Bridging the Gap Between Indexing and Retrieval for Differentiable Search Index with Query Generation
Abstract.
The Differentiable Search Index (DSI) is an emerging paradigm for information retrieval. Unlike traditional retrieval architectures where indexing and retrieval are two different and separate components, DSI uses a single transformer model to perform both indexing and retrieval.
In this paper, we identify and tackle an important issue of current DSI models: the data distribution mismatch that occurs between the DSI indexing and retrieval processes. Specifically, we argue that, at indexing, current DSI methods learn to build connections between the text of long documents and the identifier of the documents, but then retrieval of document identifiers is based on queries that are commonly much shorter than the indexed documents. This problem is further exacerbated when using DSI for cross-lingual retrieval, where document text and query text are in different languages.
To address this fundamental problem of current DSI models, we propose a simple yet effective indexing framework for DSI, called DSI-QG. When indexing, DSI-QG represents documents with a number of potentially relevant queries generated by a query generation model and re-ranked and filtered by a cross-encoder ranker. The presence of these queries at indexing allows the DSI models to connect a document identifier to a set of queries, hence mitigating data distribution mismatches present between the indexing and the retrieval phases. Empirical results on popular mono-lingual and cross-lingual passage retrieval datasets show that DSI-QG significantly outperforms the original DSI model.
1. Introduction

Information retrieval (IR) systems aim to return a ranked list of relevant documents for a given user query. Most modern information retrieval systems are based on the index-then-retrieve pipeline where documents are first encoded and stored in an inverted index (Zobel and Moffat, 2006; Formal et al., 2021; Gao et al., 2021a; Lin and Ma, 2021; Zhuang and Zuccon, 2021b; Dai and Callan, 2020; Mallia et al., 2021) or a nearest neighbor search index (Chappell et al., 2015; Lin, 2022; Karpukhin et al., 2020; Xiong et al., 2020; Gao and Callan, 2022; Zhan et al., 2021; Lin et al., 2020; Khattab and Zaharia, 2020) and search results are then constructed based on a retrieval model that exploits the information in the index. By doing so, the indexing and retrieval processes are decoupled.
Recently, an alternative approach called Differentiable Search Index (DSI) has been proposed (Tay et al., 2022). Instead of separating indexing and retrieval into two different components in an IR system, DSI aims to encode all information of the corpus and conduct retrieval within a single Transformer language model (Vaswani et al., 2017). To do so, in the indexing phase, DSI learns to build connections within its model parameters between the text in documents and the corresponding document identifiers (docids). Then, in the retrieval phase, the trained Transformer model takes as input a query text and directly outputs a potentially-relevant ranked docid using beam search. Compared to traditional IR pipelines, DSI learns an end-to-end search system in a unified manner, thus considerably simplifying the architecture of IR systems.
Despite the original DSI method being shown effective on the document retrieval task (Tay et al., 2022), in this paper we argue that this model is affected by a significant data distribution mismatch problem. More specifically, in the indexing phase, long text from documents is fed as input to the DSI model. However, in the retrieval phase, the model only observes short query texts as inputs. Therefore, the input data at indexing time is considerably different from the input data at retrieval time. It is well-known that pre-trained language models are not robust to data distribution drift between training (indexing) and inference (retrieval) (Li et al., 2020; Ma et al., 2020; Li et al., 2021; Wang et al., 2021a; Zhuang and Zuccon, 2021a, 2022): we thus argue that the original DSI model might be sub-optimal. Furthermore, in our experiments we demonstrate that the negative impact of the data distribution mismatch problem is even more considerable when adapting DSI to the cross-lingual retrieval setting, where documents and queries are from different languages.
Intuitively, DSI may be more effective for collections of short documents because short documents are similar to queries – at least in terms of text length. Thus, the data distribution mismatch problem may be lesser when documents are short in length. Indeed, in the original paper, although not explicitly recognising the data distribution mismatch problem, Tay et al. have shown that truncating long documents into shorter lengths displays higher effectiveness(Tay et al., 2022, Section 4.4.5). To further improve effectiveness, they also attempted adding labeled relevant queries into the indexing data so that the DSI model could learn to directly link a query to its relevant document identifier. However, for the majority of the documents in the collection where there is no labeled query provided, the model builds connections for the document identifiers with the original document texts only, as it is never exposed to the corresponding relevant queries: hence the data distribution mismatch problem still persists.
Based on our intuition of the data distribution mismatch problem that affects the DSI model, in this paper we propose DSI-QG, a simple yet effective indexing framework for DSI. The core idea of DSI-QG is that, instead of using the original long text from documents for indexing, DSI-QG uses a set of queries that are relevant to the original document for indexing. Specifically, for each document in the corpus, we employ a query generation model to generate a large set of potentially relevant queries which we use to represent each document. For the cross-lingual retrieval task, this query generation model is trained to be able to generate queries in different languages. To control the quality of the generated queries, all the generated queries are fed into a cross-encoder ranker along with their corresponding documents. This model ranks all the generated queries according to their relevance to the document; then queries are filtered to only pass the top- most relevant queries to the DSI module for indexing. By doing so, the same type of data is fed into the DSI in both the indexing and retrieval phases, hence avoiding the data distribution mismatch problem. Figure 1 illustrates our proposed DSI-QG indexing framework.
Our contributions can be summarised as follows:
-
•
We identify a crucial problem that affects the original DSI model: the data distribution mismatch between indexing and retrieval.
-
•
We show that DSI performs poorly in the presence of data distribution mismatches: this is further exacerbated in the cross-lingual document retrieval setting, emphasizing the gap between documents and queries.
-
•
We propose the DSI-QG indexing framework which is aimed at tackling the data distribution mismatch problem. Our framework uses query generation models (including a cross-lingual query generation model) and a cross-encoder ranker to generate and rank a set of potentially relevant queries that are used to represent documents for indexing.
-
•
We conduct extensive experiments on both mono-lingual and cross-lingual document retrieval datasets. Our results show that, with our proposed framework, the effectiveness of DSI is improved by a large margin on these tasks.
