Audio-visual Representation Learning for
Anomaly Events Detection in Crowds
Abstract
In recent years, anomaly events detection in crowd scenes attracts many researchers’ attentions, because of its importance to public safety. Existing methods usually exploit visual information to analyze whether any abnormal events have occurred due to only visual sensors are generally equipped in public places. However, when an abnormal event in crowds occurs, sound information may be discriminative to assist the crowd analysis system to determine whether there is an abnormality. Compare with vision information that is easily occluded, audio signals has a certain degree of penetration. Thus, this paper attempt to exploit multi-modal learning for modeling the audio and visual signals simultaneously. To be specific, we design a two-branch network to model different types of information. The first is a typical 3D CNN model to extract temporal appearance feature from video clips. The second is an audio CNN for encoding Log Mel-Spectrogram of audio signals. Finally, by fusing the above features, the more accurate prediction will be produced. We conduct the experiments on SHADE dataset, a synthetic audio-visual dataset in surveillance scenes, and find introducing audio signals effectively improves the performance of anomaly events detection and outperforms other state-of-the-art methods. Furthermore, we will release the code and the pre-trained models as soon as possible.
Index Terms:
Crowd analysis, Anomaly events detection, Audio-visual representation learning, Multi-modal learningI Introduction
Crowd analysis is an essential task in the field of public safety including crowd counting [1, 2], localization [3, 4, 5], anomaly events detection [6, 7], flow/motion analysis [8, 9], segmentation [10, 11], group detection [12, 13], etc. Especially, anomaly events detection is a fundamental task for safety warning in crowd scenes. Timely alarming of anomaly events that are occurring is essential to ensure public safety. By our observation, we find that when an abnormal event occurs, it is often accompanied by some special sounds. Unfortunately, since the common surveillance cameras are not equipped with audio collection recorders, many researchers only pay attention to the visual information and ignore the audio signal. However, there are many cases that occur in the blind spot of surveillance cameras, resulting in the security system not being able to recognize and warn for police or others in advance. Thus, in this paper, we attempt to explore the effect of ambient sound on the task of anomaly event detection.

With the development of deep learning on computer vision, there are many phenomenal works in the fields of image recognition [14, 15, 16], temporal modeling [17, 18, 19], and audio signals processing [20, 21, 22]. In the field of crowd analysis, most of the existing work focuses on the research of still images [23, 24] and image sequences [25, 26], namely visual crowd analysis. However, currently there is only one method that combines visual and auditory information [27], which proposes a multi-modal learning to encode still images and ambient sounds simultaneously. The method significantly reduces the estimation errors for crowd counting in extreme conditions. Inspired this, we investigate common abnormal events under video surveillance in crowd scenes, such as fighting, fleeing, chasing, chaos, etc. and find that the crowd can make some special sounds, which may aid model extract more discriminative features to recognize the event. Fig. 1 illustrates the videos and the corresponding audio data of some typical samples in SHADE dataset [7]. From it, there are many differences among different events’ ambient sound. Besides, the surveillance camera may be blocked by obstacles and cannot capture effective content. In this case, the sound signal shows its unique advantage: it can bypass obstacles and be collected by recording equipment.
Based on the aforementioned observation, this paper propose a multi-modal learning to extract features from image sequences and audio data for anomaly event detection in crowd scenes. It named as “Audio-visual Representation Learning” (AVRL for short), which consists of two streams: a Residual 3D CNN [28] is developed on image clips and a audio CNN on processed audio information represented by Log Mel-Spectrogram algorithm [29]. After obtaining two types of features, a feature-level fusion mechanism is presented to integrate them and the event class is directly predicted.
In summary, this paper has three-fold contributions:
-
1)
Propose a new framework, Audio-visual Representation Learning (AVRL), to extract appearance and sound features from image sequences and the corresponding audio signals.
-
2)
Present an effective scheme to fuse the spatial-temporal 3D-CNN’s features and temporal audio features, which can achieve the balanced trade-off between visual and audio representations and reaches better anomaly detection accuracy.
-
3)
Outperform the state-of-the-art method on the anomaly events detection task in crowd scenes.
The rest of this paper is organized as follows: Section II briefly lists and reviews the related works about crowd analysis and multi-modal learning; Section III presents the proposed AVRL method for anomaly event detection; Section IV and V conduct the extensive experiments and further analyze the the key settings of the method. Finally, this work is summarized in Section VI.

II Related Work
This section briefly reviews the related works about research fields in this paper: abnormal events detection in crowd scenes and audio-visual representation learning.
