CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Abstract
Deep neural network based object detection has become the cornerstone of many real-world applications. Along with this success comes concerns about its vulnerability to malicious attacks. To gain more insight into this issue, we propose a contextual camouflage attack (CCA for short) algorithm to influence the performance of object detectors. In this paper, we use an evolutionary search strategy and adversarial machine learning in interactions with a photo-realistic simulated environment to find camouflage patterns that are effective over a huge variety of object locations, camera poses, and lighting conditions. The proposed camouflages are validated effective to most of the state-of-the-art object detectors.
I Introduction
Object detection has become a crucial part for many applications, such as autonomous driving [1], law enforcement and orbital surveillance [2], to name a few. The rapid development of artificial intelligence (AI) and deep neural networks(DNNs) in the past few years boost the advancement of this task. However, state-of-the-art object detectors [3, 4, 5, 6] heavily depend on convolutional neural networks (CNNs) [7] which, unfortunately, have been shown vulnerable to adversarial attack—an adversary which can manipulate the CNNs’ output by adding imperceptible perturbations to an input image [8]. Moreover, some recent works also show an adversary can even fool object detectors in the real world by adding small distractions to physical objects [9, 10].
Unlike previous adversarial attack works, in this paper we intend to attack object detectors’ performance by learning a perturbation on the contextual object of the input image. Our approach hinges on an evolution search strategy [11] for the optimization of the non-differentiable objective function, which involves a complex 3D environmental simulation when mapping from an input (a camouflage pattern) to an output (the object detection accuracy). The simulated output images are shown in Fig. 1. Given a batch of vehicles and a collection of simulated environments [12], our goal is to generate a camouflage for one of the vehicle and influence the detectors’ performance on the other unpainted vehicles in those environments. To be noted, our algorithm is also different from the classic patch-based adversarial attacks [13, 14]. Instead of placing the patch in a random location within the image, we directly change the appearance of the object to investigate the effect on other object detection performance, which could be more powerful and general for different scenarios.
Many steps in this procedure are like black-boxes to us. Knowing the camouflage pattern, we are able to paint it onto the vehicle, but we have no idea how to write out a differentiable expression for the “painting function”. Similarly, we can drive the vehicle with the painted camouflage to various places in the environments and take pictures of the vehicle, but we cannot write out a differentiable “photographing function”. The list goes on. As a result, we have to explicitly deal with the black-box steps.
A clone function is employed in [11] to approximate the black-box steps. The authors propose to alternatively learn the clone function and search for the camouflage using this clone function. However, the quality of the camouflage highly depends on the performance of this clone function. When the two inter-dependent items are jointly learned, it is easy to be trapped at a poor local optimum. Besides, the simulators often introduce some randomness into the rendering procedure, making the clone function actually a mis-specified model. In this paper, we instead explicitly leverage the randomness of the simulator, along with the unknown black-box steps in the procedure from painting a camouflage onto a contextual vehicle to the results of detecting the other vehicles within the image. According to the evolution search strategy [11], we are estimating the expected gradient of a distribution via dense sampling the distribution. The gradient error, which is caused by a noisy function, is naturally bounded during the optimization by the reciprocal of the square root of the size of the search distribution, thus eliminating the need for ad-hoc steps such as repeated queries. Since we directly estimate the expected gradient w.r.t the camouflage, there would not be local minimum deadlock as mentioned in [12].

To sum up, we make the following contributions:
-
•
We demonstrate that, for the first time, by learning a camouflage on a contextual vehicle, we could attack the detectors’ performance on the unpainted vehicles in the same image. Our learned camouflage is validated to work on all of the three state-of-the-art object detectors.
-
•
We proposed a new method that jointly models the transformation distribution and camouflage variations.
-
•
In addition to the contextual adversarial attack, we demonstrate the applicability of our CCA model to enhance the performance of object detectors.
II Related Work
In this section, we introduce some related works which aim to defunctionalize CNNs. While other authors use adversarial learning for purposes different from ours, such as extracting private information [15], we narrow our scope to those that aim to defunctionalize CNNs.
