Automatic Sign Reading and Localization for Semantic Mapping with an Office Robot
Abstract
Semantic mapping is the task of providing a robot with a map of its environment beyond the open, navigable space of traditional Simultaneous Localization and Mapping (SLAM) algorithms by attaching semantics to locations. The system presented in this work reads door placards to annotate the locations of offices. Whereas prior work on this system developed hand-crafted detectors, this system leverages YOLOv5 for sign detection and EAST for text recognition. Placards are localized by computing their pose from a point cloud in a RGB-D camera frame localized by a modified ORB-SLAM. Semantic mapping is accomplished in a post-processing step after robot exploration from video recording. System performance is reported in terms of the number of placards identified, the accuracy of their placement onto a SLAM map, the accuracy of the map built, and the correctness transcribed placard text.
I Introduction
Simultaneous Localization And Mapping (SLAM) techniques provide navigational maps that enable robots to autonomously explore an environment. The emerging family of Semantic Mapping techniques add semantic information about locations and objects in the environment to this basic map data. Semantic mapping enables robots to navigate based on a location’s semantics rather than simple geometric poses, and by extension allows the robot to reason about locations using automated planning or based on semantic parses of natural language commands [1]. Semantic maps can be particularly useful for consumer-facing robotic applications, such as aiding visitors in navigating an unfamiliar building [2] or object retrieval [3]. Manually labeling map semantics can be tedious or impractical for large maps. This work focuses on the autonomous semantic labeling of a mapped environment.
Buildings often feature signage that annotates important semantics for the benefit of human occupants, such as placards indicating office numbers. Modern Optical Character Recognition (OCR) methods can be used to extract semantic meaning from text found in optical frames. Prior work used hand crafted detectors to identify door placards, register their position on a map, and transcribe their labels [4] [5]. These methods require either the construction of a map prior to scanning for placards, or for a human to guide the robot while scanning for placards. The contribution of this work is to construct the map and semantics in post-processing of video RGB-D data recorded during exploration.
This work utilizes RGB-D sensor data collected from a robot equipped with an Azure Kinect camera [6]. Video data was recorded during human-guided exploration of an office floor. From the video recording, a navigation map is built using a version of ORB-SLAM [7] which has been modified to improve performance in the presence of very challenging input, in the form of flat-colored walls with few obvious features to match during visual reconstruction (an important step in the ORB-SLAM pipeline). After the navigation map is built, extracted keyframes are utilized to build a full 3D reconstruction of the hallways from sensor data. At the same time, a trained YOLOv5 [8] object-detector is used to identify door placards in each frame. The detector used in this study is specifically trained to detect door number placards. If a placard is detected, it is localized in frame and added to the reconstruction. EAST [9] and Tesseract-OCR [10] are used to read and record each placard’s text. The text contains information such as room numbers, which then is used to mark up the semantics of room locations on the constructed map.
This paper demonstrates an effective semantic mapping system for recorded RGB-D data of an office hallway which reads and localizes room numbers (Sec. III). The success of this work is measured in terms of the number of placards identified, the accuracy of the localization, the ability to make accurate maps in the presence of featureless walls, and the number of placards successfully read.
II Related Work
Simultaneous Localization and Mapping (SLAM) refers to the problem of exploring an environment, mapping the features of that environment, and placing the robot on the map [11]. Semantic Mapping is the problem of placing semantic labels on map features [12] for efficient task completion or natural communication with humans [13][14]. Semantic SLAM tackles both problems at once, often using semantic labels in the localization process [15].
Much of the work on Semantic Mapping and Semantic SLAM, has focused on identifying object labels with the sensor being considered, often with RGB or RGB-D cameras [16][12][17], although identifying rooms and spaces is also a common problem [18]. Objects are placed onto a map using a representative model ranging from detailed 3D models [19], to bounding ellipsoids and cubes [17], or a labelled point cloud and voxel grid [20].
Labels are generally categorized a-priori by type, without discrimination between instances of the same type [21]. An alternative is to discover labels through text in the environment that uniquely identify objects or spaces, thereby improving the specificity of the semantic map. Prior work identified text as a useful indicator of planar objects rich in distinct visual features useful for optical SLAM methods [22][23]. Transcribing text has been used for localization on a given map [24][25]. Text recognition as a part of a SLAM system has also been used in self-driving cars and retail spaces [26][27][28]. A major difference between street signs and office signs is that the former is designed to be easily read from forward facing fast moving vehicles, while the latter by slow moving pedestrians capable of reorienting their view at will. This difference causes many of the challenges discussed in this paper.