II-A Abnormal Events Detection in Crowds
The recent anomaly detection methods can be divided into two main categories: local analysis and global analysis. As for local analysis methods, the locations where abnormal events occur are detected. The typical local analysis methods include [30, 31, 32, 33], etc. These methods detect the abnormal objects, such as trucks or running people in crowds and localize the position where anomalies occur. Liao et al. [34] use video descriptors to detect the fighting event in video frames. The other category, global analysis, usually analyze the whole video clips and predict whether there are abnormal events in the video clips. The global analysis methods have three typical schemes: trajectory points based, optical flow based, and classification based. [35, 36, 37] utilize the object trajectories extracted from crowd video clips for anomaly detection. Helbing et al. [38] proposed is a typical trajectory points based method named social force model for crowd interaction description. Inspired by [38], [35] and [37] introduce the social force model into the social events analysis in videos. Cui et al. [36] attempt to cluster trajectories by Fuzzy C-Means Clustering [39] and predict the category of input trajectory through clustering. Du et al. [33] propose a change detector named DSFA, and it utilizes two symmetric streams and slow feature analysis module to acquire better performance on changes in remote sensing imagery.
Because the definition of abnormal events in statistic based methods is ambiguous and inchoate, the VSD [40] and UCF-Crime [41] are proposed for abnormal events detection in crowd scenes, containing 7 and 13 different categories about anomalies respectively. The video clips in these two datasets are gained from movies and videos on internet. [42] is a typical method for video classification with VSD benchmark. In the meantime, [43] estimates the crowd emotion for abnormal behavior analysis and understanding on dataset in [44]. The datasets mentioned above define the abnormal events in crowd detailedly, leading the abnormal detection task to the video classification task. Therefore, we deploy the recent video classification methods into the anomaly detection and receive excellent results.
II-B Audio-Visual Multi-Modal Learning
The joint audio-visual multi-modal learning attempts to the learn the representation from visual and auditory modalities for special tasks. The early researches on this field concentrate on the speech recognition task [45]. The motivation of these works is that the visual modality provides auxiliary information for audio analysis with noisy. A typical research on audio-visual multi-modal learning is to model the movement of face and mouth through the videos and corresponding audio signals [46, 47]. Similarly, the multi-modal learning is introduced into other tasks [48, 49].
In recent years, the audio-visual multi-modal learning is utilized in more general scenes. Owens et al. [50, 51] try to transfer the knowledge from audio learning to visual learning. Arandjelovic et al. [52] analyze the video through audio-visual relations. Meanwhile, this work is employed to sound localization [53, 54] and audio-visual separation [55].
This paper is inspired by these audio-visual multi-modal learning methods and we attempt to introduce the audio modality into the traditional visual-based abnormal detection methods. The anomaly detection in crowd scenes benefits from special ambient sounds in some events.
III Our Approach
The proposed framework AVRL contains three main modules: visual representation learning, audio representation learning, and audio-visual representation fusion, showing in Fig. 2. Compared with the conventional video anomaly detection method, our framework has the unique audio representation learning, and audio-visual representation fusion modules for abnormal events detection in crowd analysis. As mentioned above, the motivation of our framework is that some abnormal events have the extremely special ambient sounds, such as shooting, scattering, etc. and these discriminating ambient sounds is beneficial for abnormal events recognition. For example, when the shooting rampage occurred, some people near the crime scene may not see the shooter at all, but the loud gunfire helps the people in judging the abnormal event. To introduce this judgment capacity, we design a audio representation learning module in the traditional video abnormal events detection framework, gaining the Audio-visual Representation Learning (AVRL) framework.
III-A Visual Representation Learning
Compared with the images, videos have inherent temporal correlation, and video data have extra time dimension. In order to extract the temporal information, 3D convolutional filter, a 2D convolutional filter with time dimension, is proposed and introduced into the vision task on videos. Thus, the video representation learning module in AVRL framework uses 3D-ResNet [28] to extract the visual representation with temporal correlation among video frames.
Here, the input videos with frames are sampled to a fixed length ( in this paper) with a fixed sample interval . This fixed length frame sequence is passed to the visual representation learning module . The visual representation is extracted with the equation:
| (1) |
where is the finally output of 3D-ResNet-34, and is the number of channels ( in 3D-ResNet).
In vanilla 3D-ResNet, the representation is mapped to logits for events classification, achieving the abnormal events detection. In our proposed AVRL framework, this video representation do not use for classification directly, it will be merged with audio representation to realize the multi-modal learning system.
III-B Audio Representation Learning
With the development of deep learning, there are some CNN-based methods [29] have applied on audio analysis successful. The CNN-based method are usually utilized to the image data due to the characteristic of convolutional layer. However, the audio signals from videos only has one-dimension, and a audio signal preprocess is necessary for the CNN-based audio representation learning.
In this paper, Log Mel Spectrogram (LMS) for audio preprocess is used in audio representation learning module, because the LMS features from audio is used in CNN-based audio task generally. According to the VGGish [29], the input audio signal from video is first resampled with 16kHz, and then the time-frequency map of resampled audio signal is gain through a Short Time Fourier Transform (STFT) with Hann window, and the details of preprocess are same as VGGish. The LMS feature has two-dimensiom, and the CNN-based methods can easily extract the hidden feature from audio signal. In AVRL, we use VGGish as audio representation learning module . The audio representation extraction is defined as:
| (2) |
where is the audio representation, and in VGGish.
