Benchmarking Japanese Speech Recognition on ASR-LLM Setups with Multi-Pass Augmented Generative Error Correction
Abstract
With the strong representational power of large language models (LLMs), generative error correction (GER) for automatic speech recognition (ASR) aims to provide semantic and phonetic refinements to address ASR errors. This work explores how LLM-based GER can enhance and expand the capabilities of Japanese language processing, presenting the first GER benchmark for Japanese ASR with 0.9-2.6k text utterances. We also introduce a new multi-pass augmented generative error correction (MPA GER) by integrating multiple system hypotheses on the input side with corrections from multiple LLMs on the output side and then merging them. To the best of our knowledge, this is the first investigation of the use of LLMs for Japanese GER, which involves second-pass language modeling on the output transcriptions generated by the ASR system (e.g., -best hypotheses). Our experiments demonstrated performance improvement in the proposed methods of ASR quality and generalization both in SPREDS-U1-ja and CSJ data.
Index Terms— Automatic speech recognition (ASR), Large language models (LLM), generative error correction (GER), Japanese corpus.
1 Introduction
The automatic generative error correction (GER) task involves using pre-trained models and algorithms (e.g., contextual biasing) to automatically revise and improve the quality of written content, such as documents, articles, or translations. This process typically includes correcting grammar, syntax, style, and coherence errors and adjusting language to meet specific requirements or preferences. Automatic GER tasks aim to streamline the editing process, saving time and effort while enhancing the overall readability and effectiveness of the post-recognition transcript quality.
GER tasks involve revising outputs from automatic speech recognition (ASR) systems. When speech is transcribed into text, errors can arise due to variations in accents, background noise, or misinterpretations of words. Recent advanced GER algorithms, such as text-to-text modeling [1] and speech-language representation alignments [2], address these issues in ASR transcriptions. For instance, GER-based methods correct inaccuracies, enhance grammar and syntax, and ensure that the text accurately represents the spoken content. This refinement process significantly improves the quality and usability of the transcribed text, making it more valuable for applications such as captioning, transcription services, or voice-controlled systems.


In recent years, pretrained big neural network-based language models (LMs) have been used in ASR-related GER tasks. Zhang et al. [3] proposed a spelling corrector based on the transformer [4] to reduce the substitution error in Mandarin speech recognition. Zhang et al. [5] improved the BERT [6] effectiveness in detecting spelling errors with the soft-masking technique as the bridge between the error detector and corrector. Futami et al. [7] generated soft labels for ASR training with the BERT distilling knowledge. There are also some works [8, 9] studying to improve ASR rescoring by BERT. Additionally, BERT has also been successfully applied in multi-modal studies in vision-language pretraining [10, 11, 12, 13] or voice-language pretraining [14, 15, 16].
More recently, [1, 17] proposed combining large language models (LLMs) into a speech recognition system. In this work, we extend the correction methods described in [17] and apply them to Japanese ASR tasks in different settings from -best hypotheses. Additionally, Li et al. [18] investigated knowledge transfer when fine-tuning a multilingual LLM to correct 1-best hypothesis errors generated by different speech foundation models across multiple languages. We introduce a new multi-pass augmented generative error correction (MPA GER) by integrating multiple system hypotheses on the input side with corrections from multiple LLMs on the output side and then merging them. Moreover, We will also address the issue with a fairly low Character Error Rate (CER) for which the conventional Recognizer Output Voting Error Reduction (ROVER) [19] and previous LLM GER no longer provide enhancements. Our results show that MPA GER shows improved performance on ASR quality and generalization.
2 Related Work
2.1 LMs for ASR task
Using an LM in ASR improves speech recognition performance. Generally, ASR combined with LM has two strategies: first-pass decoding and second-pass rescoring.
