Channel Coding for Gaussian Channels with
Mean and Variance Constraints
Abstract
We consider channel coding for Gaussian channels with the recently introduced mean and variance cost constraints. Through matching converse and achievability bounds, we characterize the optimal first- and second-order performance. The main technical contribution of this paper is an achievability scheme which uses random codewords drawn from a mixture of three uniform distributions on -spheres of radii and , where and . To analyze such a mixture distribution, we prove a lemma giving a uniform bound, which holds with high probability, on the log ratio of the output distributions and , where is induced by a random channel input uniformly distributed on an -sphere of radius . To facilitate the application of the usual central limit theorem, we also give a uniform bound, which holds with high probability, on the log ratio of the output distributions and , where is induced by a random channel input with i.i.d. components.
Index Terms:
Channel coding, Gaussian channels, second-order coding rate, random coding, mixture distributionI Introduction
The two common forms of cost (or power) constraints in channel coding have been the maximal cost constraint specified by almost surely, or the expected cost constraint specified by , where is a random channel input vector and is an additively separable cost function defined as
Recent works [1] and [2] introduced the mean and variance (m.v.) cost constraint, specified by
for discrete memoryless channels (DMCs). With a variance parameter , the mean and variance (m.v.) cost constraint generalizes the two existing frameworks in the sense that recovers the first- and second-order coding performance of the maximal cost constraint [1] and recovers the expected cost constraint. Beyond generalization, the m.v. cost constraint for is shown to have practical advantages over both prior cost models. Unlike the maximal cost constraint, it allows for an improved second-order coding performance with feedback [1, Theorem 3], [2, Theorem 2]; even without feedback, the coding performance under the m.v. cost constraint is superior [2, Theorem 1]. In particular, for DMCs with a unique capacity-cost-achieving distribution, second-order coding performance improvement via feedback is possible if and only if . Unlike the expected cost constraint, the m.v. cost constraint enforces a controlled, ergodic use of transmission power [2, (5)]. This is essential for several practical reasons such as operating circuitry in the linear regime, minimizing power consumption, and reducing interference with other terminals. The m.v. cost constraint allows the power to fluctuate above the threshold in a manner consistent with a noise process, thus making it a more realistic and natural cost model in practice than the restrictive maximal cost constraint.
The aforementioned performance improvements under the m.v. cost constraint were shown for DMCs only, although the ergodic behavior enforced by the m.v. cost constraint is generally true. In this paper, we investigate additive white Gaussian noise (AWGN) channels with the mean and variance cost constraint with the cost function taken to be . Specifically, we characterize the optimal first- and second-order coding rates (SOCR) under the m.v. cost constraint for AWGN channels subject to a non-vanishing average probability of error . Simultaneously, we also characterize the optimal average error probability as a function of the second-order rate with the baseline first-order rate fixed as the capacity-cost function [3, (9.17)]. The latter is motivated by the fact, which itself follows from our results, that the strong converse [3, p. 208] holds under the m.v. cost constraint. This is an interesting finding since the strong converse does not hold for AWGN channels subject to expectation-only constraint [4, Theorem 77]. However, if one considers maximal probability of error instead of average probability of error, then the strong converse holds for both m.v. cost constraint and expectation-only constraint [5, (18)]. More results on AWGN channels can be found in [6] and [7]. In this paper, we only focus on the average error probability and non-feedback framework.
Our achievability proof relies on a random coding scheme where the channel input has a distribution supported on at most three concentric spheres of radii , and , where and . Each uniform distribution on a sphere induces a distribution on the channel output, and a mixture of such input uniform distributions induces a mixture distribution of and on the output. For , we have that and concentrates in probability over a set encompassing deviations around its mean. Furthermore, the probability density function is given in terms of the modified Bessel function of the first kind. To assist in the analysis of the mixture distribution, we use a uniform asymptotic expansion of the Bessel function followed by traditional series expansions to bound the ratio of and . Remarkably, the zeroth- and first-order terms, which are and respectively, cancel out, giving us an bound. This bounds holds uniformly over a set on which concentrates. Moreover, to facilitate the application of the central limit theorem, we give a similar bound on the ratio of and , where is the output distribution induced by an i.i.d. channel input. The discussion of this paragraph is formalized in Lemmas 5, 6 and 7 in Section III. The achievability theorem and its proof are also given in Section III.
