Chromatic Learning for Sparse Datasets
Abstract
Learning over sparse, high-dimensional data frequently necessitates the use of specialized methods such as the hashing trick. In this work, we design a highly scalable alternative approach that leverages the low degree of feature co-occurrences present in many practical settings. This approach, which we call Chromatic Learning (CL), obtains a low-dimensional dense feature representation by performing graph coloring over the co-occurrence graph of features—an approach previously used as a runtime performance optimization for GBDT training [1]. This color-based dense representation can be combined with additional dense categorical encoding approaches, e.g., submodular feature compression, to further reduce dimensionality [2]. CL exhibits linear parallelizability and consumes memory linear in the size of the co-occurrence graph. By leveraging the structural properties of the co-occurrence graph, CL can compress sparse datasets, such as KDD Cup 2012, that contain over 50M features down to 1024, using an order of magnitude fewer features than frequency-based truncation and the hashing trick while maintaining the same test error for linear models. This compression further enables the use of deep networks in this wide, sparse setting, where CL similarly has favorable performance compared to existing baselines for budgeted input dimension.
1 Introduction
Extremely sparse, high-dimensional datasets pose significant challenges to resource-efficient learning. In practice, these sparse datasets often arise by combining several disparate data sources, resulting in set-valued features [3, 4, 5]. Representing small subsets from a large set with a binary characteristic vector results in many zero-valued entries. For example, kdd12, a popular user behavior prediction dataset, describes topics a user has liked and other users they follow. The dataset has over 50M features in total but each row has at most 10 non-zero features. Many methods for learning over dense inputs, such as neural networks, remain largely intractable in this non-sequential sparse setting: even when restricting to the most frequent 1M features of kdd12, the Wide and Deep architecture [6] requires over 16GB of GPU memory for a 256-element minibatch, meaning these architectures computationally do not scale to the highly sparse regime. Recent work has developed techniques to learn directly from sparse datasets by encouraging model sparsity, such as Neural Factorization Machines [7], but still requires inputs of fewer than 100K features due to memory constraints on input representation given modern hardware.
In this work, we leverage the structure of many real-world sparse datasets to demonstrate a novel dimensionality reduction technique. We observe that pairs of features rarely co-occur; in kdd12 over 99.9997% of all possible feature pairs never appear in the any example simultaneously. LightGBM [1] uses this observation as a means of improving the runtime performance of training gradient-boosted decision trees (GBDTs). We generalize this approach to obtain accuracy improvements in the low-memory regime for a range of models beyond GBDTs, including linear models and deep networks, which depend on dense inputs. In contrast with the popular hashing trick [8, 9] that uses random hashing to reduce dimensions, this data-dependent approach exploits dataset structure to unlock substantial improvements in accuracy on real-world sparse datasets.
Our method, Chromatic Learning (CL), performs graph coloring to obtain a low-dimensional, dense, categorical feature representation, then applies additional dense reduction methods. First, CL creates a feature co-occurrence graph, where any features that co-occur have an edge connecting them. Since co-occurrence is rare, the resulting graph is sparse and has a low chromatic number. CL assigns each input feature a categorical variable based on its color in the graph coloring, thus representing sparse inputs using fewer categorical dimensions. This reduces memory usage because identically colored categories share the same embedding dimensions. Subsequently, CL applies one of several techniques for compressing dense categorical features, such as frequency-based truncation and submodular feature compression [2]. By enabling the application of these categorical feature compression techniques in sparse settings, CL exhibits substantial reductions in column count with equivalent accuracy compared to baselines with larger column budgets. Furthermore, representations from CL generalize because unseen examples exhibit the same sparse structure and rarely contain features identified with the same color.
We demonstrate the efficacy of CL by learning linear models directly on the compressed space of colors and achieve the same level of test error using fewer features than frequency-based truncation and hashing trick approaches across four benchmark datasets. Additionally, we show that in low-dimensional settings CL improves classification performance for a variety of neural network architectures including Factorization Machines [10], Wide and Deep learning [6], Neural Factorization Machines [7], and DeepFM [11] compared to baseline dimensionality reduction methods including the hashing trick.
2 Related Work
Our contributions relate to several lines of research literature: hashing-based kernels, gradient-boosted trees, and submodular optimization. In this section, we review each.
2.1 Hashing Trick
The hashing trick (HT) initially appeared in [8] as a method for dimensionality reduction. HT is a linear transformation which reduces sparse vectors in a high -dimensional space to a small -dimensional one using two hashes [12], , which approximately preserves linear inner products (i.e., with low variance) and thus reconstructs a linear kernel on the original space .
