BiFNet: Bidirectional Fusion Network for Road Segmentation ††thanks: This work is supported by the Beijing Science and Technology Plan under Grants Z191100007419002, and the National Natural Science Foundation of China (NSFC) under Grants No. 61803371.
Abstract
Multi-sensor fusion-based road segmentation plays an important role in the intelligent driving system since it provides a drivable area. The existing mainstream fusion method is mainly to feature fusion in the image space domain which causes the perspective compression of the road and damages the performance of the distant road. Considering the bird’s eye views(BEV) of the LiDAR remains the space structure in horizontal plane, this paper proposes a bidirectional fusion network(BiFNet) to fuse the image and BEV of the point cloud. The network consists of two modules: 1) Dense space transformation module, which solves the mutual conversion between camera image space and BEV space. 2) Context-based feature fusion module, which fuses the different sensors information based on the scenes from corresponding features. This method has achieved competitive results on KITTI dataset.
Index Terms:
multi-sensor fusion, road segmentation, adaptive learning, autonomous vehiclesI Introduction
Road segmentation is a fundamental and essential task for an intelligent driving system, which provides a driving area for self-driving system. A robust road segmentation method is the precondition for driving system safety[1][2][3]. With the development of the deep neural networks, deep neural network is also widely used in the perception[4], decision[5][6] and control[7][8] module of autonomous vehicles. The road segmentation task based on deep convolutional neural networks has been one of the research highlights for intelligent driving.
Currently, many works focus on camera image-based and LiDAR-based methods. The camera captures the rich texture of the road while the LiDAR measures the spatial structure of the environment by scanning laser beams. Benefiting from the development of semantic segmentation methods[9][10][11] based fully convolutional neural networks[12], camera image-based road segmentation has achieved a tremendous advance. However, the camera is light-sensitive and the image is vulnerable to the interference of illumination. The camera image-based methods do not work well in overexposed or dark environments. As an active light sensor, the point cloud of LiDAR is insensitive to illumination. [13][14] showed that LiDAR performed well on road segmentation task. Unfortunately, the lack of texture and short valid detection distance are the defects of the point cloud. Hence, the combination of two types of sensor — cameras, and LiDAR — has emerged as one of the most popular approaches for the road segmentation task.
The fusion-based road segmentation methods perform well by integrating the rich texture with the camera and accurate altitude with the LiDAR. These methods can be divided into two categories: post-fusion and feature fusion methods. Post-fusion methods fuse the defected results from each sensor individually and obtain better road segmentation result, such as LC-CRF method[15]. Note that the feature fusion methods obtain a merged feature by combining the features extracted from images and point clouds. Due to the combination of the texture and the accurate altitude information, the feature fusion-based methods like LidCamNet[16] and PLARD[17] are more adaptive and robust, and attract many researcher’s attention.
It should be mentioned that most feature fusion-based road segmentation methods complete feature fusion in camera space. According to the hole imaging theory, camera compresses the distant objects during the imaging processing which causes that the distant objects usually occupy few pixels than the near ones. Obviously, perspective compression increases the difficulty of the object segmentation in the distance. Fig. 1 shows the imaging compression problem for road segmentation using the current feature fusion-based method. The road near can be segmented well, while the far one is segmented coarsely, due to the imaging compression. As mentioned in [16][17], how to combine the features which at same space is the important topic of feature fusion.

Aiming at the above issues, we propose a road segmentation method which fuses the camera image and the BEV of the point cloud. On one hand, the BEV of the point cloud remains the distribution of road and has enough information of segment road area. On the other hand, camera image has rich texture feature for road and far visible distance than LiDAR. Most methods focus on the feature fusion in camera space which use perspective projection and losses the spatial structure of the point clouds. In this paper, we design a dense space transformation module which transforms the features between the camera space and BEV space. Next, compared with the most current methods which fuse the features only based on position, we propose a context-based fusion module which combines the features suitably and fuses the transformed features adaptively according to the context. To summarize, this paper presents the following contributions:
-
•
We design a dense space transformation which builds the dense mapping between the image and BEV of the point cloud. This transformation is the foundation for fusing features from different spaces.
-
•
We propose a context-based fusion module. This module fuses the multi-sensors features according to the environmental context and achieves the robust representation of the environment.
-
•
Based on the above modules, we construct the bidirectional fusion network(BiFNet) which combines the camera image and BEV of the point cloud to implement road segmentation and achieves the competitive results in the KITTI road dataset.
This paper is organized as follows. Section II describes related works in road segmentation and the sensor fusion. Section III presents our definition and analysis about the sensor fusion task. Then, we give the details of our proposed fusion module includes dense space transformation and attention based feature fusion module in Section IV. Furthermore, the ablation study and the comparison experiment are displayed and the analysis of methods is given. Finally, in Section V, we summarize our work and discuss future work.
II Related Work
II-A Image-based road segmentation
Current image-based methods can be divided into two categories: model-based and learning-based. Model-based methods[18][19][20] build the road model based on unique shapes and textures. Mohamed et al.[21] detected the lanes according to the shape color and figured out the road area in the image. Ankit et al.[22] used the appearance features of the road surface and map prior to implement the automatic labeling road area. The model built by expert domain knowledge needed to tune according to the different datasets or scenes. Model-based methods rely on the robust road model which are applicable to scenes with the similar road. For the complex illumination and textures, these methods have bad adaptive ability.
