Brain-Inspired Stepwise Patch Merging for Vision Transformers
Abstract
The hierarchical architecture has become a mainstream design paradigm for Vision Transformers (ViTs), with Patch Merging serving as the pivotal component that transforms a columnar architecture into a hierarchical one. Drawing inspiration from the brain’s ability to integrate global and local information for comprehensive visual understanding, we propose a novel technique called Stepwise Patch Merging (SPM), which enhances the subsequent attention mechanism’s ability to ’see’ better. SPM comprises two critical modules: Multi-Scale Aggregation (MSA) and Guided Local Enhancement (GLE). The MSA module integrates multi-scale features to enrich feature representation, while the GLE module focuses on refining local detail extraction, thus achieving an optimal balance between long-range dependency modeling and local feature enhancement. Extensive experiments conducted on benchmark datasets, including ImageNet-1K, COCO, and ADE20K, demonstrate that SPM significantly improves the performance of various models, particularly in dense prediction tasks such as object detection and semantic segmentation. These results underscore the efficacy of SPM in enhancing model accuracy and robustness across a wide range of computer vision tasks.
Introduction
Transformers have demonstrated remarkable advancements in natural language processing (NLP) (Vaswani et al. 2017; Devlin et al. 2018), and their application has recently extended significantly into the computer vision (CV) domain (Dosovitskiy et al. 2020; Touvron et al. 2021). To enhance their adaptability to downstream tasks, hierarchical vision transformers (HVTs) (Wang et al. 2021; Liu et al. 2021; Wu et al. 2021; Yan et al. 2021) have been developed. These architectures draw inspiration from the pyramid structure utilized in convolutional neural networks (CNNs) (Krizhevsky, Sutskever, and Hinton 2012; He et al. 2016; Tan and Le 2019; Lin et al. 2017). In HVTs, transformer blocks are segmented into multiple stages, resulting in a progressive reduction of feature map sizes and an increase in the number of channels as the network depth increases.

HVTs commonly utilize either standard convolutional layers or linear projection layers to amalgamate adjacent tokens (Wang et al. 2021; Liu et al. 2021; Ren et al. 2022), with the objective of generating hierarchical feature maps. Nevertheless, fixed-grid methods can limit the representational capacity of vision transformers in modeling geometric transformations, as not every pixel contributes equally to an output unit (Luo et al. 2016). To overcome this limitation, adaptive methods have been proposed to derive more informative downsampled tokens for subsequent processing. For example, LIT (Pan et al. 2022), drawing inspiration from deformable convolutions (Dai et al. 2017; Zhu et al. 2019), learns a grid of offsets to adaptively adjust spatial sampling locations for merging neighboring patches from a sub-window in a feature map. Similarly, TCformer (Zeng et al. 2022) employs a variant of the k-nearest neighbor-based density peaks clustering algorithm (DPC-KNN) (Du, Ding, and Jia 2016) to aggregate redundant patches, generating more patches on the target object to capture additional information. HAFA (Chen et al. 2023) integrates the methodologies of LIT and TCformer, predicting offsets to adjust the sampling center of patches in the shallow layers, while employing clustering in the deeper layers to group patches with similar semantics in the feature space. However, these methods face several common challenges. They often exhibit limited capacity for modeling long-distance relationships and suffer from a loss of spatial information due to the clustering process. Additionally, the clustering algorithms used are typically not amenable to end-to-end training, leading to inefficiencies. The integration of multiple modules, as seen in HAFA, further complicates their generalizability across different applications.
In the brain, the primary visual cortex (V1), integral to initial visual processing, houses neurons with relatively small receptive fields that are crucial for detecting fine, localized visual features such as edges and orientations. As visual information propagates to higher cortical areas like V2, V3, and V4, neurons with increasingly larger receptive fields integrate these initial perceptions, facilitating the recognition of more complex patterns and broader contextual elements (Hubel and Wiesel 1962; Livingstone and Hubel 1988; Zeki 1978). Additionally, the visual cortex benefits from a dynamic feedback system where higher-order areas like the inferotemporal cortex (IT) provide contextual modulation to lower areas. This top-down modulation is essential for refining the perception of local features within their broader environmental matrix, enhancing both the accuracy and relevance of visual processing (Gilbert and Li 2013; Bullier 2001; Lamme and Roelfsema 2000).
Inspired by the nuanced neurobiological mechanisms of the human visual cortex, particularly the orchestrated activities across various cortical areas, we introduce Stepwise Patch Merging (SPM), a novel approach designed to enhance the receptive field while preserving local details. SPM framework consists of two sequential stages: Multi-Scale Aggregation (MSA) and Guided Local Enhancement (GLE). In the MSA stage, spatial dimensions are preserved while channel dimensions are increased to a designated size. This process aggregates multi-scale information, enriching the semantic content to accommodate the increased capacity of the feature map. Subsequently, the GLE stage reduces the spatial dimensions of the feature map while maintaining the channel dimensions. Given that the input to GLE already contains rich semantic information, this stage emphasizes local information, optimizing it for downstream dense prediction tasks such as object detection and semantic segmentation. The distinct focus and reasonable division of labor between the MSA and GLE modules ensure that the SPM architecture serves as a flexible, drop-in replacement for existing hierarchical vision transformers.
