4CVC, UB, Spain; 5Baidu Research, China
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Abstract
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing. In order to study the ethnic bias for face anti-spoofing, we introduce the largest up to date CASIA-SURF Cross-ethnicity Face Anti-spoofing (CeFA) dataset (briefly named CeFA), covering ethnicities, modalities, subjects, and 2D plus 3D attack types. Four protocols are introduced to measure the affect under varied evaluation conditions, such as cross-ethnicity, unknown spoofs or both of them. To the best of our knowledge, CeFA is the first dataset including explicit ethnic labels in current published/released datasets for face anti-spoofing. Then, we propose a novel multi-modal fusion method as a strong baseline to alleviate these bias, namely, the static-dynamic fusion mechanism applied in each modality (i.e., RGB, Depth and infrared image). Later, a partially shared fusion strategy is proposed to learn complementary information from multiple modalities. Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on the CASIA-SURF, OULU-NPU, SiW and the CeFA dataset.
1 Introduction
Face anti-spoofing [7, 24, 32] is a key element to avoid security breaches in face recognition systems. The presentation attack detection (PAD) technique is a vital stage prior to visual face recognition. Although ethnic bias has been verified to severely affect the performance of face recognition systems [1, 5, 37], it still remains an open research problem in face anti-spoofing. Based on the experiment in Section 5.3, the state-of-the-art (SOTA) algorithms also suffer from ethnic bias. More specifically, the value of ACER is at least higher in Central Asia than that of East Asia in Table 3. However, there is no available dataset with ethnic labels and associated protocol for its evaluation. Furthermore, as shown in Table 1, the existing face anti-spoofing datasets (i.e.CASIA-FASD [46], Replay-Attack [9], OULU-NPU [8] and SiW [24]) have limited number of samples and most of them just contain the RGB modality. Although CASIA-SURF [45] is a large dataset in comparison to the existing alternatives, it still provides limited attack types (only 2D print attack) and single ethnicity.


| Dataset | Year | #Subject | #Num | Attack | Modality | Device | Ethnicity | |||
| Replay-Attack [9] | 2012 | 50 | 1200 | Print,Replay | RGB | RGB Camera | - | |||
| CASIA-FASD [46] | 2012 | 50 | 600 | Print,Cut,Replay | RGB | RGB Camera | - | |||
| 3DMAD [12] | 2014 | 17 | 255 | 3D print mask | RGB/Depth | RGB Camera/Kinect | - | |||
| MSU-MFSD [41] | 2015 | 35 | 440 | Print,Replay | RGB | Cellphone/Laptop | - | |||
| Replay-Mobile [11] | 2016 | 40 | 1030 | Print,Replay | RGB | Cellphone | - | |||
| Msspoof [10] | 2016 | 21 | 4704* |
|
RGB/IR | RGB/IR Camera | - | |||
| OULU-NPU [8] | 2017 | 55 | 5940 | Print,Replay | RGB |
|
- | |||
| SiW [24] | 2018 | 165 | 4620 |
|
RGB | RGB Camera |
|
|||
| CASIA-SURF [45] | 2019 | 1000 | 21000 |
|
RGB/Depth/IR | Intel Realsense | E | |||
| CeFA (Ours) | 2019 | 1500 | 18000 | Print, Replay | RGB/Depth/IR | Intel Realsense | A/E/C | |||
| 99 | 5346 | 3D print mask | ||||||||
| 8 | 192 | 3D silica gel mask | ||||||||
| Total: 1607 subjects, 23538 videos | ||||||||||
In order to alleviate above mentioned problems, in this paper we release a Cross-ethnicity Face Anti-spoofing dataset (CeFA), which is the largest face anti-spoofing dataset up to date in terms of ethnicities, modalities, number of subjects and attack types. The comparison with current available datasets is shown in Table 1. Concretely, attack types of the CeFA dataset are diverse, including printing from cloth, video replay attack, 3D print and silica gel attacks. More importantly, it is the first public dataset designed for exploring the impact of cross-ethnicity. Some samples are shown in Fig. 1.
Moreover, to improve the generalization performance of unknown attack types, multi-modal PAD methods have received special attention by an increasing number of works during last two years. Some fusion methods [45, 28] restrict the interactions among different modalities since they are independent before the fusion point. Therefore, it is difficult to effectively utilize the modality relatedness from the beginning of the network to its end. In this paper, we propose a Partially Shared Multi-modal Network (PSMM-Net) as a strong baseline to alleviate ethnic and attack pattern bias. On the one hand, it allows information exchange and interaction among different modalities. On the other hand, for a single-modal branch (e.g., RGB, Depth or IR), a Static and Dynamic-based Network (SD-Net) is formulated by taking the static and dynamic images as inputs, where the dynamic image is generated by rank pooling [15]. To sum up, the contributions of this paper are summarized as follows: (1) We release the largest face anti-spoofing dataset CeFA up to date, which includes ethnicities, subjects and diverse 2D/3D attack types. (2) We provide a benchmark with four comprehensive evaluation protocols to measure ethnic and attack pattern bias. (3) We propose the PSMM-Net as a strong baseline to learn the fused information from single-modal and multi-modal branches. (4) Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on CeFA and other public datasets.