III-C Audio-visual Representation Fusion
The traditional abnormal events detection methods only analyze the feature from videos, but some anomaly is not noticeable in crowd scene. Supposing that two people are fighting in a congested crowd, this fight event is not obvious in vision due to the dense crowd, but if the people in fight are roaring or crying, the fight event will be judged easily. Under this circumstance, the fusion of audio and visual representation has the advantages for events detection in crowd analysis. To detect abnormal events effectively, we fuse the audio and visual representation by audio-visual representation fusion module. In order to select the better fusion methods, we design several fusion strategy and compared their performances in Section IV-E. Finally, we select a simple and effective fusion method for AVRL framework.
Based on the visual/audio representation learning above, we fuse the representations through feature concatenation, and then pass this multi-modal feature into classification network to detect whether abnormal events occur in the video. The formula is shown here:
| (3) |
where is the event category prediction, is the number of categories in SHADE, denotes the feature concatenate manipulation. This simple fusion module achieve the better performance in comparison with other fusion strategy we designed, and the details of different fusion strategy is shown in Section IV-E. The classification network in audio-visual representation fusion module is a simple fully connected network.
Intuitively, the audio-visual representation fusion module combines the visual representation and audio representation, and extracts the comprehensive feature with fully connected network for abnormal events classification. With the auxiliary information from audio, the audio-visual combined representation is more discriminating compared with traditional visual methods. Although the fusion module of AVRL framework is quite simple, the experiment results illustrate that this simple strategy is effective in abnormal events detection, and even surpasses more complex fusion methods.
III-D Loss Function
Anomaly events detection in crowd scenes is a video classification task. In order to find the anomaly events, the model should judge whether the action in video is belong to abnormal events, such as shoot, scatter, fight, etc. Given a video with category and a predict category , we selected Cross Entropy Loss, a typical loss function for classification task. The loss function is defined as:
| (4) |
where is the mini-batch size, denotes the number of categories.
III-E Other Details
We select the 3D-ResNet-34 pre-trained on UCF-101 [56] as the backbone for visual representation learning on video data. 3D-ResNet is a widely used deep learning model for video vision task. 3D-ResNet replace the traditional 2D convolutional layer in ResNet with 3D convolutional layer, introducing the temporal correlation in CNN. 3D convolutional filter adds an extra length dimension in 2D convolutional filter.
To be specific, suppose is the value at position on feature map from the output of 3D convolutional layer, and the input feature of layer has channels. The 3D convolutional filter has height, width, and length. The 3D convolution is shown as follow:
| (5) |
where , and are the weight and bias of convolutional filter respectively.
In addition, we select a common audio analysis CNN, VGGish pre-trained on AudioSet [57], to learn the audio representation. The PCA postprocess of VGGish is removed from our audio representation learning module. Due to the discrepancy of audio length in SHADE dataset, the LMS features have different shapes. We impose Global Average Pooling (GAP) along channel on the output of audio representation, so that the audio representation has a unified size .
The fused audio-visual representation is passed to a fully connected network for event categories classification. We design a simple fully connected network , and the architecture of is illustrated in Table I:
| Layer | Input Size | Output Size | |
|---|---|---|---|
| 0 | Linear | 1024 | 512 |
| 1 | ReLU | 512 | 512 |
| 2 | Linear | 512 | 256 |
| 3 | ReLU | 256 | 256 |
| 4 | Linear | 256 | # of categories |
| 5 | Classification |
IV Experiments
The experiments are conducted on SHADE dataset. The experimental details and discussions are shown in this section.
IV-A Evaluation Metrics
Abnormal events detection can be considered as a video classification task, so that the classification accuracy is the core metric for this task. The Top-1 Accuracy is gauged to compare the performances among different methods:
| (6) |
| (7) |
where i indicates the category, and is the total number of categories in SHADE dataset. is the total number of samples belong to the category. and is the prediction and ground-truth of category label respectively. And the indicator function is defined as Eq. 6. In the experiments, we gauge the Top-1 Accuracy on every category separately.
IV-B Dataset
Due to the lack of audio collection recorders on current surveillance cameras, the recent abnormal events detection/classification datasets under real world only contain visual information without ambient sounds. Under this condition, the traditional action classification dataset or abnormal events detection datasets are not suitable for our AVRL framework, so that we choose a synthetic dataset: SHADE [7] which is generated in the video game named Grand Theft Auto V (GTA5), including 2149 videos (879,932 frames with the size of ). The videos in SHADE are from nine categories, arrest, chase, fight, knowkdown, run, shoot, scatter, normal type 1, and normal type 2. Every category contains about 200 videos with different weather conditions (rain, foggy, sunny, etc.) and different happening time. There are 1701 videos (about 80%) for training, and the remaining 448 videos (about 20%) for validation or testing. Meanwhile, we extract the audio sounds from videos for the training of audio representation learning module.
IV-C Experimental Settings
In this part, some experimental settings and details are explained. Both the spatial transformations and temporal transformations are imposed on the input video. The input frames are first resized to the size of , and a random horizontal flip with a probability of 0.5. The temporal transformations sample frames from the whole frame sequence with a fixed step. The audio signal only preprocess to gain the LMS feature without any other transformations.
