Cellular Network Speech Enhancement: Removing Background and Transmission Noise
Abstract
The primary objective of speech enhancement is to reduce background noise while preserving the target’s speech. A common dilemma occurs when a speaker is confined to a noisy environment and receives a call with high background and transmission noise. To address this problem, the Deep Noise Suppression (DNS) Challenge focuses on removing the background noise with the next-generation deep learning models to enhance the target’s speech; however, researchers fail to consider Voice Over IP (VoIP) applications their transmission noise. Focusing on Google Meet and its cellular application, our work achieves state-of-the-art performance on the Google Meet To Phone Track of the VoIP DNS Challenge. This paper demonstrates how to beat industrial performance and achieve 1.92 PESQ and 0.88 STOI, as well as superior acoustic fidelity, perceptual quality, and intelligibility in various metrics.

1 Introduction
Online Voice Over IP (VoIP) meeting platforms such as Google Meet, Zoom, and Microsoft Teams allow users to join conferences through a regular phone via Audio Conferencing [1]. This option is frequently used by users who are either on the go, have a poor internet connection, or would prefer to join a meeting hands-free [2]. Given the convenience such an option offers, it is an indispensable functionality that motivates our focus on the Google Meet To Phone track of the VoIP DNS Challenge. 111https://github.com/deepology/VoIP-DNS-Challenge
However, Audio Conferencing brings about the problem of transmission noise. Speech quality is degraded not only by the background noise present when taking the call but also by the transmission channel, whether it be through a telephone line or via wireless transmission [3]. This is even more prevalent with mobile telephone transmission, where additional factors, including network congestion and packet loss, further degrade transmission quality [4]. These factors result in information loss during communication [5].
Thus, it is important to mitigate information loss by introducing speech enhancement methods to reduce transmission noise. Existing deep learning approaches predominantly focus on removing background noise, and Google Meet itself has a “Noise Cancellation” feature that uses deep learning models to address this issue. However, speech enhancement to remove transmission noise and background noise remains largely unexplored. Our aim is to explore speech enhancement models and improve the speech quality of audio coming through Google Meets over calls. The code for all the experiments and ablations can be found at https://github.com/hamzakhalidhk/11785-project
2 Background
Within the current literature, datasets for speech enhancement tasks are often synthesized, a process in which noise is added to clean audio. This is because supervised optimization requires pairs of noisy inputs and clean targets. [6] introduced the INTERSPEECH 2020 Deep Noise Suppression Challenge (DNS) with a reproducible synthesis methodology. With clean speech from Librivox corpus and noise from Freesound and AudioSet, enabling upwards of 500 hours of noisy speech to be created. The VoIP DNS Challenge provides 20 hours of Google Meets to Phone relay, including synthetic background noise at the source and real-world transmission noise at the receiver.
Of the current state-of-the-art speech enhancement models on the 2020 DNS Challenge, this study focuses on Demucs and FullSubNet. Demucs operates on waveform inputs in the time domain, whose real-time denoising architecture was proposed by Defossez et al. [7]. FullSubNet operates on spectrogram inputs in the time-frequency domain and was developed by Hao et al. [8]. Baseline Demucs achieves 1.73 PESQ and 0.86 STOI, while Baseline FullSubNet achieves 1.69 PESQ and 0.84 STOI. As both of these baseline models do not account for transmission noise, our investigation is focused on fine-tuning and improving the acoustic fidelity, perceptual quality, and intelligibility for the VoIP DNS Challenge challenge.
3 Dataset
Our dataset is built off of audio clips from the open-sourced dataset222https://github.com/microsoft/DNS-Challenge/tree/interspeech2020/master/datasets released from Microsoft’s Deep Noise Suppression Challenge (DNS). Specifically, we utilize the test set of synthetic clips without reverb from the DNS data, as described by Reddy et al. [6]. Our novel dataset contains these audio clips with the addition of transmission noise resulting from taking a Google Meet call through a cellular device. It is created as described in the following steps.
