Boosting Federated Learning Convergence with Prototype Regularization
Abstract
As a distributed machine learning technique, federated learning (FL) requires clients to collaboratively train a shared model with an edge server without leaking their local data. However, the heterogeneous data distribution among clients often leads to a decrease in model performance. To tackle this issue, this paper introduces a prototype-based regularization strategy to address the heterogeneity in the data distribution. Specifically, the regularization process involves the server aggregating local prototypes from distributed clients to generate a global prototype, which is then sent back to the individual clients to guide their local training. The experimental results on MNIST and Fashion-MNIST show that our proposal achieves improvements of 3.3% and 8.9% in average test accuracy, respectively, compared to the most popular baseline FedAvg. Furthermore, our approach has a fast convergence rate in heterogeneous settings.
I Introduction
Over the past decade, significant progress has been made in deep learning, giving rise to a succession of impressive advancements in both large language models [1, 2, 3] and large vision models [4, 5, 6]. Concurrently, there has been an explosive growth of intelligent devices in distributed networks, generating a massive amount of raw data that requires processing. To address this situation, a powerful distributed machine learning paradigm called federated learning (FL) has been introduced. FL is a powerful distributed machine learning paradigm that enables edge clients and servers to collaboratively train models without compromising the privacy of the underlying data [7]. However, the data distribution of clients in federated scenarios is usually not Independent and Identically Distributed (non-IID), which can result in poor model performance [8, 9, 10, 11]. There have been some studies exploring how to enhance the performance of FL in non-IID settings. FedAvg [7] is the first optimization algorithm designed to address the challenge of data heterogeneity in federated scenarios. MPFed [8] proposes a framework for addressing non-IID challenges in federated learning. The authors utilize a multi-prototype approach, where clients and the server adopt a typical FL approach for training, and model inference is based on the distance between local representations and the target prototype. CDFed [9] proposes a dynamic federated learning paradigm based on Sharpley-value, where each client calculates its contribution to the global model in each iteration, thereby determining the probability of being selected for the next global iteration. Although effective, both of these strategies have high algorithmic complexity, which may pose difficulties in practical deployment. Furthermore, recent works in [10, 12] propose a prototype-based model inference strategy, which is claimed to achieve faster convergence than the baseline FedAvg. However, they only adopted a prototype-based approach for model inference without modifying the federated learning process, which may not fully leverage the potential of prototypes.
In this paper, we propose to use prototype regularization to assist local training of clients, which makes better use of the prototype knowledge shared by each client. A prototype is a vector representation of a class space, and learning different prototype representations from clients can provide global information about the class space. Specifically, in each global iteration, the server aggregates the prototypes from all clients as the global prototype and transmits it along with the updated model parameters to the clients to assist them in their next local training. The main contributions can be summarized as follows:
-
•
Our proposed federated training framework is based on prototypes, where both prototypes and model parameters are simultaneously optimized and updated in each iteration.
-
•
We propose a prototype-based regularization strategy, in which clients learn from the global prototype shared by all clients by minimizing the distance between their local representations and the global prototype.
-
•
Finally, based on experiments conducted on two widely-used benchmark datasets, MNIST[13] and Fashion-MNIST[14], our proposed approach achieves significant improvements in test accuracy by 3.3% and 8.9%, respectively, compared to the most popular baseline method, FedAvg. Moreover, our approach exhibits a faster convergence rate in the heterogeneous setting.
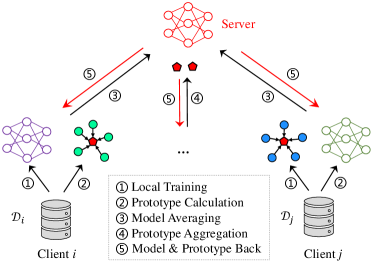
II Proposed Framework
II-A Problem Statement
Consider a distributed set of clients with their private sensitive datasets of size in a distributed edge network. In a typical federated learning (FL) training process, clients and the edge server work together to train a shared model , where represents the model parameters of the global model, and represents the feature vector of a specific client . The goal is to minimize the loss function across clients with heterogeneous data, as proposed in [8]:
| (1) |
where represents the label of a sample, and denotes the cross-entropy loss of client , respectively.
