Bayesian Inference Forgetting
Abstract
The right to be forgotten has been legislated in many countries but the enforcement in machine learning would cause unbearable costs: companies may need to delete whole models learned from massive resources due to single individual requests. Existing works propose to remove the knowledge learned from the requested data via its influence function which is no longer naturally well-defined in Bayesian inference. This paper proposes a Bayesian inference forgetting (BIF) framework to realize the right to be forgotten in Bayesian inference. In the BIF framework, we develop forgetting algorithms for variational inference and Markov chain Monte Carlo. We show that our algorithms can provably remove the influence of single datums on the learned models. Theoretical analysis demonstrates that our algorithms have guaranteed generalizability. Experiments of Gaussian mixture models on the synthetic dataset and Bayesian neural networks on the real-world data verify the feasibility of our methods. The source code package is available at https://github.com/fshp971/BIF.
Keywords: Certified knowledge removal, Bayesian inference, variational inference, and Markov chain Monte Carlo.
1 Introduction
The right to be forgotten refers to the individuals’ right to ask data controllers to delete the data collected from them. It has been recognized in many countries through legislation, including the European Union’s General Data Protection Regulation (2016) and the California Consumer Privacy Act (2018). However, enforcement may result in unbearable costs for AI industries. When a single data deletion request comes, the data controller needs to delete the whole machine learning model which might have cost massive amounts of resources, including data, energy, and time.
To address this issue, recent works [25, 24] propose to forget the influence of the requested data on the learned models via the influence function [14, 32, 38]:
where is the loss function in the optimization. This approach can provably remove knowledge learned from the requested data for optimization-based machine learning subject to some conditions on convexity and smoothness of the loss function.
However, the loss function is not always naturally well-defined. Bayesian inference approximates the posterior of probabilistic models, where a loss function may be in a different form or even do not exist. In this case, the influence function is no longer well-defined, and therefore, existing forgetting methods become invalid. Bayesian inference enables a wide spectrum of machine learning algorithms, such as probabilistic matrix factorization [46, 62, 72], topic models [30, 8, 74], probabilistic graphic models [39, 6, 71] and Bayesian neural networks [10, 37, 52, 66, 58, 61, 75]. Overlooking Bayesian inference in developing forgetting algorithms leaves a considerable proportion of machine learning algorithms costly to protect the right to be forgotten.
In this paper, we design an energy-based Bayesian inference forgetting (BIF) framework to realize the right to be forgotten in Bayesian inference. We define Bayesian inference influence functions based on the pre-defined energy functions, which help provably characterize the influence of some specific datums on the learned models. We prove that these characterizations are rigorous in first-order approximation subject to some mild assumptions on the local convexity and smoothness of the energy functions around the convergence points. Specifically, the approximation error is not larger than the order , where is the training sample size, which is negligible when the training sample set is sufficiently large. The BIF framework proposes to delete the Bayesian inference influence function of the requested data. We prove that BIF realizes -certified knowledge removal, a new notion defined to evaluate the performance of knowledge removal.
In the BIF framework, we develop certified knowledge removal algorithms for two canonical Bayesian inference algorithms, variational inference [34, 7, 31, 8] and Markov chain Monte Carlo (MCMC) [22, 45, 69, 15, 13, 57].
-
•
Variational inference forgetting. We show that the evidence lower bound function (ELBO; [7]) plays the role of energy function. Based on the ELBO, a variational inference influence function is defined, which helps deliver the variational inference forgetting algorithm. We prove that the -certified knowledge removal is guaranteed on the mean-field Gaussian variational family.
-
•
MCMC forgetting. We formulate a new energy function for MCMC, based on which an MCMC influence function is designed. The new influence function then delivers our the MCMC forgetting algorithm. We prove that the -certified knowledge removal is achieved when the training sample set is sufficiently large. The MCMC forgetting algorithm is also applicable in the stochastic gradient MCMC.
We theoretically investigated whether the BIF algorithms affect the generalizabilities of the learned Bayesian models. Based on the PAC-Bayesian theory [47, 48, 49], we prove that the generalization bounds are of the same order ( is the training sample size), no matter whether the Bayesian models are processed by BIF. Moreover, the introduced difference of the generalization bounds is not larger than the order .
From the empirical aspect, we conduct systematic experiments to verify the forgetting algorithms. We applied the BIF algorithms to two scenarios: (1) Gaussian mixture models for clustering on synthetic data; and (2) Bayesian neural networks for classification on the real-world data. Every scenario involves variational inference, SGLD, and SGHMC. The results suggest that the BIF algorithms effectively remove the knowledge learned from the requested data while protecting other information intact, which are in full agreement with our theoretical results. To secure reproducibility, the source code package is available at https://github.com/fshp971/BIF.
The rest of this paper is organized as follows. Section 2 reviews the related works. Section 3 provides the necessary preliminaries of Bayesian inference. Section 4 presents our main result, the energy-based BIF framework. Section 5 provides the forgetting algorithms dveloped under the BIF framework for variational inference and MCMC. Section 6 studies the generalization abilities of the proposed algorithms. Section 7 presents the experiment results, and Section 8 concludes the paper.
2 Related Works
Forgetting. The concept “make AI forget you” is first proposed by Ginart et al. [23], which also designs forgetting algorithms for -means. Bourtoule et al. [11] then propose a “sharded, isolated, sliced, and aggregated” (SISA) framework to approach low-cost knowledge removal via the following three steps: (1) divide the whole training sample set into multiple disjoint shards; (2) train models in isolation on each of these shards; (3) retain the affected model when a request to unlearn a training point arrives. Izzo et al. [33] develop a projective residual update (PRU) method that replaces the update vector in data removal with its projection on a low-dimensional subspace, which reduces the time complexity of data deletion to scale only linearly in the dimension of data. Guo et al. [25] and Golatkar et al. [24] propose a certified removal based on the influence function [14, 32, 38] of the requested data. Specifically, influence function characterizes the influence of a single datum on the learned model in the empirical risk minimization (ERM) regime. The definition of influence function relies on the gradient and Hessian of the objective function which does not naturally exist in Bayesian inference. Other advances include that Garg et al. [20], Baumhauer et al. [5], and Sommer et al. [63].
We acknowledge that a concurrent work [53] also studied the knowledge removal in Bayesian models. The authors employed variational inference to minimize the KL-divergence between the approximate posterior after unlearning and the posterior of the model retrained on the remaining data. However, this approach only applies to parametric models, such as those obtained by variational inference, while many non-parametric models are un-touched, including MCMC. In contrast, our BIF covers all Bayesian inference methods. Moreover, no theoretical guarantee on the knowledge removal was established, which would be necessary to meet the legal requirements.