In the training phase, we select Stochastic Gradient Descent (SGD) method as the optimizer. The momentum of SGD optimizer is 0.9, and the weight decay is 0.001. The learning rate is set as at the beginning, and the learning rate is updated automatically through minimize the validation loss. From the experiment results, the final learning rate is . The batch size in training is set as 12, and we train our model 80 epochs. The experiments run on two NVIDIA GTX 1080TI GPUs.
| Category | MLP | LSTM | LRCN | 3D ResNet | N3D ResNet | AVRL (ours) | |
|---|---|---|---|---|---|---|---|
| shoot | 0.866 | 0.916 | 0.905 | 0.898 | 0.920 | 0.959 | |
| scatter | 0.822 | 0.896 | 0.896 | 0.905 | 0.923 | 0.954 | |
| fight | 0.572 | 0.612 | 0.630 | 0.640 | 0.577 | 0.644 | |
| arrest | 0.643 | 0.703 | 0.714 | 0.823 | 0.837 | 0.900 | |
| knokdown | 0.663 | 0.649 | 0.621 | 0.771 | 0.742 | 0.808 | |
| run | 0.627 | 0.650 | 0.648 | 0.606 | 0.646 | 0.595 | |
| chase | 0.582 | 0.619 | 0.641 | 0.578 | 0.660 | 0.551 | |
| normal1 | 0.611 | 0.635 | 0.627 | 0.656 | 0.671 | 0.700 | |
| normal2 | 0.712 | 0.718 | 0.750 | 0.787 | 0.804 | 0.804 | - |
IV-D Performance on SHADE Dataset
Table II illustrates the comparisons among listed models. Specially, we compare the performance with several visual-based video classification models, such as MLP, LSTM [58], LRCN [59], 3D ResNet [28], and N3D ResNet [7]. The comparison demonstrates that the audio information improves the classification accuracy significantly. The model introducing 3D convolutional layer, e.g. 3D ResNet and N3D ResNet, achieves the better performance among visual-based methods. Compared to the state-of-the-art method, N3D ResNet, on SHADE dataset, the proposed AVRL framework achieve higher Top-1 accuracy on majority of the categories, and only two categories, run and chase, are lower than N3D ResNet. Our AVRL embeds the audio representation learning module into the visual-based method 3D ResNet with an extremely simple fusion module, reaching the notable advance on Top-1 accuracy for events classification. The events with special ambient sounds, such as shoot, scatter, arrest, and knokdown, have the remarkable increase, which means the AVRL framework learns the discriminating feature in audio signals and aids the classification effectively. Meanwhile, only a simple concatenation method to fuse the audio and visual representations can gain a great improvement, showing the superiority of the multi-modal learning in abnormal events detection.

IV-E Comparison of Fusion Strategy
In Section III, we only introduce the concatenation fusion strategy. Actually, we design several different fusion strategy and compare the performance, and we choose the concatenation fusion strategy (Concat) finally. Besides the Concat strategy, the other fusion strategies are concatenation with layer normalization (Concat w/ LN), concatenation with unified magnitude (Concat w/ UM), addition fusion strategy (Add), and low-level feature fusion strategy (LF).
From the experiments, we find that the audio representation has a lower magnitude than video representation. The average visual representation is tenfold to that of audio representation. We attempt to introduce the layer normalization and a scale factor respectively to alleviate this divergence, acquiring the Concat w/ LN and Concat w/ UM strategies. Meanwhile, to find out the suitable fusion strategy, we design different prevalent feature fusion strategies, Add and LF, to select a better fusion strategy.
The details of several fusion strategy mentioned above are shown in Fig. 3. First, the Concat ((a) in Fig. 3) directly concatenates the visual and audio representation along channel dimension. The Concat w/ LN introduces the Layer Normalization after feature concatenation to balance the visual representation and audio representation. In addition, we adjust the magnitude by multiplying an hand-craft scale factor to the audio representation in Concat w/ UM. Due to the same shape of visual and audio representations, we naturally add the audio feature to visual feature, fusing the multi-modal features. The former fusion strategies all fuse the representations in the high-level feature. In contrast, we embed the audio representation in the low-level feature from visual representation. We first calculate the inherent correlation in audio representation by outer product, gaining the audio correlation map . And the is resized to the same spatial shape with the input frames through bilinear interpolation. Then, the resized is stacked with all of input video frames along channel dimension.
