Boosting Video Captioning with Dynamic Loss Network
Abstract
Video captioning is one of the challenging problems at the intersection of vision and language, having many real-life applications in video retrieval, video surveillance, assisting visually challenged people, Human-machine interface, and many more. Recent deep learning based methods [1, 2, 3] have shown promising results but are still on the lower side than other vision tasks (such as image classification, object detection). A significant drawback with existing video captioning methods is that they are optimized over cross-entropy loss function, which is uncorrelated to the de facto evaluation metrics (BLEU, METEOR, CIDER, ROUGE). In other words, cross-entropy is not a proper surrogate of the true loss function for video captioning. To mitigate this, methods like REINFORCE, Actor-Critic, and Minimum Risk Training (MRT) have been applied but have limitations and are not very effective. This paper proposes an alternate solution by introducing a dynamic loss network (DLN), providing an additional feedback signal that reflects the evaluation metrics directly. Our solution proves to be more efficient than other solutions and can be easily adapted to similar tasks. Our results on Microsoft Research Video Description Corpus (MSVD) and MSR-Video to Text (MSRVTT) datasets outperform previous methods.
I Introduction
Video captioning is the task of describing the content in a video in natural language. With the explosion of sensors and the internet as a data carrier, automatic video understanding and captioning have become essential. It can be applied in many applications such as video surveillance, assisting visually challenged people, video retrieval, and many more. Despite having many applications, jointly modeling the spatial appearance and temporal dynamics makes it a difficult task.
Motivated by machine translation [4] and image captioning [5, 6], the encoder-decoder architecture has been adapted for the video captioning task [7, 8, 2, 9, 1]. On the encoder side, different visual features are extracted using 2D and 3D convnets. The encoder’s combined visual features are sent to the decoder to generate the caption, one word at a time. So basically, the decoder is a conditional language model, and a variant of recurrent neural networks (LSTM, GRU) is the most popular and successful. Recent improvements on the encoder-decoder baseline have happened in mainly three areas: (i) incorporation of better visual feature extraction modules at the encoder side, (ii) addition of external language models to guide the decoder, (iii) better frame selection strategy.
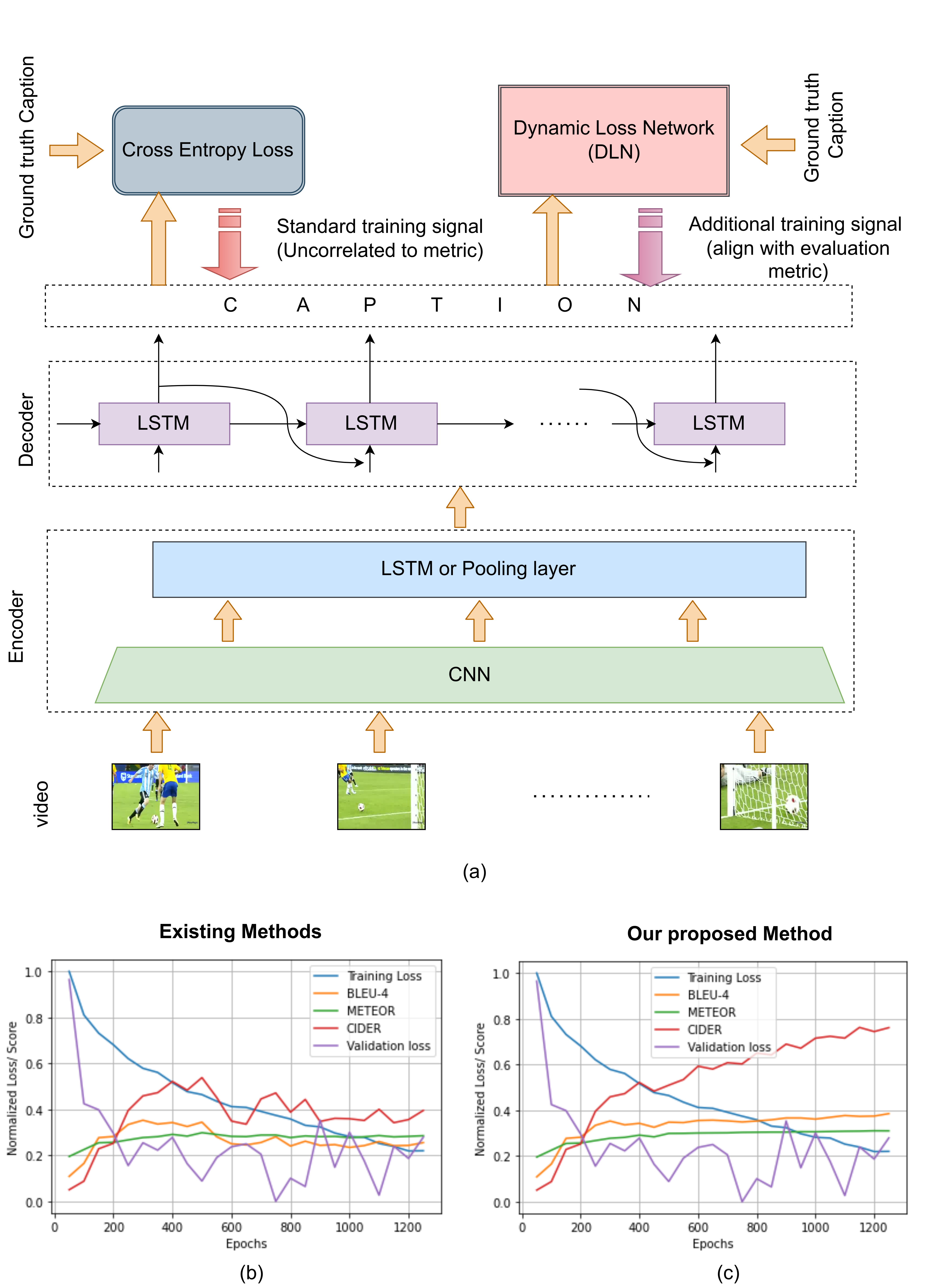
Despite the improvements, a potential drawback with these methods is that the training signal does not align with the standard evaluation metrics such as BLEU [10], METEOR [11], ROUGE-L [12], CIDER [13]. As a result, even low training and validation loss can lead to poor metric scores and vice versa, as shown in Fig.1(b). Furthermore, direct optimization over metric function is not possible due to the non-differentiable nature of the network. Alternate solutions from Reinforcement learning (REINFORCE, Actor-Critic) and Minimum Risk Training (MRT) have been applied to machine translation and image captioning. However, they have not proved to be very successful in the case of video captioning. To this end, we propose a dynamic loss network (DLN), a transformer-based model that approximates metric function and is pre-trained on external data using a self-supervised setup. Although the proposed DLN can be utilized to approximate any metric function, in our case, we approximate the BLEU, METEOR, and CIDER scores. Once trained, the DLN can be used with the video captioning model in an end-to-end manner, as shown in Fig.1(a).
