Best of Both Worlds in Online Control:
Competitive Ratio and Policy Regret
Abstract
We consider the fundamental problem of online control of a linear dynamical system from two different viewpoints: regret minimization and competitive analysis. We prove that the optimal competitive policy is well-approximated by a convex parameterized policy class, known as a disturbance-action control (DAC) policies. Using this structural result, we show that several recently proposed online control algorithms achieve the best of both worlds: sublinear regret vs. the best DAC policy selected in hindsight, and optimal competitive ratio, up to an additive correction which grows sublinearly in the time horizon. We further conclude that sublinear regret vs. the optimal competitive policy is attainable when the linear dynamical system is unknown, and even when a stabilizing controller for the dynamics is not available a priori.
1 Introduction
The study of online optimization consists of two main research directions. The first is online learning, which studies regret minimization in games. A notable framework within this line of work is online convex optimization, where an online decision maker iteratively chooses a point in a convex set and receives loss according to an adversarially chosen loss function. The metric of performance studied in this research thrust is regret, or the difference between overall loss and that of the best decision in hindsight.
The second direction is that of competitive analysis in metrical task systems. In this framework, the problem setting is similar, but the performance metric is very different. Instead of regret, the objective is to minimize the competitive ratio, i.e. the ratio of the reward of the online decision maker to that associated with the optimal sequence of decisions made in hindsight. For this ratio to remain bounded, an additional penalty is imposed on movement costs, or changes in the decision.
While the goals of the two research directions are similar, the performance metrics are very different and lead to different algorithms and methodologies. These two separate methodologies have recently been applied to the challenging setting of online control, yielding novel and exciting methods to the field of control of dynamical systems.
In the paper we unify these two disparate lines of work by establishing a connection between the two objectives. Namely, we show that the Gradient Perturbation Controller (GPC) minimizes regret against the policy that has the optimal competitive ratio for any Linear Time Invariant (LTI) dynamical system. The GPC algorithm hence gives the best of both worlds: sublinear regret, and optimal competitive ratio, in a single efficient algorithm.
Our main technical contribution is proving that the optimal competitive policy derived in [16] is well-approximated by a certain convex policy class, for which efficient online learning was recently established in the work of [2]. This implies that known regret minimization algorithms for online control can compete with this optimal competitive policy with vanishing regret.
This structural result has other important implications to online control, yielding new results: we show that sublinear regret can be attained vs. the optimal competitive policy even when the underlying dynamical system is unknown, and even when a stabilizing controller is not available.
1.1 Related work
Control of dynamical systems. Our study focuses on two types of algorithms for online control. The first class of algorithms enjoy sublinear regret for online control of dynamical systems; that is, whose performance tracks a given benchmark of policies up to a term which is vanishing relative to the problem horizon. [1] initiated the study of online control under the regret benchmark for linear time-invariant (LTI) dynamical systems. Bounds for this setting have since been improved and refined in [12, 25, 10, 29]. We are interested in adversarial noise and perturbations, and regret in the context of online control was initiated in the study of nonstochastic control setting [2], that allows for adversarially chosen (e.g. non-Gaussian) noise and general convex costs that may vary with time. This model has been studied for many extended settings, see [24] for a comprehensive survey.
Competitive control. [18] initiated the study of online control with competitive ratio guarantees and showed that the Online Balanced Descent algorithm introduced in [7] has bounded competitive ratio in a narrow class of linear systems. This approach to competitive control was extended in a series of papers [17, 27]. In recent work, [16] obtained an algorithm with optimal competitive ratio in general linear systems using techniques; in this paper we show that the competitive control algorithm obtained in [16] is closely approximated by the class of DAC policies, and use this connection to obtain our “best-of-both-worlds” result.
Online learning and online convex optimization. The regret minimization techniques that are the subject of this paper are based in the framework of online convex optimization, see [20]. Recent techniques in online nonstochastic control are based on extensions of OCO to the setting of loss functions with memory [3] and adaptive or dynamic regret [23, 33].
