Autonomous Implicit Indoor Scene Reconstruction with Frontier Exploration
Abstract
Implicit neural representations have demonstrated significant promise for 3D scene reconstruction. Recent works have extended their applications to autonomous implicit reconstruction through the Next Best View (NBV) based method. However, the NBV method cannot guarantee complete scene coverage and often necessitates extensive viewpoint sampling, particularly in complex scenes. In the paper, we propose to 1) incorporate frontier-based exploration tasks for global coverage with implicit surface uncertainty-based reconstruction tasks to achieve high-quality reconstruction. and 2) introduce a method to achieve implicit surface uncertainty using color uncertainty, which reduces the time needed for view selection. Further with these two tasks, we propose an adaptive strategy for switching modes in view path planning, to reduce time and maintain superior reconstruction quality. Our method exhibits the highest reconstruction quality among all planning methods and superior planning efficiency in methods involving reconstruction tasks. We deploy our method on a UAV and the results show that our method can plan multi-task views and reconstruct a scene with high quality.
I Introduction
Reconstructing and mapping indoor environments is crucial for various applications, including scene visualization, robot navigation, and 3D content creation for augmented and virtual reality [7, 26, 32, 18]. In recent years, the emergence of compact and agile aerial vehicles, such as UAVs, has sparked a growing interest in scene reconstruction using close-range aerial imagery.
Implicit neural representations for 3D objects have demonstrated considerable promise in scene reconstruction, scene editing, and robotics and autonomous systems [29, 22, 30]. By leveraging the expressive power of implicit representations, autonomous systems can reconstruct 3D environments online and plan optimal view paths for data acquisition [13, 15, 30, 17]. Ran et al. [15] first proposes a novel view quality criterion based on color uncertainty that is learned online for view selection. To reduce the computational complexity in querying viewpoint-specific information gain, Zeng et al. [30] introduces an implicit function approximator for the information gain field. However, these methods employ a greedy planning strategy based on the NBV, which is prone to result in local optimum when reconstructing large scenes, resulting in incomplete scene coverage.
Scene exploration methods[31, 7, 5] where agents are required to reach maximum coverage of target scenes find that incorporating global information helps to escape from the local minima. Inspired by these methods, we propose to leverage the global information in the autonomous implicit reconstruction pipeline. Particularly, we incorporate frontier-based exploration tasks with autonomous implicit reconstruction tasks, combining the benefits of both approaches to enhance the overall efficiency and efficacy of reconstruction.
However, the incorporation faces two main challenges. First, as the scene size expands, the expenses for sampling a wider range of viewpoints and calculating information gained for each viewpoint increase with the scene volume. Second, the coordination of exploration tasks and reconstruction tasks requires a trade-off between efficiency and efficacy. Generating reconstruction tasks based on implicit representation usually takes orders of time complexity than generating exploration tasks. Including reconstruction tasks in every iteration of planning will lead to an increase in planning time while merely switching between exploration tasks and reconstruction tasks in each iteration can result in poor surface quality or repeatedly getting trapped in local optimum during the scanning process.
For the first challenge, we observe that the reconstruction uncertainty of the space converges to very low values in a few iterations and the high uncertainty (or poor reconstruction quality) mainly happens near surface areas. Therefore, instead of sampling the viewpoints in all the space and calculating the Next-Best-View information gain by integrating the color uncertainty for 3D points in each viewpoint frustum, we propose to evaluate the surface quality, only sample viewpoints covering surfaces of low quality and sum the surface uncertainty in a viewpoint, similar to surface inspection methods [2, 7, 9], which reduces the complexity measuring based on 3D volume to 2D surface.
For the second challenge, we propose an adaptive mode-switching approach for view path planning based on the number of frontiers within the current neighborhood. The design comes from the intuition that when an agent enters a new area, exploration tasks dominate; when a rough overview of the area is gathered, reconstruction tasks are included to focus on finer details. To avoid getting trapped in local regions, exploration tasks are planned together with the reconstruction tasks in the latter state. With this model-switching approach, our method achieves low time cost and high-quality reconstruction.