2 Related work
2.1 Datasets
Face recognition systems are still dealing with ethnicity bias problems [17, 20, 31, 37]. As an effort in the direction of mitigating ethnicity bias in face recognition, Wang et al. [37] have recently released a face recognition dataset containing ethnicities to be used for algorithm design. However, there is no publicly available face anti-spoofing dataset with ethnic labels. Table 1 lists main features of existing face anti-spoofing datasets: (1) The maximum number of available subjects was on the SiW dataset [24] before ; (2) Most of the datasets just contain RGB data, such as Replay-Attack [9], CASIA-FASD [46], SiW [24] and OULU-NPU [8]; (3) Most datasets do not provide ethnicity information, except SiW and CASIA-SURF. Although SiW provides four ethnicities, it has neither a clear ethnic label nor a standard protocol for measuring ethnic bias in algorithms. This limitation also holds for the CASIA-SURF dataset.
2.2 Methods
Static and Temporal Methods.
In addition to some works [27, 22, 6] based on static texture feature learning, some temporal-based methods [26, 29, 21] also have been proposed, which require from a constrained human interaction. However, these methods become vulnerable if someone presents a replay attack.There are also methods [7, 23] relying on more general temporal features by simply concatenating the features of consecutive frames [40, 4]. However, these algorithms are not accurate enough because of the use of hand-crafted features, such as HOG [42], LBP [25, 16], SIFT [30] or SURF [6]. Liu et al. [24] proposed a CNN-RNN model to estimate Photoplethysmography (rPPG) signals which can be detected from real but not spoof with sequence-wise supervision. Yang et al. [43] proposed a spatio-temporal attention mechanism to fuse global temporal and local spatial information. Although these face PAD methods achieve near-perfect performance in intra-database experiments, they are vulnerable when facing complex lighting environments in practical applications. Inspired by [13], we feed the static and dynamic images to SD-Net, which the dynamic image generated by rank pooling [15] instead of optical flow map [13]. Additionally, our SD-Net not only captures the static and dynamic features, but also static-dynamic fusion features in an end-to-end way.
Multi-modal Fusion Methods.
Zhang et al. [45] proposed a fusion network with streams using ResNet-18 as the backbone, where each stream is used to extract low level features from RGB, Depth and IR data, respectively. Then, these features are concatenated and passed to the last two residual blocks. Similar to [45], Tao et al. [33] proposed a multi-stream CNN architecture called FaceBagNet, which uses patch-level images as input and modality feature erasing (MFE) operation to prevent from overfitting. All previous methods just consider as a key fusion component the concatenation of features from multiple modalities. Unlike [45, 28, 33], we propose the PSMM-Net, where three modality-specific networks and one shared network are connected by using a partially shared structure to learn discriminative fused features for face anti-spoofing.
3 CeFA dataset
In this section, we introduce the CeFA dataset, including acquisition details, attack types, and proposed evaluation protocols.
Acquisition Details.
We use the Intel Realsense to capture the RGB, Depth and IR videos simultaneously at . The resolution is pixels for each video frame. Subjects are asked to move smoothly their head so as to have a maximum of around deviation of head pose in relation to the frontal view. Data pre-processing is similar to the one performed in [45], except that PRNet [14] is replaced by 3DFFA [47] for face region detection. Examples of processed face regions for different visual modalities are shown in Fig. 1.
Statistics.
As shown in Table 1, CeFA consists of 2D and 3D attack subsets. As shown in Fig. 1, For the 2D attack subset, it consists of print and video-replay attacks captured by subjects from three ethnicities (e.g., African, East Asian and Central Asian). Each ethnicity has 500 subjects. Each subject has real sample, fake samples of print attack captured in indoor and outdoor, and fake sample of video-replay. In total, there are videos ( per modality). The age and gender statistics for the 2D attack subset of CeFA is shown in Fig. 1.
For the 3D attack subset, it has 3D print mask and silica gel face attacks. Some samples are shown in Fig. 1. In the part of 3D print mask, it has subjects, each subject with fake samples captured in three attacks and six lighting environments. 3D print includes only face mask, wearing a wig with glasses, and wearing a wig without glasses. Lighting conditions include outdoor sunshine, outdoor shade, indoor side light, indoor front light, indoor backlit and indoor regular light. In total, there are videos ( per modality). For silica gel face attacks, it has subjects, each subject has fake samples captured in two attacks styles and four lighting environments. Attacks include wearing a wig with glasses and wearing a wig without glasses. Lighting environments include indoor side light, indoor front light, indoor backlit and indoor normal light. In total, there are videos ( per modality).
Evaluation Protocols.
The motivation of CeFA dataset is to provide a benchmark to allow for the evaluation of the generalization performance of new PAD methods in three main aspects: cross-ethnicity, cross-modality and cross-attacks. We design four protocols for the 2D attacks subset, as shown in Table 2, totalling sub-protocols (1_1, 1_2, 1_3, 2_1, 2_2, 3_1, 3_2, 3_3, 4_1, 4_2, and 4_3). We divide subjects per ethnicity into three subject-disjoint subsets (second and fourth columns in Table 2). Each protocol has three data subsets: training, validation and testing sets, which contain , , and subjects, respectively.
