Characterize arbitrary quantum networks in the noisy intermediate-scale quantum era
Abstract
Quantum networks are of high interest nowadays. In short, it describes the distribution of quantum sources represented by edges to different parties represented by nodes in the network. Bundles of tools have been developed recently to characterize quantum states from the network in the ideal case. However, features of quantum networks in the noisy intermediate-scale quantum (NISQ) era invalidate most of them and call for feasible tools. By utilizing purity, covariance and topology of quantum networks, we provide a systematic approach to tackle with arbitrary quantum networks in the NISQ era, which can be noisy, intermediate-scale, random and sparse. One application of our method is to witness the progress of essential elements in quantum networks, like the quality of multipartite entangled sources and quantum memory.
pacs:
03.65.Ta, 03.65.UdNumerous works have advertised from different scales the advent of quantum network technology, as small as the storage of a single entangled pair [1], and as broad as quantum internet [2, 3, 4]. Apart from the theoretical importance, quantum networks appear naturally in practice, especially in quantum key distribution [5, 6], quantum network metrology [7, 8, 9] and quantum distributed computation [10]. A recent move is into the characterization of different quantum correlations arising from quantum networks [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23].
A quantum network can be abstracted as a hypergraph, where each node stands for a local lab and each hyperedge represents a quantum source that distributes particles only to labs associated with the corresponding nodes, see Fig. 1 for examples. A correlated quantum network (CQN) allows the pre-shared classical protocol, i.e., global classical correlation [12], an independent quantum network (IQN) allows not. Despite recent progress [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23], the study of quantum network states is still in its cradle. Past research has focused mainly on IQN, bundles of tools [17, 24, 18, 19, 25] have been added into the current toolbox. However, they become incapable to detect the underlying structure of CQN even when only a small amount of global classical correlation appears. In comparison, few methods [11, 12, 11, 13, 14, 15] exist for CQN, which either work only for special kinds of states like symmetric states [13, 15, 14], limited quantum networks like the triangle network [11, 12] or complete -partite network with -partite sources [26, 27, 28]. However, an undeniable fact is that we progress toward the noisy intermediate-scale quantum (NISQ) era, as pointed out sagaciously by Preskill [29]. The global classical correlation exists then frequently in real applications, which can even elicit from the flap of a butterfly’s wings in Brazil [30].
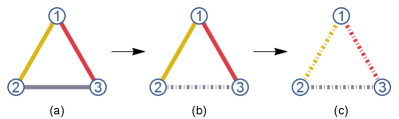
Apart from the unavoidable global noise, quantum networks in the NISQ era share at least other three features: intermediate-scale, random, and sparse. Though the size of quantum networks in the NISQ era is limited, it can be not small, considering that IBM has unveiled a quantum chip with qubits [31] already. The randomness in the network [32] can originate from the random establishment of quantum links with quantum repeaters [33, 34], and also the decoherence of established links as considered in waiting time [35]. Degeneration of a triangle quantum network until a classical network is illustrated in Fig. 1. Since genuine multipartite entanglement is hard to prepare and to maintain [36, 37], the realistic quantum networks will be sparse. Tools for quantum networks in the NISQ era regarding those features are still missing.
In this work, we characterize correlated quantum networks in the NISQ era by employing the purity of the state and covariance of the measured data. Those methods are operational in the sense that only the available experiment data is employed, without knowing the exact underlying quantum state. Purity of the network state plays an essential role here, as the classical correlation in a state can be captured by its purity. Pretty recent research shows that the purity of a multipartite state can be evaluated efficiently with only local operations [38, 39], which fits the network scenario. The methods developed here are feasible for noisy intermediate-scale or big quantum networks. Interestingly, they work even for a collection of networks with different kinds of topology, which can cover the random network models, especially the ones with probabilistic genuine bipartite sources as in the consideration of quantum repeaters [33]. Thus, they answer one corresponding open question in the review paper on nonlocality in quantum networks [22]. We can also apply our methods to a part of the network instead of the whole, which fits the sparse structure of the network in the NISQ era and reduces the difficulty of computation.
