Budget Sensitive Reannotation of Noisy Relation Classification Data Using Label Hierarchy
Abstract
Large crowd-sourced datasets are often noisy and relation classification (RC) datasets are no exception. Reannotating the entire dataset is one probable solution however it is not always viable due to time and budget constraints. This paper addresses the problem of efficient reannotation of a large noisy dataset for the RC. Our goal is to catch more annotation errors in the dataset while reannotating fewer instances. Existing work on RC dataset reannotation lacks the flexibility about how much data to reannotate. We introduce the concept of a reannotation budget to overcome this limitation. The immediate follow-up problem is: Given a specific reannotation budget, which subset of the data should we reannotate? To address this problem, we present two strategies to selectively reannotate RC datasets. Our strategies utilize the taxonomic hierarchy of relation labels. The intuition of our work is to rely on the graph distance between actual and predicted relation labels in the label hierarchy graph. We evaluate our reannotation strategies on the well-known TACRED dataset. We design our experiments to answer three specific research questions. First, does our strategy select novel candidates for reannotation? Second, for a given reannotation budget is our reannotation strategy more efficient at catching annotation errors? Third, what is the impact of data reannotation on RC model performance measurement? Experimental results show that our both reannotation strategies are novel and efficient. Our analysis indicates that the current reported performance of RC models on noisy TACRED data is inflated.
Keywords:
Noisy Dataset Dataset Reannotation Relation Classification.1 Introduction
Relation Classification (RC) is the task of predicting a relation label between a pair of real-world entities in a given natural language sentence. For example in Figure 1, the sentence has subject entity Satya Nadella and object entity Microsoft. Their types are PERSON and ORGANIZATION respectively. The assigned relation label for this sentence is . In general, the RC task considers a five-tuple as input where is a sentence in a natural language, and , are a pair of entities present in . Entity is the subject and entity is the object. The type labels for these entities are and respectively. The task of Relation Classification (RC) is to assign a relation label to where (the set of relation labels). Relation classification is an important NLP task with potential application in multiple domains such as knowledge graph completion [16], question answering [6], and reasoning [15].

The performance of state-of-the-art (SOTA) RC models is throttled in the range of 70-80% accuracy only [37, 36, 13, 33, 40]. Various paradigms such as feature based methods, kernel based methods, and Deep Learning have been explored for designing supervised models for the RC task. All the SOTA RC models are based on Deep Learning. Performance of such models depends significantly on the quality of the dataset used for training and testing. Recent studies have shown that quality of dataset is a major bottleneck in improving the performance of supervised machine learning models for RC [1, 28].
One possible solution for improving the data quality is to reannotate the data. Existing methods for RC dataset reannotation follow two extremes. They either select only a tiny fraction for reannotation [1] or go for reannotation of the complete data [28]. The existing methods also ignore the taxonomic hierarchy that exists between the relation labels.
Our work overcomes both these limitations with the following specific research contributions
-
•
We introduce the concept of reannotation budget to provide flexibility about what fraction of dataset to reannotate.
-
•
This is the first work that uses relation label hierarchy while selecting datapoints for reannotation for the RC task.
-
•
We perform extensive experiments using the popular RC dataset TACRED. We show that our reannotation strategies are novel and more efficient when compared with the existing approaches.
-
•
Our experiments suggest that the reported performance of existing RC models on the noisy dataset is inflated. The F1 score of these models drops from the range of 60%-70% to as low as below 50% when tested on clean test data generated using our reannotation strategy.
For the complete reproducibility, all data, models, relation hierarchy, and code from our work will be made available publicly on the Web111Link eliminated for double-blind review. Our current experimental results are specific to the RC task. However, our reannotation strategy can be applied to any task and dataset where the label hierarchy is available. Rest of the paper is organized as follows. We review the related work in Section 2. Our reannotation approach along with experimental results is presented in Section 3. Limitations of our work are discussed in Section 4. Finally, we conclude and point the future work in Section 5.
