BIPS: Bi-modal Indoor Panorama Synthesis via Residual Depth-aided Adversarial Learning
Abstract
Providing omnidirectional depth along with RGB information is important for numerous applications, e.g., VR/AR. However, as omnidirectional RGB-D data is not always available, synthesizing RGB-D panorama data from limited information of a scene can be useful. Therefore, some prior works tried to synthesize RGB panorama images from perspective RGB images; however, they suffer from limited image quality and can not be directly extended for RGB-D panorama synthesis. In this paper, we study a new problem: RGB-D panorama synthesis under the arbitrary configurations of cameras and depth sensors. Accordingly, we propose a novel bi-modal (RGB-D) panorama synthesis (BIPS) framework. Especially, we focus on indoor environments where the RGB-D panorama can provide a complete 3D model for many applications. We design a generator that fuses the bi-modal information and train it with residual-aided adversarial learning (RDAL). RDAL allows to synthesize realistic indoor layout structures and interiors by jointly inferring RGB panorama, layout depth, and residual depth. In addition, as there is no tailored evaluation metric for RGB-D panorama synthesis, we propose a novel metric to effectively evaluate its perceptual quality. Extensive experiments show that our method synthesizes high-quality indoor RGB-D panoramas and provides realistic 3D indoor models than prior methods. Code will be released upon acceptance.
1 Introduction
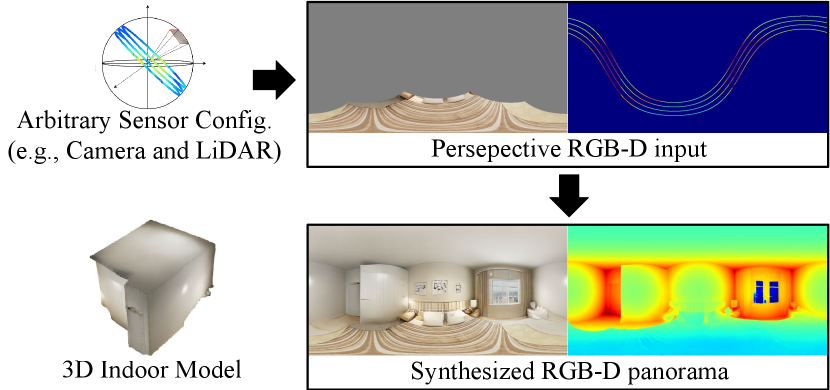
Providing omnidirectional depth along with RGB information is important for numerous applications, e.g., VR/AR. However, as the omnidirectional RGB-D data is not always available, synthesizing RGB-D panorama data from the limited information of the scene can be useful. Even though prior works have tried to synthesize RGB panorama images from perspective RGB images [21, 61], these methods show limited performance on synthesizing panoramas from small partial views and can not be directly extended for RGB-D panorama synthesis.
By contrast, jointly learning to synthesize depth data along with the RGB images allows to synthesize RGB-D panorama with two distinct advantages: (1) RGB images and depth data share the semantic correspondence that can improve the quality of the output RGB-D panorama. (2) Synthesized depth panorama provides omnidirectional 3D information, which can be potentially applied to plentiful applications. Therefore, it is promising to synthesize RGB-D panorama from the cameras and depth sensors, such that we can synthesizing realistic 3D indoor models.
In this paper, we consider a novel problem: RGB-D panorama synthesis from limited input information about a scene. To maximize the usability, we consider the arbitrary configurations of cameras and depth sensors. To this end, we design the arbitrary sensor configurations by randomly sampling the number of sensors, their intrinsic parameters, and extrinsic parameters, assuming that the sensors are calibrated such that we can align the depth data with the RGB image. This enables to represent most of the possible combinations of cameras and depth sensors. Accordingly, we propose a novel bi-modal panorama synthesis (BIPS) framework to synthesize RGB-D indoor panoramas from the camera and depth sensors in arbitrary configurations via adversarial learning (See Fig. 2). Especially, we focus on the indoor environments as the RGB-D panorama can provide the complete 3D model for many applications. We thus design a generator that fuses the bi-modal (RGB and depth) features. Through the generator, multiple latent features from one branch can help the other by providing the relevant information of different modality.
For synthesizing the depth of indoor scenes, we rely on the fact that the overall layout usually made of flat surfaces, while interior components have various structures. Thus, we propose to separate the depth of a scene into two components: layout depth and residual depth . Here, corresponds to the depth of planar surfaces, and corresponds to the depth of other objects, e.g., furniture. With this relation, we propose a joint learning scheme called Residual Depth-aided Adversarial Learning (RDAL). RDAL jointly trains RGB panorama, layout depth and residual depth to synthesize more realistic RGB-D panoramas and 3D indoor models (Sec. 3.2.1).
Previously, some metrics [57, 23] have been proposed to evaluate the outputs of generative models using latent feature distribution of a pre-trained classification network [63]. However, the input modality of utilizing off-the-shelf network is only limited to perspective RGB images. Therefore, a new tailored evaluation metric for RGB-D panoramas is needed. For this reason, we propose a novel metric, called Fréchet Auto-Encoder Distance (FAED), to evaluate the perceptual quality for RGB-D panorama synthesis (Sec. 3.3). FAED adopts an auto-encoder to reconstruct the inputs from latent features with unlabeled dataset. Then, the latent feature distribution of the trained auto-encoder is used to calculate the Fréchet distance between the synthesized and real RGB-D data.
Extensive experimental results demonstrate that our RGB-D panorama synthesis method significantly outperforms the extensions of the prior image inpainting [47, 89, 62], image outpainting [33, 61], and image-guided depth synthesis methods [12, 52, 38, 25] modified to synthesize RGB-D panorama from partial arbitrary RGB-D inputs. Moreover, we show the validity of the proposed FAED for evaluating the quality of synthesized RGB-D panorama by showing how well it captures the disturbance level [23].
In summary, our main contributions are three-fold: (I) We introduce a new problem of generating RGB-D panoramas from partial and arbitrary RGB-D inputs. (II) We propose a BIPS framework that allows to synthesize RGB-D panoramas via residual depth-aided adversarial learning. (III) We introduce a novel evaluation metric, FAED, for RGB-D panorama synthesis and demonstrate its validity.