In ASR, the task was formulated as a noisy channel model using the Bayes rule , where is the speech signal and is the corresponding text. The two distributions of and were named acoustic and language models, respectively. The LM was trained separately on the source text and only used for decoding [20]. WFST-based decoding compiles n-gram LMs into the decoding graph for efficient first-pass decoding [21]. Incorporating larger n-gram LMs made the decoding graph explode, and researchers changed the compiling improved algorithm [22] or used second-pass rescoring in both offline and on-the-fly settings [23, 24] instead. The Bayesian formulation still made sense in the hybrid DNN-HMM model era. The scores could be interpreted as pseudo-likelihoods by subtracting an appropriate prior, so the same decoding/rescoring framework carried over.
For End-to-End models, they directly estimate . We still can combine using LMs in the first-pass decoding (e.g., shallow fusion, cold fusion, etc. [25, 26]). Similar to the second-pass rescoring, hypotheses can be obtained using beam search on an ASR model and re-rank with an externally trained LM. A two-pass E2E ASR model was proposed with an encoder shared between a streaming RNN-T model and a full-context LAS decoder [27]. There are also some works [3, 5, 7, 8, 9] studying to improve ASR rescoring by the transformer and BERT.
3 Improving generative error correction using LLMs for ASR system
3.1 LLM GER with -best hypotheses in a single system
3.2 Multi-pass augmented (MPA) GER
Chen et al. [17] mentioned that the previous LLM GER failed to yield improvements when the WER was low. There was less room to correct recognition errors with the previous standard LLM GER. When the ASR error rate is low, the impact of the errors or hallucinations generated by the LLM may be greater than the impact of ASR error correction. It may result in a more significant overall error for the LLM GER. We expect this problem to occur also when applying the previous standard LLM GER in a low CER Japanese ASR task. In this study, we propose a multi-pass augmented (MPA) GER approach. This approach, which involves combining hypotheses from different ASR and LLM models, has the potential to significantly enhance LLM GER and make a substantial impact in the field. We integrate multiple system hypotheses on the input side and apply corrections from several LLMs on the output side. This approach culminates in a merging process akin to a multi-pass combination.
For MPA GER, we use the ROVER to combine the results with rescoring. The ROVER is one of the most efficient among traditional methods for reducing speech recognition errors. Its underlying principle involves constructing multiple speech recognizers with comparable performance that operate independently and then vote on their recognition results to lower the overall error rate. Our proposed MPA GER utilizes both the advantages of conventional ROVER methods and current LLM approaches. In this study, we propose two types of MPA GER: (1) -best hypotheses combination from -systems, (2) -best hypotheses combination from single system. Fig. 2 shows the overview of MPA GER in -best hypotheses combination from -systems.
| Dataset | SPREDS-U1-ja | CSJ |
|---|---|---|
| LLM | Elyza-7b | Elyza-7b (LLM1) |
| Qwen1.5-7b (LLM2) | ||
| Machine | V100 | A6000 |
| LLM test set | 100 utt. | Eval1 (424) |
| Eval2 (424) | ||
| Eval3 (424) | ||
| LLM train set | 900 utt. | Eval1+Eval2+Eval3 (2677) |
| (except LLM test set) | ||
| Training bit size | 8-bit | |
| Epoch | 15 | 20 (Elyza-7b) |
| 10 (Qwen1.5-7b) | ||
| Learning rate | 1e-4 | |
| LoRA rank | 4 | |
| Prompt Language | English | English-Japanese |
4 Experimental Setup
There are two sets of experiments in total: one with small data (SPREDS-U1-ja) to verify the basic algorithm (LLM GER) at high error rates and the other larger one (CSJ) with low error rates to validate our improved algorithm (MPA GER). The experimental settings are as follows. Table 1 shows the experiment settings for LLM GER and MPA GER.
- LLM models
-
The experiment employs the Japanese LLM (ELYZA-7b) model111huggingface.co/elyza/ELYZA-japanese-Llama-2-7b and Multilingual LLM (Qwen1.5-7b) model222https://huggingface.co/Qwen/Qwen1.5-7B. 333In this paper, we refer to the models fine-tuned by these LLMs as Elyza and Qwen1.5, respectively.
