(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
22email: {zhangzichen@mail., lhc12@mail., wzhai056@, kangduyu@, forrest@}ustc.edu.cn
Bidirectional Progressive Transformer for Interaction Intention Anticipation
Abstract
††*Corresponding Author.Interaction intention anticipation aims to jointly predict future hand trajectories and interaction hotspots. Existing research often treated trajectory forecasting and interaction hotspots prediction as separate tasks or solely considered the impact of trajectories on interaction hotspots, which led to the accumulation of prediction errors over time. However, a deeper inherent connection exists between hand trajectories and interaction hotspots, which allows for continuous mutual correction between them. Building upon this relationship, a novel Bidirectional prOgressive Transformer (BOT), which introduces a Bidirectional Progressive mechanism into the anticipation of interaction intention is established. Initially, BOT maximizes the utilization of spatial information from the last observation frame through the Spatial-Temporal Reconstruction Module, mitigating conflicts arising from changes of view in first-person videos. Subsequently, based on two independent prediction branches, a Bidirectional Progressive Enhancement Module is introduced to mutually improve the prediction of hand trajectories and interaction hotspots over time to minimize error accumulation. Finally, acknowledging the intrinsic randomness in human natural behavior, we employ a Trajectory Stochastic Unit and a C-VAE to introduce appropriate uncertainty to trajectories and interaction hotspots, respectively. Our method achieves state-of-the-art results on three benchmark datasets Epic-Kitchens-100, EGO4D, and EGTEA Gaze+, demonstrating superior in complex scenarios.
Keywords:
Interaction Intention Egocentric Videos Transformer1 Introduction
The pursuit of future prediction on egocentric videos is centered on anticipating intentions and behaviors observed from a first-person perspective [57]. Interaction intention can be reflected in the trajectory of hand motion and contact points on the next-active object [39]. This task is novel but holds significant potential value, such as AR [59, 34], robot skill acqusition [47, 24, 9, 43, 3], hand reconstruction [65, 30] and pose estimation [38, 27].
Most existing relevant research treated hand trajectory forecasting and interaction hotspots prediction as independent tasks. Bao et al. [4] proposed to predict the 3D hand trajectory from a first-person view. However, They overlooked the guiding role of interactable objects on trajectories. The prediction process was incomplete, leading to significant errors at the end of trajectories. On the other hand, there was extensive research on interaction hotspots [18, 32, 50, 61, 41, 42, 51]. Nevertheless, these studies often focused on the characteristics of the objects themselves, resulting in lower integration with subjective human behaviors in complex scenes and less accurate predictions. Other studies [37, 39] jointly predicted future hand trajectories and interaction hotspots, improving their integration. However, these studies only considered the unidirectional influence of hand trajectories on contact points. Consequently, errors accumulated continuously with the prediction time steps (Fig. 1).
In fact, this one-way causation was insufficient, as it disregarded the spatial correlation between the two factors. Conversely, there exists a mutual relationship between the predictions of hand trajectories and interaction hotspots. On one hand, the derived directions of hand trajectories suggest the approximate areas where contact points occur. On the other hand, there is an inherent connection between the spatial distribution of contact points and hand trajectory patterns, as in Fig. 2, which implies that examining the distribution of contact points can provide insights into the development of hand trajectories. Leveraging this relationship, to mitigate the process of error accumulation, we establish a Bidirectional Progressive (Bi-Progressive) mechanism, allowing continuous mutual refinement between trajectories and interaction hotspots throughout the entire prediction period, improving the accuracy of joint predictions.
In this paper, an innovative Bidirectional prOgressive Transformer (BOT) is proposed, introducing the Bi-Progressive mechanism mentioned earlier between two independent predicting branches. Firstly, the raw video input undergoes a Spatial-Temporal Reconstruction Module, which integrates the spatial information from the last observation frame and the temporal information among all observation frames. This process mitigates spatial information conflicts arising from changes in the field of view in first-person videos. Secondly, we establish separate dual branches for hand trajectory forecasting and interaction hotspots prediction, endowing them with the capability to independently perform individual prediction tasks, laying the foundation for introducing the Bi-Progressive mechanism. Subsequently, we introduce cross-attention blocks as the primary implementation of the Bi-Progressive mechanism. At each time step, the predictions of hand trajectories and interaction hotspots are alternately updated, addressing inherent errors in individual predictions. Finally, following the logic of natural human behaviors [70, 56, 49], we incorporate a Trajectory Stochastic Unit and a C-VAE for both hand trajectories and interaction hotspots, respectively, introducing appropriate uncertainties to the final prediction results.
We evaluate our approach on Epic-Kitchens-100 [14], EGO4D [28] and EGTEA Gaze+ [36] datasets. BOT demonstrates notable advantages in predicting both hand trajectories and interaction hotspots, achieving superior performance in anticipating interaction intentions. In summary, our contributions are as follows:
-
A novel BOT is introduced to jointly predict future hand trajectories and interaction hotspots in egocentric videos, attaining the optimal predictive performance with more lenient input conditions.
-
We introduce a novel Bidirectional Progressive mechanism that enhances the coherence between hand trajectories and interaction hotspots, thereby improving the completeness of the interaction intention.
2 Related Work
Action anticipation in egocentric videos. Anticipating actions in an egocentric vision is a challenging task that includes short-term and long-term action anticipation [57, 55]. Short-term action anticipation aims to predict the next action in the near future [21, 48, 23, 22, 25], while long-term action anticipation focuses on the sequence of subsequent actions performed by the camera wearer [40, 52, 26, 46]. These endeavors contribute significantly to the comprehension of actions in first-person videos. However, concerning interaction intention, action anticipation still yields information of relatively high dimensionality. Anticipating a semantic label does not furnish direct guidance for the robot, as it lacks specific instructions on task execution. Comparatively, hand trajectories and interaction hotspots offer a more intuitive representation of interaction intention, constituting a lower-dimensional depiction.
