Central limit theorem for linear spectral statistics of block-Wigner-type matrices
Abstract
Motivated by the stochastic block model, we investigate a class of Wigner-type matrices with certain block structures, and establish a CLT for the corresponding linear spectral statistics via the large-deviation bounds from local law and the cumulant expansion formula. We apply the results to the stochastic block model. Specifically, a class of renormalized adjacency matrices will be block-Wigner-type matrices. Further, we show that for certain estimator of such renormalized adjacency matrices, which will be no longer Wigner-type but share long-range non-decaying weak correlations among the entries, the linear spectral statistics of such estimators will still share the same limiting behavior as those of the block-Wigner-type matrices, thus enabling hypothesis testing about stochastic block model.
keywords:
[class=MSC2020]keywords:
, and
1 Introduction
The investigation into the limiting properties of large random matrices has been popular for over two decades. Many techniques [8][6][13][18] are developed to solve problems in this area. There are plenty of objects of interest, namely the empirical spectral distribution (ESD), the limiting spectral distribution(LSD), the largest eigenvalue, the linear spectral statistics (LSS), the eigenvector statistics, etc. Particularly, the linear spectral statistics have attracted lots of attention ever since the 90s [28]. Various methods are explored to study the behavior of the LSS, such as moment method [5], martingale difference method [7][9], cumulant expansion method [22]. Also there is progress from the stochastic calculus [17][20] and free probability [27]. Further, [14][15] generalize the Stein method and use second order Poincaré inequalities to prove a CLT for the LSS. Specifically, in recent years, a more in-depth understanding of the behavior of the LSS of Wigner and Wigner-type matrices has been achieved by researchers from various perspectives. [26] introduces an interpolation method for more general Wigner matrices than the ones that share the same cumulants with GOE/GUE. [12] extends the CLT to certain heavy-tailed random matrices. More recently, [21] studies the mesoscopic eigenvalue statistics of the Wigner matrices via the Green function and the local law, [16] yields a thorough analysis of fluctuations of regular functions of Wigner matrices and [11] establishes a near-optimal convergence rate for the CLT of LSS of Wigner matrices.
In the meantime, motivations are drawn from social networks and other associated random graph models, which brings the researchers’ attention to more involved matrix models. One of the most classic models in this field is the stochastic block model (SBM). In contrast to the Erdős-Renyi model in which all nodes are exchangeable, the SBM introduces inhomogeneity by dividing the nodes into different communities. In the SBM with nodes and edges , all edges are undirected, and different edges are independent, in the meantime, the probability that two nodes connect with each other is only determined by which communities and belong to. In other words, the adjacency matrix of the SBM can be viewed as a random 0-1 matrix whose entries have block-wise constant expectations. Thus, the centered adjacency matrices of the SBMs are Wigner-type matrices with inhomogeneous variance profiles.
One of the most important questions in the SBM is community detection, which is to recover the community structure underneath via one single observation of the adjacency matrix. Further, an induced problem is to determine the number of communities. For most community detection algorithms, the number of communities needs to be given a priori as a hyperparameter. This motivates hypothesis testing for this parameter via the distributional information of certain test statistics of the model. [25] proposes a sequential test for the renormalized adjacency matrix and based on the Tracy-Widom fluctuation of the largest eigenvalue. In the same spirit, more recently in [10], Banerjee and Ma propose a hypothesis testing for the community structure via the LSS of the renormalized adjacency matrix with the method of moments approach [5] in the cases where the SBM has only one community or two asymptotically equal-sized communities. Towards another end, [1] proves a CLT for the LSS of general Wigner-type matrices via the second order Poincaré inequality without providing the explicit formulas for the asymptotic mean and covariance function.
In this paper, We establish CLTs for the class of block-Wigner-type matrices which is motivated by the renormalization as well as a correlated matrix model induced from the renormalization . We derive the explicit formulas for the asymptotic mean functions and covariance functions with the help of precise large deviation estimates of the Green function by [4] and the application of cumulant expansion formula [22][19].
Our contributions.
We strengthen the existing results in the following ways:
-
1.
Our block-Wigner-type matrices may have not only inhomogeneous fourth moments but also inhomogeneous second moments. This greatly extends the potential range of application of the theorem. We show that the approximately low-rank structure of the entries would reproduce itself in terms of repetitive patterns in the system of equations for key moments of and other related higher-order structures.
-
2.
Further, we establish a CLT for the LSS of the data-driven variation of the above matrices, which is no longer Wigner-type and shares long-range weak correlations among the entries. This yields a direct application in the SBM.
Organization
We first introduce a few prerequisites about our main tools and ingredients in Section 2. Then we introduce the block-Wigner-type matrices and establish the CLT for LSS of such matrices in Section 3.1. In Section 3.2, we consider the application to the SBM and establish a new CLT for LSS of a data-driven variation of the block-Wigner-type matrices. In Section 4, the outlines of the proofs of the main results are shown. In Section 5, we apply the above 2 CLTs to the synthetic data of the SBM to show the efficiency of the theorems. Details of proofs are shown in Section A and B.
2 Preliminary
2.1 Notation
For simplicity of presentation, we will use for normalized trace of a square matrix , to denote centered version of a random variable , and to represent the set of positive integers from 1 to . Further, we introduce two operations related to diagonal terms: for a column vector , denotes the diagonal matrix whose diagonal elements are the entries of , and for a matrix , denotes the column vector whose entries are the diagonal element of . In particular, .
2.2 Large deviation bounds from local law for Wigner-type matrices
This section gives a quick review of the large deviation bounds from the local law for general Wigner-type matrices by Ajanki et al. [3][4], which will serve as one of the main ingredients for proving our central limit theorem.
The main object of interest is the resolvent , where is the so-called Wigner-type matrix such that is real symmetric and the entries are independent for and centered .
Let , then the system of the quadratic vector equations (QVE) is
| (1) |
There exists a unique solution of the above system on the complex upper half-plane. We refer the readers to [3] for properties of the QVE system. It is proved by Ajanki et al. [4] that under certain regularity conditions, the solution of the above system of equations may serve as a good approximation for the diagonal terms of the resolvent.
Definition 2.1 (Stochastic domination).
Suppose is a given function, depending only on certain model parameters. For two sequences, and of non-negative random variables we say that is stochastically dominated by if for all and
In this case we write or .
