Brain-inspired Search Engine Assistant
based on Knowledge Graph
Abstract
Search engines can quickly response a hyperlink list according to query keywords. However, when a query is complex, developers need to repeatedly refine the search keywords and open a large number of web pages to find and summarize answers. Many research works of question and answering (Q&A) system attempt to assist search engines by providing simple, accurate and understandable answers. However, without original semantic contexts, these answers lack explainability, making them difficult for users to trust and adopt. In this paper, a brain-inspired search engine assistant named DeveloperBot based on knowledge graph is proposed, which aligns to the cognitive process of human and has the capacity to answer complex queries with explainability. Specifically, DeveloperBot firstly constructs a multi-layer query graph by splitting a complex multi-constraint query into several ordered constraints. Then it models the constraint reasoning process as subgraph search process inspired by the spreading activation model of cognitive science. In the end, novel features of the subgraph will be extracted for decision-making. The corresponding reasoning subgraph and answer confidence will be derived as explanations. The results of the decision-making demonstrate that DeveloperBot can estimate the answers and answer confidences with high accuracy. We implement a prototype and conduct a user study to evaluate whether and how the direct answers and the explanations provided by DeveloperBot can assist developers’ information needs.
Index Terms—Knowledge Graph, Brain-inspired System, Cognitive Process, Q&A System
I Introduction
Traditional search engines (e.g., Google, Bing) provide a list of web sites in which the needed information may be found for developers. Recently, the community is increasingly recognizing that traditional retrieval models are insufficient to satisfy complex information needs, and propose to provide additional enhanced services for complex search tasks depending on their characteristics [1, 2, 3]. This is a consensus for major search engine companies (e.g. Google, Bing, Yahoo, etc.): automatic question and answer (Q&A) system (also known as a direct answer search engine, or natural language search engine, etc.) is a more advanced next-generation search engine that returns simple, direct and real-time answers instead of a ranked list of hyperlinks [4, 5, 6, 7, 8]. However, without the original semantic context, the answers generated by existing Q&A systems lack explainability that makes the answers difficult for users to trust and adopt [9, 10, 11, 12].
Knowledge graphs are semantic networks that contain a large number of concepts and relations, which make explainable Q&A system possible [13, 14]. To further provide a human-centred explanation, artificial intelligence (AI) systems should align with the cognitive model of human and explain within the basic framework of human cognition [15, 16, 17, 18, 19, 20]. But existing Q&A systems lack a unified framework of the Q&A cognitive process based on knowledge graph. To bridge this gap and equip Q&A systems with human-like cognitive capabilities, the contents of cognitive science related to Q&A are explored [21, 22, 23, 24].
These literature show that the cognitive process of Q&A is consist of the following five steps including perception, planning, reasoning, response and learning, respectively. Depending on these inspirations, a brain-inspired search engine assistant called DeveloperBot is presented in this paper. DeveloperBot proposes five modules aligned with the human cognitive process of Q&A. Its framework can be used as a basis for designing a knowledge graph based Q&A system that can understand, answer questions and provide a human-centred explanation.
In order to understand the syntax of the technical questions of developers, a rough observation and analysis are made on the closed-ended questions of Stack Overflow. Close-end questions refer to questions that could be answered with a simple response, e.g., one-word answer. The results show that these questions are often complex and diverse, and the constraints of a query are often scattered in various grammars, such as attributive clauses, coordinate clause, etc. Here the constraint consists of three basic elements represented as (category constraint, predicate relation of category constraint and property constraint, property constraint), it describes the information like category, property, etc. of a answer. However, existing query representation algorithms are insufficient for complex multi-constraint query representation and solving, and the features such as graph topological structure and indirect relations, etc. are not fully utilized in answer reasoning. To address these issues, two modules of the DeveloperBot called BotPerception and BotPlanning implement a novel query representation algorithm. Specifically, the BotPerception module incorporates the Dependency Parsing into the Tree Parsing [25] to maximize the completeness of the entities and relations extraction. Meanwhile, the BotPlanning module splits a multi-constraint query into several simple constraints and determines their solving order, then constructs these ordered constraints into a multi-layer query graph for further usage.
Then, a module of the DeveloperBot called BotReasoning is further proposed to address the complex query solving problem. This algorithm will use the query graph to search for a candidate subgraph from the knowledge graph by spreading activation algorithm inspired by cognitive science [24]. Then, the BotReasoning will extract the candidate answers and corresponding features according to direct relation, indirect relation and topological structure of candidate subgraph, etc. Next, these features will be integrated into the decision making algorithms like DNN (Deep Neural Network) to determine the final answers. In the end, a reasoning subgraph and an answer confidence will be extracted following the cognitive process as qualitative and quantitative explanations to explain “why”, “how” and “how confident” an answer is being presented.
The experimental results show that, with the novel features of the subgraph, the DNN can extract answers with higher accuracy and estimate answer confidences with lower mean square error (MSE). We also implement a prototype of DeveloperBot and customize it by loading a knowledge graph of the software engineering domain into its knowledge base. The results of the user study involving 24 participants show that compared with just using Google, with the assist of DeveloperBot, users can find answers faster and with more accuracy. In addition, using the reasoning subgraph and answer confidence as the explanations of the direct answers can significantly improve the developers’ trust and adoption to the answers. These explanations also assist the developers to understand the answers more deeply, improve the answer accuracy and form better search keywords. Furthermore, for relatively complex queries, with the assistance of DeveloperBot, the search performance improvement of the developers is more significant.
This paper makes the following four major contributions:
-
1)
A novel brain-inspired search engine assistant named DeveloperBot is proposed, which aligns with the cognitive process of human and have the capacity to answer complex queries with human-centred explainability based on knowledge graph.
-
2)
A query representation algorithm implemented by the BotPerception and BotPlanning modules is proposed, which incorporates the advantages of both Dependency Parsing and Tree Parsing to maximize the completeness of the constraint extraction and determine their solving order, which enhances the representation capacity of the complex multi-constraint query of Q&A system.
-
3)
An algorithm named BotReasoning is further proposed for answer reasoning and explanations generation. It inspires from spreading activation model and models the constraint reasoning process as candidate subgraph search and decision-making process. Based on the novel features, BotReasoning can extract answers with higher accuracy and estimate answer confidences with lower MSE.
-
4)
The prototype of the DeveloperBot system is implemented and customized by a knowledge graph of software engineering domain as a proof-of-concept. A user study is also conducted to evaluate its practical values.
