Audio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Abstract
Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.
1 Introduction
Face super resolution (SR) (also known as face hallucination) refers to the problem of generating high resolution face images from its low resolution counterpart. Resolution enhancement of the facial images has a wide range of applications in different fields of computer vision, such as face recognition [37], deep fake generation and detection [34, 25], emotion detection [7], face identification [20] and face alignment [28], etc.
There are numerous deep learning algorithms that effectively solves the face hallucination problem in images [14, 12, 11]. Despite many breakthroughs in facial super resolution, there are numerous challenges in Video Face Hallucination (VFH). Temporal and spatial information are the prerequisites for VFH models. Since, single image is considered in face hallucination problems - only spatial information has been predominantly used in most of the state-of-the-art (SOTA) approaches. On the other hand, to solve the VFH problem, temporal motions of the spatial features is a key component. Various techniques have been proposed to incorporate the temporal information in VFH models, such as, 3D convolution networks used by [24] to add temporal consistency to the network for VFH. But these methods require very high computational resources. Another methods [6, 16] include stacking multiple low resolution frames from the videos and pass them to the deep neural network model. Since, these methods naively fuse multiple frames at the input level, no implicit leaning mechanism is used to learn the temporal relationship between the spatial features. Semantic priors, facial parsing maps and 3D priors also assists the VFH networks to generate superior results. Yet, the requirement of pre-trained networks to obtain the prior information leads to extra computation.
One major limitation of generative models is their ability to fit a range of frequencies in a pattern during the training [32]. The models prioritise a smaller band of frequencies instead of learning the whole spectrum. Hence, the salient local features of the regions are harder to learn as they are generally absent in the low resolution image. This issue has been overlooked in the GAN based face super resolution literature. Most of the SOTA use objective function that only optimize the spatial domain features. Consequently, learned feature representations do not contain the high frequency detail leading to lower sharpness of the visual output. Furthermore, current VFH approaches have blurriness in the regions with higher motion, such as mouth, lips, teeth, etc. The root cause of the problem is absence on implicit mechanism to learn temporal dependence between the frame. The higher structural complexity of the region is also partially responsible for the degradation of the quality.
The audio and video have very high semantic correlation. This correlation can be used as a implicit semantic supervision in the VFH networks. Speech signal based objective can help in learning the temporal consistency between the frames. Moreover, a lot of identity, age and gender information are also carried in audio signals [23]. Hence, in the very low resolution images where gender and identity information are hard to retrieve - audio signal can play a critical role in generating such details.
In this paper, we exploit the correlation between the frequency spectrum of the speech signal and the motion of spatial regions (like, mouth and lips). We developed a multi-modal GAN architecture that uses speech and video modalities to further enhance the quality of super resolution (SR) image. The proposed method uses two feature encoder backbones in the generator network. First backbone extract the spatial features from the facial image while second extracts the audio features at corresponding time step. An axial self attention mechanism is used for the feature fusion based feature fusion between both the modalities. We also use a frequency based loss function (calculated using 2D discrete Fourier transform) in order to generate the high frequency details which are otherwise difficult to generate. We also present the lip reading loss to resolve the issue of blurriness around the mouth and lips region. Instead of directly minimizing the distance between generated image and the ground-truth image - distance between their corresponding feature maps (extracted from the intermediate layers of the pre-trained lip-reading network) are minimized. The proposed loss function propels the video face hallucination network (VFHN) to generate facial images with very fine mouth region. Main contributions are as follows:
-
•
A cross-modal learning mechanism for audio-visual data is explored to learn the fine spatial-temporal motion details and facial identity information.
-
•
An explicitly defined lip reading loss is used to learn a fine grain motion in the frames to remove the blurriness in key facial regions.
-
•
A Fourier transform based frequency domain loss is also applied to add the salient frequency features.
-
•
Visual results, quantitative numbers along with their edge restoration number (metric used to examine the restoration quality of edges in videos) shows superiority of proposed work over other SOTA methods.