Lemma 2.2 (Theorem 1.7 of [4], reformulated to a macroscopic version).
Let be a Wigner-type matrix and be defined in (1). Suppose that the following assumptions hold:
-
A
For all the matrix is flat, i.e.,
-
B
For all the matrix is uniformly primitive, i.e.;
-
C
For all the entries of the random matrix have bounded moments
are satisfied. Then uniformly for all with constant order imaginary part or real part that is bounded away from the edge of the spectrum of , the resolvents of the random matrices satisfy
| (2) |
Furthermore, for any sequence of deterministic vectors with , the averaged resolvent diagonal has an improved convergence rate.
| (3) |
A direct application of Lemma 2.2 together with the trivial bound leads to the following corollary, whose proof is omitted.
Corollary 2.3.
, there exists a s.t. when ,
| (4) | ||||
for , for any fixed , where is deterministic with .
2.3 Cumulant expansion
The cumulant expansion formula was first introduced to the random matrices literature by Pastur et al. [22].
Lemma 2.4.
| (5) |
where and depends on only.
The cumulant expansion formula will serve as another important tool in our analysis. In some literature, it is also known as the generalized Stein’s method.
3 Main results
3.1 CLT for LSS of block-Wigner-type matrices
We first define the random matrix model of concern. Note that the initial motivation comes from the stochastic block model. Intuitively, the block-Wigner-type matrix to be defined should be close to a symmetric block-wise i.i.d. matrix. Further, for simplicity and consistency with the SBM, we require that all the diagonal terms .
First, we introduce the community and the membership operator.
Definition 3.1 (Community and membership operator).
Let be any partition of with components, i.e.
We call the -th community and define the community membership operator s.t.
For simplicity, we will use to denote the (column) indicator vector of , .
Further, we assume the community number is fixed and the sizes of the communities are comparable.
Assumption 3.2.
There exists , s.t.
Definition 3.3.
[block-Wigner-type Matrix] Let be the -th cumulant of . If there exists a sequence of partitions , s.t.
-
a
is a real symmetric matrix with mean zero and zero diagonal terms,
-
b
Assumption 3.2 is satisfied.
-
c
The first 4 cumulants of will be fully determined by the partition and constant matrices , namely, let be the membership operator induced by , then
and .
-
d
There exists a deterministic sequence , s.t.
Then we say that are block-Wigner-type matrices with model parameters
. For simplicity, we will use for short in this paper when there is no confusion.
With our -block model, one can easily check that the quadratic vector equations (1) will degenerate into the following -equations.
Proposition 3.4 (Quadratic vector equation for the block-Wigner-type matrices).
Given , then for any fixed , the diagonal terms of the resolvent have the following approximation
| (6) |
where is defined to be the unique solution on the complex upper half-plane of the system
| (7) |
Thus, the Stieltjes transform of the ESD converges to
and the corresponding measure is determined by
Remark.
One may find the assumption pretty strong. In general, due to the nature of the rational number, one may only expect that . It then directly follows from the fact that
Thus, when we consider only the leading order terms of the equations, we have
In other words, the leading term of and will follow the same QVE on the complex upper half-plane by the uniqueness of the solution of the QVE. Then w.l.o.g. we may simply treat the case as .
One may argue that the above argument only implies that the limiting spectral distribution will be the same. We claim that it will not affect our CLT as well. Precisely, one may check the system of equations in the preceding sections and note that all the coefficients will count only up to order 1, and all the limiting functions will be fixed once the .
The minor order terms in do matter, not in our CLT, but in the normalization term .
Theorem 3.5.
Let the matrix be a sequence of block-Wigner-type matrices with model parameter . Let and be matrices defined by
| (8) |
and
| (9) |
respectively. Then the spectral empirical process indexed by the set of analytic functions converges weakly in finite dimension to a Gaussian process with mean function and the covariance function to be defined below. The mean function is
where is a contour that encloses the support of spectrum of and
where is the solution of
and is defined by
The covariance function is
where , and satisfies the equation
| (10) | ||||
where is a tensor and the vector satisfies the equation
| (11) |
where satisfies
3.2 Application to the stochastic block model: a step forward with the data-driven renormalized adjacency matrices of SBM
As mentioned in the introduction, the stochastic block model serves as one of the primary motivations for the block-Wigner-type matrices. Recall that a stochastic block model is a random graph with nodes which are divided into disjoint communities , the size of -th community satisfies assumption 3.2. The upper-triangular entries of the symmetric adjacency matrix are independent Bernoulli random variables whose parameters are determined by the community membership of the nodes. In other words, we have a deterministic symmetric matrix , such that the symmetric adjacency matrix of the network follows the rule:
| (12) | ||||
where is the membership operator defined by this model and indicates which community node belongs to. We can see that it fits the description of our block-Wigner-type matrices after the renormalization:
| (13) |
Further, in statistical application such as the hypothesis testing on a stochastic block model, the connection probabilities ’s are not known a priori. Instead, they need to be directly estimated from the observed graph as defined in (12). Assume the membership operator is known, we can define the empirical estimator
for , where is the total number of non-diagonal entries whose first index falls in the -th community, and the second index lies in the -th community, . Namely
| (14) |
We then consider the data-driven renormalized adjacency matrix
| (15) |
It turns out that the LSS of and will share similar asymptotic behavior. We have the following theorem.
4 Outline of the proof
4.1 Outline of the proof of Theorem 3.5
Recall the classic Cauchy integral trick which allows us to rewrite the sum
| (16) |
where is a contour that encloses the support of with high probability. Naturally one may expect that the behavior of the linear spectral statistics will be governed by that of the quantity
Inspired by the previous works such as [22][23][9][7], our proof first combines the characteristic function method with the cumulant expansion to prove the finite-dimensional convergence of the process , then with the tightness of the process we proceed to the linear spectral statistics. To be more specific, our tasks are divided into 4 steps mainly:
-
•
Expectation;
-
•
Covariance;
-
•
Normality;
-
•
Tightness.
We use the resolvent identities so that the cumulant expansion formula could be applied. Then we use the block structure to simplify the calculations. Let be the restriction of the identity matrix on the -th community , we have the following decomposition for :
| (17) | ||||
where
| (18) | ||||
| (19) | ||||
and
| (20) |
The remainder will have a vanishing order .
Though can be directly estimated from the first-order approximation from the local law, approximations for and are not so straightforward. We need to derive new systems of equations for the quantities. To be more precise, we introduce the following lemmas.
