Batch Multivalid Conformal Prediction
Abstract
We develop fast distribution-free conformal prediction algorithms for obtaining multivalid coverage on exchangeable data in the batch setting. Multivalid coverage guarantees are stronger than marginal coverage guarantees in two ways: (1) They hold even conditional on group membership—that is, the target coverage level holds conditionally on membership in each of an arbitrary (potentially intersecting) group in a finite collection of regions in the feature space. (2) They hold even conditional on the value of the threshold used to produce the prediction set on a given example. In fact multivalid coverage guarantees hold even when conditioning on group membership and threshold value simultaneously.
We give two algorithms: both take as input an arbitrary non-conformity score and an arbitrary collection of possibly intersecting groups , and then can equip arbitrary black-box predictors with prediction sets. Our first algorithm BatchGCP is a direct extension of quantile regression, needs to solve only a single convex minimization problem, and produces an estimator which has group-conditional guarantees for each group in . Our second algorithm BatchMVP is iterative, and gives the full guarantees of multivalid conformal prediction: prediction sets that are valid conditionally both on group membership and non-conformity threshold. We evaluate the performance of both of our algorithms in an extensive set of experiments. Code to replicate all of our experiments can be found at https://github.com/ProgBelarus/BatchMultivalidConformal.
1 Introduction
Consider an arbitrary distribution over a labeled data domain . A model is any function for making point predictions111Often, as with a neural network that outputs scores at its softmax layer that are transformed into label predictions, a model will also produce auxiliary outputs that can be used in the construction of the non-conformity score . The traditional goal of conformal prediction in the “batch” setting is to take a small calibration dataset consisting of labeled examples sampled from and use it to endow an arbitrary model with prediction sets that have the property that these prediction sets cover the true label with probability marginally for some target miscoverage rate :
This is a marginal coverage guarantee because the probability is taken over the randomness of both and , without conditioning on anything. In the batch setting (unlike in the sequential setting), labels are not available when the prediction sets are deployed. Our goal in this paper is to give simple, practical algorithms in the batch setting that can give stronger than marginal guarantees — the kinds of multivalid guarantees introduced by Gupta et al. (2022); Bastani et al. (2022) in the sequential prediction setting.
Following the literature on conformal prediction (Shafer and Vovk, 2008), our prediction sets are parameterized by an arbitrary non-conformity score defined as a function of the model . Informally, smaller values of should mean that the label “conforms” more closely to the prediction made by the model. For example, in a regression setting in which , the simplest non-conformity score is . By now there is a large literature giving more sophisticated non-conformity scores for both regression and classification problems—see Angelopoulos and Bates (2021) for an excellent recent survey. A non-conformity score function induces a distribution over non-conformity scores, and if is the quantile of this distribution (i.e. ), then defining prediction sets as
gives marginal coverage. Split conformal prediction (Papadopoulos et al., 2002; Lei et al., 2018) simply finds a threshold that is an empirical quantile on the calibration set222with a small sample bias correction, and then uses this to deploy the prediction sets defined above. Our goal is to give stronger coverage guarantees, and to do so, rather than learning a single threshold from the calibration set, we will learn a function mapping unlabeled examples to thresholds. Such a mapping induces prediction sets defined as follows:
Our goal is to find functions that give valid conditional coverage guarantees of two sorts. Let be an arbitrary collection of groups: each group is some subset of the feature domain about which we make no assumption and we write to denote that is a member of group . An example might be a member of multiple groups in . We want to learn a function that induces group conditional coverage guarantees—i.e. such that for every :
Here we can think of the groups as representing e.g. demographic groups (broken down by race, age, gender, etc) in settings in which we are concerned about fairness, or representing any other categories that we think might be relevant to the domain at hand. Since our functions now map different examples to different thresholds , we also want our guarantees to hold conditional on the chosen threshold—which we call a threshold calibrated guarantee. This avoids algorithms that achieve their target coverage rates by overcovering for some thresholds and undercovering with others — for example, by randomizing between full and empty prediction sets. That is, we have:
If is such that its corresponding prediction sets satisfy both group and threshold conditional guarantees simultaneously, then we say that it promises full multivalid coverage.
1.1 Our Results
We design, analyze, and empirically evaluate two algorithms: one for giving group conditional guarantees for an arbitrary collection of groups , and the other for giving full multivalid coverage guarantees for an arbitrary collection of groups . We give PAC-style guarantees (Park et al., 2019), which means that with high probability over the draw of the calibration set, our deployed prediction sets have their desired coverage properties on the underlying distribution. Thus our algorithms also offer “training-conditional coverage” in the sense of Bian and Barber (2022). We prove our generalization theorems under the assumption that the data is drawn i.i.d. from some distribution, but note that De Finetti’s theorem (Ressel, 1985) implies that our analysis carries over to data drawn from any exchangeable distribution (see Remark B.1).
Group Conditional Coverage: BatchGCP
We first give an exceedingly simple algorithm BatchGCP (Algorithm 1) to find a model that produces prediction sets that have group conditional (but not threshold calibrated) coverage guarantees. We consider the class of functions : each is parameterized by a vector , and takes value:
Here is some arbitrary initial model. Our algorithm simply finds the parameters that minimize the pinball loss of . This is a -dimensional convex optimization problem and so can be solved efficiently using off the shelf convex optimization methods. We prove that the resulting function guarantees group conditional coverage. This can be viewed as an extension of conformalized quantile regression (Romano et al., 2019) which is also based on minimizing pinball loss. It can also be viewed as an algorithm promising “quantile multiaccuracy”, by analogy to (mean) multiaccuracy introduced in Hébert-Johnson et al. (2018b); Kim et al. (2019), and is related to similar algorithms for guaranteeing multiaccuracy (Gopalan et al., 2022b). Here pinball loss takes the role that squared loss does in (mean) multiaccuracy.
Multivalid Coverage: BatchMVP
We next give a simple iterative algorithm BatchMVP (Algorithm 2) to find a model that produces prediction sets that satisfy both group and threshold conditional guarantees simultaneously — i.e. full multivalid guarantees. It iteratively finds groups and thresholds such that the current model fails to have the target coverage guarantees conditional on and , and then “patches” the model so that it does. We show that each patch improves the pinball loss of the model substantially, which implies fast convergence. This can be viewed as an algorithm for promising “quantile multicalibration” and is an extension of related algorithms for guaranteeing mean multicalibration (Hébert-Johnson et al., 2018b), which offer similar guarantees for mean (rather than quantile) prediction. Once again, pinball loss takes the role that squared loss takes in the analysis of mean multicalibration.
Empirical Evaluation
We implement both algorithms, and evaluate them on synthetic prediction tasks, and on 10 real datasets derived from US Census data from the 10 largest US States using the “Folktables” package of Ding et al. (2021). In our synthetic experiments, we measure group conditional coverage with respect to synthetically defined groups that are constructed to be correlated with label noise. On Census datasets, we aim to ensure coverage on population groups defined by reported race and gender categories. We compare our algorithms to two other split conformal prediction methods: a naive baseline which simply ignores group membership, and uses a single threshold, and the method of Foygel Barber et al. (2020), which calibrates a threshold for each group , and then on a new example , predicts the most conservative threshold among all groups belongs to. We find that both of our methods obtain significantly better group-wise coverage and threshold calibration than the baselines we compare to. Furthermore, both methods are very fast in practice, only taking a few seconds to calibrate on datasets containing tens of thousands of points.