2 Related Work
Some of the earliest methods for the RC task were based on pattern extraction. They [12, 20] use syntactic patterns to construct rule for extracting relational facts from texts. To reduce the human effort in identifying relation facts, statistical relational relation extraction has been extensively explored in two directions, namely, feature-based methods [14, 38, 21] and kernel-based methods [7, 4, 5, 31]. Following the success of embedding models in other NLP challenges, [32, 9] have made efforts in utilising low-dimensional textual embedding for relational learning.
Neural Relation Extraction models introduce neural networks for capturing relational facts within text, such as recursive neural networks [27, 19], convolutional neural networks (CNN) [17, 34, 22], recurrent neural networks (RNN) [37, 35], and attention-based neural networks [39, 30]. Recently, Transformer [29] and pre-trained language models [8] have also been explored for relation extraction [2, 3, 13, 25, 33, 40] and have achieved new state-of-the-arts performance.
Out of all the RC datasets [18, 26, 11, 37, 10], TACRED [37] is the largest and most widely used dataset. It contains more than 100 thousand sentences for 42 relation classes (Train: 68124 sentences, Dev: 22631 sentences, and Test: 15509 sentences). Sentences are collected from TAC knowledge base population 2009-2014 tasks [37]. Each sentence contains a pair of real-world entities representing subject and object entities and is annotated with either one of the 41 relations or no_relation. Sentences are manually annotated with relation labels using the Amazon Mechanical Turk crowdsourcing platform, where each annotator was provided with sentence, subject and object entities, and a set of relations to choose from.
A recent study by Alt et. al. (referred to as TACRev) trained 49 different RC models and selected 5000 most miss-classified instances from TEST and DEV partitions for reannotation [1]. Their expert annotators were trained linguists. Out of 5000 instances, they ended up modifying 960 sentences from TEST and 1610 sentences from DEV. The revised dataset resulted in an average 8% improvement in f1-score, suggesting the noisy nature of TACRED dataset. However, their work has two main bottlenecks. First, their method has a fixed set of sentences to reannotate. Second, they ignore the label hierarchy and use only model confidence to select sentences for reannotation. We compare our strategies against TACRev by extending their method for the reannotation budget. Given a specific reannotation budget, we select top sentences from the dataset where RC models have the highest confidence.
Another recent study by Stoica et. al. (referred to as ReTACRED) reannotated the complete TACRED dataset using crowd-sourcing [28]. For more effective crowd-sourcing, they have made slight modifications to the original TACRED relation list. They corrected 3936 and 5326 annotation errors in the TEST and DEV partitions respectively. They have also eliminated 2091, 3047, and 9659 sentences from TEST, DEV, and TRAIN set respectively for various reasons. We use the data from their reannotation experiment to simulate our reannotation strategies. Our work cannot be directly compared against ReTACRED as they simply use the brute-force method of complete reannotation. However, for a meaningful comparison with ReTACRED, we extend their approach by selecting a random set of sentences for a given reannotation budget.
Recently Parekh et. al. [23], have collected more than 600 relations between Person, Organization, and Location entity types from multiple knowledge bases and arranged them in a taxonomical hierarchy following is-a relationship. They manually created the relation hierarchy but did not show any applications of the generated hierarchy. In this work, we create a similar relation hierarchy for TACRED relation labels, and further use that hierarchy for calculating distance between ground-truth and prediction.
The main takeaway points from the existing work can be summarized as follows:
-
•
Deep Learning is the paradigm of SOTA RC models. Hence, we will focus only on Deep Learning based models for our work.
-
•
TACRED is the RC dataset used by SOTA models. Also, reannotation data for the complete TACRED dataset is availble. Hence, for our experiments we will used the TACRED dataset.
-
•
Both the existing works on RC dataset reannotation are rigid. They fail to provide flexibility about how much data to reannotate. Hence, we will introduce the concept of reannotation budget to overcome this limitation.
-
•
The concept of taxonomic hierarchy of relation labels is not yet used for the RC dataset reannotation. We will build such a hierarchy of relation labels in the TACRED dataset and use it for selecting datapoints for reannotation.