Lemma 4.1.
The vector
satisfies the following system of equations
| (21) |
up to order 1, where
Further, the matrix satisfies
| (22) |
Lemma 4.2.
The vector
satisfies the following equation
| (23) | ||||
Similarly, we may use the same techniques to calculate the covariance function .
First we decompose the covariance function of into the following block-wise forms
where
Our primary problem is to calculate to order 1, . Note that then we need to calculate the following expansion to the order ,
| (24) | ||||
It turns out, only ,, have contributions, which will lead to a set of systems of equations for as well. The key observation is that similar to the quantities calculated in the mean function, we will explore similar -dimensional systems of equations via cumulant expansion due to the block structure in calculating the covariance function. We refer the details to Section A.3.
Section A.7 will show the proof of the normality of the linear spectral statistics. The proof for normality is relatively routine. We will adopt the following technique originated from Tikhomirov [29]. The core idea can be simplified as follows. To prove that a sequence of real random variable converges to a Gaussian random variable with mean zero and variance , it suffices to prove that
We prove alternatively that its derivative will behave similarly to that of the derivative of a characteristic function of a Gaussian distribution
in which is a real function constructed from , from which by we can find the form , thus extract the form . Then the cumulant expansion formula can be applied. In Section A.7, we will apply the multivariate version of the above trick to establish the normality.
4.2 Outline of the proof of Theorem 3.6
Recall that in the SBM setting, given the adjacency matrix of a SBM, we may consider two renormalized versions (13) and (15). For simplicity, we will use and for short when there is no confusion.
Note that when ,
| (25) | ||||
Then by concentration inequality we know instantly that , which implies that the limiting spectral distribution of will be the same as that of . However, this stand-alone bound is not sufficient for identical CLTs. To study the LSS of , we need to follow a similar process to the one we use to prove Theorem 3.5.
Further, we investigate on the resolvents and Note also that by the resolvent identity, we have
Further, note that by and , we expect that the higher-order expansion terms would vanish.
5 Numerical results
5.1 Experiments on verifying Theorem 3.5
We test our theorems under the setting of SBM (12) since the renormalized adjacency matrix (13) is naturally a block-Wigner-type matrix. Numerical experiments are conducted for the cases where in (12) is a matrix with identical diagonal terms and identical off-diagonal terms . Under this framework, we may let both and run through the grid to obtain a total of stochastic block models. Given a test function, we can calculate the theoretical values of asymptotic means and asymptotic variances via Theorem 3.5. In the meantime, we are also able to generate real empirical data via Monte Carlo method with repetitions and get empirical means and variances for each model. Then we may compare the theoretical values and the empirical values via the 2D-mesh plots.
Note that for simplicity of presentation, we will compare instead of the truncated version .
Example.
The following parameters are used:
. . . where , , .
| Asymptotic | Empirical | maximal absolute difference | |
|---|---|---|---|
| Mean of |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/TheoMean11.jpg)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/EmpMean11.jpg)
|
0.0195 |
| Variance of |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/TheoVar11.jpg)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/EmpVar11.jpg)
|
0.0112 |
One can see from Table 1 that we obtain a quite good match between theoretical and empirical means and variances.
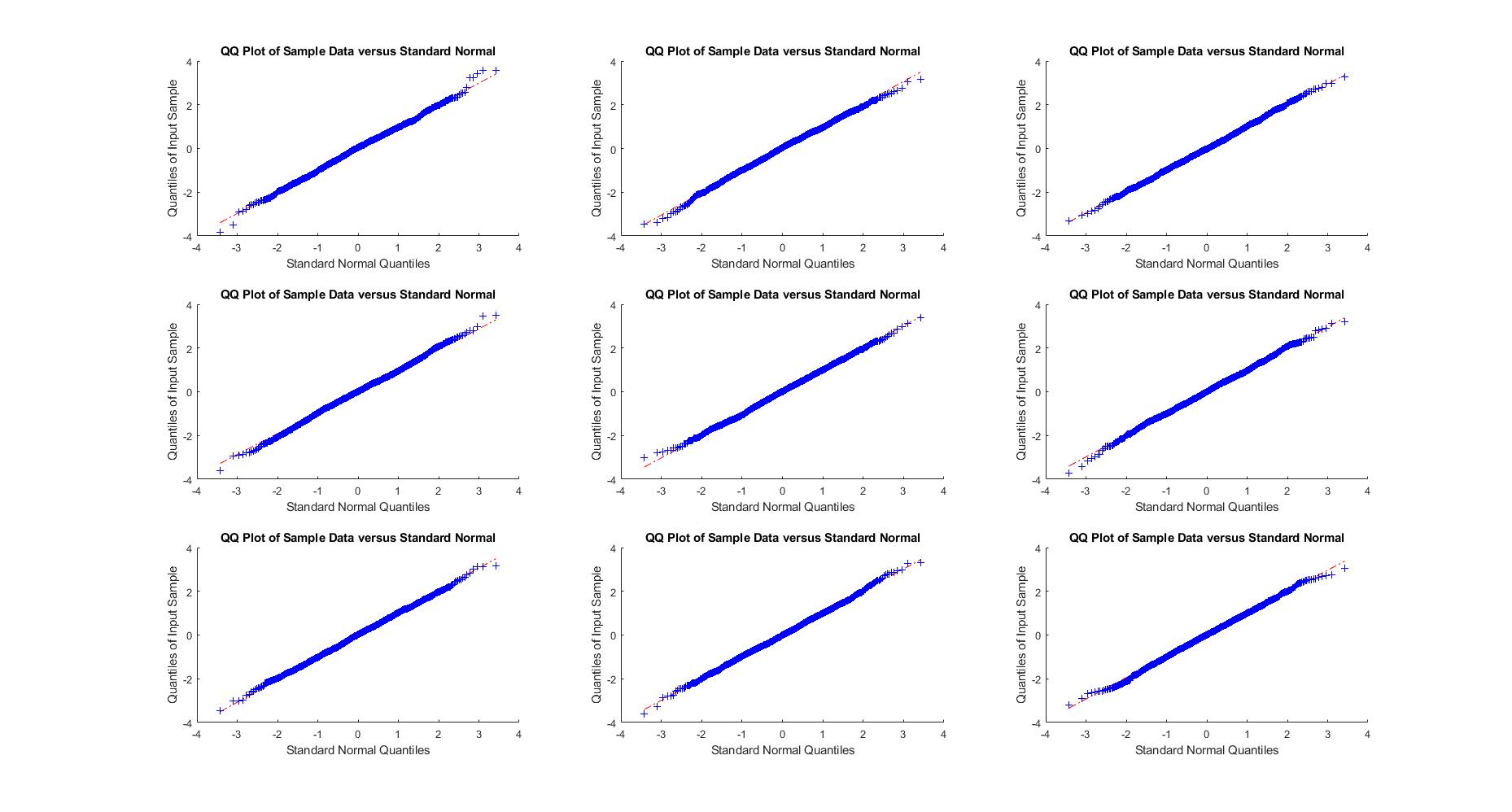
Next, we consider 9 SBMs out of the 81 in Example Example and display in Figure 1 the normal qqplots of the empirical LSS after normalization . These qqplots empirically confirm the asymptotic normality of the LSS.