Finally, we demonstrate that the feedback signals from our proposed model align with the evaluation metric, as shown in Fig.1(c).
II Related Work
II-A Video Captioning.
The main breakthrough in video captioning happened with the inception of encoder-decoder based sequence to sequence models. The encoder-decoder framework for video captioning was first introduced by MP-LSTM [7], which uses mean pooling over-frame features and then decodes caption by LSTM. Although MP-LSTM [7] outperformed its predecessors, the temporal nature of the video was first modeled by S2VT [1] and SA-LSTM [8]. The former shares a single LSTM for both the encoder and the decoder, while the latter uses attention over-frame features along with 3D HOG features. The recent methods are improved on the SA-LSTM [8] baseline. RecNet [9] uses backward flow and reconstruction loss to capture better semantics, whereas MARN [2] uses memory to capture correspondence between a word and its various similar visual context. M3 [14] also uses memory to capture long-term visual-text dependency, but unlike MARN [2], it uses heterogeneous memory. Both MARN [2] and M3 [14] use motion features along with appearance features. More recently, STG-KD [15] and OA-BTG [16] use object features along with the appearance and motion features. STG-KD [15] uses a Spatio-temporal graph network to extract object interaction features, whereas OA-BTG [16] uses trajectory features on salient objects. ORG-TRL [3] uses Graph convolutional network (GCN) to model object-relational features and an external language model to guide the decoder. Another group of methods focuses on devising a better sampling strategy to pick informative video frames. PickNet [17] uses reward-based objectives to sample informative frames, whereas SGN [18] uses partially decoded caption information to sample frames. Despite the improvements, all these methods suffer from improper training signals, and some effort has already been made to mitigate this issue.
II-B Training on evaluation metric function.
There are mainly three approaches to optimize the sequence to sequence model on the non-differentiable objective function: (i) Ranzato et al. [19] use the REINFORCE algorithm [20] to train an image captioning model directly on BLEU score and Rennie et al. [21] use the Actor-critic method [22]. Both methods use the reward signal, but these methods are not applicable for video captioning due to the sparse nature of the reward. (ii) Optimization on differentiable lower bound where Zhukov et al. [23] propose a differentiable lower bound of expected BLEU score and Casas et al. [24] reported poor training signal corresponding to their formulation of differentiable BLEU score [10]. (iii) Shiqi Shen et al. [25] use Minimum risk training (MRT) instead of Maximum likelihood estimation for neural machine translation, and Wang et al. [26] shows Minimum Risk Training (MRT) helps in reducing exposure bias. Unlike previous works, we leverage successful Transformer based pre-trained models to approximate the evaluation metrics.