II Related Works
Knowledge graph (KG) has been widely used in Q&A system, recommendation system and search engines in recent years due to its excellent knowledge representation capacity. Many research works on recommendation systems have taken advantage of the explainability of knowledge graph to improve the users’ trust and adoption prominently [26, 27, 28, 29]. Zhang & Chen summarize explainable recommendation applications in different domains [27], i.e., e-commerce, point of interest, social and multimedia. Ai et al. present an Indri system that is an explainable recommendation Q&A system to support modern language technologies [30]. Catherine, Rose, et al. [31] and Yu & Ren et al. [32] propose to use knowledge graph entities and meta-path as explanation of recommendations. There are relatively few research works of Q&A system explored to improve user trust and adoption by using explainability of knowledge graph. The content of the explanations of this paper is partially inspired by existing research works of recommendation systems.
The recent research works of Wang & Zou et al. [33] and Zhu & Ren et al. [34] are the two closest works to ours. Both their works and ours propose to assist the information needs of users expressed in natural language by knowledge graph based Q&A system. However, their works extract the entities of a query by simple token matching [35] or entity linking [33, 34]. In contrast, our model analyzes the expression pattern of natural language deeply and construct a query into a multi-layer query graph for further solving, which enhances the representation capacity of the complex multi-constraint query. Next, although all of these works extract an inference subgraph for further reasoning, this paper extracts the subgraph by spread activation model inspired from cognitive science [24], which can extract the candidate answers and corresponding subgraph more comprehensively. This paper also considers more comprehensive features of the subgraph, such as indirect relation, topological structure, predicate similarity, etc., some of the features are inspired from previous works. Furthermore, this paper integrates all the features into a decision-making algorithm to extract correct answers with high accuracy. This also allows our work to quantify the confidence of correct answers. In addition, our work presents the reasoning subgraph and the confidence as explanations of correct answers, according to the results of the experiments, this significantly improves answer adoption and user confidence. As far as we know, using Q&A system with explainability based on knowledge graph as a search engine assistant has not been attempted before.
III The Cognitive Framework of DeveloperBot

In the human brain, there are various memory types (e.g., sensory memory, episodic memory, etc.) that store different contents. One of them called semantic memory stores the general knowledge of the world, concepts and rules in the form of connected concept nodes. This is similar to the structure of knowledge graph [36, 37, 38]. Question reasoning is an advanced cognitive process of accessing the semantic memory to look for answers according to some premises [39, 40, 41, 21] as shown in the upper half of Fig. 1.

Assuming a query as a stimulus from the external environment, we summarize several key steps related to the cognitive process of query reasoning as follows: 1) Perception: to encode and explain external stimuli (query) as signals that the brain can recognize [22], 2) Planning: to divide a task into smaller, more manageable parts and decide the right executing order [23], 3) Reasoning: to access the semantic memory for the answer [24], 4) Response: to output the answers and explanations from the mouth, expression or body language [42], 5) Learning: to learn new knowledge by cognitive activities.
The lower half in Fig. 1 is the cognitive framework of DeveloperBot. It shows that how DeveloperBot emulates and aligns the cognitive process of the human brain. The BotPerception emulates the perception process for representing the stimuli of the human brain. The BotPlanning algorithm splits a query into smaller constraints and decides their solving order which is similar to the planning of cognitive process. The BotReasoning is answer reasoning based on knowledge graph mimicking the human reasoning [24]. The UI (user interface) called BotReponse is similar to the response of the cognitive process. BotLearning is a knowledge graph construction algorithm. Based on this brain-inspired framework, the human-centred explanations can be generated to show how a query is represented, planed and reasoned.
IV Approach
IV-A An Overview of DeveloperBot
DeveloperBot contains four main parts as shown in the overview of Fig. 2. The input is the query text from developers, and there are three outputs:
-
•
Direct answers: the direct answers derived by our system
-
•
Reasoning subgraph: a reasoning subgraph to explain the reasons to present each direct answer.
-
•
Confidence: the confidence of every direct answer.
BotResponse is an UI that consists of a search box to input query text and an area to visualize direct answers and explanations. BotPerception and BotPlanning represent a multi-constraint query as a multi-layer query graph. BotReasoning deduces answers and explanations by the query graph. BotLearning constructs a knowledge graph of software engineering domain offline that combines the knowledge graph from an automatical knowledge graph construction algorithm called HDSKG and expertise of the experts in software engineering domain, the detail can be found [43].
IV-B BotPerception and BotPlanning
In this part, we will elaborate on how BotPerception and BotPlanning combine dependency into constituency-based parse trees to extract, order the constraints in the query and construct them into a multi-layer query graph.
IV-B1 Annotate Query with Multi-Dimensional NLP Markup
DeveloperBot incorporates the tool named coreNLP to do the tokenization, POS (Part of Speech) tagging, dependency parsing and lemmatization to the query [44, 45, 46, 47]. The task of tokenization is to break the sentence into small pieces, called tokens, and drop some characters like punctuation. POS (Part of Speech) tagging is the process of labelling words with their grammatical properties, such as NN: Noun, singular or mass, WP: Whpronoun, VBZ: Verb, 3rd person singular present, etc. Lemmatization can reduce inflectional forms and derivative related forms of a word to a common base form.
| Dependency | Governor | Dependent |
|
|||
|---|---|---|---|---|---|---|
| det | databases-3 | Which-1 |
|
|||
| \cdashline1-4[0.8pt/2pt] nsubj | support-4 | databases-3 |
|
|||
| \cdashline1-4[0.8pt/2pt] dobj | support-4 | Python-5 |
|
|||
| \cdashline1-4[0.8pt/2pt] nmod:through | accessed-9 | languages-14 |
|
|||
| \cdashline1-4[0.8pt/2pt] conj:and | support-4 | accessed-9 |
|
Dependency is the grammatical structure between the Governor and Dependent. Tab. I presents the detailed description of key dependencies of a sample query (Unless otherwise specified, the sample query in this paper refers to the query: “Which graph databases support Python and can be accessed through the RDF query languages that support subgraph extraction?”). As Tab. I shows, “det” is the abbreviation of determiner. There are three interrogative determiners: what, which, whose. “nsubj” is a NP and acts as a passive syntactic subject of a clause [48]. For our sample query, nsubj (support-4, databases-3) means that “databases-3” is the syntactic subject of the verb “support-4”. In general, the “nmod” indicates some further adjunct relation specified by the case.