Example.
| Asymptotic | Empirical | maximal absolute difference | |
|---|---|---|---|
| Mean of |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/TheoMean112.jpg)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/EmpMean112.jpg)
|
0.3100 |
| Variance of |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/TheoVar112.jpg)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf4c9af-fcac-4207-b357-a841fd268294/EmpVar112.jpg)
|
0.0065 |
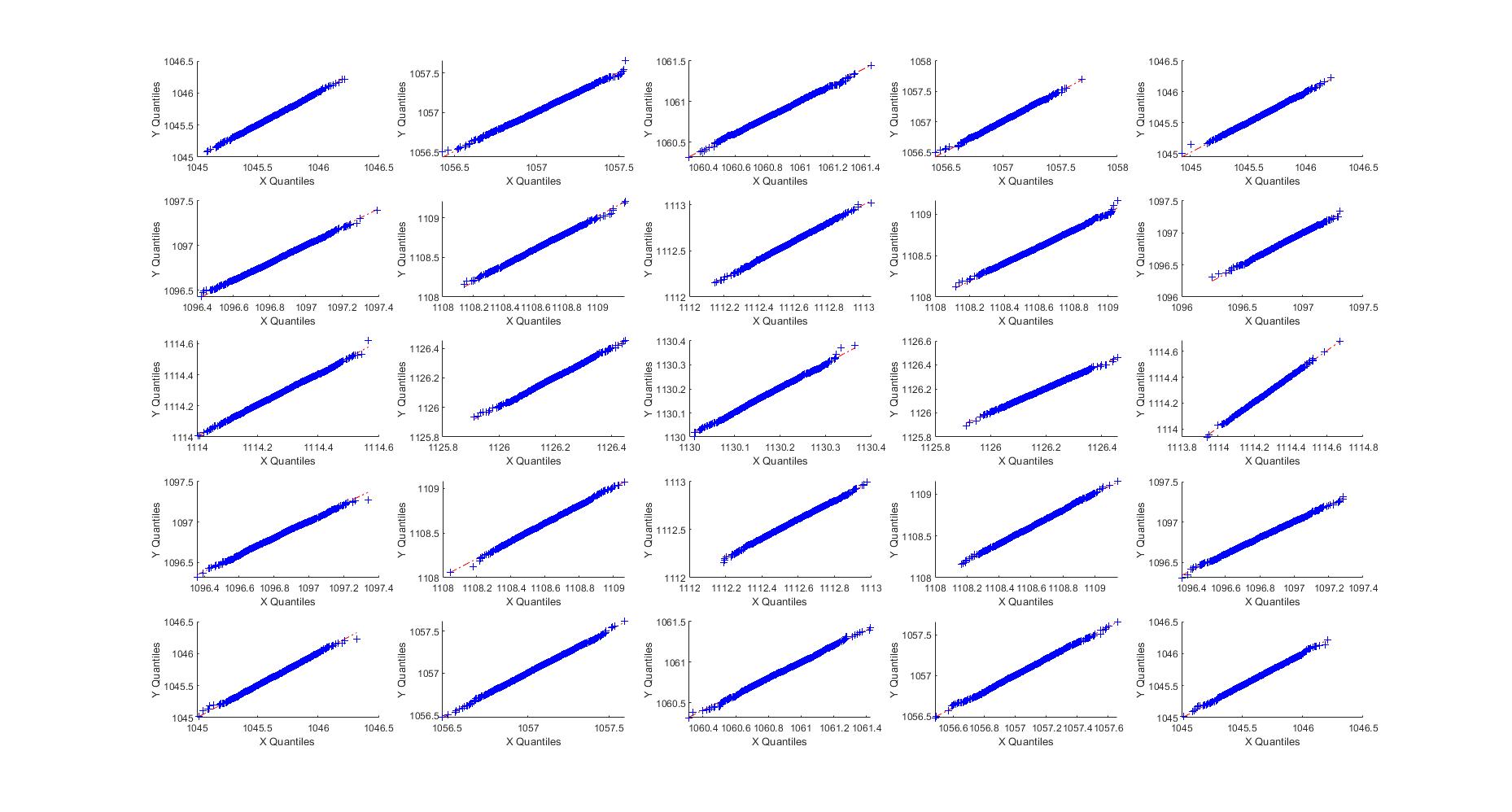
5.2 Experiments on the data-driven matrix
We have also conducted numerical experiments for the data-driven matrix . The simulation set-up much follows the one used in Section 3.2. The main purpose is to verify whether the limiting distributions of linear spectral statistics of would be the same as those of .
Towards this end, we display relative qqplots of linear spectral statistics from and , respectively. Under distributional identity, qqplots would coincide with the identity line .
Example.
The SBM parameters are as follows:
, , , , where , . Test functions are


6 Conclusion
In this paper, we consider two applicable renormalizations and of adjacency matrices of the stochastic block models. The CLTs of linear spectral statistics for both renormalizations are derived. The situations are fundamentally different from the existing literature in the sense that induces a block-Wigner-type matrix whose LSD is no longer guaranteed to be the semicircle law but governed by the so-called quadratic vector equations introduced in [3]. And the CLT for LSS also requires finer tools from the local law estimations. Meanwhile, is further perturbed by a low rank yet correlated structure, whose non-decaying correlations among the entries increase the difficulty of analysis.