Concat

Concat w/ LN

Concat w/ UM

Add

LF

| Category | Concat | Concat w/ LN | Concat w/ UM | Add | LF |
|---|---|---|---|---|---|
| shoot | 0.959 | 0.898 | 0.918 | 0.918 | 0.918 |
| scatter | 0.954 | 0.954 | 0.977 | 0.931 | 0.954 |
| fight | 0.644 | 0.644 | 0.689 | 0.689 | 0.644 |
| arrest | 0.900 | 0.783 | 0.833 | 0.800 | 0.783 |
| knokdown | 0.808 | 0.723 | 0.766 | 0.851 | 0.745 |
| run | 0.595 | 0.714 | 0.619 | 0.762 | 0.666 |
| chase | 0.551 | 0.531 | 0.510 | 0.469 | 0.531 |
| normal1 | 0.700 | 0.816 | 0.800 | 0.733 | 0.633 |
| normal2 | 0.804 | 0.848 | 0.869 | 0.848 | 0.913 |
The comparison of fusion strategy introduced above is illustrated in Table III, and the classification results are demonstrated in Fig. 4. From the comparison, the following conclusions are obtained: (1) The Concat strategy achieves relatively high performance among several fusion strategies, reaching the top place on shoot, arrest, and chase. (2) Compared to Concat, the Concat w/ LN reaches higher accuracy on run, normal1, and normal2, but the performances on events with discriminating ambient sounds (shoot and arrest) have significant decrease, which means the Concat w/ LN can not exploit the ambient sounds sufficiently. (3) The Concat w/ UM achieves better performance than Concat w/ LN, and the accuracy on run has increase, but the accuracy on chase decrease notably. We find that the Concat w/ UM strategy tends to consider the events with running people as run events, causing the increase of accuracy on run. However, the chase events contain two running people in scenes, and the Concat w/ UM confuses chase with run, leading to the decrease of accuracy on chase. (4) The Add also achieve high performances on several events, but the improvements is not higher than Concat, and there is a significant decrease of performance on chase due to the same reason as (3). Finally, the improvement of LF strategy is not obvious than other fusion strategies. In summary, with the comprehensive consideration, we select the Concat strategy in audio-video representation fusion module.
V Discussion
To further verify the advantage of AVRL and elaborate the principle about multi-modal learning in AVRL, some discussions are developed in this section.
V-A The performance on Dark Scenes
In the real world, the abnormal events usually happen in the dark environment. One of the motivations of AVRL is to aid the abnormal events detection task, especially in some degeneration scenes, such as low illumination, noise, etc. In order to stand out the robustness of AVRL, we select a subset in SHADE that only includes the dark scenes. The selected dark subset contains 147 events from 18:00 pm to 23:59 pm, 85 events from 0:00 am to 5:59 am, and 145 events occur in daytime with low illumination environments. Furthermore, the comparison between the proposed AVRL and the state-of-the-art N3D ResNet on SHADE dataset. Table IV illustrates the comparison on dark subset. From the table, we find that the proposed AVRL framework surpasses the state-of-the-art method N3D ResNet absolutely.
| Category | N3D ResNet | AVRL (ours) |
|---|---|---|
| shoot | 0.832 | 0.977 |
| scatter | 0.805 | 1.0 |
| fight | 0.551 | 0.961 |
| arrest | 0.635 | 1.0 |
| knokdown | 0.495 | 1.0 |
| run | 0.632 | 0.925 |
| chase | 0.591 | 0.914 |
| normal1 | 0.628 | 0.925 |
| normal2 | 0.754 | 0.921 |
The nighttime events in the dark subset usually occur in quite environments, so that the event sounds are discriminative, leading to a better distinguish of anomalies. Due to this point, the classification on run and chase achieves better accuracy. And some events with notable ambient sounds, such as shoot, scatter, arrest, and knokdown, have the accuracy extremely close to 1.0. Interestingly, the AVRL does not reaches high performance on fight, run, and chase in SHADE dataset, but the performance on these categories in dark subset increases significantly. The daytime samples have noise from crowds involving chatting, bustle, etc. which do harm to the assistance from audio. Overall, the AVRL framework addresses the anomaly detection with dark scenes effectively, proving the advantage of audio-visual multi-modal learning.
V-B Ablation Study
The ablation study is conduct to further compare the influences from audio representation and visual representation. We consider three schemes: only visual scheme (3D ResNet), only audio (VGGish), and audio-visual (the proposed AVRL). The results of ablation study are shown in Table V.
| Category | 3D ResNet | VGGish | AVRL (ours) |
|---|---|---|---|
| shoot | 0.898 | 0.918 | 0.959 |
| scatter | 0.905 | 0.591 | 0.954 |
| fight | 0.640 | 0.133 | 0.644 |
| arrest | 0.823 | 0.417 | 0.900 |
| knokdown | 0.771 | 0.638 | 0.808 |
| run | 0.606 | 0.476 | 0.595 |
| chase | 0.578 | 0.326 | 0.551 |
| normal1 | 0.656 | 0.433 | 0.700 |
| normal2 | 0.787 | 0.326 | 0.804 |
From the Table V, the following conclusion can be obtained: (1) The 3D ResNet (only visual) achieves better accuracy than VGGish (only audio), which means the visual representation makes heavier contributions on abnormal events detection than audio representation. (2) VGGish (only audio) reaches high classification accuracy on the events with special ambient sounds, especially the shoot. (3) Although the performance of VGGish (only audio) is weak, the AVRL (audio-visual) achieves better classification accuracy by combining the audio and video representations.


