AV-EmoDialog: Chat with Audio-Visual Users
Leveraging Emotional Cues
Abstract
In human communication, both verbal and non-verbal cues play a crucial role in conveying emotions, intentions, and meaning beyond words alone. These non-linguistic information, such as facial expressions, eye contact, voice tone, and pitch, are fundamental elements of effective interactions, enriching conversations by adding emotional and contextual depth. Recognizing the importance of non-linguistic content in communication, we present AV-EmoDialog, a dialogue system designed to exploit verbal and non-verbal information from users’ audio-visual inputs to generate more responsive and empathetic interactions. AV-EmoDialog systematically exploits the emotional cues in audio-visual dialogues; extracting speech content and emotional tones from speech, analyzing fine-grained facial expressions from visuals, and integrating these cues to generate emotionally aware responses in an end-to-end manner. Through extensive experiments, we validate that the proposed AV-EmoDialog outperforms existing multimodal LLMs in generating not only emotionally appropriate but also contextually appropriate responses.
1 Introduction
Large language models (LLMs) [45, 11, 5, 3] excel in generating coherent and contextually appropriate text. Trained on extensive dialogue text, they facilitate human-machine interaction by generating relevant responses to user queries. However, the non-linguistic aspect of dialogue, crucial for effective and human-like communication has not been sufficiently explored.
Human communication is inherently multi-modal, incorporating rich verbal and non-verbal cues. The non-linguistic cues, defined as any transfer of messages that do not involve the use of words, include facial expressions, eye movements, and paralinguistic features such as tone and pitch of voice [46, 7]. These cues convey emotions and intentions beyond words, significantly changing the meaning of a word. For example, the word "fine" when said with a cheerful tone and a smile, can genuinely mean everything is good, but when uttered with a flat tone and a stern face, it may imply dissatisfaction. This is the primary reason why many prefer face-to-face interactions over pure text-based ones to reduce potential misunderstandings. Therefore, the user’s emotional state should be precisely and sufficiently considered to generate a contextually appropriate response.
Recent research [4, 18, 21] has attempted to address the emotional aspect of dialogue systems. Typically, these methods follow a cascade approach. They rely on text input, requiring a cascade of ASR module to obtain a transcription of spoken words [4, 21]. Furthermore, they employ a pretrained emotion classifier on either audio or visual [1] to categorize into one of seven labels (i.e. happy, sad, surprised, fearful, disgusted, angry, and neutral). However, relying on a single modality to extract emotional cues limits the richness of the emotional context, and categorizing emotion into seven labels simplifies the complex and subtle emotional states that naturally evolve during interactions. Such classification limits the system’s ability to accurately learn the rich emotional nuances from the multimodal input. Moreoever, they are not optimized end-to-end across both audio and visual modalities, resulting in suboptimal emotional understanding and reduced efficiency in response generation.
In this paper, we introduce AV-EmoDialog, which directly processes audio-visual user input and generates an empathetic response based on the analyzed linguistic and non-linguistic information in end-to-end. We propose a systematic scheme to exploit fine-grained emotional cues in the audio-visual input by utilizing detailed descriptions relevant to the emotional context. The training proceeds in three stages. First, a speech encoder is trained to extract both speech content and nuanced emotion from the user’s speech input through a high-performing chat-LLM. Second, a face encoder is trained to extract the fine-grained emotion from the user’s facial video through the LLM. For fine-grained emotion extraction, we create detailed facial descriptions from the speaker face video. Last, it puts the speech and face encoders together with the LLM to directly aggregate the audio-visual information to generate emotionally resonant responses. Additionally, it generates the emotional state along with the response, enabling the model to consistently track and reflect the emotional tone throughout the conversation.
Our contributions are as follows:
-
•
We present AV-EmoDialog, an end-to-end model that directly processes audio-visual user inputs to generate emotion-aware responses. This approach enables seamless interaction without relying on intermediate text.
-
•
We systematically optimize both the speech and face encoders to extract fine-grained verbal and non-verbal communicative signals. We find that leveraging detailed user metadata beyond emotion categories enhances emotion understanding in the dialogue.
-
•
Extensive experiments demonstrate that AV-EmoDialog excels at generating emotionally appropriate responses from audio-visual inputs. We validate the importance of exploiting both audio and visual modalities not only for emotional performance but also semantic performance of dialogue generation.
2 Related Works
2.1 Spoken Dialogue Models
Recent efforts have aimed to leverage the capabilities of large language models (LLMs) [52, 16, 45, 8] for enhancing spoken dialogue systems. They aim to autoregressively model the semantic and acoustic content of raw speech to process and generate speech. d-GSLM [35] models two-channel conversations to produce natural turn-taking conversations. SpeechGPT [50] initially converts speech to discrete speech tokens, followed by a three-stage training pipeline involving paired speech data, speech instruction data, and chain-of-modality instruction data. AudioGPT [24] guides LLMs to generate commands for interacting with external tools before processing these commands within the models. Qwen-Audio-Chat [17] is trained on extensive audio understanding tasks and instruction fine-tuned on dialogue framework.