Recently, HT structural requirements were characterized by the upper bound on the ratio for all inputs [13]: with probability , if and , then the relative error between and is at most (a condition related to preserving inner products through the parallelogram law). A condition points to the generality of HT. For -sparse binary vectors in , ; however, this relies on at least non-zero values for every sparse input. For a bag of words representation, a relative norm error would require sentences of at least words. An intuitive question that we seek to answer in this work is whether there are dimensionality reduction mechanisms that can take advantage of stronger structure than , and even benefit from having few non-zero entries.
2.2 Exclusive Feature Bundling
Gradient-boosted decision trees (GBDTs) are a supervised learning algorithm for learning over a base decision tree (DT) [14]. For a weak hypothesis class of DTs , GBDTs provide a mechanism to learn in the larger class of the additive closure of , where, given a running weighted sum for , a new is fit to the gradient of the loss at at each data point and then added with an appropriately-chosen weight.
While this approach allows search over the larger class , DT training at each iteration is expensive, unless alleviated through specialized techniques like exclusive feature bundling (EFB) in [1]. In that work, the authors notice that DT training can be accelerated by reducing dataset width. EFB builds a co-occurrence graph on the set of categorical features with an edge between two vertices if they ever co-occur (i.e., attain nonzero values in at least one training example). Coloring this graph provides a map from vertices to colors, where vertices sharing a color must be mutually exclusive among all observed training examples. [1] uses an incremental but serial binary adjacency matrix construction for an greedy coloring run time.
Unifying each of these color sets into a single categorical variable reduces DT training cost, improving GBDT training speed overall. Similar dimensionality reduction techniques have been observed in other domains, such as register allocation [15]. However, many estimators require numerical inputs, such as linear models, Gaussian Process classifiers, Factorization Machines, and neural networks. Broader application of EFB is thus limited because one-hot encoding, typically used for pre-processing categorical features, inverts bundling: the one-hot encoding of a bundled feature is equivalent to the concatenation of one-hot encodings for its constituents. In this work, we present a method that adapts the general idea of compression via coloring co-occurrence but is suitable for use in models that require numerical inputs.
2.3 Submodular Optimization for Categorical Feature Compression

Recent work [2] shows that the problem of quantizing a fine categorical variable with values to one with values while preserving as much mutual information with the binary label as possible is monotone submodular.
A set-valued function is monotone if for and submodular if the gain satisfies for and . Such functions admit deterministic -approximate maximization procedures in psuedo-polynomial time [16] and polynomial randomized algorithms [17] for finding .
In a classification setting with a single -valued categorical feature and a binary label , [18] show that the mapping which maximizes is defined by splitters with when . [2] prove that selecting the set is monotone submodular maximization problem .
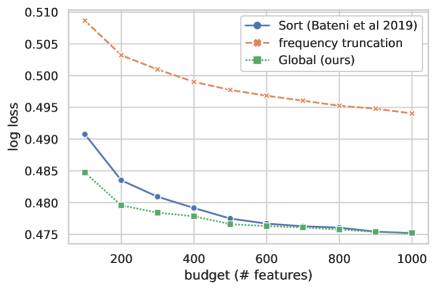
We found direct application of the method unsuccessful. Using label information to featurize results in target leakage [19]. [2] groups features together with similar conditional positive label probability. This artificially reduces label variance within each quanitzed feature cluster and results in overfitting. We verify this on the original dataset used in [2], the Criteo Ad-Click Prediction dataset. To reduce variance from the fitting procedure for evaluation, we train a logistic regression, but note that for such a cheap learner, dimensionality reduction is not necessary for the end classification goal. Figure. 1 shows the training and testing log loss of categorical feature compression applied to estimates of conditional probability made from the training set itself compared to a simple fix, data splitting. With an even split, we estimate conditional probabilities with half of the data, and train on the other half.111On a practical note, this can be done deterministically without requiring another copy of the data by hashing each example and using the first bit of the resulting hash to split training data. We find that splitting is crucial for low test loss and, as expected, training loss is conspicuously low when double-dipping.
A few challenges with the application of [2] remain:
3 Chromatic Learning
We present CL for reducing the dimensionality of sparse datasets for use in models that expect dense, numerical inputs. For simplicity of presentation, we assume dense, continuous features are set aside and focus on reducing the dimensionality of large, sparse vectors with binary features.
CL requires performing a parallelizable reduction over the data to collect the set of features and feature co-occurrences that comprise the graph from Sec. 2.2. After this collection, the graph is colored. On processors, this requires memory and serial run time for examples, where is the maximum degree in .