II-A Adversarial Attack and Blackbox Optimization
Whether targeting a classification model or a detection model, adversarial machine learning (AML) against CNNs has seen great development since Szegedy et al. [16] discovered that small perturbations could alter CNN predictions. A considerable amount of recent AML literature [17, 18, 19, 20] requires a target model to be transparent to calculate the gradient, as knowing a numerical pathway between a perturbation and a model prediction grants an enormous optimization advantage. Such a pathway is not always available given that a target model is often a blackbox in real attacks. Various proposed blackbox attack methods rely solely on query and target model output. Most of these are still based on gradient descent. The difference lies in how they estimate a perturbation gradient in the blackbox setting. ZOO [21] estimates it by coordinate descent. [22] trained a substitute model to mimic the target model behavior to obtain the gradient. [23, 24] estimate it via an evolutionary strategy. [25] is based on differential evolution. [12] shares the same task with us and they choose to minimize an end-to-end clone network that is trained to directly estimate score from camouflage.
II-B Physical Adversarial Attack
One of the sub-areas of AML is to generalize it to the physical dimension. This is challenging because training in silico often results in poor generalization to real environments. The first attempt was by [26] and they produced perturbations that remain effective when printed on paper. [10] generalize a perturbation to fool a classifier of real stop sign images. However [27, 28] found that [10]’s perturbation do not work on a real world detector. This is likely because detectors are more robust than classifiers since detectors must detect objects at multiple scales. Later, [19, 29] proposed perturbations that could attack stop-sign detectors in the real-world. However, all the aforementioned works are perturbing detectors of stop signs, which are planar objects whose images, under changes in camera geometry, are related by linear 2D projective transformations. This is in contrast to nonplanar objects whose images, under changes in camera geometry, are related by more complex range-dependent nonlinear transformations. Perturbations are easily transformed via linear 2D projective transformation without breaking the gradient chain between the perturbation and the output score [30, 10]. Complex nonlinear transformations, however, will require a dedicated 3D simulation, such as the one used in our paper, which breaks the gradient chain and greatly complicates the optimization. Besides, there are only 1983 stop sign instances in the training split of MS-COCO [31]. Meanwhile, there are 43867 cars of various appearance in it. Such a great amount and diversity benefits vehicle detectors’ generalization capacity trained on MS-COCO and makes it harder to fool.
III Approach
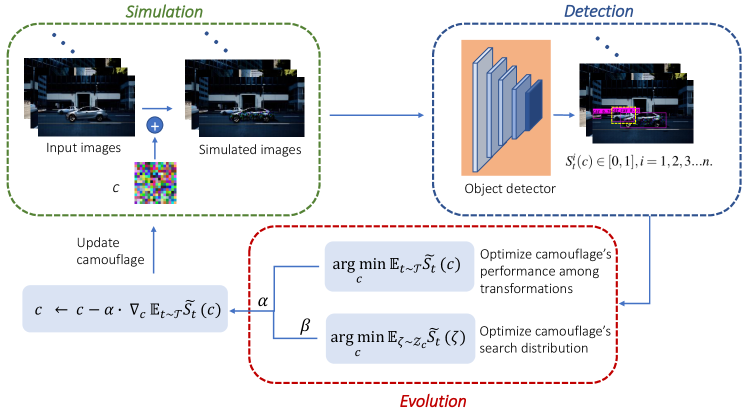
III-A Problem Statement
The framework of proposed algorithm is shown in Fig. 2. There are mainly three phases in our algorithm, including simulation, detection and evolution. Let denote a vehicle camouflage pattern represented by an RGB image. When has been painted onto the surface of a vehicle in a tiled style, state-of-the-art object detectors would completely or partially fail to detect/classify the vehicle regardless of observation angles, distances and environments. In this context, we aim to determine whether it is possible to create a camouflage pattern , being painted on a given vehicle, could mislead detectors to make incorrect detection/classification on the other vehicles (without camouflage) in the same scene. After inputting the simulated images into detectors and outputting the detection results, we conduct the optimization of the proposed camouflage from two aspects, namely the attack performance of the camouflage on detectors and search distribution of the camouflage. The workflow of proposed contextual adversarial attack is shown in Algorithm 1. We describe our approach to implementing the proposed loss function in Section III-B. In Section III-C we outline the architecture of our evolutionary model to generate the optimal camouflage pattern.