- Dataset
-
We use two Japanese datasets for GER. (1) SPREDS-U1-ja 444ast-astrec.nict.go.jp/en/release/SPREDS-U1. Of these, 900 Japanese sentences are used for fine-tuning process, and a separate set of 100 sentences are used for evaluation. (2) the “Corpus of Spontaneous Japanese (CSJ)” [28]. For training ASR models, we use approximately 600 hours of lecture recordings as the training set (Train APS+SPS (academic+simulated)) according to [29, 30, 31, 32]. Three official evaluation sets (Eval1, Eval2, and Eval3), each containing ten lecture recordings [32], are used to evaluate the speech recognition results. For the LLM test set, we extracted each 424 utterances from each Eval1 (1272), Eval2 (1292), and Eval3 (1385) prepared by the ESPnet2 [33] CSJ recipe 555https://github.com/espnet/espnet/tree/master/egs2/csj/asr1. The left Eval1, Eval2, and Eval3 not included in the LLM test set were gathered and used as our LLM train set (2677 utterances in total).
- Preparing ASR models
-
(1) For the SPREDS-U1-ja GER experiments, we prepared the open-source pre-trained ASR models, including Whisper-Large-v3, Meta MMS model, CMU OWSM v3.1 model, and Whisper-Large’s earlier versions (v1 and v2). (2) For the CSJ GER experiments, we used the Whisper models and the Conformer-based model after applying fine-tuning for Whisper (Whisper-Large-v2, Whisper-Medium, and Whisper-Small) and training Conformer from scratch by CSJ data. We applied whisper fine-tuning and conformer training from scratch using CSJ training data, following default settings in ESPnet2 [33] CSJ recipe 55footnotemark: 5 unless otherwise mentioned. We did not apply speed perturbation for data augmentation. We fine-tuned all whisper models in 3 epochs with a learning rate of 1e-5. We trained the Conformer-based model in 100 max epochs in 4 early-stop patients. The training is performed on 1 NVIDIA Tesla A6000 GPU.
- Training LLM GER models
-
The implementation of our LLM GER models is based on the repository666https://github.com/Hypotheses-Paradise/Hypo2Trans for GER task [1]. In SPREDS-U1-ja, the training is performed on a NVIDIA Tesla V100 GPU using 8-bit training. The hyperparameters for finetuning are 15 epochs, learning rate 1e-4, batch size 64, and LoRA rank 4. We used an English prompt in the repository777https://github.com/Hypotheses-Paradise/Hypo2Trans/blob/main/H2T-LoRA/templates/H2T-LoRA.json for training and testing without any change. In CSJ data, the training is performed on an NVIDIA Tesla A6000 GPU using 8-bit training. The hyperparameters for finetuning are 20 epochs in Japanese-Llama-2-7b, 10 epochs in Qwen1.5-7b, learning rate 1e-4, batch size 256, and LoRA rank 4. We used an English-Japanese prompt based on automatic translation following the previous default English prompt 888In our pilot study for CSJ data, we got roughly lower loss and lower CER trends in Elyza and Qwen1.5 using the English-Japanese prompt..
- For system combination in ROVER
-
In CSJ data, we applied ROVER [19] when getting a combined result from multiple LLM outputs for the proposed MPA GER in Fig. 2. We also applied ROVER directly for multiple ASR hypotheses as the baselines compared with the LLM GER methods. We tried two types of MPA GER: (1) -best hypotheses combination from -systems, (2) -best hypotheses combination from a single system. In (1), we tried -systems and -systems for -best hypotheses combination. In (2), we tried -best hypotheses combination from a single system.
- GER Evaluation
-
We used NIST-SCTK to evaluate the CER. In CSJ, before the CER calculation, we converted full-width characters to half-width characters and removed punctuation marks from the hypothesis and reference.
