Characterizing Sociolinguistic Variation in the Competing Vaccination Communities
Abstract
Public health practitioners and policy makers grapple with the challenge of devising effective message-based interventions for debunking public health misinformation in cyber communities. Framing and personalization of the message is one of the key features for devising a persuasive messaging strategy. For an effective health communication, it is imperative to focus on preference-based framing where the preferences of the target sub-community are taken into consideration. To achieve that, it is important to understand and hence characterize the target sub-communities in terms of their social interactions. In the context of health-related misinformation, vaccination remains to be the most prevalent topic of discord. Hence, in this paper, we conduct a sociolinguistic analysis of the two competing vaccination communities on Twitter: pro-vaxxers or individuals who believe in the effectiveness of vaccinations, and anti-vaxxers or individuals who are opposed to vaccinations. Our data analysis show significant linguistic variation between the two communities in terms of their usage of linguistic intensifiers, pronouns, and uncertainty words. Our network-level analysis show significant differences between the two communities in terms of their network density, echo-chamberness, and the EI index. We hypothesize that these sociolinguistic differences can be used as proxies to characterize and understand these communities to devise better message interventions.
Keywords:
vaccination sociolinguistic analysis social network analysis1 Introduction
Health-related misinformation has detrimental effects on the public health. According to researchers, many preventable diseases have re-emerged as a consequence of the drop in immunization rates due to declining trust in vaccines caused by the misinformation on the web [18]. Moreover, distrust in vaccines and health expertise is only expected to increase in the next decade [15].
Debunking public health misinformation requires an effective health communication such as a message-based intervention. For an effective message-based intervention, it is imperative to focus on preference-based framing where the preferences of the target sub-community are taken into consideration. These preferences can be defined over three main aspects: (i) choice of the messenger, (ii) medium of information dissemination, and (iii) content of the message. A message intervention is effective if the message is delivered by a trusted source using an optimal medium of dissemination. In online communities, this translates to identifying the influencers or nodes with high degree centrality in the social network such as shown in [20]. Choosing the content of the message, on the other hand, requires a thorough understanding of how the target community members interact with each other, what language choices they make, and how those language choices reflect their non-negotiable social identities.
Vaccination related misinformation is arguably the most prevalent form of misinformation online. Therefore, for the purposes of this study, we chose to tap into vaccination discourse on Twitter. We study the conversations between two competing groups of Twitter users: (i) those who believe in the effectiveness of vaccinations (pro-vaxxers), and (ii) those who are skeptical (anti-vaxxers). The goal of our study is to characterize the two competing vaccination communities in terms of their sociolinguistic variation. We hypothesize that understanding the interactions of the members of these communities can help devise a better messaging strategy.
Prior work includes the sociolinguistic analysis of Twitter in multilingual societies [16], predicting community membership using word frequencies [7], identifying effective vaccine communication using fuzzy trace theory [4], understanding the evolution of competing views around vaccination at the system level [15], and sociolinguistic study of online echo-chambers [10].
We extend the work by Duseja and Jhamtani in [10] to study vaccination-based communities on Twitter by understanding their differences in usage of linguistic intensifiers, pronouns, and uncertainty words. We also conduct a network-level analysis by computing the network density, EI index, and echo-chamberness for the two target communities.
2 Dataset
To construct our dataset, we employ a three-stage process: (i) we first collect data using a set of hashtags via the Twitter search and the Twitter streaming API; (ii) we use this data to identify the two communities; and (iii) finally, to mitigate survivorship bias [6] and collect more data per individual, we collect timelines of the identified pro- and anti-vaxxers. We describe this process in detail in the following subsections. In the section 2.4, we present the statistics for the final set of data we use to conduct our analyses.