III-B Loss Function Designation
Given a camouflage pattern , represented by a RGB image, we would like to convert it to a photo that looks like real. We denote as the transformation, specifically including tiling and painting the onto a vehicle, moving the vehicle to a location in an environment and at last taking a photo of that vehicle from a certain angle and distance. After transformation, we will have an image with a vehicle covered by a camouflage texture in it. We suppose that there are vehicles in the generated image except for the one with camouflage. Then, we could denote the scores of the vehicles without camouflage as . The overeaching idea of our algorithm is to find an optimal camouflage, such that the mean score of is low:
| (1) |
For the concern about the complexity of the physical world, following [32], we construct a batch of transformations for each learning procedure, involving the factors of different lighting condition, and distance and viewpoint changes. Thus, by minimizing the score in expectation, we have the following optimization problem:
| (2) |
where is the mean score of . And then we could have eq. 2 as:
| (3) |
III-C Evolutionary Model
In this section, we aim to optimize a flattened during the training process. Specifically, it contains two major components. First one is the performance over various transformations. Besides, we also want to optimize ’s search distribution’s members’ performance. Suppose is the search distribution of camouflage , then, for a fixed transformation , our goal is to optimize:
| (4) |
Inspired by [33], we design our gradient as:
| (5) | ||||
where is the number of samples from the distribution. However, different from the problem mentioned in [11], our optimization has a constraint of because of the image feature of . In our case, we propose to use a truncated multivariate normal distribution to bound both and the search radius without extra hassle.
Instead of directly minimizing , we choose to minimize the binary cross-entropy between it and zero as shown eq. 6:
| (6) |
During optimization, we assume the scores of are normally distributed given that itself is normally distributed. In this case, by normalizing into standard scores using , we could have:
| (7) | ||||
Then, we arrive at our normalized gradient:
| (8) | ||||
Then, the gradient approximation in eq. 8 is used to perform gradient descent. We choose to perform simple gradient descent which is:
| (9) |
where is the learning rate. Then we update until no longer decreases.
| Camouflages | Training set | Testing set | |||||||
|---|---|---|---|---|---|---|---|---|---|
|
mIOU(%) | [email protected](%) |
|
mIOU(%) | [email protected](%) | ||||
| Basic colors | 55.87 | 49.93 | 65.71 | 57.10 | 51.92 | 63.23 | |||
| Random camouflage | 55.02 | 48.78 | 63.70 | 54.06 | 48.57 | 61.77 | |||
| Ours | 51.35 | 47.25 | 62.35 | 53.25 | 48.15 | 60.48 | |||
| Camouflages | Training set | Testing set | |||||||
|---|---|---|---|---|---|---|---|---|---|
|
mIOU(%) | [email protected](%) |
|
mIOU(%) | [email protected](%) | ||||
| Basic colors | 48.48 | 46.61 | 49.78 | 48.87 | 47.54 | 48.19 | |||
| Random camouflage | 48.90 | 47.08 | 49.61 | 48.79 | 47.46 | 47.87 | |||
| Ours | 46.82 | 45.54 | 47.77 | 47.97 | 46.91 | 46.71 | |||
| Camouflages | Training set | Testing set | |||||||
|---|---|---|---|---|---|---|---|---|---|
|
mIOU(%) | [email protected](%) |
|
mIOU(%) | [email protected](%) | ||||
| Basic colors | 34.44 | 38.96 | 46.46 | 34.02 | 39.48 | 46.31 | |||
| Random camouflage | 34.08 | 38.75 | 45.78 | 33.77 | 39.36 | 46.39 | |||
| Ours | 33.02 | 37.81 | 44.83 | 33.60 | 38.53 | 45.42 | |||
IV Experiments
In this section, we present the experiment results to demonstrate the effectiveness of the proposed method.
