Balanced Representation Learning for Long-tailed
Skeleton-based Action Recognition
Abstract
Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.
Index Terms:
Action recognition, skeleton sequence, long-tailed visual recognition, imbalance learningI Introduction
Human action recognition has witnessed many advances in recent years. It is of vital importance in many applications, such as video analysis and behavior understanding [1, 2, 3]. Multiple modalities, such as video, depth images, optical flows [4], and body skeletons, have been employed for action recognition. In particular, skeleton-based human action recognition has attracted much attention mainly due to the compact motion-related structural information and the noise-free background [5].
In general, skeleton data can be efficiently obtained by depth sensors [6] and advanced human pose estimation algorithms [7]. Researchers construct some large, representative datasets [5, 1, 2, 8] by collecting and processing skeleton data. These datasets are usually resampled and relatively balanced among action categories for research purposes. Nevertheless, these academic datasets are not biased in favor of real-world circumstances, viz. realistic action data are imbalanced. As real-world action categories become more diverse and fine-grained, there will be a long-tailed situation where frequent action classes have massive samples but rarely-occurring action classes are associated with only a few samples. It is not surprising that current recognition methods [9, 10, 11, 12] cannot deal with the long-tailed imbalance situation well. We experimentally observed that the performance of different methods deteriorates significantly when directly tested on long-tailed simulated action datasets. Further, their deteriorated performances are close to each other. Without deliberately altering other factors, this indicates a strong connection that the representations learned by these methods are generally degraded due to the data imbalance between head and tail classes.
From the perspective of representation learning, imbalanced data brings two problems. First, imbalanced data directly leads to a skewed sample space, which is not well accommodated by current recognition methods. The skewed sample space will cause recognition models to have a bias towards the dominant class and perform poorly on the tail class. Due to the inherent differences between skeletal and image data, current approaches [13, 14, 15] that focus on long-tailed classification are not well suited to long-tailed action recognition. For action recognition, the spatial and temporal distinctive information of skeletal data is important. Rather, existing methods do not take such structural information into account well, ultimately degrading the quality of the samples. Increasing the sample quantity redundantly and repetitively using these approaches may lead to information overlap, and the marginal benefits from the data are diminishing to the model [16, 17]. This fact suggests that how to generate more valuable skeleton samples tailored for action recognition is critical to complementing the skewed sample space.
Second, imbalanced data results in representation bias. Due to the imbalanced distribution, the recognition model inclines to encode more discriminate factors of head classes, which distorts the representation space of tail classes. The representation bias would then confuse the classifier, resulting in misclassification. Many current methods [18, 19, 20, 21] adjust the weights of different classes to mitigate bias However, these re-weighting methods improve the performance of tail classes at the cost of head-class performance, which traps in a performance seesaw. Moreover, these methods do not consider generic knowledge between different action classes to compensate for imbalanced bias. For long-tailed action recognition, consensus knowledge in head and tail action classes are both important, which demands a balance in the objective of representation learning. Therefore, how to learn balanced representations needs to be seriously considered for mitigating the representation bias in long-tailed action recognition.

Faced with the above two dilemmas, a balanced representation learning method is proposed for long-tailed skeleton-based action recognition. To generate more valuable samples, a novel spatial-temporal action exploration strategy is presented. The proposed strategy contains two modules, i.e., rebalanced partial mixup and temporal reverse perception. On the one hand, rebalanced partial mixup is designed to strengthen spatial structure information of skeletal action data. This module mixes the skeleton part of different bodies in a rebalanced manner to generate new samples. The rebalanced manner means using different mixing factors in the sample space and label space. With an adaptive label factor designed to rebalance the label space, the method can assign higher weights to minority categories and alleviate the effects of imbalanced action data. On the other hand, temporal reverse perception is presented to enhance temporal information. This module uniformly divides the original sequence into splits with equal lengths and randomly takes more samples for the tail classes, which drives the sampler to take excessive enhancements for the tail classes. In addition, a skip-modal representation of the joints is adopted for multi-modal fusion. After mining different modal steams, the model can introduce additional structural information for tail classes. By coupling these components, spatial-temporal action exploration provides more valuable samples in spatial and temporal domains collaboratively, thereby complementing the skewed sample space.
To mitigate representation bias, we propose a detached action-aware learning schedule. The recognition model initially learns general knowledge of skeleton sequences through a vanilla cross-entropy loss. Subsequently, the action-aware loss is introduced to drive the model to focus on specific patterns of tail classes. After calculating sample effectiveness and category relative frequencies, an action-aware balanced term is added to the loss function in a model-agnostic manner, resulting in more effective constraints imposed on different classes. In this way, we detach specific patterns of tail classes from the learning of general knowledge and enhance them effectively. Fig. 1 illustrates our method, and extensive experimental results demonstrate the schedule mitigates existential bias in the representation space and provides a significant performance boost.
The main contributions of this paper can be summarized as follows:
-
•
The bottlenecks of long-tailed skeleton-based action recognition are explored. It is investigated that generating valuable samples and mitigating representation bias are key factors determining the performance of recognition models. Based on the observations, a balanced representation learning method is proposed.
-
•
A spatial-temporal action exploration strategy is presented, which generates more valuable skeletal samples. In addition, a detached action-aware learning schedule is proposed to mitigate the representation bias learnt from imbalanced data.
-
•
Extensive experiments and ablation studies prove the effectiveness of the proposed method. Overall, the proposed method can be easily integrated into various action recognition frameworks at the cost of a slight computational overhead.
The remainder of this paper is organized as follows: Section II presents a brief literature review of the related work. The proposed method is described in detail in Section III. The configurations and results of extensive experiments are presented in Section IV. Finally, the conclusions of this paper are summarized in Section V.
II Related Work
II-A Skeleton-based Action Recognition
In the early stages, traditional skeleton-based action recognition methods mainly focused on designing hand-crafted features [22]. The hand-crafted features are straightforward and intuitive, but weak in representing the semantic connectivity information of body parts. With the development of deep learning, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are applied to action recognition [23, 24, 25]. Subsequent applications of long short-term memory (LSTM) and attention mechanisms further exploit the spatial and temporal dynamics information [26, 27, 28, 29]. However, these methods are still limited in the exploitation of the structural topology of the joints. Considering the inherent graph structure of the skeleton point sequence, graph-based methods can be naturally utilized to deal with the skeleton graph [30, 31, 32, 33, 34]. By constructing spatial-temporal graphs, a series of graph-based approaches have been achieved and achieved promising performances, which indicates that graph networks successfully capture the most informative features for various actions.
Since then, many ingenious graph networks are proposed consecutively. Yan et al. [9] firstly apply graph-based neural networks for skeleton-based action recognition, and propose ST-GCN, which combines spatial graph convolutions and temporal dynamics convolutions for spatiotemporal modeling. Upon the baseline, 2s-AGCN [10] proposes an adaptive graph convolutional network, which adaptively models correlation between two joints. The two-stream ensemble with skeleton bone is also adopted to boost recognition performance. Subsequently, Cheng et al. [35] present shift graph operations and lightweight point-wise convolutions to improve the efficiency of the model. A concurrent work by Liu et al. [11] proposes a multi-scale aggregation scheme and directly models spatial-temporal dependencies. Correspondingly, CTR-GCN [36] explores topology-non-shared graph convolutions and proposes a channel-wise topology refinement graph convolution. InfoGCN [37] also models context-dependent intrinsic topology, but it further leverages an information-theoretic objective and multiple modalities to better represent latent information. Recently FR Head [38] propose a discriminative feature refinement module to improve the performance of ambiguous actions. Although these methods achieve encouraging performance for skeleton-based action recognition, how to design the networks to address skeleton-based action recognition is still an under-explored important question. Meanwhile, there is much room for improvement, especially from the aspect of multi-modal fusion. The way to fuse features from different modalities [10, 37] needs to be carefully investigated. In addition, some recent work [39, 40] focus on self-supervised action recognition and other interesting aspects.