3 Our Work
Considering the insights from related work, our goal is to build a budget sensitive reannotation method and show its effect on TACRED dataset and recent deep learning based models. Consider an RC dataset . Let be the sent of noisy or mislabelled sentences in . As is a subset of , . Let represent the set of sentences that we are going to reannotate from . Now, our reannotation budget is . In other words, we can afford to reannotate only sentences out of . The goal of any reannotation method should be to maximize the . In the ideal case, and should be the identical sets.
Given a reannotation budget , the immediate follow-up problem is: what subset of the data should we reannotate? If our reannotation budget permits us to reannotate a significant part of the data () then the strategy for selecting data points for reannotation does not matter. However, in the real world, the reannotation budget is far small as compared to the dataset size () for two reasons. First, reannotation is a costly and time-consuming task. Second, redundant efforts in reannotating a correctly labeled data point should be avoided. In the context of the RC task, this paper proposes two strategies for selecting data points for reannotation. Our approach capitalizes on the taxonomic hierarchy of relation labels which is largely an ignored aspect of the RC datasets. For each data point, we compute the graph distance between the actual label provided in the dataset and the predicted label using an ensemble of RC models. Data points with a higher value for this distance are given higher priority for the reannotation task. The overview of our work is presented in Figure 2. Our work is divided into three steps: Model Training, Reannotation, and Evaluation. These steps are described in the following subsections.

3.1 Model Training
The first step trains multiple RC models using the original TACRED dataset. However, we transform the relation labels to match the ReTACRED labels. This transformation is necessary as we have reannotation data available from ReTACRED only. For our experiments we have selected following five Deep Learning based RC models: PA-RNN, LSTM, and Bi-LSTM following [37], CGCN, and GCN [36]. We have trained these models using the same set of hyper-parameters as mentioned in their original papers. This step can be further improved by training more RC models. However, we were limited by available computing infrastructure.
All the input word vectors are initialised using pre-trained 300-dimensional Glove vectors [24] for CGCN and GCN and 200-dimensional Glove vectors for LSTM, BiLSTM, and PA-LSTM. For training GCN and CGCN, we used the hyper-parameters following [36]. We used LSTM hidden size and feedforward hidden size as 200. We used two GCN layers and two feedforward layers, SGD as optimizer, initial learning rate of 1.0 which is reduced by a factor of 0.9 after epoch five. We trained the model for 100 epochs. We used word dropout of 0.04 and dropout of 0.5 to LSTM layers. All other embedding (such as NER, POS) size is fixed as 30. For training PALSTM, LSTM, and BiLSTM, we followed [37] for hyper-parameters. We have used 2 layer stacked LSTM layers for all the models with hidden size of 200. We used AdaGrad with learning rate of 1.0 which is reduced by a factor 0.9 after 20th epoch. We have trained the model for 30 epochs. We used word dropout of 0.04 and dropout of 0.5 to LSTM layers. All other embedding (such as NER, POS) size is fixed as 30.
3.2 Reannotation
The second step simulates the reannotation process by creating a specific permutation of the data points in the reannotation pool. For our experiments, we have considered TEST and DEV partitions of the TACRED dataset as the reannotation pool. The reannotation data is not available for the TRAIN partition. In our simulation, the crowd-sourced workers will reannotate only a subset of data points from the reannotation pool depending on the reannotation budget. We have experimented with four reannotation strategies: two from the literature (TACRev[1] and ReTACRED[28]) and our proposed two strategies. Given a particular budget for reannotation, we have to select a set of sentences from the reannotation pool to perform the reannotation task. A reannotation strategy creates a ranked list of the reannotation pool. The goal of a reannotation strategy is to ensure that sentences having annotation errors should appear at the top of the ranked list. Such ranking is expected to use a given reannotation budget effectively. Reannotating all the sentences in the reannotation pool will require a large amount of resources. In the real world, we can typically afford to reannotate only a fraction of the reannotation pool. We expect that a good reannotation strategy should be able to catch most of the annotation errors with a relatively small reannotation budget.