| Prot. | Subset | Ethnicity | Subjects | Modalities | PAIs | # real videos | # fake videos | # all videos | |||||
| 1_1 | 1_2 | 1_3 | |||||||||||
| 1 | Train | A | C | E | 1-200 | R&D&I | Print&Replay | 600/600/600 | 1800/1800/1800 | 2400/2400/2400 | |||
| Valid | A | C | E | 201-300 | R&D&I | Print&Replay | 300/300/300 | 900/900/900 | 1200/1200/1200 | ||||
| Test | C&E | A&E | A&C | 301-500 | R&D&I | Print&Replay | 1200/1200/1200 | 6600/6600/6600 | 7800/7800/7800 | ||||
| 2_1 | 2_2 | ||||||||||||
| 2 | Train | A&C&E | 1-200 | R&D&I | Replay | 1800/1800 | 3600/1800 | 5400/3600 | |||||
| Valid | A&C&E | 201-300 | R&D&I | Replay | 900/900 | 1800/900 | 2700/1800 | ||||||
| Test | A&C&E | 301-500 | R&D&I | Replay | 1800/1800 | 4800/6600 | 6600/8400 | ||||||
| 3_1 | 3_2 | 3_3 | |||||||||||
| 3 | Train | A&C&E | 1-200 | R | D | I | Print&Replay | 600/600/600 | 1800/1800/1800 | 2400/2400/2400 | |||
| Valid | A&C&E | 201-300 | R | D | I | Print&Replay | 300/300/300 | 900/900/900 | 1200/1200/1200 | ||||
| Test | A&C&E | 301-500 | D&I | R&I | R&D | Print&Replay | 1200/1200/1200 | 5600/5600/5600 | 6800/6800/6800 | ||||
| 4_1 | 4_2 | 4_3 | |||||||||||
| 4 | Train | A | C | E | 1-200 | R | D | I | Replay | 600/600/600 | 600/600/600 | 1200/1200/1200 | |
| Valid | A | C | E | 201-300 | R | D | I | Replay | 300/300/300 | 300/300/300 | 600/600/600 | ||
| Test | C&E | A&E | A&C | 301-500 | R | D | I | 1200/1200/1200 | 5400/5400/5400 | 6600/6600/6600 | |||
Protocol 1 (cross-ethnicity): Most of the public face PAD datasets lack of ethnicity labels or do not provide with a protocol to perform cross-ethnicity evaluation. Therefore, we design the first protocol to evaluate the generalization of PAD methods for cross-ethnicity testing. One ethnicity is used for training and validation, and the left two ethnicities are used for testing. Therefore, there are three different evaluations (third column of Protocol in Table 2).
Protocol 2 (cross-PAI): Given the diversity and unpredictability of attack types from different presentation attack instruments (PAI), it is necessary to evaluate the robustness of face PAD algorithms to this kind of variations (sixth column of Protocol in Table 2).
Protocol 3 (cross-modality): Given the release of affordable devices capturing complementary visual modalities (i.e., Intel Resense, Mircrosoft Kinect), recently the multi-modal face anti-spoofing dataset was proposed [45]. However, there is no standard protocol to explore the generalization of face PAD methods when different train-test modalities are considered for evaluation. We define three cross-modality evaluations, each of them having one modality for training and the two remaining ones for testing (fifth column of Protocol in Table 2).
Protocol 4 (cross-ethnicity & PAI): The most challenging protocol is designed via combining the condition of both Protocol and . As shown in Protocol of Table. 2, the testing subset introduces two unknown target variations simultaneously. Like [8], the mean and variance of evaluated metrics for these four protocols are calculated in our experiments. Detailed statistics for the different protocols are shown in Table 2.
4 Proposed Method
Here, we propose a novel strong baseline to evaluate the proposed CeFA dataset. First, the SD-Net is proposed to process the single-modal data, which is formulated by taking the static and dynamic images as inputs. The dynamic images are generated by rank pooling. Then, the PSMM-Net is presented by learning the fusion features from multiple modalities.
4.1 SD-Net for Single Modality
Single-modal Dynamic Image Construction.
Rank pooling [15, 38] defines a rank function that encodes a video into a feature vector. The learning process can be seen as a convex optimization problem using the RankSVM [34] formulation in Eq.1. Let RGB (Depth or IR) video sequence with frames be represented as , and denote the average of RGB (Depth or IR) features over time up to -frame. The process is formulated below.
| (1) |
where is the slack variable, and . By optimizing Eq. 1, we map a sequence of frames to a single vector . In this paper, rank pooling is directly applied on the pixels of RGB (Depth or IR) frames and the dynamic image is of the same size as the input frames. In our case, given input frame, we compute its dynamic image online with rank pooling using consecutive frames. Our selection of dynamic images for rank pooling in SD-Net is further motivated by the fact that dynamic images have proved its superiority to regular optical flow [36, 15].

Single-modal SD-Net.
As shown in Fig. 2, taking the RGB modality as an example, we propose the SD-Net to learn hybrid features from static and dynamic images. It contains branches: static, dynamic and static-dynamic branches, which learn complementary features. The network takes ResNet-18 [18] as the backbone. For static and dynamic branches, each of them consists of blocks (i.e., conv, res1, res2, res3, res4) and Global Average Pooling (GAP) layer, while in the static-dynamic branch, the conv and res1 blocks are removed because it takes fused features of res1 blocks from static and dynamic branches as input.
For convenience of terminology with the rest of the paper, we divide residual blocks of the network into a set of modules according to feature level, where is an indicator of the modality and represents the feature level. Except for the first module , each module extracts static, dynamic and static-dynamic features by using a residual block, denoted as , and , respectively. The output features from each module are used as the input for the next module. The static-dynamic features of the first module are obtained by directly summing and .
In order to ensure each branch learns independent features, each branch employs an independent loss function after the GAP layer [35]. In addition, a loss function based on the summed features from all three branches is employed. The binary cross-entropy loss is used as the loss function. All branches are jointly and concurrently optimized to capture discriminative and complementary features for face anti-spoofing in image sequences. The overall objective function of SD-Net for the modality is defined as:
| (2) |
where , , and are the losses for static branch, dynamic branch, static-dynamic branch, and summed features from all three branches of the network, respectively.