IV-A Dataset
In this work, we use the Unreal Engine to build a simulation environment based on the real downtown environment. Specifically, we build different kind of cars, roads, traffic signals in the simulated environment. To obtain valid data for training and testing, we sequentially camouflage and place a professionally modeled Camry 2015 XLE in different locations in the environments. Also, 36 locations are sampled along the roads in the environment, 18 of which for training and the remaining 18 for testing. At each location, we record RGB images and groundtruth of the vehicle and the surrounding area from 20 fixed camera orientations. We manually label all the groundtruth of vehicles into two categories: the one carrying the camouflage and the normal ones. These images and groundtruths are then sent to the detector for evaluation. Inspired by [12], in our experiments, we set the resolution of camouflage to be .
IV-B Implementation Details
For evaluation, we use two MS-COCO [31] pretrained detectors in our experiments: YOLOv3 [5] and Mask-RCNN [3]. Mask-RCNN is currently one of the hallmark detectors for object detection in terms of detection performance. YOLOv3, on the other hand, balances performance with detection speed. We use the YOLOv3-SPP variant, which has the best detection performance among the YOLOv3 family.
Also, we apply three detection metrics as the indicators of performance: detection confidence, mean Intersection over Union (mIoU) [34] and [email protected] ([email protected]). The detection confidence is the mean value of the scores of the detected cars in different scenes. The Intersection over Union between predicted bounding box and ground truth bounding box is defined by [34]. In our experiments, we use the best IoU achieved among all vehicle bounding box predictions for the image as its IoU. The mIoU is the averaged IoU across all images at all locations that are being reported. The [email protected] is the percentage of images that have IoU larger than 0.5. This metric is used in the PASCAL detection challenge [34], which considers a detection prediction to be successful if its IoU is greater than 0.5.
For a thorough evaluation, inspired by [12], we compare our results with two baselines to validate the effective of the proposed camouflage, as shown in Fig. 1. The first one is conducted by painting the central vehicle with six real vehicle colors (red, black, silver, grey, blue, and white) and compute the mean value of the detection metrics. Another one is that we generate 5 random camouflages with the same resolution of the learned camouflage and report the mean values of the detection metrics for comparison.
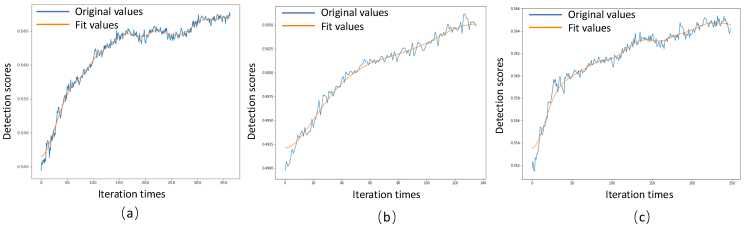
IV-C Against Object Detectors
In this section, we present the performance of our learned camouflage and the baselines against several state-of-the-art detectors, including YOLOv3, Mask-RCNN and FCOS in the downtown environment.
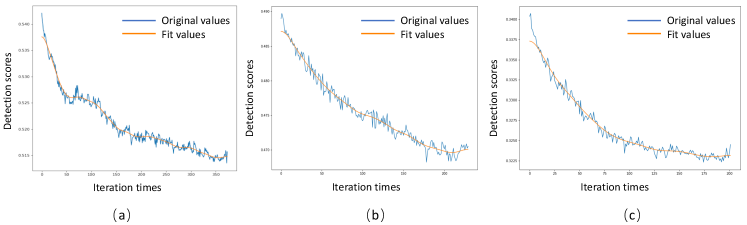
The learning process of our CCA camouflage against YOLOv3 is shown in Fig. 3 (a). In the training, we set the scores by computing the mean value of the detection scores of all the unpainted vehicles. From Fig. 3 (a), we can easily observe that the detection scores of the vehicles decreases under the proposed learning algorithm, which demonstrates the effectiveness of the evolution search strategy we applied in CCA. To further validate the effectiveness of the learned camouflage, experiments were conducted to compare the proposed camouflage to other baselines: painting basic colors or random camouflage on the context vehicle. As shown in Table I, our method outperforms baselines over all the three metrics on both training data and testing data. This supports our argument that we could misled object detector by only changing a part of the context.