2 Related work
: Earlier works in the field of FSR using GANs include numerous renowned works. Ultra resolving facial images with the help of discriminator network is one of them [36]. In this model, discriminator is fed with the image generated from the generator network along with the ground truth high resolution image, compelling the generator to mimic high resolution images. To mitigate the training difficulties in GANs and stabilize the training process, Chen et al. [10] proposed a Wasserstein distance as a training metric for FSR system.
Ko et al. [18] argued that recent GAN based methods require extra information along with the low resolution image to generate images with fine perceptual details. But they utilized only a low resolution image with its edge information at various scales to generate high resolution image. Most GAN based methods use bicubic kernels to obtain low resolution image from the high resolution image for training. So, the training dataset does not follow the natural degradation process which affects the performance of GAN based methods on realistic low resolution images. To address this problem Aakerberg et al. [1] introduced different types of noises in low resolution images for training dataset. Xiaobin et al. [14] used 3D priors that carry facial expression, pose and identity information to obtain sharp facial features. An auxiliary depth estimation branch is proposed by Fan et al. [11] in aggregation with the super resolution branch to add the depth information in facial image. He et al. [12] proposed encoder-generator based multi module architecture to mitigate the requirement of facial priors in face super resolution. By utilizing basic functions like bidirectional backpropagation and feature alignment in a systematic way. Although these prior information based methods have achieved great success in VFH, yet the requirement of pre-trained models increases the computational complexity of the overall method to an enormous rate. Chan et al. [8] achieved PSNR higher than other competing networks. Yet higher PSNR does not necessarily indicates more pleasing results visually [19].
- : Semantic correlation between the audio and visual information is utilized in numerous computer vision problems [5, 13]. For example, Tian et al. [27] used the aural information for the comprehensive study of scene. [33] and [31] proposed an attention mechanism between the cross-modal aural-visual network to abolish the temporal inconsistency during localization of events and analyze the longer videos with prominent information, respectively. By exploring the relation between speech and visual representation, Wen et al. [30] and Oh et al. [23] proposed GAN based networks that generates facial images from the speech using physical attributes like identity matching, age and gender etc. Chen et al. [9] converted the aural signals into a complex structure which corresponds to facial landmarks and using these landmarks facial images are generated.
Zhang et al. [39] embedded the aural information in the CNN architecture to enhance the facial videos and remove compression deformities. Along with low resolution image encoder, the audio encoder is used by [22] for image super resolurion. Feature maps obtained by amalgamating the hierarchical features of both the encoders are applied to the decoder, resulting in a high resolution image. Taking inspiration from cross-modal architectures in video super resolution, we propose an audio-visual module for face hallucination in videos that maps the spatial displacement across the video frames and enforces the model to learn identity and gender information in the generated images.
3 Proposed Methodology
Often, facial videos have audios associated with them. Yet, the semantic correlation between the audio features and facial frames remained unexplored in the previous literature of VFH. Therefore, a cross-modal architecture to understand the significance of aural features in facial videos is proposed. In addition, to explicitly add salient frequency features, a Fourier transform based frequency domain loss is proposed. To address the issue of blurriness of mouth region and ensure the temporal consistency across the video frames, a lip reading based loss function in introduced. The loss compels our video face hallucination network to generate the final image with fine texture around the mouth region and consistency across the frames. In this section, the proposed generator architecture and loss functions to optimize the proposed model are explained in detail.
3.1 Overview
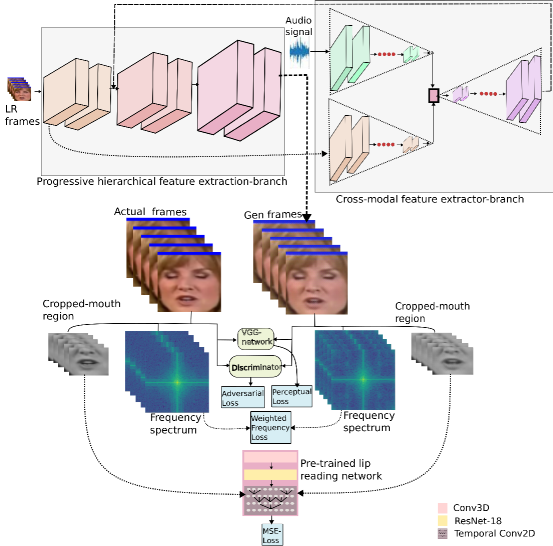
The aim to perform video face hallucination is to generate a high resolution video frame () from corresponding low resolution video frame (), its neighboring low resolution frames (,… ,..) and audio features (). Here, refers to the time step at which face hallucination is performed and are the neighboring LR frames helping the chosen LR frame to generate a high resolution video frame.