For the proof of the matching converse result, the main technical component involves obtaining convergence of the distribution of the normalized sum of information densities to a standard Gaussian CDF. Let denote the random channel output when the input to the AWGN channel, denoted by , is some fixed vector . The sum of the information densities is given by
| (1) |
A well-known observation is that the distribution of depends on only through its average power (see Lemma 2). Unlike the maximal cost constraint, is not uniformly bounded in the mean and variance cost constraint framework. Hence, we prove that the normalized sum converges uniformly in distribution to the standard Gaussian, where the convergence is only uniform over typical vectors . For atypical vectors, we use standard concentration arguments. Section IV is devoted to the converse theorem and its proof.
II Preliminaries
We write to denote a vector and to denote a random vector in . For any and , let denote the Gaussian distribution with mean and variance . Let denote the standard Gaussian CDF. Let denote the noncentral chi-squared distribution with degrees of freedom and noncentrality parameter . If two random variables and have the same distribution, we write . The modified Bessel function of the first kind of order is denoted by . We will write to denote logarithm to the base and to denote to the power of . Define to be the -sphere of radius centered at the origin, i.e., .
Let denote the set of all probability distributions over . If is an -fold product distribution induced by some , then we write
with some abuse of notation.
The additive white Gaussian noise (AWGN) channel models the relationship between the channel input and output over channel uses as , where represents independent and identically distributed (i.i.d.) Gaussian noise with variance . The noise vector is independent of the input . For a single time step, we use to denote the conditional probability distribution associated with the channel:
Let the cost function be given by . For a channel input sequence ,
For , the capacity-cost function is defined as
| (2) |
where
Definition 1
We use to denote the capacity-cost-achieving distribution in and to denote the induced output distribution. We define
Lemma 1
We have and . Thus, the capacity-cost function is given by
Furthermore, for any and ,
| (3) | ||||
| (4) |
Proof: The fact that can be found in [3, (9.17)]. The remaining content of Lemma 1 follows from elementary calculus.
Lemma 2 (Spherical Symmetry)
Let be the channel input. Let . Define
Then
where . Hence, the distribution of depends on only through its cost . Hence, we can write
| (5) |
where ’s are i.i.d. and
| (6) |
where in .
Proof: The observation of spherical symmetry with respect to the channel input is standard in most works on AWGN channels (see, e.g., [8]). For convenience and completeness, we have given a proof of this lemma in Appendix A.
Corollary 1
With the same setup as in Lemma 2, we have
Proof: Use the equality in distribution given in and Lemma 1.
With a blocklength and a fixed rate , let denote the message set. Let denote the random message drawn uniformly from the message set.
Definition 2
An code for an AWGN channel consists of an encoder which, for each message , chooses an input , and a decoder which maps the output to . The code is random if or is random.
Definition 3
An code for an AWGN channel is an code such that and , where the message has a uniform distribution over the message set .
Given , define
where denotes the minimum average error probability attainable by any random code.
Definition 4
Define the function as
| (7) |
Lemma 3
The function has the following properties:
-
1.
The infimum in is a minimum, and there exists a minimizer which is a discrete probability distribution with at most 3 point masses,
-
2.
is (jointly) continuous in ,
-
3.
for any fixed , is strictly increasing in ,
-
4.
for any and , there always exists a unique satisfying ,
-
5.
for all and , the minimizing distribution in has at least two point masses.
III Achievability Result
The design of random channel codes can be directly related to the design of the distribution of the codewords. Specifically, for each message , the channel input is chosen randomly according to . Given an observed at the decoder , the decoder selects the message with the lowest index that achieves the maximum over of
Any distribution can be used to construct an channel code using the aforementioned construction. Moreover, any distribution satisfying
| (8) | ||||
can be used to construct a random code.
Given a random code based on an input distribution , the following lemma gives an upper bound on the average error probability of the code in terms of the distribution of induced by and the channel transition probability .
Lemma 4
Consider an AWGN channel with noise variance and cost constraint . For any distribution satisfying , and any , and ,
| (9) |
where have the joint distribution specified by
and denotes the marginal distribution of . Furthermore, if for some and ,
| (10) |
then the distribution gives rise to an achievable second-order coding rate (SOCR) of , i.e.,
| (11) |
Proof: The proof can be adapted from the proof of [10, Lemma 14] by (i) replacing controllers with distributions satisfying and (ii) replacing sums with integrals.
Lemma 4 is a starting point for proving our achievability result. Hence, a central quantity of interest in the proof is
| (12) |
As discussed in the introduction, Lemmas 5, 6 and 7 are helpful in the analysis of , where is a mixture distribution. Specifically, the lemmas are helpful in approximating the output distribution in terms of a simpler distribution.
