Bio-inspired Robot Perception
Coupled With Robot-modeled Human Perception
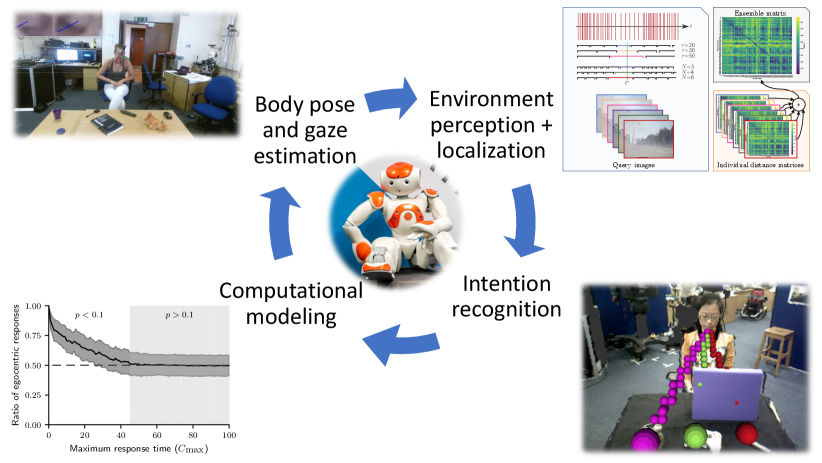
Research statement – part 1: My overarching research goal is to provide robots with perceptional abilities that allow interactions with humans in a human-like manner. To develop these perceptional abilities, I believe that it is useful to study the principles of the human visual system. I use these principles to develop new computer vision algorithms and validate their effectiveness in intelligent robotic systems. I am enthusiastic about this approach as it offers the dual benefit of uncovering principles inherent in the human visual system, as well as applying these principles to its artificial counterpart. Fig. 1 contains a depiction of my research.
Perspective-taking: In our everyday lives, we often interact with other people. Although each interaction is different and hard to predict in advance, they are usually fluid and efficient. This is because humans take many aspects into account when interacting with each other: the relationship between the interlocutors, their familiarity with the topic, and the time and location of the interaction, among many others. More specifically, humans are remarkably good at rapidly forming models of others and adapting their actions accordingly. To form these models, humans exploit the ability to take on someone else’s point of view – they take their perspective [6].
In [7], we introduced an artificial visual system that equips an iCub humanoid robot with the ability to perform perspective-taking in unknown environments using a depth camera mounted above the robot, i.e. without using a motion capture system or fiducial markers. Grounded in psychological studies [19, 12], perspective-taking is separated into two processes: level 1 perspective-taking comprises the ability to identify objects which are occluded from one perspective but not the other; this was implemented using line-of-sight tracing. Level 2 perspective-taking refers to understanding how the object is perceived from the other perspective (rather than just understanding what is visible from that perspective; see [19]); this was implemented using a mental rotation process.
While [7] implements perspective-taking in a robotic system, it does not provide any insights into the underlying mechanisms used by humans. In [8], we investigated possible implementations of perspective-taking in the human visual system using a computational model applied to a simulated robot. The model proposes that a mental rotation of the self, also termed embodied transformation, accounts for this ability. The computational model reproduces the reaction times of human subjects in several experiments and explains gender differences that were observed in human subjects.
In future works, I would like to explore the relationship between perspective-taking and active vision. Active vision refers to the manipulation of the robot’s viewpoint to extract more information from their environment, given a specific task [2]. I argue that visual perspective-taking is a subset of the active vision task, where the particular task is to gain an understanding of the other person’s viewpoint, while minimizing the movements required to gain this understanding.
Blink and gaze estimation: Perspective-taking requires the robot to follow the gaze of the person that it is interacting with. While the computer vision community has made significant progress in the area of gaze estimation, the application is typically limited to settings where the head pose is constrained, and the person is close to the camera; examples include phone [16] and tablet [15] use, as well as screen-based settings [23]. However, scenarios that are typically encountered in human-robot interactions have seen little attention [18, 22, 20].
To overcome this challenge, we proposed RT-GENE [10], a new dataset for gaze estimation in unconstrained settings. Opposed to other datasets that require the subject to gaze at a particular point and indicate once they have done so (e.g. by pressing the space bar), RT-GENE’s data labeling is fully automated. The subject wears eyetracking glasses that are equipped using motion capture markers, which enables to simultaneously collect head pose and eye gaze data – even in settings where the subject is far away (indeed even if they look away) from the camera.
However, the eyetracking glasses introduce an object at training time that is not present at inference time. To circumvent this issue, RT-GENE makes use of Generative Adversarial Networks (GANs) to inpaint the area covered by the eyetracking glasses. In particular, we collect a second dataset where the eyetracking glasses are not worn (but no gaze information is available) to train the GAN, and find the area to be inpainted by projecting down the known 3D model onto the image. RT-GENE also introduces a novel deep network that outperforms the state-of-the-art using an ensemble scheme. Interestingly, a deep model trained on RT-GENE performs exceptionally well on other datasets without any further adaptation. RT-GENE was tested in real-life settings: for example, the estimated gaze was used as the input signal on a powered wheelchair, and enabled a user to control the wheelchair purely based on their gaze.
