Beyond Random Noise: Insights on Anonymization Strategies from a Latent Bandit Study
Center for Applied Intelligent Systems Research (CAISR) Halmstad University
Halmstad , 30118
[email protected]
&
Department of Computer Science (DIDA)
Blekinge Institute of Technology
Karlskrona, 37179
[email protected]
&
Department of Computer Science (DIDA)
Blekinge Institute of Technology
Karlskrona, 37179
[email protected]
&
Center for Applied Intelligent Systems Research (CAISR) Halmstad University
Halmstad , 30118
[email protected]
Abstract
This paper investigates the issue of privacy in a learning scenario where users share knowledge for a recommendation task. Our study contributes to the growing body of research on privacy-preserving machine learning and underscores the need for tailored privacy techniques that address specific attack patterns rather than relying on one-size-fits-all solutions. We use the latent bandit setting to evaluate the trade-off between privacy and recommender performance by employing various aggregation strategies, such as averaging, nearest neighbor, and clustering combined with noise injection. More specifically, we simulate a linkage attack scenario leveraging publicly available auxiliary information acquired by the adversary. Our results on three open real-world datasets reveal that adding noise using the Laplace mechanism to an individual user’s data record is a poor choice. It provides the highest regret for any noise level, relative to de-anonymization probability and the ADS metric. Instead, one should combine noise with appropriate aggregation strategies. For example, using averages from clusters of different sizes provides flexibility not achievable by varying the amount of noise alone. Generally, no single aggregation strategy can consistently achieve the optimum regret for a given desired level of privacy.
Keywords Latent-bandit, Privacy, Linkage-attack
1 Introduction
In the era of data-driven technologies and applications, privacy-preserving machine learning has emerged as a critical concern, for example, in recommendation-based tasks which heavily rely on sensitive data. Essential steps should be considered to protect such data, especially with the introduction of stricter privacy policies like GDPR (General Data Protection Regulation) (Voigt and Von dem Bussche, 2017) in Europe, which further emphasizes the necessity for enhanced privacy measures. Given the vulnerability of traditional anonymization techniques to adversarial attacks, addressing the risks associated with inadvertently disclosing sensitive data is imperative.
To mitigate the problem, Differential Privacy (DP) has gained widespread acceptance as a fundamental metric for quantifying and ensuring provable privacy (Dwork et al., 2014). However, DP has failed, for example, in federated learning setting (Wang et al., 2021). Other strategies, such as homomorphic encryption, come with increased costs of computation (Hao et al., 2019). Therefore, this study investigates privacy-preserving machine-learning aspects and provides valuable insights into anonymization strategies beyond the conventional use of noise, striking a balance between privacy protection and recommender system performance, exemplified in the context of latent bandits.
To assess the privacy implication of our work, we investigate the potential weaknesses associated with a linkage attack scenario. Our study assumes a susceptibility to privacy breaches due to knowledge sharing among agents. If not adequately mitigated, this weakness can enable potential adversaries to re-identify anonymized records in data via collected auxiliary information. The contributions of this paper can be summarised as follows:
-
•
We demonstrate the susceptibility to attacks of simple additive noise strategies and investigate alternatives with better privacy-performance trade-offs.
-
•
We conduct our experiments using real-world datasets such as CASAS, Endomondo, and Fitbit, highlighting the importance of implementing tailored privatization strategies for each dataset.
-
•
We are the first to explore privacy concerns within a learning setup in the latent bandit context, specifically in a realistic and frequently encountered linkage attack scenario.
-
•
We investigate the popular ADS metric for estimating a dataset’s privacy level, demonstrating a significant mismatch between the metric and the level of de-anonymization in linkage attacks.
2 Related Work
The field of privacy-preserving machine learning has witnessed significant advancements in recent years. Techniques such as differential privacy (DP) (Dwork et al., 2014) and federated learning (FL) (McMahan et al., 2017) have emerged as prominent approaches to safeguard sensitive information while enabling collaborative model training. However, DP has failed, for example, in federated learning setting (Wang et al., 2021). FL assumes non-malicious participants, which is highly unlikely in real-world applications.
Linkage attacks have garnered attention in the context of privacy preservation. These attacks exploit auxiliary information to re-identify individuals within a supposedly anonymized dataset. According to Sweeny (2002), 87% of the US population can be identified by a limited combination of their attributes. They show how seemingly non-sensitive information can be used to re-identify individuals in a dataset. Further, they pioneered research in attribute inference attacks, where an adversary may infer values of privatized attributes from other attributes or datasets. Such attacks have been demonstrated across various domains, including healthcare Sweeney (1997) and social networks Gulyás et al. (2016), underscoring the importance of robust privacy mechanisms. (Shokri et al., 2017) demonstrated that an adversary with access to a black-box model can infer whether a particular data point was used in the training set, the so-called membership inference attack. This type of attack highlights vulnerabilities in the protection of individual privacy. While membership inference attacks have raised awareness about model privacy, they assume a specific threat model and may not generalize to all scenarios.