First, clean speech and noise audio are randomly selected from the DNS dataset. These audio files are then mixed, resulting in the noisy audio of clean speech with background noise. Next, to include the transmission noise of a Google Meet to a phone session, we start a Google Meet session and call into the session using a phone that is on the T-mobile network. We then play the noisy speech audio in Google Meet, and the audio that is relayed to the phone is recorded to an audio interface.
The final recorded audio captures both background noise and transmission noise on a Google Meet session. Furthermore, we note that we have recorded the audio with both the Google Meet noise cancellation feature turned on and off to compare our models with industry standards. We refer to the audio with Google Meet speech enhancement turned off as low, and the audio with speech enhancement turned on as auto. In our work, for each of the auto and low data sources, we utilize 400 audio clips (each thirty seconds long) for our training samples and 150 ten-second audio clips for our testing samples. We further apply gain normalization to transform the audio files to the same amplitude range to facilitate training. This transforms the audio files to the same amplitude range to enable better model training. Figure 1 depicts the dataset synthesis process.

4 Models
We select Demucs and FullSubNet (see Section 4.1 and 4.2), as baseline models in our work, as both models have yielded state-of-the-art results in the DNS Challenge [8, 9]. Demucs consists of 2 LSTM layers between an encoder-decoder structure. FullSubNet is a fusion model that combines a full-band model that captures the global spectral context and a sub-band model that encapsulates the local spectral pattern for single-channel real-time speech enhancement.
4.1 Demucs
The Demucs architecture is heavily inspired by the architectures of SING [10], and Wave-U-Net [11]. It is composed of a convolutional encoder, an LSTM, and a convolutional decoder. The encoder and decoder are linked with skip U-Net connections. The input to the model is a stereo mixture and the output is stereo estimate for each source. Fig 2 (a) shows the architecture of the complete model.
Demucs’ criterion minimizes the sum of the L1-norm, , between waveforms and the multi-resolution STFT loss, of the magnitude spectrograms.
Without , we observe tonal artifacts. We discuss ablating and more recent auxiliary losses in Section 5.2.
4.2 FullSubNet
FullSubNet is a full-band and sub-band fusion model, each with a similar topology. This includes two stacked unidirectional LSTM layers and one linear (fully connected) layer. The only difference between the two is that, unlike the full-band model, the output layer of the sub-band model does not use any activation functions. Fig 2 (c) shows the complete model architecture.
FullSubNet adopts the complex Ideal Ratio Mask () as their model’s learning target. They use a hyperbolic tangent to compress in training and an inverse function to uncompress the mask in inference .
5 Methods

5.1 Baseline Method
On the VoIP DNS Challenge, Google Meets To Phone track, we determine baseline performance using pre-trained Demucs and FullSubNet. Our work improves on this, ablating a variety of criteria. Table 1 and Table 2 of Section 5.4 show ablations.
5.2 TAPLoss
We introduce TAPLoss during training to outperform the state-of-the-art speech recognition models on our data. Taploss involves a set of 25 temporal acoustic parameters, including frequency-related parameters: pitch, jitter, F1, F2, F3 Frequency and bandwidth; energy or amplitude-related parameters: shimmer, loudness, harmonics-to-noise (HNR) ratio; spectral balance parameters: alpha ratio, Hammarberg Index, spectral slope, F1, F2, F3 relative energy, harmonic difference; and additional temporal parameters: rate of loudness peaks, mean and standard deviation of length of voiced/unvoiced regions, and continuous voiced regions per second.
5.2.1 Enhanced Demucs loss
Previous works have shown that Demucs model is prone to generating tonal artifacts. The multi-resolution STFT loss amplifies this issue because the error introduced by tonal artifacts is more significant and obvious in the time-frequency domain than in the time domain. Thus, we reduce the influence of in the demucs loss and, additionally, introduce the tap loss . The new demucs loss function is defined as:
5.2.2 Enhanced FullSubNet loss
We also extend the FullSubNet loss by introducing the loss. The new FullSubNet loss is defined as:
5.3 Ablations
We perform ablations to find the optimal values for each of the hyperparameters and for Demucs, and for FullSubNet. These optimal values were determined by their performance on the Perceptual Evaluation of Speech Quality (PESQ) and Short-Time Objective Intelligibility (STOI) metrics, which are defined in Table 4. Table 1 and Table 2 show the summary of our ablations for Demucs and FullSubNet, respectively.