At this point, each feature in is identified with a color, through a mapping , representing a dense categorical dataset over variables and distinct categorical values across all variables. This enables the application of several categorical encodings. We describe an extension to submodular feature compression and refer to [20] for a description of target encoding.
3.1 Chromatic Representation
Suppose our training set consists of iid examples, . Associate with each its set of active indices , and consider the co-occurrence graph defined by vertices and edges , with generating the edges from the complete graph on its argument, a set of vertices. Given a proper coloring of , , we show that the representation of the data defined by categorical vectors with categorical variables (where has cardinality ) permits learning with low generalization error.
In particular, any Lipschitz-smooth decision function on the original space can be approximated by one that operates on the chromatic representation . By construction this holds for all training examples, but for a test example , two features may have identical colors. In this case, the example must be approximated by an input with one of the colliding features missing.222Given two features mapping to the same color outside the training set, the more popular feature is dropped for our evaluation.
For a given , let be the count of color collisions, i.e., . By smoothness, bounding implies low average discrepancy between the decision function on the two representations (Appendix A). We find that a greedy coloring has an average color collision count less than one on all our sparse benchmark datasets (Tab. 1).
| dataset | avg edges per ex. | avg. degree | colors | CC | avg. nnz | |
|---|---|---|---|---|---|---|
| url | 481 | 2.71M | 74 | 395 | 0.40 | 29 |
| kdda | 682 | 19.31M | 129 | 103 | 0.30 | 36 |
| kddb | 439 | 28.88M | 130 | 79 | 0.21 | 29 |
| kdd12 | 27 | 50.33M | 32 | 22 | 0.09 | 7 |
3.2 Scalable Coloring
The previous section motivates constructing the graph explicitly to obtain a proper coloring. However, construction of can potentially be expensive. We describe how to efficiently construct .
First, we require the union of the edge sets . We process the dataset in parallel chunks on mapper threads. We maintain global sets of edges, where is the average ratio of time it takes to generate edges from each point to the time it takes to add such edges to a hashset. We split the hash space of edges into parts. Each mapper allocates local buffers and, upon processing adds edges from to the local buffer corresponding to each edge’s shard. Once a buffer is filled, the mapper locks the corresponding global set of edges and adds the global set with its local edges.
The expected contention time on each global set’s mutex is constant by the choice of .333In practice, we can choose as the hashing the edge, which is done locally on each mapper, is the most expensive operation. As a result, every edge only requires a constant amount of time to process. Each mapper only requires local working memory, independent of the data, in contrast to tree-merge paradigms such as map-reduce. This hash-join approach can be applied to vertices as well and can be extended by storing aggregate statistics for each vertex, as is necessary for Sec. 3.3.
Once is collected and converted in parallel to an adjacency list representation, is ready for approximate graph coloring, which requires time, where is the maximum degree [21]. Converting to an adjacency list in parallel can be done by mapping over the edge set: first computing the degree of each vertex across threads with atomic increments, and next using a cumulative sum across the degree array to define atomic integral offsets in an adjacency array, which can then be filled in another parallel sweep across .
3.3 Categorical Encodings
With each feature assigned a color, we view the dataset as a categorical input, with colors as categorical variables and the original input features as categorical values. This permits the use of several categorical encodings.
With target encoding (TE), the average label value replaces categories, yielding just numeric features, one for each color. With CL combined with frequency truncation (CL+FT) and a budget , we embed the most frequent categories in dimensions, yielding an embedding layer that creates -sized embeddings with parameters. For neural networks with a first hidden layer of size , using frequency truncation (FT) alone requires the first layer to use parameters, which is prohibitive for all but small .
In addition, we present an extension to submodular-based feature compression (SM). We depart from [2], which recommends compressing to a fixed budget of features by running categorical feature compression on each categorical variable to maximize , sorting results by marginal gain across all features, and using the top selections for the final encoding. This results in suboptimal compression relative to our alternative, as the final sorting stage is based on marginal gains made with respect to each individual solution, so the top- features do not necessarily maintain any optimality properties.
Instead, we maximize the global submodular problem across all colors simultaneously—adding submodular functions over disjoint inputs retains submodularity. This outperforms the sorting heuristic on the original Criteo task proposed by [2] (Fig. 2). Excerpting logarithmic factors, solving one submodular problem of size is faster than multiple of mixed sizes summing to , requiring time [22].