There has been a growing interest in balancing data privacy and the performance in different Bandits settings to better understand the fundamental trade-off imposed by privacy constraints. Ren et al. (2020) studied multi-armed-bandits where users may not want to share rewards. They study this setting under local differential privacy and proposed algorithms that match the regret lower bound of their setting up to constant factors for a given local differential privacy budget. Their work shows an increase in convergence time and, thus, delayed learning induced by the additional privacy constraint. Malekzadeh et al. (2020) developed a framework for bandit learning in a setting akin to federated learning, where multiple agents share information privately for accelerated learning. Using a clustering approach, their evaluation shows that privatized agents outperform their non-private counterparts in limited data domains while still being competitive when more data is available. These results may suggest a more complicated exploration-exploitation dilemma than in a non-private bandit setting. Privatization may aid or not significantly impact generalization, and algorithms that tailor their choice of action-taking to privatization schemes may achieve superior early-stage performance. As pointed out by Gkountouna et al. (2022), clustering approaches, while preserving data privacy, may negatively impact data utility, thus requiring more targeted instance-specific approaches that target sensitive attributes between records heterogeneously instead of simply clustering records with attributes that are close in value. They provide a privatization algorithm that resists machine-learning-based approaches and thus provides practical applicability in the face of contemporary attack methods. As of the current writing, there is no prior research showcasing privacy considerations exemplified in a latent bandit framework, a gap our work aims to address.
3 Problem formulation
In this section, we describe the recommendation system and the linkage attack scenario. This system aims to provide recommendations to users, such as music, movies, or mobile health interventions. Each user receives recommendations from an agent, a latent bandit instance in our study. The agent estimates the user’s current state, such as an activity, and chooses an item (arm) from a finite set of recommendations. Users change their state in a random manner governed by a transition matrix, and the recommender system needs to adapt to these changes as quickly as possible. More formally, we define an agent as follows.
The Agent: Non-stationary Latent Bandit. The set of arms, corresponding to items to recommend, is . The set of states is denoted as . We use capitalized letters for all random variables. The non-stationary latent bandit (Hong et al., 2020) is an online learning problem with bandit feedback. That is, only the reward of the chosen arm is revealed to the agent. At every time step :
-
1.
The agent chooses an arm according to its policy, thus acting as a mapping of history to arms in .
-
2.
The environment reveals the reward according to the joint conditional reward distribution , parameterized by , where is the space of plausible reward models. Thus, only if the agent correctly identifies the state of the user, is it able to provide the right recommendation.
The starting state comes from a prior distribution and changes using a transition kernel with parameters that maps the current state to a distribution over subsequent states. The agent does not change the environment state through its choices, and only the current state determines the distribution over the next states and the rewards.
The mean reward for an arm in latent state is defined as under the model parameters . The form of is not restricted and can be arbitrarily complex, but the rewards for a particular arm and state are assumed to be Gaussian distributed with mean and variance proxy . The optimal arm in latent state is denoted as .
In our experiments, we focus on “difficult” rewards. In essence, the agent will encounter difficulty identifying the current state using only the sequence of received rewards. This will place more importance on estimating a suitable transition matrix for decision-making and show differences in reward between different strategies more clearly. Figure 1 shows an example from the Human Activity Recognition from Continuous Ambient Sensor Data (CASAS) dataset, where a hard reward structure results in significant regret differences between transition matrices. More specifically, what makes the rewards hard is that each state has a single optimal action with , while all the other actions have exactly the same reward, namely . For all arms, we set . Therefore, once the user switches to the next state, an agent cannot immediately deduce the new state based on the rewards obtained by repeating the previous arm or by random exploration. Knowledge of the expected new state, based on a well-estimated individual transition matrix, is crucial for maximizing reward.

Each user has such a latent bandit agent, personalized for their needs. In our setup, we assume that the true reward distribution is known to the agent, while the transition kernel (transition matrix) is not. The agent needs to estimate the individual matrix based on trial and error. However, users collaborate to improve recommendation quality by sharing anonymized versions of these matrices. At the same time, this opens them to a potential attack by an adversary, which we will describe next.
Sharing transition matrices and the adversary model. The process of sharing information among users is demonstrated in Figure 2, describing the learning setup and the adversary. Distributing transition matrices is handled by a centralized server, which receives requests from all agents and authenticates their identities. The agents form a federation or learning group, and each member shares their anonymized transition matrix, and additional metadata, with the server. This way, a dataset is formed (A). Once a new agent has been added to the system, it initiates the learning process by asking the server for a suitable transition matrix. The matching is done based on the metadata, a user profile specific to each dataset. This profile is used by the server for measuring similarity across the clients and identifying the most beneficial matrix for the new arrival (B).