II-B Proposed Federated Learning Framework
The typical federated training process involves distributing the global model to each client for local training, updating the model parameters independently, and aggregating the uploaded latest model parameters at the server before sending them back to the local sides for the next communication round. Our proposed framework follows a similar process, with the addition that in each global round, clients calculate their own prototypes for each class and send them to the server along with the model parameters for aggregation. Finally, the aggregated prototypes and the updated model parameters are sent back to local clients for further training. Figure 1 provides an overview of our proposed framework.
II-C Prototype-based Model Training
In a typical deep learning model, there are two components: a feature extraction layer denoted by , and a decision-making layer denoted by . The feature extraction layer is designed to extract features from the input data, and the decision-making layer is responsible for utilizing these extracted features to make predictions or classifications.
II-C1 Prototype Calculation
According to the prototype definition proposed by [8], the prototype corresponding to the -th class of client -th can be calculated as follows:
| (2) |
where refers to the distribution of samples in the -th class belonging to client -th, and denotes the size of this distribution. This formula aims to calculate the average of the feature representations obtained from the feature extraction layer of all the samples in .
II-C2 Global Prototype Aggregation
The prototypes computed using the Eq. 2 can be aggregated by sending them to the server, and the aggregation process can be defined as follows [10]:
| (3) |
where denotes the total number of clients in the network, and represents the prototype vector for the -th class of client -th, as computed by Eq. 2. The aggregation process involves computing the average of these prototypes from all clients that have samples of the -th class, resulting in a global prototype vector .
II-C3 Local Objective
The global representation for each class obtained through Eq. 3 can be utilized for regularization purposes. Specifically, the loss function for each client can be defined as follows:
| (4) |
where belongs to which represents the set of global prototypes, is the supervised learning loss, and calculates the distance between the local representation and the corresponding global prototype in . Detailed training processes are presented in Algorithm 1.
III Experiments
III-A Dataset and Local Model
To compare our strategy with the baseline FedAvg, we use two benchmark datasets: MNIST [13] and Fashion-MNIST [14]. MNIST is a dataset composed of handwritten digits used for recognition tasks, while Fashion-MNIST consists of various clothing images. Both datasets share the same image size of 28x28x1 pixels. For both the MNIST and Fashion-MNIST datasets in our experiments, we employ a 4-layer CNN network comprising of 2 convolutional layers and 2 fully connected layers. Similar networks have also been used in previous research [8, 9].

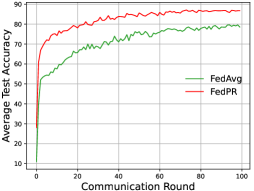
III-B Implementation Details
For all experiments, we use 10 clients. We use the SGD optimizer for all baselines, and the SGD momentum is set to 0.5. The other training parameters for both MNIST and Fashion-MNIST datasets are set to = 8 and = 0.01, which represent the local batch size and learning rate, respectively. We denote local epoch as , and set = 1 for MNIST and = 5 for Fashion-MNIST. To simulate the non-IID situation, we sample 2000 samples from the training dataset and distribute to all clients based on Dirichlet distribution Dir () [15], where the smaller the value of , the more unbalanced the distribution of data is among clients.
III-C Accuracy and Communication Efficiency Comparison
We compare our proposal with the most popular baseline FedAvg with Dir(0.05). The accuracy and communication efficiency for comparison of all methods on MNIST and Fashion-MNIST are shown in Fig.2 and Fig.3, respectively. It shows that our prototype-based regularization strategy achieves the higher test accuracy and faster convergence rate in each global communication round than the baseline FedAvg on both these two datasets. We take the test results of the last 10 rounds for both MNIST and Fashion-MNIST, and calculate the average test accuracy for our FedPR and FedAvg. For MNIST, the average accuracy of FedPR and FedAvg is 94.62% and 91.57% respectively, while for Fashion-MNIST, the average accuracy of FedPR and FedAvg is 86.05% and 79.04% respectively. In other words, our proposed approach achieves 3.3% higher accuracy than FedAvg on MNIST and 8.9% higher accuracy on Fashion-MNIST when is set to 0.05.
