11email: [email protected]
Bayesian Entailment Hypothesis: How Brains Implement Monotonic and Non-monotonic Reasoning††thanks: This paper was submitted to IJCAI 2020 and rejected.
Abstract
Recent success of Bayesian methods in neuroscience and artificial intelligence makes researchers conceive the hypothesis that the brain is a Bayesian machine. Since logic, as the laws of thought, is a product and a practice of our human brains, it is natural to think that there is a Bayesian algorithm and data-structure for entailment. This paper gives a Bayesian account of entailment and characterizes its abstract inferential properties. The Bayesian entailment is shown to be a monotonic consequence relation in an extreme case. In general, it is a non-monotonic consequence relation satisfying Classical cautious monotony and Classical cut we introduce to reconcile existing conflicting views in the field. The preferential entailment, which is a representative non-monotonic consequence relation, is shown to correspond to a maximum a posteriori entailment. It is an approximation of the Bayesian entailment. We derive it based on the fact that maximum a posteriori estimation is an approximation of Bayesian estimation. We finally discuss merits of our proposals in terms of encoding preferences on defaults, handling change and contradiction, and modeling human entailment.
1 Introduction
Bayes’ theorem is a simple mathematical equation published in 1763. Today, it plays an important role in various fields such as AI, neuroscience, cognitive science, statistical physics and bioinformatics. It lays the foundation of most modern AI systems including self-driving cars, machine language translation, speech recognition and medical diagnosis [30]. Recent studies of neuroscience, e.g., [22, 18, 14, 17, 4, 5, 12], empirically show that Bayesian methods explain several functions of the cerebral cortex. It is the outer portion of the brain in charge of higher-order functions such as perception, memory, emotion and thought. These successes of Bayesian methods make researchers conceive the Bayesian brain hypothesis that brain is a Bayesian machine [11, 31].
If the Bayesian brain hypothesis is true then it is natural to think that there is a Bayesian algorithm and data-structure for logical reasoning. This is because logic, as the laws of thought, is a product and a practice of our human brains. Such Bayesian account of logical reasoning is important. First, it has a potential to be a mathematical model to explain how the brain implements logical reasoning. Second, it theoretically supports the Bayesian brain hypothesis in terms of logic. Third. it gives an opportunity and a way to critically assess the existing formalisms of logical reasoning. Nevertheless, few research has focused on reformulating logical reasoning in terms of the Bayesian perspective (see Section 4 for discussion).
In this paper, we begin by assuming the posterior distribution over valuation functions, denoted by . The probability of each valuation function represents how much the state of the world specified by the valuation function is natural, normal or typical. We then assume a causal relation from valuation functions to each sentence, denoted by . Under the assumptions, the probability that is true, denoted by , will be shown to have
That is, the probability of any sentence is not primitive but dependent on all valuation functions probabilistically distributed. Given a set of sentences with the same assumptions, we will show to have
This equation is known as Bayesian learning [30]. Intuitively speaking, updates the probability distribution over valuation functions, i.e., for all , and then the updated distribution is used to predict the truth of . We define a Bayesian entailment, denoted by , using , as usual.
We derive several important facts from the idea. The Bayesian entailment is shown to be a monotonic consequence relation when . In general, it is a non-monotonic consequence relation satisfying Classical cautious monotony and Classical cut we introduce to reconcile existing conflicting views [13, 3] in the field. The preferential entailment [32], which is a representative non-monotonic consequence relation, is shown to correspond to a maximum a posteriori entailment. It is an approximation of the Bayesian entailment. It is derived from the fact that maximum a posteriori estimation is an approximation of Bayesian estimation. These results imply that both monotonic and non-monotonic consequence relations can be seen as Bayesian learning with a fixed probability threshold.
This paper is orgranized as follows. Section 2 gives a probabilistic model for a Bayesian entailment. For the sake of correctness of the Bayesian entailment, Section 3 discusses its inferential properties in terms of monotonic and non-monotonic consequence relations. In Section 4, we discuss merits of our proposals in terms of encoding preferences on defaults, handling change and contradiction, and modeling human entailment.
2 Bayesian Entailment
Let , and respectively denote the propositional language, the set of all propositional symbols in , and a valuation function, , where and mean the truth values, false and true, respectively. To handle uncertainty of states of the world, we assume that valuation functions are probabilistically distributed. Let denote a random variable over valuation functions. denotes the probability of valuation function . It reflects the probability of the state of the world specified by . Given two valuation functions and , represents that the state of the world specified by is more natural/typical/normal than that of . When the cardinality of is , there are possible states of the world. Thus, there are possible valuation functions. It is the case that , for all such that , and .
We assume that every propositional sentence is a random variable that has a truth value either or . For all , represents the probability that is true and that is false. We assume that denotes the set of all valuation functions in which is true and denotes the truth value under valuation function .
Definition 1 (Interpretation)
Let be a propositional sentence and be a valuation function. The conditional probability distribution over given is given as follows.
From the viewpoint of logic, it is natural to assume that a truth value of a sentence is caused only by the valuation functions. Thus, is given by
Example 1
|
|
Definition 1 implies that the probability of the truth of a sentence is not primitive, but dependent on the valuation functions. Therefore, we need to guarantee that probabilities on sentences satisfy the Kolmogorov axioms.
Proposition 1
The following expressions hold, for all formulae .
-
1.
, for all .
-
2.
.
-
3.
, for all .
Proof
Since any sentence takes a truth value either or , it is sufficient for (1) and (2) to show and . The following expressions hold.
Here, we have abbreviated to and to . (1) is true because holds, for all . (2) is true because holds. (3) can be developed as follows, where the first expression comes when and the second when .
There are four possible cases. If then the expression in the bracket of the right expressions turn out to be , if and then , if and then , and if then . All the results are consistent with .
Proposition 2
holds, for any .
Proof
It is true that .
In what follows, we thus replace by and then abbreviate to , for all sentences .
Dependency among random variables is shown in Figure 1 using a Bayesian network, a directed acyclic graphical model. A sentence has a directed edge only from a valuation function . It represents that valuation functions are the direct causes of truth values of sentences. The dependency between and another sentence is the same as . Only is coloured grey. It means that is assumed to be observed, which is in contrast to the other nodes assumed to be predicted or estimated. The box surrounding is a plate. It represents that there are sentences , , … and to which there is a directed edge from . Given the dependency, the conditional probability of given , , … and is given as follows.
Example 2 (Continued)
is given as follows.
Now, we want to investigate logical properties of . We thus define a consequence relation between and .
Definition 2 (Bayesian entailment)
Let be a sentence, be a set of sentences, and be a probability. is a Bayesian entailment of with , denoted by , if or .
Condition guarantees that is a Bayesian entailment of when is undefined due to division by zero. It happens when has no models, i.e., , or zero probability, i.e., , for all . is a special case of Definition 2. It holds when . We call Definition 2 Bayesian entailment because can be developed as follows.
The expression is often called Bayesian learning where updates the distribution over valuation functions, i.e., , and truth values of is predicted using the updated distribution. Therefore, the Bayesian entailment allows us to see consequences in logic are predictions in Bayesian learning.

3 Correctness
This section aims to show correctness of the Bayesian entailment. We first prove that a natural restriction of the Bayesian entailment is a classical consequence relation. We then prove that a weaker restriction of the Bayesian entailment can be seen as a non-monotonic consequence relation.
3.1 Propositional Entailment
Recall that propositional entailment is defined as follows: For all valuation functions , if is true in then is true in . The Bayesian entailment works in a similar way as the propositional entailment. The only difference is that the Bayesian entailment ignores valuation functions with zero probability. The valuation functions with zero probability represent impossible states of the world.
Theorem 3.1
Let be a sentence and be a set of sentences. holds if and only if, for all valuation functions such that , if is true in then is true in .
Proof
We show that holds if and only if there is a valuation function such that holds, is true in , and is false in . From Definition 2, holds if and only if and hold. From Definition 1, holds if and only if there is a valuation function such that holds and is true in . () This has been proven so far. () holds due to . Since , there is such that . is true in and is false in .
When no valuation functions take zero probability, consequences with the Bayesian entailment with probability one coincide with the propositional entailment.
Proposition 3
Let be a sentence, be a set of sentences. If there is no valuation functions such that then holds if and only if holds.
Proof
The definition of the propositional entailment is equivalent to Theorem 3.1 under the non-zero assumption.
No preference is given to valuation functions in the propositional entailment. It corresponds to the Bayesian entailment with the uniform assumption, i.e., . Note that Theorem 3.1 and Proposition 3 hold even when the probability distribution over valuation functions is uniform. It is because the uniform assumption is stricter than the non-zero assumption, i.e., . The following holds when no assumption is imposed on the probability distribution over valuation functions,
Proposition 4
Let be a sentence and be a set of sentences. If holds then holds, but not vice versa.
Proof
This is obvious from Theorem 3.1.
Since an entailment is defined between a set of sentences and a sentence, both and are subsets of . Here, denotes the power set of the language . Proposition 4 states that is a subset of , i.e., . It represents that the propositional entailment is more cautious in entailment than the Bayesian entailment. Moreover, it is obvious from Definition 2 that holds if holds.
In propositional logic, a sentence is said to be a tautology if it is true in all of the valuation functions. A sentence is thus a tautology if and only if holds. In the Bayesian entailment, holds if and only if is true in all of the valuation functions with a non-zero probability.
Proposition 5
Let be a sentence. holds if and only if, for all valuation functions such that , is true in .
Proof
. Since , holds if and only if there is such that and .
Example 3 (Continued)
holds because we have
3.2 Monotonic Consequence Relation
We investigate inferential properties of the Bayesian entailment in terms of the monotonic consequence relation. It is known that any monotonic consequence relation can be characterised by the three properties: Reflexivity, Monotony and Cut. Let denote a consequence relation on . Those properties are defined as follows, where and .
-
•
Reflexivity: ,
-
•
Monotony: , if then
-
•
Cut: , if and then
Reflexivity states that is a consequence of any set with . Monotony states that if is a consequence of then it is a consequence of any superset of as well. Cut states that an addition of any consequence of to does not reduce any consequence of . The Bayesian entailment is classical in the sense that it satisfies all of the properties.
Theorem 3.2
The Bayesian entailment satisfies Reflexivity, Monotony and Cut.
Proof
(Reflexivity) It is true because holds. (Monotony) Since holds, or holds, for all . For all , it is thus true that if holds then . Therefore,
Here, we have excluded all because of . (Cut) Since holds, or holds, for all . Since holds, or holds, for all . Let . For all , it is thus true that if holds then and hold. We thus have
The next theorem states inferential properties of the Bayesian entailment with probability where .
Theorem 3.3
Let be a probability where . The Bayesian entailment satisfies Reflexivity, but does not satisfy Monotony and Cut.
Proof
(Reflexivity) Obvious from . (Monotony) We show a counter-example. Given the set of propositional symbols, consider the probability distribution over valuation functions shown in Table 3. Note that holds. It is the case that
holds if and only if holds. It thus always true when . Therefore, but hold. (Cut) We show a counter-example. Consider the probability distribution over valuation functions shown in Table 3. Note that holds. It is the case that
always true when . Therefore, and hold, but holds.
|
|
Example 4
Therefore, in contrast to , the Bayesian entailment is not a monotonic consequence relation, for all where .
3.3 Non-monotonic Consequence Relation
We next analyze the Bayesian entailment in terms of inferential properties of non-monotonic consequence relations. It is known that there are at leat four core properties characterizing non-monotonic consequence relations: Supraclassicality, Reflexivity, Cautious monotony and Cut. Let be a consequence relation on . Those properties are formally defined as follows, where and .
-
•
Supraclassicality: , if then
-
•
Reflexivity: ,
-
•
Cautious monotony: , if and then
-
•
Cut: , if and then
We have already discussed reflexivity and cut. Supraclassicality states that the consequence relation extends the monotonic consequence relation. Cautious monotony states that if is a consequence of then it is a consequence of supersets of as well. However, it is weaker than monotony because the supersets are restricted to consequences of . Consequence relations satisfying those properties are often called a cumulative consequence relation [3].111This definition is not absolute. The authors [19] define a cumulative consequence as a relation satisfying Reflexivity, Left logical equivalence, Right weakening, Cut and Cautious monotony.
Theorem 3.4
Let be a probability where . The Bayesian entailment satisfies Supraclassicality and Reflexivity, but does not satisfy Cautious monotony and Cut.
Proof
(Reflexivity & Cut) See Theorem 3.3. (Supraclassicality) This is obvious from . (Cautious monotony) It is enough to show a counter-example. Given set of atomic propositions, consider again the distribution over valuation functions shown in Table 3. We have
holds if and only if holds. It is always false when holds.
Theorem 3.4 shows that, in general, the Bayesian entailment is not cumulative. A natural question here is what inferential properties characterize the Bayesian entailment. We thus introduce two properties: Classically cautious monotony and Classical cut.
Definition 3 (Classically cautious monotony and classical cut)
Let be sentences, be a set of sentences, and be a consequence relation on . Classically cautious monotony and Classical cut are given as follows:
-
•
Classically cautious monotony: , if and then
-
•
Classical cut: , if and then
where denotes a monotonic consequence relation.
Intuitively speaking, Classically cautious monotony and Cut state that only monotonic consequences may be used as premises of the next inference operation. It is in contrast to Cautious monotony and Cut stating that any consequences may be used as premises of the next operation. Classically cautious monotony is weaker than Cautious monotony, and Cautious monotony is weaker than Monotony. Thus, if a consequence relation satisfies Monotony then it satisfies Classically cautious monotony and Cautious monotony as well. We now define a classically cumulative consequence relation.
Definition 4 (Classically cumulative consequence relation)
Let be a consequence relation on . is said to be a classically cumulative consequence relation if it satisfies all of the following properties.
-
•
Supraclassicality: , if then
-
•
Reflexivity: ,
-
•
Classically cautious monotony: , if and then
-
•
Classical cut: , if and then
Any cumulative consequence relation is a classically cumulative consequence relation, but not vice versa. A classically cumulative consequence relation is more conservative in entailment than a cumulative consequence relation. For example, in a cumulative consequence relation , if and hold then necessary holds due to Cautious monotony. However, it does not hold in a classically cumulative consequence relation because might be the case. The same discussion is possible for Cut and Classical cut.
The next theorem shows that Bayesian entailment (where ) is a classically cumulative consequence relation.
Theorem 3.5
Let be a probability where . The Bayesian entailment is a classically cumulative consequence relation.
Proof
(Supraclassicality & Reflexivity) See Theorem 3.4. (Classically cautious monotony & Classical cut) We prove both by showing that holds if and only if holds, given holds. If holds then , and obviously hold from the definition. If then we have
We here used the facts and . is true because . is true because and .
Note that it makes no sense to show that any classically cumulative consequence relation is the Bayesian entailment. It corresponds to show that any monotonic consequence relation is the propositional entailment. The classically cumulative consequence relation is a meta-theory used to characterize various logical systems with specific logical language, syntax and semantics.
Example 5
Given in Table 3, , and . It is thus the case that , and .
3.4 Preferential Entailment
The preferential entailment [32] is a representative approach to a non-monotonic consequence relation. We show that the preferential entailment coincides with a maximum a posteriori entailment, which is an approximation of the Bayesian entailment. The preferential entailment is defined on a preferential structure (or preferential model) , where is a set of valuation functions and is an irreflexive and transitive relation on . represents that is preferable222For the sake of simplicity, we do not adopt the common practice in logic that denotes is preferable to . to in the sense that the world identified by is more normal/typical/natural than the one identified by . Given preferential structure , is a preferential consequence of , denoted by , if is true in all -maximal333 has to be smooth (or stuttered) [19] so that a maximal model certainly exists. That is, for all valuations , either is -maximal or there is a -maximal valuation such that . models of . A consequence relation is said to be preferential [19] if it satisfies the following Or property, as well as Reflexivity, Cut and Cautious monotony, where and .
-
•
Or: , if and then
In line with the fact that maximum a posterior estimation is an approximation of Bayesian estimation, we define a maximum a posteriori (MAP) entailment, denoted by , that is an approximation of the Bayesian entailment. Several concepts need to be introduced for that. is said to be a maximum a posteriori estimate if it satisfies
We now assume that the distribution has a unique peak close to 1 at a valuation function. It means that there is a single state of the world that is very normal/natural/typical. It results in
where denotes an approximation. Note that no one accepting MAP estimation can refuse this assumption in terms of the Bayesian perspective. Now, we have
where is the Kronecker delta that returns if and otherwise . It is the case that . Thus, a formal definition of the maximum a posteriori entailment is given as follows.
Definition 5 (Maximum a posteriori entailment)
Let be a sentence and be a set of sentences. is a maximum a posteriori entailment of , denoted by , if or , where .
Given two ordered sets and , a function is said to be an order-preserving (or isotone) map of into if implies that , for all . The next theorem relates the maximum a posteriori entailment to the preferential entailment.
Theorem 3.6
Let be a preferential structure and be a probability mass function over . If is an order-preserving map of into then implies .
Proof
It is obviously true when has no model. Let be a -maximal model of . It is sufficient to show and . Since , is true in . Thus, . We have
Since is true in , . Since is order-preserving, if then , for all . Thus, if is -maximal then is maximal. Therefore, holds.
It is the case that . Theorem 3.6 states that holds given an appropriate probability distribution over valuation functions.
Example 6
Suppose the probability distribution over valuation functions shown in the table in Figure 2 and the preferential structure given as follows.
The transitivity of is depicted in the graph shown in Figure 2. As shown in the graph, the probability mass function is an order-preserving map of into .
Now, holds because is true in all -maximal models of . Indeed, is true in , which is uniquely -maximal in , the models of . Meanwhile, holds because holds where .
However, holds because is false in , which is -maximal in , the maximal models of . In contrast, holds because holds where .

The equivalence relation between the maximum a posteriori entailment and the preferential entailment is obtained by restricting the preferential structure to a total order.
Theorem 3.7
Let be a totally-ordered preferential structure and be a probability mass function over . If is an order-preserving map of into then if and only if .
Proof
Same as Theorem 3.6. Only difference is that the model exists uniquely. Then, only satisfies .
4 Discussion and Conclusions
There are a lot of research papers combining logic and probability theory, e.g., [1, 8, 25, 24, 23, 26, 6, 20, 21, 9, 27, 16, 29]. Their common interest is not the notion of truth preservation but rather probability preservation, where the uncertainty of the premises preserves the uncertainty of the conclusion. They are different from ours because they presuppose and extend classical logical consequence.
Besides the preferential entailment, various other semantics of non-monotonic consequence relations have been proposed such as plausibility structure [10], possibility structure [7], ranking structure [15] and -semantics [2, 28]. The common idea of the first three approaches is that entails if is preferable to given a preference on models. The idea of the last approach is that entails if is close to one in the dependency network quantifying the strength of the causal relationship between sentences. In contrast to the last approach, we focus on the causal relationship between sentences and models, i.e., states of the world. Any sentences are conditionally independent given a model. This fact makes it possible to update the probability distribution over models using observed sentences , and then to predict the truth of unobserved sentence only using the distribution. It is different from the first three approaches assuming a preference on models prior to the analysis. It is also different from the last approach introducing a new tricky semantics, i.e., -semantics, to handle the interaction between models and sentences outside their probabilistic inference. The characteristic allows us to answer the open question [3]:
Perhaps, the greatest technical challenge left for circumscription and model preference theories in general is how to encode preferences among abnormalities or defaults.
The abnormalities or defaults can be seen as unobserved statements. We thus think that the preferences should be encoded by their posterior probabilities derived by taking into account all the uncertainties of models.
A natural criticism against our work is that the Bayesian entailment is inadequate as a non-monotonic consequence relation due to the lack of Cautious monotony and Cut. Indeed, Gabbay [13] considers, on the basis of his intuition, that non-monotonic consequence relations satisfy at least Cautious monotony, Reflexivity and Cut. However, it is controversial because of unintuitive behavior of Cautious monotony and Cut in extreme cases. A consequence relation with Cut, for instance, satisfies when it satisfies and , for all . This is very unintuitive when is large. Brewka [3] in fact points out the infinite transitivity as a weakness of Cut. In this paper, we reconcile both the positions by providing the alternative inferential properties: Classically cautious monotony and Classical cut. The reconciliation does not come from our intuition, but from theoretical analysis of the Bayesian entailment. What we introduced to define the Bayesian entailment is only the probability distribution over valuation functions, representing uncertainty of states of the world. Given the distribution, the Bayesian entailment is simply derived from the laws of probability theory. Furthermore, the preferential entailment satisfying Cautious monotony and Cut is shown to correspond to the maximum a posteriori entailment that is an approximation of the Bayesian entailment. It tells us that Cautious monotony and Cut are ideal under the special condition that a state of the world exists deterministically. They are not ideal under the general perspective that states of the world are probabilistically distributed.
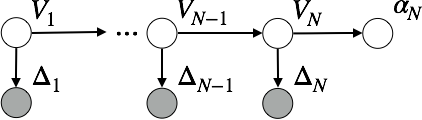
The Bayesian entailment is flexible to extend. For example, a possible extension of Figure 1 is a hidden Markov model shown in Figure 3. It has a valuation variable and a sentence(s) variable, for each time step where . Entailment defined in accordance with Definition 2 concludes by taking into account not only the current observation but also the previous states of the world updated by all of the past observations . It is especially useful when observations are contradictory, ambiguous or easy to change.
Finally, our hypothesis is that the Bayesian entailment can be a mathematical model of how human brains implement an entailment. Recent studies of neuroscience, e.g., [22, 18, 14, 17, 4, 5, 12], empirically show that Bayesian inference or its approximation explains several functions of the cerebral cortex, the outer portion of the brain in charge of higher-order functions such as perception, memory, emotion and thought. It raises the Bayesian brain hypothesis [11] that the brain is a Bayesian machine. Since logic, as the law of thought, is a product of a human brain, it is natural to think there is a Bayesian interpretation of logic. Of course, we understand that the Bayesian brain hypothesis is controversial and that it is a subject to a scientific experiment. We, however, think that this paper provides sufficient evidences for the hypothesis in terms of logic.
This paper gives a Bayesian account of entailment and characterizes its abstract inferential properties. The Bayesian entailment was shown to be a monotonic consequence relation in an extreme case. In general, it is a non-monotonic consequence relation satisfying Classical cautious monotony and Classical cut we introduced to reconcile existing conflicting views. The preferential entailment was shown to correspond to a maximum a posteriori entailment, which is an approximation of the Bayesian entailment. We finally discuss merits of our proposals in terms of encoding preferences on defaults, handling change and contradiction, and modeling human entailment.
References
- [1] Adams, E.W.: A Primer of Probability Logic. Stanford, CA: CSLI Publications (1998)
- [2] Adams, E.W.: The Logic of Conditionals. Dordrecht: D. Reidel Publishing Co (1975)
- [3] Brewka, G., Dix, J., Konolige, K.: Nonmonotonic Reasoning: An Overview. CSLI Publications (1997)
- [4] Chikkerur, S., Serre, T., Tan, C., Poggio, T.: What and where: A bayesian inference theory of attention. Vision Research 50 (2010)
- [5] Colombo, M., Seri\UTF00E8s, P.: Bayes in the brain: On bayesian modelling in neuroscience. The British Journal for the Philosophy of Science 63, 697–723 (2012)
- [6] Cross, C.: From worlds to probabilities: A probabilistic semantics for modal logic. Journal of Philosophical Logic 22, 169–192 (1993)
- [7] Dubois, D., Prade, H.: Readings in uncertain reasoning. chap. An Introduction to Possibilistic and Fuzzy Logics, pp. 742–761. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (1990), http://dl.acm.org/citation.cfm?id=84628.85368
- [8] van Fraassen, B.: Probabilistic semantics objectified: I. postulates and logics. Journal of Philosophical Logic 10, 371–391 (1981)
- [9] van Fraassen, B.: Gentlemen’s wagers: Relevant logic and probability. Philosophical Studies 43, 47–61 (1983)
- [10] Friedman, N., Halpern, J.Y.: Plausibility measures and default reasoning. In: Proc. of the 13th National Conference on Artificial Intelligence. pp. 1297–1304 (1996)
- [11] Friston, K.: The history of the future of the bayesian brain. Neuroimage 62-248(2), 1230–1233 (2012)
- [12] Funamizu, A., Kuhn, B., Doya, K.: Neural substrate of dynamic bayesian inference in the cerebral cortex. Nature Neuroscience 19, 1682–1689 (2016)
- [13] Gabbay, D.: Theoretical Foundations for Non-monotonic Reasoning in Expert Systems. Springer-Verlag (1985)
- [14] George, D., Hawkins, J.: A hierarchical bayesian model of invariant pattern recognition in the visual cortex. In: Proc. of 2005 International Joint Conference on Neural Networks. pp. 1812–1817 (2005)
- [15] Goldszmidt, M., Pearl, J.: Rank-based systems: A simple approach to belief revision, belief update, and reasoning about evidence and actions. In: Proceedings of the Third International Conference on Principles of Knowledge Representation and Reasoning. pp. 661–672. KR’92, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (1992), http://dl.acm.org/citation.cfm?id=3087223.3087290
- [16] Goosens, W.K.: Alternative axiomatizations of elementary probability theory. Notre Dame Journal of Formal Logic 20, 227–239 (1979)
- [17] Ichisugi, Y.: The cerebral cortex model that self-organizes conditional probability tables and executes belief propagation. In: Proc. of 2007 International Joint Conference on Neural Networks. pp. 1065–1070 (2007)
- [18] Knill, D.C., Pouget, A.: The bayesian brain: the role of uncertainty in neural coding and computation. Trends in Neurosciences 27, 712–719 (2004)
- [19] Kraus, S., Lehmann, D., Magidor, M.: Nonmonotonic reasoning, preferential models and cumulative logics. Artificial Intelligence 44(1-2), 167–207 (1990)
- [20] Leblanc, H.: Probabilistic semantics for first-order logic. Zeitschrift für mathematische Logik und Grundlagen der Mathematik 25, 497–509 (1979)
- [21] Leblanc, H.: Alternatives to Standard First-Order Semantics, vol. I, pp. 189–274. Dordrecht: Reidel, handbook of philosophical logic, d. gabbay and f. guenthner (eds.) edn. (1983)
- [22] Lee, T., Mumford, D.: Hierarchical bayesian inference in the visual cortex. Journal of Optical Society of America 20, 1434–1448 (2003)
- [23] Morgan, C.: Simple probabilistic semantics for propositional K, T, B, S4, and S5. Journal of Philosophical Logic 11, 443–458 (1982)
- [24] Morgan, C.: There is a probabilistic semantics for every extension of classical sentence logic. Journal of Philosophical Logic 11, 431–442 (1982)
- [25] Morgan, C.: Probabilistic Semantics for Propositional Modal Logics, pp. 97–116. New York, NY: Haven Publications, essays in epistemology and semantics, h. leblanc, r. gumb, and r. stern (eds.) edn. (1983)
- [26] Morgan, C., Leblanc, H.: Probabilistic semantics for intuitionistic logic. Notre Dame Journal of Formal Logic 24, 161–180 (1983)
- [27] Pearl, J.: Probabilistic Semantics for Nonmonotonic Reasoning, pp. 157–188. Cambridge, MA: The MIT Press, philosophy and ai: essays at the interface, r. cummins and j. pollock (eds.) edn. (1991)
- [28] Pearl, J.: Probabilistic semantics for nonmonotonic reasoning: a survey. In: Proc. of the 1st International Conference on Principles of Knowledge Representation and Reasoning. pp. 505–516 (1989)
- [29] Richardson, M., Domingos, P.: Markov logic networks. Machine Learning 62, 107–136 (2006)
- [30] Russell, S., Norvig, P.: Artificial Intelligence : A Modern Approach, Third Edition. Pearson Education, Inc. (2009)
- [31] Sanborn, A.N., Chater, N.: Bayesian brains without probabilities. Trends in Cognitive Sciences 20, 883–893 (2016)
- [32] Shoham, Y.: Nonmonotonic logics: Meaning and utility. In: Proc. of the 10th International Joint Conference on Artificial Intelligence. pp. 388–393 (1987)