However, as far as we know, research on long-tailed skeleton-based action recognition is still blank. It is believed that our work can shed light on the weaknesses of action recognition when facing long-tailed data distributions, and inspire the following work to further investigate the intrinsic nature of action recognition.
II-B Long-tailed Learning
Long-tailed dilemmas have attracted increasing attention due to the prevalence of imbalanced data in real-world applications [41, 17]. The methods on long-tailed imbalanced data can be simply divided into two regimes: re-sampling and cost-sensitive learning. Re-sampling methods [15] focus on under-sampling the head category and over-sampling the tail category, which aim to modify the training distributions to decrease the level of imbalance. Cost-sensitive learning can be traced back to importance sampling in statistics, which assigns weights to samples to match a given data distribution [42]. Through cost-sensitive loss function, re-weighting methods direct the network to allocate more attention to the samples in tail classes than head classes. Recent studies [18] make progress in the following three directions: information augmentation, class re-balancing, and module improvement. Specifically, data augmentation [14, 43, 15], transfer learning [44], logit adjustment [45, 46, 47], decoupled training [48], ensemble learning [49], and semi-supervised learning [50] are further combined with classical long-tailed learning methods.
II-C Long-tailed Skeleton-based Action Recognition
Current long-tailed learning work mainly concentrate on image classification [44, 51], detection [20], instance segmentation [18], multi-label classification [19], and video classification [52]. While extensive studies have been done for the long-tailed tasks above, little effort has been made for long-tailed action recognition. Compared with the image or video frames, the skeleton sequence is more generalized and condensed. The topological connections of joint points in the skeleton contain extensive spatial-temporal structural information. Due to the specificity of skeleton data, current algorithms are not well suited for skeleton-based action recognition. Although some existing works [53, 54, 55] attempt to adopt structural information, they are unaware of addressing the imbalance of the action data. Additional re-weighting approaches propose cost-sensitive factors such as class prediction hardness [56] and effective number [17] to impose constraints. But for skeleton graph networks, imposing constraints on the head classes throughout training will affect the learning of discriminative action representations and lead to optimization difficulties.
In contrast to the literature, a balanced representation learning method is proposed in this paper to specifically resolve the problem of long-tailed skeleton-based action recognition. Combining the philosophy of long-tailed learning, the proposed method provides a new perspective for understanding long-tailed action data especially by enhancing the sample space and mitigating representation bias.
III Methodology
The details of the proposed balanced representation learning method will be elaborated in this section and an illustration of our method is visualized in Fig. 2.
III-A Data Pre-processing
For skeletal data pre-processing, some current approaches generally adopt the augmentation solution provided by [31]. Effective augmentation for action samples can assist network learning. For representation learning of long-tailed data, the choice of data augmentation is even more critical. We absorb the previous pre-processing approach and design a more efficient augmentation scheme tailored for long-tailed action data.
The normal skeleton augmentations basically include six spatial augmentations, i.e. Flip, Rotate, Shear, Scaling, Mask, Part Drop, and four temporal augmentations, i.e. Temporal Crop, Temporal Flip, Temporal Shift, and Sampling. Filters can also be used for spatial and temporal augmentations, such as Gaussian Noise and Gaussian Blur. Furthermore, the augmentation of skeleton sequences is different from normal images and videos, which should care more about the spatial and temporal distinctive information. Thus, such structural information needs to be leveraged and further enhanced when augmenting long-tailed skeletal data. As the combination of augmentations is complicated, we make it a priority to select augmentation combinations that can introduce more novel movement information. Extensive experiments are conducted to test the effect of different strategies.
It is experimentally verified that Flip, Rotate, and Scaling in the spatial augmentations and Sampling in the temporal augmentations are more powerful for long-tailed action data. The four augmentation strategies are integrated with the current pre-processing method. The method is used to finally get diverse skeleton sequences.

III-B Spatial-Temporal Action Exploration
This section details the rebalanced partial mixup and temporal reverse perception.
III-B1 Rebalanced Partial Mixup
Mixup [53] was proposed as a regularization technique for improving the generalization of train data. The method constructs virtual training examples and extends the training distribution by linear interpolations of feature vectors. It works by mixing two images and their labels linearly as Eq.1
| (1) |
| (2) |
where and are two examples drawn at random from the training data, and .
For skeleton-based action recognition, spatial structure information is necessary to understand the action. Moreover, the same skeleton parts have distinctive significance in different actions. Hence, for generating meaningful samples to attenuate the skew in sample space, the proposed rebalanced partial mixup considers mixing the skeleton part of different bodies in a rebalanced manner.
The rebalanced manner means using two respective mixing factors to mix up in the sample space and label space. This is because the previous single mixing factors simply extend the training sample space, but do not further address the imbalance of the action data. The proposed strategy thereby turns to disentangle the mixing process of sample space and label space. An adaptive label factor is designed to provide an effective regularization focusing on tail classes. Through rebalancing the label space, the strategy can assign a higher weight to the minority class and alleviate the effects of imbalanced action data.
The formulation of the rebalanced partial mixup is defined as follows:
| (3) | |||||
| (4) |
where are the joint indices of the body. means the ratio of selected joints for the whole body. The exact form of is defined according to the following formula:
| (5) |
In Eq.5, and denote the number of samples in the corresponding action classes that sample and sample belong to. is a hyper-parameter, which indicates the degree of imbalance between the two categories. Specifically, if is more than times larger than , is set to , less than , is set to , otherwise, is equal to . Different parts of the body are chosen to formulate new samples, and the corresponding rate is adjusted accordingly. The radio for selecting random samples is set to , which means choosing one sample per samples. We adopt combining the upper body and the lower body directly as shown in Fig. 3 and apply the rebalanced label design.
Actually, the key to the proposed method is generating meaningful samples in a rebalanced manner. The rebalanced partial mixup can effectively aggregate the spatial structure information of long-tailed action samples, expanding the space of skeleton samples. And the rebalanced label design rebalances the label space and alleviates the effects of imbalanced data. The performance can be further improved by the effective regularization technique. In this way, the strategy generates more meaningful samples.

III-B2 Temporal Reverse Perception
Temporal distinctive information is also important for long-tailed action data. For the oversampling of imbalanced skeleton data, the sub-string sampling with bilinear interpolation does not make full use of the temporal information of the skeleton sequences. Hence, temporal reverse perception is proposed to help the model better understand temporal information in skeletal data.