We discuss several directions for future research. First, the CLTs introduced here are still in the dense regime of the stochastic block model. While [24] provides a more subtle analysis of the local law for the Erdős-Rényi model in the sparser regime, it makes a local law for the sparse stochastic block model possible. Thus, the CLT for LSS of SBM in the sparse regime could be doable.
Second, a natural question is that for more general Wigner-type matrices, for instance, when the patterns explore more complex structures, can we get some CLTs or non-CLTs? For instance, if the number of communities for the SBM is growing along with or the random graph model is defined via a graphon approach [2][30], then how will the linear spectral statistics behave?
Appendix A Detailed calculations for the proof of Theorem 3.5
In this section, we will show the details of the calculation of the mean function in Section A.1-A.2, covariance function in Section A.3-A.6, proof of normality in Section A.7, and tightness of the process in Section A.8 for the block-Wigner-type matrices .
Remark.
Corollary 2.3 will be extensively used in our proof. Since is arbitrarily small and essentially can be substituted by for some large enough in these large-deviation bounds. Sometimes we will use for simplicity when it is actually for some positive integer which is independent of .
Recall that in Section 4, we decompose the mean function into several components. Starting from in (17), we need to calculate to order 1.
A.1 System of equations for
Proof of Lemma 4.1.
By the identity , we have
Then by the cumulant expansion formula,
where by the cumulant expansion and the trivial bound, the error term satisfies thus minor.
In the meantime, note that when we take derivatives , the terms with the largest order of magnitude should be the ones with the form , which will be of order 1 since and , so
| (26) | ||||
It follows that
If we adopt the notation
then we may rewrite the above system of equations as
| (27) |
Now we have the system of equations (21) for vector and the system of equations (22) for matrix .
∎
Remark.
Further from the QVE (7), for and sufficiently bounded away from the spectrum of , we have
one can see that for different ’s. The coefficient matrices are the same, after simplification, we have that the matrix adopts this simple explicit form
| (28) |
which is symmetric and in accordance with the tracial property which leads to
One may be concerned about the singularity problem. Simply note that . Then when the matrix
becomes diagonal dominant, thus non-singular. Similar things happen when we are near the real axis but also sufficiently bounded away from the edge. Then we can ensure the existence and uniqueness of the solutions of our systems of equations. All we have to pay is to select a larger contour when we apply the Cauchy integral trick to proceed from the trace of the resolvent to the linear spectral statistics. Due to the homogeneity of the coefficient, similar arguments hold for other systems of equations of interest.
Specifically, we introduce the parameter , s.t. for , the existence and uniqueness of the solution are guaranteed by the above mechanism.
A.2 Leading term for and system of equations for
The next task is to identify the leading term of . Note that we need to calculate these terms up to the order . The problem arises that the trivial upper bound is far from enough since it only yields .
Recall the decomposition in (19), we further write
| (29) | ||||
where
| (30) |
Note that we cannot calculate to the desired order directly.
Simply notice that by local law, we have
| (31) |
By Cauchy-Schwarz inequality it’s easy to see that
| (32) |
Then we have
| (33) |
And for we can get the simple formulation
| (34) |
In other words, again we have obtained a function of on the RHS, note that the leading order terms of , which are of order , are known. So this motivates us to derive a system of equations for the subleading order terms of , which are of order 1.
Proof of Lemma 4.2.
By the cumulant expansion formula, we have the following equality for :
where consists of higher-order expansions of the formula
Then it suffices to show that
are minor. Let , .
| (35) | ||||
One may notice that similar to the cases above, we have
and
thus,
| (36) |
Similarly, we can proceed to ,
| (37) | ||||
| (38) | ||||
Then we may derive the system of equation for ,
| (39) | ||||
The above equation could be decomposed into two parts, one is of order , while the other is of order 1. One may easily verify that the order part yields
which directly follows from the quadratic vector equation (7), thus canceled.
∎
A.3 System of equations for
As stated in Section 4, the estimation for can be decomposed into the summation of the block-wise covariance functions . In this subsection, we will derive the system of equations for .
In this section and thereafter, we will use for centered random variables. First, note that for any two random variables and , we have
then by cumulant expansion formula,
| (40) | ||||
Now we proceed to the detailed treatments for the terms . It can be shown that are minor via similar calculations, the details for calculating are tedious and of minor importance thus omitted here and in the proof of (10).
Proof of (10).
We claim that in both and the triple-product term will be the minor terms. The second one is of order by Cauchy inequality, thus minor. The first one, however, requires a little bit effort.
To get an sufficient upper bound for , we only need to show that is of order for some . By intuition from the classic Wigner matrix, the essential order for should be . We refer to the Section A.4 for the details.
Also, gives rise to the quantities which will be treated in Section A.5 and which has already been studied in Section A.1.
| (41) | ||||
Note that one argument for higher-order expansion terms in the cumulant expansion that we will use over and over again is that we can ignore the diagonal terms in many situations since there are only diagonal terms which are at most each. To be more specific,
then w.l.o.g. we can ignore the diagonal terms here. Further, because is , we only need to show that for any to ensure that is vanishing.
Note that the trivial bounds for will not be sufficient. The trick here is to apply the cumulant expansion formula one more time to get certain equation of , hence the sufficient bounds.
By cumulant expansion, we have
| (42) | ||||
Then the problem becomes to derive bounds for the terms
In the meantime,
while the trivial upper bound is already sufficient for the -th order term
Thus, from above estimations we know
| (43) | ||||
instantly we come to the conclusion that
| (44) |
Thus, is minor and is also minor.
Simply note that , and , we have
| (45) | ||||
Further,
where we use the fact that
Similarly, we can derive that is also minor. Further note that
To conclude, the covariance function satisfies the following system of equations to order 1
| (46) | ||||
∎
A.4 Bound for
Now we show that is of minor order for any . We start from the trivial bound that . Again, we apply the cumulant expansion formula to .
Fix then we can see that we will have the system of equation for vector
where
For simplicity of illustration, we will not distinguish from below. Note further that and is non-degenerate. Our bound for then essentially comes down to the two parts, and an which comes from the terms and , while the reminder part of the above expression contributes only with an order .
Note that
by (3) we instantly know that . Thus, . Note that once we obtain this bound for , we know that they are minor, then we may claim that the system of equations (46) is an order 1 matrix equation, the solution should be also of order 1. Now the bound for is improved to and .
