CLAS: A Machine Learning Enhanced Framework for Exploring Large 3D Design Datasets
Abstract
Three-dimensional (3D) objects have wide applications. Despite the growing interest in 3D modeling in academia and industries, designing and/or creating 3D objects from scratch remains time-consuming and challenging. With the development of generative artificial intelligence (AI), designers discover a new way to create images for ideation. However, generative AIs are less useful in creating 3D objects with satisfying qualities. To allow 3D designers to access a wide range of 3D objects for creative activities based on their specific demands, we propose a machine learning (ML) enhanced framework CLAS - named after the four-step of capture, label, associate, and search - to enable fully automatic retrieval of 3D objects based on user specifications leveraging the existing datasets of 3D objects. CLAS provides an effective and efficient method for any person or organization to benefit from their existing but not utilized 3D datasets. In addition, CLAS may also be used to produce high-quality 3D object synthesis datasets for training and evaluating 3D generative models. As a proof of concept, we created and showcased a search system with a web user interface (UI) for retrieving 6,778 3D objects of chairs in ShapeNet dataset powered by CLAS. In a close-set retrieval setting, our retrieval method achieves a mean reciprocal rank (MRR) of 0.58, top 1 accuracy of 42.27%, and top 10 accuracy of 89.64%.
1 Introduction
The creative design process has been transformed by the advance of generative artificial intelligence (AI), benefiting designers in different fields (Picard et al., 2023). Text-to-text large language models (LLM) such as OpenAI’s ChatGPT (OpenAI, 2022) and Meta’s LLaMA(Touvron et al., 2023a, b) provide a convenient and powerful way for designers to formulate their design ideas (Zhu and Luo, 2021). In addition to discussing ideas in words, text-to-image generative AIs could help designers visualize and showcase their thoughts much faster. The wide adoption of latent diffusion models (Rombach et al., 2022) demonstrated by the popularity of Stable Diffusion and Midjourney proves that the use of text-to-image models is welcomed by many designers. However, the experience of designers immersed in 3D modeling might be different. It is natural and necessary to extend the success of AI-generated content (AIGC) to the three-dimensional (3D) domain, as 3D objects have many applications in diverse fields (Li et al., 2023; Luo et al., 2021; Zhang et al., 2023). However, due to the additional dimension of the output data and the relatively restricted datasets for training, the performance of the state-of-art 3D generative models developed on Generative adversarial network (GAN) (Goodfellow et al., 2014; Chan et al., 2021; Skorokhodov et al., 2023), Neural radiance fields (Nerf) (Mildenhall et al., 2020; Cen et al., 2023), 3D diffusion models (Liu et al., 2023; Qian et al., 2024) or hybrid approaches, is not on par with what has been offered by text-to-text or text-to-image models. Generated 3D objects may have lower visual quality, distorted geometry, and not fully complete 360-degree generation (Skorokhodov et al., 2023). In addition, 3D object generations perform better when intensive information is given as prior, such as multi-view images and 3D objects (Liu et al., 2023; Qian et al., 2024). Since in the ideation phase of design, 3D designers are looking for references and inspirations, such detailed prior can hardly be provided, which limits the use of the current limited 3D generation. The training data of text and image generation models can be constructed from large quantities of diverse sources since these modalities can be created and accessed by the general public. In contrast, 3D objects are generally created by professionals for professional tasks, resulting in many 3D objects being proprietary properties.

Given these constraints, instead of creating a 3D object from scratch based on the designer’s thoughts, providing them with relevant existing 3D objects in professional datasets might be more practical and useful. However, 3D Object Retrieval (3DOR) methods are generally based on modalities that are rich in 3D spacial information (He et al., 2018; Jing et al., 2021; Feng et al., 2023), such as multi-view image (Su et al., 2015), point cloud (Zhou and Tuzel, 2017) and voxel (Wu et al., 2014). These modalities are not intuitive for 3D designers to use when seeking inspiration. On the other hand, language is the most intuitive modality to describe the 3D objects designers may want as a reference. Language can be especially useful for retrievals not only based on the object’s geometry but also on the varying design concepts such as use cases, intended users, and design purpose.
We, therefore, propose a four-step framework, CLAS (capture, label, associate, and search) as summarized in Figure 1, to automatically label, index, and retrieve 3D objects based on the user’s textual prompts with varying levels of details and focus. CLAS is a flexible framework that can be applied to diverse 3D objects for different purposes. In the capture step, an image at a fixed position or a set of multi-view images can be created based on 3D models in the target dataset. A visual-language model is leveraged to create descriptions for these captured images based on specifically designed prompts in the label step. Depending on the use case, generated descriptions can have different focus (multiple descriptions can be created for an image). In the associate step, one or more CLIP models (Radford et al., 2021) can be trained on the images and descriptions to learn semantic context from text and visual context from images. More than one model should be trained if more than one purpose of descriptions is generated in the previous step. Then, the CLIP models can be used in the search step for text-based retrieval of 3D objects. This helps designers to efficiently find inspiration, overcome creative blocks, and seamlessly initiate their design process. Furthermore, the 3D datasets labeled by CLAS can also be repurposed to train 3D generative models with richer contextual semantic meanings. To showcase the efficiency of CLAS, we implemented a proof of concept search system on chairs in the ShapeNet (Chang et al., 2015) and evaluated its effectiveness.
