Bias-Eliminated Semantic Refinement for
Any-Shot Learning
Abstract
When training samples are scarce, the semantic embedding technique, i.e., describing class labels with attributes, provides a condition to generate visual features for unseen objects by transferring the knowledge from seen objects. However, semantic descriptions are usually obtained in an external paradigm, such as manual annotation, resulting in weak consistency between descriptions and visual features. In this paper, we refine the coarse-grained semantic description for any-shot learning tasks, i.e., zero-shot learning (ZSL), generalized zero-shot learning (GZSL), and few-shot learning (FSL). A new model, namely, the semantic refinement Wasserstein generative adversarial network (SRWGAN) model, is designed with the proposed multihead representation and hierarchical alignment techniques. Unlike conventional methods, semantic refinement is performed with the aim of identifying a bias-eliminated condition for disjoint-class feature generation and is applicable in both inductive and transductive settings. We extensively evaluate model performance on six benchmark datasets and observe state-of-the-art results for any-shot learning; e.g., we obtain 70.2% harmonic accuracy for the Caltech UCSD Birds (CUB) dataset and 82.2% harmonic accuracy for the Oxford Flowers (FLO) dataset in the standard GZSL setting. Various visualizations are also provided to show the bias-eliminated generation of SRWGAN. Our code is available.111Source code: https://github.com/LiangjunFeng/SRWGAN
Index Terms:
Any-shot learning, zero-shot learning, semantic representation, feature generation, modal alignment.I Introduction
Driven by advances in deep learning, there has been remarkable progress in visual recognition over recent decades [1, 2, 3]. Intelligent models, e.g., convolutional neural networks (CNNs), optimize millions of parameters to improve recognition ability based on large-scale annotated datasets and abundant computational resources [4, 5]. The classic supervised learning paradigm is effective when sufficient training samples are provided for each object category [6]. However, due to the long-tailed distribution of object categories, the collection of numerous samples for some rarely seen objects is generally challenging in practice.
To recognize these rarely seen objects, zero-shot learning (ZSL) [7, 8, 9, 10], generalized zero-shot learning (GZSL) [11, 12, 13], and few-shot learning (FSL) [14, 15, 16] have been explored in recent years. ZSL seeks to perform knowledge transfer from seen categories to unseen categories, in which some auxiliary information, e.g., the attribute and textual description of the class label, is used to bridge the class gap. This technique, known as semantic embedding, allows for the identification of a new object by having only a description of it [9, 17, 18, 19]. Empirical studies have also shown that incorporating the features from a pretrained CNN, known as feature embedding, makes ZSL more effective than using the original images [12, 20]. However, since the seminal work of Lampert et al.[7], the studies on ZSL have been limited by a strong assumption that the test data come from unseen classes by default. Since recognition for both seen and unseen object categories is usually required in practice, the unreasonable restriction on ZSL is lifted in GZSL, so that all classes are allowed at the test phase. Hence, GZSL significantly improves the task’s practicability in comparison with ZSL [11, 12]. Additionally, it may be possible for us to collect a few, e.g., one or two, training images for these rarely seen categories, and then, the FSL setting can be adjusted. Similarly, the general paradigm of FSL is to train a model on classes with sufficient training samples and generalize it to classes with few samples without learning new parameters. This strategy avoids the overfitting risk of directly training the model in the case of a few samples [14, 21]. For a unified presentation, we also name the classes with sufficient training samples as seen classes and the classes with a few samples as unseen classes in this paper.
Due to the importance and practicability of ZSL, GZSL, and FSL, many solutions have been proposed, such as classic probability-based methods [7, 22], compatibility-based methods [23, 24, 25, 26, 27], and generative models [28, 29, 30, 31]. Among these paradigms, generative models, e.g., generative adversarial networks (GANs) [32, 33] and variational autoencoders (VAEs) [34, 35], are promising solutions that synthesize the exemplars of unseen classes and naturally address the insufficient data problem. A basic semantic embedding-based feature generation paradigm is described in Figure 1. As shown, the semantic descriptions bridge the gap between the seen and unseen categories and work as essential conditions for feature generation.

In practice, semantic descriptions are usually obtained in an external paradigm, such as an individual representation model [36] and manual annotation [7, 37]. For example, eighty-five manually annotated attributes are used in the benchmark Animals with Attributes (AWA) dataset [7] to describe fifty kinds of animals, and 1,024-dimensional features extracted by the character-based CNN-RNN model [38] are used in the benchmark Oxford Flowers (FLO) [36] dataset to describe 102 kinds of flowers. As a secondary representation of objects, a semantic description is supposed to be fine-grained and aligned with visual features for reliable generation and knowledge transfer [39, 40]. However, the external paradigm usually extracts coarse-grained semantic descriptions that rarely consider the relationship between the seen and unseen classes. Specifically, Figure 1 reveals that the generator of seen categories, i.e., , is usually used as that of unseen categories, i.e., , for unseen feature generation [41, 42]. The generator transfer from seen to unseen categories tackles the insufficient data problem for learning tasks. However, the generator is not guaranteed to be fully applicable to the unseen categories, i.e., [11, 12]. Intuitively, neither the adversarial training of GAN nor the variational Bayes algorithm of VAE allows the generator to generate samples for new categories. The mismatch between the semantic and visual spaces makes the bias problem even more challenging. It is desirable to refine the coarse-grained semantic descriptions, and hence, the trained generator can then be more effective for disjoint-class feature generation.
To address the above problems, a new model, namely, the semantic refinement Wasserstein generative adversarial network (SRWGAN) model, is developed, in which the semantic description is refined for any-shot learning tasks, i.e., ZSL, GZSL, and FSL. Two proposed techniques, i.e., the multihead semantic representation and the hierarchical semantic alignment, allow SRWGAN to perform bias-eliminated feature generation with abundant and hierarchical semantic information. In SRWGAN, the semantic description of an objective category is no longer a vector but multigroup conditional Gaussian distributions and is no longer independent but highly aligned with visual features. In this way, reliable and effective features can be synthesized by the transferred generator to tackle data insufficiency. In addition, unsupervised regularization in the hierarchical semantic alignment provides effective transductive learning ability for SRWGAN, and then state-of-the-art results can be readily obtained for any-shot learning tasks. Our contributions are threefold:
(1) A new model, namely, the semantic refinement Wasserstein generative adversarial network model, is proposed for any-shot tasks and is applicable in both inductive and transductive settings.
(2) Two techniques, i.e., the multihead semantic representation and hierarchical semantic alignment, are designed to offer bias-eliminated feature generation for unseen classes.
(3) Six benchmark datasets are used in experiments to show state-of-the-art results with detailed analysis for the proposed model and techniques.
II Related Work
II-A Notations and Formulations for Any-Shot Learning
We have a set of seen classes, , and a set of unseen classes, . The two sets are disjoint, i.e., , is the number of seen classes, and is the number of unseen classes. Suppose that a dataset of seen classes is , where is a visual feature with a corresponding seen class label and a semantic description . Similarly, a dataset of unseen classes is , where , , and .
In this paper, any-shot learning contains three tasks, i.e., ZSL, GZSL, and FSL. The transductive learning scenarios [43] of ZSL and GZSL, i.e., transductive zero-shot learning (TZSL) and transductive generalized zero-shot learning (TGZSL), are also considered. The five tasks are formulated as follows:
II-A1 Zero-shot learning
II-A2 Generalized zero-shot learning
II-A3 Few-shot learning
II-A4 Transductive zero-shot learning
II-A5 Transductive generalized zero-shot learning
II-B Method Review for Any-Shot Learning
For the ZSL and GZSL tasks in any-shot learning, the solutions can be categorized into classic probability-based methods, compatibility-based methods, and generative models. The probability-based methods are represented by direct attribute-based prediction and indirect attribute-based prediction [7], as these methods learn a number of probabilistic classifiers for attributes and combine the scores to make predictions. Feng et al. [37] used incremental classifiers to balance the learning between the seen and unseen classes. The compatibility-based methods learn a compatibility function between the semantic embedding space and the visual embedding space. For example, Romera-Paredes et al. [23] applied squared loss and implicit regularization between embedding spaces to rank the class possibilities. Ji et al. [26] trained a hashing model using the semantic embedding space to transfer knowledge and implement cross-model learning. For generative models, we introduce them in detail in the third subsection. Current FSL research usually adopts meta-learning, distance-based methods, generative methods, etc. Finn et al. [48] designed a model-agnostic meta-learning strategy to learn good weight initialization that can be efficiently adapted to small datasets. Zhang et al. [49] developed a transferable graph model based on relation and distance to mitigate the domain shift problem of knowledge transfer. Xian et al. [21] trained a strong feature generation model based on GAN and VAE to tackle the insufficient data problem of FSL. Vinyals et al. [50] and Jake et al. [15] designed a matching network and prototypical network to predict an image label based on support sets and applied the episode training strategy mimicking few-shot testing. For TZSL and TGZSL, Wu et al. [44] proposed an end-to-end domain-aware generative network by integrating self-supervised learning into a feature generating model. Li et al. [45] addressed TZSL by generating classifiers from class embeddings and used target data to calibrate the classifier generator. Liu et al. [46] proposed a practical latent feature-guided attribute attention framework to perform object-based attribute attention for semantic disambiguation. Fu et al. [47] combined multiple semantic embeddings and performed hypergraph label propagation. Sariyildiz et al. [51] performed TZSL and TGZSL by designing a gradient signal matching-based unsupervised training loss to improve performance. In this paper, ZSL, GZSL, FSL, TZSL, and TGZSL problems are addressed and compared in a unified generative paradigm.