Markov chain Monte Carlo (MCMC). Hastings [26] introduces a two-step sampling method named MCMC, which first construct a Markov chain and then draw samples according to the state of the Markov chain. It is proved that the drawn samples will converge to that from the desired distribution. Since that, many improvements have been made on MCMC, including the Gibbs sampling method [22] and hybrid Monte Carlo [16]. Welling and Teh [69] propose a new framework named stochastic gradient Langevin dynamics (SGLD) that by adding a proper noise to a standard stochastic gradient optimization algorithm [59], the iterates will converge to samples from the true posterior distribution as the stepsize annealed. Ahn et al. [3] extend the algorithm based on the SGLD by leveraging the Bayesian Central Limit Theorem, to improve the slow mixing rate of SGLD. Inspired by the idea of a thermostat in statistical physics, Ding et al. [15] leverage a small number of additional variables to stabilize momentum fluctuations caused by the unknown noise. Chen et al. [13] extend the Hamiltonian Monte Carlo (HMC) to Stochastic gradient HMC (SGHMC) by adding a friction term, which enables SGHMC sample from the desired distributions without applying the MH rule. Based on Langevin Monte Carlo methods, Patterson and Teh [57] propose Stochastic gradient Riemannian Langevin dynamics by updating parameters according to both the stochastic gradients and additional noise which forces it to explore the full posterior. Ma et al. [45] introduce a general recipe for creating stochastic gradient MCMC samplers (SGMCMC), which is based on continuous Markov processes specified via two matrices and proved to be complete.
Variational inference. Jordan et al. [34] introduce the use of variational inference in graphical models [35] such as Bayesian networks and Markov random fields, in which variational inference is employed to approximate the target posterior with families of parameterized distributions. Blei et al. [8] apply variational inference to local Dirichlet allocation (LDA), which is used to modeling the text corpora. Sung et al. [64] propose a general variational inference framework for conjugate-exponential family models, in which the model parameters except latent variables are integrated in an exact manner, while the latent variables are approximated by a first-order algorithm. By using stochastic optimization [59], a technique that follows noisy estimates of the gradient of the objective, Hoffman et al. [31] derive stochastic variational inference which iterates between subsampling the data and adjusting the hidden structure based only on the subsample. Paisley et al. [55] propose an algorithm that reduces the variance of the stochastic search gradient by using control variates based on stochastic optimization and allows for direct optimization of variational lower bound. Titsias and Lázaro-Gredilla [65] propose local expectation gradients, in which the stochastic gradient estimation problem over multiple variational parameters is decomposed into smaller subtasks, and each sub-task focus on the most relevant part of the variational distribution. Zhang et al. [73] reviews recent advances of variational inference, from four aspects, scalable, generic, accurate, and amortized variational inference.
Bayesian Neural Networks (BNNs). Bayesian inference is first applied to neural networks by Neal [52], in which Hybrid Monte Carlo is employed to inference the posteriors of neural networks’ parameters. Blundell et al. [10] propose an efficient backpropagation-compatible algorithm to calculate the gradient of the variational neural networks, which expands the applicable domain of variational inference to deep learning. Based on that, Kingma et al. [37] further propose a local reparameterization technique to reduce the variance of stochastic gradients of variational neural networks. They also develop the variational dropout that can automatically learn the dropout rates. Pearce et al. [58] introduce a procedures family termed randomized MAP sampling (RMS), which includes randomize-then optimize and ensemble sampling, and then realize Bayesian inference for neural networks via ensembling under the RMS family. Roth and Pernkopf [61] successfully apply the Dirichlet process prior to BNNs, which enforces the sharing of the network weights and reduces the number of parameters. Zhang et al. [75] propose a cyclical step-size schedule for SGMCMC to learn the multimodal posterior of a Bayesian neural network.
3 Preliminaries
Suppose a data set is , where is a datum and is the sample size. One may hope to fit the dataset by a parametric probabilistic model where is the parameter.
Bayesian inference [69, 7, 22] infers the posterior of the probabilistic model
where is the prior of model parameter and is the normalization factor. In most cases, we do not know the closed form of the normalization factor . Two canonical solutions are variational inference and MCMC.
Variational inference [31, 7] employs two steps to infer the posterior:
-
1.
Define a family of distributions, , termed variational family, where is the variational distribution parameter.
-
2.
Search in the variational family for the distribution closest to the posterior measured by KL divergence, i.e., .
Minimizing the KL divergence is equivalent to maximizing the evidence lower bound (ELBO [7]):
A popular variational family is the mean-field Gaussian family [7, 36, 10, 37]. A mean-field Gaussian variational distribution has the following structure,
where .
MCMC [45, 26] constructs a Markov chain whose stationary distribution is the targeted posterior. The Markov chain performs a Monte Carlo procedure to sample the posterior. However, MCMC can be prohibitively time-consuming in large-scale models and large-scale data. To address the issue, stochastic gradient MCMC (SGMCMC [45]) introduces stochastic gradient estimation on mini-batches [59] to MCMC. In this paper, we study two major SGMCMC methods, stochastic gradient Langevin dynamics (SGLD) [69] and stochastic gradient Hamiltonian Monte Carlo (SGHMC) [13].
SGLD updates weight as follows,
where is the learning rate and is the mini-batch. Usually, one needs to anneal to small values.
SGHMC introduces a momentum to the weight update:
where (see eqs. (14), (15) in [13]), and the momentum is initialized as . Moreover, when is decay by a factor of , needs to be decayed by a factor of .
4 Bayesian Inference Forgetting
This section presents our Bayesian inference forgetting framework. We first define -certified knowledge removal in Bayesian inference, which quantitates the knowledge removal performance. Then, we study the energy functions in Bayesian inference. The forgetting algorithm for Bayesian inference is designed based on the energy functions.
4.1 -Certified Knowledge Removal
Suppose a Bayesian inference method learns a probabilistic model on the sample set . A client requests to remove her/his data . A trivial and costly approach is re-training the model on data . Suppose the re-learned probabilistic model is .
A forgetting algorithm is designed to process the distribution as follows to estimate the distribution ,
We term the distribution as the processed model.
In order to meet the regulation requirements, the algorithm needs to achieve -certified knowledge removal as follows.
Definition 4.1 (-certified knowledge removal in Bayesian inference).