CNNs perform better with image data, therefore, rather than using audio features directly in spatial domain, we transformed them into their frequency representation (spectrum) using short time Fourier transform ( ). This spectrum is further converted into mel-spectograms () for better perception and used as an input to our VFHN (refer eq 1).
| (1) |
here, is the high resolution generated video frame and represents the VFHN. and are the weights and bias parameters of video based module and audio based module, respectively. Both these network parameters are optimized by reducing the loss value calculated between the ground-truth high resolution image and the generated image from VFHN.
Proposed architecture is depicted in Figure 1. The motivation for progressive hierarchical feature extractor branch (PHFE-B) is taken from [26]. This branch comprises of two modules. The first modules rely on the complex filter formation, where input feature maps are applied to different convolution layers with increasing filter sizes (). Different size kernels allow the network to assimilate primary or the local attributes as well as hierarchical features. Second module is channel attention module, where depthwise convolution layers are utilized, establishing a computationally efficient architecture. Additionally, squeeze and excitation block is used in this module, enforces the network to emphasize on extracting feature maps from channels which are more affluent then the others.
As shown in Figure 1, cross-modal feature extraction branch splits into two branches. First branch takes feature maps from the primary convolution layers of PHFE-B as input ( and audio signal is applied as an input for the second branch (). Feature embeddings obtained from these two branches are concatenated and converted to another latent vector () (refer eq. 2). This latent vector is applied to axial attention layer to sustain the long range dependencies and give importance to feature vectors with more relevance then the others and resulting in (refer eq. 3).
| (2) |
| (3) |
Obtained feature vector () is added with the feature maps from PHFE-B resulting in high resolution facial image generated with correct identity and gender information.
3.2 Loss function
Final video frame () is generated by optimizing the overall loss function (), calculated between the ground-truth video frame () and generated video frame () over training data samples. This loss function is composed of few weighted loss functions explained in detail in this section.
3.2.1 Lip reading loss function
Accurately identifying the lip movements is elemental for visual speech recognition. Hence, this lip-reading application involves explicating the movement of teeth, tongue and lips. Another requisite for correct lip-reading is temporal dependency across the video frames. These attributes of lip-reading networks can assist our video face hallucination network to generate frames with very fine texture of mouth region and maintain temporal consistency across video frames. We used pre-trained lip-reading network [21] to extract these texture rich feature embedding. The overview of the lip-reading model we used is as follows.
Firstly, a sequence of video frames with cropped mouth region are applied as an input to the 3D convolution layer (refer eq. 4).
| (4) |
here, , is the batch size, represents the number of frames in the video sequence, height and width of video frame is denoted by and , respectively. is the feature embedding obtained after applying 3D convolution layer to the video sequence.
The output features obtained are applied to ResNet-18 () by reshaping the feature maps from to . Here, refers to the number of frames concatenated over batch dimension and represents the visual feature maps obtained from ResNet-18 model.
Obtained visual feature maps are applied to multi-scale temporal convolution network, which uses dilated convolution layers in place of convolution layer. Multi-scaling assists the network to map short term as well as long term dependencies.
We used this lip-reading network to extract high level feature embedding. Firstly, we cropped the mouth region from and , converted them into gray scale and then pass these video sequences from pre-trained lip-reading network (refer eq 5).
| (5) |
here, is the lip-reading loss. and are the feature embedding obtained from the intermediate layers of lip-reading network. loss is calculated between these feature embedding. This loss enforces our VFHN to generate images with high texture in mouth region and maintain temporal consistency across the sequence of videos.