Learning-based methods are popular at road segmentation task. These methods learn the robust classifier to identify the road pixel in the image fed by large labeled datasets. Profiting by the development of deep learning and convolutional neural networks, hand-designed features[23] used for classifier are replaced with automatic learning features[12][24]. At the same time, the development of semantic segmentation methods has greatly advanced road detection methods. Since the road has a special appearance, Zhe et al.[25] added the road boundary constraints to the deep segmentation networks and improved the performance of methods.
II-B LiDAR-based road segmentation
Although image-based segmentation methods have developed rapidly in recent years, the image noise caused by the illumination leads to the limitation of the image-based methods. As a distance sensor, LiDAR is not affected by light, and many researchers use the point cloud to detect road. Fernandes et al.[26] introduced the similarity of the histogram of the point cloud as the discriminator to classify the points and segmented the road from the point cloud. Caltagirone et al.[13] employed the fully convolutional neural networks over the BEV of the point cloud and achieved the desired result. Zhang et al.[27] proposed a sliding-beam method to segment the road by using the off-road data and applied a curb-detection method to obtain the position of curbs for each road segments.
II-C Camera and LiDAR fusion-based road segmentation
Depth information is the key to solve the problem of RGB image. How to combine depth information with color image effectively has always been a research hotspot[28][29]. Since the data of the camera and LiDAR can complement each other, fusing image and point cloud to segment road has gradually become the mainstream method. Shinzato et al.[30] proposed a fusion method which combined the distribution of the point cloud and image pixels as the discriminator. Conditional Random Field(CRF) was used for constructing the fusion model. There are many methods[31][32][33] which constructed Gibbs energy by using Euclidean distance between the points and RGB values of pixels. The above methods needed the expert knowledge to build the data features and combined the features to find robust classifier for the pixels. Gu et al.[15][34] used the CRF to fuse the results from the point cloud[35] with image features extracted by deep convolutional neural networks. Compared to the hand-selected features, this method achieved better performance. Caltagirone et al.[13] projected the point cloud into camera space and designed a cross fusion module to fuse image features with front view features of the point cloud. Since the coordinate of the point can not directly reflect the road characteristics, Chen et al.[17] proposed an altitude difference transformation which transformed the point cloud to a special front view image. And they introduced the feature space adaptation module to fuse the features from different sensors.
II-D Camera and LiDAR fusion-based 3D object detection
Image-based 2D object detection and tracking have made great progress[36][37][38][39]. Since the point cloud of LiDAR has accurate distance information[40], fusing the camera image with the point cloud also plays an important role in 3D object detection. The categories of the fusion for object detection can be divided into a region-based method and point-based method. The region-based method combined the sensors data or features from a unique 3D region and got a better feature representation[41][42]. Compared with the region-based methods, point-based methods fused the features in terms of the point and the pixel. Continuous fusion layer[43] belongs to this category. It built the relationship of pixels in the camera image and the BEV-based on 3D points and designed the continuous fusion which constructed a mapping between sparse points and BEV pixels. You et al.[44] proposed an attention fusion block which cascaded the global context feature of camera image and feature of each point. PointFusion[45] used such a method to implement 3D object detection. Wang et al.[46] proposed a sparse non-homogeneous pooling and used projection matrix to transform features between the RGB image and the BEV.
III Problem Formulation
Road segmentation refers to the analysis of sensor data by an algorithm to detect the drivable road area in the current environment. Supposing that is the sensor data, is the corresponding ground truth. Due to the difference in sensor measurement accuracy and imaging model, the key to multi-sensor fusion is to find the optimal combination between sensors to complete the segmentation task. For feature-based fusion methods, we need to determine two models: classification model and fusion model , by minimizing the objective
| (1) |
where and are weights of fusion model and classification model, respectively. Since single sensing has its limitations, such as camera image is sensitive to light and the point cloud of LiDAR is sparse and textureless. It is difficult to cope with complex scenes with a single sensor. The purpose of multi-sensor fusion is to combine the advantages of different sensors to make up for the disadvantages of a single sensor and achieve complementary advantages.
Recently, many works focus on identifying the fusion model which can be divided into three categories including pre-fusion, post-fusion, and feature fusion. The key of pre-fusion is converting different sensor data into a unified data format. Then it uses a single model to process the cascaded data. The advantage of this method is that it only needs to preprocess the data, no special design of the detection model is needed. The shortcoming is obvious. During the data preprocessing, the processed data losses the characteristics of the original data space. For example, the point cloud makes a perspective projection to the camera space, and the projected data structure cannot maintain the geometric spatial distribution of the point cloud data.
For post-fusion, the fusion model is designed for the detection results of different sensors to obtain the final fusion result. In this case, each sensor requires a separate design detection model. This method is often used in object detection and segmentation. For object detection, the most common post-fusion method is Bayesian filter. For the segmentation task, the common is CRF.
Feature fusion combines different sensor data features to form a better scene representation, and the combined features are used for road segmentation. The segmentation task has higher precision requirements for feature fusion and needs to achieve alignment of points in different data spaces to achieve point-wise feature fusion.
