Barrier Certified Safety Learning Control:
When Sum-of-Square Programming Meets Reinforcement Learning
Abstract
Safety guarantee is essential in many engineering implementations. Reinforcement learning provides a useful way to strengthen safety. However, reinforcement learning algorithms cannot completely guarantee safety over realistic operations. To address this issue, this work adopts control barrier functions over reinforcement learning, and proposes a compensated algorithm to completely maintain safety. Specifically, a sum-of-squares programming has been exploited to search for the optimal controller, and tune the learning hyperparameters simultaneously. Thus, the control actions are pledged to be always within the safe region. The effectiveness of proposed method is demonstrated via an inverted pendulum model. Compared to quadratic programming based reinforcement learning methods, our sum-of-squares programming based reinforcement learning has shown its superiority.
I Introduction
Reinforcement learning (RL) is one of the most popular methods for accomplishing the long-term objective of a Markov-decision process [1, 2, 3, 4, 5, 6]. This learning method aims for an optimal policy that can maximize a long-term reward in a given environment recursively. For the case of RL policy gradient method [7, 8, 9], this reward-related learning problem is traditionally addressed using gradient descent to obtain superior control policies.
RL algorithms might generate desired results in some academic trials, e.g., robotic experiments [10, 11] and autonomous driving contexts [12, 13]. But for realistic situations, how to completely guarantee the safety based on these RL policies is still a problem. The intermediate policies from the RL agent’s exploration and exploitation processes may sometimes ruin the environment or the agent itself, which is unacceptable for safety-critical systems. Moreover, disturbances around the system would confuse the agent over learning process, which make the control tasks more complex and challenging.
To cope with the issues above, various methods are proposed to specify dynamical safety during the learning process. Initially, the region of attraction (ROA) from control Lyapunov functions or Lyapunov-like function work [14, 15] are used to certify the dynamical safety. Related and useful work of ROA estimation are introduced in [16, 17, 18, 19]. In 2017, [20] started to execute the RL’s exploration and exploitation in ROA to maintain safety. Different from region constraint, in 2018 [21, 22] proposed a shield framework to select safe actions repeatedly. Inspired by this work, [23, 24] further combined the control barrier function (CBF) to synthesis the RL-based controller. Note that, the CBF is not new to identify safe regions in control theory, [25, 26] are representative work to combine CBF in biped robot and [27] explored its implementation of quadrotors, etc. Appropriate region constraint for RL is important for building safe RL. Hence, a reliable learning method is expected to construct a controller inside the safe region over the process.
In this paper, we will consider a state-space model in the polynomial form, including an unknown term that estimated by Gaussian process. Then, we will apply Deep Deterministic Policy Gradient (DDPG) algorithm to design a controller. The generated control action will impact system dynamics and further influence the sum-of-squares programming (SOSP) solution of control barrier functions.
The main contributions of this work are: (1) Formulate the framework to embed SOSP-based CBF into DDPG algorithm; (2) compare the performance of quadratic programming (QP)-based and SOSP-based controller with DDPG algorithm; and (3) demonstrate the safety and efficiency of DDPG-SOSP algorithm via an inverted pendulum model.
This paper is organized as follows, we first present some preliminaries about reinforcement learning, Gaussian process and control barrier function in Section II. Then, in Section III, we formulate the steps to compute an SOSP-based controller and introduce a corresponding DDPG-SOSP algorithm. Numerical examples are given for these cases in Section IV, then we discuss the learning efficiency and safety performance of QP-based and SOSP-based strategies, before concluding this paper.
II Preliminary
A discrete-time nonlinear control-affine system with state and control action is considered as:
| (1) |
where are finished within a bounded time , while and are constants.
Notation: From the infinite-horizon discounted Markov decision process (MDP) theory [28], let denote the reward of the current state-action pair in (1), let denote the probability distribution to next state , and let denote a discount factor. Thus, a MDP tuple establishes at each state .
II-A Reinforcement Learning
RL focuses on training an agent to map various situations to the most valuable actions in a long-term process. During the process, the agent will be inspired by a cumulative reward to find the best policy . Various novel RL algorithms are proposed to select optimal . For more details of selecting , we kindly refer interested readers to [1].