GHZ state under decoherence.— As a warming-up exercise we discuss the Greenberger-Horne-Zeilinger (GHZ) state of qubits under decoherence,
| (1) |
where , and describes the degree of decoherence. Despite its simplicity, this example allows us to introduce our main ideas.
If all the parties implement the same measurement , then two possible combinations of outcomes happen equally with probability , i.e., either all of the outcomes are , or all of them are . To simulate this statistical behaviour without genuine -partite entanglement, the state for simulation can only be , since no other string appear as a combination of outcomes. Such a simulation invalidates known methods with only statistical data [19, 26, 27, 28]. It costs at least one classical bit of randomness, as the Shannon entropy or the Von Neumann entropy of is . However, the Von Neumann entropy of the state is , which is strictly less than for . This means that we cannot simulate the statistical behaviour and the Von Neumann entropy of simultaneously by a quantum network with at most -partite sources.
The Von Neumann entropy is one way to measure the purity of the state, capturing partially the classical correlations in the state. To continue, we examine firstly different measures of purity and choose a suitable one for our following methods. For a given state in the -dimensional space, the common measures of its purity [40, 41, 42] are Rényi -purity , which converges to the Von Neumann entropy as tends to , and linear entropy purity . Through the whole text, we take to quantify the purity, which determines Rényi 2-purity and linear entropy purity. The advantage of over other quantifiers, like the Von Neumann entropy, is that it fits the covariance of experimental data well in our approach, as both of them contain the information of . As for the estimation of purity of a multipartite state with different measures, it can be done efficiently with only local operations [38, 39], which are feasible in the network scenario.
Noisy quantum networks.— Noise is unavoidable for the quantum network states in the NISQ era, either the local noise or the global one. Quantum networks with different noise models can all be classified as CQNs. Firstly, we develop the covariance matrix decomposition method for CQN, where a key step is to separate the part related to global classical correlation out in the whole covariance matrix. For a given hypergraph and a state from CQN of , the state can be decomposed as
| (2) |
where with and is the global classical correlation, is a local channel for the -th party, is an entangled state distributed from the source labeled by the hyperedge .
For simplicity, we assume each party has only one measurement, and denote the measurement for the -th party. Then we introduce three kinds of covariance matrices, , and , whose elements in the -th row and -th column are , and , respectively, where
| (3) |
The covariance matrix is the one that can be observed directly in experiments. The covariance matrices are hidden in the experimental data when we assume that the randomness of the sampling is inaccessible. The covariance matrix can be viewed as a classical covariance matrix, since it is only about the distribution of classical data . Throughout the whole paper, we only consider the dichotomic measurements with outcomes . A pivotal observation is that the classical covariance matrix can be separated out from the observed one perfectly, i.e.,
| (4) |
whose proof can be found in Sec. A in Supplemental Material (SM) [43]. Since are about network states from IQN, the existing method in Ref. [19] can be employed to impose constraints on them. However, if there is no limitation of , the observed covariance matrix can still have arbitrary relation with the network topology . As it turns out, the purity of the state implies a nontrivial condition on , leading to a semi-definite programming (SDP) to determine whether a state can arise from CQN with a given topology.
Observation 1.
For a given state from the CQN with the network topology , measurements , which result in the covariance matrix , it holds that
| (5) |
where is the maximal eigenvalue of , , is the -th diagonal term of , with to be the projection onto -th row.
To apply the criterion in this observation, we need firstly estimate the purity of the state , and then implement the measurements and obtain the covariance matrix from the experimental data. It should work for arbitrary network topology with around nodes in practice. This observation can be understood as follows. The term corresponds to , as each has a similar decomposition [19]. The variable plays the role of and inherits all its constraints. A detailed proof is provided in Sec. B in SM [43]. The application of Observation 1 to the triangle quantum network is illustrated in Fig. 2. We remark that the rank of the state determines the Rényi- purity which reads . By considering the rank also, we can set as a tighter bound.