1.2 Additional Related Work
Conformal prediction (see Shafer and Vovk (2008); Angelopoulos and Bates (2021) for excellent surveys) has seen a surge of activity in recent years. One large category of recent work has been the development of sophisticated non-conformity scores that yield compelling empirical coverage in various settings when paired with split conformal prediction (Papadopoulos et al., 2002; Lei et al., 2018). This includes Romano et al. (2019) who give a nonconformity score based on quantile regression, Angelopoulos et al. (2020) and Romano et al. (2020b) who give nonconformity scores designed for classification, and Hoff (2021) who gives a nonconformity score that leads to Bayes optimal coverage when data is drawn from the assumed prior distribution. This line of work is complementary to ours: we give algorithms that can be used as drop-in replacements for split conformal prediction, and can make use of any of these nonconformity scores.
Another line of work has focused on giving group conditional guarantees. Romano et al. (2020a) note the need for group-conditional guarantees with respect to demographic groups when fairness is a concern, and propose separately calibrating on each group in settings in which the groups are disjoint. Foygel Barber et al. (2020) consider the case of intersecting groups, and give an algorithm that separately calibrates on each group, and then uses the most conservative group-wise threshold when faced with examples that are members of multiple groups — the result is that this method systematically over-covers. The kind of “multivalid” prediction sets that we study here were first proposed by Jung et al. (2021) in the special case of prediction intervals: but the algorithm given by Jung et al. (2021), based on calibrating to moments of the label distribution and using Chebyshev’s inequality, also generally leads to over-coverage. Gupta et al. (2022) gave a theoretical derivation of an algorithm to obtain tight multivalid prediction intervals in the sequential adversarial setting, and Bastani et al. (2022) gave a practical algorithm to obtain tight multivalid coverage using prediction sets generated from any non-conformity score, also in the sequential adversarial setting. Although the sequential setting is more difficult in the sense that it makes no distributional assumptions, it also requires that labels be available after predictions are made at test time, in contrast to the batch setting that we study, in which labels are not available. Gupta et al. (2022) give an online-to-batch reduction that requires running the sequential algorithm on a large calibration set, saving the algorithm’s internal state at each iteration, and then deploying a randomized predictor that randomizes over the internal state of the algorithm across all rounds of training. This is generally impractical; in contrast we give a direct, simple, deterministic predictor in the batch setting.
Our algorithms can be viewed as learning quantile multiaccurate predictors and quantile multicalibrated predictors respectively — by analogy to multiaccuracy Kim et al. (2019) and multicalibration Hébert-Johnson et al. (2018b) which are defined with respect to means instead of quantiles. Their analysis is similar, but with pinball loss playing the role played by squared error in (mean) multicalibration. This requires analyzing the evolution of pinball loss under Lipschitzness assumptions on the underlying distribution, which is a complication that does not arise for means. More generally, our goals for obtaining group conditional guarantees for intersecting groups emerge from the literature on “multigroup” fairness — see e.g. (Kearns et al., 2018; Hébert-Johnson et al., 2018b; Kearns et al., 2019; Rothblum and Yona, 2021; Dwork et al., 2019; Globus-Harris et al., 2022)
2 Preliminaries
We study prediction tasks over a domain . denotes the feature domain and the label domain. We write to denote a collection of subsets of which we represent as indicator functions . The label domain might e.g. be real valued —the regression setting, or consist of some finite unordered set—the multiclass classification setting.
Suppose there is a fixed distribution . Given such a distribution, we will write to denote the marginal distribution over features: induced by . We will write to denote the conditional distribution over labels induced by when we condition on a particular feature vector . captures all of the information about the label that is contained by the feature vector , and is the object that we are trying to approximate with our uncertainty quantification. We sometimes overload the notation and write .
Our uncertainty quantification is based on a bounded non-conformity score function . Non-conformity score functions are generally defined with respect to some model —which is why in the introduction we wrote —but our development will be entirely agnostic to the specifics of the non-conformity score function, and so we will just write for simplicity. Without loss of generality333When , then we can have the learner use the nonconformity score . When the learner produces a nonconformity threshold with respect to the new scoring function , we may obtain a threshold with respect to the original score by setting ., we assume that the scoring function takes values in the unit interval: for any and . Given a distribution over and a non-conformity score function , we write to denote the induced joint distribution over feature vectors and corresponding non-conformity scores . Analogously to our notation, we write to denote the non-conformity score distribution conditional on a particular feature vector . Given a subset of the feature space , we write to denote the conditional distribution on non-conformity scores conditional on . Finally, we assume that all non-conformity score distributions are continuous, which simplifies our treatment of quantiles — note that if this is not the case already, it can be enforced by perturbing non-conformity scores with arbitrarily small amounts of noise from a continuous distribution.
Definition 2.1.
For any , we say that is a -quantile of a (continuous) nonconformity score distribution if . Similarly, is a -quantile of a conditional nonconformity score distribution if
Our convergence results will be parameterized by the Lipschitz parameter of the CDF of the underlying nonconformity score distribution. Informally speaking, a distribution with a Lipschitz CDF cannot concentrate too much of its mass on an interval of tiny width. Similar assumptions are commonly needed in related work, and can be guaranteed by perturbing non-conformity scores with noise — see e.g. the discussion in (Gupta et al., 2022; Bastani et al., 2022).
Definition 2.2.
A conditional nonconformity score distribution is -Lipschitz if we have
A nonconformity score distribution is -Lipschitz if for each , is -Lipschitz.
If we could find a model that on each input output a value that is a -quantile of the nonconformity score distribution , this would guarantee true conditional coverage at rate : for every , , where . As this is generally impossible, our aim will be to train models that allow us to make similar claims — not conditional on every , but conditional on membership of in some group and on the value of . To facilitate learning models with guarantees conditional on their output values, we will learn models whose range has finite cardinality .
3 Algorithms
3.1 Algorithmic Preliminaries
In this section we establish lemmas that will be key to the analysis of both of the algorithms we give. Both of our algorithms will rely on analyzing pinball loss as a potential function. All proofs can be found in the Appendix.
Definition 3.1.
The pinball loss at target quantile for threshold and nonconformity score is
We write
for a model and nonconformity score distribution . When quantile and/or distribution is clear, we write , , and/or .
It is well known that pinball loss is minimized by the function that predicts for each the target quantile of a conditional score distribution given , but we will need a more refined set of statements. First we define a model’s marginal quantile consistency error:
Definition 3.2.
A -quantile predictor has marginal quantile consistency error if
If , we say that satisfies marginal -quantile consistency.
Informally, we will need the pinball loss to have both a progress and an “anti-progress” property:
-
1.
If a model is far from satisfying marginal quantile consistency, then linearly shifting it so that it satisfies marginal quantile consistency will reduce pinball loss substantially, and
-
2.
If a model does satisfy marginal quantile consistency, then perturbing it slightly won’t increase pinball loss substantially.