Given MDP tuple , the RL agent is selecting an optimal policy by maximizing the expected reward
| (2) |
Furthermore, the action value function can be generated from and satisfies the Bellman equation as follows,
| (3) | ||||
In this paper, we will use DDPG algorithm, a typical actor-critic and off-policy method, to handle the concerned dynamics of (1). Let parameters and denote the neural network of actor and critic, respectively. By interacting with the environment repeatedly, the actor will generate an actor policy and be evaluated by the critic via . These actions will be stored in replay buffer to update the policy gradient w.r.t , and the loss function w.r.t , once if the replay buffer is fulfilled.
II-B Gaussian Process
Gaussian processes (GP) estimate the system and further predict dynamics based on the prior data. A GP is a stochastic process that construct a joint Gaussian distribution with concerned states . We use GP to estimate the unknown term in (1) during the system implementation. Mixed with an independent Gaussian noise , the GP model’s prior data can be computed from indirectly. Then, a high probability statement of the posterior output generates as
| (4) |
where the mean function and the variance function can describe the posterior distribution as
| (5) |
with probability greater or equal to , [29], where is a parameter to design interval . Therefore, by learning a finite number of data points, we can estimate the unknown term of any query state .
As the following lemma declaims in [30, 31], there exists a polynomial mean function to approximate the term via GP, which can predict the output of state straightly here.
Lemma 1.
Suppose we have access to measurements of in (1) that corrupted with Gaussian noise . If the norm unknown term bounded, the following GP model of can be established with polynomial mean function and covariance function ,
| (6) | ||||
within probability bounds , where , is a query state, is a monomial vector, is a coefficient vector, is a kernel Gramian matrix and .
II-C Control Barrier Function
The super-level set of the control barrier function (CBF) could validate an safety set as
| (9) |
Throughout this paper, we refer to as a safe region and
| (10) |
as unsafe regions of the dynamical system (8). Then, the state will not enter into by satisfying the forward invariant constraint below,
| (11) |
where . Before we demonstrate the computation of of the system (8), the Positivestellensatz (P-satz) needs to be introduced first [33].
Let be the set of polynomials and be the set of sum of squares polynomials, e.g., where and .
Lemma 2.
For polynomials , and , define a set . Let be compact. The condition holds if the following condition is satisfied,
Lemma 2 points out that any strictly positive polynomial lies in the cone that generated by non-negative polynomials in the set of . Based on the definition of and , P-satz will be adequately used in the safety verification.
The sufficient condition to establish a CBF is the existence of a deterministic controller . Based on Lemma 2, we can compute a polynomial controller through SOS program to avoid entering into unsafe regions at each step .
Lemma 3.
Proof.
Let us suppose that there exists a CBF that certified a safe region . Then, a deterministic input is needed to establish the necessary condition in (11) of the system (8).
Since is a polynomial function, if is also a polynomial, will maintain in the polynomial form. According to Lemma 2, we can formulate this non-negative condition of as part of SOS constraint in the cone of as
| (13) |
where the auxiliary SOS polynomials is used to project the related term into an non-negative compact domain that certified by the superlevel set of .
We continue to leverage the P-satz again to drive the dynamics of (8) far from unsafe areas as follows,
| (14) |
where denote the corresponding SOS polynomials. Guided by the optimization (LABEL:eq:CLF-CBF-discrete), we can solve a minimal cost control to maintain system safety with (LABEL:eq:text1) and (14), which completes the proof. ∎
This lemma maintains the safety of polynomial system (8) and minimizes the current control with a SOS program. Multiple unsafe regions are also considered in solving the target input in (LABEL:eq:CLF-CBF-discrete). Since Lemma 1 discussed the probabilistic relationship of (8) and (1), the computed result of (LABEL:eq:CLF-CBF-discrete) of (1) can also be a feasible control to regulate the true dynamics safely.
III CBF Guiding Control with Reinforcement Learning
In the first part of this section, we will further express the computation steps of (LABEL:eq:CLF-CBF-discrete). In the second part, we will go through the details about the SOSP-based CBF guiding control with DDPG algorithm.
III-A SOS Program Based CBF
Different from [23], our control is solved by SOS program with polynomial barrier functions, rather than the QP and linear barrier functions. In [23], they initially constructed QP with monotonous linear barrier constraints to cope with RL. Obviously, a safe but more relaxed searching area will enhance the RL training performance. We propose a SOS program to compute a minimal control with polynomial barrier function based on Lemma 3.