2 Related Works
Image Inpainting Conventional approaches explore diffusion or patch matching [5, 6, 8, 14, 17, 9, 15]. However, they require visible regions sufficiently enough to inpaint the missing regions, thus limiting their ability to synthesize novel textures or structures. The learning-based methods often use generative adversarial networks (GANs) to synthesize texture or structures [90, 39, 27, 80], optimized by the minimax loss [28]. Some works explored different convolution layers, e.g., partial convolution [41] and gated convolution [81, 51], to better handle invalid pixels in the input data to the convolution kernel. Moreover, attention mechanism [66, 67] has also been applied to better capture the contextual information and handle missing contents [80, 76, 42, 71, 40]. Recently, research has been made to synthesize high-resolution outputs [60, 73, 53] or semantically diverse outputs [43, 88]. Although endeavours have been made to tackle this large completion problem [47, 89, 62], they often fail to synthesize visually pleasing panoramas due to only using perspective RGB inputs.
Image Outpainting Conventional methods extend an input image to a larger seamless one; however, they require manual guidance [4, 7, 87] or image sets of the same scene category [30, 59, 70]. By contrast, learning-based methods synthesize large images with novel textures that do not exist in the input perspective image [56, 35, 75, 19, 31, 83, 48, 20, 32]. Some approaches focus on driving scenes [74, 85] or synthesize panorama-like landscapes with iterative extension or multiple perspective images [79, 33, 21, 61]. Although performance has been greatly improved so far, the existing methods are still afflicted by the limited quality from the perspective images.
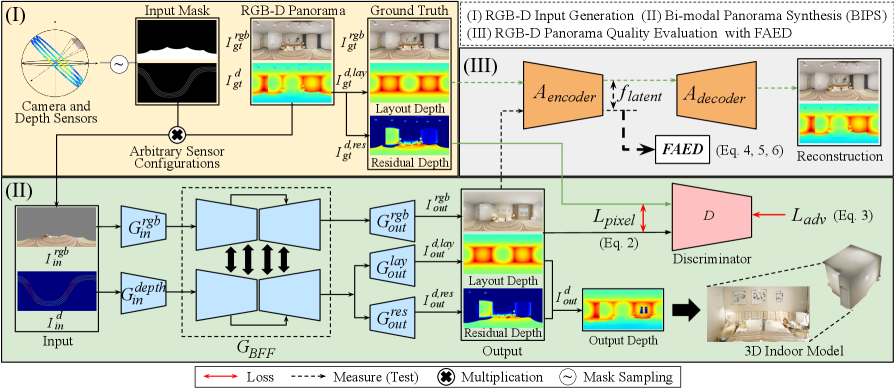
Image-guided Depth Synthesis One line of research attempts to fuse the bi-modal information, i.e., the RGB image and sparse depth. Some methods, e.g. [45], fuse the sparse depth and RGB image via early fusion while others [44, 29, 64, 18, 37, 26] utilize a late fusion scheme, or jointly utilize both the early and late fusion [65, 36, 68]. Another line of research focuses on utilizing affinity or geometric information of the scene via surface normal, occlusion boundaries, and the geometric convolutional layer [34, 54, 77, 86, 25, 12, 11, 52]. However, these works only generate dense depth maps that has the same FoV as the input perspective RGB images.
Evaluation of Generative Models Image quality assessment can be classified into three groups: full-reference (FR), reduced-reference (RR), and no-reference (NR). There exist many conventional FR metrics, e.g., PSNR, MSE, and SSIM, and deep learning (DL)-based FR metrics, e.g., LPIPS [84]. These metrics typically calculate either pixel-wise, or patch-wise similarity to the ground truth images. By contrast, NR methods, e.g., BRISQUE [49] and NIQE [50] assess image quality without any reference image. Among the DL-based NR metrics, Inception Score (IS) [57] and Fréchet Inception Distance (FID) [23] are two popular approaches [2]. IS and FID scores are calculated based on pretrained classification models, e.g., Inception model [63], aiming to capture the high-level features. Unfortunately, these metrics are less applicable for RGB-D panorama evaluation because (1) they are trained only with perspective RGB images, and (2) there are no labeled panorama images to train them. Therefore, they are highly sensitive to the distortion of panoramic images, making them hard to capture perceptual quality properly on panoramic images. Furthermore, naively using them on RGB-D information leads to imprecise measure of the semantic correspondence between the two different modalities. Therefore, we propose FAED, which aims to evaluate RGB-D panorama quality between the RGB and depth pairs. FAED can be adaptively applied to generative models on multi-modal domain, that lacks labeled dataset.
3 Proposed Methods
3.1 Problem Formulation
Previous works, e.g., [61, 21] generate an equirectangular projection (ERP) image () from input perspective image(s) (). Then, an RGB panorama can be created via a function , mapping into a [22], which can be formulated as .
However, as it is crucial to provide omnidirectional depth information [55, 1] in many applications, many studies tried to synthesize depth panoramas from input RGB panorama images and partial depth measurements [69, 24]. One solution to synthesize an RGB-D panorama would be to first synthesize RGB panorama from input perspective images, and then utilizing the depth synthesis methods to generate an omnidirectional depth map. However, such an approach is cumbersome and less effective, as shown in the experimental results (See Table 3). We solve this novel yet challenging problem by jointly utilizing the input RGB image () and depth data (). Our goal is to directly generate the RGB panorama () and depth panorama () simultaneously via a mapping function , which can be described as . can be formulated by learning a single network to synthesize and using and obtained in arbitrary sensor configurations. As the information in the left and right boundaries in ERP images should be connected, our designed G uses circular padding [58] before each convolutional operation.