III Method
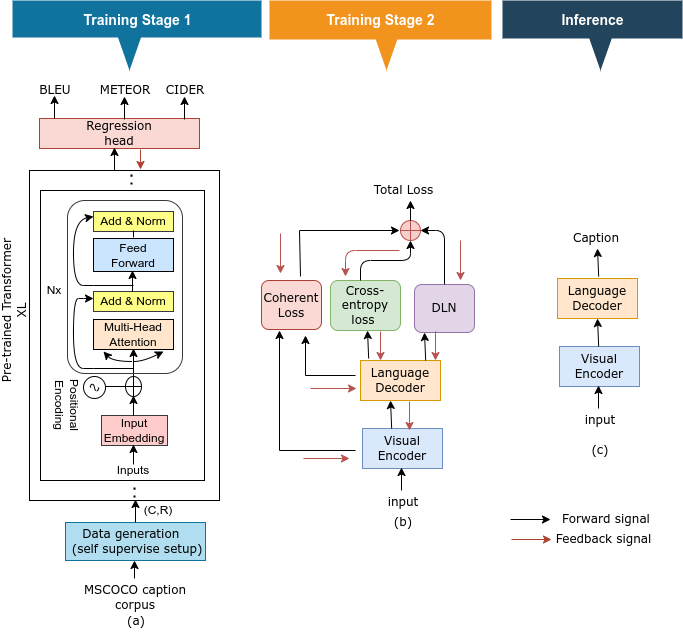
Our proposed method follows a two-stage training process. At the first stage, the DLN is trained in a self-supervised setup, whereas at the second stage, the trained DLN is used along with the existing video captioning model. The entire process flow is in the Fig.2. During the second stage, the loss from the DLN back propagates through the encoder-decoder model and forces it to capture better representation. Moreover, the proposed loss network can be combined with different encoder-decoder architectures for video captioning. Below we describe each component of our model.
III-A Visual Encoder
We uniformly sample N frames and clips from a given input video, where each is a series of clips surrounding frame . We extract appearance features and motion features using pre-trained 2D convnets [27] and 3D convnets [28] , with and , respectively. Apart from appearance and motion , we extract object characteristics through a pre-trained object detection module , where . We select prominent items from each frame based on the objectiveness threshold v and average their features. The appearance and motion characteristics aid in comprehending the video’s global context and motion information. By contrast, object characteristics are more localized, which aids in the comprehension of fine-grained information.
III-B Dynamic Loss Network (DLN)
As shown in Fig.1(a), the proposed DLN is built on top of the encoder-decoder and provides an additional training signal aligned with the evaluation metric. The proposed DLN approximates the evaluation metric BLEU [10], METEOR [11], and CIDER [13], which involves mapping from a pair of sentences to numerical values. Motivated by the tremendous success in vision and natural language processing (NLP), a pre-trained transformer network [29, 30, 31, 32] is used as the backbone for the proposed DLN.
The training of the DLN is achieved in a self-supervised manner. The training data and its ground truth to train the DLN (Fig. 2(a)) are generated following two strategies: (i) we take MSCOCO [33] caption corpus and perturb each sentence randomly with a p% probability to generate (candidate , reference ) pair. For the perturbation, deletion and swapping are done over the word(s). (ii) we train a standard encoder-decoder based video captioning model and gather the predicted and ground truth caption as (candidate, reference) pair at different epochs on MSVD [34] data. In both cases, ground truth (BLEU, METEOR, and CIDER) is generated using the NLTK [35] library and the COCO evaluation [36] server.
The self-attention layer in the transformer network (to be more specific, transformer network with the word as input) calculates the attention score between words. This characteristic makes the transformer network [29] a natural choice to model the metric score function (since BLEU, METEOR, and CIDER are precision and recall based formulas on the n-gram overlap). Although BERT [30] and GPT [31] are state-of-the-art pre-trained transformer architecture, they are not suitable to model metric scores due to subword input tokenization. Instead, we use TransformerXL [32] architecture, which works with standard word input (similar to the LSTM decoder). A regression head has been added on top of the standard TransformerXL [32] network and trained by minimizing the mean square loss between the true and predicted BLEU, METEOR, and CIDER values. The output of DLN is,
| (1) |
where, = , is transformerXL model, W and b are the learnable parameters corresponding to regression head. R, C are reference and candidate sentences, respectively.
Once trained, the DLN is combined with the standard encoder-decoder network at the second stage of training. The proposed DLN is applied only at the training stage, so there is no run-time overhead during inference. As shown in Fig.2(b), the DLN takes inputs from the output of the decoder and ground truth caption. During the backward pass, the output value of DLN is added to cross-entropy loss, and the model is trained on the combined loss function.