Lemma 3 declared that we can compute a minimal control from an approximated polynomial system (8) directly. However, it is hard to define the minimization of the convex function in (LABEL:eq:CLF-CBF-discrete). The optimal control can be searched by using the following 2 steps:
Step 1: Search an optimal auxiliary factor by maximizing the scalar ,
| (15) | ||||||
| s.t. | ||||||
where is an auxiliary factor to obtain a permissive constraint for the existing action .
Step 2: Given from last step, search an optimal control of with minimal control cost by minimizing the scalar ,
| (16) | ||||||
| s.t. | ||||||
Remark.
III-B SOS Program Based CBF with Reinforcement Learning
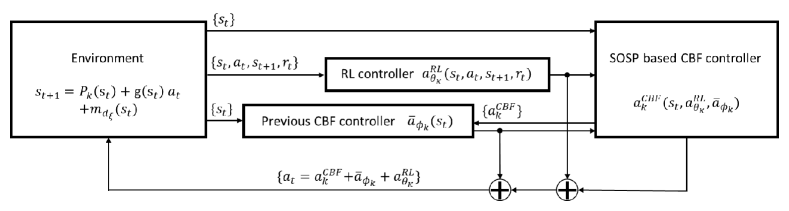
The workflow of the CBF guiding DDPG control algorithm is shown in Fig. 1, which is akin to the original idea in [23] to push the agent’s action into a safe training architecture. In Fig. 1, we list these flowing elements into brackets and highlight the corresponding input of each factor computation.
We illustrate the core idea of CBF guiding RL control as,
| (17) |
where the final action consists of a RL-based controller , a previous deployed CBF controller and a SOS program based CBF controller . A clear distinction of the subscript and is stated here: denotes the step number of each policy iteration and denotes the policy iteration number over the learning process.
More specifically, the first term in (17) is an action generated from a standard DDPG algorithm with parameter . The second term demotes a global consideration of previous CBF controllers. Since it is impractical to compute the exact value of each CBF action at each step. Supported by the work of [23], we approximate this term as , where denotes an output from the multilayer perceptron (MLP) with hyperparameters . Then, we fit the MLP and update with at each episode.
The third term in (17) is a real-time value based on the deterministic value , and . Although there exists an unknown term in the system (1), we can still solve the dynamical safety in the approximated polynomial system (8). So, the optimal in (17) can be computed by the SOS program below with deterministic and
| (18) | ||||||
| s.t. | ||||||
Thus, we can establish a controller by satisfying the solution of (LABEL:eq:sosclb) over the learning process.
Theorem 1.
Given a barrier function in (9), a partially unknown dynamical system (1) and a corresponding approximated system (8), while (8) is a stochastic statement of (1) within the probabilistic range , suppose there exists an action satisfying (LABEL:eq:sosclb) in the following form:
| (19) | ||||
Then, the controller (19) guarantees the system (1) inside the safe region within the range of probability .
Proof.
Regarding the system (8), this result follows directly from Lemma 3 by solving the SOS program (LABEL:eq:sosclb). The only different part of SOS program (LABEL:eq:sosclb) from the SOS program (LABEL:eq:CLF-CBF-discrete) in Lemma 3 is the action here contains additional deterministic value and .
Since the output of (LABEL:eq:sosclb) can regulate the dynamics of the model (8) in a safe region, while the approximated model (8) is a stochastic statement of the original system (1) with the probability greater or equal to . Then, the solution of (LABEL:eq:sosclb) can be regarded as a safe control to drive the system (1) far from dangerous, which ends the proof. ∎
We display an overview of the whole steps in the combination of the aforementioned factors over the learning process. The detailed workflow is outlined in Algorithm 1
IV Numerical Example
A swing-up pendulum model from OpenAI Gym environment (Pendulum-v1) is used to verify the above theorems,
| (20) |
Let , . The dynamics of (20) are defined as
| (21) |
where denotes unknown dynamics that generate by inaccurate parameters , , as [23] introduced. When we try to construct a polynomial system (8), the in (21) will be approximated by Chebyshev interpolants within . Then, with SOSOPT Toolbox [34], Mosek solver [35] and Tensorflow, we implement Algorithm 1 in the pendulum model.