5.4 Evaluation Metrics
After determining the optimal hyperparameter values for both models, we further evaluate the respective models with both objective metrics and acoustic parameters.
5.4.1 Objective Evaluation
In addition to PESQ and STOI, we further test the models on three more objective metrics: Log-Likelihood Ratio (LLR), Coherence and Speech Intelligibility Index (CSII), and Normalized-Covariance Measure (NCM). PESQ and LLR measure Speech Quality (SQ), while the STOI, CSII, and NCM measure Speech Intelligibility (SI). All four metrics aim to capture the human-judged quality of speech recordings, which is regarded as the gold standard for evaluating Speech Enhancement models [12]. These metrics are defined in Appendix A.2.
5.4.2 Acoustic Evaluation
In addition to objective metrics, we also utilize the set of acoustic parameters, specifically the eGeMAPSv02 functional descriptors, presented by [13] to evaluate the model further. This is a set of 88 frequency, energy/amplitude, and spectral-related parameters. We use the OpenSMILE (Open-source Speech and Music Interpretation by Large-space Extraction)333https://github.com/audeering/opensmile-python python package for these parameters.
| Industry Speech Enhancement ON | ||||||
|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 1.0 | 0.8 | 0.75 | 0.5 | |
| 0.8 | 0.5 | 0.0 | 0.5 | 0.5 | 0.5 | |
| STOI | 0.832 | 0.852 | 0.681 | 0.867 | 0.882 | 0.870 |
| PESQ | 1.658 | 1.844 | 1.488 | 1.780 | 1.921 | 1.863 |
| Industry Speech Enhancement ON | ||||||
|---|---|---|---|---|---|---|
| 1.00 | 0.30 | 0.10 | 0.03 | 0.01 | 0.00 | |
| STOI | 0.864 | 0.863 | 0.860 | 0.861 | 0.858 | 0.861 |
| PESQ | 1.843 | 1.829 | 1.805 | 1.867 | 1.787 | 1.808 |
| Industry Speech Enhancement OFF | ||||||
| 1.00 | 0.30 | 0.10 | 0.03 | 0.01 | 0.00 | |
| STOI | 0.722 | 0.731 | 0.735 | 0.740 | 0.739 | 0.739 |
| PESQ | 1.427 | 1.437 | 1.470 | 1.572 | 1.621 | 1.617 |


6 Results
6.1 Acoustic Improvement
To quantify the improvement of the acoustic parameters mentioned in section 5.4, we measure acoustic improvement as defined by [14]. First, we calculate the mean absolute error (MAE) across the time axis. The MAE between our novel dataset’s noisy and clean audio files is denoted as . The MAE between the baseline enhanced audio (output of FullSubNet or Demucs without finetuning) and clean audio files are denoted as . Lastly, the MAE between the enhanced audio from the finetuned model and clean audio files is denoted as . Then, improvement is defined as follows, where is the improvement of baseline models and is the improvement of our fine-tuned models.
| (1) |
| (2) |
6.2 Objective Metric Results
Our results for the objective metrics are depicted in Table 3. We find that our finetuned models are able to outperform the baseline Demucs and FullSubNet models across all metrics.
| Demucs | FullSubNet | |||
|---|---|---|---|---|
| Baseline | Finetuned | Baseline | Finetuned | |
| 1.727 | 1.921 | 1.694 | 1.822 | |
| 1.432 | 1.645 | 1.630 | 1.833 | |
| 0.864 | 0.883 | 0.841 | 0.860 | |
| 0.665 | 0.667 | 0.652 | 0.653 | |
| 0.535 | 0.572 | 0.514 | 0.539 | |
| 0.327 | 0.333 | 0.299 | 0.334 | |
| 0.692 | 0.756 | 0.650 | 0.675 | |
7 Conclusion
In this work, we surpass the industry-standard performance and SOTA baseline architectures – identify transmission noise as a missing component of current speech enhancement research. We achieve top performance on the VoIP DNS Challenge, improving both the transmission and background noise of audio recordings on the Google Meet To Phone track. We set a new benchmark for speech enhancement by evaluating baseline Demucs and FullSubNet models on our novel dataset. Further, we demonstrate that introducing TAPLoss into the training process and finetuning these models can further improve performance. In the future, we aim to increase our training data from 400 samples to 1200 samples in order to achieve even better performance on our models. We believe that our work can find applications in the telecom industry and directly with mobile phone manufacturers.