3.2.2 Weighted Fourier Frequency Loss
Frequency representation of images give better perception of artifacts present in an image [15]. Missing high frequency information in the frequency domain will lead to ringing artifacts in the image in spatial domain. Whereas, if solely, the high frequency information is present in the image, it corresponds to the boundaries and edges in the visual domain. Checkerboard artifacts can be seen in the spatial domain with the usage of band stop filtering in frequency representation. From the above information, we can conclude that missing frequencies in the frequency representation of an images are equivalent to various artifacts in the spatial domain. Hence, incorporating these missing frequencies in the frequency domain will lead to better perceptual quality in spatial domain.
We are using 2D discrete fourier transform (DFT) for the frequency representation of an image (refer eq. 6, 7).
| (6) | |||
| (7) | |||
here, , are the pixel values of ground-truth and generated video frames at and coordinates, respectively. Frequency spectrum coordinates are represented by and and its value by . Mean square error is calculated between the ground-truth and generated image in the frequency domain as shown in eq. 8.
| (8) |
Generative models are more inclined towards generating easy frequencies as compare to hard frequencies. Since, each frequency value have same weightage and inherent biasing allows generative models to learn easy frequencies better than the hard frequencies. During training, to put more weightage to hard frequencies, a weight matrix (refer eq . 9), similar to the shape of spectrum, is introduced which adds non-uniformity to each frequency component in the cost function.
| (9) |
is the weight matrix having range , where weights near signifies the frequencies with more weightage and signifies the frequency which is getting vanished. Therefore, frequencies which are learned by the model easily are down-weighted. And hence, the final weighted frequency cost function is shown in eq. 10.
| (10) |
3.2.3 Final loss function
Overall loss function is the weighted sum of lip-reading based loss (), weighted frequency loss (), pre-trained vgg network based perceptual loss () [19], adversarial loss ( (refer eq. 11).
| (11) |
4 Experiments
4.1 Datasets and Metrics
Datasets with videos and corresponding audios for video face hallucination are not publicly available. For training purpose, we selected LRW dataset [35], a collection of videos having 500 words spoken in various different sentences from more than speakers. We randomly selected videos from the 80 words (selected out of 500 words) and divided them in training, validation and testing. Facial landmarks estimated using OpenFace [4] are used to obtain a square crop and eliminate the undesired background from the frames. Cropped region is resized into and downsampled into for low resolution input image. For testing purpose, other than LRW dataset [35], we used Grid speech corpus [3] and LRS2 [2] datasets. All these datasets are audio-visual datasets, as required by proposed network.
In addition to the PSNR and SSIM (both calculated on Y channel after transforming RGB image into YCbCr), we evaluated our results using edge quality assessment metric (ERQA). This metric is used to estimate the networks capability to restore the real information present in the videos.
4.2 Ablation study
: In this section, we studied the importance of audio waves in the proposed architecture. At first, we use the PHFE-B, without the CMFE-B. From the Figure 2 and table 1, it is clear that there are little artifacts present in the facial keypoints of generated image and quantitative numbers are also less. After adding the CMFE-B, our results significantly improved, quantitative numbers - average PSNR (dB), SSIM () and ERQA ()) have increased. To further enhance the generated images, we added axial attention layer after the CMFE-B, compelling the our network to emphasize on more important feature vectors and improves the previous results.

| Metric | w/o audio | audio | audio and attention |
|---|---|---|---|
| PSNR(db) | 27.128 | 28.784 | 28.960 |
| SSIM | 0.862 | 0.899 | 0.915 |
| ERQA | 0.512 | 0.592 | 0.601 |
: We used the final loss function as the combination of multiple loss functions (refer 11). Initially, we applied the combination of perceptual and adversarial loss (refer Figure 3b and table 2a. The results obtained from the network have little color or texture problem. Further we added weighted frequency element to loss function which corrects the texture problem of the generated image (Figure 3c and table 2b). Still the generated image has little artifacts. We added lip-reading loss with perceptual and adversarial loss supervising our network to generate images with high resolution around the mouth region and temporal consistency across frames (Figure 3d and table 2c) . Therefore, the final image is generated by combining all these losses resulting in Figure 3e and table 2d. There is significant improvement in terms of texture and finer details in the final image.