IV-B2 Constituency-based Tree Parsing
| Name | Parsing Expression | |||
|---|---|---|---|---|
| INNP |
|
|||
| WHNP |
|
|||
| WHVP |
|
|||
| NP |
|
|||
| VP |
|
In this step, a fulltext parsing technique called “Tree Parsing” is adapted to segment a sentence into its subconstituents [49, 50, 51, 34]. As shown in Tab. II, DeveloperBot sets four subconstituents called WHNP, WHVP, NP and VP. Here NP and VP are abbreviations of the noun phrase and verb phrase, respectively. Subconstituent WHNP represents a phrase beginning with “which”, “what” or “whose” followed by a noun phrase (e.g. Which relational databases). If a phrase starts with “who”, “when” or “what” followed by a verb phrase, WHVP will be the name of this subconstituent (e.g. Who developed).

The second column of Tab. II is the parsing expressions of the above four subconstituents. These parsing expressions are represented by POS tags. In the parsing expressions, “?” stands for whether or not there is such a determinant; “*” means zero or more determinant; “+” means must have such a determinant; “-” means continue to next row. Using the tree parsing, the tokens of the sentence are segmented to WHNP, WHVP, VP and NP as shown in Fig. 3.
IV-B3 Construct Query Graph with Dependency Parsing
Assume there is a query , the query graph constructed by BotPerception and BotPlanning is represented as . A is composed of the basic units called constraint quads which consists of four basic elements represented as (category constraint, predicate relation of category constraint and property constraint, property constraint, layer number). The layer number refers to the solving order of this constraint. A higher layer number means that the constraint is outer layer of , and the solving sequence is earlier.
Firstly, we use the constituency-based tree parsing to parse and get WHNP, WHVP, NP and VP in . Assuming , , and are the th WHNP, th WHVP, th NP and th VP respectively in :
| (1) | ||||
where , , and are th, th, th and th word of , , and , and the total number of words of them are , , , and , respectively.
Secondly, the dependency parsing technique is used to add dependency markups to all words of . After in-depth observation and analysis to the questions on Stack Overflow and our data set, we summarize the query sentence structures commonly used by developers and propose the following 5 query constraints and their layers extraction patterns to construct a query graph.
Pattern 1: If in a query , and , and WHNP is detected at the beginning of . The NP following the interrogative word called is regarded as a category constraint of direct answers. Assuming is the th word of , if the following 4 dependency pairs are detected:
-
•
-
•
-
•
-
•
where means that and appear simultaneously in the result of dependency parsing of . Then a property constraints (, ) will be extracted into the .
For the sample query, “Which graph databases” is a WHNP at the beginning of the query phrase and “graph databases” is the as shown in Fig. 3. Therefore, (graph_databases) will be extracted as a category constraint of direct answers. Then, two dependency pairs and and and are detected. Here “support-4” is which means the first word in the first VP of . The “databases-3” is representing the second word of NP of WHNP and so on.
In BotPerception, all property constraints belonging to category constraints of direct answers are classified as the innermost layer of . Therefore, from the sample query, Pattern 1 can extract two constraint quads: (graph_databases, support, Python, 1) and (graph_databases, can_be_accessed_through, RDF_query_languages, 1)
Pattern 2: Assuming the “property constraints” of a constraint quads is , where is the th word of , and there are words in in total.
If a constraint quads has been extracted and its layer number equal to . And then if the following 4 dependency pair are detected:
-
•
-
•
-
•
-
•
A constraint quads (, , , ) will be extracted into the .
For the sample query, a constraint quads (graph_databases, can_be_accessed_through, RDF_query_languages, 1) has been extracted, so = “RDF query languages”. A dependency pair is detected. Here “accessed-9” is , “databases-3” is , “languages-14” is as shown in Fig. 3. So the constraint quads (RDF_query_languages, support, subgraph_extraction, 2) will be extracted into the .
Pattern 3: In a query , if is “who” and is not “is”, “PERSON” will be added to as a category constraint of direct answers. For example, a query “Who created Python?” will be constructed as (PERSON, created, Python, 1), where the equals to “when”, a category constraint “DATE” will be added into . If is “what” and is not “is”, a category constraint ANYENTITY (a wildcard of any entities) will be put into .
Pattern 4: If in a query , WHVP is detected at the beginning of the . The VP following the interrogative word is “is” and the is not “when” like query “What is Java Servlet?”. We will regard this question as a definition query and construct the as (ANYENTITY, ANYRELATION, Java_Servlet, 1) and (Java_Servlet, ANYRELATION, ANYENTITY, 1), where ANYRELATION represents a wildcard of any relation.
Pattern 5: If in a query , , and the first word of is “List” followed by only an NP. e.g. “List graph database”. We will construct the as (graph_database, ANYRELATION, ANYENTITY, 1).
IV-C BotReasoning
As described in the IV-B, a query graph is constructed. In this section, we will elaborate on how BotReasoning reasons the answers and generates explanations by .
IV-C1 Candidate Subgraph Search
Assuming the current constraint quads for candidate subgraph search is , and the knowledge graph , where is the th node of , is the nodes number of . The pseudo code of subgraph search is shown in Algorithm. 1.
Each node in has an initial associated activation value and . A link connects source to target and the weight of is where and . The nodes of have an active threshold , where and . There is a decay factor , where and .
In the beginning of the subgraph search, BotReasoning links the and to the corresponding and in . Therefore, the initial activation value of and will be greater than active threshold . These two nodes are activated and will initiate to spread the activation to all the neighbouring nodes parallelly.
Assuming connects the source node to the target node . While the activation spread from to , will compute as:
| (2) |
Then, will adjust its value to according to as following formula:
| (3) |
Once is activated, it will initiate the next spreading activation cycle to its neighbouring nodes. The spreading will be terminated under the following three situations:
-
•
The spreading arrives the endmost nodes of the or exceeds the preset upper bound .
-
•
All the nodes reach .
-
•
During searching , if the neighbouring node of belongs to . The spreading will be terminated and will be inserted into , where are the crossover relations indicating the relations of and .
IV-C2 Decision Making
Topological Structure of Subgraph : Fig. 4 illustrates an example of . The root node and leaf node refer to the most superclass node and most subclass node of , respectively. The candidate answers are all the leaf nodes of .