With this final encoding, an example is transformed into one in by taking every nonzero feature in and setting the corresponding feature , which is then one-hot encoded.
4 Evaluation
In this section, we evaluate CL relative to alternative approaches to learning over sparse data by assessing the accuracy recovered by the same learning procedure applied across several reduction procedures at different budgets for the output dimension.
While our approach allows end-to-end parallelism, we found that on real datasets coloring, initialization, and vertex (feature) processing were not the bottlenecks and did not require parallelism. We considered a feature dense if it appeared in over of training rows. Sparse features with multiple associated numerical values were treated identically.444Initial results showed this did not affect performance, so we elided these values. An alternative would track distinct feature values with a separate dictionary, binning for sparse and continuous data.
We evaluate standard sparse benchmark datasets available in Table 2. All four evaluation sets contain millions of sparse binary features, with relatively few active per example. Only the url dataset [23] had numeric features. No additional preprocessing was performed on the retrieved data.555Datasets may be retrieved from https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/.
| dataset | train ex. | test ex. | dense feat. | sparse feat. | avg. nnz | max nnz |
|---|---|---|---|---|---|---|
| url | 1.68M | 0.72M | 134 | 2.71M | 29 | 327 |
| kdda | 8.41M | 0.51M | 0 | 19.31M | 36 | 85 |
| kddb | 19.26M | 0.75M | 2 | 28.88M | 29 | 75 |
| kdd12 | 119.71M | 29.93M | 7 | 50.33M | 7 | 10 |
4.1 Dimensionality Reduction
A comparison of chromatic learning with submodular feature compression (CL+SM) to frequency-based truncation (FT) and hashing trick (HT) shows favorable performance in for linear estimators across a variety of budgets. We performed a single pass over the training data via Vowpal Wabbit with default parameters using, which performs online adaptive gradient descent [9]. Our results illustrate that, to achieve equivalent log loss on the test set, FT requires a magnitude more features and HT requires two orders of magnitude (Fig. 3).

For very large budgets that approach the original dimensionality on the two smaller datasets, FT outperforms CL+SM. In this regime, where nearly the full input dimensionality is preserved, we suspect that the quantization may interfere with model confidence.
4.2 Non-Linear Sparse Learning
With a small budget, CL enables learning more sophisticated classifiers that are otherwise not trainable in limited-memory settings. We assess the performance of several deep learning models given different dimensionality reduction approaches in the highly compressed setting of 1024 features.
We used default parameters specified by the deep learning library [24], but reduced batch size to 256 (from 2048) because of an out-of-memory error on the Nvidia V100 GPUs we were using. The library was originally configured for dense datasets, such as Criteo. We reduced the epoch count to 5 (from 15) to account for the increased number of gradient steps and did not change any other settings.
We find that CL compares favorably in terms of test accuracy with several categorical encoding strategies compared to the FT baseline (Tab. 3). Across all 5 evaluated architectures and all 4 datasets, CL+SM outperforms both HT and FT on every dataset, except for DeepFM with url, where it achieves a test log loss of 0.058, compared to FT’s 0.053. Furthermore, CL+FT presents a simpler alternative to CL+SM which enables using the full dataset and many more features directly, on 2 of the 4 datasets, this improves upon the CL+SM representation with 1024 one-hot features.
| learner | encoder | url | kdda | kddb | kdd12 |
|---|---|---|---|---|---|
| Wide and Deep [6] | FT | 0.046 | 0.326 | 0.314 | 0.172 |
| HT | 0.058 | 0.337 | 0.328 | 0.173 | |
| CL+SM | 0.037 | 0.296 | 0.276 | 0.159 | |
| CL+TE | 0.325 | 0.588 | 0.517 | 0.280 | |
| CL+FT@18 | 0.032 | 0.292 | 0.296 | 0.169 | |
| CL+FT@20 | 0.030 | 0.292 | 0.291 | 0.169 | |
| Logistic Regression | FT | 0.077 | 0.336 | 0.315 | 0.172 |
| HT | 0.087 | 0.359 | 0.330 | 0.175 | |
| CL+SM | 0.048 | 0.308 | 0.283 | 0.159 | |
| CL+TE | 0.198 | 0.571 | 0.423 | 0.204 | |
| Factorization Machines [10] | FT | 0.076 | 0.321 | 0.311 | 0.172 |
| HT | 0.086 | 0.339 | 0.323 | 0.170 | |
| CL+SM | 0.063 | 0.303 | 0.282 | 0.159 | |
| CL+TE | 0.253 | 0.691 | 0.665 | 0.206 | |
| Neural Factorization Machines [7] | FT | 0.045 | 0.320 | 0.309 | 0.172 |
| HT | 0.056 | 0.317 | 0.310 | 0.170 | |
| CL+SM | 0.040 | 0.291 | 0.271 | 0.158 | |
| CL+TE | 0.285 | 0.804 | 0.839 | 0.294 | |
| DeepFM [11] | FT | 0.053 | 0.321 | 0.313 | 0.172 |
| HT | 0.075 | 0.333 | 0.327 | 0.170 | |
| CL+SM | 0.058 | 0.302 | 0.287 | 0.159 | |
| CL+TE | 0.363 | 0.792 | 0.681 | 0.282 |
5 Discussion
In this work, we explore using graph coloring to generate virtual categorical variables that create a dense view of a sparse dataset. The strong empirical performance (Tab. 3) requires explanation, since the variables were created artificially.