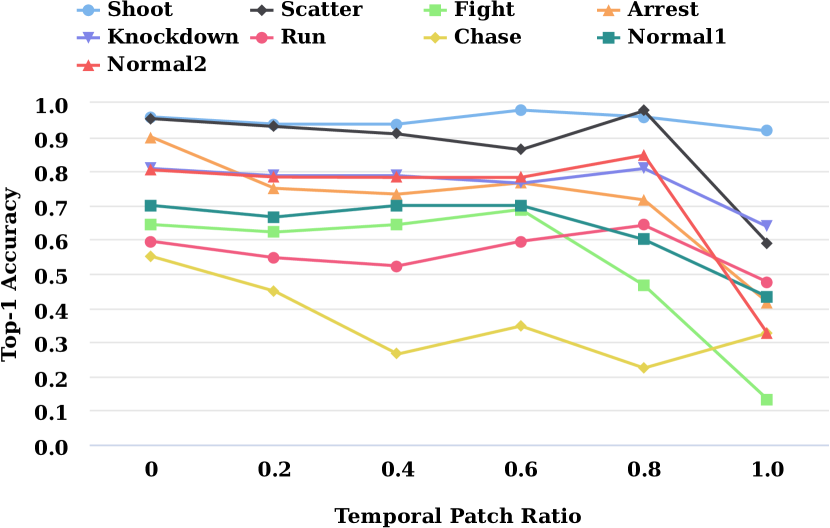

V-C Temporal and Spatial Patches
In order to probe the relationship between visual representation and audio representation, we add patches randomly in videos, as shown in Fig. 5. As for temporal patch, the video frames are randomly selected under a proportion and colored by black (Fig. 5(a)). Moreover, the black patches with a proportion of the full spatial area are put to random positions on every frames (Fig. 5(b)). The comparison results are demonstrated in Fig. 6(a) and Fig. 6(b).
With the increase of patch ratio, the classification accuracy of both temporal patch and spatial patch decreases unsurprisingly. The effect of temporal patch is less than that of spatial patch, so that the accuracy of spatial patch have fallen more against temporal patch, which means that the spatial correlation in single frame provide more contributions than temporal correlation among frames for events classification. From Fig. 6, we find that the accuracy on some categories with 80% spatial patch ratio is lower than that of the method with only audio representation. This probably because the high spatial patch ratio lead to the extremely noisy distortion on content and this distortion mislead the visual representation learning, causing the impediment to events detection.
VI Conclusion
This paper proposes a novel multi-modal learning framework AVRL for abnormal events detection. The AVRL framework attempts to improve the abnormal events detection accuracy in crowd scenes through combining the visual representation and audio representation from the surveillance videos. Specifically, a 3D ResNet is applied for visual representation learning and a audio analysis model, VGGish, is used for audio representation learning. On obtaining the audio and visual representations, a simple concatenation feature fusion module is exploited to fuse the multi-modal representations. Experiments show that the proposed AVRL has significant superiority compared with state-of-the-art visual-based methods.
In the AVRL, we attempt several feature fusion strategies preliminarily and the fusion module still needs optimize to achieve better anomaly detection accuracy. Meanwhile, due to the limitation of datasets, the experiments are only conducted on a synthetic dataset, SHADE dataset, rather than real-world dataset. With the emergence of surveillance video datasets with audio signals, we will attempt to pursue this research on more datasets.
References
- [1] Q. Wang, J. Gao, W. Lin, and Y. Yuan, “Learning from synthetic data for crowd counting in the wild,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 8198–8207.
- [2] Y. Zhou, J. Yang, H. Li, T. Cao, and S.-Y. Kung, “Adversarial learning for multiscale crowd counting under complex scenes,” IEEE transactions on cybernetics, 2020.
- [3] S. Abousamra, M. Hoai, D. Samaras, and C. Chen, “Localization in the crowd with topological constraints,” arXiv preprint arXiv:2012.12482, 2020.
- [4] Y. Wang, J. Hou, X. Hou, and L.-P. Chau, “A self-training approach for point-supervised object detection and counting in crowds,” IEEE Transactions on Image Processing, vol. 30, pp. 2876–2887, 2021.
- [5] J. Gao, T. Han, Y. Yuan, and Q. Wang, “Learning independent instance maps for crowd localization,” arXiv preprint arXiv:2012.04164, 2020.
- [6] M. Thida, H.-L. Eng, and P. Remagnino, “Laplacian eigenmap with temporal constraints for local abnormality detection in crowded scenes,” IEEE Transactions on Cybernetics, vol. 43, no. 6, pp. 2147–2156, 2013.
- [7] W. Lin, J. Gao, Q. Wang, and X. Li, “Learning to detect anomaly events in crowd scenes from synthetic data,” Neurocomputing, vol. 436, pp. 248–259, 2021.
- [8] S. Ali and M. Shah, “A lagrangian particle dynamics approach for crowd flow segmentation and stability analysis,” in 2007 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2007, pp. 1–6.
