Can Language Models Replace Programmers? RepoCod Says ‘Not Yet’
Abstract
Large language models (LLMs) have achieved high accuracy, i.e., more than 90% pass@1, in solving Python coding problems in HumanEval and MBPP. Thus, a natural question is, whether LLMs achieve comparable code completion performance compared to human developers? Unfortunately, one cannot answer this question using existing manual crafted or simple (e.g., single-line) code generation benchmarks, since such tasks fail to represent real-world software development tasks. In addition, existing benchmarks often use poor code correctness metrics, providing misleading conclusions.
To address these challenges, we create RepoCod, a code generation benchmark with 980 problems collected from 11 popular real-world projects, with more than 58% of them requiring file-level or repository-level context information. In addition, RepoCod has the longest average canonical solution length (331.6 tokens) and the highest average cyclomatic complexity (9.00) compared to existing benchmarks. Each task in RepoCod includes 313.5 developer-written test cases on average for better correctness evaluation. In our evaluations of ten LLMs, none of the models achieve more than 30% pass@1 on RepoCod, indicating the necessity of building stronger LLMs that can help developers in real-world software development. RepoCod is available at https://github.com/lt-asset/REPOCOD
Can Language Models Replace Programmers? RepoCod Says ‘Not Yet’
Shanchao Liang Purdue University liang422@purdue.edu Yiran Hu Purdue University hu954@purdue.edu Nan Jiang Purdue University jiang719@purdue.edu Lin Tan Purdue University lintan@purdue.edu
1 Introduction
Large language models (LLMs) Bian et al. (2023); Zheng et al. (2023) have seen rapid advancements in recent years, increasingly becoming integral to various aspects of our daily lives and significantly enhancing productivity. One critical application of these models is code generation Li et al. (2023a); Ouyang et al. (2023), where the models generate executable code snippets based on provided natural language descriptions Li et al. (2023b); Lozhkov et al. (2024); Touvron et al. (2023); Dubey et al. (2024); Achiam et al. (2023). Such code completion tasks are an integral part for software development.
Research of LLMs for code completion requires a high-quality dataset, whose code completion tasks satisfy three properties: (1) real-world code completion tasks, (2) realistic task complexity, and (3) reliable correctness evaluation metrics.
Specifically, first, it should contain real-world code completion tasks in real-world projects. While manually crafted code completion tasks are useful, they may not represent the actual code-completion tasks developers have to complete. HumanEval Chen et al. (2021) and MBPP Austin et al. (2021) only contain such crafted code completion tasks, thus, they are not sufficient to evaluate LLMs’ real-world code completion abilities.
Second, the code completion tasks should have realistic complexity. Realistic code completion tasks often require the generation of code that has dependencies on other functions, files, and classes in the project. HumanEval and MBPP require no external contexts, failing to evaluate LLMs’ ability to help developers build real-world projects. Benchmarks such as ClassEval Du et al. (2024), CoderEval Zhang et al. (2024), CrossCodeEval Ding et al. (2023), RepoBench Liu et al. (2024), and Long-Code-Arena Bogomolov et al. (2024) include code generation problems with project-level dependencies. Yet, their generation targets are restricted to single-line code or short functions, while realistic projects requires up to hundreds of lines of code for one function.
Third, the code completion data set should include reliable evaluation metrics and data that can accurately evaluate the correctness of LLM-generated code snippets. Some project-level code generation benchmarks Ding et al. (2023); Liu et al. (2024); Bogomolov et al. (2024) use similarity/matching-based evaluation metrics, such as exact match or CodeBLEU Ren et al. (2020), which fail to accurately evaluate the correctness of LLM-generated code. Those metrics often lead to semantically-equivalent code being considered incorrect, and incorrect (but syntactically similar) code being considered correct. For example, Figure 1 (a) illustrates two examples from RepoBench. Although the LLM-generated code is semantically equivalent to the ground truth, CodeBLEU, edit similarity, and exact match would incorrectly consider the code incorrect. In Figure 1 (b), CodeBLUE and edit similarity assign high scores to the LLM-generated code even though the code is incorrect. These examples highlight the limitations of similarity/matching-based metrics in distinguishing correct and incorrect generated solutions.

This paper proposes RepoCod, a complex code generation benchmark that not only evaluates LLMs’ capability in generating functions for real-world projects but also utilizes developer-written test cases to validate the correctness of LLM-generated functions.
This paper makes the following contributions:
-
•
A challenging code generation dataset, consisting of real-world complex coding tasks, with developer-created tests for better correctness evaluation.
-
–
RepoCod includes 980 code generation problems collected from 11 popular projects.
-
–
The average length of our canonical solutions contains 331.6 tokens, more complex than existing code generation benchmarks.
-
–
On average, each instance includes 331.6 developer-written test cases.
-
–
Over one quarter (257, 26.22%) of instances in RepoCod require repository-level contexts.
-
–
-
•
A novel real-world data collection pipeline to construct code generation dataset.
-
•
A thorough study of ten LLMs’ performance on RepoCod, and the key findings include:
-
–
LLMs are ineffective at generating functions with high content complexity (up to 25% pass@1 for tasks requiring repository-level context).
-
–
Using the current file as context results in better model performance than Dense or BM25 retrieval methods for commercial models.
-
–
There are many uniquely solvable problems for each LLM, showing RepoCod’s diversity.
-
–
2 Related Work
2.1 LLMs for Code
LLMs have been widely used for code-related tasks, among which code generation is the most important and common task Achiam et al. (2023); Li et al. (2023b); Lozhkov et al. (2024); Nijkamp et al. (2023); Rozière et al. (2024); Guo et al. (2024); Luo et al. (2024). Existing work on code generation typically forms this task as generating the self-contained programs given the function signature and natural language description. They have shown an impressive ability to generate self-contained programs.
However, the performance of LLMs for code generation within the context of projects or repositories remains underexplored. Despite the use of retrieval-augmented generation (RAG) to retrieve relevant context from the project Ding et al. (2023); Zhang et al. (2024); Wu et al. (2024), generating code within the context of projects remains more challenging and yields lower accuracy compared to generating self-contained code.