For any subset and , we call performs -certified knowledge removal, if
4.2 Energy Functions in Bayesian Inference
Bayesian inference can be formulated as minimizing an energy function, echos the free-energy principle in physics. This section studies the energy functions in Bayesian inference.
Suppose is the energy function of a probabilistic distribution parametrized by over the model parameter space . A typical energy function has the following structure,
| (1) |
where is a function defined on that characterizes the influence from individual datums, is a function defined on that characterizes the influence from the prior of . Usually, a lower energy corresponds to a smaller distance between the two distributions. In variational inference, ELBO plays as an energy function. In MCMC, we construct an energy function. Please see Sections 5.1 and 5.2 for more details.
Similarly, the energy function for is . It can be re-arranged as follows,
| (2) |
4.3 Forgetting Algorithm for Bayesian inference
Based on the energy function, the forgetting algorithm for Bayesian inference is then designed and shown as fig. 1.
Suppose that the probabilistic model learned on the training sample set is parameterized by . Then, is a local minimizer of the energy function . Similarly, suppose that the model learned on is parameterized by . Then is a local minimizer of the energy function . Also, we assume the processed model is parameterized by .
Mathematically, the forgetting in Bayesian inference can be realized by approaching the local minimizer of the energy function to the local minimizer of the energy function .
We start with a simple case that remove the influence learned from a single datum . The energy function for the posterior is as follows,
| (3) |
Let be a local minimizer of . Then,
Notice that the structures of the above two equations only differ in the term . They are two special cases of the following equation,
| (4) |
where . Eq. (4) induces an implicit mapping such that . For any , is a solution of eq. (4). Thus, is also a critical point of the following function,
| (5) |
When , is exactly , which indicates that is a critical point of , and is possible to be a local minimizer. We assume that is really a local minimizer of . We also let . Then, can be approached based on in a first-order approximation manner,
Thus, when a request of removing a datum comes, our forgetting algorithm will process the request by replacing with , in which
4.4 Theoretical Guarantee
Under some mild assumptions, we prove that (1) the mapping uniquely exists; (2) is the global minimizer of ; and (3) the approximation error between and is not larger than order , where is the training set size.
We first introduce two definitions.
Definition 4.2 (compact set).
A set is called compact if and only if it is closed and bounded.
Definition 4.3 (strong convexity).
A differentiable function is called -strongly convex, if and only if there exists a constant real , such that for any two points and in the domain of the function , the following inequality holds,
When is second-order continuously differentiable, for any , the following three propositions are equivalent:
-
1.
is -strongly convex;
-
2.
for any from the domain of the function , the smallest eigenvalue of the Hessian matrix is at least , i.e., ;
-
3.
for any from the domain of , the matrix is positive semi-definite, i.e., .
The theoretical guarantees rely on the following two assumptions.
Assumption 4.1.
Both of the supports and are compact.
Usually, the energy functions and are close to each other. Thus, it is reasonable to assume that the two local minimizers and fall in the same local region. Hence, we only need to analyze on a limited local region, which justifies Assumption 4.1.
Assumption 4.2.
Suppose and are the two inputs of the energy functions . We assume that
-
1.
is rd-order continuously differentiable and -strongly convex on ,
-
2.
is rd-order continuously differentiable with respect to in . Besides, , is -strongly convex with respect to , where is a continuous function.
Assumption 4.2 is mild in gradient-based optimization. Together with Assumption 4.1, they assume the local strong convexity and smoothness of the energy functions.
We then prove that the energy function is strongly convex, as the following lemma.
Lemma 4.1.
Proof.
We rewrite the energy function as follows,
Apparently, is strongly convex. Since , we have that . Thus, is either strongly convex or equal to zero. Hence, we have that is strongly convex with respect to .
The proof is completed. ∎
We are now able to prove that eq. (4) really induces a continuous mapping , and is the global minimizer of .
Theorem 4.1.
Proof.
According to Lemma 4.1, for any , the energy function is strongly convex with respect to . Thus, the global minimizer of the energy function is unique with respect to . Therefore, we can define the mapping as follows,
where .
Besides, The strong convexity of indicates that when is fixed, a parameter satisfies (eq. (4)), if and only if is the global minimizer of . Thus, , is the only solution of eq. (4).
Eventually, according to Definition 4.3, the strong convexity of implies that the Hessian matrix is invertible. Combining with the implicit function theorem, we have that is continuous everywhere on .
The proof is completed. ∎
Theorem 4.1 demonstrates that our algorithm can obtain the . This secures that our algorithm can remove the learned influence from the probabilistic model .
We then analyze the error introduced by our algorithm. Assume that is second-order continuously differentiable, then can be expanded by the Taylor’s series:
where , is the Cauchy form of the remainder. We prove that the Cauchy remainder term becomes negligible as the training set size goes to infinity.
Theorem 4.2.
The proof of Theorem 4.2 is presented in Appendix A. We first calculate based on eq. (4). We then upper bound the norm of by upper bounding the norm of an inverse matrix
and a vector . The norm of the inverse matrix is bounded based on the strong convexity of , while the norm of the vector is bounded based on its continuity in a compact domain.
Based on Theorem 4.2, we then prove that the norm of is no larger than order . Thus, a sufficiently large training sample size ensures that, the second and high order terms in the Taylor’s series are negligible.
Theorem 4.3.
The proof routine of Theorem 4.3 is similar to Theorem 4.2, while the calculation is more difficult. We leave the details in Appendix A.
Corollary 4.1.
Eventually, we consider removing a subset from . Follow the previous derivations, we prove that the approximation error of approaching based on is also not larger than order , as stated below:
5 Forgetting Algorithms for Bayesian Inference
In this section, we develop provably certified forgetting algorithms for variational inference and MCMC under the BIF framework.
5.1 Variational Inference Forgetting
As introduced in Section 3, variational inference aims to minimize the negative ELBO function, which can be expanded as follows,
Notice that the structure of the above equation is similar as that of the energy function (eq. (1)). Thus, we employ the negative ELBO function as the energy function.
Based on the energy function, we define the following variational inference influence function to characterize the influence of single datum on the learned model.
Definition 5.1 (Variational inference influence function).
For any example , its variational inference influence function is defined to be
We then design the variational inference forgetting algorithm, to remove the influences of a single datum from the learned variational parameter ,
We prove that variational inference forgetting can provably remove the influences of datums from the learned model.
Theorem 5.1.
Proof.
It is straightforward from Corollary 4.1. ∎
Remark 5.1.