| Before LLM GER correction | After correction |
| 12.91 | 7.77 |
| Before proposed MPA GER | After | ||||
|---|---|---|---|---|---|
| MMS | OWSM v3.1 | WPL v1 | WPL v2 | WPL v3 | LLM GER |
| 32.41 | 10.18 | 9.29 | 9.20 | 12.91 | 7.07 |
5 Experimental Results and Analyses
5.1 SPREDS-U1-ja: LLM GER in -best hypotheses and -system combination
Table 2 shows the results of the experiments using -best hypotheses. Experiments show LLM GER can effectively improve the performance of the original system output, reflected in the CER. For the -best GER experiment, we conduct the paired sample -test on the results from the best model (Epoch 11). The paired sample -test suggests that the improvement in CER is statistically significant. Another discovery is switching to the Japanese language prompt for Japanese LLM GER; in the SPREDS-U1-ja dataset, CER can be further reduced from 7.77% to 7.63%. Table 3 shows the performance changes before and after using the LLM-based system combination. It has the current best result of GER correction. The leap forward in performance is due to the diversity of different system hypotheses. Both LLM GER-based -best rescoring and system combination work on SPREDS-U1-ja.
| WP large v2 | WP medium | Conformer | WP small | |
|---|---|---|---|---|
| Eval1 (1272) | 3.7 | 4.3 | 5.0 | 5.9 |
| Eval2 (1292) | 2.9 | 3.2 | 3.5 | 4.6 |
| Eval3 (1385) | 3.3 | 3.6 | 4.1 | 5.0 |
| -systems | ✓ | ✓ | ✓ | ✓ |
| -systems | ✓ | ✓ | ✓ |
| Whisper | -best outputs from -systems | Outputs from LLM GER | |||||||
| large v2 | LLM GER (Elyza) | LLM GER (Qwen1.5) | ROVER | MPA GER (proposed) | |||||
| 1-best | -sys | -sys | -sys | -sys | -sys | -sys | -sys | -sys + -sys | |
| ID | A | B1 | B2 | C1 | C2 | D1 | D2 | A+B1+C1 | A+B1+B2+C1+C2 |
| Eval1 | 3.4 | 3.3 | 3.4 | 5.0 | 5.1 | 3.5 | 3.6 | 3.4 | 3.3 |
| Eval2 | 1.9 | 2.1 | 2.0 | 2.1 | 2.2 | 1.8 | 1.9 | 1.9 | 1.9 |
| Eval3 | 3.0 | 2.9 | 2.9 | 3.1 | 18.8 | 2.9 | 3.1 | 2.9 | 2.8 |
| -best | -best outputs from -system | Outputs from LLM GER | |||
| Hypotheses | LLM GER (Elyza) | LLM GER (Qwen1.5) | ROVER | MPA GER (proposed) | |
| ID | A | B | C | D | A+B+C |
| Whisper large v2 | |||||
| Eval1 | 3.4 | 3.7 | 3.9 | 3.7 | 3.5 |
| Eval2 | 1.9 | 2.3 | 2.2 | 2.2 | 2.0 |
| Eval3 | 3.0 | 3.3 | 3.5 | 4.0 | 3.1 |
| Whisper medium | |||||
| Eval1 | 3.8 | 4.1 | 4.1 | 4.0 | 3.8 |
| Eval2 | 2.2 | 2.5 | 2.4 | 2.4 | 2.2 |
| Eval3 | 3.3 | 3.7 | 3.4 | 4.3 | 3.2 |
| Conformer | |||||
| Eval1 | 4.6 | 4.7 | 4.8 | 4.8 | 4.6 |
| Eval2 | 2.2 | 4.3 | 2.5 | 2.5 | 2.3 |
| Eval3 | 3.7 | 4.2 | 10.2 | 4.4 | 3.8 |
| Whisper small | |||||
| Eval1 | 5.5 | 5.8 | 5.8 | 5.8 | 5.5 |
| Eval2 | 3.3 | 3.8 | 5.1 | 3.5 | 3.3 |
| Eval3 | 4.8 | 4.9 | 4.7 | 5.7 | 4.7 |
5.2 CSJ Results
5.2.1 LLM GER and MPA GER in 1-best -systems
Table 5 shows the -systems combination LLM GER results on CSJ data. Compared to SPREDS-U1-ja, the CER scores on CSJ are much lower. This would cause a slight improvement with the proposed method on CSJ compared to SPREDS-U1-ja. When we compare the LLM GER results between the -systems and -systems, the -systems tends to degrade performance compared to the -systems in Elyza and Qwen 1.5. This would be due to the lower performance of Whisper small compared to the other three models. In the first step, LLM GER for -systems or -systems, it improved in some cases, but there were various results in different test sets. That trend was also seen in direct ROVER results. Although the best score of CER=1.8% in ROVER -systems in Eval2, the score in Eval1 became worse than input scores, and there was no improvement in Eval3. In addition, the -systems ROVER also suffered the worst Whisper small model effect and resulted in lower scores than the -systems ROVER. We see that the general use of ROVER for some system outputs and the previous LLM GER could not lead to overall improvement, and when some worse systems were included, the harmful effects of such models tended to pull down those models. On the other hand, the -systems+-systems in our proposed MPA GER method resulted in equal or lower overall CERs compared to the inputs. In addition, when comparing the proposed MPA GER for -systems+-systems and -systems, -systems+-systems results were better than -systems. These results support that the LLM combination improved the CER, whereas the other methods tended to worse CER in -systems than -systems. In the proposed MPA GER, even if a worse system is included, the model can select and incorporate valuable and usable information from the system with a high CER.