III-C Language Decoder
The decoder generates the caption word by word based on the features obtained from the visual encoder. A recurrent neural network is utilized as the backbone of the decoder because of its superior temporal modeling capability. In the proposed system, the decoder is designed using LSTM [7], whose hidden memory at time step can be expressed as
| (2) |
Where is the concatenation of appearance, motion, and object features from the visual encoder and is the hidden memory of time step . To predict the word probability, a linear layer followed by a Softmax layer is added on top of the hidden layers of the LSTM.
| (3) |
where is the word in the caption and and are the learnable parameters and biases, respectively.
III-D Parameter Learning
Along with the typical cross-entropy loss, we train our model with two extra losses: Loss from DLN and Coherent loss.
III-D1 Language Decoder
The cross-entropy or negative log-likelihood function is the typical loss function for an encoder-decoder based video captioning model. For a mini-batch, the loss can be expressed as
| (4) |
Where is learnable parameters, is the video feature, is the word in the sentence of length T, and B is the mini-batch size.
III-D2 DLN Loss
The proposed DLN works in two stages. We train the DLN to predict BLEU, METEOR, and CIDER scores first. We use the Mean square error loss function as the objective for this task, and for a mini-batch, it can be expressed as,
| (5) | ||||
where, is the ground truth and is the model prediction. , , and are hyperparameters to control the relative imporance of three different losses.
The DLN predicts BLEU, METEOR, and CIDER score at the second stage and uses it to optimize the encoder-decoder model. For a mini-batch, the loss is
| (6) | ||||
where, , , are the predicted BLEU, METEOR and CIDER scores from the DLN respectively and , and are the hyperparameters.
III-D3 Coherent Loss
A video’s successive frames are exceedingly repetitious. As a result, the encoding of subsequent frames should be comparable. We use the coherence loss to constrain subsequent frames’ embeddings to be comparable. Coherent loss has been used before to normalise attention weights [2]; however, unlike Pei at al. [2], we use the coherent loss to appearance, motion, and object aspects. For a mini-batch, the total coherence loss is,
| (7) |
where , , and are hyperparameters corresponding to appearance coherent loss , motion coherent loss , object coherent loss and attention coherent loss respectively.
The individual coherent losses are calculated as, , , and where,
| (8) |
| Models | MSVD | MSR-VTT | ||||||
|---|---|---|---|---|---|---|---|---|
| B@4 | M | R | C | B@4 | M | R | C | |
| SA-LSTM [8] | 45.3 | 31.9 | 64.2 | 76.2 | 36.3 | 25.5 | 58.3 | 39.9 |
| h-RNN [37] | 44.3 | 31.1 | - | 62.1 | - | - | - | - |
| hLSTMat [38] | 53.0 | 33.6 | - | 73.8 | 38.3 | 26.3 | - | - |
| RecNet [9] | 52.3 | 34.1 | 69.8 | 80.3 | 39.1 | 26.6 | 59.3 | 42.7 |
| M3 [14] | 52.8 | 33.3 | - | - | 38.1 | 26.6 | - | - |
| PickNet [17] | 52.3 | 33.3 | 69.6 | 76.5 | 41.3 | 27.7 | 59.8 | 44.1 |
| MARN [2] | 48.6 | 35.1 | 71.9 | 92.2 | 40.4 | 28.1 | 60.7 | 47.1 |
| GRU-EVE [39] | 47.9 | 35.0 | 71.5 | 78.1 | 38.3 | 28.4 | 60.7 | 48.1 |
| POS+CG [40] | 52.5 | 34.1 | 71.3 | 88.7 | 42.0 | 28.2 | 61.6 | 48.7 |
| OA-BTG [16] | 56.9 | 36.2 | - | 90.6 | 41.4 | 28.2 | - | 46.9 |
| STG-KD [15] | 52.2 | 36.9 | 73.9 | 93.0 | 40.5 | 28.3 | 60.9 | 47.1 |
| SAAT [41] | 46.5 | 33.5 | 69.4 | 81.0 | 40.5 | 28.2 | 60.9 | 49.1 |
| ORG-TRL [3] | 54.3 | 36.4 | 73.9 | 95.2 | 43.6 | 28.8 | 62.1 | 50.9 |
| SGN [18] | 52.8 | 35.5 | 72.9 | 94.3 | 40.8 | 28.3 | 60.8 | 49.5 |
| Ours | 53.1 | 36.3 | 74.1 | 97.4 | 41.3 | 29.1 | 61.8 | 51.5 |
At the early training phase, cross entropy acts as a better training signal, so we rely more on cross entropy loss. On the other hand, we rely more on loss from the proposed loss network at the later phase of training. The total loss for a mini-batch is
| (9) |
IV Experiments and Results
We have conducted experiments to evaluate the proposed DLN-based video captioning performance on two benchmark datasets: Microsoft Research-Video to Text (MSRVTT) [42] and Microsoft Research Video Description Corpus (MSVD) [34]. In addition, We have compared the performance of our method with the state-of-the-art video captioning methods. Adding DLN provided significant gain to the captioning performance in all metrics.