The adversary, pretending to be a new user, may communicate with the server, send fake metadata, and receive a transition matrix. An adversary may perform this several times, with different metadata, to obtain different transition matrices. Thus, it is constructing an anonymized version of dataset , containing the transition matrices of potentially all the users in the learning group (C). The adversary follows a similar procedure to the one described by Narayanan and Shmatikov (2008), attempting to match collected auxiliary information (a percentage of cell values) to full transition matrices (D). First, we sample one user’s transition matrix from dataset . From the selected transition matrix, we provide the adversary with auxiliary information that contains the values of a fixed number of cells. We chose those cells uniformly at random. In our experiments, we vary the number of available cells to the adversary. For all runs, the adversary can access an anonymized version of .

We follow a similar procedure to the one described by Narayanan and Shmatikov (2008). First, we sample a transition matrix from database . Then, we provide the adversary with auxiliary information that contains the values of a fixed number of randomly chosen cells from the selected transition matrix. We chose cells uniformly at random. The adversary has access to an anonymized version of . The adversary aims to identify the transition matrix in what the auxiliary information belongs to, thus reconstructing the other cells. The process is demonstrated in figure 2.

The process diagram shown in Figure 3 illustrates the steps involved in allying various agents possessing varying levels of expertise to promote fast learning and knowledge sharing within the group and for a new agent. The process is handled by a centralized server, which receives requests from all agents and authenticates their identities. Once authenticated, the agents form a federation or learning group, and each member must share their transition matrix and environment metadata with the server.

As a result, the server must authenticate any new agents before they join the group and share their environment metadata to enable them to leverage the knowledge of other members and avoid starting from scratch, as shown in Figure 4. Once the agent has been added to the system, it can initiate the learning process by obtaining a suitable transition matrix selected by the computing algorithm in the server side based on the new agent’s provided metadata. Additionally, if any change occurs in any agent’s environment, such as adding a new sensor or feature. In that case, the agent can update their metadata and request another transition matrix that is more appropriate for its updated settings.
In certain scenarios, an adversarial entity assumes the role of a new participant seeking to infiltrate the federation with intentions such as uncovering the original data flow among participants, disrupting the entire system, or exploiting it for alternative purposes. Figure 5 outlines the sequence of actions this adversary uses to deceive the system. The adversary endeavors to integrate into the federation under the guise of a regular participant seeking knowledge sharing instead of starting anew in a separate environment.
The process begins with the adversary sending authentication requests, aiming to gain the server’s trust. Once this trust is established, the adversary is admitted into the system. Subsequently, the adversary initiates requests for a transition matrix, providing the requisite metadata. Simultaneously, this fraudulent participant allocates time to accumulate publicly available auxiliary information within the system concerning other participants. This acquired information can potentially be leveraged to extract sensitive data from the transition matrix about other participants. The adversary maintains a repository for this information, which can be continually updated.
To maximize the acquisition of the transition matrix, the adversary alters their identity and environmental settings, repeating the steps mentioned earlier until their objectives are met.

4 Data anonymization
Additive noise and lossy compression. In this paper, we investigate two popular methods for directly changing the values within individual transition matrices. The first method adds noise to sensitive information via a Laplace mechanism. For noise addition, we formally define the noisy version of the transition matrix as
| (1) |
where is a random draw from a Laplace distribution with mean and variance, and represents the weight of the added noise to individual cells and can be chosen arbitrarily.
The second method is truncated singular value decomposition (tSVD), widely used for matrix approximation. By considering only the top- eigenvalues, tSVD compresses the information in the transition matrix while preserving essential information for approximate reconstruction. Specifically, tSVD solves the problem of approximating the transition matrix with another matrix by minimizing the Frobenius norm subject to the constraint that is equal to Markovsky (2008). Importantly, tSVD also offers the benefit of removing identifying information. Cells, including those corresponding to unique user characteristics, are not reconstructed accurately if they do not affect the Frobenius norm significantly during optimization, increasing the difficulty of identifying users based on these cells.
Aggregation strategies. Besides adding noise to individual records, we investigate different methods of aggregating transition matrices across users before providing them to the agent for decision-making. We specifically focus on averaging methods, that is, calculating elementwise means of the transition matrices of several users. Averaging has the effect of hiding user-specific information, thus making linkage attacks harder. We explore three methods: nearest neighbor (NN), cluster average (Cluster average), and global average (Average). Further, we investigate some variants for the experiments. Specifically, we evaluate the impact (in terms of regret performance and privacy) of choosing a “more distant” transition matrix using the second nearest neighbor (Second NN). For clustering, we analyze the performance gain against the weakening of anonymization by doubling (2x Cluster average) and tripling (3x Cluster average) the number of clusters; more clusters mean fewer users per cluster, and, thus, more accurate transition matrix reconstructions.