In this paper, we propose the BiFNet for road segmentation and mainly solve the two problems of multi-sensor feature fusion
-
•
Aligning the features from different data space. Because of the different working principles of different sensors, the content, dimension and the data structure of the different sensors data are various. The premise of feature fusion is that feature expression needs to be in the same data space and feature space. Therefore, feature alignment in data space is the base of feature fusion.
-
•
Finding out the optimal combination of features. Different sensors have different expressive abilities for different scenes. For example, the expressive abilities of images for high exposure or very dark scenes are relatively weak, while point cloud is not affected by illumination factors. The purpose of feature combination is to find a combination that can adaptively combine the features of different sensors to form the most robust feature according to the different scenes.
To facilitate the understanding of the algorithm, we list the key parameters symbols in Table I.
| Symbol | Implication |
|---|---|
| Sensor data | |
| , | Weights of the fusion and classification models |
| Ground truth | |
| , , | Axises of LiDAR |
| Superscript means LiDAR coordinate | |
| , , | Axises of Camera |
| Superscript means camera coordinate | |
| Pixel in image | |
| , | LiDAR angular resolutions |
| , | External parameters |
| Intrinsic matrix | |
| Homogeneous camra coordinates | |
| Homogeneous 3D coordinates in LiDAR | |
| Pseudo 3D coordinates in LiDAR | |
| 3D coordinates in LiDAR | |
| Feature map | |
| Feature representation ability | |
| Context quality | |
| , | Weights of context-based fusion |
| and domain transformation | |
| Distance function | |
| Sigmoid function | |
| Multilayer perceptron |
IV Bidirectional Fusion Network
For feature alignment problem, we propose a dense space transformation module which transforms the features between camera space and BEV space. At the same time, we design a feature fusion module based on the channel attention mechanism, which fuses the transformed features adaptively according to the scene context. Based on these two modules, we construct the bidirectional fusion network which realizes the end-to-end feature fusion road segmentation based on the camera image and the point cloud.
IV-A Dense space transformation(DST)
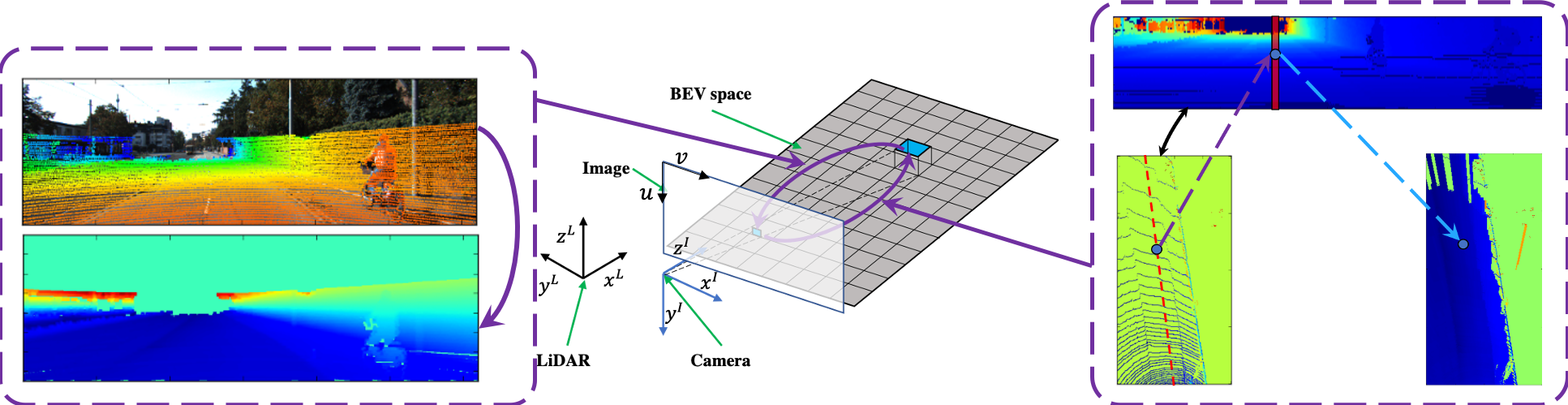
The image and point cloud can be obtained by observing the objects in 3D space with different sensors. Image is the 2D data of the camera through the principle of the hole imaging, compressing the spatial structure and retaining the texture. Far objects will scale proportionally on the imaging plane. The far road will be compressed and the proportion is much smaller than the near road proportion, which results in the perspective image based methods paying more attention to the accuracy of the near road. Point cloud is the spatial data obtained by LiDAR through scanning a beam of laser to image an object. It retains the spatial structure but loses texture. Chen et al.[41] proposed two projection methods which converted the point cloud into ordered data which we use to upsample the height. BEV is one of the common preprocessing methods used in road segmentation. It compresses only the height of the point cloud and preserves the geometry of the road. In this section, we build the relationship between the camera space and BEV space as shown in Fig. 2.
IV-A1 Upsample perspective height
In order to achieve dense mapping from BEV space to camera space, the height of each pixel in camera image is needed. Then according to the pinhole camera model, we calculate the 3D coordinate of each pixel with the 3D point cloud. However, the point cloud and perspective projection are sparse. In order to obtain the dense height map, we upsample the sparse perspective projection as shown in left part of Fig. 2. is the position of the pixel in the image. The valid projection neighbourhood region of the image pixel is , and the estimated height of this pixel in LiDAR coordinate is
| (2) |
Here is the parameter for normalization. are the neighbour positions in the image, is the height of the neighbour in 3D space.