5.2.2 LLM GER and MPA GER with -best hypotheses in each single system
Table 6 shows the single system -best LLM GER and MPA GER results on CSJ data. We applied LLM GER for -best from each single system in Table 4. We also conducted the experiments in -best settings. However, compared to the results in SPREDS-U1-ja with the -best setting for a single system, we could not observe an improvement in the -best system. We expect that increasing the size of in -best for the low CER range ASR task may result in more significant ambiguity of final outputs and result in worse scores.
Overall, the LLM GER (-best) was ineffective and often caused worse scores than -best. The proposed MPA GER was stronger than the traditional combination in ROVER, and all of the scores exceeded those of ROVER. We see that almost ROVER scores were higher than the LLM GER. On the other hand, in the proposed method, we see the lower CER (CER=3.2%; proposed MPA GER in Whisper medium) or almost the same CER compared to the LLM GER.
| Example1: phonetic similar error (Eval1, -systems+-systems combination) | |
|---|---|
| 1-best Hypotheses | 高 速 条 件 を 導 入 し た 上 で え ー ま 量 子 化 を 行 な っ た 図 な ん で す け ど も ち ょ っ と 量 子 化 の す 話 を 先 に し た い と 思 い ま す |
| MPA GER (proposed) | 拘 束 条 件 を 導 入 し た 上 で え ー ま 量 子 化 を 行 な っ た 図 な ん で す け ど も ち ょ っ と 量 子 化 の す 話 を 先 に し た い と 思 い ま す |
| Reference | 拘 束 条 件 を 導 入 し た 上 で え ー ま 量 子 化 を 行 な っ た 図 な ん で す け ど も ち ょ っ と 量 子 化 の す 話 を 先 に し た い と 思 い ま す |
| Example 2: phonetic similar error (Eval1, Whisper medium -best) | |
| -best Hypotheses | ミ ュ ン ヘ ン の 博 覧 会 は 電 子 万 華 経 の よ う だ と い う 意 味 の 文 で す が え ー 図 の 一 番 上 が |
| MPA GER (proposed) | ミ ュ ン ヘ ン の 博 覧 会 は 電 子 万 華 鏡 の よ う だ と い う 意 味 の 文 で す が え ー 図 の 一 番 上 が |
| Reference | ミ ュ ン ヘ ン の 博 覧 会 は 電 子 万 華 鏡 の よ う だ と い う 意 味 の 文 で す が え ー 図 の 一 番 上 が |
| Example 3: over-correction for disfluencies (Eval1, Whisper medium -best) | |
| 1-best Hypotheses | が 今 回 の え ー っ と 仕 事 の え ー っ と 大 ま か な も 問 題 意 識 で す ね |
| MPA GER (proposed) | が 今 回 の え ー っ と 仕 事 の え ー と 大 ま か な も 問 題 意 識 で す ね |
| Reference | が 今 回 の え ー と 仕 事 の え ー と ー 大 ま か な も 問 題 意 識 で す ね |
| Example 4: repetitions or hallucinations in LLM GER (Eval3, Conformer -best) | |
| 1-best Hypotheses | … 凄 く 残 念 な ん で す が そ の イ ル ミ ネ ー シ ョ ン を と 大 蔵 山 シ ャ ン ツ と い う |
| Elyza 3-best | … 凄 く 残 念 な ん で す が そ の イ ル ミ ネ ー シ ョ ン を と 大 蔵 山 シ ャ ン ツ と い う |
| Qwen 1.5 3-best | … 凄 く 残 念 な ん で す がそ の イ ル ミ ネ ー シ ョ ン を 見 逃 し て し ま っ て 本 当 見 れ な か っ た の が 凄 く 残 念 な ん で す が… (repeated in 11 times) |
| MPA GER (proposed) | … 凄 く 残 念 な ん で す が そ の イ ル ミ ネ ー シ ョ ン を と 大 蔵 山 シ ャ ン ツ と い う |
| Reference | … 凄 く 残 念 な ん で す が そ の イ ル ミ ネ ー シ ョ ン を と 大 倉 山 シ ャ ン ツ ェ と い う |