To summarize, our contributions are:
-
•
We incorporate frontier-based exploration tasks for efficient global coverage with implicit surface uncertainty based reconstruction tasks for high-quality reconstruction.
-
•
We propose a novel information gain calculation and corresponding viewpoint sampling strategy that evaluates the uncertainty of implicit surface and samples in the space covering the high uncertainty surface areas.
-
•
We propose an adaptive mode-switching approach for view path planning to coordinate exploration and reconstruction tasks.
II Related work
Implicit representations, exemplified by NeRF, have emerged as a powerful approach for 3D scene reconstruction. There are numerous variations of NeRF, with some focusing on appearance, such as TensoRF [3] and Instant-NGP [11], some focusing on geometry, such as Neus [21], VolSDF [28], and MonoSDF [29].
View path planning is a crucial aspect of autonomous reconstruction, aiming to determine an optimal sequence of viewpoints to efficiently reconstruct a 3D scene [9, 16, 4]. Next best view (NBV) and frontier-based methods have emerged as popular approaches for autonomous reconstruction. NBV-based methods employ a greedy strategy, selecting the viewpoint with the highest expected gain, which is expected to provide the most valuable information for the reconstruction process [12, 30]. Despite their effectiveness, the challenge of converging to local optimum within a confined region is a common issue encountered by NBV-based methods [23, 1]. This issue can be attributed to the constraints imposed by limited sampling range and resolution, which restrict the exploration of the full solution space. Frontier-based methods, on the other hand, prioritize the exploration of unknown regions in the scene through the identification and selection of frontier points, which denote the boundaries between known and unknown areas [31, 9, 5]. However, it is worth highlighting that the mere coverage of these frontiers does not guarantee improved reconstruction quality. This characteristic induces frontier-based methods more suitable for autonomous exploration rather than reconstruction.
Some studies [19, 7] propose a combination of NBV-based and frontier-based methods. Song et al. [19] select the nearest frontier task as NBV and analyze the quality of reconstructed surfaces. The resulting computed path achieves full coverage of low-quality surfaces. However, solely choosing the nearest frontier task tends to reduce exploration speed. Guo et al. [7] introduce an asynchronous collaborative autonomous scanning approach featuring mode switching, effectively utilizing multiple robots to explore, and reconstruct unknown scene environments. However, in autonomous implicit reconstruction, there is currently no method that combines these two tasks.
Autonomous implicit reconstruction has seen recent advancements [15, 30, 27]. Ran et al. [15] propose neural uncertainty as a view quality criterion and the first autonomous implicit reconstruction system. Zeng et al. [30] introduce a view information gain field to reduce the time for view selection. Yan et al. [27] provide a new perspective of active mapping from the optimization dynamics of map parameters.
III Method
III-A Problem Statement and System Overview
The primary focus of this study is to address the challenge of exploring unknown and spatially bounded 3D environments while reconstructing high-quality 3D models using a mobile robot. In previous greedy-based NBV methods[15, 30], the whole reconstruction process consists of multiple iterations, and in each iteration, viewpoints are sampled and evaluated to choose the best view for the next iteration. Different from these methods, we incorporate a frontier-based exploration strategy into the reconstruction task: the whole process consists of a series of exploration and reconstruction tasks and the two subtasks interweave in or switch between reconstruction iterations.
Under the framework of the multi-task strategy, our pipeline is composed of three components, as illustrated in Fig. 1. The method overview is shown in 2. The Mobile Robot module captures images at specified viewpoints and utilizes Droid-SLAM [20] to estimate its localization. During the simulation, Unity Engine renders images at given viewpoints similar to [30]. The Mapping module maintains two representations. For exploration tasks, a volumetric representation ( occupancy grid map) is adopted and for reconstruction tasks, an implicit neural representation (MonoSDF[29]) is adopted where monocular depth and normal are derived via Omnidata[6]. In the View Path Planning module the number of frontiers extracted from the current volumetric map determines the optimal mode: exploration or the combination of both exploration and reconstruction at each reconstruction iteration. Leveraging information extracted from the volumetric map and the partial reconstruction scene, exploration and reconstruction tasks are generated accordingly. An informative path, incorporating multiple tasks, is planned using the Asymmetric Traveling Salesman Problem (ATSP) planner. The images captured along this path are then fed into the reconstruction system until the entire autonomous reconstruction process is completed.