- [9] A. S. Rao, J. Gubbi, S. Marusic, and M. Palaniswami, “Crowd event detection on optical flow manifolds,” IEEE transactions on cybernetics, vol. 46, no. 7, pp. 1524–1537, 2015.
- [10] V. J. Kok and C. S. Chan, “Grcs: Granular computing-based crowd segmentation,” IEEE transactions on cybernetics, vol. 47, no. 5, pp. 1157–1168, 2016.
- [11] Q. Wang, J. Gao, W. Lin, and Y. Yuan, “Pixel-wise crowd understanding via synthetic data,” International Journal of Computer Vision, vol. 129, no. 1, pp. 225–245, 2021.
- [12] R. Mazzon, F. Poiesi, and A. Cavallaro, “Detection and tracking of groups in crowd,” in 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance. IEEE, 2013, pp. 202–207.
- [13] X. Li, M. Chen, F. Nie, and Q. Wang, “A multiview-based parameter free framework for group detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [14] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, pp. 1097–1105, 2012.
- [15] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [16] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [17] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale video classification with convolutional neural networks,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2014, pp. 1725–1732.
- [18] B. Zhao, H. Li, X. Lu, and X. Li, “Reconstructive sequence-graph network for video summarization,” IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI:10.1109/TPAMI.2021.3072117, 2015.
- [19] X. LI and B. ZHAO, “Video distillation,” SCIENCE CHINA Information Sciences, 2021.
- [20] S. Hershey, S. Chaudhuri, D. P. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold et al., “Cnn architectures for large-scale audio classification,” in 2017 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2017, pp. 131–135.
- [21] J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780.
- [22] D. Hu, Z. Wang, H. Xiong, D. Wang, F. Nie, and D. Dou, “Curriculum audiovisual learning,” arXiv preprint arXiv:2001.09414, 2020.
- [23] J. Wan, W. Luo, B. Wu, A. B. Chan, and W. Liu, “Residual regression with semantic prior for crowd counting,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4036–4045.
- [24] J. Gao, Q. Wang, and X. Li, “Pcc net: Perspective crowd counting via spatial convolutional network,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 10, pp. 3486–3498, 2020.
- [25] W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detection in surveillance videos,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6479–6488.
- [26] A. Singh, D. Patil, and S. Omkar, “Eye in the sky: Real-time drone surveillance system (dss) for violent individuals identification using scatternet hybrid deep learning network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018.
- [27] D. Hu, L. Mou, Q. Wang, J. Gao, Y. Hua, D. Dou, and X. X. Zhu, “Ambient sound helps: Audiovisual crowd counting in extreme conditions,” arXiv preprint arXiv:2005.07097, 2020.
- [28] K. Hara, H. Kataoka, and Y. Satoh, “Learning spatio-temporal features with 3d residual networks for action recognition,” in 2017 IEEE International Conference on Computer Vision Workshops, ICCV Workshops 2017, Venice, Italy, October 22-29, 2017. IEEE Computer Society, 2017, pp. 3154–3160.
- [29] S. Hershey, S. Chaudhuri, D. P. W. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney, R. J. Weiss, and K. W. Wilson, “CNN architectures for large-scale audio classification,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, March 5-9, 2017. IEEE, 2017, pp. 131–135.
- [30] K. Cheng, Y. Chen, and W. Fang, “Abnormal crowd behavior detection and localization using maximum sub-sequence search,” in Proceedings of the 4th ACM/IEEE international workshop on Analysis and retrieval of tracked events and motion in imagery stream, ARTEMIS@ACM Multimedia 2013, Barcelona, Spain, October 21, 2013. ACM, 2013, pp. 49–58.
- [31] B. Du, Y. Zhang, L. Zhang, and D. Tao, “Beyond the sparsity-based target detector: A hybrid sparsity and statistics-based detector for hyperspectral images,” IEEE Trans. Image Process., vol. 25, no. 11, pp. 5345–5357, 2016.
- [32] H. Chen, O. Nedzvedz, S. Ye, and S. Ablameyko, “Crowd abnormal behaviour identification based on integral optical flow in video surveillance systems,” Informatica, vol. 29, no. 2, pp. 211–232, 2018.
- [33] B. Du, L. Ru, C. Wu, and L. Zhang, “Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images,” IEEE Trans. Geosci. Remote. Sens., vol. 57, no. 12, pp. 9976–9992, 2019.
- [34] H. Liao, J. Xiang, W. Sun, Q. Feng, and J. Dai, “An abnormal event recognition in crowd scene,” in Sixth International Conference on Image and Graphics, ICIG 2011, Hefei, Anhui, China, August 12-15, 2011. IEEE Computer Society, 2011, pp. 731–736.
- [35] R. Mehran, A. Oyama, and M. Shah, “Abnormal crowd behavior detection using social force model,” in 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA. IEEE Computer Society, 2009, pp. 935–942.