The RT-GENE dataset was also re-purposed for the blink estimation task to provide a challenging new dataset for blink estimation [3]. Using a similar ensemble scheme as for RT-GENE, along with an oversampling technique (there are significantly more images with open eyes than with closed eyes), an ensemble of deep networks was trained. The ensemble was then evaluated on various blink datasets where we outperformed prior methods by a large margin.
In future works, I would like to extend RT-GENE to work in even more challenging scenarios, where the eyes might not be visible at all. Incorporating the saliency of the scene, past gaze behavior, and other modalities like audio are interesting directions to tackle these scenarios, which will also require estimating the uncertainty of the gaze predictions, for example via the agreement of the ensemble members [17].
Research statement – part 2: Part 1 of this paper introduced a variety of perceptional algorithms for robots – blink estimation, gaze estimation and perspective-taking – and how they can be used to uncover potential mechanisms of human perception. The following part 2 is concerned with localization and navigation capabilities of mobile robotic systems. As in part 1, we take inspiration from the principles discovered in the animal kingdom to develop new computer vision algorithms that are validated in mobile robotic systems [4, 9, 11, 14]. Indeed, even “simple” animals like ants and rats can rapidly explore, localize and navigate in both familiar and new environments, despite their low visual acuity.
One key component of localization is visual place recognition, which refers to the problem of retrieving the reference image that is most similar to the query image, given a reference dataset of places that have been previously visited and a query image of the current location [11]. Visual place recognition is a challenging problem, as query and reference images could be taken at different times of the day, in varying seasonal and weather conditions, and even years apart and with significant viewpoint changes.
Demystifying Visual Place Recognition (VPR): VPR is a rapidly growing topic, with over 2300 papers listed in Google Scholar matching the exact term. As VPR is researched in multiple communities with a wide range of downstream tasks, VPR research has become increasingly dissociated. For example, the evaluation metrics and datasets vary significantly across publications, which makes a comparison of methods challenging. In a recent survey [11], we highlight similarities and differences of VPR with a handful of related areas (including image retrieval, landmark recognition and visual overlap detection), and introduce three key drivers of VPR research: the platform, the operating environment, and the downstream task. Having gained this knowledge, this then enabled us to introduce and highlight several open research problems: how places should be represented (e.g. can geometric information be incorporated into global image descriptors, how can descriptors be compressed efficiently, and can we synthesize novel views) and how places should be matched (e.g. using hierarchical systems or learning to match). As with all of my research, I put an emphasis on what we can learn from biology – in this example, the definition of a ‘place’ is based on the spatial viewpoint cells that were found in the primate brain.
Event-based VPR: In [9], we argue that it is beneficial to use event cameras to sense the environment, as opposed to conventional frame-based cameras. Event cameras are bio-inspired sensors that output a near-continuous stream of events; each event is denoted by the time and pixel location where the event was observed, as well as the event’s polarity that indicates whether the intensity at the pixel decreased () or increased () [13]. Therefore, event cameras only observe changes within the environment, and an ideal event camera does not output any events in the case of a static environment. Event cameras have a range of advantages: they are so fast that no motion blur occurs, they have a very high dynamic range, and they are energy-efficient.
We first reconstructed frames from the event stream using [21], and then applied conventional VPR image retrieval techniques [1]. The main novelty is in the use of multiple image sets, whereby each image set is obtained by reconstructing the images based on a different temporal scale. The overall best matching image is then found using an ensemble scheme, which is a recurring theme of my work. We are expanding this work to avoid the computationally expensive reconstruction, and instead directly use the event stream. We are also planning to make use of the recent advances in neuromorphic engineering [5] and deploy these algorithms on spiking neural networks implemented on neuromorphic hardware.
Locally-global features for VPR: In another line of work, we introduce Patch-NetVLAD [14], a novel formulation for combining the advantages of both local and global descriptor methods. NetVLAD [1] is a popular deep-learned global descriptor method that extracts a feature representation given an image that can be compared to another image’s feature representation by means of standard distance metrics like the Euclidean distance. In Patch-NetVLAD [14], rather than aggregating across the whole feature space, we aggregate locally-global descriptors from a set of patches in the feature space. This is implemented in a computationally efficient integral feature space, which further enables a multi-scale approach to fuse multiple patch sizes. Patch-NetVLAD outperforms the state-of-the-art by large margins on seven datasets. In future works, we would like to explore whether Patch-NetVLAD’s multi-scale approach has an analogous mechanism in the animal kingdom, noting that the brain processes visual information over multiple receptive fields.