Lemma 5
Consider a random vector , where and are independent, is uniformly distributed on an sphere of radius and . Let denote the PDF of . Then
Proof: The proof is given in Appendix B.
To state the next two lemmas in a succinct way, we need to introduce some notation.
Definition 5 (Multi-parameter and multi-variable big- notation)
Let be functions of and . We write
if there exist positive constants and such that for all , and ,
Lemma 6
Consider a random vector , where and are independent, is uniformly distributed on an sphere of radius and . Let denote the PDF of . Consider another random vector , where and are independent, is uniformly distributed on an sphere of radius and . Let denote the PDF of . Let . Then
where and .
Remark 1
The parameters and in Lemma 6 may depend on .
Lemma 7
Consider a random vector , where and are independent, is uniformly distributed on an sphere of radius and . Let denote the PDF of and let . Then
where and .
Remark 2
Remark 3
Theorem 1
Fix an arbitrary . Consider an AWGN channel with noise variance . Under the mean and variance cost constraint specified by the pair , we have
Alternatively, for any second-order coding rate ,
Remark 5
When , Theorem 1 recovers the optimal second-order coding rate corresponding to the maximal cost constraint , as given in [11, Theorem 5]. In this special case, the achievability scheme in Theorem 1 simplifies to taking the channel input to be uniformly distributed on a singular -sphere of radius . Thus, for , the proof of Theorem 1 is an alternative and more direct proof technique than that of [11, Theorem 5], which relies on randomly selecting the channel input from sequences of a fixed -type over a finite alphabet of size and an implicit assumption on the convergence rate of to [11, p. 4963].
Remark 6
When , the achievability scheme involves the random channel input having a mixture distribution of two or three uniform distributions on -spheres.
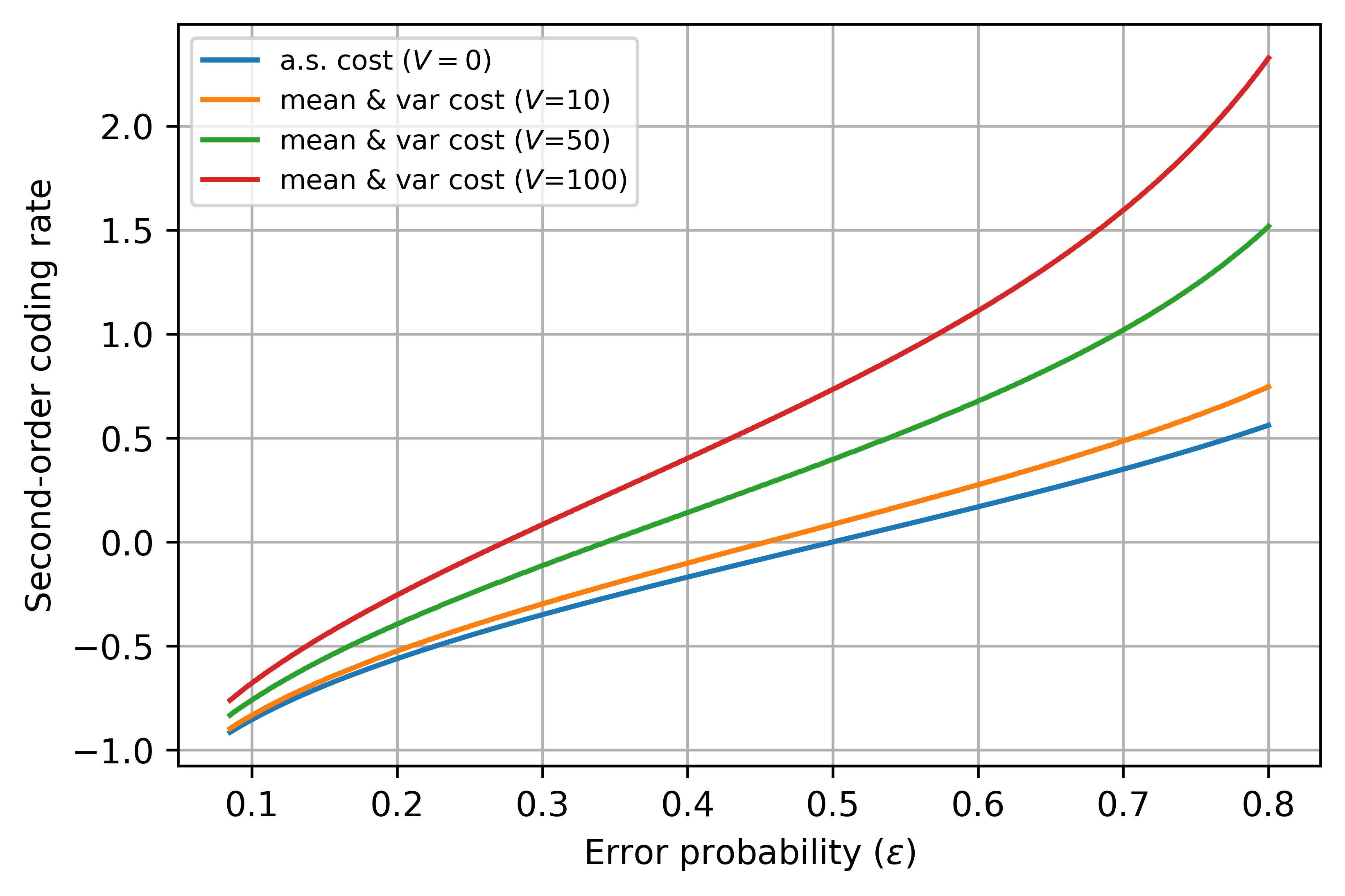
Let denote the achievable SOCR for the mean and variance cost constraint in Theorem 1, which is also the optimal SOCR as shown later in Theorem 2. As remarked earlier, is the optimal SOCR for the maximal cost constraint. Fig. 1 plots the SOCR against the average error probability for a Gaussian channel with and , showing improved SOCR for several values of . In fact, [2, Theorem 1] shows that for all .
Proof:
In view of Lemma 3, consider any distribution which achieves the minimum in
Let , where we write
Recall that and . For each , let
| (13) |