5.2.3 The GER trends from output examples
Table 7 shows some Japanese correction examples. We observed that most fixed errors by the proposed method were categorized as phonetic similarity errors. For example, in Example 1 and 2 in Table 7, “高速” was mistakenly generated instead of correct word “拘束” and “電子万華経” was mistakenly generated instead of correct word “電子万華鏡”, respectively. Those pronunciations were the same in Japanese, and the ASR models generated errors due to such phonetic similarity. In our proposed method, the errors were corrected by the proposed MPA GER both in Example 1 and 2.
Conversely, our methods face challenges when domain-specific context or outer knowledge is necessary for error correction.We expect that the prompt we used has the restriction to correct errors only with the tokens in the given hypotheses.
Then, the reconstruction of the prompt effectively injects the outer domain knowledge or grammatical knowledge from the LLM for the GER task.
In addition, the model focuses on correcting disfluencies unrelated to the contents of this study.
We made the LLM models to correct the errors in the outputs, including disfluencies and errors.
In CSJ data, the domain is spoken language, including disfluencies like fillers in speech and transcripts.
Example 3 in Table 7 is over-correcting disfluency parts.
In Example 3, “えーっと” was corrected into “えーと”.
However, the model needs to focus on correcting errors related to context words rather than errors related to disfluencies because correcting errors related to disfluencies does not matter for seriously breaking the outputs’ meaning.
5.2.4 Proposed MPA GER alleviates hallucinations or repetitions
From both Table 5 and 6, we see the especially worse CERs (CER=18.8% in Eval3, -systems+-systems, Qwen1.5 in Table 5 and CER=10.2% in Eval3, -best, Qwen1.5, Conformer in Table 6). We observed that the LLM GER error correction generated extended hallucinations or repetitions in those high CER systems. Example 4 in Table 7 shows that the single LLM GER system generates repetitions, but the repetitions were not included in the MPA GER results. Such hallucinations or repetitions in the LLM GER are sometimes inevitable and are one reason for degrading performance. However, the proposed MPA GER could complement and cancel such hallucinations or repetitions because the tendency of hallucinations or repetitions in each LLM model is different. As a result, the proposed MPA GER could get higher performance than ROVER or the LLM GER, alleviating such hallucination or repetition effects considering multiple ASR output candidates.