In summary, our contributions are as follows:
-
•
We propose an innovative technique termed Stepwise Patch Merging (SPM), which serves as a plug-in replacement within hierarchical vision transformer architectures, leading to substantial performance enhancements.
-
•
The SPM framework comprises two distinct modules: Multi-Scale Aggregation (MSA) and Guided Local Enhancement (GLE). MSA enriches feature representation by integrating multi-scale information, while GLE enhances the extraction of local details, achieving an optimal balance between long-range dependency modeling and local feature refinement.
-
•
Extensive experiments conducted on benchmark datasets, including ImageNet-1K, COCO, and ADE20K, demonstrate that SPM significantly boosts the performance of various models, particularly in downstream dense prediction tasks such as object detection and semantic segmentation.
Related Work
Vision Transformer
The Vision Transformer (ViT) (Dosovitskiy et al. 2020) revolutionized visual tasks by introducing the transformer architecture to computer vision. ViT segments images into non-overlapping patches, projects these patches linearly into token sequences, and processes them using a transformer encoder. ViT models have demonstrated superior performance in image classification and other downstream tasks, surpassing CNNs (He et al. 2016; Krizhevsky, Sutskever, and Hinton 2012; LeCun, Bengio et al. 1995) when trained with large-scale pretraining datasets and advanced training methodologies. Motivated by the success of CNNs and the necessity to address dense prediction tasks, researchers have incorporated the feature pyramid structure within transformers. This innovation has led to the development and widespread adoption of HVTs (Dong et al. 2022; Ren et al. 2022; Fan et al. 2023; Guo et al. 2022; Hou et al. 2022).
Hierarchical Feature Representation
Hierarchical feature representation plays a pivotal role in dense prediction tasks, prompting extensive research in this domain. Existing approaches can be broadly categorized into fixed-grid and dynamic feature-based methods. Fixed-grid methods, exemplified by works such as PVT (Wang et al. 2021) and Swin (Liu et al. 2021), merge patches within adjacent windows using 2D convolution. In contrast, dynamic methods, such as DynamicViT (Rao et al. 2021) adaptively extract features by eliminating redundant patches and retaining essential ones, thereby forming hierarchical feature maps. EviT (Liang et al. 2022) enhances this approach by selecting the top K tokens with the highest average values across all heads for the next stage, merging the remaining tokens. PS-ViT (Yue et al. 2021) further refines the process by iteratively adjusting patch centers towards the object to enrich object information within the hierarchical feature maps. Token Merging (Bolya et al. 2022) employs cosine similarity to progressively merge similar tokens, thereby increasing model throughput.
Fixed-grid methods are constrained by their singular and relatively small receptive fields, and excessively enlarging the grid size leads to increased computational overhead. Dynamic feature-based methods, while adaptive, may discard low-scoring tokens that contain valuable information and often lack end-to-end training capabilities. Our proposed Stepwise Patch Merging approach distinguishes itself from both fixed-grid and dynamic feature-based methods. The Multi-Scale Aggregation module in Stepwise Patch Merging provides an expanded and enriched receptive field, which is advantageous for long-distance modeling. Additionally, the Guided Local Enhancement module enhances the extraction of local discriminative features and supports end-to-end training. Moreover, Stepwise Patch Merging can be directly applied to dense prediction tasks, resulting in improved performance.
Methodology
Inspired by the brain’s ability to integrate global and local information when processing visual scenes, we propose the Stepwise Patch Merging framework, as illustrated in Fig. 1. The framework comprises two primary components: Multi-Scale Aggregation (MSA) and Guided Local Enhancement (GLE), designed to address variations in feature map dimensions. The MSA module enhances feature diversity by increasing the number of channels and capturing long-range dependencies, akin to how the brain processes information at multiple scales to form a coherent perception. In contrast, the GLE module optimizes local feature extraction by introducing context-aware guide tokens within local windows, thereby refining and enhancing feature details. This synergistic design effectively combines the strengths of both global structure processing and local detail enhancement, making it particularly beneficial for downstream dense prediction tasks.

Multi-Scale Aggregation
Our proposed Multi-Scale Aggregation (MSA) module draws inspiration from the brain’s remarkable ability to effectively model long-range dependencies when processing visual information. In the brain, the visual system achieves precise modeling of long-range dependencies through multi-level and multi-scale information processing. Neurons with small receptive fields process local features, and this information is progressively integrated over larger areas by neurons with larger receptive fields, capturing complex patterns and objects. Additionally, the brain’s extensive network of long-range neural connections allows for the exchange and integration of data from various parts of the visual field, facilitating a comprehensive understanding of the scene. Furthermore, neurons within the same level possess receptive fields of varying sizes, enabling the brain to simultaneously process local details and global features. This sophisticated mechanism of combining local and global information processing in the brain inspired the design of our MSA module, which aims to enhance feature diversity and capture long-range dependencies effectively.