There are two major investigations which we expand upon. The earliest work is Autonomous Sign Reading (ASR) for Semantic Mapping [5], and the other is Pose Registration for Integrated Semantic Mapping (PRISM) [4]. While prior work focuses on design of placard detectors, this paper focuses on efficient discovery.
III Semantic Mapping System
This semantic mapping system constructs maps from video and depth data (RGB-D video) recorded using a Microsoft Azure Kinect [6] mounted on a mobile robot (a University of Texas at Austin Building-Wide Intelligence BWIBot [29]).
Recordings are processed in two phases. In the first phase, a SLAM map is constructed with a modified ORB-SLAM [7]. The second phase extracts semantics from each keyframe. The second phrase comprises several steps:
-
1.
Detect placards (Regions of Interest - ROIs)
-
2.
Extract planar features
-
3.
Identify text lines
-
4.
Transcribe text to string
-
5.
Validate string
-
6.
Map Reconstruction and Projection
-
7.
Data aggregation
As each placard is observed, the pose and label is recorded. If the label could not be validated, it is left blank.
III-A A Modified ORB-SLAM
ORB-SLAM works by identifying distinct visual features known as ORB features [30] from visual RGB images, and matching these features across a number of video frames. Once these features are matched, it searches for the transformation between frames which best explains the visual position of the matches. ORB-SLAM also performs keyframing for efficient memory usage for storing ORB features. In this way, ORB-SLAM tracks the most current frame in a visual feed with respect to a map’s origin frame as long as enough ORB features are matched to previous keyframes. If this tracking is lost, ORB-SLAM creates a new map and begins tracking again.
Motion blur or frames which lack matching ORB features can cause ORB-SLAM to lose track of the current frame’s pose. It is possible for ORB-SLAM to merge maps only when the camera returns to a formerly observed viewpoint.
When the camera returns to a previous viewpoint, ORB-SLAM will either do a loop closure, or a map merge. If the matching frames are in the same map, then loop closure will frequently fix localization errors. However, if ORB-SLAM detects a matching frame on a different map than the one currently being tracked, a map merge is performed, and this opportunity for refined localization is lost.
Mono-colored walls present a danger that ORB-SLAM will be unable to reliably determine the camera-pose that a frame of video was shot from due to a lack of visual features, thus creating flaws in the underlying map. Every time the robot rotates — such as to face a placard head-on or recover from navigating into a tight space — there is a good chance ORB-SLAM will lose track. In the Anna Hiss Gymnasium robotics facility — where there are many beautiful, but unfortunately plain white walls — a method of merging these maps that supplements the capabilities of standard ORB-SLAM is necessary. It is also best to recover the robot’s accurate pose quickly after tracking is lost to avoid missing an opportunity for loop-closure when ORB-SLAM fails to identify sufficient matching features.
To address this, we enhanced ORB-SLAM by matching the full 3D point clouds of the last successfully localized frame in the old map with the first frame (the origin frame) of the new map. An iterative closest point (ICP) algorithm is used to identify the transform which best matches the point clouds [31]. By identifying the transform between frames based on point clouds, the new map is localized in the reference frame of the old, and the maps can be merged using ORB-SLAM’s out-of-the-box functionality.
This method is computationally expensive, so processing these supplemental map merges needs to be done offline.
III-B Detecting placards
The You Only Look Once (YOLO) neural network [32] is utilized to identify placards in frame and extract ROIs in the RGB frame of each ORB-SLAM keyframe. A YOLOv5 [8] network was re-trained on pictures of placards coming from the right half of the building in Figure 3, the other half of the building is held out as test set and unseen in the training data. Because the placards are standardized, the system generalizes well to the new space. Figure 1 shows the training metrics over epochs, along with two example validation images. A confidence threshold of is used to filter false detections.


Figure 2 a shows an image patch of a detected placard, the patch edges are defined by the bounding box returned by the trained YOLOv5.