We more formally define the cluster strategy as follows. Given records and clusters , we assign each record to one cluster . We denote as the cardinality (number of users) of cluster of record (user) . With slight abuse of notation, we abbreviate as .
The similarity between users for the nearest neighbor and clustering computations is not based on the values of the cells in the transition matrices but rather on user profiles (metadata) since, in real-world applications, the transition matrix of new users is unknown, at least initially. We compute a user profile for each dataset that approximately encapsulates the user’s behavior. We describe the details in the Experimental setup section.
5 Metrics and algorithms
Regret. For the performance metric, we use regret, the most common metric in bandit learning, defined as follows. For a fixed latent state sequence , the expected n-step regret is defined as
| (2) |
where the expectation is taken over the agent’s randomness in arm choice. We consider the Bayes regret, computing the n-step regret as an expectation over latent state randomness, defined as .
Probability of de-anonymization. In the following, we define whether a data record is successfully de-anonymized given auxiliary information depending on the performance of the scoreboard algorithm Narayanan and Shmatikov (2008). Scoreboard is a generic algorithm based on nearest-neighbor matching. The principal procedure, with some modifications, is as follows:
-
1.
Compute the score according to the average similarity of attributes between the candidate record and the auxiliary information as
The support on auxiliary information is denoted as and corresponds to the cells available to the adversary for comparison. Only the cells in are used to compute the similarity to records in .
-
2.
Compute the matching set as .
-
3.
Sample uniformly a candidate record from .
In this paper, computes distance, with some fixed constant , between cells in and the corresponding cells in a candidate record in as .
The probability of de-anonymization for a dataset is computed as
where is the number of records (one record per user) in the dataset. The probability of de-anonymization is, in other words, the average number of records correctly matched with the corresponding record using .
To interpret our experimental results correctly, it is important to note that, for clustering strategies, we only share the average transition matrix of a cluster, not the transition matrices of individual users. Thus, constitutes a set of cluster averages. Users of the same cluster have the same cluster average in , plus some possible noise individual to each user. As a result, the adversary can only hope to match the auxiliary information to a cluster as a whole. To calculate the probability of de-anonymization, we consider the success rate of matching the auxiliary information to a particular cluster, as well as the size of the cluster. For instance, if a cluster has five users, the probability of de-anonymization is for a correct match and otherwise. More formally, the level of de-anonymization using an aggregate transition matrix is denoted (interpreting and now as cluster averages instead of the transition matrix of a particular user) as
ADS privacy is a popular metric for estimating the level of privacy provided in a dataset. It is a metric used to minimize a corresponding loss in ADS-GAN, maximizing privacy intelligently while retaining performance in downstream tasks using the anonymized dataset Yoon et al. (2020). In this study, we investigate if the metric accurately captures the probability of de-anonymization via linkage attacks. We compute the ADS metric for different Laplace noise levels and the number of cells of auxiliary information available to the adversary across three datasets. ADS privacy is defined as
| (3) |
where is the indicator function, , and .
One typically uses the measure 3 to assess whether synthetic records (created by adding noise to the original transition matrices) differ sufficiently from the original records. It is based on the concept of -identifiability, which means that the probability of a synthetic observation being closer to the original observation than another original observation is less than . The value of determines the proportion of users that synthetic observations cannot identify because they differ enough from the real observations. Specifically, if the proportion of unidentifiable users is , the synthetic observations provide sufficient privacy protection. When equals 0, the data is perfectly non-identifiable (Yoon et al., 2020).
Model-based Thompson Sampling (mTS). We selected Model-based Thompson Sampling (mTS) as the recommendation algorithm, a posterior sampling technique demonstrating state-of-the-art performance in the latent bandit setting according to previous research (Galozy and Nowaczyk, 2023; Hong et al., 2020). mTS uses a posterior update rule and selects an arm based on its probability of being optimal given the history , which is expressed as . To select an arm, mTS samples a state from its posterior distribution over the belief state and chooses the arm with the highest mean reward given the sampled , as . After the reward is received for the chosen arm, the posterior of the belief state is formed using the Bayes rule. The algorithm’s pseudo-code is shown in Algorithm 1. In our experiments, mTS has access to the reward predictor , a reasonable assumption given that we may use prior collected data to construct the predictor. The available data allow mTS to quickly provide good recommendations without learning from scratch (Hong et al., 2020).