III-B Implicit scene reconstruction with surface uncertainty
In this research, we employ MonoSDF [29] with multi-grid features and monocular priors, as the foundational framework for our investigation. In alignment with the NeurAR [15] approach, we depict the rendered colors through Gaussian distributions, wherein the variance serves as a quantifier of viewpoint-related uncertainty.
Benefiting from the accurate surface characteristics of MonoSDF, we can quickly extract the surface and analyze the surface uncertainty of the reconstruction. This procedure can be decomposed into two steps. Firstly, we partition the space into grids, where , then we employ the implicit grids network to compute the sdf , gradients , and features for each grid as follows
| (1) |
Following that, by utilizing the zero-level Marching Cubes algorithm [10], we can extract the scene surface and all the vertices from . Secondly, due to our emphasis on surface uncertainty evaluation, we simplify the volume rendering process by disregarding ray directions towards surface points and can obtain surface point color and uncertainty of each surface point from rendering network as follows
| (2) |
III-C Multi-task generation
Within the framework of our approach, the scanning tasks can be divided into two tasks: exploration tasks for rapid coverage and reconstruction tasks for high-quality reconstruction.
III-C1 Exploration task generation
The exploration tasks are designed to cover more unknown regions, with denoting the total number of tasks. Each exploration task can be denoted as , where is the 3D position, represents the pitch, and represents the yaw of the robot.
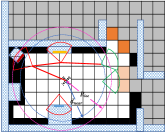
To explore unknown regions more effectively, we select viewpoints that can provide superior coverage of the frontiers as the exploration tasks. Specifically, we firstly update incremental frontiers and Euclidean Signed Distance Field (ESDF) map [8] from the maintained volumetric map similar to Fuel [31], where represent occupied, empty and unknown voxels. The ESDF map is responsible for filtering out viewpoints that are too close to obstacles. Secondly, in contrast to Fuel, to achieve more comprehensive coverage, we extract 3D principal components using Principal Component Analysis (PCA) instead of 2D and split large frontier clusters along the directions of the principal components.
Finally, for each frontier cluster , we generate a series of candidate viewpoints , where . are uniformly sampled on the spherical shell centered at the cluster, within the space , and oriented towards the center. The radius of the spherical shell ranges from to while ensuring that the distance to the nearest obstacle from is greater than . Similar to [24], We select the candidate viewpoint with the largest number of visible cluster cells as the exploration task for the frontier cluster.
III-C2 Reconstruction task generation
The reconstruction tasks are responsible for refining surface with lower quality, with denoting the total number of tasks. Each exploration task can be denoted as with the same range as exploration tasks. Algorithm 1 describes the generation process of reconstruction tasks.
Surface Downsampling To enhance the efficiency of detecting low-quality surfaces, we perform times by downsampling the surface , leading to the generation of a new set of surface elements represented as , consisting of elements. Each surface element is defined as , where is the j-th vertex on the surface. With Marching Cubes and rendering network in (2), we can obtain uncertainty , and normal vector for each surface vertex .
Local Surface Sampling and Clustering Assuming the current position of the robot is , we select all surface elements within a small radius from to ensure that the generated reconstruction tasks remain within a local scope. Considering the substantial number of surface elements, we can group these elements into surface clusters . This allows us to simplify the process of generating viewpoints from different clusters, reducing redundant computations. We adopt an uncertainty-guided iterative clustering approach. Initially, from the surface elements , we select the element with the highest uncertainty as the clustering center. We then include all points within a radius of this center in one cluster. Subsequently, we repeat the above process on the remaining surface elements until clusters are generated.