The next lemma establishes these, under the assumption that the underlying distribution is Lipschitz.
Lemma 3.1.
Fix any nonconformity score distribution that is -Lipschitz. Fix any model that has marginal quantile consistency error with respect to target quantile , and let with chosen such that is marginal quantile consistent at quantile . Then
We now define what will be a basic building block of our iterative algorithm for obtaining multivalid coverage, and of the analysis of our algorithm for obtaining group conditional coverage. It is a simple “patch” operation on a model, that shifts the model’s predictions by a constant term only on those examples that lie in some subset of the feature space:
Definition 3.3 (Patch Operation).
Given a model , a subset , and a value define the patched model to be such that
We next show that if we have a model , and we can identify a large region on which it is far from satisfying marginal quantile consistency, then “patching” the model so that it satisfies marginal quantile consistency on substantially improves its pinball loss.
Lemma 3.2.
Given some predictor , suppose we have a set of points with
Then, if is continuous and -Lipschitz, has .
3.2 BatchGCP: Obtaining Group Conditional Guarantees
We now give an extremely simple algorithm BatchGCP (Batch Group-Conditional Predictor) that obtains group conditional (but not threshold calibrated) prediction sets. BatchGCP only needs to solve a single closed-form convex optimization problem. Specifically, Algorithm 1 takes as input an arbitrary threshold model and collection of groups , and then simply minimizes pinball loss over all linear combinations of and the group indicator functions . This is a quantile-analogue of a similar algorithm that obtains group conditional mean consistency (Gopalan et al., 2022b).
Theorem 3.1.
For any input model , groups , and , Algorithm 1 returns with
In other words, we have for every ,
where . Furthermore, .
The analysis is simple: if the optimal model did not satisfy marginal quantile consistency on some , then by Lemma 3.2, a patch operation on the set would further reduce its pinball loss. By definition, this patch would just shift the model parameter and yield a model for , falsifying the optimality of among such models.
3.3 BatchMVP: Obtaining Full Multivalid Coverage
In this section, we give a simple iterative algorithm BatchMVP (Batch Multivalid Predictor) that trains a threshold model that provides full multivalid coverage — i.e. that produces prediction sets that are both group conditionally valid and threshold calibrated. To do this, we start by defining quantile multicalibration, a quantile prediction analogue of (mean) multicalibration defined in Hébert-Johnson et al. (2018b); Gopalan et al. (2022a) and a variant of the quantile multicalibration definition given in Gupta et al. (2022)444Informally, Hébert-Johnson et al. (2018b) defines an notion of multicalibration (that takes the maximum rather than expectation over levelsets ) that Gupta et al. (2022) generalizes to quantiles. Gopalan et al. (2022a) define an notion of calibration for means. Here we give an variant of calibration generalized from means to quantiles..
Definition 3.4.
The quantile calibration error of -quantile predictor on group is:
We say that is -approximately -quantile multicalibrated with respect to group collection if
Remark 3.1.
We define quantile calibration error on a group as an average over the level sets of the predictor , in a manner similar to how Gopalan et al. (2022a) define (mean) calibration. The idealized predictor that predicts the true -quantile of the conditional nonconformity score distribution on every would have 0 quantile calibration error on every group. When we define approximate calibration error, we allow for larger quantile calibration error on groups that appear less frequently. This is necessary if we are to learn a quantile multicalibrated predictor from finite data, and is what allows us to provide out-of-sample PAC guarantees in Section 4, and is consistent with similar definitions for mean multicalibration from the literature Jung et al. (2021); Gopalan et al. (2022a)
Conditional on membership in each group , the quantile multicalibration error gives a bound on the expected coverage error when conditioning both on membership in and on a predicted threshold of , in expectation over . In particular, it implies (and is stronger than) the following simple worst-case (over and ) bound on coverage error conditional on both and :
Claim 3.1.
If is -approximately quantile multicalibrated with respect to and , then
In other words, we have for every and ,
This claim follows by fixing any group and threshold value , and dropping all the (nonnegative) terms in except the one corresponding to and (see the Appendix).
Algorithm 2 is simple: Given an initial threshold model , collection of groups , and target quantile , it repeatedly checks whether its current model satisfies -approximate quantile multicalibration. If not, it finds a group and a threshold such that predicts a substantially incorrect quantile conditional on both membership of in and on — such a pair is guaranteed to exist if is not approximately quantile multicalibrated. It then fixes this inconsistency and produces a new model with a patch operation up to a target discretization parameter which ensures that the range of does not grow too large. Under the assumption that the non-conformity score distribution is Lipschitz, each patch operation substantially reduces the pinball loss of the current predictor, which ensures fast convergence to quantile multicalibration.
4 Out of Sample Generalization
We have presented BatchGCP (Algorithm 1) and BatchMVP (2) as if they have direct access to the true data distribution . In practice, rather than being able to directly access the distribution, we only have a finite calibration set of data points sampled iid. from . In this section, we show that if we run our algorithms on the empirical distribution over the sample , then their guarantees hold not only for the empirical distribution over but also—with high probability — for the true distribution . We include the generalization guarantees for BatchGCP in Appendix B.3 and focus on generalization guarantees for BatchMVP.
At a high level, our argument proceeds as follows (although there are a number of technical complications). For any fixed model , by standard concentration arguments its in- and out-of-sample quantile calibration error will be close with high probability for a large enough sample size. Our goal is to apply concentration bounds uniformly to every model that might be output by our algorithm, and then union bound over all of them to get a high probability bound for whichever model happens to be output. Towards this, we show how to bound the total number of distinct models that can be output as a function of , the total number of iterations of the algorithm. This is possible because at each round , the algorithm performs a patch operation parameterized by a group (where ), a value , and an update value — and thus only a finite number of models can result from patching the current model . The difficulty is that our convergence analysis in Theorem 3.2 gives a convergence guarantee in terms of the smoothness parameter of the underlying distribution, which will not be preserved on the empirical distribution over the sample drawn from . Hence, to upper bound the number of rounds our algorithm can run for, we need to interleave our generalization theorem with our convergence theorem, arguing that at each step—taken with respect to the empirical distribution over —we make progress that can be bounded by the smoothness parameter of the underlying distribution .
We remark that previous analyses of out-of-sample performance for similar (mean) multicalibration algorithms (Hébert-Johnson et al., 2018a; Jung et al., 2021) have studied algorithms that use a fresh sample of data at each round, or else perturb each empirical measurement using noise so as to invoke the connection between differential privacy and generalization (Dwork et al., 2015). Analyzing algorithms of this sort is convenient, but does not correspond to how one would actually want to run the algorithm. In contrast, we directly analyze the out-of-sample performance of our algorithm when it is directly trained using a single, sufficiently large sample of data.
We first prove a high probability generalization bound for our algorithm as a function of the number of steps it converges in. This bound holds uniformly for all , and so can be applied as a function of the actual (empirical) convergence time .
We let denote our sample, our nonconformity score sample, and denote the empirical distribution over . When is clear from the context, we just write .
Theorem 4.1.