2.1 Data Collection
We first collect a set of known pro-vaccination and anti-vaccination hashtags from our domain knowledge as well as from the background literature [9]. List of these hashtags can be found in Table 1. We use these hashtags to collect Twitter data through the Twitter Streaming API, and augment it with data collected from Twitter Search API. The data consists of Tweets from 29th October 2019 to 12th November 2019. Based on [5], we filter out all tweets that do not include the lemmas “vacc” or “vax” (case insensitive) as part of their tweet text. This is to remove any possible noise in the data.
| Stance | Hashtags |
|---|---|
| Pro-vaccination | VaccinesSaveLives, VaccinesWork, WorldImmunizationWeek, VaxWithMe, HealthForAll, WiW, ThankYouLaura |
| Anti-vaccination | LearnTheRisk, VaccineInjury, VaccineDeath, VaccineDamage, VaccinesCauseAutism, CDCFraud, CDCWhistleBlower, CDCTruth, WakeUpAmerica, HearUs, HealthFreedom |
| Unidentified | Vaccine, Vaccines, Vaccinate, VaccinateUS |
2.2 Community Detection
2.2.1 Label Propagation
To be able to conduct any analysis, it is imperative to identify the competing groups. Assigning a stance to a tweet or a twitter user is a non-trivial problem. Therefore, we use a similar method as described in [22, 23] to find anti-vaxxers and pro-vaxxer groups based on the weighted combination of the valence of their hashtags. In this study, we assume that retweets indicate endorsement.
In the previous studies such as [11], hashtags have been shown to work as realistic proxies for identifying stances among different groups on social media sites. In [22], hashtags are used to identify twitter users who believe in anthropogenic causes of climate change and those who do not. Similarly, in [23], hashtags could also be used to identify polarization in political discourse and how the polarization can change with time.
We use community detection method based on the work done in [23]. We first choose 2 seed hashtags for each of the polarized groups: #VaccinesSaveLives and #VaccinesWork for pro-vaccination and #VaccineInjury and #LearnTheRisk for anti-vaccination. We assign pro-vaccination seeds a valence of +1, and anti-vaccination seeds a valence of -1. 111We randomly sample 100 tweets for each of these hashtags. For pro-vaccination hashtags, of tweets with hashtag #VaccinesSaveLives and of tweets with hashtag #VaccinesWork were related to pro-vaccination. For anti-vaccination hashtags, of tweets with hashtag #LearnTheRisk and of tweets with hashtag #VaccineInjury were related to anti-vaccination. We then create a hashtag co-occurrence graph to identify most co-occurring hashtags with the chosen seeds, and choose those that are semantically similar, as well as the ones that are known to be pro-vax and anti-vax hashtags from the background literature [9, 5, 4] to manually assign a hard valence of +1 and -1. We then use a variant of label propagation algorithm [25] described as Algorithm 1 below to assign valence to each of the remaining hashtags. Similar to [23] the input to the algorithm is a hashtag-to-hashtag co-occurrence graph where hashtags represent nodes, and nodes are connected if they co-occur. The edges are weighted by the frequency of co-occurrence.
2.2.2 Stance Identification
Once we have identified the valence of a set of hashtags, we aggregate hashtags used by each user and find a weighted average of the valence of all hashtags used by a particular user. We label a user as pro-vaxxer, or anti-vaxxer if the weighted average was positive, or negative respectively.
Using the algorithm, 3295 users are identified as pro-vaxxers, 2967 as anti-vaxxers. We randomly sample 100 users that were classified as pro-vaxxers and 100 users that were classified as anti-vaxxers to evaluate the quality of assignment. We find of the labeled pro-vaxxers as pro-vaxxers, and of the labeled anti-vaxxers as anti-vaxxers.
2.3 Timeline Extraction
Both Twitter streaming API and the Twitter search API do not allow the collection of data beyond a certain time period to be able to extract historical tweets. As a consequence, we collect our initial set of tweets within a fixed time window of 15 days. Because our goal was to study how the non-negotiable social identities of users correlated to their linguistic choices on Twitter, windowing the data by time period of 15 days could lead to high survivorship bias where users with higher activity within the chosen days could introduce bias in our analyses by having a higher influence. This is why, we decided to augment our data with timelines of identified individual users. This may not remove the survivorship bias completely, but may help mitigate it.