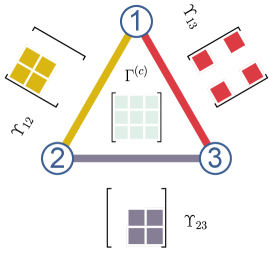
Revisit GHZ state under decoherence.— We take the state in Eq. (1) and measurements for all parties as an example to illustrate Observation 1. The covariance matrix of contains always only as its elements.
If is from the statistics of a state in a network without -partite sources, then should satisfy the decomposition in Eq. (1), where is the hypergraph with nodes and includes all subsets with elements as hyperedges. Notice that, the rank of is , and , which implies that each should be proportional to .
Since always contains element as exemplified in Fig. 2, we have , for all . Consequently, and . The rank of the state is however and the purity is . Thus, happens only for , in which case is fully separable. This leads to the conclusion that can arise from a network without -partite sources if and only if . Our criterion is therefore tight.
Intermediate-scale networks.— The advantage of covariance matrix decomposition is that it requires only experimental data of few measurements and information of purity. However, the computation becomes heavy for intermediate-scale networks with around nodes, due to the complexity of SDP in the method.
Here we propose another approach to solve this issue, which can even take care of the randomness feature in the NISQ era. Firstly, we introduce the fact that for a semidefinite matrix whose rank is , and take the triangle network as an example. According to the decomposition of in Observation 1, , where the last inequality is from the block structures of ’s and as in Fig. 2. Consequently, by applying the first equality in Eq. (1) again. For the general network topology with and to be the maximal size of hyperedges in , we have
| (6) |
In practice, we can replace in Eq. (6) by any estimation of it, like the analytical upper bound in Eq. (1) results from series of relaxations [43]. A good estimation plays a vital role in the efficiency of the inequality here, same as in the criterion in Observation 1. Nowadays, it is still hard to prepare genuine multiparite entangled states for a large system [36]. Thus, is usually much smaller than in Eq. (6), i.e., small sources in a big network.
Random networks.— The establishment of genuine multipartite entanglement among remote labs is usually random as in the scenario of quantum repeaters [33]. The established one can still degenerate to less-partite ones randomly due to decoherence. This urges us to introduce the concept of random network, where the genuine multipartite entanglement in each source exists probabilistically. As an example, we consider a genuine tripartite entangled source, whose degeneration is captured by the triangle network in Fig. 2, assumed to be with probability . The network state has then the decomposition , where is the original tripartite state and other ’s are independent triangle network states, and . This leads to the covariance matrix , where ’s are the covariance matrices for ’s, and is the classical one. As argued before, has the decomposition as in Fig. 2, which implies that . Consequently,
| (7) |
where the last inequality is from the fact that any variance should be no more than as the outcomes of the measurements are .
This result is the very first characterization of random quantum network states, which can be generalized to arbitrary random quantum networks as follows.
Observation 2.
Assume is a state from the random quantum network with parties and genuine -partite sources on average for each . If is a covariance matrix of measurements whose outcomes are , then
| such that | ||||
| (8) |
The proof is in Sec. C in SM [43]. Equation (2) is one inequality including a linear programming, which can be verified efficiently even for large random networks.
The criterion in Observation 2 is device-independent, in the sense that it works without any assumption of the underlying quantum system and measurements. Besides, it does not depend on the exact underlying network topology, but the parameters . Such results can also be used to benchmark the quality of genuine multipartite entanglement, which degenerates randomly due to decoherence. In such a case, parameters should be functions of time. Observation 2 answers an open question in Ref. [22] also, i.e., how to characterize the mixture of quantum networks with different kinds of topology.
Sparse networks.— In a reasonable prospect, the quantum network should be sparse in the near future. Even though we have a relatively large quantum network, the size and the amount of quantum sources would be relatively small as illustrated in Fig. 3. The exact numbers depend on the progress of quantum technologies.