In addition to code generation, LLMs have also been used for program repair Jiang et al. (2023); Xia et al. (2023); Hossain et al. (2024); Jin et al. (2023), automated testing Yang et al. (2017); Deng et al. (2023), code translation Yang et al. (2024); Roziere et al. (2020); Pan et al. (2023) and code summarization Zhang et al. (2020); LeClair et al. (2020); Ahmed et al. (2024), greatly enhancing the productivity within these domains.

2.2 Code Generation Benchmarks
Code generation benchmarks are important to evaluate LLMs’ ability to generate code. Self-contained benchmarks Hendrycks et al. (2021); Li et al. (2022); Xia et al. (2024); Liu et al. (2023) are unable to evaluate LLMs’ capability to generate code for real-world projects.
A few project-level code generation benchmarks have been developed. CrossCodeEval Ding et al. (2023), RepoBench Liu et al. (2024), and Long-Code-Arena Bogomolov et al. (2024) are multilingual benchmarks collected from GitHub projects. They consist of problems that require LLMs to generate a single line of code given the incomplete code and project context. These benchmarks share two limitations: (1) their target code is limited to single-line outputs, making it inadequate for evaluating LLMs’ ability to generate complex, multi-line functions, and (2) their similarity-based evaluation metrics fail to accurately evaluate the correctness of LLM-generated code.
Besides these single-line project-level code generation benchmarks, ClassEval Du et al. (2024) is a manually crafted benchmark with 100 problems that require LLMs to generate code for a given class. CoderEval Zhang et al. (2024) is made up of 230 problems collected from GitHub repositories with human-labeled documentation, which requires LLMs to generate solutions given project-level contexts. Although these two benchmarks provide test cases for evaluation and extend beyond single-line code generation, they are still inadequate in terms of problem complexity and scale.
In contrast, RepoCod combines more complex real-world problems (analyzed in Section 3.3.2) with rigorous test-based assessments and consists of 980 project-level code generation tasks that require LLMs to write large functions instead of single-line snippets, aligning model evaluation with the expectations of modern software development.
3 RepoCod Benchmark
This section introduces RepoCod’s automated data collection process (Section 3.1) and data structure (Section 3.2) first, and then demonstrates the statistics of RepoCod (Section 3.3).
| Dataset | Repository-level | File-level | Self-contained | Total | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #NL | #GT | Cyclo. | #Funcs. | #NL | #GT | Cyclo. | #Funcs. | #NL | #GT | Cyclo. | #Funcs. | #NL | #GT | Cyclo. | #Funcs. | ||||
| astropy | 274.9 | 446.4 | 9.4 | 10 | 399.4 | 407.1 | 8.8 | 37 | 291.5 | 284.8 | 7.9 | 38 | 336.5 | 357.0 | 8.5 | 85 | |||
| datasets | 497.1 | 308.4 | 9.1 | 19 | 297.3 | 196.7 | 4.8 | 20 | 311.9 | 135.3 | 3.6 | 20 | 366.6 | 211.9 | 5.8 | 59 | |||
| flask | 448.0 | 215.0 | 6.5 | 2 | 326.2 | 152.3 | 5.2 | 13 | 231.2 | 99.4 | 3.6 | 28 | 270.0 | 120.8 | 4.2 | 43 | |||
| more-itertools | 242.8 | 87.3 | 2.7 | 6 | 300.2 | 136.8 | 4.3 | 23 | 233.4 | 96.3 | 5.0 | 57 | 252.0 | 106.5 | 4.6 | 86 | |||
| plotly.py | 1806.0 | 3393.0 | 132.0 | 1 | 1366.9 | 932.2 | 23.5 | 19 | 1661.7 | 605.1 | 23.9 | 56 | 1589.9 | 723.5 | 25.3 | 76 | |||
| pylint | - | - | - | 0 | 163.9 | 432.1 | 15.2 | 9 | 176.4 | 193.1 | 7.0 | 17 | 172.0 | 275.8 | 9.8 | 26 | |||
| scikit-learn | 222.1 | 398.9 | 7.7 | 208 | 262.9 | 258.3 | 5.3 | 43 | 204.3 | 220.9 | 5.0 | 63 | 224.1 | 344.0 | 6.8 | 314 | |||
| seaborn | 349.5 | 426.0 | 10.3 | 6 | 201.2 | 236.0 | 6.4 | 42 | 240.8 | 211.6 | 6.7 | 30 | 227.9 | 241.3 | 6.8 | 78 | |||
| sphinx | - | - | - | 0 | 191.7 | 606.6 | 17.7 | 12 | 263.8 | 127.8 | 4.0 | 21 | 237.5 | 301.9 | 8.9 | 33 | |||
| sympy | 918.6 | 347.6 | 8.8 | 5 | 903.9 | 586.7 | 17.6 | 58 | 837.8 | 277.6 | 8.6 | 34 | 881.5 | 466.0 | 14.0 | 97 | |||
| xarray | - | - | - | 0 | 902.1 | 418.5 | 11.4 | 40 | 593.0 | 160.5 | 5.3 | 43 | 742.0 | 284.8 | 8.2 | 83 | |||
| Total | 269.4 | 396.7 | 8.3 | 257 | 537.6 | 394.9 | 10.6 | 316 | 522.8 | 241.4 | 8.2 | 407 | 461.1 | 331.6 | 9.0 | 980 | |||
3.1 Data Collection Pipeline
Figure 2 (a) shows the data collection pipeline. RepoCod utilizes GitHub as the source of our data. To filter noisy data such as functions with missing descriptions and test cases, we employ a three-stage data collection pipeline to efficiently collect target functions with good documentation and the corresponding test cases for validation.
Step I: Repository Selection. The selection criteria include open-sourced repositories with Python as the primary language (70%) and those with no less than 2k stars, as popular repositories tend to be well-maintained Jimenez et al. (2024). We clone the latest version of these repositories for step II and step III’s analysis.
Step II: Target Function Selection. For each collected repository, we perform both static and dynamic analysis to accurately identify the functions defined in the repository that are invoked by the developer-provided test cases, with detailed docstrings as function specifications.
