Can depth-adaptive BERT perform better on binary classification task of Chinese texts
Abstract
In light of the success of transferring language models into NLP tasks and the magnitude of those language models, we ask whether the full language model is always the best and does it exist a simple but effective method to find the winning ticket in state-of-the-art deep neural networks without complex calculations. We construct a series of BERT-based models with different size by layer truncation and compare their predictions on 8 binary classification tasks. The results show there truly exist smaller sub-networks performing better than the full model. Then we present a further study and propose a simple method to shrink BERT appropriately before fine-tuning. Some extended experiments indicate that our method could save time and storage overhead extraordinarily both in fine-tuning and testing with little even no accuracy loss.
1 Introduction
Information retrieval is always of great concern, which
Recently, pretrain-then-finetune paradigm has led to significant improvements in a wide range of the NLP tasks. Some pre-trained language models, like BERT Devlin et al. (2019), achieve state-of-the-art performance on numerous tasks, such as sentiment analysis, acceptability analysis, semantic similarity analysis and machine translation Dolan and Brockett (2005); Warstadt et al. (2019); Wang et al. (2018); Yang et al. (2019a); Hoang et al. (2019); Yang et al. (2020a). For learning general knowledge as much as possible in pre-training stage, the language models are constructed with plenties of units (i.e., the total parameters in BERTBASE are 110M, and in BERTLARGE are 340M) Devlin et al. (2019) . They are usually too huge for the downstream tasks. Taking BERTBASE as an example, fine-tuning it on some complex downstream tasks requires several hours to finish one epoch Strubell et al. (2019). That makes them impractical for resource-limited deployment scenarios and cost concerns incur, then hinders the applications. As we know, some compressed models (i.e., distilBERT, 66M Sanh et al. (2019)) are capable of achieving comparable results. These lead us to think the magnitude of those large language models when transfer to target tasks, force us to compress models and accelerate their calculations McCarley et al. (2019). However, existing model compression methods cost too much resources during fine-tuning, so we are eager to find a new way to solve the problem.
Existing model compression methods orienting to particular tasks fall into two categories, namely knowledge distillation Buciluǎ et al. (2006) and pruning Frankle and Carbin (2018). For using knowledge distillation method, there needs to construct a complex teacher model and a much simple student. After the teacher fine-tuned thoroughly, the student imitates the teacher to predict and then makes decisions independently in test period. By doing so, resources like time and memory are saved in test period Chia et al. (2019); Mirzadeh et al. (2020); Yang et al. (2020b); Wu et al. (2021). However, loading the teacher and student simultaneously and transferring knowledge from the teacher to the student during fine-tuning consume too much memory and time. Differently, pruning method only requires constructing one model, but mask parameters should be preserved to implement weight dropping. Matching the mask parameters with the original model and pruning the less important units during fine-tuning also need huge storage and time. Joulin et al. (2016); Liu et al. (2018); Voita et al. (2019); Gordon et al. (2019); Wang et al. (2020b). Some common issues could be concluded that (1) they all target at accelerating calculations in test stage at the cost of more resource-consuming during fine-tuning. And (2) all the downstream tasks apply the standard language models indiscriminately and treat them as the superior basis of pruning without taking the complexities of different tasks into consideration. Naturally, the matching relations between pre-trained language models and target tasks are neglected. Compressing models based on them is unreasonable.
According to the lottery ticket hypothesis Frankle and Carbin (2018); Chen et al. (2020b), there is some redundancy in over-parameterization BERT model. While some experiments about binary text classification tasks (like CoLA Warstadt et al. (2019) and ChnSentiCorpHou Tan and Zhang (2008)) indicate that the standard BERT model is not always the best choice, and sometimes we could find sub-networks (winning tickets) surpassing the full BERT on some tasks via layer truncation (Details are provided in section 2). Motivated by this phenomenon, we propose to truncate BERT adaptively before fine-tuning and save resources both in fine-tuning and test stages with little cost. Compared with the conventional model compressing methods, our truncation method is valuable. Because fine-tuning time is much longer (hundreds times or more) than test time, while conventional methods fail to reduce it but need more in practice. A simple way to estimate the truncating position based on the characteristics of tasks is also provided. In addition, we conduct some experiments on 8 binary text classification tasks (Binary text classification tasks are simple enough to highlight the issues and are the basis of most complex NLP tasks). The results show that our method is simple but effective.
In summary, our contributions include:
-
•
We observe that full BERT is not always the best when fine-tuning on some particular downstream tasks. Sometimes shrinking BERT by simply truncating layers leads to capable even better performances with less overhead.
-
•
We put forward a simple but effective truncation method to find out the winning ticket in BERT before fine-tuning, and provide a measure to estimate truncating position.
-
•
Experiments in this paper show that our method could surpass the traditional compressing methods on 7 tasks and even predict more precisely than full BERT on 3 tasks. In addition, our method saves about 75% fine-tuning time and 25% storage than knowledge distillation and pruning methods on average. Also, 20% storage and time are saved compared with original BERT-based models both in fine-tuning and testing while remaining near to 99% accuracy on average.