We assume sufficiently large so that for all . Let be the capacity-cost-achieving input distribution for and be the corresponding optimal output distribution. Thus, and . Let be the output distribution induced by the input distribution for .
Achievability Scheme: Let the random channel input be such that with probability , . Denoting the distribution of by , we can write
The output distribution of induced by is
We define
and show that which, by Lemma 4, would show that the random coding scheme achieves a second-order coding rate of .
Analysis: We first write
| (14) |
To proceed further, we upper bound
| (15) | |||
where depends on and is such that assigns the highest probability to . We continue the derivation as
| (16) |
In the last inequality above, we used Lemma 6. Specifically, in Lemma 6, let
-
•
,
-
•
,
-
•
so that , and
-
•
.
Consequently, is a constant from the result of Lemma 6 and
It is easy to check that for , and . Thus, it is easy to see that as using Chebyshev inequality.
Continuing the derivation from , we have
| (17) |
In the last inequality above, we used Lemma 7. Specifically, in Lemma 7, let and . Consequently, is a suitable bounding constant for both Lemma 6 and Lemma 7.
Continuing the derivation from , we have
| (18) |
In equality above, we normalize the sum to have unit variance, which follows from Corollary 1 and Equation .
In inequality above, we used the Berry-Esseen Theorem [12] to obtain convergence of the CDF of the normalized sum of i.i.d. random variables ’s to the standard normal CDF, with accounting for both the rate of convergence and . In inequality above, we used a Taylor series approximation, noting that .
Substituting into , we obtain
for some redefined sequence as . Using Equation and the formula for from Lemma 1, we can simplify the upper bound as
Therefore, since as , we have
| (20) |
To complete the proof, we choose where
| (21) |
Hence, because, from Lemma 3, is a strictly increasing function in the first argument. Hence, for , thus establishing that any is an achievable second-order coding rate. Finally, letting establishes an achievable second-order coding rate of , matching the converse in Theorem 2.
The achievability result can also be stated in terms of an upper bound on the minimum average probability of error of codes for a rate . From Lemma 4, we have for for ,
| (22) |
For any , we have eventually, so
| (23) |
where the last inequality follows from . Letting in and invoking continuity of the function establishes the result.
∎
IV Converse Result
Lemma 8
Consider an AWGN channel with noise variance and cost constraint . Then for every and ,
| (24) |
where is the set of distributions such that and for .
Proof: The proof is similar to that of [9, Lemma 2] and is omitted.