Inspired by these mechanisms, the MSA module first divides the input channels into distinct heads, each undergoing depth-wise convolutions with varying receptive fields. This method not only reduces the parameter count and computational cost but also facilitates the extraction of multi-granularity information, akin to how different neurons in the brain handle information processing. Subsequently, the MSA module employs larger convolutional kernels to further expand the receptive field, thereby enhancing its capability to model long-range dependencies. Following this, Channel Shuffle (Zhang et al. 2018) is used to interleave channels containing features of different scales, followed by a series of linear projections to fuse these multi-scale features. The number of linear projections is , with each projection having unique parameters. Finally, the heads are concatenated, and a final linear projection adjusts the number of channels to the specified .
By leveraging the brain’s mechanism for effective long-range dependency modeling, the MSA module better captures and integrates key features, significantly enhancing the model’s performance in complex visual recognition tasks.
Our proposed MSA can be formulated as follows:
| (1) | ||||
where represents the input split into multiple heads along the channel dimension, and denotes the -th head. The kernel size of the depth-wise convolution for the -th head is denoted by . Here, represents the -th head after being processed by the depth-wise convolution with , and represents the -th channel in the -th head. is the weight matrix of the linear projection. . Finally, is the weight matrix of the linear projection that adjusts the number of channels to the specified .
Guided Local Enhancement
Inspired by the brain’s ability to enhance local features through context-aware processing, we developed the Guided Local Enhancement (GLE) module. In the brain, local feature enhancement is achieved by integrating information from both local and global contexts. Higher-level cortical areas provide contextual feedback that refines the processing of local features, ensuring that details are interpreted within the broader visual context. This hierarchical processing involves neurons that respond specifically to local stimuli but are influenced by surrounding contextual information, allowing for more nuanced and precise feature extraction.
Following this principle, the GLE module acts as a local feature enhancer utilizing context-aware guide tokens, as illustrated in Fig. 3. Specifically, we implement self-attention within a local window and introduce a token into the input space. This token undergoes the same self-attention operations as the patch tokens, thereby providing high-level semantic features to the local window during pooling. By mimicking the brain’s method of using contextual information to refine local feature extraction, the GLE module ensures that the extracted local features are both precise and contextually relevant.

Formally, given an input , the tokens are generated by a large-kernel depth-wise convolution, referred to as the Guide Token Generator (GTG), which can be described as follows:
| (2) |
We focus on the operations performed on a single pixel within the input feature map. We define a set of pixels within a local window centered at pixel as . For a fixed window size of , . In our setup, is equal to the stride of the GTG, both being 2, meaning . Tokens within a window containing a token can be represented by the sequence :
| (3) |
then perform the standard self-attention operation on :
| (4) | ||||
where , and we ignore the relative positional relationships between tokens within a window, so positional encoding is not used. Finally, we select the token as the output of the GLE:
| (5) | ||||
Experiments
Image Classification on ImageNet-1K
| Backbone | #Params (M) | Mask R-CNN | ||||||||
| ResNet18 (He et al. 2016) | 31.2 | 34.0 | 54.0 | 36.7 | - | - | - | 31.2 | 51.0 | 32.7 |
| PVT-Tiny (Wang et al. 2021) | 32.9 | 36.7 | 59.2 | 39.3 | 21.6 | 39.2 | 49.0 | 35.1 | 56.7 | 37.3 |
| PVT-Tiny (HAFA) (Chen et al. 2023) | 34.5 | 39.8 | 62.6 | 43.3 | 23.3 | 42.7 | 53.3 | 37.1 | 59.4 | 39.3 |
| PVT-Tiny (SPM) | 33.7 | 40.8 (+4.1) | 63.4 | 44.3 | 24.9 | 44.0 | 54.0 | 38.0 (+2.9) | 60.4 | 40.6 |
| ResNet50 (He et al. 2016) | 44.2 | 38.0 | 58.6 | 41.4 | - | - | - | 34.4 | 55.1 | 36.7 |
| PVT-Small (Wang et al. 2021) | 44.1 | 40.4 | 62.9 | 43.8 | 22.9 | 43.0 | 55.4 | 37.8 | 60.1 | 40.3 |
| PVT-Tiny (HAFA) (Chen et al. 2023) | 45.8 | 41.8 | 64.4 | 45.7 | 26.0 | 44.6 | 56.1 | 38.9 | 61.5 | 41.9 |
| PVT-Small (SPM) | 44.9 | 43.0 (+2.6) | 65.4 | 46.7 | 25.5 | 46.2 | 57.6 | 39.6 (+1.8) | 62.3 | 42.4 |
| ResNet101 (He et al. 2016) | 63.2 | 40.4 | 61.1 | 44.2 | - | - | - | 36.4 | 57.7 | 38.8 |
| ResNeXt101-324d (Xie et al. 2017) | 62.8 | 41.9 | 62.5 | 45.9 | - | - | - | 37.5 | 59.4 | 40.2 |
| PVT-Medium (Wang et al. 2021) | 63.9 | 42.0 | 64.4 | 45.6 | - | - | - | 39.0 | 61.6 | 42.1 |
| PVT-Medium (SPM) | 64.7 | 43.3 (+1.3) | 64.9 | 47.6 | 25.8 | 46.4 | 58.3 | 39.4 (+0.4) | 61.7 | 42.2 |
Setting. We first evaluate the proposed SPM framework on the ImageNet-1K dataset (Deng et al. 2009), which comprises 1.28 million training images and 50,000 validation images spanning 1,000 categories. To ensure a fair comparison, all models are trained on the training set and report the top-1 error rate on the validation set. For data augmentation, we apply a suite of techniques including random cropping, random horizontal flipping (Szegedy et al. 2015), label smoothing regularization (Szegedy et al. 2016), mixup (Zhang et al. 2017), CutMix (Yun et al. 2019), and random erasing (Zhong et al. 2020). These augmentations are employed to enhance the robustness and generalization ability of the models. During training, we use the AdamW optimizer (Loshchilov and Hutter 2017) with a momentum parameter of 0.9, a mini-batch size of 128, and a weight decay of . The initial learning rate is set to and follows a cosine annealing schedule (Loshchilov and Hutter 2016) to gradually reduce the learning rate. All models are trained from scratch for 300 epochs on eight NVIDIA A100 GPUs. For evaluation, we adopt the standard center crop strategy on the validation set, where a patch is extracted from each image to assess the classification accuracy.