5.2.5 Sentence length influences performance
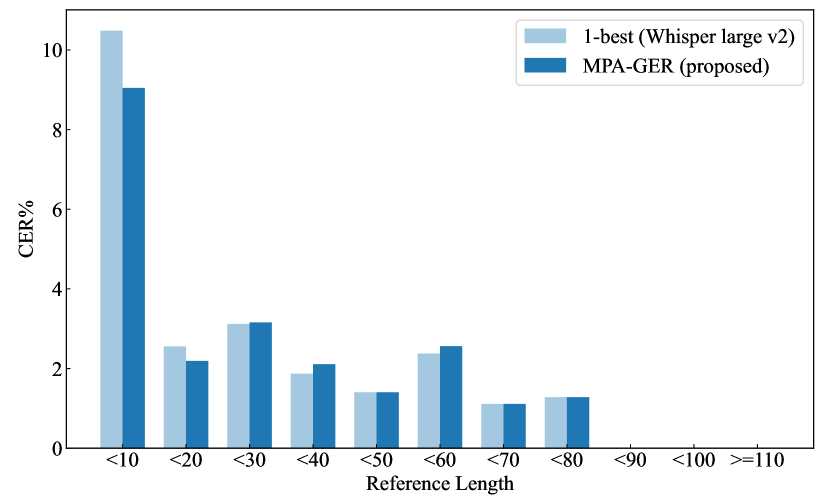
We analyze whether our error correction is effective for short or long outputs. Fig. 4 shows the utterance sample numbers in each reference length in Eval1, Eval2 and Eval3. We observe that the length distributions are different for Eval1, Eval2, and Eval3. In particular, Eval1 and Eval2 are mainly composed of long utterances with a character size of 50 or more, while Eval3 is composed of short utterances with a character size of 10, 20 or less. Fig. 4 shows the averaged CERs of 1-best and proposed MPA GER method in each reference length in Eval3. From Fig. 4, we can conclude the reduction trends in CER for short outputs below 10 or 20 and little effect for other relatively long outputs. That means the proposed MPA GER is effective, especially for short outputs in this study. This led to an overall improvement in the proposed MPA GER, especially in Eval3, which contains more relatively short outputs.
6 Conclusion
In this paper, we applied LLM GER method for Japanese ASR task and introduced a new multi-pass augmented (MPA) GER method that combines hypotheses from different ASR and LLM models. From our experiments, we found that combining different LLMs in MPA GER resulted in better CER trends than the previous standard LLM GER results even in low CER ASR task by reducing hallucinations or repetitions in LLMs. In the future, We will further validate the error correction performance of LLMs in a wider range of ASR scenarios, in a broader range of settings.
References
- [1] Chao-Han Huck Yang, Yile Gu, Yi-Chieh Liu, Shalini Ghosh, Ivan Bulyko, and Andreas Stolcke, “Generative speech recognition error correction with large language models and task-activating prompting,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8.
- [2] Srijith Radhakrishnan, Chao-Han Yang, Sumeer Khan, Rohit Kumar, Narsis Kiani, David Gomez-Cabrero, and Jesper Tegnér, “Whispering llama: A cross-modal generative error correction framework for speech recognition,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 10007–10016.
- [3] Shiliang Zhang, Ming Lei, and Zhijie Yan, “Investigation of transformer based spelling correction model for ctc-based end-to-end mandarin speech recognition,” in Proc. Interspeech, 2019, pp. 2180–2184.
- [4] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in CoRR abs/1706.03762, 2017.
- [5] Shaohua Zhang, Haoran Huang, Jicong Liu, and Hang Li, “Spelling error correction with soft-masked bert,” arXiv preprint arXiv:2005.07421, 2020.
- [6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. NAACL, 2019, pp. 4171–4186.
- [7] Hayato Futami, Hirofumi Inaguma, Sei Ueno, Masato Mimura, Shinsuke Sakai, and Tatsuya Kawahara, “Distilling the knowledge of BERT for sequence-to-sequence ASR,” CoRR, vol. abs/2008.03822, 2020.
- [8] Julian Salazar, Davis Liang, Toan Q Nguyen, and Katrin Kirchhoff, “Masked language model scoring,” arXiv:1910.14659, 2019.
- [9] Joonbo Shin, Yoonhyung Lee, and Kyomin Jung, “Effective sentence scoring method using BERT for speech recognition,” in Proc. ACML, 2019, pp. 1081–1093.
- [10] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,” arXiv preprint arXiv:1908.02265, 2019.
- [11] Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang, “Visualbert: A simple and performant baseline for vision and language,” arXiv preprint arXiv:1908.03557, 2019.
- [12] Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason Corso, and Jianfeng Gao, “Unified vision-language pre-training for image captioning and vqa,” in Proc. AAAI, 2020, pp. 13041–13049.