Suppose is -Lipschitz and . Suppose BatchMVP() (Algorithm 2) runs for rounds and outputs model . Then is -approximately -quantile multicalibrated with respect to on with probability , where
We then prove a worst-case upper bound on the convergence time , which establishes a worst-case PAC style generalization bound in combination with Theorem 4.1. We remark that although the theorem contains a large constant, in our experiments, our algorithm halts after a small number of iterations (See Sections 5 and C), and we can directly apply Theorem 4.1 with this empirical value for .
Theorem 4.2.
Suppose is -Lipschitz and continuous, , and our calibration set consists of iid. samples drawn from , where is sufficiently large:
Then BatchMVP() (Algorithm 2) halts after rounds with prob. .
5 Experiments
5.1 A Synthetic Regression Task
We first consider a linear regression problem on synthetic data drawn from a feature domain of 10 binary features and 90 continuous features, with each binary feature drawn uniformly at random, and each continuous feature drawn from a normal distribution . The 10 binary features are used to define 20 intersecting groups, each depending on the value of a single binary feature. An input’s label is specified by an ordinary least squares model with group-dependent noise as:
where each term is associated with one binary feature. We set for all . So the more groups an input is a member of, the more label noise it has, with larger index groups contributing larger amounts of label noise.
We generate a dataset of size 40000 using the above-described model, and split it evenly into training and test data. The training data is further split into training data of size 5000 (with which to train a least squares regression model ) and calibration data of size 15000 (with which to calibrate our various conformal prediction methods). Given the trained predictor , we use non-conformity score . Next, we define the set of groups where for each , . We run Algorithm 1 (BatchGCP) and Algorithm 2 (BatchMVP with buckets) to achieve group-conditional and full multivalid coverage guarantees respectively, with respect to with target coverage . We compare the performance of these methods to naive split-conformal prediction (which, without knowledge of , uses the calibration data to predict a single threshold) and the method of Foygel Barber et al. (2020) which predicts a threshold for each group in that an input is part of, and chooses the most conservative one.




Figures 1 and 2 present results over 50 runs of this experiment. Notice that both BatchGCP and BatchMVP achieve close to the desired group coverage across all groups—with BatchGCP achieving nearly perfect coverage and BatchMVP sometimes deviating from the target coverage rate by as much as 1%. In contrast, the method of Foygel Barber et al. (2020) significantly overcovers on nearly all groups, particularly low-noise groups, and naive split-conformal starts undercovering and overcovering on high-noise and low-noise groups respectively as the expected label-noise increases. Group-wise calibration error is high across all groups but the last using the method of Foygel Barber et al. (2020), and naive split-conformal has low calibration error on groups where inclusion/exclusion reflects less fluctuation in noise, and higher calibration error in groups where there is much higher fluctuation in noise based on inclusion. Both BatchGCP and BatchMVP have lower group calibration errors — interestingly, BatchGCP appears to do nearly as well as BatchMVP in this regard despite having no theoretical guarantee on threshold calibration error. A quantile multicalibrated predictor must have low coverage error conditional on groups and thresholds that appear frequently, and may have high coverage error for pairs that appear infrequently—behavior that we see in BatchMVP in Figure 2. On the other hand, for both naive split conformal prediction and the method of Foygel Barber et al. (2020), we see high mis-coverage error even for pairs containing a large fraction of the probability mass.