Assuming the red focus node in Fig. 4 is a candidate answer for making decision (to decide the candidate answer is a correct answer or not). The following two kinds of potential topological structures of the can affect the decision-making. refers to the candidate answer or any superclasses of the candidate answer connected to or any superclasses of by the predicate. indicates that the candidate answer or any superclasses of candidate answer connect to any subclasses of by the predicate.

Predicate Similarity: There are many different ways to express the same meaning and opposite meaning. Therefore, the predicates of also affect the decision-making. To measure the semantic relevance between two predicates, a technique named word2vec [52, 53, 54] is adopted. It assumes that words appear in similar context may have similar meanings [55] and transforms the words or phrases into the form of continuous vectors [52]. Then words or phrases can do relevance computation by distance measurement of vector (here we use cosine similarity).
Features Generations: In order to estimate the candidate answers, sufficient evidence need to be gathered to determine whether it surpasses the positive or negative criteria. In general, the weights of positive and negative evidence are not equal. A few negative evidence may lead to negative decisions, whereas many positive evidence are needed to make a positive decision.
| # | Name | Gloss | ||||
|---|---|---|---|---|---|---|
| 1 | p_r1_pdictSim |
|
||||
| \cdashline1-3[0.8pt/2pt] 2 | p_r2_pdictSim |
|
||||
| \cdashline1-3[0.8pt/2pt] 3 | n_r1 |
|
||||
| \cdashline1-3[0.8pt/2pt] 4 | n_r2 |
|
We synthesize the topological structure and predicate similarity into four features as shown in Tab.III. In these four features, feature #1 represents the influence of . If does not exist, the value of feature #1 takes 0, otherwise takes the maximum value of predicates similarity of all : , where and is the predicates similarity of th , and is the number of .
Feature #2 represents the influence of . If does not exist, the value takes 0. Otherwise, the more in , the higher the probability that the candidate answer meets the property constraint. Therefore, the value of feature #2 , where is the predicates similarity of th leaf nodes of connected to th subclass of . is the number of leaf nodes of and is the number of subclasses of . Take the Fig. 4 as an example, here , and , assume the value of and , the value of feature #2 is . For the feature #3 and feature #4, if negative or do not exist, the value takes 0, otherwise, takes 1.
IV-C3 Final Answer and Explanation Generation
BotReasoning extracts the layer information of and the answer reasoning will be performed from the outer layer to the inner layer. The reasoning order of the constraint quads in same layer is determined by random. Once the answers , where of a constraint quads are found, BotReasoning will replace the corresponding object constraint in the inner layer by these answers and prune the from . BotReasoning will generate pruned , and continues the reasoning process for every . If there are multiple constraints in the same layer and multiple answer sets are deduced, the union of these sets is computed. These iterations will terminate until the final answers and explanations of the most inner layer of every are achieved.
The corresponding explanations (reasoning subgraph and answer confidence) are extracted following the cognitive process of DeveloperBot. BotPerception records the entities identified in a query to the reasoning subgraph, these are also the initially activated nodes ( and ) for spreading activation in the knowledge graph. After every constraint reasoning, BotReasoning takes all the and the relational paths from or to any nodes of into the reasoning subgraph of previous iteration (if any). Therefore, the final reasoning subgraph involves the information of whole cognitive process including BotPerception, BotPlanning and BotReasoning.
The answer confidences , where for are computed by the decision-making algorithm multiplicative the answer confidence from outer layer. During the answer reasoning, the confidences will be multiplicative to every confidence of the inner layer. The confidence of an answer reasoned from multiple constraints in the same layer is obtained by multiplying the answer confidences of all the constraints in the same layer.
IV-D BotResponse: UI of DeveloperBot
A proof-of-concept prototype of DeveloperBot is implemented as shown in Fig. 5. The user can enter their query at the input bar and press the button “Direct Search”. The application can return a list of direct answers, brief introductions and their corresponding explanations. In the reasoning subgraph, the entities identified by the BotPerception module are represented as red colour. The answers reasoning by BotReasoning are presented as graded blue that shows how the BotPlanning orders the constraints.

This reasoning subgraph explains “why” “virtuoso” is the answer: virtuoso is a graph database, virtuoso supports and sparql, and sparql is a rdf query language that supports subgraph extraction. It also explain “how” “virtuoso” is achieved: firstly, DeveloperBot identifies the four entities “graph database”, “python”, “rdf query language” and “subgraph extraction”. Secondly, it gets the answer “sparql” of constraint “rdf query language support subgraph extraction”. Finally, DeveloperBot searches the “graph database” supported both python and sparql. And the confidence of answer “virtuoso” is 0.9861.
V Experiment
In this section, a series of experiments are conducted to answer the following three research questions of DeveloperBot:
-
•
RQ1: How is the performance of different decision-making algorithms in estimating the correct answers?
-
•
RQ2: Whether DeveloperBot can improve the performance of developers during answer search? If the performance is different under different task complexity?
-
•
RQ3: How is the performance of the different explanations and how these explanations affect user behavior during answer search?
V-A Data Acquisition
Knowledge Graph: The original knowledge graph is proposed by paper [43]. This knowledge graph involves the general knowledge of the software engineering domain and contains 44800 concepts, 9660 unique verb phrase and 35279 relation triples. Then, this knowledge graph is cleared up and augmented by the synonyms, expertise of domain experts, NLP techniques and partial knowledge of papers [56, 57]. After that, the final knowledge graph acquires 39022 concepts, 8173 unique predicates and 35938 relation triples. These knowledge cover the popular programming languages (e.g., Java, Javascript, Python, etc.), frameworks (e.g., Flex, Django, etc.), database (e.g., neo4j, Mysql, etc.), tools (e.g., d3, MSBuild, etc.) of software engineering domain.
Training Corpus of Word Embedding: The tag wiki of Stack Overflow is used as the training corpus. Tag wiki is not only well maintained, but also have standard grammatical structure and comprehensive technical coverage. Furthermore, the semantic context of tag wiki matches to the knowledge graph we used well. As a result, we acquire 20539 documents, then split 78466 sentences from the documents as training corpus of word embedding.
V-B Experimental Setup and Involved Tools
In the subgraph search process of this experiment, the initial activation values of all node are set to zero. Here the active threshold is set to 0.8 and the decay factor is set to 0.85. For starting the activation, the activation values of linked nodes of subject constraint and object constraint will be initialized to greater than . The maximum number of iterations is set to 30. DNN model used in this experiment is a 3 layers classifier whose hidden layer is set to [10, 20, 10]. For the decision-making process of Bayesian Decision Theory, .