We present the training process and camouflages’ performance against MaskRCNN in Fig. 3(b) and Table II. Similar to its performance against YOLOv3, our learnd CCA camouflage outperforms baseline colors and random camouflages on both training and testing data. Furthermore, we can draw the same observation from the experiment results of FCOS reported in Fig. 3(c) and Table III. All the reported experiments show the effectiveness of CCA on attacking state-of-the-art object detectors.
IV-D Qualitative Analysis
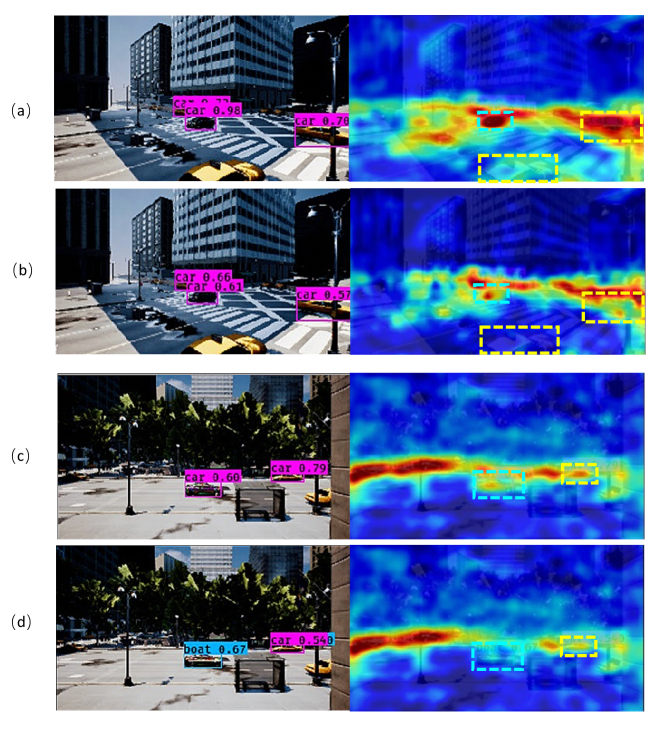
To validate the proposed CCA camouflage’s influence on object detectors, we visualize the Grad-CAM [35] maps of the samples with our learned camouflage and random camouflage. Since the Grad-CAM shows the gradient heatmap of the classification score scalar w.r.t. the input, it could help us to identify the image regions most relevant to the particular category. Fig. 4 shows two visualization examples, and each of them presents the detection result of YOLOv3 and corresponding Grad-CAM map. To be noted, YOLOv3 is a multi-scale detector and there are three layers of features with different sizes in the output. Considering of the resolution of the input and the objects’ size in the images, we use the nearest convolution layer to the feature layer of YOLOv3 as the penultimate layer and output the attention map of strategy ’car’ in each detection. For a fair comparison, we output the absolute value instead of the normalized value of the gradient scores of the feature map in our experiments. As expected, in the images with the proposed CCA camouflaged vehicle (Fig. 4 (b)(d)), the unpainted vehicles gain much lower attention than in the scenes with a random camouflaged vehicle (Fig. 4 (a)(c)). This observation further explains and validates our assumption that we could reduce the object detectors’ performance on certain objects by learning a contextual camouflage.
