Average energy dissipation rates of additive implicit-explicit Runge-Kutta methods for gradient flow problems
Abstract
A unified theoretical framework is suggested to examine the energy dissipation properties at all stages of additive implicit-explicit Runge-Kutta (IERK) methods up to fourth-order accuracy for gradient flow problems. We construct some parameterized IERK methods by applying the so-called first same as last method, that is, the diagonally implicit Runge-Kutta method with the explicit first stage and stiffly-accurate assumption for the linear stiff term, and applying the explicit Runge-Kutta method for the nonlinear term. The main part of the novel framework is to construct the differential forms and the associated differentiation matrices of IERK methods by using the difference coefficients of method and the so-called discrete orthogonal convolution kernels. As the main result, we prove that an IERK method can preserve the original energy dissipation law unconditionally if the associated differentiation matrix is positive semi-definite. The recent indicator, namely average energy dissipation rate, is also adopted for these multi-stage methods to evaluate the overall energy dissipation rate of an IERK method such that one can choose proper parameters in some parameterized IERK methods. It is found that the selection of method parameters in the IERK methods is at least as important as the selection of different IERK methods. Extensive numerical experiments are also included to support our theory.
Keywords: gradient flow problem, implicit-explicit Runge-Kutta methods, orthogonal convolution kernels, energy dissipation law, average dissipation rate
AMS subject classifications: 35K58, 65L20, 65M06, 65M12
1 Introduction
We propose a unified theoretical framework to examine the energy dissipation properties at all stages of additive implicit-explicit Runge-Kutta (in short, IERK) methods for solving the following semi-discrete semilinear parabolic problem, cf. [10, 11, 24, 32],
| (1.1) |
where is a symmetric, positive definite matrix resulting from certain spatial discretization of stiff term, typically the Laplacian operator with periodic boundary conditions, is a symmetric, negative definite matrix (having the same size as ) resulting from certain spatial discretization of the mobility operator, and represents a nonlinear but non-stiff term. Without losing the generality, the Fourier pseudo-spectral method is assumed to approximate spatial operators and we define the discrete inner product and the norm . Assume that there exists a non-negative Lyapunov function such that Then the problem (1.1) can be formulated into the following gradient flow system, see [1, 8, 12, 29, 30, 31],
| (1.2) |
The dynamics approaching the steady-state solution , that is , of this dissipative system (1.1) satisfies the following original energy dissipation law
| (1.3) |
Our recent interests in the Runge-Kutta (RK) methods are firstly to develop some high-order starting procedures for the backward differentiation formulas [22, 25], which are proven to possess certain discrete gradient structures, cf. [32, Section 5.6], and then preserve the energy dissipation law of phase field models with the original energy added with a small positive term in their original forms. Thus, it would be expected that the RK methods also have some discrete gradient structures and preserve certain discrete energy dissipation laws for gradient flow problems. Combining the scalar auxiliary variable (SAV) method [29] and the Gaussian-type RK methods, arbitrarily high-order energy-stable schemes were constructed [1, 12]. However, these SAV schemes only satisfy a modified energy law, which may not necessarily ensure the energy stability in the original form [17, 11]. Recently, Fu et al. [10, 11] proved that some exponential time difference RK methods maintain the decaying of original energy. For some parameterized explicit exponential RK methods in [15], the discrete version of (1.3) was established in [24] for certain range of the method parameters. Since the functions of matrix exponential are always involved, these explicit RK methods would be also computationally intensive. Actually, the efficient algorithm to accurately compute the matrix exponential is still limited [27, 9].
In this study, we will focus on whether and to what extent the IERK methods preserve the original energy dissipation law (1.3). Due to the relative ease of implementation, the diagonally implicit Runge-Kutta (DIRK) methods are possibly the most widely used implicit Runge-Kutta method in practical applications, see the recent review [21] and abundant references therein, especially involving stiff differential equations. The DIRK method has greatly reduced the computational complexity of the fully implicit Runge-Kutta method, but it still requires an iterative method to solve the nonlinear equations at each stage. In order to improve the computational efficiency, the IERK methods have attracted much attention and are widely used, see [2, 4, 3, 5, 6, 7, 16, 13, 18, 20, 19, 26, 31, 30]. Cooper and Sayfy [6] presented some IERK methods up to fourth-order accuracy with the implicit part is A-stable. Kennedy and Carpenter [20] constructed high-order IERK methods from third- to fifth-order to simulate convection-diffusion-reaction equations. The widespread ARS-type IERK methods by Ascher, Ruuth and Spiteri were developed in [2] to solve the convection-diffusion problems. These ARS-type methods had better stability regions than implicit-explicit multi-step schemes over a wide parameter range. Some ARS-type IERK methods from second- to fourth-order were also proposed in [26] for nonlinear differential equations with constraints, such as the Navier-Stokes equation. Cardone et.al. [5] proposed a class of ARS-type IERK methods up to fourth-order based on extrapolation of the stage values at the current step by stage values in the previous step. Izzo and Jackiewicz [16] constructed some parameterized IERK methods up to fourth-order by choosing the method parameters to maximize the regions of absolute stability for the explicit part in the method with the assumption of A-stable implicit part.
We will consider another class of parameterized IERK methods and choose the method parameters to maintain the original energy dissipation law (1.3) as much as possible. Let be the numerical approximation of at the mesh point for . For a -stage Runge-Kutta method, let be the approximation of at the abscissas , for , and . To integrate the semilinear parabolic problem (1.1) from the time () to the next grid point (typically, also represents a variable-step size), one can construct the following -stage IERK methods with explicit first stage, see [20, 26, 33]
| (1.4a) | |||
| (1.4b) | |||
where and . The implicit part of IERK methods (1.4) approximating the stiff linear term can be represented by the abscissa vector , the coefficient matrix and the vector of weights ,
where the abscissa for , and we use the so-called first same as last methods [28, 21], that is, the DIRK methods with the explicit first stage and the stiffly-accurate assumption: for such that
That is, we consider Lobatto-type DIRK methods, with the number of implicit stage which differs from the widespread Radau-type DIRK methods with or for .
The explicit part of IERK methods (1.4), namely explicit Runge-Kutta methods, for the nonlinear term can be represented by the abscissa vector , the strictly lower triangular coefficient matrix and the vector of weights ,
where the abscissa for , and introduce, to simplify our notations,
| (1.5) |
Always, we assume that for any . The IERK methods (1.4) become
| (1.6) |
Since the Lobatto-type DIRK methods are used in the implicit part, we call (1.6) as Lobatto-type IERK methods. They are quite different from the Radau-type IERK method containing the Radau-type DIRK methods in the implicit part, which are also known as ARS-type IERK methods [2, 11, 16, 31, 13, 26].
In general, the consistency of IERK methods (1.6) requires the canopy node condition
| (1.7) |
which makes the form (1.6) invariant under the transformation of IERK method to the non-autonomous system. Under the canopy node condition , Table 1 lists the order conditions for the coefficient matrices and the weights vector to make the IERK method (1.6) accurate up to fourth-order. A detailed description of these order conditions can also be found in [2, 6, 16, 31].
| Order | Stand-alone conditions | Coupling condition | |
|---|---|---|---|
| Implicit part | Explicit part | ||
| 1 | - | ||
| 2 | - | ||
| 3 | |||
| 4 | |||
* For the vectors and , and for .
In simulating the semilinear parabolic problems (1.1) and related gradient flow problems (1.2), IERK methods turned out to be very competitive. Shin et al. [30] observed that the Radau-type IERK methods combined with convex splitting technique (CSRK) exhibit the original energy stability in numerical experiments. Subsequently, they proved [31] that the proposed CSRK schemes can unconditionally maintain the original energy stability by assuming in (1.4). The proposed second-order CSRK scheme requires at least four stages, while the third-order CSRK scheme requires at least seven stages. The proposed CSRK schemes in [31] are nonlinear and would be computationally expensive due to the required inner iterations at each time stage. Very recently, Fu et al. [11] derived some sufficient conditions of Radau-type IERK methods to maintain the decay of original energy for the gradient flow problems and presented some concrete schemes up to third-order accuracy in time. It is noted that, the Radau-type IERK methods are only focused in the mentioned works, while we will construct some Lobatto-type IERK methods and present a unified theoretical framework to examine the energy dissipation properties of IERK methods up to fourth-order accurate for gradient flow problems (1.2).
The unified theoretical framework, presented in the next section, is inspired by two aspects: one is the idea by treating the stiffly-accurate (but not necessarily algebraically stable) DIRK method as the composite linear multistep method; the other is the recent discrete energy technique for the stability and convergence of multistep backward differentiation formulas [22, 25]. We will construct the differential forms and the associated differentiation matrices of IERK methods by using the difference coefficients of method and the so-called discrete orthogonal convolution kernels. It is proven that an IERK method can preserve the original energy dissipation law unconditionally if the associated differentiation matrix is positive semi-definite, see Theorem 2.1. The recent indicator in [24], namely average energy dissipation rate, is also defined for the IERK methods to evaluate the overall energy dissipation rate when applied to the gradient flow problems (1.2) such that one can choose proper parameters in some parameterized IERK methods, see Lemma 2.2. As described later, this framework will be fit for both Lobatto-type and Radau-type IERK methods, but is quite different from those in previous studies [31, 30, 11].
Section 3 addresses the details in constructing three parameterized second-order IERK (IERK2) methods and establishes the original energy dissipation laws for the resulting IERK2 methods. Also, we choose the optimal parameter in these IERK2 methods by using the concept of average dissipation rates, and present extensive tests to support our theoretical predictions, see Table 2, in which the parameter choices for the energy stability of six IERK2 methods are summarized. Third-order parameterized IERK (IERK3) methods are discussed and tested in Section 4 and, at the end of section, Table 3 collects some parameter choices for the energy stability of eight IERK3 methods. To show the existence of energy stable IERK methods with fourth-order time accuracy, two approximately fourth-order IERK (IERK4-A) methods are presented and tested in Section 5. In the last section, we summarize this article and present some further issues to be studied.
2 Stage energy laws of IERK methods
Requiring for all and immediately shows that the canopy node condition (1.7) makes the IERK method (1.6) preserve naturally the equilibria of the gradient flow problem (1.2), that is, . So one can reformulate the form (1.6) into the following steady-state preserving form
| (2.1) |
for , in which we drop the terms with the coefficients for . In this sense, we define the lower triangular coefficient matrices for the implicit and explicit parts, respectively,
The two matrices are always required in our theory on the energy dissipation property, while the coefficient vector would be not involved directly. Due to the addition of coefficients (degree of freedom) in the vector , as shown later, it would be useful in designing some computationally effective Lobatto-type IERK methods.
2.1 Our theoretical framework
Motivated by the stabilization idea from Du et al. [8] and Fu et al. [10, 11], we introduce the following stabilized operators with a parameter ,
| (2.2) |
such that the problem (1.1) becomes the stabilized version
| (2.3) |
Thus, applying (2) to (2.3), we have the following IERK method
| (2.4) |
for , where the (stage) time difference for .
To make our idea more concise, we assume further that the nonlinear function is Lipschitz continuous with a constant , cf. [32] or the recent discussions in [11]. In theoretical manner, the stabilization parameter in (2.2) is chosen properly large (determining the minimum stabilized parameter is out of our current scope although it is also practically useful). In this sense, if an IERK method is proven to maintain the original energy dissipation law (1.3) unconditionally, we mean that this IERK method can be stabilized by setting a properly large parameter . To derive the energy dissipation law of the general IERK method (2.4), we need the following result.
Lemma 2.1.
Our theoretical framework contains three main steps:
- (1)
-
Compute difference coefficients: we introduce a class of difference coefficients, for ,
It is not difficult to derive from (2.4) that
(2.5) for . The associated Butcher difference tableaux read
- (2)
-
Determine DOC kernels and differential form: we introduce the so-called discrete orthogonal convolution (DOC) kernels with respect to the explicit coefficient , cf. [22, 23, 24, 25],
(2.6) for . It is easy to check the following discrete orthogonal identity,
(2.7) where is the Kronecker delta symbol with if . Multiplying the third term of (2.5) by the DOC kernels , and summing from 1 to , one can exchange the summation order and apply the discrete orthogonal identity (2.7) to find that
for . Similarly, by multiplying the second term of (2.5) by the DOC kernels , and summing from 1 to , one has
for . With the help of the above two equalities, we have an equivalent form of the IERK method (2.4),
Thus we obtain the following differential form of the IERK method (2.4)
(2.8) for , where the elements are defined by for , and
(2.9) The associated lower triangular matrix is called the differentiation matrix.
Let be the lower triangular matrix full of element 1, and let be the identity matrix of the same size as . One has
Thus the above differentiation matrix defined in (2.9) can be formulated as
(2.10) Always, if the symmetric part is positive (semi-)definite, we say that the matrix is positive (semi-)definite.
- (3)
-
Establish stage energy dissipation law: this process is standard and we have the following result, which simulates the original energy dissipation law (1.3) at all stages.
Theorem 2.1.
Proof.
For , let be the -th sequential sub-matrix of the differentiation matrix . The above stage energy dissipation law (2.11) can be formulated as
(2.12) The involved vector and the matrix can be formulated as
(2.13) where is the identity matrix of the same size as and represents the Kronecker product. Since the matrix is symmetric and positive semi-definite, the properties of Kronecker product and the formula (2.13) arrive at the following corollary.
Corollary 2.1.
If the two matrices and are positive (semi-)definite, the results of Theorem 2.1 are valid.
2.2 Average dissipation rate
Theorem 2.1 shows that the IERK method (2.4) is unconditionally energy stable if the differentiation matrix is positive semi-definite, that is, all eigenvalues of the symmetric part are nonnegative. A necessary condition is that the average eigenvalue is nonnegative,
where is the size of and is the trace of . By comparing the discrete energy dissipation law (2.12) with the continuous counterpart (1.3), the overall energy dissipation rate of the energy could be roughly estimated by the average eigenvalue. Following the idea in [24], we will use the average dissipation rate, defined by
| (2.14) |
to examine the energy dissipation behaviors of IERK methods. By using the definitions (2.9) and (2.6), one can compute the diagonal elements of the matrices and ,
Thus, by using the Kronecker product form (2.13) and the following property
it is easy to obtain the following result.
Lemma 2.2.
If the two matrices and are positive (semi-)definite, then the average dissipation rate of the IERK method (2.4) is nonnegative, that is,
| (2.15) |
where the average eigenvalue of the symmetric, positive definite matrix is determined by the stabilized parameter , the method of spatial approximation and the grid spacing as well.
Since the average dissipation rate (2.14) is defined via the similarity between the energy dissipation law (1.3) and the discrete counterpart (2.12), we say that an IERK method is a “good” candidate to preserve the original energy dissipation law (1.3) if the average dissipation rate and is as close to 1 as possible within properly large range of . The specific expression of will depend on the phase field model involved; but always, the larger the value of , the greater the value of , while the smaller the spatial step , the greater the value of . At the same time, the values of and are entirely determined by the IERK method itself, regardless of the time-step size and the spatial step adopted by potential users. Throughout this paper, we aim to design some “good” IERK methods by minimizing the values of and as far as possible to make the associated average dissipation rate as close to 1 as possible within a given number of implicit stages.
Obviously, the average dissipation rate is only a rough indicator for describing discrete energy behavior of IERK method, that is, it would be a qualitative rather than quantitative indicator, since it ignores the computational accuracy of the algorithm. As remarked in [24], one can not expect that the long-time dynamics of the energy can be understood by such a scalar alone. Nonetheless, Lemma 2.2 provides us a very simple criterion to evaluate the overall energy dissipation rate of an IERK method so that one can choose proper parameters in some parameterized IERK methods or compare different IERK methods with the same time accuracy.
As an example, consider the first-order IERK (IERK1) method [14, p. 383],
| (2.16) |
Obviously, and such that the differentiation matrix is positive semi-definite for provided the weighted parameter according to Corollary 2.1. Lemma 2.2 says that the average dissipation rate
| (2.17) |
To enlarge the choice of , one can choose such that the average dissipation rate, , is independent of . We say that the stabilized Crank-Nicolson type scheme
is a “good” candidate to preserve the original energy dissipation law (1.3) unconditionally.
Here and hereafter, the superscript is always used to indicate the formal order of the method, that is to say, and denote the associated differential matrix and the average dissipation rate, respectively, of a -th order IERK method.
3 Discrete energy laws of IERK2 methods
3.1 Lobatto-type IERK2 methods
Second-order methods require two implicit stages, . Consider the 3-stage IERK methods that satisfy the canopy node condition and the two order conditions for the first-order accuracy,
We should determine five independent coefficients. By the two order conditions for second-order accuracy, see the second line in Table 1, one has three independent coefficients to be determined. In detail, from the stand-alone condition for explicit part, , one has . From the stand-alone condition for implicit part, , one has such that . According to Lemma 2.2 and the formula (2.15), we always choose
such that the trace can attain the minimum value, that is,
| (3.1) |
We obtain the following two-parameter class of second-order IERK (IERK2-1) methods with the associated Butcher tableaux, also see [26],
| (3.2) |
Now we are to determine the two independent coefficients and such that the IERK2-1 methods (3.2) are “good” candidates to preserve the original energy dissipation law (1.3) unconditionally. By the definition (2.10), one has
The determinant of the symmetric part
It is easy to check that
| (3.3) |
is sufficient to ensure the positive semi-definiteness of . Now compute the lower triangular matrix defined by (2.10),
The positive semi-definiteness of requires and
in which we set , or . Otherwise, the fact arrives at the negative determinant, . Thus, by using the restriction (3.3) and the fact , one has the following conditions for the coefficient ,
| (3.4) |
By using Corollary 2.1 and Lemma 2.2, we have the following theorem.
Theorem 3.1.
In simulating the gradient flow system (2.3) with , the two-parameter IERK2-1 methods (3.2) with the parameter setting (3.4) preserve the original energy dissipation law (1.3) unconditionally at all stages in the sense that
where the differentiation matrix is defined by
The associated average dissipation rate
| (3.5) |
The parameter setting (3.4) implies that one can minimize the trace by choosing the lower bound of , that is,
The minimum value is attained by setting due to the fact . In this case, the two-parameter IERK2-1 methods (3.2) reduce into the one-parameter IERK2 (IERK2-2) methods with the parameter ,
| (3.6) |
As expected, from the perspective of average dissipation rate, the optimal IERK2-2 methods maintain a fixed diagonal ratio between the implicit and explicit parts, that is, for . The associated average dissipation rate
| (3.7) |
Note that, the 3-stage Lobatto-type IERK2 method in [6, Section 2] would be not suitable for gradient flow problems because the associated differentiation matrix is not positive definite.
3.2 Radau-type IERK2 methods
For completeness, we also briefly consider the Radau-type DIRK methods, also known as ARS-type IERK methods [2, 11, 31], for the implicit part by assuming . In this case, one has three independent coefficients, see the associated Butcher tableaux as follows,
From , one has . The condition leads to . We obtain the following -parameterized class of Radau-type IERK (IERK2-Radau) methods [2]
| (3.8) |
Obviously, the restriction (3.3) is sufficient to ensure the positive semi-definiteness of . We also apply the definition (2.10) to find
The positive semi-definiteness of requires . By using Corollary 2.1 and Lemma 2.2, we have the following theorem.
Theorem 3.2.
In simulating the gradient flow system (2.3) with , the -parameterized IERK2-Radau methods (3.8) with the parameter preserve the original energy dissipation law (1.3) unconditionally at all stages in the sense that
where the associated differentiation matrix is defined by
The associated average dissipation rate
| (3.9) |
To enlarge the possible choices of , we choose such that attains the minimum value and . However, it is always larger than the average dissipation rate of the IERK2-2 methods (3.6) for . Under the same stabilization strategy, the IERK2-2 methods (3.6) would be more competitive than the IERK2-Radau methods (3.8), at least, from the perspective of average dissipation rate.
To improve the average dissipation rate of Radau-type IERK2 methods, one can consider four-stage procedure such that there are nine independent coefficients to be determined. An example is the four-stage Radau-type IERK2 procedure in [31, Section 4], which is constructed by imposing the simplifying setting and has a better average dissipation rate . It is to mention that, the 3-stage Radau-type IERK method in [2] would not be suitable for the gradient flow problems since it does not satisfy the assumptions of Corollary 2.1.
3.3 Tests of IERK2 methods
Example 1.
Consider the Cahn-Hilliard model, , subject to the initial data on with the interface parameter . The source term is set by choosing the exact solution . Always, the spatial operators are approximated by the Fourier pseudo-spectral approximation with 256 grid points.
At first, we test the convergence of IERK2-1 (3.2), IERK2-2 (3.6) and IERK2-Radau (3.8) methods by choosing the final time and the stabilized parameter . Figure 1 lists the norm error for the three classes of IERK2 methods on halving time steps for . As expected, the IERK2-1 (3.2), IERK2-2 (3.6) and IERK2-Radau (3.8) methods are second-order accurate in time. It seems that the different parameters for the IERK2-1 (3.2) and IERK2-2 (3.6) methods would arrive at different numerical precision; while the IERK2-Radau methods (3.8) with two different parameters and generates almost the same solution. Also, it can be observed that the error of IERK2-2 method for is always the smallest for the same time-step size .



Example 2.
Consider the Cahn-Hilliard model, on with the interface parameter , subject to the initial data
The reference solution is generated with a small time-step size by the IERK2-1 method (3.2) for the parameters and .
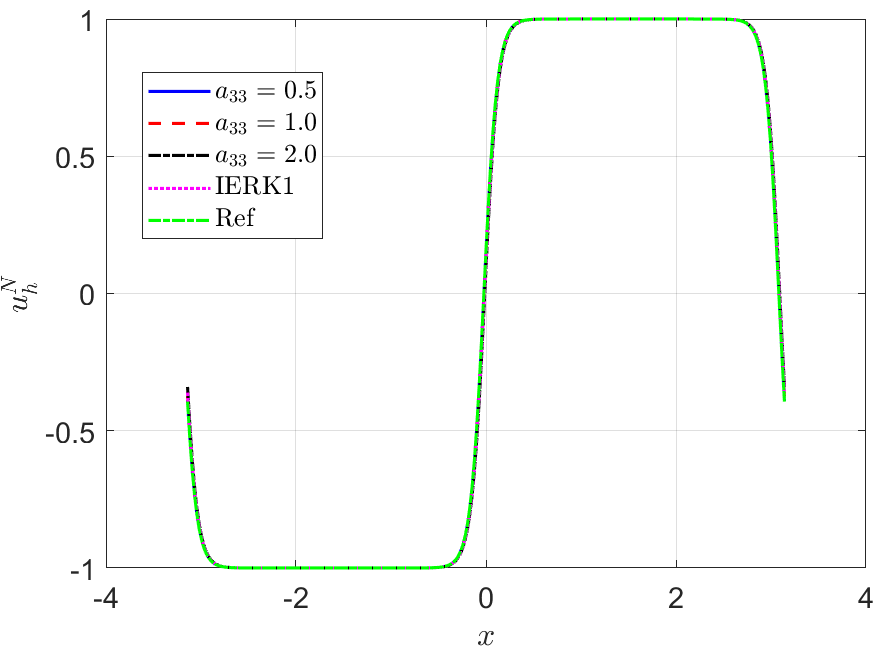
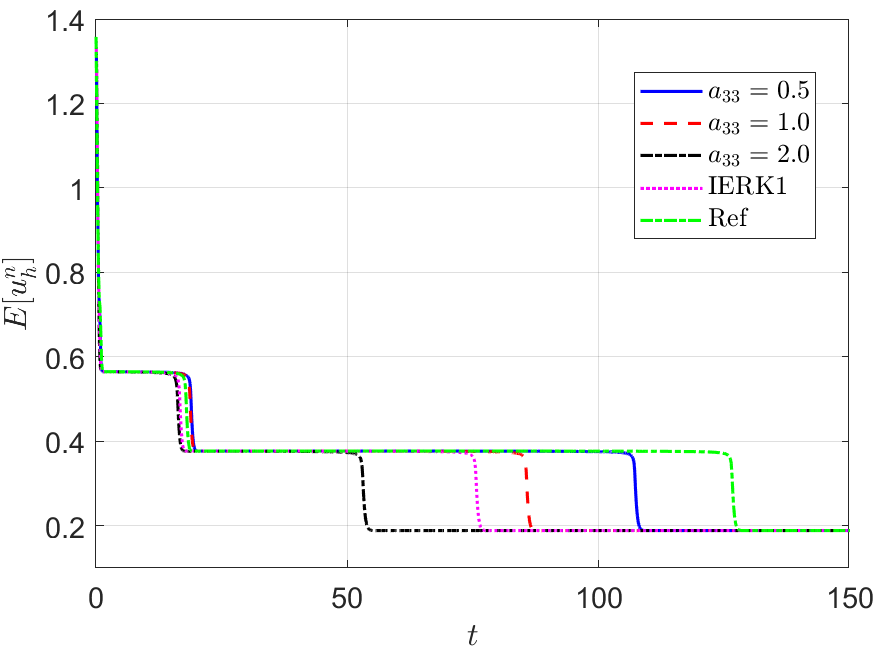
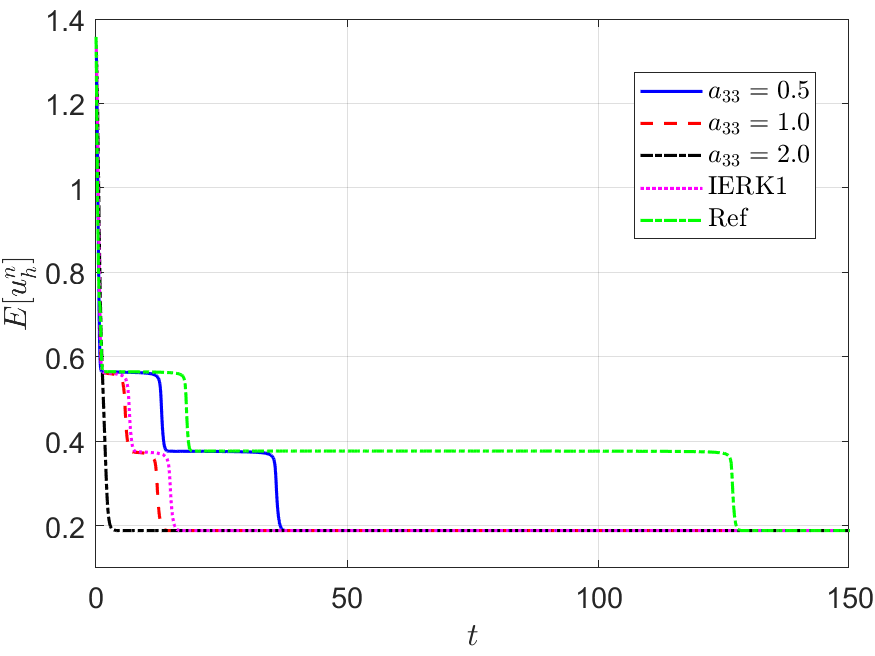
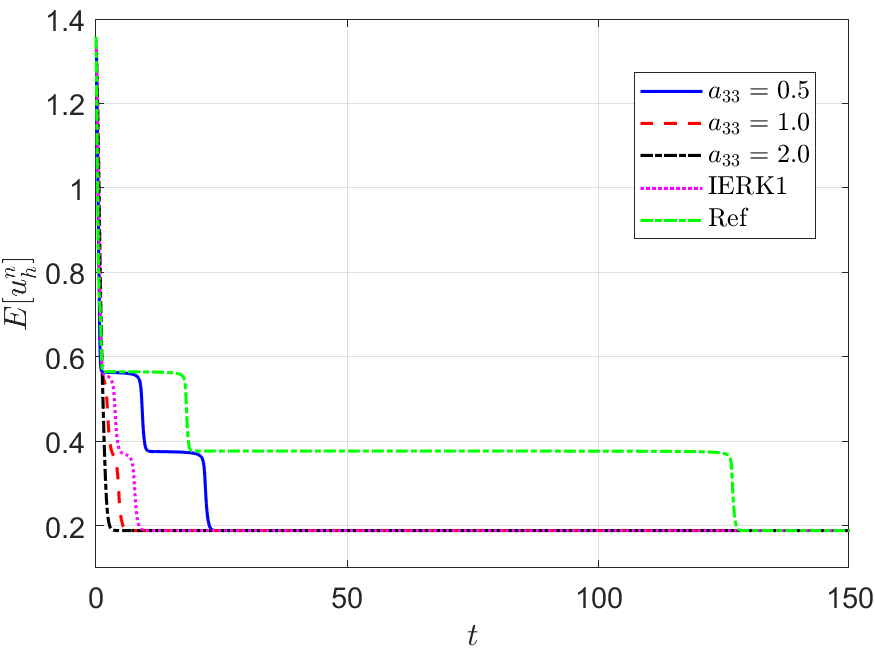
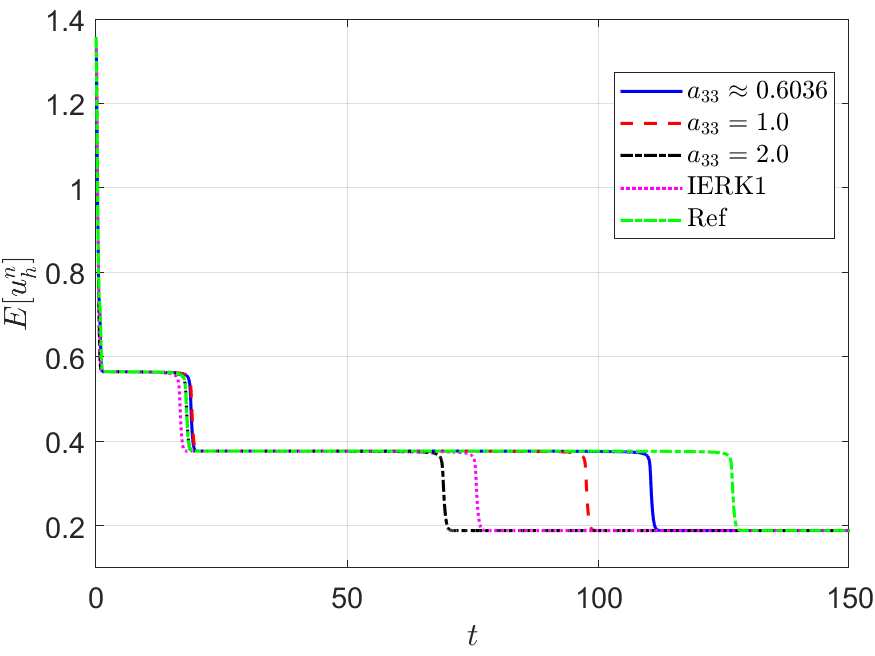
Figure 2 depicts the final solution at for , and the discrete energy generated by the IERK2-1 methods (3.2) for three different scenes: (i) ; (ii) and (iii) . As predicted by Theorem 3.1, the original energy curves in all cases always monotonically decreasing. Also, the numerical dissipation rates of original energy seem quite different for three different choices of the parameter . For three different discrete scenes in Figure 2 (b)-(d), the energy curves for are always closest to the reference energy, while the energies for are the farthest away. More interestingly, these phenomena can be predicted by (3.5), or , which suggests that the discrete energy gradually deviates from the continuous energy as the method parameter increases.
It seems that, the above differences between discrete energy curves and continuous energy shown in Figure 2 (b)-(d) can be explained by the different precision of numerical solutions. Actually, Figure 1 (a) shows that the solution for the case is a bit more accurate than that for although both of them are second-order accurate. Maybe, this would not be the whole story. In Figure 2 (b)-(d), we also include the discrete energy generated by the first-order IERK1 method (2.16) with , which has the average dissipation rate . More surprisingly, the energy curve generated by the first-order IERK1 method with is even closer to the reference one than some IERK2-1 schemes especially when the time-step size is properly large. Although we are unsure of the complete mechanism behind it, they suggest that the selection of method parameters in IERK methods is at least as important as the selection of different IERK methods, if not more important. Obviously, the choice is a good choice for IERK2-1 methods (3.2), at least, for this example.
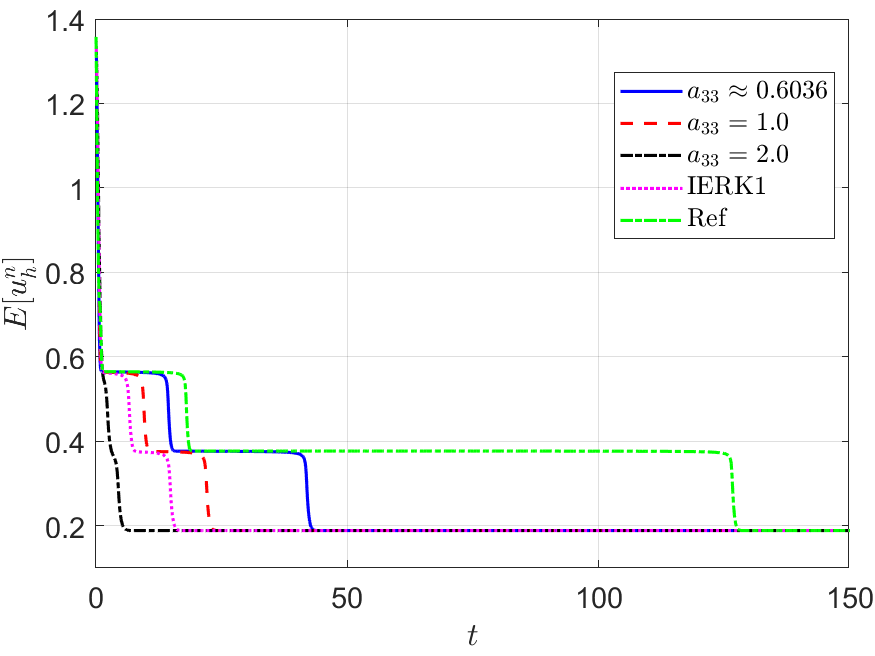
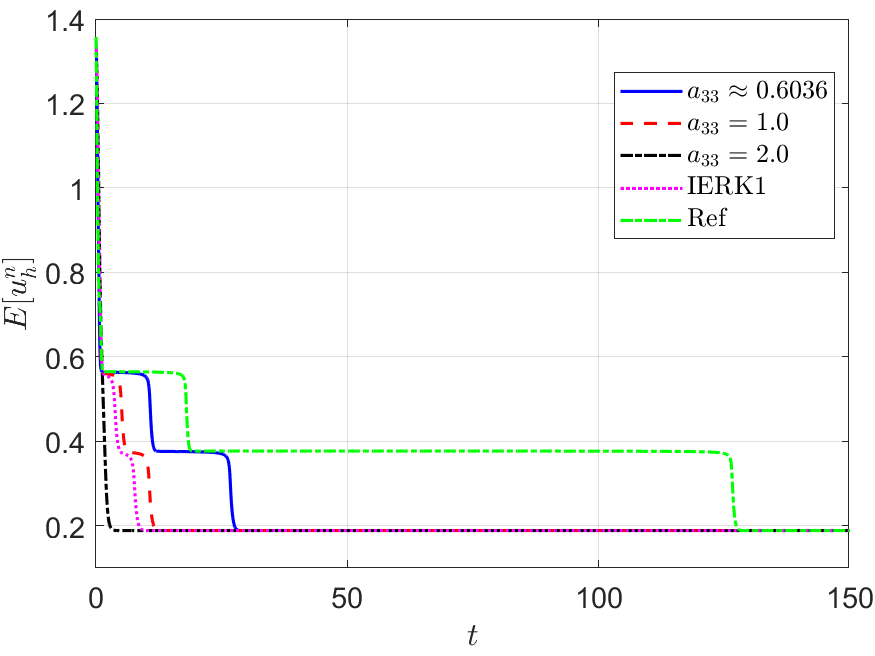
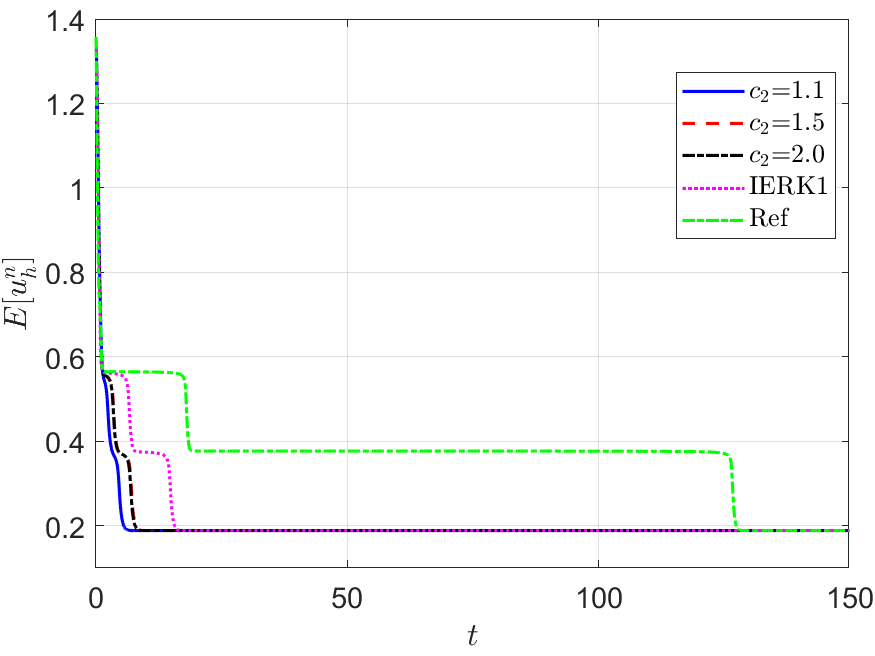
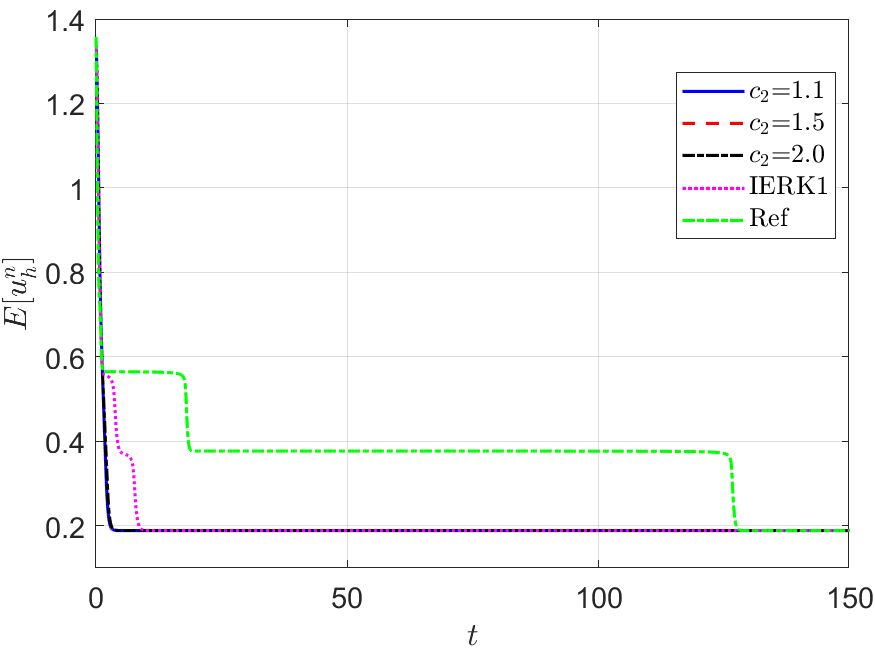
We also run the one-parameterized IERK2-2 (3.6) and IERK2-Radau (3.8) methods up to the time , and present the discrete energy curves in Figures 3 and 4, respectively, for three different scenes: (i) ; (ii) and (iii) . As predicted by our theory, the discrete energies in all cases always monotonically decrease, and the discrete energies generated by the same method gradually deviate from the continuous energy as the associated average dissipation rate deviates from 1 (reminding that the average dissipation rate is an increasing function with respect to the step size and the parameter ), cf. the formulas (3.7) and (3.9). For this example, one can find that the case of IERK2-2 methods (3.6), and the case of IERK2-Radau methods (3.8) seem better than other parameters for the same time-step size and the stabilized parameter. Again, from the difference between discrete energy and continuous energy (for the same time-step size), the IERK1 scheme (2.16) with is also comparable to some second-order IERK2 schemes, although it only has first-order time accuracy.
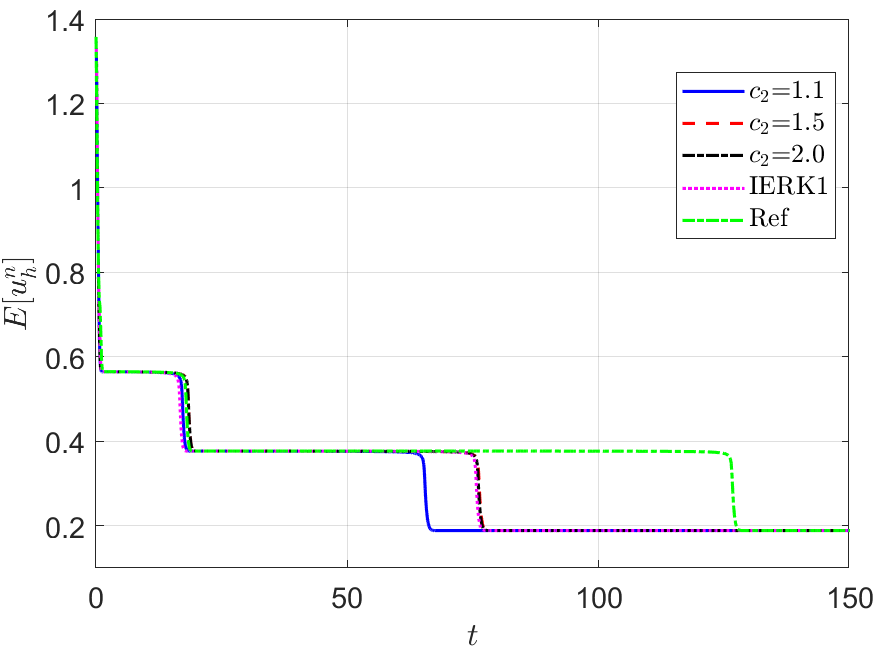
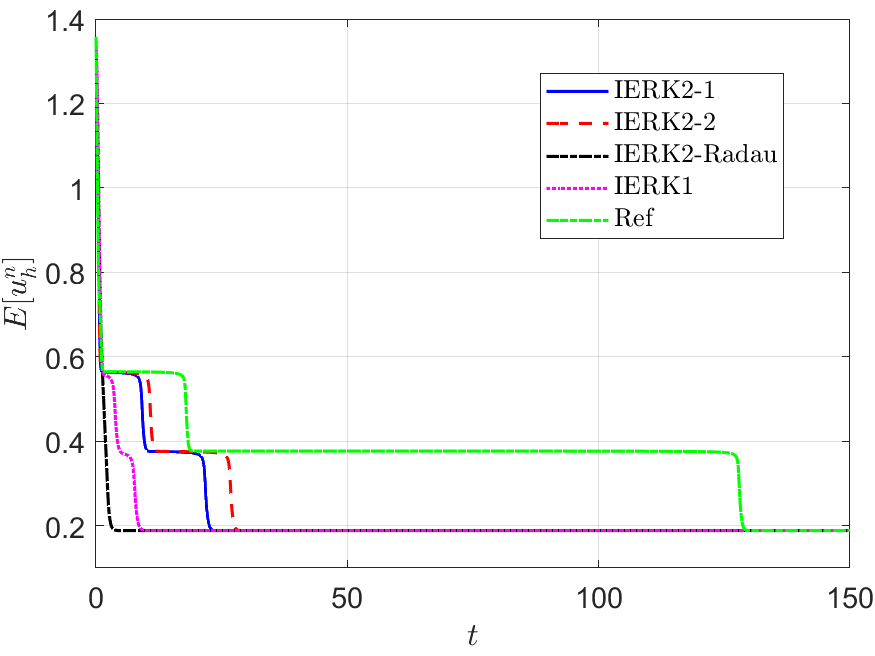
Also, in Figure 5, we compare the energy behaviors of three “good” schemes, namely, the IERK2-1 method for and , the IERK2-2 method for , and the IERK2-Radau method for , in previous tests shown in Figures 2-4. We see that, for this example, the discrete energy generated by the IERK2-2 scheme is the closest to the continuous energy; while the discrete energy generated by the IERK2-Radau method is the farthest from the continuous one. Experimentally, they confirm our theoretical predictions in previous subsection.
| Type | Method | Average dissipation rate | Best choice |
|---|---|---|---|
| Lobatto-type | 3-stage IERK2-1 (3.2) | ||
| 3-stage IERK2-2 (3.6) | |||
| 3-stage IERK2 [6] | NPD∗ | ||
| Radau-type | 3-stage IERK2-Radau (3.8) | ||
| 4-stage IERK2 [31] | |||
| 3-stage IERK2 [2] | NPD |
* NPD means there exists a such that the associated differential matrix is not positive (semi-)definite.
4 Discrete energy laws of IERK3 methods
4.1 IERK3 methods with four stages
Third-order methods require three implicit stages, , at least. We should determine eleven independent coefficients in the following four-stage IERK methods that satisfy the canopy node condition and the two order conditions for first-order accuracy,
From Table 1, eight order conditions for second- and third-order accuracy are required such that there are three independent coefficients. Considering the stand-alone conditions for explicit part, , and , we find that , and with the independent variables and . Here we have excluded the case since the case can not arrive at our aim. From the stand-alone conditions for implicit part, and , one has and Thus the coupling condition arrives at and then
that is, the procedure at the fourth stage is purely explicit. Then it follows that and . It means that the coupling condition is equivalent to the stand-alone condition for implicit part . Therefore we have four independent coefficients.
By choosing , and , we obtain the following -parameterized IERK3 methods with the associated Butcher tableaux
| (4.19) |
By the definition (2.9), one can get
Simple computing yields that the matrix is positive definite. Also, it is easy to find that , and . That is, the associated differentiation matrix can not be positive semi-definite for all , and the sufficient condition of Theorem 2.1 is not fulfilled. Although the third-order methods (4.19) may maintain the discrete energy dissipation law (1.3) under certain time-step conditions, they may not be stabilized to preserve the energy dissipation law unconditionally no matter how large the stabilization parameter we set in the current stabilization strategy (2.3).
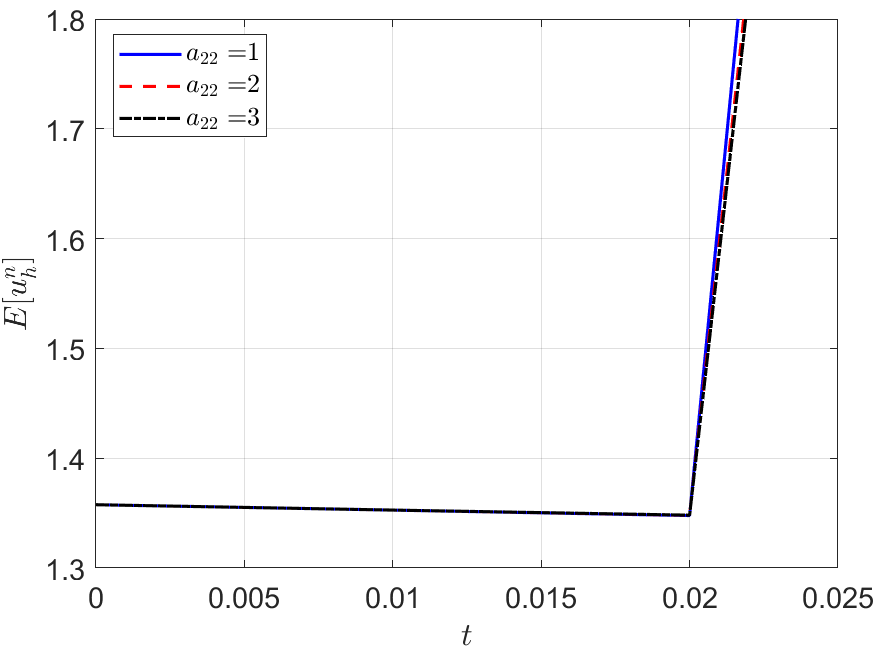
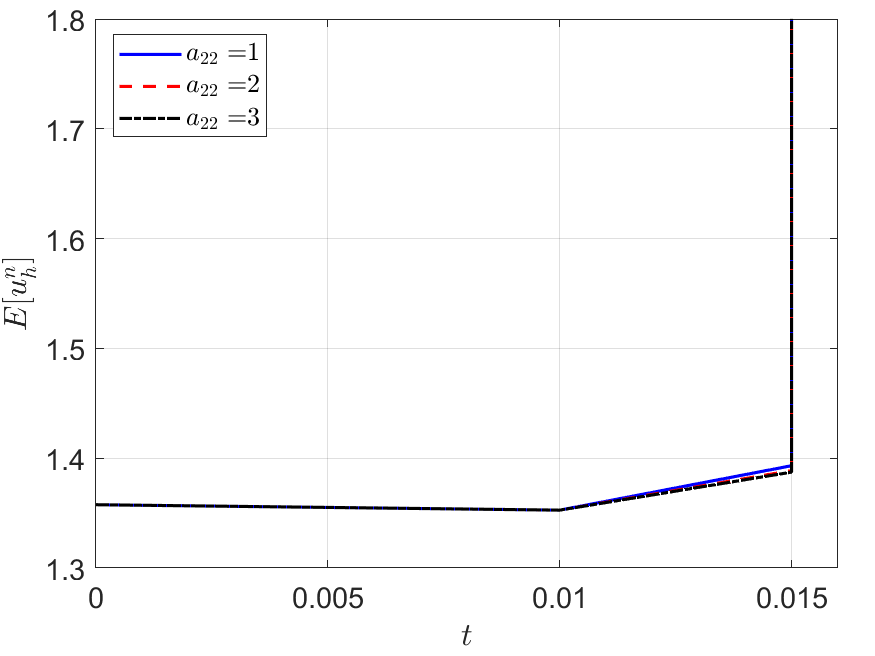
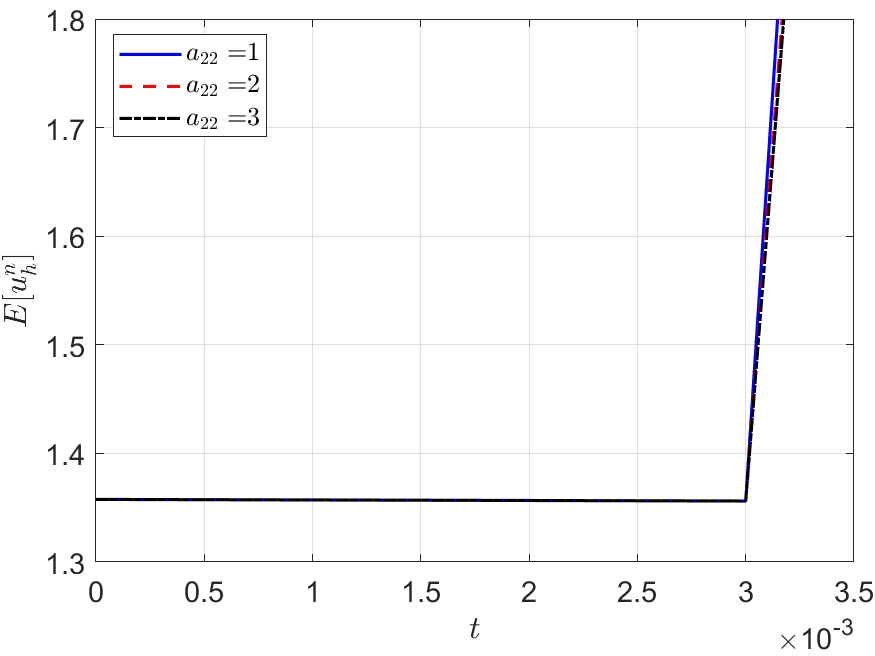
As the numerical evidence, we run the IERK3 methods (4.19) with , 2 and 3 for Example 2 with a fixed stabilized factor . The associated discrete energy curves, depicted in Figure 6, for three different time-steps , and can not maintain the decaying property. It is to mention that, the differentiation matrix can not be positive semi-definite for all if there are one zero diagonal element in the coefficient matrix of the implicit part. For example, if , the formula (2.9) gives the diagonal element , which cannot be always non-negative for all . Then the condition of Theorem 2.1 can not be fulfilled because the diagonal elements of a positive semi-definite matrix must be non-negative. As mentioned before, four-stage IERK3 methods always have a zero diagonal element, . In this sense, we say that there are no four-stage IERK3 methods fulfill the condition of Theorem 2.1. Note that, similar situations can be found in [6, Section 2] and [26, Sections 8 and 9], where many IERK methods up to fourth-order accuracy have zero diagonal elements.
4.2 IERK3 methods with five stages
We consider the five-stage third-order IERK methods with the following Butcher tableaux
where we assume and for to reduce the degree of freedom so that there are five independent variables. Such simplifying assumptions are set to maintain a fixed diagonal ratio between the implicit and explicit parts so that one can minimize the value of as far as possible according to the formula (2.15) of average dissipation rate.
After lots of trial and error processes, we keep one free variable by choosing the abscissas , , and the coefficient , and obtain the five-stage IERK3 (IERK3-1) methods with the following Butcher tableaux
| (4.34) |
where , , and .
By the definitions in (2.10), one can write out the matrices and as follows,
Simple calculations can verify the positive semi-definiteness of . For the matrix , We have , , and
One can check that the following condition
| (4.35) |
is sufficient for the positive semi-definiteness of . By using Corollary 2.1 and Lemma 2.2, we have the following theorem.
Theorem 4.1.
In simulating the gradient flow system (2.3) with , the one-parameter IERK3-1 methods (4.34) with the parameter setting (4.35) preserve the original energy dissipation law (1.3) unconditionally at all stages in the sense that
where the differentiation matrix is defined by
The associated average dissipation rate reads
| (4.36) |
Also, one can take as the free variable by choosing the abscissas , , and the diagonal element , and obtain the following one-parameter IERK3 (IERK3-2) methods with the associated Butcher tableaux
| (4.37) |
Note that, the IERK3-2 methods (4.37) is quite different from the IERK3-1 methods (4.34) in the sense that the average dissipation rate is independent of the parameter , while the average dissipation rate of the latter is always dependent on the choice of .
By the definitions in (2.10), one has and
Simple calculations gives , ,
It is easy to check that the following condition
| (4.38) |
is sufficient for the positive semi-definiteness of . Thus we have the following result.
Theorem 4.2.
In simulating the gradient flow system (2.3) with , the one-parameter IERK3-2 methods (4.37) with the parameter setting (4.38) preserve the original energy dissipation law (1.3) unconditionally at all stages in the sense that
where the differentiation matrix is defined by
The associated average dissipation rate is parameter-independent, that is,
| (4.39) |
4.3 Radau-type IERK3 methods with five stages
We also briefly discuss the five-stage Radau-type IERK3 methods by assuming . That is, consider the following Butcher tableaux that satisfy the canopy node condition and the two order conditions for first-order accuracy,
where we set () to reduce the degree of freedom. According to Table 1, eight order conditions for second- and third-order accuracy are required so that there are four independent coefficients. This simplifying setting is also useful for practical applications since it provides the same iteration matrix for the systems of linear equations at all stages.
After lots of trial and error processes, we choose , and and obtain the -parameterized Radau-type IERK3 (IERK3-Radau) methods with the Butcher tableaux
| (4.54) |
where and .
By the definition (2.10), one can get the associated matrices
and
As done in the above subsection, one can check that, if , and are positive semi-definite. Corollary 2.1 and Lemma 2.2 yield the following theorem.
Theorem 4.3.
To enlarge the possible choices of , one can choose the parameter such that
It is a little larger than the average dissipation rate of the IERK3-2 methods (4.37). From the perspective of average dissipation rate, the IERK3-Radau methods (4.54) are more competitive than the existing Radau-type IERK3 method in [11, Example 5] with the associated average dissipation rate , although they would be inferior to the one-parameter IERK3-1 (4.34) and IERK3-2 (4.37) methods.
To search a “better” IERK3 method, that is to say, to obtain a IERK method with the average dissipation rate closer to 1, one can consider higher-stage procedures. An example is the 7-stage IERK3 method in [31], which achieves a better average dissipation rate, , at the cost of two additional implicit stages. We also mentioned that, the 5-stage Radau-type IERK method in [2] does not satisfy the sufficient conditions of Corollary 2.1 so that it is not a proper candidate for the gradient flow system (1.2).
4.4 Tests for IERK3 methods



We use Example 1 to test the convergence of IERK3-1 (4.34), IERK3-2 (4.37) and IERK3-Radau (4.54) methods by choosing the final time and the stabilized parameter . Figure 7 lists the norm error for the three classes of IERK3 methods on halving time steps for . As expected, the IERK3-1 (4.34), IERK3-2 (4.37) and IERK3-Radau (4.54) methods are third-order accurate in time. It is observed that the different parameters for the IERK3-1 (4.34) and IERK3-2 (4.37) methods would arrive at different numerical precision; while the IERK3-Radau methods (4.54) with three different parameters and generates almost the same solution.
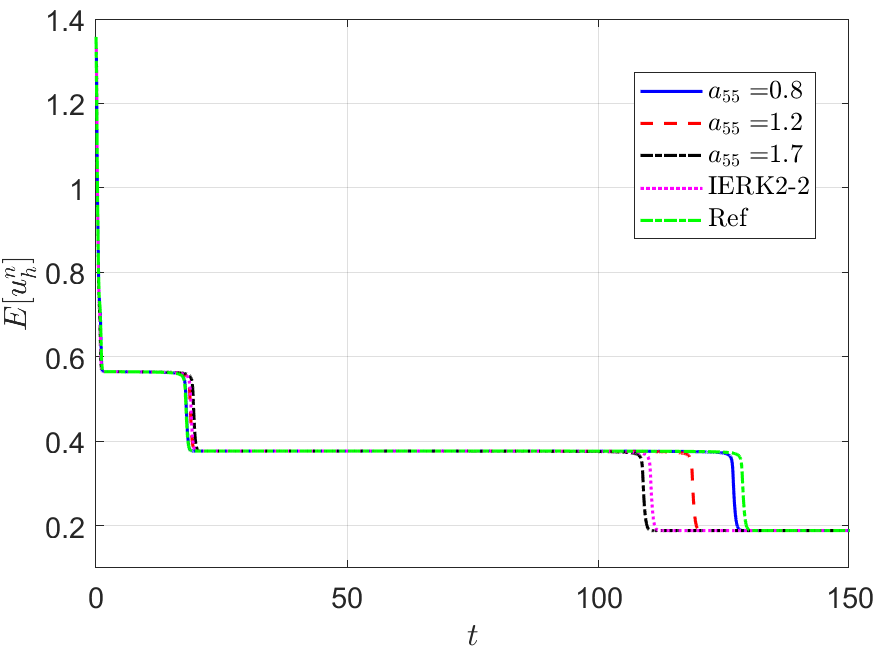
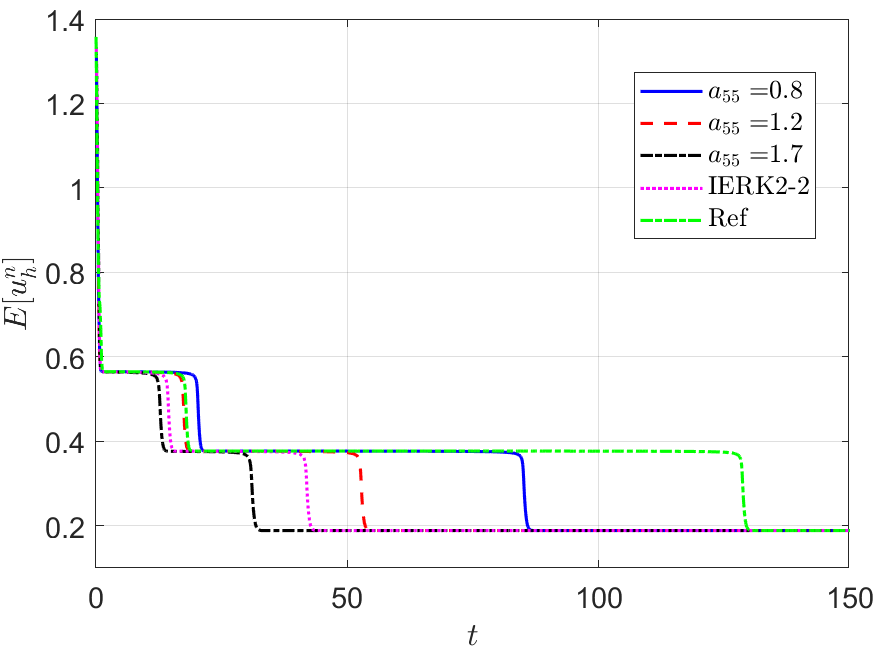
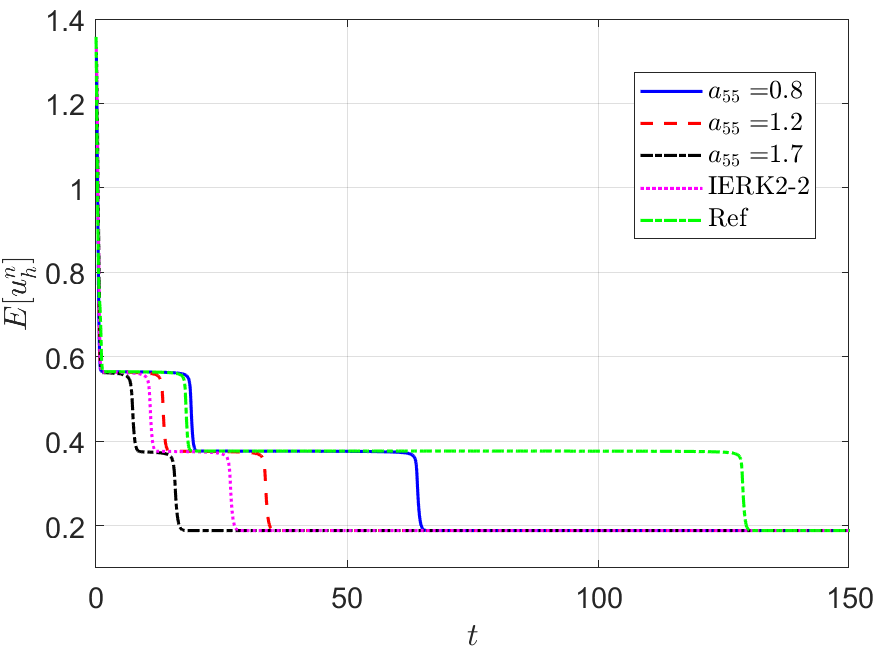
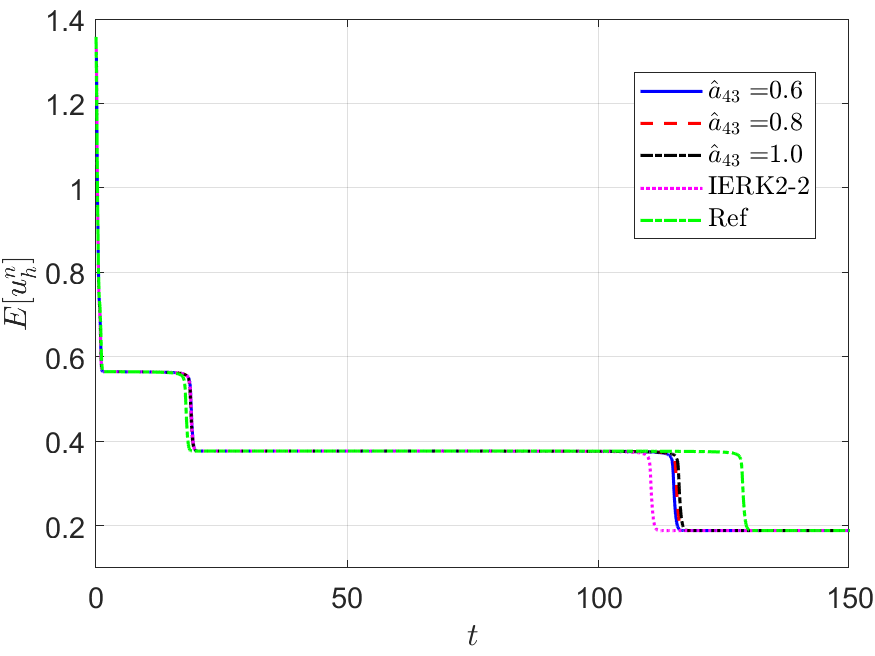
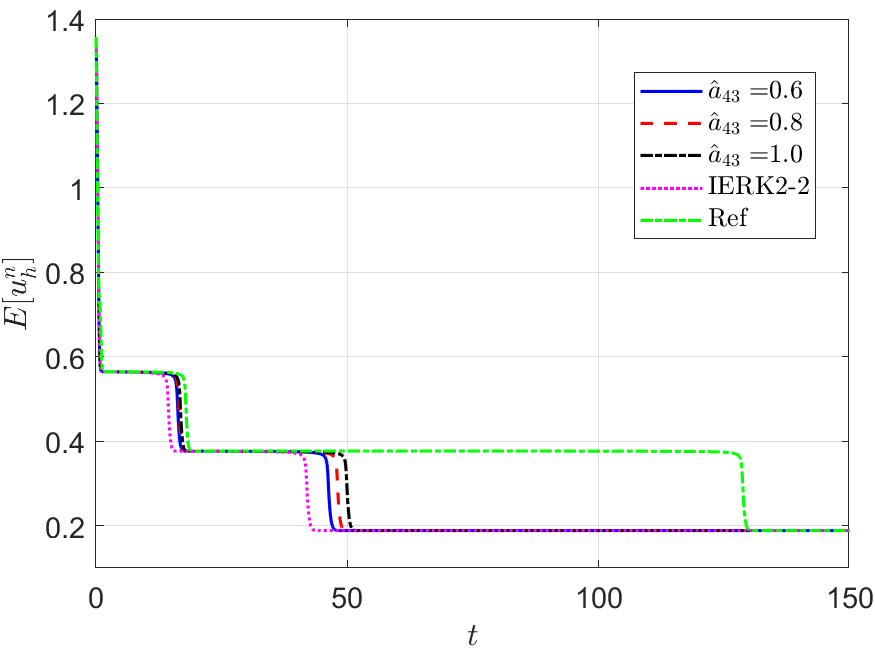
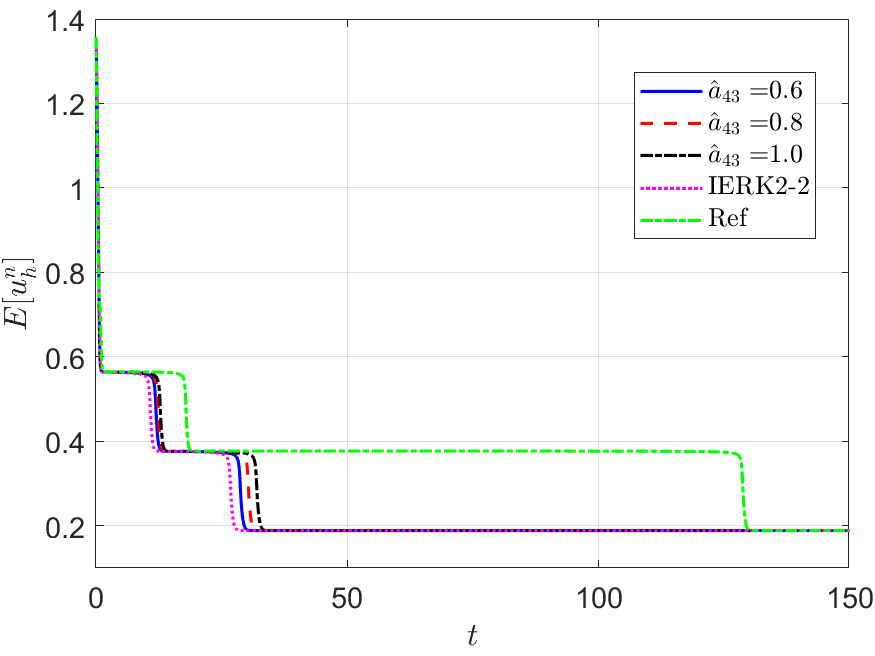
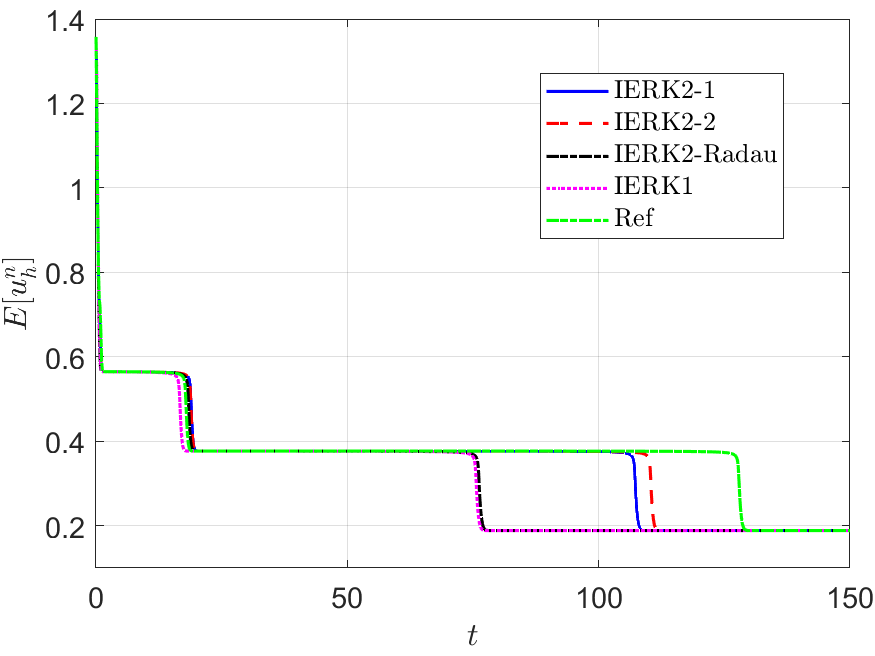
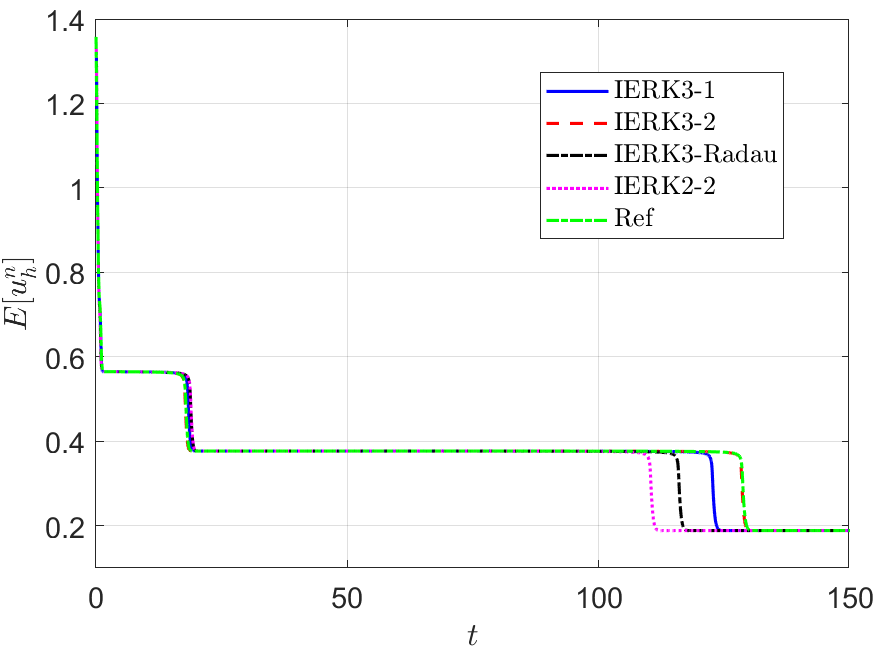
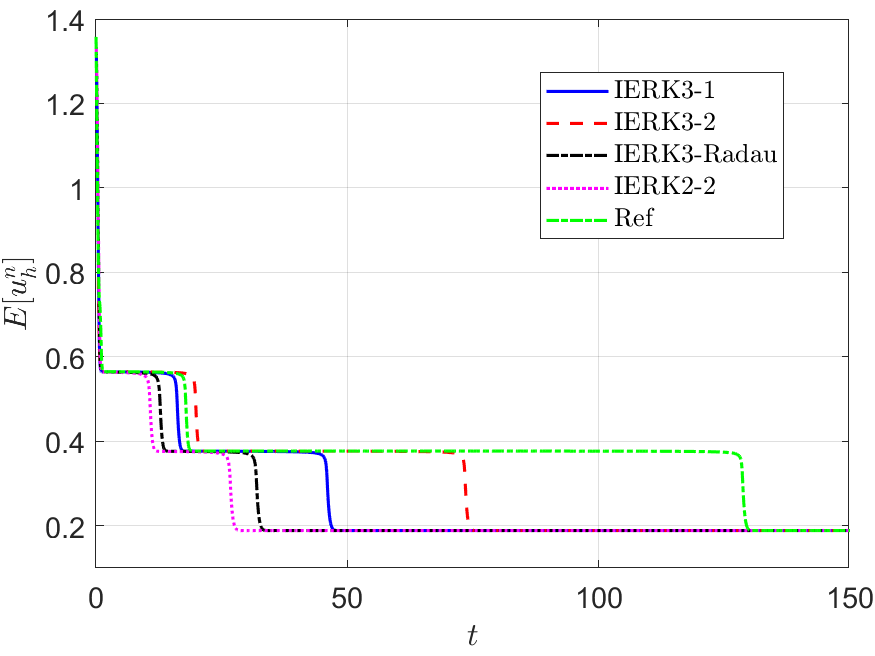
Next, we address the discrete energy behaviors of three IERK3 methods for Example 2. Always, we use a small time-step size to compute the reference solution and energy by the IERK3-2 method (4.37) for . Figures 8 and 9 depict the discrete energies generated by the IERK3-1 (4.34) and IERK3-Radau (4.54) methods, respectively, for three different scenes: (i) ; (ii) and (iii) . As predicted by our theory, the discrete energies in all cases always monotonically decrease, and the discrete energies generated by the same method gradually deviate from the continuous energy as the associated average dissipation rates deviate from 1, cf. the formulas (4.36) and (4.55). It is seen that there are always significant differences between the reference curve and the three discrete energy curves (corresponds to three different parameters) generated by the IERK3-1 methods (4.34); but such differences are not obvious for those of the IERK3-Radau methods (4.54).
The above differences between discrete energy curves and continuous energy shown in Figures 8 and 9 can be partly explained by the different precision of numerical solutions. Actually, Figure 7 (a) shows that the solution for the case of the IERK3-1 methods (4.34) is a bit more accurate than that for although both of them are third-order accurate. Figure 7 (c) shows that the solutions for the three cases 0.8 and of the IERK3-Radau methods (4.54) are very close. At the same time, this would not be the whole story. In Figures 8 and 9, we also include the discrete energy generated by the IERK2-2 method (3.6) for , which seems to be the “best” scheme of second-order accuracy. One can observe that the discrete energy curve generated by the IERK2-2 method is even closer to the reference energy curve than the IERK3-1 method (4.34) with . They suggest that the selection of method parameters in IERK3 methods is at least as important as the selection of different IERK3 methods. For this example, the parameters and are “good” choices for the IERK3-1 (4.34) and IERK3-Radau (4.54) methods, respectively.
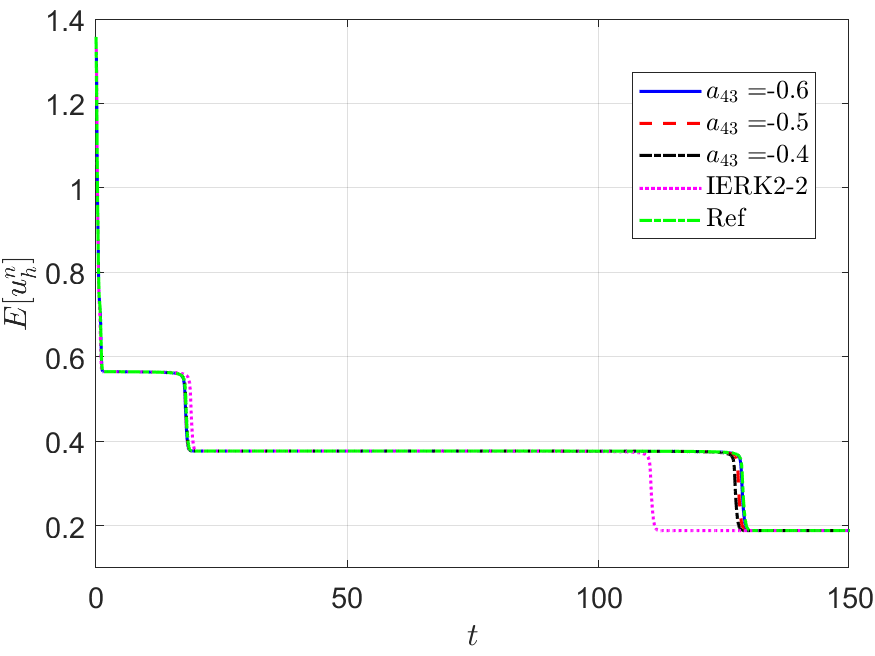
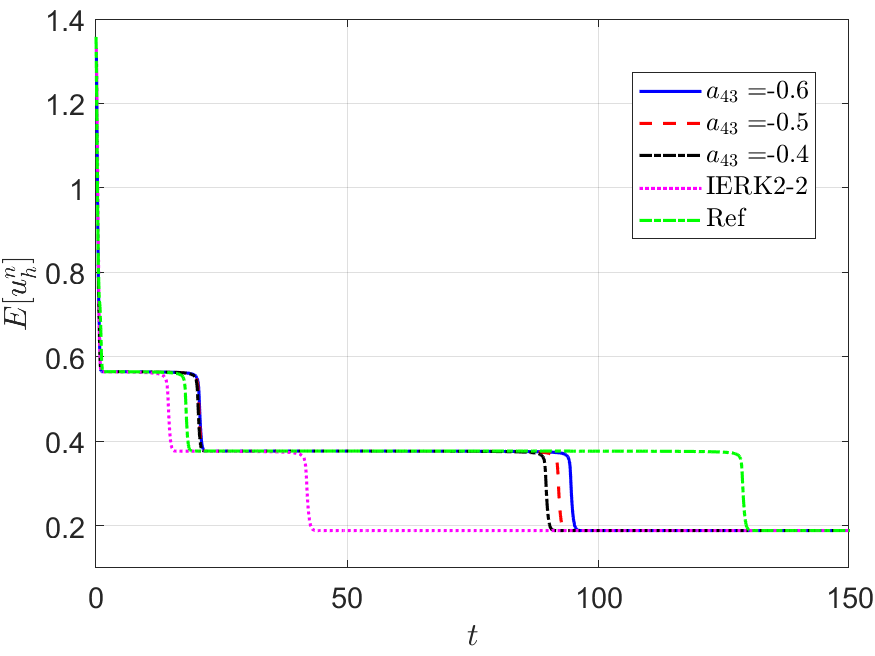
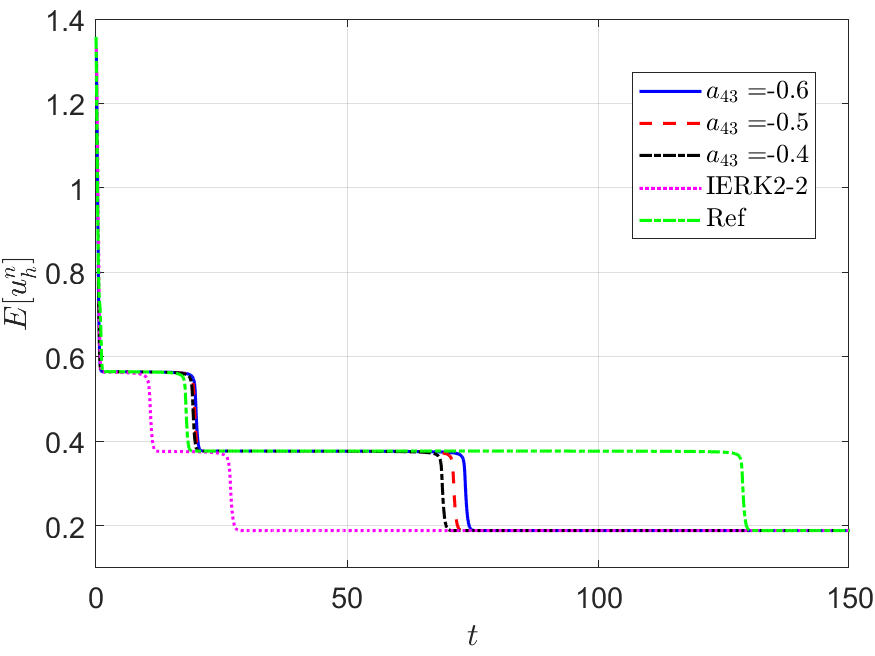
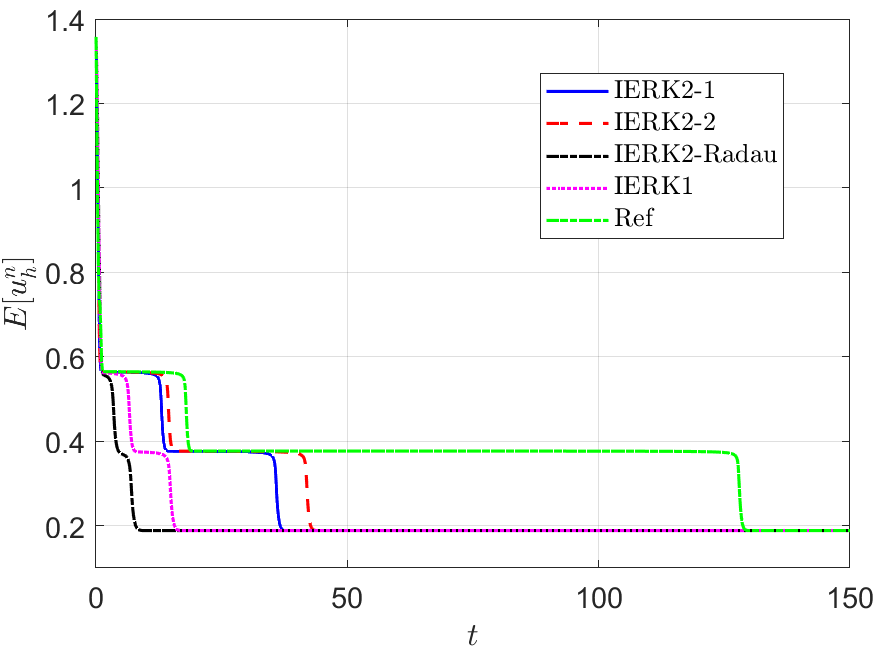
We run the IERK3-2 methods (4.37) with three parameters and up to the time , and exhibit the discrete energy curves in Figure 10 for three scenes: (i) ; (ii) and (iii) . As predicted by Theorem 4.37, the discrete energies in all cases always monotonically decreasing; however, the dissipation rates of discrete energies are quite different from those in Figures 8 and 9. We see that the discrete energies for three parameters and approach the reference curve in a staggered manner (fast and slow) at different time periods. For example, the energy curves for are always closest to the reference energy in the third fast varying period, while they are not the closest one to the reference energy in the second fast varying period. This phenomenon cannot be directly understood by the parameter-independent dissipation rate, , and remains mysterious to us. As expected, the IERK3-2 methods (4.37) perform better than the “best” second-order method (3.6).