Then we know that will contribute to the bound via an . Now suppose that for some . Then we know that will then contribute to the bound via an . And we may repeat the above process as long as we can establish the bounds simultaneously for and , which is totally applicable since they also share a similar structure of the form . Thus, we may improve the bound from to over and over again a sequence of improved bounds , , , , until we reach the limit .
Also note that the above argument only yields a bound , . However, we can further derive system of equations for all the terms above individually and establish bounds individually, since now would either break after differentiation or remain the way they are to reproduce terms of the form . However, note that will cease to produce higher-order structures. We then may obtain compact bounds for those again via the system of equations approach. The whole process is repetitive and tedious, thus omitted. Then we can conclude that those above are of order and further conclude that can be achieved.
A.5 System of equations for
Now we want to derive the system of equations that satisfies to order 1. Easy to observe that the contribution of higher-order cumulants would vanish and we have
where
the last line follows from the fact that .
Remark.
One may notice that if we fix and , we will get the system of equations for with a fixed coefficient matrix
It then becomes apparent that the coefficient matrix is actually universal regardless of and , which suggests that we can slice the tensor into matrices in which each satisfies a matrix equation and we can actually do the slicing in any of the 3 directions. We believe that this phenomenon discloses certain supersymmetric patterns explored by the higher-order tensors .
Also, the system of equations for induces another question. We still need to calculate .
A.6 System of equations for
Lemma A.1.
The vector := satisfies the following equation
where
Proof.
Analog to the case of , we derive the following system of equation
Reorganizing the proof with (7) yields the matrix form. ∎
Similar to , for , we have the following simplified form
| (47) |
which, again, is in accordance with the fact that the matrix should be symmetric
A.7 Proof of normality
In this subsection and Section B.3 only, we will use for the unit imaginary number .
To recover the covariance structure and prove normality, it’s natural to adopt the following setting as in [22] which can be viewed as variation of the Tikhomirov-Stein method. We will prove that for any integer and arbitrary collection of complex numbers from , where is taken as in the Proof of Lemma 4.1 to ensure the uniqueness and existence of the solution. The joint probability distribution of random variables converges as to the -dimensional Gaussian distribution with zero mean and the covariance matrix specified in the following section.
Proof.
Note that to prove that the process converges to a Gaussian process, we need to prove the real and imaginary parts of are jointly Gaussian in the limiting sense, so the first thing to do is to construct an adequate process.
Let and , further
and
then . And now we wanna prove that , , the joint probability distribution of random variables is the -dimensional Gaussian distribution with zero mean and covariance matrix
where should be in accordance with our covariance function previously defined in Section A.3. Then we need to consider the characteristic function of these random variables , which we shall write in the form
where . For simplicity, we shall use for when there is no confusion. Also, we would use and to denote and . Instantly, we have
and our main goal is to show that there exist sequences of coefficients of the covariance matrices s.t. for each fixed
and further, the limits of all these coefficients exist
and are in accordance with our previous results on the covariance function.
First, we need to calculate . By resolvent identity and cumulant expansion, we have
Note that higher-order expansion terms vanish, namely , thus minor.
We begin with
In other words, we observe a system of equations structure for here. Though we don’t need to derive the system explicitly, we still need to compare the system of equations for with (46). above shows the matching between the coefficient parts. Later we will compare the constant parts of both systems.
Before we proceed further, we need to calculate , Note that
It easily follows that
are minor and the detailed calculations are omitted here.
Further, note that
Thus,
Then we may conclude that
| (48) |
Compare the above formula with
where
A.8 Tightness of the process
After we establish the finite dimensional convergence, it remains to show that the process is tight.
In other words, we will show that
| (49) |
Simply note that
| (50) |
so we only need to show that . It suffices to show that
which has been proved in Section A.4. Therefore tightness is established.
∎
Appendix B Proof of Theorem 3.6
Similar to the proof of Theorem 3.5, we first derive the mean function in Section B.1 and the covariance function in Section B.2. Then we discuss the normality and the tightness for this data-driven renormalized case in Sections B.3 and B.4.
B.1 Mean function
By the fact that and the resolvent expansion formula. Note also that is essentially bounded, we have
| (51) | ||||
has been investigated in the previous sections. So we only need to estimate and .
where
Now further consider .
Similarly, decompose into
Note that the normalizing constant is of order , while the summation is over 4 independent indices . Further note that each term in the summation will be in the form , where the integers , , for each pair of , and , they are either or . Note that we have odd number of ’s and ’s and the the first of all 8 indices is , with the last one to be , so at least two won’t be diagonal terms when all four indices are different, note also that only one of could appear, which means at least one of , , or would appear in any of the products, which yields a order of , thus minor.
To be more precise, we have
For higher-order expansion terms of , , simply notice that the normalizing constant would be of order , while the summation is over 4 indices with any of the terms to be of due to the trivial bound , thus minor.
Then we proceed to .
where indicates the block matrix .
Among the above terms we know that only
is , while the others are .
B.2 Covariance function
To calculate this covariance function, first we need to do a decomposition.
| (52) | ||||
where
Instantly, we know that .
First, we consider .
The problem would be that there would be too many terms (including the terms) that need to be calculated provided with trivial bound .
Hence, we need a more efficient bound for ,
Also, note that
Thus, by Cauchy inequality we can show that
In the meantime, by Section B.1, we know
While is also known by Section A.3, we only need to consider .
Recall the system of equations for in A.3, note that the entries of the coefficient matrices are of order 1, thus
So we have Similarly, Then we see that only will count, which means that we will have exactly the same covariance function as in Section A.3. It remains to show the normality.
B.3 Proof of normality for the data-driven version
Proof.
The main procedure is exactly the same as that in Section A.7. For simplicity we will mainly focus more on the difference, some of the overlapping details will not be stated. Let and ,
and extend the definition of and , s.t.
Apparently . Then our goal is to prove that , the joint probability distribution of random variables is the -dimensional Gaussian distribution with zero mean and feasible covariance matrix. Then we consider the characteristic function of ,
where . And we will simply use when there is no confusion.
By the resolvent identity, we have
where
Note that by Cauchy inequality and adopting the same way we deal with , we can show that all the terms whose counterparts vanish in the case of will still vanish here. First, we need to approximate the derivatives.