II-C Generative Models
Generative models synthesize virtual exemplars to address the insufficient data problem and are popular in ZSL, GZSL, and FSL. The most famous generative models are VAEs and GANs. VAE uses an encoder that represents the input as a latent variable with a Gaussian distribution assumption and a decoder that reconstructs the input from the latent variable. Shao et al. [52] proposed a multichannel Gaussian mixture VAE, which introduced a Gaussian mixture model into the multimodal VAE with multiple channels. In contrast, a GAN consists of a generator that synthesizes fake samples and a discriminator that distinguishes fake samples from real samples. Since the standard GAN has a difficult training process, Arjovsky et al. [32] used the Wasserstein distance and constructed the Wasserstein GAN (WGAN) to improve learning stability. Xian et al. [53] proposed the feature-generating GAN to enhance the separability of generated features with an external softmax classifier. Gao et al. [54] designed a joint generative model that coupled VAE and GAN to generate high-quality unseen features. The redundancy-free model proposed by Han et al. [55] took feature generation one step further and extracted the redundancy-free features from virtual samples. An interesting application of the WGAN was the LisGAN by Li et al.[56], which introduced soul samples as the invariant side to regularize the generating process. In addition, meta-learning is also integrated with WGAN for ZSL and GZSL. Verma et al. [57] proposed a novel episodic training strategy to generate unseen class examples in the training stage, which contributed to overcoming the missing data problem. Our SRWGAN is also based on WGAN and improved by the proposed semantic refinement techniques.
II-D Semantic Representation and Alignment
Representation and alignment techniques have been proposed to improve coarse-grained semantic descriptions in recent years. Schonfeld et al. [58] learned latent spaces for semantic descriptions by VAE and then used the designed cross-alignment and distribution-alignment training loss to align the embedding space. Sariyildiz et al. [51] and Wang et al. [59] transferred the semantic description to a conditional multivariate Gaussian distribution to enhance its representation ability. Yu et al. [60] designed a cycle model with two generators in a meta-learning framework to improve the consistency between the visual features and semantic descriptions. Shen et al. [61] proposed an invertible zero-shot flow model to learn factorized data embeddings with a forward pass of an invertible flow network. Similarly, Vyas et al. [62] designed LsrGAN to generate visual features that mirror the semantic relationships. Peng et al. [63] encoded the semantic descriptions into tractable latent distributions, conditioned on the fact that the generative flow optimizes the exact log-likelihood of the observed visual features. However, the bias problems mentioned are usually between visual and semantic spaces. The above methods ignore the relationship between the seen and unseen scopes. From a new view, the proposed SRWGAN provides bias-eliminated generator transfer from seen to unseen classes by augmenting and refining the semantic information.

III Proposed Approach
Overall Idea The proposed SRWGAN is illustrated in Figure 2. To achieve bias-free generator transfer from seen classes to unseen classes, we perform bias-eliminated alignment between the semantic space and visual feature space , which refines the semantic description from to . With similar paradigms, auxiliary alignment and random alignment are designed to enhance the model’s feature generation ability and transductive learning ability. The three kinds of alignment loss form the proposed hierarchical semantic alignment technique for the designed multihead semantic representation . Moreover, redundancy-free mapping is applied in model implementation to make the latent feature intraclass contraction and interclass separation for classification.
III-A Motivation Analysis: Bias-Eliminated Condition for Generator Transfer
Here, the bias-eliminated condition for generator transfer from seen classes to unseen classes is analyzed to explain our motivation for semantic refinement.
Let and , denoting the category-prototype matrices in for the seen and unseen classes, respectively. Similarly, we have and , denoting the prototype matrices in . The prototype is the mean of a category, and and denote the dimensions of visual features and semantic descriptions, respectively.
Definition 1 A matching function, , for the visual feature, , and semantic description, , can be given with a trainable parameter, , as:
| (1) |
The function outputs a matrix , which scores the matching degree between each visual feature and semantic description prototype. Considering the seen scope, , and unseen scope, , we have:
Definition 2 An optimal can be obtained when the seen bridging condition (SBC) and the unseen bridging condition (UBC) are satisfied.
Here, and are one-hot labels, which denote that the visual feature and semantic description of each category are correctly matched. Additionally, we have two generators, and , for the seen and unseen classes, respectively. Without loss of generality, we assume that the generators are linear, i.e., and . The feature generation process can then be denoted by and for the seen and unseen classes, respectively. Based on the above notations and definitions, the bias-eliminated generator transfer can be given by the following lemma:
Lemma Given , if , namely, cross bridging condition (CBC), even a linear generator learned from the seen set can be used as to synthesize exemplars for without bias.
Proof The use of and replaces and in SBC and UBC, respectively, and we have:
| (2) |
| (3) |
Let and ,
| (4) | ||||
Then, identical generator , i.e., , can be obtained. The bias-eliminated condition for the disjoint-class generator transfer is summarized as follows:
Bias-Eliminated Condition (1) SBC, (2) UBC, and (3) CBC.
For better understanding, we visualize the bias-eliminated condition in Figure 3. SBC and UBC align the semantic space and feature space in the seen and unseen scopes, respectively. The third condition provides a cross-scope connection for generator transfer. In implementation, it is challenging for coarse-grained semantic descriptions to satisfy SBC, UBC, and CBC concurrently. Hence, we refine the semantic description for the bias-eliminated condition. Additionally, in UBC, unseen exemplars, i.e., , are needed, while none or a few unseen samples are available in ZSL, GZSL, and FSL for model training. We address this problem and describe the proposed semantic refinement techniques in detail in the next subsection.

III-B Semantic Refinement Techniques
In SRWGAN, two semantic refinement techniques are proposed, i.e., the multihead semantic representation and hierarchical semantic alignment. For clarification, we introduce the multihead semantic representation starting with the Gaussian semantic representation and the hierarchical semantic alignment starting with the bias-eliminated semantic alignment.
III-B1 Gaussian semantic representation
In any-shot learning, a semantic vector is provided as the learning condition for each class. To model the latent distribution corresponding to its class, the standard Gaussian distribution is usually imposed on as prior knowledge, thus defining a conditional multivariate Gaussian distribution . A sample can be taken from this distribution as the input of the feature generator. The -dimensional mean and covariance are estimated as follows:
| (5) | |||
where and are the trainable weights and biases, respectively, and is the activation function. For the -th class, the Gaussian semantic representation requests and and then takes a sample from . The reparameterization strategy in [35] is used to make the sampling differentiable. The Gaussian semantic representation is used by Verm et al. [64] and Sariyildiz et al. [51] to enhance the representation of the semantic description from a single vector to a multivariate Gaussian distribution.
III-B2 Multihead semantic representation
In this paper, we extend the Gaussian semantic representation to a multihead setting. Three different multivariate Gaussian distributions, i.e., and , are estimated conditioned on with three groups of weights and biases. As shown in Figure 2, three semantic descriptions, i.e., , , and , are sampled from , , and , constructing the refined description . In comparison with the common Gaussian semantic representation, two additional descriptions are provided for feature generation. However, it is noted that the three multivariate Gaussian distributions may have similar information, since all of them are estimated in the same way and conditioned on the common . In the next two subsections, we design three types of semantic alignment losses to regularize the three semantic descriptions for disjoint-class feature generation in a hierarchical way.
III-B3 Bias-eliminated semantic alignment
Based on the bias-eliminated condition, the bias-eliminated alignment loss for is designed as:
| (6) |
where , , and are the implementations of SBC, UBC, and CBC, respectively, and , , and are given weights.
First, is given as:
| (7) |
and
| (8) |
where is the refined semantic prototype matrix of for seen classes and is the dimension of . In a supervised paradigm, applies cross-entropy loss to achieve SBC at the sample level.
Second, is given as :
| (9) |
and
| (10) |
where is the refined semantic prototype matrix of for unseen classes. Because few real samples are available for unseen classes, applies the entropy loss to learn UBC from fake unseen samples in an unsupervised manner. Note that the fake data should not be regularized in a supervised paradigm, which may result in the mode collapse problem and has been discussed in [51].
For , the implementation is
| (11) |
Specifically, the losses and require that the refined description be aligned with the visual features in the seen scope and in the unseen scope, respectively. The loss builds connections between the seen and unseen scopes in the semantic embedding space. The bias-eliminated condition for generator transfer is implemented with the three losses together.
III-B4 Hierarchical semantic alignment
With the above discussed bias-eliminated alignment loss , the inductive hierarchical semantic alignment loss is given as:
| (12) |
and the transductive hierarchical semantic alignment loss is given as:
| (13) |
where and are the inductive and transductive auxiliary alignment loss for , respectively, and is the random alignment loss for .
The auxiliary alignment loss learns semantic-visual matching from unlabeled data and is applicable in both transductive and inductive settings. Similar to , the inductive auxiliary alignment loss is defined as:
| (14) | ||||
and the transductive is defined as:
| (15) | ||||
where and are the refined semantic prototype matrices of for the seen and unseen classes, respectively, and is the dimension of .
In comparison with , is completely based on unlabeled samples and releases the one-hot restriction in SBC and UBC, which enhances the semantic-visual matching from the entropy view and makes the model effective for transductive learning. Moreover, a random alignment loss is applied on to enrich the seen-unseen compactness randomly for disjoint-class feature generation in the semantic embedding space, which is given as:
| (16) |
where and are the refined semantic prototype matrices of for the seen and unseen classes, respectively, and is the dimension of .
To summarize, the designed hierarchical semantic alignment technique takes the bias-eliminated condition into consideration and learns from both labeled and unlabeled data with triple alignments. In experiments, the hierarchical loss provides more abundant semantic information than the single loss does and shows higher accuracy improvement.
III-C Regularized Feature Generation for Any-Shot Learning
For feature generation, we begin from the WGAN [32], which consists of a generator and a discriminator . The training loss of WGAN is
| (17) | ||||
where is the fake seen feature based on the refined description , and is the interpolation between and .
