Augmenting Iterative Trajectory for Bilevel Optimization: Methodology, Analysis and Extensions
Abstract
In recent years, there has been a surge of machine learning applications developed with hierarchical structure, which can be approached from Bi-Level Optimization (BLO) perspective. However, most existing gradient-based methods overlook the interdependence between hyper-gradient calculation and Lower-Level (LL) iterative trajectory, focusing solely on the former. Consequently, convergence theory is constructed with restrictive LL assumptions, which are often challenging to satisfy in real-world scenarios. In this work, we thoroughly analyze the constructed iterative trajectory, and highlight two deficiencies, including empirically chosen initialization and default use of entire trajectory for hyper-gradient calculation. To address these issues, we incrementally introduce two augmentation techniques including Initialization Auxiliary (IA) and Pessimistic Trajectory Truncation (PTT), and investigate various extension strategies such as prior regularization, different iterative mapping schemes and acceleration dynamics to construct Augmented Iterative Trajectory (AIT) for corresponding BLO scenarios (e.g., LL convexity and LL non-convexity). Theoretically, we provide convergence analysis for AIT and its variations under different LL assumptions, and establish the first convergence analysis for BLOs with non-convex LL subproblem. Finally, we demonstrate the effectiveness of AIT through three numerical examples, typical learning and vision applications (e.g., data hyper-cleaning and few-shot learning) and more challenging tasks such as neural architecture search.
Index Terms:
Bilevel optimization, gradient-based method, initialization auxiliary, pessimistic trajectory truncation, deep learning.1 Introduction
Recently, a variety of rising deep learning applications share similar principles to construct hierarchical optimization models, including Hyperparameter Optimization [1, 2], Meta Learning [3, 4, 3], Neural Architecture Search [5, 6], Reinforcement Learning [7, 8, 9], and have achieved highly competitive performance in different fields. With proper reformulation, these models all can be considered as Bi-Level Optimization (BLO) problems, which optimize two nested subproblems in the form as:
| (1) |
where and correspond to the Upper-Level (UL) and Lower-Level (LL) variables respectively, the UL objective and LL objective are continuously differentiable functions and is the LL solution set for all .
In general, the BLO problem can be considered as a leader-follower game process, where the follower ( i.e., the LL subproblem) continuously responds to the decision of the Leader (i.e., the UL subproblem). From the optimistic BLO perspective, we assume that the obtained LL solution always leads to the optimal solution of UL objective for any given , then the original BLO in Eq.(1) can be reduced to a simple single-level problem as
| (2) |
where is the value function of a simple bilevel problem w.r.t. for any given . Then and have the cooperative relationship towards minimizing the UL subproblem. Based on this form, various branches of methods [10, 11, 12, 13] have explored how to optimize with respective to and simultaneously, thus solve the above applications captured by this hierarchical structure with high accuracy and efficiency.
Typically, BLO problems remain challenging to be solved caused by the nature of sophisticated dependence between UL and LL variables, especially when multiple LL solutions exist in . As for classical theory, KKT condition [14] has been considered as efficient tools to solve the above optimization problems. whereas, this type of methods are impractical to be applied in modern machine learning tasks limited by existence of too many multipliers. Meanwhile, Gradient-Based Methods (GBMs) [15] have been widely adopted in various learning and vision tasks to handle real-world applications. Practically speaking, the key of solving Eq. (2) with GBMs falls to accessing the highly coupled nested gradient caused by iterative optimization to solve the LL subproblem in Eq. (1). We denote as the Best Response mapping of the follower for a given UL variable . By embedding into the simple bilevel problem in Eq. (2) as , the hyper-gradient of can be derived by using the chain rule as
| (3) |
where can be regarded as the direct gradient, and denotes the indirect gradient.
Since the calculation of hyper-gradient requires proper approximation of and indirect gradient , classical dynamics-embedded GBMs [15] tend to construct the approximations by introducing dynamical system obtained from iterative optimization steps. Typically speaking, this type of gradient-based BLO methods approximate with constructed by the following optimization dynamics: where is a fixed given initial value and denotes the iterative dynamics mapping at -th step derived with specific updating scheme. Based on the above formulation, we use to denote the historical sequence of , , which will be discussed more thoroughly in this work. In essence, reflects the iterative trajectory of LL variables to obtain , then the indirect gradient can be approximated with this by . By this way, these GBMs can be regarded as using gradient descent methods solving following approximation problem of Eq. (2),
| (4) |
It is worth noting that can be regarded as good approximation as long as uniformly converges to zero w.r.t. and converges to the real BLO objective .
To ensure the obtained approximation in Eq. (4) is good enough to guarantee the convergence of solutions towards the original BLO, restrictive assumptions of LL subproblem, such as LL Singleton (LLS) and LL Convexity (LLC), are usually required by existing GBMs. Whereas, as complex network structure with multiple convolutional blocks and loss functions with specialized regularization terms are widely employed in lots of applications, the LL subproblems always have non-convex property, which implies a gap between the provided theoretical guarantee and complex properties of real world problems. To deal with these challenges, several works [12, 16] have spared efforts to design new iterative mapping schemes or approximation theory, thus partly relax the theoretical constraints and obtain some new convergence results. Nevertheless, there is still an urgent need for general BLO framework with solid theoretical analysis to cover the non-convex scenarios.
1.1 Contributions
In this work, we propose the Augmented Iterative Trajectory (AIT) framework with two augmentation techniques, including Initialization Auxiliary (IA) and Pessimistic Trajectory Truncation (PTT), and a series of extension strategies to handle the above limitations of existing GBMs. More specifically, we first analyze the vanilla iterative trajectory constructed by the gradient-based BLO scheme, and highlight two significant deficiencies of iterative trajectory, including empirically choosing initialization of iterative trajectory (i.e., and using entire trajectory for hyper-gradient calculation by default, both of which are less noticed by existing GBMs.
Aiming at the above deficiencies of iterative trajectory, we first introduce IA to optimize the initialization value for LL trajectory simultaneously with the UL variables. Then we propose prior regularization as warm start to guide the optimization of IA, and investigate different iterative dynamic mapping schemes and acceleration dynamics to construct our AIT framework for BLOs with Convex LL subproblem ( for short). To handle the challenging non-convex scenario, we further propose PTT operation to dynamically adjust the iterative trajectory for calculation of the hyper-gradient, and introduce the acceleration gradient scheme to construct our AIT framework for Non-Convex BLOs ( for short). Theoretically, we conduct detailed convergence analysis of , and its variations to support different challenging scenarios, especially for the unexplored non-convex scenario. Finally, we demonstrate our convergence results and performance improvement with extensive experiments based on the various numerical examples, typical learning and vision applications and other more challenging deep learning tasks. We summarize our main contributions as follows.
-
•
We conduct a thorough analysis of the iterative trajectory construction for the gradient-based BLO scheme, which is a significant departure from the existing GBMs. We then identify two limitations of the vanilla iterative trajectory adopted by current GBMs, and introduce our AIT to address BLOs with more relaxed LL assumptions.
-
•
We first propose IA to guide the optimization of LL variables, and then introduce prior regularization based on IA and explore various iterative dynamic mapping schemes (e.g., Nesterov’s acceleration dynamics) to construct for BLOs with Convex followers. To handle the more challenging non-convex scenarios, we further propose PTT operation to dynamically truncate the trajectory, and investigate acceleration gradient scheme to construct .