Acknowledgments: I would like to thank all my collaborators over the last years who have made this research possible, in particular my supervisors Professor Yiannis Demiris and Professor Michael Milford. Furthermore, I would like to thank the sponsors of this research; research was funded in part by by the EU FP7 project WYSIWYD under Grant 612139, the Samsung Global Research Outreach program, the EU Horizon 2020 Project PAL (643783-RIA), the Australian Government via grant AUSMURIB000001 associated with ONR MURI grant N00014-19-1-2571, Intel Research via grant RV3.248.Fischer, and the Queensland University of Technology (QUT) through the Centre for Robotics.
References
- Arandjelovic et al. [2018] Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1437–1451, 2018.
- Bajcsy et al. [2018] Ruzena Bajcsy, Yiannis Aloimonos, and John K. Tsotsos. Revisiting active perception. Autonomous Robots, 42(2):177–196, 2018.
- Cortacero et al. [2019] Kevin Cortacero, Tobias Fischer, and Yiannis Demiris. RT-BENE: A Dataset and Baselines for Real-Time Blink Estimation in Natural Environments. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 1159–1168, 2019.
- Dall’Osto et al. [2020] Dominic Dall’Osto, Tobias Fischer, and Michael Milford. Fast and Robust Bio-inspired Teach and Repeat Navigation, 2020.
- Davies et al. [2021] Mike Davies et al. Advancing neuromorphic computing with Loihi: A survey of results and outlook. Proceedings of the IEEE, 109(5):911–934, 2021.
- Fischer [2018] Tobias Fischer. Perspective Taking in Robots: A Framework and Computational Model. PhD thesis, Imperial College London, 2018.
- Fischer and Demiris [2016] Tobias Fischer and Yiannis Demiris. Markerless Perspective Taking for Humanoid Robots in Unconstrained Environments. In Proceedings of the IEEE International Conference on Robotics and Automation, pages 3309–3316, 2016.
- Fischer and Demiris [2020] Tobias Fischer and Yiannis Demiris. Computational Modeling of Embodied Visual Perspective Taking. IEEE Transactions on Cognitive and Developmental Systems, 12(4):723–732, 2020.
- Fischer and Milford [2020] Tobias Fischer and Michael Milford. Event-Based Visual Place Recognition With Ensembles of Temporal Windows. IEEE Robotics and Automation Letters, 5(4):6924–6931, 2020.
- Fischer et al. [2018] Tobias Fischer, Hyung Jin Chang, and Yiannis Demiris. RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments. In Proceedings of the European Conference on Computer Vision, pages 339–357, 2018.
- Fischer* et al. [2021] Tobias Fischer*, Sourav Garg*, and Michael Milford. Where is your place, Visual Place Recognition? In Proceedings of the International Joint Conference on Artificial Intelligence, 2021. *: equal contributions.
- Flavell et al. [1981] John H. Flavell, Barbara Abrahams Everett, Karen Croft, and Eleanor R. Flavell. Young Children’s Knowledge About Visual Perception: Further Evidence for the Level 1-Level 2 Distinction. Developmental Psychology, 17(1):99–103, 1981.
- Gallego et al. [2020] Guillermo Gallego et al. Event-based Vision: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. to appear.
- Hausler et al. [2021] Stephen Hausler, Sourav Garg, Ming Xu, Michael Milford, and Tobias Fischer. Patch-NetVLAD: Multi-Scale Fusion of Locally Global Descriptors for Place Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 14141–14152, 2021.
- Huang et al. [2017] Qiong Huang, Ashok Veeraraghavan, and Ashutosh Sabharwal. TabletGaze: dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Machine Vision and Applications, 28(5-6):445–461, 2017.
- Krafka et al. [2016] Kyle Krafka, Aditya Khosla, Petr Kellnhofer, and Harini Kannan. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2176–2184, 2016.
- Lakshminarayanan et al. [2017] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Conference on Neural Information Processing Systems, 2017.
- Lanillos et al. [2017] Pablo Lanillos, João Filipe Ferreira, and Jorge Dias. A bayesian hierarchy for robust gaze estimation in human–robot interaction. International Journal of Approximate Reasoning, 87:1–22, 2017.
- Michelon and Zacks [2006] Pascale Michelon and Jeffrey M. Zacks. Two kinds of visual perspective taking. Perception & Psychophysics, 68(2):327–337, 2006.
- Palinko et al. [2015] Oskar Palinko, Francesco Rea, Giulio Sandini, and Alessandra Sciutti. Eye gaze tracking for a humanoid robot. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots, pages 318–324, 2015.
- Rebecq et al. [2021] Henri Rebecq, René Ranftl, Vladlen Koltun, and Davide Scaramuzza. High speed and high dynamic range video with an event camera. IEEE Transactions Pattern Analysis and Machine Intelligence, 43(6):1964–1980, 2021.
- Schillingmann and Nagai [2015] Lars Schillingmann and Yukie Nagai. Yet Another Gaze Detector: An embodied calibration free system for the iCub robot. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots, pages 8–13, 2015.
- Zhang et al. [2019] Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(1):162–175, 2019.