2 Full BERT is NOT always the best
Knowledge distillation and pruning methods accelerate testing of models by devoting additional resources during fine-tuning. That is impractical for some edge devices. In order to save cost both in fine-tuning and testing, we propose to truncate several consecutive transformer layers from top of the BERT (12-layer) and preserve the bottom part as a new encoder. In this paper, we reduce BERT ranging from 0 to 11 layers and obtain 12 different encoders. Each encoder is appended a task-specific fully-connected layer and a sigmoid layer. All these 12 shrunk models (namely trans12 to trans1) are fine-tuned on eight text classification tasks, including CoLA Warstadt et al. (2019) and ChnSentiCorpHou Tan and Zhang (2008). More details of datasets, experimental settings and results are provided in Appendix A, B and C.
Here we take CoLA and ChnSentiCorpHou as examples and plot the test accuracy, training and test time of these 12 truncated models in Figure 1. There is no doubt that the training and test time are increasing dramatically as the number of transformer layer grows. However, we do not get far satisfying predictions with so many resources cost. With the increasement of the transformer layer, we find the accuracy is gradually fluctuating within a certain range. For CoLA (Figure 1 (left)), we find two winning tickets surpassing the full BERT when number of transformer layers are 9 and 10. While the models with 8 and 11 layers are almost capable of predicting as precisely as full BERT-based model. As for ChnSentiCorpHou (Figure 1 (right)), although we do not find a winning ticket better than full BERT, models with 2 to 12 layers predict similarly. It seems that smaller models could perform well enough with less time and memory compared with full BERT.

3 Truncating BERT before fine-tuning
The results in section 2 show there exist truncated BERT models performing better than full BERT on some binary classification tasks. This inspires us that shrinking massive BERT for simple tasks is valuable and necessary. In order to clearly understand this phenomenon and find a way to solve problems well with less time and memory, we further take a closer look at these results and make some analyses about BERT truncation. In this section, we will provide some discussions about when, where and how to truncate BERT model.
3.1 Where to truncate
As discussed in section 2, the test accuracy becomes fluctuating when the number of transformer layers larger than some certain values. We then compare the predictions of each model and capture something interesting. When the test accuracies of two models are similar, the predictions on the same instance are also close. In addition, all these 12 models provide consistent predictions on most of the instances, and divisions only arise over a few indistinguishable ones. While these divisions would become less and less with the test accuracies being closer.
Specifically, given a dataset containing examples . We construct 12 truncated BERT-based classification models, namely to (here, the subscript of denotes the number of transformer layers), to make predictions on the . The test accuracy of a model is denoted as . And the calculation of on is formulated as:
| (1) | |||
| (2) |
Where is the sigmoid function, is the function of a fully-connected layer, is the function of the encoder, and is the function of the -th transformer encoder layer. As mentioned above, when is close to , we find is also close to . For classification task, we know is a generalized linear transformation targeting at finding a hyperplane separating examples best without transforming the representations. Naturally, the prediction mainly depends on the transformation of the encoder . The higher separability of the hidden states produced by the encoder is, the higher prediction probability and the higher test accuracy of the model are. As a result, we could use the hidden states to help us decide where to truncate.
Inspired by the distribution of points in high dimensional space, we treat the output representations of transformer layers in encoder as coordinates of point, and apply the separability theory of point set to expressing the distribution of examples in our datasets. We truncate BERT targeting at producing representations of dataset with maximum seperability.
Here, we introduce three widely used separability measures, namely Class Scatter Matrices (CSM) Duda et al. (1973), Thornton’s Separability Index (SI) Thornton (2002), and Hypothesis Margin (HM) Gilad-Bachrach et al. (2004).
Class Scatter Matrices, CSM : is a fraction of trace of between-cluster scatter and within-cluster scatter. It evaluates the overall distribution of an entire dataset.
| (3) | |||
| (4) | |||
| (5) |
Where denotes the trace operation: calculating the sum of one’s diagonal elements. and are the number of classes in a dataset and number of examples in class respectively. While and are the mean vectors of whole dataset and class separately. is the -th instance in class . The within-cluster scatter and between-cluster scatter are denoted as and .
Separability Index, SI: calculates the average number of instances that share the same category label as their nearest neighbors. It is a measure evaluating the class overlap.
| (6) |
Where is the label of , is the nearest neighbor of , and is the number of examples in a dataset.
Hypothesis Margin, HM: measures the sum of the distance between the hypothesis and the closest hypothesis that assigns the alternative label to the given instance.
| (7) | |||
Where nearhit() and nearmiss() denote the nearest instance to with the same and different label, respectively. And is the number of instances in a dataset. denotes the Euclidean norm.
According to the definitions above mentioned, the larger these three separability values are, the more easily the examples are classified. We could apply our truncation method with the assistance of the separability measures.
3.2 When to truncate
As we all known, BERT is pre-trained on two general tasks, namely masked language model (MLM) and next sentence prediction (NSP). It means there is little disturbance of wrong prediction corresponding to specific task brought in. Making decisions on the basis of original pre-trained BERT is more objective.
What’s more, once the fine-tuning processing starts, the predicting error would radially propagate back to each layer of the entire network. Breaking the network during this stage leads to reconstruct new matching relations among whole net, which is far more time-consuming.