| Metric | a. | b. | c. | d. |
|---|---|---|---|---|
| PSNR | 26.003 | 27.892 | 28.420 | 28.603 |
| SSIM | 0.864 | 0.893 | 0.902 | 0.911 |
| ERQA | 0.413 | 0.471 | 0.472 | 0.497 |
: We also studied the effect of different backbone architectures. Firstly, we used architecture (refer Figure 4) for the backbone of proposed model. We used two mixnet blocks in each stage. Results obtained using this architecture have high resolution with sharp features (refer Figure 5b). Yet, there is texture issue in the generated images, color in the generated image does not match with the ground-truth image. Then, we used the PFH-B [26]. This architecture solves the texture problem and gives more accurate results then the previous architecture. Therefore, for the final model we used the PFH-B as backbone architecture.


4.3 Comparison with the SOTA methods

| Method | LRW | LRS2 | GRID | ||||||
| PSNR | SSIM | ERQA | PSNR | SSIM | ERQA | PSNR | SSIM | ERQA | |
| Bicubic | 27.734 | 0.795 | 0.401 | 27.991 | 0.801 | 0.368 | 28.192 | 0.792 | 0.394 |
| SRGAN | 29.262 | 0.865 | 0.515 | 29.631 | 0.842 | 0.469 | 28.715 | 0.848 | 0.455 |
| ProgGAN | 0.847 | 0.496 | 0.831 | 0.466 | 29.988 | 0.820 | 0.419 | ||
| SICNN | 28.031 | 0.812 | 0.421 | 28.172 | 0.822 | 0.449 | 28.042 | 0.805 | 0.423 |
| GFPGAN | 28.155 | 0.870 | 0.490 | 29.414 | 0.843 | 0.485 | 28.133 | 0.825 | 0.424 |
| RealBasicVSR | 29.370 | 0.913 | 0.583 | 28.595 | 0.878 | 0.484 | 29.930 | 0.905 | 0.504 |
| Our method | 28.960 | 28.603 | |||||||
For the performance evaluation, we compared our proposed VFHN with SOTA super resolution methods: SRGAN [19], ProgGAN [17], SICNN [38], GFPGAN [29], RealBasicVSR [8] and bicubic interpolation.
: We evaluated our networks performance with other SOTA methods using grid speech corpus dataset to obtain quantitative and visual results. We randomly selected videos from the dataset and calculated average SSIM, PSNR and ERQA. Numbers represented in table 3 shows superiority of our network, since our network achieves highest numbers for all the quantitative metrics.
Visual results for the same are shown in Figure 6 (rows- 1 & 2). Facial images generated by SRGAN and ProgGAN have artifacts present near the teeth, eyes and hair. Whereas SICNN is producing blurry images. GPFGAN is changing the structure of face and producing appalling eyes area. Although images generated by RealBasicVSR looks more sharper than the other methods but they are more looks like animated pictures rather than real images. Facial images generated by our method are trying to restore the real information and generating images similar to the ground-truth image without adding any irrelevant information.
and : Similarly, we randomly selected 15 videos from both these datsets and then calculated their average numbers. Our method has achieved highest average SSIM and ERQA numbers but average PSNR is little less as compare to other comparison methods. It is proved in previous researches that we cannot rely on just PSNR in case of super resolution because high PSNR does not necessarily generates visually more appealing results. This can also be depicted from Figure 6. Although ProgGAN has the highest average PSNR in both LRS2 and LRW datasets, yet the generated results by this model have distorted images (refer Figure 6 (row 3)), have various artifacts (refer Figure 6 (row 5, 6 & 7)) and change is shape of mouth region from the original image (refer Figure 6 (row 4)). Images generated by using GFPGAN are more inclined toward an image generation rather than the super resolution task. For example, the model is adding beard to the face which is not present originally (refer Figure 6 (row 6)) and tries to open the eyes while they are closed in the ground-truth image (refer Figure 6 (row 3)). RealBasicVSR is generating results with unnecessarily sharpening some parts of face like brows, eyes, nose and wrinkles etc (refer Figure 6 (row 4, 5, 6 & 7)) leading to generate images looking fake or animated. The images generated by our model resembles to the ground truth image without any change in shape and generating realistic texture.