Code to reproduce the experiments and results presented in this paper can be found at https://github.com/ArvinZhuang/DSI-QG.
2. Preliminaries
In this section, we describe the details of the original DSI method. Then in the next section, we introduce our DSI-QG framework.
DSI performs index-then-retrieve with a single T5 transformer model (Raffel et al., 2019). During the indexing phase, the DSI model is fine-tuned to associate the text string of each document in a collection with its corresponding document identifier (docid) . It utilizes a straightforward sequence-to-sequence (seq2seq) approach that takes the document text as input and generates docids as output (Nogueira and Lin, 2019). The model is trained with the standard T5 training objective which uses the teacher forcing policy (Williams and Zipser, 1989) and the cross-entropy loss:
| (1) |
The docid can be represented using a single token (Atomic Docid) or a string of tokens (String Docid) (Tay et al., 2022). For the Atomic Docid, each docid is a single token in the T5 vocabulary and it has been encoded as an embedding vector in the T5 embedding layer. Thus the task can be considered as an extreme multi-label classification problem (Liu et al., 2021) where the model learns a probability distribution over the docid embeddings. This setting poses a limit to DSI when used on large-scale corpora, since the size of the T5 embedding layer cannot be too large. Hence, we do not consider this setting in our experiments.
On the other hand, the String Docid strategy treats the docids as arbitrary strings so that they can be generated in a token-by-token manner with the original T5 vocabulary. This configuration does not pose limitations with respect to corpus size. The original DSI paper also proposed a Semantic String Docid which uses a hierarchical clustering algorithm to force similar documents to have similar docids. Since clustering docids is not the aim of this paper and for simplicity, we only consider arbitrary String Docid, and leave extensions to the Semantic String Docid setting to future work.
In the retrieval phase, given an input query , a DSI model returns a docid by autoregressively generating the docid string using the fine-tuned T5 model. The probability of the generated docid can be computed as:
| (2) |
where is the -th token in the docid string. A ranked list of docids is then constructed using beam search (and is thus ranked by decreasing generation probability).
It is important to note that a query usually is much shorter in length than a document. This means the length of the input data at indexing is very different from the length of input data at retrieval: thus the DSI model suffers from a data distribution mismatch. To mitigate this problem, the DSI authors proposed the use of the supervised DSI fine-tuning (Tay et al., 2022). This process adds labeled relevant queries to the indexing data. Let be the set of labeled relevant queries for , then the training objective becomes:
| (3) |
where is a query relevant to . We note that having assessors labeling a relevant query for all the documents in the collection requires a large annotation effort thus not all documents can have a human-judged relevant query for supporting indexing. In other words, could be an empty (or small) set. Hence the DSI model still largely suffers from the data distribution mismatch problem (especially for large collections of documents), even when the supervised DSI fine-tuning method is used.
3. The DSI-QG Framework
In this section, we describe the details of the different components in the proposed DSI-QG framework, pictured in Figure 1. Our framework features a query generation model for generating candidate queries that are potentially relevant to the original documents. It then uses a cross-encoder ranker to rank all generated queries and only selects the top- queries which are then passed to the downstream DSI module for representing the associated document at indexing.
3.1. DSI with query generation
The original DSI method exhibits a gap between the input data used at indexing and that used at retrieval. In order to bridge this gap and improve DSI’s effectiveness, we propose DSI-QG which uses a query generation model to generate a set of potentially-relevant queries to represent each candidate document for indexing. Specifically, we denote as the set of queries generated by a query generation model given the document :
| (4) |
All the generated queries in share the same docid as , and . We then replace the original documents that need to be indexed with their corresponding generated queries, i.e. using in place of . In other words, a document is replaced by the set of queries generated for that document. Thus, during the indexing phase in DSI-QG, the modified DSI model is trained to associate the generated queries of each candidate document with its docid:
| (5) |
The retrieval phase of DSI-QG is the same as the original DSI model and takes a user query as input and uses beam search to construct a ranked docid list. Note that each query in , that was generated for , is used separately for the other queries for , i.e. queries for a document are not concatenated or combined into a single input. In summary, in our DSI-QG framework, a DSI model only observes short queries as input data during both indexing and retrieval thus eliminating the data distribution mismatch problem that affects the original DSI model.
A key factor for the success of the DSI-QG indexing framework is the query generation (QG) model. This model should generate high-quality and diverse relevant queries so that they can effectively represent the corresponding document from which they are generated. For this purpose, we train a T5 model with a similar seq2seq objective as Eq. (1), but in this case the input is the document text and the output is the labeled relevant query :
| (6) |
After training a QG model, instead of using beam search, we use a random sampling strategy to generate a set of queries for each candidate document. This is because we find random sampling gives more creative and diverse queries than beam search, thus potentially covering more relevant information about the document. To avoid randomly generating irrelevant content and grammatically incorrect queries, we adopt the top- sampling scheme (Fan et al., 2018) which only allows the most likely next words to be sampled during the query generation and the probability mass of those next words is redistributed. In our experiments, we set .
Intuitively, a document may be relevant to more than just one query, thus another factor that might impact the effectiveness of our proposed DSI-QG method is the number of generated queries to represent each document: we discuss the impact of in the result section.
3.2. DSI-QG with cross-lingual query generation
To generalize our DSI-QG framework to the cross-lingual IR setting, we also train a multi-lingual T5 model (Xue et al., 2021) to generate queries in different languages, and then in turn use these to represent a document. To achieve this, we use a prompt-based approach to control the generated query language. Specifically, we place the target language and the document text in the following template for both training and inference:
| (7) |
where [lang] and [doc] is the placeholder for the target query language and the document text. In our cross-lingual experiments, [doc] is always written in English and [lang] is a language other than English. We generate multiple queries for all the target languages and use these to represent each English document. By doing so, our DSI-QG model can learn to build connections between the English documents identifiers with queries from different languages, thus allowing to perform cross-lingual retrieval with our proposed cross-lingual query generation model.