At the end of timeline extraction, we only retain one copy of each of the tweets. More concretely, to avoid over-inflating the effect of certain tweets that are more viral than the other, we use only unique tweet texts. This is an important preprocessing step to conduct a sociolinguistic frequency-based analysis.
2.4 Data Statistics
At the end, our sociolinguistic analysis is conducted on an overall 6262 Twitter users with an aggregate of 588,110 tweets. This included 3295 pro-vaxxers with 310461 pro-vaccination tweets, and 2967 anti-vaxxers with 277649 anti-vaccination tweets, making it an average of about 94 tweets per user for both pro- and anti-vaxxers.
3 Methodology
We conduct two types of analyses to characterize the two competing groups: linguistic analysis and network analysis.
3.1 Linguistic Analysis
We test three linguistic variables which are described as follows.
3.1.1 Linguistic Intensification
We first study the differences in the usage of linguistic intensifiers. Intensifiers are words, or phrases that strengthen the meaning of other expressions and show emphasis. Examples include amplifiers (eg.“really”, “very”), usage of swear words, general interjections (eg. “wow”, “omg”), and exclamations. Intensifiers are commonly used to bolster argumentation to persuade the target audience. We hypothesize that users that are pro-vaxxers use more intensifiers. This is because pro-vaxxers have been found to frequently debunk anti-vaxxers’ claims with scientific evidence [2]. Therefore, they would seem to take the corrective approach intended to persuade anti-vaxxers, hence using more intensifiers.
3.1.2 Pronominal Usage
Pronouns play a key role in models of narrative and discourse processing [12]. Because most of the vaccine-related misinformation is based on personal anecdotes, we would expect pronominal usage to be high amongst anti-vaxxers. To test this, we identify various different categories of pronouns (eg. “subject pronouns”, “object pronouns”, “third-person pronouns”), a complete list of which can be found in Table 2.
3.1.3 Use of Uncertainty Words
Previous research [10] has found the use of uncertainty words (eg. “might”, “likely”) as a negative linguistic correlate of echo-chamberness. This is based on the hypothesis that because users not in echo-chambers are exposed to alternate views, they may be less certain of their ideas. We adopted the list of uncertainty words from [10] to test if that is true i.e. if there is a significant difference in the use of uncertainty words across the two vaccination communities.
| Lexical Category | Lexicon (vocabulary) |
|---|---|
| Intensifiers | |
| Amplifiers | amazingly, -ass, astoundingly, awful, bare, bloody, crazy, dead, dreadfully, colossally, especially, exceptionally, excessively, extremely, extraordinary, fantastically, frightfully, fucking, fully, hella, holy, incredibly, insanely, mad, mightily, moderately, most, outrageously, phenomenally, precious, quite, radically, rather, real, really, remarkably, ridiculously, right, sick, so, somewhat, strikingly, super,supremely, surpassingly, terribly, terrifically, too, totally, uncommonly, unusually, veritable, very, wicked |
| Swear words | fu*****, etc. A complete list of words can be found on Wikipedia’s English swear words page []. |
| General interjections | wow, hooray, ouch, uh oh, ew, aw, omg |
| Exclamation | !* |
| Uncertainty words | may, might, perhaps, maybe/may-be, potentially, possibly, likely, probably, probable, possible, think, seem, believe, presume, would be, could be |
| Pronouns | |
| Demonstrative | this, that, these, those |
| Possessive | ours, mine, yours, theirs, his, hers |
| Quantifier | few, several, some, all, much, one, fewer, many, more, most, plenty, less, little, enough |
| Reflexive | myself, herself, ourselves, themselves, yourself, himself, itself, yourselves |
| First-Person | I, we, us, me, myself, my, mine, our, ours |
| Second-Person | you, yours, you’re, your |
| Third-Person | he, she, theirs, themselves, them, her, him, his, himself, hers, herself, it, its, itself, they |
| Gendered third-person | he, she, her, him, his, himself, hers, herself |
| Subject | I, she, he, they, we, you, it |
| Object | me, us, them, him, you, her, it |
| IT | it, it’s, its, itself |
3.2 Network Analysis
We also compute three network-level measures to characterize the network structure of the two target communities. We describe each of these measures in detail in their respective sections below.