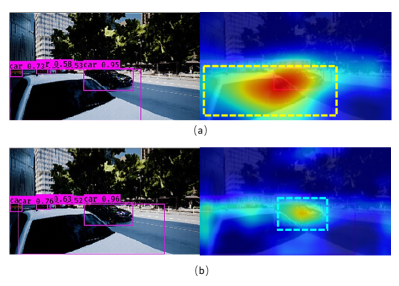
Fig. 5 shows another example, in which the detector’s attention is completely shifted from the front unpainted vehicle to the vehicle in the back. This case also proves the the proposed CCA camouflage’s capability of influencing the detector’s performance on the objects that without camouflages painted on them.
IV-E Extensions on Contextual Adversarial Attack
So far we have shown the effectiveness of our learned CCA camouflage on attacking object detector with the evolution strategy. Intuitively, we come up with the assumption that it should also be possible that we influence the detector with an opposite effected camouflage and increase the attention of the vehicles.
Here, we confirm that by experiments. In order to gain the opposite rewards, we reset the loss function proposed in Section III-B as:
| (10) |
Then we apply the evolution strategy proposed in Section III-C to figure out the potential positive affect of the CCA camouflage on object detectors. Fig. 6 shows the training process of the YOLOv3 and MaskRCNN. It shows that we can effectively improve the performance of the models with a learned contextual camouflage. Detection results comparison also proves this as shown in Table IV. The learned CCA camouflage outperforms the basic colors and random camouflage both on training and testing dataset. That means we could influence the object detectors’ performance by not only attacking them but also enhancing them with the proposed CCA pattern.
| Networks | Camouflages | Training set | Testing set | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
mIOU(%) | [email protected](%) |
|
mIOU(%) | [email protected](%) | ||||
| YOLOv3 | Random camouflage | 55.02 | 48.78 | 63.70 | 54.06 | 48.57 | 61.77 | ||
| CCA camouflage | 56.77 | 50.09 | 64.94 | 54.97 | 49.90 | 61.89 | |||
| MaskRCNN | Random camouflage | 48.90 | 47.08 | 49.61 | 48.79 | 47.46 | 47.87 | ||
| CCA camouflage | 50.61 | 47.43 | 51.09 | 49.30 | 47.86 | 49.04 | |||
| FCOS | Random camouflage | 34.08 | 38.75 | 45.78 | 33.77 | 39.36 | 46.39 | ||
| CCA camouflage | 35.21 | 39.70 | 46.74 | 34.46 | 39.97 | 46.47 | |||
V Conclusion
In this paper, we first investigate the problem of learning contextual adversarial object camouflage to attack vehicle detectors, such as YOLOv3, MaskRCNN and FCOS. We propose an evolutionary based algorithm to learn highly effective camouflages by interacting with a photo-realistic simulation. Our proposed CCA algorithm not only shows the effectiveness of attacking the state-of-the-art object detectors, but also shows its capability to enhance the detectors. The next phase of our work is to generalize the camouflages from simulation to the real world. Both adversarial domain adaptation and domain randomization seem to be promising approaches for this step.
References
- [1] S. Ingle and M. Phute, “Tesla autopilot: semi autonomous driving, an uptick for future autonomy,” International Research Journal of Engineering and Technology, vol. 3, no. 9, 2016.
- [2] T. N. Mundhenk, G. Konjevod, W. A. Sakla, and K. Boakye, “A large contextual dataset for classification, detection and counting of cars with deep learning,” in European Conference on Computer Vision. Springer, 2016, pp. 785–800.
- [3] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969.
- [4] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in European conference on computer vision. Springer, 2016, pp. 21–37.
- [5] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [6] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, 2015, pp. 91–99.
- [7] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [8] N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,” IEEE Access, vol. 6, pp. 14 410–14 430, 2018.
- [9] A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok, “Synthesizing robust adversarial examples,” arXiv preprint arXiv:1707.07397, 2017.
- [10] K. Eykholt, I. Evtimov, E. Fernandes, B. Li, A. Rahmati, C. Xiao, A. Prakash, T. Kohno, and D. Song, “Robust physical-world attacks on deep learning visual classification,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1625–1634.