III-C Extract Planar Features
The Azure Kinect uses a time-of-flight camera paired with a 4K RGB camera. These two views are registered to each other through camera calibration, allowing the extraction of a point cloud from the depth camera which is associated with a placard captured in the RGB camera. The point cloud is used to extract the plane in which the placard lies. Given the camera frame’s pose from ORB-SLAM, the placard’s pose in camera frame is transformed into ORB-SLAM’s global frame, thereby localizing the placard.
III-D Identify Text Lines
Given the pose of the placard in the camera frame, the perspective can be warped in the ROI to approximate a head-on view, as shown in Figure 2a. This warping is done to enhance text readability. An Efficient and Accurate Scene Text (EAST) [9] pre-trained detector is used to identify lines of text in each ROI. Tesseract-OCR will ignore colors which differ from the first recognized line in an image. Using EAST, the system subdivides the ROI containing the placard into regions of text with the same color. An example of these subdivisions is shown in Figure 2b, the lines of text are outlined in red.
III-E Transcribe Text to String
Once the image is subdivided by EAST into lines, each line is then passed to Tesseract-OCR [10] to transcribe the text to a character string. The system uses Tesseract’s pre-trained English dictionary.
Tesseract works best on binary images, so the images are converted to black and white and a threshold applied before transcription. Several thresholds are taken to generate multiple proposed strings. Threshold values are taken in increments of five on the range for an eight-bit color value. Figure 2c shows an example of this thresholding with a value of 85, this value was hand-picked as the most readable.
III-F Validate String
The placards follow a standardized format for indicating room numbers: the single-digit floor number, a decimal point, and a three digit room number. There are a handful of placards where the room name is given in place of the number, these are the restrooms (MEN, WOMEN, GENDER INCLUSIVE) and the stairs (STAIR1, STAIR2). The system validates that the returned string adheres to these standards with a regular expression. The decimal point is optional because it is often hard to identify due to its size. The stair ID is also optional because the distinction is not of much practical use. If successfully validated, the string is recorded as the placard’s label.
III-G Map Reconstruction and Projection
The depth-map and camera pose of each keyframe are passed into octomap to perform a full 3D reconstruction of the scene [33]. The system uses a map resolution of m. For ease of visualization the system also projects the reconstruction into a 2D map with vertical cuts applied for the floors and ceiling. Vertical camera drift in ORB-SLAM’s localization is corrected by adjusting the frame’s vertical coordinate to a constant value.
III-H Placard Aggregation
Once all keyframes have been processed, placards which are not localized to lie on walls are discarded, and those observations which lie within one placard radius (m) of each other are grouped together. Among each observation group, the average pose is taken, and the most common identified label adopted. This consistently localizes the placards and semantically labels them onto a navigable SLAM map.
IV Experimental Design
A video was recorded on an Azure Kinect sensor [6]. The color camera was set to a resolution of px @ fps, and the depth camera was set to a binned wide field of view (WFOV) with px @ fps. The color camera resolution is set such that placards viewed at far distances and poor angles have the best possible chance of being read. The depth camera is set so WFOV has the best possible overlap with the color camera and the maximum possible depth range for WFOV (m).
IV-A Recording Features
In the recording, the robot is driven near continuously making no attempt to view the placards head-on, with two full rotation in-place around the robot’s center.
Figure 3 shows a hand-crafted map of the office floor the recording was taken in. The locations of the door placards are marked by a circle, the expected labels are placed in the vicinity of the markings. Since this semantic map was hand-crafted, it is only an approximation of the land mark locations and floor plan.