5 Conclusion
In this paper, firstly we explored the semantic relation between audio waves and corresponding visual frames to maintain temporal consistency across the frames of videos. We proposed a novel lip-reading loss inspired by automatic speech recognition. This loss function supervises the proposed architecture to generate facial images with very fine texture around the mouth region. To effectively add the salient frequency features, we added a frequency based loss function in conjunction with spatial losses. Experimental results show the potential of proposed model over SOTA methods.
References
- [1] Andreas Aakerberg, Kamal Nasrollahi, and Thomas B Moeslund. Real-world super-resolution of face-images from surveillance cameras. IET Image Processing, 16(2):442–452, 2022.
- [2] Triantafyllos Afouras, Joon Son Chung, Andrew Senior, Oriol Vinyals, and Andrew Zisserman. Deep audio-visual speech recognition. IEEE transactions on pattern analysis and machine intelligence, 2018.
- [3] Najwa Alghamdi, Steve Maddock, Ricard Marxer, Jon Barker, and Guy J Brown. A corpus of audio-visual lombard speech with frontal and profile views. The Journal of the Acoustical Society of America, 143(6):EL523–EL529, 2018.
- [4] Brandon Amos, Bartosz Ludwiczuk, and Mahadev Satyanarayanan. Openface: A general-purpose face recognition library with mobile applications. Technical report, CMU-CS-16-118, CMU School of Computer Science, 2016.
- [5] Pascal Belin, Shirley Fecteau, and Catherine Bedard. Thinking the voice: neural correlates of voice perception. Trends in cognitive sciences, 8(3):129–135, 2004.
- [6] Jose Caballero, Christian Ledig, Andrew Aitken, Alejandro Acosta, Johannes Totz, Zehan Wang, and Wenzhe Shi. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4778–4787, 2017.
- [7] Jie Cai, Zibo Meng, Ahmed Shehab Khan, James O’Reilly, Zhiyuan Li, Shizhong Han, and Yan Tong. Identity-free facial expression recognition using conditional generative adversarial network. In 2021 IEEE International Conference on Image Processing (ICIP), pages 1344–1348. IEEE, 2021.
- [8] Kelvin CK Chan, Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Basicvsr: The search for essential components in video super-resolution and beyond. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4947–4956, 2021.
- [9] Lele Chen, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7832–7841, 2019.
- [10] Zhimin Chen and Yuguang Tong. Face super-resolution through wasserstein gans. arXiv preprint arXiv:1705.02438, 2017.
- [11] Zhenfeng Fan, Xiyuan Hu, Chen Chen, Xiaolian Wang, and Silong Peng. Facial image super-resolution guided by adaptive geometric features. EURASIP Journal on Wireless Communications and Networking, 2020(1):1–15, 2020.
- [12] Jingwen He, Wu Shi, Kai Chen, Lean Fu, and Chao Dong. Gcfsr: a generative and controllable face super resolution method without facial and gan priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1889–1898, 2022.
- [13] Di Hu, Feiping Nie, and Xuelong Li. Deep multimodal clustering for unsupervised audiovisual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9248–9257, 2019.
- [14] Xiaobin Hu, Wenqi Ren, John LaMaster, Xiaochun Cao, Xiaoming Li, Zechao Li, Bjoern Menze, and Wei Liu. Face super-resolution guided by 3d facial priors. In European Conference on Computer Vision, pages 763–780. Springer, 2020.
- [15] Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13919–13929, 2021.
- [16] Younghyun Jo, Seoung Wug Oh, Jaeyeon Kang, and Seon Joo Kim. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3224–3232, 2018.
- [17] Deokyun Kim, Minseon Kim, Gihyun Kwon, and Dae-Shik Kim. Progressive face super-resolution via attention to facial landmark. arXiv preprint arXiv:1908.08239, 2019.
- [18] Shanlei Ko and Bi-Ru Dai. Multi-laplacian gan with edge enhancement for face super resolution. In 2020 25th International Conference on Pattern Recognition (ICPR), pages 3505–3512. IEEE, 2021.