The fact that the colors generated by a greedy coloring are effective at representing the dataset on unseen examples is surprising, because new co-occurrences (edges) appear in the test set frequently (Tab. 1). When new edges appear between features of different colors, the chromatic representation is lossless. However, in an adversarial setting, this data-dependent property may not hold. An alternative approach (which our early experiments deemed unnecessary) would choose a random, uniform coloring over instead. If has a low maximum degree , then such a coloring can be sampled by simulating Glauber dynamics with colors [25]. Furthermore, such sampling is internally parallelizable because each update is local to a vertex’s neighborhood. Given any new co-occurrence in the test set between two features , a uniform coloring must have assigned one of colors, limiting a color collision’s probability by choice of regardless of the properties of the data’s distribution. However, greedy coloring required fewer colors than a random one and did not encounter many color collisions in practice.
Second, how can we reconcile the relationship between the discrete graphical structure and a variable training set size , which affects ? Given infinte datasets, would be complete? is a random graph obtained from sampling cliques from a true latent graph of co-occurrences. Since , it suffices for the latent graph to be sparse. However, even if is complete, edges only contribute to collisions to the extent that they appear in test examples. Thus, for the co-occurence graph , the expected count of unseen edges, , provides a better proxy for the propriety of the chromatic representation than . Given a set of training examples, admits a Good-Turing-type [26] upper bound, where . This approach lets us analyze even sparser co-occurrence graphs, such as , the co-occurrence graph with edges that appear at least twice in the training set. and its natural successors may be efficiently constructed by using a rolling set of bloom filters to prune out edges that are only generated by a few training examples [27]. Appendix A elaborates on the trade-off between chromatic representation fidelity and colors used by , and how Good-Turing-type estimators can be used to forecast new edge incidence counts between the two co-occurrence construction approaches.
Besides making learning tractable for estimators that require dense inputs, one interesting implication of CL+SM is that it yields design matrices where, typically, . For small , this opens up sketching approaches to learning whose superlinearity in input dimension otherwise makes them inaccessible to wide, sparse datasets, such as coreset construction for nearest-neighbor queries [28]. Further, in the case of linear models, an design can be represented faithfully as a one by Carathéodory’s Theorem [29], which for small can greatly simplify linear learning (e.g., tuning regularization parameters no longer requires multiple passes over the data).
Beyond the supervised setting, co-occurrence graphs may be appealing from an unsupervised learning perspective: a weighted co-occurrence graph may be used to accelerate graphical model structure learning [30] by pruning the search space of log-linear models during forward selection.
6 Conclusion
We have introduced Chromatic Learning, a method that provides a viable representation of sparse data that enables otherwise-inaccessible learning methods to be applied—such as neural networks—in memory-constrained settings, as shown in Sec. 4.2. This presents several avenues for future work. Optimizing the tradeoff in the data split for submodular feature compression between estimating conditional probabilities and training may result in lower test error. In addition, a balanced coloring scheme may further reduce color collisions, improving accuracy. Finally, the approaches presented in this work illustrate the co-occurrence graph is recoverable in explicit form for many high-dimensional, sparse datasets. This phenomenon may merit its own study.
Broader Impact
This work provides learning methods that scale effectively across many processors while limiting memory. Such methods encourage more organizations to adopt machine learning techniques because of the relative cost of horizontal versus vertical scaling and the overall cost of memory.
Open access to distributed and large-scale methods is important for leveling the playing field between organizations in general that wish to apply learning techniques on such large, realistic sparse data.
This may be positive or negative, depending one’s alignment with the values and goals of each individual organization that may apply chromatic sparse learning. Behind the veil, we believe increased accessibility of large-scale learning through cheaper processing of the same data is net positive.