The related model parameters are given in Table 1.
TABLE 1: Swing-up Pendulum Model Parameters
| Model Parameter | Symbol | Value | Units |
|---|---|---|---|
| Pendulum mass | kg | ||
| Gravity | |||
| Pendulum length | m | ||
| Input torque | N | ||
| Pendulum Angle | rad | ||
| Angle velocity | |||
| Angle acceleration | — |
We want to maintain the pendulum angle always in a safe range during the learning process. Three RL algorithms are selected and compared in this example, including the DDPG-ONLY algorithm [5], CBF-based DDPG-QP algorithm [23] and CBF-based DDPG-SOSP algorithm (our work). The codes of CBF-based DDPG-SOSP can be found at the url: https://github.com/Wogwan/CCTA2022_SafeRL.
All of these algorithms are trained in episodes and each episode contains steps. Each step is around . And the reward function is defined such that the RL agent are expected to keep the pendulum upright with minimal , and .
(a)
(b)
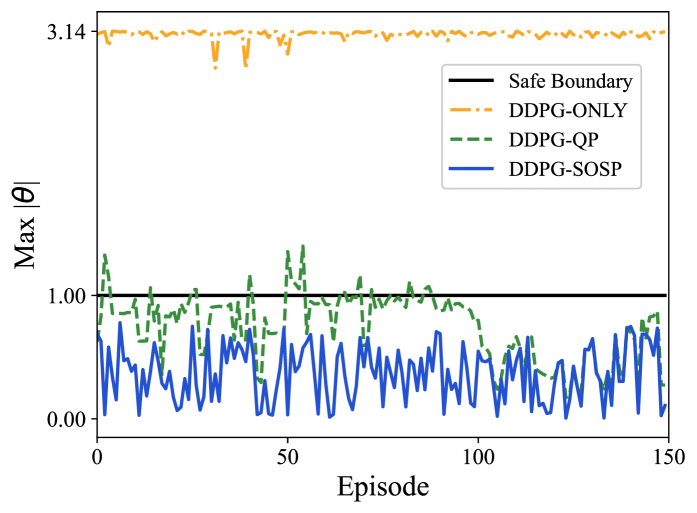
Fig. 2 compares the collected maximum at each episode by using different algorithms. As a baseline algorithm, DDPG-ONLY explored every state without any safety considerations, while DDPG-QP sometimes violated the safe state and DDPG-SOS completely kept in safe regions.
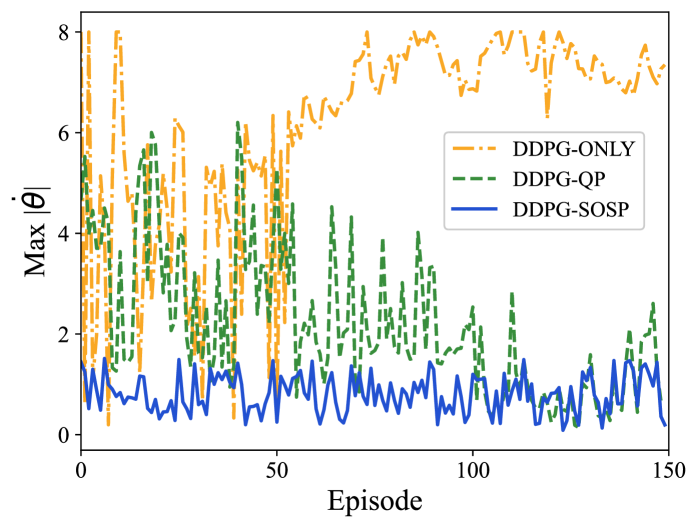
The historical maximum value of of these algorithms is compared and shown in Fig. 3. It is found that DDPG-SOS is able to maintain the pendulum into a lower easily than others over episodes.