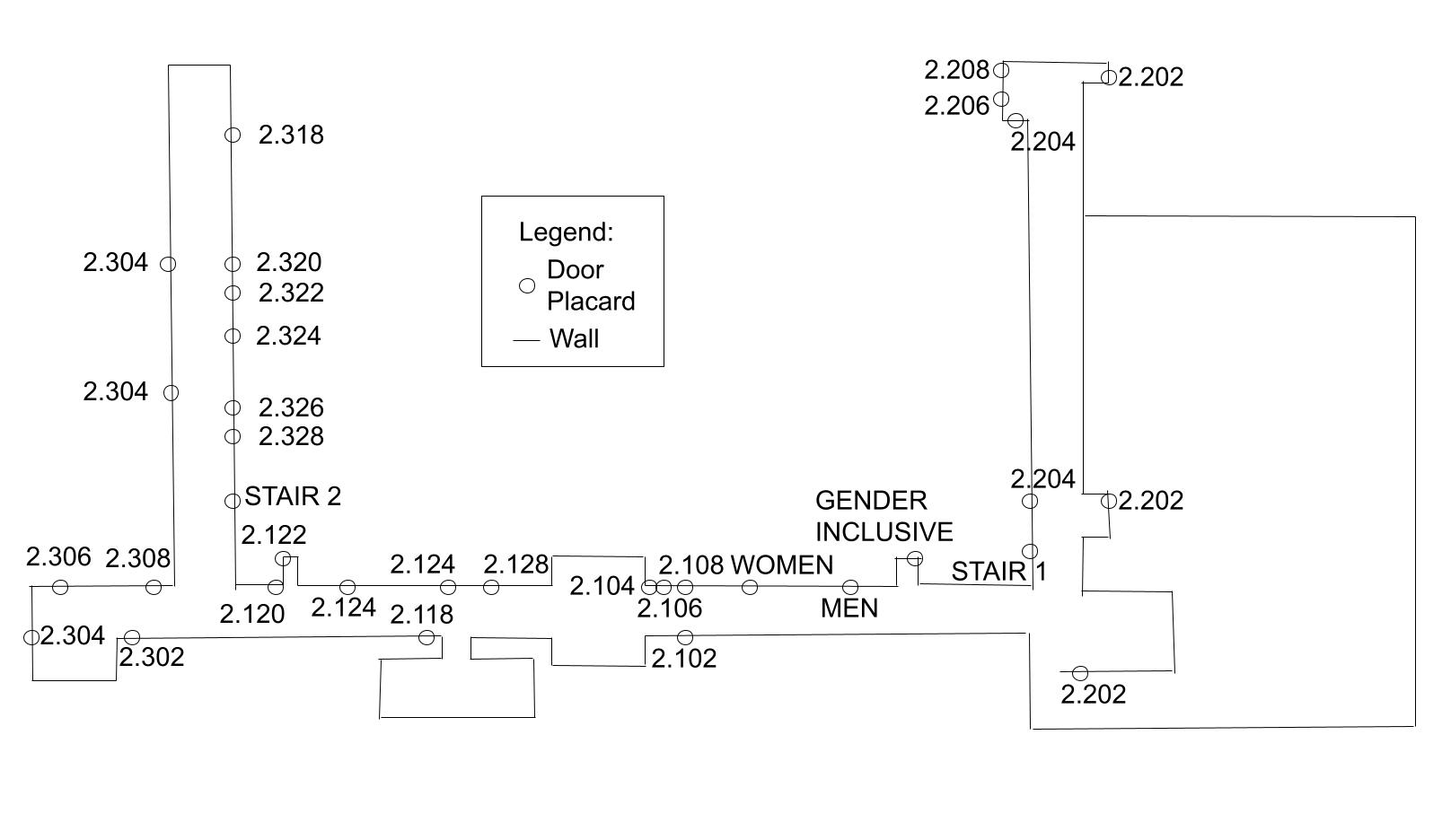
The first rotation occurs at the center of the office floor and is designed to provide ORB-SLAM with an opportunity for loop-closure. This location is feature-rich and the full rotation guarantees that the robot will see a similar viewpoint when returning to the location.
The second rotation happens in the corridor on the right hand side of the map in Figure 3, the walls on either side of the robot are nearly featureless. This second rotation is designed to test robustness to difficult localization scenarios.
The recording also roams regions of the office space which do not contain placards. The purpose is to test if the trained YOLO model provides any false positive placard detections.
IV-B Performance Metrics
A large portion of Sec. III relies on ORB-SLAM to provide reliable localization. ORB-SLAM is a stochastic process, so to properly assess the system’s capabilities, multiple maps are generated by re-running ORB-SLAM on the same recording. This provides some insight into how robust the system is to unlucky mapping trials.
No record of the precise placement of the placards is available, so a baseline for numerical comparison must be established. For this, the map which subjectively appears to best represent the real world floor plan is utilized. All other maps are compared against the baseline map to assess the consistency of placard localization.
