AutoCLINT: The Winning Method in AutoCV Challenge 2019
Abstract
NeurIPS 2019 AutoDL challenge is a series of six automated machine learning competitions. Particularly, AutoCV challenges mainly focused on classification tasks on visual domain. In this paper, we introduce the winning method in the competition, AutoCLINT (Computationally LIght Network Training). The proposed method implements an autonomous training strategy, including efficient code optimization, and applies an automated data augmentation to achieve the fast adaptation of pretrained networks. We implement a light version of Fast AutoAugment [12] to search for data augmentation policies efficiently for the arbitrarily given image domains. We also empirically analyze the components of the proposed method and provide ablation studies focusing on AutoCV datasets. Our code111https://github.com/kakaobrain/autoclint is open to the public, who wants to apply the proposed method.
1 Introduction
Due to the advance in computational resources and successes of machine learning in various domains, automated machine learning (AutoML) algorithms draw massive attention from the amounts of associations since they can reduce the exhaustive human efforts in ML engineering. Current AutoML researches mainly concentrate on hyperparameter tuning [1, 9] and model search processes. The desired AutoML system has to cover data exploration and data preprocessing before the training procedure without or less human intervention.
In this article, we introduce AutoCLINT, which won the first place in both Automated Computer Vision (AutoCV) competitions in NeurIPS 2019 AutoDL Challenge222https://autodl.chalearn.org/. The AutoDL challenge consists of a series of six challenges; AutoCV, AutoCV2, AutoNLP, AutoSpeech, AutoWeakly, and AutoDL. All competitions are multi-label classification problems and are constrained by a time-budget and computational resource. AutoCV and AutoCV2 challenges mainly focused on classification tasks on image and video data, respectively. Both competitions required an AutoML algorithm that can learn visual features universally under limited resources and constrained training time without human intervention. During the evaluation process, the participants could not identify nor directly observe the test image data except the image resolution and the number of samples. These constraints consider the situation that users of the AutoML algorithms demand not only a ML model for arbitrary data but also a time-efficient training. Additionally, a computationally cumbersome approach is impossible since only a single GPU is available during the evaluation process. These restrictions are well-formulated by the AutoCV challenge design [14]. See Appendix A for more details.
Inspired by the success of deep learning, neural architecture search (NAS) [19, 20, 13, 10] is the most notable field in AutoML research. The recent NAS algorithm [16] can find out neural architecture efficiently and outperforms a human-designed network in the image classification problem. However, searching optimal neural architecture with limited time and computational resources by NAS is still a challenging problem. In particular, NAS requires hundreds of GPU hours for extensive scale data, e.g., medical images such as CT or MRI [10]. An alternative approach, instead of NAS, is transfer learning. For computer vision tasks, ImageNet pre-trained models are widely used as the starting point. Notably, [11] reports on the strength of ImageNet pretraining in image classification. Hence, AutoCLINT applied transfer learning since a fine-tuned model does not require training from scratch in the evaluation process. Empirical studies in Appendix show that this strategy was decisive in the competitions.
In addition to transfer learning, AutoCLINT applied a modified Fast AutoAugment [12] algorithm to find data augmentation policies automatically for a given image domain. The original algorithm uses a distributed Bayesian optimization search, which requires a multi-GPU environment. Hence, we implemented a light-version of Fast AutoAugment, which is adapted for AutoCV competition. This algorithm makes it possible to find optimal data augmentation policies under a restricted time budget. Notably, some image domains get better scores than no augmentation since these image domains have less number of samples.
The main contribution of this paper is to provide the end-to-end training code for image classification by AutoML, which is easily transferrable under restricted time budget and computation resources. Our code includes a light version of Fast AutoAugment [12]. We provide empirical studies in Appendix to validate the effect of each component of the proposed method. We believe this information can help non-ML experts to apply the proposed training method for their datasets.