Theorem 2
Fix an arbitrary . Consider an AWGN channel with noise variance . Under the mean and variance cost constraints specified by the pair , we have
| (25) |
Alternatively, for any second-order coding rate ,
| (26) |
Proof:
For , we are required to prove that the upper bound in is , and the lower bound in is . But this follows from the known converse results for the maximal cost constraint, since the m.v. cost constraint for is more stringent.
We assume for the remainder of the proof. We start with Lemma 8 and first upper bound
| (27) |
Let in , where is a number to be specified later. Let for any arbitrary so that and .
Choosing in , we have
| (28) |
where in , are independent random variables and each . We define the empirical distribution of a vector as
where is the dirac delta measure at . For any given channel input and independent ’s where , we have from Corollary 1 that
For any , define
and note that as . Define the function
Fix any and . Then select such that ,
| (29) |
and
| (30) |
Also define
| (31) |
With , and fixed as above111 is used later., we divide the set of sequences into three subsets:
For , we have
| (32) |
for sufficiently large . In equality , we used Lemma 1. Inequality holds because is a constant. Inequality follows by applying Chebyshev’s inequality and Corollary 1, the latter of which gives us that
For , we have
| (33) |
for sufficiently large . In equality , we used Lemma 1. In equality , we normalize the sum to have unit variance, where we write
In equality , we use Lemma 2. In inequality , we apply the Berry-Esseen Theorem [12], where is a constant depending on the second- and third-order moments of . In inequality , we use the fact that the distribution of each depends on only through its cost . Since is uniformly bounded over the set , the constant can be uniformly upper bounded over all by some constant that does not depend on at all.
For , the following lemma shows that the probability of this set under is small.
Lemma 9
We have
| (34) |
Proof:
Let . For any ,
∎
Using the results in , and , we can upper bound as
| (35) |
To further upper bound the above expression, we need to obtain a lower bound to
where the infimum is over all random vectors such that and . Without loss of generality, we can assume since the function is monotonically increasing and the function
is monotonically nonincreasing.
Note that
| (36) |
In inequality , we used . In inequality , we used the fact that . Hence, from , we have
| (37) |
Now define so that and . Also define
Then note that
| (38) |
In inequality , we used . In inequality , we used and , noting that . In inequality , we used the inequality . Therefore, from , we have
| (39) |
Define the random variable as
so that, from and , and . Then, from , for sufficiently large ,
| (40) |
The infimum in equality above is over all random variables such that and Equality follows by the definition and properties of the function given in Definition 4 and Lemma 3.
Using to upper bound and using that upper bound in the result of Lemma 8 (with ), we obtain
| (41) |
For any given average error probability , we choose in as
| (42) |
where
| (43) | ||||
| (44) | ||||
Note that in , for and for .
Therefore, for , we have
| (45) |
Since is strictly increasing in the first argument, we have
from the definition of in and the fact that . Hence, taking the limit supremum as in , we obtain
| (46) |
for . For , a similar derivation gives us
| (47) |
We now let and go to zero in both and . Then using the fact from Lemma 3 that is continuous, we obtain
for all .
The converse result can also be stated in terms of a lower bound on the minimum average probability of error of codes for a rate . Starting again from Lemma 8, we have that for codes with minimum average error probability ,
| (48) |
Assume first that and let for some arbitrary . It directly follows from and the definition of in that
| (49) |
From and , we have
| (50) |
which evaluates to
Taking the limit as and letting , , and , we obtain
| (51) |
for any . For , let for some arbitrary . Then from and the definition of in , we have that
| (52) |
Then a similar derivation to that used from to gives us
for all .
∎
Appendix A Proof of Lemma 2
Let . We have
Hence,
| (53) |
Using the relation , we can write
By completing the square and writing , where is i.i.d. , we can write
Since
has a noncentral chi-squared distribution with degrees of freedom and noncentrality parameter given by
the assertion of the lemma follows.
Appendix B Proof of Lemma 5
Define , where and are independent, is uniformly distributed on an sphere of radius and . Let denote the PDF of . From [13, Proposition 1], we have
Since , we can apply the change-of-variables formula
to obtain the result.