A trained RC model when presented with a data point for relation classification, assigns a relation label along with the confidence score. This score indicates how confident the model is while assigning the relation label. The TACRev strategy uses multiple RC models for ranking the data points based on the confidence of the RC models. In our experiments, we have used five RC models mentioned in subsection 3.1. The ReTACRED method does not have the concept of ranking data points. It is a brute-force strategy that simply reannotates the whole reannotation pool. To simulate the ReTACRED strategy with the reannotation budget, we simply pick up random sentences from the reannotation pool to perform the reannotation task.
Our reannotation strategy is based on the taxonomic-hierarchy prepared by Parekh et al. [23]. Following their work, we arranged all relations from the TACRED dataset in a taxonomic hierarchy. The relation labels are arranged as a tree. Each relation label has a parent and multiple or zero children. Please refer to Figure 1 for an excerpt of the relation hierarchy. With such a hierarchy, it becomes feasible to measure the error in the model prediction. The complete taxonomic hierarchy is available for download along with the code. Both our reannotation strategies utilize this hierarchy for selecting candidates for reannotation.
Consider a sentence with its relation label annotated in the dataset as . Here stands for Actual Relation. We have a list of different RC models: to . Each model assigns relation label to the sentence . Here stands for Predicted Relation. Both and can be located as nodes in the relation hierarchy tree. Our first reannotation strategy measures the length of the path between these two nodes in the tree. We refer to this strategy as the Graph Distance (GD) strategy. For each sentence , we compute the following score:
,where
The function computes the length of shortest path between given two tree nodes. This is a basic problem in graph algorithms and can be solved in time complexity , where is the height of the tree. Please refer to Figure 1. Let us assume that for a given sentence , is and is . In this case, the shortest path between these two labels is (, , , , , ) with the as five. The function measures the disagreement between the prediction of model and the label given in the dataset. High value for indicates high disagreement between model and the currently assigned label in the dataset. The score computes the average across models. Our Graph Distance reannotation strategy considers sentences with a high score as preferred candidates for reannotation. Intuitively, we are selecting sentences where multiple RC models have strong disagreement with the currently assigned label.
Our second strategy fine-tunes the computation of disagreement between model prediction and currently assigned label in the dataset. We locate both and in the relation hierarchy and compute their Lowest Common Ancestor (LCA). The computation in the tree is also a basic graph problem and can be solved in time complexity , where is the height of the tree. Let us consider the same example with as and as . In this case, the of these two labels is the node . Consider the path from the root of the relation hierarchy to the node . The LCA node is the point at which the model prediction starts differing from the currently assigned label in the dataset. We compute the following score for each sentence :
,where
The function is an improvement over the previously defined function . Instead of considering the complete path between and , we are considering only the part up to the LCA of these two nodes. We call this reannotation strategy as LCA Distance (LD) strategy. Each reannotation strategy creates a permutation of the reannotation pool by sorting sentences in the descending order of the corresponding scores.
3.3 Evaluation
After Step 2, each reannotation strategy will create its own permutation of the reannotation pool. Based on the reannotation budget , we will select the top data points from each permutation. While comparing our strategies with the TACRev and ReTACRED, we need to answer two important questions. First about novelty: do our strategies provide novel candidates for reannotation? Second about efficiency: do our strategies catch more annotation errors for a given reannotation budget?

3.3.1 Novelty in Candidate Selection
Novelty of GD and LD against ReTACRED is trivial because ReTACRED selects random data points for reannotation. Please refer to Figure 3 for the analysis of novelty against TACRev. The X-axis indicates the reannotation budget. Y-axis indicates the Jaccard similarity, that is the size of the intersection divided by the size of the union. The similarity of TACRev with itself is always 100%. We can observe that for a low reannotation budget, the similarity score grows quickly and approaches 100%. This indicates that initially, all strategies choose similar candidates for reannotation. For medium budget value, the similarity falls significantly. This indicates that our strategies differ significantly from TACRev for medium-budget value. For a higher reannotation budget, the similarity score again approaches 100% as expected. When the reannotation budget is high, we are going to reannotate almost all the dataset. In such a scenario, there is hardly any chance for novel candidate selection.