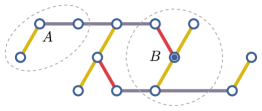
For a given state from a large network , a necessary condition is that can arise from the network with the induced subgraph on , where is an arbitrary subset of and . Then we could apply Observations 1 and 2 for each reduced state . The sparsity of the network can reduce the complexity of this approach, as we do not need too many relatively small sub-networks to cover the original one. Correspondingly, we have to estimate the classical covariance matrix for each . Since as a reduced state could be much mixed than the original state , the purity of could lead to too loose constraints in Observation 1. A key observation here is that for any , with to be the classical covariance matrix corresponding to the original network state . More explanations are provided in Sec. D in SM [43].
For instance, we consider the state as in Eq. (1) for qubits and network with only bipartite sources as shown in Fig. 3. Then the reduced state for the three qubits in region as in Fig. 3. The rank of is two, and the covariance matrix of contains only . Notice that, the sub-network in the region is a special case of the triangle network as illustrated in Fig. 1. The same argument as before implies that contains only, which does not contradict with the purity of , but with the one of the original state for . Thus, with the global purity and the statistical data of the qubits in the small region , we obtain the same tight result. This strategy saves much effort, since we only need to measure few qubits in a large network.
There is another approach to employ sub-networks to determine whether a state can arise from the original network or not, i.e., we measure out one party associated with one node and broadcast the outcomes. Then we can treat the party associated with node and all the related sources together as a new multipartite source, which distributes particles to all the parties in . If the original network is sparse, then the size of , i.e., the size of the new introduced entangled source is usually not big. For example, if is the central node in region as in Fig. 3, then the new source distributes particles to parties associated with all the other three nodes in the region . We can do this procedure for a subset of nodes sequentially. By applying Observations 1 and 2 for the resulting sub-network, we can obtain new criteria for the original network state.
Discussion.— Quantum networks work as a playground for various quantum technologies, like quantum repeaters and quantum memory. Concerning the real-life implementation of quantum networks, we examine them in the background of the noisy intermediate-scale quantum (NISQ) era. In this paper, we have focused on four aspects of such quantum networks, that is, they should be noisy, intermediate-scale, random, and sparse. We developed operational methods based on purity and covariance to address all those four features.
There exist already methods to tackle with the noisy quantum network states, e.g., the witness based on fidelity [11, 12, 14, 15] and nonlocality inequalities [28, 27, 26]. However, the witness based on fidelity works mostly either for small networks or special states like graph states in practice. The nonlocality inequalities are designed specially for the -partite network with all -partite sources. In comparison, our methods work for any kind of network topology, by employing experiment data only, without knowing the exact underlying quantum state and measurements. Nevertheless, quantum theory is assumed here, which is another difference between our consideration and network nonlocality.
‘Quantum technologists should continue to strive for more accurate quantum gates and, eventually, fully fault-tolerant quantum computing’ [29] and networks, for which our methods can provide the witness.
Acknowledgements.— I thank David Gross, H Chau Nguyen, Julio I. de Vicente, Kiara Hansenne, Mariami Gachechiladze, Nikolai Wyderka, Otfried Gühne, Shu-Heng Liu, Sixia Yu, Tristan Kraft, especially Laurens Ligthart and Thomas Cope for discussions and suggestions. Moreover, I would like to thank Tristan Kraft for careful reading of the manuscript. This work was supported by National Natural Science Foundation of China (Grant No. 12305007) and Anhui Provincial Natural Science Foundation (Grant No. 2308085QA29), the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation, project numbers 447948357 and 440958198), the Sino-German Center for Research Promotion (Project M-0294), the ERC (Consolidator Grant 683107/TempoQ), the Alexander Humboldt foundation.
Supplemental Material of
“Characterize arbitrary quantum networks in the noisy intermediate-scale quantum era”
Zhen-Peng Xu
School of Physics and Optoelectronics Engineering, Anhui University, 230601 Hefei, China and
Naturwissenschaftlich-Technische Fakultät, Universität Siegen, Walter-Flex-Straße 3, 57068 Siegen, Germany
I A. Covariance Matrix of mixed state
For a given state and a set of observables , denote
| (9) | |||
| (10) | |||
| (11) |
Then we have
| (12) |
Besides, the matrices , , are positive semi-definite.