On account of these factors, we decide to truncate BERT before fine-tuning. If we can make a reliable decision about where to truncate before fine-tuning, resources like time and storage would be saved extraordinarily.
3.3 How to truncate
In this sub-section, we provide a general algorithm about truncating BERT (12-layer) properly for downstream tasks by means of separability measures (Algorithm 1).
Given a target binary classification task and the corresponding dataset, we can estimate where to truncate before fine-tuning without building up the network. Our three-step method is simple enough and time-saving. In particular, all the instances in the dataset should be vectorized with BERT embeddings in the first step. Secondly, the vectorized instances are sent into the pre-trained BERT model and propagate forward once without backward propagation. In this step, we will obtain 12 hidden representations from different transformer layers of the BERT for every instance. The hidden representations produced by the same transformer layer are packed into a common set. Then in the third step, we calculate separability values for these 12 representation sets. The number of transformer layers related to the maximum separability is the suggested number of layers in the truncated BERT. We truncate BERT according to that and append the task-specific layer on to form the final model.
In this way, we can truncate BERT adaptively before fine-tuning according to target tasks. Putting these truncated BERT into force could save as much as time and memory with little expense.
4 Experiments
Observations in section 2 inspires us that the full BERT is not always the best choice for some binary classification tasks. And in section 3 we provide a simple but clear analysis about this phenomenon, and introduce an effective method to shrink BERT for downstream tasks. In this section we will apply our method to 8 binary classification tasks and give a further exploration.
| Corpus | Size | Input Style | Task | Language | Degree of Difficulty |
|---|---|---|---|---|---|
| ChnSentiCorpHou | 6k | single sentence | sentiment classification | Chinese | |
| WaiMai | 12k | single sentence | sentiment classification | Chinese | |
| SST-2 | 67.8k | single sentence | sentiment classification | English | |
| CoLA | 9k | single sentence | acceptability analysis | English | |
| Nikon-JD | 2.6k | sentence pair | aspect-level sentiment classification | Chinese | |
| AFQMC | 38.6k | sentence pair | semantic similarity | Chinese | |
| MRPC | 5.8k | sentence pair | semantic similarity | English | |
| RTE | 2.7k | sentence pair | natural language inference | English |
4.1 Datasets and tasks
In this sub-section, we will give a brief introduction about 8 corpora used in this paper, including ChnSentiCorpHou, WaiMai, SST-2, CoLA, Nikon-JD, AFQMC, MRPC and RTE. The ChnSentiCorpHou is a sub-set of a series of Chinese sentiment analysis corpora organized by Tan et al. Tan and Zhang (2008). The WaiMai is a binary classification corpus about reviews of delivery service and takeaway food111https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets/waimai_10k. The SST-2 Socher et al. (2013), CoLA Warstadt et al. (2019), MRPC Dolan and Brockett (2005) and RTE Dagan et al. (2005); Haim et al. (2006); Giampiccolo et al. (2007); Bentivogli et al. (2009) come from the general language understanding evaluation (GLUE) benchmark Wang et al. (2018), and AFQMC222https://dc.cloud.alipay.com/indexn#/topic/intro?id=3 is selected from the Chinese language understanding evaluation (CLUE) benchmark Xu et al. (2020). The Nikon-JD corpus is organized by our team. More details of these datasets are provided in Appendix A. In Table 1, we list some critical information about these corpora. We select two Chinese and two English single sentence classification tasks. In addition, two Chinese and two English sentence pair classification tasks are also chosen. The assignments in this section vary from sentiment classification and acceptability analysis to semantic similarity and natural language inference. Different assignment is related to different size of dataset and difficulty degree.
4.2 Implementations
We select the 12-layer BERT model (BERTBASE) as our basic language model and apply the truncation method on these 8 datasets. For each single sentence task, we put a [CLS] and [SEP] at the beginning and the end of the given text separately. And for sentence pair task, we also concatenate two texts into a sequence with [SEP] token being the separator, besides the special pre-processing at beginning and end. Then send processed sequences into the BERT for following procedures.
Before constructing models and fine-tuning, we utilize whole dev sets of ChnSentiCorpHou, Nikon-JD, MRPC and RTE, and randomly sample about 50%, 50%, 10% and 10% examples from dev sets of SST-2, CoLA, WaiMai and AFQMC separately. Then we calculate CSM, SI and HM with these prepared instances for each task, and according to that truncate BERT model adaptively. Next, we construct classification models based on the truncated BERT models, then fine-tune and test them on above mentioned corpora. More experimental details are in Appendix B.
For comparison, we also set up some baselines:
BERT base: We construct binary classification models based on BERTBASE Devlin et al. (2019) as the standard models.
Distil-Pretrain: We build up classification models based on the distilled language models (DistilBERT Sanh et al. (2019) and albert-chinese-tiny333https://huggingface.co/clue/albert_chinese_tiny). In this way, the knowledge distillation theory is used in pre-training period.
Distil-task-biLSTM: We fine-tune a BERT-based classification model as the teacher, and construct a student using the biLSTM as the encoder with the assistance of the attention mechanism. Then let the student imitates prediction of the teacher.