Competitive analysis of online algorithms and simultaneous bounds on competitive ratio and regret. Competitive analysis was introduced in [31] and was first studied in the context of Metrical Task Systems (MTS) in [6]; we refer to [5] for an overview of competitive analysis and online algorithms. A series of recent papers consider the problem of obtaining online algorithms with bounded competitive ratio and sublinear regret. In [4], it was shown no algorithm can simultaneously achieve both objectives in OCO with switching costs. On the other hand, [11] described an online algorithm for MTS with optimal competitive ratio and sublinear regret on every time interval.
2 Preliminaries
We consider the task of online control in linear time-invariant (LTI) dynamical systems. In this setting, the interaction between the learner and the environment proceeds as described next. At each time step, the learner incrementally observes the current state of the system, subsequently chooses a control input , and consequently is subject to an instantaneous cost defined via the quadratic cost function (we assume the existence of such that )
As a consequence of executing the control input , the dynamical system evolves to a subsequent state , as dictated by the following linear system parameterized by the matrices and , bounded as , and the perturbation sequence .
We assume without loss of generality that . The learner does not directly observe the perturbations, or know of them in advance. We do not make any (e.g., distributional) assumptions on the perturbations, other than that they satisfy a point-wise bound for all times steps . By the means of such interaction across time steps, we ascribe an aggregate cost to the learner as
2.1 Policy classes
Since the learner selects the control inputs adaptively upon observing the state, the behavior of a learner may be described by a (strictly causal) policy , a mapping from the observed state sequence to the immediate action. We consider the following policy classes in the paper:
-
1.
is the exhaustive set of -length sequence of control inputs.
-
2.
is the class of all strictly causal policies, mapping the heretofore observed state sequence to the next action.
-
3.
is a class of linear state-feedback policies. Each member of this class is parameterized by some matrix , and recommends the immediate action . Both the stochastic-optimal policy (-control) – Bayes-optimal for i.i.d. perturbations – and the robust policy (-control) – minimax-optimal for arbitrary perturbations – are linear state-feedback policies.
-
4.
is a class of disturbance-action controllers (DAC), defined below, that recommend actions as a linear transformation of the past few perturbations, rather than the present state.
A linear policy is called stable if . Such policies ensure that the state sequence remains bounded under their execution. The notion of strong stability, introduced by [9], is a non-asymptotic characterization of the notion of stability defined as follows.
Definition 1.
A linear policy is said to be -strongly stable with respect to an LTI if there exists exists matrices satisfying such that
A sufficient condition for the existence of a strongly stable policy is the strong controllability of the linear system , a notion introduced in [9]. In words, strong controllability measures the minimum length and magnitude of control input needed to drive the system to any unit-sized state.
Let be a fixed -strongly stable linear policy for the discussion that follows. We will specify a particular choice for in Section 3. We formally define a disturbance action controller below. The purpose of superimposing a stable linear policy on top of the linear-in-perturbation terms is to ensure that the state sequence produced under the execution of a (possibly non-stationary) disturbance-action controller remains bounded.
Definition 2.
A disturbance-action controller (DAC), specified by a horizon and parameters , chooses the action at the time as
where is state at time , and are past perturbations.
Definition 3.
For any , an -DAC policy class is the set of all -horizon DAC policies where satisfy .
2.2 Performance measures
This paper considers multiple criteria that may be used to assess the learner’s performance. We introduce these below.
Let be the perturbation sequence the dynamics are subject to. Given the foreknowledge of this sequence, we define the following notions of optimal cost; note that these notions are infeasible in the sense that no online learner can match these on all instances.
-
1.
is the cost associated with the best sequence of control inputs given the perturbation sequence. No policy, causal or otherwise, can attain a cost smaller than on the the perturbation sequence .
-
2.
For any policy class , is the cost of the best policy in , subject to the perturbation sequence. Note that .
With respect to these baselines, we define the following performance measures.
Competitive Ratio (CR): The competitive ratio of an (online) learner is the worst-case ratio of its cost to the optimal offline cost over all possible perturbation sequences.
The optimal competitive ratio is the competitive ratio of the best strictly causal controller.
The infinite-horizon optimal competitive ratio is defined as the limiting optimal competitive ratio as the horizon extends to infinity, whenever it exists.