Placard poses are measured by the coordinates localized from RGB-D sensor data and ORB-SLAM’s keyframe pose, where is the angle the vector normal to the placard’s face makes with the x-axis in the 2D map projection.
For a given observation of , , there is the true value . Since the office floor has placards mounted on walls that lie at exclusively right angles to each other, any must be one of four values in increments of . The most likely values are identified by finding the largest cluster of measurements in the baseline map, taking the average and then incrementing by multiples of . Every is assigned one of these four values by hand labeling.
To compare maps to the baseline poses, a correspondence between the observed placard in one map must be made to the same placard observed in the baseline. This is also done by hand labeling. If a placard is observed multiple times, but localized in different locations, every instance is marked as corresponding to the same baseline pose. Correspondences are identified through direct observation of video frames.
There are 34 placards present on the office floor, part of the evaluation will consider how many of these are missed, how many are duplicated in multiple localizations, and how many false positive placards are recorded. Of the observed true positive placards, error is computed over position and angular orientation and find as the standard deviation from the mean on each trial map.
To demonstrate the value of the enhancements to ORB-SLAM, example plots of the map with and without modification are shown with important features noted.
Finally, the portion of observed placards with correctly read labels is observed. This is determined by hand-labeling the true text on each placard.
V Results
Four ORB-SLAM maps were created to evaluate performance. Trial 3 serves as the baseline map. Figure 4 shows the map. The keyframe trajectory is shown in red. The localized placards are shown as blue dots with lines indicating their orientation. Orange markings show placards that have been discarded because they were are not localized close to a wall.

Figure 5 shows the clustering of values, the green vertical line indicates the selected baseline value for valid values of , the red vertical lines indicate the predicted clusters given only radian angles of all the walls. As shown, the predictions align well with the observations.

Table I summarizes the numerical results. The symbols here refer to the mean and standard deviation respectively of the indicated measurements. The displacement error on Trial 3 has been omitted since every placard excepting the duplicates are utilized for the baseline comparison.
There are two placards which every trial missed, one which was the only placard not to conform to the standard measurements, and one which was posted on the window of a dark room. Since the placards are black and the dark room gave the appearance of a black wall, both of these situations presented a unique challenge to YOLOv5 which it was not trained to handle.
Trial 4 missed one additional placard which had been discarded for not being localized close to a wall. Trial 4 and Trial 1 also falsely identify an extra placard on a section of wall with a visual similarity to the preferred objects.
Each trial contains a number of duplicate placards. Trial 2 is the worst offender because it has the worst performing map, containing segments of matching walls that are out of alignment. Placards on these walls are duplicated. Other sources of duplication come from cases where the edge of the detected placard is visually aligned with a protruding corner of a nearby wall. The resulting depth cloud includes points lying on this wall at a much closer depth thereby skewing the placard’s localization.


Figure 7 shows how the displacement errors are distributed for each trial. As the placards get further away from the origin frame, defects in the map cumulatively contribute to the localization error. Therefore, the error tends to be small near the origin, and larger further away. The worst performing trial by this metric is Trial 1, while Trial 4 is the best.

The average error in orientation remained under degrees of deviation for all trials. Again, Trial 1 has the worst results and Trial 4 the best, closely mirroring the displacement results.
| trial 1 | trial 2 | trial 3 | trial 4 | |
| observed count | 35 | 43 | 34 | 34 |
| missed count | 4 | 2 | 2 | 3 |
| duplicates count | 5 | 11 | 2 | 2 |
| false positive count | 1 | 0 | 0 | 1 |
| displace error (m) | 2.02,1.04 | 0.66,0.55 | - | 0.51,0.52 |
| error (deg) | 5.9,9.3 | 5.4,7.6 | 4.8,7.7 | 4.8,6.8 |
Figure 6 shows the impact of applying point cloud merging on an ORB-SLAM map. ORB-SLAM loses tracking in the corridor on the left-hand side of Figure 3. In this area the robot does a full rotation with blank walls on either side. Without the correction, ORB-SLAM stops tracking as it pans against each wall. Between each wall, a second map is created. After completing the rotation ORB-SLAM recognizes a return to the starting viewpoint, and begins tracking the first map again. As the robot drives back down the corridor, the localization drifts and a falsely mapped second corridor is created. When the robot returns to the half-circle viewpoint, ORB-SLAM merges the first and second maps with an added phantom hallway. However, with the modification described in Sec. III-A a single map is maintained, therefore when the robot reaches the half circle viewpoint mark ORB-SLAM instead does a loop closure which corrects the localization and merges the corridors.