II B. Estimation of mean value and variance
Lemma 5.
If the mixed state has the decomposition
| (13) |
then
| (14) |
Proof.
Denote the projection onto the subspace spanned by the eigenstates of . By definition,
| (15) |
which implies that
| (16) |
Since , we have , . Hence, is no more than the dimension of , which, by definition, is . ∎
Lemma 6.
For any projector , and two states where is in the range of , denote , we have
| (17) |
where , and is the Frobenius norm.
Proof.
| (18) |
where are the non-negative and negative part of , that is,
| (19) |
implies that
| (20) |
Denote the number of positive eigenvalues and the number of negative eigenvalues of , respectively.
| (21) |
Combining Eq. (18) and Eq. (21), we have
| (22) |
since . Notice that and as observed in Ref. [44], we finish the proof. ∎
Observation 7.
For a given set of dichotomic observables with outcome and a mixed state , we have
| (23) |
where , , , is the average purity, i.e, .
Proof.
∎
Note that and . In the case that ’s are all pure states, and .
We have two remarks. Firstly, here we have made use of the rank and the quantifier of purity to provide an upper bound. In principle, there could be other quantifiers of purity which can be employed in a tighter bound. The crucial point is how to get rid of the exact decomposition in the procedure of relaxation, since only the final state is assumed to be available. Secondly, another measure of purity is the single-shot distillable purity , which equals to [42]. Since the rank determines , but not the other way around. If we employ instead of the rank , the results might be less accurate in principle. Hence, it is also a key point that how to chose and combine different measures of purity to extract more information.
Observation 8.
For a set of hermitian operators , a mixed state ,
| (24) |
where is the maximal singular value of , are the rank and purity of and the average purity of the decomposition, respectively.
Proof.
| (25) | ||||
| (26) | ||||
| (27) | ||||
| (28) | ||||
| (29) |
where are eigenvalues of .
Note that,
| (30) |
Following the similar procedure in Lemma 6, we know that
| (31) |
which leads to
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) |
∎
In the case that are all dichotomic measurements, is no more than the size of . Hence, the bound in Eq. (24) is tighter than the one by trivially summing up the upper bound for each term in the diagonal.
In summary, we have proved the following observation. Notice that .
Observation 9.
For a given set of dichotomic measurements , a state with rank and purity ,
| (37) |
where is the maximal singular value of .
Observation 10.
where is the maximal singular value of .
Proof.
As we have observed,
| (38) | |||
| (39) |
Since the maximal singular values of is , Von Neumann’s trace inequality, and the relation between trace norm and fidelity imply that, ,
| (40) |
where and the last inequality is from the fact that
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) |
Similarly, we can proof the result for . ∎
We have two extra remarks. Firstly, for a given mixed state whose purity is , we have
| (45) |
Hence, there is a such that .
Secondly, Von Neumann’s trace inequality and the relation between trace distance and fidelity imply that
| (46) |
Besides, implies that there exist a such that . Consequently, .
III C. Covariance inequalities
For a given covariance matrix whose rows and columns are divided into blocks, we have
| (47) |
For a network , where is the set of nodes or receivers, is the set of sources, denote , the size of . For a given state , from the covariance matrix decomposition, we know that .
| (48) |
where is the size of the source . In the last inequality, we have applied the inequality in Eq. (47) for both of and .
Denote , we have
| (49) |
This leads to Corollary 1 in the main text.
In the case of an IQN with only bipartite sources and at most tripartite sources, . Similarly, we have
| (50) |
where is the maximal number of measurements per party. Here we have made use of the inequality , since the covariance of the random variable in is no more than .
For any state , where is from an IQN with only bipartite sources and at most tripartite sources, we have
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (54) |
Note that, ’s might be from different networks with different topologies, the only constraint is that there are only bipartite sources and at most tripartite sources.