First, the original input sequence is divided uniformly into some splits with equal lengths and then one frame is randomly selected from each split. Through the approach, the sampler can generate more distinctive skeleton sequences with similar temporal attributes. And the temporal integrity of the skeleton sequences is well-preserved after multiple random samplings. In addition, the set of tested skeleton sequence lengths is . It is experimentally verified that is the best for long-tailed skeleton data. The uniform sampler effectively maintains sample variability, especially when combined with the rebalanced partial mixup method.
Furthermore, due to the limited number of samples in the tail classes, oversampling can lead to information redundancy. This redundancy of temporal information reduces the benefit of generating more data, which influences representation learning. The proposed temporal reverse perception can drive the sampler to take special enhancements for the tail classes. Specifically, the reverse sampler adaptively selects the sampling frequency according to the actual action data distribution, which can further reduce the invalid overlap and maintain meaningful temporal information.
Briefly, the temporal reverse perception is composed of the uniform sampler and the reverse sampler. The approach is to sample frames uniformly from the original sequences and take more samples at random for the tail classes. Combined with rebalanced partial mixup and temporal reverse perception, the proposed spatial-temporal action exploration strategy can provide more valuable data for the network to learn better representation.
III-C Detached Action-Aware Learning Schedule
To mitigate representation bias, the detached action-aware learning schedule is proposed, which contains a detached training strategy and an action-aware loss.
The class re-weighting approach typically provides a way to assign appropriate weights to samples. However, for long-tailed action recognition, it is not that easy as the performance will gradually turn worse when using the re-weighting loss for the whole training process, especially in the head classes. This indicates that imposing constraints on the head classes throughout training actually affects the learning of general knowledge.
Therefore, we present a detached training strategy. It detaches specific patterns of tail classes from the learning of general knowledge, enabling the model to first learn generic action representations from majority classes. Afterwards, it switches to perceive specific patterns of tail classes. Specifically, the model first learns generic knowledge of action recognition through normal CE loss. After several epochs, a transition from CE loss to an action-aware loss drives the model to learn special action patterns from tail data and achieve a more comprehensive representation space. The strategy avoids neglecting the existence of tail classes in the early training process, or over-suppressing head classes in the latter re-weighting strategy, resulting in more effective constraints being imposed on different classes during training.
For an input action sample with label , suppose that the predicted output from the model for all classes are , where is the total number of classes. Given a sample with class label , the Softmax loss function for this sample is written as:
| (6) |
where the subscript denotes the target class. Here, indicates the target logit, and accordingly, denotes the predicted logit of class . Therefore, denotes the estimated class probability.
To reflect the effectiveness of different action samples adaptively, we further propose the action-aware term, which is defined as:
| (7) |
where is the number of samples for class , and denote the maximum and minimum sample number of all classes in the corresponding data. and are hyperparameters for range scaling, which are set according to the imbalance ratio of action data. Through calculating category relative frequencies as above, will be restricted to the fixed range . With scaling restriction, the term can make the weights of action classes more distinctive.
The weighting factor will be formulated as:
| (8) |
where is the action-aware term. Here, consider the case where the model has previously sampled examples and needs to sample -th sample. means the -th sample contributes to the effective number . The action-aware term is calculated by the relative probability factor and scaling hyperparameters, instead of the number of samples .
Due to , for the intuitive calculation and consistency with the previous form, is calculated as:
| (9) |
Suppose class has training samples, the action-aware loss can be expressed as follows:
| (10) |
With the proposed action-aware loss, the model will pay more attention to the tail classes and avoid excessive training of the tail classes. Further, the classifier can better distinguish the samples from tail action classes that are prone to be confused.
After combining the detached training strategy with the action-aware loss, the method can enable all samples to participate in the training more efficiently in order to converge quickly. For learning the detached tail representations, the method can better understand specific long-tailed patterns, while maintaining head performance. In general, the proposed detached action-aware learning schedule mitigates the representation bias effectively. The overall training procedure is summarized in Algorithm 1.
Require: Training dataset ;
A parameterized model .
Output: Updated model .
III-D Ensemble with Multi-Modal Representation
In contrast to normal action recognition under the balanced data setting, multi-modal fusion is more helpful for long-tailed data. The cause of the phenomenon is further analyzed, that is, different modalities provide a natural data augmentation for long-tailed data. Hence, we extend the spatial structure and define a new modal representation named skip-modal representation.
The original joint modality corresponds to the coordinate information of the skeleton joint points in space. Subsequent bone modality is represented as the vectors pointing to the target joint from the source joint. The proposed skip-modal representation is to skip one joint point on top of the bone modality. It can obtain more condensed spatial relationship information while maintaining directional information. The representation can explore the deeper connections between joints to analyze the actions. Other modalities of skipping more joint steps are also investigated, but the performances are not as good as the skip-one-joint step. Hence, we mainly use the skip-one-joint-step representation as the adopted skip-modal representation.
After training the model with each modal representation, the results of different modalities are ensembled during inference. The multi-modal fusion actually provides complementary information for obtaining more discriminative representations, leading the model to understand long-tailed action data more comprehensively.
IV Experiments
In this section, we evaluate the performance of the proposed method on four skeleton-based action recognition datasets. Ablation studies are also performed to validate the effectiveness of each component in the model. Finally, analysis of experimental results and visualizations are reported to further demonstrate the efficacy of the proposed method.
IV-A Datasets
IV-A1 NTU RGB+D 60
This indoor captured dataset [1] is a large-scale human action recognition dataset containing 56,880 skeleton action sequences of 60 action classes. The dataset recommends two benchmarks: (1) cross-subject (X-sub): training data comes from 20 subjects, and testing data comes from the other 20 subjects. (2) cross-view (X-view): training data comes from camera views 2 and 3, and testing data comes from camera view 1.
IV-A2 NTU RGB+D 120
This is currently the largest indoor action recognition dataset [2], which is an extended version of NTU RGB+D with 60 more action classes. The dataset contains 114,480 videos and consists of 120 classes. Similarly, the recommended two settings are suggested: (1) cross-subject (X-sub): training data comes from 53 subjects, and testing data comes from the other 53 subjects. (2) cross-setup (X-set): training data comes from 16 even setup IDs, and testing data comes from 16 odd setup IDs.
IV-A3 Northwestern-UCLA
Northwestern-UCLA [5] is captured by using three Kinect cameras. It contains 1494 samples covering 10 action categories, and each action category is performed by 10 subjects. We adopt the same evaluation protocol in [5]: training data comes from the first two cameras, and testing data comes from the other camera.
IV-A4 Kinetics Skeleton 400
The dataset [8] is adapted from the Kinetics 400 video dataset using the OpenPose toolbox in 2D keypoint modality. It contains 240,436 training and 19,796 evaluation skeleton clips over 400 classes, where each skeleton graph contains 18 body joints. At each time step, two people are selected for multi-person clips based on the average joint confidence. Regarding the experiments using 2D estimated skeleton, we use publicly available HRNet skeletons provided by PoseConv3D [34] for fair comparison. Typically, Top-1 classification accuracy is used in the evaluation protocol.
IV-A5 Long-tailed datasets
To validate the effectiveness of our method for long-tailed skeleton data, we construct the long-tailed datasets based on NTU 60, NTU 120, and Northwestern-UCLA. As stated before, Kinetics 400 is composed of many unique short videos. The statistics of samples versus classes indicate that the dataset itself actually exhibits a long-tailed data distribution. Therefore, we also choose Kinetics Skeleton 400 for the experiments.
For constructing the long-tailed version of the above datasets, we follow the general setting of long-tailed learning, i.e., truncating a subset with the Pareto distribution from the balanced version [16]. Specifically, to create the imbalanced version, the number of training examples per class is reduced, and the validation set is kept unchanged [45]. Imbalance ratio is utilized to denote the ratio between sample sizes of the most frequent and least frequent class, i.e., . The whole long-tailed imbalance follows an exponential decay in sample sizes across different classes. For NTU 60, the maximum number of samples per class under cross-subject and cross-view settings is set as 600. The imbalance ratio is fixed at 100. As for NTU 120, we adjust the maximum number of samples per class to 600 for the cross-subject setting and 400 for the cross-view setting, taking into account the change in the number of categories and samples. Additionally, we maintain the imbalance ratio at 100. Regarding Northwestern-UCLA, the maximum number of samples per class is set as 100. Due to the limited number of training samples per class, the tail-most class would only have one sample if the imbalance ratio is set to 100. Hence, we set the imbalance ratio to 10. Fig. 4 shows the number of training samples per class on different datasets.

IV-B Experimental Setting
IV-B1 Network Architecture
The spatial-temporal action exploration strategy and detached action-aware learning schedule of the proposed method are proposed for long-tailed skeleton-based action recognition, and can be combined with any action recognition backbones. Meanwhile, as mentioned before, various graph models do not have a large influence on the quality of representation learning. Hence, ST-GCN++ [12] is chosen as our backbone for the experiments. It is a recent representative approach using the GCN technique.
IV-B2 Implementation Details
In the experiments, the initial learning rate is set to 0.1 and decays with a cosine LR scheduler. Moreover, stochastic gradient descent (SGD) optimization with the Nesterov momentum of 0.9 and the weight decay of is employed to tune the parameters. Considering the large differences in the size of the datasets, we set the batch size for NTU 60, NTU 120, Northwestern-UCLA, and Kinetics Skeleton 400 datasets to 128, 128, 16, and 32, respectively. The model is implemented with PyTorch deep learning framework. And the maximum number of training epochs is set to 120. We set using the grid search. When adopting the detached action-aware learning schedule, the last 20 epochs are set as the detached stage. We set , i.e. and . As for the data pre-processing method and hyper-parameter settings, we follow the strategy in previous work [12]. The comparison methods use the same training and test sets as the proposed method in this paper, and these methods are implemented using official open-source code. The same data augmentation is used for fair performance comparison.
IV-C Experimental Results
IV-C1 Results of NTU RGB+D 60 dataset
The proposed method is compared with quite a few SOTA methods on both X-sub and X-view benchmarks of the NTU 60 dataset. The comparisons under standard and long-tailed settings are displayed in Table I. There are several important observations as follows.
In the long-tailed setting, there is a general degradation in the performance of previous methods. It verifies that current action recognition methods trained on balanced action datasets can not adapt well to long-tailed data. Rather, the proposed method significantly improves the performance in the long-tailed setting, i.e., 81.8% for X-sub benchmark and 85.4% for X-view benchmark. The proposed method outperforms FR Head [38] by 4.5% and 4.9%, and the baseline method ST-GCN++ by 6.8% and 5.4% on the two benchmarks respectively. In the standard setting, the proposed method also achieves the performance on par with other SOTA methods. The superiority is achieved by balanced representation learning, which generates more valuable skeletal samples and mitigates representation bias.
Note that many action recognition methods employ the multi-stream fusion framework to improve performance. For a fair comparison, we follow the rule of these methods by fusing the results of four modalities. The ensemble of 4-stream which includes joint, bone, joint motion, and bone motion is denoted as 4 ensemble. Here, motion means joint movement between two subsequent time frames. In addition, we add the skip-modal and skip-motion-modal representations, so the proposed method can be denoted as 6 ensemble. In Table I, the results of 4 ensemble and 6 ensemble are both reported in detail. In other tables, only the results of 6 ensemble are reported by default.
It is known that ST-GCN [9] is currently the most popular backbone model for skeleton-based action recognition. Our backbone network, i.e. ST-GCN++ [12], is actually an upgradation over ST-GCN, achieving better performance under the standard setting. However, under the long-tailed setting, the performances of the two models are relatively close. The imbalanced data leads to skewed sample space and results in representation bias, ultimately degrading the representations learned by previous methods. Integrated with the proposed method, the performance of ST-GCN++ under the long-tailed settings catches up with the accuracy of the original ST-GCN under the standard settings. The proposed method generates more valuable samples to reshape the sample space, and mitigates existential bias in the representation space, effectively addressing the dilemmas of skewed sample space and representation bias. The results imply that the proposed method can learn unbiased balanced representations from imbalanced data and handle imbalanced skeleton data well.
IV-C2 Results of NTU RGB+D 120 dataset
On the NTU 120 dataset, as shown in Table II, the proposed method also boosts the performance significantly when compared to other methods. The proposed method achieves the accuracy of 69.7% for the X-sub benchmark and 71.3% for the X-set benchmark under the long-tailed setting. In addition, the proposed method outperforms FR Head by 4.1% on X-sub benchmark and 3.1% on X-set benchmark, which is also a remarkable improvement. Similar to the results on NTU 60 dataset, the performances demonstrate the effectiveness of the proposed method.
IV-C3 Results of Northwestern-UCLA and Kinetics dataset
For Northwestern-UCLA and Kinetics, Table IV and Table V tabulate the experimental results. From Table IV, it can be easily found that an obvious performance improvement has been attained by the proposed method. The proposed method achieves an accuracy of 89.2% for Northwestern-UCLA under the long-tailed setting, which outperforms InfoGCN [37] by 17.2%. This improvement could be attributed to the relatively smaller sample size of Northwestern-UCLA. The proposed method can generate more distinctive samples when the data is small, which can further enhance the diversity of the data and improve the model performance more effectively. As shown in Table V, it can be seen that the proposed method outperforms the performance of other SOTA methods by 0.9% in Top-1 accuracy on Kinetics Skeleton 400 dataset, which proves that our approach works well in the real-world long-tailed datasets.
| Model | Published | Standard | Long-tailed | ||
|---|---|---|---|---|---|
| X-sub | X-view | X-sub | X-view | ||
| ST-GCN [9] | AAAI18 | 81.5 | 88.3 | 73.3 | 79.4 |
| 2s-AGCN [10] | CVPR19 | 88.5 | 95.1 | 74.0 | 78.9 |
| Shift-GCN [35] | CVPR20 | 90.7 | 96.5 | 73.6 | 79.3 |
| MS-G3D [11] | CVPR20 | 91.5 | 96.2 | 74.8 | 80.9 |
| DC-GCN+ADG [57] | ECCV20 | 90.8 | 96.6 | 75.0 | 79.7 |
| MST-GCN [58] | AAAI21 | 91.5 | 96.6 | 75.9 | 80.3 |
| CTR-GCN [36] | ICCV21 | 92.4 | 96.8 | 74.1 | 80.4 |
| EfficientGCN-B4 [32] | TPAMI22 | 91.7 | 95.7 | 75.2 | 80.9 |
| ST-GCN++ [12] | ACMMM22 | 92.6 | 97.4 | 75.0 | 80.0 |
| InfoGCN [37] | CVPR22 | 93.0 | 97.1 | 76.8 | 79.2 |
| FR Head [38] | CVPR23 | 92.8 | 96.8 | 77.3 | 80.5 |
| Ours (Joint Only) | – | 90.3 | 96.3 | 76.7 | 81.4 |
| Ours (Joint + Bone) | – | 92.0 | 97.0 | 79.6 | 84.0 |
| Ours (4 ensemble) | – | 92.4 | 97.1 | 81.0 | 84.9 |
| Ours (6 ensemble) | – | 92.7 | 97.3 | 81.8 | 85.4 |
| Model | Published | Standard | Long-tailed | ||
|---|---|---|---|---|---|
| X-sub | X-set | X-sub | X-set | ||
| ST-GCN [9] | AAAI18 | 70.7 | 73.2 | 59.1 | 62.3 |
| 2s-AGCN [10] | CVPR19 | 82.5 | 84.2 | 61.1 | 63.2 |
| Shift-GCN [35] | CVPR20 | 85.9 | 87.6 | 62.3 | 64.5 |
| MS-G3D [11] | CVPR20 | 86.9 | 88.4 | 62.7 | 64.6 |
| DC-GCN+ADG [57] | ECCV20 | 86.5 | 88.1 | 63.4 | 66.2 |
| MST-GCN [58] | AAAI21 | 87.5 | 88.8 | 63.8 | 65.9 |
| CTR-GCN [36] | ICCV21 | 88.9 | 90.6 | 63.2 | 66.0 |
| EfficientGCN-B4 [32] | TPAMI22 | 88.3 | 89.1 | 62.5 | 66.4 |
| ST-GCN++ [12] | ACMMM22 | 88.6 | 90.8 | 62.6 | 64.0 |
| InfoGCN [37] | CVPR22 | 89.8 | 91.2 | 64.2 | 67.1 |
| FR Head [38] | CVPR23 | 89.5 | 90.9 | 65.6 | 68.2 |
| Ours | – | 88.5 | 90.8 | 69.7 | 71.3 |
IV-C4 Comparisons with Algorithms for Long-tailed Data Distribution
To demonstrate the advantages of the proposed method over current algorithms for long-tailed data distribution, we have conducted extensive experiments to compare with the following competing algorithms: (1) Cross-entropy (CE) loss; (2) Focal loss [56], which is a common re-weighting loss function for imbalanced class samples; (3) Weighted softmax loss [41], which directly uses label frequencies of training samples for loss re-weighting; (4) Random oversampling (ROS) [59], which oversamples minority samples to balance the class distribution in the training data; (5) Mixup [53], which generates new training data by mixing two samples and their labels; (6) Remix [43], which oversamples minority classes by assigning higher weights to the minority labels when using Mixup; (7) CB loss [17], which introduces the effective number to approximate the expected sample number of different classes; (8) Label-Distribution-Aware Margin Loss with deferred re-weighting (LDAM-DRW) [45], which regularizes the minority classes by minimizing a margin-based generalization bound; (9) Equalization loss [20], which ignores the gradients for rare categories; (10) Balanced Softmax [46], which is an elegant unbiased extension of Softmax. (11) GumbelCE [47], which develops a Gumbel optimized strategy. (12) KPS loss [42], which presents a key point sensitive loss to improve the generalization performance of the classification model.
For fair comparisons, the same data augmentation is applied to all the compared algorithms in the experiments. Training with cross-entropy (CE) loss is regarded as the baseline method. If any algorithm utilizes a different loss function, the CE loss is substituted for the corresponding loss. Experiments are conducted on the long-tailed setting of NTU 60 and NTU 120. The performance is measured by classification accuracy using the joint data. Following [44], we also report the accuracy of three disjoint subsets: Many-shot classes (classes with more than 100 training samples), Medium-shot classes (classes with 20 to 100 samples), and Few-shot classes (classes under 20 samples).
The performance comparison is shown in Table III. It can be observed that, compared to vanilla training with CE loss, the proposed method maintains performance for the many-shot classes and significantly improves recognition accuracy for the medium-shot and few-shot classes. Meanwhile, the proposed method achieves significant performance advantages compared to other long-tailed methods. For the many-shot classes, the performance improvements of different long-tailed algorithms are relatively close, but for the medium-shot and few-shot classes, the proposed method is superior. The superiority is achieved through balanced learning of consensus knowledge and specific patterns of tail classes, resulting in more effective constraints being imposed on different classes. Balanced representation learning helps the model to understand the action data effectively regardless of the head or tail category, thus improving the overall recognition performance.
| Method | NTU 60 X-sub | NTU 120 X-sub | ||||||
|---|---|---|---|---|---|---|---|---|
| Overall | Many | Medium | Few | Overall | Many | Medium | Few | |
| CE loss | 72.3 | 82.9 | 66.8 | 60.2 | 58.4 | 81.4 | 58.9 | 40.3 |
| Focal loss [56] | 72.4 | 82.7 | 67.1 | 61.8 | 58.5 | 80.9 | 59.1 | 45.2 |
| Weighted loss [41] | 72.6 | 83.1 | 68.1 | 58.8 | 58.6 | 81.9 | 58.2 | 42.1 |
| ROS [59] | 73.4 | 81.7 | 67.2 | 66.0 | 58.2 | 81.5 | 57.6 | 45.9 |
| Mixup [53] | 71.8 | 82.9 | 66.7 | 58.7 | 58.9 | 82.6 | 57.8 | 41.3 |
| Remix [43] | 71.7 | 82.2 | 66.3 | 62.2 | 58.4 | 81.8 | 56.8 | 41.2 |
| CB loss [17] | 73.8 | 82.0 | 69.4 | 62.8 | 61.4 | 81.3 | 60.7 | 51.0 |
| LDAM-DRW [45] | 71.2 | 75.4 | 68.6 | 65.3 | 60.9 | 76.3 | 60.0 | 52.2 |
| Equalization loss [20] | 73.7 | 84.7 | 69.3 | 58.5 | 59.4 | 82.8 | 58.8 | 47.5 |
| Balanced Softmax [46] | 74.5 | 82.3 | 69.2 | 64.5 | 62.1 | 83.1 | 60.1 | 51.7 |
| GumbelCE [47] | 73.3 | 84.3 | 68.9 | 58.1 | 61.6 | 81.0 | 59.8 | 52.4 |
| KPS loss [42] | 73.6 | 83.1 | 72.3 | 61.6 | 62.4 | 82.5 | 61.2 | 52.1 |
| Ours | 76.7 | 85.5 | 73.7 | 67.8 | 65.3 | 83.0 | 62.6 | 54.3 |
IV-D Ablation Study
In this subsection, we conduct ablation experiments and provide further investigations of the proposed method in four aspects: (1) What is the impact of different components? (2) Can the proposed method be effectively integrated into other action recognition algorithms? (3) Are the learned representations indeed superior to those learned by the original methods? (4) How does the proposed method perform in the head, middle, and tail classes? The experiments are launched on the long-tailed setting of NTU 60 dataset.
IV-D1 Impact of Each Component
To further analyze the effectiveness of the proposed method, we conducted additional experiments to validate the impact of the spatial-temporal action exploration strategy and the detached action-aware learning schedule. The performance is measured by classification accuracy on NTU 60 using the joint data.
| Model | Long-tailed |
|---|---|
| Top1 | |
| 2s-AGCN [10] | 70.1 |
| MS-G3D [11] | 72.8 |
| CTR-GCN [36] | 71.6 |
| InfoGCN [37] | 72.0 |
| Ours | 89.2 |
| Model | Top1 |
|---|---|
| TCN [60] | 20.3 |
| ST-GCN [9] | 30.7 |
| AS-GCN [61] | 34.8 |
| 2s-AGCN [10] | 36.1 |
| MS-G3D [11] | 38.0 |
| PoseConv3D [34] | 47.7 |
| Ours | 48.6 |
Firstly, we analyze the spatial-temporal action exploration (STAE) and compare the accuracy gains of rebalanced partial mixup (RPM) and temporal reverse perception (TRP) in Table VI. The STAE strategy leads to significant improvements, with gains of 3.4% on X-sub benchmark and 2.9% on X-view benchmark. It is proven by the results that both RPM and TRP contribute to the action recognition model. The STAE strategy strives to aggregate spatial structure information and make full use of temporal distinctive information. The experimental results demonstrate that the proposed strategy generates more meaningful skeletal samples, and these valuable data further help the model to understand the long-tailed action.




| Model Configurations | X-sub | X-view |
|---|---|---|
| Baseline (CE loss) | 72.3 | 76.4 |
| w/ RPM | 74.8 | 78.5 |
| w/ TRP | 74.9 | 78.1 |
| w/ STAE ( RPM & TRP) | 75.7 | 79.3 |
| CE loss | 75.7 | 79.3 |
| Focal loss | 75.3 | 78.9 |
| Weighted loss | 71.0 | 76.1 |
| Action-Aware loss | 75.6 | 80.6 |
| Detached Focal loss | 75.9 | 79.8 |
| Detached Weighted loss | 74.3 | 78.5 |
| Detached Action-Aware loss | 76.7 | 81.4 |
Secondly, to validate the efficacy of the proposed detached action-aware learning schedule, we construct different ablation experiments and report their performance in Table VI. It can be seen that directly using re-weighting losses throughout the training process leads to a certain degree of performance degradation. Despite the performance of focal loss being relatively stable, the gap between the weighted loss and CE loss is obvious. In addition, for the X-sub benchmark, the accuracy of the action-aware loss also drops by 0.1%. And then the detached learning schedule is adopted. It can be observed that the performances of different losses become generally better. Meanwhile, the detached action-aware loss is more stable, bringing a performance boost compared with the original CE loss.
Finally, we scrutinize the contribution of each component. The results are listed in Table VII. and refer to the spatial-temporal action exploration strategy and detached action-aware learning schedule respectively, and denotes the ensemble of multiple streams. Accordingly, the absolute accuracy and are reported. represents the relative accuracy improvement over the baseline ST-GCN++ [12] by using combinations of different components. As shown in Table VII, we can observe that the performance of the model is improved by different components. By comparing the performance of variants denoted by , , , and , , , and bring 3.4%, 2.6%, and 0.8% improvement respectively. By mining multiple streams, the model can obtain more valuable information for action recognition. After combining all components, the method results in improvement on the NTU-60 X-sub setting. The results indicate that the components of the proposed method contribute to understanding the long-tailed action data.
| Method | ST-GCN++ | Accuracy | ||||
|---|---|---|---|---|---|---|
| ✓ | 75.0 | – | ||||
| ✓ | ✓ | 78.4 | 3.4 | |||
| ✓ | ✓ | ✓ | 81.0 | 6.0 | ||
| ✓ | ✓ | ✓ | ✓ | 81.8 | 6.8 |
| Model | X-sub | X-view | ||
|---|---|---|---|---|
| Vanilla | +BRL | Vanilla | +BRL | |
| ST-GCN++ [12] | 75.0 | 81.8 | 80.0 | 85.4 |
| +(0.0) | (+6.8) | +(0.0) | (+5.4) | |
| MS-G3D [11] | 74.8 | 82.4 | 80.9 | 85.7 |
| +(0.0) | (+7.6) | +(0.0) | (+4.8) | |
| CTR-GCN [36] | 74.1 | 81.8 | 80.4 | 85.0 |
| +(0.0) | (+7.7) | +(0.0) | (+4.6) | |
IV-D2 Integration With Other Algorithms
The proposed balanced representation learning method (BRL) also has a superior interoperability capacity and is easy to incorporate into other methods. In this subsection, the scalability of the proposed method is assessed on NTU 60 with a combination of various skeleton-based action recognition backbones. We apply the proposed BRL to popular recognition methods, i.e. ST-GCN++ [12], MS-G3D [11] and CTR-GCN [36].
The results with different recognition backbones are tabulated in Table VIII. For ST-GCN++, the method results in a 6.8% gain on X-sub benchmark and a 5.4% gain on X-view benchmark. Combined with the proposed method, the performances of other algorithms are also improved to some extent. For example, for MS-G3D, the method brings as much as 7.6% gain on X-sub benchmark and 4.8% gain on X-view benchmark. And for CTR-GCN, the method brings a 7.7% gain on X-sub benchmark and a 4.6% gain on X-view benchmark. The results show that our method consistently improves the performance of different action recognition backbones. It is inspiring that the proposed method can be easily integrated into various action recognition algorithms.



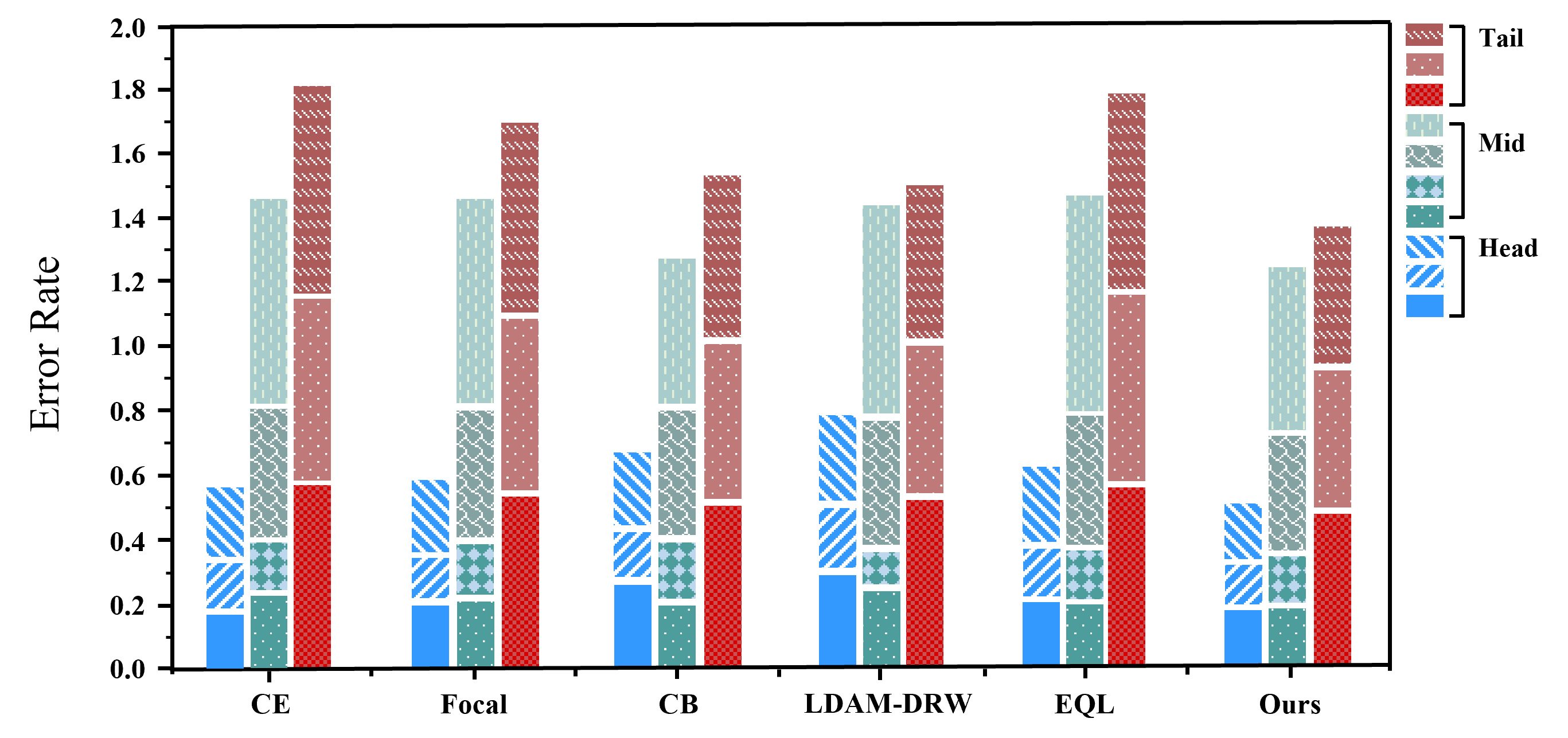
IV-D3 Visualization of Learned Representations
To further verify the effectiveness of the proposed method, the learned representations of five head categories and five tail categories are visualized in Fig. 5. It exhibits the t-SNE embeddings of the latent representations across different methods. The sample points of tail classes are overlaid by grey area to show the improvements brought by different components. It can be observed that the proposed method can obtain more accurate classification boundaries for tail classes. With more valuable data and more effective weighting constraints, the proposed method can indeed learn balanced representations for long-tailed skeleton action datasets.
IV-D4 Improvement on the Head, Middle, and Tail Classes
To analyze the performance of the proposed method on different action classes, we construct the following experiments.
On the one hand, based on Table VII, we further analyze the effects of different components on the performance of different classes. As shown in Fig. 6, three schemes are tested on the X-sub benchmark of NTU 60-LT and NTU 120-LT, including BRL, BRL without DAA, and BRL without STAE and DAA. In order to facilitate the visualization, we aggregate the classes into 10 groups according to the label frequency. To be specific, for NTU 60, the dataset has 60 classes, and each group includes 6 classes. The most frequent 3 groups are named Head1 to Head3. The 4 groups with medium frequency are named Mid1 to Mid4, and the rest 3 least frequent groups are named Tail1 to Tail3 in order. Per-class error rates on the NTU 60-LT/NTU 120-LT datasets are plotted. The results verify that the proposed components effectively improve the accuracy of tail classes and that the proposed method can simultaneously maintain the performance of head classes well.
On the other hand, we compare the proposed method with other related methods, such as Focal loss [56], CB loss [17], LDAM-DRW [45], and Equalization loss [20]. The experiments are conducted on the X-sub benchmark of NTU 60-LT and NTU 120-LT. We also aggregate the classes into ten groups based on the label frequency and further integrate the results into the head, middle, and tail parts for ease of comparison. The experimental results presented in Fig. 7 reveal a common trend across different methods, where performance is better for head classes and worse for middle and tail classes. This can be attributed to the fact that the head class is typically more diverse in terms of available samples, resulting in more consistent recognition performance. Additionally, compared to the baseline CE loss, other methods such as Focal loss, CB loss, and LDAM-DRW show improvements in reducing the error rates for middle and tail classes, while EQL is relatively less effective. Finally, in comparison with other long-tailed methods, the proposed method can learn balanced representations of the tail classes more effectively, which leads to a significant reduction in the error rates of tail classes. The proposed method can maintain the performance of head classes as well.
V Conclusion
In this work, we make two major contributions to address the long-tailed dilemmas in skeleton-based action recognition: the spatial-temporal action exploration strategy to generate more valuable samples, and the detached action-aware learning schedule to mitigate representation bias. In addition, we further introduce a skip-modal representation of the human skeleton for model ensemble. By coupling these components, the balanced representation learning method is proposed. Extensive experiments are conducted on several long-tailed simulated and real-world datasets. The imbalanced data actually degrades the representations learned by current methods. Experimental results show that the proposed method learns unbiased balanced representations from imbalanced action data and outperforms state-of-the-art methods. We believe our method can aid the development of skeleton-based action recognition, and provide a new perspective to understanding long-tailed action data.
References
- [1] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1010–1019.
- [2] J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y. Duan, and A. C. Kot, “Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2684–2701, 2019.
- [3] Z. Sun, Q. Ke, H. Rahmani, M. Bennamoun, G. Wang, and J. Liu, “Human action recognition from various data modalities: A review,” IEEE transactions on pattern analysis and machine intelligence, 2022.
- [4] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” Advances in neural information processing systems, vol. 27, 2014.
- [5] J. Wang, X. Nie, Y. Xia, Y. Wu, and S.-C. Zhu, “Cross-view action modeling, learning and recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 2649–2656.
- [6] Z. Zhang, “Microsoft kinect sensor and its effect,” IEEE multimedia, vol. 19, no. 2, pp. 4–10, 2012.
- [7] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7291–7299.
- [8] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017.
- [9] S. Yan, Y. Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” in Thirty-second AAAI conference on artificial intelligence, 2018.
- [10] L. Shi, Y. Zhang, J. Cheng, and H. Lu, “Two-stream adaptive graph convolutional networks for skeleton-based action recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 026–12 035.
- [11] Z. Liu, H. Zhang, Z. Chen, Z. Wang, and W. Ouyang, “Disentangling and unifying graph convolutions for skeleton-based action recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 143–152.
- [12] H. Duan, J. Wang, K. Chen, and D. Lin, “Pyskl: Towards good practices for skeleton action recognition,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 7351–7354.
- [13] L. Shen, Z. Lin, and Q. Huang, “Relay backpropagation for effective learning of deep convolutional neural networks,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VII 14. Springer, 2016, pp. 467–482.
- [14] S. S. Mullick, S. Datta, and S. Das, “Generative adversarial minority oversampling,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1695–1704.
- [15] S. Park, Y. Hong, B. Heo, S. Yun, and J. Y. Choi, “The majority can help the minority: Context-rich minority oversampling for long-tailed classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6887–6896.
- [16] M. Buda, A. Maki, and M. A. Mazurowski, “A systematic study of the class imbalance problem in convolutional neural networks,” Neural networks, vol. 106, pp. 249–259, 2018.
- [17] Y. Cui, M. Jia, T.-Y. Lin, Y. Song, and S. Belongie, “Class-balanced loss based on effective number of samples,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 9268–9277.
- [18] Y. Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long-tailed learning: A survey,” arXiv preprint arXiv:2110.04596, 2021.