IV-A2 Upsample BEV height
In order to achieve dense mapping from camera space to BEV space, It is required to know the spatial position of each pixel in BEV. Due to the sparsity of the point cloud, only a small portion of the pixels in BEV has a valid height value. In order to obtain the dense height of BEV, according to the principle of rotating scanning laser imaging, a height sampling method in BEV space is designed. Firstly, all points are ranked in the point cloud according to [41] and calculate the index values of each point.
Here are the coordinates of each point. and are the horizontal and vertical angular resolutions of the LiDAR, respectively. For each pixel on the BEV, we calculate the corresponding column in arrangement map which is corresponding to the top picture in the left part of Fig. 2. is the -th column from the arrangement map, corresponding to the red column in the right part of Fig. 2. It is required to find out the neighbour of the BEV pixel in .
| (3) |
Here is the distance between the projected point and LiDAR. is the pixel in BEV whose height is needed to estimate. And the estimated height of this pixel is
| (4) |
Here is horizontal distance between two points. is the valid height in arrangement map, and is the estimated height.
IV-A3 Camera to BEV space transformation
Giving the features in camera space, the goal of the camera to BEV space transformation is to calculate the corresponding features in BEV space. The rotation matrix of the LiDAR relative to the camera is . The transformation matrix is . The intrinsic matrix of the camera is . According to the pinhole camera model, we can calculate the pseudo spatial position of the pixel by inverse transform.
| (5) |
Here is the homogeneous coordinates of the pixel in the camera image. Since camera imaging is nonlinear transformation, there is a scale between the pseudo spatial position and the real spatial position. We can estimate the scale by
| (6) |
where is the axis value of . And means the axis value of . And the final 3D spatial position is
| (7) |
IV-A4 BEV to camera space transformation
In order to complete the feature transformation from BEV to camera space, we only need to estimate the spatial position of each pixel on BEV map. According to the procedure of constructing BEV, The horizontal coordinates of each pixel in the 3D space are linearly related to the coordinates in BEV. Moreover, the dense BEV height map have been calculated in previous works. Then, we build the mapping from BEV space to camera space by hole imaging theory.
| (8) |
Here is the homogeneous coordinates of the pixel in the 3D space.
IV-B Context based fusion(CBF)
Since the imaging principle and measuring range of each sensor are different, the abilities of sensors to express various environments in diverse scenarios are different. The purpose of the multi-sensor fusion is obtaining the consistent and effective representation of the environment for various scenarios. In order to achieve this effect, the direct methods are projecting the LiDAR features into camera space and adding the features into image features. The problem of this direct linear addition method is that it does not consider the different expressive abilities of sensors for various scenarios, which may result in the confusion of features when the difference between the two features is large. Inspired by SENet[47], we design a context-based adaptive feature fusion module, as shown in Fig. 3. According to the scene expression ability of different sensor features, the module can stimulate the good features and suppress the bad features, so as to get a more effective feature expression.

For the feature maps from convolutional neural networks, we argue that different channel features represent different context of the environment. We can get the feature representation ability of the current feature map as follows
| (9) |
Here and are the height and width of the feature maps, respectively. is the corresponding vector at of the feature map. which is insensitive to noise compared with max pooling.
After obtaining the expressive power of different feature channels, we need to determine which channels are conducive to the segmentation task and which ones confuse features. SENet pointed out that suppressing the poor features and encouraging the better feature is conducive to more effective feature expression. Therefore, we need to consider the relationship between channels, to evaluate the favorable feature channels and the disadvantageous feature channels. Here we use a three-layer perceptron(MLP) to predict the gain of each channel for the current segmentation task in the current scenario.
| (10) |
where represents context quality for the features. And the sigmoid function at the output layer is used to scale the weights into . is the feature representation ability vector. is the fully connected layer, and means the weight of the layer. At the middle layer of MLP, we use ReLU as the activation function. And the final feature in each channel is
| (11) |
Here , and are the original features, context quality and reweighted features of the channel , respectively. For the feature of image and point cloud, we fuse the weighted features based on context to get the final consistent feature.

IV-C Bidirectional fusion networks
Based on the dense space transformation module and the context-based fusion module, we design the bidirectional fusion module to fuse the features from different deep features. Considering the different imaging modes of images and point clouds, their data sources and data expressions are also different. There may be differences in scale and dimension arrangement between the two group features. Therefore, we add a domain transformation(DT) module between the DST and CBF. And it is realized by convolution.
| (12) |
Here is -th row, -th column and -th channel element of the feature map. is the corresponding domain transformed feature with channels. is the parameter of the convolution.
Based on this module, we construct the bidirectional fusion networks. Since ResNet[48] achieves the excellent performance in segmentation tasks, we also use ResNet as the backbone network to extract features of image and BEV of point cloud respectively. After the output of two parallel ResNet, we insert a bidirectional fusion module to realize feature fusion. The whole network architecture is shown in Fig. 4.