3.3.2 Efficiency
ReTACRED performed complete reannotation of TACRED data [28]. They observed that the set of noisy datapoints () in TACRED are: 5326 sentences from DEV partition and 3936 sentences from TEST partition. To evaluate the performance of our reannotation strategies, the obvious way is to carry out the reannotation task. However, we simulated the performance of our reannotation strategies using the set for two main reasons. First, the set is carefully prepared by designing a large and multi-stage crowdsourcing experiment by ReTACRED authors. Second, we did not have the financial budget available to carry out the large-scale reannotation task. We take the labels from ReTACRED as gold standard labels.
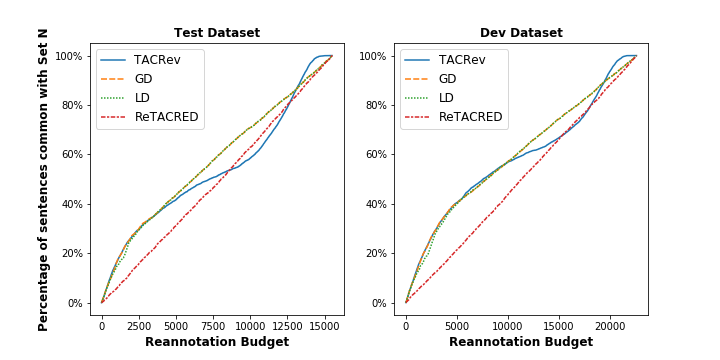
Please refer to Figure 4. The X-axis indicates the reannotation budget. Y-axis depicts the percentage of sentences from the set that we can find in the given budget using a particular reannotation strategy. For example, when we reannotate the top 1000 sentences from the TEST partition using the LD strategy, it contains 566 sentences, around 14.4% from the set . We can observe that for a low reannotation budget, GD, LD, and TACRev have the same efficiency. This is expected as their similarity was close to 100% for the low reannotation budget. However, for the medium reannotation budget our strategies outperform TACRev. For the very high value of the reannotation budget, TACRev performs slightly better than our strategies. The efficiency of GD and LD strategies is almost the same as their lines are overlapping in the figure. Efficiency of ReTACRED grows linearly as it chooses random sentences for reannotation.
3.3.3 Impact on Model Performance Measurement
Please refer to Figure 5. The X-axis indicates the reannotation budget. Y-axis indicates the F1 score of each model. Please note that we are only reannotating the TEST data here. The models are trained on the noisy TACRED dataset. We can observe that for three reannotation strategies (TACRev, GD, and LD), initially, the model performance improves with reannotation. This indicates that RC models agree with the initial reannotations. However, the performance of all models falls significantly with a higher reannotation budget. The test dataset is the cleanest when the reannotation budget is maximum. The least value of the F1 score for all models at this point indicates that the original performance reported in the literature for these models was inflated. The main reason for this inflated value is the significant noise in the TRAIN partition of the TACRED dataset.

None of the previous works could catch this trend for the following reason. We have conducted experiments here with noisy training data and a varying degree of noise reduction in the test data. However previous works can be classified in the following categories
Noisy training and noisy test data: Various works that directly used the TACRED data are training their RC models on noisy TRAIN partition of TACRED [36]. They are also testing their RC models on noisy TEST data. As a result, their reported F1 score is in the range of 60% to 70%. This corresponds to reannotation budget zero in Figure 5.
Noisy training and partially clean test data: The TACRev study had reported an average 8% improvement in the F1 score with the reannotation budget of about 2300 sentences from the TEST partition [1]. Our results for TACRev in Figure 5 correlate with their reported numbers. We can observe that while using the TACRev reannotation strategy, performance of all models peaks with the reannotation budget of around 2300. However, their results are a special case of our experiments with a fixed reannotation budget of 2300. We can observe a similar trend for our reannotation strategies GD and LD in Figure 5. Further cleaning of TEST dataset beyond the budget of 2300, actually results in the performance drop for all RC models and all reannotation strategies.
Partially clean training and completely clean test data: ReTACRED performed complete reannotation of the DEV and TEST partitions of the TACRED dataset [28]. They did not perform any reannotation of the TRAIN partition. However, they eliminated around ten thousand potentially noisy sentences from the TRAIN partition. As a result, they report at least 10% improvement in F1 score for various RC models as compared to previous works. This case cannot be captured in Figure 5 because we are not making any changes to the TRAIN partition of the TACRED dataset.
We have extended the ReTACRED approach as a reannotation strategy while keeping the training data unchanged and progressively cleaning the test data depending on the reannotation budget. In Figure 5, we can observe that for ReTACRED strategy, the model performance goes on monotonically decreasing with the reannotation budget. This is expected as the order of the sentences for reannotation is random. From other three reannotation strategies we can observe that reannotation of only about top 2500 sentences helps RC models to boost their performance. All these 2500 sentences are ordered randomly in the ReTACRED strategy. Reannotation of the rest of the sentences from the TEST partition does not agree with RC model prediction and brings down the model performance.
4 Limitations of Our Work
The first limitation of our work is that we are trusting the annotations from ReTACRED as the ground truth. In reality, the ReTACRED annotations are also done using crowd-sourcing. However, as compared to the original TACRED dataset, they have taken more precautions to avoid annotations errors. For example, they have rearranged the relation labels to avoid confusion in labeling. They have also created better instructions for the crowd-source workers. One way to further reduce the possibility of errors in the data is to get annotations from domain experts. However, considering the scale of dataset, it is a challenging task.
The second limitation of our work is that we have not yet dealt with reannotation of TRAIN partition. It will be interesting to see if the concept of reannotation budget helps to significantly improve the quality of training data while annotating only a small fraction of the training data. Currently, we are working on an automatic method for reannotating the training data using an ensemble of RC models.
The third limitation of our work is that it requires a taxonomic hierarchy of relation labels. We have created the relation hierarchy manually for the TACRED dataset. It will be helpful if such a hierarchy can be created automatically from the RC dataset.
5 Conclusion and Future Work
We presented two reannotation strategies in this paper: GD and LD. We also introduced the concept of reannotation budget to provide flexibility about how much data to reannotate. As compared to existing strategies, our strategies are novel and efficient. These reannotation strategies also help us understand the true performance of RC models trained over the noisy TACRED data. We plan to extend this work by designing strategies for selective reannotation of training data and evaluating its impact on model training.
The important conclusions from this work are: (i) relation between labels is an important but underutilized aspect of the data. It can helpful in numerous ways to improve dataset. (ii) A high rate of reannotation indicates that crowd-sourced labels are not trustworthy, especially for complex NLP tasks such as Relation Classification. Hence, data annotation should not be considered as a one-time task. Rather it should be treated as a budget-sensitive and iterative process where data is labelled in multiple iterations.
References
- [1] Alt, C., Gabryszak, A., Hennig, L.: TACRED revisited: A thorough evaluation of the TACRED relation extraction task. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 1558–1569. Association for Computational Linguistics, Online (Jul 2020). https://doi.org/10.18653/v1/2020.acl-main.142, https://www.aclweb.org/anthology/2020.acl-main.142
- [2] Alt, C., Hübner, M., Hennig, L.: Improving relation extraction by pre-trained language representations. In: Automated Knowledge Base Construction (AKBC) (2019), https://openreview.net/forum?id=BJgrxbqp67
- [3] Baldini Soares, L., FitzGerald, N., Ling, J., Kwiatkowski, T.: Matching the blanks: Distributional similarity for relation learning. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 2895–2905. Association for Computational Linguistics, Florence, Italy (Jul 2019). https://doi.org/10.18653/v1/P19-1279, https://www.aclweb.org/anthology/P19-1279
- [4] Bunescu, R., Mooney, R.: A shortest path dependency kernel for relation extraction. In: Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing. pp. 724–731 (2005)
- [5] Bunescu, R., Mooney, R.J.: Subsequence kernels for relation extraction. In: NIPS. pp. 171–178. Citeseer (2005)
- [6] Cui, W., Xiao, Y., Wang, H., Song, Y., Hwang, S.w., Wang, W.: Kbqa: Learning question answering over qa corpora and knowledge bases. Proc. VLDB Endow. 10(5), 565–576 (Jan 2017). https://doi.org/10.14778/3055540.3055549, https://doi.org/10.14778/3055540.3055549
- [7] Culotta, A., Sorensen, J.: Dependency tree kernels for relation extraction. In: Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04). pp. 423–429 (2004)
- [8] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
- [9] Gormley, M.R., Yu, M., Dredze, M.: Improved relation extraction with feature-rich compositional embedding models. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. pp. 1774–1784 (2015)
- [10] Han, X., Zhu, H., Yu, P., Wang, Z., Yao, Y., Liu, Z., Sun, M.: FewRel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4803–4809. Association for Computational Linguistics, Brussels, Belgium (Oct-Nov 2018). https://doi.org/10.18653/v1/D18-1514, https://www.aclweb.org/anthology/D18-1514
- [11] Hendrickx, I., Kim, S.N., Kozareva, Z., Nakov, P., Ó Séaghdha, D., Padó, S., Pennacchiotti, M., Romano, L., Szpakowicz, S.: SemEval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. In: Proceedings of the 5th International Workshop on Semantic Evaluation. pp. 33–38. Association for Computational Linguistics, Uppsala, Sweden (Jul 2010), https://www.aclweb.org/anthology/S10-1006
- [12] Huffman, S.B.: Learning information extraction patterns from examples. In: International Joint Conference on Artificial Intelligence. pp. 246–260. Springer (1995)
- [13] Joshi, M., Chen, D., Liu, Y., Weld, D.S., Zettlemoyer, L., Levy, O.: Spanbert: Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics 8, 64–77 (2020), https://www.aclweb.org/anthology/2020.tacl-1.5
- [14] Kambhatla, N.: Combining lexical, syntactic, and semantic features with maximum entropy models for information extraction. In: Proceedings of the ACL Interactive Poster and Demonstration Sessions. pp. 178–181 (2004)
- [15] Lin, B.Y., Chen, X., Chen, J., Ren, X.: Kagnet: Knowledge-aware graph networks for commonsense reasoning. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019. pp. 2829–2839. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/D19-1282, https://doi.org/10.18653/v1/D19-1282
- [16] Lin, Y., Liu, Z., Sun, M., Liu, Y., Zhu, X.: Learning entity and relation embeddings for knowledge graph completion. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. p. 2181–2187. AAAI’15, AAAI Press (2015)
- [17] Liu, C., Sun, W., Chao, W., Che, W.: Convolution neural network for relation extraction. In: International Conference on Advanced Data Mining and Applications. pp. 231–242. Springer (2013)
- [18] Mitchell, A., Strassel, S., Huang, S., Zakhary, R.: Ace 2004 multilingual training corpus. Linguistic Data Consortium, Philadelphia 1, 1–1 (2005)
- [19] Miwa, M., Bansal, M.: End-to-end relation extraction using lstms on sequences and tree structures. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1105–1116 (2016)
- [20] Nakashole, N., Weikum, G., Suchanek, F.: Patty: A taxonomy of relational patterns with semantic types. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. pp. 1135–1145 (2012)