4.2 PSMM-Net for Multi-modal Fusion
The architecture of the proposed PSMM-Net is shown in Fig. 2(b). It consists of two main parts: a) the modality-specific network, which contains three SD-Nets to learn features from RGB, Depth, IR modalities, respectively; b) and a shared branch for all modalities, which aims to learn the complementary features among different modalities. For the shared branch, we adopt ResNet-18, removing the first conv layer and res1 block. In order to capture correlations and complementary semantics among different modalities, information exchange and interaction among SD-Nets and the shared branch are designed. This is done in two different ways: a) forward feeding of fused SD-Net features to the shared branch, and b) backward feeding from shared branch modules output to SD-Net block inputs.
Forward Feeding.
We fuse static and dynamic SD-Nets features from all modality branches and fed them as input to its corresponding shared block. The fused process at feature level can be formulated as:
| (3) |
In the shared branch, denotes the input to the block, and denotes the output of the block. Note that the first residual block is removed from the shared branch, thus equals to zero.
Backward Feeding.
Shared features are delivered back to the SD-Nets of the different modalities. The static features and dynamic features add with for feature fusion. This can be denoted as:
| (4) |
where ranges from to . After feature fusion, and become the new static and dynamic features, which are then feed to the next module . Note that the exchange and interaction among SD-Nets and the shared branch are only performed for static and dynamic features. This is done to avoid hybrid features among static and dynamic information to be disturbed by multi-modal semantics.
Loss Optimization.
There are two main kind of losses employed to guide the training of PSMM-Net. The first corresponds to the losses of the three SD-Nets, i.e.color, depth and ir modalities, denoted as , and , respectively. The second corresponds to the loss that guides the entire network training, denoted as , which bases on the summed features from all SD-Nets and the shared branch. The overall loss of PSMM-Net is denoted as:
| (5) |
5 Experiments
In this section, we conduct a series of experiments on CeFA and public available face anti-spoofing datasets to show the significance of the presented dataset and the effectiveness of our methodology.
5.1 Datasets & Metrics
We evaluate the performance of PSMM-Net on two multi-modal (i.e., RGB, Depth and IR) datasets: CeFA and CASIA-SURF [45], while evaluate the SD-Net on two single-modal (i.e., RGB) face anti-spoofing benchmarks: OULU-NPU [8] and SiW [24]. In order to perform a consistent evaluation with prior works, we report the experimental results using the following metrics based on respective official protocols: Attack Presentation Classification Error Rate (APCER) [2], Bona Fide Presentation Classification Error Rate (BPCER), Average Classification Error Rate (ACER), and Receiver Operating Characteristic (ROC) curve [45].
5.2 Implementation Details
The proposed PSMM-Net is implemented with Tensorflow [3] and run on a single NVIDIA TITAN X GPU. We resize the cropped face region to , and use random rotation within the range of [, ], flipping, cropping and color distortion for data augmentation. All models are trained for epochs via Adaptive Moment Estimation (Adam) algorithm and initial learning rate of , which is decreased after and epochs with a factor of . The batch size of each CNN stream is , and the length of the consecutive frames used to construct dynamic map is set to by our experimental experience.
5.3 Performance Biases of Diversity Ethnicities
In this section, we investigate the performance biases of different ethnicities with two SOTA algorithms on the three ethnicities of CeFA. MS-SEF [45] is trained on CASIA-SURF for the multi-modal data while FAS-BAS [24] is trained for the RGB data on OULU-NPU. Then, the trained models are tested on CeFA. The results are shown in Table 3. Results show that both methods behave differently for the three ethnicities, i.e., East Asian () versus Center Asian () for MS-SEF and African () versus Center Asian () for MS-SEF under the ACER metric. In addition, both methods achieve relatively good results on East Asians (e.g., the values of ACER are , , respectively) because of most of the samples belong to East Asians on CASIA-SURF and OULU-NPU datasets. This indicates that existing single-ethnic anti-spoofing datasets limit the ethnic generalization performance of existing methods.
5.4 Baseline Model Evaluation
Here, we provide a benchmark for CeFA based on the proposed method. From Table 4, we can draw the following conclusions: (1) The ACER scores of three sub-protocols in Protocol are , and , respectively, which indicate the necessity to study the generalization of the face PAD methods for different ethnicities; (2) In the case of Protocol , when print attack is used for training/validation and video-replay and 3D mask are used for testing, the ACER score is (sub-protocol 2_1). When video-replay attack is used for training/validation, and print attack and 3D attack are used for testing, the ACER score is (sub-protocol 2_2). The large gap between the results caused by the different PAI (i.e., different displays and printers). (3) Protocol evaluates cross-modality. The best result is achieved for sub-protocol 3_1 (ACER=). (4) Protocol is the most difficult evaluation scenario, which simultaneously considers cross-ethnicity and cross-PAI. All sub-protocols achieve low performance, highlighting the challenges of our dataset: , , and ACER scores for 4_1, 4_2, and 4_3, respectively.