Human trajectory forecasting. The forecasting of human trajectories was extensively studied over the years [2, 44, 1, 53, 13, 12]. However, most of them were based on third-person video datasets, falling short of capturing intentions related to human-object interactions. Since hands serve as the primary medium through which humans interact with the world, predicting hand trajectories in egocentric videos can aid embodied AI in comprehending human-object interaction intentions. The approaches in [37, 39, 4] addressed the issue of hand trajectory prediction in egocentric videos. However, they did not account for the influence of contact points with objects on trajectories. This limitation resulted in the continuous accumulation of prediction errors over time.
Interaction hotspots prediction. Interaction hotspots prediction aims to locate where the hand-object interaction happens. Some research aimed to predict the next interactive object [20, 5, 6, 17, 15], going further, some work anticipated specific interaction regions on objects [37, 42, 51, 39], yielding more precise information for interaction. Differing from image input, our task aims to generate more precise predictions regarding the regions of contact points by utilizing egocentric video inputs. The incorporation of first-person videos is intended to focus on precisely localizing interaction hotspots for distinct human motions. In this task, we leverage the predicted hand trajectories to improve the accuracy of interaction hotspots predictions.
3 Method
Problem Setup. Given an original input video , where is the last observation frame, the task is predicting future hand trajectories in future keyframes and the contact point in the contact frame . We subsequently convert the contact point into a heatmap by centering a Gaussian distribution, generating interaction hotspots . To ensure the continuity of the trajectory as well as the consistency of the background, both and are projected onto the last observation frame, which enhances the overall coherence of the predictions [39].
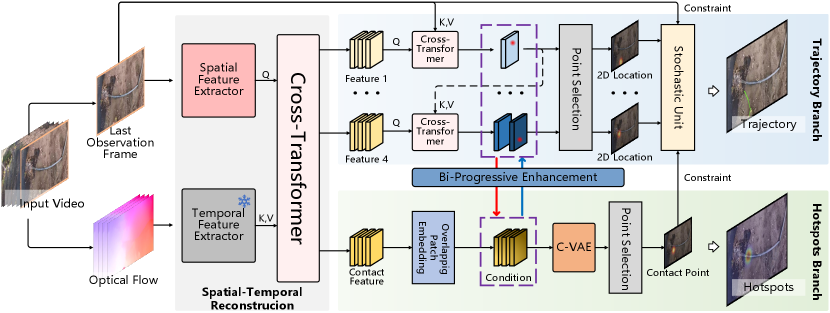
3.1 Network
Overview. As shown in Fig. 3, given the original input video , we aim to predict the future hand trajectory and interaction hotspots . Initially, to alleviate information conflicts arising from changes in the field of view, the original input video undergoes a Spatial-Temporal Reconstruction Module that integrates spatial information from the last observation frame and temporal information from the entire video, producing spatial features for each future time step. Subsequently, these features are separated, with the last one serving as the contact feature while the preceding ones are for trajectory features. These features are then fed into the interaction hotspots and trajectory prediction branches, respectively. The former employs an overlap patch embedding layer to enhance attention at the center of the field of view, while the latter introduces temporal order to trajectory features through Cross-Transformers [11]. Simultaneously, we employ a Bi-Progressive Enhancement Module consisting of cross-attention blocks between dual branches, introducing a Bi-Progressive mechanism to the joint prediction. This alternately and iteratively corrects the features of trajectories and interaction hotspots in chronological order, thereby mitigating the accumulation of prediction errors over time. Finally, considering the inherent uncertainty in natural human behaviors [70, 56, 49], we introduce a Stochastic Unit for trajectory forecasting while employing a C-VAE [60] for interaction hotspots, adding appropriate uncertainty during the completion of position decoding to achieve comprehensive predictions.
Spatial-Temporal Reconstruction. When dealing with egocentric videos, both 3D convolutions [19] and self-attention mechanisms [66] struggle to address spatial information conflicts arising from changes in views. Moreover, predictions are projected onto the last observation frame. Taking these factors into account, we establish the Spatial-Temporal Reconstruction Module. On one hand, we employ optical flow containing more comprehensive motion information as the temporal input, on the other hand, we isolate the last observation frame as the spatial input. Subsequently, the temporal input is processed by a pre-trained Temporal Segment Network [67, 22], extracting low-dimensional temporal features , and the spatial input is passed through a Segformer-b2 [68], extracting spatial features from the last observation frame. and are then fed into a Cross-Transformer [11]. The -th block is expressed as:
| (1) | |||
| (2) | |||
| (3) |
Where and represent the original spatial and temporal inputs, respectively. is encoded by overlap patch embedding layers from spatial features , enhancing the network’s focus on the center of the field of view. is encoded by positional embedding layers from temporal features , improving the overall sequentiality. Furthermore, refers to the Feed Forward Layer, comprising a two-layer MLP with an expanding ratio , and Layer normalization () is applied before each block. stands for Multi-head Cross-Attention, where query, key, and value are processed through distinct linear layers: . The output of this module corresponds to the spatial features for each prediction frame.
Interaction Hotspots Prediction Branch. Due to the spatial distribution of contact points closer to the central field of view, the contact feature undergoes processing through an overlap patch embedding layer:
| (4) |
Where represents the processed contact feature.
Hand Trajectory Prediction Branch. We employ original trajectory features as primary features and utilize features from the previously predicted frame as conditional features, subsequently merging them through the cross-attention block , ensuring the coherence of the trajectory over time. Assuming the trajectory features are and the feature map of the last observation frame is , they are updated in chronological order:
| (5) |
Where stands for the updated trajectory feature, is the prediction time step.