V-C Evaluation
In this section, quantitative evaluation (objective) and a user study (subjective) are conducted to evaluate the performance of DeveloperBot.
V-C1 Quantitative Evaluation
In the quantitative evaluation, we invited five developers to ask some multi-constraint natural language questions they interested. We require that these questions should be answered with direct answers. These questions mainly cover factual questions such as Who, What, Which, and List. Finally, the five developers proposed 160 eligible questions. Then they asked to use computer to search their answers for every question. Then they discuss together about the final answers for every question. 51 of the questions were dropped because they had no answer, or their answers could not reach a consensus. Then the 109 ground truth questions and the 1819 candidate answers generated.
To evaluate the decision-making process, the balanced accuracy, precision, recall, f1-score and confidence mean square error (MSE) are used as evaluation metrics [61]. The average result of the 10 times cross-validation will be taken as the final results of different metrics. Here the MSE measures the average squared difference between the estimated confidence values and the actual confidence values: , where is the number of answers, the 1 is the actual confidence values for correct answers. The balanced accuracy returns the average accuracy per class: , where , , , are true positives, true negatives, false positives, and false negatives, respectively.
V-C2 User Study
Tools for comparison: In this user study, we will compare the information search performance of using Google + DeveloperBot with use only Google. There are some direct answer search engines like Wolfram Alpha (https://www.wolframalpha.com/) and ASK (https://www.ask.com) which are similar to DeveloperBot. But these tools can hardly answer specific questions of software engineer domain, so it makes no sense to compare with them. Furthermore, this paper mainly focuses on a general method to answer questions and provide explanations by a knowledge graph. It can be extended to many different areas, situations and questions coverage, which depend on the knowledge graph used.
Participants: In the user study, 24 developers from different backgrounds were recruited. They are made up of the employees, undergraduate students, PhD students, professors from different universities and professional developers from IT companies, etc. Their programming proficiency distributions are 12.5%, 75% and 12.5% for expert, competent and beginner, respectively. The participants also have diverse programming background and their programming languages involved Python, Java, Javascript, SQL, C#, etc. In each proficiency level and background, the developers are halved to and randomly (12 participants per group). To exclude the effects of participants’ programming level and fatigue, and will act as experimental group (use Google + DeveloperBot) and control group (use only Google) to finish each task circularly Therefore, every developer has the opportunity to solve the simple or hard task by only Google or Google + DeveloperBot. They can also have a comprehensive comparison to the differences with or without the search engine assistant DeveloperBot.
| Task No. | Task Description | Best Answer(s) # | ||||
|---|---|---|---|---|---|---|
| 1 | Who develops Hiawatha? | 1 | ||||
| \cdashline1-3[0.8pt/2pt] 2 | List data visualization library | 5 | ||||
| \cdashline1-3[0.8pt/2pt] 3 |
|
4 | ||||
| \cdashline1-3[0.8pt/2pt] 4 | Which IDE support web2.0? | 3 | ||||
| \cdashline1-3[0.8pt/2pt] 5 |
|
3 |
Task: In this study, we have chosen 5 answer search tasks (represent as ) from the ground truth questions as shown in Tab. LABEL:tasks. The answer to these tasks cover celebrity of software engineering domain, library, operating system, IDE, and database, etc. According to the preliminary test, the difficulty of these five tasks increases in order. The participants need to evaluate all the answers given by Google or DeveloperBot comprehensively, and select best answers according to the required number of every task.
Procedure: This user study begins with a brief training of DeveloperBot by the experimenter. After finishing each task, participants need to fill their confidence to the answers they provided (on 5-point likert scale with 1 being the least confident and 5 being the most confident). A screencapture software is required to run throughout the whole process that allows us to analyze the participants’ behavior after the experiment. At the end, all the participants will be asked to fill in the System Usability Scale (SUS) questionnaire [62] and do an open discussion focusing on their options about the different features of DeveloperBot.
V-D Results and Results Analysis
V-D1 Result: performance of different decision-making algorithms (RQ1)
Here we will present the results of quantitative evaluation and answer the RQ1. Fig.6 shows the performance of different decision-making algorithms including Random Forest, Decision Tree, SVM Linear, Bayes (Bayesian Decision Theory), and DNN. With the accurate representation of candidate answers by the four features extracted by our algorithm, any decision-making algorithm can get more than 0.98 balanced accuracy. Compared with another algorithms, DNN achieves the highest precision 0.98, recall 0.98 and f1-score 0.99, respectively. From Fig.6, we can infer that some decision-making algorithms can achieve high precision, but at the cost of a low recall, like SVM Linear. The Bayesian Decision theory obtains a high recall, but the precision is low. In the future research, we might investigate the employment of other state-of-art algorithms, such as negative correlation learning [63, 64], statistical learning for probabilistic outputs [65, 66], Bayesian inference [67], etc.

Fig.7 is the MSE of confidence for different decision-making algorithms. It shows that DNN achieves the lowest MSE for the estimation of answer confidence. Bayesian Decision Theory gets the highest MSE. The estimation of answer confidence is within the acceptable range for all decision-making algorithms.

To explore the effects of different features, we train 3 DNN models using different features. These 3 models use all features, only predicate similarity feature and only topological structure feature, respectively. The only predicate similarity feature is computed by the maximal predicate similarity of , if it exists. Only topological structure features involve 4 features to represent the existence (take the value 1) or nonexistence (take the value 0) of , , and , respectively.

As shown in Fig.8, the decision-making algorithm with all features performs the best for all the metrics. This figure also indicates that the predicate similarity contributes to the precision significantly. Since with only predicate similarity feature, the precision almost can achieve as same as all features. But only predicate similarity feature obtains very low recall. These results show that the predicate similarity is a good feature in terms of identifying the right answers, but without the topological structure, a lot of right answers are missed.

Fig.9 indicates that the decision-making algorithm can obtain the lowest MSE by using all features. Compared with the topological structure, predicate similarity achieves higher MSE. From the above exploration, we can infer that both predicate similarity and topological structure we design for decision-making are useful for identifying the right answer from the candidate answers.