| Protocol name | APCER(%) | BPCER(%) | ACER(%) | |
|---|---|---|---|---|
| Protocol 1 | 1_1 | 0.5 | 0.8 | 0.6 |
| 1_2 | 4.8 | 4.0 | 4.4 | |
| 1_3 | 1.2 | 1.8 | 1.5 | |
| AvgStd | 2.22.3 | 2.21.6 | 2.22.0 | |
| Protocol 2 | 2_1 | 0.1 | 0.7 | 0.4 |
| 2_2 | 13.8 | 1.2 | 7.5 | |
| AvgStd | 7.09.7 | 1.00.4 | 4.05.0 | |
| Protocol 3 | 3_1 | 8.9 | 0.9 | 4.9 |
| 3_2 | 22.6 | 4.6 | 13.6 | |
| 3_3 | 21.1 | 2.3 | 11.7 | |
| AvgStd | 17.57.5 | 2.61.9 | 10.14.6 | |
| Protocol 4 | 4_1 | 33.3 | 15.8 | 24.5 |
| 4_2 | 78.2 | 8.3 | 43.2 | |
| 4_3 | 50.0 | 5.5 | 27.7 | |
| AvgStd | 53.822.7 | 9.95.3 | 31.810.0 | |
5.5 Ablation Analysis
To verify the performance of our proposed baseline in alleviating ethnic bias, we perform a series of ablation experiments on Protocol (cross-ethnicity) of the CeFA dataset.
Static and Dynamic Features.
We evaluate S-Net (Static branch of SD-Net), D-Net (Dynamic branch of SD-Net) and SD-Net in this experiment. Results for RGB, Depth and IR modalities are shown in Table 7. Compared to S-Net and D-Net, SD-Net achieves superior performance showing that the learned hybrid features from static and dynamic images can alleviate ethnic bias. Concretely, for RGB, Depth and IR modalities, ACER of SD-Net is , , , versus , , of S-Net (improved by , , ) and , , of D-Net (improved by , , ), respectively. It also shows that the performance of Depth and IR modalities are superior to the RGB modality because of the variability of lighting conditions interfering with feature learning of RGB samples.
| Prot.1 | RGB | Depth | IR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| APCER() | BPCER() | ACER() | APCER() | BPCER() | ACER() | APCER() | BPCER() | ACER() | |
| S-Net | 28.13.6 | 6.44.6 | 17.23.6 | 5.63.0 | 9.84.2 | 7.73.5 | 11.42.1 | 8.21.2 | 9.81.7 |
| D-Net | 20.64.0 | 19.39.0 | 19.94.0 | 11.25.1 | 7.51.5 | 9.42.0 | 8.11.8 | 14.43.8 | 11.32.1 |
| SD-Net | 14.96.0 | 10.31.8 | 12.63.4 | 7.08.1 | 5.23.5 | 6.15.4 | 7.31.2 | 5.51.8 | 6.41.3 |
| Prot.1 | PSMM-Net | ||
|---|---|---|---|
| APCER() | BPCER() | ACER() | |
| RGB | 14.96.0 | 10.31.8 | 12.63.4 |
| RGB&Depth | 2.32.9 | 9.25.9 | 5.73.5 |
| RGB&Depth&IR | 2.22.3 | 2.21.6 | 2.22.0 |
| Method | APCER(%) | BPCER(%) | ACER(%) |
|---|---|---|---|
| NHF | 25.312.2 | 4.43.1 | 14.86.8 |
| PSMM-WoBF | 12.70.4 | 3.22.3 | 7.91.3 |
| PSMM-Net | 2.22.3 | 2.21.6 | 2.22.0 |
Multiple Modalities.
In order to show the effect of analysing a different number of modalities, we evaluate one modality (RGB), two modalities (RGB and Depth), and three modalities (RGB, Depth and IR) on PSMM-Net. As shown in Fig. 2, the PSMM-Net contains three SD-Nets and one shared branch. When only RGB modality is considered, we just use one SD-Net for evaluation. When two or three modalities are considered, we use two or three SD-Nets and one shared branch to train the PSMM-Net model, respectively. Results are shown in Table 7. The best results are obtained when using all three modalities: of APCER, of BPCER and of ACER. These results show that multi-modal information has a significant effect in alleviating ethnic bias, mainly because of the smaller differences in skin color of different ethnicities in the IR modality.
Fusion Strategy.
In order to evaluate the performance of PSMM-Net, we compare it with other two variants: Naive halfway fusion (NHF) and PSMM-Net without backward feeding mechanism (PSMM-Net-WoBF). As shown in Fig. 3, NHF combines the modules of different modalities at a later stage (i.e., after module) and PSMM-Net-WoBF strategy removes the backward feeding from PSMM-Net. The fusion comparison results are shown in Table 7, showing higher performance of the proposed PSMM-Net with information exchange and interaction mechanism among SD-Nets and the shared branch.

5.6 Methods Comparison
CASIA-SURF.
The comparison results are show in Table 10. The performance of the PSMM-Net is superior to the ones of the competing multi-modal fusion methods, including Halfway fusion [45], single-scale SE fusion [45], and multi-scale SE fusion [44]. When compared with [45, 44], PSMM-Net improves the performance by at least for ACER. When the PSMM-Net is pretrained on CeFA, it further improves performance. Concretely, the performance of is increased by when pretraining with the proposed CeFA dataset. The comparison results not only illustrate the superiority of our algorithm for multi-modal data fusion, but also show that our CeFA alleviates the bias of attack pattern to a certain extent.