In order to make the network converge faster and better, we adopt the multi-task learning to train the network. We introduce the road segmentation loss in camera space and BEV. Note that the loss of camera space can make the network see objects farther away, while the loss of BEV can make the distant and near objects distribute equally. For each pixel in camera space, we use the focal loss[49] for the imbalance between road and background
Here means the loss of the pixel in image . Where reduces the impact of the imbalance between the classes. controls the weight of the hard examples. is the pixel label, and is the estimated probability belonging to the road. Multi-task learning are widely used for objects detection and segmentation[50]. And we use the multi-task objective function to train the whole networks
| (13) |
Here is the number of the pixels in one batch. is the weight for balancing the different loss from different space. The superscripts is corresponding to the camera space and LiDAR BEV space.
V Experiments
In this section, we evaluate the method on KITTI[51] dataset. Firstly, we briefly introduce the KITTI road segmentation data set and evaluation metrics. The training process of the networks is given in detail. Then, we evaluate the impact of each module proposed on the final results on the validation set of the KITTI dataset and analyze the results. Finally, we evaluate the algorithm on the test set of the data set.
V-A Dataset and evaluation metrics
KITTI is a well-know dataset which provides 289 training images and 290 testing images for road segmentation tasks. The training set and the test set contain three different road scenarios including Urban Marked road(UM), Urban Multiple Marked road(UMM), and Urban Unmarked road(UU).
In the KITTI dataset, the LiDAR data format is 3D point cloud. Because of the disorder of 3D point cloud, convolutional neural networks can not be directly applied to point cloud. As mentioned earlier, the LiDAR input part of our algorithm is the top view projection of 3D point cloud. The resolution of the BEV is 0.5 meter. Each pixel in the overhead projection contains a vector, which has 6 attributes, namely, the maximum height value, the minimum height value, the average height value, the maximum intensity value, the minimum intensity value and the average intensity value of the point set falling into the pixel area. The default value is 0.
We use the evaluation metrics in literature[52] to analyze our algorithm. The evaluation measures include precision(PRE), recall(REC) and pixelwise maximum F-measure (MaxF). PRE measures the proportion of correctly segmented pixels, and REC reflects the missing detection of the algorithm. The calculations are as follows.
| PRE | |||
| REC |
Here TP, FP and FN are true positive, false positive and false negitive, respectively. There is a bit of trade-off between PRE and REC. MaxF is designed as a comprehensive metric considering PRE and REC. Another comprehensive metric is the average precision(AP), which provides insights into the performance over the full recall range. The calculations are as follow.
| MaxF | |||
| AP |
Here represents recall threshold. All metrics are calculated in BEV space.
V-B Training procedure
In order to evaluate the algorithm in the training process, we select 58 images from 289 training sets as validation sets. In the process of algorithm analysis, in order to reduce computing resources and accelerate network training, ResNet-18 is used as the basic network to verify the modules designed in this paper. We use Adam algorithm to train the network with parameters shown in Table II, and the learning rate is decaying linearly with training epoch. In the training process, the learning rate decreases linearly with time. In the KITTI road experiment, we use ResNet-101[48] and ResNet-50[48] as the basic networks of the image and BEV branch respectively. The two networks are trained separately first. During the training, symmetric transformation, translation transformation and scaling transformation are employed for the data augmentation.
| Parameter | Value |
| Initial learning rate | 0.01 |
| Momentum of learning rate | 0.9 |
| Weight decay rate | 0.0001 |
| Max training iteration | 30000 |
V-C KITTI road experiment
To compare with state-of-the-art road detection methods, we estimate the BiFNet on the KITTI road benchmark validation set. In this experiment, we use the ResNet-101 and ResNet-50 as the backbones for the camera image and the BEV of the point cloud. We use the 5-fold cross validation on the training set and obtain the mean of the results. The overall results of BiFNet and other state-of-the-art road detection methods are shown in Table III. LC-CRF[15], LidCamNet[16] and PLARD[17] are the multi-sensor fusion-based methods. LC-CRF fused the features from camera and perspective views of LiDAR while LidCamNet used the learnable weights to add two different features. Since the proposed method has better scene adaptability, it achieves the better performance than the above two methods. According to the results, our proposed method achieves state-of-the-art in UMM scenario and competitive results in other scenarios.
Compared with PLARD, BiFNet achieves slightly better results according to Table III. However, the results of PLARD shown above are integrated from 3 different models, while BiFNet only needs single model.
| Method | LC-CRF | LidCamNet | PLARD | BiFNet(Ours) | |
|---|---|---|---|---|---|
| UM | MaxF | 94.91% | 95.62% | 97.05% | 96.61% |
| AP | 86.41% | 93.54% | 93.53% | 94.31% | |
| UMM | MaxF | 97.08% | 97.08% | 97.77% | 97.88% |
| AP | 92.06% | 95.51% | 95.64% | 95.82% | |
| UU | MaxF | 94.01% | 94.54% | 95.95% | 94.73% |
| AP | 85.24% | 92.74% | 95.25% | 93.31% |
V-D Ablation study
In order to verify the validity of different components of the proposed BiFNet, we conduct a set of ablation experiments on KITTI dataset. The training set of KITTI is split into two parts. One is used to train the networks while the other is for validation.
| Image | LiDAR BEV | DST | CBF | MaxF | AP |
|---|---|---|---|---|---|
| 93.01 | 94.41 | ||||
| 94.30 | 95.03 | ||||
| 95.57 | 95.43 | ||||
| 96.21 | 96.08 |
V-D1 Baselines of image and LiDAR BEV
In this part, we conduct single sensor-based road segmentation methods either with camera or LiDAR. The results are shown in the first two lines of Table IV. The first line shows the results based on images while the second line is LiDAR BEV-based. We find that the networks with BEV input have better performance than those with image input under the same network structure and training method. There may be two reasons for these results. The first kind of illumination and road texture have a greater impact on the network, resulting in poor network generalization performance. The second is that perspective projection compresses distant objects, which results in poor segmentation accuracy.