Distil-task-kimCNN: We construct a student according to the kimCNN Kim (2014). While the teacher models are same as those of Distil-task-biLSTM.
Pruning-AGP: We use the Automated Gradual Pruner (AGP) zhu2017prune to implement the task-specific magnitude pruning on our tasks. Here we refer to the implementation provided in the Distiller library zmora2019neural.
Random truncation: Random truncation means selecting a random number ranging from 0 to 11 as the number of layers that should be truncated. Here, we use the mean test accuracy of 12 various truncated BERT-based models to denote the random accuracy.
Note that all these baselines use the BERT embeddings, the batch size and max sequence length are same as those of our models (Table 6). Differently, during implementing task-specific distillation, we set the learning rate as 1e-3.
4.3 Results
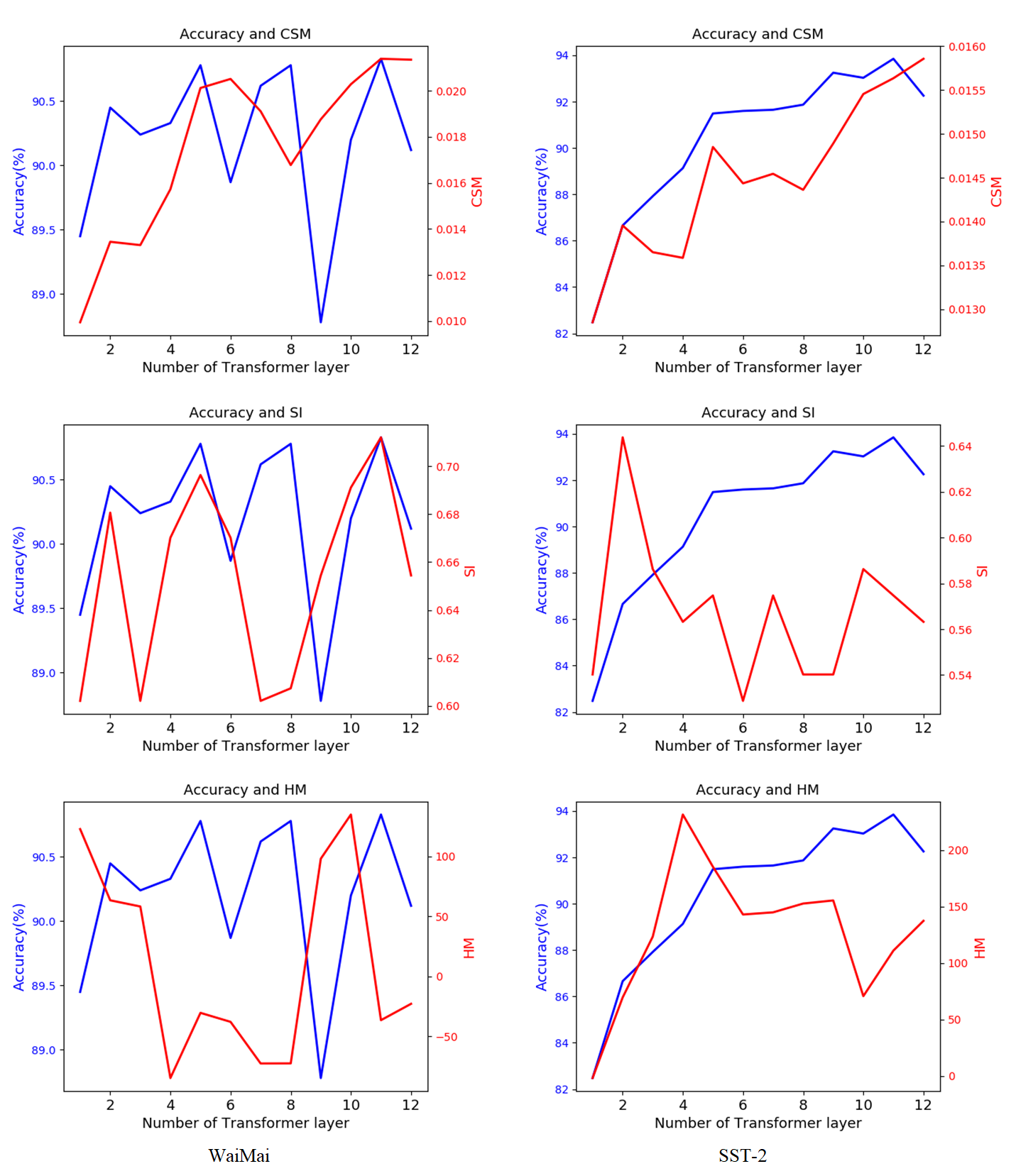
In order to evaluate whether our separability measures are appropriate or not and then choose a better one for truncating BERT, we firstly plot three measures with the test accuracies in Figure 2 (Here we only provide the results of CoLA and ChnSentiCorpHou, while others are shown in Appendix D). Obviously, we could easily find that the tendencies of these three measures are similar to the test accuracies to some extent. As revealed in the Equation 3-7, distance-based measures (CSM and HM) are more exact than the one based on number of instances (SI), while HM is easily influenced by some specific examples and loses effectiveness. Among these three measures, the CSM is more stable. To make a quantitative analysis, we use the Pearson’s correlation coefficient (PCC) to evaluate the relations. The average of PCC in Table 2 also indicates that the CSM is more relevant to test accuracy. As a result, we choose the CSM measure to help us truncate BERT.