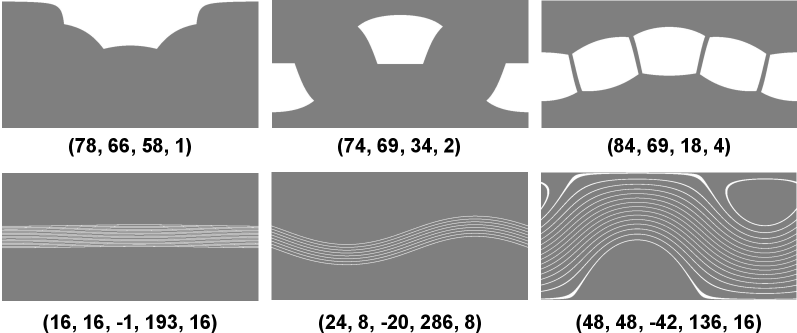
Consequently, we configure the parameters of cameras and depth sensors, and randomly sample the parameters to provide the input to the during training. These parameters can handle most of the possible sensor configurations. Figure 3 shows the input masks, sampled from the sensor configurations. To handle the cases where only cameras or depth sensors are used, we choose whether to use cameras only, depth sensors only, or both, randomly.
Parameters of RGB Cameras We denote the parameters of RGB cameras, horizontal FoV as , vertical FoV as , pitch angle as , and number of viewpoints as . When , we arrange the viewpoints in a circle having the sampled pitch angle from the equator and at the same intervals. We do not consider roll and yaw, as they do not affect the results (i.e., the output is equivariant to the horizontal shift of input) thanks to using circular padding. Practically, we sample the parameters from , , , and , where represents uniform distribution.
Parameters of Depth Sensors can be obtained from mechanical LiDARs or perspective depth sensors, thus we should generate arbitrary depth input masks for both. For the LiDARs, we denote the parameters as lower FoV , upper FoV , pitch angle , yaw angle , and the number of channels . The yaw angle is needed here to consider the relative yaw motion to the camera arrangement. For the perspective depth sensors providing dense depth, they have many similar parameters and viewpoints with those of the RGB-D cameras. Therefore, we use the same sampled parameters with the cameras (i.e., ). In practice, we first sample the parameters from , , and . Then, we sample and from . Finally, our problem is formulated as:
| (1) |
3.2 RGB-D Panorama Synthesis Framework
Overview An overview of the proposed BIPS framework is depicted in Fig. 2. BIPS consists of a generator (Sec.3.2.1) and a discriminator (Sec. 3.2.2). takes the perspective RGB image and depth as inputs. We notice that the quality of the RGB-D panorama depends on both the overall (mostly rectangular) layout and how the furniture are arranged in the indoor scene. Inspired by [82], we separate the depth data into layout depth , and residual depth (the interior components) which is defined as ( - ). The generator outputs the RGB panorama image , the layout depth and residual depth simultaneously. As these are jointly trained with adversarial loss, we call this learning scheme as Residual Depth-aided Adversarial Learning (RDAL).
3.2.1 Generator
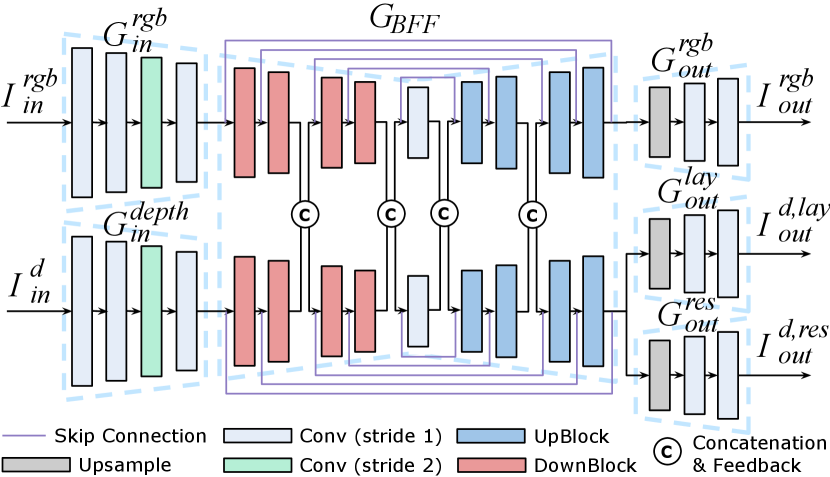
Input Branch consists of two encoding branches, and which takes and , respectively. These branches independently process and with six conv layers before fusing them. As the inputs have a resolution of 512 1024, the filter size of the first conv layer is set as 7 and then reduced to 3 and 4 gradually.
Bi-modal Feature Fusion (BFF) Branch BFF branch takes and as inputs, as shown in Fig. 4. Although and depth are in two different modalities, we assume that the cameras and depth sensors are well calibrated and synchronized. Then, to utilize this highly correlated bi-modal information in its two branches, consists of two-stream encoder-decoder networks fusing the bi-modal features. These two encoder-decoder networks have an identical structure (see Fig. 4).
Moreover, the bi-modal features are fused in between the layers of . In particular, the features from both branches are concatenated and fed back to each other. Overall, the fusion is done after the features pass two ‘DownBlocks’ and before passing two ‘UpBlocks’. In addition, multi-scale residual connections are used to vitalize transfer of information between the layers and branches. As multiple latent features from one branch help the other by sharing the information apart in both ways, can generate features by fully exploiting the information of the 3D scene.
The Output Branch Realistic indoor space comes from precise layout structure and high perceptual interior. Therefore, to enable RDAL to jointly train the layout and residual depth of the indoor scene, we design to have three decoding branches. Each of them generates RGB panorama , layout depth panorama , and residual depth panorama respectively, as shown in Fig. 4. Intuitively, determines the layout structure and determines the interior objects. Then, element-wise addition of and gives the output total depth map panorama.
3.2.2 Discriminator
We use the multi-scale discriminator from [72], but modify it to have five input and output channels (three for , one for , one for ). The detailed discriminator structure can be found in the suppl. material.
3.2.3 Loss Function
For training , we use weighted sum of pixel-wise L1 loss and adversarial loss. The pixel-wise L1 loss between the GT and the output panorama, denoted as , consists of three terms as the has three outputs (RGB, layout depth, residual depth panorama):
| (2) |
For the adversarial loss , we used LSGAN loss [46]: , where is concatenation of generator outputs , and , and is a discriminator trained to output for GT and for with MSE loss. By decomposing the total depth loss into and , our RDAL scheme allows the generator to synthesize RGB-D panorama that generates highly plausible interior. Finally, the total loss for generator is:
| (3) |
where is a weighting factor. The generator is trained by minimizing the total loss . Detailed loss terms can be found in the suppl. material.