- [19] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690, 2017.
- [20] Jiacheng Lin, Yang Li, and Guanci Yang. Fpgan: Face de-identification method with generative adversarial networks for social robots. Neural Networks, 133:132–147, 2021.
- [21] Brais Martinez, Pingchuan Ma, Stavros Petridis, and Maja Pantic. Lipreading using temporal convolutional networks. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6319–6323. IEEE, 2020.
- [22] Givi Meishvili, Simon Jenni, and Paolo Favaro. Learning to have an ear for face super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1364–1374, 2020.
- [23] Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T Freeman, Michael Rubinstein, and Wojciech Matusik. Speech2face: Learning the face behind a voice. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7539–7548, 2019.
- [24] Zhaofan Qiu, Ting Yao, and Tao Mei. Learning spatio-temporal representation with pseudo-3d residual networks. In proceedings of the IEEE International Conference on Computer Vision, pages 5533–5541, 2017.
- [25] K Remya Revi, KR Vidya, and M Wilscy. Detection of deepfake images created using generative adversarial networks: A review. In Second International Conference on Networks and Advances in Computational Technologies, pages 25–35. Springer, 2021.
- [26] Shailza Sharma, Abhinav Dhall, and Vinay Kumar. Frequency aware face hallucination generative adversarial network with semantic structural constraint. Computer Vision and Image Understanding, page 103553, 2022.
- [27] Yapeng Tian, Dingzeyu Li, and Chenliang Xu. Unified multisensory perception: Weakly-supervised audio-visual video parsing. In European Conference on Computer Vision, pages 436–454. Springer, 2020.
- [28] Jun Wan, Jing Li, Zhihui Lai, Bo Du, and Lefei Zhang. Robust face alignment by cascaded regression and de-occlusion. Neural Networks, 123:261–272, 2020.
- [29] Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. Towards real-world blind face restoration with generative facial prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9168–9178, 2021.
- [30] Yandong Wen, Bhiksha Raj, and Rita Singh. Face reconstruction from voice using generative adversarial networks. Advances in neural information processing systems, 32, 2019.
- [31] Yu Wu, Linchao Zhu, Yan Yan, and Yi Yang. Dual attention matching for audio-visual event localization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6292–6300, 2019.
- [32] Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks. arXiv preprint arXiv:1901.06523, 2019.
- [33] Hanyu Xuan, Zhenyu Zhang, Shuo Chen, Jian Yang, and Yan Yan. Cross-modal attention network for temporal inconsistent audio-visual event localization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 279–286, 2020.
- [34] Digvijay Yadav and Sakina Salmani. Deepfake: A survey on facial forgery technique using generative adversarial network. In 2019 International conference on intelligent computing and control systems (ICCS), pages 852–857. IEEE, 2019.
- [35] Shuang Yang, Yuanhang Zhang, Dalu Feng, Mingmin Yang, Chenhao Wang, Jingyun Xiao, Keyu Long, Shiguang Shan, and Xilin Chen. Lrw-1000: A naturally-distributed large-scale benchmark for lip reading in the wild. In 2019 14th IEEE international conference on automatic face & gesture recognition (FG 2019), pages 1–8. IEEE, 2019.
- [36] Xin Yu and Fatih Porikli. Ultra-resolving face images by discriminative generative networks. In European conference on computer vision, pages 318–333. Springer, 2016.
- [37] Dan Zeng, Raymond Veldhuis, and Luuk Spreeuwers. A survey of face recognition techniques under occlusion. IET biometrics, 10(6):581–606, 2021.
- [38] Kaipeng Zhang, Zhanpeng Zhang, Chia-Wen Cheng, Winston H Hsu, Yu Qiao, Wei Liu, and Tong Zhang. Super-identity convolutional neural network for face hallucination. In Proceedings of the European conference on computer vision (ECCV), pages 183–198, 2018.
- [39] Xi Zhang, Xiaolin Wu, Xinliang Zhai, Xianye Ben, and Chengjie Tu. Davd-net: Deep audio-aided video decompression of talking heads. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12335–12344, 2020.