6 Evaluation
6.1 Experimental setup
Datasets and transition matrices. We run experimentation on three datasets, each containing user activity data. From the activity data, we extract states and state transition probabilities. For all datasets, the time in seconds in each state defines the diagonal elements of the transition matrix. In contrast, the off-diagonal elements are computed from the frequency count of observed transitions between states. In the following, we describe what constitutes the states in each dataset.
-
•
Human Activity Recognition from Continuous Ambient Sensor Data (CASAS) dataset was collected from several apartments that contain ambient sensors (Cook, 2012). 41 activities in the dataset constitute the states in the transition matrix. The transition matrix is of size .
-
•
Endomondo dataset was collected from the Endomondo app (Ni et al., 2019). The types of sports activities constitute the states in the transition matrix. The transition matrix is of size .
-
•
Fitbit dataset was collected through a distributed survey conducted by Amazon Mechanical Turk based on participants’ responses (Furberg et al., 2016). The four levels of activity intensity constitute the states. The transition matrix is of size .
Different anonymization strategies, i.e., additive noise, averaging, or tSVD, can add varying amounts of total noise to the transition matrix. To ensure a fair comparison in our experiments, we -normalize the transformed matrix. Moreover, tSVD or noise addition may produce negative values in some cells, which we truncate to zero. Subsequently, the transition matrix is row-wise normalized so it sums to one. Missing states (rows and columns of the transition matrix with only zero values) are imputed with a low non-zero value. Specifically, the environment is assumed to have a uniform probability of transitioning to any other state from the missing one. An example of a transition graph for a user in the CASAS dataset can be seen in Figure 6.

User profiles. For clustering and nearest neighbor computation, the user similarity is estimated using precomputed user profiles for each dataset, generated in the following way:
-
•
CASAS. An adjacency matrix of all apartment sensors is created from the sensor activations of each user. Transitions between activations of sensors are recorded, and the corresponding cell in the adjacency matrix is filled with 1, indirectly creating a layout graph of the apartment. The graphs are embedded into a 128-dimensional vector space via Graph2Vec (Narayanan et al., 2017) using a parallel implementation in the karateclub python package (Rozemberczki et al., 2020) with standard parameters.
-
•
Endomondo. We extract the average time spent in an activity, heart rate, and distance computed over all activities. Additionally, the frequency for each activity is extracted. This results in a 43-dimensional vector constituting the user profile.
-
•
Fitbit. User profiles are created from hourly activity intensities resulting in a 24-dimensional vector containing the average intensities for each hour of the day over all days for a user.
We first cluster the user profiles in each dataset using the k-means algorithm from the scikit-learn python package (Pedregosa et al., 2011). We explored various numbers of clusters for each dataset using unsupervised clustering metrics111Scores used in this study include Akaike information criterion, Bayesian information criterion, Davies Bouldin score, and Calinski Harabasz score. without a clear optimum in the number of clusters. Thus, we have chosen a low but reasonable number of clusters: eight for Endomondo and Fitbit, and seven for CASAS.



Due to the high dimensionality of the user profile data, we first transform the user profiles using t-SNE (van der Maaten and Hinton, 2008) to embed them into a separate 2D space before clustering. The resulting clusters are shown in figure 7. It is worth noting that t-SNE, as an embedding technique, is not guaranteed to preserve intercluster distances, which may hurt the performance of mTS. Nevertheless, we have not observed this as being an issue in practice.
6.2 Run parameters and computational resources
For the ADS-metric study, we chose the number of auxiliary cells for the datasets CASAS and Endomondo between to in cell increments and between and in one-cell increments for Fitbit. In the privacy-performance trade-off experiments, we choose the number of cells available showing the most significant change in de-anonymization probability for a given noise level: cells (CASAS and Endomondo) and cells (Fitbit), respectively. We compute the regret for the time horizon of timesteps as an average of over runs. For both experiments, we vary the variance of the Laplace noise in the interval (CASAS and Endomondo) and (Fitbit) divided into evenly spaced numbers. For tSVD the number of eigenvalues varies from (CASAS), (Endomondo) and (Fitbit) to . The probability of de-anonymization is computed as an average of runs, with a random user chosen from in each run. We do this to account for the randomness of added noise. For the scoreboard algorithm, we choose for all experiments. Further, for the additive noise and the scoreboard algorithm, we define
with and entropy
The inverse entropy encodes the concept of “uniqueness” regarding the cell’s value distribution in the dataset. The more unique the cell value of a user’s transition matrix, the more noise is added.
For a specific parameter setting, regret performance experiments over runs take about 20 minutes on a Ryzen 9 5950x CPU with 32GB RAM, single-threaded. The computation of de-anonymization probability takes a fraction of a second on the same system.
6.3 Results
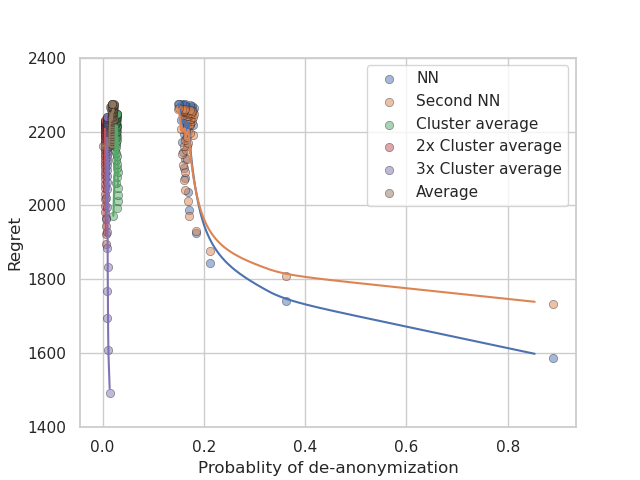
The impact of Laplace noise and tSVD on privacy and regret was investigated in conjunction with aggregation and nearest-neighbor methods. Figure 8 shows the results for the CASAS dataset, demonstrating that clustering offers a favorable balance between privacy and regret, compared to nearest-neighbor approaches at a given privacy level. Clustering significantly enhances privacy, even if no noise is added to the cluster average; and in combination with noise, it outperforms all the other methods. In particular, employing fewer clusters (e.g., seven) yields comparable performance to the nearest-neighbor approach without any noise, while achieving considerably higher (almost optimal) privacy. More clusters, on the other hand, offers a further significant benefit in terms of lower regret, at modest privacy sacrifices. The suboptimal performance of the nearest neighbor transition matrix may result from overfitting, whereas averaging over multiple users mitigates this issue without compromising privacy substantially.
Laplace noise clearly outperforms tSVD in terms of privacy and regret control across all datasets. tSVD appears to alter the transition matrix in a particularly harmful way, leading to significant regret impact even at similar privacy levels to Laplace noise. This effect is evident in the comparison of NN and Second NN regret in figure 8(b). Unlike Laplace noise, tSVD amplifies the differences between NN and Second NN, significantly affecting the regret.


Surprisingly, this relationship between the number of clusters and the probability of de-anonymization does not hold for the Endomondo dataset, where increasing the number of clusters does not significantly impact privacy while significantly reducing regret. Apparently, perfect precision in the transition matrices is not necessary for high recommendation quality. We notice that higher numbers of clusters allow for an increase in privacy level compared to the baseline of eight clusters, providing the best trade-off between privacy and performance.
Somewhat unintuitively, however, the general privacy-regret trade-off may not apply to every dataset. For example, in the case of the Fitbit dataset, privacy and performance do not have to be balanced significantly at all. As illustrated in figure 10, high levels of privacy can be achieved without sacrificing performance using Laplace noise and a cluster strategy.
These results highlight the main takeaway of our study. For a given dataset, a combination of aggregation strategies and noise allows for more flexibility that is not achievable by either aggregation or noise alone. For example, in the range between and of de-anonymization probability in the CASAS dataset (figure 8(a)), one may opt for cluster averages using double the number of clusters ( versus ) to achieve the best performances. One might increase this number even further to achieve even better performance but at the consequences of sacrificing privacy. In general, no strategy we have investigated achieves the best privacy-performance trade-off over the complete range of de-anonymization probabilities. Thus, a combination of noise and aggregation proves necessary to assess for a given privacy level.



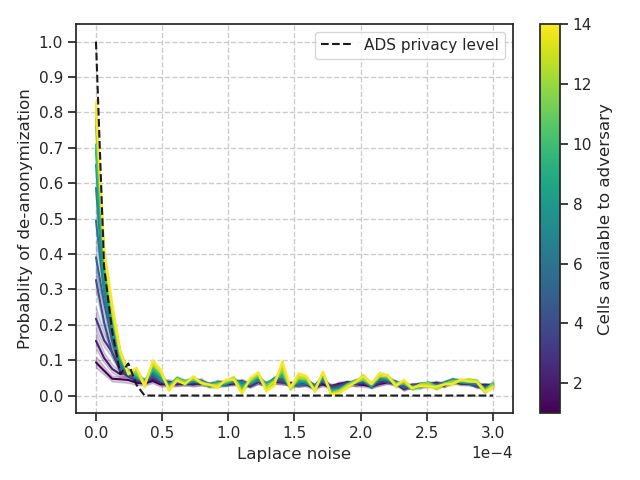
ADS privacy level versus de-anonymization. The probability of de-anonymization versus level of Laplace noise is shown in figure 11. Interestingly, we found that the privacy levels estimated by the ADS metric did not correspond well to the probability of de-anonymization. This has significant implications for privacy in cases where synthetic datasets are generated using the ADS metric for optimization. Specifically, the privacy levels may be overestimated for higher noise levels. Consequently, the ADS metric tends to zero, leading to a false sense of security for the data owners. On the other hand, via ADS, we may also underestimate the level of privacy for low noise levels. The ADS metric tends to one resulting in the addition of more noise than required for a given de-anonymization level, potentially negatively affecting performance. It might be reasonable that ADS-GAN learns a transformation that mimics a combination of additive noise and aggregation. Still, given the definition of the metric, there is no guarantee. Further, since the anonymized dataset is not analyzed in terms of performance during training, a feedback mechanism is missing that would encourage such tailored noise. These findings highlight the need to consider the attack type instead of a “one-size-fits-all” approach in loss-function design.


7 Limitations
We did not investigate contemporary end-to-end learning schemes, such as generative models like ADS-GAN (Yoon et al., 2020) that promise to be effective data anonymization techniques. These methods might alleviate some of the concerns raised in this paper. Still, as mentioned above, these end-to-end learners often rely on objective functions that are not well aligned with common attack patterns, and thus have yet to prove effective in real-world scenarios.
Our analysis is limited to a fairly simple scoreboard algorithm for deanonymization. There may exist better algorithms with stronger deanonymization capabilities. Our research illustrated that even a simple method can lead to a significant overestimation of the level of privacy, which would only increase with more sophisticated algorithms.
Furthermore, we did not examine machine learning contexts other than bandits, such as supervised or unsupervised learning. Nevertheless, results and findings from this research are expected to transfer directly to these settings as well, since they ultimately concern data privacy irrespective of how the data is used or what specific models are trained. It is not clear to what extent privacy would be compromised in specific settings, but the general trend we observe holds.
8 Conclusions
In this paper, we conducted experiments to evaluate the effectiveness of different privitization strategies, using a latent bandit setting. Our findings show that random noise added to individual records may not be a satisfactory solution for the privacy-performance trade-off. Instead, aggregations generally provide a better balance between ensuring privacy and maintaining performance for downstream tasks. There seems to be no single technique that solves the trade-off the best for a given desired level of privacy. Further, we found that one-size-fits-all metrics optimized for privacy, like the ADS-GAN metric, do not correspond well to the probability of de-anonymization in linkage attacks. Our paper highlights the need to evaluate privatization techniques on actual attack scenarios commonly employed in the real world, especially considering the abundance of useful auxiliary information collected in the wild that may render such techniques less effective.
References
- Voigt and Von dem Bussche [2017] Paul Voigt and Axel Von dem Bussche. The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10(3152676):10–5555, 2017. URL https://link.springer.com/book/10.1007/978-3-319-57959-7.
- Dwork et al. [2014] Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407, 2014. URL http://dx.doi.org/10.1561/0400000042.
- Wang et al. [2021] Chuanyin Wang, Cunqing Ma, Min Li, Neng Gao, Yifei Zhang, and Zhuoxiang Shen. Protecting data privacy in federated learning combining differential privacy and weak encryption. In Science of Cyber Security: Third International Conference, SciSec 2021, Virtual Event, August 13–15, 2021, Revised Selected Papers 4, pages 95–109. Springer, 2021.
- Hao et al. [2019] Meng Hao, Hongwei Li, Guowen Xu, Sen Liu, and Haomiao Yang. Towards efficient and privacy-preserving federated deep learning. In ICC 2019-2019 IEEE international conference on communications (ICC), pages 1–6. IEEE, 2019. URL https://ieeexplore.ieee.org/document/8761267.
- McMahan et al. [2017] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Aarti Singh and Jerry Zhu, editors, Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 of Proceedings of Machine Learning Research, pages 1273–1282. PMLR, 20–22 Apr 2017. URL https://proceedings.mlr.press/v54/mcmahan17a.html.
- Sweeny [2002] Latanya Sweeny. Achieving k-anonymity privacy protection using generalization and suppression. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 10(05):571–588, 2002. doi: 10.1142/S021848850200165X. URL https://doi.org/10.1142/S021848850200165X.
- Sweeney [1997] Latanya Sweeney. Weaving technology and policy together to maintain confidentiality. The Journal of Law, Medicine & Ethics, 25(2-3):98–110, 1997. doi: 10.1111/j.1748-720X.1997.tb01885.x. URL https://doi.org/10.1111/j.1748-720X.1997.tb01885.x. PMID: 11066504.
- Gulyás et al. [2016] Gábor György Gulyás, Benedek Simon, and Sándor Imre. An efficient and robust social network de-anonymization attack. In Proceedings of the 2016 ACM on Workshop on Privacy in the Electronic Society, WPES ’16, page 1–11, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450345699. doi: 10.1145/2994620.2994632. URL https://doi.org/10.1145/2994620.2994632.
- Shokri et al. [2017] R. Shokri, M. Stronati, C. Song, and V. Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy (SP), pages 3–18, Los Alamitos, CA, USA, may 2017. IEEE Computer Society. doi: 10.1109/SP.2017.41. URL https://doi.ieeecomputersociety.org/10.1109/SP.2017.41.
- Ren et al. [2020] Wenbo Ren, Xingyu Zhou, Jia Liu, and Ness B. Shroff. Multi-armed bandits with local differential privacy. CoRR, abs/2007.03121, 2020. URL https://arxiv.org/abs/2007.03121.
- Malekzadeh et al. [2020] Mohammad Malekzadeh, Dimitrios Athanasakis, Hamed Haddadi, and Ben Livshits. Privacy-preserving bandits. In I. Dhillon, D. Papailiopoulos, and V. Sze, editors, Proceedings of Machine Learning and Systems, volume 2, pages 350–362, 2020. URL https://proceedings.mlsys.org/paper_files/paper/2020/file/6ba1453022da1faf642d4de27241d53f-Paper.pdf.
- Gkountouna et al. [2022] Olga Gkountouna, Katerina Doka, Mingqiang Xue, Jianneng Cao, and Panagiotis Karras. One-off disclosure control by heterogeneous generalization. In 31st USENIX Security Symposium (USENIX Security 22), pages 3363–3377, Boston, MA, August 2022. USENIX Association. ISBN 978-1-939133-31-1. URL https://www.usenix.org/conference/usenixsecurity22/presentation/gkountouna.
- Hong et al. [2020] Joey Hong, Branislav Kveton, Manzil Zaheer, Yinlam Chow, Amr Ahmed, Mohammad Ghavamzadeh, and Craig Boutilier. Non-stationary latent bandits. CoRR, abs/2012.00386, 2020. URL https://arxiv.org/abs/2012.00386.
- Narayanan and Shmatikov [2008] Arvind Narayanan and Vitaly Shmatikov. Robust de-anonymization of large sparse datasets. In 2008 IEEE Symposium on Security and Privacy (sp 2008), pages 111–125, 2008. doi: 10.1109/SP.2008.33. URL https://ieeexplore.ieee.org/document/4531148.
- Markovsky [2008] Ivan Markovsky. Structured low-rank approximation and its applications. Automatica, 44(4):891–909, 2008. ISSN 0005-1098. doi: https://doi.org/10.1016/j.automatica.2007.09.011. URL https://www.sciencedirect.com/science/article/pii/S0005109807003950.
- Yoon et al. [2020] J. Yoon, L. N. Drumright, and M. van der Schaar. Anonymization Through Data Synthesis Using Generative Adversarial Networks (ADS-GAN). IEEE J Biomed Health Inform, 24(8):2378–2388, Aug 2020. URL https://ieeexplore.ieee.org/document/9034117.
- Galozy and Nowaczyk [2023] Alexander Galozy and Sławomir Nowaczyk. Information-gathering in latent bandits. Knowledge-Based Systems, 260:110099, 2023. ISSN 0950-7051. doi: https://doi.org/10.1016/j.knosys.2022.110099. URL https://www.sciencedirect.com/science/article/pii/S0950705122011959.
- Cook [2012] Diane J Cook. Learning setting-generalized activity models for smart spaces. IEEE intelligent systems, 27(1):32, 2012. URL https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+from+Continuous+Ambient+Sensor+Data.
- Ni et al. [2019] Jianmo Ni, Larry Muhlstein, and Julian McAuley. Modeling heart rate and activity data for personalized fitness recommendation. In The World Wide Web Conference, pages 1343–1353, 2019. URL https://sites.google.com/eng.ucsd.edu/fitrec-project/home?pli=1.
- Furberg et al. [2016] Robert Furberg, Julia Brinton, Michael Keating, and Alexa Ortiz. Crowd-sourced Fitbit datasets 03.12.2016-05.12.2016, May 2016. URL https://doi.org/10.5281/zenodo.53894.
- Narayanan et al. [2017] Annamalai Narayanan, Mahinthan Chandramohan, Rajasekar Venkatesan, Lihui Chen, Yang Liu, and Shantanu Jaiswal. graph2vec: Learning distributed representations of graphs, 2017. URL https://arxiv.org/abs/1707.05005.
- Rozemberczki et al. [2020] Benedek Rozemberczki, Oliver Kiss, and Rik Sarkar. Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM ’20), page 3125–3132. ACM, 2020. URL https://doi.org/10.1145/3340531.3412757.
- Pedregosa et al. [2011] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011. URL http://jmlr.org/papers/v12/pedregosa11a.html.
- van der Maaten and Hinton [2008] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(86):2579–2605, 2008. URL http://jmlr.org/papers/v9/vandermaaten08a.html.