2 Background
Considering the limitation of the current text-to-3D generation and the availability of existing datasets of 3D objects, this research instead focuses on improving 3DOR. Quick access to specific 3D objects can significantly enhance creativity and productivity for 3D designers. 3DOR refers to the computational methods to identify and fetch 3D objects within a dataset based on similarity to a query (He et al., 2018). This query, in principle, can take various forms, ranging from complex data structure (multi-view image (Su et al., 2015), point cloud (Zhou and Tuzel, 2017) and voxel (Wu et al., 2014)) to attributes of the items or simple text descriptions.
In the simplest case, a general-purpose search engine such as Google may be used to retrieve 3D objects from the internet. However, a general-purpose engine relies solely on the labels of the source of the 3D objects and some limited visual cues for retrieval. Also, such an engine has limited access to 3D datasets. In contrast, machine learning (ML)-driven algorithms can compare geometric shapes, textures, and other relevant features of 3D objects to find matches or closely related items (Gao et al., 2020; Feng et al., 2023). Existing methods are usually designed around computer vision (CV) techniques and thus focus more on the visual characteristics of 3D objects, missing the critical step of understanding the semantic meaning of user input and associating them with visual cues. Various methods have been proposed to enable 3DOR based on either single modality (Bustos et al., 2007; Wei et al., 2020; Su et al., 2020) or multiple modalities (Nie et al., 2019; Feng et al., 2023), aiming to learn the distribution of 3D objects in high dimensional space (He et al., 2018) and sorting the items according to various distance metrics. In a typical setting of closed-set 3DOR, the training set and the testing set are assumed to have the same distribution and can be represented in the same space, where is a 3D object and is the associated category of the 3D object. The retrieval method is trained on the training set to optimize:
| (1) |
This objective encourages 3D objects in the same category to be closer and objects in different categories farther apart in the representation space. It is also very dependent on the categories. The method learned may be meaningless if the category is very broad. Current 3D datasets are more focused on the representation or modality of 3D objects to capture visual and spatial information, undermining the importance of the semantic meaning of these 3D objects. Some works, such as ShapeNet (Chang et al., 2015) and Objectverse (Deitke et al., 2023), tried to fill in this blank by adding general labeling to 3D objects with limited detail. As a result, 3DOR methods tend to rely on complex visual or 3D input for retrieval. However, in the use case for 3D designers, providing visual representation to retrieve 3D objects is challenging in the ideation stage. A textual description of the 3D object might be the most practical cue to use in the ideation phase of design. In order to enable retrieval based on text with sufficient accuracy, the text label of 3D objects needs to be improved for existing 3D datasets.
To address this limitation, this research leverages the recent breakthrough in multi-modal large language models (LLMs) to propose an ML-enhanced framework CLAS, which labels datasets of 3D objects with human-readable descriptions focusing on different perspectives (such as geometry, functionality, or design concept) based on prompts and associates these descriptions with their corresponding visual characteristics in high dimensional vector space for easy retrieval using words. Systems built with CLAS offer more precision and flexibility in 3D object retrieval by understanding complex spatial and/or design-related language, where traditional methods are not specialized.
3 Method
To automate the process of labeling, indexing, and retrieving 3D objects from a dataset, we propose CLAS - an ML-enhanced four-step (capture, label, associate, and search) framework as illustrated in Figure 1. To demonstrate the framework’s effectiveness, we deploy it to create a proof of concept search system for chairs in the ShapeNet dataset (Chang et al., 2015) as demonstrated in Section 4. Applying CLAS on an existing 3D dataset creates two products: a set of descriptive labeling for the datasets, which can be used for other training or evaluation, and a 3DOR retrieval method based on text input.
Capture.
The first step in CLAS is to capture a certain number of images of the rendered 3D objects. Since 3D objects can be stored in various formats, the environment or software that could be used to render and capture these objects varies. The cross-platform game engine Unity or 3D computer graphics software Blender are able to cover most of the formats. The setting of the lens, orientations, and lighting should be tuned to suit the purpose of the dataset. The images taken are forwarded to the next step for further processing. This step generates a 2D representation of the 3D objects. Depending on the complexity of the 3D model, more than one image may be generated to preserve more details. In the proof of concept application, we used the images of 3D objects of the chair category in the ShapeNet dataset (Chang et al., 2015).
Label.
In the second step, CLAS generates a description of the image and labels the image with the corresponding description. Many 3D datasets, such as ShapeNet (Chang et al., 2015) and ModelNet (Wu et al., 2015), are released with limited labels, making reusing or repurposing these datasets outside of the research community difficult. This step is performed using a multi-modal LLM, such as ChatGPT-4V, to describe the image with a specific focus defined by the user. For example, the description can be directed to focus on the object’s appearance and/or usage. The images of 3D objects and their accompanying descriptions are used in the training in the next step. The performance of the retrieval method is very dependent on the quality of the labeled description. The prompt to generate the descriptions should be designed considering the users of the retrieval system, i.e., what kind of language is usually used to describe the objects. In the proof of concept application, we used ChatGPT-4V with engineered prompts to generate detailed descriptions of the shape and design features of the chairs.
Associate.
This step trains a multi-modal ML model, i.e., a model capable of encoding two different modalities (text and image), to associate images and their descriptions. Different models can be used for this purpose based on the design of the system, such as CLIP (Radford et al., 2021) with vision transformer (Dosovitskiy et al., 2021). After training, two vector spaces representing the textual descriptions and visual images are created, respectively. The similarity of items can be reflected by their proximity in the vector space. We fine-tuned a CLIP model for proof-of-concept application to associate the two modalities of 3D objects.