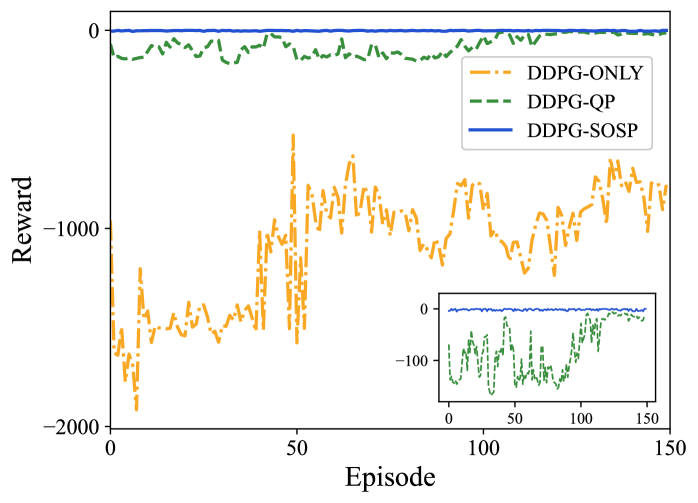
In Fig. 4, from the reward curve of these algorithms, it is easy to observe the efficiency of different algorithms: DDPG-SOS obtains comparatively lower average reward and thus a better performance.
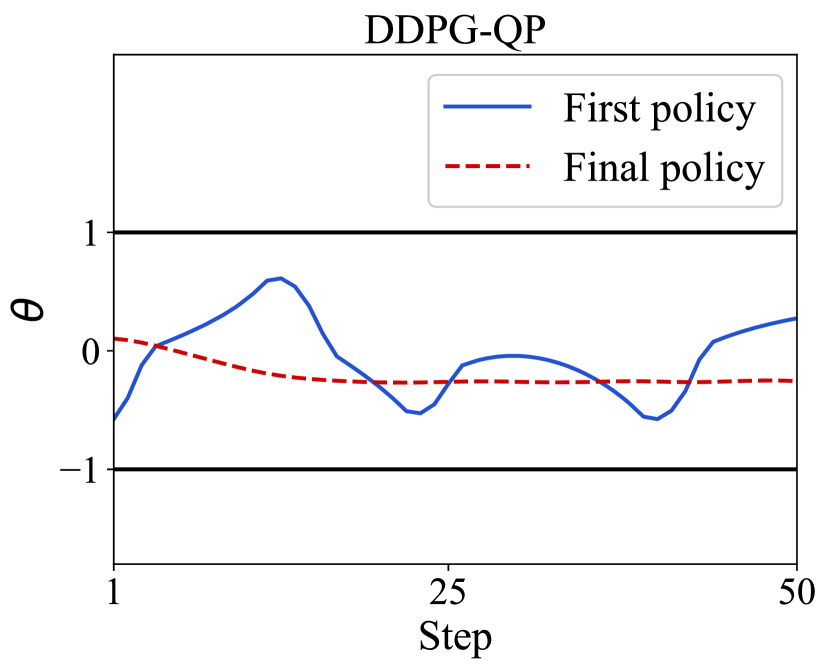
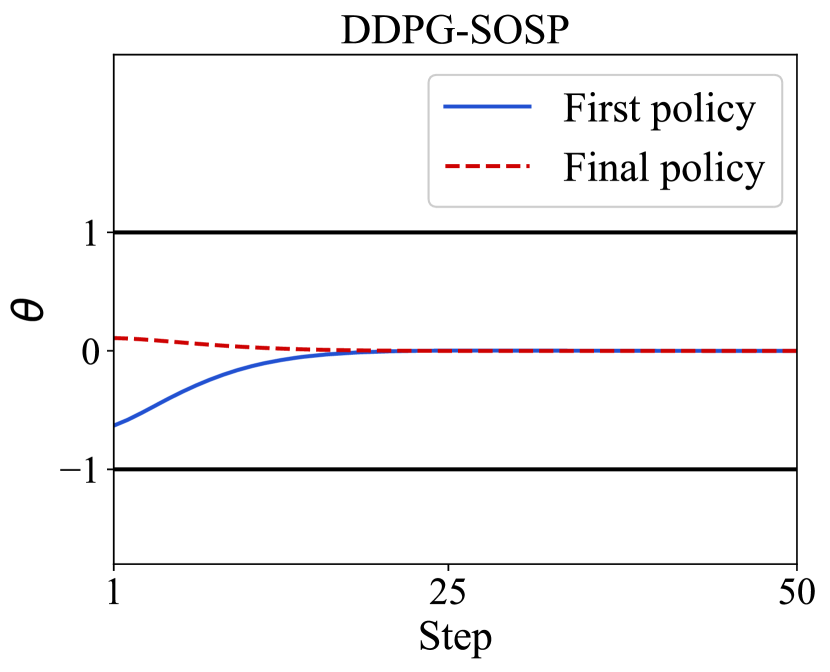
Fig. 5 shows the first ( episode) and the final ( episode) policy guided control performance between DDPG-QP and DDPG-SOSP algorithm. We observed steps of the pendulum angle to highlight the superiority of these two algorithms. Both in Fig. 5(a) and (b), the final policy can reach a smoother control output with less time. Although DDPG-SOSP takes a quicker and smoother action to stabilize the pendulum than DDPG-QP, but the time consuming will increase due to the dynamics regression and optimization computation under uncertainty. Accordingly, the result of DDPG-SOSP algorithm of model (20) is not only obviously stabler than DDPG-QP, but also maintaining the RL algorithm action’s safety strictly.