Regret: On any perturbation sequence , given a policy class , the regret of an online learner is assigned to be the excess aggregate cost incurred in comparison to that of the best policy in ,
The worst-case regret is defined as the maximum regret attainable over all perturbation sequences,
The two types of performance guarantees introduced above are qualitatively different in terms of the bound they espouse and the baseline they compare to. In particular:
Tighter bound for low regret: A sub-linear regret guarantee implies that the average costs of the learner and the baseline asymptotically match, while even an optimal competitive-ratio bound promises an average cost at most a constant factor times that of the baseline.
Stronger baseline for CR: Competitive ratio bounds holds against the optimal unrestricted policy while regret holds against the best fixed policy from a (typically parametric) policy class.
2.3 Characterization of the optimal CR algorithm
The following explicit characterization of a strictly causal policy that achieves an optimal competitive ratio in the infinite-horizon setting was recently obtained in [16]; this theorem shows that the competitive policy in the original system with state can be viewed as a state-feedback controller in a synthetic system with state .
Theorem 4 (Optimal Competitive Policy).
The strictly causal controller with an optimal infinite-horizon competitive ratio is given by the policy , where and the synthetic state evolves according to the dynamics
The sequence is recursively defined as starting with . Here the matrices (and auxiliary constants and ) satisfy
Furthermore, let be the state sequence produced under the execution of such a policy. Then, the state sequence satisfies at all time that
Let be the sub-matrix induced by the first columns of . In general, the infinite-horizon optimal competitive ratio may not be finite. However, the stability of the associated filtering operation (i.e. ) and the closed loop control system (i.e. ) is sufficient to ensure the existence of this limit. We utilize the following bounds that quantify this.
Assumption 1.
is -strongly stable with respect to the linear system , and is -strongly stable with respect to the linear system . Also, .
We note that the above bounds are quantifications, and not strengthening, of the stability criterion. In particular, any stable controller is strongly stable for some . Here, we use the same parameters to state the strong stability for both controllers, and , for convenience. Such a simplification is valid, since given - and -strongly stable controllers, the said controllers are also -strongly stable.
2.4 Low-regret algorithms
Deviating from the methodologies of optimal and robust control, [2] propose considering an online control formulation in which the noise is adversarial, and thus the optimal controller is only defined in hindsight. This motivates different, online-learning based methods for the control task. [2] proposed an algorithm called GPC (Gradient Perturbation Controller) and show the following theorem (which we restate in notation consistent with this paper), which for LTI systems shows that regret when compared against any strongly-stable policy scales at most as .
Theorem 5.
Given any , let be the set of strongly stable linear policies. There exists an algorithm such that the following holds,
Here contains polynomial factors depending on the system constants.
As can be observed from the analysis presented by [2], the above regret guarantee holds not just against the set of strongly stable linear policies but also against the set of -DAC policies. The regret bound has been extended to different interaction models such as unknown systems [21], partial observation [30] and adaptive regret [19]. Furthermore the regret bound in this setting has been improved to logarithmic in [13, 28].
3 Statement of results
3.1 Main Result
The central observation we make is that regret-minimizing algorithms subject to certain qualifications automatically achieve an optimal competitive ratio bound up to a vanishing average cost term.
Typical regret-minimizing online control algorithms [2, 22] compete against the class of stable linear state-feedback policies. In general, neither the offline optimal policy (with cost ) nor the optimal competitive-ratio policy can be approximated by a linear policy [15]. However, the algorithm proposed in [2] and follow-up works that build on it also compete with a more-expressive class, that of disturbance-action policies (DACs). In [2], this choice was made purely for computational reasons to circumvent the non-convexity of the cost associated with linear policies; in this work, however, we use the flexibility of DAC policies to approximate the optimal competitive policy.
More formally, we prove that we can find a DAC which generates a sequence of states and control actions which closely track the sequence of states and control actions generated by the optimal competitive policy by taking the history of the DAC to be sufficiently large. This structural characterization of the competitive policy is sufficient to derive our best-of-both-worlds result, since a regret-minimizing learner competitive against an appropriately defined DAC class would also be competitive against the policy achieving an optimal competitive ratio, and hence achieve an optimal competitive ratio up to a residual regret term.
Theorem 6 (Optimal Competitive Policy is Approximately DAC).
Fix a horizon and a disturbance bound . For any , set
and define be the set of -DAC policies with stabilizing component . Let be the algorithm with the optimal competitive ratio . Then there exists a policy such that for any perturbations satisfying , the cost incurred by satisfies
We prove this theorem in Section 4. We now show that this result implies best-of-both-worlds.
