyperparameters in all groups. Our method is more robust than the other methods because of the gaps in the accuracy of the unseen classes with different hyperparameter settings.
| Methods | Parameters | Candidate Values | |
|---|---|---|---|
| 1 | TL | margin | 0 to 0.8 with an interval of 0.1 |
| 2 | CKO | k | 1, 2, 3, 4, 5 |
| 3 | SSL | confidence | 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8 |
5 Conclusion
In this study, we developed a novel approach to solve the challenging zero-shot learning tasks. Our approach uses an ACGAN to transform semantic features into visual features. Meanwhile, class knowledge overlay and semi-supervised learning were used to solve the problem of the semantic consistency between the semantic features and visual features, respectively. Furthermore, triplet loss was introduced to expand the inter-class distances and shorten the intra-class distances. Extensive experiments showed that our approach significantly outperforms the state-of-the-art models on multiple zero-shot tasks. Our future works may focus on: 1) applying a sophisticated visual feature generation method to improve the quality of synthesized visual part; 2) instead of text embedding, knowledge graph embedding would be applied to enhance the ability of semantic representation.
Acknowledgments
The authors wish to acknowledge the financial support from the Natural Science Foundation of China (NSFC) under Grant No.61876166 and 61663046 and the Young Researcher Promotion Project of China Association for Science and Technology under Grant W8193209.
References
- Akata et al. [2016] Akata, Z., Malinowski, M., Fritz, M., Schiele, B., 2016. Multi-cue zero-shot learning with strong supervision, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 59–68.
- Akata et al. [2013] Akata, Z., Perronnin, F., Harchaoui, Z., Schmid, C., 2013. Label-embedding for attribute-based classification, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Akata et al. [2015] Akata, Z., Reed, S., Walter, D., Lee, H., Schiele, B., 2015. Evaluation of output embeddings for fine-grained image classification, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Ba et al. [2015] Ba, J.L., Swersky, K., Fidler, S., Salakhutdinov, R., 2015. Predicting deep zero-shot convolutional neural networks using textual descriptions .
- Biederman [1987] Biederman, I., ., 1987. Recognition-by-components: a theory of human image understanding. Psychological Review 94, 115–47.
- Changpinyo et al. [2016] Changpinyo, S., Chao, W.L., Gong, B., Sha, F., 2016. Synthesized classifiers for zero-shot learning, in: Computer Vision & Pattern Recognition.
- Chen et al. [2019] Chen, Y., Xiong, Y., Gao, X., Xiong, H., 2019. Structurally constrained correlation transfer for zero-shot learning, in: 2018 IEEE Visual Communications and Image Processing (VCIP).
- Chen et al. [2020] Chen, Z., Li, J., Luo, Y., Huang, Z., Yang, Y., 2020. Canzsl: Cycle-consistent adversarial networks for zero-shot learning from natural language, in: The IEEE Winter Conference on Applications of Computer Vision, pp. 874–883.
- Elhoseiny and Elfeki [2019] Elhoseiny, M., Elfeki, M., 2019. Creativity inspired zero-shot learning. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , 5783–5792.
- Elhoseiny et al. [2017] Elhoseiny, M., Zhu, Y., Han, Z., Elgammal, A., 2017. Link the head to the ”beak”: Zero shot learning from noisy text description at part precision, in: Computer Vision & Pattern Recognition.
- Frome et al. [2013] Frome, A., Corrado, G.S., Shlens, J., Bengio, S., Dean, J., Ranzato, M., Mikolov, T., 2013. Devise: A deep visual-semantic embedding model, in: International Conference on Neural Information Processing Systems.
- Fu et al. [2015] Fu, Y., Hospedales, T.M., Xiang, T., Gong, S., 2015. Transductive multi-view zero-shot learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 37, 2332–2345. doi:10.1109/TPAMI.2015.2408354.
- Fu et al. [2017] Fu, Y., Tao, X., Jiang, Y.G., Xue, X., Gong, S., 2017. Recent advances in zero-shot recognition .
- Fu et al. [2018] Fu, Z., Xiang, T., Kodirov, E., Gong, S., 2018. Zero-shot learning on semantic class prototype graph. IEEE Transactions on Pattern Analysis and Machine Intelligence 40, 2009–2022.
- Girshick [2015] Girshick, R., 2015. Fast r-cnn. Computer Science .
- [16] Hu, R.L., Xiong, C., Socher, R., . Zero-shot image classification guided by natural language descriptions of classes: A meta-learning approach .
- Huang et al. [2019] Huang, H., Wang, C., Yu, P.S., Wang, C.D., 2019. Generative dual adversarial network for generalized zero-shot learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Huang et al. [2020] Huang, H., Wang, C., Yu, P.S., Wang, C.D., 2020. Generative dual adversarial network for generalized zero-shot learning, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Hwang et al. [2011] Hwang, S.J., Sha, F., Grauman, K., 2011. Sharing features between objects and their attributes, in: CVPR 2011, IEEE. pp. 1761–1768.
- Hwang and Sigal [2014] Hwang, S.J., Sigal, L., 2014. A unified semantic embedding: Relating taxonomies and attributes, in: Advances in Neural Information Processing Systems, pp. 271–279.
- Jayaraman et al. [2014] Jayaraman, D., Sha, F., Grauman, K., 2014. Decorrelating semantic visual attributes by resisting the urge to share, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1629–1636.
- Ji et al. [2018] Ji, Z., Fu, Y., Guo, J., Pang, Y., Zhang, Z.M., et al., 2018. Stacked semantics-guided attention model for fine-grained zero-shot learning, in: Advances in Neural Information Processing Systems, pp. 5995–6004.
- Kipf and Welling [2016] Kipf, T.N., Welling, M., 2016. Semi-supervised classification with graph convolutional networks .
- Kodirov et al. [2017] Kodirov, E., Xiang, T., Gong, S., 2017. Semantic autoencoder for zero-shot learning, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Lampert et al. [2009] Lampert, C.H., Nickisch, H., Harmeling, S., 2009. Learning to detect unseen object classes by between-class attribute transfer, in: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 951–958. doi:10.1109/CVPR.2009.5206594.
- Lei Ba et al. [2015] Lei Ba, J., Swersky, K., Fidler, S., et al., 2015. Predicting deep zero-shot convolutional neural networks using textual descriptions, in: Proceedings of the IEEE International Conference on Computer Vision, pp. 4247–4255.
- Li and Guo [2015] Li, X., Guo, Y., 2015. Max-margin zero-shot learning for multi-class classification, in: AISTATS.
- Li et al. [2016] Li, X., Guo, Y., Schuurmans, D., 2016. Semi-supervised zero-shot classification with label representation learning, in: IEEE International Conference on Computer Vision.
- Li et al. [2018] Li, Y., Zhang, J., Zhang, J., Huang, K., 2018. Discriminative learning of latent features for zero-shot recognition .
- Long et al. [2017] Long, C., Zhang, H., Xiao, J., Wei, L., Chang, S.F., 2017. Zero-shot visual recognition using semantics-preserving adversarial embedding network .
- Meng and Guo [2018] Meng, Y., Guo, Y., 2018. Self-training ensemble networks for zero-shot image recognition .
- Mikolov et al. [2014] Mikolov, T., Bengio, S., Singer, Y., Shlens, J., Frome, A., Corrado, G., Dean, J., 2014. Zero-shot learning by convex combination of semantic embeddings, in: ICLR.
- Pambala et al. [2019] Pambala, A.K., Dutta, T., Biswas, S., 2019. Unified generator-classifier for efficient zero-shot learning .
- Porter [2013] Porter, M.F., 2013. An algorithm for suffix stripping, in: Readings in Information Retrieval.
- Qiao et al. [2016] Qiao, R., Liu, L., Shen, C., Hengel, A.V.D., 2016. Less is more: zero-shot learning from online textual documents with noise suppression .
- Romera-Paredes and Torr [2015a] Romera-Paredes, B., Torr, P., 2015a. An embarrassingly simple approach to zero-shot learning, in: International Conference on Machine Learning, pp. 2152–2161.
- Romera-Paredes and Torr [2015b] Romera-Paredes, B., Torr, P.H.S., 2015b. An embarrassingly simple approach to zero-shot learning, in: Proceedings of the 32nd international conference on Machine learning (ICML ’15).
- Sariyildiz and Cinbis [2019] Sariyildiz, M.B., Cinbis, R.G., 2019. Gradient matching generative networks for zero-shot learning, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Shigeto et al. [2015] Shigeto, Y., Suzuki, I., Hara, K., Shimbo, M., Matsumoto, Y., 2015. Ridge regression, hubness, and zero-shot learning, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer. pp. 135–151.
- Socher et al. [2013] Socher, R., Ganjoo, M., Sridhar, H., Bastani, O., Manning, C.D., Ng, A.Y., 2013. Zero-shot learning through cross-modal transfer, in: International Conference on Neural Information Processing Systems.
- Suzuki et al. [2014] Suzuki, M., Sato, H., Oyama, S., Kurihara, M., 2014. Transfer learning based on the observation probability of each attribute, in: 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 3627–3631. doi:10.1109/SMC.2014.6974493.
- Tao et al. [2017] Tao, X., Zhang, P., Huang, Q., Han, Z., He, X., 2017. Attngan: Fine-grained text to image generation with attentional generative adversarial networks .
- Verma et al. [2018] Verma, V.K., Arora, G., Mishra, A., Rai, P., 2018. Generalized zero-shot learning via synthesized examples, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Wang et al. [2017] Wang, W., Pu, Y., Verma, V.K., Fan, K., Carin, L., 2017. Zero-shot learning via class-conditioned deep generative models, in: AAAI, 2018.
- Wang et al. [2018] Wang, X., Ye, Y., Gupta, A., 2018. Zero-shot recognition via semantic embeddings and knowledge graphs, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6857–6866.
- Xian et al. [2016] Xian, Y., Akata, Z., Sharma, G., Nguyen, Q., Hein, M., Schiele, B., 2016. Latent embeddings for zero-shot classification, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Xian et al. [2018] Xian, Y., Lorenz, T., Schiele, B., Akata, Z., 2018. Feature generating networks for zero-shot learning, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Xian et al. [2017] Xian, Y., Schiele, B., Akata, Z., 2017. Zero-shot learning - the good, the bad and the ugly.
- Yang and Hospedales [2014] Yang, Y., Hospedales, T.M., 2014. A unified perspective on multi-domain and multi-task learning. arXiv preprint arXiv:1412.7489 .
- Yu and Aloimonos [2010] Yu, X., Aloimonos, Y., 2010. Attribute-based transfer learning for object categorization with zero/one training example, in: Daniilidis, K., Maragos, P., Paragios, N. (Eds.), Computer Vision – ECCV 2010, Springer Berlin Heidelberg, Berlin, Heidelberg. pp. 127–140.
- Zhang et al. [2017] Zhang, L., Xiang, T., Gong, S., 2017. Learning a deep embedding model for zero-shot learning, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2021–2030.
- Zhang and Saligrama [2015] Zhang, Z., Saligrama, V., 2015. Zero-shot learning via semantic similarity embedding, in: The IEEE International Conference on Computer Vision (ICCV).
- Zhu et al. [2018] Zhu, Y., Elhoseiny, M., Liu, B., Peng, X., Elgammal, A., 2018. A generative adversarial approach for zero-shot learning from noisy texts, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).