| Backbone | #Params (M) | Top-1 Acc. (%) |
| ResNet18 (He et al. 2016) | 11.7 | 68.5 |
| DeiT-Tiny/16 (Touvron et al. 2021) | 5.7 | 72.2 |
| PVT-Tiny (Wang et al. 2021) | 13.2 | 75.1 |
| PVT-Tiny (HAFA) (Chen et al. 2023) | 14.6 | 77.5 |
| PVT-Tiny (SPM) | 14.0 | 79.5 (+4.4) |
| ResNet50 (He et al. 2016) | 25.6 | 78.5 |
| ResNeXt50-324d (Xie et al. 2017) | 25.0 | 79.5 |
| DeiT-Small/16 (Touvron et al. 2021) | 22.1 | 79.9 |
| HRNet-W32 (Wang et al. 2020) | 41.2 | 78.5 |
| PVT-Small (Wang et al. 2021) | 24.5 | 79.8 |
| PVT-Small (HAFA) (Chen et al. 2023) | 25.8 | 80.1 |
| PVT-Small (SPM) | 25.3 | 81.7 (+1.9) |
| ResNeXt101-644d (Xie et al. 2017) | 83.5 | 81.5 |
| ViT-Base/16 (Dosovitskiy et al. 2020) | 86.6 | 81.8 |
| DeiT-Base/16 (Touvron et al. 2021) | 86.6 | 81.8 |
| PVT-Medium (Wang et al. 2021) | 44.2 | 81.2 |
| PVT-Medium (SPM) | 45.0 | 81.9 (+0.7) |
Result. In Tab. 2, we observe that incorporating the SPM framework into the PVT results in significant improvements in classification accuracy, specifically by 4.4%, 1.9%, and 0.7% in the Tiny, Small, and Medium models, respectively, while adding only a minimal number of parameters compared to the original PVT. The final experimental results indicate that the accuracy of models of various sizes has been enhanced, with the most notable improvement observed in the Tiny model. Remarkably, the combination of PVT-Tiny and SPM achieved a top-1 accuracy of 79.5%, which is comparable to the performance of PVT-Small, despite PVT-Small having nearly 70% more parameters than PVT-Tiny. Furthermore, with the integration of SPM, PVT-Small surpassed PVT-Medium by 0.5%.
Object Detection on COCO
Setting. Object detection and instance segmentation experiments were conducted on the challenging COCO benchmark (Lin et al. 2014). All models were trained on the training set comprising 118k images and evaluated on the validation set with 5k images. We validated the effectiveness of different backbones using Mask R-CNN (He et al. 2017). Before training, the weights pre-trained on ImageNet-1K were used to initialize the backbone, and the newly added layers were initialized using the Xavier initialization method (Glorot and Bengio 2010). Our models were trained with a batch size of 16 on 8 NVIDIA A100 GPUs and optimized using the AdamW optimizer (Loshchilov and Hutter 2017) with an initial learning rate of .
Result. As shown in Tab. 1, incorporating the SPM framework into the PVT resulted in significant improvements of 4.1%, 2.6%, and 1.3% in the Tiny, Small, and Medium models, respectively, for the object detection task. Notably, the SPM framework also demonstrated substantial improvements in the instance segmentation task. Several observations can be made by analyzing the detection results of models with different sizes. Models integrated with SPM show marked improvements in detecting medium-sized and large objects. This enhancement is attributed to the original patch merging’s relatively singular and small receptive fields, whereas the MSA module integrates features with diverse receptive fields, enabling the model to more accurately capture long-range dependencies. Moreover, there is a significant improvement in detecting small objects. Although larger models are typically better at modeling global relationships, the disruption of local information may hinder small objects from establishing complete semantic information, leading to missed detections. The GLE module addresses this by enhancing the perception of local discriminative information, resulting in consistent improvements in the detection performance of small objects across models of different sizes.