3.2 Best-of-Both-Worlds in Known Systems
We begin by considering the case when the learner knows the linear system . In this setting, both the regret and competitive ratio thus measure the additional cost imposed by not knowing the perturbations in advance. The result below utilizes the regret bounds against DAC policies and associated algorithms from [2, 28].
Theorem 7 (Best-of-both-worlds in online control (known system)).
Assuming is known to the learner, there exists a constant
and a computationally efficient online control algorithm which simultaneously achieves the following performance guarantees:
-
1.
(Optimal competitive ratio) The cost of satisfies for any perturbation sequence that
where is the optimal competitive ratio.
-
2.
(Low regret) The regret of relative to the best linear state-feedback or DAC policy selected in hindsight grows sub-linearly in the horizon , i.e. for all , it holds
3.3 Best-of-Both-Worlds in Unknown Systems
We now present the main results for online control of unknown linear dynamical system. The first theorem deals with the case when the learner has coarse-grained information about the linear system in the form of access to a stabilizing controller . In general, to compute such a stable controller, it is sufficient to known to some constant accuracy, as noted in [10]. This theorem utilizes low-regret algorithms from [22, 28].
Theorem 8 (Best-of-both-worlds in online control (unknown system, given a stabilizing controller)).
For a -strongly controllable linear dynamical system , there exists a constant
and a computationally efficient online control algorithm such that, when given access to a -strongly stable initial controller , it guarantees
When an initial stabilizing controller is unavailable, we make use of the “blackbox control” algorithm in [8] to establish the next theorem.
Theorem 9 (Best-of-both-worlds in online control (unknown system, blackbox control)).
For a -strongly controllable linear dynamical system , there exists a constant
and a computationally efficient online control algorithm that guarantees
4 Proof of Theorem 6
Proof of Theorem 6.
Unrolling the recursive definition of in Theorem 4, we see that
Let be the state sequence generated by the competitive control policy in the original -dimensional system and let is the sequence of states generated by the competitive policy in the -dimensional synthetic system. Additionally, let be the partition of along the first columns and the remaining . Recall that , where and . Using Theorem 4, we decompose as a linear combination of the disturbance terms:
We now describe a DAC policy which approximates the competitive control policy; recall that every DAC policy is parameterized by a stabilizing controller and a set of weights. We take the stabilizing controller to be and the set of weights to be , where is
The action generated by our DAC approximation of the competitive policy is therefore
| (1) |
where is the corresponding state sequence generated by the DAC.
We now show that the weights ’s decay geometrically in time. Recall that , where and . Similarly, , where and . Recall that , therefore . We see that
| (2) |
where we used the fact that and hence . We now bound the distance between and . Plugging our choice of given in (1) into the dynamics of , we see that
Comparing the expansions of and on a per-term basis, we observe that the terms in their difference contain either or , and thus their difference is exponentially small in under the strong stability of and . Formally, we have
Claim 10.
We now bound the distance between and . Unrolling the dynamics, we get the following,
Similar to the argument for Claim 10 we have the following,
Claim 11.
.
where we used the strong stability of , the bound on given in Claim 10 and the fact that . We now show that by taking to be sufficiently large we can ensure that We utilize the following bound on :
Lemma 12.
The execution of any policy from a -DAC policy class produces state-action sequences that obey for all time that .