- [11] D. Wierstra, T. Schaul, J. Peters, and J. Schmidhuber, “Natural evolution strategies,” in 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence). IEEE, 2008, pp. 3381–3387.
- [12] Y. Zhang, H. Foroosh, P. David, and B. Gong, “Camou: Learning physical vehicle camouflages to adversarially attack detectors in the wild,” in International Conference on Learning Representations, 2018.
- [13] X. Liu, H. Yang, Z. Liu, L. Song, H. Li, and Y. Chen, “Dpatch: An adversarial patch attack on object detectors,” arXiv preprint arXiv:1806.02299, 2018.
- [14] M. Lee and Z. Kolter, “On physical adversarial patches for object detection,” arXiv preprint arXiv:1906.11897, 2019.
- [15] F. Tramer, F. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart, “Stealing machine learning models via prediction apis,” in 25th USENIX Security Symposium (USENIX Security 16), 2016, pp. 601–618.
- [16] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv preprint arXiv:1312.6199, 2013.
- [17] A. Arnab, O. Miksik, and P. H. Torr, “On the robustness of semantic segmentation models to adversarial attacks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 888–897.
- [18] A. Athalye, N. Carlini, and D. Wagner, “Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples,” arXiv preprint arXiv:1802.00420, 2018.
- [19] J. Lu, H. Sibai, and E. Fabry, “Adversarial examples that fool detectors,” arXiv preprint arXiv:1712.02494, 2017.
- [20] C. Xie, J. Wang, Z. Zhang, Y. Zhou, L. Xie, and A. Yuille, “Adversarial examples for semantic segmentation and object detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1369–1378.
- [21] P.-Y. Chen, H. Zhang, Y. Sharma, J. Yi, and C.-J. Hsieh, “Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models,” in Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 2017, pp. 15–26.
- [22] N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, and A. Swami, “Practical black-box attacks against machine learning,” in Proceedings of the 2017 ACM on Asia conference on computer and communications security, 2017, pp. 506–519.
- [23] Y. Li, L. Li, L. Wang, T. Zhang, and B. Gong, “Nattack: A strong and universal gaussian black-box adversarial attack,” 2018.
- [24] A. Ilyas, L. Engstrom, A. Athalye, and J. Lin, “Black-box adversarial attacks with limited queries and information,” arXiv preprint arXiv:1804.08598, 2018.
- [25] J. Su, D. V. Vargas, and K. Sakurai, “One pixel attack for fooling deep neural networks,” IEEE Transactions on Evolutionary Computation, vol. 23, no. 5, pp. 828–841, 2019.
- [26] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” arXiv preprint arXiv:1607.02533, 2016.
- [27] J. Lu, H. Sibai, E. Fabry, and D. Forsyth, “No need to worry about adversarial examples in object detection in autonomous vehicles,” arXiv preprint arXiv:1707.03501, 2017.
- [28] ——, “Standard detectors aren’t (currently) fooled by physical adversarial stop signs,” arXiv preprint arXiv:1710.03337, 2017.
- [29] H. Chen, H. Zhang, P.-Y. Chen, J. Yi, and C.-J. Hsieh, “Attacking visual language grounding with adversarial examples: A case study on neural image captioning,” arXiv preprint arXiv:1712.02051, 2017.
- [30] T. Brown, D. Mane, A. Roy, M. Abadi, and J. Gilmer, “Adversarial patch,” 2017. [Online]. Available: https://arxiv.org/pdf/1712.09665.pdf
- [31] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755.
- [32] A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok, “Synthesizing robust adversarial examples,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018, pp. 284–293.
- [33] A. Berny, “Statistical machine learning and combinatorial optimization,” in Theoretical aspects of evolutionary computing. Springer, 2001, pp. 287–306.
- [34] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,” International journal of computer vision, vol. 111, no. 1, pp. 98–136, 2015.
- [35] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.