We fix the upper-limit of allowed iterations for BatchMVP to 1000, but typically the algorithm converges and halts in many fewer iterations. Across the 50 runs of this experiment, the average number of iterations taken to converge was .
5.2 An Income Prediction Task on Census Data
We also compare our methods to naive split conformal prediction and the method of Foygel Barber et al. (2020) on real data from the 2018 Census American Community Survey Public Use Microdata, compiled by the Folktables package (Ding et al., 2021). This dataset records information about individuals including race, gender and income. In this experiment, we generate prediction sets for a person’s income while aiming for valid coverage on intersecting groups defined by race and gender.
The Folktables package provides datasets for all 50 US states. We run experiments on state-wide datasets: for each state, we split it into 60% training data for the income-predictor, 20% calibration data to calibrate the conformal predictors, and 20% test data . After training the income-predictor on , we use the non-conformity score . There are 9 provided codes for race5551. White alone, 2. Black or African American alone, 3. American Indian alone, 4. Alaska Native alone, 5. American Indian and Alaska Native tribes specified; or American Indian or Alaska Native, not specified and no other races, 6. Asian alone, 7. Native Hawaiian and other Pacific Islander alone, 8. Some Other Race alone, 9. Two or More Races. and 2 codes for sex (1. Male, 2. Female) in the Folktables data. We define groups for five out of nine race codes (disregarding the four with the least amount of data) and both sex codes. We run all four algorithms (naive split-conformal, the method of Foygel Barber et al. (2020), BatchGCP, and BatchMVP with buckets) with target coverage .
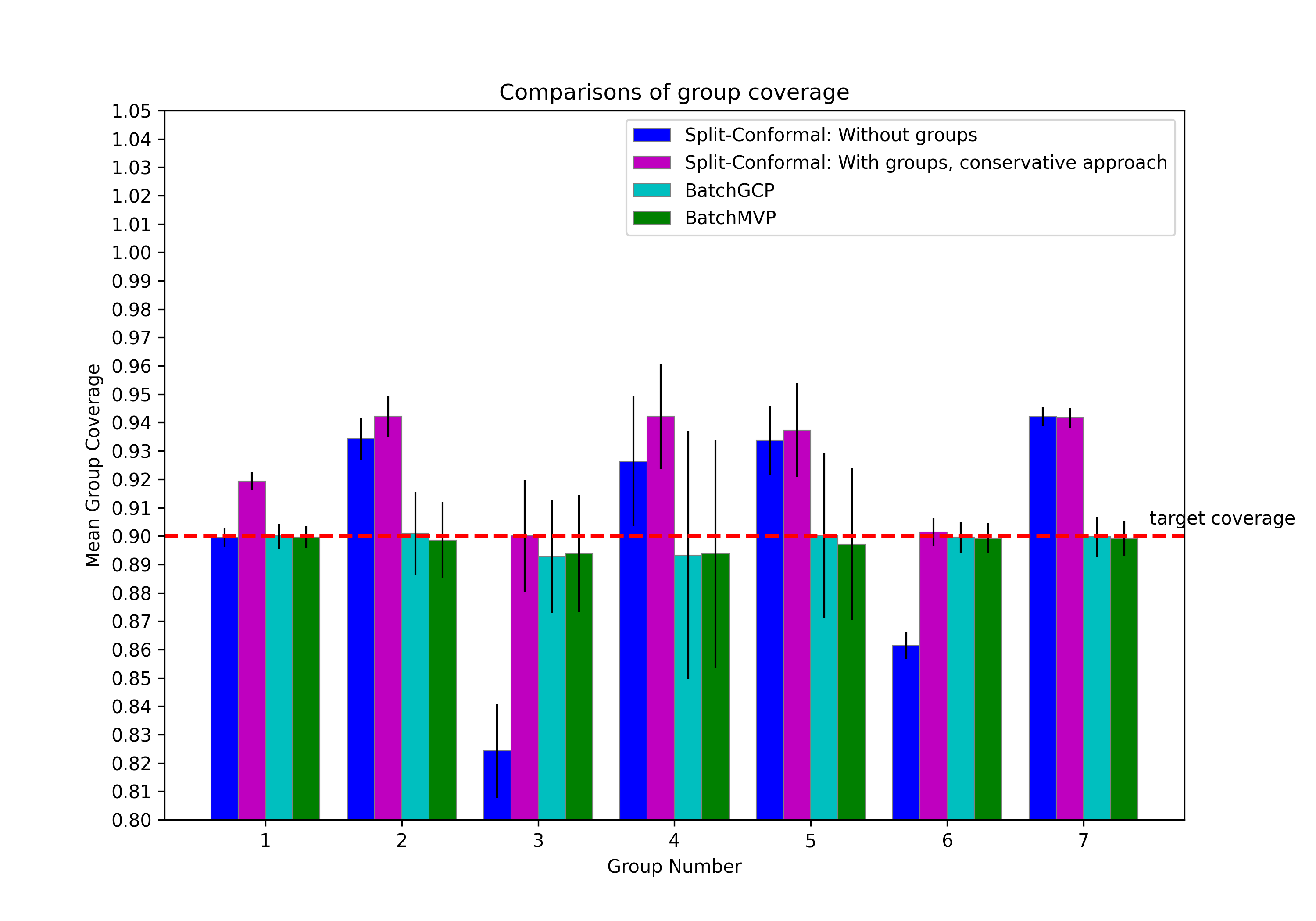
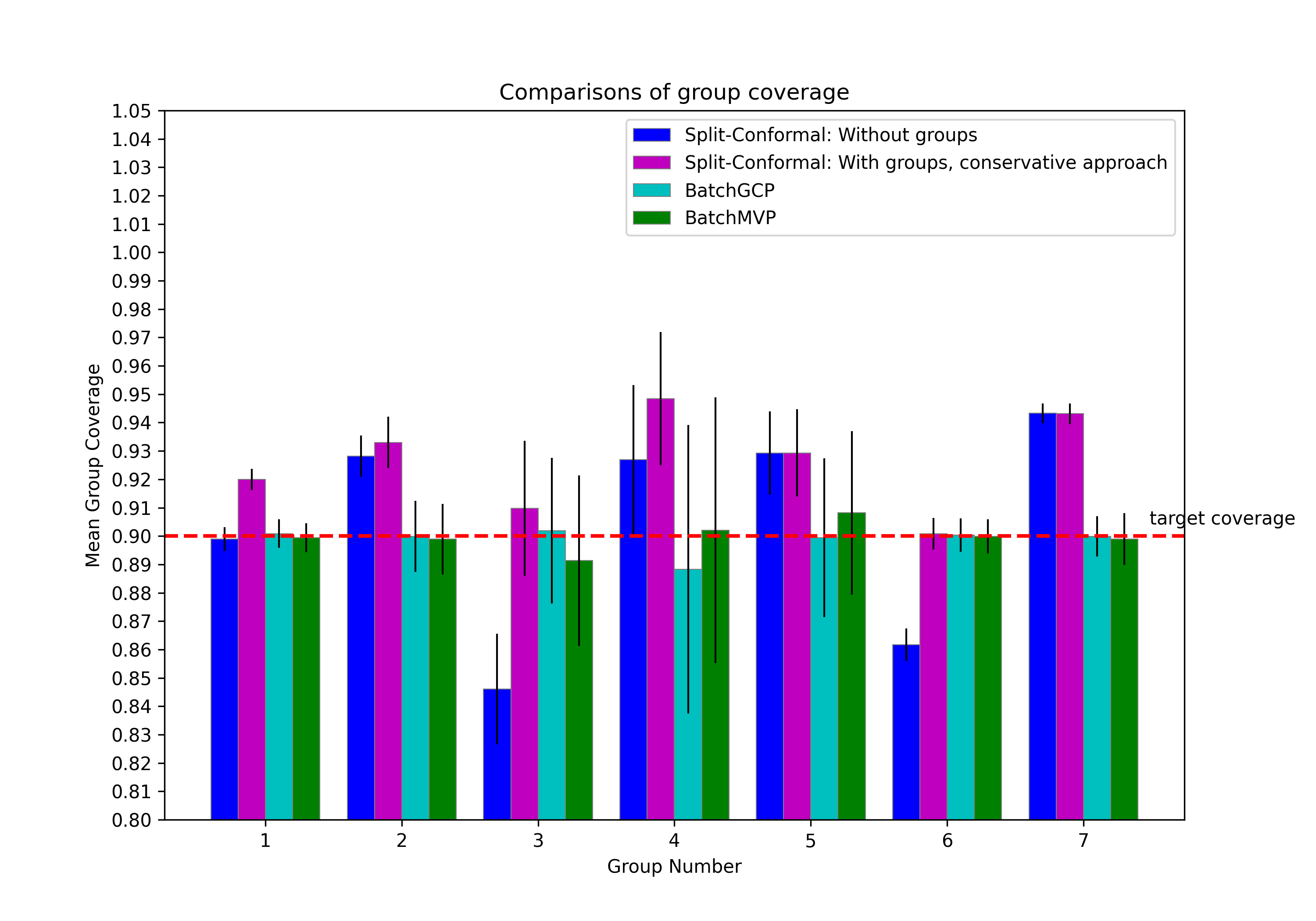
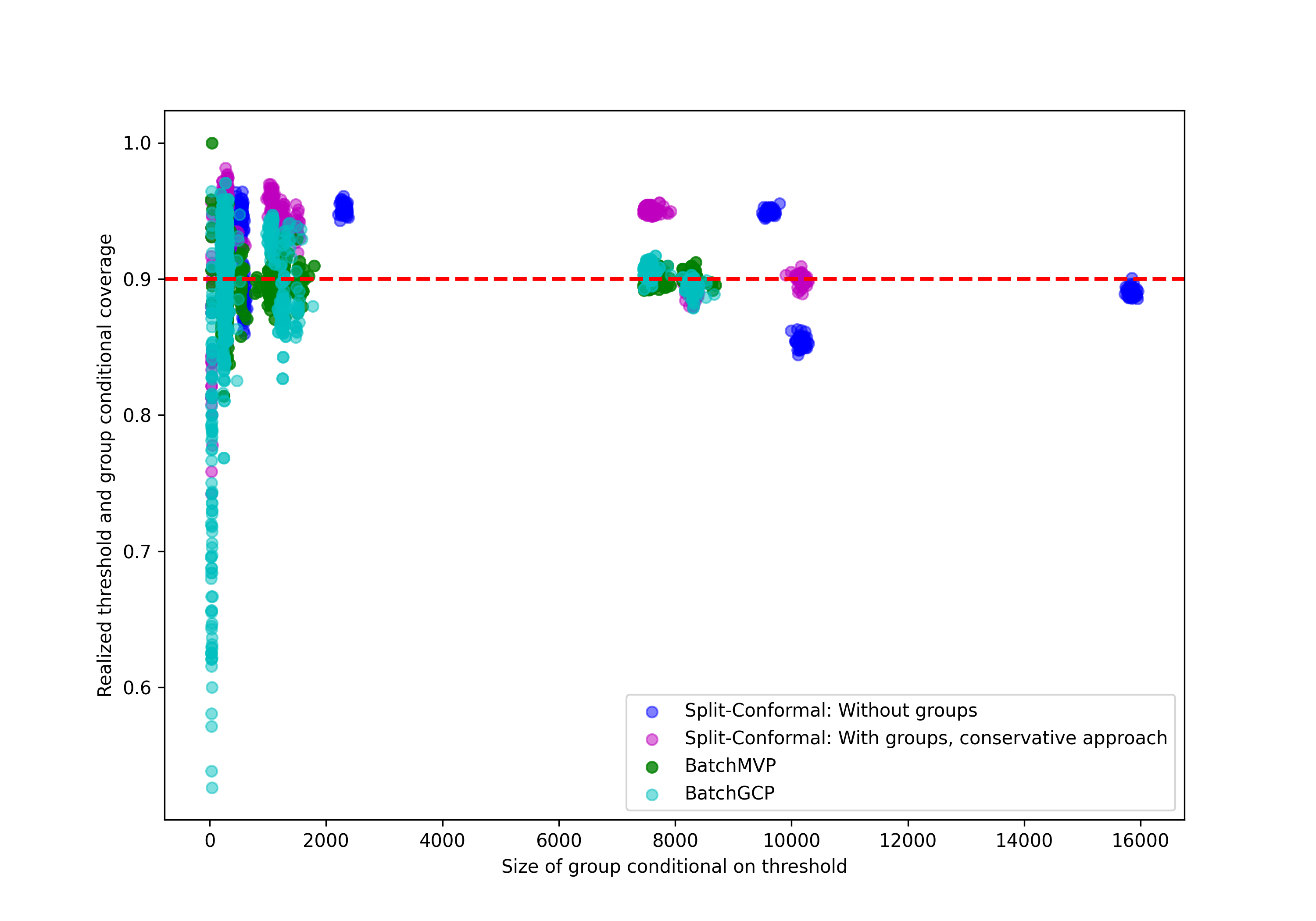
We ran this experiment on the 10 largest states. Figure 3 and Figure 4 present comparisons of the performance of all four algorithms on data taken from California, averaged over 50 different runs. Results on all remaining states are presented in Appendix C.2.
Just as in the synthetic experiments, both BatchGCP and BatchMVP achieve excellent coverage across all groups—in fact now, we see nearly perfect coverage for both BatchGCP and BatchMVP, with BatchGCP still obtaining slightly better group conditional coverage. In contrast, naive split-conformal prediction undercovers on certain groups and overcovers on others, and the method of Foygel Barber et al. (2020) significantly overcovers on some groups (here, group 4 and 7). The conservative approach also generally yields prediction sets of much larger size. We see also that BatchMVP achieves very low rates of calibration error across all groups, outperforming BatchGCP in this regard. Calibration error is quite irregular across groups for both naive split-conformal prediction and for the method of Foygel Barber et al. (2020), being essentially zero in certain groups and comparatively much larger in others. The average number of iterations BatchMVP converged in was .




Acknowledgments
We thank Varun Gupta for useful conversations at an early stage of this work. This work was supported in part by the Simons Foundation collaboration on algorithmic fairness and NSF grants FAI-2147212 and CCF-2217062.