3.2.1 Network Density
3.2.2 EI Index
The EI (External-Internal) index was developed by Krackhardt and Stern in [17] as a measure of dominance of external over internal ties. More concretely, assuming two groups based on some attribute, one group defined as internal and the other as external, the EI index is computed as follows:
| (1) |
where EL represents the number of external links and IL represents the number of internal links. EI index is a useful proxy for identifying echo-chamberness.
3.2.3 Echo-chamberness
To compare the echo-chamber effect in the two vaccination groups, we also directly compute the echo-chamberness of the two communities. We use the following definition of echo-chamberness: For a given network , the echo-chamberness (EC) is defined as:
| (2) |
where r is the reciprocity [24] of graph G or the ratio of bi-directional edges and the total number of edges in G, and d is the density of graph G.
3.3 Evaluation
3.3.1 Test Statistics
For each sub-category of the linguistic features in Table 2, we use two test statistics to compute the difference between the two groups. These are as follows:
-
1.
The overall proportion of tweets that contain any of the words for a given lexical category ()
-
2.
The mean of the proportions of tweets of individual users containing any of the words for a given lexical category ()
We use these test statistics to compute (i) the difference of proportions between the two groups, and (ii) the difference of means of proportions between the two groups.
The first test statistic regards each tweet independently. We use the second test statistic to account for differences in the linguistic choices of individual users.
3.3.2 Statistical Significance:
For the first statistic, we use a two-sample z-test for the difference of proportions (). For the second statistic, we use an independent z-test for the difference in means (). For all the tests, our .
4 Results and Discussion
4.1 Linguistic Analysis
The summary of our linguistic analysis across all the lexical categories can be found in Table 3.
| Lexical Category | (Pro) | (Anti) | z-score () | p-value () | (Pro) | (Anti) | z-score () | p-value () |
| Intensifiers | 45.90% | 50.60% | -36.25 | 11.63% | 14.96% | -6.59 | ||
| Amplifiers | 31.40% | 37.10% | -45.32 | 10.91% | 13.66% | -5.66 | ||
| Swear words | 4.0% | 5.60% | -27.40 | .57% | 1.04% | -3.26 | ||
| General interjections | 17.50% | 16.70% | 7.89 | .43% | .58% | -1.37 | .17 | |
| Exclamation | 1.10% | 2.20% | -34.17 | - | - | - | - | |
| Uncertainty words | 5.7% | 7.0% | -20.84 | 4.12% | 5.07% | -3.23 | .001 | |
| Pronouns | 55.80% | 62.20% | -49.68 | 55.94% | 61.83% | -7.38 | ||
| Demonstrative | 17.63% | 20.91% | -31.84 | 18.61% | 21.73% | -5.20 | ||
| Posessive | 1.30% | 1.60% | -9.39 | 1.49% | 1.67% | -.92 | .36 | |
| Quantifier | 15.3% | 16.0% | -6.70 | 15.20% | 16.83% | -3.06 | .002 | |
| Reflexive | .80% | .86% | -2.26 | .02 | 1.49% | .92% | 3.43 | |
| First-Person | 21.20% | 23.44% | -20.67 | 20.96% | 22.54% | -2.45 | .01 | |
| Second-Person | 16.40% | 18.5% | -20.69 | 15.22% | 16.47% | -2.23 | .03 | |
| Third-Person | 14.8% | 20.9% | -60.51 | 14.29% | 20.84% | -11.74 | ||
| Gendered third-person | 3.60% | 5.60% | -36.84 | 3.15% | 4.92% | -5.96 | ||
| Subject | 28.90% | 37.50% | -69.53 | 27.64% | 35.55% | -10.89 | ||
| Object | 21.64% | 26.90% | -46.77 | 19.66% | 24.51% | -7.91 | ||
| IT | 8.30% | 10.29% | -26.16 | 8.21% | 9.44% | -3.07 | .002 |
4.1.1 Linguistic Intensification
We observe that our initial hypothesis that pro-vaxxers use more intensifiers is false. What we find is that anti-vaxxers employ significantly more linguistic intensifiers than pro-vaxxers. This holds true across all the sub-categories of intensifiers with the exception of the use of general interjections where the difference is marginal and not significant. While intensifiers are used as a persuasion technique, the observed results can possibly be explained by an old theory in speech communication that correlates the use of intensifiers with perceived powerlessness [3, 14]. Intensifiers and hedges are used more generally by people with low social power [3]. Because anti-vaxxers are a minority group, it is a possible argument one could make as perceived minority leads to perceived low social power which could lead to high linguistic intensification.