- [21] Nguyen, D.P., Matsuo, Y., Ishizuka, M.: Relation extraction from wikipedia using subtree mining. In: Proceedings of the National Conference on Artificial Intelligence. vol. 22, p. 1414. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999 (2007)
- [22] Nguyen, T.H., Grishman, R.: Relation extraction: Perspective from convolutional neural networks. In: Proceedings of the 1st workshop on vector space modeling for natural language processing. pp. 39–48 (2015)
- [23] Parekh, A., Anand, A., Awekar, A.: Taxonomical hierarchy of canonicalized relations from multiple knowledge bases. In: Proceedings of the 7th ACM IKDD CoDS and 25th COMAD. p. 200–203. CoDS COMAD 2020, Association for Computing Machinery, New York, NY, USA (2020). https://doi.org/10.1145/3371158.3371186, https://doi.org/10.1145/3371158.3371186
- [24] Pennington, J., Socher, R., Manning, C.: Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). pp. 1532–1543 (2014)
- [25] Peters, M.E., Neumann, M., Logan, R.L., Schwartz, R., Joshi, V., Singh, S., Smith, N.A.: Knowledge enhanced contextual word representations. In: EMNLP (2019)
- [26] Riedel, S., Yao, L., McCallum, A.: Modeling relations and their mentions without labeled text. In: Balcázar, J.L., Bonchi, F., Gionis, A., Sebag, M. (eds.) Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 148–163. Springer Berlin Heidelberg, Berlin, Heidelberg (2010)
- [27] Socher, R., Huval, B., Manning, C.D., Ng, A.Y.: Semantic compositionality through recursive matrix-vector spaces. In: Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning. pp. 1201–1211 (2012)
- [28] Stoica, G., Platanios, E.A., Póczos, B.: Re-tacred: A new relation extraction dataset. In: 4th Knowledge Representation and Reasoning Meets Machine Learning Workshop (KR2ML 2020), at NeurIPS (2020)
- [29] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. pp. 5998–6008 (2017)
- [30] Wang, L., Cao, Z., De Melo, G., Liu, Z.: Relation classification via multi-level attention cnns. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1298–1307 (2016)
- [31] Wang, M.: A re-examination of dependency path kernels for relation extraction. In: Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-II (2008)
- [32] Weston, J., Bordes, A., Yakhnenko, O., Usunier, N.: Connecting language and knowledge bases with embedding models for relation extraction. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. pp. 1366–1371 (2013)
- [33] Yamada, I., Asai, A., Shindo, H., Takeda, H., Matsumoto, Y.: Luke: Deep contextualized entity representations with entity-aware self-attention. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 6442–6454. Association for Computational Linguistics, Online (Nov 2020). https://doi.org/10.18653/v1/2020.emnlp-main.523, https://www.aclweb.org/anthology/2020.emnlp-main.523
- [34] Zeng, D., Liu, K., Lai, S., Zhou, G., Zhao, J.: Relation classification via convolutional deep neural network. In: Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. pp. 2335–2344 (2014)
- [35] Zhang, S., Zheng, D., Hu, X., Yang, M.: Bidirectional long short-term memory networks for relation classification. In: Proceedings of the 29th Pacific Asia conference on language, information and computation. pp. 73–78 (2015)
- [36] Zhang, Y., Qi, P., Manning, C.D.: Graph convolution over pruned dependency trees improves relation extraction. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2205–2215. Association for Computational Linguistics, Brussels, Belgium (Oct-Nov 2018). https://doi.org/10.18653/v1/D18-1244, https://www.aclweb.org/anthology/D18-1244
- [37] Zhang, Y., Zhong, V., Chen, D., Angeli, G., Manning, C.D.: Position-aware attention and supervised data improve slot filling. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017). pp. 35–45 (2017), https://nlp.stanford.edu/pubs/zhang2017tacred.pdf
- [38] Zhou, G., Su, J., Zhang, J., Zhang, M.: Exploring various knowledge in relation extraction. In: Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05). pp. 427–434. Association for Computational Linguistics, Ann Arbor, Michigan (Jun 2005). https://doi.org/10.3115/1219840.1219893, https://aclanthology.org/P05-1053
- [39] Zhou, P., Shi, W., Tian, J., Qi, Z., Li, B., Hao, H., Xu, B.: Attention-based bidirectional long short-term memory networks for relation classification. In: Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers). pp. 207–212 (2016)
- [40] Zhou, W., Chen, M.: An improved baseline for sentence-level relation extraction. arXiv preprint arXiv:2102.01373 (2021)