2 AutoCV Competition
This section briefly introduces the description and evaluation metrics of AutoCV competition, the first series of NeurIPS 2019 AutoDL challenge. The goal of AutoCV competition is to find an automated solution that can handle any type of input image and generates a model that solves the associated task. Participants were asked to develop automatic methods for learning from raw visual information. We refer to the white paper of the AutoCV challenge design [14] for more details.
2.1 Competition Description
As previously mentioned, AutoCV competition requires universal learning machines, especially for image data, considering the time constraint and computation resources. The competition consists of three phases; public, feedback, and final. Each phase provides five image datasets of different domains; people, objects, medical, aerial, and hand-writing (see Figure 1). As one can see in Table 1, each dataset has different properties in the number of class, amounts of samples, resolution, and channel, even for the same domain but distinct phases. Furthermore, some dataset has variable image shapes; hence, the submitted code has to preprocess those data to adjust the unfixed dimension. These properties are veiled during the competition period. Therefore, participants must prepare the automated algorithm which can reveal the meta-information of a given dataset without human intervention during the evaluation process.
An import aspect of the competition is anytime learning. The principal metric of AutoDL challenge is area under learning curve (ALC) which drives the participants to submit a ready-to-predict learning algorithm at any timestamp during the time budget. The maximum time limit is 20 mins for each dataset. The competition also restricts computational resource and memory. Participants can only use a single GPU (NVIDIA Tesla P-100) with 4 CPU cores and 26GB memory during the evaluation process. These restrictions and the evaluation metric implicitly block the computationally heavy AutoML approaches, including neural architecture search and hyperparameter optimization based on the distributed system e.g., Ray [15]. Therefore, AutoCLINT applies a different strategy based on transfer learning and autonomous training strategy, including code optimization and automated augmentation.

| # of Sample | Shape | |||
|---|---|---|---|---|
| Phase | Dataset | # of Class | (Train, Test) | (row, col, ch) |
| Public | P | 26 | (80095, 19905) | (var, var, 3) |
| Public | O | 100 | (48061, 11939) | (32, 32, 3) |
| Public | M | 7 | (8050, 1965) | (600, 450, 3) |
| Public | A | 11 | (634, 166) | (var, var, 3) |
| Public | H | 10 | (60000, 10000) | (28, 28, 1) |
| Feedback | P | 15 | (4406, 1094) | (350, 350, 3) |
| Feedback | O | 257 | (24518, 6089) | (var, var, 3) |
| Feedback | M | 2 | (175917, 44108) | (96, 96, 3) |
| Feedback | A | 3 | (324000, 81000) | (28, 28, 4) |
| Feedback | H | 3 | (6979, 1719) | (var, var, 3) |
| Final | P | 100 | (6077, 1514) | (var, var, 3) |
| Final | O | 200 | (80000, 20000) | (32, 32, 3) |
| Final | M | 7 | (4492, 1114) | (976, 976, 3) |
| Final | A | 45 | (25231, 6269) | (256, 256, 3) |
| Final | H | 3 | (27938, 6939) | (var, var, 3) |
2.2 Evaluation Metric
AutoCV challenge demands those as mentioned earlier anytime learning by scoring participants with the performance as a function of time. Each time after the training, the test code is called, and the results are saved. Then, the scoring program evaluates the model with their timestamp.
Normalized Area Under ROC Curve (NAUC)
AutoCV competition treats each class as a separate binary classification problem. At each timestamp, the scoring program evaluates area under receiver operating characteristic curve (ROC AUC) for each prediction. Then, the normalized AUC (or Gini coefficient) is computed by the following formula:
| (1) |
Area under Learning Curve (ALC)
ALC is the primary metric in AutoDL competitions. Due to [14], multi-class classification metrics are not being considered in AutoCV competition, i.e., each class is scored independently. AutoCV competition computed the ALC score for each dataset and used the overall ranking as the final score in the leaderboard. ALC is weighted in favor of the early convergence of the learning curve to achieve anytime learning.
Let be the NAUC score at timestamp , which is a step function with respect to time, then ALC is defined as follows:
| (2) |
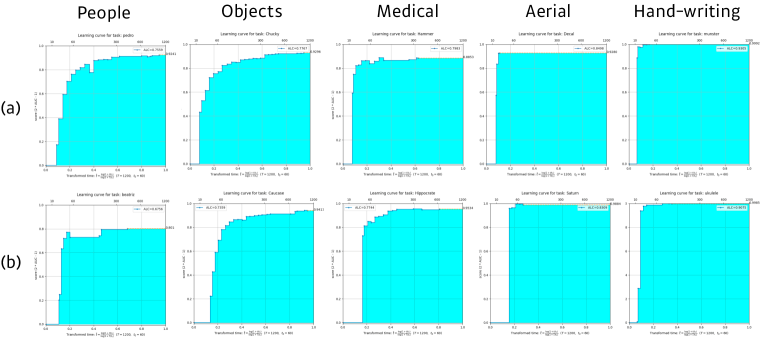
where is the time budget and is a reference time amount. In AutoCV competition, and as a default. See Figure 2 for the learning curve of the proposed method for each dataset in the public and feedback phase.
3 AutoCLINT
In this section, we provide the detail of components of the proposed method which is used in the AutoCV competition. At first, we introduce the autonomous training strategy in three-fold; (a) offline setting, (b) online data exploration, and (c) code optimization. As we mentioned above, NAS is not an appropriate strategy for fast training on arbitrarily given data since it takes a large amount of time for architecture search initially. To get a higher score in the view of Area under Learning Curve (ALC) instead of Normalized Area Under ROC Curve (NAUC), we need an AutoML algorithm that can train the target network at once without wasting substantial time in the early architecture search phase and overfitting in the final phase. In this case, Fast AutoAugment [12] is a promising approach for training a given neural network on an arbitrary image domain. We propose a light version of the Fast AutoAugment for limited computation resources and time constraints.
3.1 Autonomous Training Strategy
3.1.1 Offline Setting
Architecture
In both AutoCV and AutoCV2 competitions, we used ResNet18 for the network architecture. We also tried a bigger network, however it showed worse performances under a given time budget (see Figure 3). Before the main network blocks, our algorithm makes use of the meta information of given image data, including the spatial dimensions, the number of channels, and the number of classes. Then, the algorithm normalizes image data with 0.5-mean and 0.25-standard deviation. If the input channel is single, then we copy the channel into three channels. Otherwise, we prefix a convolution layer to the main blocks. Since the method for AutoCV is almost similar to the one for AutoCV2 competition, we only describe the former in this paper. The main difference is the split-up of the input data across time dimension and the multiplication of batch by the split data.
Pretraining and Softmax Annealing
It is empirically known that ImageNet pretraining accelerates the convergence of models on the diverse image data [11]. Even though the pretrained model and randomly initialized model both achieve a similar final performance, the convergence speed is critical in the competition since the ALC score is sensitive to the early convergence due to the time-weighted integral in ALC (see (2)). Hence, we employ the pretrained parameters of ResNet18 from torch.hub except for the final fully connected layer which outputs the logit vector. We initialize the fully connected layer by Xavier-normalization [6]. Then we divide its output, the logit vector , by :
| (3) |
Softmax annealing with higher (3) makes uniform-like vector and marginally helps the training of the network in the view of ALC. We found out is optimal in the competition through the performance on public data.
Scheduled Optimizer
We apply the scheduled SGD optimizer and warm-up [7] during 5 epochs in training for each dataset. The learning rate decreases by if the train loss plateaus during 10 epochs. After the NAUC score is above 0.99, we search augmentation policies by Fast AutoAugment (see Section 3.2), restore the learning rate to the initial one (without warm-up), and retrain the network with the augmented train dataset.