References
- Angelopoulos and Bates [2021] Anastasios N Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511, 2021.
- Angelopoulos et al. [2020] Anastasios Nikolas Angelopoulos, Stephen Bates, Michael Jordan, and Jitendra Malik. Uncertainty sets for image classifiers using conformal prediction. In International Conference on Learning Representations, 2020.
- Bastani et al. [2022] Osbert Bastani, Varun Gupta, Christopher Jung, Georgy Noarov, Ramya Ramalingam, and Aaron Roth. Practical adversarial multivalid conformal prediction. Advances in Neural Information Processing Systems, 2022.
- Bian and Barber [2022] Michael Bian and Rina Foygel Barber. Training-conditional coverage for distribution-free predictive inference. arXiv preprint arXiv:2205.03647, 2022.
- Ding et al. [2021] Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning. Advances in Neural Information Processing Systems, 34, 2021.
- Dwork et al. [2015] Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Leon Roth. Preserving statistical validity in adaptive data analysis. In Proceedings of the forty-seventh annual ACM symposium on Theory of computing, pages 117–126, 2015.
- Dwork et al. [2019] Cynthia Dwork, Michael P Kim, Omer Reingold, Guy N Rothblum, and Gal Yona. Learning from outcomes: Evidence-based rankings. In 2019 IEEE 60th Annual Symposium on Foundations of Computer Science (FOCS), pages 106–125. IEEE, 2019.
- Foygel Barber et al. [2020] Rina Foygel Barber, Emmanuel J Candès, Aaditya Ramdas, and Ryan J Tibshirani. The limits of distribution-free conditional predictive inference. Information and Inference: A Journal of the IMA, 2020.
- Globus-Harris et al. [2022] Ira Globus-Harris, Varun Gupta, Christopher Jung, Michael Kearns, Jamie Morgenstern, and Aaron Roth. Multicalibrated regression for downstream fairness. arXiv preprint arXiv:2209.07312, 2022.
- Gopalan et al. [2022a] Parikshit Gopalan, Adam Tauman Kalai, Omer Reingold, Vatsal Sharan, and Udi Wieder. Omnipredictors. In 13th Innovations in Theoretical Computer Science Conference (ITCS 2022). Schloss Dagstuhl-Leibniz-Zentrum für Informatik, 2022a.
- Gopalan et al. [2022b] Parikshit Gopalan, Michael P Kim, Mihir A Singhal, and Shengjia Zhao. Low-degree multicalibration. In Conference on Learning Theory, pages 3193–3234. PMLR, 2022b.
- Gupta et al. [2022] Varun Gupta, Christopher Jung, Georgy Noarov, Mallesh M. Pai, and Aaron Roth. Online Multivalid Learning: Means, Moments, and Prediction Intervals. In 13th Innovations in Theoretical Computer Science Conference (ITCS 2022), pages 82:1–82:24, 2022.
- Hébert-Johnson et al. [2018a] Ursula Hébert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses. In International Conference on Machine Learning, pages 1939–1948. PMLR, 2018a.
- Hébert-Johnson et al. [2018b] Úrsula Hébert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses. In International Conference on Machine Learning, pages 1939–1948, 2018b.
- Hoff [2021] Peter Hoff. Bayes-optimal prediction with frequentist coverage control. arXiv preprint arXiv:2105.14045, 2021.
- Jung et al. [2021] Christopher Jung, Changhwa Lee, Mallesh M Pai, Aaron Roth, and Rakesh Vohra. Moment multicalibration for uncertainty estimation. In Conference on Learning Theory. PMLR, 2021.
- Kearns et al. [2018] Michael Kearns, Seth Neel, Aaron Roth, and Zhiwei Steven Wu. Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In International Conference on Machine Learning, pages 2564–2572, 2018.
- Kearns et al. [2019] Michael Kearns, Seth Neel, Aaron Roth, and Zhiwei Steven Wu. An empirical study of rich subgroup fairness for machine learning. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 100–109, 2019.