3.3. Ranking generated queries with a cross-encoder ranker
Although our query generation model adopts the top- sampling scheme to balance the relevance and diversity of generated queries, it still inevitably generates irrelevant queries due to the randomness of the sampling process. This problem is even more considerable when there is not enough training data to train the query generation model or when the model is ill trained. To further mitigate this problem, we add a cross-encoder ranker to rank all the generated queries and only use the top- ranked queries to represent the original document.
Specifically, we use monoBERT (Nogueira et al., 2019) as a cross-encoder ranker: this is a transformer encoder-based model that employs BERT and that takes a query-document pair (separated by a special [SEP] token) as input and outputs a relevance score :
| (8) |
We train the ranker with supervised contrastive loss, similar to Gao et al. (Gao et al., 2021b):
| (9) |
where is the training query and is the annotated relevant document for the training query. is a hard negative document which we randomly sample from the top 100 documents retrieved by BM25 for the training query .
In our cross-encoder ranker, all the query tokens can interact with all the document tokens thus it has more substantial relevance modeling power than other ranker architectures, such as dual- or bi-encoders (Lin et al., 2020; Ren et al., 2021; Zhang et al., 2022a; Lu et al., 2022). We then rank all the generated queries for each document in decreasing order of the relevance score estimated by our ranker. From this ranking, we only select the top- queries to pass to the downstream DSI indexing training, thus effectively filtering out the remaining queries. We note that our query generation model and cross-encoder ranker are large transformer models and thus require substantial computational resources in addition to the DSI model alone. However, these additional computations only happen during the offline indexing phase, and will not affect the online query latency. We leave methods for reducing the computational resources required for indexing to future work.
4. Experimental Settings
4.1. Datasets
Following the original DSI paper, we conduct our experiments on subsets of publicly available document retrieval datasets, namely NQ 320k (Kwiatkowski et al., 2019), for the mono-lingual document retrieval task, and XOR QA 100k (Asai et al., 2021), for the cross-lingual retrieval task. The NQ 320k dataset has 307k training query-document pairs and 8k dev query-document pairs. All the queries and documents in NQ 320k are in English. We follow the description in DSI (Tay et al., 2022) and SEAL (Bevilacqua et al., 2022) to construct the dataset as the code for dataset construction is not yet publicly available at the time of writing. For XOR QA 100k, we use the gold paragraph data available in the original repository111https://github.com/AkariAsai/XORQA#gold-paragraph-data which contains around 15k gold (annotated as relevant) document-query pairs in the training set and 2k gold document-query pairs in the dev set. Queries in both train and dev sets are in 7 typologically diverse languages222They are Ar, Bn, Fi, Ja, Ko, Ru and Te. and documents are in English. The total number of documents in the XOR QA training set and dev set is around 17k. This is a very small number of documents, likely to render the retrieval task too easy. We then randomly sample 93k documents from a dump of the English Wikipedia corpus to form a 100k collection for testing our models, thus increasing how challenging retrieval in this collection is.
4.2. Baselines
We compare DSI-QG with the following baselines:
- •
-
•
BM25 + docT5query (Nogueira and Lin, 2019): a sparse retrieval method which also leverages query generation. It uses a T5 model to generate a set of queries and appends them to the original document. Then it uses an inverted index and BM25 to retrieve augmented documents. In the original study that investigated this method, only the mono-lingual retrieval task was considered (Nogueira and Lin, 2019). For fair comparison with DSI-QG, we adapt this method to the cross-lingual retrieval setting by replacing the mono-lingual T5 query generation model with the same multi-lingual T5 generation model used in our DSI-QG. We also use the Pyserini implementation for this baseline.
-
•
SEAL (Bevilacqua et al., 2022): an autoregressive generation model that is similar to DSI. It treats ngrams that appear in the collection as document identifiers; at retrieval time, it directly generates and scores distinctive ngrams that are mapped to the documents. Unlike DSI, which unifies the index into the model parameters, SEAL requires a separate index data structure to perform an efficient search. Note that no publicly available implementation of SEAL currently exists. Unlike for DSI below, the re-implementation of SEAL is outside the scope of our work, and thus we report the results obtained by Bevilacqua et al. (Bevilacqua et al., 2022) on the NQ 320k dataset. SEAL has not been devised for and experimented with the task of cross-lingual retrieval and thus no results for XOR QA 100k are reported.
-
•
mDPR (Karpukhin et al., 2020; Asai et al., 2021): a mBERT-based cross-lingual dense passage retrieval method trained with a contrastive loss and with hard negatives sampled from the top passages retrieved by BM25. mDPR relays on nearest neighbor index search (Faiss implementation (Johnson et al., 2019)) to retrieve the passages that have the closest embeddings to the query embedding. We train the mDPR model with the Tevatron dense retriever training toolkit (Gao et al., 2022). Of course, due to its cross-lingual nature, we run mDPR only on the cross-lingual dataset, XOR QA 100k.
-
•
DSI (Tay et al., 2022): The original DSI method that uses documents text as input for indexing. Since the original code has not currently been made available by the authors, we implement and train the DSI model ourselves using the Huggingface transformers Python Library. We provide the implementation of this DSI model in our public code repository, along with the implementations of the other models considered in this paper.
4.3. Evaluation Measures
Following the original DSI paper, for both datasets, we evaluate baselines and our models on the dev set with Hits@1 and Hits@10. This metric reports the proportion of the correct docids ranked in the top 1 and top 10 predictions. In addition, for XOR QA 100k we also report nDCG@10; this metric is not available for NQ 320k for some of the considered baselines and thus we do not report it as comparisons between methods cannot then be made.
| Model | NQ 320k | |
|---|---|---|
| Hits@1 | Hits@10 | |
| BM25 | 29.27 | 60.15 |
| BM25 + docT5query | 39.13 | 69.72 |
| SEAL | 26.30 | 74.50 |
| DSI-base | 27.40 | 56.60 |
| DSI-large | 35.60 | 62.60 |
| DSI-QG-base | 63.49 | 82.36 |
| DSI-QG-large | 65.13 | 82.50 |
4.4. Implementation Details
There are three Transformer models in our DSI-QG framework: a query generation model, a cross-encoder ranker, and a DSI model.