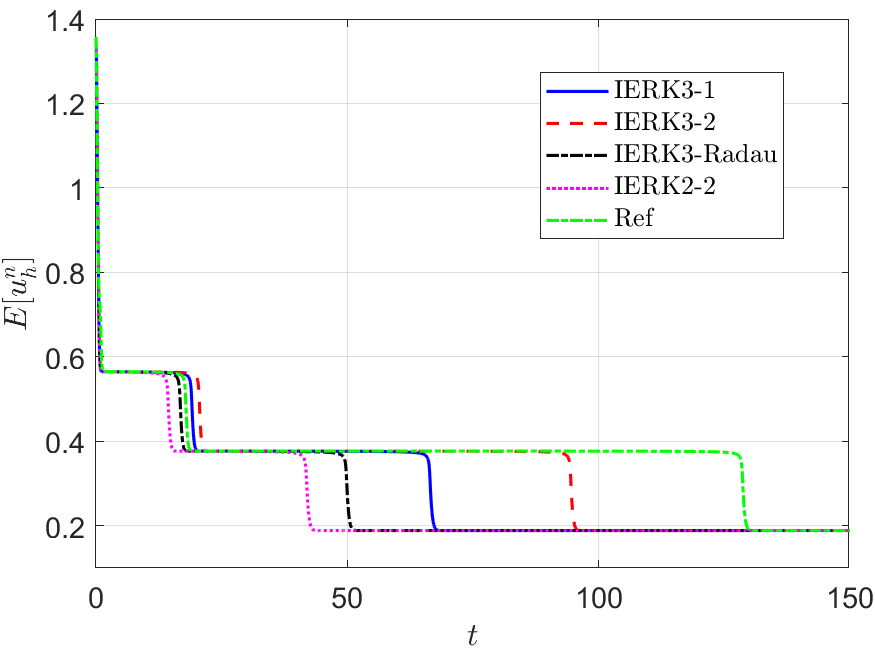
Furthermore, the IERK3-2 methods (4.37) would be the “best” candidates among the three classes of IERK3 methods. In Figure 11, we compare the energy behaviors of three “good” schemes, namely, the IERK3-1 method for , the IERK3-2 method for , and the IERK3-Radau method for , in previous tests shown in Figures 8-10. The discrete energy curve generated by the IERK3-1 method is always closer to the reference energy curve than that of the IERK3-Radau method. Thanks to the minimum dissipation rate among the three methods, the energy curve of the IERK3-2 method for is always the closest one to the reference curve. By contrast, the discrete energy generated by the IERK2-2 method stays farthest away from the reference energy. Experimentally, they support our theoretical results.
To end this section, we summarize the theoretical results in Theorems 4.1-4.3, the numerical results in this section and results of some existing IERK algorithms in the literature in Table 3, which presents the average dissipation rates and some practical choices.
| Type | Method | Average dissipation rate | Practical choice |
|---|---|---|---|
| Lobatto-type | 5-stage IERK3-1 (4.34) | ||
| 5-stage IERK3-2 (4.37) | |||
| 4-stage IERK3 [6] | NPD | ||
| 5-stage IERK3 [26] | NPD | ||
| Radau-type | 5-stage IERK3-Radau (4.54) | ||
| 5-stage IERK3 [11] | |||
| 7-stage IERK3 [31] | |||
| 5-stage IERK3 [2] | NPD |
5 Discrete energy laws of IERK4-A methods
5.1 IERK4-A methods
For six-stage IERK methods that satisfy the canopy node condition and the two order conditions for first-order accuracy, there are 29 coefficients to be determined by 26 order conditions up to fourth-order accuracy in Table 1. That is to say, there are three independent coefficients; however, we are not able to find any fourth-order IERK methods within six stages to fulfill the assumptions of Corollary 2.1, that is, the positive semi-definiteness of the two matrices and .
Unfortunately, we also fail to find energy stable fourth-order IERK methods with seven stages that fulfill all order conditions in Table 1. Alternatively, one can present some approximately fourth-order IERK (IERK4-A) methods, where the method coefficients are computed by the least squares approximation of 18 order conditions for fourth-order accuracy with a given tolerance , such as . It is to note that, for the IERK4-A methods satisfying the canopy node condition and 10 order conditions up to third-order accuracy, the truncation errors are about of if the solution is sufficiently regular. That is to say, a lower bound will be required to attain the fourth-order accuracy of IERK4-A methods although such time-step restriction is rather weak in practical applications.
The first one of fourth-order accuracy with the tolerance , called IERK4-A1 method, has the following Butcher tableaux
| (5.13) | ||||
| (5.26) |
where the coefficients for and
The associated matrices and defined by (2.10) are positive definite with the eigenvalue vectors, respectively,
| and |
The corresponding average dissipation rate is
The second one of fourth-order accuracy with the tolerance , called IERK4-A2 method, has the following Butcher tableaux
| (5.39) | ||||
| (5.52) |
where the first coefficients and for , and
The associated matrices and defined by (2.10) are positive definite with the eigenvalue vectors, respectively,
| and |
The corresponding average dissipation rate is
Theorem 5.1.
The seven-stage IERK4-1 (5.13) and IERK4-2 (5.39) methods are considered only to show the existence of the energy stable methods with fourth-order time accuracy. As mentioned early, Liu and Zou [26] proposed several Lobatto-type fourth-order IERK methods; but these methods have zero diagonal entries and do not satisfy our assumptions in Corollary 2.1. Actually, in the literature, we do not find any Lobatto-type or Radau-type fourth-order IERK methods that the associated differentiation matrices are positive (semi-)definite.
5.2 Tests for IERK4-A methods
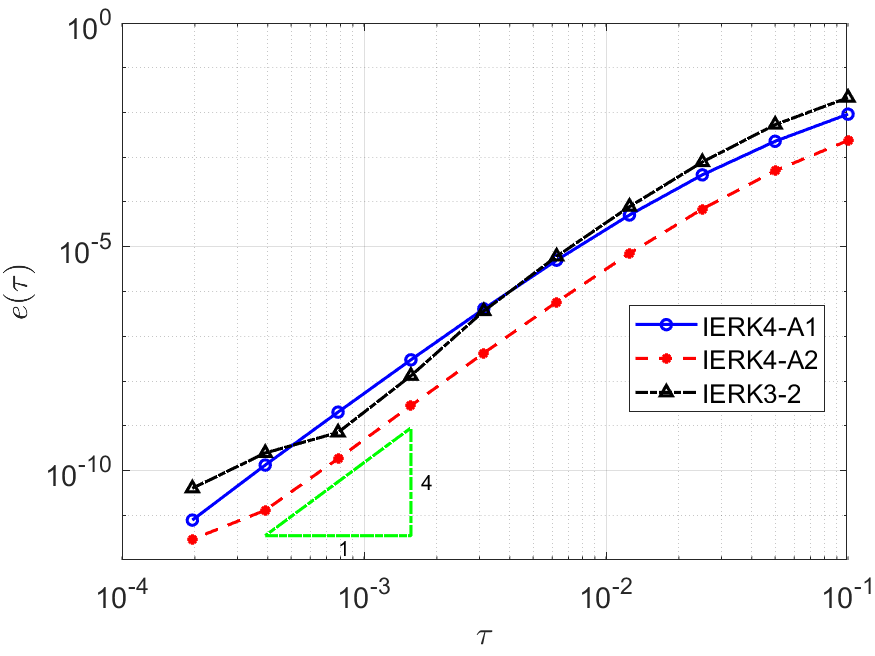
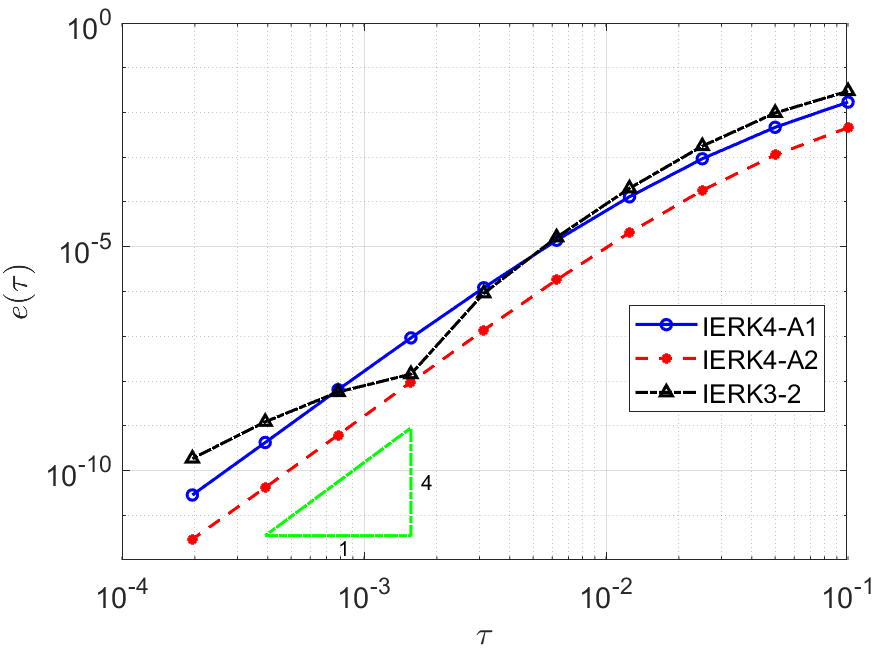
Example 1 is also used to test the convergence of IERK4-A1 (5.13) and IERK4-A2 (5.39) methods by choosing the final time with different stabilized parameters . The norm errors of the two IERK4-A methods on halving time steps for are shown in Figure 12. We see that the two IERK4-A methods can achieve fourth-order accuracy and the error of IERK4-A2 method is always smaller than the error of IERK4-A1 method.