Beyond a single datum’s removal, Corollary 4.2 further shows that the influence of a sample set can also be characterized by the variational inference influence function , as follows,
This guarantees that one can remove a group of datums at one time. It can significantly speed up and simplify the forgetting process of large amounts of datums.
We next study the -certified knowledge removal guarantee for variational inference forgetting. Here, we take the mean-field Gaussian family as an example. Proofs for other varitional families are similar.
Theorem 5.2 (-certified knowledge removal of mean-field Gaussian variational distribution).
Let be a mean-field Gaussian family where the variance of every variational distributions are bounded, i.e., such that for any , we have holds for . Let and be the variational parameters that learned on sample sets and , respectively. Suppose is the processed variational parameter. Then, performs -certified knowledge removal, where
5.2 MCMC Forgetting Algorithm
In MCMC, there is no explicit objective function. In this work, we transport to approximate . Specifically, we want to find a “drift” named drifting influence to minimize the following KL divergence,
| (6) |
The KL term in eq. (6) can be expanded as follows,
| (7) |
Despite the constant term, the remaining has the similar structure with (eq. (2)). Thus, we define the energy function for MCMC by replacing and with and , respectively.
Based on the energy function, we define an MCMC influence function to characterize the drifting influences induced by a single datum as follows.
Definition 5.2 (MCMC influence function).
For any example , its MCMC influence function is defined to be
| (8) |
Then, the MCMC forgetting algorithm is as follows,
In practice, we do not have the posterior , but only some samples drawn from . Thus, we are not able to transform the posterior to the processed distribution . However, the probability of drawing a sample from equals that of drawing a sample from . Therefore, when performing MCMC forgetting, we will replace any drawn sample by a new sample .
We prove that the MCMC forgetting algorithm can provably remove the drifting influence induced by a single datum from the learned model.
Theorem 5.3.
Remark 5.2.
Proof.
When all the conditions hold, the global minimizer of is exactly . Meanwhile, is the global minimizer of . Combining Corollary 4.1, we have that
The proof is completed. ∎
Similarly, by applying Corollary 4.2, the MCMC influence function of a sample set is as follows,
It guarantees that one can adopt MCMC forgetting algorithm to remove a group of datums at one time. This improves the efficiency of removing large amounts of datums.
The MCMC forgetting algorithm also applies to SGMCMC, because SGMCMC draws samples from some target posterior [13, 69, 45], the same as MCMC.
We then give the -certified knowledge removal guarantee for MCMC forgetting.
Theorem 5.4.
Suppose that
Let be the processed model. Then, performs -certified knowledge removal, where
and .
Theorem 5.4 assumes that the posteriors and are Gaussian. This assumption is from the Bayesian asymptotic theory [21, 42]. Suppose the training set is drawn from distribution , while is drawn from distribution . Then, under some mild assumptions, when the training sample size is sufficiently large, the posteriors and approach Gaussian distributions as below,
where , , is the Fisher information.
Combining the conditions of Theorem 5.3, we have that . Thus, as , will eventually converge to .
5.3 Efficient Implementation
A major computing burden in both variational inference forgetting and MCMC forgetting algorithms is calculating the product of , where is the Hessian matrix of some vector-valued function and is a constant vector. the calculation above would have a considerably high computational cost. We follow Agarwal et al. [2] and Koh and Liang [38] to apply a divide-and-conquer strategy to address the issue. This strategy relies on calculating the Hessian-vector product .
Hessian-vector product (HVP). We first discuss how to efficiently calculate . The calculation of can be decomposed into two steps: (1) calculate and then (2) calculate . It is worth noting that and , where is the dimension of data. Thus, is a scalar value. Calculating its gradient has a very low computational cost on platform PyTorch [56] or TensorFlow [1].
Calculating . When the norm , the matrix can be expanded by the Taylor’s series as . Define that . Then, we have the following recursive equation,
Agarwal et al. [2] prove that when , we have . Therefore, we employ to approximate .
Moreover, to secure the condition stands, we scale to by a scale , such that . Then, we approximate . Eventually, we have that . We can plug it to the applicable equations above.
6 Generalization Analysis
In this section, we study the generalization ability of the models that processed by forgetting algorithms. We derive generalization bounds for a mean-field Gaussian variational model and a specified Gaussian MCMC model, Based on PAC-Bayes framework. All the proofs in this section are presented in Appendix C.
Generalization ability is important to machine learning algorithms, which refers to the ability to make accurate predictions on unseen data. A standard measurement of the generalization ability is the generalization bound, i.e., the upper bound of the difference between expected risk and empirical risk [51, 68, 50]. An algorithm with a small generalization bound is expected to generalize well. Existing generalization bound can be roughly divided into three categories: (1) generalization bounds based on the hypothesis complexity, such as VC dimension [9, 67], Rademacher complexity [41, 40, 4], and covering number [17, 27], which suggest implementations control the hypothesis complexity to help model generalize well; (2) generalization bounds based on the algorithmic stability [60, 12], which follow the intuition that an algorithm with good generalization ability is robust to the interference of single data points; (3) generalization bounds established under the PAC-Bayesian framework [48, 47]; and (4) generalization guarantees from differential privacy [18, 54, 29]. The excellent generalization ability of the over-parameterized model, including Bayesian neural network and others in deep learning, is somehow beyond the explanation of the conventional learning theory. Establishing theoretical foundations has been attracted wide attention [19, 28].
Let be a probabilistic model. Suppose is the training sample set. Then, the expected risk and empirical risk of are defined to be
where is a hypothesis drawn from , and is the loss function ranging in . The difference of expected risk and empirical risk is the generalization error. Its magnitude characterizes the generalizability of the algorithm.
We then prove a generalization bound for mean-field Gaussian variational distributions.
Theorem 6.1.
Suppose all the conditions in Theorems 5.1 and 5.2 hold. Let denotes the mean-field Gaussian distribution learned on the training set . Let denotes the processed variational distribution parameter, where . Also, let denotes the variational inference influence function. Then, for any real , with probability at least , the following inequality holds:
| (9) |
where
and .
Remark 6.1.
This generalization bound is of order .
Corollary 6.1.
Variational inference forgetting increases the generalization bound by a value not larger than .
Proof.
Variational inference forgetting introduces the term into the generalization bound. Thus, the generalization bound is increased by the following value:
The proof is completed. ∎
This corollary secures that variational inference forgetting would not compromise the generalizability.
In Section 5.2, we have shown that when the training sample size is sufficiently large, the posterior distribution is asymptotically Gaussian. Here, we again assume that , where is the fisher information matrix. Then, we obtain a generalization bound as follows.