H-O Bi-Progressive Enhancement. Expanding on the groundwork laid by two distinct prediction branches, and to mitigate the accumulation of errors as predictions unfold over time, we introduce a Bi-Progressive Enhancement Module (Fig. 4), which alternately corrects the predictions of trajectories and interaction hotspots at each time step . Specifically, owing to observation frames and the continuity of hand trajectories, the trajectory feature at the initial predicted time step demonstrates a high level of accuracy. Exploiting this, we enhance the precision of the contact feature through the cross-attention block f, thereby minimizing the error with the ground truth. Moving to the subsequent time step , we employ the first refined contact feature from the previous time step as a condition to correct the trajectory feature . Following this, the corrected trajectory feature is utilized to further refine the contact feature. This iterative correction process persists until all trajectory features have undergone a complete round of updates. It can be represented as a recursive procedure:
| (6) | |||
| (7) | |||
| (8) |
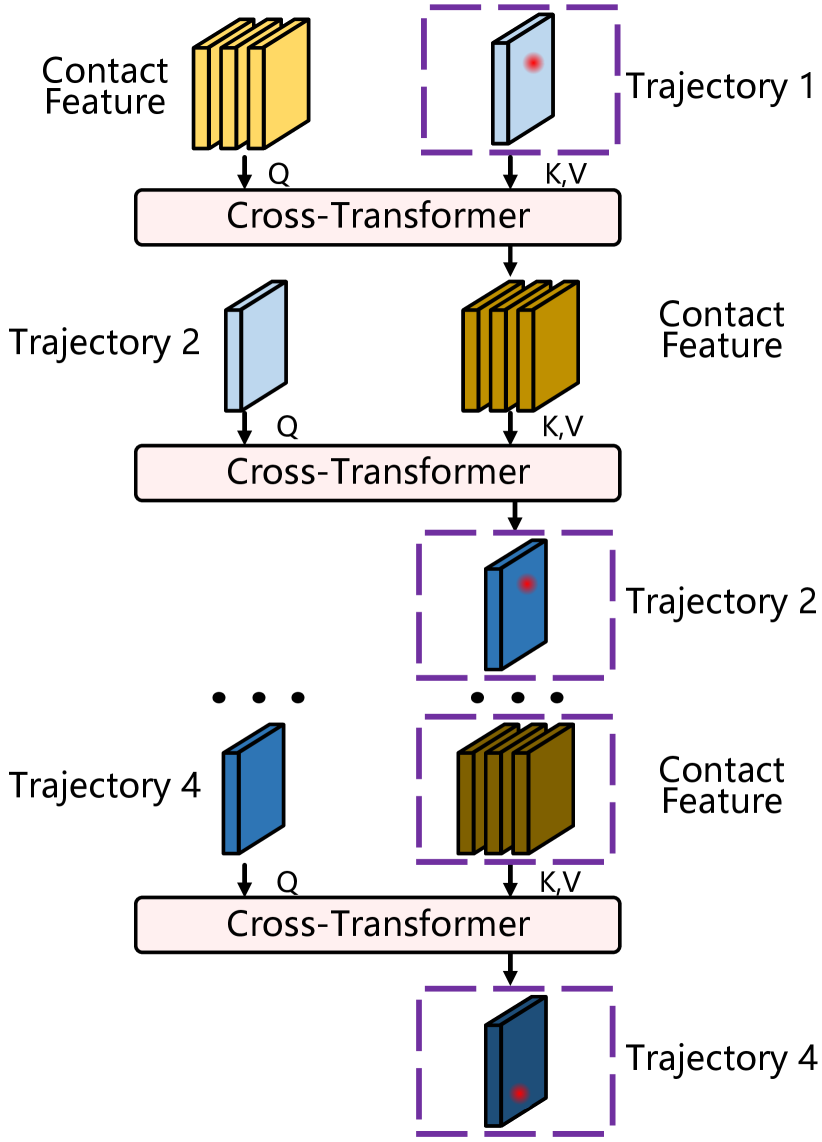
Where represents the refined trajectory feature map at time step , denotes the contact feature after the -th refinement. Via this module, we attain refined features for both trajectories and interaction hotspots, significantly reducing error accumulation in predictions.
Interaction Hotspots Decoder. Given the presence of inherent uncertainty associated with interaction hotspots [39, 41, 42], we employ a C-VAE [60] as the decoder. Due to the excessive randomness associated with directly decoding the coordinates of contact points, we instruct the C-VAE to output a feature map and select the location of the maximum value from this map as the output, thereby confining the uncertainty within a reasonable range. The C-VAE follows an encoder-decoder structure. For the encoder block, we concatenate the input with the condition through an encoding function , obtaining features in latent space which parameterized by mean and co-variance . In this context, the input is the ground truth heatmap, while the condition is the refined contact feature . In the decoder block, the first step involves sampling from the latent space and concatenating it with condition . Following that, the output heatmap is reconstructed by a decoding function . In summary, the entire process can be formulated as follows:
| (9) |
Where represents a normal distribution, is the reconstructed heatmap. Both encoding and decoding blocks consist of two MLP layers. We introduce KL-Divergence and the reconstruction error as the overall loss:
| (10) | |||
| (11) | |||
| (12) |
In this paper, we set .
Hand Trajectory Decoder. Similar to interaction hotspots, hand trajectories also exhibit uncertainty [45, 29, 33]. Given that trajectory feature maps with distinct distribution characteristics have been obtained through the Bi-Progressive Enhancement Module, in conjunction with sampling efficiency, we don’t utilize C-VAE, rather, we introduce a Trajectory Stochastic Unit to incorporate uncertainty into trajectory forecasting by calculating uncertain regions for each prediction time step instead. Since optimizing directly using point coordinates for loss calculation can pose challenges, we initially introduce a Gaussian distribution for each ground truth hand position to generate the ground truth heatmap. Subsequently, we calculate the loss between the corrected feature map and the generated ground truth heatmap, thereby enabling the network to learn the distribution of potential hand positions. The associated loss function is based on MSE Loss:
| (13) |
Where represents the ground truth heatmap at time step . We designate the coordinates of the maximum value within each feature map as the predicted trajectory points, which are then fed into the stochastic unit to generate uncertain regions. The size of the region is determined by the time step as well as the length of trajectory segments in preceding and subsequent stages. The shape is constrained by the original image dimensions and the orientation of the trajectory segments.