Out of the observed placards, Trial 1 correctly read the labels on (), Trial 2 on (), Trial 3 on (), and Trial 4 on ().
VI Conclusion
A system for adding semantic markers to a SLAM map utilizing naturally placed text markers was presented. The system can be run on recordings of RGB-D data. The system demonstrates a high degree of consistency between mapping results as well as a robustness to featureless regions in the color video. The system is able to identify all but two text markers and read about of those it identifies on average.
Acknowledgment
This work has taken place in the Learning Agents Research Group (LARG) at the Artificial Intelligence Laboratory, The University of Texas at Austin. LARG research is supported in part by the National Science Foundation (CPS-1739964, IIS-1724157, FAIN-2019844), the Office of Naval Research (N00014-18-2243), Army Research Office (W911NF-19-2-0333), DARPA, General Motors, Bosch, Cisco Systems, and Good Systems, a research grand challenge at the University of Texas at Austin. The views and conclusions contained in this document are those of the authors alone.
References
- [1] J. Thomason, A. Padmakumar, J. Sinapov, N. Walker, Y. Jiang, H. Yedidsion, J. Hart, P. Stone, and R. Mooney, “Jointly improving parsing and perception for natural language commands through human-robot dialog,” Journal of Artificial Intelligence Research, vol. 67, pp. 327–374, 2020.
- [2] H. Yedidsion, J. Deans, C. Sheehan, M. Chillara, J. Hart, P. Stone, and R. J. Mooney, “Optimal use of verbal instructions for multi-robot human navigation guidance,” in Proceedings of the International Conference on Social Robotics (ICSR), Madrid, Spain, 2019, pp. 133–143.
- [3] Y. Jiang, N. Walker, J. Hart, and P. Stone, “Open-world reasoning for service robots,” in Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), July 2019, pp. 725–733. [Online]. Available: https://ojs.aaai.org/index.php/ICAPS/article/view/3541
- [4] J. W. Hart, R. Shah, S. Kirmani, N. Walker, K. Baldauf, N. John, and P. Stone, “PRISM: Pose Registration for Integrated Semantic Mapping,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 2018, pp. 896–902.
- [5] C. Case, B. Suresh, A. Coates, and A. Y. Ng, “Autonomous sign reading for semantic mapping,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, May 2011, pp. 3297–3303.
- [6] M. Tölgyessy, M. Dekan, L. Chovanec, and P. Hubinskỳ, “Evaluation of the azure kinect and its comparison to kinect v1 and kinect v2,” Sensors, vol. 21, no. 2, p. 413, 2021.
- [7] R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017.
- [8] G. Jocher, A. Chaurasia, A. Stoken, J. Borovec, NanoCode012, Y. Kwon, TaoXie, K. Michael, J. Fang, imyhxy, Lorna, C. Wong, Z. Yifu, A. V, D. Montes, Z. Wang, C. Fati, J. Nadar, Laughing, UnglvKitDe, tkianai, yxNONG, P. Skalski, A. Hogan, M. Strobel, M. Jain, L. Mammana, and xylieong, “ultralytics/yolov5: v6.2 - YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai integrations,” Aug. 2022. [Online]. Available: https://doi.org/10.5281/zenodo.7002879
- [9] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, and J. Liang, “East: an efficient and accurate scene text detector,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 5551–5560.
- [10] R. Smith, “An overview of the tesseract ocr engine,” in Ninth international conference on document analysis and recognition (ICDAR 2007), vol. 2. IEEE, 2007, pp. 629–633.
- [11] C. Cadena, L. Carlone, H. Carrillo, Y. Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,” IEEE Transactions on robotics, vol. 32, no. 6, pp. 1309–1332, 2016.
- [12] N. Sünderhauf, T. T. Pham, Y. Latif, M. Milford, and I. Reid, “Meaningful maps with object-oriented semantic mapping,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 5079–5085.