Theorem 6.2.
Suppose all the conditions in Theorem 5.3 hold. Suppose that . Let denotes the processed distribution, where . Let denotes the MCMC influence function. Then, for any , with probability at least , the following inequality holds:
| (10) |
where
and .
Remark 6.2.
This generalization bound is of order .
Corollary 6.2.
MCMC forgetting increases the generalization bound by a value not larger than .
Proof.
MCMC forgetting introduces the term into the generalization bound. Thus, the generalization bound is increased by the following value:
The proof is completed. ∎
This corollary secures that MCMC forgetting would not compromise the generalizability.
7 Experiments
We apply our forgetting algorithm to a Gaussian mixture model and a Bayesian neural network. In every scenario, we employ variational inference and two SGMCMC methods, SGLD and SGHMC. The empirical results are in full agreement with our methods. All the experiments are conducted on a computer with a GPU of NVIDIA® GeForce® RTX 2080 Ti, a CPU of Intel® Core™ i9-9900 @ 3.10GHz, and 32GB memory. To secure reproducibility, the source code package is available at https://github.com/fshp971/BIF.
7.1 Experiments for Gaussian Mixture Model
We first conduct experiments with GMM on Synthetic data to evaluate our methods.
7.1.1 Implementation Details
The implementation details are given below.
Synthetic dataset. We generate a dataset of size for evaluating our algorithms. Every datum is two-dimensional and is possibly from classes. In this experiment, we set as . The raw data is visualized in the left of fig. 2(a), in which four different colors represent four different classes.
Gaussian mixture model (GMM). GMMs are usually employed to inference the cluster centers. GMM assumes data is drawn from Gaussian distributions centered at , respectively. The hierarchical structure of GMM is as follows: (1) draw a clustering center from the uniform distribution over ; and (2) sample from a Gaussian distribution centering at .
where , , , , , and the hyperparameter is the prior standard deviation. We set as in our experiments.
Applying SGLD and SGHMC to GMM is straightforward. Besides, for variational inference, we utilize the following mean-field variational family [7],
where , and is the variational distribution parameter. Thus, the ELBO function is calculated as follows,
where , , , and





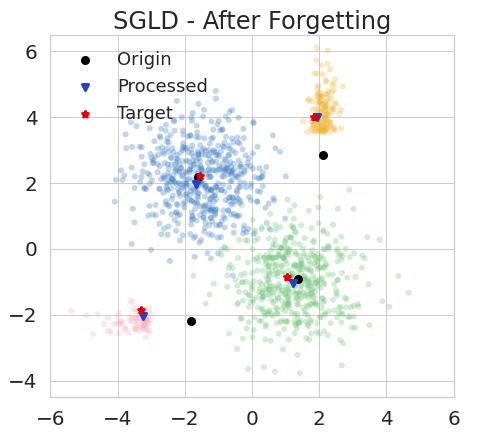


Experiment design. We employ variational inference, SGLD, and SGHMC to inference GMM on the synthetic datums. Then, we remove points from each of the pink parts and yellow parts, around of the whole dataset at all, by the proposed BIF algorithms. The remaining datums are shown in the right of fig. 2(a). We also trained models on only the remaining set with the same Bayesian inference settings in order to show the targets of the forgetting task. The experiments have two main phrases:
(1) Training phase. Every GMM is trained for iterations. The batch size is set as . For variational inference, the learning rate is fixed to , where is the training sample set size. For SGLD, the learning rate schedule is set as , where is the training iteration step. For SGHMC, the learning rate schedule is set as , and the initial factor is set as .
(2) Forgetting phase. We remove a batch of datums each time. When calculating the inversed-Hessian-vector product in the influence functions (see Section 5.3), the recursive calculation number is set as , and the scaling factor is set as , where is the number of the current remaining training datums. Notice that will gradually decrease as the forgetting process continuing. Moreover, for SGLD and SGHMC, we employ Monte Carlo method to calculate the expectations in MCMC influence functions. Specifically, we repeatedly sample model parameter for times, calculate the matrix or vector in MCMC influence functions, and average the results to approach the expectations.
7.1.2 Results Analysis
The empirical results are presented in figs. 2(b), 2(c), 2(d) respectively. In figures for variational inference, we draw the learned clustering centers as black points. In every figure for SGLD and SGHMC, (1) we draw the point drawn in the terminated iteration as a black point; and (2) we draw the points drawn in the last iterations in blue, orange, red, or green. The results obtained on the remaining parts (target) are also shown in these figures. This visualization shows that after forgetting, the learned models are close to the target models, which demonstrate that our forgetting algorithms can selectively remove specified datums while protecting others intact.
7.2 Experiments for Bayesian Neural Network
We then conduct experiments with Bayesian neural networks on real data.
7.2.1 Implementation Details
The implementation details are given below.
Dataset. We employ Fashion-MNIST [70] dataset in our experiments. It consists of gray-scale images from different classes, where each class consists of training examples and test examples. For the data argumentation, we first resize each image to and then normalize each pixel value to before feeding them into BNN. For the forgetting experiments, we divide the training set of Fashion-MNIST into two parts, the removed part and the remaining part . Apparently, . For the selection of the removed training set , we randomly choose , , , , and examples from the class “T-shirt” (i.e., examples that labeled with number ) in the training set to form . For the brevity, we denote the test set by .
Bayesian neural network (BNN). BNNs employ Bayesian inference to inference the posterior of the neural networks parameters. Two major Bayesian inference methods employed wherein are variational inference and SGMCMC.
For variational inference, one usually utilizes the mean-field Gaussian variational family [10, 37] to train BNNs. The Bayes by Backprop technique [10] is utilized to calculate the derivative of ELBO function. Specifically, for the random variable subject to the mean-field variational distribution , we have that . Let , then the derivative of the ELBO function can be varied as follows,
Hence, we can calculate the derivative in two steps: (1) repeatedly sample from and calculate based on ; and (2) average the obtained derivatives to approximate . Moreover, we also adopt the local reparameterization trick [37] to further eliminate the covariances between the gradients of examples in a batch.
Bayesian LeNet-5 [43] is employed in our experiments, which consists of two convolutional layers and three fully-connected layers. We follow Liu et al. [44] to use an isotropic Gaussian distribution as the prior of BNN, where the standard deviation is set as .