Semantic Segmentation on ADE20K
| Backbone | Semantic FPN | |
| #Params (M) | mIoU (%) | |
| ResNet18 (He et al. 2016) | 15.5 | 32.9 |
| PVT-Tiny (Wang et al. 2021) | 17.0 | 35.7 |
| PVT-Tiny (HAFA) (Chen et al. 2023) | 18.7 | 40.1 |
| PVT-Tiny (SPM) | 17.8 | 41.5 (+5.8) |
| ResNet50 (He et al. 2016) | 28.5 | 36.7 |
| PVT-Small (Wang et al. 2021) | 28.2 | 39.8 |
| PVT-Small (HAFA) (Chen et al. 2023) | 29.9 | 43.8 |
| PVT-Small (SPM) | 29.0 | 45.9 (+6.1) |
| ResNet101 (He et al. 2016) | 47.5 | 38.8 |
| ResNeXt101-324d (Xie et al. 2017) | 47.1 | 39.7 |
| PVT-Medium (Wang et al. 2021) | 48.0 | 41.6 |
| PVT-Medium (SPM) | 48.8 | 45.3 (+3.7) |

| Reference | Backbone | #Params (M) | Top-1 Acc. (%) |
| ICCV 2021 | Swin-T (Liu et al. 2021) | 29.0 | 81.3 |
| Swin-T (HAFA) (Liu et al. 2021) | 29.1 | 81.7 | |
| Swin-T (SPM) | 29.9 | 82.4 (+1.1) | |
| CVPR 2022 | Shunted-T (Ren et al. 2022) | 11.5 | 79.8 |
| Shunted-T (SPM) | 11.6 | 80.6 (+0.8) | |
| CVPR 2023 | NAT-Mini (Hassani et al. 2023) | 20.0 | 81.8 |
| NAT-Mini (SPM) | 19.9 | 82.2 (+0.4) |
Setting. The ADE20K dataset (Zhou et al. 2017) is a widely utilized benchmark for semantic segmentation, comprising 150 categories with 20,210 images for training, 2,000 images for validation, and 3,352 images for testing. All the methods compared were evaluated using the Semantic FPN framework (Kirillov et al. 2019). The backbone network of our method was initialized with the pre-trained ImageNet-1k model, and the newly added layers were initialized using the Xavier initialization method. The initial learning rate was set to 0.0001, and the model was optimized using the AdamW optimizer. We trained our models for 40,000 iterations with a batch size of 16 on eight NVIDIA A100 GPUs. The learning rate followed a polynomial decay schedule with a power of 0.9. During training, images were randomly resized and cropped to pixels. For testing, images were rescaled to have a shorter side of 512 pixels.
Result. As shown in Tab. 3, the integration of the SPM framework led to a significant enhancement in the semantic segmentation task. Specifically, the performance of the Tiny, Small, and Large models improved by 5.8%, 6.1%, and 3.7%, respectively. It is evident that the improvement achieved by SPM in segmentation tasks surpasses that in classification and detection tasks. Interestingly, in both classification and detection tasks, the relative improvement brought by SPM compared to the base model gradually decreases as the model size increases. However, on the ADE20K dataset, the performance gain of PVT-Small exceeds that of PVT-Tiny, with improvements of 6.1% and 5.8%, respectively. This phenomenon can be attributed to the GLE module within SPM, which is specifically designed to capture local information. Consequently, SPM demonstrates a significant advantage in semantic segmentation tasks, where detailed local feature extraction is crucial.
Effectiveness on other Backbones
To further validate the generalizability of the proposed SPM framework, we integrated SPM into various mainstream Transformer backbones and trained them on the ImageNet-1K dataset. We employed consistent training settings to ensure a fair comparison, and the top-1 accuracies are presented in Tab. 4. The results demonstrate that the performance improvements conferred by SPM are universal across different backbones, indicating its robust generalization capability. Specifically, our method significantly enhanced the performance of Swin-T by 1.1%, Shunted-T by 0.8%, and NAT-Mini by 0.4% on ImageNet-1K. These results underscore the effectiveness of SPM in boosting the performance of various Transformer architectures, highlighting its potential as a versatile enhancement technique in the field of computer vision.
Visualization
We compared the visualization results of the attention maps with and without using the SPM framework, as shown in Fig. 4. Specifically, we replaced the original patch merging block of PVT-Tiny with our SPM and visualized the first block of the second stage for two separate heads. For example, after employing SPM, the bird’s two wings and tail were successfully linked, whereas the vanilla PVT-Tiny failed to capture the distant tail. This demonstrates that SPM facilitates the network’s ability to establish long-range relationships at shallower layers, leading to significant improvements in classification performance.