| P | Method | APCER (%) | BPCER (%) | ACER (%) | Pr. |
| 1 | BAS [24] | 3.58 | 3.58 | 3.58 | No |
| TD-SF [39] | 1.27 | 0.83 | 1.05 | ||
| STASN [43] | - | - | 1.00 | ||
| SD-Net | 0.14 | 1.34 | 0.74 | ||
|
1.27 | 0.33 | 0.80 | Yes | |
| STASN(D) | - | - | 0.30 | ||
| SD-Net(C) | 0.21 | 0.50 | 0.35 | ||
| 2 | BAS | 0.570.69 | 0.570.69 | 0.570.69 | No |
| TD-SF | 0.330.27 | 0.290.39 | 0.310.28 | ||
| STASN | - | - | 0.280.05 | ||
| SD-Net | 0.250.32 | 0.290.34 | 0.270.28 | ||
|
0.080.17 | 0.250.22 | 0.170.16 | Yes | |
| STASN(D) | - | - | 0.150.05 | ||
| SD-Net(C) | 0.090.17 | 0.210.25 | 0.150.11 | ||
| 3 | BAS | 8.313.81 | 8.313.81 | 8.313.81 | No |
| TD-SF | 7.703.88 | 7.764.09 | 7.733.99 | ||
| STASN | - | - | 12.101.50 | ||
| SD-Net | 3.742.15 | 7.851.42 | 5.800.36 | ||
|
6.274.36 | 6.434.42 | 6.354.39 | Yes | |
| STASN(D) | - | - | 5.850.85 | ||
| SD-Net(C) | 2.701.56 | 7.101.56 | 4.900.00 |
| P | Method | APCER (%) | BPCER (%) | ACER (%) | Pr. |
| 1 | BAS [24] | 1.6 | 1.6 | 1.6 | No |
| Ds [19] | 1.2 | 1.7 | 1.5 | ||
| STASN [43] | 1.2 | 2.5 | 1.9 | ||
| SD-Net | 1.7 | 1.7 | 1.7 | ||
| STASN(D) | 1.2 | 0.8 | 1.0 | Yes | |
| SD-Net(C) | 1.0 | 1.7 | 1.4 | ||
| 2 | BAS | 2.7 | 2.7 | 2.7 | No |
| STASN | 4.2 | 0.3 | 2.2 | ||
| SD-Net | 2.8 | 2.2 | 2.5 | ||
| STASN(D) | 1.4 | 0.8 | 1.1 | Yes | |
| SD-Net(C) | 1.4 | 2.5 | 1.9 | ||
| 3 | BAS | 2.71.3 | 3.11.7 | 2.91.5 | No |
| STASN | 4.73.9 | 0.91.2 | 2.81.6 | ||
| SD-Net | 2.72.5 | 1.42.0 | 2.11.4 | ||
| STASN(D) | 1.41.4 | 3.64.6 | 2.52.2 | Yes | |
| SD-Net(C) | 2.72.5 | 0.90.9 | 1.81.4 | ||
| 4 | BAS | 9.35.6 | 10.46.0 | 9.56.0 | No |
| STASN | 6.710.6 | 8.38.4 | 7.54.7 | ||
| SD-Net | 4.65.1 | 6.36.3 | 5.42.8 | ||
| STASN(D) | 0.91.8 | 4.25.3 | 2.62.8 | Yes | |
| SD-Net(C) | 5.04.7 | 4.64.6 | 4.82.7 |
SiW and OULU-NPU.
Results for these two dataset are shown in Table 10 and 10, respectively. We compare the proposed SD-Net with other methods without pretraining. Our method achieves the best results (a lower ACER value indicates better performance) on all protocols of the SiW and protocol and of the OULU-NPU. The experimental results show that our SD-Net combined with the dynamic image generated by the rank pooling algorithm can effectively capture features related to motion difference between the real face and the fake one.
Last but not least, using the proposed dataset to pre-train our baseline method significantly improves its ACER performance in most of protocols. In Protocol and of SiW, our method trained on the CeFA dataset performs the best among all models. Note that the STASN (Data) [43] used a large private dataset to pretrain. Similar conclusions can be drawn from the OULU-NPU experiment. These results demonstrate the effectiveness and generalization capability of the CeFA dataset, and suggest SOTA methods can be further improved by using our CeFA dataset for pre-training.
5.7 Visualization and Analysis
Dynamic images.
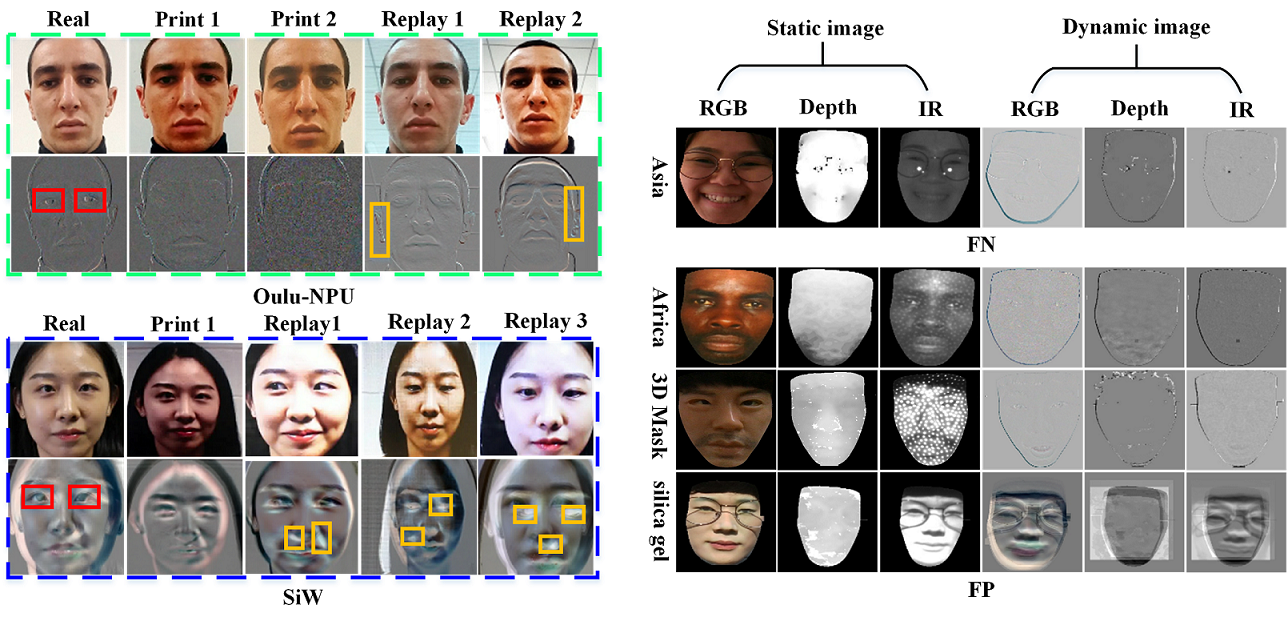
Given a video, we map a sequence of frames into a dynamic image by using rank pooling. Some samples are shown in Fig. 4(a). As for SiW and OULU-NPU datasets, the eye part (red box) of the real sample is more realistic than print or replay attack, while more speckles (orange box) caused by specular reflections are included in the replay attack. Our SD-Net can capture these discriminative dynamic features.