In light of (2), we see that we can take , leading to the bound
Using the easily-verified inequality , we put the pieces together to bound the difference in costs incurred by the competitive policy and our DAC approximation in each timestep:
Similarly,
The difference in aggregate cost is therefore
Taking concludes the proof. ∎
5 Experiments
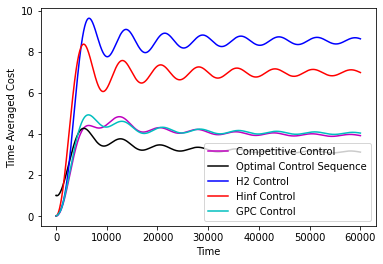
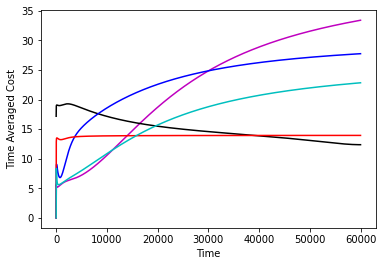
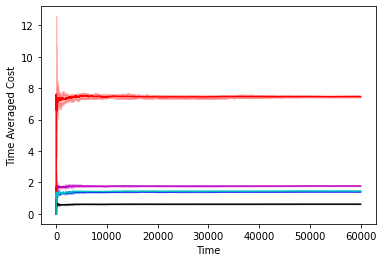
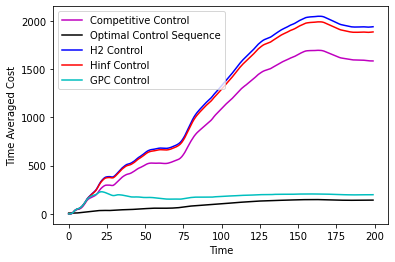
In Figure 1 we compare the performance of various controllers, namely, the controller, the controller, the infinite horizon competitive controller from [16], the GPC controller from [2] and the “clairvoyant offline” controller which selects the optimal-in-hindsight sequence of controls. We do this comparison on a two dimensional double integrator system with different noise sequences. We confirm as the results of our paper suggest that the GPC controller attaining the best of both worlds guarantee is indeed the best performing controller and in particular matches and sometimes improves over the performance of competitive control. Further experiment details along with more simulations on different systems can be found in the appendix.
6 Conclusions, Open Problems and Limitations
We have proved that the optimal competitive policy in an LTI dynamical system is well-approximated by the class of Disturbance Action Control (DAC) policies. This implies that the Gradient Perturbation Control (GPC) algorithm and related approaches are able to attain sublinear regret vs. this policy, even when the dynamical system is unknown ahead of time. This is the first time that a control method is shown to attain both sublinear regret vs. a large policy class, and simultaneously a competitive ratio vs. the optimal dynamic policy in hindsight (up to a vanishing additive term). It remains open to extend our results to time varying and nonlinear systems, the recent methods of [26, 19] are a potentially good starting point.
Acknowledgements
Elad Hazan gratefully acknowledges funding from NSF grant #1704860.
References
- [1] Yasin Abbasi-Yadkori and Csaba Szepesvári. Regret bounds for the adaptive control of linear quadratic systems. In Proceedings of the 24th Annual Conference on Learning Theory, pages 1–26, 2011.
- [2] Naman Agarwal, Brian Bullins, Elad Hazan, Sham Kakade, and Karan Singh. Online control with adversarial disturbances. In International Conference on Machine Learning, pages 111–119, 2019.
- [3] Oren Anava, Elad Hazan, and Shie Mannor. Online learning for adversaries with memory: price of past mistakes. Advances in Neural Information Processing Systems, 28, 2015.
- [4] Lachlan Andrew, Siddharth Barman, Katrina Ligett, Minghong Lin, Adam Meyerson, Alan Roytman, and Adam Wierman. A tale of two metrics: Simultaneous bounds on competitiveness and regret. In Conference on Learning Theory, pages 741–763. PMLR, 2013.
- [5] Allan Borodin and Ran El-Yaniv. Online computation and competitive analysis. Cambridge University Press, 2005.
- [6] Allan Borodin, Nathan Linial, and Michael E Saks. An optimal on-line algorithm for metrical task system. Journal of the ACM (JACM), 39(4):745–763, 1992.
- [7] Niangjun Chen, Gautam Goel, and Adam Wierman. Smoothed online convex optimization in high dimensions via online balanced descent. In Conference On Learning Theory, pages 1574–1594. PMLR, 2018.
- [8] Xinyi Chen and Elad Hazan. Black-box control for linear dynamical systems. In Conference on Learning Theory, pages 1114–1143. PMLR, 2021.
- [9] Alon Cohen, Avinatan Hasidim, Tomer Koren, Nevena Lazic, Yishay Mansour, and Kunal Talwar. Online linear quadratic control. In International Conference on Machine Learning, pages 1029–1038. PMLR, 2018.
- [10] Alon Cohen, Tomer Koren, and Yishay Mansour. Learning linear-quadratic regulators efficiently with only regret. In International Conference on Machine Learning, pages 1300–1309, 2019.