IV-A Datasets
IV-A1 MSVD
IV-A2 MSRVTT
MSRVTT is the largest open domain video captioning dataset with 10k videos and 20 categories. Each video clip is annotated with 20 sentences, resulting in 200k video-sentence pairs. We have followed the public benchmark splits, i.e., 6513 for training, 497 for validation, and 2990 for testing.
IV-B Implementation Details
We have uniformly sampled 28 frames per video and extracted 1024D appearance features from Vision Transformer [27], pre-trained on ImageNet [43]. The motion features are 2048D and extracted using C3D [28] with ResNeXt-101 [44] backbone and pre-trained on Kinetics-400 dataset. We use Faster-RCNN [45] pre-trained on MSCOCO [33] for object feature extraction. Appearance,motion, and object features are projected to 512D before sending to the decoder. At the decoder end, the hidden layer and the size of the word embedding are both set as 512D. The dimension of the attention module is set to 128D. All the sentences longer than 30 words are truncated, and the vocabulary is built by words with at least 5 occurrences. For the DLN, we use 16 multi-head and 18 layers TransformerXL [32] pre-trained on WikiText-103. A regression head composed of three fully connected (FC) layers is added on the top of the TransformerXL [32]. During both stages of training, the learning rate for DLN and the end-to-end video captioning model is set to 1e-4. Adam [46] is employed for optimization. The model selection is made using the validation set performance. The greedy search is used for the caption generation at the test time. The coherent loss weights , , , and are set as 0.01, 0.1, 0.01, and 0.1, respectively. All the experiments are done in a single Titan X GPU.
IV-C Quantitative Results
We have compared our proposed model with the existing video captioning models on MSVD and MSRVTT datasets, as shown in Table I. All four popular evaluation metrics, including BLEU, METEOR, ROUGE, and CIDER, are reported. From Table I, we can see that our proposed method significantly outperforms other methods, especially in the CIDER score. It is to be noted that CIDER is specially designed to evaluate captioning tasks. Compared to current methods (ORG-TRL [3], STG-KD [15], SAAT [41]), which uses more complex object-relational features, our method only takes mean object localization features for simplicity and to prove the effectiveness of the DLN.
IV-D Ablation Studies
In order to validate the effectiveness of the proposed DLN and prove that improvement is not because of the other components of the model, we perform ablation studies. We added the DLN on top of the methods mentioned in Table II under the same settings provided by the original paper’s authors. We report the METEOR and CIDER scores with and without the DLN on MSVD dataset. From Table II, we can see that adding the DLN has significantly boosted performance.
| Models | RL | MRT | DLN | |||
|---|---|---|---|---|---|---|
| M | C | M | C | M | C | |
| SA-LSTM [8] | 32.1 | 76.7 | 32.3 | 76.1 | 33.1 | 77.2 |
| RecNet [9] | 34.3 | 81.1 | 34.1 | 80.7 | 34.4 | 81.3 |
| M3 [14] | 33.7 | - | 33.4 | - | 34.9 | - |
| PickNet [17] | 33.5 | 77.8 | 33.3 | 77.1 | 34.5 | 78.7 |
| MARN [2] | 35.4 | 93.5 | 35.0 | 92.5 | 35.7 | 93.4 |
The comparison of the performance of the DLN with its competitors on direct metric training is shown in Table III. The experiments are done on the above-mentioned methods under the original settings for a fair comparison. Table III shows that our method outperforms its other counterparts. We report METEOR and CIDER scores for all the comparisons since these two are the most important metric to evaluate captioning tasks.
IV-E Study on the training of the DLN.