4.1.2 Pronominal Usage
From our analyses, we find that with the exception of reflexive and possessive pronouns, anti-vaxxers show a significantly high pronominal usage across all the categories. This difference is prominent specifically for third-person, gendered third-person, subject, and object pronouns. In sociolinguistic literature, pronouns are predominantly linked with narrative discourse structure. For example object pronouns such as “him” or “his” and gendered third-person pronouns “he” or “she” have a referential property, where their semantic interpretation is dependent on what they are referring to. Anaphoric references define objects already defined in the discourse [26] which creates a better narrative viewpoint. Like intensifiers, pronouns are also found to be used heavily by people with lower levels of perceived power [19].
4.1.3 Use of Uncertainty Words
In terms of the use of uncertainty words, while we do find a significant difference between the two communities, we do not observe the same effect observed in the background literature [10]. In fact, we find a counter-intuitive result i.e. that the anti-vaccination community with higher echo-chamberness (as observed in section 4.2) tends to use more uncertain words than pro-vaccination community. This is an evidence that not all echo-chamber communities show certainty in their tweets as observed in [10].
4.2 Network Analysis

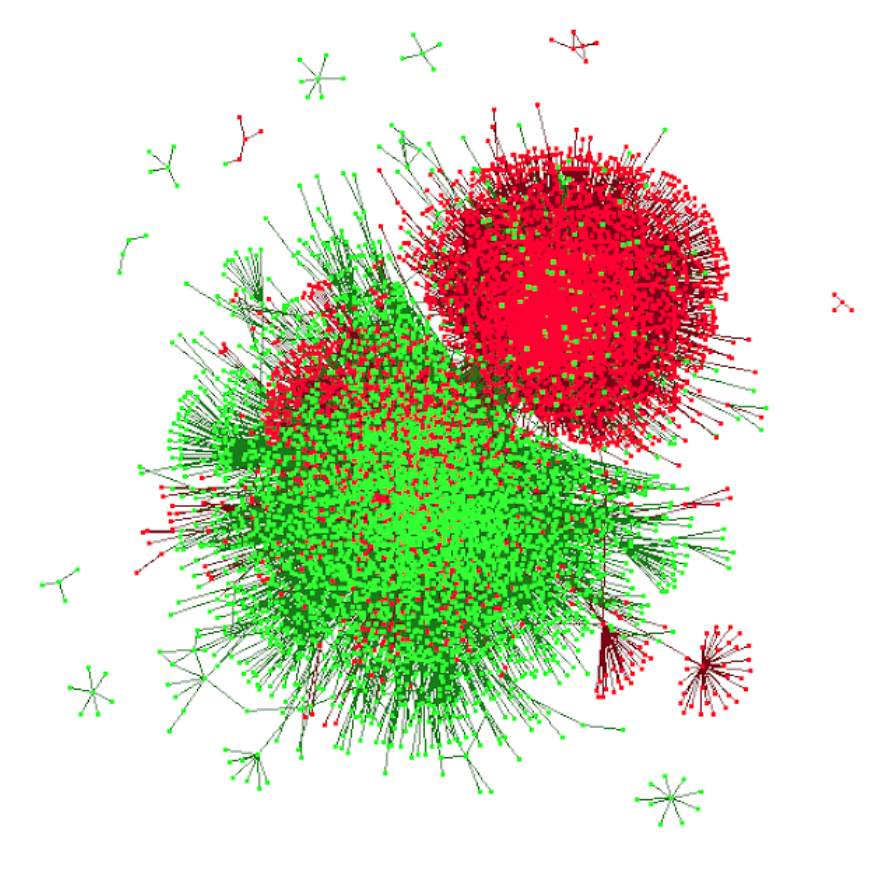

Along with the linguistic analysis, we also compute various network level measures on the communication networks of the two target groups. These measures include the network density, EI index, and echo-chamberness. We also visualize the three communication networks as shown in figure 1. All the network-based measures, and graphs were computed using ORA-PRO [1, 8].