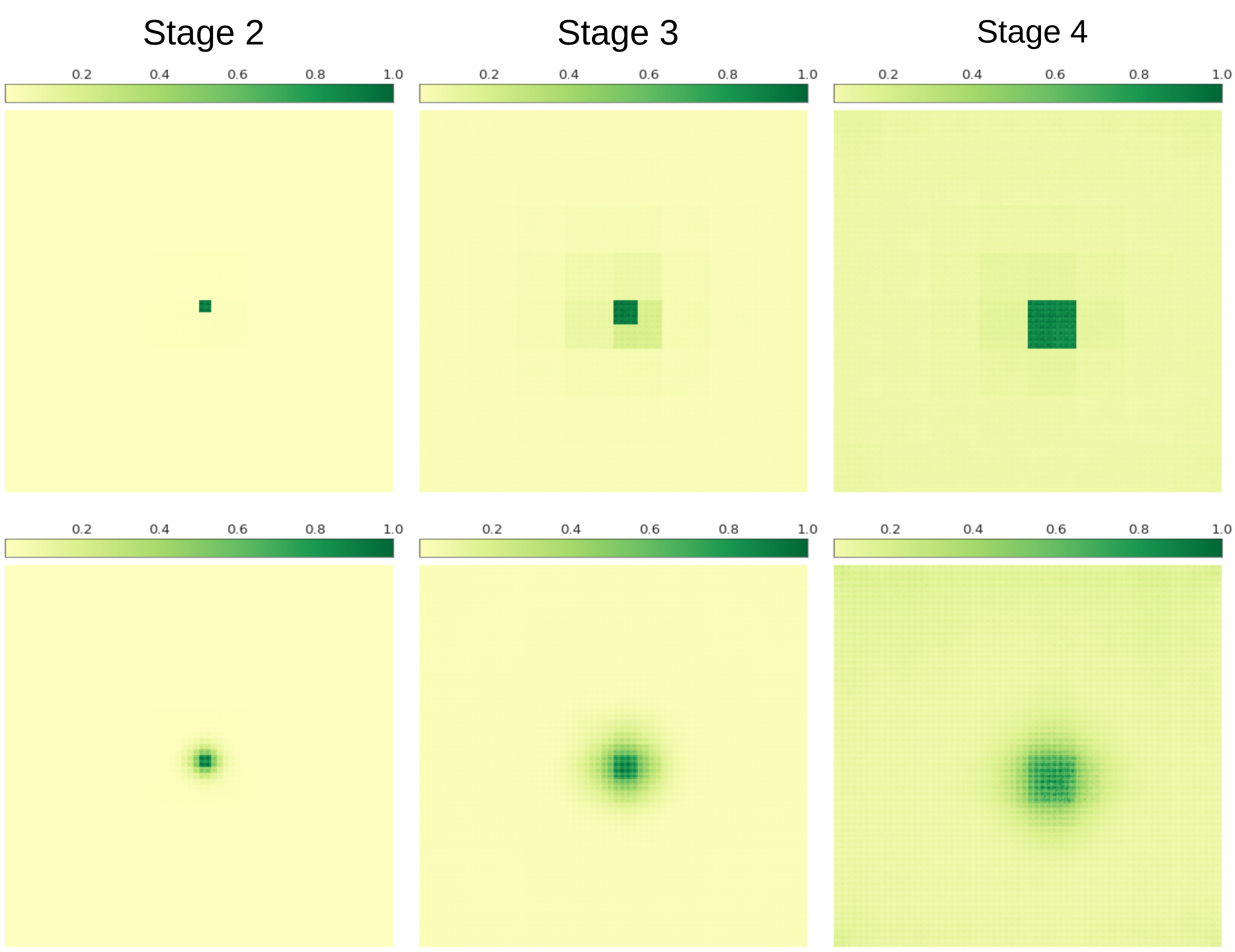
Additionally, we employed the Effective Receptive Field (ERF) method (Luo et al. 2016) as a visualization tool to compare the changes in ERF before and after using SPM, as depicted in Fig. 5. It is readily observed that after integrating SPM, the size of the ERF not only increases significantly but also changes shape from a regular square to a radial decay pattern, which aligns more closely with biological vision. This pattern can be attributed to our carefully designed MSA and GLE modules, which together achieve an excellent balance between capturing long-range relationships and preserving local detail features. Consequently, this balance leads to improved performance in classification and downstream dense prediction tasks.
Ablation Study
The Effectiveness of GLE
To evaluate the effectiveness of the proposed GLE module, we conducted experiments by replacing GLE with two alternative methods, as shown in Tab. 5). Replacing GLE with a convolution or a average pooling layer results in a performance decrease of 2.3% and 2.4%, respectively.
| Backbone | Method | #Params (M) | Top-1 Acc. (%) |
| PVT-Tiny | SPM (MSA + GLE) | 14.0 | 79.5 |
| GLE Conv. | 14.4 | 77.2 (-2.3) | |
| GLE AvgPool | 12.8 | 77.1 (-2.4) |
The Effectiveness of Guide Token
We conducted comparative experiments to evaluate the effectiveness of the proposed token against two mainstream methods: the token (Dosovitskiy et al. 2020) and global average pooling (GAP) (Chu et al. 2021), as presented in Tab. 6. The results demonstrate that the token improves model performance by approximately 1.7% compared to these methods, without significantly increasing the number of parameters.