3.1.2 Online Setting
Data Exploration
Due to the variability in image size (see Table 1), the input tensor size of the network must be automatically adapted for each dataset to allow for adequate aggregation of spatial information and to keep the aspect ratio of the original image. The proposed method automatically adapt these parameters to the median size of each dataset, so that the network effectively trains on entire datasets. Due to time constraints, we do not increase the input tensor volume (without channels) beyond . If the median shape of the dataset is smaller than , then we use the median shape as the original input.
Code Optimization
To fully utilize the computation resources, we optimize both preprocessing and training codes. First, we generate transformed image data on CPU while GPU is utilized for training. We also implement multiple processing to parallelize the preparation of training images on multiple CPU cores. The validation and test data are transformed initially and reused on GPU memory since they are unchanged until the end of the training. Finally, CPU memory caches are operated to reduce the wasting time in disk I/O and common preprocessing, such as resizing.
3.2 Automated Augment Strategy
Data augmentation is beneficial to improve the generalization ability of deep learning networks. Recently, AutoAugment [3] proposes the search space for automated augmentation and demonstrates that the obtained augmentation policies by reinforcement learning significantly improve the performances on the image classification tasks. However, AutoAugment requires impractical time for search since it needs to train child network repeatedly. Recently, Fast AutoAugment [12] overcomes this problem motivated from Bayesian hyperparameter optimization without the training of a given network twice in the search phase. Fast AutoAugment learns augmentation policies using a more efficient search strategy based on density matching. Ideally, Fast AutoAugment should be performed automatically, allowing the training data to adapt to test data. AutoCLINT modifies the search space and implements a light version of Fast AutoAugment algorithm to surmount the restricted computational resources.
AutoAugment Strategy in AutoCLINT
Similar to Fast AutoAugment, the proposed method searches the augmentation policies that match the density of train data with the density of augmented valid data. We deviate from the original version in that we replace 5-fold with a single-fold search and use the random search (within a subset of searched policy in AutoAugment [3]) instead of the Bayesian optimization on the original search space.
Let us explain the detail of search algorithm. For a given classification model that is parameterized by , an expected metric on dataset is denoted by . We use the NAUC score for . Let denote an augmentation policy which consists of sub-policies and each sub-policy has two consecutive image transformations. Every augmentation policy outputs randomly transformed images since each transformation has the different calling probability (see [3, 12] for the detail of search space in AutoAugment). We write for the augmented images of through policy .
| Rank | Time | People | Objects | Medical | Aerial | Hand-writing | |
|---|---|---|---|---|---|---|---|
| AutoCLINT (1st) | 4.0 | 46m 25s | 0.6756 (1) | 0.7359 (1) | 0.7744 (1) | 0.8309 (16) | 0.9075 (1) |
| Team A (2nd) | 6.4 | 57m 18s | 0.5815 (13) | 0.4918 (5) | 0.6682 (2) | 0.8675 (2) | 0.8344 (10) |
| Team B (3rd) | 9.2 | 56m 33s | 0.5692 (15) | 0.5574 (4) | 0.6387(5) | 0.8497 (10) | 0.8177 (12) |
| Rank | Time | People | Hand-writing | Action1 | Action2 | Action3 | |
|---|---|---|---|---|---|---|---|
| AutoCLINT (1st) | 5.2 | 1h 12m 15s | 0.6277 (8) | 0.9048 (5) | 0.4076 (8) | 0.4640 (2) | 0.2091 (3) |
| Team C (2nd) | 6.2 | 1h 11m 28s | 0.6231 (9) | 0.8406 (11) | 0.4527 (4) | 0.3688 (6) | 0.2363 (1) |
| Team D (3rd) | 6.2 | 1h 05m 13s | 0.6835 (2) | 0.9115 (3) | 0.4658 (2) | -0.0417 (16) | 0.1627 (8) |
| Linear | ResNet50-V2 | Inception-V3 | AutoCLINT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Phase | Dataset | NAUC | ALC | NAUC | ALC | NAUC | ALC | NAUC | ALC |
| Public | People | 0.2863 | 0.1733 | 0.8009 | 0.2115 | 0.5867 | 0.1805 | 0.9214 | 0.7366 |
| Public | Objects | 0.2331 | 0.1643 | 0.7877 | 0.1914 | 0.9270 | 0.3289 | 0.9353 | 0.7835 |
| Public | Medical | 0.1922 | 0.1596 | 0.1173 | 0.0238 | 0.7986 | 0.4742 | 0.9142 | 0.8286 |
| Public | Aerial | 0.0982 | 0.0893 | 0.5833 | 0.2085 | 0.8861 | 0.5712 | 0.9347 | 0.8353 |
| Public | Hand-writing | 0.9628 | 0.8223 | 0.9999 | 0.5408 | 0.9950 | 0.5883 | 0.9977 | 0.9440 |
| Feedback | People | 0.2129 | 0.1829 | 0.5675 | 0.1350 | 0.6621 | 0.3212 | 0.8014 | 0.6756 |
| Feedback | Objects | 0.1249 | 0.0683 | 0.7801 | 0.1910 | 0.9897 | 0.3367 | 0.9411 | 0.7359 |
| Feedback | Medical | 0.3743 | 0.1726 | 0.8314 | 0.2319 | 0.8452 | 0.4571 | 0.9534 | 0.7744 |
| Feedback | Aerial | 0.9003 | 0.3507 | 0.9987 | 0.2860 | 0.9665 | 0.3621 | 0.9884 | 0.8309 |
| Feedback | Hand-writing | 0.3003 | 0.2747 | 0.9986 | 0.5093 | 0.4189 | 0.1276 | 0.9985 | 0.9075 |
Assuming is trained on sufficiently, we randomly choose sub-policies from the collection of augmentation policies , which is already found by AutoAugment search algorithm on CIFAR-10. Let denote a policy composed of sampled sub-policies. Then, we evaluate and append to a list unless the score is lower than . We repeat the above process times. After the procedure, we select top- policies from the list of searched policies according to the score. In the competition, we set . See Algorithm 1 for summary.
Instead of selecting top policies from the list , one can merely apply augmentation policies at random in Algorithm 1 without evaluating the augmentation policies at the validation dataset. This strategy can reduce search time more than the proposed algorithm. In this case, however, both ALC and NAUC are empirically worse than no augmentation strategy. We empirically show a comparison between the proposed algorithm and random augmentation in Section 4.
3.3 Competition Results
As a result, AutoCLINT won the top place at both AutoCV and AutoCV2 competitions in the final leaderboard333https://autodl.lri.fr/competitions/3#home. The proposed method showed the highest average rank. (see Table 2, 3). Notably, the proposed method records the fastest training and outperforms the other approaches from the perspective of ALC on every dataset except aerial data at AutoCV competition. Here, the other participants achieve similar ALC scores on aerial data. Hence, the proposed method demonstrates its efficiency in the competitions. Furthermore, according to Table 4, AutoCLINT recorded a superior NAUC score in every image domain. Therefore, it is proven that the proposed method is anytime learnable and has excellent generalization performance for various image datasets.
4 Empirical Studies
In this section, we validate the effect of each component of AutoCLINT based on empirical results. We first present comparison between the proposed method and baseline models. Then, we analyze the effect of offline setting; (a) architectures, (b) pretraining, and (c) softmax annealing. Ablation results are provided among different offline settings. Also, we examine the proposed automated augmentation strategies compared to no augmentation and random augmentation. All scores are measured on public datasets since the other datasets are not open publicly.
4.1 Comparison to Baseline
AutoCV white paper [14] provides the baseline methods (linear, ResNet50-v2, pretrained Inception) and evaluates metrics on both public and feedback data. Likewise, we evaluate the proposed method on the same datasets.
AutoCLINT outperforms the baseline methods in ALC. See Table 3 in the main paper for the comparison between the proposed method and baseline methods on each dataset. Contrary to the public phase, AutoCLINT shows decreased ALC score at the feedback phase. However, the proposed method shows outstanding performance in NAUC score at the feedback phase (except people), while baseline models show deteriorated scores in NAUC. This result demonstrates that AutoCLINT is transferable for image classification tasks.
4.2 Effect of Offline Setting
We measure metrics by changing the components of AutoCLINT in three ways: (a) ResNet18 vs. ResNet34, (b) Pretraining vs. Random Initialization, and (c) Softmax Annealing. Figure 3-5 shows the statistical difference between variations of the components. In summary, every component is beneficial in AutoCLINT; especially, pretraining is the most necessary component in the proposed method.
ResNet18 vs. ResNet34

Figure 3 shows that ResNet18 is slightly better than ResNet34 in both ALC and NAUC. Since ResNet18 is computationally lighter than ResNet34, the ALC score of ResNet18 is higher than the ALC score of ResNet34. The NAUC score of ResNet34 is slightly lower than that of ResNet18 because the training time and computation resources are insufficient to train ResNet34. It is expected that if the more time budget is given, then a bigger model may show better performance. However, because only 20 minutes are given for each domain, we fix ResNet18 as architecture in the competition.
Pretraining vs. Random Initialization

Pretraining contributes more than the other offline setting components in the proposed method. Figure 4 shows that the ImageNet-pretrained ResNet18 overwhelms the randomly initialized networks in both metrics. Indeed, pretrained networks report a higher NAUC score on each dataset. This is an expected result since the pretraining generally helps the filters of convolution networks to learn how to discriminate features in image data. These results fairly coincide with the analysis of [11].




Softmax Annealing
Softmax annealing with higher makes the output vector as a uniform-like one. We observe that it marginally improves the performance. Figure 5 shows that are better than no annealing () in ALC. However, the effect of annealing decreases when and it shows the lower result than no annealing in the worst case. Hence we fix during the competition.
4.3 Effect of Automated Augmentation
The technical components introduced in Section 2 of the main paper are practical but well-known heuristics in deep learning communities. Therefore, the proposed automated augmentation is a unique feature in AutoCLINT compared to the other approaches in the competition. In this section, we provide ablation studies regarding the effect of the proposed augmentation strategies.
Figure 7 supports the efficiency of Algorithm 1 in the view of anytime learning. ALC score on each domain of the proposed method is higher than the other policies. Notably, objects, medical, and aerial domains get better NAUC scores than no augmentation (see Figure 8). According to Table 1, these image domains have less number of samples than the other domains (people and hand-writing) in the public phase. Thus, the proposed algorithm can help to find augmentation policies to make the target network learns better. Figure 6 shows that the proposed augmentation search algorithm significantly increases metrics on average.
Note that random augmentation decreases the performance of network rather than increase. These results indicate that Algorithm 1 is efficient in finding augmentation policies automatically for any image domain.
5 Related Works
Automated Machine Learning
AutoML is a subfield of meta-learning and continuously draws attention from industry and academia even before the great success of deep learning. We refer to [17] and references therein for the survey of the AutoML framework on classical machine learnings. The runtime of hyperparameter optimization is reduced from several hours to mere minutes. [9].
Due to the dramatic success of deep learning in the visual domain, machine learning researchers have focused on neural architecture search algorithms that can find the optimal neural network for arbitrarily given data. NAS has a significant overlap with hyperparameter optimization and meta learning. We refer to [5] and references therein for the detailed research flow of NAS. Recent researches show that reinforcement learning (RL) works well in the NAS framework [19, 16]; however, such RL based methods are not applicable to AutoCV competition since they mostly require child network training or proxy tasks, which are obstacles to anytime learning. ProxylessNAS [2] proposes a gradient-based NAS algorithm that can directly find the neural networks for target tasks and hardware platforms.
NAS is a promising technique in AutoML, but it is not an efficient strategy in the competition, which restricts the time budget within 20 minutes for each domain. Hence AutoCLINT uses a transfer learning strategy with automated augmentation.