Since ZSL, GZSL, and FSL are evaluated as a classification task, a popular strategy is to apply a pretrained classifier on the generated features [53], and hence, the fake features can be more separable. Instead, we use the similarity between the fake and real features as a classification regularization item, which is defined as:
| (18) |
where , and is the real category-prototype matrix in . In comparison with the conventional pretrained classifier, Eq. (18) optimizes the similarity between the real and fake seen features by the cross-entropy loss at each training batch, which enhances the compactness between the real and fake features.
Additionally, the redundancy-free mapping approach in [55] is used to extract clean features from the original visual features, i.e., , for better discrimination. The objective of is
| (19) | ||||
where denotes the conditional distribution of on , is a margin to make more robust, is the randomly initialized class center and is optimized with , is the class label of , is the class label other than , denotes the Kullback-Leibler (KL) divergence, and is the imposed upper bound.
| Algorithm 1 Learning Procedure of the Proposed SRWGAN | |||||
| Inductive Input -> Output: | |||||
|
|||||
| Transductive Input -> Output: | |||||
|
|||||
| Training Phase: | |||||
| 1 |
|
||||
| 2 |
|
||||
| for (number of epochs) do | |||||
| for (rounds in an epoch) do | |||||
| for (discriminator training) do | |||||
| 3 |
|
||||
| 4 |
|
||||
| 5 |
|
||||
| 6 |
|
||||
|
|||||
| 7 |
|
||||
| 8 |
|
||||
| 9 |
|
||||
| 10 |
|
||||
| 11 |
|
||||
| 12 |
|
||||
| 13 |
|
||||
| 14 |
|
||||
| end for | |||||
| end for | |||||
| Testing Phase: | |||||
| 15 |
|
||||
| 16 |
|
||||
The constraint in Eq. (19) determines how much information in can be conveyed to evaluated by the KL divergence, and the main objective decides whether the remaining information is discriminative or not. The strategy in [63] is applied to optimize an unconstrained form of Eq. (19) derived by the Lagrange multiplier method. With redundancy-free mapping , the generative adversarial loss in Eq. (17) can be rewritten as follows:
| (20) | ||||
where , , and are conditional distributions on , , and , respectively.
Inductive Objective Based on the above discussion, the final objective of the SRWGAN in the inductive setting is as follows:
| (21) | ||||
Transductive Objective The final transductive objective of the proposed SRWGAN is as follows:
| (22) | ||||
where denotes either the real or fake seen samples, is the generator, represents the weights of the matching function in the hierarchical loss, is redundancy-free mapping, and is the discriminator. , , and are given parameters. Note that the multihead semantic representation is implemented as a submodule of and that their parameters are optimized together.
In the final objective, the first item, i.e., , trains a generator for seen classes in an adversarial paradigm, which makes the synthesized features and real features as similar as possible. The second item, i.e., , allows for the generator of seen classes to be applicable for the unseen classes by refining the semantic descriptions towards a bias-eliminated condition. An additional constraint is used to extract clean features and remove redundant information from the visual features. The third item, i.e., , and the last item, i.e., , make the generated visual features and clean features more separable and effective for classification. For the transductive setting, uses the unsupervised entropy loss to learn additional knowledge from unlabeled samples.
| Dataset | # | Class number | Image number | ||||
| # | # | Total | # | #/# | |||
| CUB | 312 | 150 | 50 | 11788 | 7057 | 1764/2967 | |
| aPY | 64 | 20 | 12 | 15339 | 5932 | 7924/1483 | |
| AWA | 85 | 40 | 10 | 25517 | 19832 | 4958/5685 | |
| AWA2 | 85 | 40 | 10 | 37322 | 23527 | 5882/7913 | |
| SUN | 102 | 645 | 72 | 14340 | 10320 | 2580/1440 | |
| FLO | 1024 | 82 | 20 | 8189 | 5631 | 1403/1155 | |
| Parameters | Search Range |
| , , | {10, 25, 50, 100, 150, 200, 400, 500} |
| {1e2, 1e1, 1e0, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5} | |
| {1e2, 1e1, 1e0, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5} | |
| {1e2, 1e1, 1e0, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5} | |
| {5e0, 1e0, 5e-1, 1e-1, 5e-2, 1e-2, 5e-3, 1e-3} | |
| {5e0, 1e0, 5e-1, 1e-1, 5e-2, 1e-2, 5e-3, 1e-3} | |
| {5e0, 1e0, 5e-1, 1e-1, 5e-2, 1e-2, 5e-3, 1e-3} | |
| Dataset | CUB | aPY | AWA | AWA2 | SUN | FLO |
| , , | 150 | 150 | 200 | 150 | 200 | 200 |
| 1e-3 | 1e-1 | 1e-1 | 1e-1 | 1e-2 | 1e-2 | |
| 1e-3 | 1e-3 | 1e-3 | 1e0 | 1e0 | 1e-3 | |
| 1e-3 | 1e-1 | 1e-2 | 1e-1 | 1e-2 | 1e-3 | |
| 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-1 | |
| 5e-2 | 1e-2 | 1e-1 | 1e-1 | 1e-2 | 5e-3 | |
| 1e-2 | 1e-1 | 1e-2 | 1e-2 | 1e-1 | 1e-3 | |
| Setting | Method | CUB | aPY | AWA | AWA2 | SUN | FLO | ||||||||||||
| I | GXE(2019) [45] | 47.4 | 47.6 | 47.5 | 26.5 | 74.0 | 39.0 | 62.7 | 77.0 | 69.1 | 56.4 | 81.4 | 66.7 | 36.3 | 42.8 | 39.3 | – | – | – |
| CRNet(2019) [68] | 45.5 | 56.8 | 50.5 | 32.4 | 68.4 | 44.0 | 58.1 | 74.7 | 65.4 | 58.1 | 78.8 | 65.4 | 34.1 | 36.5 | 35.3 | – | – | – | |
| LisGAN(2019) [56] | 46.5 | 57.9 | 51.6 | – | – | – | 52.6 | 76.3 | 62.3 | – | – | – | 42.9 | 37.8 | 40.2 | 57.7 | 83.8 | 68.3 | |
| CADA-VAE(2019) [58] | 51.6 | 53.5 | 52.4 | – | – | – | 57.3 | 72.8 | 64.1 | 55.8 | 75.0 | 63.9 | 47.2 | 35.7 | 40.6 | – | – | – | |
| f-VAEGAN-D2(2019) [21] | 63.2 | 75.6 | 68.9 | – | – | – | 57.1 | 76.1 | 65.2 | – | – | – | 50.1 | 37.8 | 43.1 | 63.3 | 92.4 | 75.1 | |
| GMGAN(2019) [51] | 57.9 | 71.2 | 63.9 | – | – | – | 63.2 | 78.7 | 70.1 | – | – | – | 55.2 | 40.8 | 46.9 | – | – | – | |
| IZF(2020) [61] | 52.7 | 68.0 | 59.4 | 42.3 | 60.5 | 49.8 | 61.3 | 80.5 | 69.6 | 60.6 | 77.5 | 68.0 | 52.7 | 57.0 | 54.8 | – | – | – | |
| ZSML(2020)[57] | 60.0 | 52.1 | 55.7 | 36.3 | 46.6 | 40.9 | 57.4 | 71.1 | 63.5 | 58.9 | 74.6 | 65.8 | – | – | – | – | – | – | |
| SGV(2020) [69] | 53.2 | 80.6 | 64.1 | – | – | – | – | – | – | 57.1 | 93.1 | 70.8 | 31.4 | 43.3 | 36.4 | – | – | – | |
| DVBE(2020) [70] | 64.4 | 73.2 | 68.5 | 37.9 | 55.9 | 45.2 | – | – | – | 62.7 | 77.5 | 69.4 | 44.1 | 41.6 | 42.8 | – | – | – | |
| DAZLE(2020) [71] | 56.7 | 59.6 | 58.1 | – | – | – | – | – | – | 60.3 | 75.7 | 67.1 | 52.3 | 24.3 | 33.2 | – | – | – | |
| TIZSL(2020) [37] | 52.1 | 53.3 | 52.7 | 27.8 | 38.7 | 32.4 | 61.5 | 67.7 | 64.4 | 76.8 | 66.9 | 71.5 | 32.3 | 24.6 | 27.9 | 70.4 | 68.7 | 69.5 | |
| AFRNet(2020) [72] | – | – | – | 48.4 | 75.1 | 58.9 | 68.2 | 69.4 | 68.8 | 66.7 | 73.8 | 70.1 | 46.6 | 37.6 | 41.5 | – | – | – | |
| E-PGN(2020) [60] | 52.0 | 61.1 | 56.2 | – | – | – | 62.1 | 83.4 | 71.2 | 52.6 | 83.5 | 64.6 | – | – | – | 71.5 | 82.2 | 76.5 | |
| RFF-GZSL(2020) [55] | 59.8 | 79.9 | 68.4 | – | – | – | 67.1 | 91.9 | 77.5 | – | – | – | 58.8 | 45.3 | 51.2 | 62.0 | 91.9 | 74.0 | |
| OCD-GZSL(2020) [73] | 44.8 | 59.9 | 51.3 | – | – | – | – | – | – | 59.5 | 73.4 | 65.7 | 44.8 | 42.9 | 43.8 | – | – | – | |
| SRWGAN(Ours) | 63.7 | 78.9 | 70.2 | 48.6 | 91.9 | 63.5 | 75.0 | 91.9 | 82.6 | 72.5 | 89.4 | 80.1 | 65.2 | 51.5 | 57.5 | 71.7 | 96.3 | 82.2 | |
| T | GFZSL(2017) [64] | 24.9 | 45.8 | 32.2 | – | – | – | 31.7 | 67.2 | 43.1 | – | – | – | – | – | – | 21.8 | 75.0 | 33.8 |
| DSRL(2017) [74] | 17.3 | 39.0 | 24.0 | – | – | – | 20.8 | 74.7 | 32.6 | – | – | – | 17.7 | 25.0 | 20.7 | 26.9 | 64.3 | 37.9 | |
| UE-finetune(2018) [75] | 74.9 | 71.5 | 73.2 | – | – | – | 93.1 | 66.2 | 77.4 | – | – | – | 33.6 | 54.8 | 41.7 | – | – | – | |
| GMGAN(2019) [51] | 60.2 | 70.6 | 65.0 | – | – | – | 70.8 | 79.2 | 74.8 | – | – | – | 57.1 | 40.7 | 47.5 | – | – | – | |
| f-VAEGAN-D2(2019) [21] | 61.4 | 65.1 | 63.2 | – | – | – | 84.8 | 88.6 | 86.7 | – | – | – | 60.6 | 41.9 | 49.6 | 78.7 | 87.2 | 82.7 | |
| GXE(2019) [45] | 57.0 | 68.7 | 62.3 | – | – | – | 87.7 | 89.0 | 88.4 | 80.2 | 90.0 | 84.8 | 45.4 | 58.1 | 51.0 | – | – | – | |
| SDGN(2020) [44] | 69.9 | 70.2 | 70.1 | – | – | – | 87.3 | 88.1 | 87.7 | 88.8 | 89.3 | 89.1 | 62.0 | 46.0 | 52.8 | 78.3 | 91.4 | 84.4 | |
| SRWGAN(Ours) | 65.3 | 79.1 | 71.6 | 53.6 | 91.8 | 67.7 | 85.6 | 91.4 | 88.4 | 81.2 | 92.9 | 86.6 | 68.8 | 51.8 | 59.1 | 76.9 | 96.1 | 85.4 | |
| “I” and “T” are the inductive and transductive settings, respectively. Red font and blue font are the highest and second highest results, respectively. | |||||||||||||||||||
III-D Training Algorithm and Tricks
The algorithm of the proposed SRWGAN is summarized in Algorithm 1. In addition, some tricks used in the model implementation for accuracy improvement are discussed here.
III-D1 All categories in a batch
The designed semantic refinement loss considers the relationship between the seen and unseen classes. Hence, all classes should be contained in a training batch. We randomly select sample pairs for each seen class and (refined) semantic descriptions for each unseen class, where is the batch size. Note that none of the real unseen samples are used for inductive training.
III-D2 A large batch size
In the design of SRWGAN, the prototype matrices of semantic features and visual features are usually used, such as in Eq. (8), in Eq. (10), in Eq. (14), and in Eq. (18). It is better to set a large batch size for model training, e.g., 1,024 or 2,048, and hence, the prototype matrices can be estimated more accurately at each training batch.
III-D3 A warm-up stage
As shown in Algorithm 1, line 11, the semantic loss is applied after training for epochs. Since UBC is implemented with fake unseen samples in Eq. (9), the designed pretraining stage for warms up the regularization of . For each dataset, different numbers of pretraining epochs are set: 10 (CUB), 5 (aPY), 5 (AWA), 5 (AWA2), 10 (SUN), and 5 (FLO).
III-D4 Naive network structure
Instead of the original images, the deep features of a pretrained convolutional neural network are usually used to perform the ZSL, GZSL, and FSL tasks. Hence, we do not need to design the network in a deep learning paradigm. All the modules of the SRWGAN, e.g., the generator and discriminator, are implemented with only one or two layers, which contributes to an efficient training process and a low risk of overfitting.
IV Experiments
IV-A Experimental Setting and Model Implementation
IV-A1 Benchmark datasets
Six benchmark datasets are used for extensive model evaluation, including CUB [65], aPascal and aYahoo (aPY) [9], AWA [7], Animals with Attributes2 (AWA2) [12], SUN attributes (SUN) [66], and FLO [36]. CUB is a dataset with a few variations among different birds. aPY is a combined dataset in which the aYahoo dataset is collected from the Yahoo image search, which is different from the images in aPascal. AWA and AWA2 include fifty kinds of animals and are standard datasets for ZSL, GZSL, and FSL. SUN is a subset of the SUN scene dataset with fine-grained attributes. FLO contains 102 kinds of flowers. We use the proposed training/testing splits by Xian et al. [12] and 2,048-dimensional ResNet101 features for experiments. The statistics of the six datasets are summarized in Table I.
IV-A2 Evaluation metrics
Model performance is evaluated according to the top-1 per-class accuracy. For GZSL, we report the average top-1 per-class accuracy on the seen classes as and on the unseen classes as . Their harmonic mean, i.e., , is reported as a comprehensive index. For FSL, we also use , , and to show the accuracy improvement by a few unseen samples in comparison with GZSL. For ZSL, we use the average top-1 per-class accuracy on the unseen classes as a metric.
IV-A3 Implementation details
The proposed SRWGAN consists of a generator , a discriminator , and redundancy-free mapping . First, the generator has a 4,096-dimensional hidden layer with the function and a 2,048-dimensional output layer with the function. The discriminator is a fully connected layer without activation. The redundancy-free mapping is a 1,024-dimensional layer with the function, which is implemented with the reparameterization trick. The margin and bound of are set to 190 and 0.1, respectively. Additionally, the Adam optimizer [67] is adopted with and for all the modules. The learning rate is .
IV-A4 Parameter setting
For the proposed multihead semantic representation module and the hierarchical semantic alignment module, the essential hyperparameters include the dimension of the refined semantic descriptions , the hierarchical weights , , in Eq. (6), and the regularization weights , , in Eq. (21). We perform a detailed grid search in the GZSL setting for these hyperparameters on the six benchmark datasets, which is shown in Table II. The search results for the six benchmark datasets are listed in Table III. In addition, the training batch sizes for the six datasets are: 2048 (CUB), 1024 (aPY), 2048 (AWA), 2048 (AWA2), 800 (SUN), and 2048 (FLO).




| Setting | Method | CUB | aPY | AWA | AWA2 | SUN | FLO | ||||||||||||
| 0-Shot∗ | f-CLSWGAN(2018) | 43.7 | 57.7 | 49.7 | – | – | – | 57.9 | 61.4 | 59.6 | 52.1 | 68.9 | 59.4 | 42.6 | 36.6 | 39.4 | 59.0 | 73.8 | 65.6 |
| GMGAN(2019) | 57.9 | 71.2 | 63.9 | – | – | – | 63.2 | 78.7 | 70.1 | – | – | – | 55.2 | 40.8 | 46.9 | – | – | – | |
| RFF-GZSL(2020) | 59.8 | 79.9 | 68.4 | – | – | – | 67.1 | 91.9 | 77.5 | – | – | – | 58.8 | 45.3 | 51.2 | 62.0 | 91.9 | 74.0 | |
| LsrGAN(2020) | 48.1 | 59.1 | 53.0 | – | – | – | 52.6 | 76.3 | 62.3 | – | – | – | 44.8 | 37.7 | 40.9 | – | – | – | |
| 0-Shot | f-CLSWGAN(2018) | 41.4 | 57.3 | 48.1 | 14.9 | 81.4 | 25.2 | 57.3 | 61.5 | 59.3 | 51.3 | 70.4 | 59.3 | 39.3 | 38.6 | 38.9 | 59.1 | 71.5 | 64.7 |
| GMGAN(2019) | 57.8 | 71.5 | 63.9 | 31.2 | 86.0 | 45.8 | 60.4 | 81.1 | 69.2 | 54.8 | 86.0 | 67.0 | 53.9 | 41.7 | 47.1 | 59.9 | 87.0 | 71.0 | |
| RFF-GZSL(2020) | 58.3 | 81.9 | 68.1 | 29.6 | 92.9 | 44.8 | 69.8 | 90.0 | 78.6 | 67.8 | 91.7 | 78.0 | 58.9 | 45.2 | 51.1 | 59.5 | 93.8 | 72.8 | |
| LsrGAN(2020) | 46.2 | 61.3 | 52.7 | 32.0 | 85.9 | 46.6 | 51.9 | 79.7 | 62.9 | 45.9 | 85.6 | 59.8 | 43.7 | 37.9 | 40.6 | 58.5 | 86.0 | 69.7 | |
| SRWGAN(Ours) | 63.7 | 78.9 | 70.2 | 48.6 | 91.9 | 63.5 | 75.0 | 91.9 | 82.6 | 72.5 | 89.4 | 80.1 | 65.2 | 51.5 | 57.5 | 71.7 | 96.3 | 82.2 | |
| 1-Shot | f-CLSWGAN(2018) | 43.0 | 55.7 | 48.6 | 17.7 | 75.9 | 28.7 | 59.2 | 61.8 | 60.5 | 55.4 | 72.1 | 62.7 | 41.7 | 40.2 | 40.9 | 59.8 | 72.4 | 66.5 |
| GMGAN(2019) | 62.0 | 72.8 | 67.0 | 44.3 | 86.0 | 58.5 | 65.1 | 81.3 | 72.3 | 59.5 | 85.4 | 70.1 | 55.0 | 43.8 | 48.7 | 63.3 | 86.3 | 73.0 | |
| RFF-GZSL(2020) | 59.5 | 85.0 | 70.0 | 33.5 | 91.5 | 49.1 | 74.3 | 90.6 | 81.7 | 77.4 | 92.4 | 84.2 | 62.3 | 47.4 | 53.8 | 63.9 | 96.1 | 76.7 | |
| LsrGAN(2020) | 46.3 | 62.7 | 53.2 | 35.1 | 86.0 | 49.8 | 58.8 | 81.2 | 68.2 | 53.2 | 85.9 | 65.7 | 46.6 | 41.6 | 44.0 | 67.0 | 82.4 | 73.9 | |
| SRWGAN(Ours) | 65.5 | 80.4 | 72.2 | 50.2 | 91.7 | 64.9 | 86.0 | 91.5 | 88.6 | 80.7 | 92.4 | 86.1 | 66.5 | 51.7 | 58.2 | 74.6 | 95.9 | 83.9 | |
| 3-Shot | f-CLSWGAN(2018) | 47.6 | 60.3 | 53.2 | 27.1 | 78.4 | 40.2 | 65.9 | 60.3 | 63.0 | 60.4 | 73.3 | 66.2 | 45.8 | 39.1 | 42.2 | 69.5 | 72.4 | 70.9 |
| GMGAN(2019) | 63.2 | 71.4 | 67.1 | 50.0 | 86.0 | 63.3 | 67.8 | 81.1 | 73.8 | 72.5 | 85.6 | 78.5 | 59.0 | 43.2 | 49.9 | 74.6 | 87.6 | 80.6 | |
| RFF-GZSL(2020) | 63.6 | 85.2 | 72.8 | 38.2 | 91.3 | 53.9 | 84.5 | 90.4 | 87.4 | 82.1 | 92.4 | 87.0 | 65.3 | 46.8 | 54.5 | 74.4 | 96.6 | 84.1 | |
| LsrGAN(2020) | 50.2 | 62.3 | 55.7 | 53.5 | 86.0 | 66.0 | 64.3 | 81.9 | 72.1 | 67.2 | 85.9 | 75.4 | 49.3 | 42.8 | 45.8 | 79.4 | 82.7 | 81.0 | |
| SRWGAN(Ours) | 66.9 | 80.1 | 72.9 | 53.4 | 92.0 | 67.5 | 89.3 | 91.5 | 90.4 | 83.7 | 92.8 | 88.1 | 67.5 | 51.5 | 58.4 | 82.6 | 94.6 | 88.2 | |
| 5-Shot | f-CLSWGAN(2018) | 49.0 | 62.7 | 55.0 | 32.7 | 82.0 | 46.8 | 70.3 | 62.1 | 65.9 | 71.3 | 73.9 | 72.6 | 52.7 | 40.0 | 45.5 | 80.6 | 73.2 | 76.7 |
| GMGAN(2019) | 67.1 | 71.3 | 69.1 | 57.6 | 85.9 | 69.0 | 79.0 | 81.2 | 80.1 | 77.2 | 85.9 | 81.4 | 60.0 | 43.6 | 50.5 | 78.8 | 87.0 | 82.7 | |
| RFF-GZSL(2020) | 68.0 | 84.3 | 75.3 | 48.5 | 89.8 | 63.0 | 96.7 | 90.6 | 93.6 | 94.3 | 92.2 | 93.2 | 71.3 | 47.9 | 57.3 | 82.4 | 96.0 | 88.7 | |
| LsrGAN(2020) | 54.0 | 62.3 | 57.8 | 62.8 | 85.8 | 72.5 | 80.2 | 81.0 | 80.6 | 82.5 | 85.6 | 84.0 | 52.6 | 42.9 | 47.2 | 84.7 | 82.5 | 83.6 | |
| SRWGAN(Ours) | 73.9 | 81.1 | 77.3 | 56.3 | 91.9 | 69.8 | 95.4 | 91.5 | 93.4 | 97.1 | 92.2 | 94.6 | 73.8 | 50.5 | 60.0 | 86.3 | 95.3 | 90.6 | |
| ∗ denotes the results are from the original papers, and others are obtained by our implementation. | |||||||||||||||||||


IV-B Evaluation in a GZSL setting
Sixteen and seven strong baselines published in recent years are used for the comparison of the GZSL and TGZSL tasks, respectively. The results are referred from their papers. The proposed SRWGAN is used to generate fake samples for the unseen classes, which are combined with the seen samples to train a softmax classifier. The well-trained classifier can then be used to infer the labels for test data. For each dataset, the number of synthesized samples per unseen class is different: 800 (CUB), 400 (aPY), 400 (AWA), 4000 (AWA2), 600 (SUN), and 800 (FLO). The state-of-the-art results are compared in Table IV.
As shown, the proposed SRWGAN obtains the highest harmonic mean accuracy for all six benchmark datasets. Specifically, our approach achieves harmonic mean accuracy improvements of 1.3%, 4.6%, 5.1%, 8.6%, 6.3%, and 5.7% over state-of-the-art methods on CUB, aPY, AWA, AWA2, SUN, and FLO, respectively. The harmonic mean accuracies of SRWGAN on AWA, AWA2, and FLO exceed 80%, which means that the proposed SRWGAN has almost the same performance of a normal image classification task for the more challenging GZSL. In addition, we can observe that the proposed SRWGAN not only improves the accuracy of unseen classes but also improves the accuracy of seen classes, confirming the effectiveness of the prototype matrix-based classification loss, redundancy-free mapping, and tricks in SRWGAN. In the transductive setting, the proposed SRWGAN has the highest harmonic mean accuracy on aPY, AWA, SUN, and FLO and the second highest harmonic mean accuracy on CUB and AWA2. The satisfactory performance validates the effectiveness of the unsupervised auxiliary alignment loss in the proposed hierarchical alignment module.
In Figure 4, the results of SRWGAN under different numbers of synthesized samples per unseen class on AWA and FLO for GZSL and TGZSL are shown. Intuitively, the results for the seen classes are steady for both GZSL and TGZSL and are hardly affected by the number of synthesized unseen samples. However, the accuracy of unseen classes is greatly affected by the number of synthesized unseen samples. The generation of a few samples for unseen classes leads to an imbalanced data problem and degrades the performance on unseen classes. For example, the unseen accuracy of FLO is 66.9%, with 25 samples generated for each unseen class. However, the unseen accuracy is 68.4%, with 1600 samples generated. Empirically, the proper number of synthesized samples per unseen class should be larger than 400.
| Method | FLO | CUB | ||||||
| Model A | 71.7 | 96.3 | 82.2 | 0.00% | 63.7 | 78.9 | 70.2 | 0.00% |
| Model B | 70.6 | 96.2 | 81.4 | -0.97% | 62.0 | 77.8 | 69.0 | -1.71% |
| Model C | 70.9 | 96.3 | 81.7 | -0.61% | 64.4 | 76.2 | 69.8 | -0.57% |
| Model D | 70.4 | 96.1 | 81.2 | -1.21% | 64.3 | 75.9 | 69.6 | -0.85% |
| Model E | 68.7 | 95.8 | 80.0 | -2.67% | 64.1 | 74.1 | 68.7 | -2.14% |
| Model F | 68.4 | 95.9 | 79.8 | -2.91% | 63.1 | 75.3 | 68.7 | -2.14% |
| Model G | 66.4 | 94.8 | 78.1 | -4.98% | 63.1 | 74.4 | 68.3 | -2.71% |

IV-C Evaluation in an FSL Setting
Here, the proposed SRWGAN is compared with f-CLSWGAN [53], GMGAN [51], RFF-GZSL [55], and LsrGAN [62] on the FSL task, where a few labeled samples of unseen classes are allowed in the training phase. The implementations of f-CLSWGAN and RFF-GZSL were contributed by their authors, and GMGAN and LsrGAN were implemented. For a fair comparison, we first fine-tune the model implementations and parameters in the GZSL setting and then apply them in the FSL setting. For the five compared models, the few labeled samples of unseen classes are the same and used in each batch training with the labeled seen samples together. The results of FSL on the six benchmark datasets are shown in Table V.
First, in the few-shot settings, i.e., one-shot, three-shot, and five-shot learning settings, performance improvement is observed on all the datasets and for all the methods. However, the increase in the number of unseen samples has different effects on the six datasets. For example, the results of five-shot learning have an approximately 10% to 15% harmonic mean accuracy improvement on the AWA dataset in comparison with the results of one-shot learning, while the accuracy improvement on the SUN dataset is only 5% to 7%. This result may be caused by the numerous unseen classes in the SUN dataset. Similarly, the CUB dataset, which has fifty kinds of unseen classes, has only a 5% to 10% accuracy improvement, while the APY, AWA2, and FLO datasets, which have fewer unseen classes, have more significant accuracy improvements in the FSL setting.
Second, it can be observed that the proposed SRWGAN obtains the highest accuracy in most of the cases. However, the larger the number of provided unseen samples is, the smaller the advantages of the proposed method. As shown in Table V, the SRWGAN obtains the highest harmonic mean accuracy for all six benchmark datasets in the one-shot and three-shot learning settings. However, the highest accuracies are obtained for four benchmark datasets in the five-shot learning setting. The LsrGAN obtains the highest accuracy for the aPY dataset, and the RFF-GZSL obtains the highest accuracy for the AWA dataset in the five-shot learning setting. This is because the designed SRWGAN seeks to eliminate the bias in the disjoint-class generator transfer by semantic refinement techniques. When numerous unseen samples are provided, the bias problem is nonexistent, and the generator for unseen classes is directly trained. Hence, the SRWGAN has fewer advantages in settings with sufficient data. In contrast, the results show the effectiveness of the proposed method in cases of zero samples and few samples.
Finally, we show the effects of the number of training epochs on the CUB dataset in the FSL setting in Figure 5. In comparison, the SRWGAN and RFF-GZSL present steadier and higher harmonic mean accuracy than do the other three compared models with redundancy-free features. The SRWGAN shows better performance than RFF-GZSL based on the proposed semantic refinement techniques.









IV-D Evaluation of the Semantic Refinement Techniques
Here, seven models are designed to show the effectiveness of the proposed semantic refinement techniques and regularization items. The seven models are listed as below:
IV-D1 Model A
Model A is the original SRWGAN model defined in Eq. (21).
IV-D2 Model B
In comparison with Model A, Model B replaces the classification regularization item defined in Eq. (18) with a pretrained softmax classifier [53] for .
IV-D3 Model C
In comparison with Model A, Model C is designed with the two-head semantic representation module, which is regularized by the bias-eliminated semantic alignment loss defined in Eq. (6) and the auxiliary alignment loss defined in Eq. (14).
IV-D4 Model D
In comparison with Model A, Model D is designed with the one-head semantic representation module, which is regularized by the bias-eliminated semantic alignment loss defined in Eq. (6).
IV-D5 Model E
In comparison with Model D, the one-head semantic representation module of Model E is regularized by .
IV-D6 Model F
In comparison with Model D, the one-head semantic representation module of Model F is regularized by .
IV-D7 Model G
In comparison with Model D, Model G is implemented without semantic regularization and semantic representation techniques.












The hyperparameters of the seven models and experimental settings are the same as those in GZSL. Two datasets, i.e., FLO, and CUB, are used. In addition to the basic , , and , we provide the relative improvement (RI) of between Model A and other models for an intuitive comparison. is obtained as follows:
| (23) |
The results are summarized in Table VI.
First, in comparison with Model A, Model B has a harmonic mean accuracy degradation of on the FLO and CUB datasets. This shows that the classification regularization item defined in Eq. (18) performs better than the conventional pretrained classifier [53]. The essential difference is that Eq. (18) optimizes not only the classification ability of but also the compactness between real and fake features based on the similarity score and hence contributes to the feature generation ability. To validate this, an intuitive strategy is comparing the feature compactness between the real and fake features. The feature compactness is defined as follows:
| (24) |
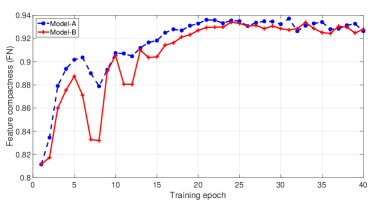
where is the cosine similarity and is the number of classes. The comparison of feature compactness of seen classes between Model A and Model B on CUB is shown in Figure 6. In comparison, Model A optimizes the feature compactness for seen classes more quickly than Model B at the beginning stage. Meanwhile, we show the average feature compactness comparison through 1200 epochs (from the 300th epoch to the 1500th epoch) for the seen and unseen classes in Figure 7. Although Model A and Model B present similar average feature compactness on seen classes, Model A obtains higher average feature compactness on unseen classes, which validates the effectiveness of Eq. (18).
Second, Model A usually performs better than Model C and Model D, which shows the contribution of random alignment loss and auxiliary alignment loss, respectively. In comparison with Model D, Model E and Model F show performance degradation since the regularization of Model E and Model F on the one-head semantic representation no longer meets the bias-eliminated condition. Meanwhile, we can observe that the loss slightly contributes to the model performance by comparing Model E and Model F. In comparison with other models, Model G shows the lowest accuracy, since it uses the combination of noise and naive attributes as the generator’s input and is implemented without any semantic regularization techniques.
In addition, it is worth mentioning that the implementation of Model G is based on RFF-GZSL with the tricks listed in the last subsection of the methodology, resulting in a strong baseline for the proposed SRWGAN. Generally, the proposed techniques achieve harmonic mean accuracy improvements of 2% to 5% on the benchmark datasets.
IV-E Visualization Study
IV-E1 Visualization of the generated features
We visualize the generated unseen features by t-SNE [76] to show the strong disjoint-class feature generation ability of SRWGAN. The real features and the features generated by f-CLSWGAN are used for comparison. This visualization is shown in Figure 8, in which the unseen classes of each dataset are divided into three groups for intuitive comparison. For the AWA and FLO datasets, the three groups of features of SRWGAN are very similar to the three groups of real features, which validates the bias-eliminated feature generation of SRWGAN. For the AWA2 dataset, there is a little bias for group A by SRWGAN. However, the features of SRWGAN present intraclass contraction and interclass separation, which are beneficial for classification. In comparison, the feature distributions of different classes by f-CLSWGAN usually overlap. The strong feature generation ability allows SRWGAN to present improved performance for the considered ZSL, GZSL, and FSL tasks.
IV-E2 Visualization of the bias-eliminated condition
In the methodology, we define the matching function to enhance the compactness between semantic and visual features. Based on , the SBC and UBC are enforced by the cross-entropy loss in Eq. (7) and entropy loss in Eq. (9), respectively. Here, we visualize the matching score and by averaging the in Eq. (8) and in Eq. (10) to demonstrate the feasibility of SBC and UBC. Meanwhile, the bias of CBC, i.e., , is visualized. Experiments are performed on the AWA2 dataset. The results are shown in Figure 9. The in Figure 9 (a) is almost the standard identity matrix, which indicates that the SBC can be satisfied well with the proposed method. For in Figure 9 (b), it is not optimized to an identity metric, since we train Eq. (9) with the entropy loss in an unsupervised manner and have no real unseen samples in the training stage. However, the diagonal items in Figure 9 (b) are usually larger than others, which indicates that Eq. (9) also contributes to semantic-visual matching. In addition, Figure 9 (c) shows that the bias of CBC is small. The three well-implemented conditions provide the bias-elimination ability for SRWGAN.
IV-E3 Visualization of the hierarchical alignment loss
In the methodology, the hierarchical alignment loss in Eq. (12), i.e., , is defined to regularize the designed multihead semantic representation, i.e., , , and . Here, we visualize the multihead semantic representation to show the effectiveness of the hierarchical alignment loss. For better visualization, we first concatenate , , and with the original and then apply the t-SNE algorithm to them. The results are summarized in Figure 10. In comparison with Figure 8, both the semantic and visual features are clustered into three groups, revealing that the semantic representation presents visual-semantic matching. Meanwhile, the three groups of semantic features show different patterns in the two-dimensional space. This property is utilized by concatenating them in the proposed SRWGAN to provide distinguished semantic information for feature generation.

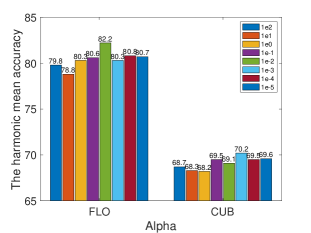
IV-F Parameter Study
In the proposed SRWGAN, the important hyperparameters include , , , , , , and , which are listed in Table II. Here, we show the grid search results in the GZSL setting on the CUB and FLO datasets for a parameter study. The results are presented in Figure 11. Generally, the semantic dimension can be set to to obtain satisfactory results. For the weights of bias-eliminated conditions, i.e., , , and , the best value is between and . For the semantic weight , the value should not be larger than 0.1 or smaller than 0.005. The classification item shows a strong regularization for feature generation. A large will lead to the failure of the generation process, and a proper value of can be selected from 0.05 to 0.005. The redundancy-free mapping weight shows different effects on the FLO and CUB datasets. A small , i.e., 0.001, contributes to the best model performance of FLO, and the best for CUB is 0.05. To summarize, the values of hyperparameters in SRWGAN are usually selected from 1 to 0.001, and the grid search method is helpful to obtain satisfactory performance. Meanwhile, the hyperparameters, , , and , usually present larger effects on the accuracy and can be optimized first. In addition, we provide an ablation study to explore the effects of batch size on FLO and SUN. The results are shown in Figure 12. Usually, a larger batch size contributes to satisfactory performance.
| Set. | Method | Gener -ative | CUB | FLO | SUN | AWA2 | ||
| I | SJE(2015) [17] | ✗ | 53.9 | 53.4 | 53.7 | 61.9 | ||
| ESZSL(2015) [23] | ✗ | 53.9 | 51.0 | 54.5 | 58.6 | |||
| SYNC(2016) [77] | ✓ | 55.6 | – | 56.3 | 49.3 | |||
| GFZSL(2017) [64] | ✓ | 49.3 | – | 62.9 | 63.8 | |||
| SE-GZSL(2018) [78] | ✓ | 59.6 | – | 63.4 | 69.2 | |||
| CycGAN(2018) [79] | ✓ | 58.6 | 70.3 | 60.0 | – | |||
| GXE(2019) [48] | ✓ | 54.4 | – | 62.6 | 71.1 | |||
| CADA-VAE(2019) [58] | ✓ | 60.4 | 64.0 | 63.0 | 63.2 | |||
| f-VAEGAN(2019) [21] | ✓ | 61.0 | 70.4 | 64.7 | – | |||
| LisGAN(2019) [56] | ✓ | 58.8 | 69.6 | 61.7 | – | |||
| GMGAN(2019) [51] | ✓ | 64.6 | – | 64.1 | – | |||
| DAZLE(2020) [71] | ✗ | 65.9 | – | – | – | |||
| IZF(2020) [61] | ✓ | 67.1 | – | 68.4 | 74.5 | |||
| ZSML(2020) [57] | ✓ | 69.7 | – | 60.2 | 77.5 | |||
| OCD(2020) [73] | ✓ | 60.3 | – | 63.5 | 71.3 | |||
| SRWGAN(Ours) | ✓ | 74.8 | 78.1 | 67.5 | 81.4 | |||
| T | GFZSL(2017) [64] | ✓ | 50.0 | – | 64.0 | – | ||
| DSRL(2017) [74] | ✗ | 48.7 | – | 56.8 | – | |||
| PREN(2019) [80] | ✗ | 66.4 | – | 62.9 | 74.1 | |||
| GMGAN(2019) [51] | ✓ | 64.6 | – | 64.3 | – | |||
| f-VAEGAN(2019) [21] | ✓ | 71.1 | – | 70.1 | – | |||
| GXE(2019) [45] | ✓ | 61.3 | – | 63.5 | 83.2 | |||
| LFGAA(2019) [81] | ✗ | 78.9 | 75.5 | 66.2 | – | |||
| SDGN(2020) [47] | ✓ | 74.9 | 84.4 | 68.4 | 89.1 | |||
| SRWGAN(Ours) | ✓ | 81.6 | 83.4 | 72.3 | 90.2 | |||
|
||||||||
| Dataset | CUB | FLO | SUN | AWA2 |
| , , | 100 | 100 | 150 | 100 |
| 1e-3 | 1e-4 | 1e-2 | 1e-3 | |
| 1e-3 | 1e-3 | 1e1 | 1e-1 | |
| 1e-2 | 1e-3 | 1e-2 | 1e-5 | |
| 1e-3 | 1e-1 | 1e-2 | 1e-3 | |
| 5e-2 | 5e-3 | 5e-3 | 1e-2 | |
| 1e-2 | 1e-2 | 1e-1 | 1e-2 | |
IV-G Evaluation in a ZSL setting
Finally, the model performance in the conventional ZSL setting is evaluated. Sixteen benchmark methods are used for the comparison in the inductive learning setting, and nine benchmark methods are used in the transductive setting. The experiments are performed on four datasets, i.e., CUB, FLO, SUN, and AWA2. The results are summarized in Table VII, and the hyperparameters obtained by the grid search method [82, 83, 84, 85] are listed in Table VIII. The number of synthesized samples per unseen class for each dataset is 1000 (CUB), 600 (FLO), 800 (SUN) and 2000 (AWA2). The proposed SRWGAN generally obtains state-of-the-art results with bias-eliminated feature generation for unseen classes. In the inductive learning setting, accuracy improvements of 5.1%, 7.7%, and 3.9% are achieved for CUB, FLO, and AWA2, respectively. Although the IZF model shows the highest accuracy on the SUN dataset, the proposed SRWGAN obtains the second highest accuracy. In the transductive setting, higher performance can be observed in our approach, which validates the effectiveness of the proposed semantic refinement techniques.
| Training Time(Hours) | FLO | AWA2 |
| f-CLSWGAN(2018) [53] | 0.34 | 0.44 |
| LisGAN(2019) [56] | 0.81 | 0.50 |
| f-VAEGAN(2019) [21] | 0.50 | 0.73 |
| RFF-GZSL(2020) [55] | 0.53 | 0.40 |
| SRWGAN (Ours) | 0.44 | 0.61 |
In addition, the training time of SRWGAN is compared with that of other generative models on FLO and AWA2. The training time here is defined as the time cost of a model to obtain its best performance. We use PyTorch 1.2.0 for model implementation and a 2080 Ti GPU for model training. The comparison is shown in Table IX. Although the proposed SRWGAN seems time-consuming and tedious with the proposed regularization, it is actually quite efficient for obtaining satisfactory results. Similarly, the complex models, i.e., RFF-GZSL and f-VAEGAN, sometimes take less time than the basic models, i.e., f-CLSWGAN and LisGAN, since additional techniques are usually helpful in improving model performance and generating reliable features with fewer epochs.
V Conclusions
In this paper, we propose to refine the semantic descriptions for any-shot learning tasks. A new model, namely, the SRWGAN, is developed by designing the multihead semantic representation technique and the hierarchical semantic alignment technique. Toward the bias-eliminated conditions, the proposed SRWGAN generates strong virtual features for the disjoint-unseen classes, the effectiveness of which is validated on six benchmark datasets in both inductive and transductive settings. In comparison with some state-of-the-art methods, accuracy improvements of 2% to 4% are observed for the ZSL, GZSL, and FSL tasks. In addition to the addressed bias problem, there may be some overlapping information in the learning for the seen and unseen classes. The problem of how to define and utilize the intersection between the seen and unseen classes for a generator or other mappings is worthy of discussion and research for any-shot learning.
References
- [1] Y. Lecun, Y. Bengio, G. Hinton. “Deep learning." Nature, vol. 521, no. 7553, pp. 436, 2015.
- [2] T. H. Chan, K. Jia, et al. “PCANet: A simple deep learning baseline for image classification?.” IEEE TIP., vol. 24, no. 12, pp. 5017-5032, 2015.
- [3] L. J. Feng, C. H. Zhao, et al. “BNGBS: An efficient network boosting system with triple incremental learning capabilities for more nodes, samples, and classes." Neuro., vol. 412, no. 28, pp. 486-501, 2020.
- [4] W. K. Yu, et al. ., “MoniNet with concurrent analytics of temporal and spatial information for fault detection in industrial processes”, IEEE TC, DOI: 10.1109/TCYB.2021.3050398.
- [5] W. K. Yu, C. H. Zhao, “Low-rank characteristic and temporal correlation analytics for incipient industrial fault detection with missing data." IEEE TII, DOI: 10.1109/TII.2020.2990975, 2021.
- [6] K. He, et al. “Deep residual learning for image recognition.” in Proc. IEEE CVPR, Jun. 2016, pp. 770-778.
- [7] C. H. Lampert, H. Nickisch, and S. Harmeling. “Learning to detect unseen object classes by between-class attribute transfer.” in Proc. IEEE CVPR, 2009, pp. 951-958.
- [8] P. Feng, P. J. Pan, et al. , “Zero shot on the cold-start problem: model-agnostic interest learning for recommender systems." in ACM CIKM, https://arxiv.org/abs/2108.13592, 2021.
- [9] F. Ali, et al. “Describing objects by their attributes.” in Proc. IEEE CVPR, 2009, pp. 1778-1785.
- [10] L. J. Feng, C. H. Zhao, et al. . “Adversarial smoothing tri-regression for robust semi-supervised industrial soft sensor," JPC, vol. 108, pp. 86-97, 2021.
- [11] Y. Xian, et al. “Zero-shot learning - the good, the bad and the ugly.” in Proc. IEEE CVPR, 2017, pp. 3077-3086.
- [12] Y. Xian , C. H. Lampert, et al. , “Zero-shot learning - a comprehensive evaluation of the good, the bad and the ugly.” IEEE TPAMI, vol. 41, no. 9, pp. 2251-2265, 2019.
- [13] S. Deutsch, et al. , “Zero-shot learning via multi-scale manifold regularization.” in Proc. IEEE CVPR, 2017, pp. 292-5299.
- [14] S. Rahman, S. Khan, and F. Porikli. “A unified approach for conventional zero-shot, generalized zero-shot and few-shot learning.” IEEE TIP, vol. 27, no. 11, pp. 5652-5667, 2018.
- [15] S. Jake, S. Kevin, et al. “Prototypical networks for few-shot learning.” in Proc. NIPS, 2017, pp. 4080-4090.
- [16] S. Blaes, T. Burwick. “Few-shot learning in deep networks through global prototyping.” Neural networks, vol. 94, pp. 159-172, 2017.
- [17] L. J. Feng, C. H. Zhao, et al. “A slow independent component analysis algorithm for time series feature extraction with the concurrent consideration of high-order statistic and slowness," JPC, vol. 84, pp. 1-12, 2019. Z. Akata, et al. . “Evaluation of output embeddings for fine-grained image classification.” in Proc. CVPR, 2015, pp. 2927-2936.
- [18] Z. Akata, F. Perronnin, et al. “Label-embedding for attribute-based classification.” in Proc. IEEE CVPR, 2013, pp. 819-826.
- [19] X. Wang, et al. , “Zero-shot recognition via semantic embeddings and knowledge graphs.” in Proc. CVPR, 2018, pp. 1211-1219.
- [20] W. L. Chao, S. Changpinyo, et al. “An empirical study and analysis of generalized zero-shot learning for object recognition in the wild.” in Proc. IEEE CVPR, 2016, pp. 52-68.
- [21] Y. Xian, S. Sharma, et al. “f-VAEGAN-D2: a feature generating framework for any-shot learning.” in Proc. IEEE CVPR, 2019, pp. 10267-10276.
- [22] L. J. Feng, C. H. Zhao, “Fault description based attribute transfer for zero-sample industrial fault diagnosis.” IEEE TII, vol. 17, no. 3, pp. 1852-1862, 2021.
- [23] B. Romera-Paredes and P. H. S. Torr, “An embarrassingly simple approach to zero-shot learning.” in Proc. ICML, 2015, pp. 2152-2161.
- [24] R. Socher, M. Ganjoo, et al. “Zero-shot learning through cross-modal transfer." in Proc. NIPS, 2013, pp. 935-943.
- [25] H. Zhang, Y. Long, et al. “Triple verification network for generalized zero-shot learning.” IEEE TIP, vol. 28, no. 1, pp. 506-517, 2019.
- [26] Z. Ji, Y. Sun, Y. Yu, et al. . “Attribute-guided network for cross-modal zero-shot hashing.” IEEE TNNLS, vol. 31, no. 1, pp. 321-330, 2020.
- [27] Z. Fu, T. A. Xiang, et al. “Zero-shot object recognition by semantic manifold distance.” in Proc. IEEE CVPR, 2015, pp. 2635-2644.
- [28] Y. Li, K. Swersky, et al. “Generative moment matching networks.” in Proc. IEEE CVPR, 2015, pp.1718-1727.
- [29] A. Odena, C. Olah, et al. “Conditional image synthesis with auxiliary classifier gans.” in Proc. ICML, 2017.
- [30] Y. Bengio, L. Yao, et al. “Generalized denoising auto-encoders as generative models.” in Proc. NIPS, 2013.
- [31] A. Makhzani, J. Shlens, et al. “Adversarial autoencoders.” arXiv:1511.05644, 2015.
- [32] M. Arjovsky, S. Chintala, and L. Bottou. “Wasserstein GAN.” in Proc. ICML, 2017.
- [33] I. J. Goodfellow, J. P. Abadie, et al. “ Generative adversarial networks.” in Proc. NIPS, 2014, pp. 2672-2680.
- [34] E. Bodin, I. Malik, et al. “Nonparametric inference for auto-encoding variational Bayes.” https://arxiv.org/abs/1712.06536, 2017.
- [35] D. P. Kingma, M. Welling. “Auto-encoding variational Bayes.” https://arxiv.org/abs/1312.6114, 2013.
- [36] M. E. Nilsback and A. Zisserman. “Automated flower classification over a large number of classes.” in Proc. ICCVGI, 2008.