Experiment design. We employ variational inference, SGLD, and SGHMC to train the BNN on the complete training set . Then, we remove the subset by the proposed BIF algorithms. We also trained models on only the remaining set in order to show the targets of the forgetting task. The experiments have two main phrases:
(1) Training phase. Every BNN is trained for iterations. The batch size is set as . For variational inference, the learning rate is initialized as , where is the training set size, and decay by every iterations. Additionally, the sampling times to perform Bayes by Backprop procedure is set as . For SGLD, the step-size schedule is set as , where is the training iteration step. For SGHMC, the step-size schedule is set as , and the initial factor is set as .
(2) Forgetting phase. We remove a batch of datums each time. When calculating the inversed-Hessian-vector product in influence functions (see Section 5.3), the recursive calculation number is set as . For variational inference, the scaling factor is set as , where is the number of the current remaining datums. Notice that will gradually decrease as the forgetting process continuing. For SGLD and SGHMC, the scaling factors are set as and , respectively. Besides, we employ the Monte Carlo method to calculate the expectations in MCMC influence functions. Specifically, we repeatedly sample model parameter for times, calculate the matrix and vector in MCMC influence function based on these sampled parameters, and average the results to approach the desired expectation.



| Variational Inference | SGLD | SGHMC | |
|---|---|---|---|
| Training Time | s | s | s |
| Removal Time | s | s | s |
| Acceleration Rate |
7.2.2 Results Analysis
For each of the obtained processed models and target models, we evaluate its classification errors on the sets , and , respectively. The results are collected and plotted in fig. 3. We also collect and present the training and forgetting times in Table 1.
From fig. 3 and Table 1, we have the following two observations: (1) the processed models are similar to the target models in terms of the classification errors on all the three sample sets , , and ; and (2) our forgetting algorithms are significantly faster than simply training models from scratch. These phenomena demonstrate that our forgetting algorithms can effectively and efficiently remove influences of datums from BNNs without hurting other remaining information.
8 Conclusion
The right to be forgotten imposes a considerable compliance burden on AI companies. A company may need to delete the whole model learned from massive resources due to a request to delete a single datum. To address this problem, this work designs a Bayesian inference forgetting (BIF) that removes the influence of some specific datums on the learned model without completely deleting the whole model. The BIF framework is established on an energy-based Bayesian inference influence function, which characterizes the influence of requested data on the learned models. We prove that BIF has an -certified knowledge removal guarantee, which is a new term on characterizing the forgetting performance. Under the BIF framework, forgetting algorithms are developed for two canonical Bayesian inference algorithms, variational inference and Markov chain Monte Carlo. Theoretical analysis provides guarantees on the generalizability of the proposed methods: performing the proposed BIF has little effect on them. Comprehensive experiments demonstrate that the proposed methods can remove the influence of specified datums without compromising the knowledge learned on the remained datums. The source code package is available at https://github.com/fshp971/BIF.
References
- [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015.
- [2] Naman Agarwal, Brian Bullins, and Elad Hazan. Second-order stochastic optimization for machine learning in linear time. The Journal of Machine Learning Research, 18(1):4148–4187, 2017.
- [3] Sungjin Ahn, Anoop Korattikara, and Max Welling. Bayesian posterior sampling via stochastic gradient Fisher scoring. In International Conference on Machine Learning, pages 1771–1778, 2012.
- [4] Peter L Bartlett and Shahar Mendelson. Rademacher and Gaussian complexities: Risk bounds and structural results. The Journal of Machine Learning Research, 3(Nov):463–482, 2002.
- [5] Thomas Baumhauer, Pascal Schöttle, and Matthias Zeppelzauer. Machine unlearning: Linear filtration for logit-based classifiers. arXiv preprint arXiv:2002.02730, 2020.
- [6] Matthew J Beal, Zoubin Ghahramani, and Carl E Rasmussen. The infinite hidden Markov model. In Advances in Neural Information Processing Systems, pages 577–584, 2002.
- [7] David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. The Journal of the American Statistical Association, 112(518):859–877, 2017.
- [8] David M Blei, Andrew Y Ng, and Michael I Jordan. Latent Dirichlet allocation. Journal of Machine Learning Research, 3:993–1022, 2003.
- [9] Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K Warmuth. Learnability and the Vapnik-Chervonenkis dimension. Journal of the ACM, 36(4):929–965, 1989.
- [10] Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. In International Conference on Machine Learning, pages 1613–1622, 2015.
- [11] Lucas Bourtoule, Varun Chandrasekaran, Christopher Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. arXiv preprint arXiv:1912.03817, 2019.
- [12] Olivier Bousquet and André Elisseeff. Stability and generalization. The Journal of Machine Learning Research, 2(Mar):499–526, 2002.
- [13] Tianqi Chen, Emily Fox, and Carlos Guestrin. Stochastic gradient Hamiltonian Monte Carlo. In International Conference on Machine Learning, pages 1683–1691, 2014.
- [14] R Dennis Cook and Sanford Weisberg. Residuals and Influence in Regression. New York: Chapman and Hall, 1982.
- [15] Nan Ding, Youhan Fang, Ryan Babbush, Changyou Chen, Robert D Skeel, and Hartmut Neven. Bayesian sampling using stochastic gradient thermostats. In Advances in Neural Information Processing Systems, pages 3203–3211, 2014.
- [16] Simon Duane, Anthony D Kennedy, Brian J Pendleton, and Duncan Roweth. Hybrid Monte Carlo. Physics Letters B, 195(2):216–222, 1987.
- [17] Richard M Dudley. The sizes of compact subsets of Hilbert space and continuity of Gaussian processes. Journal of Functional Analysis, 1(3):290–330, 1967.
- [18] Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Leon Roth. Preserving statistical validity in adaptive data analysis. In Annual ACM Symposium on Theory of Computing, pages 117–126, 2015.
- [19] Weinan E, Chao Ma, Stephan Wojtowytsch, and Lei Wu. Towards a mathematical understanding of neural network-based machine learning: What we know and what we don’t. arXiv preprint arXiv:2009.10713, 2020.
- [20] Sanjam Garg, Shafi Goldwasser, and Prashant Nalini Vasudevan. Formalizing data deletion in the context of the right to be forgotten. In Annual International Conference on the Theory and Applications of Cryptographic Techniques, pages 373–402. Springer, 2020.
- [21] Andrew Gelman, John B Carlin, Hal S Stern, David B Dunson, Aki Vehtari, and Donald B Rubin. Bayesian data analysis. CRC press, 2013.
- [22] Stuart Geman and Donald Geman. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence, (6):721–741, 1984.