- [11] Amit Daniely and Yishay Mansour. Competitive ratio vs regret minimization: achieving the best of both worlds. In Algorithmic Learning Theory, pages 333–368. PMLR, 2019.
- [12] Sarah Dean, Horia Mania, Nikolai Matni, Benjamin Recht, and Stephen Tu. Regret bounds for robust adaptive control of the linear quadratic regulator. In Advances in Neural Information Processing Systems, pages 4188–4197, 2018.
- [13] Dylan Foster and Max Simchowitz. Logarithmic regret for adversarial online control. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3211–3221. PMLR, 13–18 Jul 2020.
- [14] Dylan Foster and Max Simchowitz. Logarithmic regret for adversarial online control. In International Conference on Machine Learning, pages 3211–3221. PMLR, 2020.
- [15] Gautam Goel and Babak Hassibi. The power of linear controllers in lqr control. arXiv preprint arXiv:2002.02574, 2020.
- [16] Gautam Goel and Babak Hassibi. Competitive control. arXiv preprint arXiv:2107.13657, 2021.
- [17] Gautam Goel, Yiheng Lin, Haoyuan Sun, and Adam Wierman. Beyond online balanced descent: An optimal algorithm for smoothed online optimization. Advances in Neural Information Processing Systems, 32, 2019.
- [18] Gautam Goel and Adam Wierman. An online algorithm for smoothed regression and lqr control. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 2504–2513. PMLR, 2019.
- [19] Paula Gradu, Elad Hazan, and Edgar Minasyan. Adaptive regret for control of time-varying dynamics. arXiv preprint arXiv:2007.04393, 2020.
- [20] Elad Hazan. Introduction to online convex optimization. arXiv preprint arXiv:1909.05207, 2019.
- [21] Elad Hazan, Sham Kakade, and Karan Singh. The nonstochastic control problem. In Aryeh Kontorovich and Gergely Neu, editors, Proceedings of the 31st International Conference on Algorithmic Learning Theory, volume 117 of Proceedings of Machine Learning Research, pages 408–421. PMLR, 08 Feb–11 Feb 2020.
- [22] Elad Hazan, Sham Kakade, and Karan Singh. The nonstochastic control problem. In Proceedings of the 31st International Conference on Algorithmic Learning Theory, pages 408–421. PMLR, 2020.
- [23] Elad Hazan and Comandur Seshadhri. Efficient learning algorithms for changing environments. In Proceedings of the 26th annual international conference on machine learning, pages 393–400, 2009.
- [24] Elad Hazan and Karan Singh. Tutorial: online and non-stochastic control, July 2021.
- [25] Horia Mania, Stephen Tu, and Benjamin Recht. Certainty equivalence is efficient for linear quadratic control. In Advances in Neural Information Processing Systems, pages 10154–10164, 2019.
- [26] Edgar Minasyan, Paula Gradu, Max Simchowitz, and Elad Hazan. Online control of unknown time-varying dynamical systems. Advances in Neural Information Processing Systems, 34, 2021.
- [27] Guanya Shi, Yiheng Lin, Soon-Jo Chung, Yisong Yue, and Adam Wierman. Online optimization with memory and competitive control. Advances in Neural Information Processing Systems, 33:20636–20647, 2020.
- [28] Max Simchowitz. Making non-stochastic control (almost) as easy as stochastic. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 18318–18329. Curran Associates, Inc., 2020.
- [29] Max Simchowitz and Dylan Foster. Naive exploration is optimal for online lqr. In International Conference on Machine Learning, pages 8937–8948. PMLR, 2020.
- [30] Max Simchowitz, Karan Singh, and Elad Hazan. Improper learning for non-stochastic control, 2020.
- [31] Daniel D Sleator and Robert E Tarjan. Amortized efficiency of list update and paging rules. Communications of the ACM, 28(2):202–208, 1985.
- [32] Andras Varga. Detection and isolation of actuator/surface faults for a large transport aircraft. In Fault Tolerant Flight Control, pages 423–448. Springer, 2010.
- [33] Lijun Zhang, Tianbao Yang, Zhi-Hua Zhou, et al. Dynamic regret of strongly adaptive methods. In International conference on machine learning, pages 5882–5891. PMLR, 2018.