Some spoken models [30, 49, 2] have incorporated emotional cues from speech to enhance the model’s ability to tailor responses to diverse emotional contexts. By predicting emotion labels alongside each response, it helps the LLM better understand the user’s emotional state and enables it to generate responses that are more emotionally attuned and contextually appropriate. While these studies have discerned emotional cues within speech, they overlook non-verbal cues present in the visual modality. As human interaction is inherently multimodal, with visual cues such as facial expressions and eye contact playing a crucial role in conveying emotions and intentions, our work aims to integrate the audio and visual information of the user to better capture the communicative signals.
2.2 Multimodal Large Language Models
There has been a surge of Multimodal Large Language Models (MM-LLMs) [28, 32, 31, 34, 47, 41, 48, 26, 44] that are capable of processing multimodal input. BLIP-2 [28] introduces a Q-Former module to bridge the modality gap between the visual and text. Llava [32, 31] aligns the visual and text modality by utilizing a large-scale multimodal instruction-following dataset on image QA, image description, and complex reasoning. Video-LlaMA [51] and Video-ChatGPT [34] process the visual and audio content in a video to engage in a conversation describing the visual scenes and actions in a spatio-temporal context. HuggingGPT [41] conducts task planning to connect various AI models upon receiving a user request and NextGPT [48] builds an end-to-end system that is capable of understanding and generating audio, visual, and text modality. However, they primarily concentrate on multimodal grounding tasks. They excel in integrating multimodal data for content reasoning but do not leverage this information to enhance interaction with the human user.
Recently, a few multimodal large language models [4, 18, 21] tailored for emotion-aware dialogue system attempted to incorporate emotional context. FaceChat [4] employs a pre-trained facial emotion classifier [42] to predict textual emotion labels from the user’s facial expression and incorporate this label into the LLM’s template prompt. It also needs an ASR module to transcribe speech into text, and utilizes the zero-shot capabilities of a pre-trained text LLM for response generation. SMES [18] utilizes a pre-trained Video-Llama [51] to extract emotion labels of each time step via prompting. These emotional labels are then combined with text inputs and fed into an LLM for response generation. EmpathyEar [21] utilizes an ImageBind [22] to extract multimodal embeddings, which are also combined with text embeddings to be fed into an LLM. Notably, these approaches follow a cascade approach, relying on pre-trained components such as emotion classifiers and ASR modules, which are not optimized end-to-end on audio-visual dialogue. Moreoever, they depend on emotion classifiers that assign emotions to one of only seven broad categories, restricting emotional understanding and leading to a simplified interpretation of temporally varying and complex user emotions.
In contrast, our work presents an audio-visual spoken dialogue system that directly processes both linguistic and non-linguistic content from audio-visual input, without relying on intermediate text. Our system is trained end-to-end on audio-visual dialogue data, ensuring that the communicative signals from the input modalities are jointly learned. We demonstrate our proposed method’s strong ability to generate responses that are both contextually and emotionally aligned with the user’s current state, leading to more natural, empathetic interactions.

3 Proposed Method

Our approach to empowering large language models (LLMs) with the ability to interpret and respond to both verbal and non-verbal cues involves three stages: Sec 3.1 extracting speech content verbal emotional cues from the audio input, Sec 3.2 extracting non-verbal emotional cues from the user video input, and Sec 3.3 integrating the verbal and non-verbal cues to build an audio-visual user engaged dialogue system. Below, we detail each stage of our methodology.
3.1 Extracting Verbal Cues with Speech Encoder
From the raw audio input, we extract both the linguistic content (i.e. what the speaker says) and verbal emotional cues. This stage equips an audio encoder with the ability to understand such communicative signals directly from speech such that the LLM can directly understand. We employ a strong audio encoder, Whisper model [40] which has shown powerful capabilities in speech-text processing tasks such as speech recognition (ASR), speech translation, voice activity detection. The audio encoder is connected to the high-performing chat-LLM, Llama-3-Instruct111https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct, as illustrated in Figure 1(a). We directly feed audio features from Whisper model to the LLM and align the feature space between the audio and text using an ASR training objective as in [50, 17, 48, 43] on extensive audio-text datasets; Gigaspeech [15], CommonVoice [6], and LibriSpeech [36]. By training on ASR objective, the model can directly understand the speech content and align the speech feature that can be interpreted by the LLM.
Additionally, we incorporate speech emotion recognition (SER) objective to extract emotional tone from speech. By inputting speech features into the LLM instead of transcribed text, the LLM can infer deeper verbal aspects of speech such as the tone and pitch. We use speech data with emotion labels; RAVDESS [33], CREMA-D [13], MultiDialog [37]. The LLM remains frozen while we fine-tune the audio encoder. This dual training objective empowers the audio encoder to extract both linguistic content and emotional context that can be directly understood by the LLM. The hard prompt, namely the speech understanding prompt, given during this stage is shown in Figure 2(a).
3.2 Extracting Non-Verbal Cues with Face Encoder
The face video contains rich non-verbal cues essential for nuanced human communication. To capture these subtle non-verbal cues, we deploy a face encoder with the ability to recognize the fine-grained facial emotion that can be directly interpreted by the LLM. As shown in Figure 1(b), the face encoder consists of two components; the frame encoder and the temporal encoder. The frame encoder, CLIP-ViT [39], known for strong visual-text alignment, extracts facial features at the frame level. Then, the temporal encoder aggregates the frame-level features to learn facial dynamics as emotion varies over time. Similar to [25, 14], we employ learnable queries that cross-attend to the frame-level features to output a fixed-length video feature . This allows for the efficient processing of videos of varying lengths, which not only reduces computational costs but also facilitates handling longer dialogue sequences. The output visual features are directly fed into the LLM, and trained to recognize emotion labels on RAVDESS [33], CREMA-D [13], and MultiDialog [37] datasets.
To optimize the training of the face encoder, we incorporate detailed descriptions of the facial expressions. Specifically, emotion-labeled face videos in the training datasets are further annotated with comprehensive descriptions of facial dynamics using GPT-4, as illustrated in Figure 2. These descriptions include granular details such as movements of the cheeks, lips, and eyes, as well as the progression of emotional expressions over time. By incorporating comprehensive facial descriptions along with the emotion labels as the training objectives, the face encoder learns to recognize the nuanced and dynamic aspects of human expressions that go beyond simplified emotion categories. Emotions during communication are inherently time-varying, often not consistently maintaining the same emotion. The time-considered detailed descriptions help the model recognize the evolving emotional states that go beyond the static and singular emotion categorization. It also guides to focus on specific facial attributes for accurate emotion detection, akin to how humans process emotion from the face. The face encoder is fine-tuned while the LLM remains frozen. The hard prompt, namely the face video understanding prompt, given to LLM during this stage is shown in Figure 2 (b).
3.3 Audio-Visual Dialogue Modeling
We build an emotion-aware audio-visual dialogue framework, namely AV-EmoDialog, by integrating the speech encoder, face encoder, and a LLM as shown in Figure 1 (c). Since the speech encoder and the face encoder are equipped with strong capabilities to process the linguistic and non-linguistic cues from audio-visual user input from the previous stages, the LLM is simply adapted to incorporate the multimodal communicative signals to generate contextually appropriate responses. In our setting, each dialogue consists of rounds of turns between the AI and the user, with the AI producing textual responses to audio-visual provided by the user. We use audio-visual dialogue language modeling with the following objective:
| (1) |
where . are the emotional state and textual response of the AI at round , which the LLM has to predict given the audio feature and visual feature of the user input at round , and the dialogue history . We keep the audio and visual encoders frozen and LoRA [23] fine-tune the LLM on the target dialogue data, preserving the linguistic prowess while tailoring on the target audio-visual dialogue task. Through this focused adaptation, AV-EmoDialog not only responds accurately in text but also aligns its responses with the emotional and contextual nuances captured from the user’s audio-visual cues. The hard prompt, audio-visual dialogue prompt is shown in Figure 2 (c).

4 Experiments
4.1 Evaluation Metrics
We evaluate the dialogue generation in terms of semantic quality and emotional quality. For the semantic quality, we employ standard metrics used for text-based dialogue generation: BLEU-1, BLEU-4 [38], ROUGE [29], METEOR [9], and PPL [10]. PPL is calculated using Dialog-GPT [54] and it is calculated across the test set. For the emotional quality, we measure EmoBERT score [53] which calculates semantic similarity between the generated response and reference response using a BERT model finetuned on GoEmotion dataset [19]. We additionally measure the diversity score with DISTINCT-1 [27] which quantifies how many unique unigrams (individual words) appear in the generated text relative to the total number of unigrams. For a more comprehensive evaluation, we additionally conduct GPT-4 evaluation and human evaluation. GPT-4 evaluation rates response given the dialogue history from 0 to 5 in terms of fluency and emotional intelligence. Likewise, human evaluation directly ranks the models in terms of contextual appropriateness and emotional intelligence. The detailed instructions for the evaluations are in the Appendix.
4.2 Implementation Details
For the speech encoder, we adopt a pre-trained Whisper model [40] of Qwen-Audio [17] and fine-tune with ASR and speech emotion recognition objectives on a total of 6,485 hours of paired audio-text data, including Gigaspeech [15], CommonVoice [6], LibriSpeech [36], RAVDESS [33], CREMA-D [13], and MultiDialog [37]. Note that we utilize the extra metadata available such as emotion, gender, age, and ethnicity to enrich the non-linguistic aspect of the speech feature.
For the face encoder, we utilize a pre-trained CLIP-ViT as the frame encoder, followed by a transformer encoder with 6 layers and 8 attention heads as the temporal encoder. The videos are preprocessed into face crops of size 9696 using a face detector [20] and a facial landmark detector [12]. Each video is sampled every 10th frame to extract the frame-level features, which are further encoded into a fixed-length visual representation using the learnable queries of size 128. For obtaining the facial emotion description, we created a collage of images from the video frames as the GPT-4 is more adept at analyzing an image than a video.
For the LLM, we use LlaMA3-Instruct1 which has a strong ability to understand and generate responses based on user instructions. In the first two stages, it is frozen, and in the last stage, we LoRA fine-tune [23] on the audio-visual dialogue data, MultiDialog [37]. Multidialog is a recently introduced large-scale multimodal dialogue corpus that includes audio, visual, and text modalities. All three stages are trained on 4 A6000 GPUs with AdamW optimizer and a cosine learning rate decay with a warm-up period. The lora rank is set to 16 and we enable bias and norm tuning. The max token length is 4096 with a batch size of 32. Please refer to the Appendix for the detailed statistics of the data.
4.3 Baseline Methods
We compare with the state-of-the-art multimodal language models that use various combinations of the modality. Llava-next (video) [31] takes a video and text as input to generate a response in text. SpeechGPT [50] takes speech input to generate a response in both text and speech. Since these baseline models are not tailored for dialogue generation tasks but instead on video understanding, captioning, speech recognition, and generation, we finetuned them on the testing dataset, MultiDialog [37]. We also construct a cascaded baseline by sequentially stacking state-of-the-art pre-trained models; audio speech recognition [17], speech emotion recognition [17], and Llama3 1, where the audio model first transcribes the speech and recognizes the emotion which then goes into the LLM to generate emotion-aware response. We also finetune the cascaded baseline on the testing data for a fair comparison.
| Method | Input-Output Modality | Semantic | Emotion | Diversity | ||||
| BLEU-1 | BLEU-4 | ROUGE | METEOR | PPL | EmoBERT | Dist-1 | ||
| LLaVA-NeXT-vid [31] | vid/txt-txt | 0.137 | 0.0135 | 0.150 | 0.112 | 317.410 | 0.21 | 0.873 |
| SpeechGPT [50] | aud-txt/aud | 0.184 | 0.0145 | 0.192 | 0.163 | 285.654 | 0.14 | 0.876 |
| Qwen-Audio [17]+ llama3-Instruct | aud-txt | 0.196 | 0.0304 | 0.226 | 0.154 | 241.873 | 0.22 | 0.816 |
| \hdashline Proposed Method | ||||||||
| AV-EmoDialog* | aud/vid-txt | 0.212 | 0.0272 | 0.215 | 0.169 | 380.891 | 0.20 | 0.862 |
| AV-EmoDialog | aud/vid-txt | 0.193 | 0.0307 | 0.198 | 0.164 | 319.703 | 0.30 | 0.900 |
5 Results
5.1 Automatic Evaluation of Dialogue Generation
We quantitatively compare the dialogue generation results in Table 1. Our experiments were conducted on the test rare split of the MultiDialog dataset. For each conversation, we randomly selected four turns from the assistant’s side. Compared with state-of-the-art multimodal large language models, our method significantly improves the EmoBERT score, which assesses the emotion alignment of the generated responses with the ground truth emotion. In addition, the semantic scores were also boosted, as evidenced by the highest scores in BLEU-1, BLEU-4, and METEOR. The high semantic performance confirms that our method generates a contextually coherent response. This result is particularly notable given that other comparison methods rely on text input, a format with which large language models are trained extensively. Compared with the cascaded baseline, which stacks a high-performing ASR, Emotion Recognition (ER) model, and LLM, our method does not require separate conversion of input speech into text and emotion labels. Nevertheless, our model achieves superior emotion alignment and comparable semantic performance, highlighting the efficiency of our end-to-end approach. Finally, AV-EmoDialog also demonstrates the highest diversity scores. These quantitative results suggest that our approach to systematically exploiting communicative cues from audio-visual inputs not only enhances emotional alignment but also improves the overall semantic quality and diversity of the generated responses. This result implies that having a better emotional context enables the model to produce responses that are more attuned to the user’s state and dialogue context.
| Method | Fleuncy | Emotional Context | Empathy |
| LLaVA-NeXT-vid [31] | 4.32 | 1.46 | 1.26 |
| SpeechGPT [50] | 3.83 | 1.56 | 1.41 |
| Cascade | 4.40 | 2.29 | 1.99 |
| \hdashlineAV-EmoDialog | 4.64 | 2.45 | 2.06 |
| Method | Preference (%) |
| LLaVA-NeXT-vid [31] | 34.39 |
| SpeechGPT [50] | 10.19 |
| Cascade | 13.38 |
| \hdashlineAV-EmoDialog | 42.04 |
5.2 GPT Evaluation
We incorporated GPT-4222https://chatgpt.com/?model=gpt-4 evaluation to further assess the generated response in Table 2. Since EmoBERT only assesses alignment with ground truth emotional labels, a more thorough evaluation was necessary to understand the model’s ability to address emotions. Henceforth, we evaluated two aspects of emotional intelligence using GPT-4: empathy which is how well the response identifies and reflects the emotion of the user, and emotional context which is whether the emotional tone of the response is suitable for the given context. The high ratings in emotional intelligence particularly suggest that our system excels at interpreting and responding to the emotional states conveyed by users.
Also, although our system directly interprets audio-visual as the input, it has even superior fluency compared to other methods that rely on textual inputs. This suggests that using audio-visual modality to directly process both linguistic and non-linguistic content not only enhances emotional understanding but also linguistic capability.
5.3 Human Evaluation
We conducted a human evaluation through Prolific333https://www.prolific.com/ to compare the quality of responses generated by various dialogue models in Table 3. 10 gathered English-speaking participants were instructed to rank generated responses from four different models according to predefined criteria: relevance, coherence, contextual appropriateness, emotional coherence, and engagement. Table 3 shows the percentage with which each model was ranked first. The results indicate that AV-EmoDialog was most frequently selected as the top-performing model, which coincides with our automatic and GPT evaluations.
5.4 Analysis on Audio-Visual Emotion-Aware Response
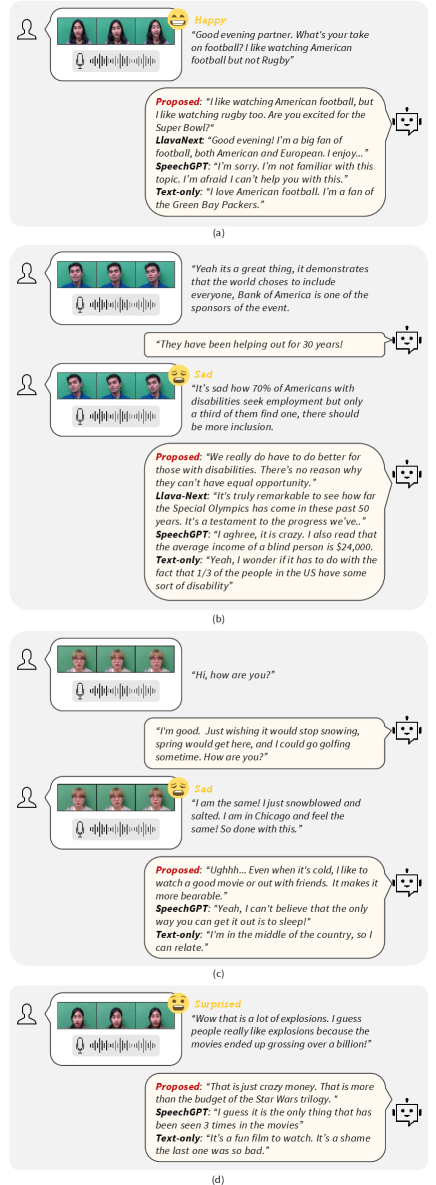
We analyzed the emotional context of response enhanced by AV-EmoDialog in Figure 4. In (a), the user speaks in a cheerful tone with a happy smile, asking the AI about its preference for football. The proposed method effectively recognizes the user’s happy emotion through audio-visual cues, which would not have been possible with text input alone. AV-EmoDialog responds accurately to the happy emotional tone of the user by saying "Are you excited for the Super Bowl?". On the other hand, the baseline methods fail to reflect the user’s emotional tone, resulting in less resonant responses such as "I’m sorry. I’m not familiar with this topic" or "Good evening! I’m a big fan of football.". In (c), the user talks with a sad and depressed face about how he feels stuck in the snow. Although it may sound like the user is frustrated from the text alone, the proposed method most accurately empathizes with the user’s sadness, responding with "Ughh…", and suggests one way to get out of the bad feeling. In contrast, baseline methods misinterpret the emotional context, responding with surprise or changing the topic. Likewise in (d), the user expresses surprise about the explosion through face, tone, and the content itself. While the baseline methods moves on to a different aspect of the topic, the proposed method mirrors the user’s surprise and engages further in the same emotional tone, by responding "That is just crazy money… That is more than the budget of the Star Wars trilogy.". In each example, the proposed method effectively recognizes the user’s emotion from the speech tone and facial expressions, providing the most emotionally appropriate responses that would have been difficult with pure text-only input. Please refer to appendix for more generation results. Note that we provide responses in speech using an off-the-shelf TTS model444https://github.com/2noise/ChatTTS for demonstration.
| Module | Training Objectives | EMR | Semantic | Emotion | |||
| Mean | BLEU-1 | BLEU-4 | ROUGE | METEOR | EmoBERT | ||
| Speech Encoder | ASR | – | 0.185 | 0.0185 | 0.185 | 0.161 | 0.13 |
| ASR + EMR | 0.56 | 0.212 | 0.0293 | 0.216 | 0.179 | 0.21 | |
| Face Encoder | EMR | 0.15 | 0.219 | 0.0355 | 0.222 | 0.166 | 0.24 |
| EMR + EMD | 0.26 | 0.193 | 0.0307 | 0.198 | 0.164 | 0.30 | |
| Input Modality | Semantic | Emotion | |||
| BLEU-4 | ROUGE | METEOR | PPL | EmoBERT | |
| T | 0.0355 | 0.222 | 0.166 | 255.60 | 0.15 |
| A | 0.0184 | 0.222 | 0.156 | 369.56 | 0.23 |
| A+V | 0.0307 | 0.198 | 0.164 | 319.70 | 0.27 |
5.5 Effectiveness of Exploiting Emotion in Audio-Visual Dialogue
We tested AV-EmoDialog with emotion excluded from the last stage of training on the audio-visual dialogue task. The results are shown in the second to last row in Table 1. There was a huge drop in emotion performance - from 0.3 to 0.2, which suggests that having the emotion label in the dialogue allows the model to keep track of the understanding of the emotional context.
We evaluated the training schemes used for the speech and face encoders in Table 3. We observed that incorporating the detailed descriptions of the facial expressions greatly increased the emotion recognition performance of the face encoder by 70%. Also, the emotion recognition performance of the speech encoder is higher than from the face. This indicates that vocal expressions, often being more expressive and straightforward, can capture emotional nuances more effectively than visual expressions. But since they distinctively have their effects, we leverage both cues to boost the performance in the dialogue generation task.
In the dialogue generation task, speech encoder trained with emotion recognition objective has better performance (rows 1 and 2). This demonstrates that having the emotion label gives better context to generate a response that is more emotionally and semantically aligned. Furthermore, the face encoder, trained with detailed facial descriptions, also showed enhanced emotion recognition capabilities, which impacted its dialogue generation performance (rows 3 and 4). While there was a notable increase in the EmoBERT score, a slight decrease in semantic scores was observed. This reduction may be due to the complexities introduced by the detailed emotion descriptions, which could complicate the dialogue modeling. Nevertheless, its effect on emotion performance is evident, and semantic performance remains competitive, surpassing that of the baselines.
5.6 Comparison of Audio, Visual, and Text as Input for Emotion-aware Dialogue
In Table 5, we conducted experiments with various modality inputs to validate the efficacy of each modality in dialogue generation. The text-only input has the highest semantic quality overall, which can largely be attributed to the fact that the underlying llm has been extensively trained on textual data. Yet, utilizing both audio-visual modalities was able to achieve on-par semantic performance while achieving superior emotional intelligence.
Another finding is that using both audio-visual modalities results in enhanced semantic and emotional performance compared to using audio modality alone. This improvement underscores the value of visual cues such as facial expressions and eye contact, which provide complementary information to audio cues such as pitch and tone of voice. Our approach reflects natural human communication, where verbal cues are typically supported and enriched by non-verbal expressions, creating a more holistic and effective interaction.
6 Conclusion and Limitation
The machine’s ability to recognize the user’s emotional state has great implications for human-machine communications; a virtual assistant that recognizes frustration can offer more targeted help, a customer service bot equipped with empathy can better handle complaints, and therapeutic service can comprehensively diagnose patients. Our proposed AV-EmoDialog contributes to the field of emotion-aware dialogue systems by exploiting linguistic and non-linguistic information directly from audio-visual inputs. AV-EmoDialog relies on audio-visual input without additional text input to optimize the system end-to-end for emotion-aware audio-visual dialogue. By leveraging fine-grained facial descriptions, AV-EmoDialog not only aligns more closely with human communication patterns but also sets a new standard for the design of empathetic and effective dialogue systems. Our extensive experiments confirm that AV-EmoDialog surpasses existing baseline models in both emotional and semantic dimensions.
To further explore the potential of our proposed model, which is designed to handle emotional interplays in dialogues, it would be beneficial to have a more diverse audio-visual dataset from real-world scenarios, where emotional interactions are more prevalent. Also, the future research direction would be to generate the speech in end-to-end. By generating speech that reflects the emotional tone of the response, it would be possible to create more immersive conversations for users. For ethical considerations, as the system directly utilizes audio-visual user data, it is crucial to ensure the privacy and security of sensitive information.
References
- Abbasian et al. [2024a] Mahyar Abbasian, Iman Azimi, Mohammad Feli, Amir M Rahmani, and Ramesh Jain. Empathy through multimodality in conversational interfaces. arXiv preprint arXiv:2405.04777, 2024a.
- Abbasian et al. [2024b] Mahyar Abbasian, Iman Azimi, Mohammad Feli, Amir M. Rahmani, and Ramesh Jain. Empathy through multimodality in conversational interfaces, 2024b.
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Alnuhait et al. [2023] Deema Alnuhait, Qingyang Wu, and Zhou Yu. Facechat: An emotion-aware face-to-face dialogue framework. arxiv. 2023.
- Anil et al. [2023] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Ardila et al. [2019] Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus. arXiv preprint arXiv:1912.06670, 2019.
- Argyle [1972] Michael Argyle. Non-verbal communication in human social interaction. Non-verbal communication, 2(1), 1972.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Banerjee and Lavie [2005] Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005.
- Bengio et al. [2000] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems, 13, 2000.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Bulat and Tzimiropoulos [2017] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In International Conference on Computer Vision, 2017.
- Cao et al. [2014] Houwei Cao, David G Cooper, Michael K Keutmann, Ruben C Gur, Ani Nenkova, and Ragini Verma. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE transactions on affective computing, 5(4):377–390, 2014.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213–229. Springer, 2020.
- Chen et al. [2021] Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, et al. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio. arXiv preprint arXiv:2106.06909, 2021.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Chu et al. [2023] Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. arXiv preprint arXiv:2311.07919, 2023.
- Chu et al. [2024] Yuqi Chu, Lizi Liao, Zhiyuan Zhou, Chong-Wah Ngo, and Richang Hong. Towards multimodal emotional support conversation systems, 2024.
- Demszky et al. [2020] Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. Goemotions: A dataset of fine-grained emotions. arXiv preprint arXiv:2005.00547, 2020.
- Deng et al. [2020] Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5203–5212, 2020.
- Fei et al. [2024] Hao Fei, Han Zhang, Bin Wang, Lizi Liao, Qian Liu, and Erik Cambria. Empathyear: An open-source avatar multimodal empathetic chatbot. arXiv preprint arXiv:2406.15177, 2024.
- Girdhar et al. [2023] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all, 2023.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Huang et al. [2023] Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. Audiogpt: Understanding and generating speech, music, sound, and talking head. arXiv preprint arXiv:2304.12995, 2023.
- Jaegle et al. [2021] Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In International conference on machine learning, pages 4651–4664. PMLR, 2021.
- Lee et al. [2024] Byung-Kwan Lee, Beomchan Park, Chae Won Kim, and Yong Man Ro. Collavo: Crayon large language and vision model. arXiv preprint arXiv:2402.11248, 2024.
- Li et al. [2015] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. arXiv preprint arXiv:1510.03055, 2015.
- Li et al. [2023] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023.
- Lin [2004] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- Lin et al. [2024] Guan-Ting Lin, Prashanth Gurunath Shivakumar, Ankur Gandhe, Chao-Han Huck Yang, Yile Gu, Shalini Ghosh, Andreas Stolcke, Hung-yi Lee, and Ivan Bulyko. Paralinguistics-enhanced large language modeling of spoken dialogue. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10316–10320. IEEE, 2024.
- Liu et al. [2024a] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024a.
- Liu et al. [2024b] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024b.
- Livingstone and Russo [2018] Steven R Livingstone and Frank A Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english. PloS one, 13(5):e0196391, 2018.
- Maaz et al. [2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
- Nguyen et al. [2023] Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Benoit Sagot, Abdelrahman Mohamed, et al. Generative spoken dialogue language modeling. Transactions of the Association for Computational Linguistics, 11:250–266, 2023.
- Panayotov et al. [2015] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
- Park et al. [2024] Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, Joanna Hong, Jeong Hun Yeo, and Yong Man Ro. Let’s go real talk: Spoken dialogue model for face-to-face conversation. arXiv preprint arXiv:2406.07867, 2024.
- Post [2018] Matt Post. A call for clarity in reporting bleu scores. arXiv preprint arXiv:1804.08771, 2018.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Radford et al. [2023] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, pages 28492–28518. PMLR, 2023.
- Shen et al. [2024] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36, 2024.
- Taigman et al. [2014] Yaniv Taigman, Ming Yang, Marc’Aurelio Ranzato, and Lior Wolf. Deepface: Closing the gap to human-level performance in face verification. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pages 1701–1708, 2014.
- Tang et al. [2023] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. arXiv preprint arXiv:2310.13289, 2023.
- Team et al. [2023] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Urakami and Seaborn [2023] Jacqueline Urakami and Katie Seaborn. Nonverbal cues in human–robot interaction: A communication studies perspective. ACM Transactions on Human-Robot Interaction, 12(2):1–21, 2023.
- Wu et al. [2023a] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023a.
- Wu et al. [2023b] Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519, 2023b.
- Xue et al. [2023] Hongfei Xue, Yuhao Liang, Bingshen Mu, Shiliang Zhang, Qian Chen, and Lei Xie. E-chat: Emotion-sensitive spoken dialogue system with large language models. arXiv preprint arXiv:2401.00475, 2023.
- Zhang et al. [2023a] Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000, 2023a.
- Zhang et al. [2023b] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023b.
- Zhang et al. [2022] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Zhang et al. [2019a] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675, 2019a.
- Zhang et al. [2019b] Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv preprint arXiv:1911.00536, 2019b.
Supplementary Material
7 Evaluation Metrics
BLEU [38] evaluates the fluency and adequacy of generated responses based on n-gram overlap. A higher BLEU score indicates a more natural and engaging dialogue model. We measure BLEU-1 and BLEU-4 score where BLEU-1 measures the overlap at unigram and BLEU-4 considers up to 4-grams, focusing more on the contextual and syntactical relationships between words.
PPL [10] measures how well a language model predicts the generated response. A lower perplexity indicates that the model is more confident and accurate in predicting the next word, suggesting higher quality in generating coherent and contextually relevant responses.
METEOR [9] assesses the quality of generated response by computing the alignment-based precision and recall between the generated output and the ground truth, considering synonyms and paraphrases.
ROUGE [29] measures the overlap of n-grams between the generated output and a set of reference outputs based on recall (i.e. how much of the reference is captured by the output).
EmoBERTscore [53] assess the semantic similarity between the generated response emotion and the reference response emotion. We utilize the BERT model specifically fine-tuned on GoEmotions [19] dataset by Google, which includes 58k Reddit comments labeled for 27 emotion categories including neutral. This model is adept at detecting a broad range of emotions. The features extracted from the BERT model are used to calculate the similarity distance between the ground truth and the generated response.
8 GPT evaluation
We ran GPT evaluation on the following criteria; coherence, fluency, and emotional intelligence. Fluency evaluates the grammatical correctness, smoothness, and natural flow of the response. The response should read as if it were spoken or written by a fluent language user. Emotional context evaluates how appropriate the emotion conveyed in response is within the context of the dialogue history. Empathy evaluates how well the response demonstrates an awareness of the user’s feelings. We instruct GPT to provide a score in the range of 0 to 5 with regard to the three criteria. The prompt given to the GPT is shown in Figure 6.
9 Human evaluation
We conducted a human evaluation through Prolific555https://www.prolific.com/ to compare the quality of responses generated by various dialogue models. Ten English-speaking participants were recruited and tasked with ranking the responses generated by four different models based on predefined criteria: relevance, coherence, contextual appropriateness, emotional coherence, and engagement. Detailed instructions provided to the participants are shown in Figure 7.
10 Datasets
Common Voice [6] is a large-scale multilingual speech-text corpus collected from volunteers around the world. It contains 2,615 hours of English speech from 92,325 voices with diverse genders, ages, and accents.
GigaSpeech [15] an English speech-text corpus from various sources such as podcasts, audiobooks, and YouTube, accompanied by accurate transcriptions. We use a large subset which is 2,500 hours. It is the common benchmark used for speech processing tasks.
LibriSpeech [36] is approximately 1,000 hours of English speech derived from audiobooks in the LibriVox project.
MultiDialog [37] is a large-scale audio-visual dialogue dataset, consisting of approximately 370 hours of 9,000 dialogues between 6 pairs of speakers. It is based on the Topical Chat dataset which is a knowledge grounded human-human conversation covering 9 broad topics. There are emotion annotations for each utterance. It is the only available large-scale audio-visual dialogue dataset to date.
RAVDESS [33] is an emotional audio-visual data consisting of 1,4440 files from 24 actors (12 female and 12 male) speaking in a natural North American accent and in six different emotions (happy, sad, angry, fearful, surprise, disgust, and calm) with two different intensity levels (normal and strong)
CREMA-D [13] is an emotional audio-visual data consisting of 7,442 audio-visual clips from 91 actors (48 male and 43 female) between the ages of 20 to 74 from various races (African American, Asian, Caucasian, Hispanic, and unspecified). They speak in six different emotions (anger, disgust, fear, happy, neutral, and sad) in four different emotion levels (low, medium, high, and unspecified).

11 Extracting Facial Descriptions
We use GPT to annotate the face video with rich facial descriptions relevant to emotions. The prompt given to the GPT is: These are the frames in a video. In the video, a person expresses emotion through facial expressions. Describe the subtle and fine-grained emotion precisely as you see in the video in two sentences. We only annotate a subset of RAVDESS, CREMA-D, and Multidialog for training. We will open-source the annotations. The samples are shown in Figure 5. The generated descriptions provide detailed information of facial dynamics associated with emotions, capturing the progression and intensity of the emotion—nuances that cannot be conveyed by a single-word emotion category.
12 More Generated Results
We have included more generation results in Figure 8, which presents a comparison of the generation results from our proposed method against those from LLaVA-Next [31], SpeechGPT [50], and the Cascade model. Our AV-EmoDialog directly audio-visual as the input and generated more emotion-aware response, guided by the audio-visual input.
In Figure 8(a), AV-EmoDialog responds with a semantically coherent answer, maintaining the context of FDA burning tons of books. In contrast, LLaVA-Next’s response deviates to an unrelated topic involving Ted Koppel’s controversy. While SpeechGPT and Cascade stay on topic, their responses lack emotional awareness. From the text user input of "Yeah, I think it’s unfair how the FD burns 6 tons of books", it’s unclear what the user’s emotion is. But since AV-EmoDialog can better recognize emotion through audio-visual input, it considers the emotion and replies, "That is awful.".
In Figure 8(b), AV-EmoDialog demonstrates its ability to empathize with the user’s sadness by responding, "It’s sad to see things like this." This response reflects a direct acknowledgment of the user’s emotional state. LLaVA-Next also appears to empathize with the user but takes a more pragmatic approach, suggesting detailed ways to address the issue, which could be explored further in a broader context. SpeechGPT fails to align with the emotional context, responding, "I think they should be happy though." The Cascade model remains contextually relevant but pays less attention to incorporating the user’s emotional tone into its response.
In Figure 8(c), AV-EmoDialog effectively maintains the context about Nintendo and builds on the previous turn by introducing another surprising fact. LLaVA-Next initially empathizes with the user’s emotion but diverges from the topic, discussing several unrelated aspects of Nintendo. The Cascade model fails to consider the user’s prior input saying, "I wonder if you can use them on other consoles, like the Nintendo switch.". SpeechGPT stays on topic, continuing the discussion about the fact, but it does not capture or reflect the user’s surprised emotion.
In Figure 8(d), the proposed method responds appropriately regarding how only a third of Americans with disabilities find employment by saying "We really do have to do better for those with disabilities ". Besides the cascade method, both LLaVA-Next and SpeehGPT diverge from the topic, failing to address the issue of high unemployment rates among disabilities or to continue the conversation meaningfully.
In Figure 8(e), the discussion focuses on Disney, with the user expressing surprise about Disney’s Big Hero 6 being rendered using a powerful supercomputer. SpeecghGPT completely misses the topic, LLaVA-Next talks about Disney characters, and Cascade reflects the surprised emotion by fails to continue on with the conversation. In contrast, our proposed model not only mirrors the user’s surprised emotion with an opening like "Wow" but also advances the discussion by asking a related question about the capabilities of such supercomputers.
From these samples, it is evident that AV-EmoDialog is more emotion-aware and generates responses that are more coherent compared to the other models. This underlines the efficacy of AV-EmoDialog in handling complex dialog scenarios where emotional context influences the response quality. We have attached a demo video of generated samples from AV-EmoDialog. For better demonstration, we have produced speech from the generated response using a TTS module.