- [13] A. Aydemir, M. Göbelbecker, A. Pronobis, K. Sjöö, and P. Jensfelt, “Plan-based object search and exploration using semantic spatial knowledge in the real world.” in Proceedings of the European Conference on Mobile Robots (ECMR), 2011, pp. 13–18.
- [14] A. Pronobis and P. Jensfelt, “Large-scale semantic mapping and reasoning with heterogeneous modalities,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2012, pp. 3515–3522.
- [15] S. L. Bowman, N. Atanasov, K. Daniilidis, and G. J. Pappas, “Probabilistic data association for semantic SLAM,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Marina Bay Sands, Singapore: IEEE, May 2017, pp. 1722–1729.
- [16] Y. Nakajima and H. Saito, “Efficient object-oriented semantic mapping with object detector,” IEEE Access, vol. 7, pp. 3206–3213, 2018.
- [17] K. Ok, K. Liu, K. Frey, J. P. How, and N. Roy, “Robust object-based slam for high-speed autonomous navigation,” in Proceedings of the International Conference on Robotics and Automation (ICRA), 2019, pp. 669–675.
- [18] R. Bormann, F. Jordan, W. Li, J. Hampp, and M. Hägele, “Room segmentation: Survey, implementation, and analysis,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 1019–1026.
- [19] M. Hosseinzadeh, K. Li, Y. Latif, and I. Reid, “Real-time monocular object-model aware sparse SLAM,” in Proceedings of the International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7123–7129.
- [20] H. Yu and B. H. Lee, “A variational feature encoding method of 3d object for probabilistic semantic SLAM,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3605–3612.
- [21] M. Sualeh and G.-W. Kim, “Simultaneous localization and mapping in the epoch of semantics: A survey,” International Journal of Control, Automation, and Systems, vol. 17, no. 3, pp. 729–742, 2019.
- [22] B. Li, D. Zou, D. Sartori, L. Pei, and W. Yu, “Textslam: Visual slam with planar text features,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 2102–2108.
- [23] L. Ma, K. Chen, J. Liu, and J. Zhang, “Homography-driven plane feature matching and pose estimation,” in 2021 6th IEEE International Conference on Advanced Robotics and Mechatronics (ICARM). IEEE, 2021, pp. 791–796.
- [24] S. Wang, S. Fidler, and R. Urtasun, “Lost shopping! monocular localization in large indoor spaces,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2695–2703.
- [25] H. Sadeghi, S. Valaee, and S. Shirani, “Ocrapose ii: An ocr-based indoor positioning system using mobile phone images,” arXiv preprint arXiv:1704.05591, 2017.
- [26] L. Kenye, R. Palugulla, M. Arora, B. Bhat, R. Kala, and A. Nayak, “Re-localization for self-driving cars using semantic maps,” in 2020 Fourth IEEE International Conference on Robotic Computing (IRC). IEEE, 2020, pp. 75–78.
- [27] V. Swaminathan, S. Arora, R. Bansal, and R. Rajalakshmi, “Autonomous driving system with road sign recognition using convolutional neural networks,” in 2019 International Conference on Computational Intelligence in Data Science (ICCIDS). IEEE, 2019, pp. 1–4.
- [28] D. Dworakowski, C. Thompson, M. Pham-Hung, and G. Nejat, “A robot architecture using contextslam to find products in unknown crowded retail environments,” Robotics, vol. 10, no. 4, p. 110, 2021.
- [29] P. Khandelwal, S. Zhang, J. Sinapov, M. Leonetti, J. Thomason, F. Yang, I. Gori, M. Svetlik, P. Khante, V. Lifschitz, J. K. Aggarwal, R. Mooney, and P. Stone, “Bwibots: A platform for bridging the gap between ai and human–robot interaction research,” The International Journal of Robotics Research, 2017. [Online]. Available: http://www.cs.utexas.edu/users/ai-lab?khandelwal:ijrr17
- [30] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in 2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571.
- [31] P. J. Besl and N. D. McKay, “Method for registration of 3-d shapes,” in Sensor fusion IV: control paradigms and data structures, vol. 1611. Spie, 1992, pp. 586–606.
- [32] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You Only Look Once: Unified, real-time object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1–10.
- [33] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: An efficient probabilistic 3D mapping framework based on octrees,” Autonomous Robots, 2013, software available at https://octomap.github.io. [Online]. Available: https://octomap.github.io