V-D2 Result: improve the performance of developers during answer search (RQ2)

Fig.10 is the result of the average answer accuracy of the two groups. It shows that for the task 1-2, both groups can finish the tasks with high accuracy (above 0.86). The answer accuracy of the participants who use only Google even reaches 1 on task 1. These prove our pre-experiment conjecture: Google has a very good performance in simple information search tasks. For the task 3-5, the experimental group can finish with higher answer accuracy. With the complexity of tasks increasing, the answer accuracy of the control group gradually decreases compared with the experimental group which maintains at a high level (above 0.78). For task 5, the difference in answer accuracy even reaches 0.64. These fully illustrate that DeveloperBot, as a search engine assistant, can significantly improve the answer accuracy during search close-end questions, especially in complex search tasks.

Fig.11 is the result of participants’ average confidences to their answers (called participants’ confidences). This figure indicates that for tasks 1-3, the participants’ confidences of control group are almost same as experimental group. For tasks 4-5, the participants’ confidences (4 and 4.3 for task 4 and task 5, respectively) of the experimental group show an overwhelming advantage. With the complexity of tasks increasing, the difference of participants’ confidences of two groups shows a clear increasing trend except task 3. According to the observation of the screen recording and results of the open discussion, this is because there is a web page that lists some direct answers of task 3, and each answer has corresponding text explanation. The participants’ confidences of control group increases by reading these text explanation. But this is at the cost of increasing the time used on task 3 as shown in Fig. 12. These indicated that for the easy tasks, the control group was more confident in their answers because they were straightforward and did not require reasoning or summarization. For the complex tasks, despite spending a long time to search answers, participants still feel less confident to their answers because they may lose during they try to summarize and reason the answers through many web pages. Therefore, as a search engine assistant, DeveloperBot can improve the participants’ confidences by providing explanations of answers.
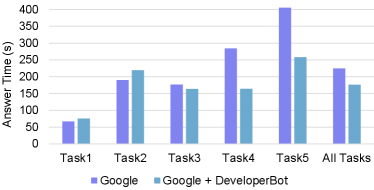
Fig.12 is the result of answers search time. It shows that, in addition to task 3, the answers search time of the control group increases significantly with the complexity of the tasks increasing. With the assistant of DeveloperBot, the answer search time of the experimental group for task 5 is 258s compared with 405s of the control group. These show that using DeveloperBot as search engine assistant can significantly reduce the participants’ answer search time especially for the complex answer search tasks that take a long time to solve with only Google. The open discussion also reflects consistent results for the above conclusion. The special performance of Google group at task 3 also illustrates that direct answers and the explanation (even text) can significantly reduce the search time and improve the participants’ confidences to their answers at the same time.
V-D3 Result: comments to explanations and behavior changes (RQ3)
We will evaluate the explanation and answer the RQ3 from three ways: the quantitative scoring (0-5) of participants in the questionnaires, the information obtained from open discussions, and our observation of screen recording.
The results of the quantitative scoring of explanations are shown in the radar graph Fig. 13. Five indexes are adopted in this experiment to evaluate the quality of the explanation. They are Readable, Understandable, Answer Convincing, Wrong Answer Identification and Search Keywords Forming [68, 69], where Readable and Understandable mean the explanation is legible, easy to read and understand. Answer Convincing means this explanation can make the direct answer more convincing. Wrong Answer Identification is the index that evaluates if the explanation can help identify the wrong answer. Search Keywords Forming shows the capacity of the explanation to help form better search keyword.
As shown in Fig. 13, the overall scores of reasoning subgraph reach 4.13-4.71. Compared with the other four indexes, the Answer Convincing achieves the highest score 4.71. The ranking of indexes of Readable and Understandable are second and third, with average values of 4.38. Even the Wrong Answer Identification achieves the lowest score, 4.13 is still acceptable. The results demonstrate that the reasoning subgraph is a reasonable and high-quality explanation of direct answer and meet the desired design goals.

In addition, Fig. 13 also shows the overall scores of using confidence as an explanation. Compared with the reasoning subgraph, the overall scores of confidence are relatively lower (3.71-4.17). The indexes Readable, Understandable and Answer Convincing achieve highest score 4.17. The scores of Wrong Answer Identification and Search Keywords Forming is 3.79 and 3.71, respectively. Even the overall scores of confidence are lower than reasoning subgraph, especially the Search Keywords Forming and Wrong Answer Identification. However, the good performance of indexes like readable, understandable and answer convincing indicate that confidences are good explanations to direct answers.
The results of the questionnaire and the contents of the open discussion show that, using the reasoning subgraph extracted following the cognitive process and answer confidence as explanations of the direct answers can significantly improve the developers’ trust and adoption to the answers. These explanations also assist the developers to understand the answers more deeply, improve the answer accuracy and form better search keywords.
VI Conclusion
The developers have a need for complex information search that provide specific direct answers. The current search engines are weak at the reasoning capacity for complex closed-end questions. In order to address these issues, in this paper, a brain-inspired search engine assistant named DeveloperBot is proposed. DeveloperBot aligns to the cognitive process of human and has the capacity to answer complex queries with good explainability by learned knowledge. The experimental results show that the novel features of the subgraph can estimate the answers and answer confidences with high accuracy. The results of user study show that compared with using only Google, with the assistance of DeveloperBot, users can find answers faster and with more accuracy. In addition, with the explanations extracted following the cognitive process, DeveloperBot can significantly improve the developers’ trust and adoption to the answers. These explanations also assist the developers to understand the answers more deeply, improve the answer accuracy and form better search keywords. Furthermore, for relatively complex queries, with the assistance of DeveloperBot, the search performance improvement of the developers is more significant. In the future, we will augment the knowledge graph through developers’ development behaviors to further improve the efficiency of information search [70, 57].
References
- [1] B. Sarrafzadeh, O. Vechtomova, and V. Jokic, “Exploring knowledge graphs for exploratory search,” in Proceedings of the 5th Information Interaction in Context Symposium. ACM, 2014, pp. 135–144.
- [2] C. N. Carlson, “Information overload, retrieval strategies and internet user empowerment,” 2003:169-173.
- [3] G. Singer, U. Norbisrath, and D. Lewandowski, “Ordinary search engine users carrying out complex search tasks,” Journal of Information Science, vol. 39, no. 3, pp. 346–358, 2013.
- [4] F. Joel, “Google: Our new search strategy is to compute answers, not links,” https://thenextweb.com/google/2011/06/01/google-our-new-search-strategy-is-to-compute-answers-not-links/, accessed June 1, 2011.
- [5] G. Seth, “Breakthrough analysis: Search is not the answer,” https://www.informationweek.com/software/information-management/breakthrough-analysis-search-is-not-the-answer/d/d-id/1046118, accessed August 14, 2006.