| CSM | SI | HM | |
|---|---|---|---|
| ChnSentiCorpHou | 0.7942 | 0.8204 | 0.4208 |
| WaiMai | 0.2171 | 0.1927 | -0.6054 |
| SST-2 | 0.8697 | -0.1703 | 0.5242 |
| CoLA | 0.9655 | 0.5444 | 0.8269 |
| Nikon-JD | 0.9517 | 0.8014 | 0.7963 |
| AFQMC | 0.7709 | -0.2119 | 0.7073 |
| MRPC | 0.2544 | 0.7389 | 0.4105 |
| RTE | 0.8720 | 0.1090 | -0.2889 |
| Avg | 0.7119 | 0.3530 | 0.3489 |

As shown in Figure 2 and Appendix D, when the number of transformer layers are 7, 11, 12, 10, 11, 12, 5 and 9, the CSM values reach the maximum on ChnSentiCorpHou, WaiMai, SST-2, CoLA, Nikon-JD, AFQMC, MRPC and RTE, respectively. So we accept these suggestions and truncate BERT for these tasks. In this way, the test accuracies of our truncated model are 93.05%, 90.83%, 92.26%, 85.96%, 97.31%, 74.12%, 76.52% and 63.68%.
The test accuracy, processing time and scale of parameters are listed in Table 3, Table 4 and Table 5, respectively. Obviously, our method, Truncated-CSM, is capable of the 99% language understanding capabilities of the full model in average, and almost surpasses the other compressing methods on all these tasks except the MRPC. Also, about 20% of time and memory are saved both in fine-tuning and test with little additional cost, which is impossible for knowledge distillation and pruning. What’s more, our method is simple to implement and transfer to other tasks. On the contrary, we can draw conclusions from Table 4 and Table 5 that distillation methods are too complex to apply and consume far more time and storage from building up the teacher model to obtaining the student. The pruning methods are of the same circumstances in fine-tuning. The overhead of knowledge distillation and pruning methods in fine-tuning is awful and unbearable. However, we do not get satisfying predictions with these two kinds of ways.
| Model | ChnSentiCorpHou (%) | WaiMai (%) | SST-2 (%) | CoLA (%) | Nikon-JD (%) | AFQMC (%) | MRPC (%) | RTE (%) |
|---|---|---|---|---|---|---|---|---|
| BERT base | 93.30 | 90.12 | 92.26 | 83.87 | 97.01 | 74.12 | 83.59 | 65.81 |
| Distil-Pretrain | 91.17 | 89.82 | 91.71 | 81.40 | 90.72 | 51.88 | 82.09 | 59.56 |
| Distil-task-biLSTM | 87.50 | 89.57 | 87.10 | 68.31 | 89.32 | 64.18 | 64.17 | 50.88 |
| Distil-task-kimCNN | 86.48 | 88.45 | 85.23 | 70.59 | 91.29 | 63.51 | 67.59 | 52.08 |
| Pruning-AGP | 92.65 | 87.11 | 91.32 | 82.73 | 95.23 | 69.95 | 77.33 | 57.50 |
| Random truncation | 92.05 | 90.21 | 90.43 | 77.29 | 95.66 | 70.90 | 76.68 | 64.21 |
| Truncated-CSM | 93.05 | 90.83 | 92.26 | 85.96 | 97.31 | 74.12 | 76.52 | 63.68 |
| Model | ChnSentiCorpHou | WaiMai | SST-2 | CoLA | Nikon-JD | AFQMC | MRPC | RTE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT base | 347 | 439 | 3918 | 334 | 104 | 1617 | 159 | 177 | ||||||||
| Distil-Pretrain | - | - | - | - | - | - | - | - | ||||||||
| Distil-task-biLSTM |
|
|
|
|
|
|
|
|
||||||||
| Distil-task-kimCNN |
|
|
|
|
|
|
|
|
||||||||
| Pruning-AGP | 10516 | 5175 | 21389 | 2326 | 1970 | 16643 | 2467 | 2004 | ||||||||
| Random truncation | - | - | - | - | - | - | - | - | ||||||||
| Truncated-CSM | 211 | 401 | 3918 | 288 | 96 | 1617 | 83 | 134 |
| Model | ChnSentiCorpHou | WaiMai | SST-2 | CoLA | Nikon-JD | AFQMC | MRPC | RTE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT base | 102 | 102 | 109 | 109 | 102 | 102 | 109 | 109 | ||||||||
| Distil-Pretrain | - | - | - | - | - | - | - | - | ||||||||
| Distil-task-biLSTM |
|
|
|
|
|
|
|
|
||||||||
| Distil-task-kimCNN |
|
|
|
|
|
|
|
|
||||||||
| Pruning-AGP | 102 | 102 | 109 | 109 | 102 | 102 | 109 | 109 | ||||||||
| Random truncation | - | - | - | - | - | - | - | - | ||||||||
| Truncated-CSM | 67 | 95 | 109 | 95 | 95 | 102 | 53 | 88 |
According to these results, we confirm our method is effective and provide the following suggestions:
-
•
Only 1 layer of transformer encoder is enough to perform well on most simple tasks.