- [36] J. Cui, W. Liu, and W. Xing, “Crowd behaviors analysis and abnormal detection based on surveillance data,” J. Vis. Lang. Comput., vol. 25, no. 6, pp. 628–636, 2014.
- [37] Y. Zhang, L. Qin, R. Ji, H. Yao, and Q. Huang, “Social attribute-aware force model: Exploiting richness of interaction for abnormal crowd detection,” IEEE Trans. Circuits Syst. Video Technol., vol. 25, no. 7, pp. 1231–1245, 2015.
- [38] D. Helbing and P. Molnár, “Social force model for pedestrian dynamics,” Phys. Rev. E, vol. 51, pp. 4282–4286, 1995.
- [39] R. L. Cannon, J. V. Dave, and J. C. Bezdek, “Efficient implementation of the fuzzy c-means clustering algorithms,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 8, no. 2, pp. 248–255, 1986. [Online]. Available: https://doi.org/10.1109/TPAMI.1986.4767778
- [40] C. Demarty, C. Penet, M. Soleymani, and G. Gravier, “Vsd, a public dataset for the detection of violent scenes in movies: design, annotation, analysis and evaluation,” Multim. Tools Appl., vol. 74, no. 17, pp. 7379–7404, 2015.
- [41] W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detection in surveillance videos,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. IEEE Computer Society, 2018, pp. 6479–6488.
- [42] I. Mironica, I. C. Duta, B. Ionescu, and N. Sebe, “A modified vector of locally aggregated descriptors approach for fast video classification,” Multim. Tools Appl., vol. 75, no. 15, pp. 9045–9072, 2016.
- [43] H. R. Rabiee, J. Haddadnia, H. Mousavi, M. Nabi, V. Murino, and N. Sebe, “Emotion-based crowd representation for abnormality detection,” CoRR, vol. abs/1607.07646, 2016.
- [44] H. R. Rabiee, J. Haddadnia, H. Mousavi, M. Kalantarzadeh, M. Nabi, and V. Murino, “Novel dataset for fine-grained abnormal behavior understanding in crowd,” in 13th IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2016, Colorado Springs, CO, USA, August 23-26, 2016. IEEE Computer Society, 2016, pp. 95–101.
- [45] S. Dupont and J. Luettin, “Audio-visual speech modeling for continuous speech recognition,” IEEE Trans. Multim., vol. 2, no. 3, pp. 141–151, 2000.
- [46] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA, June 28 - July 2, 2011. Omnipress, 2011, pp. 689–696.
- [47] D. Hu, X. Li, and X. Lu, “Temporal multimodal learning in audiovisual speech recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 3574–3582.
- [48] S. Kettebekov, M. Yeasin, and R. Sharma, “Prosody based audiovisual coanalysis for coverbal gesture recognition,” IEEE Trans. Multim., vol. 7, no. 2, pp. 234–242, 2005.
- [49] Z. Zeng, J. Tu, M. Liu, T. S. Huang, B. Pianfetti, D. Roth, and S. E. Levinson, “Audio-visual affect recognition,” IEEE Trans. Multim., vol. 9, no. 2, pp. 424–428, 2007.
- [50] A. Owens, J. Wu, J. H. McDermott, W. T. Freeman, and A. Torralba, “Ambient sound provides supervision for visual learning,” in Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I, ser. Lecture Notes in Computer Science, vol. 9905. Springer, 2016, pp. 801–816.
- [51] A. Owens, J. Wu, J. McDermott, W. Freeman, and A. Torralba, “Learning sight from sound: Ambient sound provides supervision for visual learning,” Int. J. Comput. Vis., vol. 126, no. 10, pp. 1120–1137, 2018.
- [52] R. Arandjelovic and A. Zisserman, “Look, listen and learn,” in IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEEE Computer Society, 2017, pp. 609–617.
- [53] D. Hu, F. Nie, and X. Li, “Deep multimodal clustering for unsupervised audiovisual learning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 9248–9257.
- [54] D. Hu, Z. Wang, H. Xiong, D. Wang, F. Nie, and D. Dou, “Curriculum audiovisual learning,” CoRR, vol. abs/2001.09414, 2020.
- [55] C. Gan, H. Zhao, P. Chen, D. D. Cox, and A. Torralba, “Self-supervised moving vehicle tracking with stereo sound,” in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 2019, pp. 7052–7061.
- [56] K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild,” CoRR, vol. abs/1212.0402, 2012.
- [57] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, March 5-9, 2017. IEEE, 2017, pp. 776–780.
- [58] H. Sak, A. W. Senior, and F. Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling,” in INTERSPEECH 2014, 15th Annual Conference of the International Speech Communication Association, Singapore, September 14-18, 2014, H. Li, H. M. Meng, B. Ma, E. Chng, and L. Xie, Eds. ISCA, 2014, pp. 338–342.
- [59] J. Donahue, L. A. Hendricks, M. Rohrbach, S. Venugopalan, S. Guadarrama, K. Saenko, and T. Darrell, “Long-term recurrent convolutional networks for visual recognition and description,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, pp. 677–691, 2017.