View Sampling For each surface cluster , we compute its center and generate a series of candidate viewpoints , where . These viewpoints in are uniformly sampled on the spherical shell centered at the cluster within the empty space , and they are oriented towards the cluster center. We also ensure that the count of visible cluster cells from these viewpoints exceeds the threshold . The radius of the spherical shell ranges from to while ensuring that the distance to the nearest obstacle from is greater than .
Surface Uncertainty Based Information Gain To select reconstruction tasks from these candidate viewpoints, we define the viewpoint information gain as
| (3) |
where represents the number of visible surface elements, represents the uncertainty of each visible surface element, and is the vector from the viewpoint to the surface element . Notice that the proposed surface uncertainty based information gain differs from the viewpoint information gain in [15, 30]
| (4) |
where is the uncertainty of the color for a 3D point sampled on a ray tracing through an image pixel of a viewpoint. is the number of sampled rays, is the number of sampled points on each ray, and is the weight. The viewpoint information gain integrates all the 3D points sampled in a viewpoint frustum while our information gain only integrates points on 2D surfaces. The surface uncertainty and the surface geometry also help to reduce the viewpoint sampling space.
We then choose the viewpoint with the highest information gain as the reconstruction task for this surface cluster.
III-D Adaptive view path planning
As aforementioned, the allocation of exploration and reconstruction tasks faces the challenges of trade-off between efficiency of efficacy. To address these challenges, we design a mode-switching approach for view path planning to achieve both planning efficiency and high reconstruction quality: when many frontiers are to be explored, exploration tasks dominate; otherwise, exploration and reconstruction tasks are planned together to get finer details and also avoid getting trapped in local regions.
Specifically, the switch condition depends on 1) the number of frontiers in the neighborhood of the current agent position , the neighborhood being a sphere located within a distance of from ; 2) the ratio of the frontiers in this local region to all the frontiers remained. When and , the robot performs exploration tasks, i.e. ; otherwise, the robot will simultaneously perform both exploration and reconstruction tasks, i.e. . Similar to [31], our problem becomes an ATSP Problem:
| (5) |
where is the length of A* path search from task to . represents the planned sequence of tasks.
As the map status updates with tasks executed, we choose to perform planned tasks in whose path length from the agent’s current position is smaller than a threshold to form the final execution sequence . Finally, we uniformly sample viewpoints along the sequence at a path resolution of and capture images as inputs for the mapping process. It is worth noting that when all frontiers are fully covered and exploration tasks are completed, only reconstruction tasks remain. At this stage, we increase local sampling radius , clustering radius , clustering num , preceding path length and path resolution until a certain number of images are collected, where = 3 is the amplification coefficient.
IV Results
| Method | Bhxhp | Rosser | Convoy | |||||||||||||