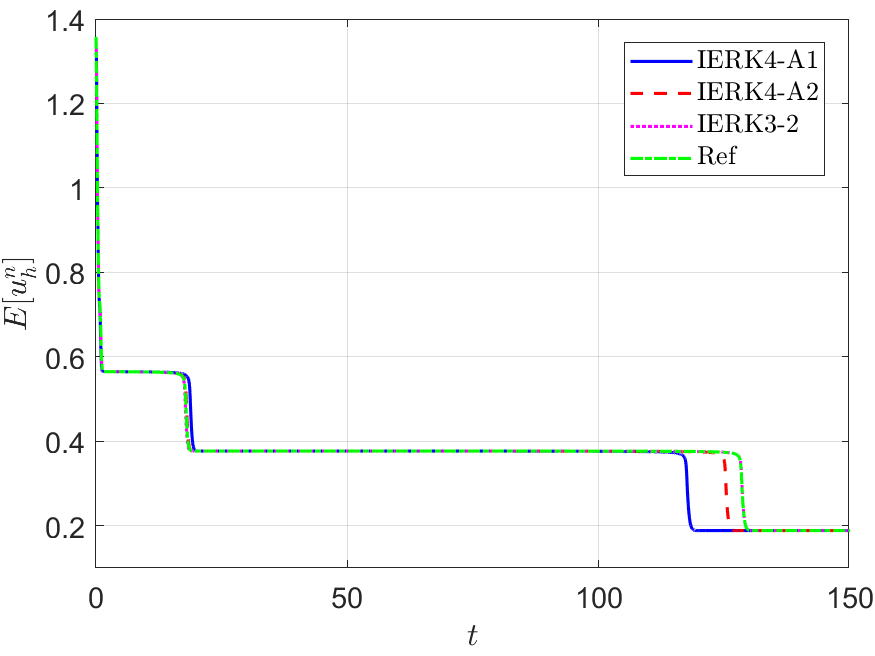
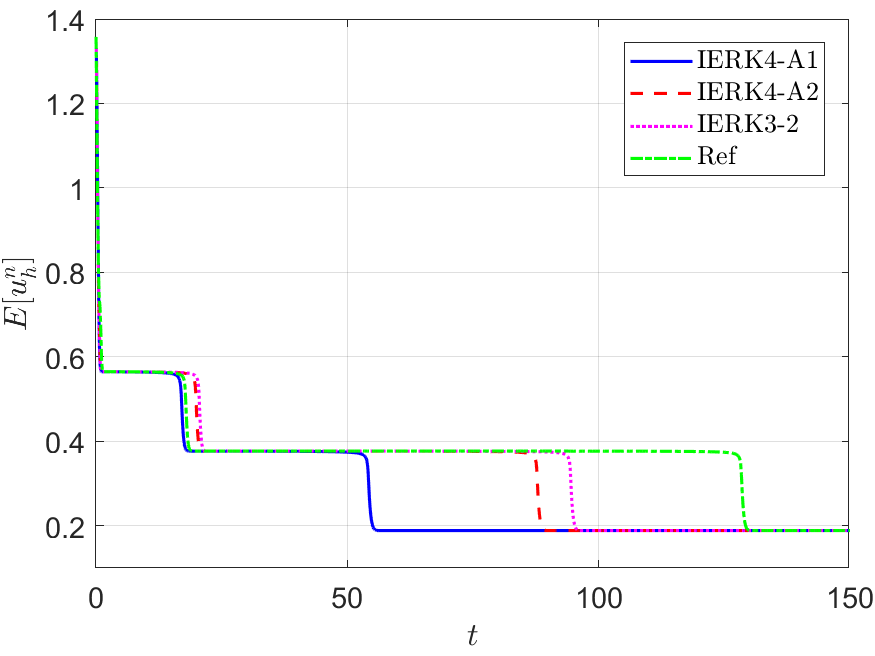
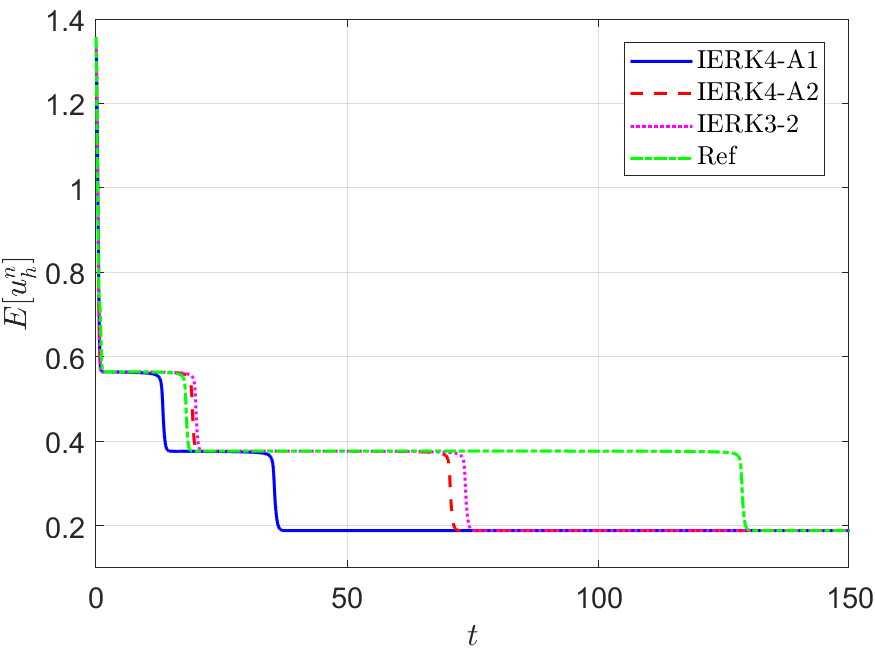
The discrete energy behaviors of the two IERK4-A methods are examined by Example 2, in which the reference solution and energy are computed by the IERK4-A1 method with a small time-step size . Figure 13 depicts the discrete energies generated by the IERK4-A1 and IERK4-A2 methods, for three different scenes: (i) ; (ii) and (iii) . As predicted by Theorem 5.1 , the discrete energies in all cases always monotonically decrease. Also, the discrete energy obtained from the IERK4-A2 method is always closer to the reference energy than that of the IERK4-A1 method. It is predictable by the numerical errors in Figure 12, which shows that the IERK4-A2 method is always more accurate than the IERK4-A1 method, and the associated average dissipation rates in (5.53), that is, .
In Figure 13 (a)-(c), we also include the discrete energy generated by the IERK3-2 method (4.37) with , which has the average dissipation rate and is regarded as the “best” IERK3 method in this paper. More surprisingly, the energy curve generated by the IERK3-2 method (4.37) with is always closer to the reference one than the two IERK4-A schemes. Actually, this phenomenon can not be explained by the precision of numerical solutions. As seen in Figure 12, the solution errors of IERK3-2 method are larger than the errors of IERK4-A1 and IERK4-A2 methods for the time-step sizes and . Obviously, the well preservation of the original energy dissipation law does not entirely depend on the numerical precision of solution although we are unsure of the complete mechanism behind it. One possible reason is that the average dissipation rates in (5.53) of the two IERK4-A schemes are relatively large.
This raises an important issue: finding some IERK4-A method or formally fourth-order IERK method that preserves the original energy dissipation law (1.3) and perform better than the “best” third-order method (4.37) with . We have planned to continue exploring this issue and will present the relevant results in a forthcoming report.
6 Concluding remarks
We construct some parameterized IERK methods by adopting the stiffly-accurate Lobatto-type DIRK methods in the implicit part, and present a unified theoretical framework to examine the energy dissipation properties at all stages of IERK methods up to fourth-order accurate for gradient flow problems. The novel framework contains two main parts: one is the differential form and the associated differentiation matrix of an IERK method by using the difference coefficients of method and the so-called discrete orthogonal convolution kernels; the other is the average energy dissipation rate defined via the average eigenvalue of the differentiation matrix. The rough but simple concept of average energy dissipation rate seems very useful to evaluate the overall energy dissipation behaviors of the IERK methods, including choosing proper parameters in some parameterized IERK methods or comparing different IERK methods with the same accuracy. Our main contributions include:
- (i)
-
(ii)
Among the third-order IERK3-1 (4.34), IERK3-2 (4.37) and IERK3-Radau (4.54) methods preserving the original energy dissipation law (1.3) unconditionally, the one-parameter IERK3-2 method (4.37) with the parameter would be the best one from both the average energy dissipation rate , and the numerical tests in Subsection 4.4.
-
(iii)
Two approximately fourth-order IERK methods with the order-condition tolerance are constructed and shown to preserve the original energy dissipation law (1.3) unconditionally. From the average dissipation rates and the numerical experiments in Subsection 5.2, the IERK4-A2 method (5.39) is better than the IERK4-A1 method (5.13).
-
(iv)
From the perspective of maintaining the original energy dissipation law (1.3), numerical tests show that the IERK1 method (2.16) with performs better than some of IERK2 methods; the IERK2-2 method (3.6) with performs better than some of IERK3 methods and the IERK3-2 method (4.37) with performs better than the two IERK4-A methods. They suggest that the time accuracy of an IERK method cannot fully characterize the degree to which it maintains the original energy dissipation law. In practice, the selection of method parameters in IERK methods is at least as important as the selection of different IERK methods, if not more important.
At the same time, our theory is far away from complete. There are many interesting issues that we have not yet addressed. Some of them are listed as follows:
- (a)
-
(b)
In order to maintain the continuous dissipation rate of the original energy as much as possible, the average dissipation rate, , is hoped to be as close to 1 as possible. It is seen from (2.17) that the value of can reach zero, while we always have for the presented eight IERK methods, cf. Tables 2-3. We wonder what the minimum value of may take, and how to construct the corresponding IERK method.
-
(c)
As we have repeatedly stated, the average dissipation rate can only be used to compare different IERK algorithms with the same accuracy. Is it possible to reasonably integrate the accuracy information of the algorithm to form a more effective indicator so that the discrete energy dissipation behaviors of IERK methods with different accuracies can be compared?
-
(d)
Last but not least, the global Lipschitz continuity assumption in Lemma 2.1 of the nonlinear function is limited. For specific gradient flow problems, weakening the above assumption is theoretically important, and as the closely related issue, determining the minimum stabilized parameter in (2.2) is also practically useful.
References
- [1] G. Akrivis, B. Li and D. Li, Energy-decaying extrapolated RK-SAV methods for the Allen-Cahn and Cahn-Hilliard equations, SIAM J. Sci. Comput., 41:6 (2019), pp. A3703-A3727.
- [2] U. Ascher, S. Ruuth and R.J. Spiteri, Implicit-explicit Runge-Kutta methods for time dependent partial differential equations, Appl. Numer. Math., 25 (1997), pp. 151-167.
- [3] S. Boscarino, L. Pareschi and G. Russo, A unified IMEX Runge-Kutta approach for hyperbolic systems with multiscale relaxation, SIAM J. Numer. Anal., 55:4 (2017), pp. 2085-2109.
- [4] S. Boscarino and G. Russo, On a class of uniformly accurate IMEX Runge-Kutta schemes and applications to hyperbolic systems with relaxation, SIAM J. Sci. Comput., 31:3 (2009), pp. 1926-1945.
- [5] A. Cardone, Z. Jackiewicz, A. Sandu and H. Zhang, Extrapolated implicit-explicit Runge-Kutta methods, Math. Model. Anal., 19:1 (2014), pp. 18-43.
- [6] G. J. Cooper and A. Sayfy, Additive Runge-Kutta methods for stiff ordinary differential equations, Math. Comp., 40:161 (1983), pp. 207-218.
- [7] G. Dimarco and L. Pareschi, Asymptotic preserving implicit-explicit Runge-Kutta methods for nonlinear kinetic equations, SIAM J. Numer. Anal., 51:2 (2013), pp. 1064-1087.
- [8] Q. Du, L. Ju, X. Li and Z. Qiao, Maximum bound principles for a class of semilinear parabolic equations and exponential time-differencing schemes, SIAM Rev., 63 (2021), pp. 317-359.
- [9] M. Fasi, S. Gaudreault, K. Lund and M. Schweitzer, Challenges in computing matrix functions, arXiv:2401.16132v1, 2024.
- [10] Z. Fu and J. Yang, Energy-decreasing exponential time differencing Runge-Kutta methods for phase-field models, J. Comput. Phys., 454 (2022), 110943.
- [11] Z. Fu, T. Tang and J. Yang, Energy diminishing implicit-explicit Runge-Kutta methods for gradient flows, Math. Comput., 2024, doi: 10.1090/mcom/3950.
- [12] Y. Gong, J. Zhao and Q. Wang, Arbitrarily high-order unconditionally energy stable schemes for thermodynamically consistent gradient flow models, SIAM J. Sci. Comput., 42:1 (2020), pp. B135-B156.
- [13] Y. Gui, C. Wang and J. Chen, IMEX-RK methods for Landau-Lifshitz equation with arbitrary damping, arXiv: 2312.15654, 2023.
- [14] W. Hundsdorfer and J.G. Verwer, Numerical Solution of Time-Dependent Advection Diffusion-Reaction Equations, Springer Ser. Comput. Math. 33, Springer-Verlag, Berlin, 2003.
- [15] M. Hochbruck and A. Ostermann, Exponential integrators, Acta Numerica., 19 (2010), pp. 209-286.
- [16] G. Izzo and Z. Jackiewicz, Highly stable implicit-explicit Runge-Kutta methods, Appl. Numer. Math., 113 (2017), pp. 71-92.
- [17] M. Jiang, Z. Zhang and J. Zhao, Improving the accuracy and consistency of the scalar auxiliary variable (SAV) method with relaxation, J. Comput. Phys., 456 (2022), 110954.
- [18] S. Jin, Runge-Kutta methods for hyperbolic conservation laws with stiff relaxation terms, J. Comput. Phys., 122:1 (1995), pp. 51-67.
- [19] A. Kanevsky, M.H. Carpenter, D. Gottlieb and J.S. Hesthaven, Application of implicit-explicit high order Runge-Kutta methods to discontinuous-Galerkin schemes, J. Comput. Phys., 225:2 (2007), pp. 1753-1781.
- [20] C.A. Kennedy and M.H. Carpenter, Additive Runge-Kutta schemes for convection-diffusion-reaction equations, Appl. Numer. Math., 44 (2003), pp. 139-181.
- [21] C.A. Kennedy and M.H. Carpenter, Diagonally implicit Runge-Kutta methods for ordinary differential equations: a review, Technical Memorandum: NASA/TM 2016-219173, 2016.
- [22] Z. Li and H.-L. Liao, Stability of variable-step BDF2 and BDF3 methods, SIAM J. Numer. Anal., 60:4 (2022), pp. 2253-2272.
- [23] H.-L. Liao, T. Tang and T. Zhou, Positive definiteness of real quadratic forms resulting from variable-step L1-type approximations of convolution operators, Sci. China. Math., 67:2 (2024), pp. 237-252.
- [24] H.-L. Liao and X. Wang, Average energy dissipation rates of explicit exponential Runge-Kutta methods for gradient flow problems, Math. Comput., 2024, doi: 10.1090/mcom/4015.
- [25] H.-L. Liao and Z. Zhang, Analysis of adaptive BDF2 scheme for diffusion equations, Math. Comput., 90 (2021), pp. 1207-1226.
- [26] H. Liu and J. Zou, Some new additive Runge-Kutta methods and their applications, J. Comput. Appl. Math., 190 (2006), pp. 74-98.
- [27] C. Moler and C. Van Loan, Nineteen dubious ways to compute the exponential of a matrix, twenty-five years later, SIAM Rev., 45:1 (2003), pp. 3-49.
- [28] H. Olsson and G. Söderlind, The approximate Runge-Kutta computational process, BIT, 40:2 (2000), pp. 351-373.
- [29] J. Shen, J. Xu and J. Yang, The scalar auxiliary variable (SAV) approach for gradient flows, J. Comput. Phys., 353 (2018), pp. 407-416.
- [30] J. Shin, H.-G. Lee and J.-Y. Lee, Convex splitting Runge-Kutta methods for phase-field models, Comput. Math. Appl., 73:11 (2017), pp. 2388-2403.
- [31] J. Shin, H.-G. Lee and J.-Y. Lee, Unconditionally stable methods for gradient flow using convex splitting Runge-Kutta scheme, J. Comput. Phys., 347 (2017), pp. 367-381.
- [32] A. M. Stuart and A. R. Humphries, Dynamical systems and numerical analysis, Cambridge University Press, New York, 1998.
- [33] X. Zhong, Additive Semi-implicit Runge-Kutta methods for computing high-speed nonequilibrium reactive flows, J. Comput. Phys., 128 (1996), pp. 19-31.