8 Acknowledgements
We would like to thank Carnegie Mellon University, Professor Bhiksha Raj, and our mentors Joseph Konan and Ojas Bhargave for their staunch support, encouragement, and guidance throughout this project.
References
- [1] B. N. Ilag, “Teams audio conferencing and phone system management,” in Understanding Microsoft Teams Administration. Springer, 2020, pp. 263–339.
- [2] B. N. Ilag and A. M. Sabale, “Microsoft teams overview,” in Troubleshooting Microsoft Teams. Springer, 2022, pp. 17–74.
- [3] J. Kaiser and T. Bořil, “Impact of the gsm amr codec on automatic vowel formant measurement in praat and voicesauce,” in 2018 41st International Conference on Telecommunications and Signal Processing (TSP). IEEE, 2018, pp. 1–4.
- [4] K. McDougall, F. Nolan, and T. Hudson, “Telephone transmission and earwitnesses: Performance on voice parades controlled for voice similarity,” Phonetica, vol. 72, no. 4, pp. 257–272, 2015.
- [5] S. Lawrence, F. Nolan, and K. McDougall, “Acoustic and perceptual effects of telephone transmission on vowel quality.” International Journal of Speech, Language & the Law, vol. 15, no. 2, 2008.
- [6] C. K. Reddy, V. Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,” arXiv preprint arXiv:2005.13981, 2020.
- [7] A. Défossez, N. Usunier, L. Bottou, and F. Bach, “Music source separation in the waveform domain,” arXiv preprint arXiv:1911.13254, 2019.
- [8] X. Hao, X. Su, R. Horaud, and X. Li, “Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6633–6637.
- [9] A. Defossez, G. Synnaeve, and Y. Adi, “Real time speech enhancement in the waveform domain,” arXiv preprint arXiv:2006.12847, 2020.
- [10] A. Défossez, N. Zeghidour, N. Usunier, L. Bottou, and F. Bach, “Sing: Symbol-to-instrument neural generator,” Advances in neural information processing systems, vol. 31, 2018.
- [11] D. Stoller, S. Ewert, and S. Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” arXiv preprint arXiv:1806.03185, 2018.
- [12] C. K. Reddy, V. Gopal, and R. Cutler, “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6493–6497.
- [13] F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. André, C. Busso, L. Y. Devillers, J. Epps, P. Laukka, S. S. Narayanan et al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,” IEEE transactions on affective computing, vol. 7, no. 2, pp. 190–202, 2015.
- [14] Zeng, Konan, Han, Bick, Yang, Kumar, Watanabe, and Raj, “Taploss: A temporal acoustic parameter loss for speech enhancement,” Unpublished manuscript, 2022.
- [15] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752.
- [16] R. Crochiere, J. Tribolet, and L. Rabiner, “An interpretation of the log likelihood ratio as a measure of waveform coder performance,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 28, no. 3, pp. 318–323, 1980.
- [17] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010, pp. 4214–4217.
- [18] J. M. Kates and K. H. Arehart, “Coherence and the speech intelligibility index,” The journal of the acoustical society of America, vol. 117, no. 4, pp. 2224–2237, 2005.
- [19] J. F. Santos, S. Cosentino, O. Hazrati, P. C. Loizou, and T. H. Falk, “Objective speech intelligibility measurement for cochlear implant users in complex listening environments,” Speech Communication, vol. 55, no. 7-8, p. 815–824, 2013.