-
•
We provide detailed theoretical investigation on , and corresponding extension strategies (e.g., proximal prior regularization and acceleration gradient scheme) to ensure the convergence property of AIT without LLS even LLC assumption. Notably, we establish the first convergence guarantee for BLO problems with non-convex LL subproblems.
-
•
A plentiful of experiments have been conducted based on numerical examples with varying LL properties. Besides, we not only implement typical learning and vision applications (e.g., few-shot classification and data hyper-cleaning), but also demonstrate the generalization performance of AIT in more challenging tasks such as neural architecture search and generative adversarial networks.
2 A Brief Review of Existing Works
In this work, we first provide a brief review of previous works to conclude the general gradient-based BLO scheme, and then we discuss the deficiencies of existing LL iterative trajectory, which have limited the application of existing GBMs to more challenging BLO scenarios.
As mentioned before, existing GBMs have explored different heuristic techniques to calculate the hyper-gradient (i.e., ) with designed approximation operations. In one of the most representative class of GBMs [17, 18, 19], it first constructs dynamical system to track the optimization path of LL variables, and then explicitly calculates the indirect gradient with respect to UL variables based on ITerative Differentiation (ITD). Typically, RHG and FHG [17, 18] are proposed, in which and thus are approximated by finite iterative optimization steps, and then the obtained approximated optimization problems are solved. Whereas, both methods suffer from the huge time and space complexity of calculating indirect gradient along the whole iterative trajectory with AD. Then Shanban et al. [2] proposed T-RHG to manually truncate the backpropagation path, thus release the computation burden. For these methods, the iterative dynamics mapping used to construct iterative trajectory is specified as the projected gradient descent. Whereas, the convergence analysis of these methods all require the LL subproblem to be strongly convex, which severely restrict the application scenarios. Recently, Liu et al. [19] proposed BDA, which aggregates the gradient information of both UL and LL subproblems to construct new to approximate and , thus successfully overcomes the LLS restriction issue. When calculating the nested hyper-gradient with ITD based on different forms of , the gradient-based BLO scheme could be summarized in Alg. 1, where . It can be observed that the iterative update of UL variables to solve the approximated subproblem (i.e., ) relies on effective iterative trajectory for hyper-gradient calculation (Step 4-6).
Since most ITD-based approaches only established their convergence theory based on the LLS restriction, they neither pay attention to the initialization of iterative trajectory nor take serious consideration of how to choose the iterative trajectory for hyper-gradient calculation. Whereas, an improper initialization position chosen for LL variables may slow down the convergence of LL and UL subproblem. More importantly, when multiple solutions exist in (i.e., without LLS), the initialization has significant influence on the UL convergence behavior, so there is no guarantee that the iterative trajectory constructed based on the chosen provides iterates optimizing the UL objective while converging to . Furthermore, suppose that the LLC assumption is not satisfied, the subsequences of the whole iterative trajectory (i.e., ) no longer have consistent convergence behavior as in the LLC case. On this basis, using the whole iterative trajectory for hyper-gradient calculation may lead to the oscillation or divergence of the approximated UL subproblem. Overall, the vanilla iterative trajectory adopted by ITD-based approaches has limited flexibility and becomes the bottleneck of existing gradient-based BLO scheme to cover more challenging scenarios. Though several researches have explored potential techniques, such as aggregating LL and UL gradient information to design new to construct a good approximated BLO problem in Eq. (4) and successfully relax the theoretical restrictions on LL subproblem to some extent, the situation where the LLC assumption does not hold still needs to be considered.
In contrast to the ITD-based approaches which compute the hyper-gradient based on the constructed LL iterative trajectories, another branch of the methods [20, 11, 21] instead adopts the implicit function theorem and derives the hyper-gradient of UL variables by solving a linear system. Whereas, computing Hessian matrix and its inverse are much more expensive and challenging especially when ill-conditioned linear system appears. Besides, these methods based on Approximated Implicit Differentiation (AID) require the LL subproblem to be strongly convex, which limits the application scenarios to a great extent. Another line of work [22] addresses the nonconvex issue by constructing value-function-based smooth approximation problems, while extra assumptions introduced on the constrained LL subproblems still remain cumbersome to handle. As for other recent efforts [23, 24] which have designed specific update formats of UL or LL variables to derive new convergence rate analysis, Hong et al. [25] proposed TTSA to introduce cheap estimates of gradients, and update the LL and UL variables simultaneously with SGD and projected SGD. In addition, Khanduri et al. [26] proposed the MSTSA algorithm to estimate the hyper-gradient with assisted momentum. Quan et.al [27] proposed two variants of the alternating implicit gradient SGD approach with improved efficiency to solve equality-constrained BLOs. The above methods also build their theoretical analysis for BLOs with strongly-convex LL subproblems.
| Method | w/o LLS | w/o LLC | w/ A. | |
| RHG/FHG | ITD | ✗ | ✗ | ✗ |
| T-RHG | ✗ | ✗ | ✗ | |
| BDA | ✔ | ✗ | ✗ | |
| CG | AID | ✗ | ✗ | ✗ |
| Neumann | ✗ | ✗ | ✗ | |
| AIT | ITD | ✔ | ✔ | ✔ |
In Tab. I, we compare the required LL assumptions of mainstream GBMs to build their convergence analysis and whether they support the acceleration technique. Based on the above analysis of gradient-based BLO scheme for ITD-based approaches, in the next section, we construct our AIT framework to address the theoretical issues and handle more challenging BLO scenarios. As it is shown, AIT not only derives similar convergence results without the LLS and LLC restriction, but also supports more flexible iterative mapping schemes including the acceleration techniques.
3 Augmented Iterative Trajectory (AIT)
Based on the prior analysis of iterative trajectory, to relax the theoretical restriction and improve the efficiency of the gradient-based BLO scheme, we first introduce the initialization auxiliary augmentation technique, which introduces a new auxiliary variable to the initialization of iterative trajectory and then optimize it together with the UL variables. Then we further investigate different extension strategies related to the initialization auxiliary augmentation technique, including prior regularization and acceleration dynamics to construct the Augmented Iterative Trajectory (AIT) for BLOs when LLC assumption is satisfied. To make the gradient-based BLO scheme be workable on BLOs without LLC, we further propose the pessimistic trajectory truncation augmentation technique to dynamically adjust the iterative trajectory for hyper-gradient calculation. Together with the initialization auxiliary, we construct the AIT for solving BLOs with non-convex follower.
3.1 BLOs with Convex LL Subproblem
Typically speaking, the initialization of iterative trajectory, i.e., , is usually chosen based on a fixed manually (randomly or by some specific strategies) set initial value of LL variable, which takes no consideration of the convergence behavior of UL subproblem. As it is mentioned before, when there exist multiple elements in LL subproblem solution set , performing projected gradient descent steps (i.e., adopted by most GBMs) to construct iterative trajectory with improper initial value usually not necessarily optimizes the UL objective while converging to . Besides, an improper initialization position for will also slow down the convergence rate of LL subproblem, even when is a singleton.