We first collect all the test functions in a repository using PyTest’s test discovery rules111https://docs.pytest.org/en/stable/announce/release-8.3.0.html. Then, we identify the functions invoked within these test functions using static and dynamic analysis techniques. For static analysis, we use tree-sitter Brunsfeld et al. (2024) to parse the test functions and collect the functions that are invoked. For dynamic analysis, Python’s trace module is used to examine the execution of each test case. This approach also identifies the indirect function calls invoked by test functions, which are challenging to detect through static analysis alone.
Finally, we filter the target functions, retaining only those with more than ten lines of docstrings and at least two lines of function body.
Step III: Relevant Test Cases Collection. To validate the correctness of LLM-generated code efficiently, we can skip running the entire test suite and instead focus on executing only the relevant test cases—those that specifically invoke the target functions. This targeted approach significantly reduces verification time in large repositories with extensive test suites.
While the previous step provides a mapping between each target function and relevant test cases, it cannot guarantee complete accuracy. For instance, test functions might use subprocess.run(command) to invoke repository functions indirectly, which may be missed by static or dynamic analysis. Therefore, we employ a two-step collection procedure to ensure the capture of all relevant test cases. First, we execute all test cases in the repository to establish a reference result. Then, for each target function, we replace it with an assertion failure, rerun all test cases, and compare the results to the reference. If a test result changes from pass to fail, it indicates that the test case is relevant to the target function.
3.2 Benchmark Structure
Figure 2 (b) illustrates the components of RepoCod’s instances: the target function description, repository snapshot, relevant test cases, and canonical solution. RepoCod uses the developer-provided docstring as the target function description. The repository snapshot, with the target function body removed, is provided as context. The relevant test cases are prepared for each task instance and the LLM generated solution is considered correct if it passes all relevant tests. Finally, the canonical solutions are the original developer-written function bodies of all instances.
3.3 Benchmark Statistics
3.3.1 Basic Statistics
Overall, RepoCod includes 980 data instances collected from a total of 11 popular repositories. These repositories cover a wide range of functionalities, including data science, scientific computing, web development, and software development tools.
Table 1 presents detailed statistics for instances from each repository, categorized by context complexity types: repository-level, file-level, and self-contained. For each category, it shows #NL (number of tokens in target function descriptions), #GT (number of tokens in canonical solutions), Cyclo. (average cyclomatic complexity of the canonical solution) McCabe (1976)), and #Funcs. (number of target functions).
We define three types of context complexities: Repository-level involves canonical solutions that call functions from other files in the repository; file-level involves calls to functions within the same file (excluding the target function) but not from other files; and self-contained includes functions that only use commonly used libraries (e.g., numpy) or Python built-in modules (e.g., os).
Among the three settings, the repository-level functions have the longest token length for the canonical solutions (396.7), compared to the file-level functions (394.9) and self-contained functions (241.4). Additionally, the repository-level functions have the shortest natural language prompt length (537.6), compared to both file-level and self-contained functions (522.8). The combination of the longest average token length for the canonical solution and the shortest natural language description makes repository-level functions the most challenging programming scenario. The average cyclomatic complexity across the three settings is quite similar, ranging from 8.3 to 10.6, indicating a comparable control flow complexity for the canonical solutions at all complexity levels.
| Datasets | #Instances | #Tokens | Cyclo. | #Tests |
|---|---|---|---|---|
| CrossCodeEval | 2,665 | 13.2 | N/A | N/A |
| RepoBench | 23,561 | 13.7 | N/A | N/A |
| Long-Code-Arena | 32,803 | 12.0 | N/A | N/A |
| CoderEval | 230 | 108.2 | 4.71 | - |
| ClassEval | 100 | 123.7 | 2.89 | 33.1 |
| RepoCod | 980 | 331.6 | 9.00 | 313.49 |
3.3.2 Comparison with Existing Benchmarks
Table 2 compares RepoCod with other popular code generation benchmarks that use repository-level or class-level context, including CrossCodeEval Ding et al. (2023), RepoBench Liu et al. (2024), Long-Code-Arena Bogomolov et al. (2024), CoderEval Zhang et al. (2024), and ClassEval Du et al. (2024). The metrics compared include #Instances (the number of samples in each benchmark), #Tokens (the average number of tokens of the canonical solution), Cyclo. (cyclomatic complexity), and #Tests (the average number of test cases per instance). Data entry with ‘N/A’ represents not applicable, and ‘-’ represents this data is not publicly available.
CrossCodeEval, RepoBench, and Long-Code-Arena contain only single-line code generation tasks, resulting in shorter canonical solutions compared to RepoCod. Additionally, they lack test cases and rely on similarity-based metrics, which are insufficient to evaluate code quality. Therefore, we mainly compare RepoCod against CoderEval and ClassEval, as they require full-function generation and include test cases for evaluation.

Dataset Scale. RepoCod has the largest number of instances compared with CoderEval and ClassEval, indicating its ability to perform more comprehensive evaluations of code generation models. Furthermore, RepoCod is collected through our automated pipeline, and is easier to further expand than the others that involve manual annotations.
Problem Complexity. RepoCod presents more challenging problems compared to CoderEval and ClassEval. It has the largest average token count for canonical solutions at 331.6 (Table 2), meaning LLMs are required to generate more than twice as much code to complete the task. It also includes a cyclomatic complexity score of 9.00, indicating that the canonical solutions in RepoCod have a higher structural complexity regarding control flow.
These statistics highlight that the problems in RepoCod are the most challenging and require the longest generation length in existing benchmarks.
| Dataset | Repository-level | File-level | Self-contained | Total |
|---|---|---|---|---|
| CoderEval | 23 | 123 | 84 | 230 |
| ClassEval | 0 | 314 | 153 | 467 |
| RepoCod | 257 | 316 | 407 | 980 |
Context Complexity. In addition to the complexity of canonical solutions, we compare the context complexity of RepoCod with CoderEval and ClassEval, which measures the difficulty of managing, understanding, and utilizing the project context.
Table 3 shows RepoCod has significantly more functions with higher context complexity compared to other benchmarks. Specifically, RepoCod contains the most repository-level dependencies (257), notably higher than CoderEval (23) and ClassEval (0). With the highest context complexity among existing code generation benchmarks, RepoCod is the most suitable for evaluating LLMs’ performance in repository-level code generation tasks.
Test Scale. RepoCod utilizes an average of 312.9 tests per instance, significantly surpassing other benchmarks, highlighting RepoCod’ robustness in evaluating models.
4 Experiment Setup
Due to the large repository sizes, most SOTA LLMs face context window limitations that prevent them from processing all the context provided by RepoCod. We evaluate with three retrieval settings to extract relevant context subsets for generating solution code: sparse retrieval, dense retrieval, and current file, detailed below.
4.1 Retrieval Settings
Sparse Retrieval. For sparse retrieval, we use BM25 Robertson and Zaragoza (2009) to extract relevant functions from repositories as context for the evaluated model. The signatures, docstrings, file paths (relative to the project’s root), and bodies of the retrieved functions are provided as context.
Dense Retrieval. We encode the repository functions using text-embedding-3-small model. The target function’s signature and specification are encoded into a query to be compared against the function embeddings. The top-ranked functions based on cosine similarity are retrieved and provided as context, in the same format as sparse retrieval.
Current File. We introduce a new setting, where the context is limited to the file containing the target function, with the entire file provided as context, excluding the target function’s body.
4.2 Prompting Format
As described in Section 3.2, the data instance of RepoCod consists of the repository snapshot, target function signature, and docstring. Figure 3 demonstrates an example of the prompt construction process, the format of the prompt, and the evaluation pipeline used for all our experiments.
The section highlighted in green represents the data instance of RepoCod (step \raisebox{-.9pt} {1}⃝). The format of the prompt is detailed in the section highlighted in blue (step \raisebox{-.9pt} {2}⃝). Our prompt consists of the system prompt, the file path to the target function (relative to the repository root), the retrieval context, and the target function description (the function signature and docstring of the target function). The retrieval context contains the relative file path, as well as the signature, the docstring, and the body of the retrieved functions. If the context exceeds LLM’s context window, we truncate it from the beginning.
Once the LLM generates the solution (step \raisebox{-.9pt} {3}⃝), the code snippet is inserted into the repository for testing (step \raisebox{-.9pt} {4}⃝, modified file highlighted in blue). Then RepoCod executes the relevant test cases (step \raisebox{-.9pt} {5}⃝) and determines the correctness of the solution (step \raisebox{-.9pt} {5}⃝). As one of the test cases fails, this generated code snippet is considered incorrect.
4.3 Model Setup
Given the complexity of RepoCod, we only select the LLMs that satisfy the following requirements to evaluate: (1) the LLMs show SOTA performance on existing benchmarks such as HumanEval and MBPP, (2) the LLMs support more than 16K context length, as shorter context length are unable to fit in the prompt we use in Figure 3.
| Models | BM25 | Dense | Current-File |
|---|---|---|---|
| CodeLlama-7B | 10.71 | 10.41 | 5.71 |
| CodeLlama-34B | 12.35 | 12.76 | 9.59 |
| DeepSeekCoder-6.7B | 13.98 | 14.08 | 10.92 |
| DeepSeekCoder-33B | 16.73 | 17.14 | 14.90 |
| OpenCodeInterpreter-6.7B | 12.14 | 12.45 | 13.16 |
| OpenCodeInterpreter-33B | 15.31 | 16.33 | 18.27 |
| Claude 3.5 Sonnet | 14.39 | 17.45 | 19.80 |
| DeepSeek-V2.5 | 18.47 | 20.71 | 27.04 |
| GPT-4o-Mini | 15.10 | 15.00 | 18.67 |
| GPT-4o | 27.35 | 27.04 | 26.84 |
Thus, we evaluate GPT-4o, GPT-4o-mini, DeepSeek-V2.5, and Claude 3.5 Sonnet, representing top-performing commercial LLMs. We also evaluate LLMs in CodeLlama, DeepSeek-Coder, and OpenCodeInterpreter series, ranging from 6.7B to 34B parameters on RepoCod. For commercial models, we use their official API, and for the open-sourced LLMs, we use the implementations provided by HuggingFace and vLLM Kwon et al. (2023). Under each experimental setting (retrieval approach), we let each LLM generate one output per instance in RepoCod using greedy decoding.
5 Result
5.1 SOTA LLMs’ Pass@1 on RepoCod
Table 4 shows ten LLMs’ performance on RepoCod, under three retrieval settings. On all retrieval methods, commercial LLMs have better performance. Specifically, GPT-4o has the best result, reaching up to 27.35% pass@1. On the other hand, none of the open-sourced LLMs has over 20% pass@1 in any retrieval settings.
This result shows that SOTA LLMs still struggle with repository-level code generation. Compared to their pass@1 on HumanEval (about 90% Guo et al. (2024)) and MBPP, SOTA LLMs are still far away from writing real-world programs requiring repository-level information. We provide a detailed discussion of the results below.

Impact of Retrieval Approach. The pass@1 results are higher for commercial models when using contexts from the current-file setting, while BM25 and dense retrieval yield similar but lower outcomes. This trend is also observed in the OpenCodeInterpreter series of LLMs. In contrast, other open-source LLMs perform better with BM25 and dense retrieval compared to the current-file setting. These findings suggest that commercial models are more likely to benefit from contexts drawn from the current-file.
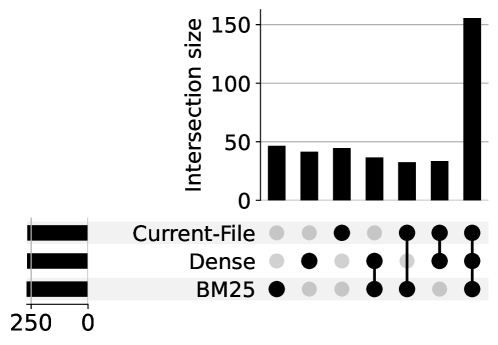
Figure 4 illustrates the overlap and uniqueness of model results using GPT-4o’s result as an example. Though most solutions (more than 150) are solvable by all retrieval settings, each retrieval setting has uniquely solvable problems, which highlights the value of each method in capturing distinct aspects of the context. This suggests that different retrieval techniques provide complementary information.
Impact of Model Size. Results from Table 4 also demonstrate the consistent advantage of larger models in solving complex repository-level code completion tasks compared to smaller models within the same architecture.
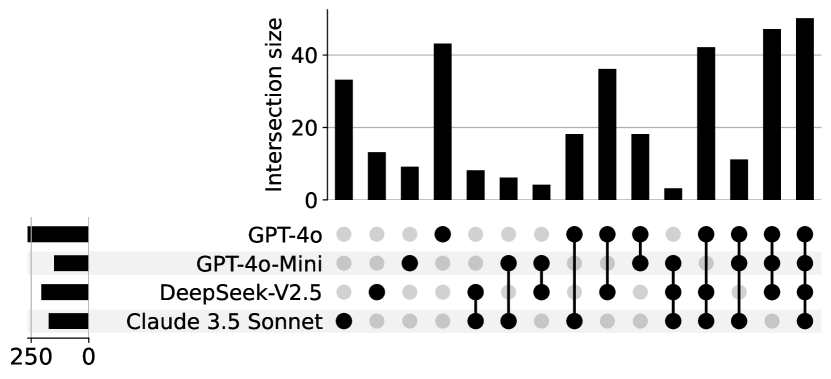
Overlap and Uniqueness of Results in Different Settings. Figure 5 provides a breakdown of all correctly generated results from the commercial LLMs on RepoCod under the Dense retrieval setting. Notably, each model has its own unique set of problems that it alone can solve, highlighting the diversity of RepoCod.
Additionally, two models—Claude 3.5 Sonnet and GPT-4o—have a higher number of uniquely solvable problems, indicating that they excel at certain tasks compared to other models.
Another interesting finding is that, despite Claude 3.5 Sonnet being only the third-best performing commercial model in the dense retrieval setting, it has the fewest overlaps in correct evaluations with other models. This suggests that Claude 3.5 Sonnet may lack some knowledge commonly shared among other commercial models, resulting in fewer overlapping solutions.
5.2 Performance under Different Complexity
We show the performance of SOTA LLMs in solving problems with different complexities. We compare two types of complexities: Context Complexity, and Canonical Solution Length. The results are collected under the dense retrieval setting.
Context Complexity. Figure 6(a) details the comparison of the evaluation results of SOTA LLMs for functions with different context complexities. All models have the lowest pass@1 when solving functions with repository-level context compared to functions with less complex contents. The overall solve rate decreases as the complexity of the context level increases. In addition, the low solve rate highlights the difficulty of solving problems with repository-level contexts and demonstrates the strength of RepoCod compared to all existing code generation benchmarks.
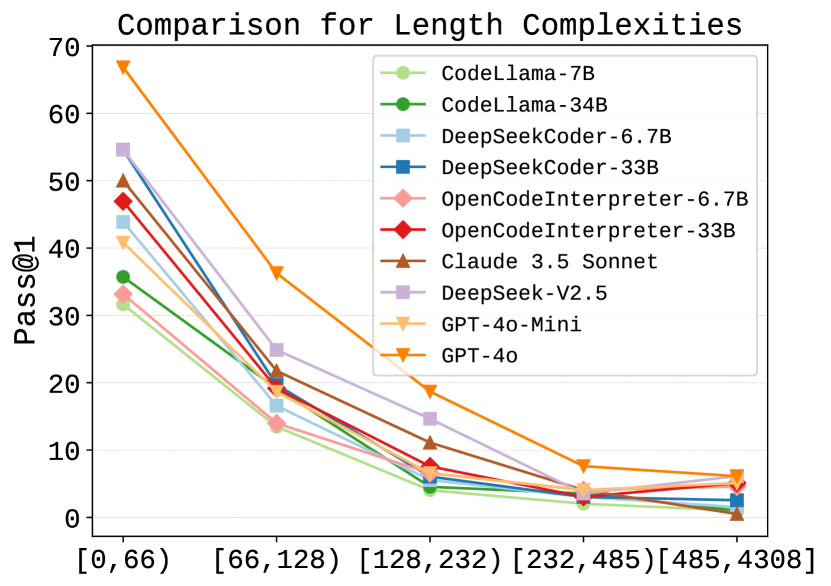
Canonical Solution Length. Figure 6(b) presents the performance of LLMs across different length complexity. Similar to the findings from the previous section, the pass@1 of the LLMs gradually decreases as the complexity of the functions increases. In the challenging scenarios (token length > 232), even the top-performing model, GPT-4o, achieves less than 10% pass@1. This low pass@1 performance indicates that while SOTA LLMs are effective at solving simpler problems, they struggle significantly with problems that have medium to long canonical solution lengths in RepoCod. Combining the fact that RepoCod has the longest canonical solution length (Table 2) and the most problems with repository-level context (Table 3), RepoCod sets a new standard for LLMs in code generation.
5.3 Ablation Studies
5.3.1 Inference Length V.S. GT length
| Models | BM25 | Dense | Current-File | |||||
|---|---|---|---|---|---|---|---|---|
| Pass | Fail | Pass | Fail | Pass | Fail | |||
| CodeLlama-7B | 43.6 | 16.1 | 38.3 | 16.8 | 25.0 | 18.7 | ||
| CodeLlama-34B | 51.0 | 24.7 | 63.3 | 22.8 | 19.0 | 28.9 | ||
| DeepSeekCoder-6.7B | 33.8 | 8.3 | 31.6 | 8.6 | 16.4 | 11.3 | ||
| DeepSeekCoder-33B | 72.1 | 11.1 | 77.6 | 9.6 | 14.5 | 22.4 | ||
| OpenCodeInterpreter-6.7B | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 | ||
| OpenCodeInterpreter-33B | 1.4 | 0.9 | 1.4 | 0.9 | 1.4 | 0.9 | ||
| DeepSeek-V2.5 | 2.7 | 1.6 | 2.5 | 1.6 | 2.9 | 1.4 | ||
| Claude 3.5 Sonnet | 18.6 | 4.0 | 21.9 | 2.7 | 7.8 | 5.7 | ||
| GPT-4o-Mini | 3.6 | 2.7 | 3.9 | 2.6 | 9.9 | 1.2 | ||
| GPT-4o | 1.3 | 1.2 | 1.3 | 1.2 | 2.1 | 1.0 | ||
We analyze the relation between the inference length and the canonical solutions’ length under all retrieval settings. Table 5 presents the average inference-to-canonical solution length ratio using micro-averaging. A lower ratio indicates the model’s ability to closely match the canonical solution’s functionality. Most open-source models produce significantly longer correct solutions compared to the canonical solution when using BM25 or Dense retrieval methods, suggesting a high portion of irrelevant information or computations are included in the generated solution. The Current-File method yields a slightly lower ratio but still exhibits these tendencies. In contrast, commercial models show relatively low ratios, indicating greater precision. On average, the LLM generated result has a longer length than canonical solutions.
5.3.2 Retrieval Results Impact
Table 6 presents the pass@1 performance of LLMs for retrieved content across different recall rate ranges: 0, (0, 0.5), [0.5, 1), and 1. These four settings reflect the proportion of correct content within the top 10 retrieved items. As the retrieved content includes more ground truth contexts, the pass@1 scores increase. This analysis focuses on samples with repository-level and file-level contexts. Across all models, pass@1 scores improve when the recall rate increases from 0–0.5 to 0.5–1 or 1. Interestingly, when recall is low, model performance is comparable to that with a 0 recall rate. Higher recall in retrieved content consistently leads to better model performance.
| Models | 0 | [0,0.5) | [0.5,1) | 1 |
|---|---|---|---|---|
| CodeLlama-7B | 6.05 | 0.00 | 13.16 | 13.27 |
| CodeLlama-34B | 5.04 | 2.50 | 21.05 | 16.33 |
| DeepSeekCoder-6.7B | 5.54 | 5.00 | 13.16 | 21.43 |
| DeepSeekCoder-33B | 7.81 | 5.00 | 15.79 | 25.51 |
| OpenCodeInterpreter-6.7B | 6.05 | 0.00 | 15.79 | 16.33 |
| OpenCodeInterpreter-33B | 9.07 | 5.00 | 15.79 | 20.41 |
| DeepSeek-V2.5 | 10.33 | 5.00 | 18.42 | 26.53 |
| Claude 3.5 Sonnet | 6.55 | 5.00 | 7.89 | 29.59 |
| GPT-4o-Mini | 6.55 | 5.00 | 18.42 | 26.53 |
| GPT-4o | 14.61 | 7.50 | 26.32 | 35.71 |
6 Limitation
Our work has several limitations. First, we currently collect data from only 11 repositories, covering a small subset of those that could be included in this benchmark; future versions of RepoCod will expand to include more popular Python repositories. Second, we evaluate only ten models, representing a subset of popular LLMs. With more time and resources, we could test a broader range, providing a more comprehensive view of LLM capabilities in repository-level code generation. We will publish RepoCod so the community can evaluate additional models, broadening the scope of tested LLMs.
7 Conclusion
We present RepoCod, a real-world, complex dataset designed for code generation tasks with repository-level context. RepoCod comprises 980 instances from 11 popular Python repositories, including 257 requiring repository-level context and 316 requiring file-level context, highlighting the complexity and comprehensiveness of the benchmark. Additionally, we introduce an innovative automatic extraction method that can scale RepoCod to any Python project, offering a scalable solution for repository-level code generation benchmarks. Our evaluation of SOTA LLMs on RepoCod reveals a maximum pass@1 of 27.35%, with even lower scores for functions requiring repository-level context, underscoring that current models fall short of generating realistic repository-level code. This work underscores the need for further research in repository-level code completion.
References
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ahmed et al. (2024) Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl Barr. 2024. Automatic semantic augmentation of language model prompts (for code summarization). In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program synthesis with large language models. ArXiv, abs/2108.07732.
- Bian et al. (2023) Ning Bian, Xianpei Han, Le Sun, Hongyu Lin, Yaojie Lu, Ben He, Shanshan Jiang, and Bin Dong. 2023. Chatgpt is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models. arXiv preprint arXiv:2303.16421.
- Bogomolov et al. (2024) Egor Bogomolov, Aleksandra Eliseeva, Timur Galimzyanov, Evgeniy Glukhov, Anton Shapkin, Maria Tigina, Yaroslav Golubev, Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, and Timofey Bryksin. 2024. Long code arena: a set of benchmarks for long-context code models. Preprint, arXiv:2406.11612.
- Brunsfeld et al. (2024) Max Brunsfeld, Andrew Hlynskyi, Amaan Qureshi, Patrick Thomson, Josh Vera, Phil Turnbull, dundargoc, Timothy Clem, ObserverOfTime, Douglas Creager, Andrew Helwer, Rob Rix, Daumantas Kavolis, Hendrik van Antwerpen, Michael Davis, Ika, Tuãn-Anh Nguyễn, Amin Yahyaabadi, Stafford Brunk, Matt Massicotte, Niranjan Hasabnis, bfredl, Mingkai Dong, Samuel Moelius, Steven Kalt, Will Lillis, Kolja, Vladimir Panteleev, and Jonathan Arnett. 2024. tree-sitter/tree-sitter: v0.22.6.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. Preprint, arXiv:2107.03374.
- Deng et al. (2023) Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, and Lingming Zhang. 2023. Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt. Preprint, arXiv:2304.02014.
- Ding et al. (2023) Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2023. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion. Preprint, arXiv:2310.11248.
- Du et al. (2024) X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y. Chen, J. Feng, C. Sha, X. Peng, and Y. Lou. 2024. Evaluating large language models in class-level code generation. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE), pages 982–994, Los Alamitos, CA, USA. IEEE Computer Society.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. 2024. The llama 3 herd of models. Preprint, arXiv:2407.21783.
- Guo et al. (2024) Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. Deepseek-coder: When the large language model meets programming – the rise of code intelligence. Preprint, arXiv:2401.14196.
- Hendrycks et al. (2021) Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Measuring coding challenge competence with apps. NeurIPS.
- Hossain et al. (2024) Soneya Binta Hossain, Nan Jiang, Qiang Zhou, Xiaopeng Li, Wen-Hao Chiang, Yingjun Lyu, Hoan Nguyen, and Omer Tripp. 2024. A deep dive into large language models for automated bug localization and repair. ArXiv, abs/2404.11595.
- Jiang et al. (2023) Nan Jiang, Kevin Liu, Thibaud Lutellier, and Lin Tan. 2023. Impact of code language models on automated program repair. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1430–1442.
- Jimenez et al. (2024) Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations.
- Jin et al. (2023) Matthew Jin, Syed Shahriar, Michele Tufano, Xin Shi, Shuai Lu, Neel Sundaresan, and Alexey Svyatkovskiy. 2023. Inferfix: End-to-end program repair with llms. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1646–1656.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- LeClair et al. (2020) Alexander LeClair, Sakib Haque, Lingfei Wu, and Collin McMillan. 2020. Improved code summarization via a graph neural network. In Proceedings of the 28th International Conference on Program Comprehension, ICPC ’20, page 184–195, New York, NY, USA. Association for Computing Machinery.
- Li et al. (2023a) Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2023a. Enabling programming thinking in large language models toward code generation. arXiv preprint arXiv:2305.06599.
- Li et al. (2023b) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. 2023b. Starcoder: may the source be with you! Preprint, arXiv:2305.06161.
- Li et al. (2022) Yujia Li, David Choi, Junyoung Chung, et al. 2022. Competition-level code generation with alphacode. Science, 378(6624):1092–1097.
- Liu et al. (2023) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. In Advances in Neural Information Processing Systems, volume 36, pages 21558–21572. Curran Associates, Inc.
- Liu et al. (2024) Tianyang Liu, Canwen Xu, and Julian McAuley. 2024. Repobench: Benchmarking repository-level code auto-completion systems. In The Twelfth International Conference on Learning Representations.
- Lozhkov et al. (2024) Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. 2024. Starcoder 2 and the stack v2: The next generation. Preprint, arXiv:2402.19173.
- Luo et al. (2024) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. Wizardcoder: Empowering code large language models with evol-instruct. In The Twelfth International Conference on Learning Representations.
- McCabe (1976) T.J. McCabe. 1976. A complexity measure. IEEE Transactions on Software Engineering, SE-2(4):308–320.
- Nijkamp et al. (2023) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2023. Codegen: An open large language model for code with multi-turn program synthesis. Preprint, arXiv:2203.13474.
- Ouyang et al. (2023) Shuyin Ouyang, Jie M Zhang, Mark Harman, and Meng Wang. 2023. Llm is like a box of chocolates: the non-determinism of chatgpt in code generation. arXiv preprint arXiv:2308.02828.
- Pan et al. (2023) Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2023. Understanding the effectiveness of large language models in code translation. arXiv preprint arXiv:2308.03109.
- Ren et al. (2020) Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. Preprint, arXiv:2009.10297.
- Robertson and Zaragoza (2009) Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3(4):333–389.
- Roziere et al. (2020) Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. 2020. Unsupervised translation of programming languages. In Advances in Neural Information Processing Systems, volume 33, pages 20601–20611. Curran Associates, Inc.
- Rozière et al. (2024) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. 2024. Code llama: Open foundation models for code. Preprint, arXiv:2308.12950.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wu et al. (2024) Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, and Xiaofei Ma. 2024. Repoformer: Selective retrieval for repository-level code completion. Preprint, arXiv:2403.10059.
- Xia et al. (2024) Chunqiu Steven Xia, Yinlin Deng, and Lingming Zhang. 2024. Top leaderboard ranking= top coding proficiency, always? evoeval: Evolving coding benchmarks via llm. arXiv preprint arXiv:2403.19114.
- Xia et al. (2023) Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1482–1494.
- Yang et al. (2017) Jinqiu Yang, Alexey Zhikhartsev, Yuefei Liu, and Lin Tan. 2017. Better test cases for better automated program repair. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2017, page 831–841, New York, NY, USA. Association for Computing Machinery.
- Yang et al. (2024) Zhen Yang, Fang Liu, Zhongxing Yu, et al. 2024. Exploring and unleashing the power of large language models in automated code translation. Proc. ACM Softw. Eng., 1(FSE).
- Zhang et al. (2020) Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2020. Retrieval-based neural source code summarization. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, ICSE ’20, page 1385–1397, New York, NY, USA. Association for Computing Machinery.
- Zhang et al. (2024) Yakun Zhang, Wenjie Zhang, Dezhi Ran, Qihao Zhu, Chengfeng Dou, Dan Hao, Tao Xie, and Lu Zhang. 2024. Learning-based widget matching for migrating gui test cases. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, volume 66 of ICSE ’24, page 1–13. ACM.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595–46623.
Appendix A Appendix
A.1 Recall of Retrieval approach
Table 7 presents the recall rates of two different retrieval settings—sparse and dense—applied across all selected repositories. These repositories include pylint, sphinx, seaborn, flask, sympy, more-itertools, scikit-learn, xarray, datasets, plotly.py, and astropy. The recall rates reflect performance at both the repository-level and file-level contexts, providing insights into how each setting performs for individual repositories as well as overall.
| Repository | Sparse | Dense |
|---|---|---|
| astropy | 0.28 | 0.25 |
| datasets | 0.25 | 0.33 |
| flask | 0.30 | 0.45 |
| more-itertools | 0.11 | 0.33 |
| plotly.py | 0.07 | 0.42 |
| pylint | 0.46 | 0.46 |
| scikit-learn | 0.07 | 0.05 |
| seaborn | 0.24 | 0.26 |
| sphinx | 0.06 | 0.12 |
| sympy | 0.22 | 0.23 |
| xarray | 0.12 | 0.29 |
| Total | 0.13 | 0.15 |
| Setting | pylint | sympy | sphinx | seaborn | flask | more-itertools | scikit-learn | xarray | datasets | plotly.py | astropy | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CodeLlama-7B | 7.69 | 7.22 | 9.09 | 23.08 | 37.21 | 13.95 | 5.10 | 6.02 | 22.03 | 6.58 | 5.88 | 10.41 |
| CodeLlama-34B | 0.00 | 4.12 | 18.18 | 21.79 | 32.56 | 24.42 | 5.73 | 16.87 | 18.64 | 14.47 | 10.59 | 12.76 |
| DeepSeekCoder-6.7B | 7.69 | 6.19 | 15.15 | 26.92 | 41.86 | 12.79 | 6.37 | 16.87 | 16.95 | 25.00 | 14.12 | 14.08 |
| DeepSeekCoder-33B | 3.85 | 7.22 | 27.27 | 28.21 | 37.21 | 11.63 | 7.32 | 15.66 | 33.90 | 43.42 | 16.47 | 17.14 |
| OpenCodeInterpreter-6.7B | 3.85 | 4.12 | 12.12 | 16.67 | 41.86 | 18.60 | 6.37 | 10.84 | 16.95 | 21.05 | 12.94 | 12.45 |
| OpenCodeInterpreter-33B | 11.54 | 7.22 | 21.21 | 20.51 | 41.86 | 29.07 | 8.28 | 13.25 | 25.42 | 23.68 | 16.47 | 16.33 |
| Claude 3.5 Sonnet | 19.23 | 11.34 | 15.15 | 25.64 | 39.53 | 38.37 | 6.05 | 9.64 | 27.12 | 36.84 | 10.59 | 17.45 |
| DeepSeek-V2.5 | 15.38 | 13.40 | 27.27 | 30.77 | 41.86 | 36.05 | 9.87 | 16.87 | 30.51 | 35.53 | 16.47 | 20.71 |
| GPT-4o-Mini | 11.54 | 11.34 | 15.15 | 25.64 | 39.53 | 18.60 | 6.05 | 10.84 | 33.90 | 25.00 | 9.41 | 15.00 |
| GPT-4o | 19.23 | 15.46 | 27.27 | 37.18 | 58.14 | 43.02 | 13.69 | 24.10 | 47.46 | 44.74 | 23.53 | 27.04 |
The recall rates for Dense retrieval are generally higher than those for BM25 retrieval across most repositories, highlighting the effectiveness of the Dense method in retrieving the invoked functions relevant to the target function.
There are notable variations between repositories. For instance, more-itertools and plotly.py show significantly higher recall rates with the Dense setting, while scikit-learn demonstrates relatively low recall rates in both settings.
The total recall rate is computed using micro-averaging, and the result shows that neither retrieval method achieves a high recall for the oracle contexts. This indicates the possibility of improving the LLM evaluation result by enhancing the retrieval approach.
A.2 Evaluation Result By Repository
Table 8 presents detailed LLM performance on RepoCod, revealing several key insights.
First, repositories differ significantly in difficulty. Models perform well on flask, with pass@1 often above 40% , indicating an alignment with LLM capabilities. Second, GPT4-o is the strongest LLM on RepoCod, consistently outperforming or matching other models across all repositories. Finally, LLMs exhibit specialization across repositories. For instance, while Claude 3.5 Sonnet and DeepSeekCoder-33B perform similarly overall, Claude excels on pylint, whereas DeepSeekCoder performs better on plotly.py.


A.3 Case Studies
Prompt Example. Figure 7 shows an example of a RepoCod prompt, consisting of the system prompt, context information retrieved by BM25, and the target function details, with specific content replaced by ....
Passed Example. Figure 8 shows an example of a correctly generated solution from RepoCod generated by GPT4-o under a dense retrieval setting. This example passes all test cases and is considered correct. Upon inspection, the generated code snippet is identical to the canonical solution except for the text content in the exception message.

Failed Example. Figure 9 shows an example of an incorrectly generated solution by GPT4-o under BM25 retrieval setting. The canonical solution incorporates repository-level context; however, the solution generated by GPT-4o fails to match the functionality of the canonical solution.

A.4 Uniqueness and Overlap of Correct Generations
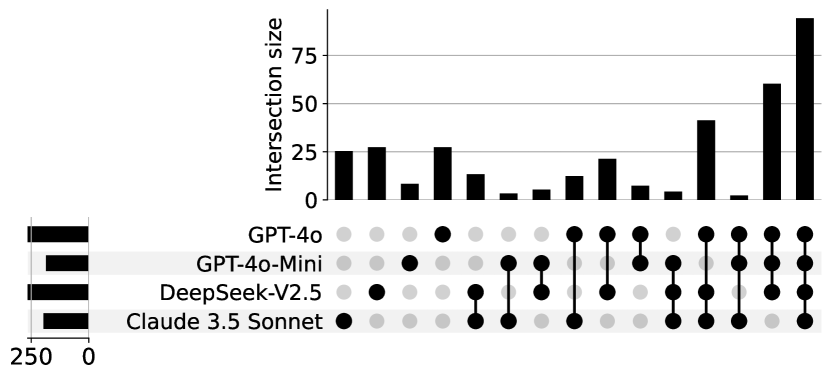
Commercial LLMs with BM25. Figure 10(a) presents the UpSet plot comparing the performance of four commercial models using contexts from BM25 retrieval, the largest overlap (more than 40) is shared by all models, indicating a significant degree of commonality. GPT-4o has the highest number of unique cases (over 60), suggesting its ability to capture distinct results in this scenario.
Commercial LLMs with Current-File. Figure 10(b) shows the Current File retrieval setting result. The overlap between all models increases greatly compared to the BM25 retrieval (to over 75 cases), demonstrating stronger alignment across models with this retrieval setting. In addition, the unique solvable problem by GPT4-o reduces greatly, to a similar level compared to Claude 3.5 Sonnet and DeepSeek-V2.5.
A.5 Impact of Retrieval Methods on Pass@1 across Varying Context Complexities
Figure 11(a) and Figure 11(b) illustrate the pass@1 for instances across various context complexities under different retrieval settings: BM25 and current file. In both settings, LLM performance tends to decrease as context complexity rises, progressing from self-contained to file-level and eventually to repository-level contexts. This trend aligns with the insights discussed in Section 5.2.
An interesting finding is that GPT-4-o achieves a higher pass@1 rate for instances under repository-level context complexity compared to file-level instances. This observation suggests two potential insights: (1) specific retrieval methods, like BM25, may enhance performance on repository-level task instances; (2) higher context complexity does not necessarily result in reduced LLM performance.