We observe that anti-vaccination communities tend to have higher network density, negative EI indices with higher absolute values, and higher echo-chamberness across all the communication networks. On the other hand, the EI index for the pro-vaccination communities is positive for mention and retweet networks displaying dominance of external ties. A summary of network-level measures can be found in Table 4. Interestingly from the network graphs we can observe that on some level the two competing groups are almost detached. This is specifically visible in the retweet network graph in Figure 1.
| Measure | Mention Network | Retweet Network | Reply Network |
|---|---|---|---|
| Network Density | 1.7e-5 | 1.1e-5 | 3.1e-6 |
| Network Density (Pro) | 1.5e-5 | 1.0e-5 | 2.2e-6 |
| Network Density (Anti) | 4.1e-5 | 3.2e-5 | 6.3e-6 |
| EI Index (Pro) | 0.025 | 0.023 | -0.167 |
| EI Index (Anti) | -0.276 | -0.432 | -0.572 |
| Echo-chamberness (Pro) | 0.0064334823 | 0.005364444 | 0.0043579605 |
| Echo-chamberness (Anti) | 0.009268834 | 0.007850341 | 0.005905038 |
5 Limitations and Future work
One minor limitation of our study is that in the data collection phase, the number of collected hashtags for the two communities was unbalanced. This could potentially have introduced some bias in our downstream tasks such as label propagation. A possible limitation pertaining to the network analysis is that we do not normalize our EI indices to avoid losing precision. This, however gives us stronger results as while the nodes in the anti-vaccination network are lower than the pro-vaccination network, the EI index for anti-vaxxers is more negative than pro-vaxxers. Finally, all our analyses are correlational in nature, and do not depict causation. This remains to be one of the important future directions to test whether a certain network characteristic causes linguistic changes in the network or vice-versa.
6 Conclusion
In this paper, we have carried out a comparison between two online competing vaccination communities: pro-vaxxers and anti-vaxxers. We have studied these communities in relation to their linguistic and social interactions. We conduct two kinds of analyses: (i) linguistic, and (ii) network-level. We observe anti-vaxxers to display more frequent usage of linguistic intensification, pronouns, and uncertainty words. We also observe significant differences in the network structures of the two communities with anti-vaxxers displaying higher echo-chamberness. These results suggest that anti-vaxxers form a tighter community prone to the presentations of anecdotes, and so may be more resistant to factual knowledge from outside the group.
Acknowledgement
This work was partially supported by a fellowship from Carnegie Mellon University’s Center for Machine Learning and Health to Shahan A. Memon. We also acknowledge Lori Levin (LTI,CMU), Bhiksha Raj (LTI,CMU), Rita Singh (LTI,CMU), Matthew Babcock (ISR,CMU), Ingmar Weber (QCRI, HBKU), and members of CMU’s Center for Computational Analysis of Social and Organizational Systems (CASOS) for insightful comments and discussions.