V-D2 Effectiveness of DST
Considering the above results, we add the DST module after ResNet backbone. DST module can transform the features from different space into the unique feature space. Then we use the element-wise addition to fuse the information. The results are shown in third line of Table IV. We find that the MaxF and AP of this method are much higher than the methods without DST. Since the DST module gathers the information from the camera and LiDAR, the method with DST is more robust for complex illumination environment.

V-D3 Effectiveness of CBF
On the above basis, we add the CBF module after the DST module. In last part, we employ the element-wise addition for fusing the gathered features from the image and LiDAR BEV by the DST module. However, element-wise addition may confuse the features from different sensors. For example, under dark environment, the image features are meaningless while the LiDAR features are not affected. The direct addition will confuse the trained LiDAR features. The CBF overcomes this problem and fuses the multi-sensors features based on the corresponding expressiveness according to the context. Compared with element-wise addition, CBF based method has a higher recall shown in the last line of Table IV. The reason is that CBF fuses the information from multi-sensors based on the context features and has higher utilization of information. Compared with direct addition, the CBF module improves the fusion efficiency and achieves better fusion results.
V-D4 Visualization of results
In order to see more clearly the advantages of our proposed fusion algorithm compared with that based on a single sensor algorithm, we visualize the results of different algorithms in different scenarios, as shown in Fig. 5. Different rows represent different algorithms, and different columns represent different scenes. As mentioned earlier, road segmentation based on camera space may result in poor remote segmentation results, which is shown in Frame 1. It can be seen that in the LiDAR BEV-based method and fusion-based method, the segmentation results of the distant intersection are significantly improved. Frame 2 and Frame 3 show that the image-based method is more sensitive to the texture on the road, but not to the height change on the road. The method based on LiDAR is more sensitive to the height change on the road surface. Therefore, when there are steps at the fork, the method based on LiDAR is better than the method based on image, and our method fully captures this advantage of LiDAR. Frame 4 and Frame 5 show that light notes have a serious impact on image-based methods, while LiDAR is not affected by them. In this case, our method tends to believe that features from LiDAR can segment the road.
V-E Comparison of space transformation
Wange et al.[46] proposed sparse non-homogeneous pooling(SHPL) module to realize the fusion of image and LiDAR BEV. Unlike DST in this paper, SHPL is based on the points of the point cloud to establish the relationship between image and BEV. Because the points are sparse, this transformation is sparse. Only a small proportion of pixels in feature maps have corresponding feature vectors. In this paper, DST is a dense transformation, which realizes the transformation relationship of each pixel of feature maps in different spaces.
In order to verify the validity of this dense transformation, we set up a comparison experiment with SHPL. During the comparison, element-wise addition is used for features fusion. The experimental results are shown in Table V. From the results, we see that the two methods have the same effect on BEV branch. For the perspective branch, DST outperforms SHPL significantly. The reason is that DST is a dense spatial transformation method, which can establish the mapping relationship between each pixel and the target feature at different scales, and thus obtain dense transformation features. In the experimental results, an interesting phenomenon is that with the sparse mapping, SHPL achieves the good performance on BEV space. One possible reason is that since the input LiDAR BEV is sparse, the neural network has adapted to the sparsity in BEV space, and has the ability to learn from the sparse input to segment the road, but the perspective image is dense, and the network can not adapt to the sparsity from the point cloud. This also proves the advantages of DST.
| Method | MaxF | AP | PRE | REC | |
|---|---|---|---|---|---|
| DST(Ours) | BEV | 95.57 | 95.43 | 95.54 | 95.39 |
| Perspective | 94.14 | 94.20 | 92.85 | 95.46 | |
| SHPL[46] | BEV | 95.11 | 94.99 | 95.14 | 95.08 |
| Perspective | 92.87 | 93.53 | 91.85 | 93.75 |
V-F CBF study
In order to verify the validity and universality of our proposed CBF module, we reproduce LidCamNet[16] and PLARD[17] methods, and migrate the module to these methods. The experimental results are shown in Table VI. In the reproduction process, we use ResNet-18 as feature extraction network, and the output features are used for fusion. Unlike the experimental results in PLARD, our reproduced LidCamNet is slightly better than PLARD. LidCamNet and PLARD both use the learnable weights for feature fusion. The difference is that LidCamNet only learns the weights of LiDAR, and each fusion connection has only one value. The difference of PLARD is that it sets a learnable weight for each pixel position of the feature, it is more adaptive than LidCamNet. However, the fusion weights of these methods remain unchanged for all sample during the inference, while the proposed method can adjust adaptively according to the content of samples. Therefore, applying CBF module to the above two methods will gain performance to a certain extent.