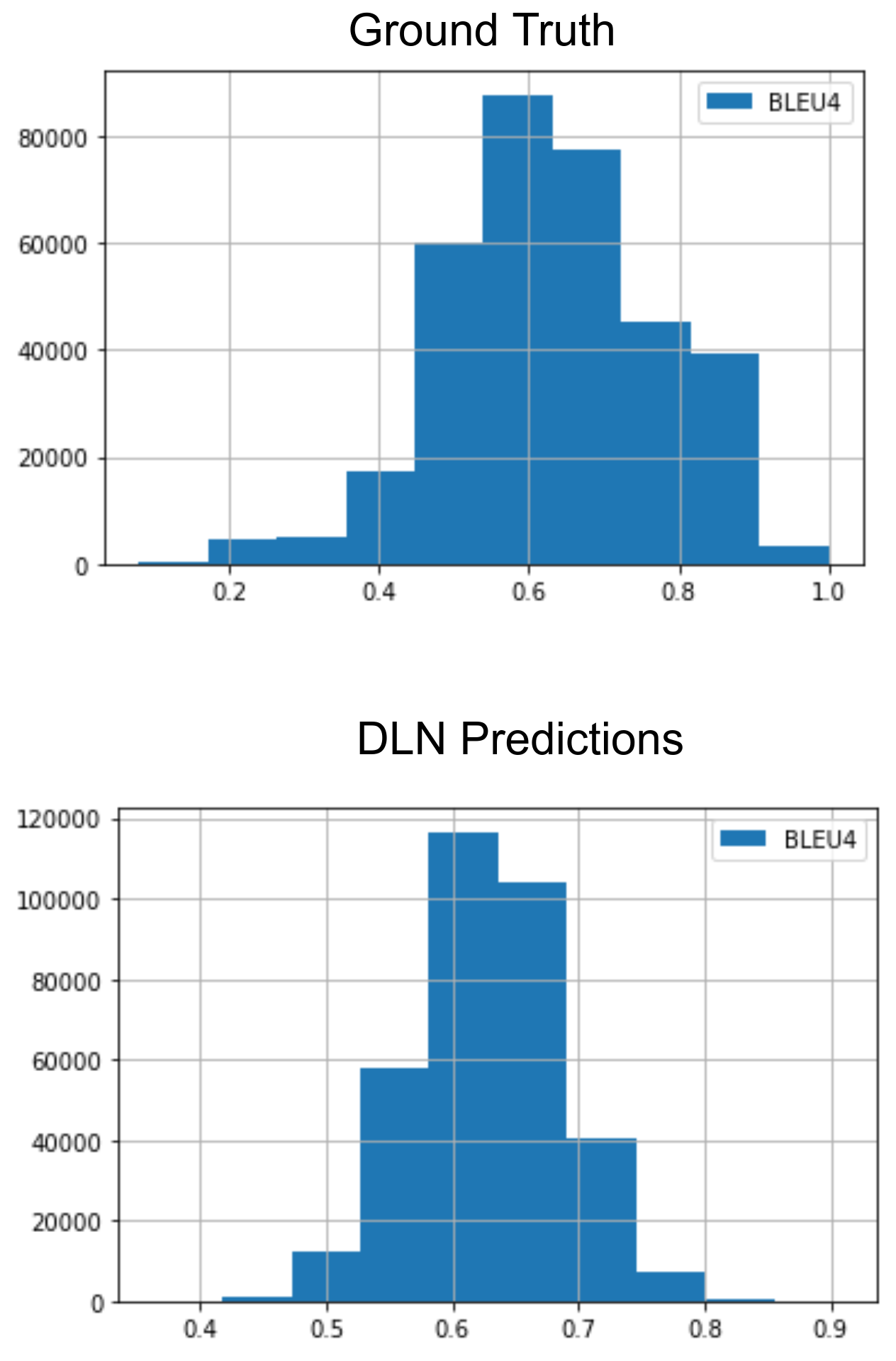
The training of the DLN is performed to predict , , and . When it comes to modeling, DLN is not as effective as other measures. Also, the signal from is not helpful to boost the model performance. The novel idea of the DLN is proposed in this paper, so no benchmark results are available for this task. Hence, the qualitative analysis is performed by comparing histograms of the ground truth and the predicted values on the test set, as shown in Fig.3. We have given the results, whereas the and stage-1 training outcomes are also similar.
IV-F Qualitative Results
The Fig.4 shows the captions generated by our model and MARN [2]. From the figure, we can see that our proposed model performs better than MARN [2] in detecting objects and actions. Also, the captions generated by our model are more grammatically sound.

V Conclusion
This work addresses the training signal evaluation metric alignment mismatch problem of existing video captioning models and proposes a dynamic loss network (DLN), which models the evaluation metric under consideration. The training is performed in two stages, and the experimental results on the benchmark datasets show superior performance than current state-of-the-art models. Also, our approach shows better performance than other existing non-differentiable training strategies for video captioning and can be easily adaptable to similar tasks. Future studies could investigate the effectiveness of our method on other tasks such as image captioning and machine translation.
References
- [1] S. Venugopalan, M. Rohrbach, J. Donahue, R. J. Mooney, T. Darrell, and K. Saenko, “Sequence to sequence - video to text,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2015, pp. 4534–4542. [Online]. Available: https://doi.org/10.1109/ICCV.2015.515
- [2] W. Pei, J. Zhang, X. Wang, L. Ke, X. Shen, and Y. Tai, “Memory-attended recurrent network for video captioning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 8347–8356.
