Backpropagation on Dynamical Networks
Supplementary Material
Appendix A Chaotic Oscillators Equations
Lorenz
where .
Chua
where .
Appendix B Recursive Partial Derivatives
The recursive relationship of the required partial derivatives for the backpropragation algorithm is given by:
where corresponds to the th component of the state of node . Similarly, is the th component of the local dynamics function and corresponds to the local dynamics contribution of the forward evolution,
| (2) |
Appendix C Other Tested Networks
C.1 FitzHugh-Nagumo Neuron Network
An additional system consisting of a network of FitzHugh-Nagumo neuron oscillators [hong2011synchronization] was used to test the capabilities of the backpropagation regression method.
The neuron network presents an additional challenge when constructing a data-driven model due to the presence of disparate time scales in the dynamics (fast spiking depolarisation and slow repolarisation). It also demonstrates the performance of the backpropagation method in a more realistic context, i.e. the inference of neuronal networks. We focus on the FitzHugh-Nagumo system operating under a chaotic regime as given by Hong [hong2011synchronization] with equations,
with constant parameters . Diffusive coupling was applied on with coupling weights normally distributed with and coupling probability and integration timestep .


C.2 Heterogeneous Networks
The formulation of the backpropagation regression algorithm assumes that the local dynamics for all nodes are identical. Whilst this is a useful property, this strong assumption is unlikely to be present in real systems. In many cases, nodes in a dynamical network may exhibit slight differences in their local dynamics. To test the effect network heterogeneity on regression performance, a 16 node Chua oscillator network was simulated with slightly differing bifurcation parameters for each node. We use the Chua system for this investigation, as it shows similar chaotic dynamics for a wide parameter range (see Figure 3).
The Chua system contains multiple coexisting attractors for particular values of the bifurcation parameter [kengne2017dynamics]. When operating in the single scroll regime (), the isolated Chua system exhibits two separate chaotic attractors corresponding to the two scrolls. These two scrolls eventually merge into the characteristic double scroll Chua attractor for larger values of (see Figure 3).
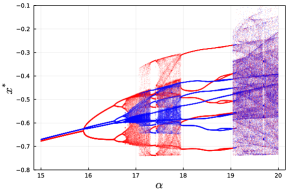
To simulate a heterogeneous network, the parameter for each node in the network was randomly perturbed by an additional amount where . The backpropagation regression algorithm was tested on 7 different configurations of increasing . Each configuration was tested on 8 randomly initialised 16 node Chua dynamical networks, with 40 regression iterations in each case.
The weight error performance was found to be robust to increasing levels of heterogeneity in network dynamics (see Figure 4). The effect of weight filtration was also found to be unchanged with increasing heterogeneity. However, increasing heterogeneity resulted in a gradual decrease in the mutual information of local model predictions (see Figure 5). The backpropagation algorithm assumes that all nodes have identical local dynamics. Heterogeneity in node dynamics results in uncertainty the true model parameters when regressing the local model in the training and refitting stage. Mutual information was also tested against the control case where the model is exactly known, but evaluated with perturbed initial conditions .


Appendix D Backpropagation Algorithm Hyperparameters
A list of hyperparameters for the algorithm are provided in Table I. The selection of hyperparameter values require experimentation and were selected based on values typically used for BPTT training of RNNs. As a general guide, affects the degree of averaging in the mean field approach when estimating the vector field of the local dynamics during initialisation. The parameters and directly control the amount of time spent in stage of backpropagation and retraining. The learning rates and are used for the training the feedforward neural network local dynamics model. Selection of these values follow the same heuristics used for machine learning function approximation with the additional criteria that to ensure that the local dynamics model does not change too much in each refit iteration. The parameters and are defined similarly to those normally used in regression and learning rate scheduler of regular BPTT training RNNs. The freerun prediction length alters the length of the trajectory used to calculate the errors for backpropagation. Larger allow the accumulation of errors over time and prioritises the adjustment of weights that have a larger impact on prediction performance, resulting in better convergence and stability at the expense of computational speed. However, should be selected to be smaller than the natural Lyapunov time scale of the system to prevent instability.
| Hyper-parameter | Value | Description |
|---|---|---|
| 8 | Number of neighbours in mean field approach for initial model training | |
| 30 | Number of training epochs used in each neural network model training run | |
| 40 | Number of backpropagation-decoupling-refit alternations to run | |
| 0.001 | Model training learning rate | |
| 0.0002 | Model refit learning rate | |
| 0.0005 | Average learning rate for of each coupling weight in the | |
| 0.9 | Learning rate momentum parameter | |
| 10 | Length of freerun predictions used to calculate and backpropagate error | |
| 0.98 | Effective learning rate decay after each decay-reset cycle in scheduler | |
| 2.0 | Amount to multiply decreased learning rate at the end of decay-reset cycle |
Notable Hyperparameters
The backpropagation algorithm requires the selection of various hyperparameters that govern the regression behaviour.
-
•
Momentum () - This quantity includes a notion of momentum in the gradient update by allowing previous calculated update steps to propagate into future steps with a decaying effect. This technique is also commonly used in RNN backpropagation to improve convergence,
(3) -
•
Model Learning Rate () - The step size of the feedforward network during the initial construction of the model and retraining.
-
•
Node Learning Rate () - The average learning rate that would be applied to each coupling weight if all real links weights are equal in the calculated gradient and exist with probability . Its relationship to the real learning rate is given by,
(4) -
•
Input History Length () - The amount of steps over which to unfold the backpropagation regression algorithm. Longer history results in the accumulation of coupling weight effects over a longer period and provides better convergence at the cost of slower computation.