- [13] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. ECCV, 2020, pp. 121–137.
- [14] Alexei Baevski and Abdelrahman Mohamed, “Effectiveness of self-supervised pre-training for asr,” in Proc. IEEE-ICASSP, 2020, pp. 7694–7698.
- [15] Wei-Ning Hsu, Yao-Hung Hubert Tsai, Benjamin Bolte, Ruslan Salakhutdinov, and Abdelrahman Mohamed, “Hubert: How much can a bad teacher benefit asr pre-training?,” in Proc. IEEE-ICASSP, 2021, pp. 6533–6537.
- [16] Chengyi Wang, Yu Wu, Shujie Liu, Ming Zhou, and Zhenglu Yang, “Curriculum pre-training for end-to-end speech translation,” arXiv preprint arXiv:2004.10093, 2020.
- [17] Cheng Chen, Yuchen Hu, Chao-Han Huck Yang, Sabato Marco Siniscalchi, Pin-Yu Chen, and Eng Siong Chng, “Hyporadise: An open baseline for generative speech recognition with large language models,” ArXiv, vol. abs/2309.15701, 2023.
- [18] S. Li, C. Chen, C.Y. Kwok, C. Chu, E.S. Chng, and H. Kawai, “Investigating asr error correction with large language model and multilingual 1-best hypotheses,” in Proc. Interspeech, 2024, pp. 1315–1319.
- [19] Jonathan G Fiscus, “A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (rover),” in 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings. IEEE, 1997, pp. 347–354.
- [20] Frederick Jelinek, “Continuous speech recognition by statistical methods,” Proceedings of the IEEE, vol. 64, pp. 532–556, 1976.
- [21] Mehryar Mohri, Fernando Pereira, and Michael Riley, Speech Recognition with Weighted Finite-State Transducers, pp. 559–584, Springer Berlin Heidelberg, Berlin, Heidelberg, 2008.
- [22] Paul R. Dixon, Chiori Hori, and Hideki Kashioka, “A specialized WFST approach for class models and dynamic vocabulary,” in Proc. INTERSPEECH, 2012, pp. 1075–1078.
- [23] Andrej et al. Ljolje, “Efficient general lattice generation and rescoring,” in EUROSPEECH, 1999.
- [24] Hasim et al. Sak, “On-the-fly lattice rescoring for real-time automatic speech recognition,” in Proc. INTERSPEECH, 2010.
- [25] Jan Chorowski and Navdeep Jaitly, “Towards better decoding and language model integration in sequence to sequence models,” in Proc. INTERSPEECH, 2016.
- [26] Anuroop Sriram and et al., “Cold fusion: Training seq2seq models together with language models,” in Proc. INTERSPEECH, 2017.
- [27] T. Sainath and et al., “Two-pass end-to-end speech recognition,” ArXiv abs/1908.10992, 2019.
- [28] K. Maekawa, “Corpus of spontaneous japanese: Its design and evaluation,” in Proc. ISCA & IEEE Workshop on Spontaneous Speech Processing and Recognition, 2003.
- [29] T. Moriya, T. Shinozaki, and S. Watanabe, “Kaldi recipe for Japanese spontaneous speech recognition and its evaluation,” in Autumn Meeting of ASJ, 2015.
- [30] N. Kanda, X. Lu, and H. Kawai, “Maximum a posteriori based decoding for CTC acoustic models,” in Proc. INTERSPEECH, 2016, pp. 1868–1872.
- [31] T. Hori, S. Watanabe, Y. Zhang, and W. Chan, “Advances in joint CTC-Attention based End-to-End speech recognition with a deep CNN Encoder and RNN-LM,” in Proc. INTERSPEECH, 2017.
- [32] T. Kawahara, H. Nanjo, T. Shinozaki, and S. Furui, “Benchmark test for speech recognition using the corpus of spontaneous japanese,” in Proc. ISCA/IEEE Workshop on Spontaneous Speech Processing and Recognition, 2003.
- [33] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “Espnet: End-to-end speech processing toolkit,” in Proc. INTERSPEECH, 2018.