Appendix A Appendix Layout
In Section B, we provide the proofs of the claims necessary to conclude Theorem 6. Following this, Section C & D proves the results for known and unknown systems respectively. Thereafter, we prove a generalization of Theorem 6 necessary for the case of unknown systems in Section E. Finally, Section F discusses the translation of the optimality results from infinite-horizon to finite-horizon. Section G provides further details on the experimental setup, along with more experimental evaluations.
Appendix B Proofs of claims substantiating Theorem 6
Proof of Claim 10.
Using the strong stability of and , we have
| (3) | ||||
| (4) |
where in the penultimate line we used the following elementary result:
Lemma 13.
For all and all , the following inequality holds:
∎
Proof of Claim 11.
Recall that by unrolling the dynamics, we get the following,
Using the strong stability of , we bound the point-wise difference between these sequences as
∎
Proof of Lemma 12.
Since is -strongly stable, there exists matrices such that with and . Also recall that for every member of a -DAC class satisfies . Observe for any that
∎
Proof of Lemma 13.
Recall that for all , therefore Also for all . We have
∎
Appendix C Proofs for known systems
Proof of Theorem 7.
The perturbation sequence has terms. Overloading this notation, we extend this to an infinite sequence with for all . Let be the class of -strongly stable linear policies, and be a -DAC class for
By the results of [2], using the GPC algorithm (Algorithm 1 in [2]) as the online learner , we have the following regret guarantee:
Now, recall that Theorem 6 asserts
where is the online learner (from Theorem 4) that achieves an optimal competitive ratio . By the non-negativity of the cost, and thereafter using the optimal competitive ratio bound, we have
An appeal to Theorem 15 concludes the -part of the claim. For the polylog regret result, we use the algorithm and the associated regret guarantee in [28]. ∎
Appendix D Proofs for unknown systems
Proof of Theorem 8.
The proof of this theorem is similar in structure to that of Theorem 7. In particular, we utilize regret-minimizing algorithms from [22] & [28] that apply even are unknown, given a -strongly stable controller for a -strongly controllable system. However, we highlight a crucial difference below.
Theorem 6 establishes that the infinite-horizon competitive control policy is contained in the class of DACs that utilize as the stabilizing baseline policy. Since this policy is derived from the competitive controller, which in turn depends on knowledge of , such a might not be available when the underlying system is unknown, or even approximately known. To alleviate this concern, we give an analogous result that holds with respect to any baseline stabilizing policy , instead of the specific choice .
Theorem 14 (Generalized policy inclusion).
Fix a horizon . For any , choose
and define be the set of -DAC policies with an arbitrary baseline stabilizing policy . Let be an online algorithm with the optimal competitive ratio . Then there exists a such that for any perturbation sequence ,
Now, with the aid of the above result, we may proceed as with Theorem 7. The algorithm and result in [22] guarantees regret against , and similarly those in [28] guarantee regret – say, this bound is in either case. Again, by the non-negativity of the cost, and thereafter using the optimal competitive ratio bound, we have
where we extend to an infinite sequence with for all . An appeal to Theorem 15 concludes the claim. ∎
Appendix E A generalized proof of policy inclusion
Proof of Theorem 14.
We begin by taking note of the explicit characterization of an optimal competitive-ratio algorithm presented in Theorem 4. In particular, unrolling the recursive definition of , we have . Let the true state sequence visited by such a competitive control policy be . Additionally, let be the partition of along the first columns and the remaining . Since , by the second part of the said theorem, we have
We now choose a DAC policy intended to emulate the competitive control policy as
and define the associated action as , where is the state sequence achieved the execution of such a DAC policy.
Before proceeding to establish that and are close, let us notice that ’s decay. To this extent, recall that due to strong stability there exist matrices with and such that and . Noting that by definition and that , we thus obtain
where the last line follows from Lemma 13.