Acknowledgments and Disclosure of Funding
The authors would like to thank Jon Gjengset, Greg Valiant, Barak Oshri, Arnaud Autef, and Kai Sheng Tai for helpful comments.
References
- Ke et al. [2017] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in neural information processing systems, pages 3146–3154, 2017.
- Bateni et al. [2019] Mohammad Hossein Bateni, Lin Chen, Hossein Esfandiari, Thomas Fu, Vahab S Mirrokni, and Afshin Rostamizadeh. Categorical feature compression via submodular optimization. arXiv preprint arXiv:1904.13389, 2019.
- Haldar et al. [2019] Malay Haldar, Mustafa Abdool, Prashant Ramanathan, Tao Xu, Shulin Yang, Huizhong Duan, Qing Zhang, Nick Barrow-Williams, Bradley C Turnbull, Brendan M Collins, et al. Applying deep learning to airbnb search. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1927–1935, 2019.
- Guo and Berkhahn [2016] Cheng Guo and Felix Berkhahn. Entity embeddings of categorical variables. arXiv preprint arXiv:1604.06737, 2016.
- Covington et al. [2016] Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems, pages 191–198, 2016.
- Cheng et al. [2016] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016.
- He and Chua [2017] Xiangnan He and Tat-Seng Chua. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, pages 355–364, 2017.
- Moody [1989] John Moody. Fast learning in multi-resolution hierarchies. pages 29–39, 1989.
- Agarwal et al. [2014] Alekh Agarwal, Olivier Chapelle, Miroslav Dudík, and John Langford. A reliable effective terascale linear learning system. The Journal of Machine Learning Research, 15(1):1111–1133, 2014.
- Rendle [2010] Steffen Rendle. Factorization machines. In 2010 IEEE International Conference on Data Mining, pages 995–1000. IEEE, 2010.
- Guo et al. [2017] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: a factorization-machine based neural network for ctr prediction. arXiv preprint arXiv:1703.04247, 2017.
- Weinberger et al. [2009] Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg. Feature hashing for large scale multitask learning. pages 1113–1120, 2009.
- Freksen et al. [2018] Casper B Freksen, Lior Kamma, and Kasper Green Larsen. Fully understanding the hashing trick. pages 5389–5399, 2018.
- Friedman [2001] Jerome H Friedman. Greedy function approximation: a gradient boosting machine. Annals of statistics, pages 1189–1232, 2001.
- Chaitin [1982] Gregory J Chaitin. Register allocation & spilling via graph coloring. ACM Sigplan Notices, 17(6):98–101, 1982.
- Minoux [1978] Michel Minoux. Accelerated greedy algorithms for maximizing submodular set functions. In Optimization techniques, pages 234–243. Springer, 1978.
- Mirzasoleiman et al. [2015] Baharan Mirzasoleiman, Ashwinkumar Badanidiyuru, Amin Karbasi, Jan Vondrák, and Andreas Krause. Lazier than lazy greedy. In Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
- Kurkoski and Yagi [2014] Brian M Kurkoski and Hideki Yagi. Quantization of binary-input discrete memoryless channels. IEEE Transactions on Information Theory, 60(8):4544–4552, 2014.
- Prokhorenkova et al. [2018] Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features. In Advances in neural information processing systems, pages 6638–6648, 2018.
- Micci-Barreca [2001] Daniele Micci-Barreca. A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. ACM SIGKDD Explorations Newsletter, 3(1):27–32, 2001.
- Gebremedhin and Manne [2000] Assefaw Hadish Gebremedhin and Fredrik Manne. Scalable parallel graph coloring algorithms. Concurrency: Practice and Experience, 12(12):1131–1146, 2000.
- Balkanski et al. [2019] Eric Balkanski, Aviad Rubinstein, and Yaron Singer. An exponential speedup in parallel running time for submodular maximization without loss in approximation. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 283–302. SIAM, 2019.
- Ma et al. [2009] Justin Ma, Lawrence K Saul, Stefan Savage, and Geoffrey M Voelker. Identifying suspicious urls: an application of large-scale online learning. In Proceedings of the 26th annual international conference on machine learning, pages 681–688, 2009.
- rixwew [2020] rixwew. Factorization machine models in pytorch. https://github.com/rixwew/pytorch-fm, 2020.
- Jerrum [1995] Mark Jerrum. A very simple algorithm for estimating the number of k-colorings of a low-degree graph. Random Structures & Algorithms, 7(2):157–165, 1995.