Appendix A Appendix
A.1 Calculating TAPLoss
To calculate the TAPLoss, we define the Temporal Acoustic Parameter Estimator . represents the acoustic parameter at a discrete time frame . To predict , we define the estimator:
The function takes in a signal input . It calculates a complex spectrogram with frequency bins. It then passes this complex spectrogram to a recurrent neural network to output the temporal acoustic parameter . TAP loss is then defined as the mean average error between the actual and the predicted estimate.
During training, parameters learn to minimize the divergence of using Adam optimization. Since this loss is end-to-end differentiable and takes only waveform as input, it enables acoustic optimization of any speech model and task with clean references.
A.2 Metrics Definitions
| Metric | Description |
|---|---|
| PESQ | Captures the human subjective rating of speech quality degradation caused by network conditions including analog connections and packet loss [15] |
| LLR | Assesses speech quality by determining the goodness of fit between clean and enhanced speech [16] |
| STOI | Measures the intelligibility of degraded speech signals caused by factors such as additive noise [17] |
| CSII | Determines speech intelligibility under bandwidth reduction and additive noise conditions by measuring the signal-to-noise ratio in separate frequency bands. It is calculated in three regions: high, mid, and low, where high measures segments at or above the root-mean-square (RMS) decibel level of the speech, mid measures segments in the range (RMS-10, RMS], and low in the range (RMS-30, RMS-10] [18] |
| NCM | Estimates speech intelligibility based on the covariance between the envelopes of the clean and noisy speech signals [19] |
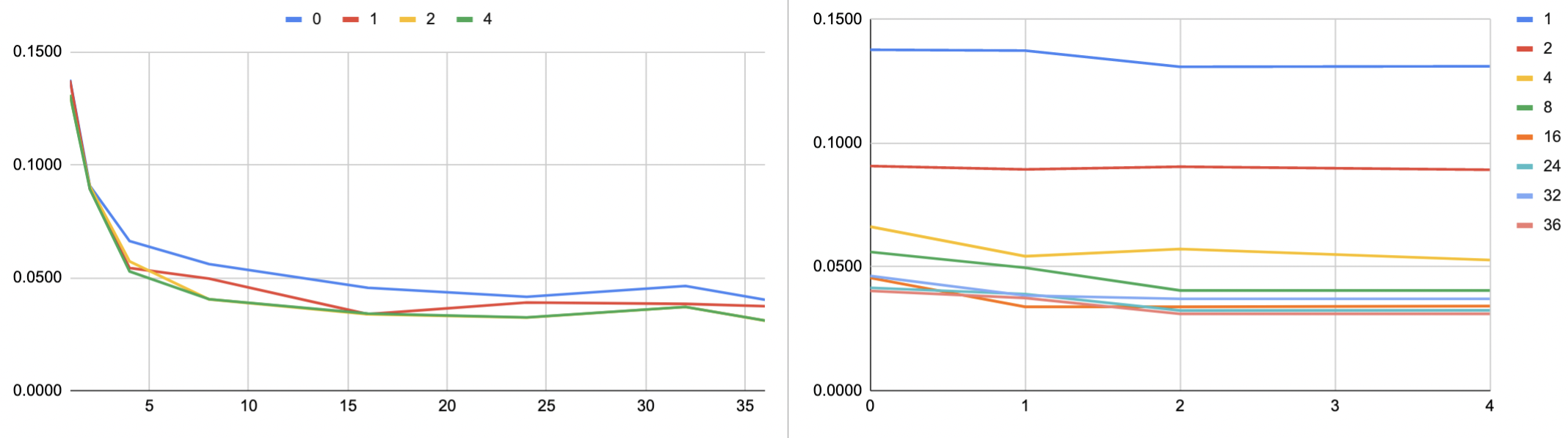


A.3 Optimal Batch Size and the Number of Workers
Figures 6 and 7 show our experiments on finding the optimal batch size for training DEMUCS and FullSubNet respectively. We finally decided on a batch size of 36 and a number of workers of 2 for DEMUCS. For FullSubNet, we went with a batch size of 16 and a number of workers of 2.
A.4 GPU Scaling
Once the batch size and number of workers were decided, we scaled our experiments over multiple GPUs to attain the most optimal time to be used for training as shown in figures 8 and 9.