V Conclusion
In this paper, we consider a novel approach to guarantee the safety of reinforcement learning (RL) with sum-of-squares programming (SOSP). The objective is to find a safe RL method toward a partial unknown nonlinear system such that the RL agent’s action is always safe. One of the typical RL algorithms, Deep Deterministic Policy Gradient (DDPG) algorithm, cooperates with control barrier function (CBF) in our work, where CBF is widely used to guarantee the dynamical safety in control theories. Therefore, we leverage the SOSP to compute an optimal controller based on CBF, and propose an algorithm to creatively embed this computation over DDPG. Our numerical example shows that SOSP in the inverted pendulum model obtains a better control performance than the quadratic program work. It also shows that the relaxations of SOSP can enable the agent to generate safe actions more permissively.
For the future work, we will investigate how to incorporate SOSP with other types of RL including value-based RL and policy-based RL. Meanwhile, we check the possibility to solve a SOSP-based RL that works in higher dimensional cases.
References
- [1] R. S. Sutton, A. G. Barto, ”Reinforcement learning: An introduction,” MIT press, 2018.
- [2] Y. Duan, X. Chen, R. Houthooft, J. Schulman, P. Abbeel, “Benchmarking deep reinforcement learning for continuous control,” in Proc. Int. Conf. on Machine Learning, pp. 1329–1338, PMLR, 2016.
- [3] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [4] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, et al., “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016.
- [5] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D. Wierstra, “Continuous control with deep reinforcement learning,” ArXiv:1509.02971, 2015.
- [6] Li, Z., Cheng, X., Peng, X. B., Abbeel, P., Levine, S., Berseth, G., Sreenath, K., ”Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots,” in Proc. Int. Conf. on Robotics and Automation, pp. 2811–2817, 2021.
- [7] J. Peters, S. Schaal, “Reinforcement learning of motor skills with policy gradients,” Neural Networks, vol. 21, no. 4, pp. 682–697, 2008.
- [8] R. S. Sutton, et al. ”Policy gradient methods for reinforcement learning with function approximation,” Advances in Neural Information Processing Systems, 1999.
- [9] D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, M. Riedmiller, “Deterministic policy gradient algorithms,” in Proc. Int. Conf. on Machine Learning, pp. 387–395, PMLR, 2014.
- [10] J. Kober, J. A. Bagnell, J. Peters, “Reinforcement learning in robotics: A survey,” Int. Journal of Robotics Research, vol. 32, no. 11, pp. 1238–1274, 2013.
- [11] P. Kormushev, S. Calinon, D. G. Caldwell, “Reinforcement learning in robotics: Applications and real-world challenges,” Robotics, vol. 2, no. 3, pp. 122–148, 2013.
- [12] J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Z. Kolter, D. Langer, O. Pink, V. Pratt, et al., “Towards fully autonomous driving: Systems and algorithms,” IEEE Intelligent Vehicles Symposium, pp. 163–168, 2011.
- [13] B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, P. Pérez, “Deep reinforcement learning for autonomous driving: A survey,” IEEE Trans. on Intelligent Transportation Systems, 2021.
- [14] L. Wang, D. Han, M. Egerstedt, “Permissive barrier certificates for safe stabilization using sum-of-squares,” in Proc. Amer. Control Conf., pp. 585–590, 2018.