VI Conclusions
In this paper, we propose a novel bidirectional fusion network named BiFNet which fuses the information of the camera image and the BEV of the point cloud. Our innovative works for the network is to design the bidirectional fusion module which is composed of DST and CBF. DST builds the dense spatial transformation relationship between the camera image and the BEV of the point cloud, while CBF fuses the features from different sensors based on the various scene representation ability. Moreover, CBF could be easily incorporated into deep neural networks and work for other forms of data. The experimental tests on the KITTI road dataset also show that our method achieves a better result.
3D object detection plays a more and more important role in robot and automatic driving. At present, the advanced 3D object detection methods[42][43] are often based on BEV space. This method faces great challenges in small object detection and object classification. Multi-sensor fusion is the key to solve the problem. Although BiFNet is used to solve the problem of road segmentation, it can also be easily embedded into the existing 3D object detection algorithm. Compared with the existing multi-sensor fusion detection methods, our proposed method can be fused from the feature pixel level, which is a potential way to improve the 3D detection algorithm.
References
- [1] J. Mei, Y. Yu, H. Zhao, and H. Zha, “Scene-adaptive off-road detection using a monocular camera,” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 1, pp. 242–253, Jan 2018.
- [2] C. Lee and J. Moon, “Robust lane detection and tracking for real-time applications,” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 12, pp. 4043–4048, Dec 2018.
- [3] A. Palffy, J. Dong, J. F. P. Kooij, and D. M. Gavrila, “CNN based road user detection using the 3D radar cube,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1263–1270, April 2020.
- [4] D. Zhao, Y. Chen, and L. Lv, “Deep reinforcement learning with visual attention for vehicle classification,” IEEE Transactions on Cognitive and Developmental Systems, vol. 9, no. 4, pp. 356–367, Dec 2017.
- [5] H. Li, Q. Zhang, and D. Zhao, “Deep reinforcement learning-based automatic exploration for navigation in unknown environment,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2019.
- [6] J. Wang, Q. Zhang, D. Zhao, and Y. Chen, “Lane change decision-making through deep reinforcement learning with rule-based constraints,” in 2019 International Joint Conference on Neural Networks (IJCNN), July 2019, pp. 1–6.
- [7] Q. Zhang, D. Zhao, and D. Wang, “Event-based robust control for uncertain nonlinear systems using adaptive dynamic programming,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 1, pp. 37–50, Jan 2018.
- [8] B. Li, X. Zhang, Y. Fang, and W. Shi, “Visual servoing of wheeled mobile robots without desired images,” IEEE Transactions on Cybernetics, vol. 49, no. 8, pp. 2835–2844, Aug 2019.
- [9] H. Li, D. Zhao, Y. Chen, and Q. Zhang, “An efficient network for lane segmentation,” in Proceedings of the IEEE Conference on Cognitive Systems and Signal Processing(ICCSIP). IEEE, 2018, pp. 177–185.
- [10] Y. Lu, Y. Chen, D. Zhao, and J. Chen, “Graph-FCN for image semantic segmentation,” in Proceedings of the IEEE International Symposium on Neural Networks (ISNN). Springer, 2019, pp. 97–105.
- [11] D. Lin, R. Zhang, Y. Ji, P. Li, and H. Huang, “SCN: Switchable context network for semantic segmentation of rgb-d images,” IEEE Transactions on Cybernetics, vol. 50, no. 3, pp. 1120–1131, March 2020.
- [12] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3431–3440.
- [13] L. Caltagirone, S. Scheidegger, L. Svensson, and M. Wahde, “Fast LIDAR-based road detection using fully convolutional neural networks,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017, pp. 1019–1024.
- [14] M. Zhang, W. Li, Q. Du, L. Gao, and B. Zhang, “Feature extraction for classification of hyperspectral and LiDAR data using patch-to-patch CNN,” IEEE Transactions on Cybernetics, vol. 50, no. 1, pp. 100–111, Jan 2020.
- [15] S. Gu, Y. Zhang, J. Tang, J. Yang, and H. Kong, “Road detection through CRF based LiDAR-camera fusion,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 3832–3838.
- [16] L. Caltagirone, M. Bellone, L. Svensson, and M. Wahde, “LIDAR-camera fusion for road detection using fully convolutional neural networks,” Robotics and Autonomous Systems, vol. 111, pp. 125–131, 2019.
- [17] Z. Chen, J. Zhang, and D. Tao, “Progressive LiDAR adaptation for road detection,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 3, pp. 693–702, 2019.
- [18] N. Qi, X. Yang, C. Li, R. Lu, C. He, and L. Cao, “Unstructured road detection via combining the model-based and feature-based methods,” IET Intelligent Transport Systems, vol. 13, no. 10, pp. 1533–1544, 2019.
- [19] J. M. Alvarez, A. Lopez, and R. Baldrich, “Illuminant-invariant model-based road segmentation,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV), June 2008, pp. 1175–1180.
- [20] Ceryen Tan, Tsai Hong, T. Chang, and M. Shneier, “Color model-based real-time learning for road following,” in Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Sep. 2006, pp. 939–944.
- [21] M. Aly, “Real time detection of lane markers in urban streets,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2008, pp. 7–12.
- [22] A. Laddha, M. K. Kocamaz, L. E. Navarro-Serment, and M. Hebert, “Map-supervised road detection,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2016, pp. 118–123.
- [23] S. Zhou, J. Gong, G. Xiong, H. Chen, and K. Iagnemma, “Road detection using support vector machine based on online learning and evaluation,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2010, pp. 256–261.