- Good [1953] Irving J Good. The population frequencies of species and the estimation of population parameters. Biometrika, 40(3-4):237–264, 1953.
- McMahan et al. [2013] H Brendan McMahan, Gary Holt, David Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, et al. Ad click prediction: a view from the trenches. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1222–1230, 2013.
- Inaba et al. [1994] Mary Inaba, Naoki Katoh, and Hiroshi Imai. Applications of weighted voronoi diagrams and randomization to variance-based k-clustering. In Proceedings of the tenth annual symposium on Computational geometry, pages 332–339, 1994.
- Maalouf et al. [2019] Alaa Maalouf, Ibrahim Jubran, and Dan Feldman. Fast and accurate least-mean-squares solvers. In Advances in Neural Information Processing Systems, pages 8305–8316, 2019.
- Petitjean et al. [2013] Francois Petitjean, Geoffrey I. Webb, and Ann E. Nicholson. Scaling log-linear analysis to high-dimensional data. In IEEE International Conference on Data Mining, pages 597–606, 2013.
- [31] David A McAllester and Robert E Schapire. On the convergence rate of good-turing estimators.
- Matula and Beck [1983] David W Matula and Leland L Beck. Smallest-last ordering and clustering and graph coloring algorithms. Journal of the ACM (JACM), 30(3):417–427, 1983.
- Dyer et al. [2006] Martin Dyer, Abraham D Flaxman, Alan M Frieze, and Eric Vigoda. Randomly coloring sparse random graphs with fewer colors than the maximum degree. Random Structures & Algorithms, 29(4):450–465, 2006.
Appendix A Reduced Co-occurrence Graphs
In this section, we elaborate on guarantees for using reduced co-occurrence graphs. Recall that we observe iid samples of vectors , equivalently represented by sets of active indices, with , the edge set of the complete graph on vertices . We assume a sparse setting, i.e., .
Consider the set of vertices and the different co-occurrence graphs constructed over by using edges that appear at least times, . These graphs will satisfy the nesting property . Denote the edge count as well as the leave-one-out edge count . This lets us build reduced co-occurrence graphs containing edges and their leave-one-out analogues and .
Then we may construct Good-Turing-type estimators [31] for the expected count of new edges. With an independent sample from the same distribution as each , our estimator upper bounds the average new edge count in expectation because . When we color a graph with colors by a function , we induce a chromatic representation in the space (to represent absences, suppose without loss of generality, where ). For simplicity, we consider a fixed lossy transformation between and , given by , where . For certain machine learning algorithms, such as neural networks, learning on is much cheaper than on directly. Furthermore, categorical dimensionality reduction techniques may be applied to , whereas they would be unavailable in .
To analyze the fidelity of the space in representing vectors from the sampling distribution, we’ll consider how lossy their one-hot encoding is in the original space. This transformation yields a color collision resolution function that describes achievable values by the chromatic representation. If exhibits no color collisions under , then the collision resolution function . If is the set of active indices in then relates to the color collision count through . Given this setup, we can construct a range of chromatic representations, parameterized by the threshold , with the following representation fidelity property for all .
Theorem 1.
Consider a measure over , a sample of independent observations , whose corresponding sets of active indices satisfy , and fix any . As above, construct the random graph over vertices with the union of edges from complete graphs which appear at least times among all . Independently sample a uniform proper -coloring over . This random coloring induces the collision resolution function that, for any input , returns the same vector but with all higher indices set to zero if for some smaller index with . Define to be the maximum degree of . Then, if , with probability over the choice of the sample, for any -Hamming-Lipschitz ,
where is defined recursively by with and is the count of edges which appear times in the multiset .
Proof.
We first reduce our error to the collision count. Consider a new, independent sample and its associated set of active indices, yielding
| Hamming-Lipschitz | ||||
where is the color collision count with respect to the coloring of , equal to . Next, every edge in contributes to at most 1 color collision, so
where we also apply the tower property. Edges in cannot result in a color collision because is proper. Further, since sampled independently of among all uniform -colorings, for any two vertices , which each have at most neighbors in , there are at least colors which may be assigned, so . Applying this bound above yields
We turn our attention to the last term , which is the expected count of new edges. per and since but both are independent of . Summing such terms over , we have
At this point, combining all of our inequalities, we have shown
To finish, we show that concentrates about its mean by applying McDiarmid’s inequality, recognizing is a function of arguments satisfying . We focus on showing bounded differences by replacing with some , also with , yielding new for . The -th term of the sum changes by , which is bounded by , as are bounded by that size. Next, the remaining -th terms of for , , can only increase by at most one relative to for every edge . If , then regardless. Otherwise, an edge in is only absent from if it appears in at most other sets . Thus, replacing with increases by at most . The alternative formulation for follows by recognizing that it can be computed explicitly as the sum of the count of edges which appear exactly times.∎


Given Thm. 1, a smooth kernel machine over can be approximated by one over the chromatic representation . The flexibility afforded by dealing with sparser graphs allows one to progressively increase as increases: the Good-Turing term provides a data-dependent estimate of unseen edge mass per new example (Fig. 4).