- Kim et al. [2019] Michael P Kim, Amirata Ghorbani, and James Zou. Multiaccuracy: Black-box post-processing for fairness in classification. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 247–254, 2019.
- Lei et al. [2018] Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression. Journal of the American Statistical Association, 113(523):1094–1111, 2018.
- Papadopoulos et al. [2002] Harris Papadopoulos, Kostas Proedrou, Volodya Vovk, and Alex Gammerman. Inductive confidence machines for regression. In European Conference on Machine Learning, pages 345–356. Springer, 2002.
- Park et al. [2019] Sangdon Park, Osbert Bastani, Nikolai Matni, and Insup Lee. Pac confidence sets for deep neural networks via calibrated prediction. In International Conference on Learning Representations, 2019.
- Ressel [1985] Paul Ressel. De finetti-type theorems: an analytical approach. The Annals of Probability, 13(3):898–922, 1985.
- Romano et al. [2019] Yaniv Romano, Evan Patterson, and Emmanuel Candes. Conformalized quantile regression. Advances in neural information processing systems, 32, 2019.
- Romano et al. [2020a] Yaniv Romano, Rina Foygel Barber, Chiara Sabatti, and Emmanuel Candès. With malice toward none: Assessing uncertainty via equalized coverage. Harvard Data Science Review, 2020a.
- Romano et al. [2020b] Yaniv Romano, Matteo Sesia, and Emmanuel Candes. Classification with valid and adaptive coverage. Advances in Neural Information Processing Systems, 33:3581–3591, 2020b.
- Rothblum and Yona [2021] Guy N Rothblum and Gal Yona. Multi-group agnostic pac learnability. In International Conference on Machine Learning, pages 9107–9115. PMLR, 2021.
- Shafer and Vovk [2008] Glenn Shafer and Vladimir Vovk. A tutorial on conformal prediction. Journal of Machine Learning Research, 9(Mar):371–421, 2008.
Appendix A Missing Details from Section 3
A.1 Missing Details from Section 3.1
Lemma A.1.
Fix any and .
Proof.
∎
See 3.1
Proof.
where the fourth equality follows from Lemma A.1.
For convenience, write . Note that
as instead of sweeping the area under the curve from to , we can sweep the area under the curve from to because .
Lemma A.2.
Fix any conformity score distribution that is -Lipschitz, , and . Then we have
Proof.
For simplicity write . Note that is a non-negative function that is increasing in .
First, we find an upper bound the area. The maximum area that can be achieved is when there’s a linear rate of increase from to between and as depicted in Figure 5. The area measured via the integral can be calculated by subtracting the area of the triangle from the area of the rectangle from to and from to .
Now, we find a lower bound of the area. The area under the curve is minimized when there’s a linear increase from to between and . The area can be calculated as the sum of the area of the rectangle from to and from to and the area of the triangle.
∎
Case (i) :
We have and .
On the other hand,
Case (ii) :
We have we have and where , we have
On the other hand, we have
∎
See 3.2
Proof.
Note that ’s marginal quantile consistency error with respect to target quantile as measured on is
Also, since is continuous, we have
In other words, satisfies marginal quantile consistency for as measured on .
A.2 Missing Details from Section 3.2
See 3.1
Proof.
Suppose is not marginally quantile consistent on some — i.e. . In other words, there exists some such that
Suppose we patch
which can be re-written as
where and for all other .
A.3 Missing Details from Section 3.3
See 3.1
Proof .
Consider any .
In particular, since each term in the sum is non-negative, we must have for every :
Dividing both sides by we see that this is equivalent to:
Taking the square root yields our claim. ∎
See 3.2
Proof.
(1) Marginal quantile consistency error in each round :
At any round , if is not -approximately quantile multicalibrated with respect to and , we have
as the average of elements is greater than .
(2) Decomposing the patch operation into two patch operations:
Write
to denote how much we would have patched by if we actually optimized over the unit interval. Then, we can divide the patch operation into two where
Now, we try to bound the change in the pinball loss separately:
(2) Bounding (**):
Lemma 3.2 yields
(3) Bounding (*):
Note that for some . Because the function is an increasing function in , we have
| for any | ||||
In other words, so we have . Because is -Lipschitz and is -quantile for , we can bound the marginal quantile consistency error of against as
as .
Note that for and for where . Applying Lemma 3.1 with , , and , we have that
(4) Combining (*) and (**):
We get
(5) Guarantees:
It directly follows that
With for any , we note that must be -approximately quantile multicalibrated with respect to and after at most many rounds. ∎
Appendix B Missing Details from Section 4
B.1 On the i.i.d. versus exchangeability assumption
Remark B.1.
In this section, we prove PAC-like generalization theorems for our algorithms under the assumption that the data is drawn i.i.d. from some underlying distribution. Exchangeability is a weaker condition than independence, and requires only that the probability of observing any sequence of data is permutation invariant. De Finetti’s representation theorem [Ressel, 1985] states that any infinite exchangeable sequence of data can be represented as a mixture of constituent distributions, each of which is i.i.d. Thus, our generalization theorems carry over from the i.i.d. setting to the more general exchangeable data setting: we can simply apply our theorems to each (i.i.d.) mixture component in the De Finetti representation of the exchangeable distribution. If for every mixture component, the model we learn has low quantile multicalibration error with probability when the data is drawn from that component, then our models with also have low quantile multicalibration error with probability in expectation over the choice of the mixture component.
B.2 Helpful Concentration Bounds
Theorem B.1 (Additive Chernoff Bound).
Let be independent random variables bounded such that for each , . Let denote their sum. Then for all ,
Theorem B.2 (Multiplicative Chernoff Bound).
Let be independent random variables bounded such that for each , . Let denote their sum. Then for all ,
Lemma B.1.
Fix any . Given , we have
Proof.
This is just a direct application of the Chernoff bound (Theorem B.2) where we set . ∎
Lemma B.2.
Fix any and . Given , we have
Proof.
This is just a direct application of the Chernoff bound (Theorem B.2) where we set . ∎
Lemma B.3.
Fix any and . Suppose . Given , we have that with probability
Proof.
With , we can show that
where for (*), we rely on the assumption that to apply the inequality for and for (**), we rely on to get .
∎
Lemma B.4.
Fix any and . Suppose . Given , we have that with probability
for any .
Proof.
where we use Lemma B.3 for the last inequality. ∎
Lemma B.5.
Fix , , and . Given , we have with probability
B.3 Out of sample guarantees for BatchGCP
Theorem B.3.
Suppose is -Lipschitz, and write and given some drawn from . Then we have with probability over the randomness of drawing from
where , , , and .
Proof.
Fix some . For any fixed where , the Chernoff Bound (Theorem B.1) with rescaling gives us that with probability over the randomness of drawing from ,
| (1) |
as is -Lipschitz.
We now show how to union bound the above concentration over all where . To do so, we first create a finite -net for a ball of radius and union-bound over each in the net. Then we can argue that due to the Lipschitzness of the pinball loss , the empirical pinball loss with respect to each that is in the ball must be concentrated around its distributional loss.