In the general case,
| (55) |
which leads to
| (56) |
where , and .
By definition, we have . Notice that
| (57) |
with to be the average number of genuine -partite sources.
IV D. Sub-networks
For a given network , a network state , and a subset of , denote the reduced state of on . By definition, the state can be decomposed as
| (58) |
where with and is the global classical correlation, is a local channel for the -th party, is an entangled state distributed from the source labeled by the hyperedge .
Firstly, the decomposition leads to the decomposition with to be the corresponding reduced state of , and is an independent network state of the original network implies that is also an independent network state of the sub-network, by definition of the state from correlated quantum networks. Secondly, if acts only nontrivially on the subset . Then the definition of the classical covariance matrices implies that , and inherits all the constraints for . To be more explicitly,
| (59) |
References
- Li et al. [2021] J. Li, Y.-P. Wang, W.-J. Wu, S.-Y. Zhu, and J. You, PRX Quantum 2, 040344 (2021).
- Kimble [2008] H. J. Kimble, Nature 453, 1023 (2008).
- Sciarrino and Mataloni [2012] F. Sciarrino and P. Mataloni, Proc. Natl. Acad. Sci. U.S.A. 109, 20169 (2012).
- Wehner et al. [2018] S. Wehner, D. Elkouss, and R. Hanson, Science 362, eaam9288 (2018).
- Gisin et al. [2002] N. Gisin, G. Ribordy, W. Tittel, and H. Zbinden, Rev. Mod. Phys. 74, 145 (2002).
- Yin et al. [2020] J. Yin, Y.-H. Li, S.-K. Liao, and et. al., Nature 582, 501 (2020).
- Komar et al. [2014] P. Komar, E. M. Kessler, M. Bishof, L. Jiang, A. S. Sørensen, J. Ye, and M. D. Lukin, Nat. Phys. 10, 582 (2014).
- Proctor et al. [2018] T. J. Proctor, P. A. Knott, and J. A. Dunningham, Phys. Rev. Lett. 120, 080501 (2018).
- Rubio et al. [2020] J. Rubio, P. A. Knott, T. J. Proctor, and J. A. Dunningham, J. Phys. A: Math. Theor. 53, 344001 (2020).
- Caleffi et al. [2018] M. Caleffi, A. S. Cacciapuoti, and G. Bianchi, in Proceedings of the 5th ACM International Conference on Nanoscale Computing and Communication (2018) pp. 1–4.
- Navascues et al. [2020] M. Navascues, E. Wolfe, D. Rosset, and A. Pozas-Kerstjens, Phys. Rev. Lett. 125, 240505 (2020).
- Kraft et al. [2021a] T. Kraft, S. Designolle, C. Ritz, N. Brunner, O. Gühne, and M. Huber, Phys. Rev. A 103, L060401 (2021a).
- Hansenne et al. [2022] K. Hansenne, Z.-P. Xu, T. Kraft, and O. Gühne, Nat. Commun. 13, 1 (2022).
- Makuta et al. [2022] O. Makuta, L. T. Ligthart, and R. Augusiak, arXiv preprint arXiv:2208.12099 (2022).
- Wang et al. [2022] Y.-X. Wang, Z.-P. Xu, and O. Gühne, arXiv preprint arXiv:2208.12100 (2022).
- Renou et al. [2019] M.-O. Renou, E. Bäumer, S. Boreiri, N. Brunner, N. Gisin, and S. Beigi, Phys. Rev. Lett. 123, 140401 (2019).
- Pozas-Kerstjens et al. [2019] A. Pozas-Kerstjens, R. Rabelo, Ł. Rudnicki, R. Chaves, D. Cavalcanti, M. Navascués, and A. Acín, Phys. Rev. Lett. 123, 140503 (2019).
- Gisin et al. [2020] N. Gisin, J.-D. Bancal, Y. Cai, P. Remy, A. Tavakoli, E. Zambrini Cruzeiro, S. Popescu, and N. Brunner, Nat. Commun. 11, 2378 (2020).
- Åberg et al. [2020] J. Åberg, R. Nery, C. Duarte, and R. Chaves, Phys. Rev. Lett. 125, 110505 (2020).
- Contreras-Tejada et al. [2021] P. Contreras-Tejada, C. Palazuelos, and J. I. de Vicente, Phys. Rev. Lett. 126, 040501 (2021).
- Pozas-Kerstjens et al. [2022] A. Pozas-Kerstjens, N. Gisin, and A. Tavakoli, Phys. Rev. Lett. 128, 010403 (2022).
- Tavakoli et al. [2021] A. Tavakoli, A. Pozas-Kerstjens, M.-O. Renou, et al., Rep. Prog. Phys. 85, 056001 (2021).
- Jones et al. [2021] B. D. Jones, I. Šupić, R. Uola, N. Brunner, and P. Skrzypczyk, Phys. Rev. Lett. 127, 170405 (2021).
- Kraft and Piani [2019] T. Kraft and M. Piani, arXiv preprint arXiv:1911.10026 (2019).
- Kraft et al. [2021b] T. Kraft, C. Spee, X.-D. Yu, and O. Gühne, Phys. Rev. A 103, 052405 (2021b).
- Mao et al. [2022] Y.-L. Mao, Z.-D. Li, S. Yu, and J. Fan, Phys. Rev. Lett. 129, 150401 (2022).
- Coiteux-Roy et al. [2021a] X. Coiteux-Roy, E. Wolfe, and M.-O. Renou, Phys. Rev. Lett. 127, 200401 (2021a).
- Coiteux-Roy et al. [2021b] X. Coiteux-Roy, E. Wolfe, and M.-O. Renou, Phys. Rev. A 104, 052207 (2021b).
- Preskill [2018] J. Preskill, Quantum 2, 79 (2018).
- Ott [2008] E. Ott, Nature 453, 300 (2008).
- Choi [2023] C. Q. Choi, IEEE Spectrum 60, 46 (2023).
- Wiersma [2010] D. S. Wiersma, Science 327, 1333 (2010).
- Briegel et al. [1998] H.-J. Briegel, W. Dür, J. I. Cirac, and P. Zoller, Phys. Rev. Lett. 81, 5932 (1998).
- Sangouard et al. [2011] N. Sangouard, C. Simon, H. de Riedmatten, and N. Gisin, Rev. Mod. Phys. 83, 33 (2011).
- Vinay and Kok [2019] S. E. Vinay and P. Kok, Phys. Rev. A 99, 042313 (2019).
- Mooney et al. [2021] G. J. Mooney, G. A. White, C. D. Hill, and L. C. Hollenberg, J. Phys. Commun. 5, 095004 (2021).
- Zhang et al. [2022] S. Zhang, Y.-K. Wu, C. Li, N. Jiang, Y.-F. Pu, and L.-M. Duan, Phys. Rev. Lett. 128, 080501 (2022).
- Elben et al. [2020] A. Elben, R. Kueng, H.-Y. R. Huang, R. van Bijnen, and et. al., Phys. Rev. Lett. 125, 200501 (2020).
- Huang et al. [2020] H.-Y. Huang, R. Kueng, and J. Preskill, Nat. Phys. 16, 1050 (2020).
- Horodecki and Oppenheim [2013] M. Horodecki and J. Oppenheim, Int. J. Mod. Phys. B 27, 1345019 (2013).
- Gour et al. [2015] G. Gour, M. P. Müller, V. Narasimhachar, R. W. Spekkens, and N. Y. Halpern, Phys. Rep. 583, 1 (2015).
- Streltsov et al. [2018] A. Streltsov, H. Kampermann, S. Wölk, M. Gessner, and D. Bruß, New J. Phys. 20, 053058 (2018).
- [43] Supplemental Material .
- Coles et al. [2019] P. J. Coles, M. Cerezo, and L. Cincio, Phys. Rev. A 100, 022103 (2019).