3.3 Fréchet Auto-Encoder Distance (FAED)
3.3.1 Auto-Encoder Network
Similar to the high-level features in a CNN trained with large-scale semantic labels, latent features in a trained auto-encoder also contain high-level information, as it is forced to reconstruct the input from the latent features. Therefore, we propose to train an auto-encoder, which can be done without any labels in the dataset, and use the latent features in the auto-encoder to extract perceptually meaningful information. In this way, performance evaluation can be performed for any data that lacks a labeled dataset. The auto-encoder consists of an encoder and decoder: and , as shown in Fig. 5. The detailed structure of is given in the suppl. material.
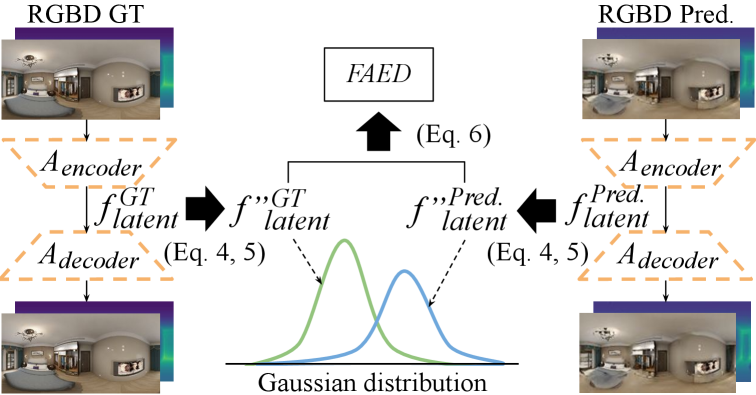
3.3.2 Calculation of FAED for RGB-D Panorama
We denote at -th channel, -th row, and -th column as . Note that as we use ERP, the and has one-to-one relation to latitude and longitude.
Longitudinal Invariance To evaluate the performance of , we extract from generated samples using . However, as we generate the upright ERP image, it is expected to have a distance metric that is invariant to the longitudinal shift. This is because an upright ERP panorama represents the same scene when it’s cyclically shifted in the longitudinal direction. Therefore, to make the resulting distance metric invariant to the longitudinal shift, we take the mean for the longitudinal direction of as:
| (4) |
Latitudinal Equivariance As the ERP has varying sampling rates depending on the latitude , we apply different weights on based on the latitude. Specifically, we multiply to feature at the latitude , because in ERP, each pixel occupies area in the spherical surface, compared with the pixels in the equator. Formally, the resulting feature is expressed as:
| (5) |
| Category | Method | Input no. () | RGB metric | Layout metric | Proposed metric | |||
| RGB | Depth | PSNR() | SSIM() | LPIPS() | 2D Corner error() | FAED() | ||
| Inpainting | BRGM [47] | 1/2/3/4 | 0 | 14.00 | 0.5310 | 0.6192 | 72.52 | 442.3 |
| CoModGAN [89] | 14.35 | 0.5837 | 0.4768 | 62.45 | 208.2 | |||
| LaMa [62] | 13.74 | 0.5207 | 0.5658 | 51.12 | 379.2 | |||
| Outpainting | Boundless [33] | 13.74 | 0.5663 | 0.6144 | 74.47 | 429.4 | ||
| Ours | 16.21 | 0.6161 | 0.4549 | 39.63 | 162.3 | |||
| Panorama syn. | Sumantri et al. [61] | 4 | 0 | 18.49 | 0.6680 | 0.4190 | 50.76 | 443.4 |
| Ours | 17.29 | 0.6510 | 0.3975 | 34.68 | 103.1 | |||

Fréchet Distance We treat the resulting as a vector and assume that it has a multi-dimensional Gaussian distribution. Then, we get the distribution of ground truths and that of generated samples , and calculate the Fréchet distance between them as given by [16]:
| (6) |
We use as a perceptual distance metric where and denote mean and covariance, respectively.
4 Experimental Results
Synthetic Dataset Structured3D dataset [91] provides various textures of indoor scenes with a resolution. We split the dataset into train, validation, and test set where the numbers of data are 17468, 2183, and 2184, respectively. In addition, with the corner locations provided in the dataset, we manually generated layout depth maps of each 3D scene. The residual depth maps are obtained by subtracting the layout depth from the GT depth map.
Real Dataset We used a combination of two datasets: Matterport3D [10], and 2D-3D-S dataset [3]. Both datasets provide real-world indoor RGB-D panorama. Since this dataset does not provide sufficient number of annotated layout, it can’t be used for training our framework and only used for test purpose. We excluded data with too many of invalid pixels from test dataset, then its number of data is 603.
Implementation Details For the details about our implementation, please refer to the supplementary material.
4.1 Verification of FAED
To show the effectiveness of FAED on measuring the perceptual quality of RGB-D panorama, we corrupt the Structured3D dataset [91] in two ways: corrupting RGB images only and corrupting depth maps only. Following [23], we corrupt the dataset by applying various types of noise: Gaussian blur, Gaussian noise, uniform patches, swirl, and salt and pepper noise. Here, we only show the plots for Gaussian blur in Fig. 6 due to the lack of space. Other results can be found in suppl. material. Note that the evaluation is done for RGB-D panorama, neither for RGB image alone nor for depth map alone. As shown in Fig. 6, the Fréchet distance for both RGB and depth panorama increases as the disturbance level (Gaussian blur) is increased. We show that the same applies to the other four types of noises in the supplementary material. This indicates the perceptual quality of RGB-D panorama becomes poorer as the FAED score increases.