For the NQ 320k dataset, we fine-tune an existing docT5query query generation model checkpoint333https://huggingface.co/castorini/doc2query-t5-large-msmarco with the training portion of the NQ 320k dataset. For the cross-encoder ranker, we train a ‘BERT-large-uncased’ checkpoint and 15 hard negatives documents sampled from BM25. For the DSI model, we use the standard pre-trained T5 model (Raffel et al., 2019) to initialize the model parameters.
For XOR QA 100k, we use the multi-lingual T5 model (Xue et al., 2021) to initialize both the query generation model and DSI model. For the cross-lingual ranker, we train ‘xlm-roberta-large’ (Conneau et al., 2020) checkpoint with BM25 hard negatives provided by the XOR QA official repository. For our trained query generation model, we train the model with a batch size of 128 and a learning rate of with Adam optimizer for 600 training steps on XOR QA 100k datasets,which is equivalent to about 6 epochs, and 9500 steps on the NQ 320k dataset which is equivalent to about 4 epochs. The DSI models in our DSI-QG method are trained for a maximum of 1M steps with a batch size of 256 and a learning rate of with 100k warmup-steps. Since the documents in DSI-QG are represented by generated short queries, we set the maximum length of the input data to 32 tokens for faster training and saving GPU memory usage. For training the original DSI model, we use the training configuration suggested in the original paper (Tay et al., 2022). For mDPR trained on XOR QA, we follow the training configuration in the XOR QA paper (Asai et al., 2021), which uses a multi-lingual BERT-base model as the backbone query and passage encoder. All Transformer models used in this paper are implemented with Huggingface transformers (Wolf et al., 2020) and training is conducted on 8 Tesla A100 GPUs.
5. Results
5.1. Effectiveness on Mono-lingual Retrieval
| Model | Ar | Bn | Fi | Ja | Ko | Ru | Te | Average |
|---|---|---|---|---|---|---|---|---|
| BM25 + docT5query | 11.96 | 19.21 | 29.17 | 20.83 | 10.21 | 25.96 | 8.02 | 17.91 |
| mDPR | 20.93 | 19.21 | 43.59 | 22.50 | 20.07 | 41.70 | 18.99 | 26.71 |
| DSI-base | 0.00 | 0.00 | 1.28 | 0.00 | 0.70 | 0.00 | 0.00 | 0.28 |
| DSI-large | 0.33 | 0.99 | 6.41 | 1.25 | 0.00 | 1.27 | 0.00 | 1.47 |
| DSI-QG-base | 34.55⋄ | 38.41⋄ | 42.95 | 42.08⋄ | 33.80 ⋄ | 57.45⋄ | 28.69⋆ | 39.17⋄ |
| DSI-QG-large | 37.21⋄ | 43.05⋄ | 45.19 | 43.33⋄ | 32.04⋄ | 61.28⋄ | 31.22⋄ | 41.90⋄ |
| Model | Ar | Bn | Fi | Ja | Ko | Ru | Te | Average |
|---|---|---|---|---|---|---|---|---|
| BM25 + docT5query | 28.24 | 37.75 | 46.47 | 41.67 | 23.59 | 40.43 | 25.32 | 34.78 |
| mDPR | 56.48 | 61.59 | 73.40 | 50.83 | 53.52 | 72.34 | 54.85 | 60.43 |
| DSI-base | 1.66 | 2.65 | 7.05 | 2.91 | 2.47 | 0.85 | 1.26 | 2.69 |
| DSI-large | 3.99 | 5.23 | 16.67 | 5.83 | 4.93 | 4.25 | 2.53 | 6.21 |
| DSI-QG-base | 59.14 | 68.54 | 68.27 | 64.58⋄ | 61.97⋆ | 71.91 | 67.09⋄ | 65.93⋄ |
| DSI-QG-large | 58.47 | 73.18⋄ | 73.08 | 67.08⋄ | 59.51 | 74.04 | 63.71⋆ | 67.01⋄ |
| Model | Ar | Bn | Fi | Ja | Ko | Ru | Te | Average |
|---|---|---|---|---|---|---|---|---|
| BM25 + docT5query | 9.83 | 12.82 | 14.52 | 13.66 | 7.40 | 13.61 | 9.30 | 11.59 |
| mDPR | 20.22 | 21.05 | 23.0 | 17.84 | 18.37 | 23.43 | 19.97 | 20.55 |
| DSI-base | 0.32 | 0.75 | 1.96 | 0.25 | 0.65 | 0.58 | 0.27 | 0.73 |
| DSI-large | 1.57 | 2.06 | 5.14 | 0.20 | 2.23 | 0.90 | 0.93 | 2.12 |
| DSI-QG-base | 19.28 | 21.47 | 20.79 | 20.88 | 19.64 | 21.94 | 22.59 | 20.94 |
| DSI-QG-large | 18.80 | 22.86 | 23.54 | 21.09 | 19.32 | 22.24 | 20.47 | 21.19 |
We start by discussing the effectiveness of the proposed DSI-QG framework on the mono-lingual retrieval task; recall that these experiments are based on the NQ 320k English mono-lingual retrieval dataset.
Table 4.3 contains the Hits scores of the baselines and our DSI-QG methods on NQ 320k. For BM25 + docTquery and DSI-QG, we first generated queries for each document; then we ranked them using the cross-encoder ranker and select only the top queries. This process thus resulted in 50 queries being used to represent each document. To explore the impact of different model sizes, we report the results for DSI and DSI-QG with T5-base (200M parameters) and T5-large (800M).
The results show that the original DSI method performs worse than other baselines, with the exception of DSI with T5 large which outperforms BM25 on both Hits scores and SEAL on Hits@1. BM25 with docT5query document augmentation, which is a simple and straightforward way of leveraging query generation, achieves the best Hits@1 among the baselines we consider. These results suggest that the existing autoregressive generation-based information retrieval methods are inferior to the considered baselines in the mono-lingual retrieval task.
On the other hand, our DSI-QG outperforms all baselines by a large margin on both Hits measures. Compared to the original DSI method, Hits@1 and Hits@10 improve by 132% and 46% for T5-base, and 83% and 32% for T5-large. This suggests that the query generation employed in DSI-QG successfully addresses the data distribution mismatch problem that afflicts the original DSI method.