References
- [1] Altman, N., Carley, K.M., Reminga, J.: Ora user’s guide 2018. Carnegie-Mellon Univ. Pittsburgh PA Inst of Software Research International, Tech. Rep. (2018)
- [2] Boser, B.L.: Mothers’ anti-vax to pro-vax conversions. Recovering Argument p. 21 (2018)
- [3] Bradac, J.J., Mulac, A., Thompson, S.A.: Men’s and women’s use of intensifiers and hedges in problem-solving interaction: Molar and molecular analyses. Research on Language and Social Interaction 28(2), 93–116 (1995)
- [4] Broniatowski, D.A., Hilyard, K.M., Dredze, M.: Effective vaccine communication during the disneyland measles outbreak. Vaccine 34(28), 3225–3228 (2016)
- [5] Broniatowski, D.A., Jamison, A.M., Qi, S., AlKulaib, L., Chen, T., Benton, A., Quinn, S.C., Dredze, M.: Weaponized health communication: Twitter bots and russian trolls amplify the vaccine debate. American journal of public health 108(10), 1378–1384 (2018)
- [6] Brown, S.J., Goetzmann, W., Ibbotson, R.G., Ross, S.A.: Survivorship bias in performance studies. The Review of Financial Studies 5(4), 553–580 (1992)
- [7] Bryden, J., Funk, S., Jansen, V.A.: Word usage mirrors community structure in the online social network twitter. EPJ Data Science 2(1), 3 (2013)
- [8] Carley, K.M.: Ora: A toolkit for dynamic network analysis and visualization. (2017)
- [9] Dredze, M., Wood-Doughty, Z., Quinn, S.C., Broniatowski, D.A.: Vaccine opponents’ use of twitter during the 2016 us presidential election: Implications for practice and policy. Vaccine 35(36), 4670–4672 (2017)
- [10] Duseja, N., Jhamtani, H.: A sociolinguistic study of online echo chambers on twitter. In: Proceedings of the Third Workshop on Natural Language Processing and Computational Social Science. pp. 78–83 (2019)
- [11] Evans, A.: Stance and identity in twitter hashtags. Language@ internet 13(1) (2016)
- [12] Gibbons, A., Macrae, A.: Pronouns in literature: Positions and perspectives in language. Springer (2018)
- [13] Giuffre, K.: Cultural production in networks (2015)
- [14] Hosman, L.A.: The evaluative consequences of hedges, hesitations, and intensifies: Powerful and powerless speech styles. Human communication research 15(3), 383–406 (1989)
- [15] Johnson, N.F., Velásquez, N., Restrepo, N.J., Leahy, R., Gabriel, N., El Oud, S., Zheng, M., Manrique, P., Wuchty, S., Lupu, Y.: The online competition between pro-and anti-vaccination views. Nature pp. 1–4 (2020)
- [16] Kim, S., Weber, I., Wei, L., Oh, A.: Sociolinguistic analysis of twitter in multilingual societies. In: Proceedings of the 25th ACM conference on Hypertext and social media. pp. 243–248 (2014)
- [17] Krackhardt, D., Stern, R.N.: Informal networks and organizational crises: An experimental simulation. Social psychology quarterly pp. 123–140 (1988)
- [18] Levy, G.: Public confidence in vaccines sags, new report finds. url=https://www.usnews.com/news/health-care-news/articles/2018-05-21/public-confidence-in-vaccines-sags-new-report-finds
- [19] Nerbonne, J.: The secret life of pronouns. what our words say about us. Literary and Linguistic Computing 29(1), 139–142 (2014)
- [20] Sanawi, J.B., Samani, M.C., Taibi, M.: # vaccination: Identifying influencers in the vaccination discussion on twitter through social network visualisation. International Journal of Business and Society 18(S4), 718–726 (2017)
- [21] Smelser, N.J., Baltes, P.B., et al.: International encyclopedia of the social & behavioral sciences, vol. 11. Elsevier Amsterdam (2001)
- [22] Tyagi, A., Babcock, M., Carley, K.M., Sicker, D.C.: Polarizing tweets on climate change. To appear in International Conference SBP-BRiMS (2020)
- [23] Tyagi, A., Field, A., Lathwal, P., Tsvetkov, Y., Carley, K.M.: A computational analysis of polarization on indian and pakistani social media (2020)
- [24] Wasserman, S., Faust, K., et al.: Social network analysis: Methods and applications, vol. 8. Cambridge university press (1994)
- [25] Xiaojin, Z., Zoubin, G.: Learning from labeled and unlabeled data with label propagation. Tech. Rep., Technical Report CMU-CALD-02–107, Carnegie Mellon University (2002)
- [26] Young, L., Harrison, C.: Systemic functional linguistics and critical discourse analysis: Studies in social change. A&C Black (2004)