One should note that truncating the infinite expansions to get approximation of the derivatives like this is always dangerous. However, note that the form of the higher-order expansion terms are always clear in the sense that will contribute one more . Also in our setting (13), , is the averaging of centered Bernoulli random variable, thus always bounded. So we may use a finite expansion here. We can see that
Comparing with , it’s not hard to see that as long as we can prove
and
the non-vanishing contribution of the terms to the covariance terms would be the same as in Section A.7.
Easy to see that
is minor. So are the other components generated by the reminder terms of the derivatives.
Similar things happen when we consider the analog of
the repetitive factors introduced by make the terms generated by the difference between and minor.
Then it remains to show that and are minor.
Thus, we may also conclude that the covariance function would be the same as that of Theorem 3.5 and the normality follows.
B.4 Tightness of the process
Similarly, after we establish the finite dimensional convergence, it left to show that the process is tight. We will show that
| (53) |
Again note that
and we can break down the question to boundedness of and adopt a similar approach to Section A.4. The details are omitted here.
∎
[Acknowledgments] The authors would like to thank Prof. Zhigang Bao at HKUST for his insightful suggestions and comments.
References
- [1] {barticle}[author] \bauthor\bsnmAdhikari, \bfnmKartick\binitsK., \bauthor\bsnmJana, \bfnmIndrajit\binitsI. and \bauthor\bsnmSaha, \bfnmKoushik\binitsK. (\byear2021). \btitleLinear eigenvalue statistics of random matrices with a variance profile. \bjournalRandom Matrices: Theory and Applications \bvolume10 \bpages2250004. \bdoi10.1142/S2010326322500046 \endbibitem
- [2] {barticle}[author] \bauthor\bsnmAiroldi, \bfnmEdoardo\binitsE., \bauthor\bsnmCosta, \bfnmThiago\binitsT. and \bauthor\bsnmChan, \bfnmStanley\binitsS. (\byear2013). \btitleStochastic blockmodel approximation of a graphon: Theory and consistent estimation. \bjournalAdvances in Neural Information Processing Systems. \endbibitem
- [3] {barticle}[author] \bauthor\bsnmAjanki, \bfnmOskari\binitsO., \bauthor\bsnmErdős, \bfnmLászló\binitsL. and \bauthor\bsnmKrüger, \bfnmTorben\binitsT. (\byear2015). \btitleQuadratic Vector Equations On Complex Upper Half-Plane. \bjournalMemoirs of the American Mathematical Society \bvolume261. \bdoi10.1090/memo/1261 \endbibitem
- [4] {barticle}[author] \bauthor\bsnmAjanki, \bfnmOskari H.\binitsO. H., \bauthor\bsnmErdős, \bfnmLászló\binitsL. and \bauthor\bsnmKrüger, \bfnmTorben\binitsT. (\byear2017). \btitleUniversality for general Wigner-type matrices. \bjournalProbability Theory and Related Fields \bvolume169 \bpages667–727. \bdoi10.1007/s00440-016-0740-2 \endbibitem
- [5] {barticle}[author] \bauthor\bsnmAnderson, \bfnmGreg W\binitsG. W. and \bauthor\bsnmZeitouni, \bfnmOfer\binitsO. (\byear2006). \btitleA CLT for a band matrix model. \bjournalProbability Theory and Related Fields \bvolume134 \bpages283–338. \bdoi10.1007/s00440-004-0422-3 \endbibitem
- [6] {bbook}[author] \bauthor\bsnmBai, \bfnmZ.\binitsZ. and \bauthor\bsnmSilverstein, \bfnmJack\binitsJ. (\byear2010). \btitleSpectral Analysis of Large Dimensional Random Matrices. \bpublisherSpringer. \bdoi10.1007/978-1-4419-0661-8 \endbibitem
- [7] {barticle}[author] \bauthor\bsnmBai, \bfnmZ. D.\binitsZ. D. and \bauthor\bsnmYao, \bfnmJ.\binitsJ. (\byear2005). \btitleOn the convergence of the spectral empirical process of Wigner matrices. \bjournalBernoulli \bvolume11 \bpages1059–1092. \bdoi10.3150/bj/1137421640 \endbibitem
- [8] {barticle}[author] \bauthor\bsnmBai, \bfnmZ D\binitsZ. D. (\byear1999). \btitleMethodologies in spectral analysis of large dimensional random matrices, a review. \bjournalStatistica Sinica \bvolume9 \bpages611–677. \endbibitem
- [9] {barticle}[author] \bauthor\bsnmBai, \bfnmZ D\binitsZ. D. and \bauthor\bsnmSilverstein, \bfnmJack W\binitsJ. W. (\byear2004). \btitleCLT for linear spectral statistics of large-dimensional sample covariance matrices. \bjournalAnnals of Probability \bvolume32 \bpages553–605. \endbibitem
- [10] {barticle}[author] \bauthor\bsnmBanerjee, \bfnmDebapratim\binitsD. and \bauthor\bsnmMa, \bfnmZongming\binitsZ. (\byear2017). \btitleOptimal hypothesis testing for stochastic block models with growing degrees. \bjournalarXiv: 1705.05305 \bpages1–77. \endbibitem
- [11] {barticle}[author] \bauthor\bsnmBao, \bfnmZhigang\binitsZ. and \bauthor\bsnmHe, \bfnmYukun\binitsY. (\byear2021). \btitleQuantitative CLT for linear eigenvalue statistics of Wigner matrices. \bjournalarXiv:2103.05402. \endbibitem
- [12] {barticle}[author] \bauthor\bsnmBenaych-Georges, \bfnmFlorent\binitsF., \bauthor\bsnmGuionnet, \bfnmAlice\binitsA. and \bauthor\bsnmMale, \bfnmCamille\binitsC. (\byear2014). \btitleCentral limit theorems for linear statistics of heavy tailed random matrices. \bjournalCommunications in Mathematical Physics \bvolume239 \bpages641-686. \bdoi10.1007/s00220-014-1975-3 \endbibitem