Based on Thm. 1, the number of requisite colors is at least . Unfortunately, in practice tends to be large due to a few vertices with high degree (Fig. 5).
By filtering out a small set of vertices and applying CL to the induced graph , which is with vertices removed, we can reduce the maximum degree of significantly, in turn dropping the color lower bound. Vertices in the hold-out set may be colored with their own unique colors. As a result, the lower bound on the number of colors necessary for fidelity with probability at least 99% based on Thm. 1 is , where is the induced graph resulting from removing from , is its maximum degree, and is the Good-Turing estimator for the average new edge count for unseen test examples on the filtered graph . The Good-Turing estimates remain valid, even with filtering (Fig. 6).
To choose the set which maximally reduces the degree, we require a largest-first order of the vertices, where is a vertex of maximum degree in the induced graph on vertices . Such an ordering may be computed in time linear in the graph size [32].
We remove vertices in largest-first order until the number of removed vertices is at least twice the maximum degree of the remaining graph . This results in a significantly smaller number of requisite colors across all thresholds compared to , even when including the distinct colors used for representing high-degree vertices (Fig. 7).


End-to-end, we can achieve low color collisions, and thus a high-fidelity representation of the original dataset, independent of the distribution of the data, through the chromatic representation by:
-
1.
Choosing an appropriate filtering threshold , given the training set size .
-
2.
Collecting the co-occurrence graph (Sec. 3.2). Using a rolling set of bloom filters allows one to collect the smaller directly [27], by doing a preliminary pass with bloom filters tracking whether each edge appeared at least times, rolling an edge to the next filter if it’s present in the prior one, and then doing another pass over the data, filtering by the last bloom filter.
-
3.
Computing the largest-first ordering of [32].
-
4.
Identifying the smallest prefix of the largest-first ordering which has size at least twice the maximum degree of the subgraph induced by the rest of the ordering.
-
5.
Uniformly sampling a coloring of from at least colors by simulating Glauber dynamics for steps [25] and coloring each vertex in with new colors.
-
6.
Using the color map to perform categorical encoding, through embeddings or submodular feature compression.
The transition dynamics for the Glauber Markov chain are determined by each vertex’s neighborhood. The Markov blanket for each vertex is exactly its neighbors, so MCMC simulation can sample multiple vertices at once. The filtered graph has vertices with average degree . By a birthday paradox calculation, with such simultaneous MCMC updates, we can expect contention on less than a single vertex at any given time, so long as . Although the end-to-end uniform coloring process above uses more colors and computation than the greedy approach in the main text, it has far fewer color collisions (Fig. 8).

More efficient color sampling on random graphs is an active area of research, suggesting that slightly modified Glauber dynamics can mix quickly with fewer colors, even in the chance presence of high-degree vertices [33]. Such work leads to opportunities that obviate the need for the discrete representation of a prefix of largest-first vertices used to lower the maximum degree on the filtered graph .
Appendix B Additional Practical Notes
Note that care must be taken to not resize under a lock to maintain the expected contention time guarantee, which can be achieved by using incremental resizing, i.e., when a hash table is full, create a new one of double the size, and keep the old, moving an edge over from old to new on every insert rather than all at once during the resize. However, we found that this optimization was not critical for efficient performance in practice.
We also note that, while HT did not perform well relative to the heuristic FT in Sec. 4.1, it nonetheless provides a valuable technique for reducing memory usage in settings where a single index over features is unavailable. Frequently, sparse data is encoded in string/value pairs, without a global index. HT points us to a low-memory way of computing such an index. We construct a mapping using an ordinary hash table from 64-bit hashes of feature strings as keys themselves to 32-bit index. This can be done in a preliminary pass, in a parallel fashion, similar to Sec. 3.2, and yields a compact mapping. With such a large hash, collisions are exceedingly rare, with the probability of a collision among a billion features being less than 3%, by a birthday paradox calculation.
Experiment code, configuration, and scripts to download the datasets are available in the GitHub repository sisudata/chromatic-learning.