Automated Data Augmentation
Data augmentation is a necessary procedure for improving the generalization ability of deep neural network models. A carefully designed set of augmentations in training improves the performance of a network significantly. Adequately designed data augmentations in training improve the performance of a model significantly. However, such planning has relied heavily on domain experts. Automated data augmentation is a subfield of AutoML research and recently draw attention from machine learning researchers, especially for computer vision tasks since they report the state-of-the-art performance. AutoAugment [3] proposes the search space of augmentation policies for image data and the search algorithm based on reinforcement learning for the classification task and detection task [18]. However, AutoAugment requires thousands of GPU hours even in a reduced setting. To overcome the time inefficiency of AutoAugment, PBA [8] and Fast AutoAugment [12] propose different search algorithms based on hyperparameter optimization. On the other hand, Randaugment [4] exceeds the predictive performance of other augmentation methods with a significantly reduced search space.
AutoCLINT uses augmentation policies from AutoAugment and implements an automated data augmentation algorithm motivated from Fast AutoAugment to reduce the search cost under the restricted time resource. As a result, the proposed method outperforms the other approaches under the time constraint.
6 Conclusion
In this paper, we provide technical details of AutoCLINT, the winning method for AutoCV competitions. AutoCLINT relies on autonomous training strategy and automated data augmentation, and it demonstrates its learning efficiency. We expect the proposed method is widely applicable to machine learning problems under limited time and computational resources.
References
- [1] James S Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems, pages 2546–2554, 2011.
- [2] Han Cai, Ligeng Zhu, and Song Han. ProxylessNAS: Direct neural architecture search on target task and hardware. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019.
- [3] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2019.
- [4] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical data augmentation with no separate search. arXiv preprint arXiv:1909.13719, 2019.
- [5] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. arXiv preprint arXiv:1808.05377, 2018.
- [6] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256, 2010.
- [7] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- [8] Daniel Ho, Eric Liang, Ion Stoica, Pieter Abbeel, and Xi Chen. Population based augmentation: Efficient learning of augmentation policy schedules. In ICML, 2019.
- [9] Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren. Automated machine learning-methods, systems, challenges, 2019.
- [10] Sungwoong Kim, Ildoo Kim, Sungbin Lim, Woonhyuk Baek, Chiheon Kim, Hyungjoo Cho, Boogeon Yoon, and Taesup Kim. Scalable neural architecture search for 3d medical image segmentation. In Medical Image Computing and Computer Assisted Intervention – MICCAI 2019, pages 220–228. Springer International Publishing, 2019.
- [11] Simon Kornblith, Jonathon Shlens, and Quoc V Le. Do better imagenet models transfer better? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2661–2671, 2019.
- [12] Sungbin Lim, Ildoo Kim, Taesup Kim, Chiheon Kim, and Sungwoong Kim. Fast autoaugment. In Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [13] Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. arXiv preprint arXiv:1806.09055, 2018.
- [14] Zhengying Liu, Isabelle Guyon, Julio Jacques Junior, Meysam Madadi, Sergio Escalera, Adrien Pavao, Hugo Jair Escalante, Wei-Wei Tu, Zhen Xu, and Sebastien Treguer. AutoCV Challenge Design and Baseline Results. In CAp 2019 - Conférence sur l’Apprentissage Automatique, Toulouse, France, July 2019.
- [15] Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging AI applications. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 561–577, 2018.
- [16] Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. In International Conference on Machine Learning, pages 4092–4101, 2018.
- [17] Marc-André Zöller and Marco F Huber. Survey on automated machine learning. arXiv preprint arXiv:1904.12054, 2019.
- [18] Barret Zoph, Ekin D Cubuk, Golnaz Ghiasi, Tsung-Yi Lin, Jonathon Shlens, and Quoc V Le. Learning data augmentation strategies for object detection. arXiv preprint arXiv:1906.11172, 2019.
- [19] Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. In International Conference on Learning Representations, 2017.
- [20] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018.