Furthermore, an important observation from Tab. 6 and Tab. 5 is that when the local window size of self-attention and the kernel size of convolution are both set to , the self-attention method achieves higher accuracy than the convolution method. This suggests that the self-attention mechanism has a superior capability in extracting high-frequency features.
Selection of GTG’s Kernel Size
To determine the optimal kernel size for GTG, we conducted a series of performance comparison experiments with different kernel sizes. Ultimately, we set the kernel size of GTG to 7, which achieved the best performance without significantly increasing the number of parameters. This indicates that information outside the local window positively influences the attention results within the window, highlighting the effectiveness of the token.
| Backbone | Kernel Size | #Params (M) | Top-1 Acc. (%) |
| PVT-Tiny | 14.0 | 78.86 | |
| 14.0 | 79.43 | ||
| 14.0 | 79.47 | ||
| 14.1 | 79.46 |
Gradually Applying SPM
Different stages represent varying levels of semantic information. To validate the generalizability of the SPM framework across different levels of semantic information, we conducted experiments by gradually replacing the original patch merging with SPM (see Tab. 8). From the second and third rows, we observe that SPM enhances network performance by 1.3% with low-level features (stage 1) and by 1.6% with high-level features (stage 3), respectively. Furthermore, from the second, fourth, and fifth rows, it is evident that progressively replacing the original patch merging with SPM linearly improves performance by 1.3%, 3.0%, and 4.4%, respectively.
| Backbone | Stage1 | Stage2 | Stage3 | #Params (M) | Top-1 Acc. (%) |
| PVT-Tiny | 13.2 | 75.1 | |||
| ✓ | 13.3 | 76.4 (+1.3) | |||
| ✓ | 13.7 | 76.7 (+1.6) | |||
| ✓ | ✓ | 13.5 | 78.1 (+3.0) | ||
| ✓ | ✓ | ✓ | 14.0 | 79.5 (+4.4) |
Conclusion
In this work, we introduced the Stepwise Patch Merging framework, inspired by the brain’s ability to integrate global and local information for comprehensive visual understanding. The proposed SPM framework, comprising Multi-Scale Aggregation and Guided Local Enhancement modules, demonstrates significant improvements in various computer vision tasks, including classification, detection, and segmentation. Through extensive experiments on ImageNet-1K and COCO benchmarks, as well as on ADE20K for semantic segmentation, we showed that SPM consistently enhances the performance of different backbone models. The robustness of SPM to different input sizes and its effective generalization to other Transformer architectures further underscore its versatility and potential as a powerful enhancement technique. Future work will explore the application of SPM in more diverse domains and its integration with other state-of-the-art models to further elevate its impact on the field of computer vision.
References
- Bolya et al. (2022) Bolya, D.; Fu, C.-Y.; Dai, X.; Zhang, P.; Feichtenhofer, C.; and Hoffman, J. 2022. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461.
- Bullier (2001) Bullier, J. 2001. Integrated model of visual processing. Brain research reviews, 36(2-3): 96–107.
- Chen et al. (2023) Chen, Y.; Liu, H.; Yin, H.; and Fan, B. 2023. Building Vision Transformers with Hierarchy Aware Feature Aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 5908–5918.
- Chu et al. (2021) Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; and Shen, C. 2021. Conditional positional encodings for vision transformers. arXiv preprint arXiv:2102.10882.
- Dai et al. (2017) Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; and Wei, Y. 2017. Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision, 764–773.
- Deng et al. (2009) Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255. Ieee.
- Devlin et al. (2018) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
- Dong et al. (2022) Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; and Guo, B. 2022. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12124–12134.
- Dosovitskiy et al. (2020) Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Du, Ding, and Jia (2016) Du, M.; Ding, S.; and Jia, H. 2016. Study on density peaks clustering based on k-nearest neighbors and principal component analysis. Knowledge-Based Systems, 99: 135–145.
- Fan et al. (2023) Fan, Q.; Huang, H.; Chen, M.; Liu, H.; and He, R. 2023. RMT: Retentive Networks Meet Vision Transformers. arXiv preprint arXiv:2309.11523.
- Gilbert and Li (2013) Gilbert, C. D.; and Li, W. 2013. Top-down influences on visual processing. Nature reviews neuroscience, 14(5): 350–363.
- Glorot and Bengio (2010) Glorot, X.; and Bengio, Y. 2010. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, JMLR Workshop and Conference Proceedings, 249–256.
- Guo et al. (2022) Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; and Xu, C. 2022. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12175–12185.
- Hassani et al. (2023) Hassani, A.; Walton, S.; Li, J.; Li, S.; and Shi, H. 2023. Neighborhood attention transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6185–6194.