- [3] Z. Zhang, Y. Shi, C. Yuan, B. Li, P. Wang, W. Hu, and Z. Zha, “Object relational graph with teacher-recommended learning for video captioning,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 13 275–13 285.
- [4] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2015. [Online]. Available: http://arxiv.org/abs/1409.0473
- [5] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015. IEEE Computer Society, 2015, pp. 3156–3164. [Online]. Available: https://doi.org/10.1109/CVPR.2015.7298935
- [6] J. Lu, C. Xiong, D. Parikh, and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 3242–3250. [Online]. Available: https://doi.org/10.1109/CVPR.2017.345
- [7] S. Venugopalan, H. Xu, J. Donahue, M. Rohrbach, R. J. Mooney, and K. Saenko, “Translating videos to natural language using deep recurrent neural networks,” in NAACL HLT 2015, The 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, Colorado, USA, May 31 - June 5, 2015, R. Mihalcea, J. Y. Chai, and A. Sarkar, Eds. The Association for Computational Linguistics, 2015, pp. 1494–1504. [Online]. Available: https://doi.org/10.3115/v1/n15-1173
- [8] L. Yao, A. Torabi, K. Cho, N. Ballas, C. J. Pal, H. Larochelle, and A. C. Courville, “Describing videos by exploiting temporal structure,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2015, pp. 4507–4515. [Online]. Available: https://doi.org/10.1109/ICCV.2015.512
- [9] B. Wang, L. Ma, W. Zhang, and W. Liu, “Reconstruction network for video captioning,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 2018, pp. 7622–7631.
- [10] K. Papineni, S. Roukos, T. Ward, and W. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA. ACL, 2002, pp. 311–318. [Online]. Available: https://aclanthology.org/P02-1040/
- [11] S. Banerjee and A. Lavie, “METEOR: an automatic metric for MT evaluation with improved correlation with human judgments,” in Proceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization@ACL 2005, Ann Arbor, Michigan, USA, June 29, 2005, J. Goldstein, A. Lavie, C. Lin, and C. R. Voss, Eds. Association for Computational Linguistics, 2005, pp. 65–72. [Online]. Available: https://aclanthology.org/W05-0909/
- [12] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013
- [13] R. Vedantam, C. L. Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015. IEEE Computer Society, 2015, pp. 4566–4575. [Online]. Available: https://doi.org/10.1109/CVPR.2015.7299087
- [14] J. Wang, W. Wang, Y. Huang, L. Wang, and T. Tan, “M3: multimodal memory modelling for video captioning,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 2018, pp. 7512–7520.
- [15] B. Pan, H. Cai, D. Huang, K. Lee, A. Gaidon, E. Adeli, and J. C. Niebles, “Spatio-temporal graph for video captioning with knowledge distillation,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 10 867–10 876.
- [16] J. Zhang and Y. Peng, “Object-aware aggregation with bidirectional temporal graph for video captioning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 8327–8336.
- [17] Y. Chen, S. Wang, W. Zhang, and Q. Huang, “Less is more: Picking informative frames for video captioning,” in Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XIII, ser. Lecture Notes in Computer Science, V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss, Eds., vol. 11217. Springer, 2018, pp. 367–384. [Online]. Available: https://doi.org/10.1007/978-3-030-01261-8_22
- [18] H. Ryu, S. Kang, H. Kang, and C. D. Yoo, “Semantic grouping network for video captioning,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, 2021, pp. 2514–2522. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/16353
- [19] M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level training with recurrent neural networks,” in 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2016. [Online]. Available: http://arxiv.org/abs/1511.06732
- [20] R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, pp. 229–256, 2004.
- [21] S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel, “Self-critical sequence training for image captioning,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 1179–1195. [Online]. Available: https://doi.org/10.1109/CVPR.2017.131
- [22] A. M. Andrew, “Reinforcement Learning: An Introduction by richard s. sutton and andrew g. barto, adaptive computation and machine learning series, MIT press (bradford book), cambridge, mass., 1998, xviii + 322 pp, ISBN 0-262-19398-1, (hardback, £31.95),” Robotica, vol. 17, no. 2, pp. 229–235, 1999. [Online]. Available: http://journals.cambridge.org/action/displayAbstract?aid=34601
- [23] V. Zhukov and M. Kretov, “Differentiable lower bound for expected BLEU score,” CoRR, vol. abs/1712.04708, 2017. [Online]. Available: http://arxiv.org/abs/1712.04708
- [24] N. Casas, J. A. R. Fonollosa, and M. R. Costa-jussà, “A differentiable BLEU loss. analysis and first results,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net, 2018. [Online]. Available: https://openreview.net/forum?id=HkG7hzyvf
- [25] S. Shen, Y. Cheng, Z. He, W. He, H. Wu, M. Sun, and Y. Liu, “Minimum risk training for neural machine translation,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Papers. The Association for Computer Linguistics, 2016. [Online]. Available: https://doi.org/10.18653/v1/p16-1159
- [26] C. Wang and R. Sennrich, “On exposure bias, hallucination and domain shift in neural machine translation,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, D. Jurafsky, J. Chai, N. Schluter, and J. R. Tetreault, Eds. Association for Computational Linguistics, 2020, pp. 3544–3552. [Online]. Available: https://doi.org/10.18653/v1/2020.acl-main.326
- [27] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy
- [28] K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 2018, pp. 6546–6555.