- [6] G. Liz, “Breakthrough analysis: Search is not the answer,” http://allthingsd.com/20130314/how-search-is-evolving-finally-beyond-caveman-queries/, accessed March 14, 2013.
- [7] X. Zhao, F. Xiao, H. Zhong, J. Yao, and H. Chen, “Condition aware and revise transformer for question answering,” in Proceedings of The Web Conference (WWW), 2020, pp. 2377–2387.
- [8] X. Wu, H. Chen, and G. o. Wu, “Knowledge engineering with big data,” IEEE Intelligent Systems, vol. 30, no. 5, pp. 46–55, 2015.
- [9] R. Hong, M. Wang, G. Li, L. Nie, Z.-J. Zha, and T.-S. Chua, “Multimedia question answering,” IEEE MultiMedia, no. 4, pp. 72–78, 2012.
- [10] M.-D. Olvera-Lobo and J. Gutiérrez-Artacho, “Searching health information in question-answering systems,” in Handbook of Research on ICTs for Human-Centered Healthcare and Social Care Services. IGI Global, 2013, pp. 474–490.
- [11] S. Quarteroni and S. Manandhar, “A chatbot-based interactive question answering system,” Decalog 2007, vol. 83, 2007.
- [12] S. Varges, F. Weng, and H. Pon-Barry, “Interactive question answering and constraint relaxation in spoken dialogue systems,” in Proceedings of the 7th SIGdial Workshop on Discourse and Dialogue, 2006, pp. 28–35.
- [13] H.-C. Tu and J. Hsiang, “An architecture and category knowledge for intelligent information retrieval agents,” Decision Support Systems, vol. 28, no. 3, pp. 255–268, 2000.
- [14] X. Wu, H. Chen, J. Liu, G. Wu, R. Lu, and N. Zheng, “Knowledge engineering with big data (bigke): a 54-month, 45-million rmb, 15-institution national grand project,” IEEE Access, vol. 5, pp. 12 696–12 701, 2017.
- [15] S. Chari, D. M. Gruen, O. Seneviratne, and D. L. McGuinness, “Foundations of explainable knowledge-enabled systems,” arXiv preprint arXiv:2003.07520, 2020.
- [16] X. Yanghua, “Opportunities and challenges of explainable artificial intelligence based on knowledge graph.”
- [17] G. Maheshwari, P. Trivedi, D. Lukovnikov, N. Chakraborty, A. Fischer, and J. Lehmann, “Learning to rank query graphs for complex question answering over knowledge graphs,” in International Semantic Web Conference. Springer, 2019, pp. 487–504.
- [18] G. Murphy, The big book of concepts. MIT press, 2004.
- [19] T. Miller, “Explanation in artificial intelligence: Insights from the social sciences,” Artificial Intelligence, vol. 267, pp. 1–38, 2019.
- [20] R. High, “The era of cognitive systems: An inside look at ibm watson and how it works,” IBM Corporation, Redbooks, pp. 1–16, 2012.
- [21] G. Giguère and B. C. Love, “Limits in decision making arise from limits in memory retrieval,” Proceedings of the National Academy of Sciences, vol. 110, no. 19, pp. 7613–7618, 2013.
- [22] M. W. Matlin and H. J. Foley, Sensation and perception. Allyn & Bacon, 1992.
- [23] A. M. Owen, “Cognitive planning in humans: neuropsychological, neuroanatomical and neuropharmacological perspectives,” Progress in neurobiology, vol. 53, no. 4, pp. 431–450, 1997.
- [24] A. M. Collins and E. F. Loftus, “A spreading-activation theory of semantic processing.” Psychological review, vol. 82, no. 6, p. 407, 1975.
- [25] C. Fellbaum, “A semantic network of english: the mother of all wordnets,” in EuroWordNet: A multilingual database with lexical semantic networks. Springer, 1998, pp. 137–148.
- [26] J. Yao and Y. Yao, “Web-based information retrieval support systems: building research tools for scientists in the new information age,” in Proceedings IEEE/WIC International Conference on Web Intelligence (WI 2003). IEEE, 2003, pp. 570–573.
- [27] Y. Zhang and X. Chen, “Explainable recommendation: A survey and new perspectives,” arXiv preprint arXiv:1804.11192, 2018.
- [28] H. Xu and A. Li, “Two-level smart search engine using ontology-based semantic reasoning.” in Proceedings of the 26th International Conference on Software Engineering and Knowledge Engineering, 2014, pp. 648–652.
- [29] W. Ma, M. Zhang, Y. Cao, W. Jin, C. Wang, Y. Liu, S. Ma, and X. Ren, “Jointly learning explainable rules for recommendation with knowledge graph,” in The World Wide Web Conference. ACM, 2019, pp. 1210–1221.
- [30] Q. Ai, V. Azizi, X. Chen, and Y. Zhang, “Learning heterogeneous knowledge base embeddings for explainable recommendation,” Algorithms, vol. 11, no. 9, p. 137, 2018.
- [31] R. Catherine, K. Mazaitis, M. Eskenazi, and W. Cohen, “Explainable entity-based recommendations with knowledge graphs,” arXiv preprint arXiv:1707.05254, 2017.
- [32] X. Yu, X. Ren, Y. Sun, Q. Gu, B. Sturt, U. Khandelwal, B. Norick, and J. Han, “Personalized entity recommendation: A heterogeneous information network approach,” in Proceedings of the 7th ACM international conference on Web search and data mining, 2014, pp. 283–292.
- [33] M. Wang, Y. Zou, Y. Cao, and B. Xie, “Searching software knowledge graph with question,” in International Conference on Software and Systems Reuse. Springer, 2019, pp. 115–131.
- [34] C. Zhu, K. Ren, X. Liu, H. Wang, Y. Tian, and Y. Yu, “A graph traversal based approach to answer non-aggregation questions over dbpedia,” in Joint International Semantic Technology Conference. Springer, 2015, pp. 219–234.
- [35] C. Chen, Z. Xing, and L. Han, “Techland: Assisting technology landscape inquiries with insights from stack overflow,” in 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2016, pp. 356–366.
- [36] S. Bernecker, “Memory knowledge,” The Routledge Companion to Epistemology. New York: Routledge, pp. 326–34, 2011.
- [37] L. R. Squire, “Declarative and nondeclarative memory: Multiple brain systems supporting learning and memory,” Journal of cognitive neuroscience, vol. 4, no. 3, pp. 232–243, 1992.