| Variant | Pitch | Switch | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | ||
| V1(Fuel[31]) | ✓ | 27.26 | 2.42 | 2.77 | 0.87 | 16.85 | 4.01 | 3.83 | 0.77 | 19.03 | 4.07 | 2.56 | 0.89 | |||
| V2 | ✓ | ✓ | 28.28 | 2.25 | 2.67 | 0.88 | 20.33 | 2.93 | 2.48 | 0.91 | 20.03 | 3.74 | 2.21 | 0.93 | ||
| V3 | ✓ | ✓ | 16.50 | 35.09 | 49.10 | 0.23 | 14.87 | 9.44 | 14.96 | 0.54 | 16.03 | 8.26 | 19.59 | 0.56 | ||
| V4 | ✓ | ✓ | ✓ | 26.66 | 17.87 | 13.32 | 0.73 | 18.87 | 4.87 | 4.05 | 0.79 | 20.59 | 5.07 | 3.98 | 0.90 | |
| V5(Ours full) | ✓ | ✓ | ✓ | ✓ | 30.45 | 1.90 | 2.18 | 0.92 | 22.04 | 2.76 | 2.27 | 0.94 | 21.24 | 3.24 | 1.96 | 0.96 |
| Variant | Pitch | Switch | P.L. | P.L. | P.L. | |||||||||||
| V1(Fuel[31]) | ✓ | 0.004 | 0.025 | 0.78 | 57.08 | 0.005 | 0.036 | 0.46 | 27.54 | 0.005 | 0.035 | 0.26 | 15.72 | |||
| V2 | ✓ | ✓ | 0.012 | 0.040 | 1.71 | 55.96 | 0.021 | 0.050 | 0.83 | 27.03 | 0.022 | 0.049 | 0.33 | 13.75 | ||
| V3 | ✓ | ✓ | 3.12 | 3.13 | 89.66 | 104.30 | 3.077 | 3.091 | 48.02 | 47.62 | 3.13 | 3.15 | 29.88 | 31.29 | ||
| V4 | ✓ | ✓ | ✓ | 3.12 | 3.18 | 46.78 | 109.09 | 3.13 | 3.17 | 28.80 | 53.42 | 3.05 | 3.09 | 13.88 | 34.55 | |
| V5(Ours full) | ✓ | ✓ | ✓ | ✓ | 0.01 / 3.33 | 0.03 / 3.37 | 40.02 | 108.23 | 0.01 / 3.06 | 0.04 / 3.11 | 26.19 | 55.56 | 0.01 / 2.93 | 0.04 / 2.96 | 8.41 | 40.56 |
| Bhxhp | Rosser | Convoy | ||||||||||||||||
| Method | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | P.L. | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | P.L. | PSNR↑ | Acc↓ | Comp↓ | Recall↑ | P.L. | |||
| EVPP[30] | 21.83 | 27.56 | 34.26 | 0.53 | 2138.93 | 47.75 | 19.74 | 4.78 | 3.25 | 0.86 | 973.81 | 26.58 | 18.83 | 7.21 | 4.52 | 0.84 | 933.89 | 15.06 |
| VPP[19] | 24.01 | 24.36 | 31.99 | 0.54 | 59.62 | 109.18 | 20.00 | 4.77 | 3.95 | 0.86 | 29.37 | 57.22 | 20.60 | 7.20 | 4.45 | 0.87 | 18.12 | 37.82 |
| Our | 30.45 | 1.90 | 2.18 | 0.92 | 40.02 | 108.23 | 22.04 | 2.76 | 2.27 | 0.94 | 26.19 | 55.56 | 21.24 | 3.24 | 1.96 | 0.96 | 8.41 | 40.56 |
IV-A Implementation details
IV-A1 Data
The experiments are conducted on three virtual scenes: () from HM3D [14], () and () from Gibson [25], which are reconstructed and modified from real scenes. In order to minimize unproductive exploration beyond the designated scene boundaries, we have sealed all windows within the scenes. We maintain the same depth noise and field of view (FOV) parameters, as specified in prior works such as [15, 30].
IV-A2 Implementation
Our method runs on two RTX3090 GPUs. The implicit surface reconstruction is on one GPU, Omnidata and view path planning is on the other one, where view path planning runs in the ROS environment. We set the maximum planned views to be 250 views for , 130 views for , and 80 views for . All scene-dependent parameters are listed in Table III.
| Scene | ||||||||
| Bhxhp | 1.0 | 2.0 | 2.5 | 1.3 | 15 | 30 | 2.0 | 6.0 |
| Rosser | 0.8 | 1.8 | 2.0 | 1.1 | 10 | 20 | 1.5 | 5.0 |
| Convoy | 0.5 | 1.5 | 1.5 | 1.0 | 10 | 15 | 1.0 | 4.0 |
IV-A3 Metric
Similar to [30], we evaluate our method from two aspects including effectiveness and efficiency. The quality of reconstructed scenes is measured in two parts: the quality of the rendered images and the quality of the geometry of the reconstructed surface. We adopt metrics from MonoSDF [29]: Accuracy (cm), Completion (cm), Recall (the percentage of points in the reconstructed mesh with Completion under 5 cm. For the geometry metrics, about 300k points are sampled from the surfaces.
For efficiency, we evaluate the path length (meter) and the planning time (second). The total path length is and the time is . For the time of our view path planning for each step of the reconstruction process, we break it into several parts for more detailed comparison: 1) the task generation time , 2) the time for the ATSP based view path planning, 3) the mode switching time during the planning. We also report the total view planning time for each step i.e. . for all the variants in Table I is about 0.02s to 0.06s. is about 0.003s.
IV-B Efficacy of the Method
Similar to [30], the efficacy of the method is evaluated regarding both the effectiveness and efficiency of our contributions. We design variants of our method based on implicit surface representation. The variants are V1 (Fuel [31]), V2 (Fuel with pitch), V3 (only reconstruction tasks), and V4 (Merging exploration and reconstruction tasks without mode switching). Our method is best for effectiveness and better than methods with reconstruction tasks for efficiency.
IV-B1 Uncertainty of implicit surface
Fig. LABEL:teaser illustrates the evolution of surface uncertainty during the training process. It can be observed that surface uncertainty gradually decreases during the training process. The high surface uncertainty in regions with poor geometric structures allows us to allocate viewpoints for scanning these low-quality surfaces. This reduces the time required for viewpoint sampling compared to NBV methods such as [30].
IV-B2 Combination of exploration and reconstruction tasks
We make V1 our baseline, which uses incremental frontiers to explore unknown environments. We make V2 with a pitch angle to verify its efficacy. To verify the efficacy of different tasks, we make V2 (exploration tasks only) and V3 (reconstruction tasks only) as our baselines.
The metrics of V2 in Table I demonstrate pitch angle can improve reconstruction quality than Fuel [31] and introduce a slight increase in planning time. Focusing solely on exploration tasks (V2) results in rapid scene coverage, but it fails to perform further detailed scans of complex details, thus reducing the reconstruction quality. When only reconstruction tasks are considered (V3), the reconstruction quality becomes very poor because it falls into the local optimum and cannot cover the entire scene. It is typical for the incorporation of reconstruction tasks to lead to an increase in planning time, as it requires surface uncertainty extraction, similar to other surface inspection methods such as [7].
IV-B3 Adaptive view path planning
To validate the effectiveness of mode switching, we establish V4 as our baseline. However, the merger of these two tasks significantly slows down the pace of scene exploration, and even leads to local optimum, especially when dealing with complex reconstruction details. The introduction of mode switching (Ours) ensures the speed of exploration and scanning of details, without falling into local optimum associated with scanning low-quality surfaces.
IV-C Comparison with existing planning methods
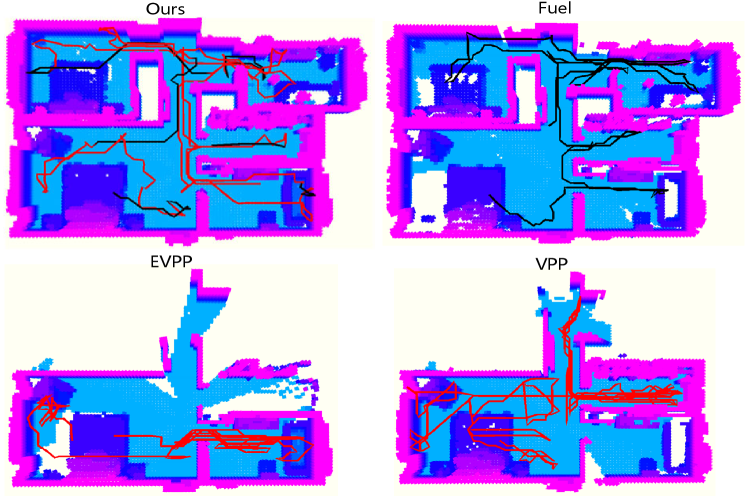
We select two recent works EVPP [30] based on view information gain filed and VPP [19], which uses the nearest exploration task as the NBV and plans a path to the NBV using surface inspection methods. The metrics in Table II show our method outperforms them in the reconstructed quality and the planning efficiency. This is because EVPP fails to avoid local minima and cannot explore the entire scene, VPP only relies on the nearest exploration task, which slows down the exploration speed.

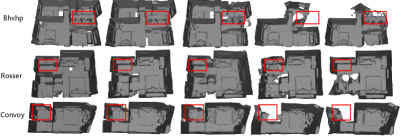
Fig. 3 shows our method provides better reconstruction results in novel views and geometry. For more visual comparisons and results, we refer readers to the supplementary video. Fig. 4 demonstrates that the trajectory of our method expands in scene that of other methods.
IV-D Robot experiments in real scene
We implemented our proposed method on an actual UAV equipped with Realsense Depth Camera D435i to perform room reconstruction, specifically targeting a room with dimensions of 8m × 2.5m × 3m. The pose of the camera is provided by Droid-SLAM [20]. For this scene, the UAV takes about 5 minutes to explore and reconstruct the room. The exploration and reconstruction results will be presented in the supplementary video.
V Conclusion
In this paper, we combine exploration and reconstruction tasks to ensure both global coverage and high-quality reconstruction. Subsequently, we introduce implicit surface uncertainty to accelerate view selection. Finally, we employ an adaptive mode switching method to improve planning efficiency without falling into local optimum. Comprehensive experiments demonstrate the superior performance of our method.
In the future, we plan to study how viewpoint selections impact pose estimation in our planning process, while also extending our research to multi-agents.
References
- [1] Randa Almadhoun, Abdullah Abduldayem, Tarek Taha, Lakmal Seneviratne, and Yahya Zweiri. Guided next best view for 3d reconstruction of large complex structures. Remote Sensing, 11(20):2440, 2019.
- [2] Andreas Bircher, Mina Kamel, Kostas Alexis, Helen Oleynikova, and Roland Siegwart. Receding horizon path planning for 3d exploration and surface inspection. Autonomous Robots, 42:291–306, 2018.
- [3] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In European Conference on Computer Vision, pages 333–350. Springer, 2022.
- [4] Liang Chen, Zhitao Liu, Weijie Mao, Hongye Su, and Fulong Lin. Real-time prediction of tbm driving parameters using geological and operation data. IEEE/ASME Transactions on Mechatronics, 27(5):4165–4176, 2022.
- [5] Siyan Dong, Kai Xu, Qiang Zhou, Andrea Tagliasacchi, Shiqing Xin, Matthias Nießner, and Baoquan Chen. Multi-robot collaborative dense scene reconstruction. ACM Transactions on Graphics (TOG), 38(4):1–16, 2019.
- [6] Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10786–10796, 2021.
- [7] Junfu Guo, Changhao Li, Xi Xia, Ruizhen Hu, and Ligang Liu. Asynchronous collaborative autoscanning with mode switching for multi-robot scene reconstruction. ACM Transactions on Graphics (TOG), 41(6):1–13, 2022.
- [8] Luxin Han, Fei Gao, Boyu Zhou, and Shaojie Shen. Fiesta: Fast incremental euclidean distance fields for online motion planning of aerial robots. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4423–4430. IEEE, 2019.
- [9] Yves Kompis, Luca Bartolomei, Ruben Mascaro, Lucas Teixeira, and Margarita Chli. Informed sampling exploration path planner for 3d reconstruction of large scenes. IEEE Robotics and Automation Letters, 6(4):7893–7900, 2021.
- [10] William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. In Seminal graphics: pioneering efforts that shaped the field, pages 347–353. 1998.
- [11] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG), 41(4):1–15, 2022.
- [12] Sicong Pan and Hui Wei. A global max-flow-based multi-resolution next-best-view method for reconstruction of 3d unknown objects. IEEE Robotics and Automation Letters, 7(2):714–721, 2021.
- [13] Xuran Pan, Zihang Lai, Shiji Song, and Gao Huang. Activenerf: Learning where to see with uncertainty estimation. In European Conference on Computer Vision, pages 230–246. Springer, 2022.
- [14] Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
- [15] Yunlong Ran, Jing Zeng, Shibo He, Jiming Chen, Lincheng Li, Yingfeng Chen, Gimhee Lee, and Qi Ye. Neurar: Neural uncertainty for autonomous 3d reconstruction with implicit neural representations. IEEE Robotics and Automation Letters, 8(2):1125–1132, 2023.
- [16] Lukas Schmid, Michael Pantic, Raghav Khanna, Lionel Ott, Roland Siegwart, and Juan Nieto. An efficient sampling-based method for online informative path planning in unknown environments. IEEE Robotics and Automation Letters, 5(2):1500–1507, 2020.
- [17] Yuanchao Shu, Yinghua Huang, Jiaqi Zhang, Philippe Coué, Peng Cheng, Jiming Chen, and Kang G. Shin. Gradient-based Fingerprinting for Indoor Localization and Tracking. IEEE Transactions on Industrial Electronics, 63(4):2424–2433, 2016.
- [18] Yuanchao Shu, Zhuqi Li, Börje F. Karlsson, Yiyong Lin, Thomas Moscibroda, and Kang Shin. Incrementally-deployable Indoor Navigation with Automatic Trace Generation. In IEEE Conference on Computer Communications (INFOCOM), 2019.
- [19] Soohwan Song, Daekyum Kim, and Sunghee Choi. View path planning via online multiview stereo for 3-d modeling of large-scale structures. IEEE Transactions on Robotics, 38(1):372–390, 2021.
- [20] Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Advances in neural information processing systems, 34:16558–16569, 2021.
- [21] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. Advances in Neural Information Processing Systems, 34:27171–27183, 2021.
- [22] Xiangyu Wang, Jingsen Zhu, Qi Ye, Yuchi Huo, Yunlong Ran, Zhihua Zhong, and Jiming Chen. Seal-3d: Interactive pixel-level editing for neural radiance fields. arXiv preprint arXiv:2307.15131, 2023.
- [23] Yiming Wang, Stuart James, Elisavet Konstantina Stathopoulou, Carlos Beltrán-González, Yoshinori Konishi, and Alessio Del Bue. Autonomous 3-d reconstruction, mapping, and exploration of indoor environments with a robotic arm. IEEE Robotics and Automation Letters, 4(4):3340–3347, 2019.
- [24] Christian Witting, Marius Fehr, Rik Bähnemann, Helen Oleynikova, and Roland Siegwart. History-aware autonomous exploration in confined environments using mavs. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–9. IEEE, 2018.
- [25] Fei Xia, Amir R. Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: real-world perception for embodied agents. In Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on. IEEE, 2018.
- [26] Beichen Xiang, Yuxin Sun, Zhongqu Xie, Xiaolong Yang, and Yulin Wang. Nisb-map: Scalable mapping with neural implicit spatial block. IEEE Robotics and Automation Letters, 2023.
- [27] Zike Yan, Haoxiang Yang, and Hongbin Zha. Active neural mapping. arXiv preprint arXiv:2308.16246, 2023.
- [28] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems, 34:4805–4815, 2021.
- [29] Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction. Advances in neural information processing systems, 35:25018–25032, 2022.
- [30] Jing Zeng, Yanxu Li, Yunlong Ran, Shuo Li, Fei Gao, Lincheng Li, Shibo He, Jiming Chen, and Qi Ye. Efficient view path planning for autonomous implicit reconstruction. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 4063–4069. IEEE, 2023.
- [31] Boyu Zhou, Yichen Zhang, Xinyi Chen, and Shaojie Shen. Fuel: Fast uav exploration using incremental frontier structure and hierarchical planning. IEEE Robotics and Automation Letters, 6(2):779–786, 2021.
- [32] Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R Oswald, and Marc Pollefeys. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12786–12796, 2022.