- [37] L. J. Feng, C. H. Zhao, “Transfer Increment for generalized zero-shot learning,” IEEE TNNLS, vol. 32 no. 6, pp. 2506-2520, 2020.
- [38] S. Reed, Z. Akata, et al. “Learning deep representations of fine-grained visual descriptions.” in Proc. IEEE CVPR, 2016, 49-58.
- [39] D. Wang, Y. Li, et al. “Relational knowledge transfer for zero-shot learning.” in Proc. AAAI, Mar. 2016, pp. 1-7.
- [40] B. Zhao, B. Wu, et al. “Zero-shot learning posed as a missing data problem." in Proc. IEEE CVPR, 2017, pp. 2616-2622.
- [41] Y. Zhu, et al. “A generative adversarial approach for zero-shot learning from noisy texts.” in Proc. CVPR, 2018, pp. 1004-1013.
- [42] H. Huang, et al. “Generative dual adversarial network for generalized zero-shot learning.” https://arxiv.org/abs/1811.04857v1, 2018.
- [43] M. Rohrbach, S. Ebert, and B. Schiele. “Transfer learning in a transductive setting.” in Proc. NIPS, 2013, pp. 46-54.
- [44] J. M. Wu, T. Z. Zhang, et al. “Self-supervised domain-aware generative network for generalized zero-shot learning,” in Proc. IEEE CVPR, 2020, pp.12767-12776.
- [45] Kai Li, Martin Renqiang Min, and Yun Fu. “Rethinking zero-shot learning: a conditional visual classification perspective.” in Proc. ICCV., 2019, pp. 3582-3591.
- [46] J. Liu, Z. J. Zha, et al. “Adaptive transfer network for cross-domain person re-identification.” in Proc. IEEE CVPR, 2019.
- [47] Y. Fu, T. M. Hospedales, et al. “Transductive multi-view zero-shot learning.” IEEE TPAMI, vol. 37, no. 11, pp. 2332-2346, 2015.
- [48] C. Finn, P. Abbeel, and S. Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” in Proc. ICML, 2017, pp. 1126-1135.
- [49] C. Zhang, X. Lyu, Z. Tang. “TGG: transferable graph generation for zero-shot and few-shot learning.” in Proc. ACM Int. Conf. on Multimedia, 2019, pp. 1641-1649.
- [50] O. Vinyals, C. Blundell, et al. “Matching networks for one shot learning.” in Proc. NIPS, 2016, pp. 3637-3645.
- [51] M. B. Sariyildiz, R. G. Cinbis, et al. “Gradient matching generative networks for zero-shot learning.” in Proc. CVPR, 2019, pp. 2163-2173.
- [52] J. Shao, X. Li. “Generalized zero-shot learning with multi-channel Gaussian mixture VAE.” IEEE SPL, vol. 27, pp. 456-460. 2020.
- [53] Y. Xian, T. Lorenz, et al. “Feature generating networks for zero-shot learning.” in Proc. IEEE CVPR, 2018, pp. 5542-5551.
- [54] R. Gao, X. Hou, et al. “Zero-vae-gan: Generating unseen features for generalized and transductive zero-shot learning.” IEEE TIP, vol. 29, pp. 3665-3680, 2020.
- [55] Z. Y. Han, Z. Y. Fu, J. Yan, “Learning the redundancy-free features for generalized zero-shot object recognition.” in Proc. IEEE CVPR, 2020, pp. 12862-12871.
- [56] J. Li, M. Jin, et al. “Leveraging the invariant side of generative zero-shot learning.” in Proc. IEEE CVPR, 2019, pp. 7394-7403.
- [57] V. K. Verma, D. Brahma, P. Rai. “Meta-learning for generalized zero-shot learning.” in Proc. IEEE AAAI, 2020, pp. 6062-6069.
- [58] E. Schonfeld, S. Ebrahimi, et al. “Generalized zero- and few-shot learning via aligned variational autoencoders.” in Proc. IEEE CVPR, 2019, pp. 8247-8255.
- [59] W. l. Wang, Y. C. Pu, et al. “Zero-shot learning via class conditioned deep generative models.” in Proc. AAAI 2018.
- [60] Y. L. Yu, Z. Ji, et al. “Episode-based prototype generating network for zero-shot learning.” in Proc. IEEE CVPR, 2020.
- [61] Y. M. Shen, J. Qin, L. Huang. “Invertible zero-shot recognition flows.” in Proc. IEEE ECCV, 2020, pp. 3722-3740.
- [62] M. R. Vyas, et al. , “Leveraging seen and unseen semantic relationships for generative zero-shot learning.” in Proc. ECCV, 2020.
- [63] X. B. Peng, A. Kanazawa, et al. “Variational discriminator bottleneck: Improving imitation learning, inverse RL, and GANs by constraining information flow.” in Proc. ICLR, 2019.
- [64] V. K. Verm and P. Rai. “A simple exponential family framework for zero-shot learning.” in Proc. ECML, 2017, pp. 792-808.
- [65] C. Wah, S. Branson, et al. “The caltech-ucsd birds-200-2011 dataset.” 2011.
- [66] G. Patterson and J. Hays. “Sun attribute database: discovering, annotating, and recognizing scene attributes.” in Proc. IEEE CVPR, 2012. pp. 2751-2758.
- [67] D. P. Kingma and J. Ba. “Adam: a method for stochastic optimization.” arXiv preprint arXiv:1412.6980, 2014.
- [68] F. Zhang and G. Shi. “Co-representation network for generalized zero-shot learning.” in Proc. ICML, 2019.
- [69] Y. Hu, et al. “Semantic graph-enhanced visual network for zero-shot learning.” https://arxiv.org/pdf/2006.04648.pdf, 2020.
- [70] S. B. Min, et al. “Domain-aware visual bias eliminating for generalized zero-shot learning.” in Proc. CVPR, 2020, pp. 12661-12670.
- [71] D. Huynh, E. Elhamifar, “Fine-grained generalized zero-shot learning via dense attribute-based attention.” in Proc. IEEE CVPR, 2020.
- [72] B. Liu, Q. Dong, Z. Hu, “Zero-shot learning from adversarial feature residual to compact visual feature.” in Proc. AAAI, 2020.
- [73] R. Keshari, R. Singh, M. Vatsa. “Generalized zero-shot learning via over-complete distribution.” in Proc. CVPR, 2020.
- [74] Meng Ye, et al. “Zero-shot classification with discriminative semantic representation learning.” in Proc. CVPR, 2017, pp. 5103-5111.
- [75] J. Song, C. Shen, et al. “Transductive unbiased embedding for zero-shot learning.” in Proc. IEEE CVPR, 2018.
- [76] J. Donaldson. “T-sne: T-distributed stochastic neighbor embedding for R (t-SNE).” J. Mach. Learn. Res., 2012.
- [77] S. Changpinyo, W. Chao, et al. “Synthesized classifiers for zero-shot learning.” in Proc. IEEE CVPR, 2016, pp. 5327-5336.
- [78] V. K. Verma, et al. “Generalized zero-shot learning via synthesized examples.” in Proc. IEEE CVPR, 2018, pp. 4281-4289.
- [79] R. Felix, B. G. V. Kumar, et al. “Multimodal cycle-consistent generalized zero-shot learning.” in Proc. ECCV, 2018.
- [80] Ye, M., Y. Guo. “Progressive ensemble networks for zero-shot recognition.” in Proc. IEEE CVPR, 2019, pp. 11728-11736.
- [81] Y. Liu, J. Guo, et al. “Attribute attention for semantic disambiguation in zero-shot learning.” in Proc. IEEE CVPR, 2019, pp. 6697-6706.
- [82] L. J. Feng, et al. , “Multichannel diffusion graph convolutional network for the prediction of end-point composition in the converter steelmaking process." IEEE TIM, vol. 70, pp. 1-13, 2021.
- [83] W. K. Yu, C. H. Zhao, “Broad convolutional neural network based industrial process fault diagnosis with incremental learning capability." IEEE TIE, vol. 67, no. 6, pp. 5081-5091, 2020.
- [84] L. J. Feng, et al. , “Dual attention-based encoder–decoder: a customized sequence-to-sequence learning for soft sensor development." IEEE TNNLS, vol. 32, no. 8, pp. 3306-3317, 2020.
- [85] W. K. Yu, et al. , “Online fault diagnosis for industrial processes with Bayesian network-based probabilistic ensemble learning strategy," IEEE TASE, vol.16, no.4, pp. 1922-1932, 2019.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c671967c-a27d-469e-b204-3465bbb18684/x29.png) |
Liangjun Feng received his B.Eng. from North China Electric Power University, Beijing, China, in 2017. He is currently pursuing his Ph.D. at the College of Control Science and Engineering, Zhejiang University, Hangzhou, China. He has authored or coauthored more than 10 papers in peer-reviewed international journals. He is the reviewer of several journals, including IEEE TII and IEEE TNNLS. His current research interests include zero-shot and few-shot learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c671967c-a27d-469e-b204-3465bbb18684/x30.png) |
Chunhui Zhao (SM’15) received her Ph.D. degree from Northeastern University, China, in 2009. From 2009 to 2012, she was a Postdoctoral Fellow with the Hong Kong University of Science and Technology and the University of California, Santa Barbara, Los Angeles, CA, USA. Since January 2012, she has been a Professor with the College of Control Science and Engineering, Zhejiang University, China. Her research interests include statistical machine learning and data mining. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c671967c-a27d-469e-b204-3465bbb18684/LiXi_color.jpg) |
Xi Li received his Ph.D. degree in 2009 from the National Laboratory of Pattern Recognition, Chinese Academy of Sciences, Beijing, China. From 2009 to 2010, he was a Post-Doctoral Researcher with CNRS Telecom ParisTech, France. He was a senior researcher at the University of Adelaide, Australia. He is currently a Full Professor at Zhejiang University, China. His research interests include visual tracking, compact learning, motion analysis, face recognition, and data mining. |