- [13] {barticle}[author] \bauthor\bsnmBenaych-Georges, \bfnmFlorent\binitsF. and \bauthor\bsnmKnowles, \bfnmAntti\binitsA. (\byear2018). \btitleLectures on the local semicircle law for Wigner matrices. \bjournalPanoramas et Syntheses, Société Mathématique de France \bvolume53 \bpages1–90. \endbibitem
- [14] {barticle}[author] \bauthor\bsnmChatterjee, \bfnmSourav\binitsS. (\byear2008). \btitleA New Method of Normal Approximation. \bjournalThe Annals of Probability \bvolume36 \bpages1584–1610. \endbibitem
- [15] {barticle}[author] \bauthor\bsnmChatterjee, \bfnmSourav\binitsS. (\byear2009). \btitleFluctuations of eigenvalues and second order Poincaré inequalities. \bjournalProbability Theory and Related Fields \bvolume143 \bpages1-40. \bdoi10.1007/s00440-007-0118-6 \endbibitem
- [16] {barticle}[author] \bauthor\bsnmCipolloni, \bfnmGiorgio\binitsG., \bauthor\bsnmErdős, \bfnmLászló\binitsL. and \bauthor\bsnmSchröder, \bfnmDominik\binitsD. (\byear2020). \btitleFunctional Central Limit Theorems for Wigner Matrices. \bjournalarXiv:2012.13218. \endbibitem
- [17] {barticle}[author] \bauthor\bsnmCostin, \bfnmOvidiu\binitsO. and \bauthor\bsnmLebowitz, \bfnmJoel L\binitsJ. L. (\byear1995). \btitleGaussian fluctuation in random matrices. \bjournalPhysical Review Letters \bvolume75 \bpages69–72. \bdoi10.1103/PhysRevLett.75.69 \endbibitem
- [18] {barticle}[author] \bauthor\bsnmErdős, \bfnmLászló\binitsL. (\byear2011). \btitleUniversality of Wigner random matrices: a survey of recent results. \bjournalRussian Mathematical Surveys \bvolume66 \bpages507–626. \bdoi10.1070/rm2011v066n03abeh004749 \endbibitem
- [19] {barticle}[author] \bauthor\bsnmErdős, \bfnmL.\binitsL. (\byear2019). \btitleThe matrix Dyson equation and its applications for random matrices. \bjournalarXiv: 1903:10060. \endbibitem
- [20] {barticle}[author] \bauthor\bsnmGuionnet, \bfnmAlice\binitsA. (\byear2002). \btitleLarge deviations upper bounds and central limit theorems for non-commutative functionals of Gaussian large random matrices. \bjournalAnnales de l’institut Henri Poincare (B) Probability and Statistics \bvolume38 \bpages341–384. \bdoi10.1016/S0246-0203(01)01093-7 \endbibitem
- [21] {barticle}[author] \bauthor\bsnmHe, \bfnmYukun\binitsY. and \bauthor\bsnmKnowles, \bfnmAntti\binitsA. (\byear2017). \btitleMesoscopic eigenvalue statistics of wigner matrices. \bjournalAnnals of Applied Probability \bvolume27 \bpages1510–1550. \bdoi10.1214/16-AAP1237 \endbibitem
- [22] {barticle}[author] \bauthor\bsnmKhorunzhy, \bfnmAlexei M.\binitsA. M., \bauthor\bsnmKhoruzhenko, \bfnmBoris A.\binitsB. A. and \bauthor\bsnmPastur, \bfnmLeonid A.\binitsL. A. (\byear1996). \btitleAsymptotic properties of large random matrices with independent entries. \bjournalJournal of Mathematical Physics \bvolume37 \bpages5033–5060. \bdoi10.1063/1.531589 \endbibitem
- [23] {barticle}[author] \bauthor\bsnmLandon, \bfnmBenjamin\binitsB. and \bauthor\bsnmSosoe, \bfnmPhilippe\binitsP. (\byear2018). \btitleApplications of mesoscopic CLTs in random matrix theory. \bjournalarXiv: 1811.05915 \endbibitem
- [24] {barticle}[author] \bauthor\bsnmLee, \bfnmJi\binitsJ. and \bauthor\bsnmSchnelli, \bfnmKevin\binitsK. (\byear2018). \btitleLocal law and Tracy-Widom limit for sparse random matrices. \bjournalProbability Theory and Related Fields \bvolume171. \bdoi10.1007/s00440-017-0787-8 \endbibitem
- [25] {barticle}[author] \bauthor\bsnmLei, \bfnmJing\binitsJ. (\byear2016). \btitleA goodness-of-fit test for stochastic block models. \bjournalAnnals of Statistics \bvolume44 \bpages401–424. \bdoi10.1214/15-AOS1370 \endbibitem
- [26] {barticle}[author] \bauthor\bsnmLytova, \bfnmA.\binitsA. and \bauthor\bsnmPastur, \bfnmL.\binitsL. (\byear2009). \btitleCentral limit theorem for linear eigenvalue statistics of random matrices with independent entries. \bjournalAnnals of Probability \bvolume37 \bpages1778–1840. \bdoi10.1214/09-AOP452 \endbibitem
- [27] {barticle}[author] \bauthor\bsnmMingo, \bfnmJames A.\binitsJ. A. and \bauthor\bsnmSpeicher, \bfnmRoland\binitsR. (\byear2006). \btitleSecond order freeness and fluctuations of random matrices: I. Gaussian and Wishart matrices and cyclic Fock spaces. \bjournalJournal of Functional Analysis \bvolume235 \bpages226-270. \bdoihttps://doi.org/10.1016/j.jfa.2005.10.007 \endbibitem
- [28] {barticle}[author] \bauthor\bsnmSinai, \bfnmYa.\binitsY. and \bauthor\bsnmSoshnikov, \bfnmA.\binitsA. (\byear1998). \btitleCentral limit theorem for traces of large random symmetric matrices with independent matrix elements. \bjournalBoletim da Sociedade Brasileira de Matemática - Bulletin/Brazilian Mathematical Society \bvolume29 \bpages1-24. \bdoi10.1007/BF01245866 \endbibitem
- [29] {barticle}[author] \bauthor\bsnmTikhomirov, \bfnmA. N.\binitsA. N. (\byear1980). \btitleOn the convergence rate in the central limit theorem for weakly dependent random variables. \bjournalTheory of Probability and Its Applications \bvolumeXXV \bpages790–809. \bdoi10.1002/0471667196.ess2714.pub2 \endbibitem
- [30] {barticle}[author] \bauthor\bsnmZhu, \bfnmYizhe\binitsY. (\byear2020). \btitleA graphon approach to limiting spectral distributions of Wigner-type matrices. \bjournalRandom Structures & Algorithms \bvolume56 \bpages251-279. \bdoihttps://doi.org/10.1002/rsa.20894 \endbibitem