Search
The final step prepares a user interface (UI) for the users to engage with the system, i.e., search and retrieve 3D models given a textual description. Based on the purpose of the system, different UIs can be used, ranging from a command line to a webpage to an immersive AR/VR environment. We created a website using React to host the proof of concept application. UI ultimately determines how users interact with the AI system.
4 Proof of concept application

In this section, we present a CLAS powered web application that allows users to search for 3D objects of chairs using words to demonstrate the usefulness of CLAS. We first introduce the background of the text-based search application, followed by a detailed explanation of how each step in CLAS is applied. An overview of this use case is provided in Figure 2. Implementation details can be found in Appendix A. The interaction between users and the system is described in details in Appendix B.
4.1 Background
Prototyping new designs can be challenging for 3D designers who need references for inspiration, but effectively matching the needs of these designers and existing 3D objects can be challenging. We chose a specific category, i.e., chairs, to demonstrate how CLAS can be applied to bridge the gap: chair designs. ShapeNet dataset (Chang et al., 2015) contains 6,778 3D chair objects, which can be potentially used for creative works. However, it is impractical for designers to manually go through these objects, considering that they often lack proper annotations that are easily readable by humans. An exemplary use case by designers is shown in Appendix B.
4.2 Implementing 3D chair search system using CLAS
This system was built using CLAS as detailed below. Note that we leveraged the existing images in the dataset so the first step in CLAS, i.e., capture, is skipped.
4.2.1 Label

We conducted prompt engineering for the ChatGPT-4V to generate image descriptions. The generated descriptions are prompted to match potential user input that designers would likely use when searching for chair objects. We design prompts echoing three focuses to achieve the goal: design purpose, structure, and template.
Design purpose.
Product design often starts from the product’s functionality to solve a specific problem and innovate from the original design. From the designers’ perspective, potential users may enter the design purpose and use case as input prompts to get ideas for the brainstorming process. The left column in Figure 3 shows a prompt containing the key questions for designers to generate a design purpose-based text description.

Structure.
Visual characteristics play an important role in distinguishing different chairs and are critical in making design decisions. A detailed description of the exact shape, uniqueness, and size relations would be very helpful for the retrieval method later to learn different 3D objects with enough precision. To discover the effective prompt, we started with the simple prompt, “Can you describe the chair’s appearance?" The optimization process of the prompt underwent iterative tests by adjusting the task description, providing hints, varying the focused aspects, etc. The generated descriptions were initially read and validated manually to omit failed prompts. Then, we evaluated the prompts by comparing the image generated by DALL-E from OpenAI to the original image. The more similar the generated image using the description to the original image, the better the prompt is. Several examples of tested prompts and corresponding results are included in Appendix C. Based on the experiments, capitalizing the critical words and adding a sentence to highlight the unnecessary part for the description would increase the performance of the prompt. On the other hand, prompts with too much information and the use of general words might produce imprecise descriptions of the provided objects. The conciseness of the generated description is important to avoid overly general expressions and highlight the characteristics of an object. The finalized structure prompt is shown as the middle column in Figure 3.