| Category | Method | Input type | Depth metric | Layout metric | Proposed metric | ||
| RGB | Depth | AbsREL() | RMSE() | 2D IoU() | FAED() | ||
| Depth syn. | CSPN [12] | Full | L/P | 0.0855 | 2214 | 0.8062 | 428.9 |
| NLSPN [52] | 0.1268 | 2807 | 0.7333 | 836.1 | |||
| MSG-CHN [38] | 0.1764 | 3296 | 0.6724 | 896.4 | |||
| PENet [25] | 0.1740 | 3145 | 0.7033 | 906.0 | |||
| Ours | 0.0844 | 1942 | 0.8286 | 131.5 | |||
4.2 RGB-D Panorama Synthesis
| Method | Metric | |
| 2D IoU() | FAED() | |
| IwDS ([89] + [12]) | 0.7561 | 640.9 |
| Ours w/o BFF | 0.7859 | 381.4 |
| Ours w/o RDAL | 0.7164 | 329.0 |
| Ours | 0.8158 | 198.0 |


RGB Panorama Evaluation Table 1 shows the quantitative comparison with the inpainting and outpainting methods on the Structured3D dataset. We use PSNR, SSIM and LPIPS to evaluate the quality of RGB panorama. We also measure 2D corner error, where the 2D GT corner points are compared with the estimated 2D corner points using DuLa-Net [78] on the synthesized RGB panorama. We also use the proposed FAED to jointly evaluate the quality of RGB-D information.
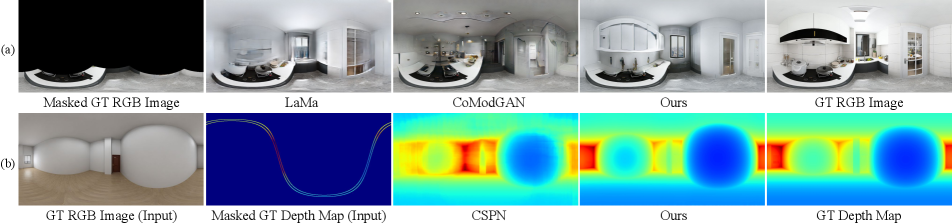
As shown in Table 1, our method outperforms the image inpainting and outpainting methods: BRGM [47], CoModGAN [89], LaMa [62] and Boundless [33], by a large margin for all metrics. For instance, our method outperforms the best inpainting method, CoModGAN, by an 4.6% decrease of LPIPS score, 36.5% drop of 2D corner error, and 22% decline of FAED score. The effectiveness can also be visually verified in Fig. 8(a). Our method produces clearer RGB panorama images compared with LaMa producing blurry images. Although CoModGAN produces clear RGB outputs, it doesn’t consider the indoor layout and semantic information of the furniture, e.g. electric cooker is combined with bookshelves, as shown in Fig. 8. Therefore, its layout is semantically inconsistent with the input RGB region and its FAED score is higher than ours.
We also compare with the panorama synthesis method, Sumantri et al. [61]. Our method shows slightly lower scores using the conventional metrics, PSNR and SSIM; however, it shows the much better LPIPS score (0.3975 vs 0.4190), 2D corner error (34.68 vs 50.76) and FAED score (103.1 vs 443.4), respectively. We argue that PSNR and SSIM merely measure local photometric similarity, and thus fail to well reflect the perceptual quality. This can be verified from Fig. 7 where we visually compare with [61]. Our method synthesizes better textures and shows much higher visual quality. More results can be found in suppl. material.
Depth Panorama Evaluation We compare our method with the image-guided depth synthesis methods on Structured3D dataset. To evaluate the quality, we use AbsREL and RMSE, and the proposed FAED. We also use layout 2D IoU, as was done in [13]. The details of the metrics and results can be found in the supplementary material.
Table 2 shows the quantitative comparison with the depth synthesis methods: CSPN [12], NLSPN [52], MSG-CHN [38] and PENet [25]. In particular, our method outperforms on of the best depth synthesis method, CSPN, with much better AbsREL score (0.0844 vs 0.0855), RMSE (1942 vs 2214), 2D IoU (0.8286 vs 0.8062) and FAED score (131.5 vs 428.9). With the proposed RDAL scheme, our method estimates the best layout depth, which is demonstrated by the highest layout 2D IoU. This in turn, considerably affects the overall depth error in other metrics as well. Figure. 8(b) shows the qualitative comparison with CSPN [12]. CSPN synthesizes the interior components, e.g., beds, relatively well; however, the depth of planes (e.g., walls and ceiling) are not clear. Therefore, it cannot synthesize a valid layout, failing to generate a realistic 3D indoor model. By contrast, our synthesized depth panorama shows an undisturbed and clear layout.
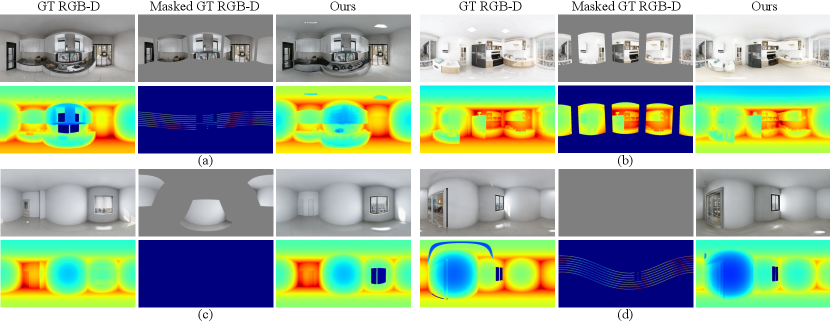
Evaluation on Real Dataset We evaluated our synthesized RGB-D panorama on real indoor scenes in Matterport3D and 2D-3D-S dataset. An output RGB-D panorama and its 3D indoor model are visualized in Fig. 11. Overall, our method synthesizes high-quality RGB-D panorama on real indoor scenes, unseen during training. Our synthesized depth panorama shows precise indoor layout and plausible residuals, generating a realistic 3D indoor model. For quantitative result, our method achieved better FAED score than IwDS (4645 vs 5099). Since the FAED score between synthetic and real dataset is 3517, it demonstrates that there exists distribution shift between the datasets and our result shows realistic RGB-D panorama and 3D indoor models consistently in both synthetic and real indoor scenes. More results can be found in suppl. material.
4.3 Ablation Study and Analysis
Inpainting w/ Depth Synthesis (IwDS) One solution to obtain RGB-D panorama from partial RGB-D inputs is sequentially accomplishing RGB synthesis (inpainting) and depth synthesis. To be specific, a RGB panorama is first synthesized from partial RGB input using the image inpainting method. Then, depth panorama is synthesized by applying the depth synthesis method to the synthesized RGB panorama and partial depth input. We chose CoModGAN [89] and CSPN [12] for RGB and depth synthesis methods, which showed the highest FAED score in Table 1 and Table 2. In Table 3, it can be seen that IwDS leads lower 2D IoU score and a much higher FAED score than our method. This indicates that the two-stage, sequential synthesis of RGB-D panorama is less effective than our BIPS framework that fuses the bi-modal features, trained with one-stage, joint learning scheme. Also, IwDS fails to generate realistic 3D indoor models, with distorted indoor layouts and severe bumpy surfaces as shown in Fig. 10.
Impact of BFF We study the effectiveness of RGB-D panorama synthesis by removing the BFF branch in the generator. In details, is replaced with a single branch network taking the concatenation of and . As shown in Table 3, the 2D IoU drops and FAED score increases without BFF. Fig. 10 shows that texture of the RGB-D output is not consistent with the given arbitrary RGB-D input. This reflects that BFF significantly contributes to well-process the bi-modal information.
Impact of RDAL We further validate the effectiveness of RDAL by comparing the results without RDAL. The number of output branches are reduced to two, and each are designed to learn RGB and total depth panorama, respectively. As shown in Table 3, the 2D IOU score drops, and FAED score increases without RDAL. It shows that RDAL is critical for estimating precise indoor layout. The impact of RDAL is visually verified in Fig. 10. The result without RDAL shows distorted indoor layout while having fewer artifacts than ours w/o BFF. In summary, dividing the total depth into layout and residual depth helps to synthesize more structural 3D indoor model.
5 Conclusion
In this paper, we tackled a novel problem of synthesizing RGB-D indoor panoramas from arbitrary configurations of RGB and depth inputs. Our method can synthesize high-quality RGB-D panoramas with the proposed BIPS framework by utilizing the bi-modal information and jointly training the layout and residual depth of indoor scenes. Moreover, a novel evaluation metric FAED was proposed and its validity was demonstrated. Extensive experiments show that our method achieves the SoTA RGB-D panorama synthesis performance.
Limitation We mainly focused on indoor scenes, and proposed RDAL is hardly applicable to outdoor scenes. Future work will extend our method to various environments.
References
- [1] Ghassem Alaee, Amit P Deasi, Lourdes Pena-Castillo, Edward Brown, and Oscar Meruvia-Pastor. A user study on augmented virtuality using depth sensing cameras for near-range awareness in immersive vr. In IEEE VR’s 4th Workshop on Everyday Virtual Reality (WEVR 2018), volume 10, 2018.
- [2] Borji Ali. Pros and cons of gan evaluation measures. Computer Vision and Image Understanding, 179:41–65, 2019.
- [3] Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2d-3d-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105, 2017.
- [4] Shai Avidan and Ariel Shamir. Seam carving for content-aware image resizing. In ACM SIGGRAPH 2007 Papers, SIGGRAPH ’07, page 10–es, New York, NY, USA, 2007. Association for Computing Machinery.
- [5] Coloma Ballester, Marcelo Bertalmio, Vicent Caselles, Guillermo Sapiro, and Joan Verdera. Filling-in by joint interpolation of vector fields and gray levels. IEEE transactions on image processing, 10(8):1200–1211, 2001.
- [6] Connelly Barnes, Eli Shechtman, Adam Finkelstein, and Dan B Goldman. Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph., 28(3):24, 2009.
- [7] Connelly Barnes, Eli Shechtman, Adam Finkelstein, and Dan B Goldman. Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph., 28(3), July 2009.
- [8] Marcelo Bertalmio, Guillermo Sapiro, Vincent Caselles, and Coloma Ballester. Image inpainting. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 417–424, 2000.
- [9] Marcelo Bertalmio, Luminita Vese, Guillermo Sapiro, and Stanley Osher. Simultaneous structure and texture image inpainting. IEEE transactions on image processing, 12(8):882–889, 2003.
- [10] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. International Conference on 3D Vision (3DV), 2017.
- [11] X. Cheng, P. Wang, G. Chenye, and R. Yang. Cspn++: Learning context and resource aware convolutional spatial propagation networks for depth completion. Proceedings of the AAAI Conference on Artificial Intelligence, 34:10615–10622, 04 2020.
- [12] X. Cheng, P. Wang, and R. Yang. Learning depth with convolutional spatial propagation network. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(10):2361–2379, 2020.
- [13] Dongho Choi. 3d room layout estimation beyond the manhattan world assumption. arXiv preprint arXiv:2009.02857, 2020.
- [14] Antonio Criminisi, Patrick Perez, and Kentaro Toyama. Object removal by exemplar-based inpainting. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings., volume 2, pages II–II. IEEE, 2003.
- [15] Antonio Criminisi, Patrick Pérez, and Kentaro Toyama. Region filling and object removal by exemplar-based image inpainting. IEEE Transactions on image processing, 13(9):1200–1212, 2004.
- [16] DC Dowson and BV Landau. The fréchet distance between multivariate normal distributions. Journal of multivariate analysis, 12(3):450–455, 1982.
- [17] Alexei A Efros and Thomas K Leung. Texture synthesis by non-parametric sampling. In Proceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1033–1038. IEEE, 1999.
- [18] Abdelrahman Eldesokey, Michael Felsberg, and Fahad Shahbaz Khan. Confidence propagation through cnns for guided sparse depth regression. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(10):2423–2436, Oct 2020.
- [19] Dewen Guo, Jie Feng, and Bingfeng Zhou. Structure-aware image expansion with global attention. In SIGGRAPH Asia 2019 Technical Briefs, SA ’19, page 13–16, New York, NY, USA, 2019. Association for Computing Machinery.
- [20] Dongsheng Guo, Hongzhi Liu, Haoru Zhao, Yunhao Cheng, Qingwei Song, Zhaorui Gu, Haiyong Zheng, and Bing Zheng. Spiral Generative Network for Image Extrapolation, pages 701–717. 11 2020.
- [21] Takayuki Hara and Tatsuya Harada. Spherical image generation from a single normal field of view image by considering scene symmetry. arXiv preprint arXiv:2001.02993, 2020.
- [22] Yuwen He, Yan Ye, Philippe Hanhart, and Xiaoyu Xiu. Geometry padding for motion compensated prediction in 360 video coding. In 2017 Data Compression Conference (DCC), pages 443–443. IEEE Computer Society, 2017.
- [23] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, pages 6626–6637, 2017.
- [24] Noriaki Hirose and Kosuke Tahara. Depth360: Monocular depth estimation using learnable axisymmetric camera model for spherical camera image. arXiv preprint arXiv:2110.10415, 2021.
- [25] Mu Hu, Shuling Wang, Bin Li, Shiyu Ning, Li Fan, and Xiaojin Gong. Towards precise and efficient image guided depth completion. 2021.
- [26] Z. Huang, J. Fan, S. Cheng, S. Yi, X. Wang, and H. Li. Hms-net: Hierarchical multi-scale sparsity-invariant network for sparse depth completion. IEEE Transactions on Image Processing, 29:3429–3441, 2020.
- [27] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Globally and locally consistent image completion. ACM Transactions on Graphics (ToG), 36(4):1–14, 2017.
- [28] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017.
- [29] Maximilian Jaritz, Raoul De Charette, Emilie Wirbel, Xavier Perrotton, and Fawzi Nashashibi. Sparse and dense data with cnns: Depth completion and semantic segmentation. In 2018 International Conference on 3D Vision (3DV), pages 52–60. IEEE, 2018.
- [30] Biliana Kaneva, Josef Sivic, Antonio Torralba, Shai Avidan, and William T. Freeman. Infinite images: Creating and exploring a large photorealistic virtual space. Proceedings of the IEEE, 98(8):1391–1407, 2010.
- [31] Sai Hemanth Kasaraneni and Abhishek Mishra. Image completion and extrapolation with contextual cycle consistency. In 2020 IEEE International Conference on Image Processing (ICIP), pages 1901–1905, 2020.
- [32] Kyunghun Kim, Yeohun Yun, Keon-Woo Kang, Kyeongbo Kong, Siyeong Lee, and Suk-Ju Kang. Painting outside as inside: Edge guided image outpainting via bidirectional rearrangement with progressive step learning. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 2121–2129, 2021.
- [33] Dilip Krishnan, Piotr Teterwak, Aaron Sarna, Aaron Maschinot, Ce Liu, David Belanger, and William Freeman. Boundless: Generative adversarial networks for image extension. pages 10520–10529, 10 2019.
- [34] B. Lee, H. Jeon, S. Im, and I. S. Kweon. Depth completion with deep geometry and context guidance. In 2019 International Conference on Robotics and Automation (ICRA), pages 3281–3287, 2019.
- [35] Donghoon Lee, Sangdoo Yun, Sungjoon Choi, Hwiyeon Yoo, Ming-Hsuan Yang, and Songhwai Oh. Unsupervised holistic image generation from key local patches. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision – ECCV 2018, pages 21–37, Cham, 2018. Springer International Publishing.
- [36] S. Lee, J. Lee, D. Kim, and J. Kim. Deep architecture with cross guidance between single image and sparse lidar data for depth completion. IEEE Access, 8:79801–79810, 2020.
- [37] Ang Li, Zejian Yuan, Yonggen Ling, Wanchao Chi, Chong Zhang, et al. A multi-scale guided cascade hourglass network for depth completion. In The IEEE Winter Conference on Applications of Computer Vision, pages 32–40, 2020.
- [38] A. Li, Z. Yuan, Y. Ling, W. Chi, S. Zhang, and C. Zhang. A multi-scale guided cascade hourglass network for depth completion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), March 2020.
- [39] Yijun Li, Sifei Liu, Jimei Yang, and Ming-Hsuan Yang. Generative face completion. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3911–3919, 2017.
- [40] Liang Liao, Jing Xiao, Zheng Wang, Chia-Wen Lin, and Shin’ichi Satoh. Image inpainting guided by coherence priors of semantics and textures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6539–6548, 2021.
- [41] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 85–100, 2018.
- [42] Hongyu Liu, Bin Jiang, Yi Xiao, and Chao Yang. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4170–4179, 2019.
- [43] Hongyu Liu, Ziyu Wan, Wei Huang, Yibing Song, Xintong Han, and Jing Liao. Pd-gan: Probabilistic diverse gan for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9371–9381, 2021.
- [44] F. Ma, G. V. Cavalheiro, and S. Karaman. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In 2019 International Conference on Robotics and Automation (ICRA), pages 3288–3295, 2019.
- [45] Fangchang Mal and Sertac Karaman. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1–8. IEEE, 2018.
- [46] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2794–2802, 2017.
- [47] Razvan V Marinescu, Daniel Moyer, and Polina Golland. Bayesian image reconstruction using deep generative models. arXiv preprint arXiv:2012.04567, 2020.
- [48] Indra Deep Mastan and Shanmuganathan Raman. Deepcfl: Deep contextual features learning from a single image. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 2896–2905, 2021.
- [49] Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain. IEEE Transactions on image processing, 21(12):4695–4708, 2012.
- [50] Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Making a “completely blind” image quality analyzer. IEEE Signal processing letters, 20(3):209–212, 2012.
- [51] Shant Navasardyan and Marianna Ohanyan. Image inpainting with onion convolutions. In Proceedings of the Asian Conference on Computer Vision, 2020.
- [52] J. Park, K. Joo, Z. Hu, C. Liu, and I. Kweon. Non-local spatial propagation network for depth completion. In Proc. of European Conference on Computer Vision (ECCV), 2020.
- [53] Jialun Peng, Dong Liu, Songcen Xu, and Houqiang Li. Generating diverse structure for image inpainting with hierarchical vq-vae. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10775–10784, 2021.
- [54] J. Qiu, Z. Cui, Y. Zhang, X. Zhang, S. Liu, B. Zeng, and M. Pollefeys. Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [55] Paul L Rosin, Yu-Kun Lai, Ling Shao, and Yonghuai Liu. RGB-D Image Analysis and Processing. Springer, 2019.
- [56] Mark Sabini and Gili Rusak. Painting outside the box: Image outpainting with gans, 2018.
- [57] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pages 2234–2242, 2016.
- [58] Stefan Schubert, Peer Neubert, Johannes Pöschmann, and Peter Pretzel. Circular convolutional neural networks for panoramic images and laser data. In 2019 IEEE Intelligent Vehicles Symposium (IV), pages 653–660. IEEE, 2019.
- [59] Qi Shan, Brian Curless, Yasutaka Furukawa, Carlos Hernandez, and Steven M. Seitz. Photo uncrop. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, Computer Vision – ECCV 2014, pages 16–31, Cham, 2014. Springer International Publishing.
- [60] Maitreya Suin, Kuldeep Purohit, and AN Rajagopalan. Distillation-guided image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2481–2490, 2021.
- [61] Julius Surya Sumantri and In Kyu Park. 360 panorama synthesis from a sparse set of images with unknown field of view. In The IEEE Winter Conference on Applications of Computer Vision, pages 2386–2395, 2020.
- [62] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. arXiv preprint arXiv:2109.07161, 2021.
- [63] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, pages 2818–2826, 2016.
- [64] Jie Tang, Fei-Peng Tian, Wei Feng, Jian Li, and Ping Tan. Learning guided convolutional network for depth completion. arXiv preprint arXiv:1908.01238, 2019.
- [65] W. Van Gansbeke, D. Neven, B. De Brabandere, and L. Van Gool. Sparse and noisy lidar completion with rgb guidance and uncertainty. In 2019 16th International Conference on Machine Vision Applications (MVA), pages 1–6, 2019.
- [66] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [67] Ziyu Wan, Jingbo Zhang, Dongdong Chen, and Jing Liao. High-fidelity pluralistic image completion with transformers. arXiv preprint arXiv:2103.14031, 2021.
- [68] B. Wang and J. An. Fis-nets: Full-image supervised networks for monocular depth estimation, 2020.
- [69] Fu-En Wang, Yu-Hsuan Yeh, Min Sun, Wei-Chen Chiu, and Yi-Hsuan Tsai. Bifuse: Monocular 360 depth estimation via bi-projection fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 462–471, 2020.
- [70] Miao Wang, Yu-Kun Lai, Yuan Liang, Ralph R. Martin, and Shi-Min Hu. Biggerpicture: Data-driven image extrapolation using graph matching. ACM Trans. Graph., 33(6), Nov. 2014.
- [71] Ning Wang, Jingyuan Li, Lefei Zhang, and Bo Du. Musical: Multi-scale image contextual attention learning for inpainting. In IJCAI, pages 3748–3754, 2019.
- [72] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8798–8807, 2018.
- [73] Wentao Wang, Jianfu Zhang, Li Niu, Haoyu Ling, Xue Yang, and Liqing Zhang. Parallel multi-resolution fusion network for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14559–14568, 2021.
- [74] Yi Wang, Xin Tao, Xiaoyong Shen, and Jiaya Jia. Wide-context semantic image extrapolation. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1399–1408, 2019.
- [75] Xian Wu, Rui-Long Li, Fang-Lue Zhang, Jian-Cheng Liu, Jue Wang, Ariel Shamir, and Shi-Min Hu. Deep portrait image completion and extrapolation. IEEE Transactions on Image Processing, 29:2344–2355, 2020.
- [76] Chaohao Xie, Shaohui Liu, Chao Li, Ming-Ming Cheng, Wangmeng Zuo, Xiao Liu, Shilei Wen, and Errui Ding. Image inpainting with learnable bidirectional attention maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8858–8867, 2019.
- [77] Y. Xu, X. Zhu, J. Shi, G. Zhang, H. Bao, and H. Li. Depth completion from sparse lidar data with depth-normal constraints. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [78] Shang-Ta Yang, Fu-En Wang, Chi-Han Peng, Peter Wonka, Min Sun, and Hung-Kuo Chu. Dula-net: A dual-projection network for estimating room layouts from a single rgb panorama. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3363–3372, 2019.
- [79] Zongxin Yang, Jian Dong, Ping Liu, Yi Yang, and Shuicheng Yan. Very long natural scenery image prediction by outpainting. In Proceedings of the IEEE International Conference on Computer Vision, pages 10561–10570, 2019.
- [80] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Generative image inpainting with contextual attention. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5505–5514, 2018.
- [81] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4471–4480, 2019.
- [82] Wei Zeng, Sezer Karaoglu, and Theo Gevers. Joint 3d layout and depth prediction from a single indoor panorama image. In European Conference on Computer Vision, pages 666–682. Springer, 2020.
- [83] Lingzhi Zhang, Jiancong Wang, and Jianbo Shi. Multimodal image outpainting with regularized normalized diversification. In 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 3422–3431, 2020.
- [84] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- [85] Xiaofeng Zhang, Feng Chen, Cailing Wang, Ming Tao, and Guo-Ping Jiang. Sienet: Siamese expansion network for image extrapolation. IEEE Signal Processing Letters, PP:1–1, 08 2020.
- [86] Y. Zhang and T. Funkhouser. Deep depth completion of a single rgb-d image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [87] Yinda Zhang, Jianxiong Xiao, James Hays, and Ping Tan. Framebreak: Dramatic image extrapolation by guided shift-maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1171–1178, 2013.
- [88] Lei Zhao, Qihang Mo, Sihuan Lin, Zhizhong Wang, Zhiwen Zuo, Haibo Chen, Wei Xing, and Dongming Lu. Uctgan: Diverse image inpainting based on unsupervised cross-space translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5741–5750, 2020.
- [89] Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, Eric I Chang, and Yan Xu. Large scale image completion via co-modulated generative adversarial networks. arXiv preprint arXiv:2103.10428, 2021.
- [90] Chuanxia Zheng, Tat-Jen Cham, and Jianfei Cai. Pluralistic image completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1438–1447, 2019.
- [91] Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3d: A large photo-realistic dataset for structured 3d modeling. arXiv preprint arXiv:1908.00222, 2019.