-
•
For some complex tasks, a few more layers (3-5 layers) could produce satisfying results.
-
•
More exact estimation could be made by randomly sampling some instances to calculate CSM value.
5 Related Work
In this section, we briefly review some work about pre-trained language models, knowledge distillation and model pruning.
Pre-trained language models: Since about 2017, there gradually appear some complex language models. The widely used BERT proposed by Devlin et al. Devlin et al. (2019) achieves pretty good results on GLUE Wang et al. (2018), SQuAD Rajpurkar et al. (2016) and SWAG Zellers et al. (2018). Before long, XLNet Yang et al. (2019b), RoBERTa Liu et al. (2019) and some others Zafrir et al. (2019); Shen et al. (2020); Wang et al. (2021) emerge and push the evaluation scores of NLP tasks much higher. With the development of pre-trained language models, a wide range of NLP tasks obtain new state-of-the-art results again and again, including question answering McCarley et al. (2019), language inference Levesque et al. (2012); Williams et al. (2018), text classification Joulin et al. (2016) and text summarization Barzilay and Elhadad (1999). Consequently, the language models has been an indispensable part in solving NLP assignments.
Knowledge distillation: Knowledge distillation is a method that can transfer knowledge from an ensemble or a large highly regularized model into a much smaller, distilled model. This concept is proposed by Caruana et al. Buciluǎ et al. (2006) and further extended to Neural Networks by Hinton’s team Hinton et al. (2015). Some like SANH et al. Sanh et al. (2019) and Jiao et al. Jiao et al. (2020) only use this theory to compress models and accelerate processing. More are inspired not only to reduce the models but also transfer extra knowledge by means of changing input style or other factors during distillation Chen et al. (2019); Ma et al. (2020); Chen et al. (2020a); Wang et al. (2020a); Sun et al. (2020).
Model pruning: Existing model pruning work could classify into two categories, namely structured pruning and unstructured pruning. The structured pruning means removing models by dropping several entire layers or some coherent groups of blocks Michel et al. (2019); Fan et al. (2019); Wang et al. (2020b). In contrast, unstructured pruning is a form of dropout that compresses model by reducing weights independently Frankle and Carbin (2018); Gordon et al. (2019); Prasanna et al. (2020); Chen et al. (2020b).
6 Conclusion
In this paper, we conduct a series of experiments to exploring whether it exist winning tickets when transferring the language models in downstream binary classification tasks and how to find them conveniently and effectively. Different from conventional model compressing methods, we insist to truncate BERT by a brute force mean that is dropping out several consecutive transformer layers once. In addition, a simple way to estimate the size of BERT before fine-tuning is provided by us. In this way, the resources are saved tremendously without losing too much accuracy. More effectively, some simple task could be solved only use one transformer layer sometimes.
Currently, there is a little work studying the over-parameterization problem of state-of-the-art networks based on language models. And researchers still fail to comprehend and explain these complex and massive deep neural networks. Also, there is little work solving the resource-consuming problem well. However, these problems should be attached importance to and solved well before the development of neural models reaching a higher level. Now we throw away a brick in order to attract more researchers to pay attention to then solve these problems.
In future, we will extend these experiments to other more complex NLP tasks and other language models, and explore more effective ways to find winning tickets in language models. Also, we are eager to find out more effective ways to solve these problems better.
References
- Barzilay and Elhadad (1999) Regina Barzilay and Michael Elhadad. 1999. Using lexical chains for text summarization. Advances in automatic text summarization, pages 111–121.
- Bentivogli et al. (2009) Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth pascal recognizing textual entailment challenge. In TAC.
- Buciluǎ et al. (2006) Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. 2006. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541.
- Chen et al. (2020a) Defang Chen, Jian-Ping Mei, Can Wang, Yan Feng, and Chun Chen. 2020a. Online knowledge distillation with diverse peers. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 3430–3437.
- Chen et al. (2020b) Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. 2020b. The lottery ticket hypothesis for pre-trained bert networks. arXiv preprint arXiv:2007.12223.
- Chen et al. (2019) Yen-Chun Chen, Zhe Gan, Yu Cheng, Jingzhou Liu, and Jingjing Liu. 2019. Distilling knowledge learned in bert for text generation. arXiv preprint arXiv:1911.03829.
- Chia et al. (2019) Yew Ken Chia, Sam Witteveen, and Martin Andrews. 2019. Transformer to cnn: Label-scarce distillation for efficient text classification. arXiv preprint arXiv:1909.03508.
- Dagan et al. (2005) Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine Learning Challenges Workshop, pages 177–190. Springer.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1).
- Dolan and Brockett (2005) William B Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005).
- Duda et al. (1973) Richard O Duda, Peter E Hart, and David G Stork. 1973. Pattern classification and scene analysis, volume 3. Wiley New York.
- Fan et al. (2019) Angela Fan, Edouard Grave, and Armand Joulin. 2019. Reducing transformer depth on demand with structured dropout. In International Conference on Learning Representations.
- Frankle and Carbin (2018) Jonathan Frankle and Michael Carbin. 2018. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations.
- Giampiccolo et al. (2007) Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B Dolan. 2007. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pages 1–9.
- Gilad-Bachrach et al. (2004) Ran Gilad-Bachrach, Amir Navot, and Naftali Tishby. 2004. Margin based feature selection-theory and algorithms. In Proceedings of the twenty-first international conference on Machine learning, page 43.
- Gordon et al. (2019) Mitchell A Gordon, Kevin Duh, and Nicholas Andrews. 2019. Compressing bert: Studying the effects of weight pruning on transfer learning.
- Haim et al. (2006) R Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. stat, 1050:9.
- Hoang et al. (2019) Mickel Hoang, Oskar Alija Bihorac, and Jacobo Rouces. 2019. Aspect-based sentiment analysis using bert. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, pages 187–196.
- Jiao et al. (2020) Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. Tinybert: Distilling bert for natural language understanding. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 4163–4174.
- Joulin et al. (2016) Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. 2016. Fasttext. zip: Compressing text classification models. arXiv preprint arXiv:1612.03651.
- Kim (2014) Y. Kim. 2014. Convolutional neural networks for sentence classification. Eprint Arxiv.
- Levesque et al. (2012) Hector Levesque, Ernest Davis, and Leora Morgenstern. 2012. The winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Liu et al. (2018) Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. 2018. Rethinking the value of network pruning. In International Conference on Learning Representations.
- Ma et al. (2020) Xinyin Ma, Yongliang Shen, Gongfan Fang, Chen Chen, Chenghao Jia, and Weiming Lu. 2020. Adversarial self-supervised data free distillation for text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6182–6192.
- McCarley et al. (2019) JS McCarley, Rishav Chakravarti, and Avirup Sil. 2019. Structured pruning of a bert-based question answering model. arXiv preprint arXiv:1910.06360.
- Michel et al. (2019) Paul Michel, Omer Levy, and Graham Neubig. 2019. Are sixteen heads really better than one? Advances in Neural Information Processing Systems, 32:14014–14024.
- Mirzadeh et al. (2020) Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. 2020. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5191–5198.
- Prasanna et al. (2020) Sai Prasanna, Anna Rogers, and Anna Rumshisky. 2020. When bert plays the lottery, all tickets are winning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3208–3229.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392.
- Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
- Shen et al. (2020) Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. 2020. Q-bert: Hessian based ultra low precision quantization of bert. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8815–8821.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642.
- Strubell et al. (2019) Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2019. Energy and policy considerations for deep learning in nlp. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645–3650.
- Sun et al. (2020) Haipeng Sun, Rui Wang, Kehai Chen, Masao Utiyama, Eiichiro Sumita, and Tiejun Zhao. 2020. Knowledge distillation for multilingual unsupervised neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3525–3535.
- Tan and Zhang (2008) Songbo Tan and Jin Zhang. 2008. An empirical study of sentiment analysis for chinese documents. Expert Systems with applications, 34(4):2622–2629.
- Thornton (2002) Chris Thornton. 2002. Truth from trash: How learning makes sense.
- Voita et al. (2019) Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5797–5808.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355.
- Wang et al. (2021) Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. 2021. Kepler: A unified model for knowledge embedding and pre-trained language representation. Transactions of the Association for Computational Linguistics, 9:176–194.
- Wang et al. (2020a) Xinyu Wang, Yong Jiang, Nguyen Bach, Tao Wang, Fei Huang, and Kewei Tu. 2020a. Structure-level knowledge distillation for multilingual sequence labeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3317–3330.
- Wang et al. (2020b) Ziheng Wang, Jeremy Wohlwend, and Tao Lei. 2020b. Structured pruning of large language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6151–6162.
- Warstadt et al. (2019) Alex Warstadt, Amanpreet Singh, and Samuel Bowman. 2019. Neural network acceptability judgments. Transactions of the Association for Computational Linguistics, 7:625–641.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122.
- Wu et al. (2021) Chuhan Wu, Fangzhao Wu, and Yongfeng Huang. 2021. One teacher is enough? pre-trained language model distillation from multiple teachers. arXiv e-prints, pages arXiv–2106.
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. 2020. Clue: A chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772.
- Xu et al. (2019) Meng Xu, Xin Zhang, and Lixiang Guo. 2019. Jointly detecting and extracting social events from twitter using gated bilstm-crf. IEEE Access, 7:148462–148471.
- Yang et al. (2019a) An Yang, Quan Wang, Jing Liu, Kai Liu, Yajuan Lyu, Hua Wu, Qiaoqiao She, and Sujian Li. 2019a. Enhancing pre-trained language representations with rich knowledge for machine reading comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2346–2357.
- Yang et al. (2020a) Jiacheng Yang, Mingxuan Wang, Hao Zhou, Chengqi Zhao, Weinan Zhang, Yong Yu, and Lei Li. 2020a. Towards making the most of bert in neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 9378–9385.
- Yang et al. (2019b) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019b. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32.
- Yang et al. (2020b) Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, and Guoping Hu. 2020b. Textbrewer: An open-source knowledge distillation toolkit for natural language processing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 9–16.
- Zafrir et al. (2019) Ofir Zafrir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. 2019. Q8bert: Quantized 8bit bert. arXiv preprint arXiv:1910.06188.
- Zellers et al. (2018) Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. 2018. Swag: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 93–104.
Appendix A Datasets Information
Here, we provide more exact descriptions about corpora used in this paper.
ChnSentiCorpHou: The ChnSentiCorpHou is a Chinese sentiment corpus about hotel comments collected by Tan et al. Tan and Zhang (2008). It consists of 3000 positive and 3000 negative reviews about hotel. We conduct our single sentence classification task on it. When given a comment, we should predict the corresponding polarity.
WaiMai: The WaiMai is a Chinese sentiment corpus about comments of delivery service and takeaway food444https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets/waimai_10k. It consists of about 4000 positive and 8000 negative examples.
SST-2: The Stanford Sentiment Treebank Socher et al. (2013) consists of about 70k English sentences from movie reviews. These sentences are annotated with positive or negative polarity. The target of this task is to predict the sentiment category when given a sentence.
CoLA: The Corpus of Linguistic Acceptability Warstadt et al. (2019) consists of a plenty of English acceptability judgments drawn from books and journal articles on linguistic theory. There are 10k examples in this corpus, and each of which is a sentence annotated with a binary label indicating whether it is a grammatical English sequence or not. Note that for privacy limitation, we only utilize the training and dev set.
Nikon-JD: The Nikon-JD is a Chinese aspect-level sentiment classification dataset consisting of 2.6k product reviews crawled from E-commerce platform, namely JingDong555https://www.jd.com/. We organize 3 professors annotating these reviews. Given a review and a target aspect category, all those 3 annotators should make a decision whether the review expresses a positive polarity or not toward the aspect. Then we label it in terms of the majority.
AFQMC: The Ant Financial Question Matching Corpus Xu et al. (2020) comes from the Ant Technology Exploration Conference Developer competition. There are 42.5k instances in this corpus, each of which is a sentence pair. It is a binary classification task that targets at predicting whether a pair of sentences are semantically similar.
MRPC: The Microsoft Research Paraphrase Corpus Dolan and Brockett (2005) is a set of English sentence pairs automatically extracted from online news platforms, each pair annotated with a label indicating whether the sentences in a pair are semantically equivalent. There are approximately 5.8k pairs in this corpus.
RTE: The Recognizing Textual Entailment (RTE) Wang et al. (2018) dataset consists of 2.7k sentence pairs. Each pair of sentences is labeled with a binary category signifying whether one sentence could entail the other or not.
Appendix B Experimental Settings
Full ChnSentiCorpHou, WaiMai, SST-2 and MRPC corpora are obtained from the original sources . Due to the privacy limitation, we only get the training and dev set of CoLA, AFQMC and RTE. For CoLA and AFQMC, we treat the original dev sets as our new test sets and randomly sample 10% instances from the original training sets forming the new dev sets while the remaining examples forming the new training sets. Then we fine-tune classification models on the training and dev sets and implement test on the test sets for WaiMai, SST-2, CoLA, AFQMC and MRPC. We perform 5-fold cross-validations on the remaining three datasets, namely ChnSentiCorpHou, Nikon-JD and RTE, which means partitioning the examples into 5 parts randomly, choosing a different fold as the test set with accuracy calculated on, and leaving the remaining 4 folds to form the training and test set each time. In the evaluation step, we use the average accuracy of 5 test sets as the final result.
| Corpus | Batch Size | Learning rate | Max Sequence length | Device |
|---|---|---|---|---|
| ChnSentiCorpHou | 32 | 1e-5 | 512 | RTX30902 |
| WaiMai | 32 | 1e-5 | 256 | RTX30902 |
| SST-2 | 32 | 2e-5 | 128 | V1001 |
| CoLA | 32 | 2e-5 | 128 | RTX30902 |
| Nikon-JD | 32 | 1e-5 | 256 | RTX30902 |
| AFQMC | 32 | 5e-6 | 256 | RTX30902 |
| MRPC | 32 | 1e-5 | 128 | RTX30902 |
| RTE | 32 | 1e-5 | 256 | V1001 |
We use 12-layer Chinese BERT-wwm-ext666https://huggingface.co/hfl/chinese-bert-wwm-ext and BERT-base-uncased777https://huggingface.co/bert-base-uncased as our basic language models for Chinese and English tasks separately. All the classification models are fine-tuned for 5 epochs. The batch size and other information are listed in Table 6. Following each epoch of training, we give a test on dev set and record the better model. Finally, the one performs best on dev set will be saved and applied.
Appendix C Accuracy curves
In Figure 3, we plot the test accuracy, training time and test time of the other 6 datasets. According to these curves, we confirm that there truly exist some smaller sub-networks surpassing the full BERT model on some downstream tasks. The more difficult the task is, the more complex the corresponding model should be.

Appendix D Separability measures and test accuracy
In this section, we provide the comparisons of separability measures and test accuracy of other 6 corpora. Similar as the Figure 2, we also capture consistent trends between the CSM measure and test accuracy on these binary classification tasks. That means our truncation method assisted by CSM is resonable and effective.