We fist provide the standard -net argument:
Lemma B.6.
Fix and . There exists a where such that the following holds true: for every where , there exists such that .
Proof.
For simplicity, write .
We say that a set is an -net of if for every , there exists such that .
Without loss of generality, we suppose . Since an -cover of can be scaled up to an -cover of — i.e. given which is an -cover of , the following set is an -cover of .
Now, choose a set to be a maximally -separated subset of : for every , and no set such that has this property.
Due to its maximal property, must be an -cover for . Otherwise, it means that there exists some point such that for every . Note that would still be an -separate subset of , contradicting the maximality of .
Due to the -separability of , we have that the balls centered at each with radius of is all disjoint, meaning the sum of the volume of these balls is the volume of their union. On the other hand, we have that they all lie in a ball of radius , . Therefore, we have
Since , we have that
∎
By union-bounding inequality (1) over , we have that with probability
Using -Lipschitzness of , we can further show that for any where , we have
where is chosen such that and we can find such because is an -net for the ball of radius .
Setting yields
for sufficiently large .
We set so that . In other words, with probability , we have simultaneously over all and where
In other words, the final output from BatchGCP and which is the optimal solution with respect to the true distribution must be such that
where . In other words,
Now, for the sake of contradiction, suppose that there exists some such that
where .
Then, Lemma 3.2 tells us that we can decrease the true pinball loss with respect to by at least by patching . However, that cannot be the case that as that would mean there exists such that
where is such that for all and is chosen to satisfy
This is a contradiction as we have already defined
∎
B.4 Out of sample guarantees for BatchMVP
B.4.1 Out-of-sample quantile multicalibration bound for fixed
See 4.1
Proof .
For each , define . Note that
as .
Fixed any and . Union-bounding Lemma B.5 over and , we have that for any , with probability ,
We can further bound as
where we used and . Inequality follows from the fact that is concave and so the optimization problem where is maximized at for each .
In other words, with probability , we simultaneously have for every
Finally, when our algorithm halts at round , is -approximately multicalibrated with respect to its empirical distribution . Therefore, we have
∎
B.4.2 Sample complexity of maintaining convergence speed of BatchMVP
We write and
to denote the set of all possible models we could obtain at round of Algorithm 2 regardless of what dataset is used as input.
Lemma B.7.
Fixing the initial model , the number of distinct models that can arise at round of Algorithm 2 (quantified over all possible input datasets ) is upper bounded by:
Proof.
The proof is by induction on . By construction we have . Now, note that because we consider all possible combinations of and . Therefore, if for some , then . ∎
See 4.2
Proof .
Fix any round . Because is not -approximately quantile multicalibrated with respect to and on , we have
Now, the patch operation in this can be decomposed into the following:
For convenience, we write
Now, we show that we decrease the empirical pinball loss as we go from to in each round with high probability.
(1) :
First, we can show progress in terms of the pinball loss on and then by a Chernoff bound, we can show that we have made significant progress on with high probability. More specifically, we must have decreased the pinball loss with respect to by going from to . Note that is chosen to satisfy the target quantile with respect to and is -Lipschitz.
Because the empirical quantile error was significant for , we can show that the true quantile error must have been significant. By union bounding Lemma B.5 over all and using Lemma B.7 to bound the cardinality of , we have with probability
as long . In other words, we have
If , then we have
As achieves the target quantile against and the quantile error was at least , applying Lemma 3.2 yields
(2) :
Recall that results from rounding to the nearest grid point in . Because is -Lipschitz and satisfies the target quantile for , we can bound the marginal quantile consistency error of against as
as .
Note that for and for where . Applying Lemma 3.1 with , , and , we have that
We have so far shown that with probability ,
By union boudning the Chernoff bound (Theorem B.1) over , we can show that concentrates around for every : with probabiliy , we simultaneously have
as .
In other words, we have with probability
(3) :
Because is chosen to minimize with respect to the empirical distribution out of grid points , we can show that the pinball loss against the empirical distribution must be lower for than .
We can calculate the derivative of the pinball loss with respect to the patch as
Because is convex in , minimizing this function is equivalent to minimizing the absolute value of its derivative, which is how is set. Therefore, is minimized at . Hence, we have with probability ( to argue that there is significant quantile consistency error on with respect to and to argue that the empirical pinall loss concentrates around its expectation),
as we have chosen .
If , we have
Because we decrease the empirical pinball loss by in each round with probability , we have that with probability , the algorithm halts at round . If
we satisfy all the requirements that we stated previous for in each round .
If we set , we have with probability , the algorithm halts in where we require
∎
Appendix C Additional Experiments and Discussion
C.1 A Direct Test of Group Conditional Quantile Consistency and Quantile Multicalibration
In this section we abstract away the non-conformity score, and directly perform a direct evaluation of the ability of BatchGCP and BatchMVP to offer group conditional and multivalid quantile consistency guarantees. We produce a synthetic regression dataset defined to have a set of intersecting groups that are all relevant to label uncertainty. Specifically, the data is generated as follows. First, we define our group collection as , where for each , the group contains all multiples of . Note that group encompasses the entire covariate space, ensuring that our methods will explicitly enforce marginal coverage in addition to group-wise coverage. Each is a random integer sampled uniformly from the range . We let the corresponding label , where is distributed as the sum of i.i.d. random variables, where is the number of groups that belongs to. After generating our data, we split it into training data and test data . We then run both methods on the group collection , for target coverage , with buckets.
The group coverage obtained by both methods on a sample run can be seen in Figure 6. Generally, both methods achieve target group-wise coverage level on all groups, with BatchMVP exhibiting less variance in the attained coverage levels across different runs. Meanwhile, the group-wise quantile calibration errors of both models are presented in Figure 7. Both BatchMVP and BatchGCP are very well-calibrated on all groups, with calibration errors on the order of — even though unlike BatchMVP, the definition of BatchGCP does not enforce this constraint explicitly.



C.2 Further Comparisons On State Census Data
In Section 5.2 we performed an income-prediction task using census data (Ding et al. [2021]) from the state of California to compare the performance of BatchGCP and BatchMVP against each other, as well as against other regularly used conformal prediction methods. Here, we present results of the same experiment using data from other US states. We selected the ten largest states (by population data) to work with, of which California is one. Results for every state are averaged over 50 runs of the experiment, taking different random splits over the data (to form training, calibration, and test sets) each time. The plots in Figure 8, Figure 9, Figure 10 and Figure 11 compare the performance of all four methods with metrics such as group-wise coverage, prediction-set size, and group-wise quantile calibration error.

































C.2.1 Halting Time
Recall that our generalization theorem for BatchMVP is in terms of the number of iterations it runs for before halting. We prove a worst-case upper bound on , but note that empirically BatchMVP halts much sooner (and so enjoys improved theoretical generalization properties). Here we report the average number of iterations that BatchMVP runs for before halting on each state, averaged over the 50 runs, together with the empirical standard deviation.
Texas: .
New York:
Florida:
Pennsylvania:
Illinois:
Ohio:
North Carolina:
Georgia:
Michigan: