CAMAv2: A Vision-Centric Approach for
Static Map Element Annotation
Abstract
The recent development of online static map element (a.k.a. HD map) construction algorithms has raised a vast demand for data with ground truth annotations. However, available public datasets currently cannot provide high-quality training data regarding consistency and accuracy. For instance, the manual labelled (low efficiency) nuScenes still contains misalignment and inconsistency between the HD maps and images (e.g., around 8.03 pixels reprojection error on average). To this end, we present CAMAv2: a vision-centric approach for Consistent and Accurate Map Annotation. Without LiDAR inputs, our proposed framework can still generate high-quality 3D annotations of static map elements. Specifically, the annotation can achieve high reprojection accuracy across all surrounding cameras and is spatial-temporal consistent across the whole sequence. We apply our proposed framework to the popular nuScenes dataset to provide efficient and highly accurate annotations. Compared with the original nuScenes static map element, our CAMAv2 annotations achieve lower reprojection errors (e.g., 4.96 vs. 8.03 pixels). Models trained with annotations from CAMAv2 also achieve lower reprojection errors (e.g., 5.62 vs. 8.43 pixels).
Index Terms:
Intelligent driving, vision-centric, 3D reconstruction, map annotation![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/x1.png)
I Introduction
Intelligent vehicles use various sensors to detect surroundings, such as cameras and LiDAR. However, these sensors have a limited perception range and are vulnerable to bad weather. Using pre-built digital maps is an effective way to overcome the limitations, enhancing perception and robustness. High-definition (HD) maps provide a detailed and precise representation of the physical environment [1], with lane-level instance and semantic information, which is vital for the navigation of intelligent vehicles. Most previous methods use simultaneous localisation and mapping (SLAM) for map construction, involving complicated pipelines and labour-intensive annotations [2, 3, 4]. The advancement of deep learning is driving a swift transformation in the technical architecture of intelligent driving perception algorithms, moving from traditional rule-based to data-driven methods [5, 6, 7]. Online HD map construction is becoming the mainstream of LiDAR-based and vision-centric Bird’s-Eye-View (BEV) perception [8]. These methods focus on analysing vectorized static map element instances in BEV and 3D space, ultimately training neural networks to generate vectorized maps directly from surrounding camera images.
Existing online HD map construction algorithms usually require high-quality and diverse annotated training data. Accordingly, public datasets that provide annotations in 3D space can be roughly divided into two categories: HD map-based and depth reprojection-based. For instance, the nuScenes [9] dataset provides human-annotated HD maps alongside ego vehicle poses. HDMapNet [10] is one of the pioneers that utilizes vectorized maps provided by nuScenes as ground truth and trains a neural network to predict static map elements directly in BEV space. OpenLane [11] proposed the first real-world 3D lane dataset using the depth reprojection method to generate 3D lane annotations. Specifically, each frame’s 3D lane point clouds are generated by combining 2D lane detection and 3D LiDAR points.
However, there are still some significant limitations to the state-of-the-art annotation approaches. In particular, 3D road element annotations should accurately reflect real-world environments. To this end, we urgently need to address two key aspects to analyze existing annotations: consistency and geometric accuracy. The consistency focuses on the correspondence between the 3D annotations and the 2D images. The geometric accuracy reflects the matching accuracy in reprojecting the 3D annotations into the images. For example, Fig. 1 (a, b) shows the HD maps that plot the lane dividers between the vehicle and bike lanes. However, the images show no corresponding lane lines in the same area. Fig. 1 (c) shows the lane dividers projected on the image plane (white and yellow lines) deviating from the actual lane dividers in the image. The main reason is that the nuScenes dataset provides 2D HD maps without elevation information, and the ego-motion is not accurate when aligned with global maps. These limitations, therefore, affect the consistency and geometric accuracy of the 3D annotations with the actual 2D image.
In light of these challenges, we propose CAMAv2: a vision-centric approach for Consistent and Accurate Map Annotation (see Fig. 2). Our proposed CAMAv2 is distinguished in three aspects: (1) We propose using a whole 3D reconstruction pipeline to get accurate camera motion and a sparse point cloud mainly from surround images. Thus, it can be applied to even low-cost intelligent driving platforms without equipping LiDAR. (2) A road surface mesh reconstruction algorithm [12] is applied to reconstruct high-accuracy road surfaces. It can produce dense 3D road surfaces with both semantic and photometric information. (3) An auto map annotation tool [13] is applied to extract the vectorized lane representation from the road surface. Consequently, as shown in Fig. 1 (bottom), CAMAv2 achieves high consistency and geometric accuracy compared with nuScenes default HD map.
The present article builds upon work first presented in [14]. Our contributions can be enumerated as follows.
-
•
We propose an efficient static element annotation framework, CAMAv2, for 3D road element annotation. The proposed CAMAv2 can generate highly consistent and geometric accurate HD map annotations. Through comprehensive experiments, we verified that such annotations can dramatically improve the accuracy and generalization of perception models in intelligent driving.
-
•
To verify our proposed framework, we apply CAMAv2 to the nuScene dataset and set up new HD map annotations, namely nuScenes-CAMAv2. MapTRv2 [15] is used as a benchmark model. Extensive experiments show that models trained on nuScenes-CAMAv2 can produce more consistent and accurate estimations of the static map elements compared with default HD map (e.g., reprojection errors of 5.62 vs. 8.43 pixels).
A preliminary version of this study was presented in [14]. The current journal extension introduces two major improvements. Firstly, we propose a parallel reconstruction method for large-scale intelligent driving scenarios, where multiple driving segments are first reconstructed separately and then stitched together, thus reducing the runtime required for SfM reconstruction (achieving five times efficiency boost). Second, we improve the reconstruction results of our pipeline on the nuScenes dataset by proposing a multi-scene aggregated reconstruction method, which solves the defects of dropping the head and tail frames in the previous single-scene reconstruction and the occlusion and blind zone problems. It ultimately results in more accurate and consistent annotations and greatly accelerates the annotation process. The nuScenes-CAMAv2 is publicly available at https://github.com/manymuch/CAMA.
II Related Work
Over the past few years, vision-centric BEV perception has become the 3D vision paradigm in intelligent driving. In particular, deep learning-based mapping methods have emerged as a prominent research interest in HD map construction. Effective view transformations are critical for improving algorithm performance and environment awareness. Data-driven BEV perception algorithms rely on high-accuracy and diverse 3D road surface element annotation. To the best of our knowledge, the public road surface element datasets provided static road elements can be roughly divided into HD map-based [9, 16, 17] and depth reprojection-based [11, 18, 19]. In this part, we present a concise survey of existing HD map construction and correlated datasets. For a more thorough treatment of vision-centric HD map construction, a recent compilation by Ma et al. [8] also offers sufficiently good reviews.
II-A Vision-centric HD Map Construction
HDMapNet [10] introduces a pioneering approach for online HD map construction by training neural networks to predict pixel-wise segmentation in BEV spaces, which requires complicated and time-consuming post-processing to obtain the vectorized representation of road elements. Following HDMapNet, VectorMapNet [20] explores the end-to-end framework of HD map prediction, modeling map elements with a two-stage framework and predicting vectorized maps. MapTR [21, 15] further boosts efficiency and performance by improving the map element decoder and loss function modeling. To make a step towards end-to-end road structure understanding, LaneGAP [22] and TopoNet [19] regress the road topology structure directly. In summary, the current trend of end-to-end mapping networks mainly focuses on improving the 2D-to-BEV transformation module and vectorized map element modeling method for greater effectiveness. The view transformation between perspective view and BEV is usually conducted in geometric projection models explicitly [23, 24, 25] or uses neural networks to learn implicit representations [26, 27, 28]. Data-driven perception algorithms drastically boost the advancement of intelligent driving applications. It offers several advantages. First, the model learns directly from the input through end-to-end training [29], eliminating the complex intermediate processing and enabling handle occlusion and extreme illuminance conditions through temporal fusion [30, 31, 32, 33]. Secondly, benefitting from the data-driven closed-loop mechanism, the models can self-optimize, reducing the engineering efforts in debugging corner cases. Thirdly, models trained on diverse datasets show better generalizability in various driving environments and complex visual conditions.
II-B Map Element Datasets
The nuScenes dataset [9] provides four human-annotated city-scale maps, forming the basis for numerous online HD map construction works [10, 20, 21]. All methods use three static map elements (lane boundary, lane divider, and pedestrian crossing) provided by the nuScenes HD map for training. Notably, nuScenes projects the reconstructed geometric map to the ground plane and annotates it in 2D space. Thus, the HD map lacks elevation information, and the reprojection accuracy between the HD map and images is not guaranteed. Fig. 1 shows the misalignment of the image with the reprojected road edges. In addition, due to the synchronization and calibration errors [34, 35], the pose between the cameras and the map is not well aligned. Consequently, the nuScenes HD map can not guarantee the consistency and accuracy of annotations.
The Argoverse2 dataset [17] is another large-scale dataset actively used for HD map construction. In contrast to the nuScenes dataset, Argoverse2 provides 3D HD map representation with high-resolution ground elevation and a map change dataset that depicts real-world HD map changes. Each scenario carries its local map region, and the advantages of per-scenario maps include more efficient queries and their ability to handle map changes. As it provides richer HD map information, more and more online mapping methods [15, 36, 37] are evaluated on the Argoverse2 dataset.
Lanes are an important map element, and 3D lane detection has become a specialized perception task. Without HD maps, some datasets employ LiDAR points for 3D lane annotation, such as OpenLane [11] and Once-3DLanes [18]. They propose to combine LiDAR points and 2D lane segmentation to generate 3D lane annotation. The steps are as follows: Firstly, the corresponding relationship between 3D and 2D is established. The sparse depth information of 2D pixels is obtained by projecting the LiDAR points to the image plane. Then, the 2D lane segmentation results combined with sparse depth information are back-projected to 3D spaces and obtain lane point clouds. Finally, a filtering algorithm is applied to filtrate outliers and generate the 3D labelling results. This method guarantees geometric accuracy between 3D annotations and 2D images. However, annotating all the lanes in each frame does not impose spatial-temporal consistency in 3D space. Meanwhile, the LiDAR points could be noisy after multi-frame stitching due to the accumulation of localization errors and synchronization. Thus, the back-projected 3D lane may not be consistent with the real one.
Unlike the above approaches, our proposed CAMAv2 reconstructs the static map element in a scene with surround view images (vision-centric). Without LiDAR and predefined HD maps, our approach can eliminate synchronization and calibration errors and impose spatial-temporal consistency in 3D space. Meanwhile, we propose a parallel reconstruction and spatial aggregation method for large-scale intelligent driving scenarios to speed up the reconstruction time. Our pipeline is verified on the nuScenes dataset, resulting in more accurate and consistent annotations.
III Approach
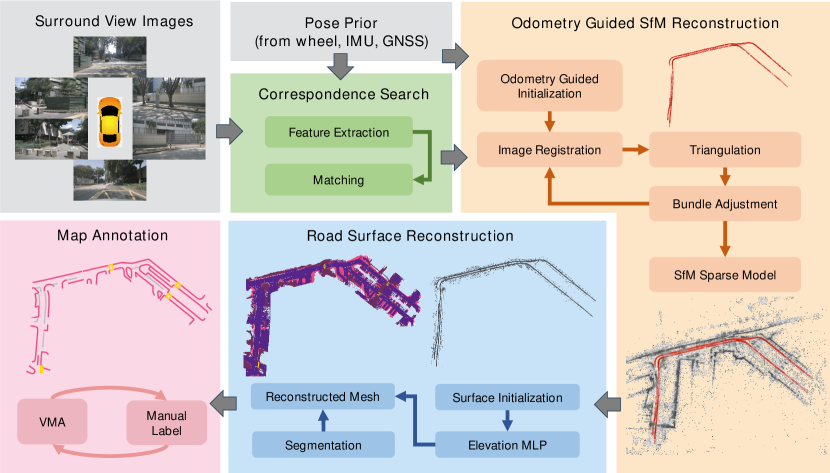
Fig. 2 illustrates the overview of our proposed CAMAv2. CAMAv2 is a vision-centric approach: the input is a set of surround view images, together with coarse ego poses obtained by auxiliary sensors (wheel, GNSS, and IMU). The whole framework mainly consists of two parts: Scene Reconstruction and Road Element Vector Annotation. The first part is fully automatic. To do so, we propose an improved Structure-from-Motion (SfM) that produces accurate sparse point clouds and ego poses for road surface initialization. Then, we apply road surface reconstruction via mesh representations (RoMe) [12] to reconstruct the dense road surfaces. The second part is addressed semi-automatically based on a human-in-the-loop annotation. Mainly, the offline map auto-annotation model [13] is first employed, followed by verification and modification by human annotators. Since CAMAv2 uses a reconstruction method based on image sequences that guarantee all 3D elements and their correspondence to 2D images, the 3D-2D correspondence and reprojection accuracy are also insured (even improved) without LiDAR.
III-A Scene Reconstruction
As shown in Fig. 2, scene reconstruction comprises wheel-IMU-GNSS-odometry (WIGO), odometry-guided SfM reconstruction, and road surface reconstruction.
III-A1 WIGO
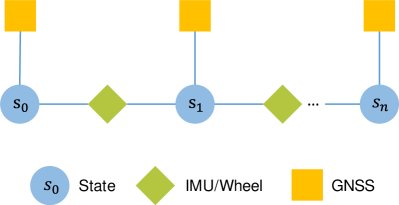
For locally accurate and globally drift-free pose estimation, multiple sensors with complementary properties are usually fused together [38]. Following VIWO [39], we propose a WIGO algorithm to combine the local sensor (wheel and IMU) with the global sensor (GNSS) in a pose graph optimization [40, 41]. As depicted in Fig. 3, each pose state serves as one node in the pose graph, which contains position and orientation in the world frame. The edge between two consecutive nodes is a local constraint from the IMU and wheel encoder. Another edge is a global constraint, which comes from the GNSS. Within graph optimization, local estimations are aligned with a global coordinate. Meanwhile, the accumulated drifts are eliminated. The WIGO algorithm gives coarse global 6-DoF (Degree of Freedom) poses with a real-world scale, and these results are used as inputs of the SfM pipeline illustrated below.
III-A2 Odometry Guided SfM Reconstruction
We introduce an efficient SfM reconstruction method based on COLMAP [42, 43] to achieve higher efficiency and accuracy. We optimize COLMAP from the following six aspects to meet the whole scene reconstruction toward intelligent driving:
Homography-guided Spatial Pairs: For a complete 3D scene reconstruction, more spatial points with accurate locations are needed. Thus, certain strategies are required to obtain dense matching points. In the case of unordered image data, exhaustive matching is frequently used, and the cost increases exponentially with the number of images. Sequential matching may alleviate this issue for sequential images captured by on-board cameras, but it introduces new problems with the lack of matching for multiple driving clips. We propose homography-guided spatial pairs (HSP) for cross-matching between multiple driving clips. HSP balance recall and efficiency of matching. Specifically, with the help of WIGO poses, we can obtain each camera’s global pose as prior, the poses are defined as:
| (1) |
| (2) |
each pose consists of position , , and orientation , , , . We use the k-nearest neighbours algorithm (KNN) [44] to find the nearest neighbour of each camera. For each pose with its neighbour , it is added as a spatial pair if they are not far apart in the z-axis direction:
| (3) |
Then, we filter potential matching image pairs by computing the visual cone overlap between different cameras. As shown in Fig. 4, we can get the optical axis centre vectors and of the two cameras from the orientation of the cameras. By calculating the cosine similarity between the optical axes vectors and the cosine similarity between the vector and the vector , we can get the visual cone overlap of these two cameras:
| (4) |
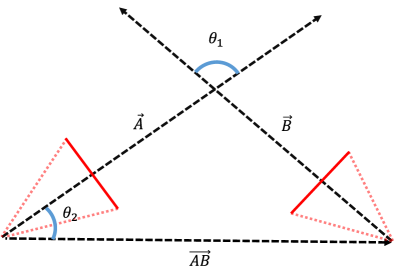
If > and >, which means that there is no visual cone overlap of the two cameras, so the spatial matching pair is filtered out. We also filter matching pairs where the camera’s optical axis direction is face-to-face and close together. Image pair matching can be misleading due to the proximity and unreasonable viewing angle. Furthermore, all the cameras have an approximate extrinsic to the ground plane for intelligent driving applications. By applying the homography transformation to the ground plane, the visual overlap between cameras can be further filtered to emphasize the importance of the road surface area.

Deep Learning Based Correspondence Search: To further improve the robustness of our pipeline in the event of insufficient illumination and extreme weather conditions, we train a feature point extraction network, SuperPoint [45], on our driving dataset and pay extra attention to the weakly-textured or textureless road surface. In addition, the matching task encounters considerable challenges for images with significant variations in viewpoint and lighting conditions. We use SuperGlue [46] for local feature matching to improve the robustness and accuracy of matching in complex scenes.
Odometry Guided Initialization: Initialization is a crucial step in SfM, which directly affects the robustness, accuracy, and performance of reconstruction. Incremental SfM computes the scene graph for a robust reconstruction process to find the best initialization. However, this initialization may suffer substantial computation burdens when dealing with large-scale reconstruction (e.g., areas and thousands of images). In real-world driving scenarios, by fusing multiple sensors (e.g., GNSS, IMU and wheel) and applying localization algorithms, the ego vehicle poses information can be obtained, from which the position and orientation of each camera can be determined. Inspired by this, we propose an odometry-guided initialization (OGI) for SfM. At the beginning of the reconstruction process, the WIGO pose is transformed into the camera coordinates with extrinsic. Given the initial poses, the incremental SfM can be replaced with the spatial-guided SfM, and the real-world scale camera pose initialization dramatically speeds up the reconstruction process.
Parallel Reconstruction: Directly reconstructing all the images in a large-scale scene is not recommended. The main reason is that it not only exceeds the memory capacity of a single computer but also makes it difficult to take full advantage of parallel computing. A large-scale reconstruction area commonly consists of multiple driving clips. We, therefore, reconstruct the driving clips individually as a unit, with each clip usually having hundreds of images, and then clips with enough visual cone overlap are merged according to HSP, finally obtaining a complete large-scale reconstruction. In practice, we reconstruct each clip parallel to OGI, followed by triangulation and bundle adjustment (BA). We perform re-triangulation and global BA on the merged model to filter outliers and improve reconstruction results.
Iterative BA: After triangulation, the first BA is severely affected by outliers, and a second BA step can significantly improve the results. Thus, we propose an iterative BA strategy, using the pre-BA results for re-triangulation, followed by an optimization step on the post-BA results. The inaccurate points can be removed from the SfM sparse model step by step so that the accuracy and robustness of the optimization results can be significantly improved. We provide an overview of our iterative BA in Algorithm 1. In the majority of cases, it is after the third iteration that we see a significant leap in the results. This is when the optimization converges, marking a key point in the process.
Rigid Prior: For intelligent driving applications, multiple cameras attached to the vehicle can be regarded as mounting on a rigid body. It means that the position and orientation between them are relatively fixed, so we do not need to optimize each camera’s position and orientation as independent variables. In the ordinary BA process, we need to optimize all the camera parameters and point parameters , which are described by the following equation:
| (5) |
where is an observed image point, is the projection of point on camera with camera parameter. Since the relative positions and orientations between the cameras are fixed, we propose to use a rigid BA instead of the ordinary BA. In this case, we optimize a global rigid transformation to adjust all camera poses. We can rewrite the Equation 5 by:
| (6) |
where is the global rigid transformation matrix, describing the position and rotation of the entire rigid body, is the pose parameter of the reference camera, is the fixed relative transformation matrix of camera with respect to the reference camera. Cameras with large relative position changes are considered incorrectly estimated and filtered after rigid BA. The application of rigid BA not only enables more efficient processing of multi-camera systems but also improves the accuracy of the reconstruction results.
With the above optimizations, we achieve roughly five times efficiency boost and 20% robustness (success rate) improvements for intelligent driving datasets (see Section IV. The accurate 6-DoF poses and corresponding sparse 3D points generated by SfM models are used as input for RoMe to reconstruct road surface mesh (Section III-A3).
III-A3 Road Surface Reconstruction
We extend our previous work RoMe [12] for road surface mesh reconstruction. The mesh reconstruction can be roughly divided into three tasks:
Surface Points Initialization: To reduce the impact of moving objects and parked vehicles on road surface reconstruction, we apply an off-the-shelf 2D segmentation network [47] to remove occluding objects and obtain lane segmentation masks. Combined with the sparse SfM models, semantic sparse point clouds can be recovered. The sparse road surface point clouds are then extracted. To further improve the robustness when the SfM points are too sparse, we initialize a narrow road surface based on ego-pose and sample the surrounding SfM points. Ultimately, a larger range of road surface points is obtained. This approach improves the overall quality of the road surface initialization.
Elevation Estimation: Using the sparse road surface obtained in the previous step, we trained an elevation multi-layer perceptron (MLP) [48] for dense road elevation prediction. Unlike RGB and semantic information, the road elevation change does not change drastically, and we use position encoding to control the smoothness of the road surface.
Mesh Optimization: A mesh is initialized based on the predicted dense road elevation. The original image and its corresponding 2D segmentation results are used for training to assign semantic labels and photometric features to each triangular facet in the mesh.
In practice, the elevation MLP is optimized and refined during the mesh optimization stage to improve the consistency between geometry and photometric features. Eventually, the highly accurate 3D road surface mesh can be obtained. Notably, for ease of annotation, the 3D road surface mesh can be represented as 2D BEV images and an elevation map, as depicted in Fig. 5. Such representation is fed into the next stage: Map Annotation (Section III-B).
III-B Map Annotation
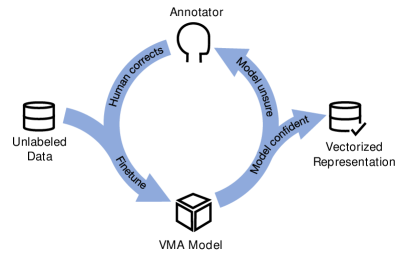
We propose a semi-automated approach based on human-in-the-loop for accelerating time-consuming HD map annotation. As shown in Fig. 6, trained annotators will manually label all the data and generate HD maps in the beginning. Once enough labelled data is collected, a neural network is trained with supervised learning to annotate HD maps automatically. During this process, we keep the high-confidence outputs of the model, relabel the low-confidence ones, and the human-annotated results are fed back to retrain the model in the next iteration. In particular, we extend the vectorized map annotation (VMA) system as a learnable annotation model. VMA is an automatic offline map annotation framework based on MapTR [21]. The input is 2D BEV images, while the output is the vectorized representation of road surface elements (e.g., lane dividers, road boundaries, pedestrian crossing). We propose to use the concatenated 2D BEV semantic photometric images as inputs since they can improve the VMA reasoning ability, especially when classifying the type of lane dividers. Note that this process is still in 2D BEV space. After obtaining the vectorized 2D representations, an elevation map is combined to lift the 2D vectors into actual 3D vectors.
In the actual annotation process, the VMA model is constantly optimized with the accumulation of annotation data. The manual works are converted from the initial annotation to verification and fine-grained modification. The human-in-the-loop mode greatly accelerates the annotation efficiency.
IV Experiment
We first introduce the dataset used to validate our proposed framework and, in this way, generate optimized annotations. Then, we evaluate the proposed CAMAv2 through a set of quantitative and qualitative comparisons, including the state-of-the-art online HD map reconstruction methods. Finally, we do not shy away from discussing the long-tail cases and dirty details behind the CAMAv2 in the last part.
IV-A Data Samples
The nuScenes dataset [9] is one of the most widely used The nuScenes dataset [9] is one of the most widely used datasets for online HD map construction [10, 20, 21, 15, 11]. It contains 1000 scenes of 20 seconds each, all taken from four different locations. There are 28130, 6019, and 6008 key samples for training, validation, and testing. All of these key samples are synchronized using LiDAR keyframes. Due to the inherent flaws in the road surface annotation pipeline, the nuScenes HD map lacks elevation information. Thus, we validate our proposed framework on the nuScenes dataset to generate and publicly release optimized annotations.
IV-B Site Reconstruction
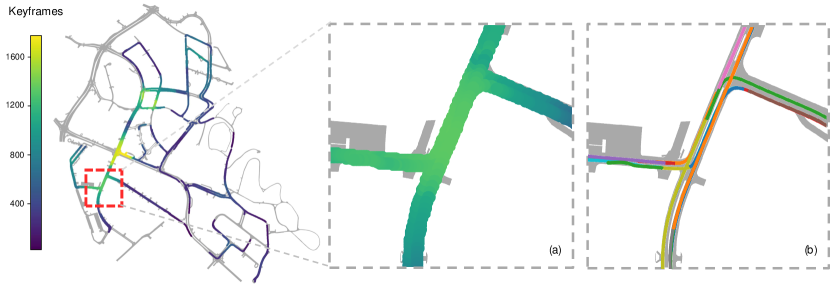
Fig. 7 (far left) presents the spatial distribution of the keyframe of all scenes on a city-scale map. It can be observed that the majority of the data comes from intersections, indicating that most of the scenes in the nuScenes dataset have geographic overlap. As the map is zoomed in, it becomes evident that multiple scenes traverse the same location and make multiple observations (see Fig. 7 (a, b)). For improvement, we propose a multi-scene aggregation reconstruction method. This reconstruction method aggregates scenes with intersecting portions into one large scene called a site. Site reconstruction utilizes more observations to reconstruct the same location, which solves the shortcoming of dropping the head and tail frames in the previous single-scene reconstruction and the occlusion and blind zone problems [14]. In the final annotation stage, we work on the site-reconstructed map only once to get each scene’s annotation. It can ensure the completeness of the local map reconstruction, meet the needs of long-distance ground-truth perception, accelerate annotation efficiency, and reduce costs. We first use the ego-pose provided by nuScenes for site aggregation. The ego pose of the aggregated site is then converted to each camera’s pose for SfM initialization. For self-acquisition data, the WIGO localization algorithm can generate precise poses to guide SfM reconstruction.
In practice, we ignore the nighttime scenes during the aggregation process. This is because most of the nighttime scenes in nuScenes datasets have poor lighting conditions, the ground is not visible, and aggregating these scenes with other daytime scenes affects the reconstruction results. To fairly compare our proposed annotations with the original ones, we subsample the nuScenes dataset according to our annotation frames, namely nuScenes-sub and nuScenes-CAMAv2.
IV-C Annotation Properties
Following the convention of existing online HD map reconstruction methods, three types of map elements are annotated: pedestrian crossing, lane divider, and road boundary. We have undertaken a comprehensive comparison between the original nuScenes-sub annotations and our proposed nuScenes-CAMAv2 annotations. This comparison is based on the number of different category annotations in the training and validation sets, as detailed in Table I.
| Lane divider | Ped. crossing | Road boundary | |
|---|---|---|---|
| nuScenes | 175665 | 44073 | 119191 |
| CAMAv2 | 141745 | 31976 | 137941 |
IV-D Quantitative Validation
We first report the time cost of each component in CAMAv2. After that, we quantitatively evaluate the accuracy and consistency of CAMAv2 annotation with the original ones, and finally quantify how many observations are required in road surface reconstruction.
Time-Costing: A comparison of the average time cost before and after the improvement for each component is detailed in Table II, which counts the time cost for reconstructing a site (around eight clips and three thousand frames per site). We find feature matching and SfM reconstruction is the most time-consuming part. The HSP and OGI SfM greatly accelerate the reconstruction process. Annotation of the static map elements using the 2.5D method is more efficient than 3D annotation. With continuous fine-tuning of the VMA model, the final annotation efficiency can be improved more than two times.
Consistency and Accuracy: As introduced in Section I, the nuScenes dataset provides HD maps for all scenes, while the annotation does not contain elevation. Reprojecting an HD map into the image space using the ego poses and calibration, as presented in Fig. 1, we can clearly observe the misalignments between the lane vectors and image space. For quantitative analysis, we propose a metric denoted semantic reprojection error (SRE) to analyze better and compare the reprojection accuracy. The detailed steps are illustrated in Algorithm 2:
-
•
Step 1: Reproject the 3D annotation vector elements into each 2D image.
- •
-
•
Step 3: Match the elements projected in step 1 and the elements extracted in step 2 using the Hungarian algorithm [51].
-
•
Step 4: Calculate the mean pixel distance for each matched element.
| Corresp. Search | SfM R.C. | Surface R.C. |
| 90 mins | 140 mins | 120 mins |
| SRE | Precision | Recall | ||
|---|---|---|---|---|
| nuScenes | 8.03 | 0.59 | 0.51 | 0.54 |
| CAMAv2 (Ours) | 4.96 | 0.89 | 0.57 | 0.69 |
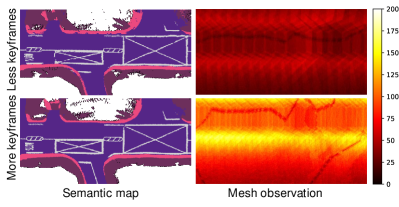
Mesh Observation: During training, each vertex is optimized by multiple images from different views. After optimizing all vertex (from thousands to millions according to mesh resolution), the final mesh (with elevation, colours, and semantics) is obtained to represent the whole road surface. Our research focuses on determining the optimal number of observations required to reconstruct the road surface effectively while maintaining a balance between performance and efficiency. We achieve this by controlling the density of keyframes involved in the reconstruction. To evaluate the amount of data needed for initialization, we count the number of times each vertex is observed from different viewpoints and visualize this data in a heatmap. As depicted in Fig. 8, the clarity of the reconstructed road surface marks improves with the increase in the number of observations, demonstrating the practicality of our approach.
| Exp. # | annotation | w/ elevation | SRE | Precision | Recall | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| # 1 | nuScenes | 60.8 | 57.7 | 61.2 | 59.9 | 8.43 | 0.51 | 0.37 | 0.42 | |
| # 2 | CAMAv2 | 41.6 | 41.8 | 38.9 | 40.7 | 6.42 | 0.75 | 0.54 | 0.63 | |
| # 3 | CAMAv2 | ✓ | 36.8 | 40.9 | 36.2 | 37.9 | 5.62 | 0.91 | 0.51 | 0.65 |
IV-E Qualitative Validation
We observe that the HD map provided by nuScenes does not always reflect the actual environments captured by cameras. For example, as shown in Fig. 1 (a, b), the HD map annotations indicate the lane divider between the ego vehicle and bicycle lane, but in the actual camera image, there is no lane marking on the ground in the relevant area. This is because lane dividers in HD maps are constructed based on rules rather than visually apparent markings, as the main goal is to map the world rather than facilitate intelligent driving applications. Such inconsistency between the image and HD map annotations increases the difficulty of training.
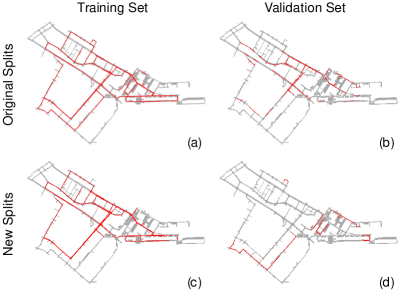
An intuitive understanding: When the image and the HD map are inconsistent, the model is more likely to “memorize” the HD map according to the surroundings instead of “reasoning” the local map based on the observations. To verify this conjecture, we visualized the distribution of each scene in the nuScenes training and validation sets. Fig. 9 (a, b) shows that the original nuScenes dataset has overlapping parts in the training and validation sets. To verify whether duplicated observation validation data in the training set affects the model results, we repartitioned the training set and validation set based on the location distribution of each scene in the nuScenes dataset, and there is no overlap between the training set and validation set after our repartitioning (Fig. 9 (c, d)). We performed training and validation based on the newly segmented set. Table V shows that the model’s accuracy on the new training data decreases substantially on the new validation data compared to the model obtained from the original data splits. It proves that the model is more inclined to memorize the HD map based on the surroundings rather than based on observations. It also thus side-steps the importance of highly accurate labelled data. Consequently, this data inconsistency weakens the potential generalizability of the perception model. In contrast, CAMAv2 can generate accurate (Fig. 1 (d)) and consistent (Fig. 1 (f)) lane marking, including road boundary, lane divider, and pedestrian crossing.
| Data Split | ||||
|---|---|---|---|---|
| Original | 59.8 | 60.2 | 61.5 | 60.5 |
| New | 26.4 | 14.4 | 37.9 | 26.2 |


IV-F Application
High accurate and spatial-temporal consistent HD map annotations are vital for training BEV perception algorithms. To verify the effectiveness of our annotations, we choose MapTRv2 as the baseline model. We removed the auxiliary dense prediction loss in MapTRv2 to reduce the influence of irrelevant supervision signals. We conduct three experiments: 1) MapTRv2 trained on nuScenes-sub dataset; this is set as the baseline. 2) MapTRv2 trained on CAMAv2 but without elevation information. 3) MapTRv2 trained on the CAMAv2 annotation with elevation information. All the experiments are trained 24 epochs with ResNet-50 backbone [52]. Table IV details the prediction accuracy and the reprojection metrics (including SRE and F1 score). We observe that models trained with CAMAv2 annotation predict higher reprojection accuracy and consistency. The SRE improves from 8.43 to 5.62 by 33 %, and the score improves from 0.42 to 0.65.
We also visually compare the predictions in Fig. 10. Due to the inconsistent annotation in the nuScenes dataset, the trained MapTRv2 makes false positive predictions (red circle in Fig. 10 (a)). With our proposed CAMAv2 annotation, the model predictions align better with the image in reprojection (red circle in Fig. 10 (b)).
IV-G Other Datasets
To verify the robustness of our proposed CAMAv2, we validate it on other public datasets. Fig. 11 (a) shows the effect of the reconstruction on the Waymo Open Dataset (WOD) [53]. We can accurately reconstruct ground elevation for the scenarios of uphill/downhill in WOD, and the reprojection results align well with the images (Fig. 11 (b)). We also annotated several reconstructed WOD scenes and calculated the SRE. As shown in Table VI, the WOD-CAMAv2 annotations achieve low reprojection error.
| SRE | Precision | Recall | ||
|---|---|---|---|---|
| CAMAv2 (Ours) | 2.77 | 0.91 | 0.73 | 0.81 |


IV-H Long-tail Cases
We present some long-tail cases in challenging driving conditions. Fig. 12 shows reconstructed results of WOD in rainy and night conditions. It is clear that the reconstructed photometric map is greatly affected due to lens soiling, but the semantic map can still be reconstructed well. In the case of poor lighting conditions, semantic segmentation is concerned, so the marking of road surface elements is unclear in the constructed semantic map.


To evaluate the effectiveness of our method for reconstruction in more extreme snowy scenes, we performed on the CADC dataset [54]. The snow-covered road surface poses a great challenge to the feature extraction task, leading to the failure of the road surface initialization. However, our method still achieves better results in the SfM stage (See Fig. 13).

IV-I Dirty Details
Some dirty details are proposed to improve the annotation quality: (1) To balance computational efficiency with sufficient visual coverage, we use consecutive video frames (called samples and sweeps) provided by nuScenes as input. Before the reconstructions, a keyframe selection step is conducted, where we set the maximum timestamp difference (40ms) for multi-view resynchronization. More dense keyframes are generated based on the relative change in ego-pose between frames (e.g., translation distance, rotation degree). (2) Some driving clips in nuScenes do not provide variation observations because the ego vehicle is stationary. Therefore, SfM reconstruction is not available. To solve this problem, we combine these stationary clips with their nearest long-driving clip. All frames of the merged clip are fed into CAMAv2 for reconstruction (without keyframe selection). Local map annotations of these stationary clips can be efficiently obtained using this method. (3) In the nuScenes dataset, the trunk is visible in the rear camera. We masked this part to avoid any impact on feature extraction and matching. (4) The parameter can be empirically set to around to ensure the accuracy of filtering matching pairs.
V Conclusion
We present CAMAv2: a vision-centric approach for consistent and accurate static map element annotations. We investigate the critical factors for the online HD map construction algorithm and argue that the annotation quality in terms of reprojection accuracy and spatial-temporal consistency is vital for perception algorithm training. Based on this insight, we propose a new baseline for the BEV perception algorithm. Experiments on the nuScenes datasets show that our proposed methods not only generate high-quality annotations respecting accuracy and consistency but also improve the performance of perception models trained with our annotation. By making the CAMAv2 source codes and nuScenes-CAMAv2 annotation publicly available, we aim to catalyze advancements in intelligent driving and 4D labelling technologies within both academic and industrial communities.
Acknowledgments
This work was supported in part by the Natural Science Foundation of the Jiangsu Higher Education Institutions of China (22KJB520008), and in part by the Research Fund of Horizon Robotics (H230666).
References
- [1] X. Tang, K. Jiang, M. Yang, Z. Liu, P. Jia, B. Wijaya, T. Wen, L. Cui, and D. Yang, “High-definition maps construction based on visual sensor: A comprehensive survey,” IEEE Transactions on Intelligent Vehicles, 2023.
- [2] J. Zhang, S. Singh et al., “Loam: Lidar odometry and mapping in real-time.” in Robotics: Science and Systems, vol. 2, no. 9, 2014, pp. 1–9.
- [3] T. Shan and B. Englot, “Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain,” in IEEE International Conference on Intelligent Robots and Systems. IEEE, 2018, pp. 4758–4765.
- [4] T. Shan, B. Englot, D. Meyers, W. Wang, C. Ratti, and D. Rus, “Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping,” in IEEE International Conference on Intelligent Robots and Systems. IEEE, 2020, pp. 5135–5142.
- [5] Q. Rao and J. Frtunikj, “Deep learning for self-driving cars: Chances and challenges,” in International Workshop on Software Engineering for AI in Autonomous Systems, 2018, pp. 35–38.
- [6] A. Gupta, A. Anpalagan, L. Guan, and A. S. Khwaja, “Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues,” Array, vol. 10, p. 100057, 2021.
- [7] J. Zhou and J. Beyerer, “Corner cases in data-driven automated driving: Definitions, properties and solutions,” in IEEE Intelligent Vehicles Symposium. IEEE, 2023, pp. 1–8.
- [8] Y. Ma, T. Wang, X. Bai, H. Yang, Y. Hou, Y. Wang, Y. Qiao, R. Yang, D. Manocha, and X. Zhu, “Vision-centric bev perception: A survey,” arXiv preprint arXiv:2208.02797, 2022.
- [9] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 621–11 631.
- [10] Q. Li, Y. Wang, Y. Wang, and H. Zhao, “Hdmapnet: An online hd map construction and evaluation framework,” in IEEE International Conference on Robotics and Automation. IEEE, 2022, pp. 4628–4634.
- [11] L. Chen, C. Sima, Y. Li, Z. Zheng, J. Xu, X. Geng, H. Li, C. He, J. Shi, Y. Qiao et al., “Persformer: 3d lane detection via perspective transformer and the openlane benchmark,” in European Conference on Computer Vision. Springer, 2022, pp. 550–567.
- [12] R. Mei, W. Sui, J. Zhang, X. Qin, G. Wang, T. Peng, T. Chen, and C. Yang, “Rome: Towards large scale road surface reconstruction via mesh representation,” IEEE Transactions on Intelligent Vehicles, 2024.
- [13] S. Chen, Y. Zhang, B. Liao, J. Xie, T. Cheng, W. Sui, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Vma: Divide-and-conquer vectorized map annotation system for large-scale driving scene,” arXiv preprint arXiv:2304.09807, 2023.
- [14] J. Zhang, S. Chen, H. Yin, R. Mei, X. Liu, C. Yang, Q. Zhang, and W. Sui, “A vision-centric approach for static map element annotation,” in IEEE International Conference on Robotics and Automation. IEEE, 2024, pp. 1–7.
- [15] B. Liao, S. Chen, Y. Zhang, B. Jiang, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Maptrv2: An end-to-end framework for online vectorized hd map construction,” arXiv preprint arXiv:2308.05736, 2023.
- [16] M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan et al., “Argoverse: 3d tracking and forecasting with rich maps,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 8748–8757.
- [17] B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Pontes et al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,” in Neural Information Processing Systems Track on Datasets and Benchmarks, 2023.
- [18] F. Yan, M. Nie, X. Cai, J. Han, H. Xu, Z. Yang, C. Ye, Y. Fu, M. B. Mi, and L. Zhang, “Once-3dlanes: Building monocular 3d lane detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 143–17 152.
- [19] T. Li, L. Chen, H. Wang, Y. Li, J. Yang, X. Geng, S. Jiang, Y. Wang, H. Xu, C. Xu, J. Yan, P. Luo, and H. Li, “Graph-based topology reasoning for driving scenes,” arXiv preprint arXiv:2304.05277, 2023.
- [20] Y. Liu, T. Yuan, Y. Wang, Y. Wang, and H. Zhao, “Vectormapnet: End-to-end vectorized hd map learning,” in International Conference on Machine Learning. PMLR, 2023, pp. 22 352–22 369.
- [21] B. Liao, S. Chen, X. Wang, T. Cheng, Q. Zhang, W. Liu, and C. Huang, “Maptr: Structured modeling and learning for online vectorized hd map construction,” in International Conference on Learning Representations, 2022.
- [22] B. Liao, S. Chen, B. Jiang, T. Cheng, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction,” arXiv preprint arXiv:2303.08815, 2023.
- [23] N. Garnett, R. Cohen, T. Pe’er, R. Lahav, and D. Levi, “3d-lanenet: end-to-end 3d multiple lane detection,” in IEEE International Conference on Computer Vision, 2019, pp. 2921–2930.
- [24] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in European Conference on Computer Vision. Springer, 2020, pp. 194–210.
- [25] L. Reiher, B. Lampe, and L. Eckstein, “A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view,” in IEEE International Conference on Intelligent Transportation Systems. IEEE, 2020, pp. 1–7.
- [26] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” in European Conference on Computer Vision. Springer, 2022, pp. 1–18.
- [27] Y. Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” in European Conference on Computer Vision. Springer, 2022, pp. 531–548.
- [28] S. Chen, T. Cheng, X. Wang, W. Meng, Q. Zhang, and W. Liu, “Efficient and robust 2d-to-bev representation learning via geometry-guided kernel transformer,” arXiv preprint arXiv:2206.04584, 2022.
- [29] S. Diamond, V. Sitzmann, F. Julca-Aguilar, S. Boyd, G. Wetzstein, and F. Heide, “Dirty pixels: Towards end-to-end image processing and perception,” ACM Transactions on Graphics, vol. 40, no. 3, pp. 1–15, 2021.
- [30] J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi-camera 3d object detection,” arXiv preprint arXiv:2203.17054, 2022.
- [31] Y. Li, H. Bao, Z. Ge, J. Yang, J. Sun, and Z. Li, “Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo,” in AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 1486–1494.
- [32] J. Huang and G. Huang, “Bevpoolv2: A cutting-edge implementation of bevdet toward deployment,” arXiv preprint arXiv:2211.17111, 2022.
- [33] T. Wang, Q. Lian, C. Zhu, X. Zhu, and W. Zhang, “Mv-fcos3d++: Multi-view camera-only 4d object detection with pretrained monocular backbones,” arXiv preprint arXiv:2207.12716, 2022.
- [34] J. Zhang, W. Sui, X. Wang, W. Meng, H. Zhu, and Q. Zhang, “Deep online correction for monocular visual odometry,” in IEEE International Conference on Robotics and Automation. IEEE, 2021, pp. 14 396–14 402.
- [35] J. Zhang, W. Sui, Q. Zhang, T. Chen, and C. Yang, “Towards accurate ground plane normal estimation from ego-motion,” Sensors, vol. 22, no. 23, p. 9375, 2022.
- [36] W. Ding, L. Qiao, X. Qiu, and C. Zhang, “Pivotnet: Vectorized pivot learning for end-to-end hd map construction,” in IEEE International Conference on Computer Vision, 2023, pp. 3672–3682.
- [37] L. Qiao, Y. Zheng, P. Zhang, W. Ding, X. Qiu, X. Wei, and C. Zhang, “Machmap: End-to-end vectorized solution for compact hd-map construction,” arXiv preprint arXiv:2306.10301, 2023.
- [38] T. Qin, S. Cao, J. Pan, and S. Shen, “A general optimization-based framework for global pose estimation with multiple sensors,” arXiv preprint arXiv:1901.03642, 2019.
- [39] W. Lee, K. Eckenhoff, Y. Yang, P. Geneva, and G. Huang, “Visual-inertial-wheel odometry with online calibration,” in IEEE International Conference on Intelligent Robots and Systems. IEEE, 2020, pp. 4559–4566.
- [40] F. Dellaert and G. Contributors, “borglab/gtsam,” May 2022. [Online]. Available: https://github.com/borglab/gtsam)
- [41] F. Dellaert and M. Kaess, Factor Graphs for Robot Perception. Foundations and Trends in Robotics, Vol. 6, 2017. [Online]. Available: http://www.cs.cmu.edu/~kaess/pub/Dellaert17fnt.pdf
- [42] J. L. Schönberger and J.-M. Frahm, “Structure-from-motion revisited,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016.
- [43] J. L. Schönberger, E. Zheng, M. Pollefeys, and J.-M. Frahm, “Pixelwise view selection for unstructured multi-view stereo,” in European Conference on Computer Vision, 2016.
- [44] T. Cover and P. Hart, “Nearest neighbor pattern classification,” IEEE Transactions on Information Theory, vol. 13, no. 1, pp. 21–27, 1967.
- [45] D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self-supervised interest point detection and description,” in IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 224–236.
- [46] P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 4938–4947.
- [47] B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 1290–1299.
- [48] M. W. Gardner and S. Dorling, “Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences,” Atmospheric Environment, vol. 32, no. 14-15, pp. 2627–2636, 1998.
- [49] J. Jain, J. Li, M. T. Chiu, A. Hassani, N. Orlov, and H. Shi, “Oneformer: One transformer to rule universal image segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 2989–2998.
- [50] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in IEEE International Conference on Computer Vision, 2023, pp. 4015–4026.
- [51] H. W. Kuhn, “The hungarian method for the assignment problem,” Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97, 1955.
- [52] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [53] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine et al., “Scalability in perception for autonomous driving: Waymo open dataset,” in IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 2446–2454.
- [54] M. Pitropov, D. E. Garcia, J. Rebello, M. Smart, C. Wang, K. Czarnecki, and S. Waslander, “Canadian adverse driving conditions dataset,” The International Journal of Robotics Research, vol. 40, no. 4-5, pp. 681–690, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/shiyuan.jpg) |
Shiyuan Chen is currently a postgraduate student at Soochow University. He earned his B.E. degree in Software Engineering from the Tiangong University in 2023. His primary research interests lie in 3D vision and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/jiaxin.jpg) |
Jiaxin Zhang is currently an Algorithm Engineer at Horizon Robotics in Beijing, China. He earned his B.S. degree in Applied Physics from the University of Science and Technology of China in 2018, followed by an M.S. degree in Electrical and Computer Engineering from Boston University in 2020. His primary research interests lie in SLAM, 3D vision, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/ruohong.jpg) |
Ruohong Mei is currently an Algorithm Engineer at Horizon Robotics in Beijing, China. He earned his B.S. Degree in Communication Engineering from Beijing University of Posts and Telecommunications in 2018, followed by an M.S. Degree in Information and Communication Engineering from Beijing University of Posts and Telecommunications in 2021. His primary research interests lie in 3D vision, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/yingfeng.jpg) |
Yingfeng Cai is currently an Algorithm Engineer at Horizon Robotics in Beijing, China. He earned his B.S. degree from Shanghai Maritime University, Shanghai, China, in 2020, followed by an M.S. degree in Computer Science and Technology from Tongji University, Shanghai, China, in 2023. His primary research interests lie in SLAM, 3D vision, and place recongnition. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/haoran.jpg) |
Haoran Yin is currently an Algorithm Engineer at Horizon Robotics in Beijing, China. He earned his B.S. degree in Communication Engineering from Jilin University, Changchun, China, in 2019, and his M.S. degree in Computer Technology from the University of the Chinese Academy of Sciences, Beijing, China. His research interests include 3D vision, end-to-end autonomous driving, Vision Transformers, and AutoML. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/tao.jpg) |
Tao Chen received the B.Sc. degree in Mechanical Design, Manufacturing and Automation, M.Sc. degree in Mechatronic Engineering, and Ph.D. degree in Mechatronic Engineering from Harbin Institute of Technology, Harbin, China, in 2004, 2006, and 2010, respectively. He is a visiting scholar in National University of Singapore in 2018. He is currently an professor at School of Future Science and Engineering, Soochow University, Suzhou, China. His main research interests include MEMS, sensors, and actuators. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/suiwei.jpg) |
Wei Sui is a senior engineer at Horizon Robotics, leading the 3D Vision Team, providing mapping, localization, calibration, and 4D labeling solutions. His research interests include SFM, SLAM, Nerf, 3D Perception, etc. Dr. Wei received his B.Eng and Ph.D. degrees from Beinghang University and NLPR (CASIA), Beijing, China, in 2011 and 2016 respectively. He led the computer vision team and successfully developed the 4D Labeling System and BEV perception for Super Drive on Journey 5. Dr. Wei Sui has published one research monograph and more than ten peer-reviewed papers in journals and conference proceedings, including elites like TIP, TVCG, ICRA, CVPR, etc. Dr. Wei received over 40 Chinese and 5 US patents. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cf9f3a6-964f-4948-9b5f-42cdfd0567c3/yangcong.jpg) |
Cong Yang is an Associate Professor at Soochow University since 2022. Before that, he was a Postdoc researcher at the MAGRIT team in INRIA (France). Later, he worked scientifically and led the computer vision and machine learning teams in Clobotics and Horizon Robotics. His main research interests are computer vision, pattern recognition, and their interdisciplinary applications. Cong earned his Ph.D. degree in computer vision and pattern recognition from the University of Siegen (Germany) in 2016. |