Misclassified Samples.
Some misclassified samples of our baseline on CeFA are shown in Fig. 4(b). Visually from static image, it is very difficult to distinguish the type of the sample from RGB and IR modalities. Furthermore, the depth modality of a 3D attack shows to be extremely similar to the real face.
6 Conclusion
In this paper, we release the largest face anti-spoofing dataset up to date in terms of modalities, number of subjects and attack types. More importantly, CeFA is the only public face anti-spoofing dataset with ethnic labels. Specially, we define four protocols to study the generalization performance of face anti-spoofing algorithms. Based on the proposed dataset, we provide a baseline by designed a partially shared PSMM-Net to learn complementary information from multi-modal data in videos, in which a SD-Net aims to learn both static and dynamic features from single modality. Extensive experiments validate the utility of our algorithm and the challenges of the released CeFA dataset.
7 Acknowledgement
This work has been partially supported by the Chinese National Natural Science Foundation Projects 61961160704, 61876179, 61872367, Science and Technology Development Fund of Macau (Grant No. 0025/2018/A1), the Spanish project TIN2016-74946-P (MINECO/FEDER, UE) and CERCA Programme / Generalitat de Catalunya, and by ICREA under the ICREA Academia programme. We acknowledge Surfing Technology Beijing co., Ltd (www.surfing.ai) to provide us this high quality dataset. We also acknowledge the support of NVIDIA Corporation with the donation of the GPU used for this research.
References
- [1] Are face recognition systems accurate? depends on your race (2016), https://www.technologyreview.com/s/601786
- [2] ISO/IEC JTC 1/SC 37 Biometrics. information technology biometric presentation attack detection part 1: Framework. international organization for standardization (2016), https://www.iso.org/obp/ui/iso
- [3] Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M.: Tensorflow: A system for large-scale machine learning
- [4] Agarwal, A., Singh, R., Vatsa, M.: Face anti-spoofing using haralick features. In: BTAS (2016)
- [5] Alvi, M., Zisserman, A., Nellaker, C.: Turning a blind eye: Explicit removal of biases and variation from deep neural network embeddings
- [6] Boulkenafet, Z., Komulainen, J., Hadid, A.: Face spoofing detection using colour texture analysis. TIFS (2016)
- [7] Boulkenafet, Z., Komulainen, J., Hadid, A.: Face antispoofing using speeded-up robust features and fisher vector encoding. SPL (2017)
- [8] Boulkenafet, Z., Komulainen, J., Li, L., Feng, X., Hadid, A.: Oulu-npu: A mobile face presentation attack database with real-world variations. In: FG (2017)
- [9] Chingovska, I., Anjos, A., Marcel, S.: On the effectiveness of local binary patterns in face anti-spoofing. In: Biometrics Special Interest Group (2012)
- [10] Chingovska, I., Erdogmus, N., Anjos, A., Marcel, S.: Face recognition systems under spoofing attacks. In: Face Recognition Across the Imaging Spectrum (2016)
- [11] Costa-Pazo, A., Bhattacharjee, S., Vazquez-Fernandez, E., Marcel, S.: The replay-mobile face presentation-attack database. In: BIOSIG (2016)
- [12] Erdogmus, N., Marcel, S.: Spoofing in 2d face recognition with 3d masks and anti-spoofing with kinect. In: BTAS (2014)
- [13] Feng, L., Po, L.M., Li, Y., Xu, X., Yuan, F., Cheung, T.C.H., Cheung, K.W.: Integration of image quality and motion cues for face anti-spoofing: A neural network approach. JVCIR (2016)
- [14] Feng, Y., Wu, F., Shao, X., Wang, Y., Zhou, X.: Joint 3d face reconstruction and dense alignment with position map regression network. In: ECCV (2018)
- [15] Fernando, B., Gavves, E., Oramas, J., Ghodrati, A., Tuytelaars, T.: Rank pooling for action recognition. TPAMI 39(4), 773–787 (2017)
- [16] de Freitas Pereira, T., Anjos, A., De Martino, J.M., Marcel, S.: Can face anti-spoofing countermeasures work in a real world scenario? In: ICB (2013)
- [17] Furl, N., Phillips, P.J., O’Toole, A.J.: Face recognition algorithms and the other-race effect: computational mechanisms for a developmental contact hypothesis. In: Cognitive science (2002)
- [18] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
- [19] Jourabloo, A., Liu, Y., Liu, X.: Face de-spoofing: Anti-spoofing via noise modeling. arXiv (2018)
- [20] Klare, B.F., Burge, M.J., Klontz, J.C., Vorder Bruegge, R.W., Jain, A.K.: Face recognition performance: Role of demographic information. vol. 7, pp. 1789–1801
- [21] Kollreider, K., Fronthaler, H., Faraj, M.I., Bigun, J.: Real-time face detection and motion analysis with application in liveness assessment. TIFS 2(3), 548–558
- [22] Komulainen, J., Hadid, A., Pietikainen, M.: Context based face anti-spoofing. In: BTAS (2013)
- [23] Komulainen, J., Hadid, A., Pietikäinen, M., Anjos, A., Marcel, S.: Complementary countermeasures for detecting scenic face spoofing attacks. In: ICB (2013)
- [24] Liu, Y., Jourabloo, A., Liu, X.: Learning deep models for face anti-spoofing: Binary or auxiliary supervision. In: CVPR (2018)
- [25] Määttä, J., Hadid, A., Pietikäinen, M.: Face spoofing detection from single images using micro-texture analysis. In: IJCB. pp. 1–7. IEEE (2011)
- [26] Pan, G., Sun, L., Wu, Z., Lao, S.: Eyeblink-based anti-spoofing in face recognition from a generic webcamera. In: ICCV (2007)
- [27] Pan, G., Sun, L., Wu, Z., Wang, Y.: Monocular camera-based face liveness detection by combining eyeblink and scene context. TCS (2011)
- [28] Parkin, A., Grinchuk, O.: Recognizing multi-modal face spoofing with face recognition networks. In: PRCVW. pp. 0–0 (2019)
- [29] Patel, K., Han, H., Jain, A.K.: Cross-database face antispoofing with robust feature representation. In: CCBR (2016)
- [30] Patel, K., Han, H., Jain, A.K.: Secure face unlock: Spoof detection on smartphones. TIFS (2016)
- [31] Phillips, P.J., Fang, J., Narvekar, A., Ayyad, J.H., O’Toole, A.J.: An other-race effect for face recognition algorithms. vol. 8, p. 14 (2011)
- [32] Shao, R., Lan, X., Li, J., Yuen, P.C.: Multi-adversarial discriminative deep domain generalization for face presentation attack detection. In: CVPR. pp. 10023–10031 (2019)
- [33] Shen, T., Huang, Y., Tong, Z.: Facebagnet: Bag-of-local-features model for multi-modal face anti-spoofing. In: PRCVW. pp. 0–0 (2019)
- [34] Smola, A.J., Schölkopf, B.: A tutorial on support vector regression. Statistics and computing 14(3), 199–222 (2004)
- [35] Tan, Z., Yang, Y., Wan, J., Guo, G., Li, S.Z.: Deeply-learned hybrid representations for facial age estimation. In: IJCAI. pp. 3548–3554 (7 2019)
- [36] Wang, J., Cherian, A., Porikli, F.: Ordered pooling of optical flow sequences for action recognition. In: WACV. pp. 168–176. IEEE (2017)
- [37] Wang, M., Deng, W., Hu, J., Tao, X., Huang, Y.: Racial faces in the wild: Reducing racial bias by information maximization adaptation network. In: ICCV (October 2019)
- [38] Wang, P., Li, W., Wan, J., Ogunbona, P., Liu, X.: Cooperative training of deep aggregation networks for rgb-d action recognition. In: Thirty-Second AAAI Conference on Artificial Intelligence (2018)
- [39] Wang, Z., Zhao, C., Qin, Y., Zhou, Q., Lei, Z.: Exploiting temporal and depth information for multi-frame face anti-spoofing. arXiv (2018)
- [40] Wei, B., Hong, L., Nan, L., Wei, J.: A liveness detection method for face recognition based on optical flow field. In: IASP (2009)
- [41] Wen, D., Han, H., Jain, A.K.: Face spoof detection with image distortion analysis. TIFS (2015)
- [42] Yang, J., Lei, Z., Liao, S., Li, S.Z.: Face liveness detection with component dependent descriptor. In: ICB (2013)
- [43] Yang, X., Luo, W., Bao, L., Gao, Y., Gong, D., Zheng, S., Li, Z., Liu, W.: Face anti-spoofing: Model matters, so does data. In: CVPR. pp. 3507–3516 (2019)
- [44] Zhang, S., Liu, A., Wan, J., Liang, Y., Guo, G., Escalera, S., Escalante, H.J., Li, S.Z.: Casia-surf: A large-scale multi-modal benchmark for face anti-spoofing. arXiv:1908.10654 (2019)
- [45] Zhang, S., Wang, X., Liu, A., Zhao, C., Wan, J., Escalera, S., Shi, H., Wang, Z., Li, S.Z.: A dataset and benchmark for large-scale multi-modal face anti-spoofing. In: CVPR (2019)
- [46] Zhang, Z., Yan, J., Liu, S., Lei, Z., Yi, D., Li, S.Z.: A face antispoofing database with diverse attacks. In: ICB (2012)
- [47] Zhu, X., Liu, X., Lei, Z., Li, S.Z.: Face alignment in full pose range: A 3d total solution. TPAMI 41(1), 78–92 (2017)