- [23] Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. Making AI forget you: Data deletion in machine learning. In Advances in Neural Information Processing Systems, pages 3518–3531, 2019.
- [24] Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9304–9312, 2020.
- [25] Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens van der Maaten. Certified data removal from machine learning models. arXiv preprint arXiv:1911.03030, 2019.
- [26] W Keith Hastings. Monte Carlo sampling methods using Markov chains and their applications. 1970.
- [27] David Haussler. Sphere packing numbers for subsets of the boolean n-cube with bounded Vapnik-Chervonenkis dimension. Journal of Combinatorial Theory, Series A, 69(2):217–232, 1995.
- [28] Fengxiang He and Dacheng Tao. Recent advances in deep learning theory. arXiv preprint arXiv:2012.10931, 2020.
- [29] Fengxiang He, Bohan Wang, and Dacheng Tao. Tighter generalization bounds for iterative differentially private learning algorithms. arXiv preprint arXiv:2007.09371, 2020.
- [30] Matthew Hoffman, Francis R Bach, and David M Blei. Online learning for latent Dirichlet allocation. In Advances in Neural Information Processing Systems, pages 856–864, 2010.
- [31] Matthew D. Hoffman, David M. Blei, Chong Wang, and John Paisley. Stochastic variational inference. The Journal of Machine Learning Research, 14(4):1303–1347, 2013.
- [32] Peter J Huber. Robust Statistics, volume 523. John Wiley & Sons, 2004.
- [33] Zachary Izzo, Mary Anne Smart, Kamalika Chaudhuri, and James Zou. Approximate data deletion from machine learning models: Algorithms and evaluations. arXiv preprint arXiv:2002.10077, 2020.
- [34] Michael I Jordan, Zoubin Ghahramani, Tommi S Jaakkola, and Lawrence K Saul. An introduction to variational methods for graphical models. Machine Learning, 37(2):183–233, 1999.
- [35] Michael Irwin Jordan. Learning in graphical models, volume 89. Springer Science & Business Media, 1998.
- [36] Diederik P Kingma and Max Welling. Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114, 2013.
- [37] Durk P Kingma, Tim Salimans, and Max Welling. Variational dropout and the local reparameterization trick. In Advances in Neural Information Processing Systems, pages 2575–2583, 2015.
- [38] Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In International Conference on Machine Learning, pages 1885–1894, 2017.
- [39] Daphne Koller and Nir Friedman. Probabilistic Graphical Models: Principles and Techniques. MIT press, 2009.
- [40] Vladimir Koltchinskii. Rademacher penalties and structural risk minimization. IEEE Transactions on Information Theory, 47(5):1902–1914, 2001.
- [41] Vladimir Koltchinskii and Dmitriy Panchenko. Rademacher processes and bounding the risk of function learning. In High Dimensional Probability II, pages 443–457. Springer, 2000.
- [42] Lucien Le Cam. Asymptotic Methods in Statistical Decision Theory. Springer Science & Business Media, 2012.
- [43] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- [44] Xuanqing Liu, Yao Li, Chongruo Wu, and Cho-Jui Hsieh. Adv-BNN: Improved adversarial defense through robust Bayesian neural network. arXiv preprint arXiv:1810.01279, 2018.
- [45] Yi-An Ma, Tianqi Chen, and Emily Fox. A complete recipe for stochastic gradient MCMC. In Advances in Neural Information Processing Systems, pages 2917–2925, 2015.
- [46] Zhanyu Ma, Andrew E Teschendorff, Arne Leijon, Yuanyuan Qiao, Honggang Zhang, and Jun Guo. Variational Bayesian matrix factorization for bounded support data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(4):876–889, 2014.
- [47] David A McAllester. Some PAC-Bayesian theorems. In Proceedings of the Annual Conference on Computational Learning Theory, pages 230–234, 1998.
- [48] David A McAllester. PAC-Bayesian model averaging. In Proceedings of the Annual Conference on Computational Learning Theory, pages 164–170, 1999.
- [49] David A McAllester. PAC-Bayesian stochastic model selection. Machine Learning, 51(1):5–21, 2003.
- [50] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of Machine Learning. MIT Press, 2018.
- [51] Mohamad T Musavi, Khue Hiang Chan, Donald M Hummels, and K Kalantri. On the generalization ability of neural network classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 16(6):659–663, 1994.
- [52] Radford M Neal. Bayesian training of backpropagation networks by the hybrid Monte Carlo method. Technical report, Citeseer, 1992.
- [53] Quoc Phong Nguyen, Bryan Kian Hsiang Low, and Patrick Jaillet. Variational bayesian unlearning. Advances in Neural Information Processing Systems, 33, 2020.
- [54] Luca Oneto, Sandro Ridella, and Davide Anguita. Differential privacy and generalization: Sharper bounds with applications. Pattern Recognition Letters, 89:31–38, 2017.
- [55] John Paisley, David Blei, and Michael Jordan. Variational Bayesian inference with stochastic search. arXiv preprint arXiv:1206.6430, 2012.
- [56] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. In NIPS-W, 2017.
- [57] Sam Patterson and Yee Whye Teh. Stochastic gradient Riemannian Langevin dynamics on the probability simplex. In Advances in Neural Information Processing Systems, pages 3102–3110, 2013.
- [58] Tim Pearce, Felix Leibfried, and Alexandra Brintrup. Uncertainty in neural networks: Approximately Bayesian ensembling. In International Conference on Artificial Intelligence and Statistics, pages 234–244. PMLR, 2020.
- [59] Herbert Robbins and Sutton Monro. A stochastic approximation method. The Annals of Mathematical Statistics, pages 400–407, 1951.
- [60] William H Rogers and Terry J Wagner. A finite sample distribution-free performance bound for local discrimination rules. The Annals of Statistics, pages 506–514, 1978.
- [61] Wolfgang Roth and Franz Pernkopf. Bayesian neural networks with weight sharing using Dirichlet processes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(1):246–252, 2018.
- [62] Ruslan Salakhutdinov and Andriy Mnih. Bayesian probabilistic matrix factorization using Markov chain Monte Carlo. In International Conference on Machine Learning, pages 880–887, 2008.
- [63] David Marco Sommer, Liwei Song, Sameer Wagh, and Prateek Mittal. Towards probabilistic verification of machine unlearning. arXiv preprint arXiv:2003.04247, 2020.
- [64] Jaemo Sung, Zoubin Ghahramani, and Sung-Yang Bang. Latent-space variational Bayes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(12):2236–2242, 2008.