- [15] D. Han, D. Panagou, “Robust multitask formation control via parametric Lyapunov-like barrier functions,” IEEE Trans. on Automatic Control, vol. 64, no. 11, pp. 4439–4453, 2019.
- [16] G. Chesi, ”Domain of attraction: analysis and control via SOS programming”, Springer Science & Business Media, vol. 415, 2011.
- [17] D. Han, G. Chesi, Y. S. Hung, “Robust consensus for a class of uncertain multi-agent dynamical systems,” IEEE Trans. on Industrial Informatics, vol. 9, no. 1, pp. 306–312, 2012.
-
[18]
D. Han, G. Chesi, “Robust synchronization via homogeneous
parameter-dependent polynomial contraction matrix,” IEEE Trans. on Circuits and Systems I: Regular Papers, vol. 61, no. 10, pp. 2931–2940, 2014. - [19] D. Han, M. Althoff, “On estimating the robust domain of attraction for uncertain non-polynomial systems: An LMI approach,” in Proc. Conf. on Decision and Control, pp. 2176–2183, 2016.
- [20] B. Felix, M. Turchetta, A. Schoellig, A. Krause, ”A Safe model-based reinforcement learning with stability guarantees,” Advances in Neural Information Processing Systems, pp. 909–919, 2018.
- [21] M. Alshiekh, R. Bloem, R. Ehlers, B. Könighofer, S. Niekum, U. Topcu, “Safe reinforcement learning via shielding,” in AAAI Conf. on Artificial Intelligence, vol. 32, no. 1, 2018.
- [22] C. Steven, N. Jansen, S. Junges, U. Topcu, ”Safe Reinforcement Learning via Shielding for POMDPs,” ArXiv:2204.00755, 2022.
- [23] R. Cheng, G. Orosz, R. M. Murray, J. W. Burdick, “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,” in AAAI Conf. on Artificial Intelligence, vol. 33, no. 1, 2019.
- [24] R. Cheng, A. Verma, G. Orosz, S. Chaudhuri, Y. Yue, J. W. Burdick, ”Control Regularization for Reduced Variance Reinforcement Learning,” in Proc. Int. Conf. on Machine Learning. pp. 1141–1150, 2019.
- [25] S. C. Hsu, X. Xu, A. D. Ames, “Control barrier function based quadratic programs with application to bipedal robotic walking,” in Proc. Amer. Control Conf., pp. 4542–4548, 2015.
- [26] T. Akshay, Z. Jun, K. Sreenath. ”Safety-Critical Control and Planning for Obstacle Avoidance between Polytopes with Control Barrier Functions,” in Proc. Int. Conf. on Robotics And Automation, accepted, 2022.
- [27] L. Wang, E. A. Theodorou, M. Egerstedt, “Safe learning of quadrotor dynamics using barrier certificates,” in Proc. Int. Conf. on Robotics And Automation, pp. 2460–2465, 2018.
- [28] P. Martin, ”Markov decision processes: discrete stochastic dynamic programming”, John Wiley & Sons, 2014.
- [29] A. Lederer, J. Umlauft, S. Hirche, “Uniform error bounds for Gaussian process regression with application to safe control,” Advances in Neural Information Processing Systems, pp. 659–669, 2019.
- [30] H. Huang, D. Han, ”On Estimating the Probabilistic Region of Attraction for Partially Unknown Nonlinear Systems: An Sum-of-Squares Approach,” in Proc. Chinese Control and Decision Conf., accepted, 2022.
- [31] D. Han, H. Huang, ”Sum-of-Squares Program and Safe Learning on Maximizing the Region of Attraction of Partially Unknown Systems,” in Proc. Asian Control Conf., 2022.
- [32] L. N. Trefethen, ”Approximation Theory and Approximation Practice,” SIAM, 2019.
- [33] M. Putinar, “Positive Polynomials on Compact Semi-algebraic Sets,” Indiana University Mathematics Journal, vol. 42, no. 3, pp. 969–984, 1993.
-
[34]
P. Seiler, ”SOSOPT: A toolbox for polynomial optimization,”
ArXiv:1308.1889, 2013. - [35] M. ApS, ”Mosek optimization toolbox for Matlab,” User’s Guide And Reference Manual, Ver. 4, 2019.