Template:
Lengthy descriptions are expected to contain more information about the chair. However, they also mean more computation is needed to train and serve the retrieval system. In this proof of concept application, the base version of the CLIP (Radford et al., 2021) was used, limiting the length of the generated description to less than 77 tokens. To compress the description’s size while maintaining each chair’s distinctive features, we used a template-like prompt as the right column in Figure 3. It focuses on both design purpose and structure and is used for the labeling process. The template can also be provided to the user for filling out during searching, which could help to establish consistency between the generated descriptions and potential user input to improve the accuracy of the retrieval system. Even though the limited structural descriptions generated by the template did not cover all the details of the complex 3D objects, they maintained the advantage of describing the design purpose and uniqueness.
4.2.2 Associate
We used CLIP (Radford et al., 2021) to associate the text descriptions and the image used to generate the text description. The architecture of the CLIP is included as Appendix D. We first produced the datasets for fine-tuning and evaluation by pairing up images of 3D chair objects and their corresponding text descriptions generated by ChatGPT-4V prompted by the template design. Pairs in the training set were fed into the CLIP model, and the fine-tuning encouraged the text embedding embedded by the text encoder and the image embedding embedded by the image encoder to be close together after projection into the vector space of the same dimension by the contrastive loss:
| (2) |
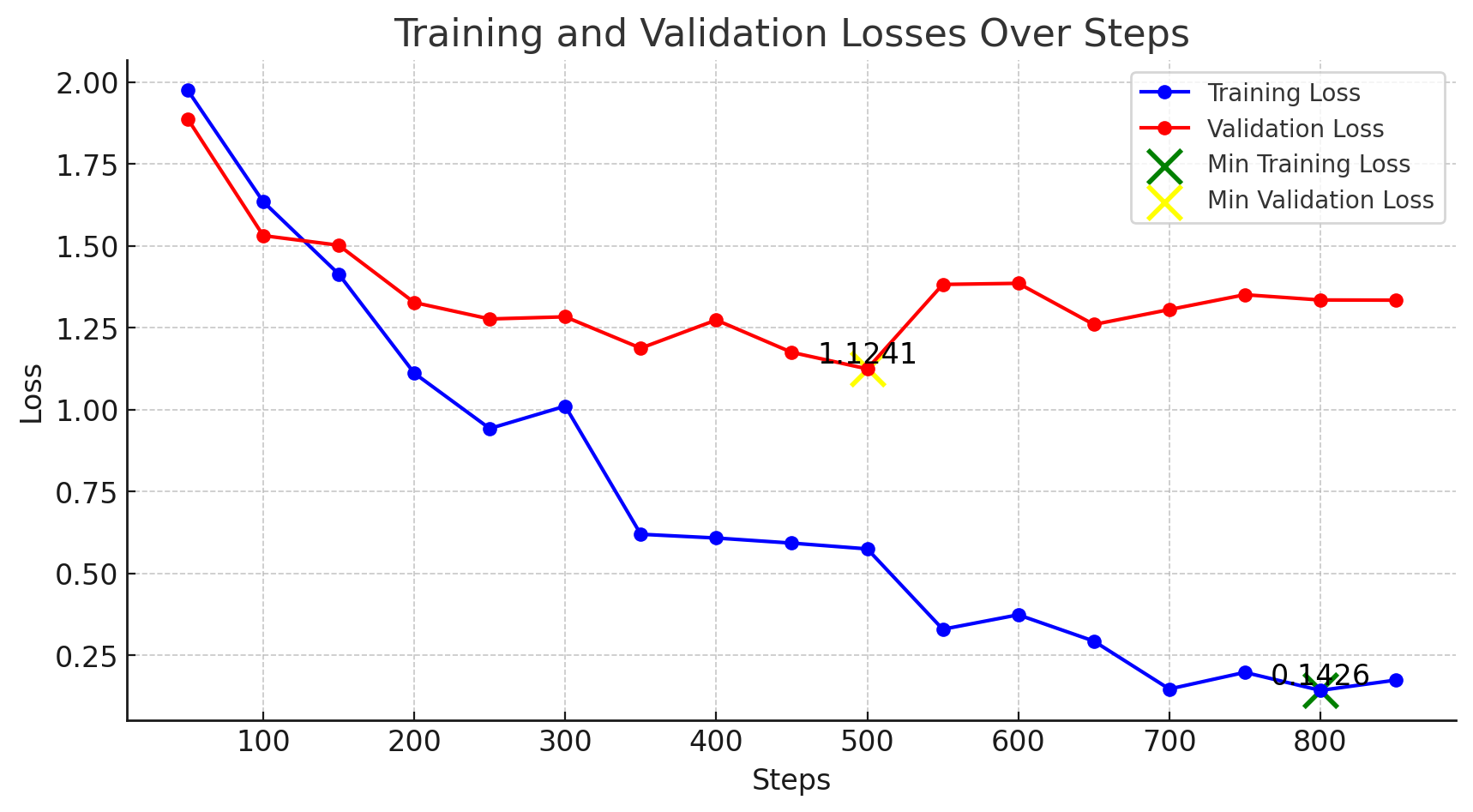
where is the number of samples in the batch, and is the cosine similarity between the image representation and the text representation . The labels are implicitly indicated by the pairs which are the correct pairs in the batch, while and for represent the negative pairs. The fine-tuning is visualized as Figure 5. We noticed that the model might overfit and did not generalize well, which is discussed in Section 4.3. After the fine-tuning, the CLIP model became more sensitive to chairs and their designs than a general model and could be used for retrieval.
4.2.3 Search
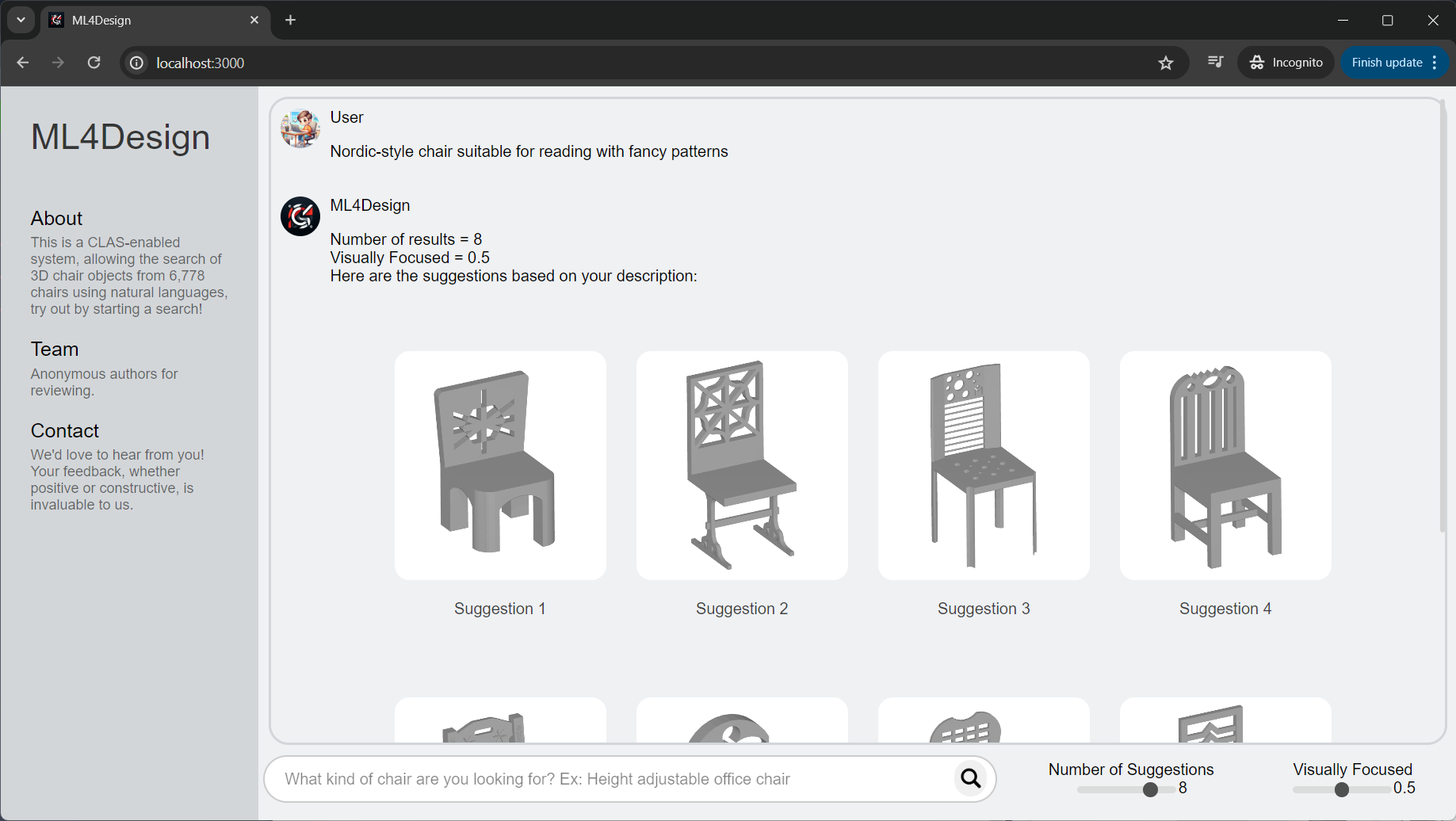

A complete web application with a front end and a back end was created to host the search system. The implementation details are included in Appendix A. When designers start a new search, the process begins with the search bar, where they enter a prompt such as “Nordic-style chair suitable for reading with fancy patterns" and then select the value for two slide bars, pressing either enter or the search button to search. Upon submitting the prompt, our system quickly retrieves 3D objects, displaying search results within a fraction of a second from a database of 6,778 chair objects. The search results in the chat window are presented in rows, with the user’s avatar displayed above, showing the user’s prompt, followed by the system’s response, “Here are the suggestions," to enhance user interaction (as demonstrated in Figure 6). As users browse through the objects, the image of the object they hover over will slightly enlarge, indicating which chair object they are considering or wish to select. Clicking on a desired model enlarges it for a closer inspection of the details (as shown in Figure 6). To download the chosen 3D object, clicking the download button redirects the user to object downloads. If the user is unsatisfied with the search results, they can click on the “show description" button to view the label/description generated by ChatGPT-4V for each model. This feature allows users to refine their search based on the labels or start a new search by entering a more precise prompt. If the user wants to search for more 3D objects that are similar to one of the result models, simply click on “search similar"; the website will search again using the selected object as a query, thereby providing similar object suggestions. These functions offer a tailored and interactive browsing experience.
This website was designed for designers seeking inspiration and resources for 3D object designs. The visual and workflow designs help users focus more on the search system. The pre-filled prompt in the search bar enables users to quickly start their initial search, while the navigation bar offers additional information and content about the project. Most importantly, the search results page makes the search process more intuitive and convenient, allowing users to easily find and download the object they seek, leaving a good impression and a great user experience.

4.3 Evaluation
| Size | MRR (0-1) | Top-1 Acc (%) | Top-10 Acc (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | Best Tr. | Best Val. | Baseline | Best Tr. | Best Val. | Baseline | Best Tr. | Best Val. | ||
| Train | 5422 | 0.02 | 0.57 | 0.20 | 0.57 | 41.53 | 9.94 | 3.50 | 88.68 | 42.05 |
| Test | 1365 | 0.05 | 0.24 | 0.18 | 2.36 | 11.95 | 9.37 | 7.96 | 47.64 | 38.20 |
| Complete | 6778 | 0.02 | 0.45 | 0.16 | 0.55 | 31.53 | 7.73 | 3.24 | 72.68 | 33.60 |
| Close-set | 6778 | 0.02 | 0.58 | 0.55 | 42.27 | 3.24 | 89.64 | |||
Before the CLAS implementation, no efficient solution was available to retrieve chairs in the ShapeNet using natural languages. Potential users must go through all the chairs to manually decide which are wanted, which requires much time and effort. To the best of our knowledge, this exemplary use case is the first attempt to enable this convenient search using natural language on 3D chair datasets.
The out-of-box CLIP model (Radford et al., 2021) from OpenAI is used as the baseline to demonstrate the effectiveness of the fine-tuning using three standard metrics in evaluating retrieval systems. Mean reciprocal rank (MRR) calculates the mean of the reciprocals of the rank at which the true objects are retrieved. MRR takes a value between 0 and 1 such that the closer to 1, the better the performance, i.e., the system ranks the intended item higher in all the possible items. Top-1 accuracy calculates the percentage of retrieved objects as the true object. Top- accuracy expands on the top-10 accuracy to the scope of the top 10 most probable objects selected by the model.
As shown in Table 1, there is a huge increase in performance in all the metrics for both the training, testing, and complete sets. The fine-tuned model with the best train loss performs noticeably better than the best validation model, even for unseen samples in the test set. We argue that for close-set retrieval, where objects to be retrieved are from a fixed dataset, it is reasonable to train the retrieval model on all data. We, therefore, overfitted the model on the complete set to achieve a loss of 0.02 in 10 epochs. The overfitted model achieved the best retrieval results, as shown in the last row of Table 1. As demonstrated in Figure 7, the text and image representation of the 3D chair objects can be closely associated even with 6,778 samples.
5 Discussion
CLAS targets the problem space around the inefficiencies in finding relevant 3D objects based on user specifications, which often hinder the design process. Recognizing the importance of facilitating designers in finding inspiration and overcoming creative blocks, we aim to enable efficient usage of existing 3D datasets. We propose an ML-enhanced framework CLAS to enable effective 3D datasets indexing, labeling, and prompt-driven retrieval. Compared to existing methods, CLAS differentiates itself by offering incredible flexibility in the 3D datasets, which operate on and prompts with different levels of details and focus, filling a gap left by generative models and general search engines.
5.1 Limitations
Dealing with potentially much larger datasets with hybrid categories.
In the proof of concept application, we tested CLAS on a dataset of 6,778 chairs. However, various methods can be experimented with to expand the capacity of the current formulation of CLAS. For instance, one may add a classifier model to classify the 3D objects into different categories and forward them to corresponding CLIP models (assuming there are multiple CLIP models for multiple categories). One may also increase the length of descriptions and the dimension of embedding to encourage the CLIP model to learn the complex relation directly, assuming there is enough data.
Enhancing understanding of negative prompts.
The current search function provided by CLAS struggles to understand negative prompts and often does the opposite. For example, if a user states not to retrieve objects with certain properties, the system would actively pick objects with unwanted properties. This occurs primarily as no negative example exists in training for retrieval systems. The text description generated for each image usually highlights what the object has rather than does not have. To fix this, one may change the prompt to generate different descriptions or change searching in the embedding space to substrate the embedding of features that are not wanted. More in-depth study is required as negative prompts are usually not supported by retrieval.
Enhancing support for retrieval of sets of items or scenes.
Currently, the CLAS-powered system only retrieves a single subject in each suggestion. However, it would be beneficial to many designers if the application could understand the relation between objects of different categories and combine them while evaluating the overall design effect. Future developments could focus on integrating different items to form sets or scenes, allowing designers to gain more inspiration and obtain a comprehensive overview of their designs. This function would enable users to explore various combinations of different items and evaluate designs more effectively.
5.2 Social impact
CLAS enables any person or organization to repurpose and/or reuse their existing 3D datasets effectively. CLAS-processed 3D dataset allows users to search its content using natural languages with high accuracy and precision. We hope that exposing numerous references to designers when designing new concepts can assist them in ideation. We demonstrate the usefulness of CLAS in powering the search for 6,778 3D chairs, which can be used by furniture designers. Similarly, CLAS can be applied to different 3D datasets for different purposes. By adjusting the prompt used to generate text descriptions for images of 3D objects, the search function can be tuned to work with different aspects of the objects suiting different use cases. By bridging the gap between user prompts and relevant 3D models, we aspire to enhance the design process and foster creativity within the community.
Acknowledgments and Disclosure of Funding
We sincerely thank the support of our project advisor, Professor Kosa Goucher-Lambert, offered throughout the project. We would also like to thank Kevin Ma in the lab and Daniele Grandi from Autodesk for regular meetings and feedback on our project. It would not be possible for us to complete this project as it is without the help of anyone mentioned above.
References
- Brown [2008] Tim Brown. Design thinking. Harvard Business Review, 86(6):84–92, 2008.
- Bustos et al. [2007] Benjamín Bustos, Daniel A. Keim, Dietmar Saupe, and Tobias Schreck. Content-based 3d object retrieval. IEEE Computer Graphics and Applications, 27, 2007.
- Cen et al. [2023] Jiazhong Cen, Zanwei Zhou, Jiemin Fang, chen yang, Wei Shen, Lingxi Xie, Dongsheng Jiang, XIAOPENG ZHANG, and Qi Tian. Segment anything in 3d with nerfs. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 25971–25990. Curran Associates, Inc., 2023.
- Chan et al. [2021] Eric Chan, Connor Z. Lin, Matthew Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J. Guibas, Jonathan Tremblay, S. Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3d generative adversarial networks. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16102–16112, 2021.
- Chang et al. [2015] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015.
- Deitke et al. [2023] Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects, 2023.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
- Feng et al. [2023] Yifan Feng, Shuyi Ji, Yu-Shen Liu, Shaoyi Du, Qionghai Dai, and Yue Gao. Hypergraph-based multi-modal representation for open-set 3d object retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46:2206–2223, 2023.
- Gao et al. [2020] Zan Gao, Yinming Li, and Shaohua Wan. Exploring deep learning for view-based 3d model retrieval. ACM Trans. Multimedia Comput. Commun. Appl., 16(1), feb 2020. ISSN 1551-6857. doi: 10.1145/3377876.
- Goodfellow et al. [2014] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63:139 – 144, 2014.
- He et al. [2018] Xinwei He, Yang Zhou, Zhichao Zhou, Song Bai, and Xiang Bai. Triplet-center loss for multi-view 3d object retrieval. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1945–1954, 2018.
- Jing et al. [2021] Longlong Jing, Elahe Vahdani, Jiaxing Tan, and Yingli Tian. Cross-modal center loss for 3d cross-modal retrieval. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3141–3150, 2021.
- Li et al. [2023] Chenghao Li, Chaoning Zhang, Atish Waghwase, Lik-Hang Lee, Francois Rameau, Yang Yang, Sung-Ho Bae, and Choong Seon Hong. Generative ai meets 3d: A survey on text-to-3d in aigc era, 2023.
- Liu et al. [2023] Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. arXiv preprint arXiv:2311.07885, 2023.
- Luo et al. [2021] Shitong Luo, Jiaqi Guan, Jianzhu Ma, and Jian Peng. A 3d generative model for structure-based drug design. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 6229–6239. Curran Associates, Inc., 2021.
- Mildenhall et al. [2020] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020.
- Nie et al. [2019] Weizhi Nie, Qi Liang, Anan Liu, Zhendong Mao, and Yangyang Li. Mmjn: Multi-modal joint networks for 3d shape recognition. Proceedings of the 27th ACM International Conference on Multimedia, 2019.
- OpenAI [2022] OpenAI. Introducing chatgpt, 2022.
- Picard et al. [2023] Cyril Picard, Kristen M. Edwards, Anna C. Doris, Brandon Man, Giorgio Giannone, Md Ferdous Alam, and Faez Ahmed. From concept to manufacturing: Evaluating vision-language models for engineering design, 2023.
- Qian et al. [2024] Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, Peter Wonka, Sergey Tulyakov, and Bernard Ghanem. Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors. In The Twelfth International Conference on Learning Representations (ICLR), 2024.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022.
- Skorokhodov et al. [2023] Ivan Skorokhodov, Aliaksandr Siarohin, Yinghao Xu, Jian Ren, Hsin-Ying Lee, Peter Wonka, and Sergey Tulyakov. 3d generation on imagenet. In International Conference on Learning Representations, 2023.
- Su et al. [2015] Hang Su, Subhransu Maji, Evangelos Kalogerakis, and Erik G. Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. 2015 IEEE International Conference on Computer Vision (ICCV), pages 945–953, 2015.
- Su et al. [2020] Yuting Su, Yuqian Li, Weizhi Nie, Dan Song, and Anan Liu. Joint heterogeneous feature learning and distribution alignment for 2d image-based 3d object retrieval. IEEE Transactions on Circuits and Systems for Video Technology, 30:3765–3776, 2020.
- Touvron et al. [2023a] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023a.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b.
- Wei et al. [2020] Xin Wei, Ruixuan Yu, and Jian Sun. View-gcn: View-based graph convolutional network for 3d shape analysis. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1847–1856, 2020.
- Wu et al. [2014] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1912–1920, 2014.
- Wu et al. [2015] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015.
- Zhang et al. [2023] Jianfeng Zhang, Zihang Jiang, Dingdong Yang, Hongyi Xu, Yichun Shi, Guoxian Song, Zhongcong Xu, Xinchao Wang, and Jiashi Feng. Avatargen: A 3d generative model for animatable human avatars. In Leonid Karlinsky, Tomer Michaeli, and Ko Nishino, editors, Computer Vision – ECCV 2022 Workshops, pages 668–685, Cham, 2023. Springer Nature Switzerland. ISBN 978-3-031-25066-8.
- Zhou and Tuzel [2017] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4490–4499, 2017.
- Zhu and Luo [2021] Qihao Zhu and Jianxi Luo. Generative pre-trained transformer for design concept generation: An exploration. Proceedings of the Design Society, 2:1825 – 1834, 2021.
Appendix A Web application


This web application will be made available to collect feedback.
A.1 Implementation details
Front end:
Our website’s design aims to offer an intuitive user interface for designers seeking 3D model design suggestions, and prioritizing search functionality to minimize distractions. The main color theme is light gray, with the central space occupied by a chat window—where users interact most with our website (as shown in Figure 9). At the center of this chat window is our logo, “ML4Design," with a subtitle, “A machine learning system for exploring a large 3D chair model dataset," which explains our website’s purpose. Below the chat window is the search bar, filled with “What kind of chair are you looking for?" in light grey font color to hint the user at our service. An example, “Height adjustable office chair," is immediately provided to guide users on how to engage with our site to encourage interaction. To the right of the search bar is a slider labeled “Number of results." Users can adjust this slider to select the desired number of results, allowing for focused attention on a few suggestions or a broader exploration of up to ten recommended models. The “Visually Focused. Slide bar allows the user to adjust the weighting of image search and text search. Our website can search in the image vector space and the text vector space. For instance, toggling the visual focus value to 0.1 means the image search will weigh 10 percent and the text search will weigh 90 percent of the result. These features enhance the interactive and engaging experience of our website.
Back end:
The back end coordinates the CLIP model, which is hosted online using Huggingface’s endpoint service, and the database, which is hosted online using AWS service. When a user enters a query into the website, the input is processed and sent to the CLIP model endpoint, which returns the IDs of the retrieved 3D chair objects to the back end. The back end then fetches the corresponding models from the database based on the received IDs and forwards them to the front end for display.
Dataset:
Chairs in ShapeNet are stored as objects and images, i.e., every 3D chair object is paired with an image of the chair. We manage this dataset of chairs using Amazon Web Services (AWS) cloud services for optimized storage and accessibility. Image and 3D object files are stored in AWS Simple Storage Service (S3), providing reliable and scalable cloud storage. Metadata, including file names, image links, 3D object download links, and corresponding descriptions, are logged in a MySQL relational database. This database is hosted on AWS Relational Database Service (RDS), ensuring stable and efficient data handling and enhancing data accessibility.
A.2 User Experience
When designers start a new search, the process begins with the search bar, where they enter a prompt such as “Nordic-style chair suitable for reading with fancy patterns" and then select the value for two slide bars, pressing either enter or the search button to search. Upon submitting the prompt, our system quickly retrieves 3D objects, displaying search results within a fraction of a second from a database of 6,778 chair objects. The search results in the chat window are presented in rows, with the user’s avatar displayed above, showing the user’s prompt, followed by the system’s response, “Here are the suggestions," to enhance user interaction (as demonstrated in Figure 10). As users browse through the objects, the image of the object they hover over will slightly enlarge, indicating which chair object they are considering or wish to select. Clicking on a desired model enlarges it for a closer inspection of the details (as shown in Figure 11). To download the chosen 3D object, clicking the download button redirects the user to object downloads. If the user is unsatisfied with the search results, they can click on the “show description" button to view the label/description generated by ChatGPT-4V for each model. This feature allows users to refine their search based on the labels or start a new search by entering a more precise prompt. If the user wants to search for more 3D objects that are similar to one of the result models, simply click on “search similar"; the website will search again using the selected object as a query, thereby providing similar object suggestions. These functions offer a tailored and interactive browsing experience.
On the left side of the website, the top of the navigation bar displays our logo, “ML4Design," followed by three subtitles: “About," “Team," and “Contact." Below these subtitles is a brief description summarizing the content on these pages. The description under the "About" title reads, “This is a CLAS framework system, enabling the search of 3D chair models from a dataset of 6,778 chairs. Try it out by starting a search!" This succinctly describes what our system is and its capabilities. Upon clicking on the About page, users can see a slideshow demonstrating how our system’s CLAS framework operates. Below, the slideshow showcases different prompts, offering search examples using various criteria, including searching with chair geometry, design purpose, or a combination of both.
Back to the Navigation bar, the “Team" page introduces our project members. The “Contact" page communicates our openness to suggestions and opinions, allowing users to leave feedback. This structure ensures that visitors can easily understand the purpose of our system, learn about the team behind it, and engage with us directly. After viewing these pages, by clicking the top left ML4design logo, the user will be guided back to start their search.
Appendix B Interaction between 3D designers and the system
In this section, we discuss how designers can benefit from a search system enabled by CLAS and the resources it provides. First, we briefly introduce the design thinking method proposed by Tim Brown [Brown, 2008]. This method later evolved into the 5-step design thinking approach proposed by IDEO, also known as the Double Diamond. This method outlines the process a designer, such as a product designer or 3D model designer, goes through when designing. The first step is “empathize," where designers must understand people’s problems and identify issues even if they are not immediately apparent to the users. The second step is “define." In this phase, designers must define the core problem and specifically define what they aim to solve using the POG (Product Opportunity Gap) statement. The third step is “ideate," where a CLAS-enabled system becomes particularly valuable. In this phase, designers generate and brainstorm solutions for the identified problem. We discuss this in more detail in the following paragraph. The last two steps are “prototyping" and “testing", where designers bring their solutions into the real world and test their effectiveness through user interviews and other methods. Through several iterations, they refine their designs to arrive at the final product.
For a retrieval system powered by CLAS, the primary goal is to assist 3D model designers during the “ideate" process and the “prototyping" phase. To help understanding, we consider a simple persona and a specific scenario to introduce the entire process the target designers will experience.



Peter is a 3D model designer working at a famous office chair company. His daily job involves proposing new ideas and creating CAD designs for the company’s next product. Typically, he searches online for pictures, reads books, and discusses ideas with teammates to come up with new concepts. However, after years of work, he has started to struggle with generating innovative ideas that can satisfy his manager. In searching for inspirations, a search system enabled by CLAS can be helpful.
This time, his design challenge is to propose a modern minimalist office chair suitable for reading novels, targeting a specific market. He typed “modern minimalist office chair suitable for reading novels" into the system and chose to receive 10 suggestions to maximize the variety of ideas as shown in Figure 12. The system quickly retrieved 10 models within seconds, providing precise 3D designs. Peter was impressed by the third suggestion and clicked on it for more details, as shown in Figure 13. After reading the description and confirming it matched his requirements, he used the “search similar" feature to find more related suggestions, as shown in Figure 14. This time, the second suggestion caught his eye and perfectly aligned with his design needs. He downloaded the model as a reference and worked on it to further refine the design.
This example illustrates how CLAS-enabled search system can assist designers during the “ideate" and “prototyping" phases. CLAS-enabled search system not only helps designers overcome creative blocks but also reduces the time they spend on 3D modeling work.
Appendix C Evaluate effectiveness of prompts for generating descriptions of chairs

| Can you describe the chair’s appearance? |  |
 |
 |
|---|---|---|---|
| Can you describe the chair’s appearance? Try to include as many details as possible. |  |
 |
 |
| Please describe the provided object within 5 sentences. The texture, material, shadowing and color are not important. The first sentence should focus on its intended purpose and the type of user who would be most suited for this design. For the remaining four sentences, please focus on the unique geometry and proportion. |  |
 |
 |
| Please describe the provided object within 5 sentences. Please focus on the SHAPE, PROPORTION, and UNIQUENESS of the object. |  |
 |
 |
Appendix D CLIP architecture
CLIPModel(
(text_model): CLIPTextTransformer(
(embeddings): CLIPTextEmbeddings(
(token_embedding): Embedding(49408, 512)
(position_embedding): Embedding(77, 512)
)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(layer_norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
)
(layer_norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(vision_model): CLIPVisionTransformer(
(embeddings): CLIPVisionEmbeddings(
(patch_embedding): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32), bias=False)
(position_embedding): Embedding(50, 768)
)
(pre_layrnorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(visual_projection): Linear(in_features=768, out_features=512, bias=False)
(text_projection): Linear(in_features=512, out_features=512, bias=False)
)
Appendix E Retrieval results