We further compare our results with those reported by Wang et al. ([n.d.]), who developed the DSI-based technique in parallel with ours. On NQ320k they report their query-generation methods based on a docT5query fine-tuned on the dataset achieves Hits@10 values of 88.48 and 88.45 for the base and large backbones, respectively. This result supports the superiority of DSI models that exploit query generation, and confirms the backbone model size has minor influence on effectiveness.
Next, we specifically focus on the impact of model size on retrieval effectiveness. We note that the effectiveness of the original DSI method decreases dramatically with a smaller base model. In contrast, model size has relatively little impact on the effectiveness of DSI-QG. This suggests that when using the DSI-QG framework, a large pre-trained T5 model is not necessarily required. The use of a smaller T5 model means that DSI-QG can feature faster retrieval inference time and lower GPU memory requirements.
5.2. Effectiveness on Cross-lingual Retrieval
Next we examine the effectiveness of the proposed DSI-QG framework on the cross-lingual retrieval task; recall that these experiments are based on the XOR QA 100k cross-lingual dataset.
In Table 2(c), we report the results obtained across the different languages. For BM25 + docTquery and DSI-QG, we first generated queries for each document (100 per language) and then separately rank the generated queries for each language using the cross-encoder ranker and the cutoff .This resulted in 70 generated queries being used to represent each document (10 for each language).
The results show that the original DSI model performs much worse on XOR QA 100k than on NQ 320k (cfr. Table 4.3). In fact, across many languages, DSI-base fails to retrieve any relevant document in the top rank position (Hits@1). This is likely due to the data distribution mismatch problem being further exacerbated by the language gap in the cross-lingual document retrieval task (Zhang et al., 2022b). In contrast, our proposed DSI-QG achieves the highest Hits values across all languages with the only exceptions that its Hit@10 on Finnish is lower than that of mDPR, as are the nDCG@10 values for Arab and Russian.
These results suggest that, with a cross-lingual query generation model, our DSI-QG not only can address the indexing and retrieval gap brought by the data type mismatch but can also address the gap brought by the language mismatch that instead affects the original DSI model.
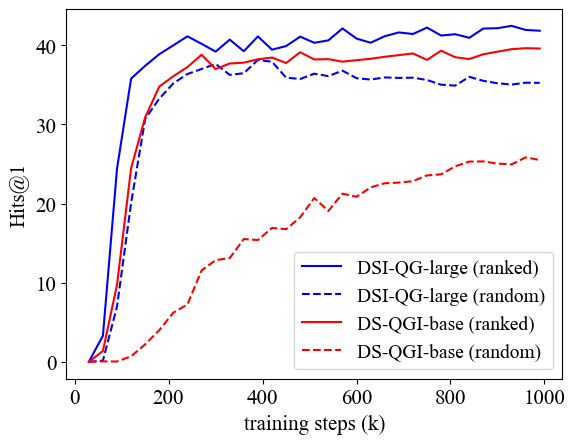
5.3. Impact of Cross-encoder Ranker and Query Selection
Next, we discuss the effect of different components and factors on our DSI-QG model. Specifically, we study the effect of the cross-encoder ranker and the impact of the rank cut-off used when ranking and selecting the generated queries.
5.3.1. Impact of Cross-encoder Ranker
Figure 2 reports the Hit@1 learning curves on the XOR QA 100k dataset obtained by DSI-QG when trained with and without the cross-encoder ranker. For this experiment, we use the same experimental configuration used for the experiments of Table 2(c). The plot shows that ranking and selecting the top generated queries before passing them to the DSI indexing training yields higher Hit@1 convergence than randomly picking queries from the generated query set. This result is valid for both the base and the large model. This process is however particularly important for the base model to achieve faster convergence and higher final Hits. These results suggest that our use of the cross-encoder ranker, although comes at higher computational and energy costs (Scells et al., 2022), can further improve the effectiveness of DSI-QG by controlling which queries are passed to DSI during indexing.
5.3.2. Impact of rank cut-off .
Figure 3 reports the Hit@1 learning curves on NQ 320k for DSI-QG-base trained with different re-ranking cut-off values . For this experiment, we explored cut-off values . We note that the value of also represents the number of queries used to represent each document: when , all the generated queries are used and thus the cross-encoder ranker has no effect on the final results. As shown in the plot, effectiveness dramatically increases as jumps from 1 to 5. When , DSI-QG already achieves a higher Hits@1 than the original DSI method (reported in Table 4.3). Improvements provided by settings with are not significant compared to values . These results align with recent findings in sparse neural retrieval where query generation is adapted as a document expansion method (Lin and Ma, 2021; Mallia et al., 2021; Zhuang and Zuccon, 2021b): a larger number of generated queries can capture more information about the original document, thus providing a better representation of a document.

Figure 3 also provides further insights into DSI-QG and its indexing behavior with respect to the number of selected queries for representing a document, . At the beginning of the indexing process, when less than 100,000 training steps (iterations) have taken place, the setting with is less effective than other settings (with ). Indeed, it is only when more than iterations have taken place, that the setting with achieves the same effectiveness than the setting with . Similar behaviors, though less remarked in the figure due to scale, occur when comparing other settings, e.g. against .