- [65] Michalis Titsias and Miguel Lázaro-Gredilla. Local expectation gradients for black box variational inference. In Advances in Neural Information Processing Systems, pages 2638–2646, 2015.
- [66] DM Titterington et al. Bayesian methods for neural networks and related models. Statistical Science, 19(1):128–139, 2004.
- [67] Vladimir Vapnik. Estimation of Dependences Based on Empirical Data. Springer Science & Business Media, 2006.
- [68] Vladimir Vapnik. The Nature of Statistical Learning Theory. Springer Science & Business Media, 2013.
- [69] Max Welling and Yee W Teh. Bayesian learning via stochastic gradient Langevin dynamics. In International Conference on Machine Learning, pages 681–688, 2011.
- [70] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms, 2017.
- [71] Qiaoling Ye, Arash Amini, and Qing Zhou. Optimizing regularized Cholesky score for order-based learning of Bayesian networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [72] Hongwei Yong, Deyu Meng, Wangmeng Zuo, and Lei Zhang. Robust online matrix factorization for dynamic background subtraction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(7):1726–1740, 2017.
- [73] Cheng Zhang, Judith Bütepage, Hedvig Kjellström, and Stephan Mandt. Advances in variational inference. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(8):2008–2026, 2018.
- [74] Hao Zhang, Bo Chen, Yulai Cong, Dandan Guo, Hongwei Liu, and Mingyuan Zhou. Deep autoencoding topic model with scalable hybrid Bayesian inference. IEEE Transactions on Pattern Analysis and Machine Intelligence, 68:5795–5809, 2020.
- [75] Ruqi Zhang, Chunyuan Li, Jianyi Zhang, Changyou Chen, and Andrew Gordon Wilson. Cyclical stochastic gradient MCMC for Bayesian deep learning. In International Conference on Learning Representations, 2020.
Appendix A Proofs in Section 4
This section provides the missing proofs in Section 4.
Proof of Theorem 4.2.
We first calculate based on eq. (4), i.e., the following equation,
Calculate the derivatives of the both sides of the above equation with respect to , we have that
| (11) |
By lemma 4.1, is strongly convex with respect to . Thus, the following Hessian matrix
is positive definite, hence invertible. Combining with eq. (11), we have that
| (12) |
We then upper bound the norm of . Based on eq. (12), we have that
| (13) |
We first consider the first term of the right-hand side of eq. (13). By assumption 4.2, is -strongly convex and is -strongly convex, where is a positive real number, is a positive continuous real function on . Thus we have that
Applying Assumption 4.1, we have that is continuous on the compact set . This suggests that there exists a real constant such that , . Therefore, we further have that
Let denotes the smallest eigenvalue of the matrix . Then, the above inequality implies that . Hence, we have the following,
| (14) |
We then upper bound the second term of the right-hand side of eq. (13). Applying Assumptions 4.2 and 4.1, we have that is continuous on compact support . This demonstrates that both and are bounded. Therefore, as , we have
| (15) |
The proof is completed. ∎
Proof of Theorem 4.3.
We first calculate based on eq. (4). Similar to the proof of Theorem 4.2, we calculate the second-order derivatives of the both sides of eq. (4) with respect to and have that
which means
| (16) |
where the invertibility of is guaranteed by Lemma 4.1, , and for , we have the following,
| (17) | |||
| (18) |
We then upper bound the norm of . Based on eq. (16), we have that
| (19) | |||
| (20) |
where eq. (20) is obtained by inserting eq. (14) (in the proof of Theorem 4.2) into eq. (19). Thus, the remaining is to upper bound the norms of , and .
We first upper bound . Applying Theorem 4.2, we have that . Applying Assumptions 4.2 and 4.1, we have that is bounded on its support . As a result, the norm of is also bounded. Therefore, we have that
| (21) |
For , we similarly have that
| (22) |
The proof is completed. ∎
Appendix B Proofs in Section 5
This section provides the detailed proofs in Section 5.
Proof of Theorem 5.2.
Let , be the variational parameters learned on and , respectively. Let be the processed variational parameter. Then, to establish a certified knowledge removal guarantee for , we need to bound the KL divergence .
For the brevity, we denote that
where , , and
where , .
We then have the following (we assume that ),
| (24) |
Therefore, performs -certified knowledge removal.
The proof is completed. ∎
Proof of Theorem 5.4.
Let the processed model be . For the brevity, we denote that
where , and
Then, to establish the certified removal guarantee, we need to calculate the KL divergence .
Since
we have that (we assume that )
which means that . Therefore, performs -certified knowledge removal.
The proof is completed. ∎
Appendix C Proofs in Section 6
This section provides the detailed proofs in Section 6.
We derive generalization bounds for BIF under the PAC-Bayesian framework [47, 48, 49]. The framework can provide guarantees for randomized predictors (e.g. Bayesian predictors).
Specifically, let a distribution on the parameter space , denotes the prior distribution over the parameter space . Then, the expected risks is bounded in terms of the empirical risk and KL-divergence by the following result from PAC-Bayes.
Lemma C.1 (cf. [49], Theorem 1).
For any real , with probability at least , we have the following inequality for all distributions :
| (25) |
proof of Theorem 6.1.
Let the prior distribution be the standard Gaussian distribution , be the distribution that obtained after conducting variational inference BIF. Suppose the density functions of , are , respectively, then we have
where and .
Therefore, we can calculate the KL-divergence as follows (where we assume that ),
| (26) |
where
Eq. (26) gives an upper bound of the KL-divergence between the obtained distribution after BIF and the prior distribution. Inserting eq. (26) into eq. (25) in Lemma C.1, we obtain the PAC-Bayesian generalization bound.
Furthermore, since all the conditions in Theorem 5.1 hold, we can apply Theorem 4.2 and have that . Besides, by applying the conditions in Theorem 5.2, we have that for any , , where is a constant. Therefore, we have that
The proof is completed. ∎
proof of Theorem 6.2.
Let the prior distribution be the standard Gaussian distribution , be the processed distribution that obtained after conducting MCMC BIF. Suppose the density functions of , are , respectively, then we have
where .
Thus, we can calculate the KL-divergence as follows (where we assume that ),
| (27) |
where
Eq. (27) bounds the KL-divergence between the processed distribution after conducting BIF and the prior distribution. Inserting eq. (27) into eq. (25) in Lemma C.1, we then obtain the PAC-Bayesian generalization bound.
Eventually, since all the conditions in Theorem 5.3 hold, we can apply Theorem 4.2 and have that . Therefore, we have the following,
The proof is completed. ∎