IV Conclusion
In this article, we have proposed a FL framework based on prototype regularization to improve the model convergence rate. Specifically, we first introduce the prototype computation method, followed by the prototype aggregation method. Finally, we propose a prototype-based regularization strategy to regularize the local training of each client. Experimental results show that compared to the baseline FedAvg, our strategy can improve accuracy by 3.3% and 8.9% on MNIST and Fashion-MNIST, respectively, and achieve faster convergence speed. For future work, our proposal will be combined with other state-of-the-art methods and tested on more datasets.
References
- [1] C. Zhang, C. Zhang, M. Zhang, and I. S. Kweon, “Text-to-image diffusion model in generative ai: A survey,” arXiv preprint arXiv:2303.07909, 2023.
- [2] C. Zhang, C. Zhang, S. Zheng, Y. Qiao, C. Li, M. Zhang, S. K. Dam, C. M. Thwal, Y. L. Tun, L. L. Huy et al., “A complete survey on generative ai (aigc): Is chatgpt from gpt-4 to gpt-5 all you need?” arXiv preprint arXiv:2303.11717, 2023.
- [3] C. Zhang, C. Zhang, C. Li, Y. Qiao, S. Zheng, S. K. Dam, M. Zhang, J. U. Kim, S. T. Kim, J. Choi et al., “One small step for generative ai, one giant leap for agi: A complete survey on chatgpt in aigc era,” arXiv preprint arXiv:2304.06488, 2023.
- [4] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
- [5] Y. Qiao, C. Zhang, T. Kang, D. Kim, S. Tariq, C. Zhang, and C. S. Hong, “Robustness of sam: Segment anything under corruptions and beyond,” arXiv preprint arXiv:2306.07713, 2023.
- [6] C. Zhang, D. Han, Y. Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong, “Faster segment anything: Towards lightweight sam for mobile applications,” arXiv preprint arXiv:2306.14289, 2023.
- [7] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- [8] Y. Qiao, M. S. Munir, A. Adhikary, A. D. Raha, S. H. Hong, and C. S. Hong, “A framework for multi-prototype based federated learning: Towards the edge intelligence,” in 2023 International Conference on Information Networking (ICOIN). IEEE, 2023, pp. 134–139.
- [9] Y. Qiao, M. S. Munir, A. Adhikary, A. D. Raha, and C. S. Hong, “Cdfed: Contribution-based dynamic federated learning for managing system and statistical heterogeneity,” in NOMS 2023-2023 IEEE/IFIP Network Operations and Management Symposium. IEEE, 2023.
- [10] Y. Qiao, S.-B. Park, S. M. Kang, and C. S. Hong, “Prototype helps federated learning: Towards faster convergence,” arXiv preprint arXiv:2303.12296, 2023.
- [11] Y. Qiao, C. Zhang, H. Q. Le, A. D. Raha, A. Adhikary, and C. S. Hong, “Knowledge distillation in federated learning: Where and how to distill?” in 2023 24th Asia-Pacific Network Operations and Management Symposium (APNOMS). IEEE, 2023, pp. 1–6.
- [12] Y. Qiao, M. S. Munir, A. Adhikary, H. Q. Le, A. D. Raha, C. Zhang, and C. S. Hong, “Mp-fedcl: Multi-prototype federated contrastive learning for edge intelligence,” arXiv preprint arXiv:2304.01950, 2023.
- [13] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [14] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [15] M. Yurochkin, M. Agarwal, S. Ghosh, K. Greenewald, N. Hoang, and Y. Khazaeni, “Bayesian nonparametric federated learning of neural networks,” in International conference on machine learning. PMLR, 2019, pp. 7252–7261.