5.4. Qualitative Analysis of Generated Queries and Ranking
DSI-QG involves a step of query generation and further ranking and selection of queries to represent a document at indexing. In Table 3 we report an example of a document from the XOR QA dataset, one of the multilingual query for which this document has been assessed as relevant in the collection, and a sample of the queries that are generated by DSI-QG for the same target language (Russian). The sample of the queries are ordered according to the scores generated for these queries by the cross-encoder ranker. While all the top 3 queries would be used by DSI-QG to represent the document at indexing (when ), the bottom 3 queries would be discarded by all DSI-QG settings we experimented with in the paper, except when .
| Gold Query | Как звали первого капитана ‘‘Сорю’’? |
|---|---|
| (What was the name of the first captain of the Soryu?) | |
| Document | Ryusaku Yanagimoto |
| On 6 October 1941, Yanagimoto was given command of the aircraft carrier ‘‘Sōryū’’, on which he participated in the attack on Pearl Harbor in the opening stages of the Pacific War. He was subsequently at the Battle of Wake Island and the Indian Ocean raids. Yanagimoto chose to go down with his ship when “Soryu” was sunk by United States Navy aircraft at the Battle of Midway. He was posthumously promoted to the rank of rear admiral. | |
| Query 1 | Когда погиб капитан юсуsaka Янагимото? |
| (When did Captain Yuusaka Yanagimoto die?) | |
| Query 2 | Как назывался первый корабль, на котором служил японец Рюсаку Янагимото? |
| (What was the name of the first ship on which the Japanese Ryusaku Yanagimoto served?) | |
| Query 3 | В какой войне участвовал Риуsaku Yanagimoto? |
| (What war did Ryusaku Yanagimoto participate in?) | |
| Query 98 | Сколько было кораблей на яхте Янагемита? |
| (How many ships were on Yanagemit’s yacht?) | |
| Query 99 | Где находилось корабль ‘‘Сорю’’ на апрель 2019? |
| (Where was the Soryu ship in April 2019?) | |
| Query 100 | Сколько лет правил корабль ‘‘Сорою’’? |
| (How many years did the ship “Soroy” rule?) |
We then generalise the above analysis by considering all queries that have been generated for all documents in the dataset. Figure 4 shows the effectiveness, measured in terms of mean reciprocal rank (MRR) of each of the generated queries (ordered by the cross-encoder ranker) at retrieving the relevant document when retrieval is performed using the mDPR baseline. Recall that mDPR is generally highly effective on this dataset, as seen in Table 2(c)(c). Thus, we use mDPR to provide an estimation of “query quality” as in this way we decouple this estimation from the training of DSI-QG. The trend observed in the plot suggests that the quality of the generated queries decreases as their rank assigned by the cross-encoder ranker increases, i.e. generally queries in early rank positions are associated to higher mDPR effectiveness than queries at later rank positions, attesting to the importance of ranking queries for use in DSI-QG.

5.5. Analysis of Length of DSI-QG Input
While the original DSI uses the full length of a document as input to the Transformer used for indexing the document, DSI-QG uses queries to represent a document, each of them passed separately as input to the DSI Transformer. We argued that the effectiveness of the original DSI method is limited by the mismatch between the length of the input provided at indexing (documents, usually long) and retrieval (queries, usually short). The new framework we devised, DSI-QG, uses queries for indexing in lieu of documents: this aligns the lengths of the input at indexing (now generated queries, usually short) and the input at retrieval (real queries, usually short).
We then analyze the input lengths of DSI and DSI-QG to demonstrate that indeed DSI-QG’s indexing lengths are shorter and more aligned with the query lengths observed at retrieval. Input lengths are measured according to the T5 model tokenizer used in DSI, i.e. the number of tokens T5 produces for a text input. These statistics are reported in Table 4, and show that indeed for DSI input lengths greatly differ at indexing and retrieval, while these are similar in DSI-QG.
| Dataset | Input | Mean Std. | [Min, Max] |
|---|---|---|---|
| NQ 320k | Original | 7,478.03 8,251.83 | [3, 153,480] |
| Generated | 12.67 2.05 | [8, 29.42] | |
| Test Queries | 12.07 3.23 | [7, 32] | |
| XOR QA | Original | 164.55 43.25 | [11, 1,640] |
| Generated | 15.10 1.66 | [7, 22.83] | |
| Test Queries | 14.8 5.55 | [5, 66] |
6. Related Work
6.1. Retrieval via autoregressive generation
Pretrained transformer-based autoregressive generation models have been shown effective across many NLP tasks (Raffel et al., 2019; Brown et al., 2020). Recent studies also explored adapting this type of models to the information retrieval task.
Cao et al. have applied autoregressive generation models to conduct entity retrieval where queries are texts with a mention span and documents are entities in a knowledge base (Cao et al., 2021; Cao et al., 2022). In this setting, the documents’ identifiers are the entity names.
Different from the entity retrieval setting, Tay et al. proposed the differentiable search index (DSI) scheme (Tay et al., 2022), which is an autoregressive generation model trained to perform ad hoc document retrieval where the input of the model is a natural language query and the model regressively generates documents’ identifier strings that are potentially relevant to the given query.
In another direction, Bevilacqua et al. proposed the SEAL model which treats ngrams that appear in the collection as document identifiers (Bevilacqua et al., 2022). At inference time, SEAL directly generates ngrams which can be used to score and retrieve documents stored in an FM-index (Ferragina and Manzini, 2000).
In contrast to the original DSI scheme and SEAL, our work focuses on augmenting document representations at indexing time so to bridge the gap between indexing and retrieval in the existing autoregressive generation IR systems.
The method of Wang et al. ([n.d.]), which was developed in parallel with ours and with no communication between the research groups, shares some commonalities with our DSI-QG in that it also uses query generation for augmenting document representations. However, while their work only considers English document retrieval and thus monolingual augmentation, our work goes beyond that and delves into the setting of cross-lingual document retrieval, offering a more comprehensive approach to the field.
6.2. Generate-then-rank
Our DSI-QG indexing framework relies on a cross-encoder model to rank all generated queries in order to identify high-quality queries to represent documents. The intuition behind this design is that, for deep learning models, the generation task is usually a harder task than the classification task. Thus, many deep generation models follow the generate-then-rank paradigm to improve the generation quality. For example, the recent text-to-image generation model DALLE (Ramesh et al., 2021) also uses a ranker called CLIP (Radford et al., 2021) to rank all generated images and only present to the users the top-ranked images. On the other hand, while the GPT-3 language model (Brown et al., 2020) has been shown to perform poorly in solving mathematical problems (Hendrycks et al., 2021), Cobbe et al. (Cobbe et al., 2021) have found that simply training verifiers to judge the correctness of the solutions generated by GPT-3 can significantly improve the success of the model for this task. DSI-QG can be seen as following this generate-then-rank paradigm.