- [38] M. R. Quillan, “Semantic memory,” BOLT BERANEK AND NEWMAN INC CAMBRIDGE MA, Tech. Rep., 1966.
- [39] A. Jaya and G. Uma, “A knowledge based approach for semantic reasoning of stories using ontology,” in Thinkquest~ 2010. Springer, 2011, pp. 310–315.
- [40] D. Van Knippenberg, L. Dahlander, M. R. Haas, and G. George, “Information, attention, and decision making,” 2015.
- [41] J. G. Lynch, “Memory and decision making,” pp. 1–9, 1991.
- [42] J. Olds, M. Khan, M. Nayebpour, and N. Koizumi, “Explainable ai: A neurally-inspired decision stack framework,” arXiv preprint arXiv:1908.10300, 2019.
- [43] X. Zhao, Z. Xing, M. A. Kabir, N. Sawada, J. Li, and S.-W. Lin, “Hdskg: Harvesting domain specific knowledge graph from content of webpages,” in 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2017, pp. 56–67.
- [44] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky, “The stanford corenlp natural language processing toolkit.” in ACL (System Demonstrations), 2014, pp. 55–60.
- [45] K. Toutanova and C. D. Manning, “Enriching the knowledge sources used in a maximum entropy part-of-speech tagger,” in Proceedings of the 2000 Joint SIGDAT conference on Empirical methods in natural language processing and very large corpora: held in conjunction with the 38th Annual Meeting of the Association for Computational Linguistics-Volume 13. Association for Computational Linguistics, 2000, pp. 63–70.
- [46] J. Nivre, M.-C. de Marneffe, F. Ginter, Y. Goldberg, J. Hajic, C. D. Manning, R. McDonald, S. Petrov, S. Pyysalo, N. Silveira et al., “Universal dependencies v1: A multilingual treebank collection,” in Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016), 2016.
- [47] S. Schuster and C. D. Manning, “Enhanced english universal dependencies: An improved representation for natural language understanding tasks,” in Proceedings of the 10th International Conference on Language Resources and Evaluation, 2016.
- [48] M.-C. De Marneffe and C. D. Manning, “Stanford typed dependencies manual,” Technical report, Stanford University, Tech. Rep., 2008.
- [49] C. Grover and R. Tobin, “Rule-based chunking and reusability,” in Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC 2006), 2006.
- [50] T. Zhang, F. Damerau, and D. Johnson, “Text chunking based on a generalization of winnow,” Journal of Machine Learning Research, vol. 2, no. Mar, pp. 615–637, 2002.
- [51] E. Loper and S. Bird, “Nltk: the natural language toolkit,” arXiv preprint cs/0205028, 2002.
- [52] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, 2013, pp. 3111–3119.
- [53] J. Xu, J. Liu, L. Zhang, Z. Li, and H. Chen, “Improve chinese word embeddings by exploiting internal structure,” in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016, pp. 1041–1050.
- [54] J. Liu, Z. Liu, and H. Chen, “Revisit word embeddings with semantic lexicons for modeling lexical contrast,” in 2017 IEEE International Conference on Big Knowledge (ICBK). IEEE, 2017, pp. 72–79.
- [55] Z. S. Harris, “Distributional structure,” Word, vol. 10, no. 2-3, pp. 146–162, 1954.
- [56] X. Zhao, “Hdso: Harvest domain specific non-taxonomic relations of ontology from internet by deep neural networks (dnn),” BSR winter school Big Software on the Run: Where Software meets Data, p. 74.
- [57] H. Li, S. Li, J. Sun, Z. Xing, X. Peng, M. Liu, and X. Zhao, “Improving api caveats accessibility by mining api caveats knowledge graph,” in 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2018, pp. 183–193.
- [58] C. D. Manning, M. Surdeanu, J. Bauer, J. Finkel, S. J. Bethard, and D. McClosky, “The Stanford CoreNLP natural language processing toolkit,” in Association for Computational Linguistics (ACL) System Demonstrations, 2014, pp. 55–60. [Online]. Available: http://www.aclweb.org/anthology/P/P14/P14-5010
- [59] R. Rehurek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora,” in Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA, May 2010, pp. 45–50.
- [60] S. Bird, “Nltk: the natural language toolkit,” in Proceedings of the COLING/ACL on Interactive presentation sessions. Association for Computational Linguistics, 2006, pp. 69–72.
- [61] M. David, “Powers. 2011. evaluation: From precision, recall and f-score to roc, informedness, markedness & correlation,” Journal of Machine Learning Technologies, vol. 2, no. 1.
- [62] J. Brooke et al., “Sus-a quick and dirty usability scale,” Usability evaluation in industry, vol. 189, no. 194, pp. 4–7, 1996.
- [63] H. Chen and X. Yao, “Multiobjective neural network ensembles based on regularized negative correlation learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 12, pp. 1738–1751, 2010.
- [64] H. Chen and X. Yao, “Regularized negative correlation learning for neural network ensembles,” IEEE Transactions on Neural Networks, vol. 20, no. 12, pp. 1962–1979, 2009.
- [65] S. Lyu, X. Tian, Y. Li, B. Jiang, and H. Chen, “Multiclass probabilistic classification vector machine,” IEEE Transactions on Neural Networks and Learning Systems, 2019.
- [66] H. Chen, P. Tiňo, and X. Yao, “Efficient probabilistic classification vector machine with incremental basis function selection,” IEEE Transactions on neural networks and learning systems, vol. 25, no. 2, pp. 356–369, 2013.
- [67] H. Chen, P. Tino, and X. Yao, “Probabilistic classification vector machines,” IEEE Transactions on Neural Networks, vol. 20, no. 6, pp. 901–914, 2009.
- [68] R. Confalonieri, T. R. Besold, T. Weyde, K. Creel, T. Lombrozo, S. T. Mueller, and P. Shafto, “What makes a good explanation? cognitive dimensions of explaining intelligent machines.” in CogSci, 2019, pp. 25–26.
- [69] R. R. Hoffman, S. T. Mueller, G. Klein, and J. Litman, “Metrics for explainable ai: Challenges and prospects,” arXiv preprint arXiv:1812.04608, 2018.
- [70] X. Zhao, H. Li, Y. Tang, D. Gao, L. Bao, and C.-H. Lee, “A smart context-aware program assistant based on dynamic programming event modeling,” in 2018 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW). IEEE, 2018, pp. 24–29.