- [19] T. Wu, Q. Huang, Z. Liu, Y. Wang, and D. Lin, “Distribution-balanced loss for multi-label classification in long-tailed datasets,” in European Conference on Computer Vision. Springer, 2020, pp. 162–178.
- [20] J. Tan, C. Wang, B. Li, Q. Li, W. Ouyang, C. Yin, and J. Yan, “Equalization loss for long-tailed object recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 662–11 671.
- [21] M. Li, Y.-m. Cheung, and Y. Lu, “Long-tailed visual recognition via gaussian clouded logit adjustment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6929–6938.
- [22] R. Vemulapalli, F. Arrate, and R. Chellappa, “Human action recognition by representing 3d skeletons as points in a lie group,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 588–595.
- [23] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4489–4497.
- [24] Y. Du, W. Wang, and L. Wang, “Hierarchical recurrent neural network for skeleton based action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1110–1118.
- [25] H. Wang and L. Wang, “Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 499–508.
- [26] S. Song, C. Lan, J. Xing, W. Zeng, and J. Liu, “An end-to-end spatio-temporal attention model for human action recognition from skeleton data,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017.
- [27] C. Si, Y. Jing, W. Wang, L. Wang, and T. Tan, “Skeleton-based action recognition with spatial reasoning and temporal stack learning,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 103–118.
- [28] C. Si, W. Chen, W. Wang, L. Wang, and T. Tan, “An attention enhanced graph convolutional lstm network for skeleton-based action recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1227–1236.
- [29] X.-Y. Zhang, H.-C. Shi, C.-S. Li, and L.-X. Duan, “Twinnet: twin structured knowledge transfer network for weakly supervised action localization,” Machine Intelligence Research, vol. 19, no. 3, pp. 227–246, 2022.
- [30] Y.-F. Song, Z. Zhang, C. Shan, and L. Wang, “Richly activated graph convolutional network for robust skeleton-based action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 5, pp. 1915–1925, 2020.
- [31] P. Zhang, C. Lan, W. Zeng, J. Xing, J. Xue, and N. Zheng, “Semantics-guided neural networks for efficient skeleton-based human action recognition,” in proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1112–1121.
- [32] Y.-F. Song, Z. Zhang, C. Shan, and L. Wang, “Constructing stronger and faster baselines for skeleton-based action recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [33] M. Ren, Y.-L. Wang, and Z.-F. He, “Towards interpretable defense against adversarial attacks via causal inference,” Machine Intelligence Research, vol. 19, no. 3, pp. 209–226, 2022.
- [34] H. Duan, Y. Zhao, K. Chen, D. Lin, and B. Dai, “Revisiting skeleton-based action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2969–2978.
- [35] K. Cheng, Y. Zhang, X. He, W. Chen, J. Cheng, and H. Lu, “Skeleton-based action recognition with shift graph convolutional network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 183–192.
- [36] Y. Chen, Z. Zhang, C. Yuan, B. Li, Y. Deng, and W. Hu, “Channel-wise topology refinement graph convolution for skeleton-based action recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 359–13 368.
- [37] H.-g. Chi, M. H. Ha, S. Chi, S. W. Lee, Q. Huang, and K. Ramani, “Infogcn: Representation learning for human skeleton-based action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 186–20 196.
- [38] H. Zhou, Q. Liu, and Y. Wang, “Learning discriminative representations for skeleton based action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 608–10 617.
- [39] T. Guo, H. Liu, Z. Chen, M. Liu, T. Wang, and R. Ding, “Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 1, 2022, pp. 762–770.
- [40] O. Moliner, S. Huang, and K. Åström, “Bootstrapped representation learning for skeleton-based action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4154–4164.
- [41] C. Huang, Y. Li, C. C. Loy, and X. Tang, “Learning deep representation for imbalanced classification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5375–5384.
- [42] M. Li, Y.-m. Cheung, and Z. Hu, “Key point sensitive loss for long-tailed visual recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [43] H.-P. Chou, S.-C. Chang, J.-Y. Pan, W. Wei, and D.-C. Juan, “Remix: rebalanced mixup,” in European Conference on Computer Vision. Springer, 2020, pp. 95–110.
- [44] Z. Liu, Z. Miao, X. Zhan, J. Wang, B. Gong, and S. X. Yu, “Large-scale long-tailed recognition in an open world,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2537–2546.
- [45] K. Cao, C. Wei, A. Gaidon, N. Arechiga, and T. Ma, “Learning imbalanced datasets with label-distribution-aware margin loss,” Advances in neural information processing systems, vol. 32, 2019.
- [46] J. Ren, C. Yu, X. Ma, H. Zhao, S. Yi et al., “Balanced meta-softmax for long-tailed visual recognition,” Advances in neural information processing systems, vol. 33, pp. 4175–4186, 2020.
- [47] K. P. Alexandridis, J. Deng, A. Nguyen, and S. Luo, “Long-tailed instance segmentation using gumbel optimized loss,” in European Conference on Computer Vision. Springer, 2022, pp. 353–369.
- [48] B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y. Kalantidis, “Decoupling representation and classifier for long-tailed recognition,” arXiv preprint arXiv:1910.09217, 2019.
- [49] B. Zhou, Q. Cui, X.-S. Wei, and Z.-M. Chen, “Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9719–9728.
- [50] Y. Yang and Z. Xu, “Rethinking the value of labels for improving class-imbalanced learning,” Advances in neural information processing systems, vol. 33, pp. 19 290–19 301, 2020.
- [51] B.-B. Jia and M.-L. Zhang, “Multi-dimensional classification via selective feature augmentation,” Machine Intelligence Research, vol. 19, no. 1, pp. 38–51, 2022.
- [52] X. Zhang, Z. Wu, Z. Weng, H. Fu, J. Chen, Y.-G. Jiang, and L. S. Davis, “Videolt: Large-scale long-tailed video recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 7960–7969.
- [53] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [54] K. Xu, F. Ye, Q. Zhong, and D. Xie, “Topology-aware convolutional neural network for efficient skeleton-based action recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 3, 2022, pp. 2866–2874.
- [55] Z. Chen, H. Liu, T. Guo, Z. Chen, P. Song, and H. Tang, “Contrastive learning from spatio-temporal mixed skeleton sequences for self-supervised skeleton-based action recognition,” arXiv preprint arXiv:2207.03065, 2022.
- [56] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [57] K. Cheng, Y. Zhang, C. Cao, L. Shi, J. Cheng, and H. Lu, “Decoupling gcn with dropgraph module for skeleton-based action recognition,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIV 16. Springer, 2020, pp. 536–553.
- [58] Z. Chen, S. Li, B. Yang, Q. Li, and H. Liu, “Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 2, 2021, pp. 1113–1122.
- [59] J. Van Hulse, T. M. Khoshgoftaar, and A. Napolitano, “Experimental perspectives on learning from imbalanced data,” in Proceedings of the 24th international conference on Machine learning, 2007, pp. 935–942.
- [60] T. S. Kim and A. Reiter, “Interpretable 3d human action analysis with temporal convolutional networks,” in 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW). IEEE, 2017, pp. 1623–1631.
- [61] M. Li, S. Chen, X. Chen, Y. Zhang, Y. Wang, and Q. Tian, “Actional-structural graph convolutional networks for skeleton-based action recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3595–3603.