6.3. Query generation for information retrieval
Our DSI-QG framework relies on the query generation model to generate high-quality and relevant queries to represent each document. Query generation has been the topic of a number of recent works in the field of Information Retrieval.
A common example is docT5query (Nogueira and Lin, 2019), a neural document expansion technique that generates relevant queries and appends them to each document in the collection. Then, BM25 is used to perform retrieval on the augmented collection. This simple method can significantly improve on BM25. A follow-up study shows that even completely discarding the original document text and only using the generated queries to represent the documents can achieve better retrieval effectiveness than using the original document text (Lin et al., 2021b).
The TILDEv2 model, an effective and efficient sparse neural retrieval model, also uses document expansion based on query generation (Zhuang and Zuccon, 2021b). While one of the query generation methods adopted in TILDEv2 is docT5query, Zhuang&Zuccon have shown how the TILDE (Zhuang and Zuccon, 2021c) retrieval model can be exploited as a lightweight query generator. The use of TILDE in place of docT5query leads to similar retrieval effectiveness than docT5query but it requires several order of magnitude less computations (Zhuang and Zuccon, 2021b; Scells et al., 2022). The query generation method we use in DSI-QG is akin to docT5query. While the use of TILDE in place of docT5query for the query generation step of DSI-QG may be attractive because of its lower computational costs, we note that TILDE produces query terms that are independent of each other and thus is unlikely to be effective in for DSI-QG. In other words: TILDE generates unigram query tokens, not queries (i.e. sequences of tokens) – and these then are not representative of the inputs that the model will observe at retrieval time (e.g., Table 4 shows that queries in the two datasets considered in our work consists of, on average, 12.1 and 14.8 query tokens, respectively).
Query generation has also been used for the task of domain adaption and for generating training data for the zero-shot setting. Wang et al. proposed GPL, a framework for training domain adaptation rankers by generating pseudo labels with a query generation model (Wang et al., 2021b). Bonifacio et al. directly used the GPT-3 model (Brown et al., 2020) to generate queries for training rankers in the few-shot setting (Bonifacio et al., 2022). Luo et al. introduced a domain-relevant template-based query generation approach which uses a sequence-to-sequence model conditioned on the templates to generate a large number of domain-related queries in a bid to mitigate the train-test overlap issue (Luo et al., 2022).
These prior works only focus on the mono-lingual retrieval setting. In contrast, our work also explores the usability of the query generation model for the cross-lingual information retrieval task.
7. Conclusion
In this paper, we show that the current DSI model is affected by the problem of data distribution mismatch that occurs between the indexing and retrieval phases. This problem negatively impacts the effectiveness of DSI on the mono-lingual passage retrieval task and is further exacerbated in the cross-lingual passage retrieval task, where DSI becomes of impractical use.
To address this fundamental issue, we propose the DSI-QG indexing framework which adopts a query generation model with a cross-encoder ranker to generate and select a set of relevant queries, which are in turn used to represent each to-be-indexed document. Our experimental results on both mono-lingual and cross-lingual passage retrieval tasks show that our DSI-QG significantly outperforms the original DSI model and other popular baselines.
Acknowledgment
Part of this work was conducted when Shengyao Zhuang was a research intern at Microsoft STCA, China.
References
- (1)
- Asai et al. (2021) Akari Asai, Jungo Kasai, Jonathan H Clark, Kenton Lee, Eunsol Choi, and Hannaneh Hajishirzi. 2021. XOR QA: Cross-lingual Open-Retrieval Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 547–564.
- Bevilacqua et al. (2022) Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Wen-tau Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers. arXiv preprint arXiv:2204.10628 (2022).
- Bonifacio et al. (2022) Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. 2022. InPars: Unsupervised Dataset Generation for Information Retrieval. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2387–2392.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Cao et al. (2021) Nicola De Cao, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. 2021. Autoregressive Entity Retrieval. In International Conference on Learning Representations. https://openreview.net/forum?id=5k8F6UU39V
- Cao et al. (2022) Nicola D Cao, Ledell Wu, Kashyap Popat, Mikel Artetxe, Naman Goyal, Mikhail Plekhanov, Luke Zettlemoyer, Nicola Cancedda, Sebastian Riedel, and Fabio Petroni. 2022. Multilingual autoregressive entity linking. Transactions of the Association for Computational Linguistics 10 (2022), 274–290.
- Chappell et al. (2015) Timothy Chappell, Shlomo Geva, and Guido Zuccon. 2015. Approximate nearest-neighbour search with inverted signature slice lists. In european conference on information retrieval. Springer, 147–158.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Édouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 8440–8451.
- Dai and Callan (2020) Zhuyun Dai and Jamie Callan. 2020. Context-aware term weighting for first stage passage retrieval. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 1533–1536.
- Fan et al. (2018) Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 889–898.
- Ferragina and Manzini (2000) Paolo Ferragina and Giovanni Manzini. 2000. Opportunistic data structures with applications. In Proceedings 41st annual symposium on foundations of computer science. IEEE, 390–398.
- Formal et al. (2021) Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2288–2292.
- Gao and Callan (2022) Luyu Gao and Jamie Callan. 2022. Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2843–2853.
- Gao et al. (2021a) Luyu Gao, Zhuyun Dai, and Jamie Callan. 2021a. COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 3030–3042.
- Gao et al. (2021b) Luyu Gao, Zhuyun Dai, and Jamie Callan. 2021b. Rethink training of BERT rerankers in multi-stage retrieval pipeline. In European Conference on Information Retrieval. Springer, 280–286.
- Gao et al. (2022) Luyu Gao, Xueguang Ma, Jimmy J. Lin, and Jamie Callan. 2022. Tevatron: An Efficient and Flexible Toolkit for Dense Retrieval. ArXiv abs/2203.05765 (2022).
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021).
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769–6781.
- Khattab and Zaharia (2020) Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 452–466.
- Li et al. (2020) Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. 2020. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6193–6202.
- Li et al. (2021) Zongyi Li, Jianhan Xu, Jiehang Zeng, Linyang Li, Xiaoqing Zheng, Qi Zhang, Kai-Wei Chang, and Cho-Jui Hsieh. 2021. Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 3137–3147.