Appendix C Proof of Lemma 6
To approximate the Bessel function, we first rewrite it as
where and . Since by assumption, we have that lies in a compact interval for sufficiently large , where . Hence, we can use a uniform asymptotic expansion of the modified Bessel function (see [14, 10.41.3] whose interpretation is given in [14, 2.1(iv)]): as , we have
| (54) |
where
Since , the term in can be uniformly bounded over . Using the approximation in , we have
| (55) |
where it is easy to see that the term can be made to be uniformly bounded over . Using , we have
Hence,
To simplify the notation, we write . Recall that and . Then
| (56) |
where we define
Using the Taylor series approximation
we have
Let
so that
Further set and . Then
Now
Thus
Combining all the terms, we have
Note that
Hence,
| (57) |
Now we turn to
We first simplify the expression inside the square root as follows:
Therefore,
Therefore,
Finally,
| (58) |
Substituting and in , we obtain
Appendix D Proof of Lemma 7
From Lemma 5, we have
From the standard formula for the multivariate Gaussian, we have
Then
| (59) |
In equality , we used an asymptotic expansion of the log gamma function (see, e.g., [14, 5.11.1]). To approximate the Bessel function, we first rewrite it as
where and . Since by assumption, we have that lies in a compact interval for sufficiently large , where . Hence, we can use a uniform asymptotic expansion of the modified Bessel function (see [14, 10.41.3] whose interpretation is given in [14, 2.1(iv)]): as , we have
| (60) |
where
Since , the term in can be uniformly bounded over . Using the approximation in , we have
| (61) |
where it is easy to see that the term can be made to be uniformly bounded over . Substituting in , we obtain
| (62) |
where in the last equality above, we have
| (63) | ||||
to facilitate further analysis. Recall that .
From , we have
Thus, we can simplify the first term in square brackets in as
| (64) |
Similarly, from , we have
Thus, we can simplify the second term in square brackets in as
| (65) |
Adding and gives us . Hence, going back to , we have
where the last equality follows from the assumption that .
Acknowledgment
This research was supported by the US National Science Foundation under grant CCF-1956192.
References
- [1] A. Mahmood and A. B. Wagner, “Channel coding with mean and variance cost constraints,” in 2024 IEEE International Symposium on Information Theory (ISIT), 2024, pp. 510–515.
- [2] ——, “Improved channel coding performance through cost variability,” 2024. [Online]. Available: https://arxiv.org/abs/2407.05260
- [3] T. M. Cover and J. A. Thomas, Elements of Information Theory, 2nd ed. Hoboken, N.J.: Wiley-Interscience, 2006.
- [4] Y. Polyanskiy, “Channel coding: Non-asymptotic fundamental limits,” Ph.D. dissertation, Dept. Elect. Eng., Princeton Univ., Princeton, NJ, USA, 2010.
- [5] W. Yang, G. Caire, G. Durisi, and Y. Polyanskiy, “Optimum power control at finite blocklength,” IEEE Transactions on Information Theory, vol. 61, no. 9, pp. 4598–4615, 2015.
- [6] S. L. Fong and V. Y. F. Tan, “Asymptotic expansions for the awgn channel with feedback under a peak power constraint,” in 2015 IEEE International Symposium on Information Theory (ISIT), 2015, pp. 311–315.
- [7] ——, “A tight upper bound on the second-order coding rate of the parallel Gaussian channel with feedback,” IEEE Transactions on Information Theory, vol. 63, no. 10, pp. 6474–6486, 2017.
- [8] Y. Polyanskiy, H. V. Poor, and S. Verdu, “Channel coding rate in the finite blocklength regime,” IEEE Transactions on Information Theory, vol. 56, no. 5, pp. 2307–2359, 2010.
- [9] A. Mahmood and A. B. Wagner, “Channel coding with mean and variance cost constraints,” 2024. [Online]. Available: https://arxiv.org/abs/2401.16417
- [10] A. B. Wagner, N. V. Shende, and Y. Altuğ, “A new method for employing feedback to improve coding performance,” IEEE Transactions on Information Theory, vol. 66, no. 11, pp. 6660–6681, 2020.
- [11] M. Hayashi, “Information spectrum approach to second-order coding rate in channel coding,” IEEE Transactions on Information Theory, vol. 55, no. 11, pp. 4947–4966, 2009.
- [12] P. van Beek, “An application of Fourier methods to the problem of sharpening the Berry-Esseen inequality,” Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, vol. 23, no. 3, pp. 187–196, 1972.
- [13] A. Dytso, M. Al, H. V. Poor, and S. Shamai Shitz, “On the capacity of the peak power constrained vector Gaussian channel: An estimation theoretic perspective,” IEEE Transactions on Information Theory, vol. 65, no. 6, pp. 3907–3921, 2019.
- [14] F. W. J. Olver, D. W. Lozier, R. F. Boisvert, and C. W. Clark, Eds., NIST Handbook of Mathematical Functions. New York: Cambridge University Press, 2010.