Note the identity . Using this twice, we have
Thus proceeding with the above identities, this time invoking the strong stability of , we have
Similarly the corresponding control inputs are nearly equal. By the previous display concerning states, we have
Being the iterates produced by a DAC policy, are bounded as indicated by Lemma 12. Now, in terms of cost, since and given Equation 2, we note that
The difference in aggregate cost is at most times the quantity above. Therefore, setting is sufficient to ensure the validity of the claim. We have already established that the DAC satisfies and . ∎
Appendix F To finity and beyond
In this section, we relate the infinite-horizon cost , as used in earlier proofs, to the finite variant . By the non-negativity of the instantaneous cost, it is implied that . We prove the reverse inequality, up to constant terms.
Theorem 15.
Extend the perturbation sequence to an infinite sequence , by defining for . Then, we have
Proof.
Let ; these are the actions of the finite-horizon optimal offline controller attaining cost . Let be an algorithm that executes for the first time steps and (or any other -strongly stable policy) thereafter. Let be the state-action sequence associated with . Now, we have by the definition of , specifically its optimality, that
where on the last line we use the observation that for the first steps executes . Henceforth, we wish to establish a bound on the remainder term. With this aspiration, let us note that for all implying for that
To conclude the proof of the claim, we invoke Lemma C.9 and C.6 in [14], whereby the authors establish a bound on the state sequence produced by an optimal offline policy using an explicit characterization of the same, to note that
∎
Appendix G Experiment Setup & Further Evaluations
We compare 5 controllers in our experiments, the controller, the controller, the infinite horizon competitive controller from [16], the GPC controller from [2] and the “clairvoyant offline” controller which selects the optimal-in-hindsight sequence of controls. We consider two systems a standard 2 dimensional double integrator where the system is given as follows
and a system derived from Boeing [32]. The exact system details can be found in the code supplied with the supplementary. On a high level the system has a 5-dimensional state and a 9-dimensional control.
The perturbations we add fall into 6 categories.
-
•
Sin Perturbations: every entry of where is the time horizon.
-
•
Sin Perturbations with changing Amplitude: every entry of where is the time horizon.
-
•
Constant Perturbations: every entry of is set to 1.
-
•
Uniform Perturbations: every entry of is drawn uniformly and independently in the range .
-
•
Gaussian Perturbations: drawn independently from .
-
•
Gaussian Random Walk Perturbations: Every entry of drawn independently from .
The performance of the controllers on the double integrator system can be found in Figure 2 and the performance of the controllers on the Boeing system can be found in 3. The experiments confirm our theorems, that over a large time horizon GPC performs at par and sometimes can be better than the competitive controller. We note that the optimal competitive ratio for the competitve controller turns out to be 14.67 in the double integrator system and 5.686 in the Boeing system.
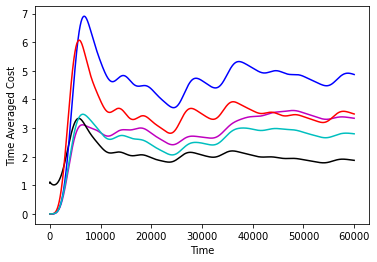
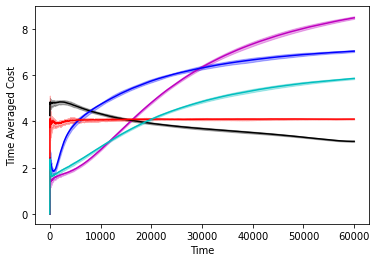
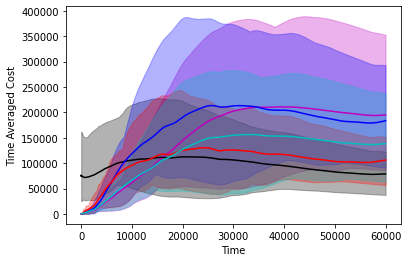
Hyperparameter setup for GPC
GPC is only the controller with hyperparameters. We describe the hyperparameters used here.
-
•
Double Integrator System: For all perturbations . For all perturbations except the Gaussian Random walk perturbations, GPC was run with learning rate . For Gaussian Random walk perturbations, GPC was run with learning rate .
-
•
Boeing System: For all perturbations . For all perturbations except the Gaussian Random walk perturbations, GPC was run with learning rate . For Gaussian Random walk perturbations, GPC was run with learning rate .
We note that the learning rate needs to be reduced significantly for the Gaussian Random walk perturbations as the noise magnitude is growing in time and in this sense our theorem does not immediately apply to this setting.