- Lin (2022) Jimmy Lin. 2022. A proposed conceptual framework for a representational approach to information retrieval. In ACM SIGIR Forum, Vol. 55. ACM New York, NY, USA, 1–29.
- Lin and Ma (2021) Jimmy Lin and Xueguang Ma. 2021. A few brief notes on deepimpact, coil, and a conceptual framework for information retrieval techniques. arXiv preprint arXiv:2106.14807 (2021).
- Lin et al. (2021a) Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021a. Pyserini: A Python Toolkit for Reproducible Information Retrieval Research with Sparse and Dense Representations. In Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021). 2356–2362.
- Lin et al. (2021b) Jimmy Lin, Rodrigo Nogueira, and Andrew Yates. 2021b. Pretrained transformers for text ranking: Bert and beyond. Synthesis Lectures on Human Language Technologies 14, 4 (2021), 1–325.
- Lin et al. (2020) Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. 2020. Distilling dense representations for ranking using tightly-coupled teachers. arXiv preprint arXiv:2010.11386 (2020).
- Liu et al. (2021) Weiwei Liu, Haobo Wang, Xiaobo Shen, and Ivor Tsang. 2021. The emerging trends of multi-label learning. IEEE transactions on pattern analysis and machine intelligence (2021).
- Lu et al. (2022) Yuxiang Lu, Yiding Liu, Jiaxiang Liu, Yunsheng Shi, Zhengjie Huang, Shikun Feng Yu Sun, Hao Tian, Hua Wu, Shuaiqiang Wang, Dawei Yin, et al. 2022. ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval. arXiv preprint arXiv:2205.09153 (2022).
- Luo et al. (2022) Man Luo, Arindam Mitra, Tejas Gokhale, and Chitta Baral. 2022. Improving Biomedical Information Retrieval with Neural Retrievers. Proceedings of the AAAI Conference on Artificial Intelligence 36, 10 (Jun. 2022), 11038–11046.
- Ma et al. (2020) Wentao Ma, Yiming Cui, Chenglei Si, Ting Liu, Shijin Wang, and Guoping Hu. 2020. CharBERT: Character-aware Pre-trained Language Model. In Proceedings of the 28th International Conference on Computational Linguistics. 39–50.
- Mallia et al. (2021) Antonio Mallia, Omar Khattab, Torsten Suel, and Nicola Tonellotto. 2021. Learning passage impacts for inverted indexes. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1723–1727.
- Nogueira and Lin (2019) Rodrigo Nogueira and Jimmy Lin. 2019. From doc2query to docTTTTTquery.
- Nogueira et al. (2019) Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. 2019. Multi-stage document ranking with BERT. arXiv preprint arXiv:1910.14424 (2019).
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning. PMLR, 8748–8763.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683 (2019).
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. In International Conference on Machine Learning. PMLR, 8821–8831.
- Ren et al. (2021) Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2021. RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2825–2835.
- Robertson and Zaragoza (2009) Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 3, 4 (2009), 333–389.
- Scells et al. (2022) Harrisen Scells, Shengyao Zhuang, and Guido Zuccon. 2022. Reduce, Reuse, Recycle: Green Information Retrieval Research. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2825–2837.
- Tay et al. (2022) Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Prakash Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer Memory as a Differentiable Search Index. CoRR abs/2202.06991 (2022). arXiv:2202.06991 https://arxiv.org/abs/2202.06991
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 6000–6010.
- Wang et al. (2021b) Kexin Wang, Nandan Thakur, Nils Reimers, and Iryna Gurevych. 2021b. GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval. arXiv e-prints (2021), arXiv–2112.
- Wang et al. (2021a) Xiao Wang, Qin Liu, Tao Gui, Qi Zhang, et al. 2021a. TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations. 347–355.
- Wang et al. ([n.d.]) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. [n.d.]. A Neural Corpus Indexer for Document Retrieval. In Advances in Neural Information Processing Systems.
- Williams and Zipser (1989) Ronald J Williams and David Zipser. 1989. A learning algorithm for continually running fully recurrent neural networks. Neural computation 1, 2 (1989), 270–280.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 38–45.
- Xiong et al. (2020) Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N Bennett, Junaid Ahmed, and Arnold Overwijk. 2020. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. In International Conference on Learning Representations.
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 483–498.
- Zhan et al. (2021) Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. 2021. Optimizing dense retrieval model training with hard negatives. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1503–1512.
- Zhang et al. (2022b) Fuwei Zhang, Zhao Zhang, Xiang Ao, Dehong Gao, Fuzhen Zhuang, Yi Wei, and Qing He. 2022b. Mind the Gap: Cross-Lingual Information Retrieval with Hierarchical Knowledge Enhancement. Proceedings of the AAAI Conference on Artificial Intelligence 36, 4 (Jun. 2022), 4345–4353.
- Zhang et al. (2022a) Hang Zhang, Yeyun Gong, Yelong Shen, Jiancheng Lv, Nan Duan, and Weizhu Chen. 2022a. Adversarial Retriever-Ranker for Dense Text Retrieval. In International Conference on Learning Representations. https://openreview.net/forum?id=MR7XubKUFB
- Zhuang and Zuccon (2021a) Shengyao Zhuang and Guido Zuccon. 2021a. Dealing with Typos for BERT-based Passage Retrieval and Ranking. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2836–2842.
- Zhuang and Zuccon (2021b) Shengyao Zhuang and Guido Zuccon. 2021b. Fast passage re-ranking with contextualized exact term matching and efficient passage expansion. arXiv preprint arXiv:2108.08513 (2021).
- Zhuang and Zuccon (2021c) Shengyao Zhuang and Guido Zuccon. 2021c. TILDE: Term independent likelihood moDEl for passage re-ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1483–1492.
- Zhuang and Zuccon (2022) Shengyao Zhuang and Guido Zuccon. 2022. CharacterBERT and Self-Teaching for Improving the Robustness of Dense Retrievers on Queries with Typos. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Zobel and Moffat (2006) Justin Zobel and Alistair Moffat. 2006. Inverted files for text search engines. ACM computing surveys (CSUR) 38, 2 (2006), 6–es.