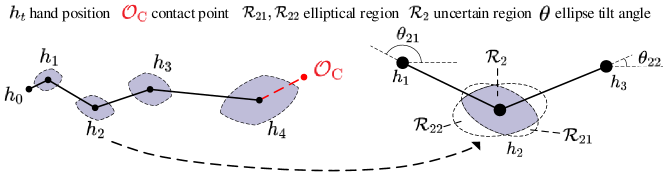
Formally, the uncertain region (Fig. 5) can be shown as:
| (14) |
Where is the uncertain region in future time step , and are the width and length of the input video, respectively. satisfies the following constraints:
| (15) |
Where and are elliptical regions constrained by and , which can be represented as:
| (16) | |||
| (17) | |||
| (18) | |||
| (19) |
Specifically, denotes the overall scale of , signifies the temporal growth rate, stands for the ellipse tilt angle, represent the coordinates of . Additionally, and represent the slope and Euclidean distance between points and , respectively. In BOT, we set and .
3.2 Training and Inference
Training. During training, we freeze parameters in TSN [67]. Training loss combines both trajectory loss and interaction hotspots loss:
| (20) |
In this paper, we set .
4 Experiments
4.1 Datasets
We conducted experiments on three first-person video datasets Epic-Kitchen s-100 [14], EGO4D [28], and EGTEA Gaze+ [36]. Epic-Kitchens-100 [14] and EGTEA Gaze+ [36] predominantly include kitchen scenes, while EGO4D [28] encompasses a broader range of activities such as handicrafts, painting, and outdoor tasks. For each dataset, the observation time is set to 2 seconds. We configure the prediction time horizon to 5, corresponding to 4 trajectory points and one contact point for each hand. Specifically, we predict 1-second trajectories on Epic-Kitchens-100 [14] and EGO4D [28], while on EGTEA Gaze+ [36], 0.5-second trajectories are forecast. Additional dataset information is available in the supplementary materials.
4.2 Implementation Details
In EGO4D [28], We use the method [39] to automatically generate hand trajectories, while contact points are manually annotated based on the last observation frame and the contact frame. We employ GMFLOW [69] to generate optical flow from EGO4D [28] and EGTEA Gaze+ [36]. For each dataset, we resize the original videos to 456 256 size, extracting both trajectory and contact features of size 114 64. In the Spatial-Temporal Reconstruction Module, we set the dimension in Cross-Transformer to 1024, with depth and attention head number . For the trajectory forecasting branch and H-O Bi-Progressive Enhancement Module, we configure the dimension to 256, with depth and head number . Additionally, for the introduced C-VAE, we set the dimension of both input and condition to 114 64, while the hidden and latent sizes are set to and , respectively. Our method is implemented by PyTorch and trained with the AdamW optimizer. We train the model for 100 epochs on 4 NVIDIA 3090 GPUs with an initial learning rate of - and a batch size of 40.
For comparison, We first select methods for individual tasks including Kalman Filter (KF) [8], Seq2Seq [63] and Hotspots [51]. Additionally, the methods for image/video understanding are chosen as the compared methods, which lack a joint mechanism. The former includes VIT [16], HRNet [62], UNet [58], Segformer [68], while the latter contains I3D [10], Slowfast [19], Timesformer [7], Uniformer-V2 [35]. Furthermore, we select methods with high task relevance and joint design, including FHOI [37] and OCT [39]. We conduct experiments using these approaches on Epic-kithens-100 [14], EGO4D [28], and EGTEA Gaze+ [36] datasets.
4.3 Evaluation Metrics
Hand Trajectory Evaluation. The predicted hand trajectories are referenced to the last observation frames. ADE [39] and FDE [39] are chosen as hand trajectory evaluation metrics, which respectively represent the overall accuracy and endpoint accuracy of trajectories. Detailed descriptions are available in the supplementary materials.
Interaction Hotspots Evaluation. For all datasets, we downsample each predicted heatmap to the size of 3232. We choose SIM [64], AUC-J [31], and NSS [54] as interaction hotspots evaluation metrics. For a detailed explanation of the metrics, please refer to the supplementary materials.
| Method | EK100 [14] | EGO4D [28] | EGTEA [36] | |||||||||||||
| ADE | FDE | SIM | AUC-J | NSS | ADE | FDE | SIM | AUC-J | NSS | ADE | FDE | SIM | AUC-J | NSS | ||
| unilateral | Center | – | – | 0.09 | 0.61 | 0.33 | – | – | 0.07 | 0.57 | 0.15 | – | – | 0.09 | 0.63 | 0.27 |
| KF [8] | 0.33 | 0.32 | – | – | – | – | – | – | – | – | 0.49 | 0.48 | – | – | – | |
| Seq2Seq [63] | 0.18 | 0.14 | – | – | – | – | – | – | – | – | 0.18 | 0.14 | – | – | – | |
| Hotspots [51] | – | – | 0.15 | 0.66 | 0.53 | – | – | – | – | – | – | – | 0.15 | 0.71 | 0.69 | |
| non-joint | I3D [10] | 0.22 | 0.23 | 0.13 | 0.56 | 0.46 | 0.22 | 0.22 | 0.12 | 0.57 | 0.42 | 0.23 | 0.22 | 0.13 | 0.60 | 0.49 |
| SLOWFAST [19] | 0.22 | 0.24 | 0.14 | 0.62 | 0.47 | 0.23 | 0.22 | 0.13 | 0.58 | 0.44 | 0.21 | 0.23 | 0.14 | 0.58 | 0.46 | |
| Timesformer [7] | 0.23 | 0.23 | 0.14 | 0.60 | 0.42 | 0.24 | 0.24 | 0.12 | 0.59 | 0.40 | 0.21 | 0.22 | 0.14 | 0.58 | 0.45 | |
| Uniformer-V2 [35] | 0.20 | 0.20 | 0.13 | 0.59 | 0.43 | 0.21 | 0.22 | 0.12 | 0.62 | 0.40 | 0.20 | 0.21 | 0.13 | 0.58 | 0.46 | |
| UNet [58] | 0.19 | 0.18 | 0.15 | 0.62 | 0.57 | 0.18 | 0.18 | 0.14 | 0.59 | 0.55 | 0.18 | 0.18 | 0.14 | 0.60 | 0.60 | |
| HRNet [62] | 0.18 | 0.19 | 0.16 | 0.62 | 0.63 | 0.19 | 0.20 | 0.14 | 0.62 | 0.58 | 0.18 | 0.18 | 0.16 | 0.63 | 0.65 | |
| VIT [16] | 0.18 | 0.19 | 0.14 | 0.65 | 0.63 | 0.21 | 0.21 | 0.13 | 0.59 | 0.45 | 0.19 | 0.19 | 0.15 | 0.63 | 0.61 | |
| CrossVIT [11] | 0.19 | 0.20 | 0.14 | 0.62 | 0.59 | 0.19 | 0.20 | 0.13 | 0.60 | 0.55 | 0.20 | 0.21 | 0.13 | 0.59 | 0.49 | |
| Segformer-b2 [68] | 0.17 | 0.17 | 0.16 | 0.64 | 0.66 | 0.16 | 0.16 | 0.15 | 0.64 | 0.62 | 0.17 | 0.17 | 0.16 | 0.63 | 0.65 | |
| joint | FHOI [37] | 0.36 | 0.35 | 0.10 | 0.55 | 0.39 | – | – | – | – | – | 0.34 | 0.34 | 0.12 | 0.63 | 0.42 |
| OCT [39] | 0.15 | 0.17 | – | – | – | 0.15 | 0.16 | – | – | – | 0.16 | 0.16 | – | – | – | |
| OCT* [39] | 0.12 | 0.11 | 0.19 | 0.72 | 0.72 | 0.12 | 0.12 | 0.22 | 0.73 | 0.88 | 0.14 | 0.14 | 0.23 | 0.75 | 1.01 | |
| Ours | 0.12 | 0.14 | – | – | – | 0.11 | 0.13 | – | – | – | 0.12 | 0.14 | – | – | – | |
| Ours* | 0.10 | 0.08 | 0.34 | 0.81 | 2.07 | 0.09 | 0.08 | 0.32 | 0.77 | 1.70 | 0.09 | 0.08 | 0.32 | 0.80 | 2.03 | |
4.4 Quantitative and Qualitative Comparisons
As shown in Tab. 1, our method achieves state-of-the-art performance in both trajectory prediction and interaction hotspots anticipation, with comparable leading margins across all three datasets. Taking the EGO4D dataset [28] with the richest variety of scenes as an example. In trajectory prediction, to ensure fair comparison, we additionally present results for OCT and BOT with only one sampling iteration. Under this single-sampling condition, BOT outperforms Segformer-b2, the best method in image/video understanding, with respective leads of 31.3% and 18.8% in ADE and FDE. Compared to OCT, BOT maintains advantages of 26.7% and 18.8% in ADE and FDE, respectively. These advantages persist even with 20 samplings, while the lead in FDE expands to 33.3%, underscoring the rationale behind BOT’s stochastic sampling mechanism. Regarding interaction hotspots, we achieve the best results across all metrics. Specifically, BOT surpasses the second-best approach (OCT) by 45.5% in SIM, 5.5% in AUC-J, and 93.2% in NSS, respectively. In summary, our method leverages the intrinsic correlations between hand trajectories and interaction hotspots more effectively, enhancing overall prediction accuracy of interaction intention, and exhibiting robustness across the three benchmark datasets.
| Method | Inf. time | Param |
| Segformer-b2 [68] | 21ms | 2.7M |
| Uniformer-V2 [35] | 310ms | 35.4M |
| OCT [39] | 52ms | 3.9M |
| OCT* [39] | 923ms | 3.9M |
| Ours | 55ms | 14.3M |
| Ours* | 92ms | 14.3M |
To investigate the efficiency of the model, we provide statistics on inference time and parameter count (Tab. 2). For each method, we test the inference time of one sample on a single NVIDIA 3090 GPU. In comparison to OCT, although our model has a larger parameter count, it exhibits a similar inference time when sampling once. With multiple samplings, our model displays a notable advantage in inference time. This can be attributed to the improved efficiency of the Stochastic Unit in BOT, obviating the necessity for repetitive inference of complete trajectories compared to OCT. Given BOT’s superior inference capability, our approach demonstrates enhanced efficiency.
To further explore the subjective outcomes of models, we report the visualization results of three datasets, as shown in Fig. 6. Compared to other methods, our model provides more accurate prediction results in both hand trajectories and interaction hotspots. When there is significant movement of hands (column 1,3,8), the BOT’s predictions exhibit the highest accuracy. It indicates that our Spatial-Temporal Reconstruction Module can efficiently utilize the human motion information to exploit the hand interaction intention and thus accurately predict the hand trajectory. In cases where there are no identifiable interactive objects in the field of view (column 6), our method anticipates more accurate interaction intentions. It illustrates that our Bi-Progressive mechanism can eliminate the uncertainty in the interaction process by mining the intrinsic connection between the hand trajectory and the contact points, which results in a more accurate inference in the interaction region and the hand trajectory. Moreover, our predictions closely align with the actual scenario when both hands simultaneously exhibit trajectories and interaction hotspots (columns 4,5), which suggests the strategy of differentiating between left and right hands during the prediction of interaction intentions, thereby mitigating cross-hand interference. More visualization results are available in the supplementary materials.
4.5 Ablation Study
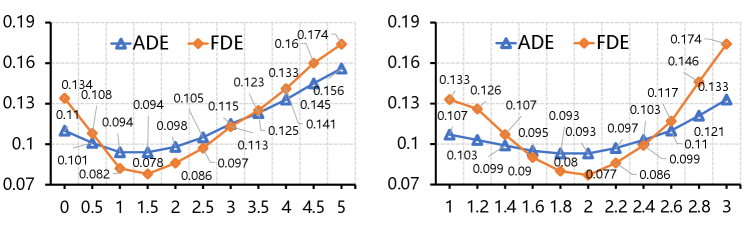
Different joint approaches. To explore the impact of the Bi-Progressive mechanism on model performance, we experiment with five different joint configurations: Individual, Hand, Object, Bidirectional and Bi-Progressive. The results are shown in Tab. 3 and Fig. 8. It suggests that the network is challenging to accurately predict trajectories and interaction hotspots during individual predictions, and the separate incorporation of hands and objects can effectively improve the prediction accuracy of interaction hotspots. With the combination of hand and object information, the prediction performance of the trajectory and interaction region is greatly improved. However, there is still a gap compared to the Bi-Progressive mechanism. Further, Fig. 8 shows that the introduction of the progressive mechanism plays a pivotal role in mitigating the


accumulation of prediction errors over time.
Conditions in dual branches. The left portion in Fig. 9 delineates various conditions for the trajectory prediction branch. None signifies the absence of the fusion between two consecutive trajectory points, spatial denotes the exchange between the main and the condition input, point and heatmap represent different
| Method | Trajectory | Interaction Hotspots | |||
| ADE | FDE | SIM | AUC-J | NSS | |
| Individual | 0.14 | 0.14 | 0.18 | 0.68 | 0.86 |
| Hand | 0.13 | 0.12 | 0.25 | 0.72 | 1.19 |
| Object | 0.12 | 0.12 | 0.23 | 0.70 | 1.04 |
| Bidirectional | 0.10 | 0.09 | 0.28 | 0.73 | 1.48 |
| Bi-Progressive | 0.09 | 0.08 | 0.32 | 0.77 | 1.70 |
modes of the condition, where the former is a coordinate and the latter is a heatmap, incorporating the potential distribution of the hand position. Experimental results indicate that the cross-attention block contributes to the temporal continuity of the trajectory, and global spatial features exert a more substantial influence on the prediction. Furthermore, employing an appropriate region to
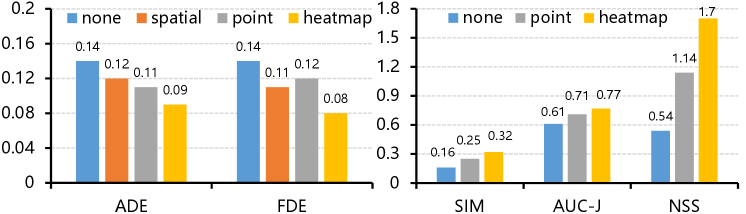
depict the hand position contributes more significantly to the propagation of trajectory features. The right side of Fig. 9 illustrates conditions within the interaction hotspots prediction branch. It is evident that using heatmap as the condition for the C-VAE yields superior results compared to point. This implies that the contact point also exhibits a degree of uncertainty within a specific range.
Uncertainty in anticipation. Uncertainty is a crucial consideration in interaction intention anticipation. Following the logic of natural human behavior [70, 56, 49], both hand trajectories [45, 29, 33] and interaction hotspots [39, 41, 42] predictions inherently possess a degree of uncertainty.




To investigate the impact of uncertain region scale and the magnitude of uncertainty variations in hand trajectories, we modify and in Eq. 17, with the resultant outcomes depicted in Fig. 10. denotes the overall scale of the uncertain region, when equals 0, the region’s size is zero, and the network output yields a unique result. As increases, the uncertainty of trajectories grows, leading to improved accuracy due to random samplings. However, given the limitations in sampling times, as continues to increase, the accuracy naturally decreases. determines the magnitude of trajectory uncertainty increasing from front to back, when equals 1, each trajectory point has the same level of uncertainty. Considering the escalating complexity and uncertainty in trajectory prediction over time, an elevation in initially corresponds to augmented accuracy, followed by a subsequent decline. This gradual increase in uncertainty also renders the FDE more sensitive to and , as shown in Fig. 11(a)-11(c). Regarding interaction hotspots, BOT exhibits relatively small uncertainty (Fig. 11(d)), as for a specific intention, the interaction area becomes increasingly influenced by object constraints. This is achieved by tightly controlling the uncertainty within a reasonably small range through the process of enabling C-VAE to generate feature maps and subsequently select points, thereby ensuring the network’s high confidence in predicting interaction regions.
5 Discussion
Conclusion. We plan to anticipate interaction intentions, encompassing the joint prediction of future hand trajectories and interaction hotspots with objects. We propose a novel BOT framework to establish an inherent connection between hand trajectories and contact points by introducing a Bi-Progressive mechanism, which eliminates the effect of error accumulation and achieves more accurate intention anticipation. Experimental results on three challenging benchmarks achieve state-of-the-art performance, thereby proving the superiority of our method in intention anticipation.
Future Work. BOT currently predicts hand trajectories and interaction hotspots on 2D images. However, human-object interactions occur in 3D space. To enable the model to be applied to real-world scenarios, we will consider the geometric structure and spatial relationships between objects in the scene in the future, providing the model with the ability to anticipate interaction intentions for the real world.
References
- [1] Adeli, V., Adeli, E., Reid, I., Niebles, J.C., Rezatofighi, H.: Socially and contextually aware human motion and pose forecasting. IEEE Robotics and Automation Letters 5(4), 6033–6040 (2020)
- [2] Adeli, V., Ehsanpour, M., Reid, I., Niebles, J.C., Savarese, S., Adeli, E., Rezatofighi, H.: Tripod: Human trajectory and pose dynamics forecasting in the wild. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13390–13400 (2021)
- [3] Bahl, S., Gupta, A., Pathak, D.: Human-to-robot imitation in the wild. arXiv preprint arXiv:2207.09450 (2022)
- [4] Bao, W., Chen, L., Zeng, L., Li, Z., Xu, Y., Yuan, J., Kong, Y.: Uncertainty-aware state space transformer for egocentric 3d hand trajectory forecasting. arXiv preprint arXiv:2307.08243 (2023)
- [5] Bertasius, G., Park, H.S., Yu, S.X., Shi, J.: First person action-object detection with egonet. arXiv preprint arXiv:1603.04908 (2016)
- [6] Bertasius, G., Soo Park, H., Yu, S.X., Shi, J.: Unsupervised learning of important objects from first-person videos. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1956–1964 (2017)
- [7] Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: ICML. vol. 2, p. 4 (2021)
- [8] Bewley, A., Ge, Z., Ott, L., Ramos, F., Upcroft, B.: Simple online and realtime tracking. In: 2016 IEEE international conference on image processing (ICIP). pp. 3464–3468. IEEE (2016)
- [9] Bharadhwaj, H., Gupta, A., Tulsiani, S., Kumar, V.: Zero-shot robot manipulation from passive human videos. arXiv preprint arXiv:2302.02011 (2023)
- [10] Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
- [11] Chen, C.F.R., Fan, Q., Panda, R.: Crossvit: Cross-attention multi-scale vision transformer for image classification. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 357–366 (2021)
- [12] Chen, G., Chen, Z., Fan, S., Zhang, K.: Unsupervised sampling promoting for stochastic human trajectory prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17874–17884 (2023)
- [13] Choi, C., Dariush, B.: Looking to relations for future trajectory forecast. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
- [14] Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: European Conference on Computer Vision (ECCV) (2018)
- [15] Dessalene, E., Devaraj, C., Maynord, M., Fermuller, C., Aloimonos, Y.: Forecasting action through contact representations from first person video. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
- [16] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. ICLR (2021)
- [17] Fan, C., Lee, J., Ryoo, M.S.: Forecasting hands and objects in future frames. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops. pp. 0–0 (2018)
- [18] Fang, K., Wu, T.L., Yang, D., Savarese, S., Lim, J.J.: Demo2vec: Reasoning object affordances from online videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2139–2147 (2018)
- [19] Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recognition. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6202–6211 (2019)
- [20] Furnari, A., Battiato, S., Grauman, K., Farinella, G.M.: Next-active-object prediction from egocentric videos. Journal of Visual Communication and Image Representation 49, 401–411 (2017)
- [21] Furnari, A., Battiato, S., Maria Farinella, G.: Leveraging uncertainty to rethink loss functions and evaluation measures for egocentric action anticipation. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops. pp. 0–0 (2018)
- [22] Furnari, A., Farinella, G.M.: What would you expect? anticipating egocentric actions with rolling-unrolling lstms and modality attention. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6252–6261 (2019)
- [23] Furnari, A., Farinella, G.M.: Rolling-unrolling lstms for action anticipation from first-person video. IEEE transactions on pattern analysis and machine intelligence 43(11), 4021–4036 (2020)
- [24] Geng, Y., An, B., Geng, H., Chen, Y., Yang, Y., Dong, H.: End-to-end affordance learning for robotic manipulation. arXiv preprint arXiv:2209.12941 (2022)
- [25] Girdhar, R., Grauman, K.: Anticipative video transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13505–13515 (2021)
- [26] Gong, D., Lee, J., Kim, M., Ha, S.J., Cho, M.: Future transformer for long-term action anticipation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3052–3061 (2022)
- [27] Gong, J., Foo, L.G., Fan, Z., Ke, Q., Rahmani, H., Liu, J.: Diffpose: Toward more reliable 3d pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13041–13051 (2023)
- [28] Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Hamburger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18995–19012 (2022)
- [29] Gupta, A., Johnson, J., Fei-Fei, L., Savarese, S., Alahi, A.: Social gan: Socially acceptable trajectories with generative adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2255–2264 (2018)
- [30] Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reasoning for human grasps generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11107–11116 (2021)
- [31] Judd, T., Ehinger, K., Durand, F., Torralba, A.: Learning to predict where humans look. In: 2009 IEEE 12th international conference on computer vision. pp. 2106–2113. IEEE (2009)
- [32] Kjellström, H., Romero, J., Kragić, D.: Visual object-action recognition: Inferring object affordances from human demonstration. Computer Vision and Image Understanding 115(1), 81–90 (2011)
- [33] Lee, N., Choi, W., Vernaza, P., Choy, C.B., Torr, P.H., Chandraker, M.: Desire: Distant future prediction in dynamic scenes with interacting agents. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 336–345 (2017)
- [34] Li, C., Zheng, P., Yin, Y., Pang, Y.M., Huo, S.: An ar-assisted deep reinforcement learning-based approach towards mutual-cognitive safe human-robot interaction. Robotics and Computer-Integrated Manufacturing 80, 102471 (2023)
- [35] Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Wang, L., Qiao, Y.: Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer. arXiv preprint arXiv:2211.09552 (2022)
- [36] Li, Y., Liu, M., Rehg, J.M.: In the eye of beholder: Joint learning of gaze and actions in first person video. In: Proceedings of the European conference on computer vision (ECCV). pp. 619–635 (2018)
- [37] Liu, M., Tang, S., Li, Y., Rehg, J.M.: Forecasting human-object interaction: joint prediction of motor attention and actions in first person video. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. pp. 704–721. Springer (2020)
- [38] Liu, S., Jiang, H., Xu, J., Liu, S., Wang, X.: Semi-supervised 3d hand-object poses estimation with interactions in time. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14687–14697 (2021)
- [39] Liu, S., Tripathi, S., Majumdar, S., Wang, X.: Joint hand motion and interaction hotspots prediction from egocentric videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3282–3292 (2022)
- [40] Liu, T., Lam, K.M.: A hybrid egocentric activity anticipation framework via memory-augmented recurrent and one-shot representation forecasting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13904–13913 (2022)
- [41] Luo, H., Zhai, W., Zhang, J., Cao, Y., Tao, D.: Learning affordance grounding from exocentric images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2252–2261 (June 2022)
- [42] Luo, H., Zhai, W., Zhang, J., Cao, Y., Tao, D.: Learning visual affordance grounding from demonstration videos. IEEE Transactions on Neural Networks and Learning Systems (2023)
- [43] Mandlekar, A., Xu, D., Martín-Martín, R., Savarese, S., Fei-Fei, L.: Learning to generalize across long-horizon tasks from human demonstrations. arXiv preprint arXiv:2003.06085 (2020)
- [44] Mangalam, K., An, Y., Girase, H., Malik, J.: From goals, waypoints & paths to long term human trajectory forecasting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15233–15242 (2021)
- [45] Mangalam, K., Girase, H., Agarwal, S., Lee, K.H., Adeli, E., Malik, J., Gaidon, A.: It is not the journey but the destination: Endpoint conditioned trajectory prediction. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. pp. 759–776. Springer (2020)
- [46] Mascaró, E.V., Ahn, H., Lee, D.: Intention-conditioned long-term human egocentric action anticipation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6048–6057 (2023)
- [47] Mendonca, R., Bahl, S., Pathak, D.: Structured world models from human videos. arXiv preprint arXiv:2308.10901 (2023)
- [48] Miech, A., Laptev, I., Sivic, J., Wang, H., Torresani, L., Tran, D.: Leveraging the present to anticipate the future in videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 0–0 (2019)
- [49] Mohamed, A., Qian, K., Elhoseiny, M., Claudel, C.: Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14424–14432 (2020)
- [50] Myers, A., Teo, C.L., Fermüller, C., Aloimonos, Y.: Affordance detection of tool parts from geometric features. In: 2015 IEEE International Conference on Robotics and Automation (ICRA). pp. 1374–1381. IEEE (2015)
- [51] Nagarajan, T., Feichtenhofer, C., Grauman, K.: Grounded human-object interaction hotspots from video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8688–8697 (2019)
- [52] Nawhal, M., Jyothi, A.A., Mori, G.: Rethinking learning approaches for long-term action anticipation. In: European Conference on Computer Vision. pp. 558–576. Springer (2022)
- [53] Parsaeifard, B., Saadatnejad, S., Liu, Y., Mordan, T., Alahi, A.: Learning decoupled representations for human pose forecasting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2294–2303 (2021)
- [54] Peters, R.J., Iyer, A., Itti, L., Koch, C.: Components of bottom-up gaze allocation in natural images. Vision research 45(18), 2397–2416 (2005)
- [55] Plizzari, C., Goletto, G., Furnari, A., Bansal, S., Ragusa, F., Farinella, G.M., Damen, D., Tommasi, T.: An outlook into the future of egocentric vision. arXiv preprint arXiv:2308.07123 (2023)
- [56] Qi, H., Wang, X., Pathak, D., Ma, Y., Malik, J.: Learning long-term visual dynamics with region proposal interaction networks. arXiv preprint arXiv:2008.02265 (2020)
- [57] Rodin, I., Furnari, A., Mavroeidis, D., Farinella, G.M.: Predicting the future from first person (egocentric) vision: A survey. Computer Vision and Image Understanding 211, 103252 (2021)
- [58] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. pp. 234–241. Springer (2015)
- [59] Shen, J., Dudley, J., Kristensson, P.O.: Fast and robust mid-air gesture typing for ar headsets using 3d trajectory decoding. IEEE Transactions on Visualization and Computer Graphics (2023)
- [60] Sohn, K., Lee, H., Yan, X.: Learning structured output representation using deep conditional generative models. Advances in neural information processing systems 28 (2015)
- [61] Song, D., Kyriazis, N., Oikonomidis, I., Papazov, C., Argyros, A., Burschka, D., Kragic, D.: Predicting human intention in visual observations of hand/object interactions. In: 2013 IEEE International Conference on Robotics and Automation. pp. 1608–1615. IEEE (2013)
- [62] Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5693–5703 (2019)
- [63] Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. Advances in neural information processing systems 27 (2014)
- [64] Swain, M.J., Ballard, D.H.: Color indexing. International journal of computer vision 7(1), 11–32 (1991)
- [65] Tu, Z., Huang, Z., Chen, Y., Kang, D., Bao, L., Yang, B., Yuan, J.: Consistent 3d hand reconstruction in video via self-supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023)
- [66] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [67] Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Van Gool, L.: Temporal segment networks: Towards good practices for deep action recognition. In: European conference on computer vision. pp. 20–36. Springer (2016)
- [68] Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems 34, 12077–12090 (2021)
- [69] Xu, H., Zhang, J., Cai, J., Rezatofighi, H., Tao, D.: Gmflow: Learning optical flow via global matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8121–8130 (2022)
- [70] Ye, Y., Singh, M., Gupta, A., Tulsiani, S.: Compositional video prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10353–10362 (2019)