- [24] G. L. Oliveira, W. Burgard, and T. Brox, “Efficient deep models for monocular road segmentation,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 4885–4891.
- [25] Z. Chen and Z. Chen, “RBNet: A deep neural network for unified road and road boundary detection,” in Proceedings of the International Conference on Neural Information Processing (NeurIPS). Springer, 2017, pp. 677–687.
- [26] R. Fernandes, C. Premebida, P. Peixoto, D. Wolf, and U. Nunes, “Road detection using high resolution LiDAR,” in Proceedings of the IEEE Vehicle Power and Propulsion Conference (VPPC). IEEE, 2014, pp. 1–6.
- [27] Y. Zhang, J. Wang, X. Wang, and J. M. Dolan, “Road-segmentation-based curb detection method for self-driving via a 3D-LiDAR sensor,” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 12, pp. 3981–3991, Dec 2018.
- [28] J. Xiao, R. Stolkin, Y. Gao, and A. Leonardis, “Robust fusion of color and depth data for RGB-D target tracking using adaptive range-invariant depth models and spatio-temporal consistency constraints,” IEEE Transactions on Cybernetics, vol. 48, no. 8, pp. 2485–2499, Aug 2018.
- [29] J. Han, H. Chen, N. Liu, C. Yan, and X. Li, “CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion,” IEEE Transactions on Cybernetics, vol. 48, no. 11, pp. 3171–3183, Nov 2018.
- [30] P. Y. Shinzato, D. F. Wolf, and C. Stiller, “Road terrain detection: Avoiding common obstacle detection assumptions using sensor fusion,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2014, pp. 687–692.
- [31] L. Xiao, B. Dai, D. Liu, T. Hu, and T. Wu, “CRF based road detection with multi-sensor fusion,” in Proceedings of the IEEE Intelligent Vehicles Symposium (IV). IEEE, 2015, pp. 192–198.
- [32] X. Han, H. Wang, J. Lu, and C. Zhao, “Road detection based on the fusion of LIDAR and image data,” International Journal of Advanced Robotic Systems, vol. 14, no. 6, p. 1729881417738102, 2017.
- [33] L. Xiao, R. Wang, B. Dai, Y. Fang, D. Liu, and T. Wu, “Hybrid conditional random field based camera-LIDAR fusion for road detection,” Information Sciences, vol. 432, pp. 543–558, 2018.
- [34] S. Gu, T. Lu, Y. Zhang, J. M. Alvarez, J. Yang, and H. Kong, “3D LiDAR + monocular camera: An inverse-depth-induced fusion framework for urban road detection,” IEEE Transactions on Intelligent Vehicles, vol. 3, no. 3, pp. 351–360, Sep. 2018.
- [35] S. Gu, Y. Zhang, X. Yuan, J. Yang, T. Wu, and H. Kong, “Histograms of the normalized inverse depth and line scanning for urban road detection,” IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 8, pp. 3070–3080, Aug 2019.
- [36] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems (NeurIPS), 2015, pp. 91–99.
- [37] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proceedings of the European Conference on Computer Vision (ECCV). Springer, 2016, pp. 21–37.
- [38] J. Redmon and A. Farhadi, “YOLO9000: better, faster, stronger,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263–7271.
- [39] Y. Chen, D. Zhao, H. Li, D. Li, and P. Guo, “A temporal-based deep learning method for multiple objects detection in autonomous driving,” in Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN). IEEE, 2018, pp. 1–6.
- [40] H. Li, X. Zhou, Y. Chen, Q. Zhang, D. Zhao, and D. Qian, “Comparison of 3D object detection based on LiDAR point cloud,” in 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS). IEEE, 2019, pp. 678–685.
- [41] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3D object detection network for autonomous driving,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1907–1915.
- [42] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. L. Waslander, “Joint 3D proposal generation and object detection from view aggregation,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1–8.
- [43] M. Liang, B. Yang, S. Wang, and R. Urtasun, “Deep continuous fusion for multi-sensor 3D object detection,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 641–656.
- [44] H. You, Y. Feng, R. Ji, and Y. Gao, “PVNet: A joint convolutional network of point cloud and multi-view for 3D shape recognition,” in Proceedings of the ACM Multimedia Conference on Multimedia Conference. ACM, 2018, pp. 1310–1318.
- [45] D. Xu, D. Anguelov, and A. Jain, “PointFusion: Deep sensor fusion for 3d bounding box estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 244–253.
- [46] Z. Wang, W. Zhan, and M. Tomizuka, “Fusing bird’s eye view LIDAR point cloud and front view camera image for 3D object detection,” in 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 1–6.
- [47] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018, pp. 7132–7141.
- [48] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016, pp. 770–778.
- [49] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PP, no. 99, pp. 2999–3007, 2017.
- [50] Y. Chen, D. Zhao, L. Lv, and Q. Zhang, “Multi-task learning for dangerous object detection in autonomous driving,” Information Sciences, vol. 432, pp. 559–571, 2018.
- [51] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” International Journal of Robotics Research (IJRR), 2013.
- [52] J. Fritsch, T. Kuehnl, and A. Geiger, “A new performance measure and evaluation benchmark for road detection algorithms,” in Proceedings of IEEE Conference on Intelligent Transportation Systems (ITSC). IEEE, 2013, pp. 1693–1700.