Bridging Sim2Real Gap Using Image Gradients for the Task of End-to-End Autonomous Driving
Keywords
Reinforcement Learning, Sim2Real Transfer, Racecar, Computer Vision
1 Introduction
While simulations are vital for developing and testing robotic agents, the ability to transfer robotics skills learned in simulation to reality is equally challenging. Simulation to real-world transfer, popularly known as Sim2Real transfer, is an indispensable line of research for utilizing knowledge learned from simulated data to derive meaningful inferences from real-world observations and function in actual operational environments. Sim2Real is critical for developing Autonomous Vehicles (AV) and other field-deployed intelligent robotic systems.
The NeurIPS 2021 AWS DeepRacer challenge is a part of a series of competitions in the area of AV called The AI Driving Olympics (AI-DO). In this competition, the task is to train a Reinforcement Learning (RL) agent (i.e., an autonomous car) that learns to drive by interacting with a virtual environment (a simulated track). The agent achieves this by taking action based on previous observations and a current state to maximize the expected reward. We test the trained agent’s driving performance when maneuvering an AWS DeepRacer car on a real-world mock track. The driving performance metric is time to lap completion without going off the same in the context of AWS DeepRacer competition. In Fig 1, we show the images of the simulated (left) and actual (right) track as captured by the camera mounted on the vehicle with matching extrinsic parameters.

As the car navigates through the environment (in a simulator or in real world), it is allowed to observe a greyscale monocular image from a front-facing camera mounted on the vehicle. At any instance, the car can take a set of actions from a discrete action space , where and capture the intensity of taking a particular direction. The vehicle’s speed remains constant and is not part of the action space.
Given the limited access to the vehicle’s controls, we modeled our approach as a classification task over the action space in an imitation learning setup, which takes the current image observation at any given time . While driving in the simulator environment S, we record the action taken at every time instant , along with the corresponding camera image . Similarly, while driving in the real environment R, we record the corresponding camera image . The task is to obtain a probability distribution over the set of actions , , with the simulator recorded data as the training set.
1.1 Related Work
Imitation Learning: Imitation learning (IL) has seen recent surge for the task of autonomous driving (Zhang and Cho (2016), Pan et al. (2017)). IL uses expert demonstrations to directly learn a policy that maps states to actions. The pionerring work of (Pomerleau (1988)) intoduced IL for self-driving - where a direct mapping from the sensor data to steering angle and acceleration is learned. (Zeng et al. (2019), Viswanath et al. (2018)) also follow the similar approach of going from sensor data to throttle and steering.
With the advent of high end driving simulators like (Dosovitskiy et al. (2017)), approaches like (Codevilla et al. (2018)) exploit conditional models with additional exploit conditional models with additional high-level commands such as continue, turn-left, turn-right. Methods like (Müller et al. (2018)) use intermediate representations derived from sensor data, which is then converted to steering commands.
Sim2Real transfer: Simulation to real-world transfer, popularly known as Sim2Real transfer has contributed immensely in training of models for different robotics tasks. Sim2Real transfer provides several benefits like bootstrapping, hardware in loop optimization and aiding when there is a real-world data starvation. However, Sim2Real methods suffer from domain gap between the simulated and real world. Approaches have explored domain randomization (Amiranashvili et al. (2021)), explicit transferable abstraction (Julian et al. (2020)) and domain adaption vis GANs (Zhu et al. (2017)) to bridge the Sim2Real gap.