To address the issues mentioned above, we suggest to introduce an Initialization Auxiliary (IA) variable as the initialization position of LL variable to construct for approximating LL subproblem as follows,
| (5) |
which leads to the following approximation problem of Eq. (2): It is worth noting that, the iterative trajectory constructed based on this optimization dynamics formulates the approximation parameterized by and . By this form, we avoid fixing initialization position chosen with empirical strategies, and update the initialization auxiliary together with to continuously search for the “best” initial points of LL variables to calculate . By taking into consideration of the convergence behavior of UL subproblem, with updated initial value can approach solutions to the BLO problem in Eq. (1). The idea of IA variable is first proposed for the convergence theory [22] of non-convex first-order optimization methods.
As mentioned above, the initialization auxiliary variable is introduced and optimized simultaneously with UL variable for helping the LL subproblem dynamics approach the appropriate that minimizes UL objective . To further guide the update of the IA variable and thus boost the convergence of the LL subproblem dynamics, we propose to introduce a constraint set and an extra prior regularization term to the IA variable , which leads to the following approximation problem to Eq. (2),
| (6) |
In practice, can be specified as penalty on distance between and the prior determined value , where usually serves as some known state of that is very close to the optimal LL variable. As one option for machine learning tasks, we could properly define as the pretrained weights of the LL variables, and verify its effectiveness with BLO applications.
Another feature of this new approximation format is that the iterative dynamics mapping for constructing iterative trajectory can be flexibly specified as different forms proposed in existing works. Here, for general BLOs with convex LL subproblem, we suggest applying the aggregation scheme proposed in BDA [19] to construct as follows
| (7) | ||||
where and denote the gradient directions of UL and LL objective with introduced IA, respectively.
Specially, for the case where the LLS condition is satisfied, following the vanilla update format in RHG, could be simply chosen as
| (8) |
where denotes the step size parameter. By this means, embedding the IA technique still helps optimize the initialization to construct the iterative trajectory, thus further improves the convergence behavior of BLOs under LLS assumption.
Besides, our new scheme with IA technique also supports to consistently improve the existing methods with embedded acceleration dynamics. As one of the practical implementation, we could embed the Nesterov’s acceleration methods [28] with our IA technique, which has been widely used for convex optimization problem to accelerate the convergence of gradient descent, then we obtain the accelerated version as
| (9) |
where denotes the step size parameter.
In Alg. 2, we illustrate the algorithm of our Augmented Iterative Trajectory for BLOs with Convex LL subproblem ( for short), where . Whereas, to make the gradient-based BLO scheme be efficient and convergent for the BLOs with nonconvex LL subproblem, the proposed IA technique is not enough. In the next part, we will propose another augmentation technique named Pessimistic Trajectory Truncation, and discuss how to use this new technique together with IA to derive a new gradient-based BLO algorithm that is convergent and efficient for the BLOs with nonconvex LL subproblem. The detailed convergence analysis could be found in the next section.
3.2 BLOs with Non-convex LL Subproblem
As another important issue of the existing gradient-based BLO scheme, they used to select the whole iterative trajectory (i.e., ) to perform the hyper-gradient calculation. When the LL subproblem is nonconvex, the subsequences of show no consistent convergence behavior as in the LLC case, even the initialization is continuously optimized by the IA technique. Therefore, directly using results in improper approximation of , and may not uniformly converge to zero w.r.t. while converges to the real BLO objective . In short, this empirical strategy for constructing actually invalidates the convergence and may result in oscillation even divergence of the optimization process in the nonconvex case.
Based on the constructed approximation formats in Eq. (5), we introduce another significant technique, i.e., Pessimistic Trajectory Truncation (PTT) to extend the application scenarios and derive new convergence results without requiring LLC assumption. Note that the idea of PTT operation is inspired by the convergence result of the projected gradient method on nonconvex optimization problem. We define as the proximal gradient residual mapping to measure the optimality of LL subproblem. When the LL subproblem is nonconvex, may not uniformly converge to the LL subproblem solution set w.r.t. and . Therefore, directly embedding into the UL objective may not necessarily provide a proper approximation strategy as mentioned before. Fortunately, it is well understood that as tends to infinity, uniformly converges to zero w.r.t. and .
Whereas, it still remains to be impractical to explicitly select for using to construct an approximation. Therefore, we choose to minimize the worst case of in terms of the UL objective values in a compromise, i.e., , to guarantee the convergence of no matter how this is chosen. The theoretical convergence guarantee for the above approximation is organized in Section 4. Practically speaking, the varying actually considers the behavior of UL objectives during the LL optimization to truncate the whole iterative trajectory. In this case, the is more reasonable to represent the whole trajectory for hyper-gradient calculation, which can not be directly reflected by using fixed without PTT operation.
By introducing both IA and PTT operation, our new algorithm avoids directly using the oscillating iterative trajectory of LL variables for hyper-gradient calculation, and successfully removes the LLC assumption to handle non-convex scenarios in various real-world applications. In addition, the PTT operation always leads to a small , thus effectively shortens the path to compute the indirect hyper-gradient through backpropagation, which saves the computational cost in practice. We also conduct the running time analysis based on the nonconvex numerical example to confirm this conclusion numerically.
Note that the iterative mapping scheme can be chosen as the projected gradient method in Eq. (8). Besides, we also investigate available accelerated gradient scheme [29] to improve the efficiency for this non-covnex case, which is given as follows
| (10) |
where , and , and .
With two proposed augmentation techniques and supported iterative acceleration gradient scheme, the complete algorithm of our AIT for BLOs with Non-convex LL subproblem ( for short) is illustrated in Alg. 3. In the following sections, we will provide the asymptotic convergence analysis of and and further discuss the applicable scenarios of different variations.
4 Theoretical Analysis
In this section, we present the asymptotic convergence analysis of in Alg. 2 and in Alg. 3 under mild conditions on the general schematic iterative module . And we also show that these conditions on are satisfied for some specific choices of . Specifically, for convex BLOs, we show the asymptotic convergence of Alg. 2 when is chosen as BDA [19] in Eq.(7). And for convex BLOs whose LL solution set is singleton, we show the asymptotic convergence of Algorithm 2 when is chosen as projected gradient in Eq. (8) and Nesterov’s acceleration scheme in Eq. (9). For nonconvex BLOs, we show the asymptotic convergence of Algorithm 3 when is specifically chosen as projected gradient method and accelerated gradient scheme proposed by [29] in Eq. (10).
4.1 Convergence Analysis for
We first derive the asymptotic convergence analysis of Alg. 2 for convex BLOs with general schematic iterative module . Alg. 2 can be regarded as the application of projected gradient method on the following single-level approximation problem of Eq. (1),
| (11) | ||||
where , the function and the closed set are the function and compact set that are with prior information on lower level variable . To show the asymptotic convergence of Alg. 2, i.e., the approximation problem in Eq. (11) converges to the original bilevel problem in Eq. (1), i.e., , we make following mild assumptions on BLOs throughout this subsection.
Assumption 4.1.
We make following standing assumptions throughout this subsection:
-
(1)
are continuous functions on .
-
(2)
is -smooth, convex and bounded below by for any .
-
(3)
is -smooth and convex for any . is level-bounded in uniformly in
-
(4)
, and are compact sets, and is a convex set.
-
(5)
is nonempty for all .
-
(6)
is continuous on .
Assumption 4.1 is standard for convex BLOs in the related literature, which is satisfied for the convex BLO numerical example given in Section 6.1. Before presenting the convergence result, we recall the auxiliary function , and rewrite the approximation problem in Eq. (11) into the following compact form,
| (12) |
We propose following two essential properties for general schematic iterative module for the convergence analysis:
-
(1)
UL property with IA: For each , ,
-
(2)
LL property with IA: is uniformly bounded on , and for any , there exists such that whenever ,
Now, we are ready to present the asymptotic convergence result of Alg. 2.
Theorem 4.1.
Proof.
For any limit point of the sequence , let be a subsequence of such that . As is uniformly bounded on and is bounded, we can further find a subsequence of satisfying and for some and . It follows from the LL property with IA that for any , there exists such that for any , we have
Thanks to the continuity of , we have that is Upper Semi-Continuous (USC for short) on (see, e.g., [12, Lemma 2]). By letting , and since is continuous and is USC on , we have . As is arbitrarily chosen, we have and thus . Next, as is continuous at and g is continuous at , for any , there exists such that for any , it holds
Then, we have, for any and ,
| (13) | ||||
Taking , and by the UL property with IA, we have
By taking , we have which implies . ∎
In the above convergence result, we can see that the convergence of Eq. (11) to the original bilevel problem in Eq. (1) does not require any restrictive assumptions on and . It means that we can add any prior information into and to help us speed up the convergence of the method without destroying the convergence of the algorithm.
Next, we show that both the UL and LL properties with IA hold when is chosen as some specific schemes. Here we provide the asymptotic convergence analysis of Alg. 2, when is defined as BDA[19] in Eq. (7).
Theorem 4.2.
Let be the output generated by (7) with , , , , with some , with some , then we have that both the LL and UL properties with IA hold.
Proof.
We can easily obtain the UL property with IA from [19, Theorem 3]. Next, since Assumption 4.1 holds, , and are compact, by using the convergence rate result established in [19, Theorem 4] and the similar arguments in the proof of [19, Theorem 5], it can be shown that there exists such that for any , , we have
Because as , , and is compact, LL property with IA holds. ∎
4.1.1 Lower-Level Singleton Case
In this part, we focus on the convex BLOs whose lower-level problem solution set is singleton for any . We first consider constructing the iterative module by projected gradient method as described in Eq. (8).
Theorem 4.3.
Suppose is singleton for all . Let be the output generated by (8) with , then we have that both the LL and UL convergence properties with IA hold.
Proof.
According to [22, Theorem 10.21], when is convex and -smooth for any , and , satisfies
| (14) | ||||
where denotes the distance from to the set . Since , and are all compact sets, then there exists such that for . Then we can easily obtained that LL property with IA holds from Eq. (14), and is compact. Next, given any , for any limit point of sequence , we have and thus from (14). Therefore, since is bounded and is singleton, we have and thus UL property with IA holds. ∎
Next, we consider the iterative module as the Nesterov’s acceleration schemes described in Eq. (9).
Theorem 4.4.
Suppose is singleton for all . Let be the output generated by Eq. (9) with , then we have that both the LL and UL convergence properties with IA hold.
Proof.
According to [22, Theorem 10.34], when is convex and -smooth for any , and , admits the following property,
| (15) | ||||
Since , and are compact sets, by using the above inequality and the similar arguments as in the proof of Theorem 4.3, we can show that both the LL and UL convergence properties with IA hold. ∎
4.2 Convergence Analysis for
In this part, we first conduct the asymptotic convergence analysis of in Alg. 3 with general schematic iterative module . Indeed, Alg. 3 can be regarded as the application of projected gradient method on the following single-level approximation problem of Eq. (1),
| (16) | ||||
Then we investigate the convergence of solutions of this approximation problem towards those of the original BLO under following mild assumptions.
Assumption 4.2.
We make following standing assumptions throughout this subsection:
-
(1)
are continuous functions on .
-
(2)
is -smooth for any .
-
(3)
and are convex compact sets.
-
(4)
is nonempty for any .
-
(5)
For any minimizing over constraints and , it holds that .
Note that denotes the set of LL stationary points, i.e., Assumption 4.2 is standard in bi-level optimziation related literature, which is satisfied for the numerical example given in Section 6.1.
We propose the weak LL property with IA for the asymptotic convergence analysis of Algorithm 3 with general schematic iterative module . We say that weak LL property with IA is satisfies if is uniformly bounded on , and there exists such that for any , there exists such that whenever ,
where
It should be noticed that if and only if . In the following theorem, we establish the asymptotic convergence of Alg. 3 when the weak LL property with IA is satisfied.
Theorem 4.5.
Proof.
For any , we define
For any limit point of the sequence , let be a subsequence of such that . As and is compact, we can find a subsequence of satisfying for some . It follows from the weak LL convergence property that for any , there exists such that for any , we have
As is a convex compact set, it follows from [30, Theorem 6.42] that is continuous. Combined with the assumed continuity of , we get that is continuous. Then, by letting , we have
As is arbitrarily chosen, we have and thus . Then by using the same arguments as in the proof of [31, Theorem 3.1], we can get the conclusion. ∎
Next, we will show that when is chosen as the classical projected gradient method and the accelerated gradient scheme proposed by [29] in Eq. (10), the weak LL property with IA is satisfied. We first consider constructing the iterative module by the classical projected gradient method as,
| (17) |
where denotes the step size parameter, and .
Theorem 4.6.
Let be the output generated by (17) with , then we have that the weak LL property with IA holds.
Proof.
It follows from [31, Lemma 3.1] that there exists such that
Then the conclusion follows immediately. ∎
The iterative module can also be the accelerated gradient scheme proposed in [29], which has been described in Eq. (10).
Theorem 4.7.
Let be the output generated by Eq. (10), then we have that the weak LL property with IA holds.
Proof.
Since when is a compact set, and are both uniformly bounded for any . Then, it follows from [29, Corollary 2] that there exists such that
Then the conclusion follows immediately. ∎
5 Applications
As mentioned above, although many popular hierarchical learning and vision tasks have been well understood as the BLO problem in Eq. (1), almost no solution strategies with high efficiency and accuracy are available for some challenging tasks due to high-dimensional search space and complex theoretical properties. Moreover, many complex deep learning models endowed with nested constrained objectives are still lack of proper reformulation and reliable methodology with grounded theoretical guarantee.
Neural Architecture Search. We first consider one of the most representative large-scale high-dimensional BLO application, i.e., Neural Architecture Search (NAS). Typically, NAS aims to find high-performance neural network structures with automated process. Here, we focus on the gradient-based differentiable NAS methods, which have been widely investigated recently. This type of methods select certain search strategy to find the optimal network architecture based on the well defined architecture search space. DARTS [7], ones of the representative differentiable NAS methods, relaxes the discrete search space to be continuous, and jointly optimize the architecture parameter (i.e., the UL variable ) and network weights (i.e., the LL variable ) with gradient descent step, which implies a typical BLO problem. In details, the searched architecture consists of multiple computation cells, and each cell is a directed acyclic graph including nodes. The nodes in each cell, denoted as , represent the latent feature map, while the directed edges between nodes and indicate the candidate operations based on defined search space denoted as . Then is supposed to be defined as the whole continuous variables , where denotes the vector of the operation mixing weights for nodes pair of dimension . Hence is supposed to be the ideal operation chosen by operation, i.e., . For most learning and vision tasks which employ NAS to optimize the network structure, the LL subproblem usually has high-dimensional search space and complex task-specific constraints.
As one of the mostly widely used solution strategies, DARTS introduces finite difference approximation with a single-step gradient update of to avoid the complex matrix-vector production. On top of that, a series of variations [32, 33, 34] based on DARTS have been developed and applied in numerous applications. In addition to this approximation operation adopted by DARTS, we could also solve this BLO application with other GBMs such as RHG and CG. Whereas, since the LL variables contain a cumbersome number of parameters from different searching cells, all the above methods suffer from poor theoretical investigation on this non-convex high-dimensional BLO problem. In comparison, by effective augmentation of the iterative trajectory, AIT updates the UL variables with more accurate hyper-gradient, which is more qualified for this BLO problem with non-convex follower.
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |
Generative Adversarial Networks. We move one more step to apply our AIT to other challenging tasks with nested constrained learning objectives, i.e., Generative Adversarial Network (GAN), which has been one of the most popular deep learning applications and achieved impressive progress in various computer vision tasks. In general, GAN [35] based model is widely recognized as a minimax game between two adversarial players: the generator network (parameterized by ) and the discriminator network (parameterized by ). The generative model depicts the distribution , and is supposed to fool with generated data sampled from by optimizing to minimize the distance between and the real data distribution . Thus the generic GAN can be defined as , where denotes a joint loss function to optimize both objectives, and are sampled data from some real data distribution and generated fake distribution , respectively.
Typically speaking, first generates , and then corresponds with predicted probability that is sampled from . Based on this, most related methods, e.x., Vanilla GAN (VGAN) [36] and Wasserstein GAN (WGAN) [37], alternatively train and , and simply treat them on an equal footing, which ignores the intrinsic leader-follower relationship between and . In this work, we first refer to the reformulation in [1] to depict the original GAN as below:
Thus the LL objective targets on enhancing the ability of to distinguish the fake data generate by , while the UL objective optimizes to generate more “real” data distribution to confuse the discriminator. Under this BLO formulation, most existing methods with alternating training strategies essentially directly compute the hyper-gradient with the final state of trajectory instead of the sequence, which contains more high-order gradient information. In comparison, our methods admit multiple solutions and non-convexity of the LL subproblem, thus could solve the above problem with self contained theoretical guarantee.
6 Experiments
In this section, we report the quantitative and visualization results of the numerical examples, typical learning and vision applications and more challenging tasks. We run the experiments of toy examples based on a PC with Intel Core i7-8700 CPU, 32GB RAM and implement the real-world BLO applications on a Linux server with NVIDIA GeForce RTX 2080Ti GPU (12GB VRAM).
6.1 Numerical Evaluations
At first, we validate the provided theoretical results of our AIT based on numerical examples with different LL assumptions. More specifically, we focus on the UL variable (i.e., ) and approximative UL subproblem ( is used as unified denotation for in Eq. (4), in Eq. (12) and in Eq. (16) under convex and non-convex scenarios, respectively), and analyze the convergence behavior of ( is equal to in some cases) and during the UL optimization. We use the numerical example under LLC assumption to show the effectiveness of with IA and the prior regularization term, and compare the convergence behavior of with a series of mainstream GBMs. Next, we use another example with the well defined LLS assumption to implement our with IA and the Nesterov’s acceleration dynamics.
Moving forward to the toy example with LL non-convexity, we first verify the effectiveness of with IA, PTT and the acceleration gradient scheme, and compare with the above GBMs to show its great improvement. Furthermore, we depict the loss surfaces and the derived solutions to show the significant improvement of under the non-covnex scenario, and analyze the running time influenced by different factors, including initialization points, dimension of LL variables (i.e., ) and LL iterations (i.e, ).
6.1.1 Convex Scenario
We first consider the LLC scenario and conduct the numerical experiments with the following example from [12]. With and :
| (18) | ||||
where , and represents the vector of which the elements are all equal to 1. Note that we use bold text to represent scalars for all the following description. We set , and choose as the initialization point. By simple calculation, we can obtain the unique optimal solution as , . This numerical example satisfies the LLC assumption for BDA while violating the LLS assumption admitted by most GBMs such as RHG, CG [20] and Neumann [21].
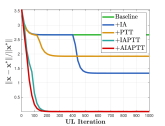
To investigate the effectiveness of Alg. 2, we take BDA as the baseline, and implement our by incrementally adding IA and the prior regularization. In the first two subfigures of Fig. 1, we analyze the convergence behavior of and . As it has been proved in [1], the convergence property of BDA can be consistently verified and obtain expected convergence results for this BLO problem. As for the augmentation technique, the embedded IA of helps dynamically adjust the initialization of and , and the augmented optimization trajectory further improves the convergence speed of UL variable (i.e., ) and approximative UL subproblem (i.e., ). Besides, with prior regularization to guide the optimization process of , our can obtain higher convergence precision and speed.
In the last two subfigures of Fig. 1, we compare our with series of mainstream GBMs including CG, Neumann, RHG, and BDA. Since the LLS assumptions of CG, Neumann and RHG can not be satisfied, no convergence property for these methods could be guaranteed in this case. In comparison with BDA, also gains advantage over convergence speed and precision.
Furthermore, to demonstrate the performance of other iterative formats and acceleration dynamics, we further introduce another toy example with more strict LL property, i.e, the well-defined LLS assumption:
| (19) | ||||
where , , . Given any , it satisfies , then the unique optimal solution of this BLO problem is , . Since the solution set of this LL subproblem (i.e., ) is a singleton, we can verify that the above example can be properly solved with GBMs under LLS assumption.
 |
 |
| (a) | (b) |
In this case, we implement our with RHG as the baseline, and further incorporate the Nesterov’s acceleration dynamics to facilitate the convergence behavior. When an appropriate initialization position is chosen, commonly used GBMs are also supposed to converge with acceptable speed. To demonstrate the effectiveness of IA, we set the initialization point as , where is further away from the optimal solution . In Fig 2, it can be seen that the IA technique could effectively accelerate the convergence of UL variables towards the global optimal solution even when RHG converges slower due to improper initialization of LL variable. In addition, the Nesterov’s strategy further helps the LL variable (i.e., ) converge faster with embedded acceleration dynamics.
6.1.2 Non-Convex Scenario
 |
 |
 |
 |
| (a) | (b) | ||
 |
 |
 |
 |
| (a) | (b) | ||
To validate the superiority of AIT, we move on to more challenging scenario and introduce another toy example [16] with non-convex LL subproblem, which takes the form of:
| (20) | ||||
where both and are constants, and denotes the i-th element of the vector. Then the optimal solution of this problem can be calculated in the following form:
where
and the corresponding value of UL objective is . Here we set , and . It can be easily verified that this example satisfies the theoretical assumption of while violating the LLS assumption for RHG, CG, Neumann and the LLC assumption for BDA due to existence of multiple local optimal solutions of the LL subproblem. At first, we set to investigate the convergence property based on the simplified form and draw the loss surfaces. Then we use larger when analyzing the influence of dimension of LL variables on the running time. We can calculate the corresponding optimal solution as . In consideration of distance between the initialization position and the global optimal solution, we choose two initialization points for and including and .
In Fig. 3, we take RHG as the baseline, and start by incrementally embedding two augmentation techniques and the acceleration gradient scheme of into the baseline. It can be seen that adding PTT technique shows consistently better convergence results with respective of , while the convergence of may be influenced by different initialization points without dynamically optimized . When we implement our with both techniques, since the theoretical convergence property is guaranteed, our algorithm can uniformly improve the convergence behavior of and on this non-convex problem. Furthermore, by embedding the acceleration gradient scheme in Eq. (10) under our , the convergence rate of gradient descent for this non-convex BLO problem could be further improved.
 |
|
 |
|
| (b) UL Trajectory | |
 |
|
| (a) Loss Surface | (c) LL Trajectory |
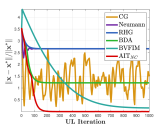
Furthermore, In Fig 4, we compare with mainstream GBMs, including CG, Neumann, RHG, BDA and BVFIM with the same initialization points. As it is expected, all the above methods except BVFIM can be easily stuck at the local optimal solution. Besides, BVFIM may not converge exactly to the true optimal solution influenced by its sensitivity to the added penalty terms. In comparison, under our algorithm, by dynamically adjusting the initial value of LL variables and truncation of for computation of hyper-gradients, the convergence results without LLC assumption can be consistently verified.
More vividly, in Fig. 5, we mark the initialization point (i.e., ), optimal solution (i.e., ), iterative solution (i.e., ) and derived convergence solutions (i.e., ) for RHG and on the UL and LL surfaces. As confirmed earlier by the convergence analysis, since quantities of local optima exist along the path from to , the iterative solutions of RHG are easily stuck at the local optima on the loss surface, which leads to convergence solution distant from . In contrast, the introduced together with PTT under our , (i.e., ), goes over the local optima and makes its own way towards the true optimal solution, which further helps find reasonable for computation of hyper-gradient. Finally, overcomes the trap of local optima and converges to the global optimal solution, thus demonstrates the superiority of AIT.
 |
 |
|
| (a) | (b) |
In Fig. 6, we report the average running time of hyper-gradient computation with respective to different initialization points in this numerical case. It can be observed that as the PTT operation of dynamically truncates the optimization trajectory and selects after LL iterations of LL optimization, the computational burden of hyper-gradient w.r.t. and is continuously eased. In addition, we found that as the curve converges with favorable convergence speed in Fig. 4, tends to stabilize around a fixed number independent of the chosen initialization points.
 |
 |
|
| (a) Influence of | (b) Influence of |
To evaluate the performance for high-dimensional BLO problems, we further investigate how dimension of LL subproblems (i.e., ) and LL iteration (i.e., ) influence the computation efficiency. Known that the computation burden has been evaluated to be less dependent on the dimension of UL subproblem when calculating the hyper-gradient with AD [15] (adopted by classical GBMs, e.g., RHG), so in Fig. 7, we continuously increase the dimension of and record the average time for gradient computation of RHG and . We can observe that always decreases the time cost for the UL optimization process compared with RHG, even extra computation for and hyper-gradient of is introduced in the . Besides, we also evaluate the runtime of RHG and with increasing . Compared with , the increasing has more influence on the computation for iterative optimization of and hyper-gradient of . Accordingly, the PTT technique chooses smaller for backpropagation ( Step 12-14 in Alg. 3), thus reduces the computation burden of backpropagation (i.e., and ).
6.2 Typical Learning and Vision Applications
In the following, we further demonstrate the performance of AIT with typical BLO applications influenced by the nonconvex LL objectives and nonconvex LL network structure, including few-shot learning and data hyper-cleaning.
6.2.1 Data Hyper-Cleaning
The goal of data hyper-cleaning is to cleanup the dataset in which the labels have been corrupted. This BLO problem defines the UL variables as a vector, and the dimension of equals to the number of corrupted samples, while the LL variable corresponds to parameters of the classification model. Following the common problem setting of existing works [2], we first split the dataset into three disjoint subsets: , and , and then randomly pollute the labels in with fixed ratio. Then the UL subproblem can be well defined as where represents the data pairs, denotes the cross-entropy loss function with classifier parameter and data pairs from different subsets. By introducing as the element-wise sigmoid function to constrain the element in the range of , the LL subproblem can be well defined as: .
| Method | MNIST | CIFAR10 | ||
| Acc. | F1 score | Acc. | F1 score | |
| CG | ||||
| Neumann | ||||
| RHG | ||||
| BDA | ||||
| AIT | ||||
| Method | MNIST | FashionMNIST | CIFAR10 | |||
| Acc. | F1 score | Acc. | F1 score | Acc. | F1 score | |
| CG | ||||||
| Neumann | ||||||
| RHG | ||||||
| BDA | ||||||
| AIT | ||||||
| Network | Methods | MiniImagenet | TieredImagenet | ||
| 5-way 1-shot | 5-way 5-shot | 5-way 1-shot | 5-way 5-shot | ||
| ConvNet-4 | MAML | ||||
| RHG | |||||
| T-RHG | |||||
| BDA | |||||
| AIT | |||||
| ResNet-12 | MAML | ||||
| RHG | |||||
| AIT | |||||
Typically, to satisfy the LLC assumption admitted by existing GBMs, the LL classification model is usually defined as a single fully-connected layer, and multiple-layer classifier with more parameters are not accessible. Based on the AIT, the constraints could be continuously relaxed thus we have more choices when designing the LL model. Besides, the prior regularization also serves as effective tool to help improve the performance of AIT. To find prior determined value for the IA, (i.e., ), we pretrain the LL classification model on and restore the pretrained model weights as the proximal prior to adjust the updates and facilitate the convergence behavior of . Then we could specify the form of prior regularization in Eq. (12). Practically, we implement the prior regularization as regularization, and add this term only for the first iteration to investigate how this regularization term influence the latter optimization process. Three well known datasets including MNIST, FashionMNIST and CIFAR10 are used to conduct the experiments. Specifically, 5000, 5000, 10000 samples are randomly selected to construct , and , then half of the labels in are tampered.
We first implement this application with convex LL network structure including a single-layer fully-connected classifier. Then the shape of is , where denotes the dimension of the flattened input data. In Tab. II, we compare our AIT with CG, Neumann, RHG and BDA. As it has been verified in the numerical experiments before, we can observe that AIT helps improve the performance on both Accuracy and F1 score based on MNIST and CIFAR10 dataset. Besides, though the prior regularization term only exists in the first iteration, it helps correct the initial state of constructed optimization dynamics, and further improves the performance of AIT on both datasets.
In addition, we introduce the non-convex network structure with two layers of fully-connected network to expand the search space of LL subproblem, where . In Tab. III, we compare our AIT and the variation with prior regularization, (i.e., ) with RHG, BDA, CG and Neumann on validation accuracy, F1 score and running time. As it is shown, our method performs the best compared with other GBMs on both accuracy and F1 score. Besides, although only used as a practical technique for solving non-convex BLOs, the embedded proximal prior also consistently improve the performance of on three datasets.
6.2.2 Few-Shot Learning
Few-shot learning applications, more specifically, the few-shot classification tasks [38], train the model to classify unseen instances with only a few samples based on prior training data of similar tasks. As for the N-way K-shot classification, we first define the training dataset as , where corresponds to the meta-train and meta-validation set for the task. In the training phase, we select samples from each of the classes in for meta training, and use more data from these classes in for meta validation. Then in the test phase, we construct new tasks on test dataset under the same data distribution to test the performance.
We follow the commonly used parameter setting for GBMs, where the UL variables correspond to the shared hyper representation module model, while the LL variables correspond to the task-specific classifier. For this classification problem, the cross-entropy function (denoted as ) is commonly used for the LL objective and UL objective . Besides, regularization with can be applied to stabilize the training and effectively avoid over-fitting, while existing methods only guarantee the convergence for convex scenario where , our AIT supports more flexible non-convex LL objective without the LLC or LLS constraints. Then we add as the non-convex regularization term to define the LL objectives as The above implementation of non-convex LL objective implies another class of complex LL subproblem for BLOs, which could be used to verify the significant improvement of AIT.
We implement -way -shot and -way -shot classification tasks to validate the performance based on MiniImagenet [39] and TieredImagenet [40] datasets. Both datasets are subsets constructed from the larger ILSVRC-12 dataset, while TieredImagenet includes more classes than MiniImagenet. Besides, TieredImagenet categorizes the source data with hierarchical structure to split the training and test datasets and also simulates more real scenarios.
In Tab. IV, we compare our AIT with representative methods including MAML [4], RHG, T-RHG [2] and BDA. We also consider two structures as the backbones of hyper representation module, including ConvNet-4 with layers of convolutional blocks and the larger ResNet-12 with Residual blocks. We use a single fully-connected layer as the task-specific classifier for both backbones. For MAML, the hyper representation module and the classifier are treated as a whole and update as the initialization parameters. We first use ConvNet-4 as the backbone and compare AIT with RHG, T-RHG, BDA and MAML, then we also implement the ResNet-12 backbone and compare AIT with initialization based (i.e., MAML) and recurrence based methods (i.e., RHG). As it is shown in IV, for the 5-way 1-shot and 5-way 5-shot classification tasks on MiniImagenet and TieredImagenet, AIT shows significant performance improvement on the accuracy with different backbones as the hyper representation module.
6.3 Extensions for More Challenging Tasks
In this subsection, we first implement AIT to solve large-scale and high-dimensional real-world BLO applications, e.g., neural architecture search. Then we move on to other complex deep learning models, e.g., generative adversarial networks, to demonstrate its generalization performance.
6.3.1 Neural Architecture Search
We denote the training set, validation set, and test set as , then the UL objective and LL objective can be written as and . Then we follow the standard training strategies in DARTS, which consists of the searching and the inference stages. As for the searching stage, DARTS executes a single-step LL optimization (Step 4 in Alg.1) with , and continuously optimizes the architecture parameter (Step 9 in Alg.1) to find better cell structures according to the UL objectives . When it comes to the inference stage, the architecture parameter is fixed, and we reuse the searched cell structure to construct larger architecture and train it from scratch based on . Finally, we test the performance of trained model at the inference stage on . In this paper, we conduct the experiments on CIFAR-10 dataset, and use the same search space and similar experimental settings of DARTS. The stacked cell for final architecture has two types, including reduction cells and normal cells. In the reduction cell, operations adjacent to the input nodes use stride 2 to reduce the input shape, while normal cells maintain the original shape with stride 1 for the first two nodes. We use layers of cells for searching with epochs and construct larger structure with layers of the searched cells, and train the model from scratch with 600 epochs in total.
 |
 |
| (a) Validation Loss | (b) Validation Accuracy |
In Fig. 8, we report the validation loss and accuracy after each epoch to evaluate the convergence behavior of DARTS, RHG, CG and our AIT. It can be seen that RHG, CG and DARTS gain similar validation performance on this non-convex BLO application, while AIT significantly improves the convergence results on . Noticed that several works [41, 42] found that DARTS may find the global minimum with very small search space but it starts overfitting the architecture parameters on , which leads to poor generalization performance. To demonstrate that the searched architecture has consistent performance, in Tab. V, we also report the accuracy on and at different stages. It can be observed that only AIT maintains better performance on both and , and it also improves the test performance of finally constructed network structure by a large margin.
| Method | Searching | Inference | Test | Params | ||
| Train | Valid | Train | Valid | |||
| DARTS | ||||||
| RHG | ||||||
| CG | ||||||
| AIT | ||||||
| Normal Cell | ||
| (a) DARTS | (b) RHG | |
| Reduction Cell | (c) CG | (d) AIT |
| (a) DARTS | (b) RHG | |
| (c) CG | (d) AIT |
|
2D Pentagram |
 |
 |
 |
 |
 |
| Target | (a) VGAN | (b) WGAN | (c) UGAN | (d) AIT |
Besides, it have been investigated [42] that DARTS tends to choose more parameter-less operations such as skip connection instead of convolution since the skip connection often leads to rapid gradient descent especially on the proxy datasets which are small and easy to fit. As a result, the generated structure may contains less learnable parameters to some extent. In Fig. 9, we illustrate the searched structure for normal cells and reduction cells to show the difference between these GBMs and AIT. As it is depicted, since DARTS derives approximative hyper-gradient w.r.t. compared to RHG, both of them found similar structure while RHG uses complex edges with more parameters as reported in Tab. V. Besides, though CG found significantly different structures from DARTS and RHG, it has no guarantee of convergence and generalization performance on the test set. In comparison, with convergence guarantee, AIT constructs normal cells and reduction cells with more complex separable convolutions, thus significantly improve the expression ability and generalization performance of the searched architecture.
6.3.2 Generative Adversarial Networks
In practice, we conduct the experiments with synthesized 2 dimensional mixture of Gaussian distributions. Specifically, we generate 10 Gaussians to form the shape of pentagram with maximum radius . In Fig. 10, we compare the visualization results generated by the VGAN, Unrolled GAN [43] (UGAN), WGAN and AIT. It can be seen that AIT generates more modes than the above methods to fit the target distribution. In comparison, the original GAN methods only capture a small number of distribution, which also shows the effectiveness of AIT to solve GAN based applications. As for the quantitative results, in Tab. VI, we report three commonly used metrics including Frechet Inception Distance (FID) [36], Jensen-Shannon divergence (JS) [44], number of Modes (Mode) . In comparison, our AIT not only always generate all the modes with different random seeds, but also gains significant performance improvement on both JS and FID.
| Method | 2D Pentagram (Max Mode=10) | ||
| FID | JS | Mode | |
| VGAN | 1.214 0.37 | 0.191 0.094 | 8.00 0.00 |
| WGAN | 2.404 3.80 | 0.746 0.064 | 3.33 2.52 |
| UGAN | 2.355 2.93 | 0.762 0.083 | 3.33 2.89 |
| AIT | 0.256 0.13 | 0.187 0.046 | 10.00 0.00 |
7 Conclusion
To summarize, our approach involves a thorough analysis of the gradient-based BLO scheme, identifying two significant deficiencies of the existing iterative trajectory. To address these deficiencies, we propose two augmentation techniques, namely Initialization Auxiliary (IA) and Pessimistic Trajectory Truncation (PTT), and develop a series of variations based on these techniques, such as prior regularization and different forms of acceleration dynamics, to construct our Augmented Iterative Trajectory (AIT) for both convex and non-convex scenarios (i.e., and ). Theoretically, we establish detailed convergence analysis of AIT for different types of BLOs, which fills the gap in non-convex theory. Finally, we conduct a series of experiments on various BLO settings using numerical examples, and demonstrate the effectiveness of our approach on typical learning and vision tasks as well as more challenging deep learning models such as NAS and GANs.
Acknowledgments
This work is partially supported by the National Key R&D Program of China (2022YFA1004101), the National Natural Science Foundation of China (Nos. U22B2052, 61922019, 12222106), the Shenzhen Science and Technology Program (No. RCYX20200714114700072), the Pacific Institute for the Mathematical Sciences (PIMS), and the Guangdong Basic and Applied Basic Research Foundation (No. 2022B1515020082).
References
- [1] R. Liu, J. Gao, J. Zhang, D. Meng, and Z. Lin, “Investigating bi-level optimization for learning and vision from a unified perspective: A survey and beyond,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [2] A. Shaban, C.-A. Cheng, N. Hatch, and B. Boots, “Truncated back-propagation for bilevel optimization,” in AISTATS, 2019.
- [3] A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,” arXiv:1803.02999, 2018.
- [4] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML, 2017.
- [5] B. Wu, X. Dai, P. Zhang, Y. Wang, F. Sun, Y. Wu, Y. Tian, P. Vajda, Y. Jia, and K. Keutzer, “Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search,” in IEEE CVPR, 2019, pp. 10 734–10 742.
- [6] Y. Hu, X. Wu, and R. He, “Tf-nas: Rethinking three search freedoms of latency-constrained differentiable neural architecture search,” in ECCV, 2020.
- [7] H. Liu, K. Simonyan, and Y. Yang, “Darts: Differentiable architecture search,” arXiv preprint arXiv:1806.09055, 2018.
- [8] H. Zhang, W. Chen, Z. Huang, M. Li, Y. Yang, W. Zhang, and J. Wang, “Bi-level actor-critic for multi-agent coordination,” in AAAI, vol. 34, no. 05, 2020, pp. 7325–7332.
- [9] L. Wang, Q. Cai, Z. Yang, and Z. Wang, “On the global optimality of model-agnostic meta-learning: Reinforcement learning and supervised learning,” in ICML, 2020.
- [10] G. M. Moore, Bilevel programming algorithms for machine learning model selection. Rensselaer Polytechnic Institute, 2010.
- [11] A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine, “Meta-learning with implicit gradients,” in NeurIPS, 2019.
- [12] R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A generic first-order algorithmic framework for bi-level programming beyond lower-level singleton,” in International Conference on Machine Learning, 2020, pp. 6305–6315.
- [13] L. L. Gao, J. Ye, H. Yin, S. Zeng, and J. Zhang, “Value function based difference-of-convex algorithm for bilevel hyperparameter selection problems,” in International Conference on Machine Learning. PMLR, 2022, pp. 7164–7182.
- [14] A. B. Zemkoho and S. Zhou, “Theoretical and numerical comparison of the karush–kuhn–tucker and value function reformulations in bilevel optimization,” Computational Optimization and Applications, pp. 1–50, 2020.
- [15] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “Forward and reverse gradient-based hyperparameter optimization,” arXiv:1703.01785, 2017.
- [16] R. Liu, X. Liu, S. Zeng, J. Zhang, and Y. Zhang, “Value-function-based sequential minimization for bi-level optimization,” arXiv preprint arXiv:2110.04974, 2021.
- [17] D. Maclaurin, D. Duvenaud, and R. Adams, “Gradient-based hyperparameter optimization through reversible learning,” in ICML, 2015.
- [18] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and meta-learning,” in ICML, 2018.
- [19] R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A general descent aggregation framework for gradient-based bi-level optimization,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [20] F. Pedregosa, “Hyperparameter optimization with approximate gradient,” arXiv:1602.02355, 2016.
- [21] J. Lorraine, P. Vicol, and D. Duvenaud, “Optimizing millions of hyperparameters by implicit differentiation,” in AISTATS, 2020.
- [22] R. Liu, X. Liu, X. Yuan, S. Zeng, and J. Zhang, “A value-function-based interior-point method for non-convex bi-level optimization,” in ICML, 2021.
- [23] K. Ji, J. Yang, and Y. Liang, “Provably faster algorithms for bilevel optimization and applications to meta-learning,” 2020.
- [24] T. Chen, Y. Sun, Q. Xiao, and W. Yin, “A single-timescale method for stochastic bilevel optimization,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 2466–2488.
- [25] M. Hong, H.-T. Wai, Z. Wang, and Z. Yang, “A two-timescale framework for bilevel optimization: Complexity analysis and application to actor-critic,” arXiv preprint arXiv:2007.05170, 2020.
- [26] P. Khanduri, S. Zeng, M. Hong, H.-T. Wai, Z. Wang, and Z. Yang, “A momentum-assisted single-timescale stochastic approximation algorithm for bilevel optimization,” 2021.
- [27] Q. Xiao, H. Shen, W. Yin, and T. Chen, “Alternating implicit projected sgd and its efficient variants for equality-constrained bilevel optimization,” arXiv preprint arXiv:2211.07096, 2022.
- [28] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” 2009.
- [29] S. Ghadimi and G. Lan, “Accelerated gradient methods for nonconvex nonlinear and stochastic programming,” Mathematical Programming, vol. 156, no. 1, pp. 59–99, 2016.
- [30] A. Beck, First-order methods in optimization. SIAM, 2017.
- [31] R. Liu, Y. Liu, S. Zeng, and J. Zhang, “Towards gradient-based bilevel optimization with non-convex followers and beyond,” Advances in Neural Information Processing Systems, vol. 34, pp. 8662–8675, 2021.
- [32] Y. Xu, L. Xie, X. Zhang, X. Chen, G.-J. Qi, Q. Tian, and H. Xiong, “Pc-darts: Partial channel connections for memory-efficient architecture search,” arXiv preprint arXiv:1907.05737, 2019.
- [33] X. Chen, L. Xie, J. Wu, and Q. Tian, “Progressive differentiable architecture search: Bridging the depth gap between search and evaluation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1294–1303.
- [34] X. Dong and Y. Yang, “Searching for a robust neural architecture in four gpu hours,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 1761–1770.
- [35] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020.
- [36] ——, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [37] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,” 2017. [Online]. Available: https://arxiv.org/abs/1701.07875
- [38] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [39] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al., “Matching networks for one shot learning,” in NeurIPS, 2016.
- [40] M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,” arXiv:1803.00676, 2018.
- [41] X. Chu, T. Zhou, B. Zhang, and J. Li, “Fair darts: Eliminating unfair advantages in differentiable architecture search,” in European conference on computer vision. Springer, 2020, pp. 465–480.
- [42] T. E. Arber Zela, T. Saikia, Y. Marrakchi, T. Brox, and F. Hutter, “Understanding and robustifying differentiable architecture search,” in International Conference on Learning Representations, vol. 2, 2020.
- [43] L. Metz, B. Poole, D. Pfau, and J. Sohl-Dickstein, “Unrolled generative adversarial networks,” arXiv preprint arXiv:1611.02163, 2016.
- [44] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017.