- [29] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5998–6008.
- [30] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Association for Computational Linguistics, 2019, pp. 4171–4186. [Online]. Available: https://doi.org/10.18653/v1/n19-1423
- [31] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- [32] Z. Dai, Z. Yang, Y. Yang, J. G. Carbonell, Q. V. Le, and R. Salakhutdinov, “Transformer-xl: Attentive language models beyond a fixed-length context,” in Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, A. Korhonen, D. R. Traum, and L. Màrquez, Eds. Association for Computational Linguistics, 2019, pp. 2978–2988. [Online]. Available: https://doi.org/10.18653/v1/p19-1285
- [33] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, ser. Lecture Notes in Computer Science, D. J. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds., vol. 8693. Springer, 2014, pp. 740–755. [Online]. Available: https://doi.org/10.1007/978-3-319-10602-1_48
- [34] D. L. Chen and W. B. Dolan, “Collecting highly parallel data for paraphrase evaluation,” in The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, 19-24 June, 2011, Portland, Oregon, USA, D. Lin, Y. Matsumoto, and R. Mihalcea, Eds. The Association for Computer Linguistics, 2011, pp. 190–200. [Online]. Available: https://aclanthology.org/P11-1020/
- [35] N. Xue, “Steven bird, evan klein and edward loper. Natural Language Processing with Python. o’reilly media, inc 2009. ISBN: 978-0-596-51649-9,” Nat. Lang. Eng., vol. 17, no. 3, pp. 419–424, 2011. [Online]. Available: https://doi.org/10.1017/S1351324910000306
- [36] X. Chen, H. Fang, T. Lin, R. Vedantam, S. Gupta, P. Dollár, and C. L. Zitnick, “Microsoft COCO captions: Data collection and evaluation server,” CoRR, vol. abs/1504.00325, 2015. [Online]. Available: http://arxiv.org/abs/1504.00325
- [37] H. Yu, J. Wang, Z. Huang, Y. Yang, and W. Xu, “Video paragraph captioning using hierarchical recurrent neural networks,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 4584–4593. [Online]. Available: https://doi.org/10.1109/CVPR.2016.496
- [38] J. Song, L. Gao, Z. Guo, W. Liu, D. Zhang, and H. T. Shen, “Hierarchical LSTM with adjusted temporal attention for video captioning,” in Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017, C. Sierra, Ed. ijcai.org, 2017, pp. 2737–2743. [Online]. Available: https://doi.org/10.24963/ijcai.2017/381
- [39] N. Aafaq, N. Akhtar, W. Liu, S. Z. Gilani, and A. Mian, “Spatio-temporal dynamics and semantic attribute enriched visual encoding for video captioning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 12 487–12 496.
- [40] B. Wang, L. Ma, W. Zhang, W. Jiang, J. Wang, and W. Liu, “Controllable video captioning with POS sequence guidance based on gated fusion network,” in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 2019, pp. 2641–2650. [Online]. Available: https://doi.org/10.1109/ICCV.2019.00273
- [41] Q. Zheng, C. Wang, and D. Tao, “Syntax-aware action targeting for video captioning,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 13 093–13 102.
- [42] J. Xu, T. Mei, T. Yao, and Y. Rui, “MSR-VTT: A large video description dataset for bridging video and language,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 5288–5296. [Online]. Available: https://doi.org/10.1109/CVPR.2016.571
- [43] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and L. Fei-Fei, “Imagenet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, 2015. [Online]. Available: https://doi.org/10.1007/s11263-015-0816-y
- [44] S. Xie, R. B. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 5987–5995. [Online]. Available: https://doi.org/10.1109/CVPR.2017.634
- [45] S. Ren, K. He, R. B. Girshick, and J. Sun, “Faster R-CNN: towards real-time object detection with region proposal networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2017. [Online]. Available: https://doi.org/10.1109/TPAMI.2016.2577031
- [46] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2015. [Online]. Available: http://arxiv.org/abs/1412.6980