2 Methods
2.1 Algorithm
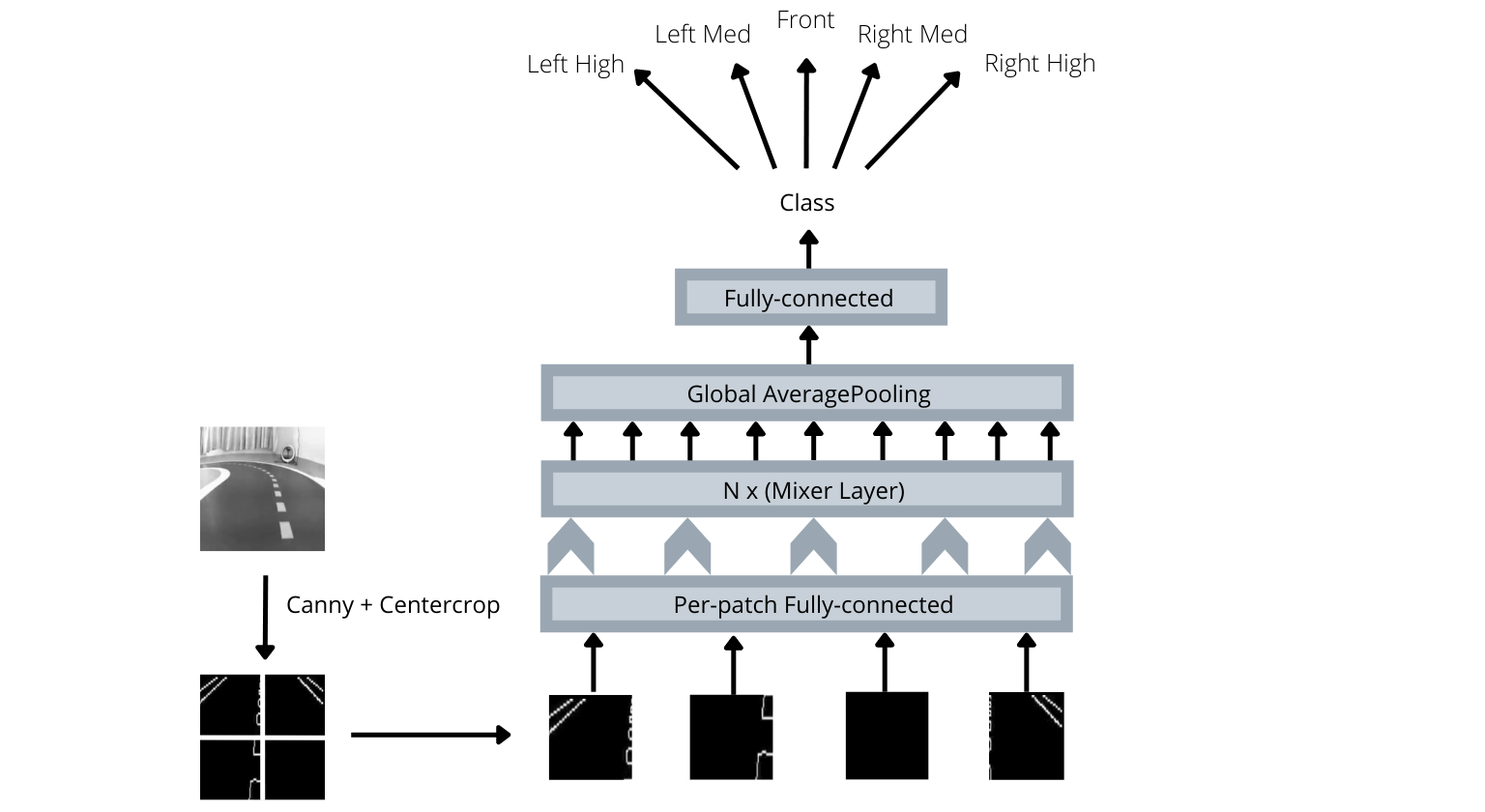
We model our approach as a classification task over the action space in an imitation learning setup. Specifically, while driving in the simulator environment S, we record the action taken at every time instant , along with the corresponding camera image . Motivated by (Tolstikhin et al. (2021)), we train a MLP-Mixer , where are the parameters of the network. The model takes in as input where , where is the gradient computation function. The output of the model is scored actions :
The loss term for training this stage is the cross entropy between the predicted scores and ground truth scores:
At test time, we receive the image recorded from the DeepRacer car moving in the real world. Gradient computed image is passed through the above trained network , to obtain the scores on the action space . The most likely action is then chosen and relayed to the vehicle to execute.