- He et al. (2017) He, K.; Gkioxari, G.; Dollár, P.; et al. 2017. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, 2961–2969.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Hou et al. (2022) Hou, Q.; Lu, C.-Z.; Cheng, M.-M.; and Feng, J. 2022. Conv2former: A simple transformer-style convnet for visual recognition. arXiv preprint arXiv:2211.11943.
- Hubel and Wiesel (1962) Hubel, D. H.; and Wiesel, T. N. 1962. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology, 160(1): 106.
- Kirillov et al. (2019) Kirillov, A.; Girshick, R.; He, K.; and Dollár, P. 2019. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6399–6408.
- Krizhevsky, Sutskever, and Hinton (2012) Krizhevsky, A.; Sutskever, I.; and Hinton, G. E. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
- Lamme and Roelfsema (2000) Lamme, V. A.; and Roelfsema, P. R. 2000. The distinct modes of vision offered by feedforward and recurrent processing. Trends in neurosciences, 23(11): 571–579.
- LeCun, Bengio et al. (1995) LeCun, Y.; Bengio, Y.; et al. 1995. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10): 1995.
- Liang et al. (2022) Liang, Y.; Ge, C.; Tong, Z.; Song, Y.; Wang, J.; and Xie, P. 2022. Not all patches are what you need: Expediting vision transformers via token reorganizations. arXiv preprint arXiv:2202.07800.
- Lin et al. (2017) Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; and Belongie, S. 2017. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2117–2125.
- Lin et al. (2014) Lin, T.-Y.; Maire, M.; Belongie, S.; et al. 2014. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, volume 13, 740–755. Springer International Publishing.
- Liu et al. (2021) Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, 10012–10022.
- Livingstone and Hubel (1988) Livingstone, M.; and Hubel, D. 1988. Segregation of form, color, movement, and depth: anatomy, physiology, and perception. Science, 240(4853): 740–749.
- Loshchilov and Hutter (2016) Loshchilov, I.; and Hutter, F. 2016. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983.
- Loshchilov and Hutter (2017) Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Luo et al. (2016) Luo, W.; Li, Y.; Urtasun, R.; and Zemel, R. 2016. Understanding the effective receptive field in deep convolutional neural networks. Advances in neural information processing systems, 29.
- Pan et al. (2022) Pan, Z.; Zhuang, B.; He, H.; Liu, J.; and Cai, J. 2022. Less is more: Pay less attention in vision transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 2035–2043.
- Rao et al. (2021) Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; and Hsieh, C.-J. 2021. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems, 34: 13937–13949.
- Ren et al. (2022) Ren, S.; Zhou, D.; He, S.; Feng, J.; and Wang, X. 2022. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10853–10862.
- Szegedy et al. (2015) Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; and Rabinovich, A. 2015. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9.
- Szegedy et al. (2016) Szegedy, C.; Vanhoucke, V.; Ioffe, S.; et al. 2016. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2818–2826.
- Tan and Le (2019) Tan, M.; and Le, Q. 2019. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, 6105–6114. PMLR.
- Touvron et al. (2021) Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; and Jégou, H. 2021. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, 10347–10357. PMLR.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2020) Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. 2020. Deep high-resolution representation learning for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 43(10): 3349–3364.
- Wang et al. (2021) Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; and Shao, L. 2021. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF international conference on computer vision, 568–578.
- Wu et al. (2021) Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; and Zhang, L. 2021. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, 22–31.
- Xie et al. (2017) Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; and He, K. 2017. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1492–1500.
- Yan et al. (2021) Yan, H.; Li, Z.; Li, W.; Wang, C.; Wu, M.; and Zhang, C. 2021. Contnet: Why not use convolution and transformer at the same time? arXiv preprint arXiv:2104.13497.
- Yue et al. (2021) Yue, X.; Sun, S.; Kuang, Z.; Wei, M.; Torr, P. H.; Zhang, W.; and Lin, D. 2021. Vision transformer with progressive sampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 387–396.
- Yun et al. (2019) Yun, S.; Han, D.; Oh, S. J.; Chun, S.; Choe, J.; and Yoo, Y. 2019. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international conference on computer vision, 6023–6032.
- Zeki (1978) Zeki, S. M. 1978. Functional specialisation in the visual cortex of the rhesus monkey. Nature, 274(5670): 423–428.
- Zeng et al. (2022) Zeng, W.; Jin, S.; Liu, W.; Qian, C.; Luo, P.; Ouyang, W.; and Wang, X. 2022. Not all tokens are equal: Human-centric visual analysis via token clustering transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11101–11111.
- Zhang et al. (2017) Zhang, H.; Cisse, M.; Dauphin, Y. N.; and Lopez-Paz, D. 2017. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412.
- Zhang et al. (2018) Zhang, X.; Zhou, X.; Lin, M.; and Sun, J. 2018. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, 6848–6856.
- Zhong et al. (2020) Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; and Yang, Y. 2020. Random erasing data augmentation. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 13001–13008.
- Zhou et al. (2017) Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; and Torralba, A. 2017. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, 633–641.
- Zhu et al. (2019) Zhu, X.; Hu, H.; Lin, S.; and Dai, J. 2019. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9308–9316.