2.2 Sim2Real Transfer
We achieve Sim2Real transfer for our method by passing the input images from simulator and real world through Canny edge detection. Specifically, when we get an input image from any of the real or simulator environment, we pass it through a Canny edge detector to obtain the corresponding image gradients . The training set then updates to . We showcase the results for both the real image and simulated image once after performing Canny edge detection in Fig.3. Image gradient of along X and along Y axis was set while running Canny edge detection. We remove unnecessary image regions, which contain irrelevant information for driving, by cropping top of the image before computing the image gradients.

3 Results
To increase robustness, we perform filtering of training data: removing sub-optimal observation and action pairs . Due to this, we were able to achieve robust performance in track completion even when of the commands were randomly changed. The overall runtime of the model was only ms on a modern CPU.
Our method ranked on the NeurIPS 2021 AWS DeepRacer challenge, outperforming over participants from teams worldwide.
4 Discussion
Automatic dataset filtering has been performed to ensure that the training data only contains the optimal observation, action and reward triplet. For this we have utilized the reward signal provided by the simulator and ensured that the subsequent reward only improves from the previous value. This aids in removing the error that creeps in due to human-expert based data collection. We have iteratively arrived at the optimal network architecture and the corresponding input image preprocessing. While Canny edge detecion enables Sim2Real transfer, it also help in overcoming issues like reflection on the marble floor which was causing the network to select the wrong action. To overcome the low-end spec hardware in the DeepRacer car, we used MLP-Mixer architecture (Tolstikhin et al. (2021)) which gave us a runtime of ms.
4.1 Failed ideas
References
- Amiranashvili et al. (2021) A. Amiranashvili, M. Argus, L. Hermann, W. Burgard, and T. Brox. Pre-training of deep rl agents for improved learning under domain randomization. arXiv preprint arXiv:2104.14386, 2021.
- Codevilla et al. (2018) F. Codevilla, M. Müller, A. López, V. Koltun, and A. Dosovitskiy. End-to-end driving via conditional imitation learning. In 2018 IEEE international conference on robotics and automation (ICRA), pages 4693–4700. IEEE, 2018.
- Dosovitskiy et al. (2017) A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. Carla: An open urban driving simulator. In Conference on robot learning, pages 1–16. PMLR, 2017.
- Julian et al. (2020) R. C. Julian, E. Heiden, Z. He, H. Zhang, S. Schaal, J. J. Lim, G. S. Sukhatme, and K. Hausman. Scaling simulation-to-real transfer by learning a latent space of robot skills. The International Journal of Robotics Research, 39(10-11):1259–1278, 2020.
- Mnih et al. (2013) V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. 2013. URL http://arxiv.org/abs/1312.5602. cite arxiv:1312.5602Comment: NIPS Deep Learning Workshop 2013.
- Mnih et al. (2016) V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. 2016. doi: 10.48550/ARXIV.1602.01783. URL https://arxiv.org/abs/1602.01783.
- Müller et al. (2018) M. Müller, A. Dosovitskiy, B. Ghanem, and V. Koltun. Driving policy transfer via modularity and abstraction. arXiv preprint arXiv:1804.09364, 2018.
- Pan et al. (2017) Y. Pan, C.-A. Cheng, K. Saigol, K. Lee, X. Yan, E. Theodorou, and B. Boots. Agile autonomous driving using end-to-end deep imitation learning. arXiv preprint arXiv:1709.07174, 2017.
- Pomerleau (1988) D. A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network. Advances in neural information processing systems, 1, 1988.
- Tolstikhin et al. (2021) I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. Advances in Neural Information Processing Systems, 34, 2021.
- Viswanath et al. (2018) P. Viswanath, S. Nagori, M. Mody, M. Mathew, and P. Swami. End to end learning based self-driving using jacintonet. In 2018 IEEE 8th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), pages 1–4. IEEE, 2018.
- Zeng et al. (2019) W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8660–8669, 2019.
- Zhang and Cho (2016) J. Zhang and K. Cho. Query-efficient imitation learning for end-to-end autonomous driving. arXiv preprint arXiv:1605.06450, 2016.
- Zhu et al. (2017) J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017.